SPSS_Clementine典型案例分析
数据挖掘工具(一)Clementine

数据挖掘工具(一)SPSS Clementine18082607 洪丹Clementine是ISL(Integral Solutions Limited)公司开发的数据挖掘工具平台。
1999年SPSS公司收购了ISL公司,对Clementine产品进行重新整合和开发,现在Clementine已经成为SPSS公司的又一亮点。
作为一个数据挖掘平台, Clementine结合商业技术可以快速建立预测性模型,进而应用到商业活动中,帮助人们改进决策过程。
强大的数据挖掘功能和显著的投资回报率使得Clementine在业界久负盛誉。
同那些仅仅着重于模型的外在表现而忽略了数据挖掘在整个业务流程中的应用价值的其它数据挖掘工具相比, Clementine其功能强大的数据挖掘算法,使数据挖掘贯穿业务流程的始终,在缩短投资回报周期的同时极大提高了投资回报率。
近年来,数据挖掘技术越来越多的投入工程统计和商业运筹,国外各大数据开发公司陆续推出了一些先进的挖掘工具,其中spss公司的Clementine软件以其简单的操作,强大的算法库和完善的操作流程成为了市场占有率最高的通用数据挖掘软件。
本文通过对其界面、算法、操作流程的介绍,具体实例解析以及与同类软件的比较测评来解析该数据挖掘软件。
1.1 关于数据挖掘数据挖掘有很多种定义与解释,例如“识别出巨量数据中有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。
” 1、大体上看,数据挖掘可以视为机器学习和数据库的交叉,它主要利用机器学习界提供的技术来分析海量数据,利用数据库界提供的技术来管理海量数据。
2、数据挖掘的意义却不限于此,尽管数据挖掘技术的诞生源于对数据库管理的优化和改进,但时至今日数据挖掘技术已成为了一门独立学科,过多的依赖数据库存储信息,以数据库已有数据为研究主体,尝试寻找算法挖掘其中的数据关系严重影响了数据挖掘技术的发展和创新。
尽管有了数据仓库的存在可以分析整理出已有数据中的敏感数据为数据挖掘所用,但数据挖掘技术却仍然没有完全舒展开拳脚,释放出其巨大的能量,可怜的数据适用率(即可用于数据挖掘的数据占数据库总数据的比率)导致了数据挖掘预测准确率与实用性的下降。
spss主成分分析案例

spss主成分分析案例SPSS主成分分析案例。
主成分分析(Principal Component Analysis, PCA)是一种常用的数据降维方法,它可以将原始变量转换成一组新的互相无关的变量,这些新变量被称为主成分。
主成分分析可以帮助我们发现数据中的模式和结构,从而更好地理解数据的特性。
本文将以一个实际案例来介绍如何在SPSS软件中进行主成分分析,并解释如何解读分析结果。
案例背景:某公司想要了解员工的工作满意度,为了更全面地了解员工对工作的感受,公司设计了一份包含多个问题的调查问卷,涉及到工作内容、工作环境、薪酬福利等方面。
为了简化分析,公司希望利用主成分分析来提取出最能代表员工工作满意度的几个维度。
数据收集:公司对全体员工进行了调查,共有300份有效问卷。
每份问卷包含了20个问题,涉及到不同方面的工作满意度评价。
这些问题涵盖了工作内容、同事关系、上级领导、薪酬福利等多个方面。
数据分析:首先,我们需要将数据导入SPSS软件中,然后依次点击“分析”-“数据降维”-“主成分”命令。
在弹出的对话框中,我们选择需要进行主成分分析的变量,即员工对不同问题的评分。
在选择了变量后,我们可以点击“选项”按钮,对分析进行进一步设置,比如选择旋转方法、提取条件等。
在进行了上述设置后,我们点击“确定”按钮,SPSS将会为我们生成主成分分析的结果。
在结果中,我们可以看到提取的主成分个数、每个主成分的方差解释比例、成分矩阵等信息。
通过这些信息,我们可以判断提取的主成分是否符合要求,以及每个主成分的解释能力如何。
解读结果:在这个案例中,我们提取了3个主成分,这3个主成分分别解释了总方差的60%、25%和15%。
成分矩阵显示了每个问题对应的主成分载荷,通过分析载荷大小,我们可以判断每个主成分所代表的具体内容。
比如,第一个主成分可能代表工作内容满意度,第二个主成分可能代表同事关系满意度,第三个主成分可能代表薪酬福利满意度。
实验二 Clementine12购物篮分析(关联规则)

