中文分词切词超详细分析
百度中文分词技巧

百度中文分词技巧什么是中文分词?我们都知道,英文句子都是由一个一个单词按空格分开组成,所以在分词方面就方便多了,但我们中文是一个一个汉字连接而成,所以相对来说是比较复杂的。
中文分词指的是将一个汉语句子切分成一个一个单独的词,按照一定的规则重新组合成词序列的过程。
这个也称做“中文切词”。
分词对于搜索引擎有着很大的作用,是文本挖掘的基础,可以帮助程序自动识别语句的含义,以达到搜索结果的高度匹配,分词的质量直接影响了搜索结果的精确度。
目前搜索引擎分词的方法主要通过字典匹配和统计学两种方法。
一、基于字典匹配的分词方法这种方法首先得有一个超大的字典,也就是分词索引库,然后按照一定的规则将待分词的字符串与分词库中的词进行匹配,若找到某个词语,则匹配成功,这种匹配有分以下四种方式:1、正向最大匹配法(由左到右的方向);2、逆向最大匹配法(由右到左的方向);3、最少切分(使每一句中切出的词数最小);4、双向最大匹配法(进行由左到右、由右到左两次扫描)通常,搜索引擎会采用多种方式组合使用。
但这种方式也同样给搜索引擎带来了难道,比如对于歧义的处理(关键是我们汉语的博大精深啊),为了提高匹配的准确率,搜索引擎还会模拟人对句子的理解,达到识别词语的效果。
基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。
通常包括三个部分:分词子系统、句法语义子系统、总控部分。
在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。
这种分词方法需要使用大量的语言知识和信息,当然我们的搜索引擎也在不断进步。
二、基于统计的分词方法虽然分词字典解决了很多问题,但还是远远不够的,搜索引擎还要具备不断的发现新的词语的能力,通过计算词语相邻出现的概率来确定是否是一个单独的词语。
所以,掌握的上下文越多,对句子的理解就越准确,分词也越精确。
举个例子说,“搜索引擎优化”,在字典中匹配出来可能是:搜索/引擎/优化、搜/索引/擎/优化,但经过后期的概率计算,发现“搜索引擎优化”在上下文相邻出现的次数非常多,那么基于统计就会将这个词语也加入进分词索引库。
词语的拆分知识点

词语的拆分知识点词语的拆分是中文语言学中的一个重要环节,它能够帮助人们更好地理解和掌握词语的构成及含义。
在本文中,我们将探讨词语的拆分知识点,包括基本原则、常见方法和注意事项等。
一、基本原则1. 四大原则词语的拆分遵循四大原则:意义原则、声韵原则、形态原则和语法原则。
- 意义原则:词语的拆分应符合其意义的整体性,不能破坏原有的语义结构。
- 声韵原则:对于由声音组成的词语,要根据其读音进行拆分,保留其读音特点。
- 形态原则:根据词语的形态结构进行拆分,保留词的词素或词根。
- 语法原则:拆分后的词语在语法上能够得到正确的解释和使用。
2. 词语边界词语的拆分需要准确定位其边界,即确定词语的起始和结束位置。
通常根据语义和语法的要求,结合上下文来判断。
二、常见方法1. 语义拆分根据词语的意义进行拆分,将其分解为具有独立意义或语义关系的词素。
例如,将“阳光”拆分为“阳”和“光”,分别表示太阳和光线。
2. 音形拆分根据词语的声音和形状进行拆分,常见的方法有:假名拆分、词素拆分和形音拆分等。
- 假名拆分:根据拼音或假名的读音拆分词语,例如将“中文”拆分为“zhōng”和“wén”。
- 词素拆分:根据词语的词素进行拆分,例如将“笑话”拆分为“笑”和“话”。
- 形音拆分:根据词语的形状和读音进行拆分,例如将“悲”拆分为“北”和“哀”,表示悲伤的意思。
3. 语法拆分根据句子结构和语法规则进行拆分,主要针对复合词语或短语的拆分。
例如将“绿茶”拆分为“绿”和“茶”,表示绿色的茶。
三、注意事项1. 上下文的影响词语的拆分需要根据上下文的语境进行判断,有时会影响词语的边界和拆分方式。
因此,在拆分时应充分考虑上下文的信息。
2. 专有名词的处理对于专有名词,由于其特殊性,拆分的方式可能会和普通词语有所不同。
需根据名词的习惯用法和语义特点进行合理拆分。
3. 多音字的处理多音字存在着不同的读音和不同的拆分方式,需要根据具体的语境和词语意义进行选择。
中文切词方法学习

中文切词方法学习
中文切词指的是对中文文本进行分词,即将连续的汉字序列按照一定的规则切分成词语。
中文切词是中文自然语言处理的关键技术之一、以下介绍几种常用的中文切词方法:
1.基于词典匹配:建立一个包含常用词语的词典,使用词典中的词语作为基本的切分单位。
对于输入文本,从左到右依次匹配词典中的词语,将匹配到的词语切分出来。
当遇到无法匹配的字符时,采用回溯、最长匹配等策略寻找最合适的切分点。
常用的词典包括常见词汇、专业词汇、人名、地名等。
2.基于统计模型:统计模型是根据大规模的中文文本语料库训练得到的模型,能够通过概率计算每个位置的最佳切分点。
常用的统计模型包括隐马尔可夫模型(HMM)、条件随机场(CRF)等。
这些模型利用上下文信息、词语频率等因素进行切词,提高切分的准确度。
3.基于规则的切词:通过预先定义一些规则来完成切词任务。
规则可以包括词语的长度、词性、词语之间的关系等。
规则可以手动定义,也可以通过机器学习算法自动学习得到。
4.结合多种方法:常常使用多种方法的组合来进行中文切词,以提高切词的准确性和效果。
如结合词典匹配和统计模型来进行切词,先用词典进行基本的切分,再通过统计模型进一步调整切分结果。
需要注意的是,中文切词是一个非常具有挑战性的任务,由于中文的特殊结构,切分的准确性和效果可能会受到多个因素的制约。
因此,选择合适的切词方法和处理策略,以及合适的语料库进行训练,是提高切词效果的关键。
中文分词原理

