数据挖掘中文版
数据挖掘工具(一)Clementine

数据挖掘工具(一)SPSS Clementine18082607 洪丹Clementine是ISL(Integral Solutions Limited)公司开发的数据挖掘工具平台。
1999年SPSS公司收购了ISL公司,对Clementine产品进行重新整合和开发,现在Clementine已经成为SPSS公司的又一亮点。
作为一个数据挖掘平台, Clementine结合商业技术可以快速建立预测性模型,进而应用到商业活动中,帮助人们改进决策过程。
强大的数据挖掘功能和显著的投资回报率使得Clementine在业界久负盛誉。
同那些仅仅着重于模型的外在表现而忽略了数据挖掘在整个业务流程中的应用价值的其它数据挖掘工具相比, Clementine其功能强大的数据挖掘算法,使数据挖掘贯穿业务流程的始终,在缩短投资回报周期的同时极大提高了投资回报率。
近年来,数据挖掘技术越来越多的投入工程统计和商业运筹,国外各大数据开发公司陆续推出了一些先进的挖掘工具,其中spss公司的Clementine软件以其简单的操作,强大的算法库和完善的操作流程成为了市场占有率最高的通用数据挖掘软件。
本文通过对其界面、算法、操作流程的介绍,具体实例解析以及与同类软件的比较测评来解析该数据挖掘软件。
1.1 关于数据挖掘数据挖掘有很多种定义与解释,例如“识别出巨量数据中有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。
” 1、大体上看,数据挖掘可以视为机器学习和数据库的交叉,它主要利用机器学习界提供的技术来分析海量数据,利用数据库界提供的技术来管理海量数据。
2、数据挖掘的意义却不限于此,尽管数据挖掘技术的诞生源于对数据库管理的优化和改进,但时至今日数据挖掘技术已成为了一门独立学科,过多的依赖数据库存储信息,以数据库已有数据为研究主体,尝试寻找算法挖掘其中的数据关系严重影响了数据挖掘技术的发展和创新。
尽管有了数据仓库的存在可以分析整理出已有数据中的敏感数据为数据挖掘所用,但数据挖掘技术却仍然没有完全舒展开拳脚,释放出其巨大的能量,可怜的数据适用率(即可用于数据挖掘的数据占数据库总数据的比率)导致了数据挖掘预测准确率与实用性的下降。
数据挖掘工具软件介绍(weka)

11
WEKA EXPLORER CLASSIFY
分类器输出文本
Classifier output 区域的文本有一个滚动条以便浏览结果。按住 Alt 和 Shift 键,在这个区域点击鼠标左键,会出现一个对话框, 让你用各种格式(目前可用 JPEG 和 EPS)保存输出的结果。
输出结果
16
WEKA EXPLORER Visualize
3. Polygon. 创建一个形式自由的多边形并选取其中的点。左键点 击添加多边形的顶 点,右键点击完成顶点设置。起始点和最终点会自动连接起来因 此多边形总是闭 合的。 4. Polyline. 可以创建一条折线把它两边的点区分开。左键添加折 线顶点,右键结束 设置。折线总是打开的(与闭合的多边形相反)。 使用 Rectangle,Polygon 或 Polyline 选取了散点图的一个区域后 ,该区域会变成灰色。这时点击Submit 按钮会移除落在灰色区域 之外的所有实例。点击Clear 按钮会清除所选区域而不对图形产 生任何影响。
17
Weka 试验(Experiment)
Experimenter 有两种模式:一种具有较简单的界面, 并提供了试验所需要的大部分功能,另一种则 提供了一个可以使用 Experimenter 所有功能的界面。 你可使用 Experiment Configuration Mode 单选 按钮在这两者间进行选择。 ������ Simple ������ Advanced
8
WEKA EXPLORER
处理属性
顶尖数据挖掘平台安装手册

顶尖数据挖掘平台(TipDM),在线网址:
第3页
顶尖数据挖掘平台(TipDM)
文档编号: TipDM_008
1. 引言
1.1. 产品简介
顶尖数据挖掘平台(TipDM)是广州太普软件自主研发的一个数据挖掘工具,基于云计算和 SOA 架构,使用 JAVA 语言开发,能从各种数据源获取数据,建立各种不同的数据挖掘模型(目前已集成 数十种预测算法和分析技术,基本覆盖了国外主流挖掘系统支持的算法,用户也可以嵌入其它自己 开发的任何算法),使用 TipDM 算法功能进行数据挖掘工作。平台支持数据挖掘流程所需的主要过程, 完成包括对数据进行预处理,包括空值处理、降维处理、离散处理,因子分析、主成分分析、抽样、 过滤等,创建、训练、评估模型,预测,修改模型参数,误差分析等一系列功能。
1.3. 在线试用...................................................................................................................4
2.
系统安装 ....................................................................................................................... 4
2. 系统安装
找 文 然后双击 文 :界面 到安装 件 TipDM.exe,
TipDM.exe 件,安装系统
如下:
顶尖数据挖掘平台(TipDM),在线网址:
第4页
顶尖数据挖掘平台(TipDM)
文档编号: TipDM_008
选择中文简体,点击“OK“按钮。按照安装向导进入下一步:
信息技术常用术语中英文对照表

