oracle over partition by 条件
Oracle分析函数row_number()over(partitionbyorderby)

Oracle分析函数row_number()over(partitionbyorderby)1、格式row_number() over(partition by 列名1 order by 列名2 desc)2、解析表⽰根据列名1 分组,然后在分组内部根据列名2 排序,⽽此函数计算的值就表⽰每组内部排序后的顺序编号,可以⽤于去重复值与rownum的区别在于:使⽤rownum进⾏排序的时候是先对结果集加⼊伪列rownum然后再进⾏排序,⽽此函数在包含排序从句后是先排序再计算⾏号码.3、实例--分析函数SELECT USER_NAME,SCHOOL,DEPART,ROW_NUMBER() OVER(PARTITION BY USER_NAME ORDER BY SCHOOL, DEPART DESC)FROM USER_M;结果--分析函数SELECT *FROM (SELECT USER_NAME,SCHOOL,DEPART,ROW_NUMBER() OVER(PARTITION BY USER_NAME ORDER BY SCHOOL, DEPART DESC) RNFROM USER_M)WHERE RN = 1;结果--结合分页SELECT *FROM (SELECT ER_NAME,A.SCHOOL,A.DEPART,ROW_NUMBER() OVER(PARTITION BY SCHOOL ORDER BY USER_NAME, DEPART DESC) RNFROM (SELECT * FROM USER_M) AWHERE ROWNUM <= 10)WHERE RN >= 1;结果。
oracle over partition by用法

oracle over partition by用法在Oracle 数据库中,`OVER` 子句与`PARTITION BY` 子句一起使用,通常用于在SQL 窗口函数中定义分区。
`PARTITION BY` 子句用于将结果集划分为不同的分区,然后窗口函数将在每个分区内独立执行。
以下是一个简单的例子,演示了如何在Oracle 中使用`OVER PARTITION BY`:假设有一个名为`sales` 的表,包含`product_id`、`sales_date` 和`revenue` 列。
我们想要计算每个产品的销售总额,并在每个产品内进行分区:```sqlSELECTproduct_id,sales_date,revenue,SUM(revenue) OVER (PARTITION BY product_id ORDER BY sales_date) AS running_total FROMsales;```在这个查询中,`SUM(revenue) OVER (PARTITION BY product_id ORDER BY sales_date)` 表示计算每个产品的销售总额,同时在每个产品内按照销售日期排序。
`PARTITION BY` 子句将结果集划分为不同的分区,每个分区都有相同的`product_id`。
然后,`SUM` 窗口函数计算了每个分区内的销售总额,并在每个分区内按照`sales_date` 进行排序。
这样,对于每个产品,你都会得到一个包含销售日期、销售额和在该日期之前的销售总额的结果集。
总的来说,`OVER PARTITION BY` 是在窗口函数中使用的一种强大的功能,用于在结果集中定义分区,以便对每个分区应用窗口函数。
oracle max over partition by用法

oracle max over partition by用法全文共四篇示例,供读者参考第一篇示例:Oracle数据库是一种关系数据库管理系统,提供了丰富的功能和语法来处理数据。
在处理数据的时候,我们经常需要使用分析函数来进行复杂的计算和分析,max over partition by是一种常用的功能之一。
本文将介绍max over partition by的用法以及它在实际应用中的作用。
在Oracle数据库中,max over partition by是一种分析函数,它可以在一组数据中查找指定列的最大值,并返回结果。
它的语法如下:```max(column) over (partition by column_name)```column是要查找最大值的列,而column_name则是根据哪个列进行分区。
通过在max后面加上over partition by关键字,我们可以在指定的分区内查找最大值。
举个例子来说明max over partition by的用法:假设有一个销售订单表orders,包含了订单号(order_id)、商品编号(product_id)和销售额(amount)三个字段,我们现在想要查找每个商品的销售额最大值。
我们可以使用max over partition by来实现:```select order_id, product_id, amount,max(amount) over (partition by product_id) asmax_amountfrom orders```在实际应用中,max over partition by有很多用途。
我们可以使用它来查找每个员工的最高工资、每个部门的最大利润等等。
通过对数据进行分区并利用分析函数,我们可以更方便地对数据进行深入分析和计算。
除了max over partition by之外,Oracle还提供了其他一些强大的分析函数,如min over partition by、sum over partition by等等,它们都可以帮助我们更加高效地处理复杂的数据分析任务。
Oracle查询中OVER(PARTITIONBY..)用法

