编译原理作业答案
编译原理试题及答案

编译原理试题及答案一、选择题1. 编译器的主要功能是什么?A. 程序设计B. 程序翻译C. 程序调试D. 数据处理答案:B2. 下列哪一项不是编译器的前端处理过程?A. 词法分析B. 语法分析C. 语义分析D. 代码生成答案:D3. 在编译原理中,词法分析器的主要作用是什么?A. 识别程序中的关键字和标识符B. 将源代码转换为中间代码C. 检查程序的语法结构D. 确定程序的运行环境答案:A4. 语法分析通常采用哪种方法?A. 自顶向下分析B. 自底向上分析C. 正则表达式匹配D. 直接解释执行答案:B5. 语义分析的主要任务是什么?A. 检查程序的语法结构B. 检查程序的类型安全C. 识别程序中的变量和常量D. 将源代码转换为机器代码答案:B二、简答题1. 简述编译器的工作原理。
答案:编译器的工作原理主要包括以下几个步骤:词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成。
词法分析器将源代码分解成一系列的词素;语法分析器根据语法规则检查词素序列是否合法;语义分析器检查程序的语义正确性;中间代码生成器将源代码转换为中间代码;代码优化器对中间代码进行优化;最后,目标代码生成器将优化后的中间代码转换为目标机器代码。
2. 什么是词法分析器,它在编译过程中的作用是什么?答案:词法分析器是编译器前端的一个组成部分,负责将源代码分解成一个个的词素(tokens),如关键字、标识符、常量、运算符等。
它在编译过程中的作用是为语法分析器提供输入,是编译过程的基础。
三、论述题1. 论述编译器中的代码优化技术及其重要性。
答案:代码优化是编译过程中的一个重要环节,它旨在提高程序的执行效率,减少资源消耗。
常见的代码优化技术包括:常量折叠、死代码消除、公共子表达式消除、循环不变代码外提、数组边界检查消除等。
代码优化的重要性在于,它可以显著提高程序的运行速度和性能,同时降低程序对内存和处理器资源的需求。
四、计算题1. 给定一个简单的四则运算表达式,请写出其对应的逆波兰表达式。
《编译原理》作业参考答案

《编译原理》作业参考答案一、填空1.图二图一。
2.文法是无ε产生式,且任意两个终结符之间至多有一种优先关系的算符文法。
3.最右推导最右推导。
4.对于循环中的有些代码,如果它产生的结果在循环中是不变的,就把它提到循环外来。
把程序中执行时间较长的运算替换为执行时间较短的运算。
5.对于文法中的每个非终结符A的各个产生式的候选首符集两两不相交;对文法中的每个非终结符A,若它存在某个候选首符集包含ε,则FIRST(A)∩FOLLOW(A)= ø6.控制。
7.语义分析和中间代码产生8.自上而下自下而上自上而下9.自下而上表达式10.自下而上11.源程序单词符号12. DFA初态唯一,NFA初态不唯一;DFA弧标记为Σ上的元素,NFA弧标记为Σ*上的元素;DFA的函数为单射,NFA函数不是单射13.词法,词法分析器,子程序,语法14.ε,a,ab,ab15.终结符号,非终结符号,产生式16.L(G)={a n | n≥1}17.1型,2型,3型18.二义的19.快20.终态,输入字21.单词符号,终结符22.归约23.必须24.直接25.终结符,更快26.E→E+∙T, E→E∙+T, E→∙E+T, E→E+T∙27.归约—归约28.类型检查,一致性检查29.词法分析、词法30.语法分析程序、语法31。
终结符号、产生式、开始符号、非终结符32.2、2、333.不需要避开34.符合、不符合35.推导36.包括37.Ass38.一定没有、一定没有、至多只有一个39.SLR(1)40.移进——归约41.a.控制流检查、b.一致性检查、c.相关名字检查二、判断下面语法是否正确1 ×2 ×3 √4 ×5 √6 ×三、简答题1.词法分析的任务是对输入的源程序进行单词及其属性的识别,为下一步的语法分析进行铺垫;有两种方法可以实现词法分析器:一,手工编写词法分析程序。
二,由词法分析器自动生成程序生成。
编译原理作业与答案

编译原理作业与答案编译原理独⽴作业2010.5⼀、简答题1、构造⼀个⽂法使其⽣成的语⾔是不允许0打头的偶正整数集合。
2、⽂法][E G :TT E T E E-+→,FF T F T T/*→,i E F )(→,构造句型i T T T*+-的语法树,并指出该句型的短语、直接短语、句柄、素短语和最左素短语。
3、某LL(1)⽂法的预测分析表如下,请在下述分析过程表中填⼊输⼊串( a , a )$ 的分析过程。
分析过程表:4、⽂法][S G :RL S=→,R S →,R L *→,i L →,L R →,求增⼴⽂法中LR(1)项⽬集的初态项⽬集I 0。
5、⽂法][S G :GG S S ;→,()G G t H →,)(S a H →,求出各⾮终结符的FISTVT 和LASTVT集合。
⼆、分析题:1、构造⾃动机,使得它能识别字母表{0,1}上以00结尾的符号串,将构造的⾃动机确定化,并写出相应的正规⽂法。
2、⽂法][S G :RT eT S →εDR T →εdR R → bd a D →,写出每个⾮终结符的FIRST 集和FOLLOW 集,并判断该⽂法是否为LL(1)⽂法。
3、若有⽂法][S G :AB S →εaBa A →εb A b B → (1)试证明该⽂法是SLR(1) ⽂法,并构造SLR(1)分析表。
(2)给出输⼊串aa # 的分析过程。
参考答案⼀、简答题1、构造⼀个⽂法使其⽣成的语⾔是不允许0打头的偶正整数集合。
8|6|4|2|ABC Z → 9|8|7|6|5|4|3|2|1→A ε|0|B AB B →|8|6|4|2|0→C2、⽂法][E G :TT E T E E-+→,FF T F T T/*→,i E F )(→,构造句型i T T T *+-的语法树,并指出该句型的短语、直接短语、句柄、素短语和最左素短语。
短语:T ,T-T ,i ,T*i ,T-T+T*i直接短语:T , i 句柄: T素短语(P72):T-T,i 最左素短语:T-T3 某LL(1)⽂法的预测分析表如下,请在下述分析过程表中填⼊输⼊串( a , a )$ 的分析过程。
编译原理作业参考答案