信息技术常用术语中英文对照表1. 计算机网络 Computer Network2. 互联网 Internet3. 局域网 Local Area Network (LAN)4. 带宽 Bandwidth5. 路由器 Router6. 交换机 Switch7. 防火墙 Firewall8. 病毒 Virus9. 木马 Trojan10. 黑客 Hacker11. 中央处理器 Central Processing Unit (CPU)12. 内存 Random Access Memory (RAM)13. 硬盘 Hard Disk Drive (HDD)14. 固态硬盘 Solid State Drive (SSD)15. 显卡 Graphics Card16. 主板 Motherboard17. BIOS Basic Input/Output System18. 操作系统 Operating System19. 应用程序 Application20. 编程语言 Programming Language21. 数据库 Database22. 服务器 Server23. 客户端 Client24. 云计算 Cloud Computing25. 大数据 Big Data27. 机器学习 Machine Learning28. 深度学习 Deep Learning29. 虚拟现实 Virtual Reality (VR)30. 增强现实 Augmented Reality (AR)31. 网络安全 Network Security32. 数据加密 Data Encryption33. 数字签名 Digital Signature34. 身份验证 Authentication35. 访问控制 Access Control36. 数据备份 Data Backup37. 数据恢复 Data Recovery38. 系统升级 System Upgrade39. 系统优化 System Optimization40. 技术支持 Technical Support当然,让我们继续丰富这个信息技术常用术语的中英文对照表:41. 网络协议 Network Protocol42. IP地址 Internet Protocol Address43. 域名系统 Domain Name System (DNS)44. HTTP Hypertext Transfer Protocol45. Hypertext Transfer Protocol Secure46. FTP File Transfer Protocol47. SMTP Simple Mail Transfer Protocol48. POP3 Post Office Protocol 349. IMAP Internet Message Access Protocol50. TCP/IP Transmission Control Protocol/Internet Protocol51. 无线局域网 Wireless Local Area Network (WLAN)52. 蓝牙 Bluetooth53. 无线保真 WiFi (Wireless Fidelity)54. 4G Fourth Generation55. 5G Fifth Generation56. 物联网 Internet of Things (IoT)57. 云服务 Cloud Service58. 网络存储 Network Attached Storage (NAS)59. 分布式文件系统 Distributed File System60. 数据中心 Data Center61. 系统分析 Systems Analysis62. 系统设计 Systems Design63. 软件开发 Software Development64. 系统集成 Systems Integration65. 软件测试 Software Testing66. 质量保证 Quality Assurance67. 项目管理 Project Management68. 技术文档 Technical Documentation69. 用户手册 User Manual70. 知识库 Knowledge Base71. 网络拓扑 Network Topology72. 星型网络 Star Network73. 环形网络 Ring Network74. 总线型网络 Bus Network75. 树形网络 Tree Network76. 点对点网络 PeertoPeer Network77. 宽带接入 Broadband Access78. DSL Digital Subscriber Line79. 光纤到户 Fiber To The Home (FTTH)80. VoIP Voice over Internet Protocol通过这份对照表,希望您能更加轻松地理解和应用信息技术领域的专业术语。
数据挖掘导论习题答案(中文版)

介绍数据挖掘教师的解决方案手册陈甘美华Pang-NingMichael教授Vipin Kumar版权所有2006年Pearson Addison-Wesley。
保留所有权利。
内容。
1 Introduction 52 Data 53 Exploring Data 194 Classification: Basic Concepts, Decision Trees, and Model24 Evaluation 245 Classification: Alternative Techniques 446 Association Analysis: Basic Concepts and Algorithms 717 Association Analysis: Advanced Concepts 958 Cluster Analysis: Basic Concepts and Algorithms 1259 Cluster Analysis: Additional Issues and Algorithms 14510 Anomaly Detection 153三1介绍1.讨论是否执行下列每项活动的是一种数据miningtask。
(a)把客户的公司根据他们的性别。
否。
这是一种简单的数据库查询。
(b)把客户的公司根据他们的盈利能力。
第这是一种会计计算、应用程序的门限值。
然而,预测盈利的一种新的客户将数据挖掘。
(c)计算的总销售公司。
否。
这又是简单的会计工作。
(d)排序的学生数据库基于学生的身份证号码。
第再次,这是一种简单的数据库查询。
(e)预测结果丢(公平)的一对骰子。
否。
既然死是公正的,这是一种概率的计算。
如果死是不公平的,我们需要估计的概率对每个结果的数据,那么这更象研究的问题数据挖掘。
然而,在这种特定的情况下,要解决这一问题是由数学家很长一段时间前,因此,我们不认为它是数据挖掘。
(f)预测未来股价的公司使用。
(完整版)数据挖掘_概念与技术(第三版)部分习题答案

1.4 数据仓库和数据库有何不同?有哪些相似之处?答:区别:数据仓库是面向主题的,集成的,不易更改且随时间变化的数据集合,用来支持管理人员的决策,数据库由一组内部相关的数据和一组管理和存取数据的软件程序组成,是面向操作型的数据库,是组成数据仓库的源数据。
它用表组织数据,采用ER数据模型。
相似:它们都为数据挖掘提供了源数据,都是数据的组合。
1.3 定义下列数据挖掘功能:特征化、区分、关联和相关分析、预测聚类和演变分析。
使用你熟悉的现实生活的数据库,给出每种数据挖掘功能的例子。
答:特征化是一个目标类数据的一般特性或特性的汇总。
例如,学生的特征可被提出,形成所有大学的计算机科学专业一年级学生的轮廓,这些特征包括作为一种高的年级平均成绩(GPA:Grade point aversge)的信息,还有所修的课程的最大数量。
区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。
例如,具有高GPA 的学生的一般特性可被用来与具有低GPA 的一般特性比较。
最终的描述可能是学生的一个一般可比较的轮廓,就像具有高GPA 的学生的75%是四年级计算机科学专业的学生,而具有低GPA 的学生的65%不是。
关联是指发现关联规则,这些规则表示一起频繁发生在给定数据集的特征值的条件。
例如,一个数据挖掘系统可能发现的关联规则为:major(X, “computing science”) ⇒ owns(X, “personal computer”)[support=12%, confidence=98%] 其中,X 是一个表示学生的变量。
这个规则指出正在学习的学生,12%(支持度)主修计算机科学并且拥有一台个人计算机。
这个组一个学生拥有一台个人电脑的概率是98%(置信度,或确定度)。
分类与预测不同,因为前者的作用是构造一系列能描述和区分数据类型或概念的模型(或功能),而后者是建立一个模型去预测缺失的或无效的、并且通常是数字的数据值。
《大数据挖掘及应用》课程教学大纲 (2022版)