Oracle查询中OVER(PARTITIONBY..)⽤法为了⽅便⼤家学习和测试,所有的例⼦都是在Oracle⾃带⽤户Scott下建⽴的。
注:标题中的红⾊order by是说明在使⽤该⽅法的时候必须要带上order by。
⼀、rank()/dense_rank() over(partition by ...order by ...)现在客户有这样⼀个需求,查询每个部门⼯资最⾼的雇员的信息,相信有⼀定oracle应⽤知识的同学都能写出下⾯的SQL语句:select e.ename, e.job, e.sal, e.deptnofrom scott.emp e,(select e.deptno, max(e.sal) sal from scott.emp e group by e.deptno) mewhere e.deptno = me.deptnoand e.sal = me.sal;在满⾜客户需求的同时,⼤家应该习惯性的思考⼀下是否还有别的⽅法。
这个是肯定的,就是使⽤本⼩节标题中rank()over(partition by...)或dense_rank() over(partition by...)语法,SQL分别如下:select e.ename, e.job, e.sal, e.deptnofrom (select e.ename,e.job,e.sal,e.deptno,rank() over(partition by e.deptno order by e.sal desc) rankfrom scott.emp e) ewhere e.rank = 1;select e.ename, e.job, e.sal, e.deptnofrom (select e.ename,e.job,e.sal,e.deptno,dense_rank() over(partition by e.deptno order by e.sal desc) rankfrom scott.emp e) ewhere e.rank = 1;为什么会得出跟上⾯的语句⼀样的结果呢?这⾥补充讲解⼀下rank()/dense_rank() over(partition by e.deptno order by e.sal desc)语法。
oracle中over函数用法

oracle中over函数用法(实用版)目录1.Oracle 中 over 函数的概述2.over 函数的基本语法与参数3.over 函数的使用场景与实例4.over 函数与其他分析函数的配合使用5.总结正文一、Oracle 中 over 函数的概述Oracle 中的 over 函数是一种分析函数,用于对查询结果进行分区和排序。
它可以让我们在查询成绩时,按照不同的条件对数据进行汇总和分析,从而得到更加精确和具体的结果。
二、over 函数的基本语法与参数over 函数的基本语法如下:```over(partition, by, expr2, order, by, expr3)```其中,各个参数的含义如下:- partition:用于对结果进行分区的条件,可以是一个表分区或者一个列;- by:指定分区的顺序,可以是升序(ASC)或降序(DESC);- expr2:指定分区内的排序条件,可以是一个列或者一个表达式;- order:指定排序的顺序,可以是升序(ASC)或降序(DESC);- by:指定排序的列名;- expr3:可选参数,用于指定在每个分区内需要计算的聚合函数,如 sum、avg、count 等。
三、over 函数的使用场景与实例over 函数通常与 rownumber()、rank() 和 denserank、lag() 和lead() 等分析函数配合使用,以实现更加复杂的查询需求。
以下是一些常见的使用场景与实例:1.按照班级统计每个班级的总分和平均分:```select over(partition, by, t.class) sum(t.score) astotal_score, over(partition, by, t.class) avg(t.score) as average_scorefrom tscore t, ts_student swhere t.student_id = s.idorder by s.class;```2.按照时间分区,统计每个时间段内的总销售额:```select to_char(order_date, "YYYY-MM-DD") as sales_date, over(partition, by, to_char(order_date, "YYYY-MM-DD"))sum(sales_amount) as total_salesfrom salesorder by order_date;```3.计算每个学生的成绩排名:```select student_id, over(partition, by, rank()) rank_score from (select student_id, score, rownumber() over(order by score) as rankfrom exams) t;```四、over 函数与其他分析函数的配合使用over 函数可以与其他分析函数相互配合,以实现更加复杂的数据分析需求。
ORACLE中OVER函数的用法

oracle over函数详解今天在javaeye上看到一道面试题,很多人都用over函数解决的特意查了一下它的用法SQL> select deptno,ename,sal2 from emp3 order by deptno;DEPTNO ENAME SAL---------- ---------- ----------10 CLARK 2450KING 5000MILLER 130020 SMITH 800ADAMS 1100FORD 3000SCOTT 3000JONES 297530 ALLEN 1600BLAKE 2850MARTIN 1250JAMES 950TURNER 1500WARD 1250已选择14行。
2.先来一个简单的,注意over(...)条件的不同,使用sum(sal) over (order by ename)... 查询员工的薪水“连续”求和,注意over (order by ename)如果没有order by 子句,求和就不是“连续”的,放在一起,体会一下不同之处:SQL> select deptno,ename,sal,2 sum(sal) over (order by ename) 连续求和,3 sum(sal) over () 总和, -- 此处sum(sal) over () 等同于sum(sal)4 100*round(sal/sum(sal) over (),4) "份额(%)"5 from emp6 /DEPTNO ENAME SAL 连续求和总和份额(%)---------- ---------- ---------- ---------- ---------- ----------20 ADAMS 1100 1100 2902530 ALLEN 1600 2700 2902530 BLAKE 2850 5550 2902510 CLARK 2450 8000 2902520 FORD 3000 11000 2902530 JAMES 950 11950 2902520 JONES 2975 14925 2902510 KING 5000 19925 2902530 MARTIN 1250 21175 2902510 MILLER 1300 22475 2902520 SCOTT 3000 25475 2902520 SMITH 800 26275 2902530 TURNER 1500 27775 2902530 WARD 1250 29025 29025已选择14行。
oracle over()用法