实验二Clementine12购物篮分析(关联规则)一、[实验目的]设计关联规则分析模型,通过模型演示如何对购物篮分析,并根据细分结果对采取不同的营销策略。
体验以数据驱动的模型计算给科学决策带来的先进性。
二、[知识要点]1、购物蓝分析概念;2、管来呢规则算法原理;3、购物蓝分析工具;4、Clementine12.0关联规则分析流程。
三、[实验要求和内容]1、初步了解使用工作流的方式构建分析模型;2、理解智能数据分析流程,主要是CRISP-DM工业标准流程;3、理解关联规则模型原理;4、设计关联规则分流;5、运行该流,并将结果可视化展示;6、得出模型分析结论7、运行结果进行相关营销策略设计。
四、[实验条件]Clementine12.0挖掘软件。
五、[实验步骤]1、启动Clementine12.0软件;2、在工作区设计管来呢规则挖掘流;3、执行模型,分析计算结果;4、撰写实验报告。
六、[思考与练习]1、为什么要进行关联规则分析?它是如何支持客户营销的?实验内容与步骤一、前言“啤酒与尿布”的故事是营销届的神话,“啤酒”和“尿布”两个看上去没有关系的商品摆放在一起进行销售、并获得了很好的销售收益,这种现象就是卖场中商品之间的关联性,研究“啤酒与尿布”关联的方法就是购物篮分析,购物篮分析曾经是沃尔玛秘而不宣的独门武器,购物篮分析可以帮助我们在门店的销售过程中找到具有关联关系的商品,并以此获得销售收益的增长!“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市中,沃尔玛的超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中,这种独特的销售现象引起了管理人员的注意,经过后续调查发现,这种现象出现在年轻的父亲身上。
在美国有婴儿的家庭中,一般是母亲在家中照看婴儿,年轻的父亲前去超市购买尿布。
父亲在购买尿布的同时,往往会顺便为自己购买啤酒,这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。
课题_SPSS Clementine 数据挖掘入门 (3)

SPSS Clementine 数据挖掘入门(3)了解SPSS Clementine的基本应用后,再对比微软的SSAS,各自的优缺点就非常明显了。
微软的SSAS是Service Oriented的数据挖掘工具,微软联合SAS、Hyperion等公司定义了用于数据挖掘的web服务标准——XMLA,微软还提供OLE DB for DM接口和MDX。
所以SSAS的优势是管理、部署、开发、应用耦合方便。
但SQL Server 2005使用Visual Studio 2005作为客户端开发工具,Visual Studio的SSAS项目只能作为模型设计和部署工具而已,根本不能独立实现完整的Crisp-DM流程。
尽管MS Excel也可以作为SSAS的客户端实现数据挖掘,不过Excel显然不是为专业数据挖掘人员设计的。
PS:既然说到Visual Studio,我又忍不住要发牢骚。
大家都知道Visual Studio Team System是一套非常棒的团队开发工具,它为团队中不同的角色提供不同的开发模板,并且还有一个服务端组件,通过这套工具实现了团队协作、项目管理、版本控制等功能。
SQL Server 2005相比2000的变化之一就是将开发客户端整合到了Visual Studio中,但是这种整合做得并不彻底。
比如说,使用SSIS开发是往往要一个人完成一个独立的包,比起DataStage 基于角色提供了四种客户端,VS很难实现元数据、项目管理、并行开发……;现在对比Clementine也是,Clementine最吸引人的地方就是其提供了强大的客户端。
当然,Visual Studio本身是很好的工具,只不过是微软没有好好利用而已,期望未来的SQL Server 2K8和Visual Studio 2K8能进一步改进。
所以我们不由得想到如果能在SPSS Clementine中实现Crisp-DM过程,但是将模型部署到SSAS就好了。
数据挖掘第三部分SPSSclementine11数据处理cindy

▪ 追加节点假定读入的数据源和最初输入源有相 似的数据结构,根据不同数据文件的字段名合 并数据。
