试验设计与数据处理复习题1
何少华等. 试验设计与数据处理

何少华等. 试验设计与数据处理1. 试验设计的重要性试验设计是科学研究的重要一环,它直接决定了研究结果的有效性和可信度。
好的试验设计能够最大程度地减少干扰因素,保证实验结果的准确性和可靠性。
在进行科研工作时,科学家们都需要对试验设计非常重视,并严格遵循科学的原则进行设计。
2. 如何进行良好的试验设计良好的试验设计需要考虑多方面因素。
要确定研究目的和问题,明确实验的目标和内容。
需要选择合适的实验材料和方法,确保实验的可行性和有效性。
应当进行充分的实验前准备,包括实验流程、操作步骤、数据记录等。
在进行实验过程中要注意控制干扰因素,保证实验结果的准确性和可靠性。
3. 数据的收集和处理在实验进行过程中,科学家们需要充分地收集和记录实验数据。
数据的收集需要严格按照预定的计划和方法进行,确保数据的完整性和真实性。
在数据处理过程中,还需要进行数据的整理、统计和分析,以得出科学合理的结论。
数据的处理过程需要符合统计学的原则和方法,确保得出的结论具有科学的可信度。
4. 数据处理中常见的问题和解决方法在数据处理过程中,科学家们常常会遇到各种各样的问题。
数据缺失、异常值、分布不均等问题都会影响到数据处理的结果。
针对这些问题,科学家们需要采取相应的方法进行处理,如插补缺失数据、剔除异常值、进行数据转换和标准化等。
还需要借助适当的统计工具和软件进行数据分析和处理,确保得出的结论具有科学的可信度和说服力。
5. 结论试验设计和数据处理是科学研究中非常重要的环节,直接决定了研究结果的准确性和可信度。
科学家们在进行研究工作时需要严格遵循科学的原则进行试验设计,并在数据的收集和处理过程中注意各种可能出现的问题,采取相应的方法进行处理,以确保得出的结论具有科学的可信度和说服力。
在实验设计和数据处理中的关键要素在实验设计和数据处理过程中,有一些关键要素需要特别引起科研人员的注意。
这些要素涉及到实验的可重复性、对照组的设立、实验误差的控制等方面,它们对于最终结论的可信度具有重要的影响。
工程实验设计数据处理试题整理

1、名词解释。
(1)数量数据:当试验结果表现为数量上的变化,由计数或测量所得到的数据称数量数据。
(2)算术平均值:一个样本内各个观察值的总和除以观察值总个数的商即为该样本的算术平均数,一般称为平均数或均数。
(3)方差:各因素或交互作用的偏差平方和除以各自相应的自由度。
(4)区域控制: 将试验处理按系统进行区组划分,使同一区组内的单元间环境因素保持一致,保证同一区组中局部范围内单元间误差的同质性,以便于消除系统误差。
区域控制又称划分区组。
(5)全面实验设计法:对各因素各水平排列组合成的全部试验处理都加以实施,称为全面试验。
(6)试验水平:在实验中,为了考察试验因素对试验指标的影响,必须使试验因素处于不同的状态,把因素所处的各种状态称为试验水平,简称水平或位级。
(7)Ln(m k)中各字母表示含义:L——表示正交表;n——试验次数(处理数);m——水平数;k——表的列数,即最多可以安排的因素数。
最多可安排k个因素,每个因素m水平,共做n次实验的等水平正交表。
(8)部分实施:在试验的全部组合处理中,选取有代表性的部分处理加以实施,称为部分实施。
(9)样本容量:样本容量又称“样本数”。
指一个样本的必要抽样单位数目。
(10)试验因素:在实验中,能对试验指标产生影响的原因或要素,都称为因素或因子。
通常也称为影响因素。
(11)试验处理:在试验中,不同因素的不同水平的搭配组合称为处理(12)极差:样本中最大值与最小值之差为极差。
(13)试验指标:在实验设计中,根据试验目的而选定的用来衡量试验效果的特征值。
2.简答(1)请回答,在实验设计中,为减少误差要遵循哪些原则,并解释其作用。
(2)(1)重复:即一种处理要重复两次以上。
设置重复的主要作用有两方面:一是估计试验误差:二是降低试验误差。
(3)(2)随机化:随机可以消除任何人为的主观偏性及各种干扰因子的影响,以保证获得处理效应及对误差有效无偏估计。
(4)(3)区域控制区域控制是将试验处理按系统进行区组划分,使同一区组内的单元间环境因素保持一致,保证同一区组中局部范围内单元间误差的同质性,以便于消除系统误差。
研究生《试验设计与数据处理》试题
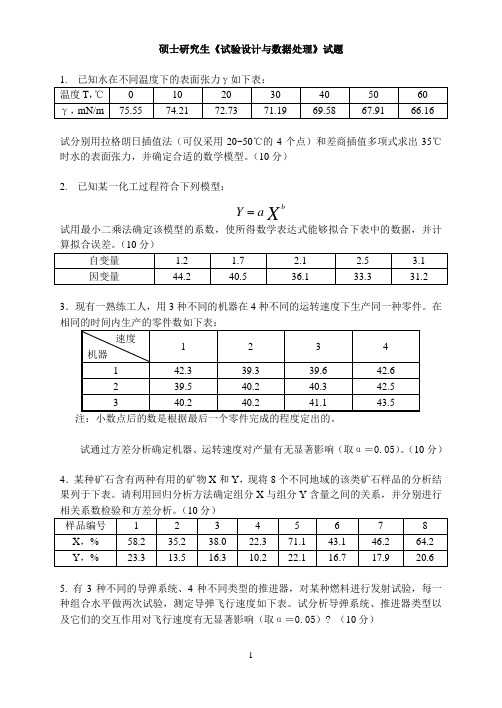
硕士研究生《试验设计与数据处理》试题试分别用拉格朗日插值法(可仅采用20~50℃的4个点)和差商插值多项式求出35℃时水的表面张力,并确定合适的数学模型。
(10分)2. 已知某一化工过程符合下列模型:试用最小二乘法确定该模型的系数,使所得数学表达式能够拟合下表中的数据,并计3.现有一熟练工人,用3种不同的机器在4种不同的运转速度下生产同一种零件。
在相同的时间内生产的零件数如下表:试通过方差分析确定机器、运转速度对产量有无显著影响(取α=0.05)。
(10分)4.某种矿石含有两种有用的矿物X 和Y ,现将8个不同地域的该类矿石样品的分析结果列于下表。
请利用回归分析方法确定组分X 与组分Y 含量之间的关系,并分别进行5. 有3种不同的导弹系统、4种不同类型的推进器,对某种燃料进行发射试验,每一种组合水平做两次试验,测定导弹飞行速度如下表。
试分析导弹系统、推进器类型以及它们的交互作用对飞行速度有无显著影响(取α=0.05)? (10分)Xba Y6. 病毒学家在研究一种特殊病毒时发现:不同培养媒质、不同培养时间对病毒生长情况有影响。
现取两种媒质、两个培养时间,每一种组合下重复观察6次,病毒生长情况列在下表。
试用22设计分析法分析这些数据,考察媒质、时间对病毒生长的影响(取α=0.05、0.01)。
(10分)7.在研究显影剂浓度(A )和显影时间(B )对胶卷不透明度的影响时,采用3种浓度和3个时间,每一种组合下做4次重复试验。
得出不透明度的数据如下表。
试用32设计分析法分析这些数据,并得出结论(取α=0.05、0.01)。
(10分)8.为提高某种药品的合成率,对生产工艺进行了试验。
各因素及其水平如下表。
根据经验,采用液态醛有助于提高药品的合成率,用拟水平法、选L 9(34)正交表安排试验,将各因素放在正交表的1-4列上,9次试验所得合成率(%)依次为69.2、71.8、78.0、74.1、77.6、66.5、69.2、69.7、78.8。
试验设计与数据处理复习题

