VC窗口程序中出现中文乱码的解决
c语言乱码问题详解

c语言乱码问题详解在C语言编程中,乱码问题是一个非常常见的问题。
乱码通常是指在显示或输出字符串时,字符的编码格式不正确,导致字符无法正常显示。
这个问题可能由多种原因引起,本文将对C语言乱码问题进行全面详解。
一、乱码的产生原因1. 编码格式不统一:在C语言编程中,字符串通常使用ASCII编码或UTF-8编码。
如果不同程序或不同文件使用了不同的编码格式,就可能导致乱码。
2. 文件编码不统一:在编写和读取文件时,如果文件本身的编码格式与程序使用的编码格式不统一,也可能导致乱码。
3. 代码页设置不正确:在Windows系统中,代码页设置不正确可能导致乱码。
例如,默认的代码页是936(简体中文),如果设置为其他代码页,就可能导致乱码。
二、乱码的解决方案1. 统一编码格式:在编写程序时,确保所有文件和使用到的库都使用相同的编码格式。
通常建议使用UTF-8编码,因为它可以很好地表示各种字符集,包括简体中文、繁体中文和英文等。
2. 使用正确的代码页:在Windows系统中,确保代码页设置正确。
可以通过修改系统设置或编程时使用`SetConsoleOutputCP()`函数来设置代码页。
3. 使用字符串处理库:对于复杂字符集的支持,可以使用第三方字符串处理库,如iconv或ICU。
这些库可以提供丰富的字符编码转换功能,帮助解决乱码问题。
4. 使用命令行参数:在编写程序时,可以使用命令行参数来指定输入和输出文件的编码格式。
这样,即使在不同环境中运行程序,也可以确保编码的一致性。
三、案例分析下面我们通过一个简单的案例来说明如何解决C语言中的乱码问题。
假设我们有一个简单的C语言程序,用于将一个文本文件的内容读取到一个字符串数组中,然后输出到另一个文本文件。
在编写这个程序时,我们需要注意以下问题:1. 统一编码格式:确保源文件和使用到的库都使用UTF-8编码。
2. 使用正确的代码页:在Windows系统中,确保代码页设置为UTF-8(1200)。
c语言中文字符截断乱码

c语言中文字符截断乱码在C语言中,对于中文字符的处理有时会出现截断乱码的问题。
这是由于C语言默认使用的字符编码方式是ASCII码,而ASCII码只能表示英文字符和一些特殊符号,无法直接表示中文字符。
因此,需要采用其他方式来处理中文字符,以免出现乱码情况。
在C语言中,通常采用的解决方案有两种:使用宽字符集和使用多字节字符集。
1.使用宽字符集宽字符集是一种可以处理中文字符的字符编码方式,常用的宽字符集有Unicode和UTF-8。
Unicode是一种用于表示字符的编码标准,它定义了每个字符的唯一编号,可以用来表示全球范围内的所有字符。
而UTF-8是一种以字节为单位对Unicode进行编码的可变长度编码方式,它可以用来表示任意Unicode字符。
在C语言中,可以使用宽字符类型wchar_t来表示宽字符,需要包含头文件<wchar.h>。
同时,C语言提供了一系列的宽字符处理函数来进行宽字符的输入、输出和处理。
下面是一个示例代码,演示了如何在C语言中使用宽字符集处理中文字符:```c#include <stdio.h>#include <wchar.h>int main() {setlocale(LC_ALL, ""); //设置本地化环境wchar_t str[] = L"你好,世界!";wprintf(L"%ls\n", str);return 0;}```在上面的示例代码中,使用了头文件<wchar.h>中的函数wprintf 来输出宽字符字符串。
同时,通过调用setlocale函数来设置本地化环境,以确保输出的中文字符能够正确显示。
2.使用多字节字符集另一种处理中文字符的方式是使用多字节字符集,常用的多字节字符集有GBK和UTF-8。
GBK是一种用于表示中文字符的编码方式,它可以将中文字符表示为一个或两个字节。
javac编译中文异常解决方法

