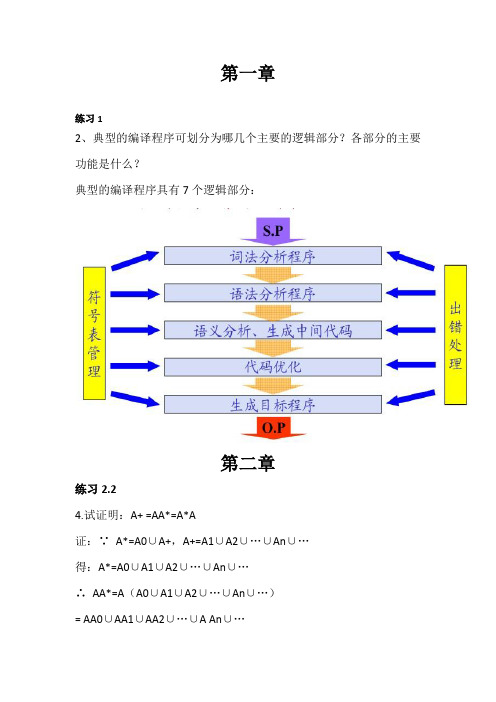
编译原理(求First集)
编译原理-第4章 语法分析--习题答案

第4章语法分析习题答案1.判断(1)由于递归下降分析法比较简单,因此它要求文法不必是LL(1)文法。
(× )LL(1)文法。
(× )(3)任何LL(1)文法都是无二义性的。
(√)(4)存在一种算法,能判定任何上下文无关文法是否是LL(1) 文法。
(√)(× )(6)每一个SLR(1)文法都是LR(1)文法。
(√)(7)任何一个LR(1)文法,反之亦然。
(× )(8)由于LALR是在LR(1)基础上的改进方法,所以LALR(× )(9)所有LR分析器的总控程序都是一样的,只是分析表各有不同。
(√)(10)算符优先分析法很难完全避免将错误的句子得到正确的归约。
(√)2.文法G[E]:E→E+T|TT→T*F|FF→(E)|i试给出句型(E+F)*i的短语、简单短语、句柄和最左素短语。
答案:画出语法树,得到:短语: (E+F)*i ,(E+F) ,E+F ,F ,i简单短语: F ,i句柄: F最左素短语: E+F3.文法G[S]:S→SdT | TT→T<G | GG→(S) | a试给出句型(SdG)<a的短语、简单短语、句柄和最左素短语。
答案:画出语法树,得到:短语:(SdG)<a 、(SdG) 、SdG 、G 、a简单(直接)短语:G 、a句柄:G最左素短语:SdG4.对文法G[S]提取公共左因子进行改写,判断改写后的文法是否为LL(1)文法。
S→if E then S else SS→if E then SS→otherE→b答案:提取公共左因子;文法改写为:S→if E then S S'|otherS'→else S|E→bLL(1)文法判定:① 文法无左递归② First(S)={if,other}, First(S')={else, }First(E)={b}Follow(S)= Follow(S')={else,#}Follow(E)={then}First(if E then S S')∩First(other)=First(else S)∩First( )=③First(S')∩Follow(S')={else}不为空集故此文法不是LL(1)文法。
编译原理(第三版)答案

1 {1,2,3} Φ {2,3,4} {2,3,4} {2,3,4} {2,3,4,Y} {2,3,4}
0
1 0
0 1
0 2
1
1
3 0
1
0 4
1
5
6
0
0
1
1
最小化:{0,1,2,3,4,5},{6}
{0,1,2,3,4,5}0={1,3,5}
{0,1,2,3,4,5}1={1,2,4,6}
{0,1,2,3,4},{5},{6}
E⇒E+T⇒E+T*F⇒E+T*i⇒E+F*i⇒E+i*i⇒T+i*i⇒F+i*i⇒i+i*i
E⇒T⇒T*F⇒T*(E)⇒T*(E+T)⇒T*(E+F)⇒T*(E+i)⇒T*(T+i)⇒T*(F+i)⇒T*(i+i)
⇒F*(i+i)⇒i*(i+i)
1
语法树: E
E
+
T
E
E
+
T
E
+
TF
T
T
*
F
T
i F
N⇒ND⇒N4⇒D4⇒34
N⇒ND⇒N8⇒ND8⇒N68⇒D68⇒568
P-36-7 G(S):(没有考虑正负符号问题) S→P|AP P→1|3|5|7|9 A→AD|N N→2|4|6|8|P D→0|N
或者:(1)S→ABC|C A→1|2|3|4|5|6|7|8|9 B→BA|B0|ε C→1|3|5|7|9
then advance else if sym=‘(’
then begin advance;T; if sym = ‘)’ then advance; else error;
编译原理中first集合的定义

编译原理中的first集合是指在文法中,一个非终结符号的所有可能的开始终结符号的集合。
在编译过程中,求解文法的first集合有着重要的意义。
下面将从定义、性质、求解方法和应用四个方面来详细介绍first集合。
一、定义在上下文无关文法中,对于一个非终结符号X,它的first集合定义为:1. 如果X可以直接推导出终结符号a,则将a加入X的first集合中;2. 如果X可以通过若干步推导出ε(空串),则将ε加入X的first集合中;3. 如果X可以通过若干步推导出Y1Y2...Yk,其中Y1,Y2,...,Yk是终结符号或者非终结符号,并且Y1不可为空,则将Y1的first集合中的所有元素(除去ε)加入X的first集合中。
二、性质1. first集合是关于文法的。
即不同的文法可能得到不同的first集合。
2. first集合可以为空。
即某些非终结符号的first集合可能为空集。
3. first集合的求解不一定唯一。
即针对同一个文法,可能有多种不同的求解方式。
三、求解方法在对文法的first集合进行求解时,常用的方法有两种:直接法和间接法。
1. 直接法:直接根据first集合的定义,对每个非终结符号进行推导,找出所有可能的开始终结符号。
2. 间接法:先求解终结符号的first集合,然后根据非终结符号的产生式和已经求解出的非终结符号和终结符号的first集合,来逐步求解非终结符号的first集合。
四、应用1. 在LL(1)文法的构造中,first集合的求解是至关重要的步骤。
通过求解文法符号的first集合,可以帮助我们构造出LL(1)文法,从而用于自顶向下的语法分析。
2. 在语法制导翻译中,通过利用first集合,可以帮助我们优化翻译过程,提高翻译的效率和准确性。
3. 在编译器的错误处理中,通过利用文法符号的first集合,可以帮助我们更好地定位并处理语法错误,提高编译器的鲁棒性和容错性。
first集合在编译原理中具有重要的地位和作用,它的求解对于文法分析、语法制导翻译和编译器的错误处理都具有重要意义。
【编译原理】语法分析LL(1)分析法的FIRST和FOLLOW集

