ceph分布式存储介绍
分布式存储系统对比之 Ceph VS MinIO

分布式存储系统对比之 Ceph VS MinIO分布式存储系统对比之Ceph VS MinIO对象存储概述对象存储通常会引用为基于对象的存储,它是能够处理大量非结构化数据的数据存储架构,在众多系统中都有应用。
对于部署在公有云的服务来说,公有云一般都提供对象存储服务,如阿里云的 OSS, 华为云的 OBS ,腾讯云的 COS 。
通过提供的 SDK 就可以访问。
如果不想用公有云的话,也有一些开源方案可以自己搭建。
一些开源的对象存储都会遵循 Amazon s3 协议。
Amazon s3 协议定义了操作对象存储的Resestfull 风格的 API 。
通过在 pom 中引用 aws-java-sdk-s3 可以实现对存储的操作。
开源方案对比存储的方案分成两种:① 一种是可以自定对象名称的;②另一种是系统自动生成对象名称。
不能自定义名称的有领英的 Ambry , MogileFS 。
TFS 是淘宝开源的,但是目前已经很少有人维护它并且也不是很活跃。
Ceph 是一个比较强大的分布式存储,但是它整个系统非常复杂需要大量的人力进行维护。
GlusterFS 为本身是一个非常成熟的对象存储的方案, 2011 年被收购了,原班的人马又做了另外一个存储系统 MinIO 。
其中 Ceph 跟 MinIO 是支持 s3 协议的。
后面对这两种方案做了一个详细的介绍。
对象存储选型①MinIOMinIO 是一个基于 Apache License V2.0 开源协议的对象存储服务,它兼容亚马逊 S3 云存储服务,非常适合于存储大容量非结构化的数据,如图片,视频,日志文件等。
而一个对象文件可以任意大小,从几 KB 到最大的 5T 不等。
它是一个非常轻量级的服务,可以很简单的和其它的应用结合,类似于 NodeJS, Redis 或者 MySQL 。
MinIO 默认不计算 MD5 ,除非传输给客户端的时候,所以很快,支持 windows ,有 web 页进行管理。
ceph存储原理

ceph存储原理ceph是一种开源、分布式的对象存储和文件系统,它能够在大规模的集群中存储和管理海量数据。
在ceph中,数据被分割成对象,并将这些对象存储在不同的存储节点上以实现高可用性和容错性。
这篇文章将介绍ceph存储的原理,包括ceph的架构、数据的存储和调度方式以及ceph如何处理故障。
ceph架构ceph的架构包括三个主要组成部分:客户端、存储集群和元数据服务器。
客户端是使用ceph存储的应用程序,它们通常是通过ceph API或者对象存储接口来访问ceph集群。
存储集群由一个或多个monitors、object storage devices(OSD),以及可能的元数据服务器组成。
monitors是ceph集群的核心组件,它负责管理ceph的全局状态信息、监控OSD 状态,并为客户端提供服务发现和配置信息。
OSD是实际存储数据的存储节点,它负责存储和处理对象,并在节点故障时自动重新平衡数据。
元数据服务器用于管理ceph文件系统中的元数据信息,包括文件和目录的名称、属性和层次关系等。
ceph存储数据的方式ceph将数据分割成对象,并使用CRUSH算法将这些对象分布在集群中的OSD上。
CRUSH 算法是ceph中存储调度的核心算法,它通过一系列计算将对象映射到存储集群中的OSD。
CRUSH将对象映射到OSD的方式是通过建立CRUSH映射表以实现负载均衡和容错。
CRUSH映射表可以根据管理员的需求进行调整,以达到最佳的性能和可扩展性。
ceph的CRUSH算法有以下特点:1. CRUSH将对象映射到可扩展的存储后端,以实现分布式存储和高可用性。
2. CRUSH使用元数据信息来动态调整对象的存储位置,并根据OSD的状态和磁盘使用情况等信息来实现负载均衡。
3. CRUSH允许管理员对存储策略进行调整,以适应不同的应用场景。
ceph的故障处理ceph具有强大的故障处理机制,它能够自动处理节点故障和数据损坏等问题,以确保数据的完整性和可用性。
分布式软件定义存储Ceph介绍

•Xfs
•Btrfs
•Ext4
•新版本中将支持更多的后端形式,如直接管理
块设备
•在一个集群中支持3-10000+的OSD
MON
Mon1
Mon2
Mon3
•Monitoring daemon •维护集群的视图和状态 •OSD和monitor之间相互传输节点状态信息,共同得出系统的总体 工作状态,并形成一个全局系统状态记录数据结构,即所谓的集群 视图(cluster map)
Ceph的历史
•2003年项目成立; •2006年作者将其开源; •2009年Inktank公司成立并发布Ceph的第一个稳定版本”Argonaut” ; •2014年红帽公司收购了Inktank,丰富了自己的软件定义存储的产品 线,此次收购使红帽成为领先的开源存储产品供应商,包括对象存储 、块存储和文件存储。
•通过RESTFUL API管理所有的集群和对象存储功能
特性总结-安全
•访问控制列表
•高细腻度的对象存储用户和用户组的安全控制
•配额
•支持对Cephfs设定使用额度
特性总结-可用性
•在集群节点之间条带和复制数据
•保证数据的持久性、高可用和高性能
•动态块设备大小调整
•扩卷缩卷不会导致宕机
•快速数据定位
•扩展的RADOS •RADOS可以横跨2个异地的数据中心并经过优化设计(低网络延时)
归档/冷 存储
CEPH STORAGE CLUSTER
成本
•支持瘦部署
•支持超量分配(block only)
•支持普通硬件设备
•将廉价PC服务器转换成存储设备满足不同负载和大容量、高可用、可扩展 的需求
•Erasure Coding纠删码
ceph使用方法

ceph使用方法摘要:1.Ceph简介2.Ceph组件及其作用3.安装Ceph4.Ceph使用方法5.Ceph的日常维护与管理6.Ceph性能优化7.常见问题与解决方案正文:Ceph是一款开源的分布式存储系统,具有高性能、可靠性高、可扩展性强等特点。
它主要由以下几个组件构成:1.Ceph Monitor(CMS):负责维护整个Ceph集群的元数据信息,包括监控各个节点的状态、集群映射关系等。
2.Ceph OSD:负责存储数据,包括数据存储和数据恢复。
OSD节点之间通过CRUSH算法实现数据分布和平衡。
3.Ceph Metadata Server:为Ceph客户端提供元数据服务,包括存储卷配置、快照、克隆等。
接下来,我们来了解一下如何安装和配置Ceph。
1.安装Ceph:首先,确保操作系统为CentOS 7及以上版本。
然后,按照官方文档的指引,依次安装Ceph Monitor、OSD和Metadata Server组件。
2.配置Ceph:安装完成后,需要对Ceph进行配置。
编辑Ceph配置文件(/etc/ceph/ceph.conf),设置相关参数,如:osd pool默认配置、monitor 选举算法等。
3.初始化Ceph:使用ceph-init命令初始化Ceph,之后启动Ceph相关服务。
4.创建存储池:使用ceph-volume命令创建存储池,为存储池分配OSD 节点。
5.创建卷:使用ceph-volume命令创建卷,并将卷挂载到客户端节点。
6.扩容存储池:当存储池空间不足时,可以通过添加OSD节点或调整pool参数进行扩容。
7.维护与管理:定期检查Ceph集群状态,使用ceph命令监控性能指标,如:osd tree、health monitor等。
8.性能优化:根据实际需求,调整Ceph配置文件中的相关参数,如:调整osd的osd_cache_size、osd_timeout等。
9.常见问题与解决方案:遇到问题时,可通过查询官方文档、社区论坛等途径寻求解决方案。
分布式文件存储CephFS详尽介绍及使用经验