一、理论题1.根据研究目的确定的研究对象的全体称为总体(population),其中的一个研究单位称为个体(individual);总体的一部分称为样本(sample)。
通常把n≤30的样本叫小样本,n>30的样本叫大样本。
2.由总体计算的特征数叫参数(parameter), ;由样本计算的特征数叫统计量(statistic)。
常用希腊字母表示参数,例如用μ表示总体平均数,用σ表示总体标准差;常用拉丁字母表示统计量,例如用x表示样本平均数,用S表示样本标准差。
3. 准确性(accuracy)指在调查或试验中某一试验指标或性状的观测值与其真值接近的程度,精确性(precision)指调查或试验中同一试验指标或性状的重复观测值彼此接近的程度。
4. 高斯对数理统计和试验设计学科的主要贡献包括:1.建立了回归分析的最小二乘法;2.运用极大似然法及其他数学知识,推导出测量误差的概率分布公式,发现误差的高斯分布曲线,即今天的正态分布。
5.方差分析由R. 费雪于1918年首创, “方差分析法是一种在若干能相互比较的资料组中,把产生变异的原因加以区分开来的方法与技术”。
6.20世纪50年代,日本田口玄一将试验设计中应用最广的正交设计表格化;同一时期,我国著名数学家华罗庚积极倡导和普及“优选法”;在1978年我国数学家王元和方开泰首先提出了均匀设计。
7.两组精度不同的同一试验结果在计算加权平均数时权重通常由绝对误差平方倒数的比值来确定,即认为测量结果的可靠程度与测量次数成正比。
8.样本标准误差的无偏计算公式中分母的n-1来自于自由度的概念。
9. 实验最重要的因素是混杂问题。
所谓混杂是指,由于实验处理,针对你的假说所作的处理,导致的差异与其他因素可能导致的差异无法区分开来。
10. 重复是指在符合实验条件的空间和时间范围内,各组要有足够数量的例数。
重复非常必要,因为变异(差异)是生物体遗传固有的本质。
11. 生物数据中比正态分布更常见的是正偏斜,偏斜数据通常必须进行数据转换(例如对数和幂转换),以改善它们的正态性。
《试验设计与数据处理》考试题

广东海洋大学2009——2010 学年第二学期2009级硕士研究生《试验设计与数据处理》课程试题姓名:学号:专业:注意:请用A4纸答题,计算题将软件处理结果按要求写出来,并进行分析。
一、简答题(每题5分,20分)1、什么是标准误和标准差?它们有什么区别和联系?在论文中的正确的表示方法有哪些?2、什么是变异系数?它有什么意义?3、什么是单尾检验和双尾检验,并举例说明?4、多个平均数相互比较时,可以采用什么方法?这些方法之间有何联系?二、试验设计与数据处理题(共80分)1、随机抽测了某一班次10袋小包装奶粉的重量,其数据为:18.7、19.0、18.9、19.6、19.1、19.8、18.5、19.7、19.2、18.4(g),已知该品牌奶粉小包装重量总体平均数=19.5g,试进行统计分析确定生产中包装机是否工作正常?(5分)2、海关抽检出口罐头质量,发现有胀听现象,随机抽取了6个样品,同时随机抽取6个正常罐头样品测定其SO2含量,测定结果见表。
分析两种罐头的SO2含量有无差异。
(5分)3、现某食品公司研制出减肥食品,用11只雄鼠进行一个月实验,试验结果见下表(单位:g),请进行统计分析说明该食品是否具有减肥效果?(5分)4、对某地区4类海产食品中无机砷含量进行检测,以鲜重计测定结果见表。
分析不同类型海产品的砷含量差异是否显著。
(5分)5、在食品质量检查中,对4种不同品牌腊肉的酸价进行了随机抽样检测,结果见表,试分析4种不同品牌腊肉的酸价有无差异。
(5分)6、某厂现有化验员3人,担任该厂牛奶酸度(°T)的检验。
每天从牛奶中抽样一次进行检验,连续10天的检验分析结果见表。
试分析3名化验员的化验技术有无差异,以及每天的原料牛奶酸度有无差异。
(5分)7、试对下列资料进行直线回归分析,求出回归方程,并列出方差分析表。
(5分)8、有一组数据如下,已知y与x1,x2,x3之间存在着线形关系,求出回归方程,并列出方差分析表。
大学生期末考试真题《实验设计与数据处理》试验设计与数据处理(附有答案)

