第5章 无失真信源编码定理
第5章_无失真信源编码定理

si , s j S Wi ,W j C
信源符号
概率
编码1
编码2
编码3
编码4
编码5
p(ai )
a1 a2 a3 a4
1/2
00
0
0
0
1
1/4
01
0
1
10
01
1/8
10
1
00
1100011/8111011
111
0001
如表中的“编码2”是奇异码,其他码是非奇异码。
(6)同价码
P( s ) 1
i 1 i
4
而其依赖关系为:
P(s2 / s1 ) P(s1 / s2 ) P(s4 / s3 ) P(s3 / s4 ) 1, 其余P(s j / si ) 0
s1 s2 s3 s4
s1 0 1 P 0 0
s2 1 0 0 0
s3 0 0 0 1
s4
p (s4)
11
101
(4)非奇异码
若一组码中所有码字都不相同(即所有信源符号
映射到不同的码符号序列),则称为非奇异码。
si s j Wi W j
则称码C为非奇异码。
si , s j S Wi ,W j C
(5)奇异码 若一组码中有相同的码字,则为奇异码。
si s j Wi W j
P(s2 / s1 ) P(s1 / s2 ) P(s4 / s3 ) P(s3 / s4 ) 1, 其余P(s j / si ) 0
s3 s2 s4 S s1 P( s ) P( s ) P( s ) P( s ) P( s ) 1 2 3 4
第5章无失真信源编码定理

如果我们要对信源的N次扩展信源进行编码,也必须满足
qN rl , 两边取对数得: l log q
l
N log r
N 表示平均每个信源符号所需的码符号个数。
5.2 等长码
例:对英文电报得32个符号进行二元编码,根据上述关系:
l log 32 5 log 2
我们继续讨论上面得例子,我们已经知道英文的极限 熵是1.4bit,远小于5bit,也就是说,5个二元码符号只携带 1.4bit的信息量,实际上,5个二元符号最多可以携带5bit 信息量。我们可以做到让平均码长缩短,提高信息传输率
0.8112
0.4715
若采用等长二元编码,要求编码效率 0.96 ,允许错误率
105 ,则: N 4.13107
也就是长度要达到4130万以上。
5.5 变长码
1、唯一可译变长码与及时码
信源符号 出现概率 码1
码2
码3
码4
s1
1/2
0
0
1
1
s2
1/4
11
10
10
01
s3
1/8
00
00
密码:是以提高通信系统的安全性为目的的编码。通常通过加 密和解密来实现。从信息论的观点出发,“加密”可视为增熵 的过程,“解密”可视为减熵的过程。
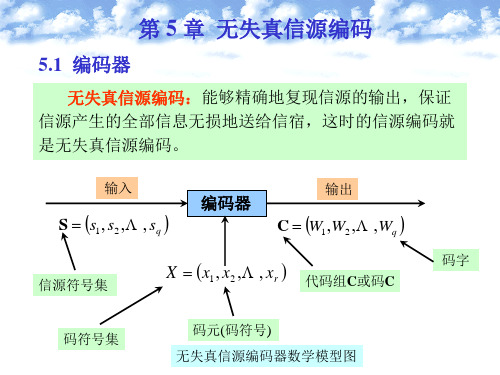
5.1 编码器
信源编码理论是信息论的一个重要分支,其理论基础是信源编 码的两个定理。 无失真信源编码定理:是离散信源/数字信号编码的基础; 限失真信源编码定理:是连续信源/模拟信号编码的基础。
5.1 编码器
信源编码:以提高通信有效性为目的的编码。通常通过压缩信 源的冗余度来实现。采用的一般方法是压缩每个信源符号的平 均比特数或信源的码率。即同样多的信息用较少的码率传送, 使单位时间内传送的平均信息量增加,从而提高通信的有效性。
第5章无失真信源编码定理

R 0.811比特/二元码符号
通信与信息基础教学部
33
信息论课件
对该信源的二次扩展信源进行编码如下
0 10 110 111 X 2 x1 x1 x1 x2 x2 x1 x2 x2 9 3 3 1 16 16 16 P( x) 16 这个码的平均长度 L2 27 16 得信源中每一个单个符号的平均码长 L L2 2 27 32 编码效率 2 0.961 信道信息传输率为 R 0.961比特/二元码符号 2 同样可得 R 0.985, R 0.991, 3 4
信源编码器的主要任务:完成输入消息
集合与输出代码集合之间的映射。若要 实现无失真编码,则这种映射必须是一 一对应的、可逆的。
通信与信息基础教学部
4
信息论课件
常用码型
1、二元码:若信道码符号集A={0,1
}, 编码输出的码字都是二元码,称为二元 码。 2 、等长码:若一组码中所有码字的码长 都相同,称为等长码。 3 、变长码:若一组码中所有码字的码长 Ki 各不相同,即任意码字由不同长度的 码符号序列组成,则称为变长码。
信息论课件
第5章 无失真信源编码
编码器 5.2 等长码 5.3 渐进等分割性和e典型序列* 5.4 等长信源编码定理 5.5 变长码 5.6 变长信源编码定理
5.1
通信与信息基础教学部
1
信息论课件
5.1 编码器
对整个通信系统来说,要解决两个问题:信源 编码和信道编码。 对信源来说有两个重要问题:一个是信源输出 信息量的定量度量问题。这在前面信源及其信 息熵章中已讨论。本章将要讨论第二个问题: 如何有效地表示信源输出问题。即将重点讨论 对信源进行无失真信源编码的要求、方法及理 论极限,从而得出香农第一定理。
信息论基础与应用-李梅-第五章 无失真信源编码解析