《大数据挖掘及应用》课程教学大纲一、课程基本情况表1 课程基本情况表二、课程简介(中英文版)《大数据挖掘及应用》是计算机科学与技术院智能科学技术的必修课,是掌握数据分析能力的一门重要基础课程。
本课程首先讲授了数据分析的基本知识概念、数据分析预处理的手段,接着从数据分析方法的角度,介绍了数据挖掘关联分析、分类以及聚类三大类算法的基本知识、必要理论基础以及一些经典的数据挖掘算法。
通过对本门课程的学习,学生能够系统地获得数据分析方法的基本概念和理论技术,掌握关联规则分析、分类和聚类等数据挖掘算法,从而使学生学会利用数据预处理和数据挖掘的技术去分析和解决不同行业应用领域中对数据进行处理和获取知识的问题,对培养学生形成良好的计算机科学技术和人工智能领域知识的运用能力有很大的帮助。
《大数据挖掘及应用》是计算机科学与技术学院智能科学与技术专业的必修课,是培养学生具备数据分析能力的重要专业课程。
本课程教学内容涵盖了数据分析从特征提取,特征工程直至模型构建和可视化的全流程。
具体包括数据分析的基本知识概念,各种不同数据分析预处理的手段,以及不同类型的经典数据分析方法,如数据分析的关联分析、无标签分析以及有标签分析三大类算法的基本知识和理论原理。
和实际工程应用中的数据仓库基础知识介绍。
三、课程目标通过本课程的学习,使学生系统地获得数据挖掘基本知识和基本理论;本课程重点学习关联规则挖掘算法、分类和聚类算法,并注重培养学生熟练的编程能力和较强的抽象思维能力﹑逻辑推理能力﹑以及从海量数据中挖掘知识的能力,有助于学生能够利用相关算法去分析法和解决一些实际问题,为学习后续课程和进一步增强计算机编程能力奠定必要的算法基础.课程目标对应的学生知识和能力要求如下:课程目标1: 掌握数据挖掘基本概念和数据预处理知识(支撑毕业要求2.2)课程目标2:掌握关联规则分析、分类分析、聚类分析、深度学习中的经典算法,熟悉算法原理和理论基础(支撑毕业要求3.2)课程目标3: 掌握关联规则分析、分类分析、聚类分析、深度学习中的实验评价指标(支撑毕业要求4.2)课程目标4:熟悉分布式与并行计算基本概念及技术知识,能够对各类数据分析算法进行综合运用,具备分析和解决复杂工程实际问题的能力(支撑毕业要求5.3)课程目标5:通过撰写报告和口头表达,具有良好的沟通交流能力(支撑毕业要求10.1)四、“立德树人”育人内涵结合数据挖掘课程的相关教学内容,通过对数据分析算法与应用技术的讲授、课程大作业、前沿技术探讨等教学组织形式,在培养学生的创新意识和复杂工程问题解决能力的同时,培养学生的辩证思维、人工智能伦理和法律意识,以及求真务实精益求精的专业精神,踏实严谨的科学素养和理论联系实际的学习与创新方法,引导学生认识到新一代人工智能技术变革带来的机遇与挑战,爱党爱国,自觉践行社会主义核心价值观,坚定理想信念,勇担时代使命。
数据挖掘导论习题答案(中文版)

介绍数据挖掘教师的解决方案手册陈甘美华Pang-NingMichael教授Vipin Kumar版权所有2006年Pearson Addison-Wesley。
保留所有权利。
内容。
1 Introduction 52 Data 53 Exploring Data 224 Classification: Basic Concepts, Decision Trees, and Model28 Evaluation 285 Classification: Alternative Techniques 536 Association Analysis: Basic Concepts and Algorithms 857 Association Analysis: Advanced Concepts 1158 Cluster Analysis: Basic Concepts and Algorithms 1539 Cluster Analysis: Additional Issues and Algorithms 17710 Anomaly Detection 187三1介绍1.讨论是否执行下列每项活动的是一种数据miningtask。
(a)把客户的公司根据他们的性别。
否。
这是一种简单的数据库查询。
(b)把客户的公司根据他们的盈利能力。
第这是一种会计计算、应用程序的门限值。
然而,预测盈利的一种新的客户将数据挖掘。
(c)计算的总销售公司。
否。
这又是简单的会计工作。
(d)排序的学生数据库基于学生的身份证号码。
第再次,这是一种简单的数据库查询。
(e)预测结果丢(公平)的一对骰子。
否。
既然死是公正的,这是一种概率的计算。
如果死是不公平的,我们需要估计的概率对每个结果的数据,那么这更象研究的问题数据挖掘。
然而,在这种特定的情况下,要解决这一问题是由数学家很长一段时间前,因此,我们不认为它是数据挖掘。
(f)预测未来股价的公司使用。
(完整word版)数据挖掘_概念与技术(第三版)部分习题答案