一、单选题(题数:50,共 50.0 分)1在正交实验设计中,定量因素各水平的间距是( )(1.0分)1.0分正确答案:C 我的答案:C答案解析:2*随机单位设计要求( )。
(1.0分)0.0分单位组内没有个体差异,单位组间差异大正确答案:A 我的答案:3当组数等于2时,对于同一资料,方差分析结果与t检验结果( ) 。
(1.0分)0.0分t检验结果更准确完全等价且正确答案:D 我的答案:B答案解析:方差分析与t检验的区别与联系。
对于同一资料,当处理组数为2时,t检验和方差分析的结果一致且,因此,正确答案为D。
4下列结论正确的是( )①函数关系是一种确定性关系;②相关关系是一种非确定性关系;③回归分析是对具有函数关系的两个变量进行统计分析的一种方法;④回归分析是对具有相关关系的两个变量进行统计分析的一种常用方法.(1.0分)0.0分正确答案:C 我的答案:5在对两个变量,进行线性回归分析时,有下列步骤:①对所求出的回归直线方程作出解释;②收集数据、),,…,;③求线性回归方程;④求未知参数; ⑤根据所搜集的数据绘制散点图。
如果根据可行性要求能够作出变量具有线性相关结论,则在下列操作中正确的是( ) (1.0分)0.0分正确答案:D 我的答案:6*方差分析中变量变换的目的是( )。
(1.0分)0.0分正确答案:D 我的答案:7两个变量与的回归模型中,通常用来刻画回归的效果,则正确的叙述是( ) (1.0分)0.0分越小,残差平方和越小越大,残差平方和越大与残差平方和无关越小,残差平方和越大正确答案:D 我的答案:答案解析:8在一个正交实验中,因素A和B的水平数都为3,那么A和B的交互作用的自由度为( )(1.0分)0.0分正确答案:C 我的答案:答案解析:9单因素方差分析中,当P<0.05时,可认为( )。
(1.0分)0.0分正确答案:B 我的答案:答案解析:方差分析的检验假设及统计推断。
方差分析用于多个样本均数的比较,它的备择假设(H1)是各总体均数不等或不全相等,当P<0.05时,接受h1,即认为总体均数不等或不全相等。
试验设计与数据分析(考题)

上海应用技术学院2009-2010 学年第 1 学期《试验设计与数据处理》期(末)试卷班级:研究生学号:姓名:我已阅读了有关考试规定和纪律要求,愿意在考试中遵守《考场规则》,如有一、在用原子吸收分光光度法测定镍电解液中微量杂质铜时,研究了乙炔和空气流量变化对铜在某波长上吸光度的影响,得到下表所示的吸光度数据。
试根据二、根据下表中的试验数据,画出散点图,求某物质在溶液中的浓度c(%)与其沸点温度T之间的函数关系,并检验所建立的函数方程式是否有意义。
(本题15三、某厂在制作某种饮料时,需要加入白砂糖,为了工人操作和投料的方便,白砂糖的加入以桶为单位,经初步摸索,加入量在3~8桶范围中优选。
由于桶数只宜取整数,采用分数法进行单因素优选,优选结果为6桶,试问优选过程是如何进行的。
假设在试验范围内试验指标是白砂糖桶数的单峰函数。
(本题10分)(1)利用正交表L8(27)进行试验方案设计;(2)若试验结果(得率)依次为86,95,91,94,91,96,83,88,试用直观分析法分析试验结果;(3)确定最佳水平组合。
(本题20分)五、在啤酒生产的某项工艺试验中,选取了底水量x1和吸氨时间x2两个因素,六、某产品的产量取决于3个因素x1(60~80),x2(1.2~1.5), x3(0.2~0.3),还要考虑因素x1,x2的交互作用。
选用正交表L8(27)进行一次回归正交试验设计,给出相应的试验方案。
(本题10分)七、已知某合成剂由3种组分组成,它们的实际百分含量分别为x1,x2,x3,且受下界约束x1≥0.2, x2≥0.4,x3≥0.2,运用单纯形重心配方设计寻找最优配方,试给出相应的试验方案。
(本题15分)。
实验设计与数据处理第一章例题及课后习题(附答案)

1、 根据三组数据的绝对误差计算权重:12322211110000,25,400000.010.20.005w w w ====== 因为123::400:1:1600w w w = 所以1.54400 1.71 1.53716001.53840011600pH ⨯+⨯+⨯==++2、 因为量程较大的分度值也较大,用量程大的测量数值较小的物理量会造成很大的系统误差。
3.、含量的相对误差为0.2g ,所以相对误差为:0.20.99790525.3Rx E x ∆===。
4、 相对误差18.20.1%0.0182x mg mg ∆=⨯= 故100g 中维生素C 的质量范围为:18.2±0.0182。
5、1)、压力表的精度为1.5级,量程为0.2,则max 0.2 1.5%0.003330.3758R x MPa KPa x E x ∆=⨯==∆===2)、1的汞柱代表的大气压为0.133,所以max 20.1330.133 1.6625108R x KPax E x -∆=∆===⨯ 3)、1水柱代表的大气压为gh ρ,其中29.8/g m s =则:3max 339.8109.810 1.225108R x KPax E x ---∆=⨯∆⨯===⨯6、样本测定值算术平均值 3.421666667 3.48 几何平均值 3.421406894 3.37 调和平均值 3.421147559 3.47 标准差s 0.046224092 3.38 标准差 0.04219663 3.4 样本方差 0.002136667 3.43 总体方差0.001780556 算住平均误差 0.038333333极差 0.117、依题意,检测两个分析人员测定铁的精密度是否有显著性差异,用F双侧检验。
根据试验值计算出两个人的方差及F值:221221223.733, 2.3033.7331.621232.303s s s F s ===== 而0.9750.025(9,9)0.248386,(9,9) 4.025994F F ==, 所以0.9750.025(9,9)(9,9)F F F <<两个人的测量值没有显著性差异,即两个人的测量方法的精密度没有显著性差异。
试验设计与数据处理课后习题

