摄像头编程并且对图像的处理以及直方图的算法
ov7725数字摄像头编程基本知识笔记
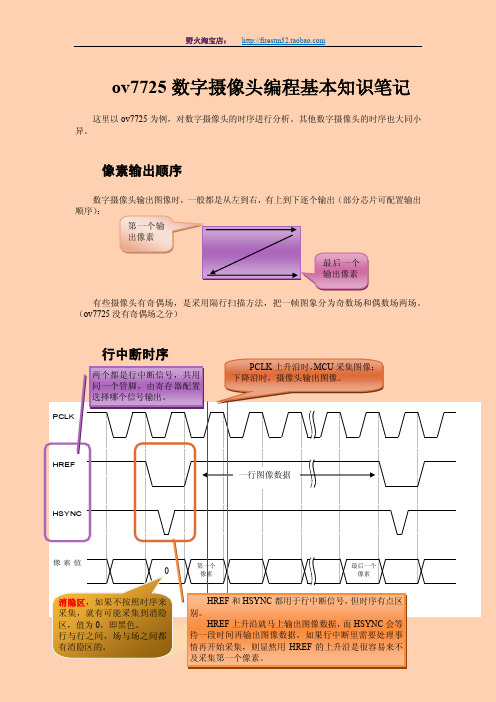
PCLKHREFHSYNC 像素值ov7725数字摄像头编程基本知识笔记这里以ov7725为例,对数字摄像头的时序进行分析。
其他数字摄像头的时序也大同小异。
像素输出顺序数字摄像头输出图像时,一般都是从左到右,有上到下逐个输出(部分芯片可配置输出顺序):有些摄像头有奇偶场,是采用隔行扫描方法,把一帧图象分为奇数场和偶数场两场。
(ov7725没有奇偶场之分)行中断时序0 第一个输出像素最后一个输出像素 最后一个像素 消隐区,如果不按照时序来采集,就有可能采集到消隐区,值为0,即黑色。
行与行之间,场与场之间都一行图像数据 第一个 像素 PCLK 上升沿时,MCU 采集图像;下降沿时,摄像头输出图像。
HREF 和HSYNC 都用于行中断信号,但时序有点区别。
HREF 上升沿就马上输出图像数据,而HSYNC 会等待一段时间再输出图像数据,如果行中断里需要处理事情再开始采集,则显然用HREF 的上升沿是很容易来不两个都是行中断信号,共用同一个管脚,由寄存器配置选择哪个信号输出。
场中断时序采集图像思路①使用for 循环延时采集1. 需要采集图像时,开场中断2. 场中断来了就开启行中断,关闭场中断3. 行中断里用for 循环延时采集像素,可以在行中断里添加标志位,部分行不采集,即可跨行采集。
4. 行中断次数等于图像行数时即可关闭行中断,标志图像采集完毕。
②使用场中断和行中断,DMA 传输1. 需要采集图像时,开场中断2. 场中断来了,开行中断和初始化DMA 传输3. 行中断来了就设置DMA 地址,启动DMA 传输。
如果先过滤部分行不采集,则设置一个静态变量,每次行中断来了都自加1,根据值来选择采集或不采集某些行。
4. 每个PCLK 上升沿来了都触发DMA 传输,把摄像头输出的值读取到内存数组里。
当触发n 次(n=图像列数目)后就停止DMA 传输。
5. 行中断次数等于一幅图像的行数,或者等待下一个场中断来临 就结束图像采集,关闭行中断和场中断。
图像处理算法的开发教程与实现方法

图像处理算法的开发教程与实现方法图像处理是计算机科学领域中一个重要的研究方向,它涉及到对数字图像的获取、处理、分析和识别等一系列操作。
图像处理算法的开发则是实现这些操作的核心。
本文将为读者介绍图像处理算法的开发教程与实现方法。
一、图像处理算法的基本概念图像处理算法是指用来处理数字图像的数学或逻辑操作方法。
在开发图像处理算法之前,我们需要对一些基本概念有所了解。
1. 像素:像素是构成数字图像的最小单元,代表了图像中的一个点。
每个像素都有自己的位置和像素值,像素值可以表示颜色、亮度或灰度等信息。
2. 空间域与频率域:在图像处理算法中,我们常常需要在空间域和频率域之间进行转换。
空间域指的是图像中像素的位置和像素值,而频率域则是指图像中各个频率分量的分布。
3. 直方图:直方图是对图像像素分布的统计图,它可以描述图像中不同像素值的数量。
直方图分析在图像处理中非常重要,可以用来检测图像的亮度、对比度等特征。
二、图像处理算法的开发流程在开发图像处理算法之前,我们需要明确自己的目标并制定开发流程。
一般而言,图像处理算法的开发流程包括以下几个步骤。
1. 图像获取:首先,我们需要获取待处理的图像。
图像可以由摄像机、扫描仪等设备采集获得,也可以从存储设备或网络中读取。
2. 图像预处理:在进行实际的图像处理之前,我们需要对图像进行预处理。
预处理包括图像的去噪、增强、平滑等操作,可以提高后续处理的效果。
3. 图像分割:图像分割是将图像划分为若干个区域的过程。
分割可以基于像素值、纹理、形状等特征进行,常用的分割方法有阈值分割、边缘检测、区域生长等。
4. 特征提取:在图像处理中,我们通常需要从图像中提取出一些重要的特征。
特征可以用来描述图像的形状、颜色、纹理等属性,常用的特征提取方法有哈尔特征、色彩直方图等。
5. 图像识别与分析:通过对提取出的特征进行分类和分析,我们可以实现图像的识别和分析。
图像识别涉及到将图像归类到不同的类别中,而图像分析则是对图像中的目标进行定位、计数等。
摄像头采集信息的算法

摄像头采集信息的算法全文共四篇示例,供读者参考第一篇示例:摄像头在现代社会中扮演着重要角色,不仅在监控系统、安防领域有着广泛的应用,还在智能手机、笔记本电脑、平板电脑等设备中被广泛使用。
摄像头采集信息的算法是指利用摄像头获取的视频信息进行处理和分析的算法,其涉及到图像处理、计算机视觉和人工智能等多个领域,是当前研究热点之一。
摄像头采集信息的算法可以用于多种应用场景,例如人脸识别、车辆识别、动作检测、人体姿态识别等。
在这些应用中,摄像头首先将所拍摄的图像或视频传输至计算机系统中,而后算法会对图像进行分析和处理,从中提取出有意义的信息,并作出相应的判断和行为反应。
对于摄像头采集信息的算法来说,图像处理是其中一个重要的环节。
图像处理技术包括图像的采集、预处理、特征提取和特征匹配等步骤。
在图像采集阶段,摄像头会不断地捕获图像或视频,将其传输至计算机系统中。
在预处理阶段,图像可能需要进行去噪、平滑处理等,以便提高后续处理的效果。
特征提取是指从图像中提取出具有代表性的信息,例如像素级的颜色、纹理、形状等信息。
特征匹配则是将提取出的特征与预先训练好的模型进行匹配,从而实现对图像中物体或场景的识别和分类。
除了图像处理,计算机视觉也是摄像头采集信息的算法中不可或缺的一部分。
计算机视觉是一门研究如何让计算机“看懂”图像或视频的学科,其包括目标检测、目标跟踪、图像识别、物体检测等多个领域。
通过计算机视觉的技术,摄像头可以实现人脸识别、动作检测、人体姿态识别等功能。
在人工智能领域,深度学习和神经网络技术也被广泛应用于摄像头采集信息的算法中。
深度学习是一种基于人工神经网络的机器学习方法,通过大量的训练数据和复杂的网络结构,可以实现更加精准的图像识别和分类。
神经网络模仿了人脑的神经元网络结构,在处理图像时可以提取出更多的高级特征,提高图像处理的准确性和效率。
在工业领域,摄像头采集信息的算法也被广泛应用于生产自动化和机器视觉系统中。
sift算法原理

