calltrace收集查看方法
IBM AIX trace工具的介绍和使用

trace工具的介绍和使用环境AIX操作系统问题Trace 主要用来跟踪和记录系统的内核(Kernel)、内核扩展程序(Kernel Extension)和用户程序(User Program),尤其是对系统调用(System Call),内核服务(Kernel Service)和中断处理(Interrupthandlers)进行详细的记录。
它的记录单位是微秒,并按照时间的顺序记录各个事件。
由于Trace记录中所涉及的是操作系统底层事件,因此需要对AIX的内核、系统调用以及中断处理非常了解的人来解读,因此对于普通的系统管理员最重要的是知道如何去收集Trace的信息。
解答 1. Trace 的工作模式Trace 命令有三种工作模式 -- 默认模式、单一模式和循环模式。
默认模式是将Trace数据直接写到磁盘上,而单一模式和循环模式则都是先将Trace数据写到内存的缓冲区,待trace进程终止后再写回到磁盘;不同的是,单一模式是当缓冲区满了后,trace进程会自动停止,并将Trace数据写到磁盘,而在循环模式下,当缓冲区满后,trace进程不会停止,缓冲区会被覆盖并循环使用,只有输入“trcstop”命令后,trace进程才停止,并将Trace数据写到磁盘。
2. Trace的启动和停止启动trace的方法有很多种,用户可参考“man trace”来获得帮助。
这里举一个最常用的收集trace的命令作为例子:trace -a -l -T2000000 -L4000000 -o trace.out(2000000 和 4000000 只是一个例子)-a : 表示trace进程在后台运行(异步运行)-l :表示trace工作在循环模式-o :指定trace输出文件的目录和文件名,默认的输出文件名为 /var/adm/ras/trcfile-T :表示缓冲区的大小,单位为byte,默认值为128KB。
-L :表示写到磁盘上的trace输出文件的大小,单位为byte,默认值为1MB。
一次利用trace文件解决问题的全过程
一次利用trace文件解决问题的全过程市三院星期二反映住院医保病人销帐速度很慢,介绍一下解决引问题的全过程,供大家参考。
先给大家介绍一下如何生成trace文件,trace文件包括用户会话所有的SQL语句,执行SQL语句所花的代价,执行计划等重要信息,对于我们诊断问题很有帮助,因本人水平有限,错误之处难免,敬请不吝赐教。
一、生成trace文件方法一:利用pl/sql devoloper工具的跟踪功能。
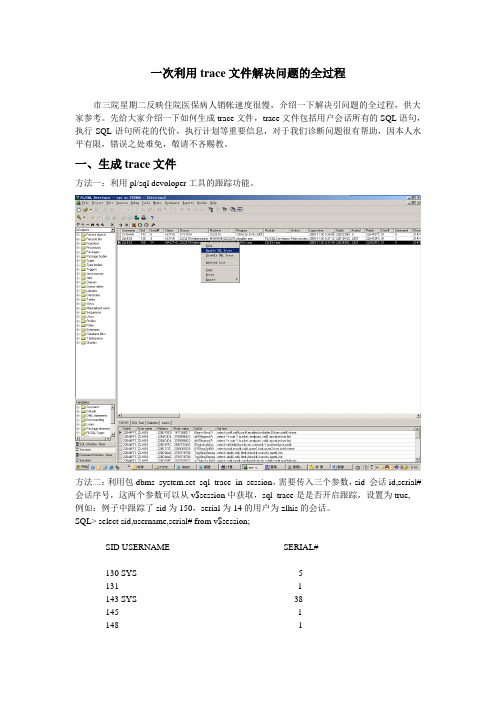
方法二:利用包dbms_system.set_sql_trace_in_session,需要传入三个参数,sid 会话id,serial# 会话序号,这两个参数可以从v$session中获取,sql_trace是是否开启跟踪,设置为true,例如:例子中跟踪了sid为150,serial为14的用户为zlhis的会话。
SQL> select sid,username,serial# from v$session;SID USERNAME SERIAL#---------- ------------------------------ ----------130 SYS 5131 1143 SYS 38145 1148 1150 ZLHIS9 14SQL> exec dbms_system.set_sql_trace_in_session(sid => 150,serial# => 14,sql_trace => true); PL/SQL procedure successfully completedSQL>二trace文件的格式化生成的trace文件,格式比较乱,需要对它进行格式化,一般使用oracle自带的tkprof命令行工具。
Tkprof工具有很多的参数,我只介绍其中常用的几个参数,更详细的文档请参照相关资料。
命令格式如下:tkprof tracefile outputfile [explain= ] [table= ][print= ] [insert= ] [sys= ] [sort= ]Tracefile为trace文件Outputfile为格化后的输出文件Explain 登录的用户名及密码SYS 是否生成属于SYS用户的信息,一般设置为no例如:tkprof d:\Oracle\Admin\Orcl\udump\ORA00152.TRC c:\333.txt sys=no explain=zlhis9/his 将生成c:\333.txt文件。
Linux Call Trace原理分析

