centos下hadoop2.6.0配置
hadoop2.6.0安装

hadoop2.6.0安装搭建hadoop2.6.0开发环境前言:因为没有物理机器要测试,所以学习如何构建Hadoop环境并在本地笔记本中创建三个Linux虚拟机是一个不错的选择。
安装VMware并准备三台相同的Linux虚拟机Linux虚拟机ISO:虚拟机平台服务器版本:PS:关于软件,软件描述如下:本地笔记本:t420,8g内存,64位操作系统,配置如下:1.安装虚拟机1.1安装vmware-workstation,一路下一步即可,导入centos,使用iso方式搭建linux虚拟机2.安装Linux虚拟机2.1安装vmware-workstation完成后,选择新建虚拟机,导入centos,使用iso方式搭建linux虚拟机选择路径选择多核选择2G内存选择桥连接的方式选择磁盘I/O模式创建全新的虚拟机选择磁盘类型虚拟机文件存储方式设置虚拟机文件的存储路径完成打开,报错如下:无法准备安装说明:\\software\\wmware\\centos-6.5-x86 64-bin-dvd1。
iso。
确保您正在使用有效的Linux安装光盘。
如果出现错误,您可能需要安装VMWareWorkstation。
原因是笔记本没有开启虚拟机功能选项,重启电脑,然后按住f1键,进入bios设置,找到virtual选项,设置成enable,然后保存退出。
打开时出现错误消息:EDD:Error8000ReadingSector 2073976原因是:vmwareworkstation9,版本太老,升级到10版本,就ok了。
设置虚拟机网络连接(固定IP),并将连接模式设置为NAT模式看下是否能上外网,左键点击笔记本右下角无线图标,再点击打开网络与共享中心,关闭vmnet01,只保留vmnet08,然后使用默认的ipv4的ip地址192.168.52.1像两颗豌豆一样克隆另一颗。
在虚拟机name02上右键弹出菜单里点击”管理(m)”,然后点击右边下拉菜单”克隆(c)”,如下所示:继续下一步选择创建完成克隆(f)设置名称和位置,然后单击finish开始复制,时间较长,耐心等待,如下单击“关闭”按钮以完成克隆。
Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu_CentOS

Hadoop集群安装配置教程_Hadoop2.6.0_Ubuntu/CentOS本教程讲述如何配置Hadoop 集群,默认读者已经掌握了Hadoop 的单机伪分布式配置,否则请先查看Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置。
本教程由厦门大学数据库实验室出品,转载请注明。
本教程适合于原生Hadoop 2,包括Hadoop 2.6.0, Hadoop 2.7.1 等版本,主要参考了官方安装教程,步骤详细,辅以适当说明,保证按照步骤来,都能顺利安装并运行Hadoop。
另外有Hadoop安装配置简略版方便有基础的读者快速完成安装。
为了方便新手入门,我们准备了两篇不同系统的Hadoop 伪分布式配置教程。
但其他Hadoop 教程我们将不再区分,可同时适用于Ubuntu 和CentOS/RedHat 系统。
例如本教程以Ubuntu 系统为主要演示环境,但对Ubuntu/CentOS 的不同配置之处、CentOS 6.x 与CentOS 7 的操作区别等都会尽量给出注明。
环境本教程使用Ubuntu 14.04 64位作为系统环境,基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1,Hadoop 2.4.1 等。
本教程简单的使用两个节点作为集群环境: 一个作为Master 节点,局域网IP 为192.168.1.121;另一个作为Slave 节点,局域网IP 为192.168.1.122。
准备工作Hadoop 集群的安装配置大致为如下流程:1.选定一台机器作为Master2.在Master 节点上配置hadoop 用户、安装SSH server、安装Java 环境3.在Master 节点上安装Hadoop,并完成配置4.在其他Slave 节点上配置hadoop 用户、安装SSH server、安装Java 环境5.将Master 节点上的/usr/local/hadoop 目录复制到其他Slave 节点上6.在Master 节点上开启Hadoop配置hadoop 用户、安装SSH server、安装Java 环境、安装Hadoop 等过程已经在Hadoop安装教程_单机/伪分布式配置或CentOS安装Hadoop_单机/伪分布式配置中有详细介绍,请前往查看,不再重复叙述。
centos7环境下hadoop2.6.1完全分布式部署

1、环境: 3台CentOS7 64位(1).安装centos 7(2).修改三台服务器/etc下的hosts和hostname:三台服务器的Hostname分别修改:master-hadoop、slave1-hadoop、slave2-hadoop 三台服务器的Hosts文件修改为一致的:master-hadoopslave1-hadoopslave2-hadoop注意:这里的IP为三台主机实际IP地址.(3). 关闭防火墙(三台机器全部关闭)# systemctl status --查看防火墙状态# systemctl stop --关闭防火墙# systemctl disable --永久关闭防火墙2、SSH免密码登录设置.因为Hadoop需要通过SSH登录到各个节点进行操作,我用的是root用户,每台服务器都生成公钥,再合并到authorized_keys。
(1)CentOS默认没有启动ssh无密登录,去掉/etc/ssh/sshd_config其中2行的注释,每台服务器都要设置,#RSAAuthentication yes#PubkeyAuthentication yes(2)输入命令,ssh-keygen -t rsa,生成key,都不输入密码,一直回车,/root就会生成.ssh 文件夹,每台服务器都要设置,(3)合并公钥到authorized_keys文件,在Master服务器,进入/root/.ssh目录,通过SSH 命令合并,cat >> authorized_keysssh cat ~/.ssh/>> authorized_keysssh cat ~/.ssh/>> authorized_keys(4)把Master服务器/root/.ssh的authorized_keys、known_hosts两个文件复制到两台Slave服务器的/root/.ssh目录在两台slave服务器上执行:/sbin/restorecon -Rv /root/.ssh(5)完成,ssh、ssh就不需要输入密码了3、安装JDK先卸载系统原版本# java –version使用# rpm -qa | grep java 会看到自带的Java卸载JDK,执行以下操作:# rpm -e --nodeps rpm -e --nodeps rpm -e --nodeps 安装新的JDK上传新的软件到/usr/local/执行以下操作:# rpm -ivhJDK默认安装在/usr/java中。
RedHat7 Hadoop-2.6.0