oracle over()用法Oracle OVER()用法在Oracle数据库中,OVER()是一种功能强大的窗口函数,用于对查询结果进行分组和排序。
它可以用于计算聚合函数、排序、分析和显示每个分组的结果。
下面是一些常见的OVER()用法示例:1. 分组统计OVER()可以用于对查询结果进行分组统计。
比如,我们可以使用SUM()函数计算每个部门的销售总额,并在每行结果中显示该部门的总销售额。
SELECT department_id, SUM(sales) OVER (PARTITION BY department_id) AS total_salesFROM sales_table;上面的语句中,PARTITION BY子句指定了按照department_id 字段进行分组,SUM()函数计算每个分组的销售总额,并使用OVER()函数在每行结果中显示该总额。
2. 排序OVER()还可以用于对查询结果进行排序。
例如,我们可以使用ROW_NUMBER()函数为查询结果中的每一行添加一个序号,并按照某个字段进行排序。
SELECT product_id, product_name, ROW_NUMBER() OVER (ORDER BY product_id) AS row_numFROM products_table;上述语句中,ORDER BY子句指定了按照product_id字段进行排序,ROW_NUMBER()函数为每一行结果添加一个序号,并使用OVER()函数应用排序。
3. 分析函数OVER()还可以用于执行更复杂的分析操作。
例如,我们可以使用LAG()函数获取上一行的值,并计算相邻两行的差值。
SELECT value,value - LAG(value, 1, 0) OVER (ORDER BY id) AS di ffFROM values_table;上述语句中,LAG()函数获取上一行的值,diff列计算了当前值与上一行值的差值,并使用OVER()函数指定按照id字段进行排序。
oracle rownum() over partition by用法

oracle rownum() over partition by用法
在Oracle 数据库中,ROWNUM 是一个伪列,它为查询结果集中的每一行分配一个唯一的数字,从1 开始。
但是,ROWNUM 在使用上与 OVER (PARTITION BY ...) 子句不兼容,因
为 ROWNUM 是在查询结果返回之前分配的,而 OVER (PARTITION BY ...) 是在结果返回后用于窗口函数的。
如果你想要对分区内的行进行编号,你应该使
用 ROW_NUMBER() 窗口函数,而不是 ROWNUM。
以下是 ROW_NUMBER() OVER (PARTITION BY ...) 的用法示例:
假设你有一个名为 employees 的表,其中包含员工的信息,你想为每个部门的员工分配一个唯一的行号:
sql复制代码
SELECT
department_id,
employee_id,
first_name,
last_name,
ROW_NUMBER() OVER (PARTITION BY department_id ORDER BY employee_id) as row_num
FROM
employees;
在这个查询中:
•PARTITION BY department_id 表示你想要为每
个 department_id 分区内的行分配行号。
•ORDER BY employee_id 表示在每个分区内,行号将基
于 employee_id 的顺序分配。
•ROW_NUMBER() 函数为每个分区内的行生成一个唯一的数字,从1 开始。
这样,结果集将为每个部门的每个员工分配一个唯一的行号。
Oracle的根据某一列进行去重查询

Oracle的根据某⼀列进⾏去重查询
推荐使⽤函数
row_number() over(partition by k.f_id order by1desc) rn
//这⾥的partition by后⾯是想要去重的字段
//order by必须要有,可以order by常量⽤来提⾼性能默认asc
//rn 是别名
学号姓名成绩性别年龄
1张三97male27
2李四98male28
3王⼆97male29
4⿇⼦91male30
如上表:上表数据是由学⽣表和成绩表联合查出来的⼀张虚表,此时需求为省去成绩重复的学⽣(⽆论省去谁都可以)。
实际开发中经常碰到这样的需求
select s.id,,g.grade,s.sex,s.age from student s left join gradetion g on s.id = g.stuId
上⾯sql是原始sql
select
a.id,
,
a.grade,
a.sex,
a.age
from
(select
s.id,
,
g.grade,
s.sex,
s.age,
rownum() over(partition by g.grade order by1) rn
from
student s
left join
gradetion g on s.id = g.stuId) a
where a.rn =1
经过优化的sql,存在⼦查询,性能可能出现问题。
谨待道友⽀持。
【Oracle】OVER(PARTITIONBY)函数用法