可编辑版
6
字段数目不同时的读入规则
▪ 如果一个输入的字段数目比最初数据源少,输 入源记录缺失的字段用未定义值($null$)填补。
Clementine的数据处理
介绍Clementine的数据处理技术,学习如何合并和处理文 件,样本数据,处理缺失值和时序数据
培训内容
▪ 第一章 合并多个数据源数据 ▪ 第二章 抽取样本,选择和缓存数据 ▪ 第三章 处理缺失数据 ▪ 第四章 处理日期 ▪ 第五章 处理时序数据 ▪ 第六章 文件操作 ▪ 第七章 效率
可编辑版
19
第二章
抽取样本,选择和缓存数据
可编辑版
20
第二章 抽取样本,选择和缓存数据
▪ 内容:
▪ 使用区分节点删除副本 ▪ 使用抽样和选择节点抽取样本 ▪ 使用分割节点分割数据为训练和测试样本 ▪ 使用缓存数据加速数据处理和冻结样本
▪ 目的:
▪ 介绍一系列对数据进行预处理的方法
▪ 数据:
▪ 前一章合并生成的数据,存储于文件fulldata.txt
▪ 使用变量文件节点分别读入这三个数据文件。
▪ 连接三个制表节点,检查数据文件的读入是否正确。
▪ 用Append节点,追加两个记录顾客信息的数据文件。编 辑节点,并检查节点设置是否正确(确保 custtravel1.dat是第一个数据文件),用制表节点,查 看追加结果。
▪ 用Merge节点,合并holtravel.dat和生成的数据文件,选 择包括匹配和不匹配记录。用制表节点,查看合并结果 。
SPSS-Clementine和KNIME数据挖掘入门
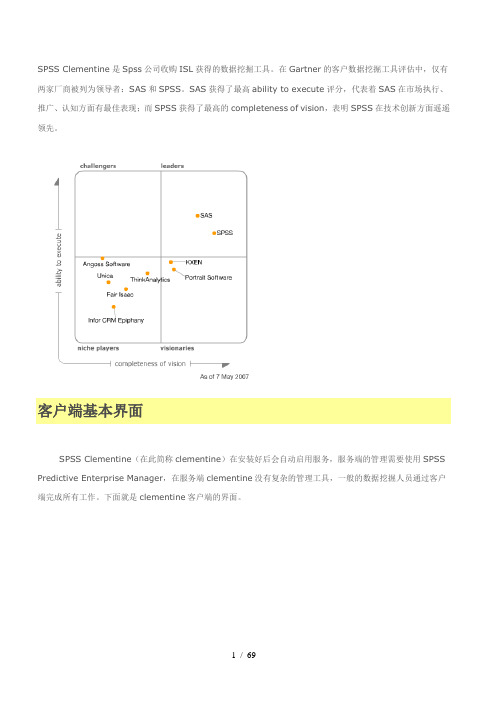
SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具。
在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS。
SAS获得了最高ability to execute评分,代表着SAS在市场执行、推广、认知方面有最佳表现;而SPSS获得了最高的completeness of vision,表明SPSS在技术创新方面遥遥领先。
客户端基本界面SPSS Clementine(在此简称clementine)在安装好后会自动启用服务,服务端的管理需要使用SPSS Predictive Enterprise Manager,在服务端clementine没有复杂的管理工具,一般的数据挖掘人员通过客户端完成所有工作。
下面就是clementine客户端的界面。
一看到上面这个界面,我相信只要是使用过SSIS+SSAS部署数据挖掘模型的,应该已经明白了六、七分。
是否以跃跃欲试了呢,别急,精彩的还在后面^_’项目区顾名思义,是对项目的管理,提供了两种视图。
其中CRISP-DM (Cross Industry Standard Process for Data Mining,数据挖掘跨行业标准流程)是由SPSS、DaimlerChrysler(戴姆勒克莱斯勒,汽车公司)、NCR(就是那个拥有Teradata的公司)共同提出的。
Clementine里通过组织CRISP-DM的六个步骤完成项目。
在项目中可以加入流、节点、输出、模型等。
工具栏工具栏总包括了ETL、数据分析、挖掘模型工具,工具可以加入到数据流设计区中,跟SSIS中的数据流非常相似。
Clementine中有6类工具。
源工具(Sources)相当SSIS数据流中的源组件啦,clementine支持的数据源有数据库、平面文件、Excel、维度数据、SAS数据、用户输入等。
记录操作(Record Ops)和字段操作(Field Ops)相当于SSIS数据流的转换组件,Record Ops是对数据行转换,Field Ops是对列转换,有些类型SSIS的异步输出转换和同步输出转换(关于SSIS异步和同步输出的概念,详见拙作:)。
Clementine关联规则实验论文

Clementine关联规则试验目的:通过使用SPSS Clementine数据挖掘平台,了解数据挖掘的目的、过程,理解数据挖掘的结果,并能够根据所学习的数据挖掘的相关知识,对挖掘的过程参数和结果数据进行分析。
试验内容:建立数据源,进行关联规则挖掘。