最左推导:NNDDD3D34
NNDNDDDDD5DD56D568
最右推导:NNDN4D434
NNDN8ND8N68D68568
2*.写出一个文法,使其语言是奇数集,且每个奇数是不以0开头。
答:
SCAB|B(考虑了正负号)
A1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | AA | A0 |
低级语言:机器语言和汇编语言。
高级语言:是人们根据描述实际问题的需要而设计的一个记号系统。如同自然语言(接近数学语言和工程语言)一样,语言的基本单位是语句,由符号组和一组用来组织它们成为有确定意义的组合规则。
翻译程序:能够把某一种语言程序(源语言程序)改变成另一种语言程序(目
标语言程序),后者与前者在逻辑上是等价的。其中包括:编译程序,解释程序,汇编程序。
{2,4}a = {1,0},{2,4}b = {3,5},无需划分
{3,5}a = {3,5},{3,5}b = {2,4},无需划分
{0,1}a = {1},{0,1}b = {2,4},无需划分
因此,最终的划分为:{0,1}、{2,4}和{3,5},化简后的结果:
5.(P65,14)构造一个DFA M,它接受={0,1}上所有满足如下条件的字符串:每个1都有0直接跟在右边。
T*(i+i)F*(i+i)i*(i+i)
⑵构造语法树
E最左推导构造语法树
E + T
E + T i
T i
i
3.(P36, 9)证明下面的文法是二义的:
SiSeS | iSi
答:对于句子iiiei有两棵不同的语法树。因此该文法是二义的。
SiSeSiiSeSiiieSiiiei
编译原理答案整理

1第2章 习题2-1 设有字母表A 1 ={a,b,c,…,z},A 2={0,1,={0,1,……,9},9},试回答下列问题:,试回答下列问题:,试回答下列问题:(1) 字母表A 1上长度为2的符号串有多少个?的符号串有多少个? (2) 集合A 1A 2含有多少个元素?含有多少个元素?(3) 列出集合A 1(A 1∪A 2)*中的全部长度不大于3的符号串。
的符号串。
2-2 试分别构造产生下列语言的文法:试分别构造产生下列语言的文法:试分别构造产生下列语言的文法: (1){a nb n|n≥0};|n≥0}; (2){a n b m c p |n,m,p≥0};|n,m,p≥0};(3){a n#b n|n≥0}∪|n≥0}∪{c {c n#d n|n≥0};|n≥0};(4){w#w r # | w ∈{0,1}*,w r 是w 的逆序排列的逆序排列 } }; (5)任何不是以0打头的所有奇整数所组成的集合;的集合;(6)所有由偶数个0和偶数个1所组成的符号串的集合。
号串的集合。
2-3 试描述由下列文法所产生的语言的特点:试描述由下列文法所产生的语言的特点: (1)S→10S0)S→10S0 S→aA S→aA A→bA A→bA A→a A→a (2)S→SS S→1A0S→1A0 A→1A0A→1A0A→ε (3)S→1A )S→1A S→B0S→B0 A→1A A→1A A→C A→C B→B0B→B0 B→C B→C C→1C0C→1C0C→ε(4)S→aSS )S→aSS S→a S→a 2-4 试证明文法试证明文法试证明文法 S →AB|DC A →aA|a B →bBc|bc C →cC|c D →aDb|ab为二义性文法。
为二义性文法。
2-5 对于下列的文法对于下列的文法对于下列的文法 S →AB|c A →bA|a B →aSb|c试给出句子bbaacb 的最右推导,并指出各步直接推导所得句型的句柄;指出句子的全部短语。
编译原理习题及答案(整理后)

第一章1、将编译程序分成若干个“遍”是为了。
b.使程序的结构更加清晰2、构造编译程序应掌握。
a.源程序b.目标语言c.编译方法3、变量应当。
c.既持有左值又持有右值4、编译程序绝大多数时间花在上。
d.管理表格5、不可能是目标代码。
d.中间代码6、使用可以定义一个程序的意义。
a.语义规则7、词法分析器的输入是。
b.源程序8、中间代码生成时所遵循的是- 。
c.语义规则9、编译程序是对。
d.高级语言的翻译10、语法分析应遵循。
c.构词规则二、多项选择题1、编译程序各阶段的工作都涉及到。
b.表格管理c.出错处理2、编译程序工作时,通常有阶段。
a.词法分析b.语法分析c.中间代码生成e.目标代码生成三、填空题1、解释程序和编译程序的区别在于是否生成目标程序。
2、编译过程通常可分为5个阶段,分别是词法分析、语法分析中间代码生成、代码优化和目标代码生成。
3、编译程序工作过程中,第一段输入是源程序,最后阶段的输出为标代码生成程序。
4、编译程序是指将源程序程序翻译成目标语言程序的程序。
一、单项选择题1、文法G:S→xSx|y所识别的语言是。
a. xyxb. (xyx)*c.x n yx n(n≥0) d. x*yx*2、文法G描述的语言L(G)是指。
a. L(G)={α|S+⇒α , α∈V T*}b. L(G)={α|S*⇒α, α∈V T*}c. L(G)={α|S*⇒α,α∈(V T∪V N*)} d. L(G)={α|S+⇒α, α∈(V T∪V N*)}3、有限状态自动机能识别。
a. 上下文无关文法b. 上下文有关文法c.正规文法d. 短语文法4、设G为算符优先文法,G 的任意终结符对a、b有以下关系成立。
a. 若f(a)>g(b),则a>bb.若f(a)<g(b),则a<bc. a~b都不一定成立d. a~b一定成立5、如果文法G是无二义的,则它的任何句子α。
a. 最左推导和最右推导对应的语法树必定相同b. 最左推导和最右推导对应的语法树可能不同c. 最左推导和最右推导必定相同d. 可能存在两个不同的最左推导,但它们对应的语法树相同6、由文法的开始符经0步或多步推导产生的文法符号序列是。
编译原理习题答案