中文分词原理中文分词是指将一个汉字序列切分成一个个具有语言意义的词语的过程,是中文信息处理的基础工作之一。
在计算机领域中,中文分词是自然语言处理的重要环节,对于搜索引擎、信息检索、文本挖掘等应用具有重要意义。
本文将介绍中文分词的原理及相关内容。
首先,中文分词的原理是基于词语的语言学特征来进行切分。
中文词语之间并没有像英文那样的明显分隔符号,因此要进行中文分词就需要依靠词语的语言学特征来进行判断。
中文词语通常由一个或多个汉字组成,而且词语之间具有一定的语义关联,因此可以通过词语的语言学特征来进行切分。
其次,中文分词的原理还涉及到词语的频率统计和语境分析。
在进行中文分词时,需要利用大量的语料库来进行词语的频率统计,以确定词语的常见组合和概率。
同时,还需要进行语境分析,即根据词语在句子或文章中的上下文来确定词语的边界,以保证切分结果的准确性。
另外,中文分词的原理还包括了一些特定的算法和模型。
目前常用的中文分词算法包括基于词典的最大匹配法、逆向最大匹配法、双向最大匹配法等。
此外,还有基于统计模型的中文分词方法,如隐马尔可夫模型(HMM)、条件随机场(CRF)等。
这些算法和模型都是基于中文词语的语言学特征和频率统计来进行切分的。
总的来说,中文分词的原理是基于词语的语言学特征、频率统计和语境分析来进行切分的。
通过对词语的特征和语境进行分析,结合相应的算法和模型,可以实现对中文文本的准确切分。
中文分词的准确性对于中文信息处理具有重要意义,因此对于中文分词原理的深入理解和研究具有重要意义。
总结一下,中文分词原理是基于词语的语言学特征、频率统计和语境分析来进行切分的,通过相应的算法和模型实现对中文文本的准确切分。
中文分词对于中文信息处理具有重要意义,对其原理的深入理解和研究对于提高中文信息处理的效率和准确性具有重要意义。
字词拆解秘籍

字词拆解秘籍字词拆解是学习语言的基础,也是提升写作能力的关键。
在本文中,我将为大家介绍一些字词拆解的秘籍,帮助大家更好地理解和运用汉语词汇。
一、异构拆解法异构拆解法是将一个字词按照发音和词义进行拆解,把字词的不同部分进行组合,形成新的词语或句子。
这种方法非常适合记忆词汇和理解词义。
例如,看到汉字“忽”和“视”,我们可以通过异构拆解法进行拆解,得到“忽视”的词义:“忽”表示短暂的时间,而“视”表示观察、看待。
因此,我们可以推断出“忽视”的意思是短暂地不去观察或关注某事物。
二、形声拆解法形声拆解法是根据字的构造特点来进行拆解,字形部分通常暗示着字的音义信息。
这种方法能够帮助我们辨析字义和记忆字形。
例如,看到汉字“战”,我们可以发现它是由“戈”和“占”两个字形组合而成。
通过形声拆解法,我们可以推测出“战”字与战争或战斗相关。
这样的字拆解方法,可以帮助我们更好地记忆字义和区分语义相近的词语。
三、构词法拆解构词法拆解是指通过对字词的部首和词根进行分析和拆解,从而得到更深层次的理解和运用。
例如,看到汉字“骄傲”,我们可以通过构词法拆解看到,这个字词由“马”和“姜”组成。
通过拆解我们可以知道,“骄傲”一词中的“马”是表示高昂的意思,“姜”表示挺立的意思。
整个字词的构成暗示了一个人自豪、自信的态度。
通过上述三种拆解方法,我们可以更加准确地理解和运用汉语词汇,提升自己的写作能力。
同时,这些拆解方法也能够帮助我们拓展词汇量,丰富表达方式。
四、注意事项在进行字词拆解时,需要注意以下几点:1.上下文语境:字词的意义往往是与上下文相关的,需要结合具体的语境判断。
2.多方面参考:不同的拆解方法可以相互印证,多方面参考能够帮助我们理解和记忆字词。
3.辨析字义:有些字词在发音和构造上相似,但意义不同,需要进行仔细区分。
4.灵活运用:拆解方法不是刻板的规则,需要灵活运用,根据实际情况加以变通。
总之,字词拆解是学习汉语和提高写作能力的重要方法之一。
简易中文分词

