kruskal基于Python的代码实现
数学建模-最小生成树-kruskal算法及各种代码

kruskal算法及代码---含伪代码、c代码、matlab、pascal等代码K r u s k a l算法每次选择n- 1条边,所使用的贪婪准则是:从剩下的边中选择一条不会产生环路的具有最小耗费的边加入已选择的边的集合中。
注意到所选取的边若产生环路则不可能形成一棵生成树。
K r u s k a l算法分e 步,其中e 是网络中边的数目。
按耗费递增的顺序来考虑这e 条边,每次考虑一条边。
当考虑某条边时,若将其加入到已选边的集合中会出现环路,则将其抛弃,否则,将它选入。
目录Kruskal算法Kruskal算法的代码实现Kruskal算法Kruskal算法的代码实现算法定义克鲁斯卡尔算法假设 WN=(V,{E}) 是一个含有 n 个顶点的连通网,则按照克鲁斯卡尔算法构造最小生成树的过程为:先构造一个只含 n 个顶点,而边集为空的子图,若将该子图中各个顶点看成是各棵树上的根结点,则它是一个含有 n 棵树的一个森林。
之后,从网的边集 E 中选取一条权值最小的边,若该条边的两个顶点分属不同的树,则将其加入子图,也就是说,将这两个顶点分别所在的两棵树合成一棵树;反之,若该条边的两个顶点已落在同一棵树上,则不可取,而应该取下一条权值最小的边再试之。
依次类推,直至森林中只有一棵树,也即子图中含有n-1条边为止。
举例描述克鲁斯卡尔算法(Kruskal's algorithm)是两个经典的最小生成树算法的较为简单理解的一个。
这里面充分体现了贪心算法的精髓。
大致的流程可以用一个图来表示。
这里的图的选择借用了Wikipedia上的那个。
非常清晰且直观。
首先第一步,我们有一张图,有若干点和边如下图所示:第一步我们要做的事情就是将所有的边的长度排序,用排序的结果作为我们选择边的依据。
这里再次体现了贪心算法的思想。
资源排序,对局部最优的资源进行选择。
排序完成后,我们率先选择了边AD。
这样我们的图就变成了第二步,在剩下的变中寻找。
kruskal算法(克鲁斯卡尔算法)python代码

Kruskal算法(克鲁斯卡尔算法)Python代码简介K r us ka l算法是一种用于解决最小生成树问题的贪心算法。
它通过逐步选择边,将未连接的顶点逐渐合并成一个连通分量,并且保证最后形成的树中不会出现环。
本文将介绍K ru sk al算法的基本思想及其在Py th on 中的实现。
算法原理K r us ka l算法的基本思想是将图的所有边按照权重(即边的长度)从小到大进行排序,然后逐条选择边,并判断是否会形成环。
如果不会形成环,则将该边加入最小生成树中,直到最小生成树的边数等于节点数减一为止。
算法步骤1.根据图的边的权重进行排序。
2.初始化一个空的最小生成树列表,用于存放已选择的边。
3.初始化一个空的并查集,用于判断边的端点是否已经在同一个连通分量中。
4.遍历排序后的边,对于每一条边:-判断边的两个端点是否已经在同一个连通分量中,如果不在,将该边加入最小生成树列表,并将边的两个端点合并到同一个连通分量中。
5.返回最小生成树列表作为最终的生成树。
Pytho n实现下面是使用P yt ho n实现Kr us ka l算法的代码:c l as sU ni on Fi nd:d e f__i ni t__(se lf,n):s e lf.p ar en t=li st(r an ge(n))s e lf.r an k=[0]*nd e ff in d(se lf,x):i f se lf.p ar en t[x]!=x:s e lf.p ar en t[x]=se l f.fi nd(s el f.par e nt[x]) r e tu rn se lf.p ar ent[x]d e fu ni on(s el f,x,y):r o ot_x,r oo t_y=sel f.f in d(x),s el f.f i nd(y) i f ro ot_x!=ro ot_y:i f se lf.r an k[ro ot_x]>se lf.r an k[roo t_y]:s e lf.p ar en t[ro ot_y]=ro ot_xe l se:s e lf.p ar en t[ro ot_x]=ro ot_yi f se lf.r an k[ro ot_x]==s el f.ra nk[ro o t_y]: s e lf.r an k[ro ot_y]+=1d e fk ru sk al(g ra ph):e d ge s=[]f o ri,r ow in en um era t e(gr ap h):f o rj,c os ti ne nu mer a te(r ow):e d ge s.ap pe nd((cos t,i,j))e d ge s.so rt()n u m_no de s=le n(gra p h)t r ee=[]u n io n_fi nd=U ni onF i nd(n um_n od es)f o rc os t,i,ji ne dge s:i f un io n_fi nd.f ind(i)!=un io n_fi nd.f in d(j):u n io n_fi nd.u ni on(i,j)t r ee.a pp en d((i,j))r e tu rn tr ee使用示例为了更好地理解K rus k al算法的实现,下面给出一个使用示例:构建图的邻接矩阵表示g r ap h=[[0,2,3,1],[2,0,0,4],[3,0,0,5],[1,4,5,0]]使用Kruskal算法计算最小生成树m i ni mu m_sp an ni ng_t re e=kr us ka l(gra p h)输出最小生成树的边f o re dg ei nm in im um_s pa nn in g_tr ee:p r in t(ed ge)输出结果为:(0,3)(0,1)(1,0)总结K r us ka l算法是一种高效的求解最小生成树问题的算法。
最小生成树kruskal算法python代码解析