【Oracle】OVER(PARTITIONBY)函数⽤法dss 1 95ffd 1 95fda 1 80gds 2 92gf 3 99ddd 3 99adf 3 45asdf 3 553dd 3 78select * from(select name,class,s,rank()over(partition by class order by s desc) mm from t2)where mm=1;得到的结果是:dss 1 95 1ffd 1 95 1gds 2 92 1gf 3 99 1ddd 3 99 1注意:1.在求第⼀名成绩的时候,不能⽤row_number(),因为如果同班有两个并列第⼀,row_number()只返回⼀个结果;select * from(select name,class,s,row_number()over(partition by class order by s desc) mm from t2)where mm=1;1 95 1 --95有两名但是只显⽰⼀个2 92 13 99 1 --99有两名但也只显⽰⼀个2.rank()和dense_rank()可以将所有的都查找出来:如上可以看到采⽤rank可以将并列第⼀名的都查找出来;rank()和dense_rank()区别:--rank()是跳跃排序,有两个第⼆名时接下来就是第四名;select name,class,s,rank()over(partition by class order by s desc) mm from t2dss 1 95 1ffd 1 95 1fda 1 80 3 --直接就跳到了第三gds 2 92 1cfe 2 74 2gf 3 99 1ddd 3 99 13dd 3 78 3asdf 3 55 4adf 3 45 5--dense_rank()l是连续排序,有两个第⼆名时仍然跟着第三名select name,class,s,dense_rank()over(partition by class order by s desc) mm from t2dss 1 95 1ffd 1 95 1fda 1 80 2 --连续排序(仍为2)gds 2 92 1cfe 2 74 2gf 3 99 1ddd 3 99 13dd 3 78 2asdf 3 55 3adf 3 45 4--sum()over()的使⽤select name,class,s, sum(s)over(partition by class order by s desc) mm from t2 --根据班级进⾏分数求和dss 1 95 190 --由于两个95都是第⼀名,所以累加时是两个第⼀名的相加ffd 1 95 190 fda 1 80 270 --第⼀名加上第⼆名的gds 2 92 92cfe 2 74 166gf 3 99 198ddd 3 99 1983dd 3 78 276asdf 355 331adf 3 45 376first_value() over()和last_value() over()的使⽤ --找出这三条电路每条电路的第⼀条记录类型和最后⼀条记录类型SELECT opr_id,res_type, first_value(res_type) over(PARTITION BY opr_id ORDER BY res_type) low, last_value(res_type) over(PARTITION BY opr_id ORDER BY res_type rows BETWEEN unbounded preceding AND unbounded following) high FROMrm_circuit_routeWHERE opr_id IN ('000100190000000000021311','000100190000000000021355','000100190000000000021339') ORDER BY opr_id; 注:rows BETWEEN unbounded preceding AND unbounded following 的使⽤--取last_value时不使⽤rows BETWEEN unboundedpreceding AND unbounded following的结果 SELECT opr_id,res_type, first_value(res_type) over(PARTITION BY opr_id ORDER BYres_type) low, last_value(res_type) over(PARTITION BY opr_id ORDER BY res_type) high FROM rm_circuit_route WHERE opr_id IN ('000100190000000000021311','000100190000000000021355','000100190000000000021339') ORDER BY opr_id;如下图可以看到,如果不使⽤rows BETWEEN unbounded preceding AND unbounded following,取出的last_value由于与res_type进⾏进⾏排列,因此取出的电路的最后⼀⾏记录的类型就不是按照电路的范围提取了,⽽是以res_type为范围进⾏提取了。
oracle over partition by 原理 -回复

oracle over partition by 原理-回复Oracle的over partition by是一种用于窗口函数的特殊语法,它可以根据指定的列对结果集进行分组,并在每个分组内运行窗口函数。
这个功能在处理需要对数据进行分组计算或者统计时非常有用。
本文将详细解释Oracle over partition by的原理和使用方法。
首先,我们来了解一下窗口函数。
窗口函数是一类特殊的SQL函数,它可以在查询语句中使用,并且可以对按特定条件分组的数据集进行计算。
窗口函数可以在每一行数据上运行,并返回一个标量值。
常见的窗口函数包括sum、avg、count等。
使用窗口函数时,我们需要指定一个窗口规范来定义计算的范围。
窗口规范可以由以下几个部分组成:partition by子句、order by子句和窗口帧定义。
在介绍over partition by的原理之前,我们先来看一个例子。
假设我们有一个员工表,包含员工的姓名、部门和工资三个字段。
现在我们想要计算每个部门的平均工资,并将结果显示在每一行中。
我们可以使用over partition by来实现这个需求。
sqlSELECT姓名,部门,工资,AVG(工资) OVER (PARTITION BY 部门) AS 平均工资FROM员工表;上述查询中,我们在AVG函数后面加上了over partition by子句,指定了以部门进行分组计算。
结果集中的每一行都会计算该行所属部门的平均工资,并将结果显示在每一行中。
现在让我们来具体分析一下over partition by的原理。
over partition by 的作用是将结果集按照指定的列进行分组,并在每个分组内运行窗口函数。
具体实现过程分为以下几步:1. 首先,查询语句会执行普通的数据查询操作,得到一个初始的结果集。
2. 然后,根据over partition by子句指定的列,对初始结果集进行分组。
oracle高级用法,decode排序,over(partitionbyxorderbyy。。。