【编译原理】语法分析LL(1)分析法的FIRST和FOLLOW集 近来复习编译原理,语法分析中的⾃上⽽下LL(1)分析法,需要构造求出⼀个⽂法的FIRST和FOLLOW集,然后构造分析表,利⽤分析表+⼀个栈来做⾃上⽽下的语法分析(递归下降/预测分析),可是这个FIRST集合FOLLOW集看得我头⼤。
教课书上的规则如下,⽤我理解的语⾔描述的:任意符号α的FIRST集求法:1. α为终结符,则把它⾃⾝加⼊FIRSRT(α)2. α为⾮终结符,则:(1)若存在产⽣式α->a...,则把a加⼊FIRST(α),其中a可以为ε(2)若存在⼀串⾮终结符Y1,Y2, ..., Yk-1,且它们的FIRST集都含空串,且有产⽣式α->Y1Y2...Yk...,那么把FIRST(Yk)-{ε}加⼊FIRST(α)。
如果k-1抵达产⽣式末尾,那么把ε加⼊FIRST(α) 注意(2)要连续进⾏,通俗地描述就是:沿途的Yi都能推出空串,则把这⼀路遇到的Yi的FIRST集都加进来,直到遇到第⼀个不能推出空串的Yk为⽌。
重复1,2步骤直⾄每个FIRST集都不再增⼤为⽌。
任意⾮终结符A的FOLLOW集求法:1. A为开始符号,则把#加⼊FOLLOW(A)2. 对于产⽣式A-->αBβ: (1)把FIRST(β)-{ε}加到FOLLOW(B) (2)若β为ε或者ε属于FIRST(β),则把FOLLOW(A)加到FOLLOW(B)重复1,2步骤直⾄每个FOLLOW集都不再增⼤为⽌。
⽼师和同学能很敏锐地求出来,⽽我只能按照规则,像程序⼀样⼀条条执⾏。
于是我把这个过程写成了程序,如下:数据元素的定义:1const int MAX_N = 20;//产⽣式体的最⼤长度2const char nullStr = '$';//空串的字⾯值3 typedef int Type;//符号类型45const Type NON = -1;//⾮法类型6const Type T = 0;//终结符7const Type N = 1;//⾮终结符8const Type NUL = 2;//空串910struct Production//产⽣式11 {12char head;13char* body;14 Production(){}15 Production(char h, char b[]){16 head = h;17 body = (char*)malloc(strlen(b)*sizeof(char));18 strcpy(body, b);19 }20bool operator<(const Production& p)const{//内部const则外部也为const21if(head == p.head) return body[0] < p.body[0];//注意此处只适⽤于LL(1)⽂法,即同⼀VN各候选的⾸符不能有相同的,否则这⾥的⼩于符号还要向前多看⼏个字符,就不是LL(1)⽂法了22return head < p.head;23 }24void print() const{//要加const25 printf("%c -- > %s\n", head, body);26 }27 };2829//以下⼏个集合可以再封装为⼀个⼤结构体--⽂法30set<Production> P;//产⽣式集31set<char> VN, VT;//⾮终结符号集,终结符号集32char S;//开始符号33 map<char, set<char> > FIRST;//FIRST集34 map<char, set<char> > FOLLOW;//FOLLOW集3536set<char>::iterator first;//全局共享的迭代器,其实觉得应该⽤局部变量37set<char>::iterator follow;38set<char>::iterator vn;39set<char>::iterator vt;40set<Production>::iterator p;4142 Type get_type(char alpha){//判读符号类型43if(alpha == '$') return NUL;//空串44else if(VT.find(alpha) != VT.end()) return T;//终结符45else if(VN.find(alpha) != VN.end()) return N;//⾮终结符46else return NON;//⾮法字符47 }主函数的流程很简单,从⽂件读⼊指定格式的⽂法,然后依次求⽂法的FIRST集、FOLLOW集1int main()2 {3 FREAD("grammar2.txt");//从⽂件读取⽂法4int numN = 0;5int numT = 0;6char c = '';7 S = getchar();//开始符号8 printf("%c", S);9 VN.insert(S);10 numN++;11while((c=getchar()) != '\n'){//读⼊⾮终结符12 printf("%c", c);13 VN.insert(c);14 numN++;15 }16 pn();17while((c=getchar()) != '\n'){//读⼊终结符18 printf("%c", c);19 VT.insert(c);20 numT++;21 }22 pn();23 REP(numN){//读⼊产⽣式24 c = getchar();25int n; RINT(n);26while(n--){27char body[MAX_N];28 scanf("%s", body);29 printf("%c --> %s\n", c, body);30 P.insert(Production(c, body));31 }32 getchar();33 }3435 get_first();//⽣成FIRST集36for(vn = VN.begin(); vn != VN.end(); vn++){//打印⾮终结符的FIRST集37 printf("FIRST(%c) = { ", *vn);38for(first = FIRST[*vn].begin(); first != FIRST[*vn].end(); first++){39 printf("%c, ", *first);40 }41 printf("}\n");42 }4344 get_follow();//⽣成⾮终结符的FOLLOW集45for(vn = VN.begin(); vn != VN.end(); vn++){//打印⾮终结符的FOLLOW集46 printf("FOLLOW(%c) = { ", *vn);47for(follow = FOLLOW[*vn].begin(); follow != FOLLOW[*vn].end(); follow++){48 printf("%c, ", *follow);49 }50 printf("}\n");51 }52return0;53 }主函数其中⽂法⽂件的数据格式为(按照平时做题的输⼊格式设计的):第⼀⾏:所有⾮终结符,⽆空格,第⼀个为开始符号;第⼆⾏:所有终结符,⽆空格;剩余⾏:每⾏描述了⼀个⾮终结符的所有产⽣式,第⼀个字符为产⽣式头(⾮终结符),后跟⼀个整数位候选式的个数n,之后是n个以空格分隔的字符串为产⽣式体。
编译原理习题解答参考

编译原理习题解答参考1.计算机执行用高级语言编写的程序的途径有哪些?它们之间主要区别是什么?答:计算机执行用高级语言编写的程序途径有两种:解释方式和编译方式。
解释方式下直接对源程序进行解释执行,并得到计算结果,特点是计算机并不事先对高级语言进行全盘翻译将其全部变为机器代码,而是每读入一条语句,就用解释器将其翻译为机器代码,予以执行,然后再读入下一条高级语句,翻译为机器代码,再执行,如些反复,即边翻译边执行;编译方式下对源程序的执行需要经过翻译阶段和运行阶段才能得到计算结果,其特点是计算机事先对高级语言进行全盘翻译将其全部变为机器代码,再统一执行,即先翻译后执行。
简单来说解释方式不生成目标代码,编译方式生成目标代码。
2.名字与标识符的区别是什么?答:在程序设计语言中,凡是以字母开头的有限个字母数字的序列都是标识符。
当给予一个标识符确切的含义后,该标识符就叫做一个名字。
标识符是一个没有意义的字符序列,而名字有确切的含义,一个名字代表一个存储单元,该单存放该名字的值。
此外,名字还有属性(如类型和作用域等)。
如objectint, 作为标识符,它没有任何含义,但作为名字,它可能表示变量名、函数名等。
3.许多编译程序在真正编译之前都要进行预处理操作,请问预处理的目的是什么?预处理主要做哪些工作?答:在源程序中有时存在多个连续的空格、回车、换行及注释等编辑性字符,它们不是程序的必要组成部分,它们的意义只是改善程序的易读性和易理解性。
为了降低编译程序的处理负担,许多编译程序在编译之前通过预处理工作将这些部分删除。
预处理的主要工作是对源程序进行格式方面的规范化处理,如去掉注释、将回车换行变成空格、将多个空格替换为一个空格等。
P35 4,6,7,8,9,11(1,2)4.答:256,86.(1)答:所产生的语言是:所有正整数集,且可以以0打头;0127,34,568的推导略。
7.答:S→ABD|AD|DA→2|4|6|8|DB→0|A|B0|BAD→1|3|5|7|98.答:略。
编译原理实验LL(1)文法的判断及转换