分布式文件存储 CephFS详尽介绍及使用经验1. Ceph架构介绍Ceph是一种为优秀的性能、可靠性和可扩展性而设计的统一的、分布式文件系统。
特点如下:- 高性能a. 摒弃了传统的集中式存储元数据寻址的方案,采用CRUSH算法,数据分布均衡,并行度高。
b.考虑了容灾域的隔离,能够实现各类负载的副本放置规则,例如跨机房、机架感知等。
c. 能够支持上千个存储节点的规模,支持TB到PB级的数据。
- 高可用性a. 副本数可以灵活控制。
b. 支持故障域分隔,数据强一致性。
c. 多种故障场景自动进行修复自愈。
d. 没有单点故障,自动管理。
- 高可扩展性a. 去中心化。
b. 扩展灵活。
c. 随着节点增加而线性增长。
- 特性丰富a. 支持三种存储接口:块存储、文件存储、对象存储。
b. 支持自定义接口,支持多种语言驱动。
使用场景:•块存储 (适合单客户端使用)o典型设备:磁盘阵列,硬盘。
o使用场景:a. docker容器、虚拟机远程挂载磁盘存储分配。
b. 日志存储。
...•文件存储 (适合多客户端有目录结构)o典型设备:FTP、NFS服务器。
o使用场景:a. 日志存储。
b. 多个用户有目录结构的文件存储共享。
...•对象存储 (适合更新变动较少的数据,没有目录结构,不能直接打开/修改文件) o典型设备:s3, swift。
o使用场景:a. 图片存储。
b. 视频存储。
c. 文件。
d. 软件安装包。
e. 归档数据。
...系统架构:Ceph 生态系统架构可以划分为四部分:1.Clients:客户端(数据用户)2.mds:Metadata server cluster,元数据服务器(缓存和同步分布式元数据)3.osd:Object storage cluster,对象存储集群(将数据和元数据作为对象存储,执行其他关键职能)4.mon:Cluster monitors,集群监视器(执行监视功能)2. NFS介绍1. NAS(Network Attached Storage)- 网络存储基于标准网络协议NFSv3/NFSv4实现数据传输。
ceph中磁盘健康检测指标获取和存放

在文章中,我将深度分析并撰写有关ceph中磁盘健康检测指标获取和存放的主题。
首先我将介绍ceph的基本概念和磁盘健康检测的重要性,然后详细讨论如何获取和存放磁盘健康检测指标,并且结合实际案例和个人观点进行深入解读。
我会进行总结和回顾性的内容,使读者能够全面、深刻和灵活地理解主题。
1. ceph的基本概念在介绍磁盘健康检测指标获取和存放之前,有必要先了解一下ceph 的基本概念。
Ceph是一个开源的分布式存储系统,具有高性能、高可靠性和高扩展性的特点。
它采用一种称为CRUSH(Controlled Replication Under Scalable Hashing)的伸缩性散列算法,实现了数据的分布式存储和动态数据迁移。
2. 磁盘健康检测的重要性磁盘健康检测对于保证存储系统的稳定运行非常重要。
通过监控磁盘的健康状态和性能指标,可以预测磁盘故障,及时进行数据迁移和替换,从而保证存储系统的可靠性和稳定性。
3. 如何获取磁盘健康检测指标获取磁盘健康检测指标的方法有多种,包括使用第三方监控工具、通过ceph自带的管理接口获取、通过系统日志等。
其中,ceph自带的管理接口提供了丰富的指标和状态信息,可以方便地获取磁盘的健康检测指标。
4. 磁盘健康检测指标的存放获取到磁盘健康检测指标之后,如何进行有效地存放和管理也是非常重要的。
可以将这些指标存放到时序数据库中,以便进行长期的存储和分析。
还可以通过可视化工具对这些指标进行展示和分析,帮助管理员及时发现问题并进行处理。
5. 实际案例和个人观点通过实际案例和个人观点,我将结合自己的经验和理解,对磁盘健康检测指标获取和存放进行更深入的解读。
我会共享一些在实际环境中遇到的问题和解决方案,以及对磁盘健康检测的一些思考和看法。
总结和回顾性的内容通过本文的阐述,相信读者对ceph中磁盘健康检测指标获取和存放有了更深入的理解。
在文章中,我们介绍了ceph的基本概念、磁盘健康检测的重要性,以及如何获取和存放磁盘健康检测指标。
Ceph概念理解

Ceph概念理解简介Ceph是⼀个可靠地、⾃动重均衡、⾃动恢复的分布式存储系统,根据场景划分可以将Ceph分为三⼤块,分别是对象存储、块设备存储和⽂件系统服务。
在虚拟化领域⾥,⽐较常⽤到的是Ceph的块设备存储,⽐如在OpenStack项⽬⾥,Ceph的块设备存储可以对接OpenStack的cinder后端存储、Glance的镜像存储和虚拟机的数据存储。
⽐较直观的是Ceph集群可以提供⼀个raw格式的块存储来作为虚拟机实例的硬盘。
与其他存储相⽐的优势:充分利⽤了存储节点上的计算能⼒在存储每⼀个数据时,都会通过计算得出该数据存储的位置,尽量将数据分布均衡。
不存在传统的单点故障的问题,且随着规模的扩⼤性能并不会受到影响。
采⽤了CRUSH算法、HASH环等⽅法。
核⼼组件Ceph OSD(Object Storage Device):主要功能是存储数据、复制数据、平衡数据、恢复数据等,与其它OSD间进⾏⼼跳检查等,并将⼀些变化情况上报给CephMonitor。
⼀般情况下⼀块硬盘对应⼀个OSD,由OSD来对硬盘存储进⾏管理,当然⼀个分区也可以成为⼀个OSD。
Ceph OSD的架构实现由物理磁盘驱动器、Linux⽂件系统和Ceph OSD服务组成。
对于Ceph OSD Deamon⽽⾔,Linux⽂件系统显性的⽀持了其拓展性,⼀般Linux⽂件系统有好⼏种,⽐如有BTRFS、XFS、Ext4等,BTRFS。
虽然它们有很多优点特性,但现在还没达到⽣产环境所需的稳定性,⼀般⽐较推荐使⽤XFS。
⼀般写数据到Ceph集群时,都是先将数据写⼊到Journal盘中,然后每隔⼀段时间⽐如5秒再将Journal盘中的数据刷新到⽂件系统中。
⼀般为了使读写时延更⼩,Journal盘都是采⽤SSD,⼀般分配10G以上,当然分配多点那是更好。
Ceph中引⼊Journal盘的概念是因为Journal允许Ceph OSD功能很快做⼩的写操作。
ceph mgr指标说明