oracle⾼级⽤法,decode排序,over(partitionbyxorderbyy。
场景 01 (IN 语句排序 decode() 函数):1,我们在查询中会经常使⽤这样的⽤法, select * from table_name t where t.id in (1, 3, 7, 9),这是⼀条查询表中 id 为 1, 3, 7, 9 的数据现在我们加上⼀个需求,要求查出来的数据的顺序和括号内 id 的顺序⼀致,有⼈会说直接 order by t.id 啊,多简单,那假设顺序是乱的呢?⼜假如 id 不是数字,⽽是字符串呢?如 select * from table_name t where t.id in (1, 13, 7, 9) 或者 select * from table_name t where t.id in (‘hjkhjk’, 'sfhjsf', 'sdasda', 'dasdad')2,这时候排序就会很⿇烦,oracle 数据库为我们提供了⼀个强⼤的函数 decode,具体⽤法如下:select * from table_name t where t.id in (1, 3, 7, 9) order by decode (t.id, 1, 1, 3, 2, 7, 3, 9, 4)其中 decode 函数的结果作为 order by 的内容,括号内的参数为(排序字段,值,顺序,值,顺序……),其中,顺序值越⼩,排序越靠前场景 02 (分组排序查询,开窗函数 OVER (PARTITION BY COL1 ORDER BY COL2) ):1,平时做项⽬的时候,我们会经常遇到这种情况,假设⼀张表,每⼀天都会给表中的每⼀个种类添加⼀条数据,现在我们要求根据某个⽇期查询出所有种类的对应数据,这很简单,如 select * from table_name t where t.date = '20190101'2,接下来我们增加难度,要求如果该种类当前查询的⽇期不存在数据,那么取最近的前⼀个有数据的⽇期下的对应数据,通俗点说就是我们要查 20190101 这个⽇期下各种类的数据,但是 A 种类该⽇期没数据,那么就把⽇期提前,⽐如 20181231,如果还没有,就查 20191230,直到找到有数据的⽇期为⽌3,这时候有⼈会说,我们可以先查出每个种类下⼩于等于查询⽇期有数据的最⼤⽇期,在查询数据,这种⽅式可⾏,但是如果表中有⼏千⼏万个种类,这回对性能造成很⼤的压⼒4,这时我们会想到我们要是能把数据根据种类分组,然后按时间倒序取每个分组的第⼀条,不就 OK 了吗?这是我们就要⽤到 oracle 为我们提供的强⼤分析函数,也叫开窗函数 OVER(PARTITION BY X ORDER BY Y DESC)该函数⼀般好结合 ROW_NUMBER() 这个获取序号的函数⼀起结合起来,作为 select 的查询字段使⽤,如:select row_number() over(partition by x order by y desc) rn …… (这种⽅式获取的 rn 就是排序之后的序号)5,其中 PARTITION BY X 是根据 X 字段分组,ORDER BY Y DESC 根据 Y 排序, ROW_NUMBER() 在分组排序完成之后,为每个分组中的数据逐条添加序号,每个分组之间互不⼲扰,都是从 1 开始往后排,这是后我们直接取⾏号为 1 的数据,就完美的完成了 2 提出的需求具体如下,⼀个简单的例⼦6,更多关于开窗函数的⽤法请参考。
oracle over partition by 条件 -回复