试验设计与数据处理课后习题机械工程6120805019 李东辉第三章3-7分别使用金球和铂球测定引力常数(单位:)1. 用金球测定观察值为 6.683,6.681, 6.676, 6.678, 6.679, 6.6722. 用铂球测定观察值为 6.661, 6.661,6.667, 6.667, 6.664设测定值总体为N(u,)试就1,2两种情况求u的置信度为0.9的置信区间,并求的置信度为0.9的置信区间。
用sas分析结果如下:第一组:第二组:3-13下表分别给出两个文学家马克吐温的8篇小品文以及斯诺特格拉斯的10篇小品文中由3个字母组成的词的比例:马克吐温:0.225 0.262 0.217 0.240 0.230 0.229 0.235 0.217斯诺特格拉斯:0.209 0.205 0.196 0.210 0.202 0.207 0.224 0.223 0.220 0.201设两组数据分别来自正态总体,且两个总体方差相等,两个样本相互独立,问两个作家所写的小品文中包含由3个字母组成的词的比例是否有显著差异(a=0.05)取假设H0:u1-u2≤0和假设H1:u1-u2>0用sas分析结果如下:Sample StatisticsGroup N Mean Std. Dev. Std. Error----------------------------------------------------x 8 0.231875 0.0146 0.0051y 10 0.2097 0.0097 0.0031Hypothesis TestNull hypothesis: Mean 1 - Mean 2 = 0Alternative: Mean 1 - Mean 2 ^= 0If Variances Are t statistic Df Pr > t----------------------------------------------------Equal 3.878 16 0.0013Not Equal 3.704 11.67 0.0032由此可见p值远小于0.05,可认为拒绝原假设,即认为2个作家所写的小品文中由3个字母组成的词的比例均值差异显著。
实验设计与数据处理试题库

一、名词解释:〔20分〕1.准确度与准确度:同一处理观察值彼此的接近程度同一处理的观察值与其真值的接近程度2.重复与区组:试验中同一处理的试验单元数将试验空间按照变异大小分成假设干个相对均匀的局部,每个局部就叫一个区组3回归分析与相关分析:对能够明确区分自变数与因变数的两变数的相关关系的统计方法:对不能够明确区分自变数与因变数的两变数的相关关系的统计方法4.总体与样本:具有共同性质的个体组成的集合从总体中随机抽取的假设干个个体做成的总体5.试验单元与试验空间:试验中能够实施不同处理的最小试验单元所有试验单元构成的空间二、填空:〔20分〕1.资料常见的特征数有:〔3空〕算术平均数方差变异系数2.划分数量性状因子的水平时,常用的方法:等差法等比法随机法〔3空〕3.方差分析的三个根本假定是〔3空〕可加性正态性同质性4.要使试验方案具有严密的可比性,必须〔2空〕遵循“单一差异〞原那么设置对照5.减小难控误差的原那么是〔3空〕设置重复随机排列局部控制6.在顺序排列法中,为了防止同一处理排列在同一列的可能,不同重复内各处理的排列方式常采用〔2空〕逆向式阶梯式7.正确的取样技术主要包括:〔〕确定适宜的样本容量采用正确的取样方法8.在直线相关分析中,用〔相关系数〕表示相关的性质,用〔决定系数〕表示相关的程度。
三、选择:〔20分〕1试验因素对试验指标所引起的增加或者减少的作用,称作〔C〕A、主要效应B、交互效应C、试验效应D、简单效应2.统计推断的目的是用〔A〕A、样本推总体B、总体推样本C、样本推样本D、总体推总体3.变异系数的计算方法是〔B〕4.样本平均数分布的的方差分布等于〔A〕5.t检验法最多可检验〔C〕个平均数间的差异显著性。
6.对成数或者百分数资料进展方差分析之前,须先对数据进展〔B〕A、对数B、反正弦C、平方根D、立方根7.进展回归分析时,一组变量同时可用多个数学模型进展模拟,型的数据统计学标准是〔B〕A、相关系数B、决定性系数C、回归系数D、变异系数8.进展两尾测验时,u0.10=1.64,u0.05=1.96,u0.01=2.58,那么进展单尾检验,u0.05=(A)9.进展多重比拟时,几种方法的严格程度〔LSD\SSR\Q〕B10.自变量X与因变量Y之间的相关系数为0.9054,那么Y的总变异中可由X与Y的回归关系解释的比例为〔C〕四、简答题:〔15分〕1.回归分析与相关分析的根本内容是什么?〔6分〕配置回归方程,对回归方程进展检验,分析多个自变量的主次效益,利用回归方程进展预测预报:计算相关系数,对相关系数进展检验2.一个品种比拟试验,4个新品种外加1个对照品种,拟安排在一块具有纵向肥力差异的地块中,3次重复〔区组〕,各重复内均随机排列。
临床试验设计与数据处理(一)--临床试验设计的三要素