2016.11.30LL(1)文法的判断及转换目录一、实验名称 (2)二、实验目的 (2)三、实验原理 (2)1、First集定义 (2)2、Follow集定义 (2)3、Select集定义 (3)4、含左递归文法 (3)四、实验思路 (3)1、求非终结符是否能导出空 (3)2、求First集算法 (3)3、求Follow集算法 (4)4、求Select集算法 (4)五、实验小结 (4)六、附件 (4)1、源代码 (4)2、运行结果截图 (11)一、实验名称LL(1)文法的判断及转换二、实验目的输入:任意一个文法输出:(1)是否为LL(1)文法(2)若是,给出每条产生式的select集(3)若不是,看看是否含有左公共因子或者含有左递归,并用相应的方法将非LL(1)文法变成LL(1)文法,并输出新文法中每条产生式的select集。
三、实验原理1、First集定义令X为一个文法符号(终止符或非终止符)或ε,则集合First(X)有终止符组成,此外可能还有ε,它的定义如下:1. 若X是终止符或ε,则First(X)= {X}。
2. 若X是非终结符,则对于每个产生式X—>X1X2…Xn,First(X)包含了First(X1)-{ε}。
若对于某个i < n,所有的集合First(X1),... ,First (Xi)都包含了ε,则First(X)也包括了First(Xi+1)- {ε}。
若所有集合First(X1),...,First(Xn)都包括了ε,则First(X)也包括了ε。
2、Follow集定义给出一个非终结符A,那么集合Follow(A)则是由终结符组成,此外可能还含有#(#是题目约定的字符串结束符)。
集合Follow(A)的定义如下:1. 若A是开始符号,则#在Follow(A)中。
2. 若存在产生式B—>αAγ,则First(γ)- {ε}在Follow(A)中。
3. 若存在产生式B—>αAγ,且ε在First(γ)中,则Follow(A)包括Follow(B)。
编译原理 FIRST集和FOLLOW集的求法

First集合的求法:First集合最终是对产生式右部的字符串而言的,但其关键是求出非终结符的First集合,由于终结符的First集合就是它自己,所以求出非终结符的First集合后,就可很直观地得到每个字符串的First集合。
1. 直接收取:对形如U-a…的产生式(其中a是终结符),把a收入到First(U)中2. 反复传送:对形入U-P…的产生式(其中P是非终结符),应把First(P)中的全部内容传送到First(U)中。
Follow集合的求法:Follow集合是针对非终结符而言的,Follow(U)所表达的是句型中非终结符U所有可能的后随终结符号的集合,特别地,“#”是识别符号的后随符。
1. 直接收取:注意产生式右部的每一个形如“…Ua…”的组合,把a直接收入到Follow(U)中。
2.直接收取:对形如“…UP…”(P是非终结符)的组合,把First(P)除ε直接收入到Follow(U)中。
3.反复传送:对形如P-…U的产生式(其中U是非终结符),应把Follow(P)中的全部内容传送到Follow(U)中。
(或 P-…UB且First(B)包含ε,则把First(B)除ε直接收入到Follow(U)中,并把Follow(P)中的全部内容传送到Follow(U)中)例1:判断该文法是不是LL(1)文法,说明理由 S→ABc A→a|ε B→b|ε?First集合求法就是:能由非终结符号推出的所有的开头符号或可能的ε,但要求这个开头符号是终结符号。
如此题A可以推导出a和ε,所以FIRST(A)={a,ε};同理FIRST (B)={b,ε};S可以推导出aBc,还可以推导出bc,还可以推导出c,所以FIRST(S)={a,b,c}。
Follow集合的求法是:紧跟随其后面的终结符号或#。
但文法的识别符号包含#,在求的时候还要考虑到ε。
具体做法是把所有包含你要求的符号的产生式都找出来,再看哪个有用。
编译原理first集 计算工具

编译原理first集计算工具
编译原理中的First集是用于构造LL(1)文法的一种重要工具。
它用于确定一个文法的非终结符号的首个终结符号集合。
计算
First集的过程可以通过以下步骤进行:
1. 对于文法的每个终结符号,它的First集就是它本身。
即First(terminal) = {terminal}。
2. 对于文法的每个非终结符号,首先初始化它的First集为空集。
例如,对于非终结符号A,初始化 First(A) = {}。
3. 对于每个非终结符号A,按照以下规则计算它的First集:
a. 如果存在一个产生式A → ε,那么将ε 加入到
First(A) 中。
b. 如果存在一个产生式A → X1X2...Xk,其中 Xi 是一个
终结符号或非终结符号,那么将 First(Xi) 中的所有非空元素加入
到 First(A) 中,并且停止添加元素的过程当遇到一个 Xi 有ε
并且 Xi+1,Xi+2,...,Xk 都有ε,那么将ε 加入到 First(A) 中。
c. 重复步骤 b,直到没有新的元素可以添加到 First(A) 中。
4. 重复步骤 3,直到所有的非终结符号的 First集都不再改
变为止。
需要注意的是,计算First集时可能会遇到左递归和间接左递
归的情况,需要进行相应的处理,以避免进入无限循环。
此外,对
于某些文法,可能存在无法计算First集的情况,这时需要考虑其
他方法或技巧来处理。
总结起来,计算编译原理中文法的First集是一个重要的过程,它可以帮助我们分析和构造LL(1)文法,进而实现编译器的语法分
析部分。
编译原理习题参考答案

编译原理习题参考答案第⼆章2.构造产⽣下列语⾔的⽂法(2){a n b m c p|n,m,p≥0}解: G(S) :S→aS|X,X→bX|Y,Y→cY|ε(3){a n # b n|n≥0}∪{cn # dn|n≥0}解: G(S):S→X,S→Y,X→aXb|#, Y→cYd|# }(5)任何不是以0 打头的所有奇整数所组成的集合解:G(S):S→J|IBJ,B→0B|IB|ε,I→J|2|4|6|8, J→1|3|5|7|9}(6)(思考题)所有偶数个0 和偶数个1 所组成的符号串集合解:对应⽂法为 S→0A|1B|ε,A→0S|1C B→0C|1S C→1A|0B3.描述语⾔特点(2)S→SS S→1A0 A→1A0 A→ε解:L(G)={1n10n11n20n2… 1nm0nm |n1,n2,…,nm≥0;且n1,n2,…nm 不全为零}该语⾔特点是:产⽣的句⼦中,0、1 个数相同,并且若⼲相接的1 后必然紧接数量相同连续的0。
(5)S→aSS S→a解:L(G)={a(2n-1)|n≥1}可知:奇数个a5. (1) 解:由于此⽂法包含以下规则:AA→ε,所以此⽂法是0 型⽂法。
7.解:(1)aacb 是⽂法G[S]中的句⼦,相应语法树是:最右推导:S=>aAcB=>aAcb=>aacb最左推导:S=>aAcB=>aacB=>aacb(3)aacbccb 不是⽂法G[S]中的句⼦aacbccb 不能从S推导得到时,它仅是⽂法G[S]的⼀个句型的⼀部分,⽽不是⼀个句⼦。
11.解:最右推导:(1) S=>AB=>AaSb=>Aacb=>bAacb=>bbAacb=>bbaacb上⾯推导中,下划线部分为当前句型的句柄。
对应的语法树为:3 假设M:⼈ W:载狐狸过河,G:载⼭⽺过河,C:载⽩菜过河6 根据⽂法知其产⽣的语⾔是L={a m b n c i| m,n,i≧1}可以构造如下的⽂法VN={S,A,B,C}, VT={a,b,c}P={ S →aA, A→aA, A→bB, B→bB, B→cC, C→cC, C→c} 其状态转换图如下:7 (1) 其对应的右线性⽂法是:A →0D, B→0A,B→1C,C→1|1F,C→1|0A,F→0|0E|1A,D→0B|1C,E→1C|0B(2) 最短输⼊串011(3) 任意接受的四个串: 011,0110,0011,000011(4) 任意以1 打头的串.9.对于矩阵(iii)(1) 状态转换图:(2) 3型⽂法(正规⽂法)S→aA|a|bB A→bA|b|aC|a B→aB|bC|b C→aC|a|bC|b(3)⽤⾃然语⾔描述输⼊串的特征以a 打头,中间有任意个(包括0个)b,再跟a,最后由⼀个a,b 所组成的任意串结尾或者以b 打头,中间有任意个(包括0个)a,再跟b,最后由⼀个a,b 所组成的任意串结尾。
计算first集合和follow集合--编译原理