sift算法原理SIFT算法原理。
SIFT(Scale-invariant feature transform)算法是一种用于图像处理和计算机视觉领域的特征提取算法。
它能够在不同尺度和旋转角度下提取出稳定的特征点,并且对光照、噪声等干扰具有较强的鲁棒性。
SIFT算法由David Lowe于1999年提出,至今仍被广泛应用于图像拼接、目标识别、三维重建等领域。
本文将介绍SIFT算法的原理及其关键步骤。
1. 尺度空间极值检测。
SIFT算法首先通过高斯滤波构建图像的尺度空间金字塔,然后在不同尺度空间上寻找局部极值点作为关键点。
这些关键点在不同尺度下具有不变性,能够在不同大小的目标上被检测到。
2. 关键点定位。
在尺度空间极值点的基础上,SIFT算法通过对尺度空间进行插值,精确定位关键点的位置和尺度。
同时,为了提高关键点的稳定性,还会对梯度方向进行进一步的精确计算。
3. 方向分配。
为了使关键点对旋转具有不变性,SIFT算法会计算关键点周围像素点的梯度方向直方图,并选择主方向作为关键点的方向。
这样可以使得关键点对于图像的旋转具有不变性。
4. 特征描述。
在确定了关键点的位置、尺度和方向后,SIFT算法会以关键点为中心,提取周围区域的梯度信息,并将其转换为具有较强区分度的特征向量。
这些特征向量可以很好地描述关键点周围的图像信息,从而实现对图像的匹配和识别。
5. 特征匹配。
最后,SIFT算法使用特征向量进行特征匹配,通常采用欧氏距离或者余弦相似度进行特征匹配。
通过匹配不同图像的特征点,可以实现图像的配准、目标的识别等应用。
总结。
SIFT算法作为一种经典的特征提取算法,在图像处理和计算机视觉领域具有重要的应用价值。
其关键在于通过尺度空间极值点的检测和特征描述子的构建,实现了对图像的稳健特征提取。
同时,SIFT算法对于光照、噪声等干扰具有较强的鲁棒性,能够应对复杂环境下的图像处理任务。
因此,SIFT算法在目标识别、图像拼接、三维重建等领域有着广泛的应用前景。
ENVI实习直方图匹配,校正,分类

ENVI实习一实验目的(1)主要学习ENVI软件的基本功能(2)ENVI 软件完成影像增强(包括直方图匹配和去云)、融合、正射校正和监督、非监督分类四个大方面的试验。
(3)掌握视窗操作模块的功能和操作技能二软件和设备ENVI4.5一套三实验原理各个任务的试验原理和操作详细见下面操作,再次不详述。
一、图像增强(算法、原理、对比图)1、直方图匹配在ENVI 中使用Histogram Matching 工具可以自动地把一幅实现图像的直方图匹配到另一幅上,从而使两幅图像的亮度分布尽可能地接近。
使用该功能以后,在该功能被启动的窗口内,输入直方图将发生变化,以与所选图像显示窗口的当前输出直方图相匹配。
在灰阶和彩色图像上,都可以使用该功能。
操作步骤:选择Enhance > Histogram Matching,出现Histogram Matching Input parameters 对话框,在Match To中选择想匹配的图像。
在Input Histogram 会有Image、Scroll、Zoom、Band、、ROI来选择如数直方图的来源,下图为输入图像数据及其所用的拉伸(直方图匹配之前):下图为Match To 想匹配的图像及其拉伸:利用直方图匹配后图像2的直方图结果:从结果可以看出,匹配后的图像在亮度上已经明显增强,从偏暗增强为较亮;其直方图与#1中的图像直方图在亮度上分布也很接近。
2、图像去云常规的云处理算法会随云的覆盖类型的不同而不同,对在大范围内存在薄云的影像来说,采用同态滤波法较好。
同态滤波法把频率过滤与灰度变化结合起来,分离云与背景地物,最终从影像中去除云的影响,这种方法由于涉及到滤波器以及截至频率的选择,在滤波的过程中有时会导致一些有用信息的丢失。
对于局部有云的影像来说,一般使用时间平均法,这种算法适用于地物特征随时间变化较小的地区,如荒漠、戈壁等地区;对于植被覆盖茂密的地区,由于植被的长势与时间有密切的关系,不同时相的植被长势在影像中有明显的区别,这种简单的替代算法不再适用。
了解图像识别和处理的基本原理和算法

了解图像识别和处理的基本原理和算法图像识别和处理是计算机视觉领域的重要研究方向,它涉及到对图像进行分析、理解和处理的技术和方法。
本文将介绍图像识别和处理的基本原理和算法。
一、图像识别的基本原理图像识别是指通过计算机对图像进行分析和理解,从而识别出图像中的对象、场景等信息。
其基本原理包括以下几个方面:1. 特征提取:特征是图像中的一些具有代表性的属性或者模式,通过提取这些特征可以描述图像的内容。
常用的特征包括颜色、纹理、形状等。
特征提取可以通过局部特征描述子(如SIFT、SURF等)或者深度学习模型(如卷积神经网络)来实现。
2. 特征匹配:将待识别图像的特征与已知图像库中的特征进行匹配,找出最相似的图像。
匹配算法可以使用最近邻算法、支持向量机等。
3. 分类器训练:通过使用已标注的图像数据集来训练分类器,使其能够自动学习图像的特征和类别之间的关系。
常用的分类器包括支持向量机、随机森林、深度学习模型等。
二、图像处理的基本原理图像处理是指对图像进行各种操作和变换,以改善图像的质量、增强图像的特征或者提取图像中的有用信息。
其基本原理包括以下几个方面:1. 图像增强:通过对图像的亮度、对比度、颜色等进行调整,使图像更加清晰、鲜艳。
常用的图像增强方法包括直方图均衡化、对比度拉伸等。
2. 图像滤波:通过对图像进行滤波操作,去除噪声、平滑图像或者增强图像的边缘等。
常用的图像滤波器包括均值滤波器、中值滤波器、高斯滤波器等。
3. 图像分割:将图像分成若干个不同的区域或者对象,以便进一步分析和处理。
常用的图像分割方法包括阈值分割、边缘检测等。
4. 特征提取:提取图像中的特征以描述图像的内容。
常用的特征包括边缘、纹理、形状等。
特征提取可以通过使用滤波器、边缘检测算法等实现。
三、图像识别和处理的常见算法在图像识别和处理领域,有许多经典的算法被广泛应用。
以下是其中一些常见的算法:1. SIFT算法:尺度不变特征转换(Scale-Invariant Feature Transform,SIFT)是一种用于图像特征提取和匹配的算法。
摄像机标定原理及源码