编译原理习题答案《编译原理》习题答案:第⼀次:P142、何谓源程序、⽬标程序、翻译程序、汇编程序、编译程序和解释程序?它们之间可能有何种关系?答:被翻译的程序称为源程序;翻译出来的程序称为⽬标程序或⽬标代码;将汇编语⾔和⾼级语⾔编写的程序翻译成等价的机器语⾔,实现此功能的程序称为翻译程序;把汇编语⾔写的源程序翻译成机器语⾔的⽬标程序称为汇编程序;解释程序不是直接将⾼级语⾔的源程序翻译成⽬标程序后再执⾏,⽽是⼀个个语句读⼊源程序,即边解释边执⾏;编译程序是将⾼级语⾔写的源程序翻译成⽬标语⾔的程序。
关系:汇编程序、解释程序和编译程序都是翻译程序,具体见P4 图 1.3。
P143、编译程序是由哪些部分组成?试述各部分的功能?答:编译程序主要由8个部分组成:(1)词法分析程序;(2)语法分析程序;(3)语义分析程序;(4)中间代码⽣成;(5)代码优化程序;(6)⽬标代码⽣成程序;(7)错误检查和处理程序;(8)信息表管理程序。
具体功能见P7-9。
P144、语法分析和语义分析有什么不同?试举例说明。
答:语法分析是将单词流分析如何组成句⼦⽽句⼦⼜如何组成程序,看句⼦乃⾄程序是否符合语法规则,例如:对变量 x:= y 符合语法规则就通过。
语义分析是对语句意义进⾏检查,如赋值语句中x与y类型要⼀致,否则语法分析正确,语义分析则错误。
P155、编译程序分遍由哪些因素决定?答:计算机存储容量⼤⼩;编译程序功能强弱;源语⾔繁简;⽬标程序优化程度;设计和实现编译程序时使⽤⼯具的先进程度以及参加⼈员多少和素质等等。
补充:1、为什么要对单词进⾏内部编码?其原则是什么?对标识符是如何进⾏内部编码的?答:内部编码从“源字符串”中识别单词并确定单词的类型和值;原则:长度统⼀,即刻画了单词本⾝,也刻画了它所具有的属性,以供其它部分分析使⽤。
对于标识符编码,先判断出该单词是标识符,然后在类别编码中写⼊相关信息,以表⽰为标识符,再根据具体标识符的含义编码该单词的值。
编译原理考试题及答案

编译原理考试题及答案一、选择题(每题5分,共20分)1. 编译器的主要功能是什么?A. 代码优化B. 代码翻译C. 代码调试D. 代码运行答案:B2. 下列哪个选项不属于编译器的前端部分?A. 词法分析B. 语法分析C. 语义分析D. 代码生成答案:D3. 在编译原理中,文法的产生式通常表示为:A. A -> αB. A -> βC. A -> γD. A -> δ答案:A4. 下列哪个算法用于构建语法分析树?A. LL(1)分析B. LR(1)分析C. SLR(1)分析D. LALR(1)分析答案:A二、填空题(每空5分,共20分)1. 编译器的前端通常包括词法分析、语法分析和________。
答案:语义分析2. 编译器的后端主要负责________和目标代码生成。
答案:代码优化3. 编译器中的词法分析器通常使用________算法来识别单词。
答案:有限自动机4. 语法分析中,________分析是一种自顶向下的分析方法。
答案:递归下降三、简答题(每题10分,共30分)1. 简述编译器的作用。
答案:编译器的主要作用是将高级语言编写的源代码转换成计算机能够理解的低级语言或机器代码,以便执行。
2. 解释一下什么是语法制导翻译。
答案:语法制导翻译是一种翻译技术,它利用源语言的语法信息来指导翻译过程,使得翻译过程能够更好地理解源代码的语义。
3. 什么是词法分析器?答案:词法分析器是编译器前端的一部分,它的任务是将源代码文本分解成一系列的标记(tokens),这些标记是源代码的最小有意义的单位。
四、计算题(每题10分,共30分)1. 给定一个简单的文法G(E):E → E + T | TT → T * F | FF → (E) | id请计算文法的非终结符号E的FIRST集和FOLLOW集。
答案:E的FIRST集为{(, id},FOLLOW集为{), +, $}。
2. 假设编译器在进行语法分析时,遇到一个语法错误的代码片段,请简述编译器如何处理这种情况。
奥鹏14秋《编译原理》作业1满分答案

14秋《编译原理》作业1
一,单选题
1. ( )是把中间代码进行变换或者进行改造,目的是使生成的目标代码更为高效,即省时间和省空间。
A. 语法分析
B. 语义分析
C. 中间代码生成
D. 代码优化
E. 目标代码生成
?
正确答案:D
2. 编译程序是将高级语言程序翻译成( )。
A. 高级语言程序
B. 机器语言程序
C. 汇编语言程序
D. 汇编语言或机器语言程序
?
正确答案:D
3. 文法G 所描述的语言是_____的集合。
A. 文法G 的字母表V 中所有符号组成的符号串
B. 文法G 的字母表V 的闭包V* 中的所有符号串
C. 由文法的开始符号推出的所有终极符串
D. 由文法的开始符号推出的所有符号串
?
正确答案:C
4. 下列______优化方法不是针对循环优化进行的。
A. 强度削弱
B. 删除归纳变量
C. 删除多余运算
D. 代码外提
?
正确答案:C
5. 文法分为四种类型,即0型、1型、2型、3型。
其中0型文法是_____。
A. 短语文法
B. 正则文法
C. 上下文有关文法
D. 上下文无关文法
?。
编译原理平时作业-答案
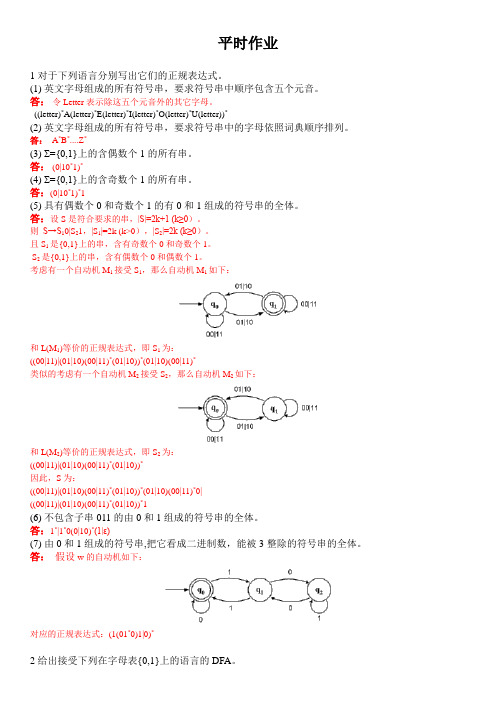
平时作业1 对于下列语言分别写出它们的正规表达式。
(1) 英文字母组成的所有符号串,要求符号串中顺序包含五个元音。
答:令Letter表示除这五个元音外的其它字母。
((letter)*A(letter)*E(letter)*I(letter)*O(letter)*U(letter))*(2) 英文字母组成的所有符号串,要求符号串中的字母依照词典顺序排列。
答:A*B*....Z*(3) Σ={0,1}上的含偶数个1的所有串。
答: (0|10*1)*(4) Σ={0,1}上的含奇数个1的所有串。
答:(0|10*1)*1(5) 具有偶数个0和奇数个1的有0和1组成的符号串的全体。
答:设S是符合要求的串,|S|=2k+1 (k≥0)。
则S→S10|S21,|S1|=2k (k>0),|S2|=2k (k≥0)。
且S1是{0,1}上的串,含有奇数个0和奇数个1。
S2是{0,1}上的串,含有偶数个0和偶数个1。
考虑有一个自动机M1接受S1,那么自动机M1如下:和L(M1)等价的正规表达式,即S1为:((00|11)|(01|10)(00|11)*(01|10))*(01|10)(00|11)*类似的考虑有一个自动机M2接受S2,那么自动机M2如下:和L(M2)等价的正规表达式,即S2为:((00|11)|(01|10)(00|11)*(01|10))*因此,S为:((00|11)|(01|10)(00|11)*(01|10))*(01|10)(00|11)*0|((00|11)|(01|10)(00|11)*(01|10))*1(6) 不包含子串011的由0和1组成的符号串的全体。
答:1*|1*0(0|10)*(1|ε)(7) 由0和1组成的符号串,把它看成二进制数,能被3整除的符号串的全体。
答:假设w的自动机如下:对应的正规表达式:(1(01*0)1|0)*2 给出接受下列在字母表{0,1}上的语言的DFA。
编译原理习题答案