二次扩展码码字 w j ( j 1, 2,...,16)
w1 w1w1 00 w 2 w1w2 001 w3 w1w3 0001 w16 w4 w4 111111
第五章:无失真信源编码
一、信源编码的相关概念
4. 关于编码的一些术语
编码器输出的码符号序列 wi称为码字;长度 li 称为码 字长度,简称码长;全体码字的集合C称为码。 若码符号集合为X={0,1},则所得的码字都是二元序 列,称为二元码。
将信源符号集中的每个信源符号
si 固定的映射成某
一个码字 wi ,这样的码称为分组码。
码字与信源符号一一对应
2) 不同的信源符号序列对应不同的码字序列
第五章:无失真信源编码
一、信源编码的相关概念
6. 唯一可译性(续2)
例1:
1) 奇异码
s1 s2 s3 s4
0 11 00 Байду номын сангаас1
译码 11
s2 s4
奇异码一定不是唯一可译码
第五章:无失真信源编码
一、信源编码的相关概念
6. 唯一可译性(续3)
译码 0 0 0 1 1 0 1 1
s1s2 s3 s4
第五章:无失真信源编码
一、信源编码的相关概念
6. 唯一可译性(续5)
4)
唯一可译码 1 1 0 1 0 0 1 0 0 0 0
s1 s2
1 10
1 0
1
s2 / s3 ?
s3 100 s4 1000
为非即时码
第五章:无失真信源编码
一、信源编码的相关概念
《信息论与编码原理》孟放-第五八章无失真信源编码(编码定理编码算法)-2016-打印版
【5】无失真信源编码定理【7】保真度准则下的信源编码【8】无失真的信源编码【6】有噪信道编码定理【9】信道的纠错编码271.1、概述–编码器概论(续)✹信源编码理论是信息论的一个重要分支,其理论基础:无失真信源编码定理;限失真信源编码定理。
✹本章主要介绍无失真信源编码,它实质上是一种统计匹配编码,根据信源的不同概率分布而选用与之相匹配的码。
✹信源的统计剩余度主要决定于以下两个因素无记忆信源中,符号概率分布的非均匀性。
有记忆信源中,符号间的相关性及符号概率分布的非均匀性。
81.1、概述–信源编码器模型✹信源编码:将信源符号序列按一定的数学规律映射成码符号序列的过程。
信宿信道信源编码器译码器X ’XSS ’信源编码器模型{}qs s s S ,,,21 =12{,,,}r X x x x = 91.1、概述–信源编码器模型(续)✹将信源符号集中的符号(或者长为N 的信源符号序列)映射成由码符号组成的长度为的一一对应的码符号序列。
{}q W W W C ,,,21 =编码器},...,,{:21r x x x X {}q s s s S ,,,21 ={}ili i i i x x x W 21=i x i s il i W 101.2、概述–基本术语{}q W W W C ,,,21 =编码器},...,,{:21r x x x X {}q s s s S ,,,21 ={}il i i i i x x x W 21=信源符号集码符号集码字码元/ 码符号代码组C / 码Cr 元码定长码、变长码;奇异码、非奇异码平均码长()∑=ii i l s p L 11信源符号出现概率码字码1码2码3S 1p (S 1)W 10000S 2p (S 2)W 2010111S 3p (S 3)W 31000100S 4p (S 4)W 411111111.2、概述–基本术语–例题5.1()()()()⎥⎦⎤⎢⎣⎡=⎥⎦⎤⎢⎣⎡43214321s p s p s p s p s s s s P S 例题:设有二元信道的信源编码器,其概率空间如右:定长码:变长码:非奇异码:奇异码:码1码2、码3码1、码2码3121.3、概述–N 次扩展码✹实际接收:N 次无记忆扩展信源--〉N 次扩展码{}q W W W C ,,,21 ={}qs s s S ,,,21 =is {}12,,,NN q S ααα= },,,{21N q N C W W W =12Nj j j js s s α= Nq j ,,2,1 =qj j j N ,,2,1,,,21 =iW Nj j j j W W W 21=W131.3、概述–N 次扩展码✹例题5.1 -续()16,,2,1 =j j W 00111==W W W 001212==W W W 二次扩展信源符号二次扩展码码字(1,2, (16)j j α=111s s α=212s s α=313s s α=1644s s α=0001313==W W W 1111114416==W W W 信源符号码字码2S 1W 10S 2W 201S 3W 3001S 4W 411114✹信源编码器✹分组码✹定长码和定长编码定理✹变长码主要内容定义唯一可译性即时码的判别与构造152.1、分组码✹分组码:将信源符号集中的每个信源符号映射成一个固定的码字。
第5章2无失真和限失真信源编码

28
5.2.3
最佳变长编码
最佳变长编码 凡是能载荷一定的信息量,且码字的 平均长度最短,可分离的变长码的码字集 合称为最佳变长码。
29
5.2.3
最佳变长编码
能获得最佳码的编码方法主要有:
香农(Shannon)
费诺(Fano)
哈夫曼(Huffman)等
30
5.2.3
最佳变长编码
2
2.83
7.11
Pe=0.04 太大
16
5.2.1
定长编码定理
0.28
H(X ) = 0.90, H(X )
2 8 i 1
( X ) D[ I ( xi )] pi (log pi ) 2 [ H ( X )]2 7.82(bit) 2
若要求译码错误概率 10-6
对于平均符号熵为 HL(X) 的离散平稳 无记忆信源,必存在一种无失真编码方法, 使平均信息率满足不等式
H L (X) K H L (X)
其中为任意小正数。
20
5.2.2
变长编码定理
用变长编码来达到相当高的编码效率, 一般所要求的符号长度 L可以比定长编码小得 多。 编码效率的下界:
编码。
12
5.2.1
定义
定长编码定理
H L ( X) K
为编码效率,即信源的平均符号熵为H(X), 采用平均符号码长为 来编码,所得的效 K 率。 编码效率总是小于1,且最佳编码效率为
H L ( X) , 0 H L ( X)
13
5.2.1
定长编码定理
编码定理从理论上阐明了编码效率接 近1的理想编码器的存在性,它使输出符号 的信息率与信源熵之比接近于1,即
第5章 信源编码 第1讲 无失真信源编码 定长编码定理 2016