试验步骤:1、导入数据源a)选择“可变文件”节点,把节点图标拖入数据流区域b)右键点击“可变文件”节点,弹出节点细节选择界面c)导入BASKETS.txt数据2、查看导入的数据a)点击节点选项卡“输出”,双击“表格”节点b)右键点击“BASKETS.txt”节点,选择“Connect”选项,单击“Table”(在两个节点中产生一个箭头,从“BASKETS.txt”指向“Table”节点。
)c)右键点击“表格”节点,弹出细节选择界面,单击“执行”d)查看结束,单击“确定”退出查看表格3、对数据进行清洗a)选择节点选项卡的“字段选项”,把“类型”节点拖入数据流区域。
b)连接“BASKETS.txt”节点和“类型”节点c)双击数据流区域中的“类型”节点,单击“读取值”按钮d)对值为“T/F”的“方向”改为“两者”,把其他行的“方向”的值改为“无”4. 使用Apriori节点分析a)双击“建模”选项卡的“Apriori”节点b)连接“类型”节点与“Apriori”节点 (箭头指向“Apriori”节点)c)双击“Apriori”节点,弹出选项界面d)单击“执行”按钮5、查看挖掘结果a)左键单击管理器的“模型”选项卡,右键点击第5部执行以后出现的模型图标b)选择“浏览”,弹出图表c)查看结果如图可以得到最少置信度百分之八十以上,frozenmeal,cannedveg,beer三者之间支持度的关系,也就是购买者在购买其中之二同时购买其他另外一样东西的关联性大小。
6、提升a)双击“Apriori”节点,弹出选项界面,修改参数b)选择“模型”选项卡修改参数c)修改“最低规则置信度”为50(或者修改“最低条件支持度”和“最大前项数”)d)查看结果Wine confectionery50.174%下面做关于GRI的生成关联分析在选择面板中的建模目录中我们选择GRI结点加入到数据流中。
基于Clementine软件的时间序列分析--以浦发银行股票为例

基于Clementine软件的时间序列分析——以A股浦发银行(600000)股票为例摘要本文的主要内容是借助SPSS Clementine 软件研究A股浦发银行(600000)股票价格随时间的变化规律,并用时间序列分析的有关知识对其进行建模预测。
本文首先对Clementine软件作简要介绍,说明其在数据挖掘领域的广泛应用;然后介绍了3种时间序列分析预测的模型,分别为专家模型、Holt指数平滑模型和ARIMA模型;最后借助Clementine 软件对浦发银行股价分别进行专家建模、指数平滑建模和ARIMA建模,并对股价进行短期预测,通过模型参数比较及预测值误差对比,找出最佳模型。
在建模的同时,也给出了使用Clementine软件建立数据流的具体过程。
关键词:Clementine软件时间序列浦发银行股票一、引言数据挖掘是一个利用各种方法,从海量数据中提取隐含和潜在的对决策有用的信息和模式的过程。
通过数据挖掘提取的信息可应用于很多领域,如决策支持、预测、预报和估计等。
当今我们正面临这样一个问题,一边是对知识的饥渴,另一边却是大量数据的闲置未被利用,“我们被淹没在信息里,但却感受到知识的饥饿”。
因此,我们迫切需要借助数据挖掘技术对这些数据进行及时有效的处理,从这些海量的、有噪音的、随机的数据中提取有效的、潜在有用的而又新颖事先未知的信息[1]。
数据挖掘的工具有很多,本文选用SPSS Clementine软件。
二、Clementine软件简介Clementine是由SPSS公司开发的一款著名且非常实用的数据挖掘软件,也是目前众多软件中最成熟和最受欢迎的一款数据挖掘产品。
Clementine拥有丰富的数据挖掘算法,操作简单易用,分析结果直观易懂,图形功能强大,支持与数据库之间的数据和模型交换,可以使用户方便快捷地实现数据挖掘。
Clementine 形象地将数据分析的各个环节表示成若干个节点,将数据分析过程看作数据在各个节点之间的流动,并通过图形化的数据流方式直观表示整个数据挖掘的各个环节。
spssclementines预测分析模型

SPSS Clementines 预测分析模型----啤酒+尿片故事的实现机理(使用11版本实现)SPSS Clenmentines提供众多的预测模型,这使得它们可以应用在多种商业领域中:如超市商品如何摆放可以提高销量;分析商场营销的打折方案,以制定新的更为有效的方案;保险公司分析以往的理赔案例,以推出新的保险品种等等,具有很强的商业价值。