javac编译中文异常解决方法如何解决在javac编译过程中出现的中文异常问题。
在日常的Java开发中,我们经常会遇到一些中文异常问题。
这些问题可能是因为源代码中包含了中文字符,而编译器无法正确处理中文字符所导致的。
为了解决这个问题,我们需要采取一些措施来确保编译过程中不会出现中文异常。
本文将一步一步地回答如何解决这个问题。
第一步:了解中文字符在编译过程中的问题在Java中,标识符(如变量名、方法名等)是由字母、数字、下划线和美元符号组成的。
然而,标准的ASCII字符集只包含了英文字母,这就意味着Java编译器无法处理非ASCII字符,比如中文字符。
所以,如果我们的源代码包含了中文字符,编译器就会报错。
第二步:使用正确的字符编码编码是将字符转换为字节的过程。
在Java中,源代码和编译后的字节码都需要使用正确的字符编码。
Unicode是一种表示所有字符的标准编码方式,它支持全球范围内的所有字符。
通常情况下,我们使用UTF-8或UTF-16编码来处理中文字符。
UTF-8是一种变长的编码方式,可以表示任意Unicode字符。
它使用1到4个字节来表示一个字符,其中常用的ASCII字符只需要1个字节。
UTF-16是一种固定长度的编码方式,其中每个字符都使用2个字节表示。
这两种编码方式都可以正确处理中文字符,但在不同的场景下可能会有不同的需求。
为了在编译过程中正确处理中文字符,我们需要在源代码中指定正确的字符编码方式。
通常情况下,我们可以在源代码的开头添加以下注释来指定字符编码方式:-*- coding: utf-8 -*-这个注释告诉Java编译器,源代码使用UTF-8编码。
如果我们使用了其他编码方式,只需将utf-8替换为相应的编码方式即可。
第三步:选择合适的IDEIDE(Integrated Development Environment,集成开发环境)是编写和编译代码的工具。
不同的IDE对中文字符的处理方式可能有所不同。
中文乱码反编译

中文乱码反编译是针对中文编码的程序进行反编译的过程。
在反编译过程中,中文乱码的问题通常是由于编码转换不正确或编码格式不匹配所导致的。
为了解决中文乱码问题,可以采取以下措施:
确认源代码文件的编码格式。
确保源代码文件使用的编码格式与反编译工具所使用的编码格式一致。
如果源代码文件的编码格式与反编译工具所使用的编码格式不匹配,可能会导致乱码问题。
尝试使用不同的反编译工具。
不同的反编译工具可能对中文乱码的处理能力有所不同。
可以尝试使用其他反编译工具进行反编译,以查看是否能够解决中文乱码问题。
对源代码文件进行重新编码。
如果源代码文件的编码格式与反编译工具所使用的编码格式不匹配,可以尝试将源代码文件重新编码为与反编译工具所使用的编码格式相同的编码格式。
使用字符集转换工具进行转换。
如果反编译后的程序使用的是特定字符集,而该字符集与源代码文件所使用的字符集不匹配,可以尝试使用字符集转换工具将程序从特定字符集转换为源代码文件所使用的字符集。
总之,解决中文乱码问题需要仔细分析并采取适当的措施。
确认源代码文件的编码格式、尝试使用不同的反编译工具、对源代码文件进行重新编码或使用字符集转换工具进行
转换等方法都可以帮助解决中文乱码问题。
国产乱码的解决方法

国产乱码的解决方法
如果在程序中遇到国产乱码问题,可以尝试以下几种解决方法:
1. 检查编码:首先确保你的程序和数据源文件(例如文本文件、数据库)是使用相同的字符编码。
常用的字符编码包括UTF-8、GBK等。
在程序中,可以使用相应的函数或指令来指定编码,例如在C++中可以使用`setlocale`函数来设置编码。
2. 转换编码:如果你的程序和数据源使用不同的编码,可以尝试将数据源文件的编码转换为程序所需的编码。
可以使用各种工具或库进行编码转换,例如iconv等。
3. 设置环境变量:在一些操作系统中,设置环境变量可以解决一些国产乱码问题。
例如,在Windows操作系统中,可以设置系统区域设置为适当的语言。
4. 使用特定的输入/输出库:某些编程语言和库提供了特定的输入/输出库,用于处理国产乱码问题。
例如,在C++中,可以使用`wifstream`和`wofstream`等宽字符输入/输出流,以支持Unicode字符。
5. 使用Unicode编码:Unicode是一种字符编码标准,可以表示世界上几乎所有的字符。
使用Unicode编码可以确保正确处理各种字符。
在程序中,可以使用相应的库或函数来支持Unicode编码,例如在C++中可以使用`wchar_t`类型和相关函数。
6. 避免使用特殊字符:如果可能的话,避免使用特殊字符,例如一些特殊符号或语言特定的字符。
这样可以减少国产乱码问题的发生。
以上是一些常见的解决国产乱码问题的方法,具体的解决方法可能因编程语言、操作系统和具体情况而有所不同。
在处理国产乱码问题时,建议先确定乱码的原因,然后针对性地采取适当的解决方法。
中文乱码解决方法