00 01 10 11
0 01 001 111
12/62
余 映 云南大学
5.1 编码的定义
• 采用分组编码方法,需要分组码具有某些属性, 以保证在接收端能够迅速准确地将码译出。 • 下面讨论分组码的属性:
余 映 云南大学
13/62
5.1 编码的定义
• (1) 奇异码和非奇异码
– 若信源符号和码字是一一对应的,则该码为非奇异码; 反之为奇异码。 – 例如表中码1是奇异码,其他是非奇异码。
信源符号 出现概率 码1 码2 码3 码4
A B C D
1/2 1/4 1/8 1/8
0 11 00 11
余 映 云南大学
0 10 00 01
1 10 100 1000
1 01 001 0001
18/62
5.1 编码的定义
• (3) 即时码和非即时码
– 唯一可译码又分为非即时码和即时码。 – 即时码是一种没有一个码字构成另一码字前缀的码。 在译码时没有延迟,收到一个完整码字后就能立即译 码。 – 如果收到一个完整码字后,不能立即译码,还需等下 一个码字开始接收后才能判断是否可以译码,这样的 码叫做非即时码。
信源符号
出现概率
码1
码2
码3
码4
a1 a2 a3 a4
1/2 1/4 1/8 1/8
0 11 00 11
余 映 云南大学
0 10 00 01
1 10 100 1000
1 01 001 0001
14/62
5.1 编码的定义
• (2) 唯一可译码和非唯一可译码
– 若任意有限长的码元序列,只能被唯一地分割成一个 个的码字,则称为唯一可译码。 – 例如{0, 10, 11}是一种唯一可译码。 – 因为任意一串有限长码序列, – 如100111000
信息论基础第5章无失真信源编码

r 元霍夫曼编码步骤:
1) 验证所给 q 是否满足 q (r 1) r ,若不满足该式,
可以人为地增加 t 个概率为零的符号,满足式
n (r 1) r ,以使最后一步有 r 个信源符号;
2) 取概率最小的 r 个符号合并成一个新符号,并分别用 0, 1,…,(r 1) 给各分支赋值,把这些符号的概率相加作为该新 符号的概率;
上述不等式只是即时码存在的充要条件,而不能作为判别的依据。
需要注意的是,克拉夫特不等式是即时码存在的充要条件,而 不能作为判别的依据。后来麦克米伦(B. McMillan)证明唯一可译 码也满足克拉夫特不等式。这说明在码长选择的条件上,即时码与 唯一可译码是一致的。
【例】 对于二元码,即 r 2 ,如果 q 4 , L1 2 , L2 2 ,
原始信源普遍存在剩余度,香农信息论认为信源的剩余度主 要来自两个方面:一是信源符号间的相关性,二是信源符号概率 分布的不均匀性。为了去除信源剩余度,提高信源的信息传输率, 必须对信源进行压缩编码。
目前去除信源符号间相关性的主要方法是预测编码和变换编 码,而去除信源符号概率分布不均匀性的主要方法是统计编码。
《信息论基础》
第5章 无失真信源编码
第 2 章已经讨论了离散信源的信息度量—信源熵, 本章将讨论信源的另一个重要问题:如何对信源的输出 进行适当的编码,才能用尽可能少的码元来表示信源信 息,做到以最大的信息传输率无差错地传输信息呢?即 无失真信源编码,它解决的是通信的有效性问题。
本章将首先介绍信源编码器;然后从理论上阐述无 失真信源编码定理,得出“平均码长的理论极限值就是
无失真信源编码定理

内容提要 用尽可能少的符号来传输信源消息,目的是提高传输 效率,这是信源编码应考虑的问题,等长编码定理给 出了等长编码条件下,其码长的下限值,变长编码定 理(香农第一定理)给出了信源无失真变长编码时其 码长的上、下限值。
信源编码包括两个功能:
(1) 将信源符号变换成适合信道传输的符号;
15
K =
∑ p ( x )l
i i =1
q
i
它是每个信源符号平均需用的码元数。
2. 平均每个码元携带的信息量---即编码后信道的信息传输速率为
3.
编码后每秒钟信道的信息传输速率为 Rt =
H (S ) (S R= K
∴
比特/码符号
H (S ) tK 比特/秒
K ↓⇒ Rt ↑
对某一信源来说,若有一个唯一可译码,其平均长度小于所有 其它的唯一可译码的平均长度,则该码称为紧致码,或称最佳 码。无失真变长信源编码的基本问题就是要找最佳码。
η=
H L (U ) R
则可实现无失真传输
四、编码效率:
设U=X
最佳编码效率为
HL (X ) η= HL (X ) + ε
无失真信源编码定理从理论上阐明了编码效率接近于1的理想 编码器的存在性,它使输出符号的信息率与信源熵之比接近于1, 但要在实际中实现,则要求信源符号序列的L非常大进行统一编码 才行,这往往是不现实的。
i =1
对信源符号采用定长二元编码,要求编码效率 η = 90% 无记忆信源有 H L ( X ) = H ( X ) 因此
12
H(X ) η= = 90% H (X ) + ε
可以得到
ε = 0.28
如果要求译码错误概率
第五章无失真信源编码分析