oracle over partition by 条件-回复【Oracle over partition by 条件】是Oracle数据库中的一种特殊语法,用于对查询结果进行分组和排序操作。
本文将以Over Partition By 条件为主题,详细介绍其使用方法和实际应用。
一、什么是Over Partition ByOver Partition By是Oracle数据库中的一种分析函数,用于在查询结果的基础上进行分组和排序操作。
它通常用于在不更改查询结果集结构的情况下,对结果进行进一步的处理和分析。
二、语法和基本用法Over Partition By语法如下:SELECT column1, column2, ..., aggregate_function(column) OVER (PARTITION BY column1, column2, ... ORDER BY column1, column2, ...)FROM table_name;其中,column1, column2, ...表示需要进行分组和排序的列名,aggregate_function(column)表示需要进行聚合操作的列。
Over Partition By的基本用法如下:1. 根据指定的列进行分组:通过在Over Partition By子句中指定需要分组的列名,可以将查询结果按照该列的值进行分组。
2. 对每个分组进行排序:通过在Over Partition By子句中指定需要排序的列名,可以在每个分组内按照该列的值进行排序。
3. 对每个分组应用聚合函数:通过在SELECT子句中指定需要进行聚合操作的列,并结合Over Partition By子句,可以对每个分组应用聚合函数,生成最终的结果。
三、示例为了更好地理解Over Partition By的实际用途,我们将通过一个具体的示例进行说明。
假设有一个存储了学生成绩的表student_scores,包含了学生姓名(name)、科目(subject)和分数(score)三列。
ORACLE逐行累计求和方法(OVER函数)
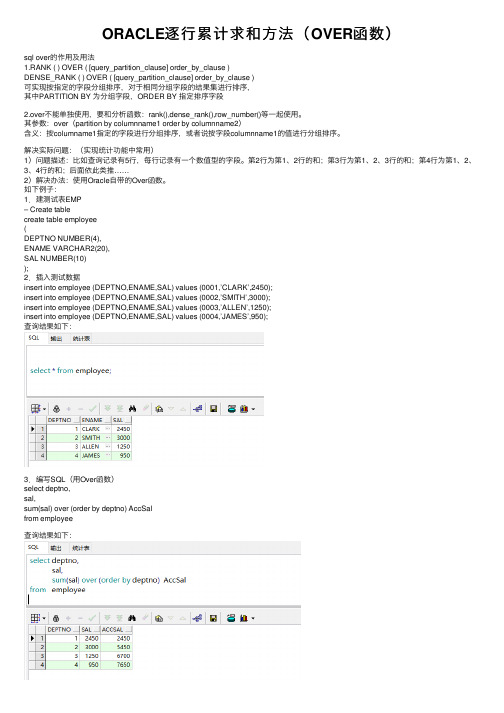
ORACLE逐⾏累计求和⽅法(OVER函数)sql over的作⽤及⽤法1.RANK ( ) OVER ( [query_partition_clause] order_by_clause )DENSE_RANK ( ) OVER ( [query_partition_clause] order_by_clause )可实现按指定的字段分组排序,对于相同分组字段的结果集进⾏排序,其中PARTITION BY 为分组字段,ORDER BY 指定排序字段2.over不能单独使⽤,要和分析函数:rank(),dense_rank(),row_number()等⼀起使⽤。
其参数:over(partition by columnname1 order by columnname2)含义:按columname1指定的字段进⾏分组排序,或者说按字段columnname1的值进⾏分组排序。
解决实际问题:(实现统计功能中常⽤)1)问题描述:⽐如查询记录有5⾏,每⾏记录有⼀个数值型的字段。
第2⾏为第1、2⾏的和;第3⾏为第1、2、3⾏的和;第4⾏为第1、2、3、4⾏的和;后⾯依此类推……2)解决办法:使⽤Oracle⾃带的Over函数。
如下例⼦:1.建测试表EMP– Create tablecreate table employee(DEPTNO NUMBER(4),ENAME VARCHAR2(20),SAL NUMBER(10));2.插⼊测试数据insert into employee (DEPTNO,ENAME,SAL) values (0001,’CLARK’,2450);insert into employee (DEPTNO,ENAME,SAL) values (0002,’SMITH’,3000);insert into employee (DEPTNO,ENAME,SAL) values (0003,’ALLEN’,1250);insert into employee (DEPTNO,ENAME,SAL) values (0004,’JAMES’,950);查询结果如下:3.编写SQL(⽤Over函数)select deptno,sal,sum(sal) over (order by deptno) AccSalfrom employee查询结果如下:未完待续…。
oracle的窗口函数

oracle的窗口函数
Oracle的窗口函数是一种强大的查询工具,它使得在查询中应用聚合函数成为可能,而不会导致分组。
通过使用窗口函数,用户可以计算每行的聚合值,而不是整个查询结果集。
窗口函数也可以用来实现排名和窗口化计算。
Oracle支持多种窗口函数,包括SUM、AVG、COUNT、MAX、MIN 等。
这些函数可以在SELECT语句中使用,并配合OVER子句使用。
使用窗口函数的语法是:
<窗口函数> OVER ([PARTITION BY <列1>,<列2>,…] [ORDER BY <列1>,<列2>,…])
其中,PARTITION BY子句定义了窗口函数的分组,而ORDER BY 子句定义了窗口函数计算的顺序。
通过使用窗口函数,用户可以轻松地进行各种聚合计算,从而更好地理解数据。
- 1 -。
oracle over partition by 原理 -回复

