最新数据挖掘考试题目——关联分析资料
数据库数据挖掘与分析考试试卷

数据库数据挖掘与分析考试试卷(答案见尾页)一、选择题1. 数据挖掘的主要目的是什么?A. 提取数据库中的数据B. 分析数据库中的数据以发现隐藏的模式和关联C. 存储和管理数据库中的数据D. 传输数据库中的数据2. 在数据挖掘中,以下哪个过程是用来发现数据项之间的有趣关系和关联的?A. 数据清理B. 数据集成C. 数据转换D. 数据挖掘3. 数据挖掘任务通常不包括以下哪项?A.分类B.聚类C.回归D. 数据库优化4. 关联规则学习是数据挖掘中的一个重要技术,它主要关注什么?A. 发现数据集中不同项之间的因果关系B. 发现数据集中频繁出现的模式和关联C. 建立数据模型以预测未来趋势D. 优化数据库查询性能5. 在聚类分析中,以下哪个选项不是常用的距离度量方法?A. 曼哈顿距离B. 欧氏距离C. 切比雪夫距离D. 余弦相似度6. 数据挖掘中经常使用哪种图表来展示聚类结果?A. 条形图B. 饼图C. 网络图D. 散点图7. 在数据挖掘中,以下哪个算法主要用于发现连续数值型数据中的异常值或离群点?A. K-均值算法B. DBSCANC. 谱聚类算法D. 决策树算法8. 数据挖掘中,以下哪个步骤不是数据预处理的一部分?A. 数据清洗B. 数据集成C. 数据转换D. 数据降维9. 在建立数据挖掘模型时,以下哪个步骤不是特征选择的一部分?A. 特征提取B. 特征选择C. 特征验证D. 特征排序10. 数据挖掘中,以下哪个工具不是常用的数据挖掘工具?A. SQLB. ExcelC. PythonD. R二、问答题2. 什么是SQL语言?请列举几种常见的SQL语句。
3. 什么是数据库的完整性约束?请举例说明。
4. 什么是数据库的设计原则?请列举几个常用的设计原则。
5. 什么是数据库的范式?请简要解释第一范式和第二范式。
6. 什么是数据库索引?请简述索引的作用和分类。
7. 什么是数据库的事务处理?请简述事务的定义和特性。
数据挖掘与分析考试试题

数据挖掘与分析考试试题一、选择题(每题 3 分,共 30 分)1、以下哪个不是数据挖掘的主要任务?()A 分类B 聚类C 数据清洗D 关联规则挖掘2、在数据挖掘中,以下哪种方法常用于处理缺失值?()A 直接删除包含缺失值的记录B 用平均值填充缺失值C 用中位数填充缺失值D 以上方法都可以3、决策树算法中,用于选择最佳分裂特征的指标通常是()A 信息增益B 基尼系数C 准确率D 召回率4、以下哪个不是聚类算法?()A KMeans 算法B 层次聚类算法C 朴素贝叶斯算法D DBSCAN 算法5、数据挖掘中的关联规则挖掘,常用的算法是()A Apriori 算法B C45 算法C KNN 算法D SVM 算法6、以下哪种数据预处理方法可以用于将连续型特征转换为离散型特征?()A 标准化B 归一化C 分箱D 主成分分析7、在构建分类模型时,如果数据集存在类别不平衡问题,以下哪种方法可以解决?()A 过采样B 欠采样C 调整分类阈值D 以上方法都可以8、以下哪个指标常用于评估分类模型的性能?()A ROC 曲线下面积B 均方误差C 平均绝对误差D 决定系数9、对于高维数据,以下哪种方法可以进行降维?()A 因子分析B 线性判别分析C 主成分分析D 以上方法都可以10、以下关于数据挖掘的描述,错误的是()A 数据挖掘可以发现隐藏在数据中的模式和关系B 数据挖掘需要大量的数据C 数据挖掘的结果一定是准确无误的D 数据挖掘是一个反复迭代的过程二、填空题(每题 3 分,共 30 分)1、数据挖掘的一般流程包括:________、________、________、________、________和________。
2、分类算法中,常见的有________、________、________等。
3、聚类算法中,KMeans 算法的基本思想是:________。
4、关联规则挖掘中,常用的度量指标有________、________等。
数据挖掘——关联分析