s jN
C N {w 1 , w 2 , , w q N }
w j w j1 w j2 w jN
s j s j1 s j2
j 1, 2 , , q N
j1 , j 2 , , j N 1, 2 , , q
第五章:无失真信源编码
一、信源编码的相关概念
3. N次扩展码(续1)
2 2.5 3 3
s1= s1 s1 s2= s1 s2 s3= s1 s3 s4= s1 s4 s5= s2 s1 s6= s2 s2 s7= s2 s3 s8= s2 s4
1/4 1/8 1/16 1/16
1/8
1/16 1/32
1.5
2 2.5
1/32
2.5
s9 = s3 s 1 s10= s3 s2 s11= s3 s3 s12= s3 s4 s13= s4 s1 s14= s4 s2 s15= s4 s3 s16= s4 s4
2) 非奇异码
s1 0 s2 10 s3 s4 00 01
译码 0 10 00 01 0 译码
s1 s 2 s 3 s 4 s1
01 00
00 10
s 4 s3 s3 s 2
第五章:无失真信源编码
一、信源编码的相关概念
6. 唯一可译性(续4)
3)
等长码
非奇异码
唯一可译码
s1 s2
00 01
s3 10 s4 11
第五章:无失真信源编码
一、信源编码的相关概念
8. 即时码的构造方法(续4)
非分组码 奇异码 非唯一可译码 码 分组码 非奇异码 即时码 唯一可译码 非即时码
第5章无失真信源编码定理12

第5章无失真信源编码定理●通信的实质是信息的传输。
高效率、高质量地传送信息又是信息传输的基本问题。
●信源信息通过信道传送给信宿,需要解决两个问题:第一,在不失真或允许一定失真条件下,如何用尽可能少的符号来传送信源信息,以提高信息传输率。
第二,在信道受干扰的情况下,如何增强信号的抗干扰能力,提高信息传输的可靠性同时又使得信息传输率最大。
●为了解决以上两个问题,引入了信源编码和信道编码。
●提高抗干扰能力(降低失真或错误概率)往往是增加剩余度以降低信息传输率为代价的;反之,要提高信息传输率往往通过压缩信源的剩余度来实现,常常又会使抗干扰能力减弱。
●上面两者是有矛盾的,然而在信息论的编码定理中,已从理论上证明,至少存在某种最佳的编码或信息处理方法,能够解决上述矛盾,做到既可靠又有效地传输信息。
●第5章着重讨论对离散信源进行无失真信源编码的要求、方法及理论极限,得出极为重要的极限定理——香农第一定理。
5.1编码器●编码实质上是对信源的原始符号按一定的数学规则进行的一种变换。
●图5.1就是一个编码器,它的输入是信源符号集S={s 1,s 2,…,s q }。
同时存在另一符号集X={x 1,x 2, …,x r },一般元素x j 是适合信道传输的,称为码符号(或称为码元)。
编码器是将信源符号集中的符号s i (或者长为N 的信源符号序列a i )变换成由x j(j=1,2, …,r )组成的长度为l i的一一对应序列。
●这种码符号序列W i 称为码字。
长度l i称为码字长度或简称码长。
所有这些码字的集合C 称为码。
●编码就是从信源符号到码符号的一种映射,若要实现无失真编码,必须这种映射是一一对应的、可逆的。
编码器S :{s 1,s 2,…s q }X :{x 1,x 2,…x r }C :{w 1,w 2,…w q }(w i 是由l i 个x j (x j 属于X ))组成的序列,并于s i 一一对应一些码的定义●二元码:若码符号集为X={0,1},所得码字都是一些二元序列,则称为二元码。
第五章 信源编码定理

信源编码定理和方法
• 编码的定义和类型
• 无失真编码定理
• 限失真编码定理 • 最佳变长编码方法
• 常用信源编码方法
离散信源编码
离散信源编码过程
离散信源编码过程
编码码字的码长
平均码长
码长偏差
信源编码过程
假设信源输出符号序列长度L 1,则 信源符号集合为: A (a1 , a2 a2 , , an ) a1 an X a1 信源概率空间为: P p(a1 ) p(a1 ) p(an ) 需要将这样的符号进行传输,常见的一种信道就是二元 信道,它的基本符号集合为{0,,若要将X 通过这样的 1} 二元信道传输,就必须把信源符号ai 变为由0, 1符号组成的 码符号序列,这个过程就是信源编码。
即时码
各类码的隶属关系
唯一可译码:码字集合 0,10,11,序列 10, 0,11,10, 0, 0 非唯一可译码:码字集合 0,10, 00, 01,序列 10, 0, 0, 01, 00 10, 00, 01, 0, 0 非即时码:码字集合 1,10,100,1000,序列 1,100,10,1000,1 即时码:码字集合 1, 01, 001, 0001,序列 1, 001, 0001, 01
Ki n
信源编码定理和方法
• 编码的定义和类型
• 无失真编码定理
• 限失真编码定理 • 最佳变长编码方法
• 常用信源编码方法
信源编码器
信源序列 X ( X 1 , X 2 ,, X L ), X l a1 , a2 ,, an , l 1, 2,, n 编码序列(码字) Y (Y1 , Y2 ,, YK L ), Yk b1 , b2 ,, bm , k 1, 2,, m K L
(信息论)第5章无失真信源编码
定长编码定理
定长信源编码定理讨论了编码的有关参数对译 码差错的限制关系
sq p s q
定理 5.3.1 设离散无记忆信源
S s1 P p s 1 p s 2 s2
的熵为H S ,其 N 次扩展信源为
S N 1 p 1 P
2 q p 2 p q
N N
现在用码符号集 X x1 , x2 ,, xr 对N次扩展信源 S N 进行长度为 l 的定长编码,对于 0, 0 ,只要满足
l H S N log r
则当 N 足够大时,译码错误概率为任意小,几乎可以实 现无失真编码。 反之,若满足
l H S 2 N log r
则不可能实现无失真编码。而当N足够大时,译码错误概 14 率近似等于1。
以上的定理5.3.1 和定理5.3.2实际上说明的是一个 问题,虽然该定理是在平稳无记忆离散信源的条件下 证明的,但它也同样适合于平稳有记忆信源,只要要 2 求有记忆信源的极限熵 H S 和极限方差 存在 即可。对于平稳有记忆信源,式(5.6)和式(5.7 ) 中 H S 应该为极限熵 H S 。
变长码(可变长度码)
2
奇异码:若码中所有码字都不相同,则称此码为非
奇异码。反之,称为奇异码。
同价码:每个码符号所占的传输时间都相同的码。定
长码中每个码字的传输时间相同。而变长码中的每个码 字的传输时间不一定相等。
表 5.1
信源符号si
信源符号出现概率 si p
第五章 编码定理