ceph mgr指标说明Ceph MGR指标说明Ceph是一种可扩展的分布式存储系统,它由多个组件构成,其中之一就是Ceph MGR(Manager)。
Ceph MGR是Ceph集群的管理器,它负责收集和处理集群的运行时数据,并提供一系列的监控指标来帮助管理员了解集群的状态。
本文将详细介绍Ceph MGR的常见指标及其含义。
1. 总体性能指标- OPS:每秒完成的操作数,包括读取、写入和其他操作。
- Latency:操作的平均延迟时间,反映了集群的响应速度。
- Bandwidth:数据传输的带宽,表示集群的传输能力。
2. 集群状态指标- PGs:代表数据的物理分区组,用于管理数据的分布和复制。
PGs 的数量和状态反映了集群的健康状况。
- OSDs:物理存储设备节点,负责存储和管理数据。
OSDs的数量和状态反映了集群的可用性和容错性。
- Monitors:监视器节点,负责集群的状态和配置信息。
Monitors 的数量和状态反映了集群的可用性和稳定性。
3. 存储指标- Used:已使用的存储容量。
- Available:可用的存储容量。
- Utilization:存储利用率,表示已使用存储与总存储容量的比值。
4. MDS指标- Active:活动的元数据服务器数量,反映了文件系统的负载情况。
- Inodes:索引节点的数量,反映了文件系统的大小和文件数量。
5. 网络指标- Connections:当前连接到集群的客户端数量。
- Throughput:网络传输的吞吐量,表示集群的网络性能。
6. 健康指标- Health:集群的健康状态,包括正常、警告和错误状态。
- Degraded:集群中处于降级状态的组件数量,反映了集群的可用性和稳定性。
7. 资源指标- CPU:集群中各组件的CPU使用率。
- Memory:集群中各组件的内存使用率。
8. 事件指标- Events:集群中发生的事件数量,包括错误、警告和通知。
ceph的数据存储之路(12)----cachetier

YY的中对提升到中命()2026:判断缓存模式2028:如果是writeback模式,如果在未命中的情况下,writeback模式如何处理。
2029:如果现在cache已经满了,需要全部的evict。
2031:如果是读操作,可以proxy_read的直接do_proxy_read(),否则do_cache_redirect()直接转向到base pool中。
2046:如果是写操作,添加到waiting_for_cache_not_full等待队列,缓存evict后会重新处理该op。
下⾯就是如果cache 在⾮full情况下的处理:2050:如果是写请求的情况2052:则需要从base pool 提升object到cache pool中。
2056:剩下后⾯的情况就都是读操作了,这⾥判断是否可以proxyread,如果可以则直接do_proxy_read()。
2061:如果这object是block住的,则不能进⾏操作。
在writeback模式下,读操作未命中时,min_read_recency_for_promote 该值默认情况下为1,这个在ceph osd pool ls detail 时也能看到。
默认⾛了case1。
如果近期访问过,说明object⽐较热,可以提升到cache 中,如果可以proxy read则在上⾯已经do_proxy_read(),如果不可以proxy_read,则直接do_cache_redirect()。
最后break ,return。
1.5.2 forward模式:Forward模式就是把所有的请求都转向给base pool。
2135:如果是forward模式2136:直接调⽤do_cache_redirect()直接告诉客户端,将请求转给base pool。
1.5.3 readonly 模式:2139:case 当cache 的mode是readonly模式。
2141:如果不存在obc 并且没有创建,说明是读操作。
ceph学习资料
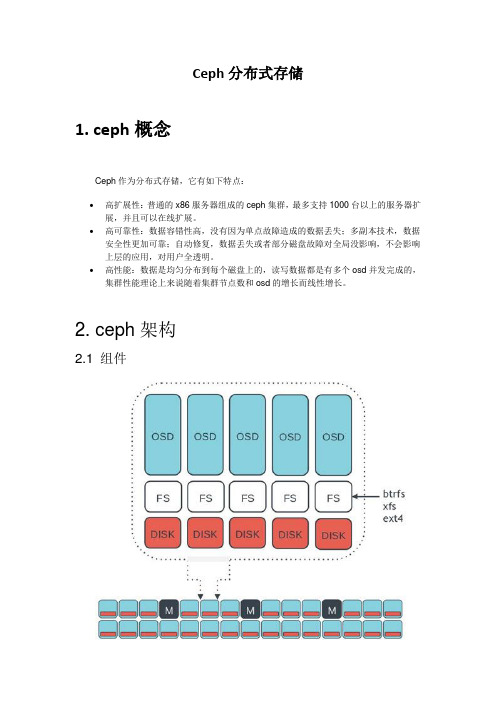
Ceph分布式存储1. ceph概念Ceph作为分布式存储,它有如下特点:•高扩展性:普通的x86服务器组成的ceph集群,最多支持1000台以上的服务器扩展,并且可以在线扩展。
•高可靠性:数据容错性高,没有因为单点故障造成的数据丢失;多副本技术,数据安全性更加可靠;自动修复,数据丢失或者部分磁盘故障对全局没影响,不会影响上层的应用,对用户全透明。
•高性能:数据是均匀分布到每个磁盘上的,读写数据都是有多个osd并发完成的,集群性能理论上来说随着集群节点数和osd的增长而线性增长。
2. ceph架构2.1 组件Ceph的底层是RADOS,它的意思是“A reliable, autonomous, distributed object storage”(一个可靠的自治的分布式存储,字面意思哈)。
RADOS系统逻辑架构图:RADOS主要由两个部分组成。
一种是大量的、负责完成数据存储和维护功能的OSD(Object Storage Device),另一种则是若干个负责完成系统状态检测和维护的monitor。
osd和monitor之间相互传输节点状态信息。
而ceph集群主要包括mon、mds、osd组件其中,mon负责维护整个集群的状态以及包括crushmap、pgmap、osdmap等一系列map 信息记录与变更。
Osd负责提供数据存储,数据的恢复均衡。
Mds(元数据服务器)主要是使用文件系统存储的时候需要,它主要负责文件数据的inode 信息,并让客户端通过该inode信息快速找到数据实际所在地。
2.2 数据映射流程在Ceph中,文件都是以object(对象)的方式存放在众多osd上。
一个file(数据)的写入顺序:首先mon根据map信息将file(数据)切分成多个的object;再通过hash算法决定这些个object对象分别会存放在那些pg(放置组)里面;接下来在通过crushmap再决定将pg放在底层的那些osd上,pg与osd的关系属于一对多的关系。
ceph中mon的作用