1。
4 数据仓库和数据库有何不同?有哪些相似之处?答:区别:数据仓库是面向主题的,集成的,不易更改且随时间变化的数据集合,用来支持管理人员的决策,数据库由一组内部相关的数据和一组管理和存取数据的软件程序组成,是面向操作型的数据库,是组成数据仓库的源数据.它用表组织数据,采用ER数据模型。
相似:它们都为数据挖掘提供了源数据,都是数据的组合.1。
3 定义下列数据挖掘功能:特征化、区分、关联和相关分析、预测聚类和演变分析。
使用你熟悉的现实生活的数据库,给出每种数据挖掘功能的例子。
答:特征化是一个目标类数据的一般特性或特性的汇总。
例如,学生的特征可被提出,形成所有大学的计算机科学专业一年级学生的轮廓,这些特征包括作为一种高的年级平均成绩(GPA:Grade point aversge)的信息,还有所修的课程的最大数量。
区分是将目标类数据对象的一般特性与一个或多个对比类对象的一般特性进行比较。
例如,具有高GPA 的学生的一般特性可被用来与具有低GPA 的一般特性比较.最终的描述可能是学生的一个一般可比较的轮廓,就像具有高GPA 的学生的75%是四年级计算机科学专业的学生,而具有低GPA 的学生的65%不是。
关联是指发现关联规则,这些规则表示一起频繁发生在给定数据集的特征值的条件.例如,一个数据挖掘系统可能发现的关联规则为:major(X,“computing science”) ⇒owns(X,“personal computer”)[support=12%, confidence=98%] 其中,X 是一个表示学生的变量。
这个规则指出正在学习的学生,12%(支持度)主修计算机科学并且拥有一台个人计算机。
这个组一个学生拥有一台个人电脑的概率是98%(置信度,或确定度)。
分类与预测不同,因为前者的作用是构造一系列能描述和区分数据类型或概念的模型(或功能),而后者是建立一个模型去预测缺失的或无效的、并且通常是数字的数据值.它们的相似性是他们都是预测的工具:分类被用作预测目标数据的类的标签,而预测典型的应用是预测缺失的数字型数据的值.聚类分析的数据对象不考虑已知的类标号。
数据挖掘软件SPSS-Clementine-12安装教程

数据挖掘软件SPSS Clementine 12安装教程SPSS Clementine 12安装包比较特殊,是采用ISO格式的,而且中文补丁、文本挖掘模块都是分开的,对于初次安装者来说比较困难。
本片文章将对该软件的安装过程进行详细介绍,相信大家只要按照本文的安装说明一步一步操作即可顺利完成软件的安装和破解。
步骤一:安装前准备1、获取程序安装包SPSS Clementine 12的安装包获取的方法比较多,常用的方法是通过baidu或google搜索关键词,从给出的一些上进行下载。
为了方便大家安装,这里给出几个固定的下载供大家安装:论坛上下载:.kddchina./thread-538-1-1.html百度网盘:pan.baidu./s/1pEcS9提取密码:rhor腾讯微云:/OVYtFW相信这么多下载方式大家一定能成功获得安装程序的。
2、ISO文件查看工具由于程序安装包是ISO光盘镜像形式的,如果你的操作系统是win8之前的系统,那么就需要安装能够打开提取ISO文件的工具软件了。
在此推荐UltraISO这款软件,主要是既能满足我们的需要,而且文件又较小,安装方便。
这里提供几个下载UltraISO程序的地址:百度网盘pan.baidu./s/1mqkmN腾讯微云:pan.baidu./s/1qZY5GUltraISO安装成功后在计算机资源管理器中可以看到如下虚拟光驱的图标(接下来需要用到)右键点击该图标可以看到如下的一些选项,点击“加载”,选择相应的ISO文件就可以将文件加载到虚拟光驱中并打开。
步骤二:安装Clementine 121、安装Clementine 12主程序在计算机资源管理器中右键“CD驱动器”>>UtraISO>>加载,选择”SPSS_Clementine_v12.0-CYGiSO.bin”这个文件然后在打开计算机资源管理器可以看到如下情况双击打开,选择setup.exe运行,在弹出框中选择第一个选项(Install Clementine)即可,然后依次完成安装过程。
WEKA中文详细教程

Weka可以将分析结果导出为多种格式,如CSV、ARFF、LaTeX等,用户可以通过“文件”菜单 选择“导出数据”来导出数据。
数据清理
缺失值处理
Weka提供了多种方法来处理缺失值, 如删除含有缺失值的实例、填充缺失 值等。
异常值检测
Weka提供了多种异常值检测方法, 如基于距离的异常值检测、基于密度 的异常值检测等。
Weka中文详细教程
目录
• Weka简介 • 数据预处理 • 分类算法 • 关联规则挖掘 • 回归分析 • 聚类分析 • 特征选择与降维 • 模型评估与优化
01
Weka简介
Weka是什么
01 Weka是一款开源的数据挖掘软件,全称是 "Waikato Environment for Knowledge Analysis",由新西兰怀卡托大学开发。
解释性强等优点。
使用Weka进行决策树 分类时,需要设置合 适的参数,如剪枝策 略、停止条件等,以 获得最佳分类效果。
决策树分类结果易于 理解和解释,能够为 决策提供有力支持。
贝叶斯分类器
贝叶斯分类器是一种 基于概率的分类算法, 通过计算不同类别的 概率来进行分类。
Weka中的朴素贝叶斯 分类器是一种基于贝 叶斯定理的简单分类 器,适用于特征之间 相互独立的场景。
08
模型评估与优化
交叉验证
01
交叉验证是一种评估机器学习模型性能的常用方法,通过将数据集分成多个子 集,然后使用其中的一部分子集训练模型,其余子集用于测试模型。
02
常见的交叉验证方法包括k-折交叉验证和留出交叉验证。在k-折交叉验证中, 数据集被分成k个大小相近的子集,每次使用其中的k-1个子集训练模型,剩余 一个子集用于测试。
knime白皮书(中文版)