作者单位: !"!!#$
石家庄
河北医科大学卫生统计学教研室
! #3
! "! "# "#
疑难病杂志 #<<# 年 1 月第 ! 卷第 # 期
D E*BB*$ ,&- F%78’ F,), G(>()+ #<<#, H%’ I! 准是选择受试者
本身和制剂的质量、 被检者的消化吸收功能、 代谢和排 泄器官 的状态以及所用测试仪器、 测试方法都可能影响到测试结果。 所以, 该法的科学性、 可信性也不是绝对理想。今后 尚需研究 更加优良可信的评价依从性的方法。 !"!"#"6 在选择受试对象时还要充分尊重受试者的知情权。使 每个受试对象都了解试验的目的要求、 预期效果和潜在风险, 自 主决定是否参加试验。这也是提高依从性的一项重要措施。对 自愿参加试验、 符合入选条 件的对象要请其签署知情同意书。 同意书中必须申明受试者有随时退出试验的权利。 !"!"5 客观评价 临床 效应: 在临 床试 验设计 方案 中对 如何 客观真实地评价临 床效应 也应有明 确规定。 由于临 床效应 一般都是通过某些观测指标来反映的 , 因此正确地选择观测 指标就成为客观评 价临床 效应的关 键所在。 选择观 测指标 要从以下几方面综合考虑。 !"!"5"! 指标的合理性。所谓是否 “合理 ” 就 是指所 选指标 是否能真实客观地 反映出 干预措施 的临床 效应。在 专业上 能否得到合理的解释。例如一次临床 试验, 目的是要考核某 药有无预防冠心病 的作用。由 于从专 业理论 上知道 高血脂 是发生冠心病的危险因素, 降低血脂可以减少冠心病发病的 危险。因此, 血脂作为评价预防冠心病效应的指标在专业上 是说得通的, 但如果临床试验目的是评价对冠心病患者有无 治疗效果, 用血脂作为效 应指标 就不合理 了, 因为血 脂的高 低与冠心病症状的改善程度 并无必然的联系。 !"!"5"# 指标的客观性。在临床试 验中应该 尽量选 择客观 性指标, 即通过测试仪器或工具获得观测结果的指标而避免 选用由研究者主观判 断观测 结果或 根据受试 对象主 诉获取 观测结果的主观性 指标。因为 前者的 可靠性 和可重 复性都 优于后者。在客观指标 中能做 到定量 测定的 又优于 只能定 性测定的。因为定量的 客观指 标能更 精细地 反映出 临床效 应的微小差别。如果必须应用主观 性指标, 要严格防止由于 研究者或受试对象的心理效应所带 来的主观偏性, 必要时应 采用盲法设计。 !"!"5"5 指标的灵敏 性和 特异 性。灵 敏性 ( )/&)*+*@*+A) 是指 所选用的指标对干 预措施 反应的灵 敏程度。 这在很 大程度 上决定于所用的检测方法和手 段。因此 , 要尽可能选用最灵 敏的检测方法和最先 进的检 测仪器 以提高检 测结果 的灵敏 性。在 考 虑 指 标 灵 敏 性 的 同 时 还 要 兼 顾 指 标 的 特 异 性 ()8/$*B*$*+A) 、 即检测结 果的 专一 性, 以便 把假 阳性 结果 控制 在最低水平。最好是选用灵敏度高、 特异性又好的指标。 !"!"5"6 指标的精确性。精确性包括准确性 (,$$(.,$A) 和精 密性 (8./$*)*%&) 两个方面。前者是指观 测结果与真 实情况接 近的程度, 主要受系统误差的影响。后者是指观测结果的稳 定程度, 即重复观测时, 观察值与平均值 接近的程度, 属于随 机误差的范畴, 在临床试验中选择的指标在准确性和精密性 上都要有一定的保证。 除了以上四方面, 选择临床效应指标还要考虑到经济性 (检测成本是否在 受 试对 象所 能 承受 的范 围 之内 ) , 损 伤性 (检测是否会对受试对象带 来损伤 及损伤 的严重 程度) 和快 速性 (是否能尽快得到检测结果) 。 (未完待续)
实验设计与数据处理

填空1.单因素试验的数学模型可归纳为:效应的可加性、分布的正态性、方差的同质性。
这是方差分析的前提条件或基本假定。
2.多重比较的方法甚多,常用的有最小显著差数法和 最小显著极差法.3.生物试验中,由于试验误差较大,常采用新复极差法4.两因素试验按水平组合的方式不同,分为交叉分组和系统分组两类5.随机模型在遗传、育种和生态试验研究方面有广泛的应用。
6.统计推断主要包括假设检验和参数估计两个方面7.判断处理效应是否存在是假设检验的关健。
8.区间估计是在一定概率保证下指出总体参数的可能范围,所给出的可能范围叫置信区间,给出的概率称为 置 信 度 或 置 信概 率9.在实际进行直线回归分析时,可用相关系数显著性检验代替直线回归关系显著性检验10.我们用正交表安排的试验,具有均衡分散和整齐可比的特点。
11.反映两个连续变量间的相关性的指标可采用 相关系数 表示;反映一个连续变量和一组连续变量间的相关性的指标可采用 复相关系数 表示;讨论一组连续变量和一组连续变量间的相关性可采用 典型相关分析 方法讨论。
12.在数据处理中概率可用 频率 近似;分布的数学期望可用 样本均值 近似;分布的方差可用 样本方差 近似.13.配方试验中,若成分A 、B 、C 的总份数必须满足A+B+C=60份,采用正交试验的因素水平见表若正交)3(49L 的第9号试验条件 为(A 、B 、C )=(3、3、2),请给出具体的试验方案(取小数点后一位)A= 6.7 份,B= 13.3 份,C= 40 份14.抽样调查不同阶层对某改革方案的态度,统计分析方法应为 方差分析 ;研究学历对收入的影响,统计分析方法应为 回归分析 或相关性分析 。
P5315.设x1,x2,…,xn 是出自正态总体N (μ,σ2)的样本,其中σ2未知。
对假设检验H0∶μ=μ0, H1∶μ≠μ0,则当H0成立时,常选用的统计量是__T =(x ˉ-μ0)S /√n _______,它服从的分布为____t_(n-1)_____.16.设有100件同类产品,其中20件优等品,30件一等品,30件二等品,20件三等品,则这四个等级的标准分依次为 1.28 、0.39 、 -0.39 、 -1.28 A B C 水平1 18份 1.5倍A 1倍B 水平2 20份 1倍A 3倍B水平3 22份 2倍A 2倍B≤)=α查标准正态表可得u65.0=0.39,u7.0=0.12,u8.0=0.84, u9.0=1.28) (记P(U uα17.正交表有三个典型特点,分别是正交性、均衡性、独立性。
试验设计与数据处理(第1与2章)