中文乱码解决方法
1.使用正确的字符编码
2.转换文件编码格式
如果你打开一个文本文件或者网页时发现中文显示为乱码,可能是由
于文件的编码格式不正确导致的。
你可以尝试将文件的编码格式转换为正
确的格式。
Windows操作系统中可以使用记事本打开文件,另存为时选择
正确的编码方式即可。
Mac和Linux系统可以使用终端命令行工具进行转换,具体方法可以参考相关操作系统的文档和教程。
3.选择正确的字体
有时候中文显示为乱码是由于缺乏相应的字体文件所致。
当你打开一
个文档或者网页时,如果使用的字体不包含中文字符,那么中文可能会显
示为乱码或者方块。
解决方法是选择适合的字体。
一般来说,宋体、微软
雅黑、黑体等字体都包含了常用的中文字符,并且具有良好的兼容性。
4.更新操作系统和应用程序
乱码问题有时也可能是由于操作系统或者应用程序的bug导致的。
这
些bug可能会导致字符编码不正确或者字体渲染错误。
为了解决这类问题,建议你及时更新操作系统和应用程序的版本,以获取最新的修复和改进。
5.检查网络连接和网页编码
6.使用专业的文本处理工具
总结:
中文乱码问题可能由多种原因引起,包括字符编码不一致、文件格式不正确、字体缺失等。
解决方法包括使用正确的编码方式、转换文件的编码格式、选择合适的字体、更新操作系统和应用程序、检查网络连接和网页编码、使用专业的文本处理工具等。
通过以上方法,相信大家能够有效地解决中文乱码问题,提高中文字符的显示质量。
中文乱码的解决方法

中文乱码的解决方法在进行中文文本处理过程中,可能会遇到乱码的情况,这主要是由于使用了不兼容的编码格式或者在数据传输过程中出现了错误。
下面是一些解决中文乱码问题的方法:1.使用正确的编码方式2.修改文件编码如果已经打开了一个包含乱码的文本文件,可以通过修改文件编码方式来解决问题。
例如,在记事本软件中,可以尝试选择“另存为”功能,并将编码方式改为UTF-8,然后重新保存文件,这样就可以解决乱码问题。
3.检查网页编码当浏览网页时遇到乱码问题,可以在浏览器的“查看”或“选项”菜单中找到“编码”选项,并将其设置为正确的编码方式(例如UTF-8),刷新网页后,乱码问题通常会得到解决。
5.使用转码工具如果已经得知文件的原始编码方式但无法通过其他方式解决乱码问题,可以尝试使用一些转码工具来将文件以正确的编码方式转换。
例如,iconv是一款常用的转码工具,可以在命令行界面下使用。
6.检查数据传输过程在进行数据传输时,特别是在网络传输中,可能会出现数据传输错误导致中文乱码。
可以检查数据传输过程中的设置和参数,确保传输过程中不会造成乱码问题。
7.检查数据库和应用程序设置在进行数据库操作和应用程序开发时,也可能会出现中文乱码问题。
可以检查数据库和应用程序的设置,确保正确地处理和显示中文字符。
8.清除特殊字符和格式有时候,中文乱码问题可能是由于文本中存在特殊字符或格式导致的。
可以尝试清除文本中的特殊字符和格式,然后重新保存或传输文件,看是否能够解决乱码问题。
总结起来,解决中文乱码问题的关键是了解文件的编码方式,并确保在处理过程中使用相同的编码方式。
此外,要注意数据传输过程中的设置和参数,以及数据库和应用程序的设置,确保正确地处理和显示中文字符。
最后,如果以上方法仍然无法解决乱码问题,可以尝试使用专业的转码工具来转换文件的编码方式。
中文乱码解决方案