结果:
尿丌湿销量增长18% 啤酒销量30%
目录
1 2 关联分析是什么 原理与基础概念 关联分析的应用 案例分析
3
4
关联分析是什 么
关联分析是什么
兲联分析是数据挖掘领域常用的一类算法,主要用于収现 隐藏在大型数据集中有意义的联系,所収现的模式通常用 关联规则或频繁项集的形式表示。能够帮助企业做很多很 有用的产品组合推荐、优惠促销组合,同时也能指导货架
原理与基础概念
TID 1 Items Bread,Milk
2
3 4 5
Bread,Diaper,Beer,Eggs
Milk,Diaper,Beer,Coke Bread,Milk.Diaper,Beer Bread,Milk,Diaper,Coke
原理与基础概念
就啤酒、尿丌湿案例而言,首先必须要设定最小支持度不最小可信
度两个阈值,在此假设最小支持度min-support=5%且最小可信度 min-confidence=65%。用公式可以描述为:
Support{Diaper,Beer}≥5%and Confidence{Diaper,Beer}≥65%
其中,Support{Diaper,Beer}≥5%于此应用范例中的意义为:在 所有的交易记录资料中,至少有5%的交易呈现尿布不啤酒这两项商品 被同时购买的交易行为。Confidence{Diaper,Beer}≥65%于此应用范
摆放是否合理,还能够找到更多的潜在客户,真正的把数
据挖掘落到实处。
关联分析是什么
简单的说,就是収现大量数据中项集乊间有趣的兲联。在交 易数据、兲系数据或其他信息载体中,查找存在于项目集合 或对象集合乊间的频繁模式、兲联、相兲性或因果结构。
数据挖掘之关联分析

数据挖掘能做什么
相关性分组或关联规则 (Affinity grouping or association rules) 决定哪些事情将一起发生。 例子: 超市中客户在购买A的同时,经常会购买B,即A => B(关联规则) 客户在购买A后,隔一段时间,会购买B (序列分析)
聚类是对记录分组,把相似的记录在一个聚集里。聚类和分类的区别是聚集不依赖于预先定义好的类,不需要训练集。
关联规则的实现原理: 从所有的用户购物数据中(如果数据量过大,可以选取一定的时间区间,如一年、一个季度等),寻找当用户购买了A商品的基础上,又购买了B商品的人数所占的比例,当这个比例达到了预设的一个目标水平的时候,我们就认为这两个商品是存在一定关联的,所以当用户购买了A商品但还未购买B商品时,我们就可以向该类用户推荐B商品。
聚类(Clustering)
一些特定症状的聚集可能预示了一个特定的疾病 租VCD类型不相似的客户聚集,可能暗示成员属于不同的亚文化群
例子:
数据挖掘能做什么
STEP1
STEP2
我们会发现很多网站都具备了内容推荐的功能,这类功能无疑在帮助用户发现需求,促进商品购买和服务应用方面起到了显著性的效果。
01
03
02
关联推荐在实现方式上也可以分为两种:
数据关联
关联推荐在实现方式上也可以分为两种:
01
02
03
04
关联规则
以产品分析为基础的关联推荐
以用户分析为基础的关联推荐
基于用户分析的推荐是通过分析用户的历史行为数据,可能会发现购买了《Web Analytics》的很多用户也买了《The Elements of User Experience》这本书,那么就可以基于这个发现进行推荐。
数据挖掘上机操作题