摄像机标定原理及源码一、摄像机标定原理1.1相机模型在进行摄像机标定之前,需要了解相机模型。
常用的相机模型是针孔相机模型,它假设光线通过小孔进入相机进行成像,形成的图像符合透视投影关系。
针孔相机模型可以通过相机内部参数和外部参数来描述。
1.2相机内部参数相机内部参数主要包括焦距、光心坐标等信息,可以通过相机的标定板来获取。
标定板上通常有已知尺寸的标定点,通过计算图像中的标定点坐标和实际世界中的标定点坐标之间的关系,可以求解出相机的内部参数。
1.3相机外部参数相机外部参数主要包括相机在世界坐标系中的位置和姿态信息。
可以通过引入已知的点和相机对这些点的投影来求解相机的外部参数。
也可以通过运动捕捉系统等设备获取相机的外部参数。
1.4标定算法常用的摄像机标定算法有张正友标定法、Tsai标定法等。
其中,张正友标定法是一种简单和广泛使用的标定方法。
该方法通过对标定板上的角点进行提取和匹配,利用通用的非线性优化算法(如Levenberg-Marquardt算法)最小化像素坐标与世界坐标的重投影误差,从而求解出相机的内部参数和外部参数。
二、摄像机标定源码下面是使用OpenCV实现的摄像机标定源码:```pythonimport numpy as npimport cv2#棋盘格尺寸(单位:毫米)square_size = 25#棋盘内角点个数pattern_size = (9, 6)#获取标定板角点的世界坐标objp = np.zeros((np.prod(pattern_size), 3), dtype=np.float32) objp[:, :2] = np.mgrid[0:pattern_size[0],0:pattern_size[1]].T.reshape(-1, 2) * square_sizedef calibrate_camera(images):#存储角点的世界坐标和图像坐标objpoints = []imgpoints = []for img in images:gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)#查找角点ret, corners = cv2.findChessboardCorners(gray, pattern_size, None)if ret:objpoints.append(objp)#亚像素精确化criteria = (cv2.TERM_CRITERIA_EPS +cv2.TERM_CRITERIA_MAX_ITER, 30, 0.001)corners2 = cv2.cornerSubPix(gray, corners, (11, 11), (-1, -1), criteria)imgpoints.append(corners2)#标定相机ret, mtx, dist, rvecs, tvecs = cv2.calibrateCamera(objpoints, imgpoints, gray.shape[::-1], None, None)return ret, mtx, dist, rvecs, tvecs#读取图像images = []for i in range(1, 21):img = cv2.imread(f'image_{i}.jpg')images.append(img)#相机标定ret, mtx, dist, rvecs, tvecs = calibrate_camera(images)#保存相机参数np.savez('calibration.npz', ret=ret, mtx=mtx, dist=dist, rvecs=rvecs, tvecs=tvecs)```以上代码首先定义了棋盘格尺寸和格子个数,然后定义了函数`calibrate_camera`来进行相机标定。
曝光、影调与照相机的直方图
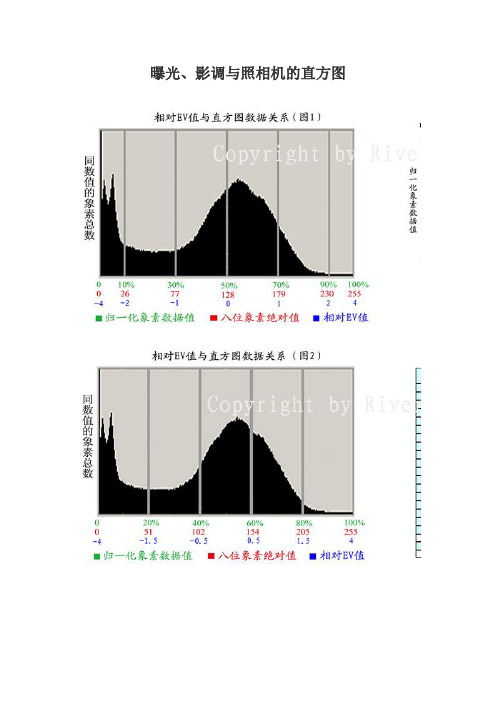
曝光、影调与照相机的直方图先看图4,光圈系数F=镜头焦距/镜头光圈的直径,直径越大,光圈系数越小,光圈孔面积越大,进的光线越多。
光圈系数F与直径相关所以每级差1.414倍面积才能差一倍。
快门速度、亮度、感光度每级都是两倍的关系。
对于初学者,光圈、快门、感光度的系列数字是要记住的。
好记,就是光圈是1.4倍,其他是两倍的关系。
有的照相机的数据是按1/3或1/2级调整的,只要记住基本差一级的数据就可以了。
他们与AV、TV、BV、SV的对应关系不需要记,用的时候查查就行。
公式EV=AV+TV=B V+SV是要懂的,不然与别人无法交流。
测光测出来的是BV,SV是自己预先选好的,根据BV+SV=EV就确定了EV,再根据EV=AV+TV确定光圈、快门。
对应同一个EV有多种AV、TV的组合,固定一种方式选就是P-程序曝光。
自己选定AV,照相机选TV就是光圈优先。
自己选TV,照相机选AV,就是快门优先。
如果测光决定了BV后SV、AV、TV都让照相机选就是AUTO。
SV感光度一般是预先设定的,此时EV=BV+常数,研究EV、BV相对变化时,可以忽略掉常数部分,所以在感光度SV确定的前提下,经常用EV直接代表BV来讨论问题,比如说亮度范围是5EV,或者说亮度范围EV是5。
至于说是真正的从EV=3到EV=7,还是从EV =5到EV=9,就不关心了。
再比如曝光补偿时经常说+1EV,-2EV等等,此时的1EV实际是使曝光量变化一级的意思。
可以称之为相对EV值。
数码照相机记录的不是景物的亮度值,而是BV值,亮度值和BV是对数关系。
这一点与传统照相机一样,因为这种关系不是由照相机决定的,是由人眼的视神经传导规律决定的。
数码照相机记录BV值后生成的数据不是线性关系,而是如图3的曲线关系,这一点与传统照相机的胶片密度曲线有些相似。
在图3中用相对EV来代替BV的变化范围。
横轴的0是照相机的标准测光点的亮度值,1是亮度两倍,2是亮度4倍。
camshift算法原理