超市典型案例如何摆放超市的商品引导消费者购物从而提高销量,这对大型连锁超市来说是一个现实的营销问题。
关联规则模型自它诞生之时为此类问题提供了一种科学的解决方法。
该模型利用数据挖掘的技术,在海量数据中依据该模型的独特算法发现数据内在的规律性联系,进而提供具有洞察力的分析解决方案。
通过一则超市销售商品的案例,利用“关联规则模型”,来分析商品交易流水数据,以其发现合理的商品摆放规则,来帮助提高销量。
关联规则简介关联规则的定义关联规则表示不同数据项目在同一事件中出现的相关性,就是从大量数据中挖掘出关联规则。
有关数据挖掘关联规则的具体理论依据这里不做详细讲解,大家可以参看韩家炜的数据挖掘概论。
为了更直观的理解关联规则,我们首先来看下面的场景。
一个市场分析人员经常要考虑这样一个问题:哪些商品是频繁被顾客同时购买的?顾客1:牛奶+面包+谷类顾客2:牛奶+面包+糖+鸡蛋顾客3:牛奶+面包+黄油顾客4:糖+鸡蛋以上的情景类似于当年沃尔玛做的市场调查:啤酒+尿片摆放在同一个货架上,销售业绩激增的著名关联规则应用。
市场分析员分析顾客购买商品的场景,顾客购买面包同时也会购买牛奶的购物模式就可用以下的关联规则来描述:面包 => 牛奶 [ 支持度 =2%, 置信度 =60%] (式 1)式 1中面包是规则前项(Antecedent),牛奶是规则后项 (Consequent)。
实例数(Instances)表示所有购买记录中包含面包的记录的数量。
支持度(Support)表示购买面包的记录数占所有的购买记录数的百分比。
实验二、SPSSClementine数据可视化

实验报告学院 南徐学院 班级 09428031 姓名 朱亚军 成绩课程 名称 数据挖掘实验项目名 称SPSS Clementine 数据可视化指导教师教师评语教师签名:年 月 日一、 实验目的1、熟悉SPSS Clementine 绘图。
2、了解SPSS Clementine 图形选项面板各节点的使用方法。
3、熟练掌握SPSS Clementine 数据可视化流程。
二、实验内容1、打开SPSS Clementine 软件,逐一操作各图形选项面板,熟悉软件功能。
2、打开一有数据库、或新建数据文件,读入SPSS Clementine,并使用各种输出节点,熟悉数据输入输出。
(要求:至少做分布图、直方图、收集图、多重散点图、时间散点图)三、实验步骤1、启动 Clementine:请从 Windows 的“开始”菜单中选择:所有程序SPSS Clementine 12.0SPSS Clementine client 12.02、建立一个流、导入相关数据,打开图形选项面板3、绘制以下各类图形 (1)以颜色为层次的图(2)以大小为层次的图(3)以颜色、大小、形状和透明度为层次的图(4)以面板图为层次的图(5)三维收集图(6)动画散点图(7)分布图(8)直方图(9)收集图(10)多重散点图(11)网络图四、实验体会熟悉了SPSS Clementine 的绘图特点,了解SPSS Clementine 图形选项面板各节点的使用方法并熟练掌握SPSS Clementine 数据可视化流程。
SPSS数据挖掘工具——Clementine介绍

Scripts可以完成用户应用数据流可以完成的所有工 作 Scripting经常用于自动执行数据流,这样就可以避免 用户去执行那些重复性特别大或者特别耗时的工作
控制数据流执行的顺序 建立复杂的应用 建立Clementine过程使之可以嵌入用户的应用系统或者 通过在Batch模式下调用Clementine执行Script
数据描述
变量名称 Age Sex 变量含义 备注 年龄 性别 分为高(high)、低(low)和正常 BP 血压 (normal)三种 Cholestero 胆固醇含 分为高(high)、低(low)和正常 l 量 (normal)三种 Na 钠含量 K 钾含量 以下五种之一: 最适合药 Drug drugA、drugB 、drugC、drugX、 物 drugY
遵循CRISP-DM的数据挖掘过程
数据理解(数据流) 商业理解(文档)
数据准备(数据流)
结果发布(数据流) 建立模型(数据流)
模型评估(数据流)
模型发布——分析应用
1. 大量的操作在数据库端进行.
2.建模等工作在Server 上进行
4. 数据无需在 网上无谓的传输.
3. 客户端用于 查看数据挖掘结果.