计算first 集合和follow 集合姓名:彦清 学号:E10914127一、实验目的输入:任意的上下文无关文法。
输出:所输入的上下文无关文法一切非终结符的first 集合和follow 集合。
二、实验原理设文法G[S]=(V N ,V T ,P ,S ),则首字符集为:FIRST (α)={a | α⇒*a β,a ∈V T ,α,β∈V *}。
若α⇒*ε,ε∈FIRST (α)。
由定义可以看出,FIRST (α)是指符号串α能够推导出的所有符号串中处于串首的终结符号组成的集合。
所以FIRST 集也称为首符号集。
设α=x 1x 2…x n ,FIRST (α)可按下列方法求得:令FIRST (α)=Φ,i =1;(1) 若x i ∈V T ,则x i ∈FIRST (α);(2) 若x i ∈V N ;① 若ε∉FIRST (x i ),则FIRST (x i )∈FIRST (α);② 若ε∈FIRST (x i ),则FIRST (x i )-{ε}∈FIRST (α);(3) i =i+1,重复(1)、(2),直到x i ∈V T ,(i =2,3,…,n )或x i∈V N 且若ε∉FIRST (x i )或i>n 为止。
当一个文法中存在ε产生式时,例如,存在A →ε,只有知道哪些符号可以合法地出现在非终结符A 之后,才能知道是否选择A →ε产生式。
这些合法地出现在非终结符A 之后的符号组成的集合被称为FOLLOW 集合。
下面我们给出文法的FOLLOW 集的定义。
设文法G[S]=(V N ,V T ,P ,S ),则FOLLOW (A )={a | S ⇒… Aa …,a ∈V T }。
若S *…A ,#∈FOLLOW (A )。
由定义可以看出,FOLLOW (A )是指在文法G[S]的所有句型中,紧跟在非终结符A 后的终结符号的集合。
FOLLOW 集可按下列方法求得:(1) 对于文法G[S]的开始符号S ,有#∈FOLLOW (S );(2) 若文法G[S]中有形如B →xAy 的规则,其中x ,y ∈V *,则FIRST(y )-{ε}∈FOLLOW (A );(3) 若文法G[S]中有形如B →xA 的规则,或形如B →xAy 的规则且ε∈FIRST (y ),其中x ,y ∈V *,则FOLLOW (B )∈FOLLOW (A );三、源程序#include<iostream.h>#include<string.h>//产生式struct css{char left;char zhuan;//用“-”表示箭头char right[20];};//空标志struct kong{int kongzuo;int kongyou;};struct biaoji//第三步扫描式子的右部标记号{int r[100];};struct first//初步求first 集合时用{ char fjihe[200];};struct first2//保存最终的first 集合{ char fjihe2[200];};struct follow//初步求follow 集合时用{ char fow[200];};struct follow2//保存最终的follow 集合{ char fow2[200];};void main(){ int i,n,k;//产生式条数css shizi[100];kong kongshi[100];cout<<"请输入产生式的条数n(n<100):"<<endl;cin>>n;cout<<"请从开始符输入产生式(空用“#”表示,产生式由字母组成):"<<endl;for(i=0;i<n;i++){cin>>shizi[i].left>>shizi[i].zhuan>>shizi[i].right;}int l,m,j,h,g,f;for(l=0;l<n;l++)for(m=0;m<sizeof(shizi[l].right);m++){ if(shizi[l].right[m]=='#'){kongshi[l].kongzuo=1;break;}else while(shizi[l].right[m]>='a' && shizi[l].right[m]<='z' ){kongshi[l].kongyou=0; break;}}for(j=0;j<=n;j++)for(h=0;h<n;h++){ if(j==h)break;if(shizi[j].left==shizi[h].left){if(kongshi[j].kongyou==0 && kongshi[h].kongyou==0)kongshi[j].kongzuo=kongshi[h].kongzuo=0;break;}}int d,s,a,q,w,e;char linshi;biaoji biaoyou[100];for(d=0;d<n;d++){if(!(kongshi[d].kongzuo==1||kongshi[d].kongyou==0)){for(s=0;shizi[d].right[s]!='\0';s++)for(a=0;a<=n;a++){ linshi=shizi[d].right[s];if(linshi==shizi[a].left && kongshi[a].kongzuo==1){ biaoyou[d].r[s]=1;}else {kongshi[d].kongyou=0;}}}}int sum,t,y;//第三部-1sum=0;for(e=0;e<n;e++){for(q=0;shizi[e].right[q]!='\0';q++){ t=biaoyou[e].r[q];if(t==1){ for(sum;shizi[e].right[q]!='\0';){sum++;y=sum-1;if(q==y)kongshi[e].kongzuo=1;break;}}else break;}}int a1,a2;/*第二次扫描判断转为否的式子*/for(a1=0;a1<=n;a1++)for(a2=0;a2<n;a2++){ if(a1==a2)break;if(shizi[a1].left==shizi[a2].left&&kongshi[a1].kongzuo!=1&&kongsh i[a2].kongzuo!=1){if(kongshi[a1].kongyou==0 && kongshi[a2].kongyou==0)kongshi[a1].kongzuo=kongshi[a2].kongzuo=0;break;}}//计算first集合first fji[100];int u,a3,a5,a6,a7,a8;//char linshi2[2]="-";//for(u=0;u<n;u++){ fji[u].fjihe[0]='\0';}for(a3=0;a3<=n;a3++){if(shizi[a3].right[0]>='a' && shizi[a3].right[0]<='z') {linshi2[0]=shizi[a3].right[0];strcat(fji[a3].fjihe,linshi2);}else { if(kongshi[a3].kongzuo==1){ strcat(fji[a3].fjihe,"#");}}}for(a5=0;a5<=n;a5++)for(a6=0;shizi[a5].right[a6]!='\0';a6++)if(shizi[a5].right[a6]>='A' && shizi[a5].right[a6]<='Z'){ if(shizi[a5].right[0]>='a' && shizi[a5].right[0]<='z')break;for(a7=0;a7<n;a7++)if(a5!=a7 && shizi[a5].right[a6]==shizi[a7].left){ {if(kongshi[a7].kongzuo!=1)strcat(fji[a5].fjihe,fji[a7].fjihe);if(a6==(strlen(shizi[a5].right)-1))for(a8=0;a8<n;a8++)if(a5!=a8 && shizi[a5].right[a6]==shizi[a8].left)if(kongshi[a5].kongzuo!=1){strcat(fji[a5].fjihe,fji[a8].fjihe);}else{strcat(fji[a5].fjihe,fji[a8].fjihe);strcat(fji[a5].fjihe,"#");}}}}//求follow集合follow fw[100];int b1,b2,b3,b4,b5,b6,b7,b8,b9,b10;char linshi5[2];for(b1=0;b1<n;b1++){ fw[b1].fow[0]='\0';}fw[0].fow[0]='#';fw[0].fow[1]='\0';for(b8=0;b8<n;b8++){ if(shizi[b8].left==shizi[0].left)fw[b8].fow[0]='#';fw[b8].fow[1]='\0';}int e1;for(e1=0;e1<2;e1++)for(b2=0;b2<n;b2++)for(b3=0;b3<n;b3++){ if(shizi[b2].right[b3]>='A'&&shizi[b2].right[b3]<='Z')if(shizi[b2].right[b3+1]>='a'&&shizi[b2].right[b3+1]<='z'){ linshi5[0]=shizi[b2].right[b3+1];linshi5[1]='\0';for(b9=0;b9<n;b9++){if(shizi[b2].right[b3]==shizi[b9].left)strcat(fw[b9].fow,linshi5);}}if(shizi[b2].right[b3+1]>='A'&&shizi[b2].right[b3+1]<='Z'){ for(b4=0;b4<n;b4++){if(shizi[b2].right[b3+1]==shizi[b4].left){ if(kongshi[b4].kongzuo!=1){for(b10=0;b10<n;b10++){if(shizi[b2].right[b3]==shizi[b10].left)strcat(fw[b10].fow,fji[b4].fjihe);}}else { for(b5=0;b5<n;b5++)if(shizi[b2].right[b3]==shizi[b5].left)strcat(fw[b5].fow,fw[b2].fow);}}}}if((b3+1)==strlen(shizi[b2].right)){ for(b7=0;b7<n;b7++)if(shizi[b2].right[b3]==shizi[b7].left)strcat(fw[b7].fow,fw[b2].fow);}}first2 fji2[100];int a11,a12,a13;for(a11=0;a11<n;a11++){ fji2[a11].fjihe2[0]='\0';}for(a12=0;a12<=n;a12++)for(a13=0;a13<n;a13++){ if(a12!=a13 && shizi[a12].left==shizi[a13].left)strcat(fji[a12].fjihe,fji[a13].fjihe);}char linshi3[100];char linshi4[2];int a15,a16,a17=0,a19=0,a21,a18;//for(a15=0;a15<n;a15++){ {for(a21=0;a21<99;a21++)linshi3[a21]='\0';}{for(a16=0;a16<strlen(fji[a15].fjihe);a16++){if(a16==0){linshi4[0]=fji[a15].fjihe[a16];linshi4[1]='\0';strcat(linshi3,linshi4);a16++;}for(a17=0;a17<=strlen(linshi3);a17++)if(linshi3[a17]==fji[a15].fjihe[a16])break;//if(linshi3[a17]=='\0'){ linshi4[0]=fji[a15].fjihe[a16];linshi4[1]='\0';strcat(linshi3,linshi4);}}}strcat(fji2[a15].fjihe2,linshi3);}follow2 fw2[100];int b11,b12,b13;for(b11=0;b11<n;b11++){ fw2[b11].fow2[0]='\0';}for(b12=0;b12<=n;b12++)for(b13=0;b13<n;b13++){ if(b12!=b13 && shizi[b12].left==shizi[b13].left) strcat(fw[b12].fow,fw[b13].fow);}char linshi6[100];char linshi7[2];int b15,b16,b17,b19=0,b21,b18;//for(b15=0;b15<n;b15++){ { {for(b21=0;b21<99;b21++)linshi6[b21]='\0';}{for(b16=0;b16<strlen(fw[b15].fow);b16++){if(b16==0){linshi7[0]=fw[b15].fow[b16];linshi7[1]='\0';strcat(linshi6,linshi7);b16++;}for(b17=0;b17<=strlen(linshi6);b17++)if(linshi6[b17]==fw[b15].fow[b16])break;//if(linshi6[b17]=='\0'){ linshi7[0]=fw[b15].fow[b16];linshi7[1]='\0';strcat(linshi6,linshi7);}}}}strcat(fw2[b15].fow2,linshi6);}int c1,c2;cout<<"非终结符"<<" "<<"first集合"<<endl;cout<<" "<<shizi[0].left<<" "<<fji2[0].fjihe2<<endl;for(c1=1;c1<n;c1++){for(c2=0;c2<c1;c2++){ if(shizi[c1].left!=shizi[c2].left&&c2==(c1-1))cout<<" "<<shizi[c1].left<<" "<<fji2[c1].fjihe2<<endl;}}int d1,d2;cout<<"非终结符"<<" "<<"follow集合"<<endl;cout<<" "<<shizi[0].left<<" "<<fw2[0].fow2<<endl;for(d1=1;d1<n;d1++){for(d2=0;d2<d1;d2++){ if(shizi[d1].left!=shizi[d2].left&&d2==(d1-1))cout<<" "<<shizi[d1].left<<" "<<fw2[d1].fow2<<endl;}}}四、运行截图。
编译原理实验二:LL(1)语法分析器