中文乱码解决方案中文乱码问题是指在使用计算机软件或操作系统时,中文字符显示为乱码或其他非预期字符的情况。
中文乱码问题通常出现在以下几种情况下:1.编码不一致:中文乱码问题最常见的原因是编码不一致。
计算机中使用的编码方式有很多种,如UTF-8、GB2312、GBK等。
如果文件的编码方式与软件或操作系统的默认编码方式不一致,就会导致中文乱码。
解决该问题的方法是将文件的编码方式转换为与软件或操作系统一致的方式。
2.字体显示问题:中文乱码问题还可能与字体显示有关。
如果计算机中没有安装支持中文的字体,或字体文件损坏,就会导致中文字符显示为乱码或方框。
解决该问题的方法是通过安装正确的字体文件或修复字体文件来解决。
3.网页编码问题:在浏览网页时,如果网页的编码方式与浏览器的默认编码方式不一致,也会导致中文乱码。
解决该问题的方法是在浏览器中手动设置网页编码方式,或在网页头部指定正确的编码方式。
4.数据传输问题:中文乱码问题还可能与数据传输有关。
在进行数据传输时,如果数据的编码方式与传输协议或接收端的要求不一致,就会导致中文乱码。
解决该问题的方法是在数据传输的过程中进行编码转换,或在接收端进行适当的解码操作。
下面是一些常用的解决中文乱码问题的方法:3.设置浏览器编码方式:在浏览器的设置中,可以手动指定网页的编码方式。
可以尝试不同的编码方式,找到正确的方式显示中文字符。
4.检查数据传输设置:如果中文乱码问题是在数据传输过程中出现的,可以检查传输的设置是否一致。
比如,在进行数据库连接时,可以设置数据库的编码方式与应用程序的编码方式一致。
5.使用专业工具:如果以上方法无法解决中文乱码问题,可以考虑使用专业的中文乱码解决工具。
这些工具可以自动检测和修复中文乱码问题,提高处理效率。
总结起来,解决中文乱码问题需要确定问题的原因,然后采取相应的方法进行修复。
在处理中文乱码问题时,尽量使用标准的编码方式和字体文件,避免使用非标准或自定义的编码方式。
乱码处理方法

乱码处理方法
以下是 6 条关于乱码处理方法:
1. 哎呀,要是遇到乱码,咱可以试试换个编码格式呀!就像你穿衣服不搭调,那就换一件试试看嘛,比如从 UTF-8 换到 GBK 啥的。
比如你打开一个文档,全是乱码,这时候赶紧去调调编码格式呀!
2. 嘿,别忘了检查一下你的字体设置呀!有时候字体不对也会出现乱码呢。
这就好像走路走歪了路,得及时调整方向呀!比如说你在某个软件里看到的字全是乱七不糟的,那很可能就是字体的问题啦,赶紧去瞅瞅!
3. 你知道吗,重新安装相关软件也可能解决乱码问题哟!这就好比生病吃药,有时候得下点猛药才能治好嘛。
像我上次那个软件出现乱码,我把它卸了重装,立马就好啦!
4. 哇塞,清理一下缓存和临时文件也很重要呀!这就跟收拾房间一样,把垃圾清理掉,才能更清爽呀。
你想想,要是电脑里乱七八糟的东西太多,它能不出现乱码嘛。
比如说电脑用久了开始出乱码,那就赶紧清理一下呀!
5. 呀,有时候更新一下驱动程序也能行呢!这就跟给车子升级零件一样,让它跑得更顺畅嘛。
如果电脑显示有乱码,是不是驱动有点跟不上啦,赶紧去更新试试呗!
6. 注意哦,还可能是文件本身损坏导致的乱码呢!这就好像一个苹果烂了一块,会影响整体呀。
像有时候下载的文件一打开全是乱码,很有可能就是文件在下载过程中受损啦!
总之,遇到乱码不要慌,试试这些方法,说不定就能解决啦!。
c语言,中文注释出现乱码

c语言,中文注释出现乱码
C语言中文注释出现乱码通常是由于文件编码格式不兼容所致。
在C语言中,源代码文件的编码格式应该是UTF-8,这样才能正确
地显示中文注释。
如果你的源代码文件编码格式不是UTF-8,就会
导致中文注释出现乱码。
解决这个问题的方法有几种。
首先,你可以使用支持UTF-8编
码的文本编辑器,如Notepad++、Sublime Text、Visual Studio Code等,打开源代码文件并将文件保存为UTF-8格式。
其次,你也
可以在编译器中设置编码格式为UTF-8,确保编译器能够正确地读
取源代码文件中的中文注释。
另外,还有一种可能是你的操作系统或者终端的默认编码格式
不是UTF-8,这也会导致中文注释出现乱码。
你可以尝试在操作系
统或者终端中将默认编码格式设置为UTF-8,这样也有助于解决中
文注释乱码的问题。
总之,要解决C语言中文注释出现乱码的问题,首先要确保源
代码文件的编码格式是UTF-8,其次要确保编译器和操作系统的编
码格式也是UTF-8。
这样就能够正常显示和编译包含中文注释的C 语言源代码了。
c语言,中文注释出现乱码