1、正规文法又称 DA、0型文法B、1型文法C、2型文法D、3型文法2、对于无二义性的文法,规范归约是 BA. 最左推导B. 最右推导的逆过程C.最左归约的逆过程D.最右归约的逆过程。
3、扫描器的任务是从源程序中识别出一个个单词符号。
4、程序所需的数据空间在程序运行前就可确定,称为 A 管理技术。
A 静态存储B 动态存储C 栈式存储D 堆式存储5、编译过程中,语法分析器的任务是(B)。
①分析单词是怎样构成的②分析单词串是如何构成语句和说明的③分析语句和说明是如何构成程序的④分析程序的结构A、②③B、②③④C、①②③D、①②③④6、文法G:E→E+T|T T→T*P|P P→ (E)| i则句型P+T+i的句柄和最左素短语分别为 B 。
A、P+T和iB、P和P+TC、i和P+T+iD、P和P7、四元式之间的联系是通过B实现的A.指示器B.临时变量C.符号表D.程序变量8、程序语言的单词符号一般可以分为保留字、标识符、常数、运算符、界符等等。
9、下列 B 优化方法是针对循环优化进行的。
A.删除多余运算B.删除归纳变量C.合并已知量D.复写传播10、若文法G 定义的语言是无限集,则文法必然是 AA、递归的B、前后文无关的C、二义性的D、无二义性的11、文法G 产生的D的全体是该文法描述的语言。
A、句型B、终结符集C、非终结符集D、句子12、Chomsky 定义的四种形式语言文法中,0 型文法又称为 A文法;1 型文法又称为 C 文法。
A.短语文法B.上下文无关文法C.上下文有关文法D.正规文法A.短语文法B.上下文无关文法C.上下文有关文法D.正规文法13、语法分析最常用的两类方法是自顶向下和自底向上分析法。
14、一个确定的有穷自动机DFA是一个 A 。
A 五元组(K,∑,f, S, Z)B 四元组(V N,V T,P,S)C 四元组(K,∑,f,S)D 三元组(V N,V T,P)A、语法B、语义C、代码D、运行15、 B不属于乔姆斯基观点分类的文法。
编译原理习题答案

对应的if与else等。它们的存在必定因下列规则的必定存在:
E::=E+T|T T::=T*F|F F::=(E)|i
以及 S::=if(E)S else S
因此,E=>* xEy x, y≠
与 S=>* uSv u, v≠ ,
即, E与S等必定是具有自嵌套特性的非终结符号。因此通常的程序设计语言
的文法必具有自嵌套特性的非终结符号,也就是说不可能是正则文法。
不能写:E =>T=>F =>(E) => (i )
可以写: E => T => F => (E) => + (i)
E =>E-T =>T-T =>T*F-T =>F*F-T
=>i*F-T=>i * i - T=>i * i - F =>i * i - i (最左推导)
或
E =>E-T =>E-F =>E-i =>T-i =>T*F-i
G [W]: W::=A0 A::=0{01|0}
第十六页,共六十二页。
6.试消去文法G[S]:
S::=Qc|Rd|c Q::=Rb|Se|b R::=Sa|Qf|a
解: 步骤1 首先判定是文法左递归还是规则左递归
步骤2 是文法左递归,按相应算法处理如下。 步 骤2.1 把非终结符号排序成
U1=S U2=Q U3=R (n=3)
=> T*i-i => F*i-i =>i*i-i
(最右推导)
第四页,共六十二页。
E => T => T/F => F/F => (E)/F => (E+T)/F
(完整版)编译原理习题及答案(整理后)

2、对无二义性文法来说,一棵语法树往往代表了 。
a. 多种推导过程
b. 多种最左推导过程
c.一种最左推导过程
d.仅一种推导过程 e.一种最左推导过程
3、如果文法 G 存在一个句子,满足下列条件 之一时,则称该文法是二义文法。
a. 该句子的最左推导与最右推导相同
b. 该句子有两个不同的最左推导
c. 该句子有两棵不同的最右推导
T→T*P|P
P→(E)|I
则句型 P+T+i 的句柄和最左素短语为 。
a.P+T 和 i b. P 和 P+T c. i 和 P+T+i d.P 和 T
8、设文法为:S→SA|A
A→a|b
则对句子 aba,下面 是规范推导。
a. SSASAAAAAaAAabAaba
b. SSASAAAAAAAaAbaaba
标语言
第二章
一、单项选择题
1、文法 G:S→xSx|y 所识别的语言是 。
a. xyx
b. (xyx)* c. xnyxn(n≥0) d. x*yx*
2、文法 G 描述的语言 L(G)是指 。
a. L(G)={α|S⇒+ α , α∈VT*}
b. L(G)={α|S⇒* α, α∈VT*}
c. L(G)={α|S⇒* α,α∈(VT∪VN*)} d. L(G)={α|S⇒+ α, α∈(VT∪VN*)}
第一章
1、将编译程序分成若干个“遍”是为了
。
a.提高程序的执行效率
b.使程序的结构更加清晰
c.利用有限的机器内存并提高机器的执行效率
d.利用有限的机器内存但降低了机器的执行效率
编译原理习题与答案