简易中文分词中文分词是指将连续的汉字序列切分成一个个词语的任务,是中文自然语言处理领域中非常重要的任务之一。
中文分词在文本处理、机器翻译、信息检索等应用中起着至关重要的作用。
下面将介绍中文分词的基本概念、算法以及一些常见的分词工具。
一、中文分词的基本概念中文分词的目标是将一个句子或一个文本按照词语的粒度进行切分,得到一个词语序列。
中文分词的挑战在于中文没有像英文那样使用空格来分隔单词,而且往往存在词语之间重叠的情况,如“千万”、“怎么办”等。
因此,中文分词需要结合词典、规则以及统计等方法来解决这些问题。
1.词语的定义在中文分词中,词语的定义往往是基于语言学的角度,即在语义上具有一定完整含义的最小语言单位。
词语可以是单个汉字,也可以是由多个汉字组成的词组。
例如,“中国”、“人民”、“共和国”等都是一个词语。
2.分词的准则中文分词的准则主要包括正向最大匹配法、逆向最大匹配法、双向最大匹配法等。
正向最大匹配法是从左到右将句子进行扫描,每次选择最长的词语作为分词结果;逆向最大匹配法与正向最大匹配法相反,从右到左进行扫描;双向最大匹配法则是将正向和逆向两个方向的结果进行比较,选择最优的分词结果。
这些方法都是基于词典进行匹配的。
3.未登录词的处理未登录词是指在词典中没有出现的词语,比如一些新词、专有名词等。
处理未登录词是中文分词中的一个难点,可以通过统计、规则以及机器学习等方法进行处理。
二、中文分词的常见算法和方法1.基于词典的分词算法基于词典的分词算法是指利用已有的词典对文本进行匹配,找出其中的词语作为分词结果。
基于词典的方法包括正向最大匹配、逆向最大匹配、双向最大匹配等。
这些方法的优点是简单高效,但对于未登录词的处理较为困难。
2.基于统计的分词算法基于统计的分词算法是指利用已有的大规模语料库进行统计,通过分析词语的频率、邻接关系等信息来进行分词。
常用的统计方法包括隐马尔可夫模型(Hidden Markov Model,HMM)、最大熵模型(Maximum Entropy Model,MEM)、条件随机场(Conditional Random Field,CRF)等。
现代汉语语料库加工规范——词语切分与词性标注

现代汉语语料库加工规范——词语切分与词性标注1999年3月版北京大学计算语言学研究所1999年3月14日⒈ 前言北大计算语言学研究所从1992年开始进行汉语语料库的多级加工研究。
第一步是对原始语料进行切分和词性标注。
1994年制订了《现代汉语文本切分与词性标注规范V1.0》。
几年来已完成了约60万字语料的切分与标注,并在短语自动识别、树库构建等方向上进行了探索。
在积累了长期的实践经验之后,最近又进行了《人民日报》语料加工的实验。
为了保证大规模语料加工这一项重要的语言工程的顺利进行,北大计算语言学研究所于1998年10月制订了《现代汉语文本切分与词性标注规范V2.0》(征求意见稿)。
因这次加工的任务超出词语切分与词性标注的范围,故将新版的规范改名为《现代汉语语料库加工规范》。
制订《现代汉语语料库加工规范》的基本思路如下:⑴ ⑴ 词语的切分规范尽可能同中国国家标准GB13715“信息处理用现代汉语分词规范” (以下简称为“分词规范”)保持一致。
由于现在词语切分与词性标注是结合起来进行的,而且又有了一部《现代汉语语法信息词典》(以下有时简称“语法信息词典”或“语法词典”)可作为词语切分与词性标注的基本参照,这就有必要对“分词规范”作必要的调整和补充。
⑵ ⑵ 小标记集。
词性标注除了使用《现代汉语语法信息词典》中的26个词类标记(名词n、时间词t、处所词s、方位词f、数词m、量词q、区别词b、代词r、动词v、形容词a、状态词z、副词d、介词p、连词c、助词u、语气词y、叹词e、拟声词o、成语i、习用语l、简称j、前接成分h、后接成分k、语素g、非语素字x、标点符号w)外,增加了以下3类标记:①专有名词的分类标记,即人名nr,地名ns,团体机关单位名称nt,其他专有名词nz;②语素的子类标记,即名语素Ng,动语素Vg,形容语素Ag,时语素Tg,副语素Dg等;③动词和形容词的子类标记,即名动词vn(具有名词特性的动词),名形词an(具有名词特性的形容词),副动词vd(具有副词特性的动词),副形词ad(具有副词特性的形容词)。
切词