oracle over partition by 原理-回复Oracle的over partition by是一种强大的查询功能,它允许我们在数据库中进行分区分析和计算。
通过使用这个功能,我们可以根据指定的分区条件对数据进行分组,然后在每个分区内执行计算操作。
在本文中,我们将通过详细的步骤和示例来回答“[oracle over partition by 原理]”这个问题。
1. 了解分区概念在开始讨论over partition by之前,我们首先需要了解什么是分区。
分区是将数据划分为相互独立的子集的过程,每个子集被称为一个分区。
这种分区可以基于特定的条件,例如根据某个列的值或按时间划分。
2. 解释over partition by的含义over partition by是一种用于分析函数的子句,它用于指定分区条件。
这意味着我们可以按照特定的列或表达式对数据进行分组,然后对每个分组执行计算操作。
3. 分析函数的基本语法要使用over partition by,我们需要使用分析函数。
下面是分析函数的基本语法:<analytic_function> OVER (PARTITION BY <columnname> [ORDERBY <columnname>])其中,analytic_function是要执行的分析函数,columnname是用于分区的列名,order by是可选的排序列名用于排序分区结果。
4. 学习over partition by的常见用途over partition by的用途非常广泛,它可以用于各种分析和计算操作。
一些常见的用途包括:- 计算每个分区内的行数或比例- 计算每个分区内的累计和或平均值- 查找每个分区内的最大或最小值- 使用行号对每个分区进行排序5. 举例说明over partition by的使用为了更好地理解over partition by的原理,让我们来看一个实际的示例。
row_number()overpartitionby去重复

row_number()overpartitionby去重复oracle row_number() over partition by去重复最近做一个项目用到distinct去除重复的数据,但是多字段的去重复不好用。
mysql里可以用select *,count(distinct name) from table group by name来欺骗下oracle里可以用 row_number()连子查询进行处理select distinct table1.id,from (select a.id,, row_number() over (partition by c.wzbah order by b.id desc)rnfrom T1 a,T2 bwhere a.id = b.id ) table1where rn = 1ps:partition by是用后面字段进行分割, rn是行号这样就只取到行号为1的那一行了可以用到max()函数1、要求,在一个表中,某一字段为重复字段。
需要去除重复字段。
同时将所有字段显示出来。
SELECT * FROM (select a1,a2,a3,Row_number() OVER (PARTITION BY a1 ORDER BY a1) rnfrom a) where RN = 1Row_number() OVER (PARTITION BY a1 ORDER BY a1)作用Oracle分析函数RANK(),ROW_NUMBER(),LAG()等的使用方法ROW_NUMBER() OVER (PARTITION BY COL1 ORDER BY COL2)表示根据COL1分组,在分组内部根据COL2排序,而这个值就表示每组内部排序后的顺序编号(组内连续的唯一的)RANK() 类似,不过RANK 排序的时候跟派名次一样,可以并列2个第一名之后是第3名LAG 表示分组排序后,组内后面一条记录减前面一条记录的差,第一条可返回 NULLBTW: EXPERT ONE ON ONE 上讲的最详细,还有很多相关特性,文档看起来比较费劲row_number()和rownum差不多,功能更强一点(可以在各个分组内从1开时排序)rank()是跳跃排序,有两个第二名时接下来就是第四名(同样是在各个分组内)dense_rank()l是连续排序,有两个第二名时仍然跟着第三名。
oracle的开窗函数