本文介绍了在Linux环境下根据EABI标准进行call trace调试的一般性原理。
本文所说的call trace是指程序出问题时能把当前的函数调用栈打印出来。
本文只介绍了得到函数调用栈的一般性原理,没有涉及Linux的core dump机制。
下面简单介绍powerpc环境中如何实现call trace。
内核态call trace内核态有三种出错情况,分别是bug,oops和panic。
bug属于轻微错误,比如在spin_lock期间调用了sleep,导致潜在的死锁问题,等等。
oops代表某一用户进程出现错误,需要杀死用户进程。
这时如果用户进程占用了某些信号锁,所以这些信号锁将永远不会得到释放,这会导致系统潜在的不稳定性。
panic是严重错误,代表整个系统崩溃。
OOPS先介绍下oops情况的处理。
Linux oops时,会进入traps.c中的die函数。
int die(const char*str,struct pt_regs*regs,long err)。
show_regs(regs);void show_regs(struct pt_regs*regs)函数中,会调用show_stack函数,这个函数会打印系统的内核态堆栈。
具体原理为:从寄存器里找到当前栈,在栈指针里会有上一级调用函数的栈指针,根据这个指针回溯到上一级的栈,依次类推。
在powerpc的EABI标准中,当前栈的栈底(注意是栈底,不是栈顶,即Frame Header的地址)指针保存在寄存器GPR1中。
在GPR1指向的栈空间,第一个DWORD为上一级调用函数的Frame Header指针(Back Chain Word),第二个DWORD是当前函数在上一级函数中的返回地址(LR Save Word)。
通过此种方式一级级向上回溯,完成整个call dump。
除了这种方法,内建函数__builtin_frame_address函数理论上也应该能用,虽然在内核中没有见到。
trace方法

trace方法trace方法是一种非常有用的技术,它可以帮助开发者在程序运行时进行调试和排错。
本文将介绍trace方法的原理、使用方法以及一些实际应用案例。
一、trace方法的原理trace方法是一种在程序运行时输出调试信息的方法。
它通过在代码中插入一些打印语句,记录程序运行过程中的关键信息,以便开发者在调试时查看。
一般来说,trace语句会输出一些变量的值、函数的调用情况、程序的执行路径等信息。
在JavaScript中,我们可以使用console.log()方法来实现trace功能。
console.log()方法可以将指定的信息输出到控制台上,方便开发者进行查看。
例如:console.log('Hello, world!');这条语句会在控制台上输出一个字符串“Hello, world!”。
在实际应用中,我们可以将console.log()语句插入到程序的关键位置,以便跟踪程序的执行过程。
二、trace方法的使用方法在JavaScript中,我们可以使用console.log()方法来实现trace功能。
console.log()方法可以接受多个参数,将它们连接在一起输出。
例如:var name = 'Tom';var age = 18;console.log('My name is', name, 'and I am', age, 'years old.');这条语句会在控制台上输出一个字符串“My name is Tom and I am 18 years old.”。
在实际应用中,我们可以将console.log()语句插入到程序的关键位置,以便跟踪程序的执行过程。
除了console.log()方法外,JavaScript还提供了其他一些trace方法,例如console.debug()、console.warn()和console.error()等。
trace的用法