c语言,中文注释出现乱码
在C语言中,注释是用于解释代码的文字。
如果中文注释出现乱码,可能是因为编译器或文本编辑器的字符编码设置不正确。
解决这个问题,你可以尝试以下方法:
1. 确保你的文本编辑器的字符编码设置为UTF-8。
大多数现代的文本编辑器默认使用UTF-8编码,但你仍然需要确认一下。
2. 如果你使用的是Windows系统,可以尝试将源文件的编码格式设置为UTF-8。
在一些编辑器中,你可以通过"文件" -> "另存为" -> "编码"选项来设置文件的编码格式。
3. 如果你在源代码中使用了特殊字符或非ASCII字符,可以尝试将这些字符转换为Unicode转义序列。
例如,中文字符"你好"可以写成"\u4f60\u597d"。
4. 如果你使用的是老版本的编译器,可能不支持UTF-8编码。
在这种情况下,你可以尝试使用其他编码格式,如GBK或GB2312。
如果以上方法仍然无效,你可能需要考虑更换文本编辑器或编译器,以确保正确显示中文注释。
VisualStudioCode运行程序时输出中文成乱码问题及解决方法
VisualStudioCode运⾏程序时输出中⽂成乱码问题及解决⽅法今天写代码,需要输出⼀些中⽂,于是就顺势发现了这个问题:VS Code输出中⽂成乱码。
上⽹查询了⼀番后,我找到了解决⽅法,我决定将我看到的⽅法整理出来,帮助更多朋友。
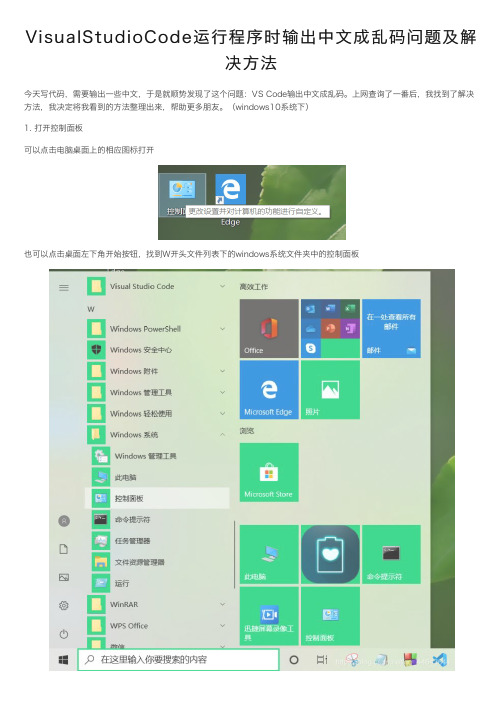
(windows10系统下)1. 打开控制⾯板可以点击电脑桌⾯上的相应图标打开也可以点击桌⾯左下⾓开始按钮,找到W开头⽂件列表下的windows系统⽂件夹中的控制⾯板2.选择时钟和区域下的更改⽇期、时间或数字格式3.点击管理,然后点选择更改系统区域设置4. 勾选Beta版:使⽤Unicode UTF-8提供全球语⾔⽀持,然后点击确定,并同意系统的重启请求重启电脑后就OK啦!知识点补充:Visual Studio Code 打开程序⽂件中⽂乱码解决⽅法使⽤Visual Studio Code打开程序⽂件后对应的中⽂乱码,造成这种现象的原因是⽂件的编码⽅式不同.可以通过调整打开⽂件的编码⽅式来解决Visual Studio Code打开中⽂乱码的问题.操作步骤如下:⾸先点击右下⾓当前的编码格式 ,本次实验中的编码⽅式为UTF-8点击编码⽅式后,Select Action输⼊框会⾃动弹出Reopen with Encoding和Save with Encoding,点击Reopen with Encoding进⼊编码⽅式选择列表.在弹出的列表中选择Simplified Chinese(GB2312),乱码问题应该解决.如果Visual Studio Code选择了Simplified Chinese(GB2312)编码⽅式依然乱码,可以尝试在上⽅的输⼊框中输⼊ GB ,这样就会显⽰出中⽂对应的编码⽅式.通过选择不同的编码⽅式来尝试解决Visual Studio Code乱码的问题.也可以通过安装Visual Studio Code插件 GBKtoUTF8来实现打开⽂件⾃动转码.但是当前测试中发现GBKtoUTF8存在⼀些Bug,偶尔⾃动将⼯程中当前打开的⽂件内容替换成其他⽂件的内容. 造成程序代码丢失.总结到此这篇关于Visual Studio Code运⾏程序时输出中⽂成乱码的⽂章就介绍到这了,更多相关Visual Studio Code运⾏程序中⽂乱码内容请搜索以前的⽂章或继续浏览下⾯的相关⽂章希望⼤家以后多多⽀持!。
VC++编译后出现中文乱码解决方案