第三章
正规表达式:a(b|a(a|b))|b(a|b)
a a X b 2 1 b a b 3 a Y b
a a X b 2 1 b a
3 a
b
第三章
用子集法将NFA确定化。
I {X} {1} {2} {3} {Y} Ia {1} {3} {Y} {Y} - Ib {2} {Y} {Y} {Y} -
S→A B→C|B+C
A→B|AiB C→)A*|(
第四章
1)将文法G[S]改写为LL(1)文法。 文法G[S]为左递归文法,削去文法左递归 后的文法为: S→A A→BA’ A’→ iBA’|ε B→CB’ B’ → +CB’|ε C→)A*|(
S→A A→BA’ A’→ iBA’|ε B→CB’ B’ → +CB’|ε C→)A*|(
2 3 4 5 6 7
a 1 3 - 3 3 5 6 6
b 2 4 5 6 5 7 6 7
第三章
{0,1,2,5}, {4}, {3,6,7}
对于非终态集,在输入字符 a 、
b 后按其下一状态落入的状态集 不同而最终划分为
{0}, {1}, {2}, {5}, {4}, {3,6,7}
按顺序重新命名为 0 、 1 、 2 、 3 、
b
6
b
b
0 1 2 3 4 5 6 7
a 1 3 - 3 3 5 6 6
b 2 4 5 6 5 7 6 7
第三章
对上图的 DFA 进行最小化。首先将
状态分为非终态集和终态集两部分: 0 {0,1,2,5}和{3,4,6,7}。 1
由终态集可知,对于状态 3、 6、 7,
无论输入字符是 a 还是 b 的下一状态 均为终态集,而状态 4 在输入字符 b 的下一状态落入非终态集,故将其 化为分{0,1,2,5}, {4}, {3,6,7}
《编译原理》习题及答案

第一章1、将编译程序分成若干个“遍”是为了。
b.使程序的结构更加清晰2、构造编译程序应掌握。
a.源程序b.目标语言c.编译方法3、变量应当。
c.既持有左值又持有右值4、编译程序绝大多数时间花在上。
d.管理表格5、不可能是目标代码。
d.中间代码6、使用可以定义一个程序的意义。
a.语义规则7、词法分析器的输入是。
b.源程序8、中间代码生成时所遵循的是- 。
c.语义规则9、编译程序是对。
d.高级语言的翻译10、语法分析应遵循。
c.构词规则二、多项选择题1、编译程序各阶段的工作都涉及到。
b.表格管理c.出错处理2、编译程序工作时,通常有阶段。
a.词法分析b.语法分析c.中间代码生成e.目标代码生成三、填空题1、解释程序和编译程序的区别在于是否生成目标程序。
2、编译过程通常可分为5个阶段,分别是词法分析、语法分析中间代码生成、代码优化和目标代码生成。
3、编译程序工作过程中,第一段输入是源程序,最后阶段的输出为标代码生成程序。
4、编译程序是指将源程序程序翻译成目标语言程序的程序。
一、单项选择题1、文法G:S→xSx|y所识别的语言是。
a. xyxb. (xyx)*c. x n yx n(n≥0)d. x*yx*2、文法G描述的语言L(G)是指。
a. L(G)={α|S+⇒α , α∈V T*}b. L(G)={α|S*⇒α, α∈V T*}c. L(G)={α|S*⇒α,α∈(V T∪V N*)}d. L(G)={α|S+⇒α, α∈(V T∪V N*)}3、有限状态自动机能识别。
a. 上下文无关文法b. 上下文有关文法c.正规文法d. 短语文法4、设G为算符优先文法,G的任意终结符对a、b有以下关系成立。
a. 若f(a)>g(b),则a>bb.若f(a)<g(b),则a<bc. a~b都不一定成立d. a~b一定成立5、如果文法G是无二义的,则它的任何句子α。
a. 最左推导和最右推导对应的语法树必定相同b. 最左推导和最右推导对应的语法树可能不同c. 最左推导和最右推导必定相同d. 可能存在两个不同的最左推导,但它们对应的语法树相同6、由文法的开始符经0步或多步推导产生的文法符号序列是。
编译原理习题参考答案

编译原理习题参考答案第⼆章2.构造产⽣下列语⾔的⽂法(2){a n b m c p|n,m,p≥0}解: G(S) :S→aS|X,X→bX|Y,Y→cY|ε(3){a n # b n|n≥0}∪{cn # dn|n≥0}解: G(S):S→X,S→Y,X→aXb|#, Y→cYd|# }(5)任何不是以0 打头的所有奇整数所组成的集合解:G(S):S→J|IBJ,B→0B|IB|ε,I→J|2|4|6|8, J→1|3|5|7|9}(6)(思考题)所有偶数个0 和偶数个1 所组成的符号串集合解:对应⽂法为 S→0A|1B|ε,A→0S|1C B→0C|1S C→1A|0B3.描述语⾔特点(2)S→SS S→1A0 A→1A0 A→ε解:L(G)={1n10n11n20n2… 1nm0nm |n1,n2,…,nm≥0;且n1,n2,…nm 不全为零}该语⾔特点是:产⽣的句⼦中,0、1 个数相同,并且若⼲相接的1 后必然紧接数量相同连续的0。
(5)S→aSS S→a解:L(G)={a(2n-1)|n≥1}可知:奇数个a5. (1) 解:由于此⽂法包含以下规则:AA→ε,所以此⽂法是0 型⽂法。
7.解:(1)aacb 是⽂法G[S]中的句⼦,相应语法树是:最右推导:S=>aAcB=>aAcb=>aacb最左推导:S=>aAcB=>aacB=>aacb(3)aacbccb 不是⽂法G[S]中的句⼦aacbccb 不能从S推导得到时,它仅是⽂法G[S]的⼀个句型的⼀部分,⽽不是⼀个句⼦。
11.解:最右推导:(1) S=>AB=>AaSb=>Aacb=>bAacb=>bbAacb=>bbaacb上⾯推导中,下划线部分为当前句型的句柄。
对应的语法树为:3 假设M:⼈ W:载狐狸过河,G:载⼭⽺过河,C:载⽩菜过河6 根据⽂法知其产⽣的语⾔是L={a m b n c i| m,n,i≧1}可以构造如下的⽂法VN={S,A,B,C}, VT={a,b,c}P={ S →aA, A→aA, A→bB, B→bB, B→cC, C→cC, C→c} 其状态转换图如下:7 (1) 其对应的右线性⽂法是:A →0D, B→0A,B→1C,C→1|1F,C→1|0A,F→0|0E|1A,D→0B|1C,E→1C|0B(2) 最短输⼊串011(3) 任意接受的四个串: 011,0110,0011,000011(4) 任意以1 打头的串.9.对于矩阵(iii)(1) 状态转换图:(2) 3型⽂法(正规⽂法)S→aA|a|bB A→bA|b|aC|a B→aB|bC|b C→aC|a|bC|b(3)⽤⾃然语⾔描述输⼊串的特征以a 打头,中间有任意个(包括0个)b,再跟a,最后由⼀个a,b 所组成的任意串结尾或者以b 打头,中间有任意个(包括0个)a,再跟b,最后由⼀个a,b 所组成的任意串结尾。
编译原理练习题及答案