一、服务器版本查看cat /etc/redhat-release二、新建目录:mkdir -p /softwares上传hadoop-2.6.0.tar.gz三、解压cd /softwarestar zxvf hadoop-2.6.0.tar.gz四、设置环境变量分别修改主机名称vim /etc/hostname(修改主机名)修改host名称vim /etc/hosts192.168.18.202 Master.Hadoop192.168.18.203 Slave1.Hadoop192.168.18.208 Slave2.Hadoop192.168.18.202 192.168.18.203 192.168.18.208 五、设置免密登录创建hadoop用户【在master\slave1\slave2上】# useradd hadoop --创建用户名为hadoop的用户# passwd hadoop --为用户hadoop设置密码# su - hadoop --切换到root用户# cd ~ --打开用户文件夹# ssh-keygen -t rsa -P '' --生成密码对,/home/hadoop/.ssh/id_rsa和/home/hadoop/.ssh/ id_rsa.pub# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys --把id_rsa.pub追加到授权的k ey里面去# chmod 600 ~/.ssh/authorized_keys --修改权限# chmod 700 ~/.ssh# su hadoop --切换到hadoop用户# scp ~/.ssh/id_rsa.pub hadoop@192.168.18.203:~/.ssh/master# scp ~/.ssh/id_rsa.pub hadoop@192.168.18.208:~/.ssh/master# su hadoop --切换到hadoop用户# scp ~/.ssh/id_rsa.pub hadoop@192.168.18.202:~/.ssh/slave1# su hadoop --切换到hadoop用户# scp ~/.ssh/id_rsa.pub hadoop@192.168.18.202:~/.ssh/slave2# su root --切换到root用户# vim /etc/ssh/sshd_config --修改ssh配置文件RSAAuthentication yes #启用RSA认证PubkeyAuthentication yes #启用公钥私钥配对认证方式AuthorizedKeysFile .ssh/authorized_keys #公钥文件路径# systemctl restart sshd.service ---重启 sshd 服务在slave1、slave2上# su hadoop --切换到hadoop用户# cat ~/.ssh/master >> ~/.ssh/authorized_keys在master上# su hadoop --切换到hadoop用户# cat ~/.ssh/slave1 >> ~/.ssh/authorized_keys# cat ~/.ssh/slave2 >> ~/.ssh/authorized_keys重启sshd 服务:systemctl restart sshd.service验证无密码登陆,在slave1和slave2上# su hadoop --切换到hadoop用户# ssh Master.Hadoop验证无密码登陆,在master上# su - hadoop# ssh Slave1.Hadoop# ssh Slave2.Hadoop六、修改hadoop文件mkdir -p /softwares/hadoop/tmpcd /softwares/hadoop-2.6.0/etc/hadoopvim core-site.xml<property><name>hadoop.tmp.dir</name><value>/softwares/hadoop/tmp</value><description>Abase for other temporary directories.</description> </property><property><name>fs.defaultFS</name><value>hdfs://Master.Hadoop:9000</value></property><property><name>io.file.buffer.size</name><value>4096</value></property>vim hadoop-env.sh和yarn-env.sh在开头添加如下环境变量cd /softwares/hadoop-2.6.0/etc/hadoopvim hadoop-env.shvim yarn-env.shexport JAVA_HOME=/usr/local/java/jdk1.8.0_112mkdir -p /softwares/hadoop/dfs/namemkdir -p /softwares/hadoop/dfs/datamkdir -p /softwares/hadoop/dfs/name/currentcd /softwares/hadoop-2.6.0/etc/hadoopvim hdfs-site.xml<property><name>.dir</name><value>file:///softwares/hadoop/dfs/name</value> </property><property><name>dfs.datanode.data.dir</name><value>file:///softwares/hadoop/dfs/data</value> </property><property><name>dfs.replication</name><value>2</value></property><property><name>services</name><value>Master.Hadoop:9000</value></property><property><name>node.secondary.http-address</name> <value>Master.Hadoop:50090</value></property><property><name>dfs.webhdfs.enabled</name><value>true</value></property>cd /softwares/hadoop-2.6.0/etc/hadoopcp mapred-site.xml.template mapred-site.xmlvim mapred-site.xml<property><name></name><value>yarn</value><final>true</final></property><property><name>mapreduce.jobtracker.http.address</name><value>Master.Hadoop:50030</value></property><property><name>mapreduce.jobhistory.address</name><value>Master.Hadoop:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name> <value>Master.Hadoop:19888</value></property><property><name>mapred.job.tracker</name><value>http://Master.Hadoop:9001</value></property>cd /softwares/hadoop-2.6.0/etc/hadoopvim yarn-site.xml<property><name>yarn.resourcemanager.hostname</name><value>Master.Hadoop</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.resourcemanager.address</name><value>Master.Hadoop:8042</value></property><property><name>yarn.resourcemanager.scheduler.address</name><value>Master.Hadoop:8040</value></property><property><name>yarn.resourcemanager.resource-tracker.address</name> <value>Master.Hadoop:8041</value></property><property><name>yarn.resourcemanager.admin.address</name><value>Master.Hadoop:8043</value></property><property><name>yarn.resourcemanager.webapp.address</name><value>Master.Hadoop:8048</value></property>配置Hadoop的集群cd /softwares/hadoop-2.6.0/etc/hadoopvim slavesSlave1.HadoopSlave2.Hadoop在master上把hadoop 目录的权限交给hadoopsu - rootchown -R hadoop:hadoop /softwares/hadoop-2.6.0chown -R hadoop:hadoop/softwares/hadoop将hadoop-2.6.0整个的copy到另外两台机器上面scp -r /softwares/hadoop-2.6.0 192.168.18.203:/softwares/ scp -r /softwares/hadoop 192.168.18.203:/softwares/scp -r /softwares/hadoop-2.6.0 192.168.18.208:/softwares/ scp -r /softwares/hadoop 192.168.18.208:/softwares/在slave1和slave2上把hadoop 目录的权限交给hadoopchown -R hadoop:hadoop /softwares/hadoop-2.6.0chown -R hadoop:hadoop /softwares/hadoop在master上格式化HDFS 系统su - hadoopcd /softwares/hadoop-2.6.0/bin./hadoop namenode -format启动整个Hadoop集群及其验证在master上su - hadoopcd /softwares/hadoop-2.6.0/sbin./start-dfs.sh./start-yarn.sh或者用下面的./start-all.sh(./stop-all.sh)使用java 的jps 小工具可以看到ResourceManager , NameNode 都启动了:master上【ResourceManager、NameNode】slave1上【DataNode、NodeManager】slave2上【DataNode、NodeManager】如果都运行了,就可以用浏览器查看了http://192.168.18.202:8048/cluster/nodes用./bin/hdfs dfsadmin -report查看状态cd /softwares/hadoop-2.6.0/bin./hdfs dfsadmin -report在系统中使用下面的命令可以看到hadoop 使用的端口:netstat -tnulp | grep java概念说明NamenodeNamenode 管理文件系统的Namespace。
centos下Hadoop配置和使用11