最小生成树kruskal算法python代码解析Krulskal算法是一种常用于计算最小生成树的算法,主要用于求解无向带权图的最小生成树。
下面我们来了解一下Krulskal算法的具体实现方法。
算法设计思路Krulskal算法的实现主要通过以下几个步骤:1. 初始化:对于给定的图G,首先需要把图中所有的边按照权重大小从小到大排序,然后初始化一个空的边集合T。
2. 遍历:按照边的权重从小到大的顺序遍历所有的边。
3. 判定:对于当前遍历到的边,如果这条边的两个端点不在同一个连通块中,那么就将这条边加入到集合T中,同时将这两个端点所在的连通块合并成一个连通块。
4. 输出:最终输出的集合T即为图G的最小生成树。
代码解析下面给出Krulskal算法的Python代码实现。
1. 初始化```def init(graph):edges = []nodes = set()for start in graph:nodes.add(start)for end, weight in graph[start]:edges.append((start, end, weight))edges = sorted(edges, key=lambda e: e[2]) # 对边按照权重排序 return edges, nodes```在初始化中,我们将图G中所有的边按照权重大小从小到大排序,同时用一个set集合来存储所有的节点,方便后面的查找。
2. 遍历```def kruskal(graph):edges, nodes = init(graph)tree_edges = []disjoint_sets = [{node} for node in nodes]for start, end, weight in edges:start_set = find_set(disjoint_sets, start)end_set = find_set(disjoint_sets, end)if start_set != end_set:tree_edges.append((start, end))merge_sets(disjoint_sets, start_set, end_set)return tree_edges```在这一步中,我们按照边的权重从小到大的顺序遍历所有的边,同时查找每条边的两个端点所在的连通块。
kruskal算法回环判断方法

kruskal算法回环判断方法(原创实用版4篇)《kruskal算法回环判断方法》篇1Kruskal 算法是一种用于寻找最小生成树的算法。
在Kruskal 算法中,边按照权重从小到大排序,然后依次将边加入到图中,但要避免形成环。
为了判断是否形成环,Kruskal 算法使用了一种称为“回环判断方法”的技术。
具体来说,在加入一条边之前,需要检查这条边是否与已加入的边形成环。
如果形成环,则这条边不能加入到图中。
回环判断方法的实现可以通过使用并查集数据结构来实现。
具体来说,对于每一条边,都使用一个并查集来记录这条边所连接的顶点属于哪个连通分量。
在加入一条边之前,需要检查这条边的两个端点是否属于同一个连通分量。
如果属于同一个连通分量,则说明加入这条边会形成环,不能加入。
《kruskal算法回环判断方法》篇2Kruskal 算法是一种用于寻找最小生成树的算法。
在寻找最小生成树时,需要判断一个树是否是一个回环。
回环是指一个节点通过一条边连接到自己,形成一个环。
Kruskal 算法使用并查集数据结构来维护边集,并使用disjoint sets data structure 来判断是否存在回环。
在disjoint sets data structure 中,每个节点代表一个连通分量(也可以理解为森林中的一个组成部分),每个节点的父节点是指向它的连通分量的根节点。
当加入一条新边时,需要将这条边的两个端点的节点合并到同一个连通分量中。
如果这条边的两个端点已经在同一个连通分量中,那么就说明存在回环。
具体实现时,可以使用一个数组来记录每个节点的父节点,当加入一条新边时,需要遍历这条边的两个端点的父节点,如果它们相同,就说明存在回环。
以下是一个示例代码:``` pythonclass DisjointSet:def __init__(self):self.size = 0self.parent = [None] * (100000 + 1)def find(self, x):if self.parent[x] is None:return xelse:return self.find(self.parent[x])def union(self, x, y):x_root = self.find(x)y_root = self.find(y)if x_root == y_root:#存在回环returnelse:if self.size[x_root] < self.size[y_root]:self.size[x_root] += self.size[y_root]self.parent[x_root] = x_rootelse:self.size[y_root] += self.size[x_root]self.parent[y_root] = x_root```在以上代码中,`self.size[i]` 表示连通分量i 的大小,`self.parent[i]` 表示连通分量i 的根节点。
凯撒密码python编程代码

凯撒密码python编程代码凯撒密码,也叫移位密码,是一种简单的加密算法。
它是由古罗马大军领袖凯撒所使用的一种加密方式。
凯撒密码是一种替换加密的技术,通过移动字母来对原来的文本进行混淆。
在凯撒密码中,每一个字母都会向前或者向后移动一个固定的数量,这个数量就决定了加密的强度。
凯撒密码使用的是整数移位,使用较为简单,是最古老的密码之一。
凯撒密码的加密算法如下:将明文的每一个字母都向后移动n个位置成为密文,其中n是一个整数。
代码实现在python中,可以使用ord()函数来获取某个字符的ASCII码。
同时,也可以使用chr()函数来将ASCII码转换为字符。
1.加密过程对于凯撒密码的加密过程,可以定义一个函数caesar_encrypt(),实现将明文加密为密文的功能。
函数的参数包括明文和移动距离。
具体实现如下:```pythondef caesar_encrypt(plain_text, shift):cipher_text = ""for char in plain_text:if char.isalpha():if char.isupper():cipher_text += chr((ord(char) + shift -65) % 26 + 65)else:cipher_text += chr((ord(char) + shift - 97) % 26 + 97)else:cipher_text += charreturn cipher_text```在上述代码中,plain_text表示明文,shift表示移动距离。
cipher_text表示加密后的密文字符串。
代码中使用了字符的ASCII码,ord()函数来获取某个字符的ASCII码,chr()函数将ASCII码转换为字符。
需要注意的是,在加密过程中,只对字母进行加密,而对其他字符(例如空格、数字、标点等)不进行加密,直接复制到密文中即可。
最小生成树matlab代码