trace的用法一、什么是Trace?Trace,即追踪,指的是通过查找、记录和分析特定对象或事件的过程。
在计算机技术领域,Trace通常用于跟踪程序的执行路径、系统调用或网络数据包等信息。
二、Trace在软件开发中的应用1. 调试与故障排除在软件开发中,调试和故障排除是一个必不可少的环节。
使用Trace工具可以帮助开发人员追踪程序中出现问题的原因,并根据跟踪结果进行修复。
通过记录程序执行期间的变量值、函数调用关系和异常情况,开发人员可以更轻松地定位代码中出现的bug,并快速解决问题。
2. 性能优化对于需要处理大规模数据或高并发请求的应用程序来说,性能优化是至关重要的。
Trace可以帮助开发人员分析代码运行时的性能瓶颈所在,并找出导致低效率或资源浪费的原因。
例如,通过追踪函数调用次数、耗时以及内存占用情况,可以识别出影响系统性能的瓶颈点,在这些位置进行优化。
3. 用户行为分析对于Web应用程序或移动应用程序来说,了解用户行为是提升用户体验和产品质量的重要途径。
Trace可以帮助开发人员分析用户的操作路径、使用时长等信息,从而了解用户的行为习惯和需求,为产品迭代和功能改进提供依据。
三、常用的Trace工具1. Log4jLog4j是一个Java语言编写的日志记录工具包。
它提供了丰富的日志级别设置,可以在不同场景下灵活地记录应用程序的运行状态。
通过使用Log4j,开发人员可以将Trace信息输出到文件、数据库或者远程服务器,并进行后续的分析和处理。
2. WiresharkWireshark是一款开源网络封包捕获与分析软件。
它能够监控网络接口上发送和接收的数据包,并对数据包进行解码和分析。
Wireshark可以用于跟踪网络流量中的异常请求、疑似攻击等情况,帮助管理员识别和解决网络问题。
3. XdebugXdebug是一个强大的PHP调试器扩展。
它通过在PHP代码中插入特定指令,并与调试客户端(如IDE)配合使用,实现对PHP代码执行过程的追踪、变量查看等功能。
oracle ebs 收集 trace 方法

oracle ebs 收集trace 方法Oracle EBS 是一款常用的企业资源规划(ERP)系统,用于管理企业的财务、物流、供应链和人力资源等方面的业务。
在使用Oracle EBS 进行故障排查时,收集trace 信息是一种常见的方法。
本文将详细介绍如何收集trace,以及如何分析和利用这些trace 数据解决问题。
一、什么是trace?Trace 是Oracle 数据库中用于跟踪和记录执行过程的一种机制。
通过启用trace 功能,Oracle 数据库可以在执行过程中生成详细的日志,包括SQL 语句、程序调用、执行计划等信息。
这些信息对于分析和解决性能问题非常有帮助。
二、为什么需要收集trace?在Oracle EBS 中,性能问题是常见的挑战之一。
当用户反馈系统运行缓慢或者出现异常时,我们通常需要通过收集trace 数据来了解执行过程中的细节,定位问题的根本原因。
通过收集trace,我们可以获得SQL 语句的执行计划,了解SQL 语句执行时的资源消耗情况,进而分析和优化SQL 语句,提升系统性能。
三、如何收集trace?1. 确定跟踪级别:根据问题的性质,选择合适的跟踪级别。
Oracle 提供了多种级别的trace,如最详细的10046 级别,用于跟踪单个SQL 语句的执行过程;还有更高级别的10053 级别,用于跟踪SQL 语句执行计划的生成过程。
2. 开启trace:可以通过以下方法启用trace 功能:a. 对于单个会话的trace,可以使用ALTER SESSION 命令。
例如,执行`ALTER SESSION SET SQL_TRACE=TRUE;` 开启跟踪,执行`ALTER SESSION SET SQL_TRACE=FALSE;` 关闭跟踪。
b. 对于整个系统的trace,可以在数据库的初始化参数文件中设置`SQL_TRACE=TRUE;` 来开启所有会话的跟踪。
3. 收集trace 文件:在启用trace 后,Oracle 将在指定的位置生成跟踪文件。
TCH拥塞的原理和解决方法(2)