5、聚2015新品夏季必买爆品巴西havaianas人字 拖鞋TOP黑男女哈瓦 6、包邮Crocs卡骆驰男女中性 彩威夷热带风情人 字拖鞋|200701 7、小贝克汉姆情侣男女款人字拖鞋夏季韩版潮流 男士沙滩潮男拖凉拖鞋 8、AE美国鹰夏季厚底情侣人字拖韩版平底男女鞋 沙滩橡胶防滑凉拖鞋潮
从以上8个标题,我们可以看出点 什么了。 也就是说,“男女人字拖”这个 词,在淘宝的搜索系统看来,他 不是一个完整的词。他会对其进 行切分。 按照上面红色的词,我们大概可 以看出。 “男女人字拖鞋”,被切成了 “男女”,“人字拖”两个词。
当我们搜“男 女 人字拖”时,是“男”,“女”, “人字拖”,三个词。 而当我们搜“男女 人字拖”时,是“男女”,“人字 拖”,两个词。 在我们搜“男 女 人字拖时”,空格起到了分词作用, 因为“男”,“女”,已经是不能再分了。 那为什么“男女人字拖”,会自动分成“男女 人字拖”, 而不是“男 女 人字拖”呢? 这就是词库的作用了。 很明显“男女”这个词,比“男” “女”,是更稀有的 词。所以,分词的时候,直接选了“男女”。 也就是说,淘宝的分词过程可能是这样的: “男女人字拖”,首先会被切成“男”,“女”, “人”,“字”,“拖“男女” ,“人字拖”。
中文切词(又称中文分词 ChineseWordSegmentation)指的是将一个汉字 序列切分成一个一个单独的词。中文分词是文 本挖掘的基础,对于输入的一段中文,成功的 进行中文分词,可以达到电脑自动识别语句含 案例:在淘宝上输入“男女人字拖” 义的效果。这种方法又叫做机械分词方法,它 是按照一定的策略将待分析的汉字串与一个 “充分大的”机器词典中的词条进行匹配,若 在词典中找到某个字符串,则匹配成功(识别 出一个词)。
所以,对于消费者来说,在进行淘宝搜 索宝贝时要合理利用空格,准确搜索到 自己想要的宝贝 对于商家来说,由于计算机的分 词技术,商家更要做出合理的标题让消 费者找到宝贝而不失自己的商机
汉语分词简介

汉语分词
7
双向匹配法
比较FMM法与BMM法的切分结果,从而 决定正确的切分 可以识别出分词中的交叉歧义 算法时间、空间复杂性较高
汉语分词
8
主要的分词方法(二)
基于理解的分词方法:通过让计算机模 拟人对句子的理解,达到识别词的效果。 其基本思想就是在分词的同时进行句法、 语义分析,利用句法信息和语义信息来 处理歧义现象。 由于汉语语言知识的笼统、复杂性,难 以将各种语言信息组织成机器可直接读 取的形式,因此目前基于理解的分词系 统还处在试验阶段。
2011.12
汉语分词 1
分词的定义
中文分词 (Chinese Word Segmentation) 指的是将一 个汉字序列切分成一个一个单独的词。分词就是将连 续的字序列按照一定的规范重新组合成词序列的过程。 我们知道,在英文的行文中,单词之间是以空格作为 自然分界符的,而中文只是字、句和段能通过明显的 分界符来简单划界,唯独词没有一个形式上的分界符, 虽然英文也同样存在短语的划分问题,不过在词这一 层上,中文比之英文要复杂的多、困难的多。 通俗的说,中文分词就是要由机器在中文文本中词与 词之间加上标记。
汉语分词
13
切分歧义( ) 切分歧义(2)
真歧义
歧义字段在不同的语境中确实有多种切分形式 例: 地面积 这块/地/面积/还真不小 地面/积/了厚厚的雪
伪歧义
歧义字段单独拿出来看有歧义,但在所有真实语境中,仅有一种切 分形式可接受 例: 挨批评 挨/批评(√) 挨批/评(╳)
等
如“建设/有”、“中国/人民”、“各/地方”、 “本/地区”
汉语分词 15
未登录词(OOV)
虽然一般的词典都能覆盖大多数的词语,但有 相当一部分的词语不可能穷尽地收入系统词典 中,这些词语称为未登录词或新词 分类:
中文分词的三种方法

中文分词的三种方法
中文分词是对汉字序列进行切分和标注的过程,是许多中文文本处理任务的基础。
目前常用的中文分词方法主要有基于词典的方法、基于统计的方法和基于深度学习的方法。
基于词典的方法是根据预先构建的词典对文本进行分词。
该方法将文本与词典中的词进行匹配,从而得到分词结果。
优点是准确率较高,但缺点是对新词或专业术语的处理效果不佳。
基于统计的方法是通过建立语言模型来实现分词。
该方法使用大量的标注语料训练模型,通过统计词语之间的频率和概率来确定分词结果。
优点是对新词的处理有一定的鲁棒性,但缺点是对歧义性词语的处理效果有限。
基于深度学习的方法是利用神经网络模型进行分词。
该方法通过训练模型学习词语与其上下文之间的依赖关系,从而实现分词。
优点是对新词的处理效果较好,且具有较强的泛化能力,但缺点是需要大量的训练数据和计算资源。
综上所述,中文分词的三种方法各自具有不同的优缺点。
在实际应用中,可以根据任务需求和资源条件选择合适的方法进行处理。
例如,在自然语言处理领域,基于深度学习的方法在大规模数据集的训练下可以取得较好的效果,可以应用于机器翻译、文本分类等任务。
而基于词典的方法可以适用于某些特定领域的文本,如医药领
域或法律领域,因为这些领域往往有丰富的专业词汇和术语。
基于统计的方法则可以在较为通用的文本处理任务中使用,如情感分析、信息抽取等。
总之,中文分词方法的选择应根据具体任务和数据特点进行灵活调整,以期获得更好的处理效果。
一年级语文字词拆分小技巧