最小生成树matlab代码在Matlab中,最小生成树可以通过Kruskal算法和Prim算法来实现。
本文将分别介绍两种算法的代码实现,并对其进行详细解析。
Kruskal算法Kruskal算法是基于贪心算法的最小生成树算法。
其基本思想是将边按照权值从小到大进行排序,然后逐个加入到树中,直到树连通为止。
如果加入一条边使得形成环,则不加入该边。
定义一个函数Kruskal(weight,n)来实现Kruskal算法。
参数weight是一个n*n的矩阵,表示图的邻接矩阵;n表示图中节点的个数。
该函数的返回值为最小生成树的边集。
function edges=Kruskal(weight,n)%初始化[rows,cols,vals]=find(weight);edge_num=length(rows);%边数edges=zeros(n-1,2);%初始化,存放最小生成树的边%边按照权重从小到大排序[~,idx]=sort(vals);rows=rows(idx);cols=cols(idx);%初始化并查集par=1:n;rank=zeros(1,n);%依次加入边n_edge=0;%表示已加入的边数for i=1:edge_num%如果两个节点已经在同一连通块中,则不能加入当前边if FindPar(par,rows(i))==FindPar(par,cols(i))continue;end%将当前边加入到最小生成树中n_edge=n_edge+1;edges(n_edge,:)=[rows(i),cols(i)];%将两个节点合并Union(par,rank,rows(i),cols(i));%如果当前已经加入足够的边,则退出循环if n_edge==n-1break;endendFindPar函数和Union函数是实现并查集的两个函数,用于判断是否形成环以及将两个节点合并。
具体代码如下:%查找节点的祖先function par=FindPar(par,idx)if par(idx)==idxpar=idx;elsepar=FindPar(par,par(idx));end%将两个节点合并function Union(par,rank,x,y)x_par=FindPar(par,x);y_par=FindPar(par,y);if rank(x_par)>rank(y_par)par(y_par)=x_par;elsepar(x_par)=y_par;if rank(x_par)==rank(y_par)rank(y_par)=rank(y_par)+1;endendPrim算法Prim算法也是一种贪心算法,基本思想是从任意一个点开始,找到与该点相邻的最短边,然后将这个边连接的点加入到集合中,继续寻找与该集合相邻的最短边。
Kruskal算法实现步骤

Kruskal算法实现步骤Kruskal算法是一种用于解决最小生成树问题的贪心算法。
它的基本思想是通过不断选取权值最小的边来构建最小生成树。
下面将详细介绍Kruskal算法的实现步骤。
步骤一:初始化首先,我们需要将所有的边按照权值从小到大进行排序。
这可以使用快速排序等常用的排序算法来实现。
同时,我们也需要一个数组来记录每个顶点所在的连通分量。
步骤二:选择最小边从排序后的边中选择权值最小的一条边,并判断这条边所连接的两个顶点是否在不同的连通分量中。
如果是的话,则选择这条边加入最小生成树中;如果不是,则舍弃这条边继续选择下一条权值最小的边。
步骤三:更新连通分量将所选取的边连接的两个顶点加入同一个连通分量中。
这可以通过更新数组来实现,将其中一个顶点的连通分量值赋为另一个顶点的连通分量值。
步骤四:重复步骤二和步骤三依次选择下一条权值最小的边,并重复进行步骤二和步骤三,直到最小生成树的边数达到顶点数减一,或者遍历完所有的边。
步骤五:输出最小生成树最后,将构建好的最小生成树输出,即得到了问题的解。
通过上述的五个步骤,我们可以使用Kruskal算法来求解最小生成树问题。
该算法的时间复杂度主要取决于对边的排序操作,一般为O(ElogE),其中E为边的数量。
总结Kruskal算法是一种简单而有效的贪心算法,用于解决最小生成树问题。
它通过选择权值最小的边,并更新连通分量来逐步构建最小生成树。
该算法的核心是边的排序和判断两个顶点是否在同一连通分量中。
通过合理地使用该算法,我们可以在图论等领域中快速求解最小生成树的问题。
注意:本文仅为描述Kruskal算法实现步骤,未提供具体的代码实现。
如果您需要具体的代码,请参考相关的教材、论文或互联网资源。
实现最小生成树算法(Python)

实现最小生成树算法(Python)最小生成树(MST)是图论中的一个重要问题,它的应用非常广泛。
在计算机科学中,最小生成树问题被广泛应用在网络设计、电路布线、系统优化等领域。
在本文中,我们将介绍最小生成树算法的基本概念、常见的算法实现以及应用场景。
1.最小生成树的定义首先,让我们来了解一下最小生成树的定义。
最小生成树是指一个无向图的生成树,它的所有边的权值之和最小。
换句话说,最小生成树是一个连通图的生成树,它包含图中的所有顶点,但是边的权值之和最小。
在一个无向图G=(V,E)中,V表示顶点集合,E表示边集合。
每条边e∈E都有一个权值w(e)。
一个最小生成树T是一个包含了图中所有顶点的生成树,并且它的边的权值之和最小。
换句话说,如果T'是G的另一个生成树,那么T的权值小于等于T'的权值。
最小生成树问题是一个经典的优化问题,在实际应用中有着广泛的应用。
接下来,我们将介绍常见的最小生成树算法实现,包括Prim算法和Kruskal算法。
2. Prim算法Prim算法是一种常见的贪心算法,它可以求解最小生成树问题。
Prim算法的基本思想是从一个初始顶点开始,逐步加入未访问的顶点,并选择与当前生成树相连的权值最小的边。
该算法的具体步骤如下:步骤1:初始化一个空的生成树T,选择一个初始顶点作为起始点。
步骤2:将起始点加入T,并将其标记为已访问。
步骤3:重复以下步骤,直到T包含所有顶点为止。
步骤4:从T中找到与未访问顶点相连的权值最小的边e,并将其加入T。
步骤5:将边e相连的顶点标记为已访问。
步骤6:重复步骤4和步骤5,直到T包含所有顶点。
通过上述步骤,Prim算法可以得到一个最小生成树。
该算法的时间复杂度为O(V^2),其中V表示图中的顶点数。
在实际应用中,Prim算法通常通过优先队列来实现,以降低时间复杂度。
3. Kruskal算法Kruskal算法是另一种常见的最小生成树算法,它基于图的边来构造最小生成树。
python实现简单俄罗斯方块