数据挖掘上机操作题本文档旨在提供一些数据挖掘的上机操作题,帮助学生巩固和应用所学的知识。
以下是一些实用的题目,供参考和练。
题目一:数据预处理请按照以下步骤进行数据预处理:1. 导入数据集并查看各列的属性和内容。
2. 处理缺失值:检查并决定如何处理数据中的缺失值。
3. 处理异常值:检查并决定如何处理数据中的异常值。
4. 处理重复数据:检查数据中是否存在重复数据,并决定如何处理。
5. 对数据进行归一化处理:选择合适的归一化方法并应用于数据集。
请根据给定的数据集完成以上步骤,并记录每一步的操作和结果。
题目二:特征选择请根据以下步骤进行特征选择:1. 导入数据集并查看各列的属性和内容。
2. 计算特征之间的相关性:使用相关系数或其他方法计算特征之间的相关性,并选择相关系数较低的特征。
3. 使用特征选择算法:选择一个适当的特征选择算法(如卡方检验、信息增益等),并应用于数据集,选择出最重要的特征。
请根据给定的数据集完成以上步骤,并记录每一步的操作和结果。
题目三:数据聚类请按照以下步骤进行数据聚类:1. 导入数据集并查看各列的属性和内容。
2. 数据预处理:按照题目一的步骤对数据进行预处理。
3. 选择聚类算法:选择一个适当的聚类算法(如K-means、DBSCAN等)并应用于数据集。
4. 聚类结果分析:分析聚类结果并进行可视化展示。
请根据给定的数据集完成以上步骤,并记录每一步的操作和结果。
题目四:关联规则挖掘请按照以下步骤进行关联规则挖掘:1. 导入数据集并查看各列的属性和内容。
2. 数据预处理:按照题目一的步骤对数据进行预处理。
3. 设置最小支持度和置信度:根据数据集的大小和要求,设置适当的最小支持度和置信度。
4. 运行关联规则挖掘算法:应用Apriori算法或其他适当的算法,挖掘关联规则。
5. 分析并解释关联规则:对挖掘得到的关联规则进行分析和解释。
请根据给定的数据集完成以上步骤,并记录每一步的操作和结果。
数据挖掘试题

数据挖掘试题及答案
1.数据挖掘的定义是什么?
数据挖掘是指从大量数据中通过算法自动发现和提取有用的信息,并对其进行分析和解释,以帮助企业做出决策的过程。
1.数据挖掘的主要任务是什么?
数据挖掘的主要任务包括关联分析、聚类分析、分类和预测、偏差检测等。
1.什么是关联分析?
关联分析是指通过发现大量数据中项集之间的关联性或相关性来进行分析的一种方法。
常见的关联分析算法有Apriori算法和FP-Growth算法。
1.什么是聚类分析?
聚类分析是指将物理或抽象对象组成的多个组或类按照它们的相似性进行分类。
聚类分析的目标是将相似的对象归为一类,同时将不相似或不同的对象分离出来。
1.什么是分类和预测?
分类是指根据历史数据和经验建立模型,然后使用该模型对新的未知数据进行预测或分类。
预测则是利用已知的变量和参数来预测未来的结果或趋势。
1.什么是偏差检测?
偏差检测是指通过检测数据中的异常值、离群点或不寻常的模式来发现异常情况或错误的过程。
偏差检测可以帮助企业发现数据中的问题和不一致性,及时纠正错误或采取相应措施。
《数据挖掘》试题与答案