一年级语文字词拆分小技巧语文学习是一年级学生的重要内容,其中文字词的拆分是学习的基础和关键。
本文将为一年级的学生们分享一些拆分文字词的小技巧,帮助他们更好地理解和运用语文知识。
一、什么是文字词拆分文字词是一种由一个或多个汉字组成的语言符号,拥有独立的意义。
文字词拆分即将一个词拆分成由单个汉字组成的形式,并逐字逐句地分析每个字的含义和功能。
二、为什么进行文字词拆分文字词拆分是语文学习的基础,具有以下几点重要作用:1. 帮助理解词义:通过拆分词语,可以更加深入地理解每个字的意义和词语的整体含义,提高对词义的理解和运用能力。
2. 培养语感:逐字逐句地分析每个字的含义和功能,有助于培养学生对语言的感觉,提高语文表达能力。
3. 拓展词汇量:通过拆分文字词,可以将一个复杂的词语拆分成多个简单的字,有助于拓展学生的词汇量。
三、文字词拆分的小技巧1. 逐字拆分:将一个词语逐字拆分,理解每个字的含义和读音。
例如,“苹果”这个词可以拆分成“苹”和“果”,分别表示一种水果的名称。
2. 词性分析:通过词性分析,理解每个字在词语中的功能和作用。
例如,“快乐”这个词可以拆分成“快”和“乐”,其中“快”表示速度快,而“乐”表示高兴和快乐的意思。
3. 语法关系:理解词语在句子中的语法关系,帮助学生准确理解和运用词语。
例如,“小猫在树上”这个句子中,“小猫”可以拆分成“小”和“猫”,而“在”和“上”表示位置和动作。
4. 反义词拆分:通过拆分反义词,可以理解相反意义的词汇。
例如,“大”和“小”是一对反义词,“大”表示事物大小的概念,“小”表示事物大小的相反概念。
四、文字词拆分的注意事项在进行文字词拆分时,需要注意以下几点:1. 拆分的准确性:拆分文字词时要准确无误,确保每个字的含义和读音都能理解和运用。
2. 意义的综合理解:拆分文字词后,需要综合理解每个字的意义,整体把握词语的含义和用法。
3. 语境的影响:在进行文字词拆分时要考虑到上下文的语境,理解词语在句子中的具体意义和作用。
中文分词的三种方法(一)

中文分词的三种方法(一)中文分词的三种中文分词是指将一段中文文本划分为一个个有实际意义的词语的过程,是自然语言处理领域中的一项基本技术。
中文分词技术对于机器翻译、信息检索等任务非常重要。
本文介绍中文分词的三种方法。
基于词典的分词方法基于词典的分词方法是将一段文本中的每个字按照词典中的词语进行匹配,将匹配到的词作为分词结果。
这种方法的优点是分词速度快,但缺点是无法解决新词和歧义词的问题。
常见的基于词典的分词器有哈工大的LTP、清华大学的THULAC等。
基于统计的分词方法基于统计的分词方法是通过对大规模语料库的训练,学习每个字在不同位置上出现的概率来判断一个字是否为词语的一部分。
这种方法能够较好地解决新词和歧义词的问题,但对于生僻词和低频词表现不够理想。
常见的基于统计的分词器有结巴分词、斯坦福分词器等。
基于深度学习的分词方法基于深度学习的分词方法是通过神经网络对中文分词模型进行训练,来获取词语的内部表示。
这种方法的优点是对于生僻词和低频词的表现较好,但需要大量的标注数据和计算资源。
常见的基于深度学习的分词器有哈工大的BERT分词器、清华大学的BERT-wwm分词器等。
以上是中文分词的三种方法,选择哪种方法需要根据实际应用场景和需求进行评估。
接下来,我们将对三种方法进行进一步的详细说明。
基于词典的分词方法基于词典的分词方法是最简单的一种方法。
它主要针对的是已经存在于词典中的单词进行分词。
这种方法需要一个词典,并且在分词时将文本与词典进行匹配。
若匹配上,则将其作为一个完整的单词,否则就将该文本认为是单字成词。
由于它只需要匹配词典,所以速度也是比较快的。
在中文分词中,“哈工大LTP分词器”是基于词典的分词工具之一。
基于统计的分词方法基于统计的分词方法是一种基于自然语言处理技术的分词方法。
其主要思路是统计每个字在不同位置出现的概率以及不同字的组合出现的概率。
可以通过训练一个模型来预测哪些字符可以拼接成一个词语。
现代汉语文本的词语切分技术[技巧]
![现代汉语文本的词语切分技术[技巧]](https://img.taocdn.com/s3/m/aefc852d86c24028915f804d2b160b4e767f81c0.png)
现代汉语文本的词语切分技术一、引言1、汉语自动分词的必要性汉语自动分词是对汉语文本进行自动分析的第一个步骤。
可以这样设想汉语自动分词过程的困难:如果把某个英语文本中的所有空格符都去掉,然后让计算机自动恢复文本中原有的空格符,这就是词的识别过程,此过程的主要问题是对大量歧义现象的处理。
切词体现了汉语与英语的显著的不同。
英语文本是小字符集上的已充分分隔开的词串,而汉语文本是大字符集上的连续字串。
把字串分隔成词串,就是自动分词系统需要做的工作。
词是最小的、能独立活动的、有意义的语言成分。
计算机的所有语言知识都来自机器词典(给出词的各项信息)、句法规则(以词类的各种组合方式来描述词的聚合现象)以及有关词和句子的语义、语境、语用知识库。
汉语信息处理系统只要涉及句法、语义(如检索、翻译、文摘、校对等应用),就需要以词为基本单位。
例如汉字的拼音-字转换、简体-繁体转换、汉字的印刷体或手写体的识别、汉语文章的自动朗读(即语音合成)等等,都需要使用词的信息。
切词以后在词的层面上做转换或识别,处理的确定性就大大提高了。
再如信息检索,如果不切词(按字检索),当检索德国货币单位"马克"时,就会把"马克思"检索出来,而检索"华人"时会把"中华人民共和国"检索出来。
如果进行切词,就会大大提高检索的准确率。
在更高一级的文本处理中,例如句法分析、语句理解、自动文摘、自动分类和机器翻译等,更是少不了词的详细信息。
2、汉语自动分词中的困难在过去的十几年里, 汉语自动分词工作虽然也取得了很大成绩,但无论按照人的智力标准,还是同实用的需要相比较,差距还很大。
我们首先需要对这一工作的困难有充分的认识。
1).分词规范的问题(1)汉语词的概念汉语自动分词的首要困难是词的概念不清楚。
书面汉语是字的序列,词之间没有间隔标记,使得词的界定缺乏自然标准,而分词结果是否正确需要有一个通用、权威的分词标准来衡量。
中文分词方法