四、我国试验设计方法的研究与应用概况
我国对试验设计方法的研究与推广应用起 步较晚,建国后才逐渐开展这方面的工作。 进入70年代后,正交试验设计方法在我国工 农业科研、生产中的应用越来越广,解决了 不少科研生产中的关键问题。 1978年,我国数学家方开泰和王元将数论和 多元统计相结合,在正交试验设计基础上,创 立了一种新的适用于多因素多水平试验的设计 方法——均匀试验设计法,并很快在很多领域 中得到广泛应用。
试验设计在试验研究中具有非常重要的作 用,它可以有效地解决以下问题: 1、通过试验设计可以分清各试验因素对试验 指标影响的大小,找出主要因素。 2、通过试验设计可以了解每个因素的水平改 变时,试验指标是怎么变化的。 3、通过试验设计可以了解各个因素之间的相 互影响情况,即因素之间的交互作用。
4、通过试验设计可以迅速地找出最优生产条 件或工艺条件,确定最优方案,并能预估在 最优生产条件或工艺条件下的试验指标值。
描述随机变量的某些特征的量叫做随机变 量的数字特征。常用的数字特征是数学期 望和方差。
(一)数学期望(均值) 1、数学期望的概念
首先举一个例子,假设对某种食品的水分进行 了n次测量,其中有m1次测得的结果为x1,m2次 测得的结果为x2,…,mk次测得的结果为xk,则 测定结果的平均值为
k mi 1 ξ = (x1 m1+x 2 m 2+... x k m k )= x i + n n i=1
五、学习《试验设计和数据处理》课程的意 义
试验设计和数据处理方法已成为一种现代 通用技术,是工程技术人员必备的基础知识。 通过本课程的学习,可使学生掌握试验设 计和数据处理的基本原则和常用方法,可培 养学生从事试验研究工作的能力,提高学生 的综合素质,成为高质量的应用型人才。
试验设计与数据处理(第二版)课后习题答案

R
0.992299718
R Square 0.984658731
Adjusted
R Square 0.969317462
标准误差 2.742554455
观测值
7
方差分析
回归分析 残差 总计
Signific
df
SS
MS
F
ance F
3 1448.292 482.7641 64.18366 0.003211
4.4
试验号 T/℃ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
Na2O(x1) siO2(x2) CaO(x3)/
/%
/%
%
X1=x1 X2=x1x2
1029
14
72
9.1
14 1008
1011
14
72
8.1
0.000291
3.887206
4.3
煎煮时间 试验号 /min(x1)
1 2 3 4 5 6 7
煎煮次数 加水量/ 含量
(x2) 倍(x3) /(mg/L)y
30
1
8
15
40
2
11
37
50
3
7
46
60
1
10
26
70
2
6
34
80
3
9
57
90
3
12
57
SUMMARY OUTPUT
回归统计
Multiple
9.5
8.1
ph值
30 25 20 15 10
5 0
(完整word版)实验设计与数据处理试题库

一、名词解释:(20分)1.准确度和精确度:同一处理观察值彼此的接近程度同一处理的观察值与其真值的接近程度2.重复和区组:试验中同一处理的试验单元数将试验空间按照变异大小分成若干个相对均匀的局部,每个局部就叫一个区组3回归分析和相关分析:对能够明确区分自变数和因变数的两变数的相关关系的统计方法:对不能够明确区分自变数和因变数的两变数的相关关系的统计方法4.总体和样本:具有共同性质的个体组成的集合从总体中随机抽取的若干个个体做成的总体5.试验单元和试验空间:试验中能够实施不同处理的最小试验单元所有试验单元构成的空间二、填空:(20分)1.资料常见的特征数有:(3空)算术平均数方差变异系数2.划分数量性状因子的水平时,常用的方法:等差法等比法随机法(3空)3.方差分析的三个基本假定是(3空)可加性正态性同质性4.要使试验方案具有严密的可比性,必须(2空)遵循“单一差异”原则设置对照5.减小难控误差的原则是(3空)设置重复随机排列局部控制6.在顺序排列法中,为了避免同一处理排列在同一列的可能,不同重复内各处理的排列方式常采用(2空)逆向式阶梯式7.正确的取样技术主要包括:()确定合适的样本容量采用正确的取样方法8.在直线相关分析中,用(相关系数)表示相关的性质,用(决定系数)表示相关的程度。
三、选择:(20分)1试验因素对试验指标所引起的增加或者减少的作用,称作(C)A、主要效应B、交互效应C、试验效应D、简单效应2.统计推断的目的是用(A)A、样本推总体B、总体推样本C、样本推样本D、总体推总体3.变异系数的计算方法是(B)4.样本平均数分布的的方差分布等于(A)5.t检验法最多可检验(C)个平均数间的差异显著性。
6.对成数或者百分数资料进行方差分析之前,须先对数据进行(B)A、对数B、反正弦C、平方根D、立方根7.进行回归分析时,一组变量同时可用多个数学模型进行模拟,型的数据统计学标准是(B)A、相关系数B、决定性系数C、回归系数D、变异系数8.进行两尾测验时,u0.10=1.64,u0.05=1.96,u0.01=2.58,那么进行单尾检验,u0.05=(A)9.进行多重比较时,几种方法的严格程度(LSD\SSR\Q)B10.自变量X与因变量Y之间的相关系数为0.9054,则Y的总变异中可由X与Y的回归关系解释的比例为(C)A、0.9054B、0.0946C、0.8197D、0.0089四、简答题:(15分)1.回归分析和相关分析的基本内容是什么?(6分)配置回归方程,对回归方程进行检验,分析多个自变量的主次效益,利用回归方程进行预测预报:计算相关系数,对相关系数进行检验2.一个品种比较试验,4个新品种外加1个对照品种,拟安排在一块具有纵向肥力差异的地块中,3次重复(区组),各重复内均随机排列。
试验设计与数据处理思考复习题