建立模型
Clementine的特征
有监督的数据挖掘模型
预测算法:神经网络、 C&RT、线性回归 分类算法:C5.0、 Logistic回归、C&RT、神 经网络 无监督的数据挖掘模型 聚类算法:K-means、 Kohonen、TwoStep
返回
一个演示—客户价值评估
——数据挖掘更多的时候是一种理念,而不是表现在复杂的方法
商业问题: 微软公司提供的例子数据库——罗斯文商贸公司,如何对客户 价值进行评估 数据挖掘问题: (1)如何描述客户价值?——购买总金额?购买频次?平均 每次购买金额?最近购买金额?它们的线性组合? (2)需要什么样的数据挖掘方法?——描述汇总?分类?预 测?概念描述?细分?相关分析? 商业问题解决方案 从所有客户中找出最有价值的10个客户,将名单发给市场部门 ,让其对这些客户进行更多的关注
Clementine示例01-因子分析

1、因子分析(factor. str)研究从变量群中提取共性因子的统计技术。
最早由英国心理学家C.E.斯皮尔曼提出。
他发现学生的各科成绩之间存在着一定的相关性,一科成绩好的学生,往往其他各科成绩也比较好,从而推想是否存在某些潜在的共性因子,或称某些一般智力条件影响着学生的学习成绩。
因子分析可在许多变量中找出隐藏的具有代表性的因子。
将相同本质的变量归入一个因子,可减少变量的数目,还可检验变量间关系的假设。
因子分析的主要目的是用来描述隐藏在一组测量到的变量中的一些更基本的,但又无法直接测量到的隐性变量(latent variable, latent factor)。
比如,如果要测量学生的学习积极性(motivation),课堂中的积极参与,作业完成情况,以及课外阅读时间可以用来反应积极性。
而学习成绩可以用期中,期末成绩来反应。
在这里,学习积极性与学习成绩是无法直接用一个测度(比如一个问题)测准,它们必须用一组测度方法来测量,然后把测量结果结合起来,才能更准确地来把握。
换句话说,这些变量无法直接测量。
可以直接测量的可能只是它所反映的一个表征(manifest),或者是它的一部分。
在这里,表征与部分是两个不同的概念。
表征是由这个隐性变量直接决定的。
隐性变量是因,而表征是果,比如学习积极性是课堂参与程度(表征测度)的一个主要决定因素。
那么如何从显性的变量中得到因子呢?因子分析的方法有两类。
一类是探索性因子分析,另一类是验证性因子分析。
探索性因子分析不事先假定因子与测度项之间的关系,而让数据“自己说话”。
主成分分析是其中的典型方法。
验证性因子分析假定因子与测度项的关系是部分知道的,即哪个测度项对应于哪个因子,虽然我们尚且不知道具体的系数。
示例factor.str是对孩童的玩具使用情况的描述,它一共有76个字段。
过多的字段不仅增添了分析的复杂性,而且字段之间还可能存在一定的相关性,于是我们无需使用全部字段来描述样本信息。
spss主成分分析案例

spss主成分分析案例SPSS主成分分析案例。
主成分分析(Principal Component Analysis, PCA)是一种常用的多元统计分析方法,它可以将原始变量转换为一组新的互相无关的变量,称为主成分,用于降低数据维度、挖掘数据内在结构和简化数据分析。
本文将以一个实际案例来介绍如何使用SPSS进行主成分分析。
案例背景。
某市一家公司想要了解员工工作满意度的情况,因此进行了一次员工满意度调查,涉及到多个方面的问题,如工作环境、薪酬福利、工作压力等。
为了更好地分析这些数据,他们决定使用主成分分析方法来挖掘数据背后的信息。
数据准备。
首先,我们需要收集员工满意度调查的数据,包括各个方面的评分。
在收集完数据后,我们将数据录入SPSS软件中进行后续的主成分分析。
数据分析。
1. 打开SPSS软件,导入员工满意度调查的数据文件。
2. 选择“分析”菜单中的“降维”选项,然后点击“主成分”。
3. 在弹出的对话框中,选择需要进行主成分分析的变量,将其添加到“变量”框中。
4. 点击“提取”按钮,设置提取条件,如特征值大于1的主成分。
5. 点击“旋转”按钮,选择适当的旋转方法,如方差最大旋转。
6. 点击“OK”按钮,完成主成分分析的设置。
结果解释。
主成分分析完成后,我们将得到主成分的系数矩阵、特征值、解释方差等结果。
通过这些结果,我们可以进行如下解释:1. 主成分系数矩阵,通过系数矩阵,我们可以了解各个原始变量与主成分之间的关系,从而解释主成分的含义。
2. 特征值,特征值表示了每个主成分所能解释的原始变量的方差比例,特征值越大的主成分解释的信息越多。
3. 解释方差,解释方差表明了各个主成分对原始变量的解释程度,可以帮助我们选择保留的主成分数量。
结论与建议。