第一章练习题(绪论)一、选择题1.编译程序是一种常用的软件。
A) 应用B) 系统C) 实时系统D) 分布式系统2.编译程序生成的目标代码程序是可执行程序。
A) 一定B) 不一定3.编译程序的大多数时间是花在上。
A) 词法分析B) 语法分析C) 出错处理D) 表格管理4.将编译程序分成若干“遍”将。
A)提高编译程序的执行效率;B)使编译程序的结构更加清晰,提高目标程序质量;C)充分利用内存空间,提高机器的执行效率。
5.编译程序各个阶段都涉及到的工作有。
A) 词法分析B) 语法分析C) 语义分析D) 表格管理6.词法分析的主要功能是。
A) 识别字符串B) 识别语句C) 识别单词D) 识别标识符7.若某程序设计语言允许标识符先使用后说明,则其编译程序就必须。
A) 多遍扫描B) 一遍扫描8.编译方式与解释方式的根本区别在于。
A) 执行速度的快慢B) 是否生成目标代码C) 是否语义分析9.多遍编译与一遍编译的主要区别在于。
A)多遍编译是编译的五大部分重复多遍执行,而一遍编译是五大部分只执行一遍;B)一遍编译是对源程序分析一遍就立即执行,而多遍编译是对源程序重复多遍分析再执行;C)多遍编译要生成目标代码才执行,而一遍编译不生成目标代码直接分析执行;D)多遍编译是五大部分依次独立完成,一遍编译是五大部分交叉调用执行完成。
10.编译程序分成“前端”和“后端”的好处是A)便于移植B)便于功能的扩充C)便于减少工作量D)以上均正确第二章练习题(文法与语言)一、选择题1.文法 G 产生的 (1) 的全体是该文法描述的语言。
A.句型B. 终结符集C. 非终结符集D. 句子2.若文法 G 定义的语言是无限集,则文法必然是 (2) A递归的 B 上下文无关的 C 二义性的 D 无二义性的3. Chomsky 定义的四种形式语言文法中, 0 型文法又称为(A)文法;1 型文法又称为(C)文法;2 型语言可由(G) 识别。
A 短语结构文法B 上下文无关文法C 上下文有关文法D 正规文法E 图灵机F 有限自动机G 下推自动机4.一个文法所描述的语言是(A);描述一个语言的文法是(B)。
(完整版)编译原理课后习题答案

(完整版)编译原理课后习题答案第一章1.典型的编译程序在逻辑功能上由哪几部分组成?答:编译程序主要由以下几个部分组成:词法分析、语法分析、语义分析、中间代码生成、中间代码优化、目标代码生成、错误处理、表格管理。
2. 实现编译程序的主要方法有哪些?答:主要有:转换法、移植法、自展法、自动生成法。
3. 将用户使用高级语言编写的程序翻译为可直接执行的机器语言程序有哪几种主要的方式?答:编译法、解释法。
4. 编译方式和解释方式的根本区别是什么?答:编译方式:是将源程序经编译得到可执行文件后,就可脱离源程序和编译程序单独执行,所以编译方式的效率高,执行速度快;解释方式:在执行时,必须源程序和解释程序同时参与才能运行,其不产生可执行程序文件,效率低,执行速度慢。
第二章1.乔姆斯基文法体系中将文法分为哪几类?文法的分类同程序设计语言的设计与实现关系如何?答:1)0型文法、1型文法、2型文法、3型文法。
2)2. 写一个文法,使其语言是偶整数的集合,每个偶整数不以0为前导。
答:Z→SME | BS→1|2|3|4|5|6|7|8|9M→ε | D | MDD→0|SB→2|4|6|8E→0|B3. 设文法G为:N→ D|NDD→ 0|1|2|3|4|5|6|7|8|9请给出句子123、301和75431的最右推导和最左推导。
答:N?ND?N3?ND3?N23?D23?123N?ND?NDD?DDD?1DD?12D?123N?ND?N1?ND1?N01?D01?301N?ND?NDD?DDD?3DD?30D?301N?ND?N1?ND1?N31?ND31?N431?ND431?N5431?D5431?7 5431N?ND?NDD?NDDD?NDDDD?DDDDD?7DDDD?75DDD?754 DD?7543D?75431 4. 证明文法S→iSeS|iS| i是二义性文法。
答:对于句型iiSeS存在两个不同的最左推导:S?iSeS?iiSesS?iS?iiSeS所以该文法是二义性文法。
编译原理课后作业参考答案