ceph中mon的作用摘要:1.Ceph 简介2.Mon 的作用3.Mon 的组件和功能4.Mon 的部署和优化5.总结正文:1.Ceph 简介Ceph 是一种开源的、高度可扩展的分布式存储系统,旨在提供优秀的性能、可靠性和可扩展性。
Ceph 采用了一种去中心化的设计,由多个节点组成,可以实现数据的自动分布和平衡。
在Ceph 中,有一个称为Mon 的角色,扮演着至关重要的任务。
2.Mon 的作用Mon,全称为Monitor,是Ceph 中的一个核心组件,负责管理整个集群的状态和监控各个节点的运行状况。
Mon 的主要作用包括:- 维护集群的拓扑结构和状态信息- 监控节点的健康状况,发现并替换故障节点- 管理数据分布和平衡- 协调数据复制和恢复操作3.Mon 的组件和功能Mon 主要由以下几个组件组成:- Mon daemon:Mon 的主要服务进程,负责集群管理、状态监控和命令处理等功能。
- Mon map:Mon 的状态数据库,存储了集群的拓扑结构、状态信息和元数据等。
- Mon event:Mon 的事件机制,用于触发和处理各种监控事件。
- Mon debug:Mon 的调试工具,用于诊断和调试Mon 的运行状态。
Mon 的主要功能包括:- 集群管理:Mon 负责创建、删除和更新集群的拓扑结构,以及维护节点之间的连接关系。
- 状态监控:Mon 实时监控节点的健康状况,包括CPU 利用率、内存使用情况、磁盘空间等,发现故障节点并及时替换。
- 数据分布和平衡:Mon 根据集群的负载情况,动态调整数据分布,实现负载均衡和性能优化。
- 数据复制和恢复:Mon 协调节点之间的数据复制和恢复操作,确保数据的安全性和一致性。
4.Mon 的部署和优化为了确保Ceph 集群的高可用性和性能,Mon 的部署和优化至关重要。
以下是一些建议:- 至少部署3 个Mon 节点,以实现冗余和故障转移。
- 确保Mon 节点的硬件配置足够强大,以承载集群的管理和监控任务。
ceph mds cache 参数

ceph mds cache 参数Ceph是一种开源的分布式存储系统,具有高性能、可靠性和可扩展性。
在Ceph中,MDS(Meta Data Server)负责存储文件的元数据信息。
为了提高MDS的性能和数据访问速度,可以配置缓存参数。
本文将介绍Ceph MDS缓存参数的重要性、常用参数及其调整方法。
一、Ceph MDS概述Ceph MDS作为分布式存储系统中的关键组件,负责处理客户端与OSD (Object Storage Device)之间的元数据请求。
MDS通过缓存元数据信息,降低客户端与OSD之间的通信量,提高系统性能。
二、Ceph MDS缓存参数的重要性Ceph MDS缓存参数对于整个分布式存储系统的性能具有重要作用。
合理的缓存参数配置可以提高数据访问速度、降低网络延迟、提高系统吞吐量。
以下为常用Ceph MDS缓存参数:1.max_object_size:设置MDS缓存的最大对象大小,单位为字节。
根据实际应用场景和数据量进行调整。
2.max_object_count:设置MDS缓存的最大对象数量。
根据MDS的性能和存储需求进行调整。
3.cache_size:设置MDS缓存的总体大小,单位为字节。
根据MDS的性能要求和存储容量进行调整。
4.cache_policy:设置MDS缓存策略,包括以下几种:- CACHE_POLICY_NONE:不使用缓存。
- CACHE_POLICY_FIFO:先进先出缓存策略。
- CACHE_POLICY_LRU:最近最少使用缓存策略。
- CACHE_POLICY_RANDOM:随机缓存策略。
5.eviction_policy:设置MDS缓存的淘汰策略,包括以下几种:- EVICTION_POLICY_NONE:不进行缓存淘汰。
- EVICTION_POLICY_FIFO:先进先出淘汰策略。
- EVICTION_POLICY_LEAST_REcentLY_USED:最近最少使用淘汰策略。
分布式存储对象存储概述--ppt课件

优点
S如:AN , 提供高性 能的随机I/O和数据 吞吐率
缺点
可扩展性和可管理性较 差、价格较高、不能满 足成千上万CPU 规模的 系统
文
块存储设备 如:NAS, 扩展性好、 开销高、带宽低、延迟
件
文件
+文件系统 易于管理、价格便宜 大,不利于高性能集群中
储
应用
存
对
块存储设备 支持高并行性、可伸 处于发展阶段,相应的硬
ppt课件
11
2.2 对象存储解释优势
对象存储就是分布式系统,也可理解为依托于分布式存储架 构的一个特性,高级功能
1)传统的块存储读写快而不利于共享, 2 )文件存储读写慢但利于共享 对象存储则集成二者优点,是一个利于共享、读写快的“云 存储”技术。作为一种分布式存储,最重要的一点是能解决 对非结构化数据快速增长带来的问题。
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
8 16 247 231 115.464 108 0.357958 0.53742
9 16 274 258 114.633 108 0.449163 0.539057
括处理器、RAM 内存、网络接口、存储介质等以及运行在其中的控制软件 • MDS 元数据服务器(Metadata Server)
系统提供元数据、Cache一致性等服务
ppt课件
15
2.5:传统存储数据存储过程
传统文件储存过程。
ppt课件
16
2.6:对象存储数据储存过程
对象文件储存过程。
ppt课件
Stddev Bandwidth: 41.2795
ceph的基本命令

ceph的基本命令Ceph是一个开源的分布式存储系统,它提供了一系列的基本命令,用于管理和操作Ceph集群。
本文将介绍Ceph的一些基本命令,并说明其用法和功能。
1. ceph-deploy命令ceph-deploy命令用于部署和配置Ceph集群。
它可以在一台主机上执行,通过SSH连接到其他节点,并自动完成Ceph集群的安装和配置过程。
使用ceph-deploy命令,可以轻松地创建Ceph集群,添加和删除节点,以及配置不同的存储池。
2. ceph命令ceph命令是Ceph集群的主要管理工具,它提供了许多子命令来执行不同的管理操作。
例如,使用ceph status命令可以查看Ceph 集群的状态,包括健康状况、存储池的使用情况、OSD的状态等。
使用ceph osd tree命令可以查看Ceph集群的OSD树,了解每个OSD的位置和状态。
3. ceph-disk命令ceph-disk命令用于管理Ceph集群的磁盘设备。
它可以扫描系统上的磁盘,将其添加到Ceph集群中,并为其创建OSD。
使用ceph-disk命令,可以轻松地扩展Ceph集群的存储容量,并管理集群中的磁盘设备。
4. rados命令rados命令是Ceph分布式对象存储的主要管理工具,它提供了一系列子命令来管理和操作Ceph集群中的对象。
例如,使用rados ls命令可以列出Ceph集群中的所有对象,使用rados get命令可以从Ceph集群中获取对象,使用rados put命令可以将对象放入Ceph集群中。
5. rbd命令rbd命令是Ceph分布式块设备的管理工具,它提供了一系列子命令来管理和操作Ceph集群中的块设备。
例如,使用rbd create命令可以创建一个新的块设备,使用rbd map命令可以将块设备映射到本地主机上,使用rbd snap命令可以创建和管理块设备的快照。
6. ceph-mon命令ceph-mon命令用于管理Ceph集群中的监视器。
ceph分布式存储多副本恢复机制