TCH拥塞的原理和解决方法(2)1.2 话务分布环境这种情况往往是在网络规划时基站选址不当所产生的。
前面提到了TCH拥塞率的概念,它是由TCH占用失败次数除以TCH占用请求次数。
因此当无线信号不好时经常会出现TCH信道占用不上,即会出现TCH拥塞。
需要注意的是这类拥塞并非是TCH信道真的没有资源可以分配了,而是由于无线接口的原因使TCH信道占用不上产生拥塞。
例如在基站覆盖的边缘区域,有用户群村镇存在。
由于在这个区域内,手机所接收到的信号已经非常微弱,同样手机上行的信号也很微弱。
因此在这里手机发起呼叫,很容易产生TCH占用失败的情况,从而造成TCH拥塞。
应当指出的是,此时系统的TCH资源却有可能是很充足的。
解决这类问题需要调整天线的方位角或下倾角,并将基站的静态发射功率开到最大,总之需要增强该区域的信号强度。
另外BSC参数中可适当降低RACH忙门限,来使手机占用TCH信道时尽可能成功,从而减小TCH拥塞率。
若这些方法都不能起到根本作用则需要在该用户群的近处增加基站。
2 设备安装及故障2.1 天馈安装及故障在基站的天馈安装及配置中,有多种情况将会导致TCH占用失败。
1) CDU/SCU配置导致TCH占用失败例如在一个4载频的小区中我们通常会使用CDU+SCU的合路配置方式,经常是BCCH所在的TRX通过CDU上天线,TRX通过SCU 进行合路,然后再通过CDU上天线。
这样BCCH所经过的通道和非BCCH所经过的通道合路损耗就有较大的差别,所以非BCCH所在的信道发射的功率比BCCH所在的信道要小。
在手机发起呼叫时(特别是在离基站较远的时候),若系统给手机指配了非BCCH所在TRX上的TCH信道,则由于它的发射功率很低,就很容易造成TCH信道占用失败。
解决该问题有两种方法一是在配置时BCCH所在的TRX放在经过SCU的通道上,这样它的发射功率相对较小,不会出现指配非BCCH 所在TRX上的TCH信道时出现失败。
TDD-13-1 Call trace功能与操作

Call trace功能介绍1.跟踪类型定义在规范TS32.422和TS32.423中定义了两种类型的call trace: Management Based Trace 和Signaling Based Trace ,Management Based Trace 采集的是eNodeB接口信息,Signaling Based Trace采集的是MME,EPC,以及eNodeB接口信息。
两种方式采集的都是上层信令消息。
eNodeB支持两种跟踪方式,但是一次只能激活一种,Management Based Trace优先级高于Signaling Based Trace。
对于卡特系统,Management Based Trace通过SAM采集,Signaling Based Trace 由MME采集。
2.Management Based Trace涉及的参数定义如下,可以通过SAM或者是WPS设置:TRACE REFERENCE:标识一个trace session的唯一ID号,组成方式:MCC+MNC+Trace ID,对于Signaling Based Trace,Trace ID是激活消息中发给eNodeB。
TRACE Depth:定义call trace采集的信令内容Management Based Trace 又分为两种:cell traffic trace和Event-Based Trace。
两种方式一次只能激活一种。
如果trafficThreshold,rrcReestablishmentThreshold和iratHOThreshold 中任意一个参数值设置不为0,那么默认激活的是Event-Based Trace。
Cell traffic trace记录触发条件:收到RRC Connection Request收到S1接口的handover request收到X2接口的handover request以下情况停止记录:呼叫结束;呼叫从一个小区切换到另一个小区,而另一个小区未开启call trace;呼叫切换到另一个eNodeB;呼叫切换到其它网络;3.Signaling Based Trace只能通过核心网即MME侧激活。
trace原理