python实现简单俄罗斯⽅块本⽂实例为⼤家分享了python实现俄罗斯⽅块的具体代码,供⼤家参考,具体内容如下# teris.py# A module for game teris.# By programmer FYJfrom tkinter import *from time import sleepfrom random import *from tkinter import messageboxclass Teris:def __init__(self):#⽅块颜⾊列表self.color = ['red','orange','yellow','purple','blue','green','pink']# Set a core squre and any shape can be drawn by the relative location.#字典存储形状对应7种形状元组存储坐标self.shapeDict = {1:[(0,0),(0,-1),(0,-2),(0,1)], # shape I2:[(0,0),(0,-1),(1,-1),(1,0)], # shape O3:[(0,0),(-1,0),(0,-1),(1,0)], # shape T T型4:[(0,0),(0,-1),(1,0),(2,0)], # shape J 右长倒L盖⼦5:[(0,0),(0,-1),(-1,0),(-2,0)], # shape L6:[(0,0),(0,-1),(-1,-1),(1,0)], # shape Z7:[(0,0),(-1,0),(0,-1),(1,-1)]} # shape S#旋转坐标控制self.rotateDict = {(0,0):(0,0),(0,1):(-1,0),(0,2):(-2,0),(0,-1):(1,0),(0,-2):(2,0),(1,0):(0,1),(2,0):(0,2),(-1,0):(0,-1),(-2,0):(0,-2),(1,1):(-1,1),(-1,1):(-1,-1),(-1,-1):(1,-1),(1,-1):(1,1)}# 初始⾼度,宽度核⼼块位置self.coreLocation = [4,-2]self.height,self.width = 20,10self.size = 32# Map can record the location of every square.i宽 j⾼self.map = {}#全部置0for i in range(self.width):for j in range(-4,self.height):self.map[(i,j)] = 0#添加边界for i in range(-4,self.width+4):self.map[(i,self.height)] = 1for j in range(-4,self.height+4):for i in range(-4,0):self.map[(i,j)] = 1for j in range(-4,self.height+4):for i in range(self.width,self.width+4):self.map[(i,j)] = 1# 初始化分数0 默认不加快按下时加快self.score = 0self.isFaster = False# 创建GUI界⾯self.root = Tk()self.root.title("Teris")self.root.geometry("500x645")self.area = Canvas(self.root,width=320,height=640,bg='white')self.area.grid(row=2)self.pauseBut = Button(self.root,text="Pause",height=2,width=13,font=(18),command=self.isPause)self.pauseBut.place(x=340,y=100)self.startBut = Button(self.root,text="Start",height=2,width=13,font=(18),command=self.play)self.startBut.place(x=340,y=20)self.restartBut = Button(self.root,text="Restart",height=2,width=13,font=(18),command=self.isRestart)self.restartBut.place(x=340,y=180)self.quitBut = Button(self.root,text="Quit",height=2,width=13,font=(18),command=self.isQuit)self.quitBut.place(x=340,y=260)self.scoreLabel1 = Label(self.root,text="Score:",font=(24))self.scoreLabel1.place(x=340,y=600)self.scoreLabel2 = Label(self.root,text="0",fg='red',font=(24))self.scoreLabel2.place(x=410,y=600)#按键交互self.area.bind("<Up>",self.rotate)self.area.bind("<Left>",self.moveLeft)self.area.bind("<Right>",self.moveRight)self.area.bind("<Down>",self.moveFaster)self.area.bind("<Key-w>",self.rotate)self.area.bind("<Key-a>",self.moveLeft)self.area.bind("<Key-d>",self.moveRight)self.area.bind("<Key-s>",self.moveFaster)self.area.focus_set()#菜单self.menu = Menu(self.root)self.root.config(menu=self.menu)self.startMenu = Menu(self.menu)self.menu.add_cascade(label='Start',menu=self.startMenu)self.startMenu.add_command(label='New Game',command=self.isRestart)self.startMenu.add_separator()self.startMenu.add_command(label='Continue',command=self.play)self.exitMenu = Menu(self.menu)self.menu.add_cascade(label='Exit',command=self.isQuit)self.helpMenu = Menu(self.root)self.menu.add_cascade(label='Help',menu=self.helpMenu)self.helpMenu.add_command(label='How to play',command=self.rule)self.helpMenu.add_separator()self.helpMenu.add_command(label='About...',command=self.about)#先将核⼼块的所在位置在map中的元素设为1,通过self.shapeDict获取其余⽅块位置,将map中对应元素设为1。
python版最小生成树Prim和Kruskal算法
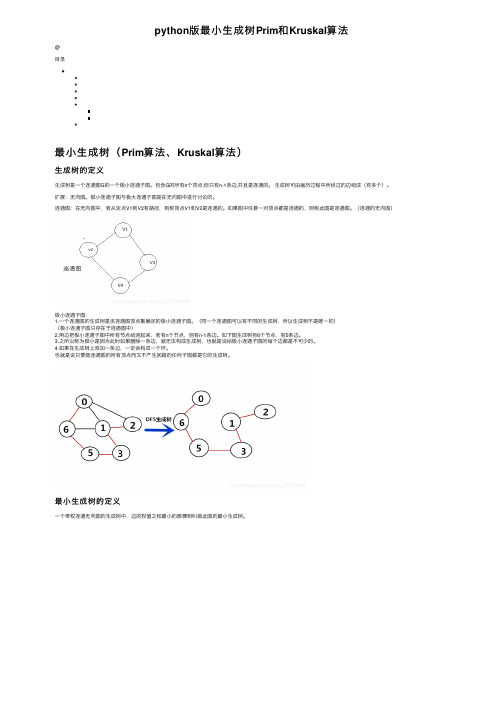
python版最⼩⽣成树Prim和Kruskal算法@⽬录最⼩⽣成树(Prim算法、Kruskal算法)⽣成树的定义⽣成树是⼀个连通图G的⼀个极⼩连通⼦图。
包含G的所有n个顶点,但只有n-1条边,并且是连通的。
⽣成树可由遍历过程中所经过的边组成(有多个)。
扩展:⽆向图。
极⼩连通⼦图与极⼤连通⼦图是在⽆向图中进⾏讨论的。
连通图:在⽆向图中,若从定点V1到V2有路径,则称顶点V1和V2是连通的。
如果图中任意⼀对顶点都是连通的,则称此图是连通图。
(连通的⽆向图)极⼩连通⼦图:1.⼀个连通图的⽣成树是该连通图顶点集确定的极⼩连通⼦图。
(同⼀个连通图可以有不同的⽣成树,所以⽣成树不是唯⼀的)(极⼩连通⼦图只存在于连通图中)2.⽤边把极⼩连通⼦图中所有节点给连起来,若有n个节点,则有n-1条边。
如下图⽣成树有6个节点,有5条边。
3.之所以称为极⼩是因为此时如果删除⼀条边,就⽆法构成⽣成树,也就是说给极⼩连通⼦图的每个边都是不可少的。
4.如果在⽣成树上添加⼀条边,⼀定会构成⼀个环。
也就是说只要能连通图的所有顶点⽽⼜不产⽣回路的任何⼦图都是它的⽣成树。
最⼩⽣成树的定义⼀个带权连通⽆向图的⽣成树中,边的权值之和最⼩的那棵树叫做此图的最⼩⽣成树。
图⼀的最⼩⽣成树就是图⼆(最⼩⽣成树在某些情况下并不唯⼀)。
最⼩⽣成树的⽣成算法:求解最⼩⽣成树的算法主要有两个:1.Prim(普⾥姆)算法;2.Kruskal(克鲁斯卡尔)算法。
Prim算法1. 输⼊:⼀个加权连通图,其中顶点集合为V,边集合为E;2. 初始化:定义存放当前已⾛点的集合Vnew = {x},其中x为集合V中的任意节点(作为起始点),定义存放当前已⾛边的集合Enew = { },为空;3. 重复下列操作,直到 Vnew = V:①在集合E中选取权值最⼩的边<u, v>,其中u为集合Vnew中的元素,⽽v不在Vnew集合当中,并且v∈V(如果存在有多条满⾜前述条件即具有相同权值的边,则可任意选取其中之⼀);②将v加⼊集合Vnew中,将<u, v>边加⼊集合Enew中;4. 输出:使⽤集合Vnew和Enew来描述所得到的最⼩⽣成树。
python 进行q检验的代码