camshift算法原理Camshift算法是一种基于颜色统计的物体跟踪算法,常被用于计算机视觉领域中的目标跟踪任务。
该算法通过对目标对象的颜色特征进行建模,并在视频序列中实时追踪目标的位置和大小。
Camshift算法的原理基于直方图反向投影技术和Meanshift算法。
首先,算法通过用户选取的初始目标区域,计算该区域的颜色直方图模型。
然后,将该直方图模型与整幅图像的直方图进行比较,得到反向投影图像。
反向投影图像中的每个像素值表示该像素属于目标对象的概率。
接下来,利用Meanshift算法对反向投影图像进行均值漂移操作,寻找目标对象的最大概率区域。
均值漂移操作的原理是根据概率分布的重心不断迭代,使得目标区域的中心点逐渐向最大概率区域移动。
这样,在每次迭代过程中,目标区域的位置和大小都会根据图像的颜色分布而自适应地调整。
为了进一步提高目标区域的准确性和稳定性,Camshift算法引入了一个自适应窗口大小的机制。
在Meanshift算法的每次迭代中,算法会根据当前目标区域的大小,自动调整搜索窗口的大小。
当目标对象静止或运动缓慢时,窗口大小会自动缩小以提高精度;当目标对象运动较快时,窗口大小会自动扩大以保持目标的完整性。
Camshift算法还可以通过加权直方图模型来对目标对象的颜色特征进行动态更新。
在每次迭代中,算法会根据当前目标区域的位置和大小,调整颜色直方图的权重,使其更好地适应目标对象的变化。
总结来说,Camshift算法通过对目标对象的颜色特征进行建模和追踪,能够在复杂的背景环境中实现准确、稳定的目标跟踪。
该算法的原理基于直方图反向投影和Meanshift算法,通过自适应窗口大小和加权直方图模型的机制,能够适应目标对象的位置、大小和颜色的变化,具有较高的鲁棒性和实时性。
在计算机视觉和视频分析领域中,Camshift算法被广泛应用于目标跟踪、行为分析、视频监控等方面,为实现智能视觉系统提供了重要的技术支持。
医疗影像处理中图像配准算法的对比与评估

医疗影像处理中图像配准算法的对比与评估概述:医学影像处理在现代医学领域扮演着重要角色。
为了准确地诊断和治疗疾病,医生需要依赖于医学影像,如X射线、核磁共振(MRI)、计算机断层扫描(CT)等,对患者的身体进行观察和分析。
然而,由于多种因素的影响,获取的医学影像经常存在位置偏移和形态变化等问题,这使得医生在进行多模态影像配准时面临着巨大困难。
因此,图像配准技术的发展对于提高医学诊断和治疗的准确性具有重要的意义。
图像配准算法的分类:在医学影像处理中,常用的图像配准算法可以分为以下几类:1. 基于特征的配准算法:基于特征的配准算法通过提取图像中的特征点或区域来实现不同图像之间的对应关系。
这些特征可以是角点、边缘、纹理等。
常见的算法有SIFT、SURF和ORB等。
这类算法的优点是可以在不同图像间进行准确的匹配,但对于图像中的遮挡或变形等情况不够稳健。
2. 基于形变场的配准算法:基于形变场的配准算法通过将一个图像的像素映射到另一个图像上,来实现两个图像的对齐。
这些算法可以利用地标点或控制网格来定义形变场。
常见的算法有Thin-Plate Splines(TPS)、B-splines和光流场等。
这类算法可以灵活地处理图像的形变,但需要较长的计算时间。
3. 基于互信息的配准算法:基于互信息的配准算法通过计算两个图像中灰度值之间的相似性来实现图像的对齐。
互信息可以基于直方图来计算,也可以基于滤波器等方法来进行估计。
这类算法适用于多模态图像的配准,但对于图像质量和噪声等因素较为敏感。
对比与评估:在医疗影像处理中,不同的图像配准算法各具特点,适用于不同的实际需求。
下面将对几种常用的图像配准算法进行对比和评估。
1. SIFT算法:尺度不变特征转换(Scale-Invariant Feature Transform,SIFT)是一种常用的基于特征的配准算法。
该算法通过有效地检测稳定尺度下的关键点,并计算描述关键点特征,实现不同图像之间的匹配。
摄像机的图像直方图功能介绍和使用方法

摄像机的图像直方图功能介绍和使用方法摄像机作为现代科技的产物,已经成为人们生活中不可或缺的一部分。
它不仅能够记录下我们生活中的美好瞬间,还可以帮助我们更好地理解图像的特性。
在摄像机的功能中,图像直方图是一个非常有用的工具,它可以帮助我们分析图像的亮度分布和对比度,从而得到更好的拍摄效果。
一、图像直方图的概念和作用图像直方图是指图像中各个亮度级别的像素数量统计图。
它以亮度级别为横坐标,像素数量为纵坐标,通过直方图可以直观地了解图像的亮度分布情况。
图像直方图的作用主要有以下几个方面:1. 亮度分布分析:通过图像直方图,我们可以了解图像中各个亮度级别的像素数量,从而判断图像的整体亮度分布情况。
如果直方图呈现出均匀的分布,表示图像的亮度分布较为均衡;而如果直方图呈现出集中在某个亮度级别附近的分布,表示图像的亮度分布较为不均衡。
2. 对比度分析:图像直方图还可以帮助我们分析图像的对比度。
对比度是指图像中不同亮度级别之间的差异程度。
通过直方图,我们可以观察到直方图中的高峰和低谷,从而判断图像的对比度。
如果直方图中的高峰较多,表示图像的对比度较高;而如果直方图中的高峰较少,表示图像的对比度较低。
3. 曝光调整:通过图像直方图,我们可以判断图像是否过曝或者欠曝。
如果直方图中的像素数量集中在亮度级别较高或较低的部分,表示图像可能存在过曝或欠曝的问题。
通过调整摄像机的曝光参数,可以使直方图更加均衡,从而得到更好的曝光效果。
二、使用方法在摄像机中使用图像直方图功能,一般需要按照以下步骤进行:1. 打开图像直方图功能:在大部分摄像机中,图像直方图功能都是默认开启的。
如果没有开启,可以在摄像机的设置菜单中找到图像直方图选项,并将其打开。
2. 拍摄图像:在打开图像直方图功能后,可以通过摄像机拍摄一张照片或者录制一段视频。
摄像机会自动记录下图像的直方图数据。
3. 查看直方图:在摄像机的回放模式中,可以选择查看刚刚拍摄的图像的直方图。
监控摄像头的图像处理技术

监控摄像头的图像处理技术随着科技的进步和社会的发展,监控摄像头已经成为保障人们安全、维护社会秩序的重要工具。
而要让这些监控摄像头发挥更大的作用,就需要对监控摄像头的图像进行处理,提高其识别和分析能力。
一、数字图像处理技术在监控摄像头中的应用数字图像处理技术是一种基于计算机技术的,对数字图像进行处理和分析的方法。
在监控摄像头中,数字图像处理技术不仅可以提高监控图像的清晰度,减少干扰噪声,还可以实现针对性的处理和分析,如人脸识别、车牌识别、行人轨迹分析等。
1. 图像增强技术监控图像往往受到光线、天气、拍摄角度等因素的影响,图像质量较低。
因此,图像增强技术是监控图像处理中的重要环节之一。
常见的图像增强技术包括去噪、增强对比度、锐化边缘等。
2. 人脸识别技术人脸识别技术是数字图像处理技术在监控图像处理中的一个应用。
利用计算机对监控图像中的人脸进行分析,识别人脸特征,并将其与已有的人脸信息数据库进行比对,从而判断出人物身份和行为。
通过这种方式,可以便捷地找到想要的人或追踪嫌疑人。
3. 车牌识别技术车牌识别技术是利用数字图像处理技术识别监控图像中的车牌,提取车牌号码信息的过程。
这种技术主要应用于交通监控、停车场管理等领域,可以帮助管理人员更加方便地管理车辆信息。
4. 行人轨迹分析技术行人轨迹分析技术是利用数字图像处理技术对监控图像中的行人进行分析,了解行人运动轨迹,预测可能发生的问题。
这种技术可以应用于公共场所、商场、学校等场所的安全监控,及时发现异常行为并采取措施。
二、未来监控摄像头的发展趋势未来监控摄像头的发展趋势主要包括以下几点:1. 智能化未来监控摄像头将越来越智能化。
通过利用人工智能技术,监控摄像头可以更加精准地识别图像中的人、物、车辆,快速地分析物体运动轨迹,从而更快速地捕捉异常行为,提高安保水平。
2. 多样化未来监控摄像头的类型将变得更加多样化。
在保障社会安全的情况下,监控摄像头的应用领域将会不断扩大,包括工业、医疗、军事等领域。
stm32 uvc编程