Linux下Hadoop分布式配置和使用秦召红 2011年12月目录介绍 (2)0 集群网络环境介绍 (2)1 /etc/hosts文件配置 (3)2 建立ssh无密码登陆 (3)3 JDK安装和Java环境变量配置 (4)3.1 安装 JDK 1.6 (4)3.2 Java环境变量配置 (4)4 Hadoop集群配置 (4)5 Hadoop集群启动 (6)6 Hadoop使用 (8)6.1 客户机与HDFS进行交互 (9)6.1.1 客户机配置 (9)6.1.2 列出HDFS根目录/下的文件 (9)6.1.3 列出当前用户主目录下的文件 (10)6.1.4 HDFS用户管理 (10)6.1.5 复制本地数据到HDFS中 (10)6.1.6 数据副本说明 (11)6.1.7 hadoop-site.xml参数说明 (11)6.1.8 HDFS中的路径 (12)6.1.8 Hadoop相关命令 (13)6.2 客户机提交作业到集群 (13)6.2.1 客户机配置 (13)6.2.2 一个测试例子WordCount (14)16.2.3 编写Hadoop应用程序并在集群上运行 (14)6.2.4 三种模式下编译运行Hadoop应用程序 (15)6.2.5 提交多个作业到集群 (16)附程序 (17)介绍这是本人在完全分布式环境下在Cent-OS5.6中配置Hadoop-0.20.203.0时的总结文档,但该文档也适合其他版本的Linux系统和目前各版本的Hadoop(Hadoop-0.20之后的版本配置文件hadoop-site.xml被拆分成了三个core-site.xml,hdfs-site.xml和mapred-site.xml,这里会说明0.20后的版本中如何配置这三个文件)。
Hadoop配置建议所有配置文件中使用主机名进行配置,并且机器上应在防火墙中开启相应端口,并设置SSHD服务为开机启动,此外java环境变量可以在/etc/profile中配置。
Hadoop2.6集群配置

groupadd hadoop
useradd -g hadoop hadoop
#修改用户密码
passwd hadoop
2.安装配置hadoop集群(nn01上操作)
2.1解压
tar -zxvf hadoop-2.6.4.tar.gz -C /tiandun/
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>node.rpc-address.ns1.nn2</name>
<value>tiandun02:9000</value>
</property>
export JAVA_HOME=/usr/java/jdk1.8.0_71
2.2.2修改core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为ns1 -->
<property>
<name>fs.defaultFS</name>
</property>
</configuration>
2.2.3修改hdfs-site.xml
<configuration>
<!--指定hdfs的nameservice为ns1,需要和core-site.xml中的保持一致 -->
<property>
<value>hdfs://ns1</value>
hadoop2.6基于yarn安装配置详解

Hadoop2.6配置详解在hadoop2.0中通常由两个NameNode组成,一个处于active状态,另一个处于standby状态。
Active NameNode对外提供服务,而Standby NameNode则不对外提供服务,仅同步active namenode的状态,以便能够在它失败时快速进行切换。
这里还配置了一个zookeeper集群,用于ZKFC(DFSZKFailoverController)故障转移,当Active NameNode挂掉了,会自动切换Standby NameNode为standby状态hadoop-2.2.0中依然存在一个问题,就是ResourceManager只有一个,存在单点故障,hadoop-2.6解决了这个问题,有两个ResourceManager,一个是Active,一个是Standby,状态由zookeeper进行协调hadoop2.0官方提供了两种HDFS HA的解决方案,一种是NFS,另一种是QJM(由cloudra提出,原理类似zookeeper)。
这里我使用QJM完成。
主备NameNode之间通过一组JournalNode同步元数据信息,一条数据只要成功写入多数JournalNode即认为写入成功。
通常配置奇数个JournalNode1安装前准备1.1示例机器192.168.0.10 hadoop1192.168.0.20 hadoop2192.168.0.30 hadoop3192.168.0.40 hadoop4每台机器都有一个hadoop用户,密码是hadoop所有机器上安装jdk1.7。
在hadoop2,hadoop3,hadoop4上安装Zookeeper3.4集群。
1.2配置ip与hostname用root用户修改每台机器的hostsVi /etc/hosts添加以下内容:192.168.0.10 hadoop1192.168.0.20 hadoop2192.168.0.30 hadoop3192.168.0.40 hadoop4应用配置source /etc/hosts1.3关闭防火墙切换到管理员su root连接设备,键入命令“service iptables status”查看防火墙状态关闭命令“chkconfig iptables off”,重启后生效。
(完整word版)centos6下安装部署hadoop2.2