ceph分布式存储多副本恢复机制摘要:1.Ceph 分布式存储概述2.多副本恢复机制的原理3.多副本恢复机制的实现过程4.多副本恢复机制的优点与不足5.总结正文:1.Ceph 分布式存储概述Ceph 是一种开源的分布式存储系统,旨在提供优秀的性能、可靠性和可扩展性。
它采用去中心化的设计,通过多个节点的存储数据副本来实现数据冗余和故障恢复。
Ceph 支持多种存储类型,如对象存储、块存储和文件存储等,能够满足不同应用场景的需求。
2.多副本恢复机制的原理Ceph 的分布式存储系统通过数据副本来实现数据的可靠性和容错能力。
在Ceph 中,每个数据节点(OSD)都可以存储多个数据副本,这些副本分布在不同的节点上。
当某个节点发生故障时,Ceph 会根据副本的数量和分布情况,自动选择一个或多个副本来恢复数据。
这种机制被称为多副本恢复机制。
3.多副本恢复机制的实现过程多副本恢复机制的实现过程主要包括以下几个步骤:(1)数据写入:当客户端写入数据时,Ceph 会在多个节点上存储数据的副本,以实现数据的冗余。
(2)数据监控:Ceph 会实时监控各个节点的状态,以检测可能的故障。
(3)故障检测:当某个节点发生故障时,Ceph 会立即进行故障检测,并确定需要恢复的数据副本。
(4)数据恢复:Ceph 会根据故障检测的结果,选择一个或多个副本来恢复数据。
恢复过程可能涉及到数据迁移、数据重构等操作。
(5)恢复完成:恢复完成后,Ceph 会将恢复后的数据返回给客户端,确保业务的正常运行。
4.多副本恢复机制的优点与不足多副本恢复机制具有以下优点:(1)较高的数据可靠性:通过多个副本的存储,提高了数据的可靠性和容错能力。
(2)自动故障恢复:当发生硬件故障时,Ceph 能够自动检测并进行恢复。
(3)可扩展性:多副本恢复机制可以灵活地扩展存储容量,以满足业务需求。
然而,多副本恢复机制也存在一些不足:(1)存储空间利用率:多个副本会占用更多的存储空间,可能导致存储空间的浪费。
ceph nfs-ganesha fsal 参数

Ceph NFS-Ganesha FSAL 参数1. 介绍Ceph是一个开源的分布式存储系统,它提供了高性能、高可靠性和可伸缩性的存储解决方案。
而NFS-Ganesha则是一个基于NFS协议的开源文件系统网关,它为Ceph提供了文件系统接口,使得用户可以通过NFS协议来访问Ceph存储集群中的数据。
而FSAL(File System Abstraction Layer)则是NFS-Ganesha中的一个组件,它负责将底层存储系统(如Ceph)的特性映射为NFS-Ganesha可理解的接口。
2. FSAL参数的重要性在配置NFS-Ganesha以接入Ceph存储时,FSAL参数的设置非常重要。
通过合理的设置,可以有效地提高文件系统的性能、安全性和可靠性。
我们需要对FSAL参数进行全面的评估和了解,以便正确地配置NFS-Ganesha,从而充分发挥Ceph存储的优势。
3. FSAL参数的具体内容在对FSAL参数进行评估时,我们需要考虑以下几个方面:- 块大小:Ceph存储系统中的数据以对象的形式进行存储,而NFS-Ganesha需要将对象映射为文件系统的块。
块大小的设置将直接影响到文件系统的性能和效率。
- 缓存策略:由于NFS-Ganesha和Ceph存储系统位于不同的层级,为了提高文件系统的访问速度,需要合理地配置缓存策略,包括读写缓存的大小和更新策略等。
- 安全设置:在配置NFS-Ganesha时,需要考虑到文件系统的安全性,并根据实际需求设置相应的权限、认证方式和访问控制策略,确保数据的安全性和隐私性。
- 高可用性:Ceph存储系统具有高可用性的特点,而NFS-Ganesha也需要具备相应的高可用性能力,因此需要对FSAL参数进行合理的配置,以确保文件系统在各种故障情况下能够快速恢复和提供持续的访问服务。
4. 个人观点和理解在我看来,FSAL参数的设置是配置NFS-Ganesha的关键步骤之一。
ceph分布式存储介绍

Ceph分布式存储1Ceph存储概述Ceph 最初是一项关于存储系统的PhD 研究项目,由Sage Weil 在University of California, Santa Cruz(UCSC)实施。
Ceph 是开源分布式存储,也是主线 Linux 内核()的一部分。
1.1Ceph 架构Ceph 生态系统可以大致划分为四部分(见图 1):客户端(数据用户),元数据服务器(缓存和同步分布式元数据),一个对象存储集群(将数据和元数据作为对象存储,执行其他关键职能),以及最后的集群监视器(执行监视功能)。
图 1 Ceph 生态系统如图 1 所示,客户使用元数据服务器,执行元数据操作(来确定数据位置)。
元数据服务器管理数据位置,以及在何处存储新数据。
值得注意的是,元数据存储在一个存储集群(标为“元数据I/O”)。
实际的文件 I/O 发生在客户和对象存储集群之间。
这样一来,更高层次的 POSIX 功能(例如,打开、关闭、重命名)就由元数据服务器管理,不过 POSIX 功能(例如读和写)则直接由对象存储集群管理。
另一个架构视图由图 2 提供。
一系列服务器通过一个客户界面访问 Ceph 生态系统,这就明白了元数据服务器和对象级存储器之间的关系。
分布式存储系统可以在一些层中查看,包括一个存储设备的格式(Extent and B-tree-based Object File System [EBOFS] 或者一个备选),还有一个设计用于管理数据复制,故障检测,恢复,以及随后的数据迁移的覆盖管理层,叫做Reliable Autonomic Distributed Object Storage(RADOS)。
最后,监视器用于识别组件故障,包括随后的通知。
图 2 ceph架构视图1.2Ceph 组件了解了 Ceph 的概念架构之后,您可以挖掘到另一个层次,了解在 Ceph 中实现的主要组件。
Ceph 和传统的文件系统之间的重要差异之一就是,它将智能都用在了生态环境而不是文件系统本身。
ceph mgr指标说明

ceph mgr指标说明摘要:1.Ceph简介2.Ceph Manager(MGR)概述3.Ceph MGR指标分类4.具体指标说明5.指标应用场景与实践正文:CEPH是一种开源的分布式存储系统,具有高可靠性、可扩展性和高性能等特点。
CEPH Manager(MGR)是CEPH的一个重要组件,负责监控和管理整个CEPH集群。
本文将介绍CEPH MGR的指标说明,以帮助用户更好地理解和使用这一工具。
一、Ceph简介Ceph是一个开源的分布式存储系统,旨在提供高度可靠、可扩展且高性能的存储解决方案。
Ceph适用于多种存储场景,如对象存储、块存储和文件存储等。
其独特的架构使得Ceph能够在大规模部署中保持高性能和可靠性。
二、Ceph Manager(MGR)概述Ceph Manager(MGR)是CEPH集群的管理组件,负责监控和管理整个CEPH集群。
MGR通过收集和处理各种指标,为用户提供有关CEPH集群状态和性能的实时信息。
用户可以通过分析这些指标来优化CEPH集群的配置和性能。
三、Ceph MGR指标分类Ceph MGR指标主要分为以下几类:1.集群状态:包括集群健康状况、容量使用情况、OSD数量等。
2.存储池:包括存储池容量、池内OSD分布、最小和最大副本数等。
3.OSD:包括OSD健康状况、OSD状态、OSD日志等。
4.磁盘:包括磁盘使用情况、磁盘I/O性能等。
5.网络:包括网络带宽使用、跨集群连接状态等。
6.监控:包括监控节点状态、监控指标采集频率等。
四、具体指标说明1.集群状态:通过监控集群内OSD的数量、集群健康状况、容量使用情况等指标,用户可以了解集群的整体状态。
2.存储池:存储池指标可以帮助用户了解存储池的容量使用情况、副本分布等信息,以便调整存储策略。
3.OSD:OSD指标可以让用户实时了解OSD的运行状况,如OSD健康状况、OSD状态等。
4.磁盘:通过磁盘指标,用户可以了解磁盘的使用情况和I/O性能,为磁盘分区调整和优化提供依据。
Ceph集群概念以及部署