stm32 uvc编程【STM32 UVC编程】一视觉摄像头开发的实践指南引言:随着物联网和智能家居的快速发展,嵌入式视觉应用变得越来越重要。
而具备UVC(USB Video Class)功能的STM32单片机,成为了开发者普遍选择的工具。
本文将以STM32 UVC编程为主题,从基础知识到实践案例,一步一步地解析其实现原理、操作步骤和常见问题。
第一步:UVC基础知识概述UVC(USB Video Class)是一种通用的标准,用于定义视频和音频流的传输方式。
基于UVC的相机,通过USB接口与计算机进行数据传输。
了解UVC的基础知识对于理解STM32 UVC编程是至关重要的。
以下是几个重要概念的简要说明:1. 设备描述符(Device Descriptor):描述相机的基本信息,如供应商ID、产品ID、设备版本等。
2. 配置描述符(Configuration Descriptor):定义该相机支持的配置及其参数。
3. 接口描述符(Interface Descriptor):描述一个相机的接口,可能包含视频流、音频流、控制命令等等。
4. 控制命令(Control Command):通过USB控制传输管道发送到设备的命令。
5. 帧描述符(Frame Descriptor):描述一帧视频的参数,如图像大小、格式、帧率等。
第二步:准备开发环境在进行STM32 UVC编程之前,需要准备好以下工具和资源:1. STM32开发板:选择一款具备USB接口的STM32单片机开发板,例如STM32F4 Discovery、NUCLEO-F446RE等。
2. STM32CubeMX:一款由STMicroelectronics提供的集成开发环境(IDE)插件,用于生成STM32项目的代码框架。
3. STM32Cube USB Device库:一个用于USB设备通信的库,提供了创建UVC相机所需的基础功能。
4. USB摄像头:任何符合UVC标准的USB摄像头均可,既可以使用已有的USB摄像头,也可以购买专门的UVC相机模块。
摄像头算法的介绍和应用

摄像头算法的介绍和应用在今天的社会中,摄像头已经成为了我们生活中不可缺少的一部分。
几乎无论在哪个场景下,都离不开摄像头的应用。
而其中最核心的部分,便是摄像头算法。
本文将对摄像头算法的介绍和应用进行一定的探讨。
一、摄像头算法的介绍1. 图像处理图像处理是一种基于数学、物理、计算机科学等多学科交叉的技术,其主要目的是对数字图像进行处理和分析,提取出其中有用的信息,从而实现对图像的各种操作。
在摄像头中,图像处理是摄像头算法必不可少的一部分。
2. 视频编解码视频编解码是一种将数字视频信号进行压缩和解压缩的技术,其目的是为了减少视频数据的存储空间和传输带宽。
视频编解码在摄像头算法中起到了非常重要的作用,能够将摄像头捕获的海量数据进行有效地压缩和解压缩,提高了视频信号的传输效率。
3. 特征识别特征识别是一种通过对图像中的特征进行分析和识别,从而实现各种功能的技术。
它在摄像头算法中主要用于人脸识别、车牌识别等功能。
二、摄像头算法的应用1. 安防领域在安防领域中,摄像头是不可或缺的一部分。
它可以捕捉到各种场景下的视频信号,通过摄像头算法对图像进行处理,提取出其中的人脸、车牌等特征信息,从而实现安防监控的各种功能。
2. 物联网领域随着物联网的不断发展,越来越多的智能设备需要使用摄像头进行数据采集。
通过摄像头算法对采集到的图像进行处理,可以提取出其中的各种信息,从而实现智能物联网设备的更加智能化。
3. 人机交互领域在人机交互领域中,摄像头也扮演了重要的角色。
通过摄像头算法对人脸进行识别和跟踪,可以实现更加自然和智能的人机交互方式,增强用户体验和便捷性。
三、结语摄像头算法在各行各业中起着越来越重要的作用。
它不仅可以提高各种设备的智能化和自动化水平,还能够通过对图像的分析和处理,提取出其中的有用信息,实现各种功能。
未来,随着各种新技术的不断涌现,摄像头算法的应用将会越来越广泛,值得我们深入研究和探索。
图像直方图的名词解释

图像直方图的名词解释图像直方图,是指用来表示图像中像素值分布的统计图表。
它是计算机视觉中一种常用的图像描述工具,多用于图像处理和分析领域。
通过对图像像素值的统计,直方图能够展示图像的亮度、对比度、颜色分布等信息。
下面将从历史起源、计算方式、应用领域三个方面,对图像直方图进行名词解释。
历史起源在20世纪50年代初,人们开始研究数字图像处理,并提出了图像直方图的概念。
当时,由于计算机存储和处理速度的限制,图像直方图只能在小尺寸的图像上进行操作。
随着计算机技术的进步,图像直方图逐渐被广泛应用于大尺寸图像和实时图像处理中。
计算方式图像直方图可以通过对图像中每个像素的像素值进行统计,来得到不同像素值的频数或概率。
其计算方式包括以下几个步骤:1. 获取图像像素矩阵:图像直方图的计算首先需要将图像转换为数字矩阵,即将图像的像素值映射到一个矩阵中。
2. 统计像素值频数:对图像像素值矩阵进行遍历,统计每个像素值的频数。
以灰度图为例,每个像素值的频数可以表示图像中该像素值所占的像素数量。
3. 绘制直方图:通过将像素值对应的频数进行可视化,即可绘制出图像的直方图。
直方图的横坐标表示像素值,纵坐标表示频数或概率。
应用领域图像直方图具有广泛的应用领域,下面将从图像增强、边缘检测和目标跟踪三个方面进行解释。
1. 图像增强:直方图均衡化是一种常用的图像增强方法,通过对图像直方图进行变换,可以增加图像的对比度,使得图像更加清晰和饱满。
通过将直方图均衡化应用于彩色图像的RGB三个通道,可以获得更好的图像增强效果。
2. 边缘检测:直方图对于边缘检测同样具有重要作用。
通过对图像直方图进行二阶导数计算,可以找到直方图中的局部极值点,进而定位图像中的边缘。
这种基于直方图的边缘检测方法在医学影像处理、人脸识别等领域有着广泛应用。
3. 目标跟踪:在计算机视觉中,目标跟踪是一个常见的问题。
图像直方图在目标跟踪中可以用来表示目标模型。
通过提取目标模型的直方图特征,可以在视频序列中进行目标匹配和跟踪。
envi图像处理基本操作