centos6下安装部署hadoop2。
2hadoop安装入门版,不带HA,注意理解,不能照抄.照抄肯定出错。
我在安装有centos7(64位)的机器上,使用hadoop2。
5版本,安装验证过,但我没有安装过hadoop2。
2,仅供参考.如果你的(虚拟机)操作系统和JVM/JDK是64位的,就直接安装hadoop 2.5版本,无需按照网上说的去重新编译hadoop,因为它的native库就是64位了;如果你的(虚拟机)操作系统和JVM/JDK是32位的,就直接安装hadoop 2。
4以及之前的版本.安装小技巧和注意事项:1. 利用虚拟机clone的技术。
2. 不要在root用户下安装hadoop,自己先事先建立一个用户。
3。
如果需要方便操作,可以把用户名添加到sudoers文件中,使用sudo命令执行需要root权限的操作。
4。
Linux里面有严格的权限管理,很多事情普通用户做不了,习惯使用windows的同学,需要改变观念。
5。
centos7与之前的版本,在很多命令上有区别,centos与ubuntu有存在很多操作上的差别。
6. Hadoop 2.5版本中的native lib库是64位的,而hadoop 2。
2版本中的native lib库是32位的。
网上教程大多数针对hadoop2。
2写的,如果你是64位的虚拟机,你直接安装Hadoop 2.5版本就行。
7. 确认虚拟机安装并启用了sshd服务后,用xshell客户端连接Linux虚拟机,不要在vmware workstation 里面操作。
用xshell可以非常方便的复制文字和命令等。
学习Hadoop安装的步骤(1)可以先参考网上的资料“虾皮博客”http://www。
/xia520pi/xia520pi/archive/2012/05/16/2503949.html安装一个hadoop 1.2 版本,熟悉一下,搞明白后,再安装hadoop 2.x版本。
hadoop2.6配置文件说明

<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<property>
<name></name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
2 hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
3 mapred-site.xm
<configuration>
<property>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
<name></name>
hadoop2.6完全分布式安装

系统准备Hadoop完全分布式安装,服务器最好都是基数,我用了三台虚拟机。
hadoop2.6.0完全分布式masterhadoop2.6.0完全分布式salves01hadoop2.6.0完全分布式salves02系统环境设置修改虚拟机的主机名称代码如下:1、修改第一台虚拟机vim /etc/sysconfig/networkNETWORKING=yesHOSTNAME=masterGAREWAY=192.168.83.22、修改第一台虚拟机vim /etc/sysconfig/networkNETWORKING=yesHOSTNAME=salves01GAREWAY=192.168.83.23、修改第一台虚拟机vim /etc/sysconfig/networkNETWORKING=yesHOSTNAME=salves02GAREWAY=192.168.83.2配置IP地址1、修改第一台服务器vim /etc/sysconfig/network-scripts/ifcfg-eth0DEVICE=eth0#HWADDR=00:0C:29:8C:FB:39TYPE=EthernetUUID=92d31d5c-369a-4e3d-8fbc-140ef4ff3ec3 ONBOOT=yes //虚拟机启动时就启动网络NM_CONTROLLED=yesBOOTPROTO=staticIPADDR=192.168.83.100GATEWAY=192.168.83.2NETMASK=255.255.255.0DNS1=192.168.83.22、修改第二台服务器vim /etc/sysconfig/network-scripts/ifcfg-eth0DEVICE=eth0#HWADDR=00:0C:29:8C:FB:39TYPE=EthernetUUID=92d31d5c-369a-4e3d-8fbc-140ef4ff3ec3 ONBOOT=yes //虚拟机启动时就启动网络NM_CONTROLLED=yesBOOTPROTO=staticIPADDR=192.168.83.101GATEWAY=192.168.83.2NETMASK=255.255.255.0DNS1=192.168.83.23、修改第三台服务器vim /etc/sysconfig/network-scripts/ifcfg-eth0DEVICE=eth0#HWADDR=00:0C:29:8C:FB:39TYPE=EthernetUUID=92d31d5c-369a-4e3d-8fbc-140ef4ff3ec3 ONBOOT=yes //虚拟机启动时就启动网络NM_CONTROLLED=yesBOOTPROTO=staticIPADDR=192.168.83.102GATEWAY=192.168.83.2NETMASK=255.255.255.0DNS1=192.168.83.2service network restart //使配置的ip起作用修改主机名和IP的映射关系以及其他虚拟机的关系(hosts)vim /etc/hosts127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6192.168.83.100 master192.168.83.101 salves01192.168.83.102 salves02三台虚拟机都需要配置,三台虚拟机的hosts一样关闭防火墙三台虚拟机都需要关闭防火墙重启系统安装jdk准备jdk在网上下载64位的jdk,下载好了之后上传到虚拟机中在Ubuntu下切换到root用户解压jdk(jdk-7u55-linux-x64.tar.gz)代码如下:配置坏境变量代码如下:重启/etc/profile代码如下:查看是否配置成功(jdk的版本) java –version统默认自己配置的jdk代码如下:配置ssh免密码登录代码如下:ssh-keygen -t rsa//创建keycat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys//把key写在authorized_keys中ll ~/.ssh/authorized_keys//查看是否有这个文件chmod 600 authorized_keys//给这个文件赋予权限ssh localhost //执行切换,看是否是免密码登录把三台服务器中的id_rsa.pub(key),分别加入三台服务器中的authorized_keys文件中,打通三台服务器免密码登录。
Hadoop2.6.0安装----环境准备