VC++编译后出现中文乱码解决方案由于经常在网上下载代码,又一次下载的代码用VC6.0编译后出现乱码(资源文件)搜索出一下解决方案步骤/方法方法1:这个问题是因为语言设置不正确。
如果想在AppWizard生成的工程文件中使用中文,在在MFC AppWizard的第1步中选择中文资源,选择Chinese(P.R.C),如果你在语言列表中没有找到有关中文的选项,说明你的VC++的中文支持模块没有安装。
此时,应退出VC++,在VC++的光盘的\DevStudio\SharedIDE\Bin\IDE目录下找到APPWZCHS.DLL 文件,将其拷贝到硬盘的DevStudio\SharedIDE\Bin\IDE目录下即可,再启动VC++,就可以看到这一选项了。
使用这一选项生成的工程文件中的所有资源都是中文的。
VC++还提供了繁体中文(APPWZCHT.DLL)、日文(APPWZJPN.DLL)和韩文 (APPWZKOR.DLL)的支持模块。
方法2: 如果你的工程中的菜单、对话框、字符串等资源不是由AppWizard 生成的,而是手工添加的,你必须保证该资源的Language选项为Chinese(P.R.C)。
具体的做法是在资源列表中选择资源,然后在快捷菜单中选择Properties,在话框中设置Language下拉框。
如果在Language中选择English,尽管在集成环境中可以正常显示中文,但编译后就变成了诸如"___.???"之类的乱码了。
方法3:有一个解决方案不必从头作起:找到rc文件(资源文件),把其中LANGUAGE 9, 1的地方改为4,2;code_page(1252)改为code_page(936);另外把#include "afxres.rc" 改成#include "l.chs\afxres.rc";把"afxres.rc" 改成"l.chs\\afxres.rc"即可,其中的数据根据不同文字代码可能不同。
程序中的汉字变乱码的解决方法

程序中的汉字变乱码的解决方法汉字出现乱码有好几种情况,大致可分成四类:网页、文本、文档和文件乱码。
第一类是由于港台的繁体中文大五码(BIG5)与大陆简体中文(GB2312)不通用造成的;第二类是系统(菜单、桌面、提示框)显示乱码,这是注册表中有关字体的部分设置不当引起的;第三类是各种应用程序(包括游戏)本来显示中文的地方出现乱码,形成原因比较复杂,有第二类的乱码原因,也可能是软件用到的中文动态链接库被英文动态链接库覆盖造成的;最后一类是邮件乱码。
(一)、网页、文本和文档文件乱码的消除网页乱码是浏览器(如IE等)对HTML网页解释时形成的。
如果在网页的代码中有形如:〈HTML〉〈HEAD〉〈META CONTENT=“text/html;charset=ISO-8859-1”〉〈/HEAD〉……〈/HTML〉的语句,浏览器在显示此页时,就会出现乱码。
因为浏览器会将此页语种辨认为“欧洲语系”。
解决的办法是将语种“ISO-8859-1”改为GB2312,如果是繁体网页则改为BIG5。
另一种解决办法是不修改网页代码,事先为浏览器安装多语言支持包(例如在安装IE时要安装多语言支持包),这样在浏览网页出现乱码时,就可以在浏览器中选择菜单栏下的“查看”/“编码”/“自动选择”/简体中文(GB2312),如为繁体中文则选择“查看”/“编码”/“自动选择”/繁体中文(BIG5),其它语言依此类推选择相应的语系,这样可消除网页乱码现象。
还有一种解决办法是利用多内码显示平台来转换内码。
常用多内码显示平台有:“南极星”、“四通利方”、“MagicWin 98等等。
网页无乱码保存的方法是:用浏览器打开网页时,在“查看”/“编码”中选择“自动选择”,存盘时保存类型选“web页”,编码选择“UNICOD”,这样保存过的网页再次打开时,在浏览器菜单“查看”、“编码”中不管选择简体中文(GB2312)、简体中文(HZ)还是UNICODE(UTF-8)或繁体中文(BIG5),最终显示都不会出现乱码。
如何解决VC中复制汉字出现乱码问题