技术报告(Knime: The Konstanz Information Miner)摘要---knime是一个能用来很简单的虚拟装配和交互执行数据管道的标准的环境Knime被设计成为一个教学,研究以及合作的平台,在这里你可以很容易的集成新的算法,数据操纵或者是可视化的方法比如一个新的模块或是节点。
在这本白皮书我们将介绍有关设计方面的基础构架以及怎样将新节点插入的简单过程。
第一概述在过去的几年里,人们对标准的数据分析环境的迫切需求已经达到前所未有的程度。
为了充分利用大量不同种类的数据分析方法,这样一个环境是必须的—--能够简单而直观的使用,允许对分析进行快速和交互式的变换,用户可以可视化的搜索结果。
为了应付这些挑战,数据流水线操作环境是再合适不过一种模型。
它允许用户通过标准的组建模块可视化地组装和修改数据分析流,同时提供一种直观,图示的方法来记载操作日记。
Knime就能提供这样的一个环境。
图1展示的是一个例子的数据分析流截图在中间,一个数据流正从三个源节点读入同时在多处进行处理,也跟分析流相平行,包括预处理,建模,以及可视化节点。
在这种类繁多的节点中,你可以选择数据源,数据处理步骤,模型搭建算法,可视化技术甚至是输入输出模型工具,然后将它拖到工作区,可以让它和其他节点连接起来。
让所有操作实现图形交互的能力创建了检索你手中的数据集功能强大的环境Knime是用Java编写的而他的图形作业编辑区是一个类似Eclipse插件程序的工具。
扩充是很容易的,通过打开API和数据抽象框架,把正确定义的新节点快速加入就可以了。
在这本白皮书里我们会描述一些有关Knime内核的细节。
更多信息你可以登陆网站查询。
第二部分构架Knime的构架在设计之初就有三个主要的原则:•可视化,交互式构架:数据流应该通过简单的拖放各种处理单元来组合。
标准的应用程序能被设计通过单个的数据管道。
•模块化:处理单元和数据容器不应该相互依靠,以便分布式计算和不同算法的独立开发的实现更简单。
spss21中文安装与破解
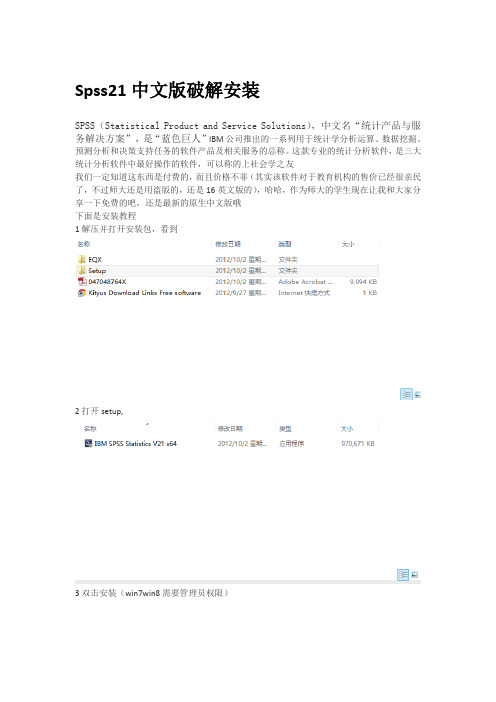
Spss21中文版破解安装SPSS(Statistical Product and Service Solutions),中文名“统计产品与服务解决方案”,是“蓝色巨人”IBM公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称。
这款专业的统计分析软件,是三大统计分析软件中最好操作的软件,可以称的上社会学之友我们一定知道这东西是付费的,而且价格不菲(其实该软件对于教育机构的售价已经很亲民了,不过师大还是用盗版的,还是16英文版的),哈哈,作为师大的学生现在让我和大家分享一下免费的吧,还是最新的原生中文版哦下面是安装教程1解压并打开安装包,看到2打开setup,3双击安装(win7win8需要管理员权限)3 4下一步注,这里可以选择语言,点击语言前方的图标,选择在本机运行即可,这里默认简体中文,你觉得汉字好看些,也可以选择繁体中文,可多选注:在这里,可以更改一下安装目录,不要放在c盘,造成C盘压力上大2——3分钟后,就安装完毕了不要着急,首次运行软件时会有激活提示,先关掉软件打开安装包中EQX文件,接下来就是见证的时刻1将EQX中的"lservrc"(屏蔽命令)复制到安装目录文件夹里,也就是我刚才更改安装目录后的文件夹2然后打开“许可证授权向导”也就是这个图标,非win8可以在开始菜单里找到3输入授权密码QA3AW8U62Z4ZWTSPV44VXI65P59OLE547WHIQVZYWLARL9JEYQEGDUBLH8Z3ZCJAL3FLXMS98V 95TSDYI7FOEXUPRR看到“许可证到期日期:无”了吗,我们成功了,打开SPSS,让他为你服务吧谢谢,谢谢spss的三位斯坦福的前辈,谢谢IBM。
数据挖掘导论完整中文