Hadoop2.6.0安装----环境准备准备工作:1、笔记本4G内存,操作系统WIN7 (屌丝的配置)2、工具VMware Workstation3、虚拟机:CentOS6.4共四台虚拟机设置:每台机器:内存512M,硬盘40G,网络适配器:NAT模式选择高级,新生成虚机Mac地址(克隆虚拟机,Mac地址不会改变,每次最后手动重新生成)编辑虚拟机网络:点击NAT设置,查看虚机网关IP,并记住它,该IP在虚机的网络设置中非常重要。
NAT设置默认IP会自动生成,但是我们的集群中IP需要手动设置。
本机Win7 :VMnet8 网络设置注意:克隆的虚拟机网卡MAC地址已经改变,但是文件里面没有修改,我们启动网络服务会遇到下面错误:Bringing up interface eth0: Error: No suitable device found: no device found for cone解决办法:# vi /etc/udev/rules.d/70-persistent-net.rules(内容如下图)查看ifcfg-eth0 中的“HWADDR ”是否和第一个网卡启动信息中的ATTR{address}值相同,如果两个值相同则删除eth0中的所有内容在eth1中进行相关IP配置安装JDK72.1下载JDK安装包安装版本:jdk-7u60-linux-x64.gz查看最新:/technetwork/java/javase/downloads/ind ex.html2.2解压安装我们把JDK安装到这个路径:/usr/lib/jvm如果没有这个目录,我们就新建一个目录cd /usr/libsudomkdirjvm将jdk-7u60-linux-x64.tar.gz复制到linux桌面tarzxvf jdk-7u60-linux-x64.tar.gz -C /usr/lib/jvm2.3配置环境变量(1)只对当前用户生效vim ~/.bashrcexport JAVA_HOME=/usr/lib/jvm/jdk1.7.0_60export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=${JAVA_HOME}/bin:$PATH保存退出,然后输入下面的命令来使之生效source ~/.bashrc(2)对所有用户生效(root用户登录)vim /etc/profileexport JAVA_HOME=/usr/lib/jvm/jdk1.7.0_60export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/libexport PATH=${JAVA_HOME}/bin:$PATH保存退出,然后输入下面的命令来使之生效source /etc/profile2.4配置默认JDK(一般情况下这一步都可以省略)由于一些Linux的发行版中已经存在默认的JDK,如OpenJDK等。
hadoop-part2-集群环境搭建(centos6)

Hadoop集群搭建目录1、基础集群环境准备 (1)1.1、修改主机名 (1)1.2、设置系统默认启动级别 (2)1.3、配置hadoop用户sudoer权限 (2)1.4、配置IP (2)1.5、关闭防火墙/关闭Selinux (3)1.6、添加内网域名映射 (3)1.7、安装JDK (3)1.8、同步服务器时间 (4)1.9、配置免密登录 (4)2、Hadoop集群环境安装 (6)2.1、Hadoop版本选择 (6)2.2、安装hadoop (6)2.2.1 hadoop伪分布式模式安装 (6)2.3.2 hadoop分布式集群安装 (8)3、集群初步使用 (11)3.1、Hadoop集群启动 (11)3.2、HDFS初步使用 (11)3.3、mapreduce初步使用 (11)4、hadoop集群安装高级知识 (12)4.1、Hadoop HA安装 (12)4.2、Hadoop 配置机架感知 (13)4.3、Hadoop Fedaration (13)1、基础集群环境准备1.1、修改主机名1、在root账号下用命令:vi /etc/sysconfig/network或者如果配置了hadoop sudo 权限,则在hadoop登录情况下使用命令:sudo vi /etc/sysconfig/network2、修改好后,保存退出即可1.2、设置系统默认启动级别1、在root账号下输入vi /etc/inittab1.3、配置hadoop用户sudoer权限1、在root账号下,命令终端输入:vi /etc/sudoers2、找到root ALL=(ALL) ALL这一行,然后在他下面添加一行:hadoop ALL=(ALL) ALL保存,退出1.4、配置IPLinux服务器的IP修改方式有三种,在此不细讲,请参考文档:资料-linux修改IP三种方式.pdf1.5、关闭防火墙/关闭Selinux防火墙操作相关:关闭Selinux:具体做法是修改/etc/selinux/config配置文件中的SELINUX=disabled1.6、添加内网域名映射修改配置文件:vi /etc/hosts1.7、安装JDK1、上传jdk-8u73-linux-x64.tar.gz2、解压到/usr/local目录下tar -zxvf jdk-8u73-linux-x64.tar.gz -C /usr/local3、配置环境变量a)vi /etc/profileb)在最后加入两行:export JAVA_HOME=/usr/local/jdk1.8.0_73export PATH=$PATH:$JAVA_HOME/binc)保存退出4、source /etc/profile5、检测是否安装成功,输入命:java -version做完以上步骤后,可以开始克隆虚拟机。
hadoop 2.6.0详细安装过程和实例(有截图)