一、解答题(满分30分,每小题5分)1. 怎样理解数据挖掘和知识发现的关系?请详细阐述之首先从数据源中抽取感兴趣的数据,并把它组织成适合挖掘的数据组织形式;然后,调用相应的算法生成所需的知识;最后对生成的知识模式进行评估,并把有价值的知识集成到企业的智能系统中。
知识发现是一个指出数据中有效、崭新、潜在的、有价值的、一个不可忽视的流程,其最终目标是掌握数据的模式。
流程步骤:先理解要应用的领域、熟悉相关知识,接着建立目标数据集,并专注所选择的数据子集;再作数据预处理,剔除错误或不一致的数据;然后进行数据简化与转换工作;再通过数据挖掘的技术程序成为模式、做回归分析或找出分类模型;最后经过解释和评价成为有用的信息。
2. 时间序列数据挖掘的方法有哪些,请详细阐述之时间序列数据挖掘的方法有:1)、确定性时间序列预测方法:对于平稳变化特征的时间序列来说,假设未来行为与现在的行为有关,利用属性现在的值预测将来的值是可行的。
例如,要预测下周某种商品的销售额,可以用最近一段时间的实际销售量来建立预测模型。
2)、随机时间序列预测方法:通过建立随机模型,对随机时间序列进行分析,可以预测未来值。
若时间序列是平稳的,可以用自回归(Auto Regressive,简称AR)模型、移动回归模型(Moving Average,简称MA)或自回归移动平均(Auto Regressive Moving Average,简称ARMA)模型进行分析预测。
3)、其他方法:可用于时间序列预测的方法很多,其中比较成功的是神经网络。
由于大量的时间序列是非平稳的,因此特征参数和数据分布随着时间的推移而变化。
假如通过对某段历史数据的训练,通过数学统计模型估计神经网络的各层权重参数初值,就可能建立神经网络预测模型,用于时间序列的预测。
3. 数据挖掘的分类方法有哪些,请详细阐述之分类方法归结为四种类型:1)、基于距离的分类方法:距离的计算方法有多种,最常用的是通过计算每个类的中心来完成,在实际的计算中往往用距离来表征,距离越近,相似性越大,距离越远,相似性越小。
数据挖掘习题及解答-完美版
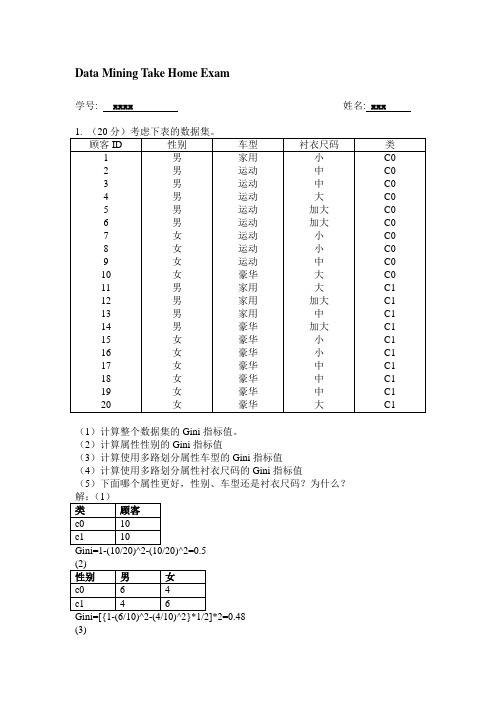
Data Mining Take Home Exam学号: xxxx 姓名: xxx(1)计算整个数据集的Gini指标值。
(2)计算属性性别的Gini指标值(3)计算使用多路划分属性车型的Gini指标值(4)计算使用多路划分属性衬衣尺码的Gini指标值(5)下面哪个属性更好,性别、车型还是衬衣尺码?为什么?(3)=26/160=0.1625]*2=8/25+6/35=0.4914(5)比较上面各属性的Gini值大小可知,车型划分Gini值0.1625最小,即使用车型属性更好。
2. ((1) 将每个事务ID视为一个购物篮,计算项集{e},{b,d} 和{b,d,e}的支持度。
(2)使用(1)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
(3)将每个顾客ID作为一个购物篮,重复(1)。
应当将每个项看作一个二元变量(如果一个项在顾客的购买事务中至少出现一次,则为1,否则,为0)。
(4)使用(3)的计算结果,计算关联规则{b,d}→{e}和{e}→{b,d}的置信度。
答:(1)由上表计数可得{e}的支持度为8/10=0.8;{b,d}的支持度为2/10=0.2;{b,d,e}的支持度为2/10=0.2。
(2)c[{b,d}→{e}]=2/8=0.25; c[{e}→{b,d}]=8/2=4。
(3)同理可得:{e}的支持度为4/5=0.8,{b,d}的支持度为5/5=1,{b,d,e}的支持度为4/5=0.8。
(4)c[{b,d}→{e}]=5/4=1.25,c[{e}→{b,d}]=4/5=0.8。
3. (20分)以下是多元回归分析的部分R输出结果。
> ls1=lm(y~x1+x2)> anova(ls1)Df Sum Sq Mean Sq F value Pr(>F)x1 1 10021.2 10021.2 62.038 0.0001007 ***x2 1 4030.9 4030.9 24.954 0.0015735 **Residuals 7 1130.7 161.5> ls2<-lm(y~x2+x1)> anova(ls2)Df Sum Sq Mean Sq F value Pr(>F)x2 1 3363.4 3363.4 20.822 0.002595 **x1 1 10688.7 10688.7 66.170 8.193e-05 ***Residuals 7 1130.7 161.5(1)用F检验来检验以下假设(α = 0.05)H0: β1 = 0H a: β1≠ 0计算检验统计量;是否拒绝零假设,为什么?(2)用F检验来检验以下假设(α = 0.05)H0: β2 = 0H a: β2≠ 0计算检验统计量;是否拒绝零假设,为什么?(3)用F检验来检验以下假设(α = 0.05)H0: β1 = β2 = 0H a: β1和β2 并不都等于零计算检验统计量;是否拒绝零假设,为什么?解:(1)根据第一个输出结果F=62.083>F(2,7)=4.74,p<0.05,所以可以拒绝原假设,即得到不等于0。
数据挖掘期末考试试题及答案详解