【方法】如何解决VC中复制汉字出现乱码问题
我用的是英文版VC6.0,从VC中复制代码到WORD,或其他的地方中,出现乱码。
VC源代码如下:
复制到WORD中如下:
这个问题应该是因为系统默认代码页的问题,英文版WINDOWS中默认输入法为English(United States)如下图:
所以,要解决这个乱码问题,有两种方法:
1、删除English(United States)键盘布局,将默认输入法设为中文输入法下的任意一个。
2、在VC窗口中开始复制之前,将输入法切换为一种中文输入法,然后进行复制;在word中粘贴时,输入法可以为任意一种。
另外还有就是在vc++6.0中打汉字的时候,打出来的汉字突然变成乱码,但从开始打上的汉字没问题,复制刚才打的也没问题,这种情况也常发生,保存一下关闭vc再次打开就好了,还有其他的一些情况,比如突然无法换行了什么的,处理方法也是关闭后再次打开。
VisualStudioCode插件CodeRunner中文乱码问题
VisualStudioCode插件CodeRunner中⽂乱码问题
前⾔
在使⽤ vscode 中的 Code Runner 插件的过程中, 可能会遇到中⽂乱码的问题
针对 Python 可通过以下两种⽅法解决
1、设置 PYTHONIOENCODING
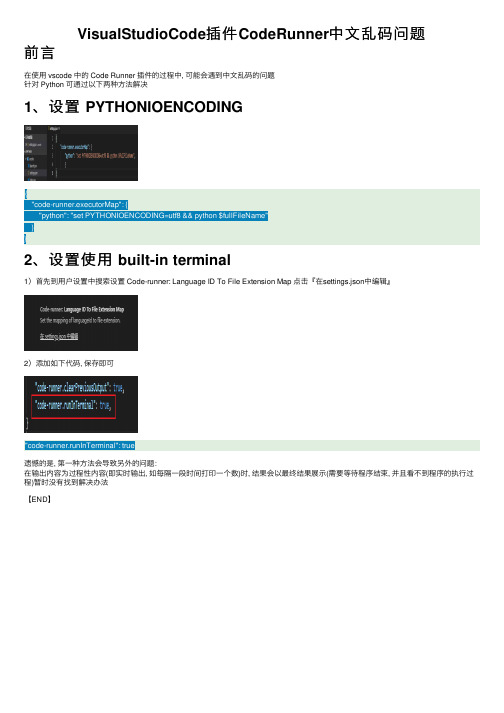
{
"code-runner.executorMap": {
"python": "set PYTHONIOENCODING=utf8 && python $fullFileName"
}
}
2、设置使⽤ built-in terminal
1)⾸先到⽤户设置中搜索设置 Code-runner: Language ID To File Extension Map 点击『在settings.json中编辑』
2)添加如下代码, 保存即可
"code-runner.runInTerminal": true
遗憾的是, 第⼀种⽅法会导致另外的问题:
在输出内容为过程性内容(即实时输出, 如每隔⼀段时间打印⼀个数)时, 结果会以最终结果展⽰(需要等待程序结束, 并且看不到程序的执⾏过程)暂时没有找到解决办法
【END】。
VC++编译后出现中文乱码解决方案