trace原理Trace原理是一种追踪和分析系统中各个组件间传递的数据和信息的方法。
通过在系统中添加Trace代码,可以追踪到数据在系统中的流动路径,从而帮助开发人员定位和解决问题。
本文将从Trace 原理的定义、作用、实现方式和应用场景等方面进行介绍。
一、Trace原理的定义Trace原理是一种用于分析系统中数据和信息流动路径的方法。
它通过在系统的各个组件中添加Trace代码,记录数据在系统中的传递过程,并生成相应的Trace日志。
通过分析这些Trace日志,开发人员可以了解数据在系统中的流动路径,从而定位和解决问题。
二、Trace原理的作用Trace原理在系统开发和维护过程中起着重要的作用。
它可以帮助开发人员追踪和分析系统中的数据流动路径,从而在出现问题时快速定位和解决。
具体来说,Trace原理的作用有以下几个方面:1. 问题定位:当系统出现问题时,通过分析Trace日志可以追踪到数据在系统中的流动路径,从而帮助开发人员定位问题的根源。
比如,当用户反馈系统响应缓慢时,可以通过Trace日志追踪到数据在系统中的各个组件间传递的过程,找出导致系统响应缓慢的原因。
2. 性能优化:Trace原理可以帮助开发人员了解系统中各个组件的性能瓶颈,从而进行性能优化。
通过分析Trace日志,可以找出系统中数据传递过程中的瓶颈点,优化这些瓶颈点可以提高系统的性能。
3. 异常分析:当系统出现异常情况时,通过分析Trace日志可以追踪到异常数据的流动路径,帮助开发人员分析异常原因并进行修复。
比如,当系统出现数据丢失的情况时,可以通过Trace日志追踪到数据在系统中的流动路径,找出导致数据丢失的原因。
三、Trace原理的实现方式Trace原理的实现方式主要包括以下几个步骤:1. 添加Trace代码:在系统的各个关键组件中添加Trace代码,用于记录数据的流动路径。
Trace代码可以记录数据的发送和接收时间、发送和接收方的地址等信息。
关于SUSE LINUX系统假死问题(魔术键和Serial Console配置)

关于SUSE LINUX系统假死问题,我们需要分几个方面来看:一、如果这个时候系统网络能有响应(比如能ping通),但是kernel运行正常,同时,我们也要确保Ctrl+ALt+F1--F6键时console控制台正常,那么我们可以通过下面的方法来获取一些信息:基于SUSE LINUX操作系统方面,我们部署在故障发生时通过魔术键将系统状态的CALLTRACE(如内存、线程堆栈等)抓出来,则可以清晰的了解系统当时的状态。
可通过配置串口控制台及操作本地键盘魔术键来将系统状态导出到控制台上。
此时可以通过触发魔术键来获取有用信息。
服务器发生死机前,必须先配置服务器,具体步骤如下:1、进入以下的界面提示后按<F2>进入BIOS设置。
“Press <ESC> to view diagnostic messagesPress <F2> to enter SETUP,<F12>Network Boot ”选择Server Mangement菜单下:Console Redirection,即选择控制台重定向的串口,设置为enable记录下默认的串口波特率等参数以备死机时连接使用。
2、有运行业务的机器上开启sysrq功能:echo 1 > /proc/sys/kernel/sysrq 这种方法不用重启系统修改上面目录下的sysrq文件,将文件内容改为1,可知系统已启用sysrq。
再通过修改/etc/sysctl.conf文件,这样可以保证系统启动后自动开启sysrq功能。
方法是:在/etc/sysctl.conf文件中加入:kernel.sysrq=1运行:sysctl -p使之立即生效3、现某台机器业务中断后,先尝试网络登录,如果可以,执行下面命令:echo t > /proc/sysrq-triggerecho p > /proc/sysrq-triggerecho m > /proc/sysrq-trigger如果网络不能登录,可尝试本地操作,串口登入,在控制台执行上述3条命令。
call trace操作