第五章 编码定理
无失真编码定理→ 无失真编码定理 第一极限定理 信源 限失真编码定理→ 限失真编码定理 第三极限定理 编码定理 信道 连续信道编码定理 以上定理有其逆定理,即当信息率小于信源熵( 以上定理有其逆定理, 即当信息率小于信源熵 (或 R(D))时,或信息率大于信道容量时,被传送的信 或信息率大于信道容量时, ) 息必然有失真 离散信道编码定理 →第二极限定理
N σ 2 (S ) P {| I ( a N ) − NH ( S ) |≥ N ε } ≤ (Nε )2 I (a N ) σ 2 (S ) P{| − H ( S ) |≥ ε } ≤ N Nε 2
即:
由于信源取值有q种,则N长信源序列就有 N种, 长信源序列就有q 由于信源取值有 种 长信源序列就有 将qN种序列分成两个互补的集
ε δ
第五章 编码定理
以上为正定理部分的证明。 以上为正定理部分的证明。 利用表达式: 利用表达式: r
当 N→∞时,由④式得: 式得:
rl Mε
exp(− Nε ) < 2 Mε σ (S ) 1− 2 Nε
l
④
→0
绝大部分在 Aε 中的序列已 无对应的码字, 无对应的码字,译码一定出错
在N→∞时,由①式得 P( Aε ) →1
第五章 编码定理
2、码树 、 某节点被安排为码字后, 某节点被安排为码字后,不再继续
中间 节点
终端 节点
伸枝, 终端节点,其它为中间节点, 伸枝,称终端节点,其它为中间节点, 中间节点 中间节点不安排码字。 中间节点不安排码字。 3、克拉夫特不等式: 、克拉夫特不等式: 对于码符号为X= ‥‥, 的任意即时码 的任意即时码, 对于码符号为 ={x1,x2,‥‥,xr}的任意即时码, ‥‥, 所对应的码长为l 其码字为w 其码字为 1,w2, ‥‥, wq,所对应的码长为 1, l2, ‥‥ , lq,则必定满足克拉夫特不等式; 反之 , ‥‥, 则必定满足克拉夫特不等式;反之, 若码长满足克拉夫特不等式, 则一定存在码长为l 若码长满足克拉夫特不等式 , 则一定存在码长为 i 的即时码。 的即时码。
第五章 无失真信源编码

第五章 无失真信源编码在第二章与第三章,我们给出了计算信源信息量的方法,在这一章,我们要讲 如何用二进制符号(当然也可采用别的方式)来表示各个信源符号(这个过程 叫信源编码)。
在这个过程中,我们要思考的问题主要是:如何给出一种好的信源编码方法? 我们要解决这样两个问题:1:从理论上来讲,信源编码的编码效率最好能好到什么程度?2:从设计算法的角度来讲,如何使得你的编码算法的效率非常接近最佳的编码效率? 首先我们要谈谈评价信源编码好坏的标准:一:编码的正确性 一个好的信源编码方法首先必须是正确的。
也就是说, 当信宿接收到信源发出的经过信源编码的信息后,它能正确地译码成 信源符号。
为了保证能正确译码,在编码时必须让一个信源符号或 多个信源符号构成的串对应的二进制符号串是唯一的(我们把这种编码 称为唯一可译码)。
唯一可译码要满足什么条件呢?设一个信源符号在信源编码时称为一个码字,首先唯一可译码要求任何两个不同 的信源符号在信源编码时不能用同一个码字表示:如下面的四种编码方法中,码1c 就不是一种唯一可译码。
因为在码1c 中,2s 与4s 的编码都为11,这样信宿就不知道该把11翻译成4s 还是2s (我们把码1c 这种编码方法称为奇异码)。
那么是否所有的非奇异码都是唯一可译的呢?不一定,因为在对某些非奇异码进行译码时我们无法确定一串二进制符号 对应的是一个码字还是多个码字。
如对于码2c 来说,00既可以翻译成11s s ,也可翻译成3s ,所以码2c 还不是唯一可译码。
我们的结论是:若对于任意有限的整数N ,其N 阶扩展码均为非奇 异的,则是唯一可译码。
二:译码的效率高低在编码时不仅要考虑能否正确译码,还要考虑译码的速度是否很快。
讲个例子说明这个问题。
上面的码3c 与码4c 都是唯一可译码,但两种码在译码的时候效率是不一样的。
对于码3c 来说,当信宿接收到符号1时,它不能马上对1进行译码,它必须 等接收到1后面的符号再译码,若1后的符号是1,则可把前一个1翻译成1s ;若1后的符号是0,则信宿也不能马上对10进行译码。
信息论基础与应用-李梅-第五章 无失真信源编码资料