编译原理实验⼆:LL(1)语法分析器⼀、实验要求 1. 提取左公因⼦或消除左递归(实现了消除左递归) 2. 递归求First集和Follow集 其它的只要按照课本上的步骤顺序写下来就好(但是代码量超多...),下⾯我贴出实验的⼀些关键代码和算法思想。
⼆、基于预测分析表法的语法分析 2.1 代码结构 2.1.1 Grammar类 功能:主要⽤来处理输⼊的⽂法,包括将⽂法中的终结符和⾮终结符分别存储,检测直接左递归和左公因⼦,消除直接左递归,获得所有⾮终结符的First集,Follow集以及产⽣式的Select集。
#ifndef GRAMMAR_H#define GRAMMAR_H#include <string>#include <cstring>#include <iostream>#include <vector>#include <set>#include <iomanip>#include <algorithm>using namespace std;const int maxn = 110;//产⽣式结构体struct EXP{char left; //左部string right; //右部};class Grammar{public:Grammar(); //构造函数bool isNotTer(char x); //判断是否是终结符int getTer(char x); //获取终结符下标int getNonTer(char x); //获取⾮终结符下标void getFirst(char x); //获取某个⾮终结符的First集void getFollow(char x); //获取某个⾮终结符的Follow集void getSelect(char x); //获取产⽣式的Select集void input(); //输⼊⽂法void scanExp(); //扫描输⼊的产⽣式,检测是否有左递归和左公因⼦void remove(); //消除左递归void solve(); //处理⽂法,获得所有First集,Follow集以及Select集void display(); //打印First集,Follow集,Select集void debug(); //⽤于debug的函数~Grammar(); //析构函数protected:int cnt; //产⽣式数⽬EXP exp[maxn]; //产⽣式集合set<char> First[maxn]; //First集set<char> Follow[maxn]; //Follow集set<char> Select[maxn]; //select集vector<char> ter_copy; //去掉$的终结符vector<char> ter; //终结符vector<char> not_ter; //⾮终结符};#endif 2.1.2 AnalyzTable类 功能:得到预测分析表,判断输⼊的⽂法是否是LL(1)⽂法,⽤预测分析表法判断输⼊的符号串是否符合刚才输⼊的⽂法,并打印出分析过程。
蒋立源编译原理第三版第四章习题与答案