oracle的开窗函数开窗函数指的是OVER(),和分析函数配合使⽤。
语法:OVER(PARTITION BY分组字段ORDER BY排序字段 ROWS BETWEEN排序字段范围值1 AND排序字段范围值2)语法说明:开窗函数为分析函数带有的,包含三个分析⼦句:1. 分组(PARTITION BY)。
2. 排序(ORDER BY)。
3. 窗⼝(ROWS)-- 指定范围。
ROWS 有多个范围值:1. UNBOUNDED PRECEDING ⽆限/不限定先前⾏。
2. N PRECEDING N个先前⾏(N为1则是1个先前⾏,2则是2个先前⾏,以此类推)。
3. UNBOUNDED FOLLOWING ⽆限/不限定的跟随⾏。
4. N FOLLOWING N个跟随⾏(N为1则是1个跟随⾏,2则是2个跟随⾏,以此类推)。
5. CURRENT ROW 当前⾏。
⽰例1:SELECTCCTI.CTR_TYPE_ID,CCTI.ORDER_NUM,,WMSYS.WM_CONCAT() OVER(PARTITION BY CCTI.CTR_TYPE_ID) CTR_TYPE_ITEM_STRFROM T_CTRG_CTR_TYPE_ITEM CCTI;结果1:分析1:区别于GROUP BY⼦句的只返回分组⾏的结果,开窗函数每⼀⾏都会返回⼀个结果。
⽰例1的写法相当于指定了ROWS范围从不限定先前⾏到不限定跟随⾏(默认):SELECTCCTI.CTR_TYPE_ID,CCTI.ORDER_NUM,,WMSYS.WM_CONCAT() OVER(PARTITION BY CCTI.CTR_TYPE_ID ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) CTR_TYPE_ITEM_STRFROM T_CTRG_CTR_TYPE_ITEM CCTI;⽰例2:SELECTCCTI.CTR_TYPE_ID,CCTI.ORDER_NUM,,WMSYS.WM_CONCAT() OVER(PARTITION BY CCTI.CTR_TYPE_ID ORDER BY CCTI.ORDER_NUM) CTR_TYPE_ITEM_STRFROM T_CTRG_CTR_TYPE_ITEM CCTI;结果2:分析2:加上了ORDER BY 之后,返回结果变成了逐级递增的效果。
oraclepartitionby用法

oraclepartitionby用法Oracle的PARTITION BY子句是用于在查询中定义分区的一种方法。
它允许将结果集分成不同的分区,并在每个分区内进行分析或操作。
PARTITIONBY子句可以与多个SQL查询和分析函数一起使用,例如SELECT、UPDATE、DELETE语句,以及聚合函数MAX、MIN、COUNT、SUM等。
它的基本语法如下:SELECT column1, column2, ... , analytic_function(column)FROM tablePARTITION BY columnORDER BY column;在这个语法中,PARTITION BY后面的column指定用于分区的列,分区意味着将结果集按照该列的不同值进行分组。
然后,analytic_function(column)将在每个分区内对column进行分析或操作。
PARTITIONBY常用于在查询结果中计算移动平均数、累积总数、排名等指标。
下面是一些常见的用法示例:1.计算每个分区内的行数:SELECT column1, column2, ... , COUNT(*) OVER (PARTITION BY column)FROM table;这个查询将返回每个分区内的行数,并将其作为新的列添加到查询结果中。
2.计算每个分区内的累积总数:SELECT column1, column2, ... , SUM(column) OVER (PARTITION BY column ORDER BY column)FROM table;这个查询将计算每个分区内column列的累积总数,并将结果作为新的列添加到查询结果中。
3.计算每个分区内的行数和行号:SELECT column1, column2, ... , COUNT(*) OVER (PARTITION BY column) as row_count,ROW_NUMBER( OVER (PARTITION BY column ORDER BY column) as row_numberFROM table;这个查询将返回每个分区内的行数,并为每个分区的行号分配一个唯一的值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
oracle over partition by 条件
摘要:
1.Oracle 概述
2.分区概念
3.条件查询
4.Oracle over partition by 条件
5.示例
正文:
1.Oracle 概述
Oracle 是一款广泛应用的关系型数据库管理系统,以其高效、安全和可扩展性而闻名。
Oracle 数据库提供了许多高级特性以满足各种业务需求,其中之一就是分区功能。
2.分区概念
分区是一种将表或索引划分为多个逻辑存储单元的方法,每个存储单元被称为一个分区。
这样可以在查询时大大减少数据扫描的范围,提高查询效率。
在Oracle 中,可以使用分区来对表进行分区存储,从而提高查询性能。
3.条件查询
在实际应用中,我们经常需要根据某些条件对数据进行查询。
例如,根据日期、地区等条件对销售数据进行分析。
条件查询可以帮助我们更有针对性地获取所需数据,减少无效数据扫描,提高查询效率。
4.Oracle over partition by 条件
Oracle 的over partition by 子句就是用于实现根据某个条件对分区进行
查询的。
它可以让我们在查询时只对满足特定条件的分区进行数据检索,从而提高查询效率。
例如,假设我们有一个销售表(sales),其中包含以下字段:日期(date)、地区(region)和销售额(sales)。
我们可以使用over partition by 子句根据地区对销售额进行分区查询,以获取各地区的销售情况。
5.示例
以下是一个使用Oracle over partition by 子句的示例:
```sql
SELECT date, region, SUM(sales) OVER (PARTITION BY region) as sales_by_region
FROM sales;
```
这个查询将根据地区对销售额进行分区汇总,返回一个包含日期、地区和各地区销售额的结果集。