00
01 10 11
0
01 001 111
第五章:无失真信源编码
一、信源编码的相关概念
3. N次扩展码
S s1 , s2 ,, sq
siBiblioteka C {w1 , w2 ,
, wq }
wi
S s1 , s2 ,
N
, sqN
s jN
计匹配编码,根据信源的不同概率分布而选用与之相 匹配的码。
第五章:无失真信源编码
一、信源编码的相关概念
1. 信源编码概述(续2)
信源的统计剩余度主要决定于以下两个因素 : 1)无记忆信源中,符号概率分布的非均匀性; 2)有记忆信源中,符号间的相关性及符号概率分布 的非均匀性。
怎样压缩信源的冗余度?
C N {w1 , w 2 ,, w q N }
w j w j1 w j2 w jN
s j s j1 s j2
j 1,2,, q N
j1 , j2 ,, jN 1,2,, q
第五章:无失真信源编码
一、信源编码的相关概念
3. N次扩展码(续1)
二次扩展信源符号 s j ( j 1, 2,...,16)
若一个码中所有码字的码长都相等,则称为定长码;
否则为变长码。
第五章:无失真信源编码
一、信源编码的相关概念
5. 奇异性
若一个码中所有码字互不相同,则称为非奇异码; 否则为奇异码。
信源符号si 码1 码2
s1 s2 s3 s4
0 11 00 11
0 10 00 01
第五章:无失真信源编码
第5章_信源—信道编码定理

这种编码方法,可以看成是一种特殊的试验信道
1 P (v j / ui ) 0
d (C )
v j C , v j f (ui ) v j f (ui )
1 N
P (U ) d [ u , f ( u )]
U
1 1 1 [0 1 1 1 0 1 1 1] 3 8 4
要使信源在此二元信道中传输,必须对X进行二元编码:
x1 C1 C2 000 0000
x2 001 0001
x3 010 0010
H (X ) 3
H (X ) 4
x4 011 0011
x5 100 0100
x6 101 0101
对于码 对于码
C1
R1
0 .6 4 6
(比特/信道符号) (比特/信道符号)
第5章
信道—信源编码定理
通用通信系统
其中:编码器包括信源编码和信道编码两个部分; 译码器包括信道译码和信源译码两个部分; 信道为有噪信道。
•信道编码 •给定信道输入符号集AX; •给定信道输出符号集AY; •对每个输入符号x,存在一个非负实数b(x),为传输x的 代价。 定义n阶容量—代价函数:
信息率为1/3,而平均失真为1/4,根据香农第三定理, 若允许失真D=1/4时,总可以找到一种编码,使信息输出 率达到极限R(1/4)
1 1 R ( ) 1 H ( ) 0 .1 8 9 4 4
信源—信道匹配
• 当信源与信道相连接时,其信息传输率并未 达到最大. • 希望能使信息传输率越大越好,能达到或尽 可能接近于信道容量, 信息传输率接近于信道 容量只有在信源取最佳分布时才能实现。 • 由此可见,当信道确定后,信道的信息传输 率与信源分布是密切相关的。当达到信道容 量时,我们称信源与信道达到匹配,否则认 为信道有剩余。
信息论与编码[第五章无失真信源编码定理与编码]山东大学期末考试知识点复习
![信息论与编码[第五章无失真信源编码定理与编码]山东大学期末考试知识点复习](https://img.taocdn.com/s3/m/80df4dc9b90d6c85ed3ac6c3.png)
第五章无失真信源编码定理与编码5.1.1 信源编码和码的类型1.信源编码2.码的类型若码符号集中符号数r=2称为二元码,r=3称为三元码,……,r元码。
若分组码中所有码字的码长都相同则称为等长码,否则称为变长码。
若分组码中所有码字都不相同则称为非奇异码,否则称为奇异码。
若每个码符号x i∈X的传输时间都相同则称为同价码,否则称为非同价码。
若分组码的任意一串有限长的码符号只能被唯一地译成所对应的信源符号序列则称为唯一可译码,否则称为非唯一可译码。
若分组码中,没有任何完整的码字是其他码字的前缀,则称为即时码(又称非延长码或前缀条件码),否则称为延长码。
本章主要研究的是同价唯一可译码.5.1.2 即时码及其树图构造法即时码(非延长码或前缀条件码)是唯一可译码的一类子码。
即时码可用树图法来构造。
构造的要点是:(1)最上端为树根A,从根出发向下伸出树枝,树枝总数等于r,树枝的尽头为节点。
(2)从每个节点再伸出r枝树枝,当某节点被安排为码字后,就不再伸枝,这节点为终端节点。
一直继续进行,直至都不能伸枝为止。
(3)每个节点所伸出的树枝标上码符号,从根出发到终端节点所走路径对应的码符号序列则为终端节点的码字。
即时码可用树图法来进行编码和译码。
从树图可知,即时码可以即时进行译码。
当码字长度给定,即时码不是唯一的。
可以认为等长唯一可译码是即时码的一类子码。
5.1.3 唯一可译码存在的充要条件(1)对含有q个信源符号的信源用含r个符号的码符号集进行编码,各码字的码长为l1,l2,…,l q的唯一可译码存在的充要条件是,满足Kraft不等式5.1.4 唯一可译码的判断法唯一可译码的判断步骤:首先,观察是否是非奇异码.若是奇异码则一定不是唯一可译码。
其次,计算是否满足Kraft不等式。
若不满足一定不是唯一可译码。
再次,将码画成一棵树图,观察是否满足即时码的树图的构造,若满足则是唯一可译码。
或用Sardinas和Patterson设计的判断方法:计算出分组码中所有可能的尾随后缀集合F,观察F中有没有包含任一码字,若无则为唯一可译码;若有则一定不是唯一可译码.上述判断步骤中Sardinas和Patterson设计的判断方法是能确切地判断出是否是唯一可译码的方法,所以可以跳过前三个步骤直接采用该判断法。
无失真信源编码