Python 是一种广泛应用于数据分析和统计学领域的编程语言,其强大的库和工具使得对数据进行假设检验变得更加简单和高效。
以下是使用 Python 进行常见假设检验的代码示例,包括 t 检验、方差分析、卡方检验等。
通过这些代码示例,读者可以学习如何在 Python 环境下进行假设检验,并根据实际情况对代码进行适当的修改和扩展。
1. t 检验假设我们有两组数据,分别为 group1 和 group2,我们想要检验它们的均值是否有显著差异。
我们可以使用 scipy 库中的 ttest_ind 函数进行 t 检验,示例代码如下:```pythonimport scipy.stats as statsgroup1 = [1, 2, 3, 4, 5]group2 = [2, 3, 4, 5, 6]t_stat, p_value = stats.ttest_ind(group1, group2)print("t 统计量:", t_stat)print("p 值:", p_value)```其中,t_stat 为 t 统计量,p_value 为对应的 p 值。
如果 p 值小于显著性水平(通常取 0.05),则可以拒绝原假设,认为两组数据的均值存在显著差异。
2. 方差分析假设我们有多组数据,我们想要检验它们的均值是否存在显著差异。
我们可以使用 scipy 库中的 f_oneway 函数进行方差分析,示例代码如下:```pythonf_stat, p_value = stats.f_oneway(group1, group2, group3) print("F 统计量:", f_stat)print("p 值:", p_value)```其中,f_stat 为 F 统计量,p_value 为对应的 p 值。
如果 p 值小于显著性水平,则可以拒绝原假设,认为多组数据的均值存在显著差异。
python凯撒密码编写程序详解

python凯撒密码编写程序详解凯撒密码是一种简单的密码算法,它是通过将字母表中的每个字母按照一定的偏移量(或称为密钥)进行替换来加密明文。
在这里,我们将介绍如何用 Python 编写一个凯撒密码编码程序。
首先,让我们定义一个字符串变量 `plain_text` 作为待加密的明文。
这个字符串变量可以包含任意字符和空格,但是只能由大写或小写字母、数字、逗号等常规字符组成。
我们也需要定义一个整数变量 `key`,这将是偏移量或者密钥,它将用于加密明文。
```pythonplain_text = "Hello, world!"key = 3```接下来,我们需要将明文字符串中的每个字符按照偏移量进行替换。
具体来说,我们可以使用 Python 的循环结构和字符串函数来实现这个过程。
首先,我们可以将字符串转换为一个列表,这将使得我们可以方便地处理每个字符。
然后,我们可以使用内置的 `ord()` 函数将每个字符转换为其 ASCII 码值。
这个函数接受一个字符作为输入,并返回一个整数,代表这个字符的 ASCII 码值。
接下来,我们需要应用密钥对每个字符的 ASCII 码值进行修改。
这可以通过使用内置的`chr()` 函数进行字符和 ASCII 码值之间的转换来完成。
最后,我们需要将修改后的字符再次组合成一个字符串,以生成密文。
```pythoncipher_text = ""for char in list(plain_text):if char.isalpha():if char.isupper():cipher_text += chr((ord(char) - 65 + key) % 26 + 65)else:cipher_text += chr((ord(char) - 97 + key) % 26 + 97)else:cipher_text += char```在这个程序中,我们首先检查每个字符是否是字母,如果是的话,我们就根据它是大写还是小写字母,来对其进行偏移量地加密。
kruskal算法c++程序