中文分词方法
中文分词是对一段中文文本进行切分成一个一个词语的过程,是
中文自然语言处理中非常重要的一步。
中文分词的目的是为了让计算
机能够理解中文文本,进而做出对文本的各种处理与分析。
以下是常见的中文分词方法:
一、基于规则的分词方法
基于规则的分词方法是一种最基础也是最常用的分词方法。
它使
用一系列规则来对文本进行划分。
例如,最常用的规则是“最大匹配法”,即先将文本从左往右按照最大匹配的原则进行划分,然后判断
每个词语的正确性并进行纠正。
虽然基于规则的分词方法的效率相对
较高,但是对于新词的处理存在局限性。
二、基于词典的分词方法
基于词典的分词方法是将一个大规模的中文词库加载到计算机中,然后在文本中进行搜索匹配。
这种方法的优点在于可以对文本进行精
确切分,但是存在歧义切分和新词处理的问题。
三、基于统计模型的分词方法
基于统计模型的分词方法是利用已知的分好的中文文本来学习新文本并进行分词的方法。
这种方法分为两种:HMM(隐马尔科夫模型)和CRF(条件随机场)。
虽然这种方法对于新词的处理较为灵活,但是需要大量的训练语料和时间。
四、基于深度学习的分词方法
基于深度学习的分词方法是将深度学习技术应用到中文分词中,使用神经网络进行词语的切分。
这种方法在处理歧义切分等难题时效果具有优势。
总之,中文分词方法有多种,每种方法都有其独特的优缺点。
在实际应用中,我们可以根据文本数据的特点和需求来选择不同的分词方法。
浅谈中文切词算法

浅谈中文切词算法作者:黎佳来源:《软件》2013年第07期摘要:如何高效率的获取满足个性化的需求成为了新时代的一个热门话题,搜索引擎在一定程度上体现了这一点。
然而在搜索引擎中,内部分词算法机制是关键环节,它的目的在于选取好的关键字。
一个好的分词算法会降低用户搜索信息的时间和难度,大大提高查询信息的效率。
然而目前有很多分词算法,它们的性能和效率各不相同,本文的主要研究目的是探讨目前几种比较流行分词器算法的工作机制,根据它们自身的不同特点,在准确率和召回率这两个方面来比较它们的性能,并进一步研究它们是如何处理用户关键字的。
关键词:智能信息处理;网页处理;切词算法;网络爬虫中图分类号: TP391 文献标识码:A DOI:10.3969/j.issn.1003-6970.2013.07.027本文著录格式:[1]黎佳.浅谈中文切词算法[J].软件,2313,34(7):75-760 引言所谓中文切词[1]就是将一个汉字序列切分成一个一个单独的词。
这些词可以让信息检索系统理解用户的检索要求,进而为其搜索相关的内容。
可以说它是搜索引擎[2]的关键,是文本挖掘的基础。
但是如何分,分好之后如何让计算机理解,其处理过程就是分词算法。
目前相关的中文分词算法有很多,但总的来说可分为三大类[3][4][5]:机械分词方法、理解分词方法和统计分词方法。
机械分词方法又称为基于字符串匹配的分词方法,按照一定的策略和相对应的机器词典中的词条进行匹配,如果找到了词典中的某个词条与之相对应,那就算是匹配成功。
其后又出现了机械分词的改进方法:一种是改进扫描方法,另一种方法则是词类标记和分词一起使用利用丰富的词类信息对分词决策提供帮助,并且在标注过程中又反过来对分词结果进行检验、调整,从而极大地提高切分的准确率。
理解分词方法是让计算机模拟人类的思想语言逻辑来对句子理解划分,从而达到识别词的效果。
这种方法一般需要大量的语言信息和知识,其复杂性较高。
三种分一刻词