<<试验设计与数据处理>>思考复习题根据实验数据进行合理猜想并作出探究和验证是科学研究重要的环节,而在“知识本位、解题至上”的传统偏见影响下,这恰恰是许多老师最忽视的环节。
我想起一节“探究单摆的周期与摆长的关系”实验的课堂教学实例,在此谈谈几点粗浅的认识。
本节内容的大致教学流程是这样的:学生分组实验收集数据——分析实验数据——得出实验结论。
在引导学生从实验数据得出结论的过程处理上,通常会出现两种处理的方式:1)第一种方式就是直接把数据分析的结果告诉学生,“根据这样的实验数据,同学们可以发现周期的二次方与摆长是成正比的”。
2)第二种方式是教师引导学生先观察数据的特点、变化趋势,然后作出猜想;或者先通过计算机作出周期与摆长的非线性图象,然后再作出猜想。
第一种方式的教学是功利性、以考试为本的教学,完全忽视了科学探究过程对学生的价值,不值得提倡。
但在实际教学中,身边很多老师为了课堂“知识传授的高效”,为了节省出时间来让学生做题目,依然以这种方式教学。
第二种方式稍微好点,我在设计这一部分教学时,以前通常采用第二种方式,而且还留足了时间给学生思考和讨论,希望学生能够体验这趟由已有数据到未知结论的美妙思维之旅,并为之感到震撼。
但是实际的效果似乎并不好。
学生在实验完成之后,虽然能够很好地配合教师开展下一步的教学,但对结论的探究热情明显下降了很多。
我在认真观察和思考后推测:一方面可能学生刚刚还兴奋于动手实验,现在突然来个了枯燥的数据分析,感觉一下子物理又从有趣变成无趣了,少了点心理上的缓冲。
而且实验热热闹闹地得到了数据然后就被扔到一边凉快去了,两部分的教学似乎被割裂了;另一方面,根据数据猜想线性关系的思想在“探究加速度与力和质量的关系”实验和“功和物体动能变化的关系”实验中已有体现,对学生的吸引力不大,容易引起心理疲劳。
不知各位同行可有什么高招可以使学生能够对处理数据、分析得到结论的过程保持兴趣?。
医院临床试验设计与数据管理知识考核试卷

C.不良事件信息
D.研究者评价
13.以下哪些是临床试验中可能遇到的挑战?()
A.患者招募困难
B.数据收集和管理的复杂性
C.研究经费的限制
D.遵守法规要求
14.以下哪些是知情同意书必须包含的内容?()
A.研究目的和过程
B.预期风险和不适
C.患者补偿信息
D.研究终止的权利
15.以下哪些人可能参与临床试验数据管理?()
答案:__________、__________
9.在临床试验中,__________是衡量研究质量的一个重要指标。
答案:__________
10.临床试验结束后,所有的研究资料应按照规定进行__________,以备后续的审计和检查。
答案:__________
四、判断题(本题共10小题,每题1分,共10分,正确的请在答题括号中画√,错误的画×)
A.随机化
B.对照
C.双盲
D.重复
2.临床试验分为几个阶段?()
A.两个
B.三个
C.四个
D.五个
3.以下哪种研究设计不属于临床试验?()
A.随机对照试验
B.观察性研究
C.横断面研究
D.病例对照研究
4.数据管理过程中的SDV指的是什么?()
A.数据标准化
B.数据验证
C.数据审核
D.数据锁定
5.以下哪项不是临床试验数据管理的目的?()
6.知情同意书应确保患者了解研究的目的、过程、潜在风险和__________。
答案:__________
7.伦理委员会在临床试验中的作用是审查研究方案,保护研究对象的__________和__________。
答案:__________、__________
试验设计与数据分析试题A