Kruskal算法是一种用于求解最小生成树的贪心算法,它能够有效地找到一个加权连通图中的最小生成树。
在本文中,我们将通过C++程序来实现Kruskal算法,并对其原理进行详细的讲解和分析。
一、Kruskal算法原理1. Kruskal算法的基本思想Kruskal算法的基本思想是:将图中的所有边按照权值的大小进行递增排序,然后依次选取权值最小的边,若加入该边不会形成环,则将其加入最小生成树中,直到最小生成树中含有V-1条边为止。
2. Kruskal算法的步骤Kruskal算法的具体步骤如下:(1)将图中的所有边按照权值的大小进行递增排序(2)依次选取权值最小的边(3)若加入该边不会形成环,则将其加入最小生成树中(4)直到最小生成树中含有V-1条边为止3. Kruskal算法的实现要点(1)利用并查集来判断加入边是否会形成环(2)采用排序算法对边进行排序(3)采用循环遍历所有边,并判断是否加入最小生成树二、Kruskal算法C++程序实现```C++#include <iostream>#include <vector>#include <algorithm>using namespace std;// 定义边的结构体struct Edge {int from, to, weight;Edge(int f, int t, int w) : from(f), to(t), weight(w) {} };// 定义并查集class UnionFind {public:vector<int> parent;UnionFind(int n) : parent(n) {for (int i = 0; i < n; i++) {parent[i] = i;}}int find(int x) {return x == parent[x] ? x : (parent[x] = find(parent[x]));}void unite(int x, int y) {parent[find(x)] = find(y);}bool same(int x, int y) {return find(x) == find(y);}};// 定义Kruskal算法vector<Edge> kruskal(int n, vector<Edge> edges) {sort(edges.begin(), edges.end(), [](const Edge a, const Edge b) {return a.weight < b.weight;});UnionFind uf(n);vector<Edge> res;for (const Edge e : edges) {if (!uf.same(e.from, e.to)) {uf.unite(e.from, e.to);res.push_back(e);}}return res;}int main() {int n = 6;vector<Edge> edges = {Edge(0, 1, 4), Edge(0, 2, 4), Edge(1, 2, 2), Edge(1, 3, 3), Edge(1, 4, 1), Edge(2, 3, 4), Edge(3, 4, 2), Edge(3, 5, 5), Edge(4, 5, 3)};vector<Edge> minSpanningTree = kruskal(n, edges);for (const Edge e : minSpanningTree) {cout << e.from << " - " << e.to << " : " << e.weight << endl;}return 0;}```三、Kruskal算法C++程序分析1. 我们定义了一个边的结构体来表示图中的边,并且定义了并查集来判断加入边是否会形成环。
编程实现高斯克吕格投影代号计算

编程实现高斯克吕格投影代号计算高斯克吕格投影代号计算是指根据地面的经纬度坐标和相应的大地基准面,确定该点在高斯克吕格投影中的投影坐标。
以下是使用Python编程实现高斯克吕格投影代号计算的代码:```pythonimport mathdef gauss_kruger_projection(lon, lat, a, b, phi0, lambda0, k0):# 转换为弧度制phi = math.radians(lat)lambda_ = math.radians(lon)lambda0 = math.radians(lambda0)phi0 = math.radians(phi0)# 计算中间值e2 = (a**2 - b**2) / a**2e_2 = (a**2 - b**2) / b**2n = a / math.sqrt(1 - e2 * math.sin(phi)**2)t = math.tan(phi)**2c = e_2 * math.cos(phi)**2A = (lambda_ - lambda0) * math.cos(phi)M = a * ((1 - e2 / 4 - 3*e2**2 / 64 - 5*e2**3 / 256) * phi- (3*e2 / 8 + 3*e2**2 / 32 + 45*e2**3 / 1024) * math.sin(2*phi)+ (15*e2**2 / 256 + 45*e2**3 / 1024) *math.sin(4*phi)- (35*e2**3 / 3072) * math.sin(6*phi)) # 计算投影坐标x = k0 * n * (A + (1-t+c)*A**3/6 + (5-18*t+t**2+72*c-58*e2)*A**5/120)y = k0 * (M + n * math.tan(phi) * (A**2/2 + (5-t+9*c+4*c**2)*A**4/24+ (61-58*t+t**2+600*c-330*e2)*A**6/720))return x, y```其中,输入参数包括经度 `lon`、纬度 `lat`、椭球长半轴 `a`、椭球短半轴 `b`、中央经线经度 `lambda0`、中央纬线纬度 `phi0`,以及投影比例因子 `k0`。
python实现简单的恺撒密码加密并输出

python实现简单的恺撒密码加密并输出描述恺撒密码是古罗马恺撒⼤帝⽤来对军事情报进⾏加解密的算法,它采⽤了替换⽅法对信息中的每⼀个英⽂字符循环替换为字母表序列中该字符后⾯的第三个字符,即,字母表的对应关系如下:原⽂:A B C D E F G H I J K L M N O P Q R S T U V W X Y Z密⽂:D E F G H I J K L M N O P Q R S T U V W X Y Z A B C对于原⽂字符P,其密⽂字符C满⾜如下条件:C=(P+3) mod 26上述是凯撒密码的加密⽅法,解密⽅法反之,即:P=(C-3) mod 26假设⽤户可能使⽤的输⼊包含⼤⼩写字母a~zA~Z、空格和特殊符号,请编写⼀个程序,对输⼊字符串进⾏恺撒密码加密,直接输出结果,其中空格不⽤进⾏加密处理。
使⽤input()获得输⼊。
输⼊⽰例1: python is good输出⽰例1: sbwkrq lv jrrg1 pwd = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'2 before = input() #输⼊要加密的话3 beforeUp = before.upper() #将输⼊的所有字符变⼤写4 result = ''5for i in range(len(before)):6if beforeUp[i] in pwd: #过滤⾮字母7 start = pwd.index(beforeUp[i])8 end = (start+3)%26 #得到在pwd中的下标9if before[i].islower():10 result += pwd[end].lower()11else:12 result +=pwd[end]13else:14 result +=before[i]15print(result)⼤家有什么别的好⽅法吗。
浅谈算法之最小生成树Kruskal的Python实现