• 算法9.1 基本模糊c均值算法
• 选择一个初始模糊伪划分,即对所有的wij赋值
• Repeat
•
使用模糊伪划分,计算每个簇的质心
•
重新计算模糊伪划分,即wij
• Until 质心不发生变化
第19页/共109页
• FCM的结构类似于K均值。 K均值可以看作FCM的特例。 • K均值在初始化之后,交替地更新质心和指派每个对象到最近的质心。具体地说,计算模糊伪划分等价于指
第27页/共109页
第28页/共109页
算法
• 估计数据分布: • 确定分布:一般假设数据取自高斯混合分布。然后,对分布的参数进行估计:利用EM算法进行最大似 然估计 • 利用直方图估计分布
• 对分布进行划分、分离。每个分布对应于一个簇。
第29页/共109页
优点和缺点
• 混合模型比k均值或模糊c均值更一般,因为它可以使用各种类型的分布。 • 利用简单的估计分布的方法(如直方图)可能会错误估计数据的原始分布,导致结果不好。 • 利用复杂的方法(如EM算法),计算复杂性会大大增加。
第22页/共109页
• 更新模糊伪划分
1
• 公式:
wij
(1/ dist(xi , c j )2 ) p1
k
1
(1/ dist(xi , cq )2 ) p1
q 1
• 如果p>2,则该指数降低赋予离点最近的簇的权值。事实上,随着p趋向于 无穷大,该指数趋向于0,而权值趋向于1/k。
• 另一方面,随着p趋向于1,该指数加大赋予离点最近的簇的权值。随着p趋 向于1,关于最近簇的隶属权值趋向于1,而关于其他簇的隶属权值趋向于0。 这时对应于k均值。
的特例。DBSCAN不基于任何形式化模型。
数据挖掘导论第一章

2020/9/29
数据挖掘导论
3
2020/9/29
数据挖掘导论
4
2020/9/29
数据挖掘导论
5
Jiawei Han
在数据挖掘领域做出杰出贡献的郑州大学校友——韩家炜
2020/9/29
数据挖掘导论
6
第1章 绪论
?
No
S in g le 4 0 K
?
No
M a rrie d 8 0 K
?
10
Training Set
Learn Classifier
Test Set
Model
2020/9/29
数据挖掘导论
23
分类:应用1
Direct Marketing Goal: Reduce cost of mailing by targeting a set of consumers likely to buy a new cell-phone product. Approach: Use the data for a similar product introduced before. We know which customers decided to buy and which decided otherwise. This {buy, don’t buy} decision forms the class attribute. Collect various demographic, lifestyle, and company-interaction related information about all such customers. Type of business, where they stay, how much they earn, etc. Use this information as input attributes to learn a classifier model.
SPSS19中文版超经典教程