CTB、CTG、Cell Trace、CTN的建立Call Trace是系统中非常重要的分析方法,能收集包括单个或多个小区,单个或多个手机在内的多种trace,收集的trace可以用RFO进行分析,能快速定位错误发生点。
并提供完整的消息流程。
Call trace的流向:RNC呼叫处理模块→RNC内部Call Trace处理模块→OMCR.更多详细信息,请参看”all Trace user guide”(目前只有英文版)。
Step1:进入Call trace。
Step2: 进入Call trace, 然后下一步选择”Manage Call trace Session”Step3:选择新建Call Trace Session。
Call Trace Session在系统中是很占用系统资源的,对于已经没有用的和结束的Call Trace 应该予以删除。
删除call trace不会影响已经收集的Call trace问价。
每个Call trace都有一个标记,如果忘了这个标记,就不知道trace文件存在什么地方,用”list all call trace session”可以看到所有的call trace(包括已经停止收集的Call trace),并可以看到他们的标记。
因此每个Call Trace都应该有时间限制(如只收30分钟的Cell trace),禁止设置无限期的Call Trace,Step4:选择Call trace的种类,常用Call trace有CTB,CTG,OTCELL,分类说明Trace文件保存路径CTB(Access Session) 这种任务允许跟踪一个用户的信令,用户可以用基于IMSI/TMSI/IMEI/P-TMSI标识。
/opt/nortel/data/utran/callTrace/onOAMdemand/CTG(Geographical Session) 可以同时收集多个小区中的所有呼叫。
android trace的用法

android trace的用法"Android Trace的用法"在Android开发中,性能优化是非常重要的,而Android Trace工具是帮助开发人员分析和优化应用程序性能的重要工具之一。
Android Trace工具允许开发人员在应用程序中插入性能跟踪代码,以便在运行时收集性能数据并进行分析。
Android Trace工具可以通过以下几种方式使用:1. 使用Systrace进行系统级跟踪,Systrace是Android开发工具中一个非常有用的工具,它可以帮助开发人员分析应用程序在系统级别上的性能问题。
通过Systrace,开发人员可以查看应用程序的CPU使用情况、内存使用情况、绘制性能等方面的数据,从而找出性能瓶颈并进行优化。
2. 使用Trace类进行应用程序级跟踪,在应用程序代码中,开发人员可以使用Android SDK中提供的Trace类来插入性能跟踪代码。
通过Trace类,开发人员可以在代码中标记开始和结束位置,并在运行时收集性能数据。
这些数据可以帮助开发人员找出应用程序中的性能问题,并进行相应的优化。
3. 使用Android Profiler进行实时性能监控,Android Profiler是Android Studio中一个非常强大的工具,它可以帮助开发人员实时监控应用程序的性能。
通过Android Profiler,开发人员可以查看应用程序的CPU使用情况、内存使用情况、网络使用情况等数据,并及时发现性能问题。
总之,Android Trace工具是帮助开发人员分析和优化应用程序性能的重要工具,开发人员可以通过Systrace进行系统级跟踪,使用Trace类进行应用程序级跟踪,以及使用Android Profiler进行实时性能监控。
通过这些工具,开发人员可以及时发现应用程序中的性能问题,并进行相应的优化,从而提升应用程序的性能和用户体验。
trace调试技巧