Ceph集群概念以及部署⼀、Ceph基础: 1、基础概念: ceph 是⼀个开源的分布式存储,同时⽀持对象存储、块设备、⽂件系统 ceph是⼀个对象(object)式存储系统,它把每⼀个待管理的数据流(⽂件等数据)切分伟⼀到多个固定⼤⼩(默认4M)的对象数据,并以其为原⼦单元(原⼦是构成元素的最⼩单元)完成数据的读写 对象数据的底层存储服务是由多个存储主机(host)组成的存储集群,该集群也被称之为RADOS(reliable automatic distributed object store)存储集群,即可靠的、⾃动化的、分布式的对象存储系统 librados是RADOS存储集群的API,⽀持C/C++/JAVA/Python/ruby/go/php等多种编程语⾔客户端 2、ceph的设计思想: ceph的设计宗旨在实现以下⽬标: 每⼀组件皆可扩展 ⽆单点故障 基于软件(⽽⾮专业设备)并且开源(⽆供应商) 在现有的廉价硬件上运⾏ 尽可能⾃动管理,减少⽤户⼲预 3、ceph版本: x.0.z - 开发版 x.1.z - 候选版 x.2.z - 稳定、修正版 4、ceph集群⾓⾊定义: 5、ceph集群的组成部分: 若⼲的Ceph OSD(对象存储守护进程) ⾄少需要⼀个Ceph Monitor 监视器(数量最好为奇数1,3,5,7........) 两个或以上的Ceph管理器 managers,运⾏Ceph⽂件系统客户端时还需要⾼可⽤的Ceph Metadata Server(⽂件系统元数据服务器) RADOS Cluster:由多台host存储服务器组成的ceph集群 OSD(Object Storage Daemon):每台存储服务器的磁盘组成的存储空间 Mon(Monitor):Ceph的监视器,维护OSD和PG的集群状态,⼀个Ceph集群⾄少有⼀个Mon节点,可以是⼀三五七等这样的奇数个 Mgr(Manager):负责跟踪运⾏时指标和Ceph集群的当前状态,包括存储利⽤率,当前性能指标和系统负载等 6、Ceph集群术语详细介绍: 6.1 Monitor(ceph-mon)ceph监视器: 软件包名&进程名:ceph-mon 在⼀个主机上运⾏的⼀个守护进程,⽤于维护集群状态映射(maintains maps of the cluster state),⽐如ceph 集群中有多少存储池、每个存储池有多少PG 以及存储池和PG的映射关系等, monitor map, manager map, the OSD map, the MDS map, and the CRUSH map,这些映射是Ceph 守护程序相互协调所需的关键群集状态,此外监视器还负责管理守护程序和客户端之间的⾝份验证(认证使⽤cephX 协议)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Ceph分布式存储1Ceph存储概述Ceph 最初是一项关于存储系统的PhD 研究项目,由Sage Weil 在University of California, Santa Cruz(UCSC)实施。
Ceph 是开源分布式存储,也是主线Linux 内核(2.6.34)的一部分。
1.1Ceph 架构Ceph 生态系统可以大致划分为四部分(见图1):客户端(数据用户),元数据服务器(缓存和同步分布式元数据),一个对象存储集群(将数据和元数据作为对象存储,执行其他关键职能),以及最后的集群监视器(执行监视功能)。
图1 Ceph 生态系统如图1 所示,客户使用元数据服务器,执行元数据操作(来确定数据位置)。
元数据服务器管理数据位置,以及在何处存储新数据。
值得注意的是,元数据存储在一个存储集群(标为“元数据I/O”)。
实际的文件I/O 发生在客户和对象存储集群之间。
这样一来,更高层次的POSIX 功能(例如,打开、关闭、重命名)就由元数据服务器管理,不过POSIX 功能(例如读和写)则直接由对象存储集群管理。
另一个架构视图由图2 提供。
一系列服务器通过一个客户界面访问Ceph 生态系统,这就明白了元数据服务器和对象级存储器之间的关系。
分布式存储系统可以在一些层中查看,包括一个存储设备的格式(Extent and B-tree-based Object File System [EBOFS] 或者一个备选),还有一个设计用于管理数据复制,故障检测,恢复,以及随后的数据迁移的覆盖管理层,叫做Reliable Autonomic Distributed Object Storage(RADOS)。
最后,监视器用于识别组件故障,包括随后的通知。
图2 ceph架构视图1.2Ceph 组件了解了Ceph 的概念架构之后,您可以挖掘到另一个层次,了解在Ceph 中实现的主要组件。
Ceph 和传统的文件系统之间的重要差异之一就是,它将智能都用在了生态环境而不是文件系统本身。
图3 显示了一个简单的Ceph 生态系统。
Ceph Client 是Ceph 文件系统的用户。
Ceph Metadata Daemon 提供了元数据服务器,而Ceph Object Storage Daemon 提供了实际存储(对数据和元数据两者)。
最后,Ceph Monitor 提供了集群管理。
要注意的是,Ceph 客户,对象存储端点,元数据服务器(根据文件系统的容量)可以有许多,而且至少有一对冗余的监视器。
那么,这个文件系统是如何分布的呢?图3简单的Ceph 生态系统1.3Ceph 客户端因为Linux 显示文件系统的一个公共界面(通过虚拟文件系统交换机[VFS]),Ceph 的用户透视图就是透明的。
管理员的透视图肯定是不同的,考虑到很多服务器会包含存储系统这一潜在因素(要查看更多创建Ceph 集群的信息,见参考资料部分)。
从用户的角度看,他们访问大容量的存储系统,却不知道下面聚合成一个大容量的存储池的元数据服务器,监视器,还有独立的对象存储设备。
用户只是简单地看到一个安装点,在这点上可以执行标准文件I/O。
Ceph 文件系统—或者至少是客户端接口—在Linux 内核中实现。
值得注意的是,在大多数文件系统中,所有的控制和智能在内核的文件系统源本身中执行。
但是,在Ceph 中,文件系统的智能分布在节点上,这简化了客户端接口,并为Ceph 提供了大规模(甚至动态)扩展能力。
Ceph 使用一个有趣的备选,而不是依赖分配列表(将磁盘上的块映射到指定文件的元数据)。
Linux 透视图中的一个文件会分配到一个来自元数据服务器的inode number(INO),对于文件这是一个唯一的标识符。
然后文件被推入一些对象中(根据文件的大小)。
使用INO 和object number(ONO),每个对象都分配到一个对象ID(OID)。
在OID 上使用一个简单的哈希,每个对象都被分配到一个放置组。
放置组(标识为PGID)是一个对象的概念容器。
最后,放置组到对象存储设备的映射是一个伪随机映射,使用一个叫做Controlled Replication Under Scalable Hashing(CRUSH)的算法。
这样一来,放置组(以及副本)到存储设备的映射就不用依赖任何元数据,而是依赖一个伪随机的映射函数。
这种操作是理想的,因为它把存储的开销最小化,简化了分配和数据查询。
分配的最后组件是集群映射。
集群映射是设备的有效表示,显示了存储集群。
有了PGID 和集群映射,您就可以定位任何对象。
1.4Ceph 元数据服务器元数据服务器(cmds)的工作就是管理文件系统的名称空间。
虽然元数据和数据两者都存储在对象存储集群,但两者分别管理,支持可扩展性。
事实上,元数据在一个元数据服务器集群上被进一步拆分,元数据服务器能够自适应地复制和分配名称空间,避免出现热点。
如图4 所示,元数据服务器管理名称空间部分,可以(为冗余和性能)进行重叠。
元数据服务器到名称空间的映射在Ceph 中使用动态子树逻辑分区执行,它允许Ceph 对变化的工作负载进行调整(在元数据服务器之间迁移名称空间)同时保留性能的位置。
图4 元数据服务器的Ceph 名称空间的分区但是因为每个元数据服务器只是简单地管理客户端人口的名称空间,它的主要应用就是一个智能元数据缓存(因为实际的元数据最终存储在对象存储集群中)。
进行写操作的元数据被缓存在一个短期的日志中,它最终还是被推入物理存储器中。
这个动作允许元数据服务器将最近的元数据回馈给客户(这在元数据操作中很常见)。
这个日志对故障恢复也很有用:如果元数据服务器发生故障,它的日志就会被重放,保证元数据安全存储在磁盘上。
元数据服务器管理inode 空间,将文件名转变为元数据。
元数据服务器将文件名转变为索引节点,文件大小,和Ceph 客户端用于文件I/O 的分段数据(布局)。
1.5Ceph 监视器Ceph 包含实施集群映射管理的监视器,但是故障管理的一些要素是在对象存储本身中执行的。
当对象存储设备发生故障或者新设备添加时,监视器就检测和维护一个有效的集群映射。