推论性统计:利用 样本信息推断总体 特征,通过样本统 计量推断总体参数, 进行假设检验和方 差分析等
参数估计:根据样 本信息,对总体参 数进行点估计或区 间估计,以推断总 体的未知特征
假设检验:根据样 本信息,对总体参 数进行假设检验, 以确定样本数据是 否符合预期的假设
高级统计分析
因子分析:用于 研究变量之间的
描述性统计的指标:平均数、中位 数、众数、方差、标准差等。
添加标题
添加标题
添加标题
添加标题
目的:通过对数据的描述性统计, 可以更好地理解数据,发现数据中 的规律和趋势,为后续的数据分析 提供基础。
描述性统计的应用范围:在各个领 域都有广泛的应用,如社会科学、 医学、经济学等。
推论性统计
描述性统计:对数 据进行整理、分组、 计算和图形展示, 以描述数据的分布 特征和规律
数据挖掘概述
定义:从大量数据中提取有价值信息和知识的过程 目的:发现数据中的模式、趋势和关联 方法:聚类分析、决策树、神经网络等 应用领域:商业智能、金融、医疗等
数据预处理
数据清洗:去除无效、错误、重复的数据 数据转换:将数据转换成易于分析和可视化的格式 数据分组:对数据进行分组和归类,便于后续分析 数据筛选:选择与主题相关的数据,去除无关的数据
Part One
SPSS19中文版基 础操作
安装和启动
安装步骤:按照提示进行安装
启动步骤:点击桌面图标或开始 菜单,选择SPSS 19,进入软 件界面
界面介绍:主界面包括菜单栏、 工具栏、数据编辑栏等
软件帮助:提供帮助文档和在线 支持,方便解决遇到的问题
界面介绍
菜单栏:包括文 件、编辑、查看、 分析等选项
Simple & Creative
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
目录第一章引言 1.1 什么激发数据挖掘?为什么它是重要的?1.2 什么是数据挖掘?1.3 数据挖掘——在何种数据上进行?1.3.1 关系数据库1.3.2 数据仓库1.3.3 事务数据库1.3.4 高级数据库系统和高级数据库应用 1.4 数据挖掘功能——可以挖掘什么类型的模式? 1.4.1 概念/类描述:特征和区分1.4.2 关联分析1.4.3 分类和预测1.4.4 聚类分析 1.4.5 局外者分析 1.4.6 演变分析 1.5 所有模式都是有趣的吗? 1.6 数据挖掘系统的分类1.7 数据挖掘的主要问题1.8 总结.习题第二章数据仓库和数据挖掘的OLAP 技术 2.1 什么是数据仓库?2.2.1 操作数据库系统与数据仓库的区别2.1.2 但是,为什么需要一个分离的数据仓库. 2.2 多维数据模型2.2.1 由表和电子数据表到数据方 2.2.2 星形、雪花和事实星座:多维数据库模式. 2.2.3 定义星形、雪花和事实星座的例子 2.2.3 度量:它们的分类和计算.2.2.5 引入概念分 2.2.6 多维数据模型上的OLAP 操作2.2.7 查询多维数据库的星形网查询模型. 2.3 数据仓库的系统结构 2.3.1 数据仓库的设计步骤和结构 2.3.2 三层数据仓库结构2.3.3 OLAP 服务器类型:ROLAP、MOLAP 、HOLAP 的比较2.4 数据仓库实现2.4.1 数据方的有效计算2.4.2 索引OLAP 数据2.4.3 OLAP 查询的有效处理2.4.4 元数据存储2.5 数据方技术的进一步发展 2.5.1 数据方发现驱动的探查 2.5.2 多粒度上的复杂聚集: 多特征方2.5.3 其它进展2.6 由数据仓库到数据挖掘2.6.1 数据仓库的使用2.6.2 由联机分析处理到联机分析挖掘2.7 总结习题第三章数据预处理 3.1 为什么要预处理数据? 3.2 数据清理3.2.1 遗漏值3.2.2 噪音数据3.3 数据集成和变换3.3.1 数据集成3.3.2 数据变换3.4 数据归约3.4.1 数据方聚集3.4.2 维归约3.4.3 数据压缩3.4.4 数值归约3.5 离散化和概念分层产生3.5.1 数值数据的离散化和概念分层产生3.5.2 分类数据的概念分层产生. 3.6 总结习题第一章引言本书是一个导论,介绍什么是数据挖掘,什么是数据库中知识发现。
书中的材料从数据库角度提供,特别强调发现隐藏在大型数据集中有趣数据模式的数据挖掘基本概念和技术。
所讨论的实现方法主要面向可规模化的、有效的数据挖掘工具开发。
本章,你将学习数据挖掘如何成为数据库技术自然进化的一部分,为什么数据挖掘是重要的,以及如何定义数据挖掘。
你将学习数据挖掘系统的一般结构,并考察挖掘的数据种类,可以发现的数据类型,以及什么样的模式提供有用的知识。
除学习数据挖掘系统的分类之外,你将看到建立未来的数据挖掘工具所面临的挑战性问题。
1.1 什么激发数据挖掘?为什么它是重要的?需要是发明之母。
近年来,数据挖掘引起了信息产业界的极大关注,其主要原因是存在大量数据,可以广泛使用,并且迫切需要将这些数据转换成有用的信息和知识。
获取的信息和知识可以广泛用于各种应用,包括商务管理、生产控制、市场分析、工程设计和科学探索等。
数据挖掘是信息技术自然进化的结果。
进化过程的见证是数据库工业界开发以下功能(图 1.1):数据收集和数据库创建,数据管理(包括数据存储和提取,数据库事务处理),以及数据分析与理解(涉及数据仓库和数据挖掘)。
例如,数据收集和数据库创建机制的早期开发已成为稍后数据存储和提取、查询和事务处理有效机制开发的必备基础。
随着提供查询和事务处理的大量数据库系统广泛付诸实践,数据分析和理解自然成为下一个目标。
自60 年代以来,数据库和信息技术已经系统地从原始的文件处理进化到复杂的、功能强大的数据库系统。
自70 年代以来,数据库系统的研究和开发已经从层次和网状数据库发展到开发关系数据库系统(数据存放在关系表结构中;见 1.3.1 小节)、数据建模工具、索引和数据组织技术。
此外,用户通过查询语言、用户界面、优化的查询处理和事务管理,可以方便、灵活地访问数据。
联机事务处理(OLTP)将查询看作只读事务,对于关系技术的发展和广泛地将关系技术作为大量数据的有效存储、提取和管理的主要工具作出了重要贡献。
自80 年代中期以来,数据库技术的特点是广泛接受关系技术,研究和开发新的、功能强大的数据库系统。