trace调试技巧在软件开发过程中,使用trace调试是非常常见的。
trace调试是一种通过在代码中插入跟踪信息来诊断程序运行过程中的问题的方法。
下面我会从多个角度来介绍一些trace调试的技巧。
首先,要正确使用trace调试,我们需要在代码中插入足够的跟踪信息。
这些信息可以是变量的值、函数的执行顺序、条件语句的判断结果等。
通过在关键位置插入trace语句,我们可以更清晰地了解程序的运行情况。
其次,要注意trace信息的输出方式。
在调试过程中,我们可以选择将trace信息输出到控制台、日志文件或者特定的调试工具中。
选择合适的输出方式可以帮助我们更方便地查看和分析trace 信息。
另外,要善于利用条件trace。
有时候我们并不需要在每次程序运行时都输出trace信息,这时可以通过条件语句来控制trace 信息的输出,比如只在特定条件下输出trace信息,这样可以减少不必要的输出,同时也更方便地定位问题。
此外,要注意trace信息的格式化。
为了方便阅读和分析,我们可以对trace信息进行适当的格式化,比如添加时间戳、调用栈信息等,这样可以更清晰地了解程序的执行流程。
最后,要善于利用调试工具。
现在有很多强大的调试工具可以帮助我们进行trace调试,比如Visual Studio的调试器、GDB、Xcode等。
这些工具提供了丰富的功能,比如设置断点、单步执行、查看变量值等,能够极大地提高我们的调试效率。
总的来说,trace调试是一种非常有效的调试方法,通过合理地插入trace信息、选择合适的输出方式、使用条件trace、格式化trace信息和善于利用调试工具,我们可以更快速、更准确地定位和解决程序中的问题。
希望以上介绍的技巧能够对你有所帮助。
systemtrace 抓取方法

systemtrace 抓取方法Systemtrace是Linux系统的一种工具,可以用来抓取系统的跟踪日志。
这个工具可以帮助开发者诊断系统问题和优化系统性能。
下面是 systemtrace 的抓取方法:1. 安装 systemtrace 工具在 Ubuntu 系统下,可以使用以下命令安装 systemtrace 工具: $ sudo apt-get install systemtap systemtap-doc 在其他 Linux 发行版下,可以按照该发行版的安装方式进行安装。
2. 编写 systemtrace 脚本systemtrace 的语法类似于 C 语言,需要编写一个systemtrace 脚本文件。
以下是一个简单的 systemtrace 脚本示例: ```#!/usr/bin/env stapglobal countprobe begin {count = 0printf('Tracing...')}probe syscall.read {count++}probe end {printf('Total read syscalls: %d', count)}```这个脚本会跟踪系统中的 read 系统调用,并统计调用次数。
3. 运行 systemtrace 脚本在终端中运行以下命令,使用 systemtrace 工具运行脚本:$ sudo stap -v script.stp其中,script.stp 是 systemtrace 脚本的文件名。
4. 查看 systemtrace 输出systemtrace 会将脚本的输出打印到终端上。
在上面的示例中,输出会显示 read 系统调用的总调用次数。
以上是 systemtrace 的抓取方法。
通过使用这个工具,开发者可以更方便地调试和优化 Linux 系统。
tracemalloc用法 -回复