Hadoop 环境搭建时间:2015—07—26作者:周乐相环境搭建之前准备工作我的笔记本配置:硬盘:500G (实际上用不完)CPU: Intel(R) Core(TM)i5-2450M CPU @ 2。
50GHz内存:10G操作系统:WIN7 (64位)软件准备1)。
虚拟机软件:vmwareworkstation64.exe (VMware work station 64 bit V 11。
0)2). Linux 版本: Red Hat Enterprise Linux Server release 6.5 (Santiago)(rhel-server-6.5—x86_64-dvd.iso)3). hadoop 版本: hadoop—2.6。
0。
tar。
gz4)。
JAVA 版本:java version "1。
6.0_32" (jdk—6u32-linux-x64.bin)安装VMware 软件傻瓜操作下一步。
安装Linux操作系统傻瓜操作下一步。
...。
安装完成.1)。
创建hadoop操作系统安装hadoop的用户第一台操作系统命主机名为: master2) 拷贝该虚拟机master 分别为node01 、node02 两个节点数3)分别对拷贝的node01 、node02 修改IP和主机名称主机名: IPmaster : 192。
168.2。
50node01: 192.168.2.51node02: 192。
168.2.52jdk安装并设置好环境变量##设置JAVA_HOME环境变量配置ssh 免密码通信三台服务器SSH关系上面这个图可以表达这三台服务器之间的关系.对master主节点SSH配置执行:ssh-keygen –t dsa 回车一直回车下去会在$HOME/。
ssh目录生成id_dsa 和id_dsa.pub两个文件将id_dsa。
pub文件放到authorized_keys文件,注意需要修改权限chmod 600 authorized_keys依次将node01、node02两台的密码追加到authorized_keys 文件里面对node01节点SSH配置这样master与node01就可以正常的互通无需密码对node02节点SSH配置这样master与node02就可以正常的互通无需密码Hadoop安装配置修改配置文件用红线框起来的都需要修改配置修改:mapred-site。
HDP服务器配置
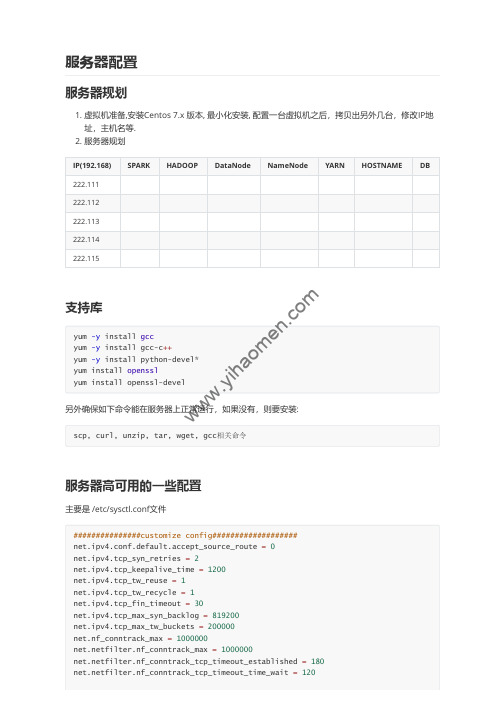
登陆mysql 修改密码配置数据库,登陆mysql, 创建数据库,导入表信息.use ambari;source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql;启动:ambari-server start检查是否正常,可以打开网页:http://192.168.222.111:8080, 如果启动报错, 一般是没找到mysql驱动包,需要去/etc/ambari-server/conf/ambari.properties 里面配置mysql 驱动包路径, ambari用的C3P0连接池。
默认登陆用户和密码:admin/admin创建集群按照wizard 创建一个集群,起名,并选择安装版本后面选择:Use Local Repository ,并在redhat7 栏中输入相应的地址, 通过nginx可以访问的地址配置机器,ssh private key, 用命令 cat ~/.ssh/id_rsa 可以得到 private key , 然后拷贝进来.继续下一步,如果出现警告: The following hostnames are not valid FQDNs, 则点击继续。
因为机器名没安装FQDN标准配置,但不代表找不到.只做测试,先只安装HDFS和zookeeper,如果需要更多的服务,安装完之后还可以添加的.密码都输入为 admin保持默认目录配置账号由ambari去管理, 默认配置所有配置项页面,默认继续下一步, 部署点击 deploy ,进入部署。
等待部署,需要花一些时间,直到部署完成到此为止,HDFS, ZOOKEEPER部署完成,点击 COMPLETE.还可以打开HDFS的网页查看: http://192.168.222.111:50070/用Ambari 添加Service1. YARN2. HIVE HBASE这个问题的解决, 修改 /etc/yum.repos.d 文件, 修改 installonly_limit=5000, 然后重启 ambari-server。
(完整word版)Hadoop 2.6.0分布式部署参考手册

Hadoop 2。
6.0分布式部署参考手册1。
环境说明 (2)1。
1安装环境说明 (2)2。
2 Hadoop集群环境说明: (2)2。
基础环境安装及配置 (2)2.1 添加hadoop用户 (2)2.2 JDK 1.7安装 (2)2.3 SSH无密码登陆配置 (3)2.4 修改hosts映射文件 (3)3.Hadoop安装及配置 (4)3.1 通用部分安装及配置 (4)3。
2 各节点配置 (4)4。
格式化/启动集群 (4)4.1 格式化集群HDFS文件系统 (4)4。
2启动Hadoop集群 (4)附录1 关键配置内容参考 (5)1 core-site.xml (5)2 hdfs-site。
xml (5)3 mapred—site.xml (6)4 yarn-site。
xml (6)5 hadoop-env。
sh (6)6 slaves (6)附录2 详细配置内容参考 (7)1 core-site.xml (7)2 hdfs-site.xml (7)3 mapred—site。
xml (8)4 yarn-site。
xml (9)5 hadoop-env。
sh (12)6 slaves (12)附录3 详细配置参数参考 (12)conf/core—site.xml (12)conf/hdfs-site。
xml (12)o Configurations for NameNode: (12)o Configurations for DataNode: (13)conf/yarn—site。
xml (13)o Configurations for ResourceManager and NodeManager: (13)o Configurations for ResourceManager: (13)o Configurations for NodeManager: (15)o Configurations for History Server (Needs to be moved elsewhere): 16 conf/mapred—site.xml (16)o Configurations for MapReduce Applications: (16)o Configurations for MapReduce JobHistory Server: (16)1。
(完整版)Hadoop安装教程_伪分布式配置_CentOS6.4_Hadoop2.6.0