∑ 其中 z = (z1, z2,
所以,
zN )
,z
=
E( 1 N
N i=1
zi )
,σ
2
= Var(zi )
pr
⎧⎨x ⎩
:
log p(x) N
+
H(X)
≥
δ
⎫ ⎬
≤
⎭
σ2 Nδ 2
(5. 2. 10)
其中,自信息的方差
σ 2 = Var [log p ( x i )]
q
∑ = E⎡⎣log2 p(xi)⎤⎦ − H2(X) = pi log2 pi − H2(X) (5. 2. 11) i=1
(5. 2.6)
因为信源是无记忆的,所以 p(x) = p(x1 )
得到
N
log p(x) = ∑ log p(xi )
i =1
将(5. 2. 7)代入(5. 2. 6),得
p(xN ) ,
(5. 2. 7)
∑ 1
N
N
log p(xi ) + H ( X )
i =1
≥δ
(5. 2. 8)
14
令 zi = log p ( xi ) , 可得 E(zi ) = −H ( X ) , 所以
第五章 无失真信源编码
中山大学 信息科学与技术学院
主要内容
本章主要介绍无失真信源编码定理与一 些重要的无失真信源编码方法
一、概述 二、定长码 三、变长码 四、哈夫曼编码 五、几种实用的信源编码方法
1
信源编码:将信源符号序列按一定的数学规律映射 成由码符号组成的码序列的过程。
信源译码:根据码序列恢复信源序列的过程。 无失真信源编码:即信源符号可以通过编码序列
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2、信道编码:是以提高信息传输的可靠性为目的的编码。
通常通过增加信源的冗余度来实现。采用的一般方法是 增大码率/带宽。与信源编码正好相反。
3、密码:是以提高通信系统的安全性为目的的编码。通
常通过加密和解密来实现。从信息论的观点出发,“加
密”可视为增熵的过程,“解密”可视为减熵的过程。 4、信源编码理论是信息论的一个重要分支,其理论基础是 信源编码的两个定理。
N log q ≤ l log r
l log q ≥ N log r
log q l≥ log r
平均每个信 源符号所需 码符号个数
当r=2(二元码),则有
l ≥ log q N
例:对英文电报的32个符号进行二元编码,根据上述关系:
若N 1
log 32 l 5 log 2
我们继续讨论上面的例子,我们已经知道英文的极限 熵是1.4bit,远小于5bit,也就是说,5个二元码符号只携 带1.4bit的信息量,实际上,5个二元符号最多可以携带 5bit信息量。我们可以做到让平均码长缩短,提高信息传 输率。下面举例阐明 设信源
s3 s2 s4 S s1 P( s ) P( s ) P( s ) P( s ) P( s ) 1 2 3 4
4
P( s ) 1
i 1 i
而其依赖关系为:
P(s2 / s1 ) P(s1 / s2 ) P(s4 / s3 ) P(s3 / s4 ) 1, 其余P(s j / si ) 0
定理5.6 若存在一个码长为 l1, l2 ,, lq 唯一可译码,则一定
存在一个同样长度的即时码。
这说明,其他唯一可译码在码长方面并不比即时码占 优。所以在讨论唯一可译码时,只需要讨论即时码就可 以了。源自5.5.4 惟一可译变长码的判断法
萨得纳斯(Sardinas)-彼得森(Patterson)准则
将产生的尾随后缀列出。依此下去,直至没有一个尾随 后缀是码字的前缀或没有新的尾随后缀产生为止。由此 得到由码C的所有可能的尾随后缀组成的集合F。
例5.2 (p210) C={0,10,1100,1110,1011,1101}
码字 00 11 10 10 01 尾随后缀 0 11 1 0 100 110 011 101 0 0 1 11 1
l log r H ( S ) N
令:R ' log r 称之为编码信息率。可见,编码信息 N 率大于信源的熵,才能实现无失真编码。
l
为了衡量编码效果,引进
H (S ) H (S ) l R' log r N
称为编码效率。 最佳编码效率为:
H (S ) H (S ) ' R H (S )
第5章 无失真信源编码定理
◆ 编码器 ◆ 等长码 ◆ 等长信源编码定理 ◆ 变长码
◆ 变长信源编码定理
引 言
1、信源编码:以提高通信有效性为目的的编码。通常通 过压缩信源的冗余度来实现。采用的一般方法是压缩每
个信源符号的平均比特数或信源的码率。即同样多的信
息用较少的码率传送,使单位时间内传送的平均信息量 增加,从而提高通信的有效性。
s1 s2 s3 s4
00 01 10 11
00 11 10 11
若对一个信源S进行等长编码,那么信源S存在惟一
可译等长码的条件是 信源S的 符号个数 等长码的码长
q ≤r
l
码符号个数
若对信源S的N次扩展信源 S N 进行等长编码,要编得 等长码是惟一可译则必须满足
q ≤r
N
l
两边取对数有 或 若N=1,则有
N log r
则不可能实现无失真编码,当N趋向于无穷大是,译码错 误率接近于1。
•定理5.3的条件式可写成:
l log r NH ( S )
左边表示长为 l 的码符号所能载荷的最大信息量,而右
边代表长为N的序列平均携带的信息量。因此,只要码字
传输的信息量大于信源序列携带的信息量,总可以实现无 失真编码 。 •定理5.3的条件式也可写成:
但码3和码4也不太一样,码4称作逗点码,只要收到1,就
可以立即作出译码;而码3不同,当收到一个或几个码时,
必须参考后面的码才能作出判断。 定义 在唯一可译码中,有一类码,它在译码是无须参考 后面的码字就可以作出判断,这种码称为即时码。 定义 如果一个码组中的任一个码字都不是另一个码字 的续长,或者说,任何一个码字后加上若干码元后都不是
F={11,00,10,01,0,1,100,110,011,101}
0
0 0
01
001 0001
树枝数——码的数
节数——码长 端点——码字 满树——等长码 非满树——变长码
码4的树图
码3的树图
在每个节点上都有r个分枝的树称为整树,否则称为非 整树。即时码的树图还可以用来译码。
5.5.3 克拉夫特(Kraft)不等式
定理5.4 对于码符号为 X {x1 , x2 ,..., xr } 的任意即时码,其 码字为 W1 ,W2 ,...,Wq 所对应的码长为 l1 , l2 ,..., lq ,则必定满
足:
r li 1
i 1
q
反之,若码长满足上式,则一定存在这样的即时码 。 可以根据即时码的树图构造法来证明。 1956年,B.McMillan证明了对于唯一可译码也必须满足 上面的不等式, 定理5.5 对于码符号为 X {x1 , x2 ,..., xr }的任意r元唯一 可译码,其码字为 W1 ,W2 ,...,Wq 所对应的码长为l1 , l2 ,..., lq
性之后,我们对信源作N次扩展,在扩展后形成的信源
(也就是句子)中,有些句子是有意义的,而有些句子是 没有意义的,我们可以只对有意义的句子编码,而对那些
没有意义的句子不进行编码,这样就可以缩短每个信源符
号所需的码长。
5.4 等长信源编码定理
定理5.3(等长信源编码定理) 一个熵为H(S)的离散无记 忆信源,若对其N次扩展信源进行等长r元编码,码长为 l 对于任意 大于0,只要满足 l H (S ) N log r 当N无穷大时,则可以实现几乎无失真编码,反之,若: l H ( S ) 2
2、等长码:
若一组码中所有码字的长度都相同,称为等长码。 3、变长码: 若一组码中所有码字的长度各不相同,称为变长码。 4、非奇异码:
若一组码中所有码字都不相同,称为非奇异码。
si s j Wi Wj si , s j S Wi ,Wj C
5、奇异码:
若一组码中有相同的码字,称为奇异码。
si s j Wi Wj si , s j S Wi ,Wj C
6、若码符号集 X ( x1 , x2 ,, xr ) 中每个码符号所占的传
输时间都相同,则编码所得的码C为同价码。
7、码的N次扩展:
若码 C :{W1,W2 ,...,Wq } , 码 B :{Bi (Wi1Wi 2 ...WiN )} 则称码B为 码C的N次扩展码。 8、唯一可译码: 若码的任意一串有限长的码符号序列只能被唯一的译成
码 C 2 的二次扩展码
二次扩展信源符号 码字
αi ,i = 1,2, ,16
Wi,i 1, 2,, 16
1 s1s1 2 s1s2 3 s1s3
16 s4 s4
00 001 0001
111111
5.2
信源符号 s i
等长码
表5.2 等长码
码 C1
码 C2
码组中另一个码字,则称为即时码,也称非延长码或前缀
条件码。 这两个定义是一致的。
所有的码 非奇异码 唯一可译码 即时码
5.5.2 即时码的树图构造法 我们可以用树图的形式构造即时码,如 0 0 0 1 1 1 1 1 1 1 1 0 树根——码字的起点 0 10 100 1000 节点数——码字的一部分
信源符号 s i 符号出现概率p( si ) 码 C1 码C 2
s1
p( s1 )
p ( s2 ) p( s3 ) p ( s4 )
00
0 01 001 111
s2
s3 s4
01 10 11
信源S的二次扩展信源为
S 2 [1 s1s1 2 s1s2 3 s1s3 16 s4 s4 ]
无失真信源编码定理:是离散信源/数字信号编码的基础;
限失真信源编码定理:是连续信源/模拟信号编码的基础。 5、信源编码的分类:离散信源编码、连续信源编码和相关 信源编码三类。 离散信源编码:独立信源编码,可做到无失真编码; 连续信源编码:独立信源编码,只能做到限失真信源编码; 相关信源编码:非独立信源编码。
所对应的信源符号序列,则称此码为唯一可译码。
举例讨论N次扩展码
s2 s3 s4 S s1 p( s ) p( s ) p( s ) p( s ) p( s ) 1 2 3 4
p( s ) 1
i 1 i
4
表5.1 信源S的两种不同编码码字
5.1 编码器
编码器可以看作这样一个系统,它的输入端为原始信 源S,其符号集为 S {S1, S2 ,..., Sq };而信道所能传输的符号集 为 X {x1, x2 ,..., xr } 编码器的功能是用符号集X中的元素,将 原始信源的符号 S i 变换为相应的码字符号 wi ,所以编码器 输出端的符号集为 C :{W1,W2 ,...,Wq }
S {S1 , S2 ,..., Sq }
编码器
C :{W1 ,W2 ,...,Wq }
X {x1 , x2 ,..., xr }
wi 称为码字,Li 为码字wi 的码元个数,称为码字 w 的码字 i 长度,简称码长。 编码就是从信源符号到码符号的一种映射。