蒋⽴源编译原理第三版第四章习题与答案第4章习题14-1 消除下列⽂法的左递归性。
(1) S→SA|A A→SB|B|(S)|( ) B→[S]|[ ](2) S→AS|b A→SA|a(3) S→(T)|a|ε T→S|T,S4-2 对于如下⽂法,求各候选式的FIRST集和各⾮终结符号的FOLLOW集。
S→aAB|bA|ε A→aAb|ε B→bB|ε4-3 验证下列⽂法是否为LL(1)⽂法。
(1) S→AB|CDa A→ab|c B→dE|εC→eC|ε D→fD|f E→dE|ε(2) S→aABbCD|ε A→ASd|ε B→SAc|eC|εC→Sf|Cg|ε D→aBD|ε4-4 对于如下的⽂法G[S]:S→Sb|Ab|bA→Aa|a(1) 构造⼀个与G等价的LL(1)⽂法G′[S];(2) 对于G′[S],构造相应的LL(1)分析表;(3) 利⽤LL(1)分析法判断符号串aabb是否是⽂法G[S]的合法句⼦。
4-5 设已给⽂法S→SaB|bB A→S|a B→Ac(1) 构造⼀个与G等价的LL(1)⽂法G′[S];(2) 对于G′[S],构造相应的LL(1)分析表;(3) 利⽤LL(1)分析法判断符号串bacabc是否是⽂法G[S]的合法句⼦。
第4章习题答案4-1 解:(1) ⽂法G[S]中的S,A都是间接左递归的⾮终结符号。
将A产⽣式的右部代⼊产⽣式S→A中,得到与原⽂法等价的⽂法G′[S]:S→SA|SB|B|(S)|( )A→SB|B|(S)|( )B→[S]|[ ]⽂法G′[S]中的S是直接左递归的⾮终结符号,则消除S产⽣式的直接递归性后,我们便得到了与原⽂法等价且⽆任何左递归性的⽂法G"[S]:S→BS′|(S)S′|( )S′A→SB|B|(S)|( )B→[S]|[ ](2) ⽂法G[S]中的S,A都是间接左递归的⾮终结符号。
将A产⽣式代⼊产⽣式S→AS中,得到与原⽂法等价的⽂法G′[S]:S→SAS|aS|bA→SA|a⽂法G′[S]中的S是直接左递归的⾮终结符号,则消除S产⽣式的直接递归性后,我们便得到了与原⽂法等价且⽆任何左递归性的⽂法G"[S]:S→aSS′|bS′S′→ASS′|εA→SA|a(3) ⽂法G[S]中的T是直接左递归的⾮终结符号。
编译原理及编译程序构造 部分课后答案(张莉 杨海燕编著)
第一章练习12、典型的编译程序可划分为哪几个主要的逻辑部分?各部分的主要功能是什么?典型的编译程序具有7个逻辑部分:第二章练习2.24.试证明:A+ =AA*=A*A证:∵A*=A0∪A+,A+=A1∪A2∪…∪An∪…得:A*=A0∪A1∪A2∪…∪An∪…∴AA*=A(A0∪A1∪A2∪…∪An∪…)= AA0∪AA1∪AA2∪…∪A An∪…=A∪A2∪A3∪An +1∪…= A+同理可得:A*A =(A0∪A1∪A2∪…∪An∪…)A=A0 A∪A1A∪A2A∪…∪AnA∪…= A∪A2∪A3∪An+1∪…= A+因此:A+ =AA*=A*A练习2.31.设G[〈标识符〉]的规则是:〈标识符〉::=a|b|c|〈标识符〉a|〈标识符〉c|〈标识符〉0|〈标识符〉1试写出VT和VN,并对下列符号串a,ab0,a0c01,0a,11,aaa给出可能的一些推导。
解:VT ={a,b,c,0,1},VN ={〈标识符〉}(1) 不能推导出ab0,11,0a(2)〈标识符〉=>a(3)〈标识符〉=>〈标识符〉1=>〈标识符〉01=>〈标识符〉c01=>〈标识符〉0c01=> a0c01(4)〈标识符〉=>〈标识符〉a=>〈标识符〉aa=>aaa2.写一文法,其语言是偶整数的集合解:G[<偶整数>]:<偶整数>::= <符号> <偶数字>| <符号><数字串><偶数字> <符号> ::= + | —|ε<数字串>::= <数字串><数字>|<数字><数字> ::= <偶数字>| 1 | 3 | 5 | 7 | 9<偶数字> ::=0 | 2 | 4 | 6 | 84. 设文法G的规则是:〈A〉::=b<A>| cc试证明:cc, bcc, bbcc, bbbcc∈L[G]证:(1)〈A〉=>cc(2)〈A〉=>b〈A〉=>bcc(3)〈A〉=>b〈A〉=>bb〈A〉=>bbcc(4)〈A〉=>b〈A〉=>bb〈A〉=>bbb〈A〉=>bbbcc又∵cc, bcc, bbcc, bbbcc∈Vt*∴由语言定义,cc, bcc, bbcc, bbbcc∈L[G]5 试对如下语言构造相应文法:(1){ a(bn)a | n=0,1,2,3,……},其中左右圆括号为终结符。
【编译原理】FIRST集、FOLLOW集算法原理和实现

【编译原理】FIRST集、FOLLOW集算法原理和实现书中⼀些话,不知是翻译的原因。
还是我个⼈理解的原因感觉不是⾮常好理解。
个⼈重新整理了⼀下。
不过相对于消除左递归和提取左公因,FIRST集和FOLLOW集的算法相对来说⽐较简单。
书中的重点给出:FIRST:⼀个⽂法符号的FIRST集就是这个符号能推导出的第⼀个终结符号的集合, 包括空串。
例: A -> abc | def | ε那么FIRST(A) 等于 { a, d, ε }。
FOLLOW:蓝线画的部分很重要。
特别是这句话:请注意,在这个推导的某个阶段,A和a之间可能存在⼀些⽂法符号。
单如果这样,这些符号会推导得到ε并消失。
这句话的意思就是好⽐说: S->ABa B->c | ε 这个⽂法 FOLLOW(A)的值应该是FIRST(B)所有的终结符的集合(不包含ε),但是FIRST(B)是包含ε的,说明B是可空的,既然B是可空的S->ABa 也可以看成 S->Aa。
那么a就可以跟在A的后⾯.所以在这种情况下,FOLLOW(A)的值是包含a的。
换句话说就是。
⼀个⽂法符号A的FOLLOW集合就是它的下⼀个⽂法符号B的FIRST集合。
如果下⼀个⽂法符号B的FIRST集合包含ε,那么我们就要获取下⼀个⽂法符号B的FOLLOW集添加到FOLLOW(A)中代码中的注释已经很详细// 提取First集合func First(cfg []*Production, sym *Symbolic) map[string] *Symbolic {result := make(map[string] *Symbolic)// 规则⼀如果符号是⼀个终结符号,那么他的FIRST集合就是它⾃⾝if sym.SymType() == SYM_TYPE_TERMINAL || sym.SymType() == SYM_TYPE_NIL {result[sym.Sym()] = symreturn result}// 规则⼆如果⼀个符号是⼀个⾮终结符号// (1) A -> XYZ 如果 X 可以推导出nil 那么就去查看Y是否可以推导出nil// 如果 Y 推导不出nil,那么把Y的First集合加⼊到A的First集合// 如果 Y 不能推导出nil,那么继续推导 Z 是否可以推导出nil,依次类推// (2) A -> XYZ 如果XYZ 都可以推导出 nil, 那么说明A这个产⽣式有可能就是nil,这个时候我们就把nil加⼊到FIRST(A)中for _, production := range cfg {if production.header == sym.Sym() {nilCount := 0for _, rightSymbolic := range production.body { // 对于⼀个产⽣式ret := First(cfg, rightSymbolic) // 获取这个产⽣式体的First集合hasNil := falsefor k, v := range ret {if v.SymType() == SYM_TYPE_NIL { // 如果推导出nil, 标识当前产⽣式体的符号可以推导出nilhasNil = true} else {result[k] = v}}if false == hasNil { // 当前符号不能推导出nil, 那么这个产⽣式的FIRST就计算结束了,开始计算下⼀个产⽣式break}// 当前符号可以推导出nil,那么开始推导下⼀个符号nilCount++if nilCount == len(production.body) { // 如果产⽣式体都可以推导出nil,那么这个产⽣式就可以推导出nilresult["@"] = &Symbolic{sym: "@", sym_type: SYM_TYPE_NIL}}}}}return result}// 提取FOLLOW集合func Follow(cfg []*Production, sym string) [] *Symbolic {fmt.Printf("Follow ------> %s\n", sym)result := make([] *Symbolic, 0)// ⼀个⽂法符号的FOLLOW集就是可能出现在这个⽂法符号后⾯的终结符// ⽐如 S->ABaD, 那么FOLLOW(B)的值就是a。
first集合和follow集合的求法