Hadoop安装教程_伪分布式配置_CentOS6.4/Hadoop2.6.0都能顺利在CentOS 中安装并运行Hadoop。
环境本教程使用CentOS 6.4 32位作为系统环境,请自行安装系统(可参考使用VirtualBox安装CentOS)。
如果用的是Ubuntu 系统,请查看相应的Ubuntu安装Hadoop教程。
本教程基于原生Hadoop 2,在Hadoop 2.6.0 (stable)版本下验证通过,可适合任何Hadoop 2.x.y 版本,例如Hadoop 2.7.1, Hadoop 2.4.1等。
Hadoop版本Hadoop 有两个主要版本,Hadoop 1.x.y 和Hadoop 2.x.y 系列,比较老的教材上用的可能是0.20 这样的版本。
Hadoop 2.x 版本在不断更新,本教程均可适用。
如果需安装0.20,1.2.1这样的版本,本教程也可以作为参考,主要差别在于配置项,配置请参考官网教程或其他教程。
新版是兼容旧版的,书上旧版本的代码应该能够正常运行(我自己没验证,欢迎验证反馈)。
装好了CentOS 系统之后,在安装Hadoop 前还需要做一些必备工作。
创建hadoop用户如果你安装CentOS 的时候不是用的“hadoop” 用户,那么需要增加一个名为hadoop 的用户。
首先点击左上角的“应用程序” -> “系统工具” -> “终端”,首先在终端中输入su,按回车,输入root 密码以root 用户登录,接着执行命令创建新用户hadoop:如下图所示,这条命令创建了可以登陆的hadoop 用户,并使用/bin/bash 作为shell。
CentOS创建hadoop用户接着使用如下命令修改密码,按提示输入两次密码,可简单的设为“hadoop”(密码随意指定,若提示“无效的密码,过于简单”则再次输入确认就行):可为hadoop 用户增加管理员权限,方便部署,避免一些对新手来说比较棘手的权限问题,执行:如下图,找到root ALL=(ALL) ALL这行(应该在第98行,可以先按一下键盘上的ESC键,然后输入:98 (按一下冒号,接着输入98,再按回车键),可以直接跳到第98行),然后在这行下面增加一行内容:hadoop ALL=(ALL) ALL(当中的间隔为tab),如下图所示:为hadoop增加sudo权限添加上一行内容后,先按一下键盘上的ESC键,然后输入:wq (输入冒号还有wq,这是vi/vim编辑器的保存方法),再按回车键保存退出就可以了。
centos环境下hadoop的安装与配置实验总结

centos环境下hadoop的安装与配置实验总结实验总结:CentOS环境下Hadoop的安装与配置一、实验目标本次实验的主要目标是学习在CentOS环境下安装和配置Hadoop,了解其基本原理和工作机制,并能够运行简单的MapReduce程序。
二、实验步骤1. 准备CentOS环境:首先,我们需要在CentOS上安装和配置好必要的基础环境,包括Java、SSH等。
2. 下载Hadoop:从Hadoop官方网站下载Hadoop的稳定版本,或者使用CentOS的软件仓库进行安装。
3. 配置Hadoop:解压Hadoop安装包后,需要进行一系列的配置。
这包括设置环境变量、配置文件修改等步骤。
4. 格式化HDFS:使用Hadoop的命令行工具,对HDFS进行格式化,创建其存储空间。
5. 启动Hadoop:启动Hadoop集群,包括NameNode、DataNode等。
6. 测试Hadoop:运行一些简单的MapReduce程序,检查Hadoop是否正常工作。
三、遇到的问题和解决方案1. 环境变量配置问题:在配置Hadoop的环境变量时,有时会出现一些问题。
我们需要检查JAVA_HOME是否设置正确,并确保HADOOP_HOME 在PATH中。
2. SSH连接问题:在启动Hadoop集群时,需要确保各个节点之间可以通过SSH进行通信。
如果出现问题,需要检查防火墙设置和SSH配置。
3. MapReduce程序运行问题:在运行MapReduce程序时,可能会遇到一些错误。
这通常是由于程序本身的问题,或者是由于HDFS的权限问题。
我们需要仔细检查程序代码,并确保运行程序的用户有足够的权限访问HDFS。
四、实验总结通过本次实验,我们深入了解了Hadoop的安装和配置过程,以及如何解决在安装和运行过程中遇到的问题。
这对于我们今后在实际应用中部署和使用Hadoop非常重要。
同时,也提高了我们的实践能力和解决问题的能力。
Hadoop 2.6.0伪分布式配置详解分享_光环大数据培训