浅谈算法之最⼩⽣成树Kruskal的Python实现⽬录⼀、前⾔⼆、树是什么三、从图到树四、解决⽣成问题五、从⽣成树到最⼩⽣成树六、实际问题与代码实现七、结尾⼀、前⾔我们先不讲算法的原理,也不讲⼀些七七⼋⼋的概念,因为对于初学者来说,看到这些术语和概念往往会很头疼。
头疼也是正常的,因为⽆端突然出现这么多信息,都不知道它们是怎么来的,也不知道这些信息有什么⽤,⾃然就会觉得头疼。
这也是很多⼈学习算法热情很⾼,但是最后⼜被劝退的原因。
我们先不讲什么叫⽣成树,怎么⽣成树,有向图、⽆向图这些,先简单点,从最基本的内容开始,完整地将这个算法梳理⼀遍。
⼆、树是什么⾸先,我们先来看看最简单的数据结构——树。
树是⼀个很抽象的数据结构,因为它在⾃然界当中能找到对应的物体。
我们在初学的时候,往往都会根据⾃然界中真实的树来理解这个概念。
所以在我们的认知当中,往往树是长这样的:上⾯这张图就是⾃然界中树的抽象,我们很容易理解。
但是⼀般情况下,我们看到的树结构往往不是这样的,⽽是倒过来的。
也就是树根在上,树叶在下。
这样设计的原因很简单,没什么特别的道理,只是因为我们在遍历树的时候,往往从树根开始,从树根往叶⼦节点出发。
所以我们倒过来很容易理解⼀些,我们把上⾯的树倒过来就成了这样:上⾯的两种画法当然都是正确的,但既然树可以正着放,也可以倒过来放,我们⾃然也可以将它伸展开来放。
⽐如下⾯这张图,其实也是⼀棵树,只是我们把它画得不⼀样⽽已。
我们可以想象⼀下,假如有⼀只⽆形的⼤⼿抓住了树根将它“拎起来”,那么它⾃然⽽然就变成了上⾯的样⼦。
然后你会发现,如果真的有这样⼤⼿,它不管拎起哪个节点,都会得到⼀棵树。
也就是说,如果树根的位置对我们不再重要的话,树其实就等价于上⾯这样的图。
那么这样的图究竟是什么图呢?它有什么性质呢?所有的图都能看成是树吗?显然这三种情况都不是树,第⼀种是因为图中的边有⽅向了。
有了⽅向之后,图中连通的情况就被破坏了。
贪心算法之Kruskal

贪⼼算法之Kruskal克鲁斯卡尔Kruskal算法同Prim算法⼀样,都是求最⼩⽣成树。
Kruskal是不断的找最短边,加⼊集合,且不构成回路。
所以,我们可以给每个点定义⼀个集合,⼀边的起点和终点查看是否属于同⼀集合,如果是说明是回路,不成⽴,找下⼀条边。
如果不属于同⼀集合,则成⽴,并把其中的⼀个集合的全部节点的集合改为另外⼀个集合,进⾏统⼀。
具体代码如下:#include <iostream>#include <algorithm>using namespace std;#define MAXNODE 1000int n,m;struct Edge{int u;int v;int w;} e[MAXNODE * MAXNODE];int nodeset[MAXNODE]; //每个顶点的集合int Kruskal(int n);bool Merge(int u, int i);bool comp(Edge a, Edge b){return a.w < b.w;}void Init(int n){for(int i=0; i < n; i++){nodeset[i] = i;}}int main(){cout<<"请输⼊节点数n和边数m:";cin>>n>>m;Init(n);cout << "请输⼊节点边的权值:";for(int i = 0; i < m; i++){cin>>e[i].u>>e[i].v>>e[i].w;}sort(e, e+m, comp);int ans = Kruskal(n);cout<<ans<<endl;}int Kruskal(int n) {int ans = 0;for(int i = 0; i < m; i++){if(Merge(e[i].u, e[i].v)){//可以合并ans += e[i].w;n--;if(n==1)return ans;}}return0;}bool Merge(int u, int i) {int a = nodeset[u];int b = nodeset[i];if(a == b)return false;//归并节点集合for(int j = 0; j < n; j++){if(nodeset[j] == b){nodeset[j] = a;}}return true;}同时,与Prim算法相⽐,因为Kruskal是按照边进⾏的,所以适合边少的情况,即稀疏图。
数据结构最小生成树克鲁斯卡尔算法代码

数据结构最小生成树克鲁斯卡尔算法代码以下是克鲁斯卡尔算法的实现代码:```python# 定义边的类class Edge:def __init__(self, src, dest, weight):self.src = srcself.dest = destself.weight = weight# 定义图的类class Graph:def __init__(self, vertices):self.V = verticesself.edges = []def add_edge(self, src, dest, weight):edge = Edge(src, dest, weight)self.edges.append(edge)# 查找顶点的根节点def find(self, parent, i):if parent[i] == i:return ireturn self.find(parent, parent[i])# 合并两个集合def union(self, parent, rank, x, y):xroot = self.find(parent, x)yroot = self.find(parent, y)if rank[xroot] < rank[yroot]:parent[xroot] = yrootelif rank[xroot] > rank[yroot]:parent[yroot] = xrootelse:parent[yroot] = xrootrank[xroot] += 1# 使用克鲁斯卡尔算法计算最小生成树def kruskal(self):result = []i = 0e = 0 # 已选择的边的数量# 按权重对边进行排序self.edges = sorted(self.edges, key=lambda x:x.weight)parent = []rank = []# 初始化每个顶点的父节点和秩for node in range(self.V):parent.append(node)rank.append(0)while e < self.V - 1:# 选择权重最小的边edge = self.edges[i]i += 1x = self.find(parent, edge.src)y = self.find(parent, edge.dest) # 判断是否形成环路if x != y:e += 1result.append(edge)self.union(parent, rank, x, y) return result# 测试代码g = Graph(4)g.add_edge(0, 1, 10)g.add_edge(0, 2, 6)g.add_edge(0, 3, 5)g.add_edge(1, 3, 15)g.add_edge(2, 3, 4)result = g.kruskal()for edge in result:print(f"{edge.src} -- {edge.dest} == {edge.weight}")```这段代码实现了克鲁斯卡尔算法,其中`Graph`类表示图,`Edge`类表示边。
最小生成树-Kruskal算法java代码实现