作业参考答案第二章 高级语言及其语法描述6、(1)L (G 6)={0,1,2,......,9}+(2)最左推导:N=>ND=>NDD=>NDDD=>DDDD=>0DDD=>01DD=>012D=>0127 N=>ND=>DD=>3D=>34N=>ND=>NDD=>DDD=>5DD=>56D=>568 最右推导:N=>ND =>N7=>ND7=>N27=>ND27=>N127=>D127=>0127 N=>ND=>N4=>D4=>34N=>ND=>N8=>ND8=>N68=>D68=>568 7、G:S →ABC | AC | CA →1|2|3|4|5|6|7|8|9B →BB|0|1|2|3|4|5|6|7|8|9C →1|3|5|7|98、(1)最左推导:E=>E+T=>T+T=>F+T=>i+T=>i+T*F=>i+F*F=>i+i*F=>i+i*iE=>T=>T*F=>F*F=>i*F=>i*(E)=>i*(E+T)=>i*(T+T)=>i*(F+T)=>i*(i+T)=>i*(i+F)=>i*(i+i) 最右推导:E=>E+T=>E+T*F=>E+T*i=>E+F*i=>E+i*i=>T+i*i=>F+i*i=>i+i*iE=>T=>T*F=>T*(E)=>T*(E+T)=>T*(E+F)=>T*(E+i)=>T*(T+i)=>T*(F+i)=>T*(i+i)=>F*(i+i)=>i*(i+i) (2)9、证明:该文法存在一个句子iiiei 有两棵不同语法分析树,如下所示,因此该文法是二义的。
编译原理第4章作业答案
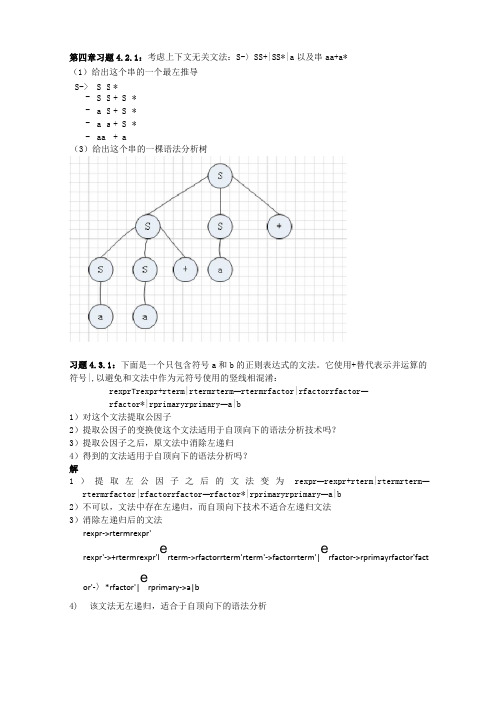
第四章习题4.2.1:考虑上下文无关文法:S-〉SS+|SS*|a 以及串aa+a* (1)给出这个串的一个最左推导 S-> S S *-> S S + S * -> a S + S * -> a a + S * -aa +a(3)给出这个串的一棵语法分析树习题4.3.1:下面是一个只包含符号a 和b 的正则表达式的文法。
它使用+替代表示并运算的符号|,以避免和文法中作为元符号使用的竖线相混淆:rexpr T rexpr+rterm|rtermrterm —rtermrfactor|rfactorrfactor —rfactor*|rprimaryrprimary —a|b1)对这个文法提取公因子2)提取公因子的变换使这个文法适用于自顶向下的语法分析技术吗? 3)提取公因子之后,原文法中消除左递归4)得到的文法适用于自顶向下的语法分析吗? 解1)提取左公因子之后的文法变为rexpr —rexpr+rterm|rtermrterm —rtermrfactor|rfactorrfactor —rfactor*|rprimaryrprimary —a|b 2)不可以,文法中存在左递归,而自顶向下技术不适合左递归文法 3)消除左递归后的文法rexpr->rtermrexpr'rexpr'->+rtermrexpr'l e rterm->rfactorrterm'rterm'->factorrterm'|erfactor->rprimayrfactor'fact or'-〉*rfactor'|erprimary->a|b4) 该文法无左递归,适合于自顶向下的语法分析习题4.4.1:为下面的每一个文法设计一个预测分析器,并给出预测分析表。
可能要先对文法进行提取左公因子或消除左递归 (3)S-〉S(S)S|*(5)S->(L)|aL->L,S|S 解 (3)①消除该文法的左递归后得到文法S-〉S'S'-〉(S)SS'|*②计算FIRST 和FOLLOW 集合FIRST(S)={(,*}FOLLOW(S)={),$} FIRST(S')={(,*}FOLLOW(S')={),$}③构建预测分析表①消除该文法的左递归得到文法S-〉(L)|a L->SL' L'-〉,SL'|£②计算FIRST 与FOLLOW 集合FIRST(S)={(,a}FOLLOW(S)={),,,$}FIRST(L)={(,a}FOLLOW(L)={)} FIRST(L')={,,£}FOLLOW(L')={)}习题4.4.4计算练习4.2.2的文法的FIRST 和FOLLOW 集合3)S T S(S)S|5) S T (L)|a,L T L,S|S 解:3)FIRST(S)={£,(}FOLLOW(S)={(,),$} 5) FIRST(S)={(,a}FOLLOW(S)={),,,$}FIRST (L )={(,a}FOLLOW (L )={),,}习题4.6.2为练习4.2.1中的增广文法构造SLR 项集,计算这些项集的GOTO 函数,给出这个文法的语法分析表。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《编译原理》第一次作业参考答案一、下列正则表达式定义了什么语言(用尽可能简短的自然语言描述)?1.b*(ab*ab*)*所有含有偶数个a的由a和b组成的字符串.2.c*a(a|c)*b(a|b|c)* | c*b(b|c)*a(a|b|c)*答案一:所有至少含有1个a和1个b的由a,b和c组成的字符串.答案二:所有含有子序列ab或子序列ba的由a,b和c组成的字符串.说明:答案一要比答案二更好,因为用自然语言描述是为了便于和非专业的人员交流,而非专业人员很可能不知道什么是“子序列”,所以相比较而言,答案一要更“自然”.二、设字母表∑={a,b},用正则表达式(只使用a,b, ,|,*,+,?)描述下列语言:1.不包含子串ab的所有字符串.b*a*2.不包含子串abb的所有字符串.b*(ab?)*3.不包含子序列abb的所有字符串.b*a*b?a*注意:关于子串(substring)和子序列(subsequence)的区别可以参考课本第119页方框中的内容.~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~《编译原理》第二次作业参考答案一、考虑以下NFA:1.这一NFA接受什么语言(用自然语言描述)?所有只含有字母a和b,并且a出现偶数次或b出现偶数次的字符串.2.构造接受同一语言的DFA.答案一(直接构造通常得到这一答案):答案二(由NFA构造DFA得到这一答案):二、正则语言补运算3.画出一个DFA,该DFA恰好识别所有不含011子串的所有二进制串.1.画出一个DFA,该DFA恰好识别所有不含011子串的所有二进制串.规律:构造语言L的补语言L’的DFA,可以先构造出接受L的DFA,再把这一DFA的接受状态改为非接受状态,非接受状态改为接受状态,就可以得到识别L’的DFA.说明:在上述两题中的D状态,无论输入什么符号,都不可能再到达接受状态,这样的状态称为“死状态”.在画DFA时,有时为了简明起见,“死状态”及其相应的弧(上图中的绿色部分)也可不画出.2.再证明:对任一正则表达式R,一定存在另一正则表达式R',使得L(R')是L(R)的补集.证明:根据正则表达式与DFA的等价性,一定存在识别语言L(R)的DFA. 设这一DFA为M,则将M的所有接受状态改为非接受状态,所有非接受状态改为接受状态,得到新的DFA M’. 易知M’识别语言L(R)的补集. 再由正则表达式与DFA的等价性知必存在正则表达式R’,使得L(R’)是L(R)的补集.三、设有一门小小语言仅含z、o、/(斜杠)3个符号,该语言中的一个注释由/o开始、以o/结束,并且注释禁止嵌套.1.请给出单个正则表达式,它仅与一个完整的注释匹配,除此之外不匹配任何其他串. 书写正则表达式时,要求仅使用最基本的正则表达式算子( ,|,*,+,?).