通过主成分分析,我们可以得到员工满意度调查数据的主要结构和特征,从而为公司提供以下结论与建议:1. 根据主成分的系数矩阵,我们发现工作环境和薪酬福利两个方面对第一个主成分影响较大,说明这两个方面对员工满意度的影响最为显著。
【精品推荐】clementine spss modeler 香水销售数据分析案例(获奖作品) 图文

• 销售策略方面:消费者在购买香水产品时体现出了明显的价格敏 感性,价格低的销量更好。组合装的香水销量好于其他包装。商 家需要结合不同使用场合推出更多的香水组合和礼品装香水,以 刺激消费
香水适用场所的关联分析
• 对源数据进行预处理,将适用场所分隔开,生成不同的字段,总共为8类 • 将含有该类适用场所的值设置为1.0,否则设置为0.0, • 在关联分析前滤除除适用场合外的所有本次分析不需要的字段,将所有适用
场合的类型设置为任意
香水适用场所的关联分析
• 采用Apriori算法,将最低条件支持度设为60%,最小规则置信度设置为 90%
分类
分类
分类
分类
淡香水EDT (100.0%) 浓香水EDP (100.0%) 淡香水EDT (100.0%)淡香水EDT (80.0%)
包装
包装
包装
包装
独立装 (83.6%) 独立装 (88.6%) 独立装 (92.3%) Q版香水 (52.6%)
适用场合数量 1.000 (34.9%)
适用场合数量 6.000 (26.1%)
适用场合数量 6.000 (61.0%)
适用场合数量 1.000 (40.0%)
商品产地 法国 (43.5%)
商品产地 法国 (60.5%)
商品产地 法国 (46.5%)
商品产地 法国 (34.1%)
性别 女 (98.7%)
性别 女 (99.5%)
性别 女 (92.9%)
性别 女 (98.9%)
香调
影响香水销量的因素分析
• 使用“类型”节点,将“销量等级”字段设置为目标,其他字段设置为输入
Clementine示例03-聚类分析

3.聚类分析(cluster.str)聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。
它是一种重要的人类行为。
聚类与分类的不同在于,聚类所要求划分的类是未知的。
聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
聚类分析的目标就是在相似的基础上收集数据来分类。
聚类源于很多领域,包括数学,计算机科学,统计学,生物学和经济学。
在不同的应用领域,很多聚类技术都得到了发展,这些技术方法被用作描述数据,衡量不同数据源间的相似性,以及把数据源分类到不同的簇中。
从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。
传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。
采用k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名的统计分析软件包中,如SPSS、SAS等。
从机器学习的角度讲,簇相当于隐藏模式。
聚类是搜索簇的无监督学习过程。
与分类不同,无监督学习不依赖预先定义的类或带类标记的训练实例,需要由聚类学习算法自动确定标记,而分类学习的实例或数据对象有类别标记。
聚类是观察式学习,而不是示例式的学习。
从实际应用的角度看,聚类分析是数据挖掘的主要任务之一。
而且聚类能够作为一个独立的工具获得数据的分布状况,观察每一簇数据的特征,集中对特定的聚簇集合作进一步地分析。
聚类分析还可以作为其他算法(如分类和定性归纳算法)的预处理步骤。
Clementine提供了多种可用于聚类分析的模型,包括Kohonen,Kmeans,TwoStep方法。
示例Cluster.str是对人体的健康情况进行分析,通过测量人体类胆固醇、Na、Ka等的含量将个体归入不同类别。
示例中采用了三种方法对数据进行分类,这里我们重点讨论Kmeans聚类方法。
Step 一:读入数据和前两步一样,在建立数据流时首先应读入数据文件。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
24.1.4 建模
对字段设置完毕之后,下一步就是选择挖掘 所需要的模型,在这里我们会选择使用三 种不同的模型来挖掘该数据集。 1. “Apriori”模型节点 2.GRI模型 3.“网络”节点
24.2 利用决策树模型挖掘商业信息
过程如下 : Step1:添加一个“变项文件”节点。 Step2:加入一个“导出”节点。 Step3:对“导出”节点进行设置。 Step4:加入“Healthfood”字段之后,在“导出”节 点后再加入一个“类型”节点,用来选择哪些字 段用来进行数据挖掘。根据挖掘的目标,可以设 置个人信息为“输入”,“Healthfood”设置为 “输出” Step5:加入 “C5.0”节点。 Step6:点选“执行(E)” Step7:从“查看器”中查看该结果