使用ENVI进行图像处理主要介绍利用envi进行图像处理的基本操作,主要分为图像合成、图像裁减、图像校正、图像镶嵌、图像融合、图像增强。
分辨率:空间分辨率、波谱分辨率、时间分辨率、辐射分辨率。
咱们平时所说的分辨率是指?怎么理解?1、图像合成对于多光谱影像,当我们要得到彩色影像时,需要进行图像合成,产生一个与自然界颜色一致的真彩色(假彩色)图像。
对于不同类型的影像需要不同的波段进行合成,如中巴CCD影像共5个波段,一般选择2、4、3进行合成。
(为什么不选择其他波段?重影/不是真彩色)。
SOPT5影像共7个波段,一般选择7、4、3三个波段。
操作过程以中巴资源卫星影像为例中巴资源卫星影像共有五个波段,选择2、4、3三个波段对R、G、B赋值进行赋值。
在ENVI中的操作如下:(1)file→open image file→打开2、3、4三个波段,选择RGB,分别将2、4、3赋予RGB。
(2)在#1窗口file---〉save image as-→image file。
(3)在主菜单中将合成的文件存为tiff格式(file-→save file as-→tiff/geotiff)即可得到我们需要的彩色图像。
2、图像裁减有时如果处理较大的图像比较困难,需要我们进行裁减,以方便处理。
如在上海出差时使用的P6、SOPT5,图幅太大不能直接校正需要裁减。
裁减图像,首先制作AOI文件再根据AOI进行裁减。
一般分为两种:指定范围裁减、不指定范围裁减。
不指定范围裁减在ENVI中的操作如下:(1)首先将感兴趣区存为AOI文件file→open image file打开原图像→选择IMAGE窗口菜单overlay→region of interesting选择划定感兴趣区的窗口如scroll,从ROI_Type菜单选择ROI的类型如Rectangle,在窗口中选出需要选择的区域。
在ROI窗口file→Save ROIs将感兴趣区存为ROI文件。
相机算法入门知识点总结

相机算法入门知识点总结相机算法是指在数字图像处理领域对相机图像进行处理和优化的算法。
相机算法广泛应用于数字相机、手机相机和摄像头等设备中,其作用是提高图像质量、增强图像效果、改善拍摄体验等。
相机算法涉及到图像处理、计算机视觉、图像识别等多个领域,是一个综合性的技术。
本文将从基本概念、常见算法和应用实践等方面对相机算法进行系统的介绍和总结。
基本概念1. 数字图像数字图像是使用数字化设备对具体对象、场景、图形等进行记录、传输和展示的一种视觉媒体。
数字图像由像素组成,每个像素代表图像中的一个点,具有颜色和亮度信息。
数字图像通常用二维矩阵表示,其中每个元素为像素的亮度和颜色值。
数字图像处理就是对数字图像进行处理和分析的一种技术,其目的是改善图像质量、提取图像特征、实现图像识别等。
2. 相机基本原理相机是一种光学设备,能够将被摄物体的光线投射到感光介质上并记录下来。
相机包括镜头、曝光系统、感光介质和成像管路等部分。
当光线通过镜头进入相机时,会成像在感光介质上,并形成一幅图像。
感光介质通常是指胶片或传感器,可以记录下被摄物体的光线信息。
成像管路是指光线从镜头到感光介质的传输路径,包括镜头系统、镜筒、快门等部分。
3. 相机参数相机的参数包括焦距、光圈、快门速度、感光度等。
焦距是指镜头到感光介质的距离,影响照片中景深和透视关系。
光圈是指镜头的光圈大小,控制进入镜头的光线量,影响照片的景深和亮度。
快门速度是指感光介质暴露在光线下的时间,决定照片的清晰度和运动停顿。
感光度是指感光介质对光线敏感程度的参数,影响照片的噪点和颗粒度。
4. 相机图像处理相机图像处理是指对相机采集的图像进行处理和优化的过程。
图像处理包括色彩校正、锐化、去噪、对比度调整、亮度调整等操作,可以提高图像质量,增强图像效果。
相机图像处理也可以涉及到特效处理、美颜处理、人脸识别等高级算法,对图像进行进一步的加工和修改。
常见算法1. 色彩校正色彩校正是指对图像进行色彩平衡的处理,使图像的颜色看上去更加真实和自然。
直方图规定化计算

直方图规定化计算直方图规定化是一种图像处理技术,通过对图像的亮度分布进行调整来改变图像的视觉效果。
它可以用于增强图像的对比度和细节,使图像更加清晰和易于观察。
在直方图规定化过程中,我们需要计算原始图像和目标图像的累积分布函数,并将原始图像的像素值映射到目标图像的像素值。
首先,我们需要计算原始图像的直方图。
直方图是一个反映图像亮度分布的统计图,它描述了图像中各个亮度级别的像素数量。
我们可以通过统计图像中每个像素值的出现次数来得到直方图。
然后,我们将直方图进行归一化,以便进行比较和计算。
接下来,我们计算原始图像直方图的累积分布函数(CDF)。
CDF描述了累积到某个亮度级别的像素数量与图像总像素数量之间的关系。
通过计算CDF,我们可以得到原始图像的亮度累积分布。
同样,我们也需要计算目标图像的直方图和CDF。
然后,我们使用原始图像的CDF和目标图像的CDF来计算映射函数。
映射函数将原始图像的像素值映射到目标图像的像素值。
在计算映射函数时,我们可以使用线性插值方法,即通过对两个CDF之间的差异进行比例缩放来得到映射函数。
这样,我们就可以将原始图像的每个像素值映射到目标图像的相应像素值。
最后,我们将经过映射函数处理的原始图像和目标图像进行比较。
通过观察比较后的图像,我们可以看到一些改进的细节和对比度。
如果比较后的图像满足我们的期望,那么我们就可以将规定化后的图像保存下来。
直方图规定化是一种非常有用的图像处理技术,它可以用于改善图像的质量和视觉效果。
通过调整图像的亮度分布,我们可以增强图像的对比度和细节,使其更加清晰和易于观察。
同时,直方图规定化还可以用于图像的风格转换和图像的特征提取等应用领域。
在实际应用中,直方图规定化往往需要一定的计算时间和处理能力。
对于大尺寸的图像和高分辨率的图像,计算直方图和累积分布函数需要耗费较多的时间和计算资源。
因此,在实际应用中,我们需要根据具体需求和计算能力选择合适的图像处理方法和算法,以获得满意的结果。
颜色直方图的跟踪算法在视频监控中的应用

i n t h e n o n l i n e r a a n d n o n - g a u s s i n a n o i s e s y s t e m . he T s i m u l a t i o n r e s u l t s s h o w t h a t t h e s i n g l e o b j e c t o r m u l t i p i e t r a g e t s re a t r a c k e d i n r e a l t i m e .
L I De n g h u i , W ANG Ya n h o n g
a .I n s t i t u t e o fI n f o r m a t i o n T e c h n o l o g y ; b . S c h o o l o fI n f o r ma t o i n a n d C o m mu n i c a t i o n ,
b a s e d O f t h e c o l o r h i s t o g r a m i s a d o p t e d.F i r s ly, t t h e t rg a e t ra t c k i n g mo d e l i s d e t e r mi n e d a n d t h e n o ma r l i z e d C o l o r h i s t o ra g m i s c a l c u l a t e d .S e c o n d l y, t h e p a r t i c l e’ S i n i t i a l i z a t i o n p a r a me t e r s a r e s e t , pa r t i c l e p ra a me t e r s re a c lc a u l a t e d, c o l o r h i s t o ra g ms a r e c o mp a r e d nd a t a r g e t l o c a t i o n i s d e t e r mi n e d.F i n ll a y, t h e
视频目标跟踪算法与实现