tracemalloc用法-回复tracemalloc用法:Python中内存分配跟踪工具的详解近年来,Python作为一门高级编程语言,越来越受到开发者们的喜爱。
然而,由于Python的动态类型和自动内存管理机制,我们有时很难准确地知道程序中内存的使用情况。
为了解决这个问题,Python提供了一个名为tracemalloc的工具,它可以帮助我们分析和跟踪内存分配的情况。
本文将详细介绍tracemalloc工具的使用方法,以帮助读者更好地了解和利用此工具。
第一步:安装和导入tracemalloc模块在开始使用tracemalloc之前,我们需要先安装相关的依赖包。
在命令行中运行以下命令进行安装:pip install tracemalloc安装完成后,在Python脚本中导入tracemalloc模块:pythonimport tracemalloc第二步:开启内存分配跟踪在我们需要跟踪内存分配的代码段之前,我们需要手动启用内存分配的跟踪。
为此,我们可以使用tracemalloc的`start()`函数:pythontracemalloc.start()当我们开始跟踪内存分配后,tracemalloc将开始记录当前的内存分配信息。
第三步:执行跟踪的代码段现在,我们可以执行需要跟踪的代码段。
这个代码段可以是任何可能导致内存分配的代码,比如创建对象、分配数组或读取大文件等。
在代码段执行完之后,我们就可以分析跟踪到的内存分配信息了。
第四步:查看内存分配快照当我们完成了跟踪代码段的执行后,我们可以使用tracemalloc的`take_snapshot()`方法来获取内存分配的快照:pythonsnapshot = tracemalloc.take_snapshot()这个快照将包含跟踪期间记录的所有内存分配信息。
第五步:显示内存分配信息获取内存分配快照后,我们可以使用`snapshot.statistics()`方法来查看内存分配的统计信息:pythontop_stats = snapshot.statistics('lineno')这个方法将返回一个列表,列表中的每个元素都是一个包含文件名、行号和内存分配大小的元组。
如何收集CUCM9.x或以上的跟踪.pdf

如何收集CUCM 9.x或以上的跟踪ContentsIntroductionPrerequisitesRequirementsComponents Used背景信息安装RTMT应用程序配置或确认呼叫管理服器务的详细的追踪配置或确认CTI Manager服务的详细的追踪再生产问题并且采取附注搜集被请求的跟踪验证跟踪文件覆盖附有跟踪程序包您的服务请求分析摘要Introduction本文描述步骤通过Cisco Unified通信管理器高效地指导您(CUCM/CallManager)的跟踪收集进程。
常见情况使用为说明。
PrerequisitesRequirementsCisco 建议您了解以下主题:实时监视工具(RTMT)应用程序q呼叫管理服器务的详细的追踪qComputer-Telephony Integration (CTI)管理器服务的详细的追踪qComponents Used本文的信息根据CUCM的当前版本。
关于版本早于CUCM 9.x,请参阅收集CUCM跟踪从CUCM 8.6.2关于TAC SR。
The information in this document was created from the devices in a specific lab environment.All of the devices used in this document started with a cleared (default) configuration.If your network is live, make sure that you understand the potential impact of any command.背景信息如果工作与关于通信管理器问题的一位技术协助工程师(TAC)工程师,您也许需要收集CUCM跟踪。
这可能是您偶尔地执行或以前从未执行的任务。
在此方案中,您排除未被记录的一次呼叫故障,即使CUCM侧配置看来是正确的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
目录
1在SAM上开启该站的calltrace,方法如下: (2)
2 从服务器上下载calltrace的方法如下: (7)
3用WTA打开calltrace的方法: (9)
1在SAM上开启该站的calltrace,方法如下:
点击配置-移动呼叫跟踪-eNodeB呼叫跟踪会话,在弹出来的会话框里点击创建一个新会话
点击弹出的会话框右上角的添加按钮
在搜索栏输入该站点搜索,选中之后点确定
点击添加小区
全部选中之后点确定
给该会话取一个名字,勾上下面三项点击确定
最后点击激活就能开启这个站的calltrace,根据该站的服务器地址可以到相应的服务器上收取calltrace,如果想关闭,只需要点击激活按钮旁边的Deactivate按钮
2 从服务器上下载calltrace的方法如下:
打开filezille输入对应的calltrace目录地址和用户名密码,点击连接,
输入calltrace的目录/oamdata/tce/lte/CallTrace,选择需要下载的时间-站名进去之后即可把calltrace文件下载到自己的电脑
3用WTA打开calltrace的方法:
打开WTA,点击左上角的file点击new project创建一个新项目
选择calltrace文件,点击打开
点击view-message explorer-Project1/Study1
即可查看calltrace信息。