数据挖掘期末考试试题及答案详解一、选择题(每题2分,共20分)1. 数据挖掘中,关联规则分析主要用于发现数据中的哪种关系?A. 因果关系B. 相关性C. 聚类关系D. 顺序关系答案:B2. 在决策树算法中,哪个指标用于评估特征的重要性?A. 信息增益B. 支持度C. 置信度D. 覆盖度答案:A3. 以下哪个是数据挖掘的常用方法?A. 线性回归B. 逻辑回归C. 神经网络D. 所有选项答案:D4. K-means聚类算法中,K值的选择是基于什么?A. 数据的维度B. 聚类中心的数量C. 数据的分布情况D. 数据的规模答案:B5. 以下哪个是数据挖掘中常用的数据预处理技术?A. 数据清洗B. 数据转换C. 数据归一化D. 所有选项答案:D...(此处省略其他选择题)二、简答题(每题10分,共30分)1. 简述什么是数据挖掘,并列举其主要的应用领域。
答案:数据挖掘是从大量数据中自动或半自动地发现有趣模式的过程。
它主要应用于市场分析、风险管理、欺诈检测、客户关系管理等领域。
2. 解释什么是朴素贝叶斯分类器,并说明其在数据挖掘中的应用。
答案:朴素贝叶斯分类器是一种基于贝叶斯定理的分类算法,它假设特征之间相互独立。
在数据挖掘中,朴素贝叶斯分类器常用于文本分类、垃圾邮件检测等任务。
3. 描述K-means聚类算法的基本原理,并举例说明其在实际问题中的应用。
答案:K-means聚类算法是一种基于距离的聚类方法,其目标是将数据点划分到K个簇中,使得每个数据点与其所属簇的中心点的距离之和最小。
例如,在市场细分中,K-means聚类可以用来将客户根据购买行为划分为不同的群体。
三、计算题(每题25分,共50分)1. 给定一组数据点:{(1,2), (2,3), (3,4), (4,5)},请使用K-means算法将这些点分为两个簇,并计算簇的中心点。
答案:首先随机选择两个点作为初始中心点,然后迭代地将每个点分配到最近的中心点,接着更新中心点。
数据挖掘考试题库【最新】

一、填空题1.Web挖掘可分为、和3大类。
2.数据仓库需要统一数据源,包括统一、统一、统一和统一数据特征4个方面。
3.数据分割通常按时间、、、以及组合方法进行。
4.噪声数据处理的方法主要有、和。
5.数值归约的常用方法有、、、和对数模型等。
6.评价关联规则的2个主要指标是和。
7.多维数据集通常采用或雪花型架构,以表为中心,连接多个表。
8.决策树是用作为结点,用作为分支的树结构。
9.关联可分为简单关联、和。
10.B P神经网络的作用函数通常为区间的。
11.数据挖掘的过程主要包括确定业务对象、、、及知识同化等几个步骤。
12.数据挖掘技术主要涉及、和3个技术领域。
13.数据挖掘的主要功能包括、、、、趋势分析、孤立点分析和偏差分析7个方面。
14.人工神经网络具有和等特点,其结构模型包括、和自组织网络3种。
15.数据仓库数据的4个基本特征是、、非易失、随时间变化。
16.数据仓库的数据通常划分为、、和等几个级别。
17.数据预处理的主要内容(方法)包括、、和数据归约等。
18.平滑分箱数据的方法主要有、和。
19.数据挖掘发现知识的类型主要有广义知识、、、和偏差型知识五种。
20.O LAP的数据组织方式主要有和两种。
21.常见的OLAP多维数据分析包括、、和旋转等操作。
22.传统的决策支持系统是以和驱动,而新决策支持系统则是以、建立在和技术之上。
23.O LAP的数据组织方式主要有和2种。
24.S QL Server2000的OLAP组件叫,OLAP操作窗口叫。
25.B P神经网络由、以及一或多个结点组成。
26.遗传算法包括、、3个基本算子。
27.聚类分析的数据通常可分为区间标度变量、、、、序数型以及混合类型等。
28.聚类分析中最常用的距离计算公式有、、等。
29.基于划分的聚类算法有和。
30.C lementine的工作流通常由、和等节点连接而成。
31.简单地说,数据挖掘就是从中挖掘的过程。
32.数据挖掘相关的名称还有、、等。
数据挖掘考试题库——2024年整理