三种分一刻词摘要:一、引言二、三种分词方法的介绍1.基于词典的分词方法2.基于统计的分词方法3.基于机器学习的分词方法三、每种方法的优缺点分析1.基于词典的分词方法2.基于统计的分词方法3.基于机器学习的分词方法四、结论正文:在中文自然语言处理领域,分词是非常重要的基础工作。
分词是指将连续的文本切分成有意义的独立词汇或短语。
本文将对三种常见的分词方法进行介绍和分析。
一、基于词典的分词方法基于词典的分词方法是最早也是最常用的一种分词方法。
这种方法主要依赖预先构建好的词典库,按照词典中词汇的顺序将文本切分成词汇。
这种方法的优点是简单易实现,对于常用词汇的处理效果较好。
然而,对于未登录词(即词典中没有的词汇)和歧义词的处理能力较弱。
二、基于统计的分词方法基于统计的分词方法主要通过对大量语料库进行分析,计算词汇的概率分布以及相邻字之间的概率,从而进行分词。
这种方法的优点是可以处理未登录词和歧义词,对于新词和生僻词的处理能力较强。
但是,这种方法的计算量较大,需要大量的语料库进行训练,而且对于词汇的切分准确性相对较低。
三、基于机器学习的分词方法基于机器学习的分词方法综合了词典方法和统计方法的优势,通过训练分类器对文本进行分词。
这种方法可以自动从语料库中学习词汇的规律,具有较强的处理未登录词和歧义词的能力。
同时,通过调整分类器的参数,可以提高分词的准确性。
然而,这种方法需要大量的训练数据和计算资源。
综上所述,三种分词方法各有优缺点。
在实际应用中,可以根据具体需求和场景选择合适的方法。
中文分词切词超详细分析
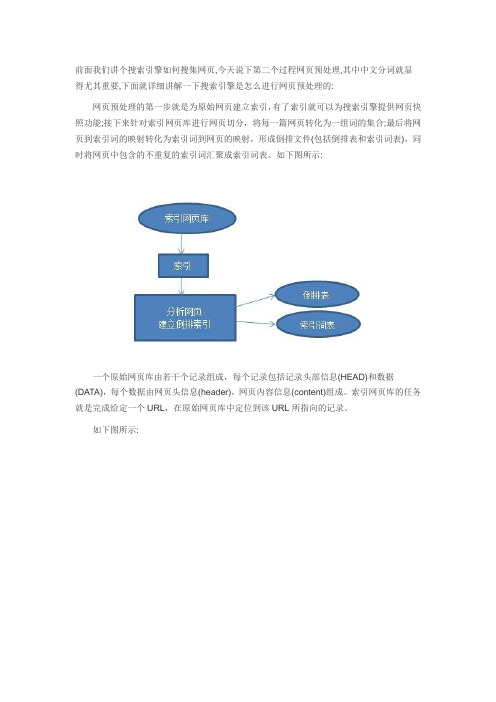
前面我们讲个搜索引擎如何搜集网页,今天说下第二个过程网页预处理,其中中文分词就显得尤其重要,下面就详细讲解一下搜索引擎是怎么进行网页预处理的:网页预处理的第一步就是为原始网页建立索引,有了索引就可以为搜索引擎提供网页快照功能;接下来针对索引网页库进行网页切分,将每一篇网页转化为一组词的集合;最后将网页到索引词的映射转化为索引词到网页的映射,形成倒排文件(包括倒排表和索引词表),同时将网页中包含的不重复的索引词汇聚成索引词表。
如下图所示:一个原始网页库由若干个记录组成,每个记录包括记录头部信息(HEAD)和数据(DATA),每个数据由网页头信息(header),网页内容信息(content)组成。
索引网页库的任务就是完成给定一个URL,在原始网页库中定位到该URL所指向的记录。
如下图所示:对索引网页库信息进行预处理包括网页分析和建立倒排文件索引两个部分。
中文自动分词是网页分析的前提。
文档由被称作特征项的索引词(词或者字)组成,网页分析是将一个文档表示为特征项的过程。
在对中文文本进行自动分析前,先将整句切割成小的词汇单元,即中文分词(或中文切词)。
切词软件中使用的基本词典包括词条及其对应词频。
自动分词的基本方法有两种:基于字符串匹配的分词方法和基于统计的分词方法。
1) 基于字符串匹配的分词方法这种方法又称为机械分词方法,它是按照一定的策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。
按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大或最长匹配,和最小或最短匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。
常用的几种机械分词方法如下:? 正向最大匹配;? 逆向最大匹配;? 最少切分(使每一句中切出的词数最小)。
还可以将正向最大匹配方法和逆向最大匹配方法结合起来构成双向匹配法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
前面我们讲个搜索引擎如何搜集网页,今天说下第二个过程网页预处理,其中中文分词就显得尤其重要,下面就详细讲解一下搜索引擎是怎么进行网页预处理的:
网页预处理的第一步就是为原始网页建立索引,有了索引就可以为搜索引擎提供网页快照功能;接下来针对索引网页库进行网页切分,将每一篇网页转化为一组词的集合;最后将网页到索引词的映射转化为索引词到网页的映射,形成倒排文件(包括倒排表和索引词表),同时将网页中包含的不重复的索引词汇聚成索引词表。
如下图所示:
一个原始网页库由若干个记录组成,每个记录包括记录头部信息(HEAD)和数据(DATA),每个数据由网页头信息(header),网页内容信息(content)组成。
索引网页库的任务就是完成给定一个URL,在原始网页库中定位到该URL所指向的记录。
如下图所示:
对索引网页库信息进行预处理包括网页分析和建立倒排文件索引两个部分。
中文自动分词是网页分析的前提。
文档由被称作特征项的索引词(词或者字)组成,网页分析是将一个文档表示为特征项的过程。
在对中文文本进行自动分析前,先将整句切割成小的词汇单元,即中文分词(或中文切词)。
切词软件中使用的基本词典包括词条及其对应词频。
自动分词的基本方法有两种:基于字符串匹配的分词方法和基于统计的分词方法。
1) 基于字符串匹配的分词方法
这种方法又称为机械分词方法,它是按照一定的策略将待分析的汉字串与一个充分大的词典中的词条进行匹配,若在词典中找到某个字符串,则匹配成功(识别出一个词)。