first集合和follow集合的求法编译原理是计算机专业中的重要学科,其中语法分析是编译原理的基础。
而语法分析器(Parser)的核心就是构建语法分析表格。
而在构建语法分析表格的过程中,first集合和follow集合的求法是一个非常重要的问题,本文就将详细介绍first集合和follow集合的求法。
一、first集合first集合指的是文法中每个非终结符号的经过一次推导得到的所有终结符号的集合,也就是最小前缀(First)的集合。
例如对于一个简单的文法表达式E→E+T|T,其中E和T是非终结符号,+是终极符号。
那么开始寻找E的first集合时,我们应该先判断E能够推导出哪些符号,根据文法表达式,E可以推导出E+T和T。
接着我们可以判断E+T和T 所能推导出的所有终结符号,并将这些终结符号加入到E的first集合中。
具体步骤可以参考下面的推导过程:E → E + TE → TT → a那么最终E的first集合就是{a,+}。
二、follow集合follow集合指的是文法中每个非终结符号在所有推导过程中后跟的符号的集合。
例如对于一个简单的文法表达式E→E+T|T,其中E和T是非终结符号,+是终极符号。
求解E的follow集合时,首先要考虑的是E出现在了哪些地方。
通过分析E在文法表达式中的位置,我们可以发现E出现在了三种不同的情况下:1. E是文法的起始符号,此时E的follow集合中必须包含结束符$。
2. E出现在某些规则的右侧,此时E的follow集合中必须包含右侧的符号的first集合,但是需要注意的是,如果推导出空串,则应该将右侧的非终结符号所在位置的follow集合添加进来。
3. E的右侧是其所在规则的最末尾,此时需要将E所在规则的左侧符号所在位置的follow集合添加到E的follow集合中。
根据以上三种情况,我们可以结合上面的文法表达式来推导出E的follow集合。
具体步骤可以参考下面的推导过程:S → EE → E + TE → TT → a1. $ ∈ follow(E)2. follow(T) = {+, $}follow(E) = first(T) ∪ {+, $}follow(E) = {+, a, $}3. follow(E) = {+, $}那么最终E的follow集合就是{+, a, $}。
编译原理(王力红著)习题答案 (2) (1)

习题11-1 说明解释程序和编译程序的区别。
答:通常,翻译程序可分为解释程序、汇编程序和编译程序。
所谓解释程序是一种将源程序按动态顺序逐句进行分析解释编译,边解释边执行、不产生目标程序的一种翻译程序。
这种翻译程序结构简单、占用内存较少,易于在执行过程中对源程序进行修改,但工作效率低,只适合一些规模较小的语言,如解释BASIC等。
而编译程序(也称编译器)是源语言为某种高级语言,目标语言为相应于某一计算机的汇编语言或机器语言的一种翻译程序。
这种编译程序将源程序翻译成执行时可完全独立于源程序的经优化的目标语言代码,因而运行效率高。
更为重要的是,它使工作于高级语言环境下的程序设计人员,不必考虑与机器有关的繁琐细节,却能完成机器语言所能完成的绝大多数工作。
在解释方式下,并不生成目标代码,而是直接执行源程序本身。
这是编译方式与解释方式的根本区别。
1-2 简述高级语言程序按编译方式的执行过程。
答:高级语言程序按编译方式的执行过程一般可分为两个阶段:编译阶段和运行阶段。
其中,编译阶段完成由源程序到目标程序的翻译,若目标程序是汇编语言程序,还需再通过汇编程序进一步翻译成机器语言程序。
而运行阶段的任务是在目标计算机上执行编译阶段所得到的目标程序。
但目标程序往往不能由计算机直接执行,一般还应有运行系统进行配合,这个运行系统包括链接程序和由这样一些子程序组成的系统库,如标准函数计算子程序、数组动态存储子程序等。
由链接程序将目标程序和系统库连接在一起,最终形成一个可执行程序,在计算机上直接执行。
1-3 什么是编译系统?答:通常将编译程序、链接程序、系统库、源程序编辑程序等软件组成的系统称为编译系统。
1-4 编译过程通常有哪几个阶段?简述各阶段的主要任务。
答:程序设计语言的编译过程一般可以分为词法分析、语法分析、语义分析和中间代码生成、代码优化、目标代码生成5个阶段。
词法分析是编译过程的第一个阶段。
该阶段的主要任务是从构成源程序的字符串中识别出一个个具有独立意义的最小语法单位——单词,并指出其属性。
编译原理考题
第一章引论1. 解释下列术语:编译程序、编译程序的前端和后端答:(1)编译程序:如果源语言为高级语言,目标语言为某台计算机上的汇编语言或机器语言,则此翻译程序称为编译程序。
(2)编译程序的前端:它由这样一些阶段组成:这些阶段的工作主要依赖于源语言而与目标机无关。
通常前端包括词法分析、语法分析、语义分析和中间代码生成这些阶段,某些优化工作也可在前端做,也包括与前端每个阶段相关的出错处理工作和符号表管理等工作。
(3)后端:指那些依赖于目标机而一般不依赖源语言,只与中间代码有关的那些阶段,即目标代码生成,以及相关出错处理和符号表操作。
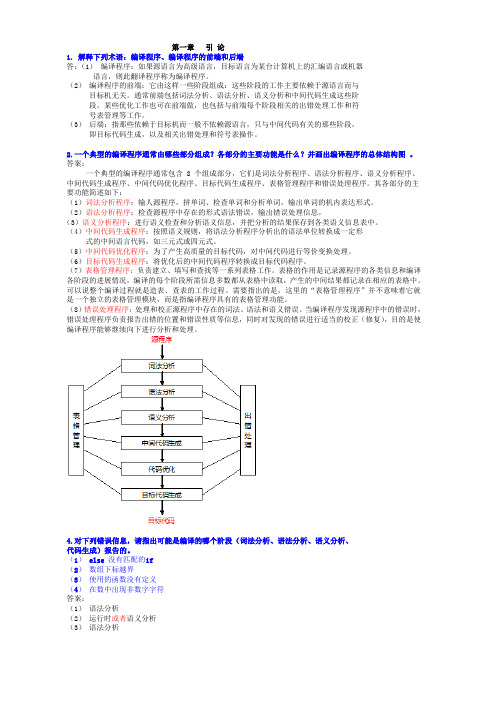
2.一个典型的编译程序通常由哪些部分组成?各部分的主要功能是什么?并画出编译程序的总体结构图。
答案:一个典型的编译程序通常包含 8 个组成部分,它们是词法分析程序、语法分析程序、语义分析程序、中间代码生成程序、中间代码优化程序、目标代码生成程序、表格管理程序和错误处理程序。
其各部分的主要功能简述如下:(1)词法分析程序:输人源程序,拼单词、检查单词和分析单词,输出单词的机内表达形式。
(2)语法分析程序:检查源程序中存在的形式语法错误,输出错误处理信息。
(3)语义分析程序:进行语义检查和分析语义信息,并把分析的结果保存到各类语义信息表中。
(4)中间代码生成程序:按照语义规则,将语法分析程序分析出的语法单位转换成一定形式的中间语言代码,如三元式或四元式。
(5)中间代码优化程序:为了产生高质量的目标代码,对中间代码进行等价变换处理。
(6)目标代码生成程序:将优化后的中间代码程序转换成目标代码程序。
(7)表格管理程序:负责建立、填写和查找等一系列表格工作。
表格的作用是记录源程序的各类信息和编译各阶段的进展情况,编译的每个阶段所需信息多数都从表格中读取,产生的中间结果都记录在相应的表格中。
可以说整个编译过程就是造表、查表的工作过程。
需要指出的是,这里的“表格管理程序”并不意味着它就是一个独立的表格管理模块,而是指编译程序具有的表格管理功能。
南邮《编译原理》习题解答