24.3.2 理解数据
在建模之前,需要了解数据集中都有哪些 字段,这些字段如何分布,它们之间是否 隐含着某种相关性等信息。只有了解这些 信息后才能决定使用哪些字段,应用何种 挖掘算法和算法参数。这个过程就是一个 理解数据的过程。
24.3.3 准备数据
首先考虑数据集中可能存在的欺诈类型。 在该数据流中连接一个“条形图”节点并选 定字段名为“name”的字段 。 选中“name”字段之后,点击“执行” 。
24.3 利用神经网络对数据进行欺诈探测
背景是关于农业发展贷款的申请。使用虚构重点为标识那些异常和需要更 深一步调查的记录。要解决的问题是找出那 些就农场类型和大小来说申请贷款过多的农 场主 。
24.3.1 定义数据源
使用一个“变项文件”节点连接到数据集 grantfraudN.db。在“变项文件”节点之后 增加一个“类型”节点到数据流中。
进行深一步的分析。在该数据流中增加一个 “导出”节点,对该节点进行设置。 为了说明真实值和估计值之间的差距,可以 参考claimdiff的直方图。主要对那些由神经 网络得出的申请超出预期的人感兴趣。 在数据流中再添加一个“直方图”节点。双 击打开该节点,在“字段”下拉列表中选择 “claimdiff”,单击“执行(E)” 。 增加一个分割带到直方图中,右击带区生成 一个选择节点,进一步查看那些claimdiff值 较大的数据。
24.3.4 建模
将一个“类型”节点添加到当前数据流中。对 数据集中的数据进行设置。
在数据流上添加一个“神经网络”节点。执 行此数据流。神经网络经过训练后,会产生 一个模型。将产生的模型加入到数据流流中。 然后在数据流中再增加一个“散点图”节点, 对“散点图”节点进行设置。设置完成之后, 执行。
最后,在数据流中增加一个“条形图”节点。 双击该节点,在“字段”下拉列表中选择 “name”字段,点击“执行(E)”,得出 结果如图所示。在图中所显示的就是我们要 重点关注的数据。
24.4小结
本章通过使用Apriori模型、GRI模型、可视化网 络图、决策树、神经网络等来说明如何使用 Clementine在数据库中发现知识。Clementine系 统中提供了很多种模型,对于这些模型的使用, 要考虑到实际情况来酌情进行使用。 本章所展示的只是Clementine系统的一部分应 用。随着社会的不断发展,数据库技术的不断进 步。Clementine将会越来越多的被重视、使用。
数据挖掘原理与SPSS Clementine应用宝典
本章包括:
市场购物篮分析 利用决策树模型挖掘商业信息 利用神经网络对数据进行欺诈探测
24.1市场购物篮分析
本节的例子采用Clementine系统自带的 数据 集BASKETS1n。该数据集是超市的“购物 篮” (一次购物内容的集合)数据和购买者个人 的背景数据,目标是发现购买物品之间的关 联分析。
输出类型除了选用“决策树”之外,还可以选择“规则集” 来显示结果。用“规则集”表示的结果很多时候比“决策 树”更加直观、易懂。。
一般生成的决策树都是经过剪枝的。下面看 看剪枝程度的高低对挖掘结果的影响。选中 “模式”中的“专家”,把“修剪严重性” 的值改为“0”,这意味着在挖掘过程中,进 行的剪枝程度将很小。模型名称改为 “nocut”。
24.1.1 定义数据源
24.1.2 理解数据
在建模之前,我们需要了解数据集中都有哪些字段,这些字段如何分 布,它们之间是否隐含着某种相关性等信息。只有了解这些信息后才能决 定使用哪些字段,应用何种挖掘算法和算法参数。这个过程就是一个理解 数据的过程。
24.1.3 准备数据
在这18个字段中,有一些对于挖掘知识来说 是没有用的,如cardid等,这时我们就可以 把这些暂时没有用到的字段剔除出挖掘过程。 这样可以节约挖掘时间和效率。
选择“执行(E)”。在右面管理器窗口中选中“模型(S)”, 在“nocut”上右击,选择“浏览(B)”,查看生成模型结 果。
利用剪枝程度较高的决策树、剪枝程度低的决 策树、规则集生成的结果,可以通过 Clementine系统提供的很多模型来进行精度 测试。 在这儿选用“分析”节点。生成的结果显示剪 枝程度高的模型正确率为93.8% 。同样的原 理,测试“nocut” 。剪枝程度低的精度为 94.7%。
在数据流区域中添加一个“选择”节点,对 该节点进行设置。 以农场大小、主要作物类型、土壤质量等为 自变量建立一个回归模型来估计一个农场的 收入是多少。
为了发现那些偏离估计值的农场,先生成一个字段――diff, 代表估计值与实际值偏离的百分数。在数据流中再增加一 个“导出”节点 进行设置。 在数据流中增加一个“直方图”节点。对“直方图”节点进 行设置。。