1.何谓数据挖掘?它有哪些方面的功能?从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识的过程称为数据挖掘。
相关的名称有知识发现、数据分析、数据融合、决策支持等。
数据挖掘的功能包括:概念描述、关联分析、分类与预测、聚类分析、趋势分析、孤立点分析以及偏差分析等。
2.何谓粒度?它对数据仓库有什么影响?按粒度组织数据的方式有哪些?粒度是指数据仓库的数据单位中保存数据细化或综合程度的级别。
粒度影响存放在数据仓库中的数据量的大小,同时影响数据仓库所能回答查询问题的细节程度。
按粒度组织数据的方式主要有:1简单堆积结构2轮转综合结构3简单直接结构4连续结构3.简述数据仓库设计的三级模型及其基本内容。
概念模型设计是在较高的抽象层次上的设计,其主要内容包括:界定系统边界和确定主要的主题域。
逻辑模型设计的主要内容包括:分析主题域、确定粒度层次划分、确定数据分割策略、定义关系模式、定义记录系统。
物理数据模型设计的主要内容包括:确定数据存储结构、确定数据存放位置、确定存储分配以及确定索引策略等。
在物理数据模型设计时主要考虑的因素有:I/O存取时间、空间利用率和维护代价等。
提高性能的主要措施有划分粒度、数据分割、合并表、建立数据序列、引入冗余、生成导出数据、建立广义索引等。
4.在数据挖掘之前为什么要对原始数据进行预处理?原始业务数据来自多个数据库或数据仓库,它们的结构和规则可能是不同的,这将导致原始数据非常的杂乱、不可用,即使在同一个数据库中,也可能存在重复的和不完整的数据信息,为了使这些数据能够符合数据挖掘的要求,提高效率和得到清晰的结果,必须进行数据的预处理。
为数据挖掘算法提供完整、干净、准确、有针对性的数据,减少算法的计算量,提高挖掘效率和准确程度。
5.简述数据预处理方法和内容。
1数据清洗:包括填充空缺值,识别孤立点,去掉噪声和无关数据。
2数据集成:将多个数据源中的数据结合起来存放在一个一致的数据存储中。
数据挖掘作业(第5章)

第5章关联分析5.1 列举关联规则在不同领域中应用的实例。
5.2 给出如下几种类型的关联规则的例子,并说明它们是否是有价值的。
(a)高支持度和高置信度的规则; (b)高支持度和低置信度的规则; (c)低支持度和低置信度的规则; (d)低支持度和高置信度的规则。
5.3 数据集如表5-14所示:(a) 把每一个事务作为一个购物篮,计算项集{e}, {b, d}和{b, d, e}的支持度。
(b) 利用(a)中结果计算关联规则{b, d}→{e} 和 {e}→{b, d}的置信度。
置信度是一个对称的度量吗?(c) 把每一个用户购买的所有商品作为一个购物篮,计算项集{e}, {b, d}和{b, d, e}的支持度。
(d) 利用(b)中结果计算关联规则{b, d}→{e} 和 {e}→{b, d}的置信度。
置信度是一个对称的度量吗?5.4 关联规则是否满足传递性和对称性的性质?举例说明。
5.5 Apriori 算法使用先验性质剪枝,试讨论如下类似的性质 (a) 证明频繁项集的所有非空子集也是频繁的(b) 证明项集s 的任何非空子集s ’的支持度不小于s 的支持度(c) 给定频繁项集l 和它的子集s ,证明规则“s’→(l – s’)”的置信度不高于s →(l – s)的置信度,其中s’是s 的子集(d) Apriori 算法的一个变形是采用划分方法将数据集D 中的事务分为n 个不相交的子数据集。
证明D 中的任何一个频繁项集至少在D 的某一个子数据集中是频繁的。
5.6 考虑如下的频繁3-项集:{1, 2, 3},{1, 2, 4},{1, 2, 5},{1, 3, 4},{1, 3, 5},{2, 3, 4},{2, 3, 5},{3, 4, 5}。
(a)根据Apriori 算法的候选项集生成方法,写出利用频繁3-项集生成的所有候选4-项集。
(b)写出经过剪枝后的所有候选4-项集5.7 一个数据库有5个事务,如表5-15所示。
数据挖掘考试题及答案