《编译原理》习题解答:第一次作业:P14 2、何谓源程序、目标程序、翻译程序、汇编程序、编译程序和解释程序?它们之间可能有何种关系?答:被翻译的程序称为源程序;翻译出来的程序称为目标程序或目标代码;将汇编语言和高级语言编写的程序翻译成等价的机器语言,实现此功能的程序称为翻译程序;把汇编语言写的源程序翻译成机器语言的目标程序称为汇编程序;解释程序不是直接将高级语言的源程序翻译成目标程序后再执行,而是一个个语句读入源程序,即边解释边执行;编译程序是将高级语言写的源程序翻译成目标语言的程序。
关系:汇编程序、解释程序和编译程序都是翻译程序,具体见P4 图 1.3。
P14 3、编译程序是由哪些部分组成?试述各部分的功能?答:编译程序主要由8个部分组成:(1)词法分析程序;(2)语法分析程序;(3)语义分析程序;(4)中间代码生成;(5)代码优化程序;(6)目标代码生成程序;(7)错误检查和处理程序;(8)信息表管理程序。
具体功能见P7-9。
P14 4、语法分析和语义分析有什么不同?试举例说明。
答:语法分析是将单词流分析如何组成句子而句子又如何组成程序,看句子乃至程序是否符合语法规则,例如:对变量x:= y 符合语法规则就通过。
语义分析是对语句意义进行检查,如赋值语句中x和y类型要一致,否则语法分析正确,语义分析则错误。
补充:为什么要对单词进行内部编码?其原则是什么?对标识符是如何进行内部编码的?答:内部编码从“源字符串”中识别单词并确定单词的类型和值;原则:长度统一,即刻画了单词本身,也刻画了它所具有的属性,以供其它部分分析使用。
对于标识符编码,先判断出该单词是标识符,然后在类别编码中写入相关信息,以表示为标识符,再根据具体标识符的含义编码该单词的值。
P38 1、设T1={11,010},T2={0,01,1001},计算:T2T1,T1*,T2+。
T2T1={011,0010,0111,01010,100111,1001010}T1*={ε,11,010,1111,11010,01011,010010……}T2+={0,01,1001,00,001,01001,010,0101……}P38-39 8、设有文法G[S]:S∷=aAbA∷=BcA | BB∷=idt |ε试问下列符号串(1)aidtcBcAb (2)aidtccb(4)abidt是否为该文法的句型或句子。
编译原理first算法实现

编译原理first算法实现编译原理是计算机科学中一个非常重要的领域,相信很多学习计算机相关专业的学生都会学习这门课程。
在编译原理中,First算法是一种非常重要的算法,用于对文法进行分析和解析。
下面我将就First算法的实现进行介绍。
一、First算法是什么?First算法是一种用于对文法进行分析和解析的算法。
它可以求出一个非终结符号所能推导出的所有终结符号的集合。
在编译原理中,First 算法常常用于语法分析和语法制导翻译中。
二、First算法的实现步骤1、对每个非终结符号X求解First(X)。
2、对于一个非终结符号X,假设它可以推导出串αβγ,那么根据定义,First(X)应该包含串α的首字符的集合。
3、如果α能够推导出空串(ε),那么First(X)也应该包含β的首字符的集合。
4、如果β能够推导出空串(ε),那么First(X)也应该包含γ的首字符的集合。
5、重复以上步骤,直到没有新的符号可以加入First(X)。
三、First算法实现的示例假设有以下文法:S → aAB | bCDA → cB → d | εC → eD → f | ε我们可以先对终结符号和非终结符号进行划分。
终结符号:a,b,c,d,e,f。
非终结符号:S,A,B,C,D。
接下来,对每一个非终结符号求解对应的First集合。
对于非终结符号S,有:First(S)={a,b}因为S可以推导出aAB和bCD,而a和b分别是其所能推导出的第一个字符。
对于非终结符号A,有:First(A)={c}因为A只能推导出一个c。
对于非终结符号B,有:First(B)={d,ε}因为B可以推导出一个d或者空串(ε)。
对于非终结符号C,有:First(C)={e}因为C只能推导出一个e。
对于非终结符号D,有:First(D)={f,ε}因为D可以推导出一个f或者空串(ε)。
四、总结通过以上实例,我们可以看到,求出First集合并不是一件非常困难的事情。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
4、运行结果分析 5、总结
2、分析、设计、实现 通过对产生式的顺序扫描,运用上述规则,把每种规则都转换为相应的算法,经过规则后 将产生的 First 集存下来。 流程图 3、函数与过程的功能(MFC) CString CFirstAndFollow::First(char Vn,char PVn) { CString result,tmpresult; char tmpmid; int tmpflag; if(Vns.Find(Vn,0)==-1&&Vn!=';'&&Vn!='|') { result.Insert(result.GetLength(),Vn); return result; } for(int ix=0;ix<Vpro.GetLength();ix++) { ix=Vpro.Find(Vn,ix); if(Vpro.GetAt(ix-1)==';') { tmpflag=ix; break; } } tmpflag+=3; for(ቤተ መጻሕፍቲ ባይዱnt index=tmpflag;index<Vpro.GetLength();index++) { char tmp=Vpro.GetAt(index); tmpmid=tmp; if(Vns.Find(tmp,0)>=0) // Vn { if(tmp==PVn || tmp==Vn) { do
1、问题描述
题目: First 集和 Follow 集生成算法模拟 设计一个由正规文法生成 First 集和 Follow 集并进行简化的算法动态模拟。 动态模拟算法的基本功能是: ⅰ. 输入一个文法 G; ⅱ. 输出由文法 G 构造 FIRST 集的算法; ⅲ. 输出 First 集; ⅳ. 输出由文法 G 构造 FOLLOW 集的算法; ⅴ. 输出 FOLLOW 集。
{ index++; tmpmid=Vpro.GetAt(index); }while(tmpmid!='|'&&tmpmid!=';'); } else { CString tmpr=First(tmp,PVn); if(tmpr.Find('_',0)==-1) //Vn { tmpflag=tmpresult.Find('_',0); while(tmpflag>=0) { tmpresult.Delete(tmpflag,1); tmpflag=tmpresult.Find('_',0); } index--; do { index++; tmpmid=Vpro.GetAt(index); }while(tmpmid!='|'&&tmpmid!=';'); } else // Vn { tmpmid=Vpro.GetAt(index); } tmpresult+=tmpr; } } else { if(tmp!='|'&&tmp!=';') { tmpflag=tmpresult.Find('_',0); while(tmpflag>=0) { tmpresult.Delete(tmpflag,1); tmpflag=tmpresult.Find('_',0); } if(tmpresult.Find(tmp,0)==-1) { tmpresult.Insert(tmpresult.GetLength(),tmp); }
index--; do { index++; tmpmid=Vpro.GetAt(index); }while(tmpmid!='|'&&tmpmid!=';'); } } if(tmpmid==';'||tmpmid=='|') { for(int ii=0;ii<tmpresult.GetLength();ii++) //insert follow { if(result.Find(tmpresult.GetAt(ii),0)==-1) result.Insert(result.GetLength(),tmpresult.GetAt(ii)); } if(tmpmid==';') break; tmpresult.Empty(); } } return result; }