这些使用了先进的数据模型,如扩充关系、面向对象、对象-关系和演绎模型。
包括空间的、时间的、多媒体的、主动的和科学的数据库、知识库、办公信息库在内的面向应用的数据库系统百花齐放。
涉及分布性、多样性和数据共享问题被广泛研究。
异种数据库和基于Internet的全球信息系统,如WWW 也已出现,并成为信息工业的生力军。
在过去的三十年中,计算机硬件稳定的、令人吃惊的进步导致了功能强大的计算机、数据收集设备和存储介质的大量供应。
这些技术大大推动了数据库和信息产业的发展,使得大量数据库和信息存储用于事务管理、信息提取和数据分析。
现在,数据可以存放在不同类型的数据库中。
最近出现的一种数据库结构是数据仓库(1.3.2 小节)。
这是一种多个异种数据源在单个站点以统一的模式组织的存储,以支持管理决策。
数据仓库技术包括数据清理、数据集成和联机分析处理(OLAP)。
OLAP 是一种分析技术,具有汇总、合并和聚集功能,以及从不同的角度观察信息的能力。
尽管OLAP 工具支持多维分析和决策,对于深层次的分析,如数据分类、聚类和数据随时间变化的特征,仍然需要其它分析工具。
图1.1:数据库技术的进化数据丰富,伴随着对强有力的数据分析工具的需求,被描述为“数据丰富,但信息贫乏”。
快速增长的海量数据收集、存放在大型和大量数据库中,没有强有力的工具,理解它们已经远远超出了人的能力(图 1.2)。
结果,收集在大型数据库中的数据变成了“数据坟墓”——难得再访问的数据档案。
这样,重要的决定常常不是基于数据库中信息丰富的数据,而是基于决策者的直观,因为决策者缺乏从海量数据中提取有价值知识的工具。
此外,考虑当前的专家系统技术。
通常,这种系统依赖用户或领域专家人工地将知识输入知识库。
不幸的是,这一过程常常有偏差和错误,并且耗时、费用高。
数据挖掘工具进行数据分析,可以发现重要的数据模式,对商务决策、知识库、科学和医学研究作出了巨大贡献。
数据和信息之间的鸿沟要求系统地开发数据挖掘工具,将数据坟墓转换成知识“金块”。
图1.2 我们数据丰富,知识贫乏1.2 什么是数据挖掘?简单地说,数据挖掘是从大量数据中提取或“挖掘”知识。
该术语实际上有点用词不当。
注意,从矿石或砂子挖掘黄金称作黄金挖掘,而不是砂石挖掘。
这样,数据挖掘应当更正确地命名为“从数据中挖掘知识”,不幸的是它有点长。
“知识挖掘”是一个短术语,可能不能强调从大量数据中挖掘。
毕竟,挖掘是一个很生动的术语,它抓住了从大量的、未加工的材料中发现少量金块这一过程的特点(图 1.3)。
这样,这种用词不当携带了“数据”和“挖掘”,成了流行的选择。
还有一些术语,具有和数据挖掘类似,但稍有不同的含义,如数据库中知识挖掘、知识提取、数据/模式分析、数据考古和数据捕捞。
图1.3 数据挖掘:在你的数据中搜索知识(有趣的模式)许多人把数据挖掘视为另一个常用的术语“数据库中知识发现”或KDD 的同义词。
而另一些人只是把数据挖掘视为数据库中知识发现过程的一个基本步骤。
知识发现过程如图1.4 所示,由以下步骤组成:1. 数据清理(消除噪音或不一致数据)2. 数据集成(多种数据源可以组合在一起)3. 数据选择(从数据库中提取与分析任务相关的数据)4. 数据变换(数据变换或统一成适合挖掘的形式;如,通过汇总或聚集操作)1 信息产业界的一个流行趋势是将数据清理和数据集成作为预处理步骤执行,结果数据存放在数据仓库中。
2 有时,数据变换和数据统一在数据选择过程之前进行,特别是在数据仓库情况下。
5. 数据挖掘(基本步骤,使用智能方法提取数据模式)6. 模式评估(根据某种兴趣度度量,识别提供知识的真正有趣的模式;1.5 节)7. 知识表示(使用可视化和知识表示技术,向用户提供挖掘的知识)。
图1.4:数据挖掘视为知识发现过程的一个步骤数据挖掘步骤可以与用户或知识库交互。
有趣的模式提供给用户,或作为新的知识存放在知识库中。
注意,根据这种观点,数据挖掘只是整个过程中的一步,尽管是最重要的一步,因为它发现隐藏的模式。
我们同意数据挖掘是知识发现过程的一个步骤。
然而,在工业界、媒体和数据库研究界,“数据挖掘”比较长的术语“数据库中知识发现”更流行。
因此,在本书中,我们选用术语数据挖掘。
我们采用数据挖掘的广义观点:数据挖掘是从存放在数据库、数据仓库或其它信息库中的大量数据挖掘有趣知识的过程。
基于这种观点,典型的数据挖掘系统具有以下主要成分(图 1.5):1.3.1 关系数据库数据库系统,也称数据库管理系统(DBMS ),由一组内部相关的数据,称作数据库,和一组管理和存取数据的软件程序组成。
软件程序涉及如下机制:数据库结构定义,数据存储,并行、共享或分布的数据访问,面对系统瘫痪或未授权的访问,确保数据的一致性和安全性。
关系数据库是表的集合,每个表都赋予一个唯一的名字。
每个表包含一组属性(列或字段),并通常存放大量元组(记录或行)。
关系中的每个元组代表一个被唯一关键字标识的对象,并被一组属性值描述。
语义数据模型,如实体-联系(ER )数据模型,将数据库作为一组实体和它们之间的联系进行建模。
通常为关系数据库构造ER 模型。
考虑下面的例子。
例 1.1 AllElectronics 公司由下列关系表描述:customer, item, employee 和branch。
这些表的片段在图1.6 中给出。
为便于制定决策,数据仓库中的数据围绕诸如顾客、商品、供应商和活动等主题组织。
数据存储,从历史的角度(如过去的5-10 年)提供信息,并且是汇总的。
例如,数据仓库不是存放每个销售事务的细节,而是存放每个商店,或(汇总到较高层次)每个销售地区每类商品的销售事务汇总。
通常,数据仓库用多维数据库结构建模。
其中,每个维对应于模式中一个或一组属性,每个单元存放聚集度量,如count 或sales_amount 。
数据仓库的实际物理结构可以是关系数据存储或多维数据方。
它提供数据的多维视图,并允许快速访问预计算的和汇总的数据。
例 1.2 AllElectronics 的汇总销售数据数据方在图1.8(a)中。
该数据方有三个维:address (城市值),time (季度值Q1, Q2, Q3, Q4)和item (商品类型值:家庭娱乐、计算机、电话、安全)。