参考答案一:/o(o*z|/)*o+/思路:基本思路是除了最后一个o/,在注释中不能出现o后面紧跟着/的情况;还有需要考虑的是最后一个o/之前也可以出现若干个o.参考答案二(梁晓聪、梁劲、梁伟斌等人提供):/o/*(z/*|o)*o/2.给出识别上述正则表达式所定义语言的确定有限自动机(DFA). 你可根据问题直接构造DFA,不必运用机械的算法从上一小题的正则表达式转换得到DFA.~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ 《编译原理》第三次作业参考答案一、考虑以下DFA的状态迁移表,其中0,1为输入符号,A~H代表状态:其中A为初始状态,D为接受状态,请画出与此DFA等价的最小DFA,并在新的DFA状态中标明它对应的原DFA 状态的子集.说明:有些同学没有画出状态H,因为无法从初始状态到达状态H. 从实用上讲,这是没有问题的. 不过,如果根据算法的步骤执行,最后是应该有状态H的.二、考虑所有含有3个状态(设为p,q,r)的DFA. 设只有r是接受状态. 至于哪一个状态是初始状态与本问题无关. 输入符号只有0和1. 这样的DFA总共有729种不同的状态迁移函数,因为对于每一状态和每一输入符号,可能迁移到3个状态中的一个,所以总共有3^6=729种可能. 在这729个DFA中,有多少个p和q是不可区分的(indistinguishable)?解释你的答案.解:考虑对于p和q,在输入符号为0时的情况,在这种情况下有5种可能使p和q无法区分:p和q在输入0时同时迁移到r(1种可能),或者p和q在输入0时,都迁移到p或q(4种可能).类似地,在输入符号为1时,也有5种可能使p和q无法区分.如果再考虑r的迁移,r的任何迁移对问题没有影响. 于是r在输入0和输入1时各有3种可能的迁移,总共有3*3=9种迁移.因此,总共有5*5*9=225个DFA,其中p和q是不可区分的.三、证明:所有仅含有字符a,且长度为素数的字符串组成的集合不是正则语言.证明:用反证法.假设含有素数个a的字符串组成的集合是正则语言,则必存在一个DFA接受这一语言,设此DFA为D. 由于D 的状态数有限,而素数有无限多个,所以必存在两个不同的素数p和q(设p<q),使得从D的初始状态出发,经过p个a和q个a后到达同一状态s,且s为接受状态. 由于DFA每一步的迁移都是确定的,所以从状态s 出发,经过(q-p)个a,只能到达状态s.考虑仅含有字母a,长度为p+p(q-p)的字符串T. T从初始状态出发,经过p个a到达状态s,再经过(q-p)个a仍然到达s;同样,经过p(q-p)个a后仍然到达s. 因此,从初始状态出发,经过p+p(q-p)个a后必然到达状态s. 由于p+p(q-p)=p(q-p+1)是合数,而s为接受状态,因而得出矛盾. 原命题得证.~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~《编译原理》第四次作业参考答案一、用上下文无关文法描述下列语言:1.定义在字母表∑={a, b}上,所有首字符和尾字符相同的非空字符串.S → aTa | bTb | a | bT → aT | bT | є说明:1. 用T来产生定义在字母表∑={a, b}上的任意字符串;2. 注意不要漏了单个a和单个b的情况.2.L={0i1j|i≤j≤2i且i≥0}.S → 0S1 | 0S11 | є3.定义在字母表∑={0, 1}上,所有含有相同个数的0和1的字符串(包括空串).S → 0S1 | 1S0 | SS | є思路:分两种情况考虑.1)如果首尾字母不同,那么这一字符串去掉首尾字母仍应该属于我们要定义的语言,因此有S → 0S1 |1S0;2)如果首尾字母相同,那么这一字符串必定可以分成两部分,每一部分都属于我们要定义的语言,因此有S → SS.二、考虑以下文法:S → aABeA → Abc|bB → d1.用最左推导(leftmost derivation)推导出句子abbcde.S ==> aABe ==> aAbcBe ==> abbcBe ==> abbcde2.用最右推导(rightmost derivation)推导出句子abbcde.S ==> aABe ==> aAde ==> aAbcde ==> abbcde3.画出句子abbcde对应的分析树(parse tree).三、考虑以下文法:S → aSbS → aSS →1.这一文法产生什么语言(用自然语言描述)?所有n个a后紧接m个b,且n>=m的字符串.2.证明这一文法是二义的.对于输入串aab,有如下两棵不同的分析树3.写出一个新的文法,要求新文法无二义且和上述文法产生相同的语言.答案一:S → aSb | TT → aT | ε答案二:S → TS’T → aT | εS’→ aS’b | ε~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~《编译原理》第五次作业参考答案一、考虑以下文法:S → aTUV | bVT → U | UUU →ε | bVV →ε | cV写出每个非终端符号的FIRST集和FOLLOW集.FIRST(S)={a, b} FIRST(T)={є, b} FIRST(U)={ є, b} FIRST(V)={є, c}FOLLOW(S)={$} FOLLOW(T)={ b, c, $} FOLLOW(U)={ b, c, $} FOLLOW(V)={b, c , $}二、考虑以下文法:S → (L) | aL → L, S | S1.消除文法的左递归.S → (L) | aL → SL’L’→ ,SL’ | ε2.构造文法的LL(1)分析表.FIRST(S) = {‘(‘, ‘a’} FIRST(L) = {‘(‘, ‘a’} FIRST(L’) = {‘,’, ε}FOLLOW(S) = {‘$’, ‘,’, ‘)’} FOLLOW(L) = {‘)’ } FOLLOW(L’) = {‘)’}三、考虑以下文法:S → aSbS | bSaS | ε这一文法是否是LL(1)文法?给出理由.这一文法不是LL(1)文法,因为S有产生式S →ε,但FIRST(S) = {a, b, ε}, FOLLOW(S) = {a, b},因而FIRST(S)∩FOLLOW(S)≠∅. 根据LL(1)文法的定义知这一文法不是LL(1)文法.~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~《编译原理》第六次作业参考答案一、考虑以下文法:(0) E’→ E(1) E → E+T(2) E → T(3) T → TF(4) T → F(5) F → F*(6) F → a(7) F b1. 写出每个非终端符号的FIRST集和FOLLOW集.FIRST(E’)= FIRST(E)= FIRST(T)= FIRST(F)={a, b}FOLLOW(E’)={$} FOLLOW(E)={+, $} FOLLOW(T)={+, $, a, b} FOLLOW(F)= {+, *, $, a, b}2. 构造识别这一文法所有活前缀(viable prefixes)的LR(0) 自动机(参照课本4.6.2节图4.31).~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ ~\(≧▽≦)/~ 《编译原理》第八次作业参考答案最终答案:34二、以下文法定义了二进制浮点数常量的语法规则:S → L.L | LL → LB | BB → 0 | 1试给出一个S属性的语法制导定义,其作用是求出该二进制浮点数的十进制值,并存放在开始符号S相关联的一个综合属性value中。