这个功能按一种分布的方式执行,这种方式中映射升级可以和当前的流量通信。
Ceph 使用Paxos,它是一系列分布式共识算法。
1.6Ceph 对象存储和传统的对象存储类似,Ceph 存储节点不仅包括存储,还包括智能。
传统的驱动是只响应来自启动者的命令的简单目标。
但是对象存储设备是智能设备,它能作为目标和启动者,支持与其他对象存储设备的通信和合作。
从存储角度来看,Ceph 对象存储设备执行从对象到块的映射(在客户端的文件系统层中常常执行的任务)。
这个动作允许本地实体以最佳方式决定怎样存储一个对象。
Ceph 的早期版本在一个名为EBOFS 的本地存储器上实现一个自定义低级文件系统。
这个系统实现一个到底层存储的非标准接口,这个底层存储已针对对象语义和其他特性(例如对磁盘提交的异步通知)调优。
今天,B-tree 文件系统(BTRFS)可以被用于存储节点,它已经实现了部分必要功能(例如嵌入式完整性)。
因为Ceph 客户实现CRUSH,而且对磁盘上的文件映射块一无所知,下面的存储设备就能安全地管理对象到块的映射。
这允许存储节点复制数据(当发现一个设备出现故障时)。
分配故障恢复也允许存储系统扩展,因为故障检测和恢复跨生态系统分配。
Ceph 称其为RADOS。
2Ceph快速配置资源:两台机器:一台server,一台client,安装ubuntu12.10其中,server安装时,另外分出两个区,作为osd0、osd1的存储,没有的话,系统安装好后,使用loop设备虚拟出两个也可以。
步骤:1、安装操作系统2、添加key到APT中,更新sources.list,安装ceph#sudo wget -q -O- 'https:///git/?p=ceph.git;a=blob_plain;f=keys/release.asc' | sudo apt-key add -#sudo echo deb /debian/ $(lsb_release -sc) main | sudo tee /etc/apt/sources.list.d/ceph.list# sudo apt-get update && sudo apt-get install ceph3、查看版本# ceph-v //将显示ceph的版本和key信息如果没有显示,请执行如下命令# sudo apt-get update && apt-get upgrade4、在/etc/ceph/下创建ceph.conf配置文件,并将配置文件拷贝到Client 。
[global]# For version 0.55 and beyond, you must explicitly enable# or disable authentication with "auth" entries in [global].auth cluster required = noneauth service required = noneauth client required = none[osd]osd journal size = 1000#The following assumes ext4 filesystem.filestore xattr use omap = true# For Bobtail (v 0.56) and subsequent versions, you may# add settings for mkcephfs so that it will create and mount# the file system on a particular OSD for you. Remove the comment `#`# character for the following settings and replace the values# in braces with appropriate values, or leave the following settings# commented out to accept the default values. You must specify the# --mkfs option with mkcephfs in order for the deployment script to# utilize the following settings, and you must define the 'devs'# option for each osd instance; see below.osd mkfs type = xfsosd mkfs options xfs = -f # default for xfs is "-f"osd mount options xfs = rw,noatime # default mount option is "rw,noatime"# For example, for ext4, the mount option might look like this:#osd mkfs options ext4 = user_xattr,rw,noatime# Execute $ hostname to retrieve the name of your host,# and replace {hostname} with the name of your host.# For the monitor, replace {ip-address} with the IP# address of your host.[mon.a]host = ubuntumon addr = 192.168.60.125:678[osd.0]host = ubuntu# For Bobtail (v 0.56) and subsequent versions, you may# add settings for mkcephfs so that it will create and mount# the file system on a particular OSD for you. Remove the comment `#`# character for the following setting for each OSD and specify# a path to the device if you use mkcephfs with the --mkfs option.devs = /dev/loop0[osd.1]host = ubuntudevs = /dev/loop1[mds.a]host = ubuntu说明:1)配置文件请将认证设置成none2)指定osd0、osd1的位置如果没有/sda,可使用loop设备虚拟,方法如下:# losetup –a //查看loop设备的使用情况# dd if=/dev/zero of=osd1 bs=1M count=1000 //格式化# losetup /dev/loop0 osd0 //建立对应关系#mkfs –t xfs /dev/loop0 //格式化按照相同的方法设置loop1为osd15、创建目录sudo mkdir -p /var/lib/ceph/osd/ceph-0sudo mkdir -p /var/lib/ceph/osd/ceph-1sudo mkdir -p /var/lib/ceph/mon/ceph-asudo mkdir -p /var/lib/ceph/mds/ceph-a6、执行初始化cd /etc/cephsudo mkcephfs -a -c /etc/ceph/ceph.conf -k ceph.keyring7、启动# sudo service ceph -a start8、执行健康检查sudo ceph health如果返回的是HEALTH_OK,代表成功!