视频目标跟踪算法与实现目标跟踪是计算机视觉领域中的重要任务之一。
它可以用于监控、智能交通、虚拟现实等众多领域。
在视频目标跟踪中,我们的目标是根据输入视频序列找出感兴趣的目标,然后在不同帧之间追踪目标的位置。
为了实现视频目标跟踪,我们需要采用适当的算法。
目前,常用的视频目标跟踪算法可以分为两大类:基于特征的跟踪算法和深度学习算法。
基于特征的跟踪算法主要依靠图像特征来进行目标跟踪。
其中,常见的算法包括:1. 光流法:光流法利用相邻帧之间的像素亮度差异来估计目标的运动。
通过对光流向量的计算和分析,可以推断出目标的位置和速度。
然而,光流法容易受到光照变化和纹理丰富度等因素的影响,导致跟踪结果不准确。
2. 直方图匹配法:直方图匹配法利用目标区域的颜色直方图进行跟踪。
它通过计算帧间颜色直方图的相似度来判断目标的位置。
直方图匹配法简单易懂,但对目标的颜色分布要求较高,不适用于复杂场景。
3. 卡尔曼滤波器:卡尔曼滤波器是一种用于状态估计的优化算法,可以对目标的位置和速度进行预测和修正。
它可以利用先验知识和测量结果来逐步调整估计值。
卡尔曼滤波器具有较好的鲁棒性和实时性,但对目标运动模型的假设较为严格。
与基于特征的算法相比,深度学习算法能够更准确地捕捉目标的特征,从而实现更精确的目标跟踪。
深度学习算法通常采用卷积神经网络(Convolutional Neural Network,CNN)来提取特征,并使用适当的分类器或回归器来预测目标的位置。
常见的深度学习算法包括:1. 基于卷积神经网络的目标跟踪:利用卷积神经网络对输入帧进行特征提取,然后通过分类器或回归器来预测目标的位置。
这种方法能够较好地捕捉目标的纹理和形状特征,实现精确的目标跟踪。
2. 循环神经网络(Recurrent Neural Network,RNN):循环神经网络可以对目标的时序信息进行建模,从而实现更准确的目标跟踪。
它通过学习帧间的时序关系来预测目标的位置。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
题目:图像的基本处理班级:2011级软件2班姓名:刘磊磊时间:20130907摘要:随着数字化与多媒体时代的来临,数字图像处理已经成为必备的基础知识。
全国各大专院校的计算机、电子、通信、医学、光学及许多相关专业都开设了与数字图像预处理相关的课程。
数字图像二值化是图像预处理中的一项重要技术,其在模式识别、光学字符识别、医学成像等方面都有着重要应用。
本论文主要为大家介绍24位真彩图像的灰度、二值处理以及图像的一些简单的打开和保存和如何画直方图,还有一些通过这次小学期学到的一些知识。
关键字:灰度处理,二值化图像的打开void CText1Dlg::ShowPic(){if(m_path =="") //判断图片路径是否存在{return;}hwnd = GetDlgItem(IDC_pic);hDesDC = hwnd->GetDC()->m_hDC;hSrcDC = CreateCompatibleDC(hDesDC);hBitmap=(HBITMAP)LoadImage(AfxGetInstanceHandle(),m_path,IMAGE_BITMAP,0,0, LR_LOADFROMFILE|LR_CREATEDIBSECTION);GetObject(hBitmap, sizeof(BITMAP), &bm);SelectObject(hSrcDC, hBitmap);hwnd->GetClientRect(&rect);::SetStretchBltMode(hDesDC,COLORONCOLOR);::StretchBlt(hDesDC, rect.left, rect.top, rect.right, rect.bottom, hSrcDC,0, 0, bm.bmWidth, bm.bmHeight,+SRCCOPY);UpdateData(false);}void CText1Dlg::Onopenpicture() //打开图像{// TODO: Add your control notification handler code hereinum = 1;CFileDialog dlg(TRUE,"bmp",".bmp",OFN_HIDEREADONL Y,"BMP Files(*.jpg)|*.bmp||");//设置所能打开图像的格式// CFileDialog dlg(TRUE,"jpg",".jpg",OFN_HIDEREADONL Y,"JPG Files(*.bmp)|*.jpg||");这是jpg图像的打开方式if(dlg.DoModal() != IDOK) // dlg_jpg.DoModal(){return;}m_path = dlg.GetPathName(); //获得图片路径UpdateData(false); //更新路径公共变量ShowPic(); //调用显示图片函数}图像的保存我的方法是先选择需要保存的图片并且这张图片是已经命名的,然后选择路径,最后用CopyFile(“原始图像全名包括扩展名”,“保存的全名包括路径+新的命名+扩展名”,false)就OK了。
下面是代码:void CForm::Onsaveroud(){// TODO: Add your control notification handler code hereCString strFolderPath="";TCHAR szPath[_MAX_PA TH];BROWSEINFO bi;bi.hwndOwner = GetSafeHwnd();bi.pidlRoot = NULL;bi.lpszTitle = _T("选择文件夹");bi.pszDisplayName = szPath;bi.ulFlags = BIF_RETURNONL YFSDIRS;bi.lpfn = NULL;bi.lParam = NULL;LPITEMIDLIST pItemIDList = SHBrowseForFolder(&bi);if(pItemIDList){if(SHGetPathFromIDList(pItemIDList,szPath)){strFolderPath = szPath;}// 防止内存泄露,要使用IMalloc接口IMalloc* pMalloc;if( SHGetMalloc(&pMalloc) != NOERROR ){TRACE(_T("无法取得外壳程序的IMalloc接口\n"));}pMalloc->Free(pItemIDList);if(pMalloc)pMalloc->Release();}ScanDiskFile(strFolderPath);}void CForm::ScanDiskFile(CString& strPath){CFileFind find;CString strTemp = strPath;CString strDirectory = strPath + _T("\\") + _T("\\*.*");CString strFile;BOOL IsFind = find.FindFile(strDirectory);IsFind=find.FindNextFile();// 如果是"." 则不扫描if(find.IsDots()){}// 如果是是目录,继续扫描此目录elseif(find.IsDirectory()){strFile = find.GetFileName();strTemp = strTemp ;//+ _T("\\") + strFile;//ScanDiskFile(strTemp);}m_path=strTemp;//m_path就是所要保存图片的路径UpdateData(false);find.Close();}彩色图像的灰度处理:图像灰度处理就是把各个像素点的R,G,B值设置为同一个值,当然要根据图像来取值。