Hadoop 2.6.0伪分布式配置详解分享_光环大数据培训首先先不看理论,搭建起环境之后再看;搭建伪分布式是为了模拟环境,调试方便。
电脑是Windows 10,用的虚拟机VMware Workstation 12 Pro,跑的Linux 系统是CentOS6.5 ,安装的hadoop2.6.0,jdk1.8;1.准备工作准备工作:把JDK和Hadoop安装包上传到linux系统(hadoop用户的根目录)系统环境:IP:192.168.80.99,linux用户:root/123456,hadoop/123456主机名:node把防火墙关闭,root执行:service iptables stop2.jdk安装1 .在 hadoop 用户的根目录, Jdk 解压,( hadoop 用户操作)tar -zxvfjdk-8u65-linux-x64.tar.gz 解压完成后,在 hadoop 用户的根目录有一个 jdk1.8.0_65目录2.配置环境变量,需要修改 /etc/profile 文件( root 用户操作)切到 root 用户,输入 su 命令 vi /etc/profile 进去编辑器后,输入 i ,进入 vi 编辑器的插入模式在 profile 文件最后添加JAVA_HOME=/home/hadoop/jdk1.8.0_65export PATH=$PATH:$JAVA_HOME/bin编辑完成后,按下 esc 退出插入模式输入:,这时在左下角有一个冒号的标识q 退出不保存wq 保存退出q! 强制退出3. 把修改的环境变量生效( hadoop用户操作)执行 source /etc/profile4.执行java -version 查看版本,如果成功证明jdk配置成功3.Hadoop 安装1.在 hadoop 用户的根目录,解压( hadoop 用户操作)tar -zxvf hadoop-2.6.0.tar.gz解压完成在 hadoop 用户的根目录下有一个 hadoop-2.6.0目录2.修改配置文件hadoop-2.6.0/etc/hadoop/hadoop-env.sh ( hadoop 用户操作)export JAVA_HOME=/home/hadoop/jdk1.8.0_653.修改配置文件hadoop-2.6.0/etc/hadoop/core-site.xml ,添加( hadoop 用户操作)<property><name>fs.defaultFS</name><value>hdfs://node:9000</value></property>4.修改配置文件hadoop-2.6.0/etc/hadoop/hdfs-site.xml ,添加( hadoop 用户操作)<property><name>dfs.replication</name><value>1</value></property>5.修改修改配置文件hadoop-2.6.0/etc/hadoop/mapred-site.xml ( hadoop 用户操作),这个文件没有,需要复制一份cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml添加<property><name></name><value>yarn</value></property>6.修改配置文件hadoop-2.6.0/etc/hadoop/yarn-site.xml ,添加( hadoop 用户操作)<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>7.修改主机名称(root 用户操作),重启生效vi /etc/sysconfig/network修改HOSTNAME 的值为用户名8.修改 /etc/hosts 文件( root 用户操作) , 添加: ip 主机名称192.168.44.199(用自己的ip,下边讲如何获得) node附:查看ip地址编辑-->虚拟网络编辑器net模式,选DHCP设置,得到ip地址起始net设置,得到网关点右边小电脑,选择VPN Connections-->Configue VPN选中eth0,点有右边edit选择IP Settings ,根据自己的ip按图修改,Address就是你的ip地址,在起始ip地址和结束ip地址之间选一个就行9. 格式化 HDFS ,在 hadoop 解压目录下,执行如下命令:( hadoop 用户操作)bin/hdfs namenode -format注意:格式化只能操作一次,如果因为某种原因,集群不能用,需要再次格式化,需要把上一次格式化的信息删除,在 /tmp 目录里执行 rm –rf *10. 启动集群,在 hadoop 解压目录下,执行如下命令:( hadoop 用户操作,截图用机后来改过,主机为gp )启动集群: sbin/start-all.sh 需要输入四次当前用户的密码 ( 通过配置 ssh 互信解决,截图用机已经配置过ssh不用输密码 )启动后,在命令行输入 jps 有以下输出关闭集群: sbin/stop-all.sh 需要输入四次当前用户的密码 ( 通过配置 ssh 互信解决,我的同上)4.SSH互信配置(hadoop用户操作)rsa加密方法,公钥和私钥1.生成公钥和私钥在命令行执行ssh-keygen,然后回车,然后会提示输入内容,什么都不用写,一路回车在hadoop用户根目录下,有一个.ssh目录id_rsa 私钥id_rsa.pub 公钥known_hosts 通过SSH链接到本主机,都会在这里有记录2.把公钥给信任的主机(本机)在命令行输入ssh-copy-id 主机名称ssh-copy-id hadoop复制的过程中需要输入信任主机的密码3.验证,在命令行输入:ssh 信任主机名称ssh hadoop如果没有提示输入密码,则配置成功为什么大家选择光环大数据!大数据培训、人工智能培训、Python培训、大数据培训机构、大数据培训班、数据分析培训、大数据可视化培训,就选光环大数据!光环大数据,聘请专业的大数据领域知名讲师,确保教学的整体质量与教学水准。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hadoop-2.6.0配置
前面的部分跟配置Hadoop-1.2.1的一样就可以,什么都不用变,完全参考文档1即可。
下面的部分就按照下面的做就可以了。
hadoop-2.6.0的版本用张老师的。
下面的配置Hadoop hadoop-2.6.0的部分
1.修改hadoop-
2.6.0/etc/hadoop/hadoop-env.sh,添加JDK支持:
export JAVA_HOME=/usr/java/jdk1.6.0_45
如果不知道你的JDK目录,使用命令echo $JAVA_HOME查看。
2.修改hadoop-2.6.0/etc/hadoop/core-site.xml
注意:必须加在<configuration></configuration>节点内
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadoop-2.6.0/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name></name>
<value>hdfs://master:9000</value>
</property>
</configuration>
3.修改hadoop-2.6.0/etc/hadoop/hdfs-site.xml
<property>
<name>.dir</name>
<value>/home/hadoop/hadoop-2.6.0/dfs/name</value>
<description>Path on the local filesystem where the NameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/hadoop-2.6.0/dfs/data</value>
<description>Comma separated list of paths on the local filesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
4.修改hadoop-2.6.0/etc/hadoop/mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>master:9001</value>
<description>Host or IP and port of JobTracker.</description>
</property>
5. 修改hadoop-2.
6.0/etc/hadoop/masters
列出所有的master节点:
master
6.修改hadoop-2.6.0/etc/hadoop/slaves
这个是所有datanode的机器,例如:
slave1
slave2
slave3
slave4
7.将master结点上配置好的hadoop文件夹拷贝到所有的slave结点上
以slave1为例:命令如下:
scp -r ~/hadoop-2.6.0slave1:~/
安装完成后,我们要格式化HDFS然后启动集群所有节点。
8.启动Hadoop
1.格式化HDFS文件系统的namenode
(这里要进入hadoop-2.6.0目录来格式化好些):
cd hadoop-2.6.0 //进入hadoop-2.6.0目录
bin/hdfs namenode -format //格式化
2.启动Hadoop集群
启动hdfs命令如下:
sbin/start-dfs.sh //开启进程
成功的话输入jps会出现如下界面:
补充,关闭hdfs集群的命令如下:
sbin/stop-dfs.sh
我们也可以通过网页来看是否正常安装与配置,地址如下:http://master:50070/或者是http://master:50070/dfshealth.html#tab-overview
下面是运行pi的示例。
Hadoop-2.6.0中是没有示例包的,需要把Hadoop-1.2.1中的hadoop-examples-1.2.1.jar考入到Hadoop-2.6.0目录下。
输入命令:hadoop jar hadoop-examples-1.2.1.jar pi 1 10
运行结果如下:。