最小生成树 -Kruskal算法 java代码实现
/* *日期:2010-04-18 20:02 *开发者:heroyan *联系方式:zndxysf@ *功能:无向图最小生成树Kruskal算法实现案例 */ import java.util.Scanner; import java.util.Arrays; import java.util.ArrayList;
public class Kruskal{ private static int MAX = 100; private ArrayList<Edge> edge = new ArrayList<Edge>();//整个图的边 private ArrayList<Edge> target = new ArrayList<Edge>();//目标边,最小生成树 private int[] parent = new int[MAX];//标志所在的集合 private static double INFINITY = 99999999.99;//定义无穷大 private double mincost = 0.0;//最小成本 private int n;//结点个数
mincost = 0.0;
for(int i = 1; i <= n; ++i){ parent[i] = i; } } //集合合并 public void union(int j, int k){ for(int i = 1; i <= n; ++i){ if(parent[i] == j){ parent[i] = k; } } }
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
通信网课程设计
Project2_Kruskal算法
(基于union_find实现)
一源代码
# -*- coding: utf-8 -*-
"""
Created on Wed May 23 09:31:49 2018
@author: 15193
"""
import numpy as np
import time
start=time.clock()
class Graph(object):
def __init__(self): #初始化
self.nodes=[]
self.edge={}
def insert(self,a,b,c): #添加相应的边
if not(a in self.nodes):
self.nodes.append(a)
self.edge[a]={}
if not(b in self.nodes):
self.nodes.append(b)
self.edge[b]={}
self.edge[a][b]=c
self.edge[b][a]=c
def succ(self,a): #返回点的有关的边
return self.edge[a]
def getnodes(self): #返回点集
return self.nodes
class union_find(object): #搭建union-find数据结构
def __init__(self,size):
self.parent=[]
self.rank=[]
self.count=size
for i in range(0,size):
self.parent.append(i)
self.rank.append(1)
def find(self,i):
if self.parent[i]!=i:
self.parent[i]=self.find(self.parent[i])
return self.parent[i]
def union(self,i,j):
p=self.find(i)
q=self.find(j)
if p==q:
return False
if self.rank[p]<self.rank[q]: #根据树的大小进行合并,尽量使得小树并到大树上self.parent[p]=q
self.rank[q]=self.rank[q]+self.rank[p]
elif self.rank[p]>self.rank[q]:
self.parent[q]=p
self.rank[p]=self.rank[p]+self.rank[q]
else:
self.parent[q]=p
self.rank[p]=self.rank[p]+self.rank[q]
self.count=self.count-1
return True
f=open('D:\graph_1.txt','r') #打开D盘的graph文件,用f表示
graph=Graph()
lineList = f.readlines()
length=len(lineList) #读取的行数
i=0
for line in lineList: #一行读取点的关系
if line in lineList[0]:
n,m=line.split()
print("该图有",n,"个点")
print("该图有",m,"条边")
nodes_list=np.zeros((length-1,3), dtype=np.int16)
else:
a,b,c=line.split()
nodes_list[i,0]=a
nodes_list[i,1]=b
nodes_list[i,2]=c
i=i+1
graph.insert(a,b,c) #将图结构的相关信息读进去
f.close() #将读取得到的图关掉
#print(graph.getnodes())
##接下来将图中所有边的权值进行排序
nodes_list=nodes_list[nodes_list[:,2].argsort()] #按照第3列对行排序
#print(nodes_list)
nodes=graph.getnodes()
world=union_find(int(n))
T=0 #T作为记录MST的标志
j=0 #j作为按照降序排列的边序号
while(world.count!=1):
if world.union(int(nodes_list[j,0]),int(nodes_list[j,1]))==True: T=T+nodes_list[j,2]
else:
pass
j=j+1
print("MST:",T)
end=time.clock()
total_time=end-start
print("总耗时:"+str(total_time)) #整个算法的运行时间
二运行时间及结果展示:
Graph_0.txt
Graph_1.txt
Graph_2.txt
Graph_3.txt
Graph_4.txt
Graph_5.txt
Graph_6.txt
Graph_7.txt
Graph_8.txt
Graph_9.txt
Graph_10.txt
Graph_11.txt
Graph_12.txt
三算法复杂度分析:
根据理论分析,Kruskal算法(union-find)的复杂度为O(mlogn)
我先将graph0-graph12的运算结果画图,感觉graph11和graph12的结果对于验证存在一定的偏差,所以我又选取graph0-graph10的运算结果作图,最终得到线性关系,即证。
所以Kruskal算法(union-find)的复杂度为O(mlogn)
四收获和反思:
在完成了整个算法的实现,最后得到相应算法的验证和仿真,我感觉我收获了很多。
集中体现在几个方面:
1 对python的代码功底得到提升,动手能力和逻辑思考能力得到锻炼。
2 在编程的时候,寻找合适的数据结构,对于算法的优化很有帮助。
3 kruskal的调试过程中,还算简单,相比于难受的prim算法,我用了四个小时用在了调试上,这一点上,还是得说kruskal选取了一个合适的union_find数据结构。