试验设计与数据分析试题AIMB standardization office【IMB 5AB- IMBK 08- IMB 2C】试验设计与数据分析试题(A)一、选择题:1、已知某样品质量的称量结果为:2.010±g,则其相对误差,为:A、2.0,B、2.0±, C、%2 D、%2.02、用法寻找某实验的最优加入量时,若当前存优范围是[628,774],好点是718,则此时要做试验的加入点值是 ()A、.628+7742 B、628+×(774-628)C、628+774-718D、2×718-7743、经过平面上的6个点,一定可以找到一个次数不高于()的多项式。
A、4B、5C、6D、74.有一条1 000 m长的输电线路出现了故障,在线路的开始端A处有电,在末端B 处没有电,现在用对分法检查故障所在位置,则第二次检查点在 () A.500 m处 B.250 m处C.750 m处 D.250 m或750 m处5、 L8(27)中的7代表()A. 最多允许安排因素的个数B. 因素水平数C. 正交表的横行数D. 总的实验次数6、. 在L9(34)表中,有A,B,C三个因素需要安排。
则它们应该安排在()列A. 1,2,3B. 2,3,4C. 3,4,5D. 任意3列★7、某实验因素对应的目标函数是单峰函数,若用分数法需要从[0,21]个试验点中找最佳点,则需要做试验的次数是 ()A.6次 B.7次 C.10次 D.20次★8、. 用L 8(27)进行正交实验设计,若因素A 和B 安排在第1、2列,则A×B ,应排在第( )列。
A. 3B. 4C. 5D. 6★9、正方体的边长为2.010±,则体积的绝对误差限为: A 、32.0 B 、32.0⨯ C 、2.0 D 、60★10、有一双因素优选试验,20≤x ≤40,10≤y ≤20.使用纵横对折法进行优选.分别对因素x 和y 进行了一次优选后其新的存优范围的面积为( )A 、200B 、100C 、150D 、50二、填空题1.已知某样品质量的称量结果为:2.07.58±g ,则其绝对误差限为 ;相对误差为 。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一•填空题
1反映两个连续变量间的相关性的指标可采用
相关系数 _________ 表示;
反映一个连续变量和一组连续变量间的相关性的指标可采用 复相关系数 _______ 表示;
讨论一组连续变量和一组连续变量间的相关性可采用
典型相关分析 __________ 方法讨论。
2.在数据处理中概率可用
频率 近似;分布的数学期望可用
样本均值
近似;
分布的方差可用 样本方差 _____________ 近似.
3•配方试验中,若成分 A 、B 、C 的总份数必须满足 A+B+C=60份,采用正交试验的因素 水平见表
若正交L g (3
4
)的第9号试验条件 为(A 、B 、C ) = (3、3、2),请给出具体的试验方案(取
小数点后一位)
研究学历对收入的影响,统计分析方法应为
回归分析或相关性分析 ________________
P53 5.
设x1 , x2,…,xn 是出自正态总体N (卩,d )的样本,其中
/未知。
对假设检验
H0 :卩=^0 H1 :卩工&0则当HO 成立时,常选用的统计量是
_T=(x --卩o )S/ V n ____________
它服从的分布为 ____ t_ (n-1) ____ .
6. 设有100件同类产品,其中20件优等品,30件一等品,30件二等品,20件三等品,则这四个等
级的标准分依次为 1.28 、0.39 、 -0.39 、 -1.28 ____________
(记 P (U 兰山)=。
查标准正态表可得
U
0.65 =
.39,
U
0.7=
.12,
U
0.8=
.84, U 0.9=1.28)
.求解
1.抗牵拉强度是硬橡胶的一项重要性能指标
,现试验考察下列两个因素对该指标的影响
A (硫化时间):A 1(40秒),A 2(60秒)
B (催化剂种类):B 1 (甲种),B 2(乙种),B 3(丙种)
以上六种水平组合下,各重复做了两次试验,测得数据(单位:kg/cm 2
)如表:
试在显著性水平 二=0.05下分析因素A 和因素B 对指标的主效应及交互效应是否显著
The GLM Procedure
Dependent Variable: STRE
A= 6.7
份,
B= 13.3
份, C= 40
份
4.抽样调查不同阶层对某改革方案的态度 ,统计分析方法应为
方差分析 _________________
Source DF Squares Mean Square F Value Pr > F Model 5 9866.66667 1973.33333
13.16
0.0035
Error
6
900.00000
150.00000
Corrected Total 11 10766.66667
R-Square Coeff Var Root MSE STRE Mean 0.916409
3.074673
12.24745
398.3333
Source DF Type III SS Mean Square F Value Pr > F A 1 533.333333 533.333333 3.56
0.1083 B 2 9316.666667 4658.333333 31.06 0.0007
A*B 2
16.666667
8.333333
0.06
0.9464
由p 值可知A,A*B 不显著;B 高度显著
2•以下是用SAS 对三个指标的数据进行主成份分析的部分输出结果
Eigenvect or sr
z 1 z2 z3 取
1
0. 706330
■■035689
0. 706982
0. 043501
IX @93叮E0
CL 006971
K 3
TO0544
一.
C25S3Q 一*
707197
(一) 在Proportion 及Cumulative 以下划线处填相应数值
0.666 0.666 0.333 0.999
0.001 1
(二) 求第一主成份的表达式 z1=0.70633x1 + 0.043501x2 + 0.706544x3 _________________________ (三) 按85%阈值截取主成份并构造综合指标得
:
Source DF Type I SS Mean Square F Value Pr > F 533.333333
533.333333 3.56 0.1083 9316.666667
4658.333333 31.06 0.0007
A*B
2
16.666667
8.333333
0.06
0.9464
Pr oport ion
Cumulat ivc
of izh.e C o rr e 1 at □. on r ±K
1
1-99015^93 2
0.99816418
3
Ox 00269089
则x3忽略,将其他两个归一后得出:z=0.667x1 + 0.333x2代入数据,合并同类项得出结果z=0.459x1 + 0.362x2 +0.462x3
3•在单纯形优化设计中,已知三因素的初始单纯形的试验方案及试验结果见下表(指标以
大为好)
E E= 1010/3 5
(二)若试验点E的试验指标值Y E为下表第一行中的各种情况,填表以表示下一推
移动作名称及参数a的范围
A (3.5, 3, 1.5) B不变;C (2.5, 2.5, 2.5); D (2.535,3)
4.利用SAS在一次回归正交设计的输出部分结果如下:
Sum of Mea n
Source DF Squares Square F Value Pr > F
Model 4 543.10250 135.77562 4.38 0.0908
Error 4 123.94830 30.98708
Corrected Total 8 667.05080
Parameter
Variable DF Estimate Pr >
|t| Type I SS
In tercept 1 56.46000 <.0001 28690
x1 1 2.92500 0.2675 51.33375
x2 1 5.27333 0.0811 166.84827
x3 1 7.28833 0.0327 318.71882
x4 1 -1.01667 0.6778 6.20167
由于发现因子x1与x4不显著,故从回归方程中删去x1,x4.
1y=56.46 + 5.2733x2 + 7.28833x3
2 2 485.576 242.784 8.0267
6 181.484 30.2473
8 667.0508
(-)
请给出新的回归方程y=
(二
填空完成下面方差外折
A
Sum uf
Source
DF
Squares
Square
F Value
Ft > F+J
0.0201
Error
d
Corr eat ed Tert al _
5•轴承硬度合格率 y (%)与因素A (上升温度:C )、因素 B (保温时间:小时)、因素 C
6•测量圆柱体体积,体积公式
V 「R 2h,其中R 为底圆半径,h 为圆柱体高。
若测得底
圆周长C=40cm ,其均方差 % =0.05cm ;测得高h=10cm ,其均方差匚0.2cm ,求圆柱 体体积V 的均方差二v 。
(出炉温度:C )有关,采用正交表
L g (34
)安排试验,试验方案及试验结果见表:
(1) 填表
(2) 指出3号试验的具体条
件:
(3 )指出可能好的水平组合
820, 8, 400
(4) 排出因素的主次顺序
BAC
(5) 画因素水平趋势图, 并检验有无因 素取值范围选偏的情况
7
10
试作综合评判
(1)依据最大隶属原则; (2 )依据秩加权平均原则;
(3)若评语“优”对应分值 100分,“良好”对应 80分,“一般”对应 60分“差”对应
40分,问此类食品罐头可得评分值多少分?
(0.20 0.40 0.20
0.10
0.10)* 0
0.2 0.6 0.2
0.1 0.4 0.3 0.2 0.3 0.4 0.2 0.1 0.1 0.4 0.5 0
0 0.3 0.6 0.1
B=( 0.11 0.35 0.39
0.15)
1 0.39为最大,依据最大隶属度原则,判定为良好
2 4 * 0.11 + 3*0.35 + 2*0.39 + 1*0.15 = 2.42 判定为良偏一般
3
40* 0.11 +60*0.35 + 80*0.39 + 100*0.15 =71.6
&设对某多层次模糊指标评价的态度有赞成、不表态、反对 量见图,求模糊综合指标 U 的表态隶属向量
qo. 2, 0. 3」0.5) 3,0. 5, D. Z)⑪ 1,0.5」0 4)
,其分层的权向量和表态隶属向。