void CText1Dlg::Oncolortogray() //彩色转换灰度{// TODO: Add your control notification handler code here// m_dwOperation = IMAGE_Text1_color_grayed_out;UpdateData();CString str;if(inum == 1)//判别是否是从其他路径读取{m_sourcefile = m_path;//m_sourcefile 是所要处理的彩色图片的路径及全名m_targetfile = m_path+"gray.bmp";//m_targetfile是处理过的图片的路径及全名str = m_targetfile;}m_sourcefile = CStimes;m_targetfile = "gray.bmp";str = m_targetfile;if(m_sourcefile == "" || m_targetfile == "")return;FILE *sourcefile,*targetfile;//位图文件头和信息头BITMAPFILEHEADER sourcefileheader,targetfileheader;BITMAPINFOHEADER sourceinfoheader,targetinfoheader;memset(&targetfileheader,0,sizeof(BITMAPFILEHEADER));memset(&targetinfoheader,0,sizeof(BITMAPINFOHEADER));sourcefile=fopen(m_sourcefile,"rb");fread((void*)&sourcefileheader,1,sizeof(BITMAPFILEHEADER),sourcefile);//提取原图文件头if(sourcefileheader.bfType!=0x4d42){fclose(sourcefile);MessageBox("原图象不为BMP图象!");return;}fread((void*)&sourceinfoheader,1,sizeof(BITMAPINFOHEADER),sourcefile);//提取文件信息头if(sourceinfoheader.biBitCount!=24){fclose(sourcefile);MessageBox("原图象不为24位真彩色!");return;}if(sourceinfoheader.biCompression!=BI_RGB){fclose(sourcefile);MessageBox("原图象为压缩后的图象,本程序不处理压缩过的图象!");return;}//构造灰度图的文件头targetfileheader.bfOffBits=54+sizeof(RGBQUAD)*256;targetfileheader.bfSize=targetfileheader.bfOffBits+sourceinfoheader.biSizeImage/3;targetfileheader.bfReserved1=0;targetfileheader.bfReserved2=0;targetfileheader.bfType=0x4d42;//构造灰度图的信息头,这些都是固定值targetinfoheader.biBitCount=8;targetinfoheader.biSize=40;targetinfoheader.biHeight=sourceinfoheader.biHeight;targetinfoheader.biWidth=sourceinfoheader.biWidth;targetinfoheader.biPlanes=1;targetinfoheader.biCompression=BI_RGB;targetinfoheader.biSizeImage=sourceinfoheader.biSizeImage/3;targetinfoheader.biXPelsPerMeter=sourceinfoheader.biXPelsPerMeter;targetinfoheader.biYPelsPerMeter=sourceinfoheader.biYPelsPerMeter;targetinfoheader.biClrImportant=0;targetinfoheader.biClrUsed=256;//构造灰度图的调色版RGBQUAD rgbquad[256];// color=(RGBMixPlate *)malloc(sizeof(RGBMixPlate)*256);// index=(BYTE *)malloc(sizeof(BYTE)*infohead.readSize);int i,j,m,n,k;for(i=0;i<256;i++){rgbquad[i].rgbBlue=i;rgbquad[i].rgbGreen=i;rgbquad[i].rgbRed=i;rgbquad[i].rgbReserved=0;}targetfile=fopen(m_targetfile,"wb");//写入灰度图的文件头,信息头和调色板信息fwrite((void*)&targetfileheader,1,sizeof(BITMAPFILEHEADER),targetfile);fwrite((void*)&targetinfoheader,1,sizeof(BITMAPINFOHEADER),targetfile);fwrite((void*)&rgbquad,1,sizeof(RGBQUAD)*256,targetfile);BYTE* sourcebuf;BYTE* targetbuf;//这里是因为BMP规定保存时长度和宽度必须是4的整数倍,如果不是则要补足m=(targetinfoheader.biWidth/4)*4;if(m<targetinfoheader.biWidth)m=m+4;n=(targetinfoheader.biHeight/4)*4;if(n<targetinfoheader.biHeight)n=n+4;sourcebuf=(BYTE*)malloc(m*n*3);//读取原图的颜色矩阵信息fread(sourcebuf,1,m*n*3,sourcefile);fclose(sourcefile);targetbuf=(BYTE*)malloc(m*n);BYTE BYcolor[3];// 通过原图颜色矩阵信息得到灰度图的矩阵信息for(i=0;i<n;i++){for(j=0;j<m;j++){for(k=0; k<3; k++)BYcolor[k]=sourcebuf[(i*m+j)*3+k];targetbuf[(i*m)+j]=BYcolor[0]*0.114+BYcolor[1]*0.587+BYcolor[2]*0.299;if(targetbuf[(i*m)+j]>255)targetbuf[(i*m)+j]=255;}}fwrite((void*)targetbuf,1,m*n+1,targetfile);fwrite(&targetinfoheader,1,12,targetfile);fwrite(&targetinfoheader,1,40,targetfile);fclose(targetfile);////////////////////////////////////////////////////preview(IDC_pic,str);//灰度预览}void CText1Dlg::preview(int control, CString CStimes)//预览图片{//conture是所要显示图片的picture控件的ID,CStimes是所要预览的图片的全名(包括扩展名)CString filepath;filepath = CStimes;IStream* stream;IPicture* picture;OLE_XSIZE_HIMETRIC m_width;OLE_YSIZE_HIMETRIC m_height;HGLOBAL hmem;CFile file;file.Open(filepath,CFile::modeReadWrite);DWORD len=file.GetLength();hmem=GlobalAlloc(GMEM_MOVEABLE,len);LPVOID pData=NULL;pData=GlobalLock(hmem);file.ReadHuge(pData,len);file.Close();GlobalUnlock(hmem);CreateStreamOnHGlobal(hmem,TRUE,&stream);OleLoadPicture(stream,len,TRUE,IID_IPicture,(LPVOID*)&picture);picture->get_Height(&m_height);picture->get_Width(&m_width);int width=(int)(240);int height=(int)(225);// int width=(int)(m_width/26.45);// int height=(int)(m_height/26.45);CRect rect1,rect2;GetClientRect(rect1);GetWindowRect(rect2);int x,y;x=rect1.Width()>(width+10)?0:(width+10-rect1.Width());y=rect1.Height()>(height+10)?0:(height+10-rect1.Height());rect2.InflateRect(x/2,y/2);MoveWindow(rect2);CenterWindow();//CDC* pDC=GetDC();CWnd *pi=GetDlgItem(control);//---注意:GetDlgItem是Cwnd类中函数,在此格式是继承;CDC *dc=pi->GetDC(); //picture->Render(dc->m_hDC,0,0,width,height,0,m_height,m_width,-m_height,NULL);pi->ReleaseDC(dc);////}彩色图像的二值化:图像的二值化就是将图像上的每个像素点的灰度值设置为0或255,也就是将整个图变为明显的黑白效果。