出现:HEALTH_WARN 576 pgs stuck inactive; 576 pgs stuck unclean; no osds之类的,请执行:#ceph pg dump_stuck stale#ceph pg dump_stuck inactive#ceph pg dump_stuck unclean再次健康检查是,应该是OK注意:重新执行如下命令#sudo mkcephfs -a -c /etc/ceph/ceph.conf -k ceph.keyring 前,请先清空创建的四个目录:/var/lib/ceph/osd/ceph-0、/var/lib/ceph/osd/ceph-1、/var/lib/ceph/mon/ceph-a、/var/lib/ceph/mds/ceph-a# rm –frv /var/lib/ceph/osd/ceph-0/*# rm –frv /var/lib/ceph/osd/ceph-1/*# rm –frv /var/lib/ceph/mon/ceph-a/*# rm –frv /var/lib/ceph/mds/ceph-a/*3CephFS的使用在客户端上操作:sudo mkdir /mnt/mycephfssudo mount -t ceph {ip-address-of-monitor}:6789:/ /mnt/mycephfs或者sudo mkdir /home/{username}/cephfssudo ceph-fuse -m {ip-address-of-monitor}:6789 /home/{username}/cephfs# sudo mount -l……192.168.60.125:6789:/ on /mnt/mycephfs type ceph (0)# cd /mnt/mycephfs可进行文件操作4源码包编译流程:1、安装好系统后,选择系统设置-软件源,将APT的源修改为/ubuntu#sudo apt-get update2、添加ceph的源到/etc/apt/sources.list中deb /debian quantal maindeb-src /debian quantal main3、新建目录,存放ceph源码包# mkdir ceph# ce ceph4、下载最新的ceph源码包# apt-get source ceph包含四个文件目录ceph_0.56.3-1quantal_amd64.debceph_0.56.3.orig.tar.gzceph_0.56.3-1quantal.diff.gzceph_0.56.3-1quantal.dscceph-0.56.35、进入到ceph-0.56.3,开始编译工作# cd ceph-0.56.36、查看README文件,按步骤编译,如下:# apt-get install automake autoconf automake gcc g++ libboost-dev libedit-dev libssl-dev libtool libfcgi libfcgi-dev libfuse-dev linux-kernel-headers libcrypto++-dev libaio-dev libgoogle-perftools-dev libkeyutils-dev uuid-dev libatomic-ops-dev libboost-program-options-dev libboost-thread-dev# sudo apt-get dpkg-dev# dpkg-checkbuilddeps # make sure we have all dependenciesapt-get install 安装缺少的依赖包# dpkg-buildpackage 编译,需要一段时间7、编译完成后,在ceph-0.56.3生成二进制文件和执行文件,并在上层目录(ceph)打成.deb包8、修改后可使用make编译# make9、修改代码,make只编译修改的部分,并指明编译文件和修改文件5源码编译测试情况1、替换编译后的mds到/usr/bin下,启动成功,健康检查如下:root@ubuntu:/usr/bin# ceph healthHEALTH_WARN 576 pgs stale //是不是一段时间没动?root@ubuntu:/usr/bin# ceph pg dump_stuck staleokpg_stat o bjects mip degr unf bytes log disklogstate state_stamp v reported up acting last_scrub scrub_stamp last_deep_scrubdeep_scrub_stamproot@ubuntu:/usr/bin# ceph healthHEALTH_OKClient可正常创建、拷贝文件2、替换osd后,OKroot@ubuntu:/usr/bin# scp ************.60.115:/home/xiao/ceph/ceph-0.56.3/src/ceph-osd .************.60.115'spassword:ceph-osd100% 93MB 10.4MB/s 00:09root@ubuntu:/usr/bin# service ceph -a start=== mon.a ===Starting Ceph mon.a on ubuntu...starting mon.a rank 0 at 192.168.60.125:6789/0 mon_data /var/lib/ceph/mon/ceph-a fsid d188f2d1-d8f3-4f6d-94c6-0a271ff64dab=== mds.a ===Starting Ceph mds.a on ubuntu...starting mds.a at :/0=== osd.0 ===Starting Ceph osd.0 on ubuntu...starting osd.0 at :/0 osd_data /var/lib/ceph/osd/ceph-0 /var/lib/ceph/osd/ceph-0/journal === osd.1 ===Starting Ceph osd.1 on ubuntu...starting osd.1 at :/0 osd_data /var/lib/ceph/osd/ceph-1 /var/lib/ceph/osd/ceph-1/journal root@ubuntu:/usr/bin# service ceph status=== mon.a ===mon.a: running {"version":"0.56.3"}=== mds.a ===mds.a: running {"version":"0.56.3"}=== osd.0 ===osd.0: running {"version":"0.56.3"}=== osd.1 ===osd.1: running {"version":"0.56.3"}root@ubuntu:/usr/bin# ceph healthHEALTH_OKClient可正常创建、拷贝文件3、替换mon,OKroot@ubuntu:/usr/bin# cp ceph-mon ceph-mon.bakroot@ubuntu:/usr/bin# scp ************.60.115:/home/xiao/ceph/ceph-0.56.3/src/ceph-mon .************.60.115'spassword:ceph-mon100% 46MB 11.4MB/s 00:04root@ubuntu:/usr/bin# service ceph -a start=== mon.a ===Starting Ceph mon.a on ubuntu...starting mon.a rank 0 at 192.168.60.125:6789/0 mon_data /var/lib/ceph/mon/ceph-a fsid d188f2d1-d8f3-4f6d-94c6-0a271ff64dab=== mds.a ===Starting Ceph mds.a on ubuntu...starting mds.a at :/0=== osd.0 ===Starting Ceph osd.0 on ubuntu...starting osd.0 at :/0 osd_data /var/lib/ceph/osd/ceph-0 /var/lib/ceph/osd/ceph-0/journal === osd.1 ===Starting Ceph osd.1 on ubuntu...starting osd.1 at :/0 osd_data /var/lib/ceph/osd/ceph-1 /var/lib/ceph/osd/ceph-1/journal root@ubuntu:/usr/bin# service ceph status=== mon.a ===mon.a: running {"version":"0.56.3"}=== mds.a ===mds.a: running {"version":"0.56.3"}=== osd.0 ===osd.0: running {"version":"0.56.3"}=== osd.1 ===osd.1: running {"version":"0.56.3"}root@ubuntu:/usr/bin# ceph healthHEALTH_OKClient可正常创建、拷贝文件6mds源码分析暂时未完成……附录问题记录ceph health命令ceph按照官方文档部署成功,健康检查为health_OK,一段时间没有使用,也没有关机,下次使用时,各节点均能够重启启动成功,但健康检查提示:HEALTH_ERR 576 pgs stuck inactive; 576 pgs stuck unclean; no osds客户端挂在cephfs文件系统无法成功。