按照扫描方向的不同,串匹配分词方法可以分为正向匹配和逆向匹配;按照不同长度优先匹配的情况,可以分为最大或最长匹配,和最小或最短匹配;按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。
常用的几种机械分词方法如下:
? 正向最大匹配;
? 逆向最大匹配;
? 最少切分(使每一句中切出的词数最小)。
还可以将正向最大匹配方法和逆向最大匹配方法结合起来构成双向匹配法。
由于汉语单字成词的特点,正向最小匹配和逆向最小匹配一般很少使用。
一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。
对于机械分词方法,可模型化表示为ASM(d,a,m),即Automatic Segmentation Model。
其中,
d:匹配方向,+表示正向,-表示逆向;
a:每次匹配失败后增加或减少字串长度(字符数),+为增字,-为减字;
m:最大或最小匹配标志,+为最大匹配,-为最小匹配。
例如,ASM(+, -, +)就是正向减字最大匹配法(Maximum Match based approach,MM),ASM(-, -, +)就是逆向减字最大匹配法(简记为RMM方法)。
2)基于统计的分词方法
从形式上看,词是稳定的字的组合,因此上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。
因此字与字相邻共现的频率或概率能够较好的反映成词的可信度。
可以对语料中相邻共现的各个字的组合的频度进行统计,计算它们的互现信息。
互现信息体现类汉字之间结合关系的紧密程度。
当紧密程度高于某一个阈值时,便可认为此字组可能构成了一个词。
这种方法只需对语料中的字组频度进行统计,不需要切分词典,因而又叫做无词典分词法或统计取词方法。
实际应用的统计分词系统都要使用一部基本的分词词典(常用词词典)进行串匹配分词,同时使用统计方法识别一些新的词,即将串频统计和串匹配结合起来,既发挥匹配分词切分速度快、效率高的特点,又利用了无词典分词结合上下文识别生词、自动消除歧义的优点。
正向减字最大匹配法
这是主要的中文切词方法,正向减字最大匹配法切分的过程是从自然语言的中文语句中提取出设定的长度字串,与词典比较,如果在词典中,就算一个有意义的词串,并用分隔符分隔输出,否则缩短字串,在词典中重新查找(词典是预先定义好的)。
算法要求为:
输入:中文词典,待切分的文本d,d中有若干被标点符号分割(我们可以利用标点符号协助搜索引擎准确分词)的句子s1,设定的最大词长MaxLen。
输出:每个句子s1被切为若干长度不超过MaxLen的字符串,并用分隔符分开,记为s2,所有s2的连接构成d切分之后的文本。
该中文分词的算法思想是:事先将网页预处理成每行是一个句子的纯文本格式。
从d
中逐句提取,对于每个句子s1从左向右以MaxLen为界选出候选字串w,如果w在词典中,处理下一个长为MaxLen的候选字段;否则,将w最右边一个字去掉,继续与词典比较;s1切分完之后,构成词的字符串或者此时w已经为单字,用分隔符隔开输出给s2。
从s1中减去w,继续处理后续的字串。
s1处理结束,取T中的下一个句子赋给s1,重复前述步骤,直到整篇文本d都切分完毕。
其中MaxLen是一个经验值,通常设为8个字节(即4个汉字),MaxLen过小,长词会被切断;过长,又会导致切分效率低。
除了上述从左到右切分一遍句子,还从右到左切分一遍,对于两遍切分结果不同的字符串,用回溯法重新处理。
例如“学历史知识”顺向扫描的结果是:“学历/ 史/ 知识/”,通过查词典知道“史”不在词典中,于是进行回溯,将“学历”的尾字“历”取出与后面的“史”组成“历史”,再查词典,看“学”,“历史”是否在词典中,如果在,就将分词结果调整为:“学/ 历史/ 知识/”。
为网页建立全文索引是网页预处理的核心部分,包括分析网页和建立倒排文件。
二者是顺序进行,先分析网页,后建立倒排文件(也称为反向索引)。
如下图所示:
分析网页过程包括提取正文信息(指过滤网页标签,scripts,css,java,
embeddedobjects,comments等信息)和把正文信息切分为索引词两个阶段。
形成的结果是文档号到索引词的对应关系表。
每条记录中包括文档编号,索引词编号,索引词在文档中的位置信息,“索引词载体信息”(这些信息标识类文档中索引词的字体和大小等信息,或称载体信息)。
得到网页正文信息,调用切词模块,获得正向索引。
每一个网页由两行信息组成,第一行是文档编号,第二行是使用切分模块将文档正文信息划分成索引词后的集合。
如上图所示,创建倒排索引包括建立正向索引和反向索引。
分析完网页后,得到以网页编号为主键的正向索引表。
然后将相同索引词对应的数据合并到一起,就得到了以索引词为主键的最终的倒排文件索引,即反向索引.
最后就可以为最后一个阶段信息查询服务提供服务了, 传递到信息查询服务阶段的数
据包括索引网页库和倒排文件,倒排文件中包括倒排表和索引词表。
查询代理接受用户输入的查询短语,切分后,从索引词表和倒排文件中检索获得包含查询短语的文档并返回给用户。
这样搜索引擎的三个阶段就算完成了.。