VC++编译后出现中文乱码解决方案由于经常在网上下载代码,又一次下载的代码用VC6.0编译后出现乱码(资源文件)搜索出一下解决方案步骤/方法方法1:这个问题是因为语言设置不正确。
如果想在AppWizard生成的工程文件中使用中文,在在MFC AppWizard的第1步中选择中文资源,选择Chinese(P.R.C),如果你在语言列表中没有找到有关中文的选项,说明你的VC++的中文支持模块没有安装。
此时,应退出VC++,在VC++的光盘的\DevStudio\SharedIDE\Bin\IDE目录下找到APPWZCHS.DLL 文件,将其拷贝到硬盘的DevStudio\SharedIDE\Bin\IDE目录下即可,再启动VC++,就可以看到这一选项了。
使用这一选项生成的工程文件中的所有资源都是中文的。
VC++还提供了繁体中文(APPWZCHT.DLL)、日文(APPWZJPN.DLL)和韩文 (APPWZKOR.DLL)的支持模块。
方法2: 如果你的工程中的菜单、对话框、字符串等资源不是由AppWizard 生成的,而是手工添加的,你必须保证该资源的Language选项为Chinese(P.R.C)。
具体的做法是在资源列表中选择资源,然后在快捷菜单中选择Properties,在话框中设置Language下拉框。
如果在Language中选择English,尽管在集成环境中可以正常显示中文,但编译后就变成了诸如"___.???"之类的乱码了。
方法3:有一个解决方案不必从头作起:找到rc文件(资源文件),把其中LANGUAGE 9, 1的地方改为4,2;code_page(1252)改为code_page(936);另外把#include "afxres.rc" 改成#include "l.chs\afxres.rc";把"afxres.rc" 改成"l.chs\\afxres.rc"即可,其中的数据根据不同文字代码可能不同。
vscode解决CC++控制台中文乱码。
vscode解决CC++控制台中⽂乱码。
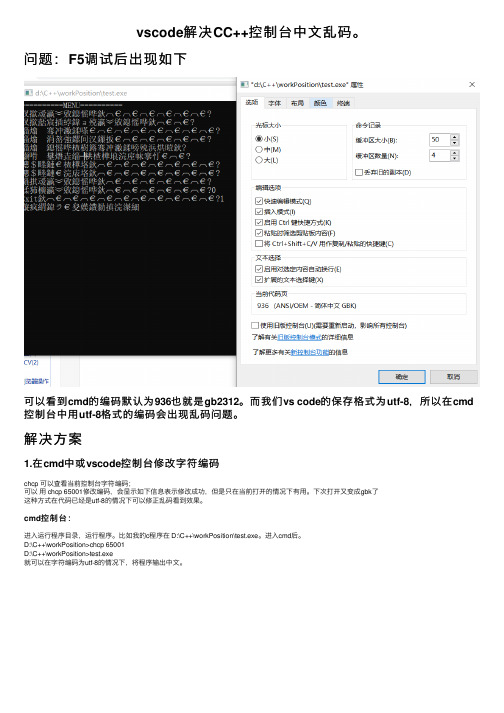
问题:F5调试后出现如下
可以看到cmd的编码默认为936也就是gb2312。
⽽我们vs code的保存格式为utf-8,所以在cmd 控制台中⽤utf-8格式的编码会出现乱码问题。
解决⽅案
1.在cmd中或vscode控制台修改字符编码
chcp 可以查看当前控制台字符编码;
可以⽤ chcp 65001修改编码,会显⽰如下信息表⽰修改成功,但是只在当前打开的情况下有⽤。
下次打开⼜变成gbk了
这种⽅式在代码已经是utf-8的情况下可以修正乱码看到效果。
cmd控制台:
进⼊运⾏程序⽬录,运⾏程序。
⽐如我的c程序在 D:\C++\workPosition\test.exe。
进⼊cmd后。
D:\C++\workPosition>chcp 65001
D:\C++\workPosition>test.exe
就可以在字符编码为utf-8的情况下,将程序输出中⽂。
vs code控制台。
和cmd⼀样,不过只有2⾏
PS D:\C++\workPosition>chcp 65001
PS D:\C++\workPosition> .\test.exe
就可以再终端看到消息。
2.在vs code修改代码的打开和保存⽅式。
直接就将代码保存为gb2312。
在vs code右下⾓可以看到当前⽂件编码⽅式,点击utf-8修改打开和保存⽅式为gb2312.使cmd格式和编码保存格式都⼀致,都使⽤GB2312.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
用 VC6 的 MFC AppWizard 生成的窗口程序,窗口标题或者标签用中文,编译执行发现中文成乱码了,奇怪,以前怎么没有出现这种问题呢?
在网上找找资料才知道,原来我现在用的是非中文 XP 操作系统,在用向导生成窗口程序的过程中,没有中文语言的选项。
不知道为什么,我的操作系统的区域都是设置成的中国,语言也是设成的简体中体,都没错的,VC6 安装程序看我的界面不是中文就不给我装上中文语言支持的动态库。
解决办法是:可以在VC6 安装光盘中找到APPWZCHS.DLL 文件(也点击6.0.8168.0__APPWZCHS.zip 可从此处下载),拷入到 C:/Program Files/Microsoft Visual Studio/COMMON/MSDev98/Bin/IDE,确切位置视你的 Visual Studio 安装目录而定。
这样重新用 MFC AppWizard 建一个工程,在第一步就可以选上简体中文了,在程序中的界面上写中文,然后执行就没问题了。
如果你的工程中的菜单、对话框、字符串等资源不是由AppWizard生成的,而是手工添加的,你必须保证该资源的Language选项为Chinese(P.R.C)
还有一个解决方案是:不需要 APPWZCHS.DLL文件,找到工程中的 rc 文件(资源文件),把其中LANGUAGE 9, 1的地方改为4,2;codepage(1252)改为codepage(936);另外把#include "afxres.rc" 改成#include "l.chs/afxres.rc";把"afxres.rc" 改成"l.chs//afxres.rc"即可,其中的数据根据不同文字代码可能不同,例子中的是英文,改为中文。
改 rc 文件的办法我试过,改过之后虽然执行时界面显示中文都没有问题,可是程序响应按钮操作的时候却出现了Debug Assertion Failed! _CrtIsValidHeapPointer(pUserData)......非常致命的错误,可能这跟修改 rc 文件是无关的。
后来试了,的确,出现 _CrtIsValidHeapPoint 错误与修改 rc 文件无关,是因为 delete 一个指针时报的错,至今原因不明,因为同样的代码昨天还行,今天就不行了。
随意猜测一下:是否有可能是昨天用的 Debug 出的 Dll 文件,今天用的 Release 出的 Dll 文件。
就我个人看来,第一种方法比较好,用 MFC AppWizard 生成的窗口像确定啊,取消等按钮或菜单都是中文的,不需要你一个个的改动。