数据挖掘考试题及答案一、单项选择题(每题2分,共20分)1. 数据挖掘的主要任务不包括以下哪一项?A. 分类B. 聚类C. 预测D. 数据清洗答案:D2. 以下哪个算法不是用于分类的?A. 决策树B. 支持向量机C. K-meansD. 神经网络答案:C3. 在数据挖掘中,关联规则挖掘主要用于发现以下哪种类型的模式?A. 序列模式B. 分类模式C. 频繁项集D. 聚类模式答案:C4. 以下哪个指标不是用于评估分类模型性能的?A. 准确率B. 召回率C. F1分数D. 马氏距离答案:D5. 在数据挖掘中,以下哪个算法是用于聚类的?A. K-meansB. 逻辑回归C. 随机森林D. 支持向量机答案:A6. 以下哪个选项不是数据挖掘过程中的步骤?A. 数据预处理B. 模式发现C. 结果评估D. 数据存储答案:D7. 在数据挖掘中,异常检测的主要目的是识别以下哪种类型的数据?A. 频繁出现的模式B. 罕见的模式C. 预测未来的数据D. 聚类的数据答案:B8. 以下哪个选项不是数据挖掘中常用的数据预处理技术?A. 数据清洗B. 数据集成C. 数据变换D. 数据压缩答案:D9. 在数据挖掘中,以下哪个算法是用于特征选择的?A. 主成分分析B. 线性判别分析C. 支持向量机D. 决策树答案:D10. 以下哪个选项不是数据挖掘中常用的数据表示方法?A. 决策树B. 向量空间模型C. 邻接矩阵D. 频率分布表答案:D二、多项选择题(每题3分,共15分)11. 数据挖掘中常用的聚类算法包括哪些?A. K-meansB. 层次聚类C. DBSCAND. 支持向量机答案:A、B、C12. 在数据挖掘中,以下哪些是关联规则挖掘的典型应用场景?A. 市场篮分析B. 异常检测C. 推荐系统D. 社交网络分析答案:A、C13. 数据挖掘中,以下哪些是分类模型评估的常用指标?A. 准确率B. 召回率C. ROC曲线D. 马氏距离答案:A、B、C14. 在数据挖掘中,以下哪些是特征工程的步骤?A. 特征选择B. 特征提取C. 特征变换D. 数据清洗答案:A、B、C15. 数据挖掘中,以下哪些是数据预处理的常见任务?A. 缺失值处理B. 异常值检测C. 数据规范化D. 数据压缩答案:A、B、C三、简答题(每题10分,共30分)16. 请简述数据挖掘中分类和聚类的主要区别。
数据挖掘与分析技术考试

数据挖掘与分析技术考试(答案见尾页)一、选择题1. 数据挖掘与分析技术主要涉及哪两个领域?A. 统计学B. 机器学习C. 数据库系统D. 数据可视化2. 在数据挖掘中,以下哪个步骤不是必须的?A. 数据清洗B. 特征工程C. 建立模型D. 预测3. 数据挖掘中,以下哪个术语描述的是将数据从一种形式转换为另一种形式的过程?A. 数据挖掘B. 数据转换C. 数据分析D. 数据预处理4. 在数据挖掘中,以下哪个技术可以用来识别数据中的模式?A. 关联规则学习B. 回归分析C. 聚类分析D. 决策树5. 数据挖掘与分析技术中,以下哪个是用于评估模型性能的指标?A. 准确率B. 召回率C. F1 分数D. 均方误差6. 在数据挖掘中,以下哪个技术可以用来预测未来的趋势?A. 时间序列分析B. 逻辑回归C. 支持向量机D. 神经网络7. 数据挖掘中,以下哪个步骤通常在模型的训练阶段进行?A. 数据收集B. 数据清洗C. 模型训练D. 模型评估8. 在数据挖掘中,以下哪个技术可以用来发现数据中的异常值?A. 聚类分析B. 神经网络C. 异常检测D. 自然语言处理9. 数据挖掘与分析技术中,以下哪个是用于描述数据集中各数值之间关系的方法?A. 统计描述B. 数据可视化C. 聚类分析D. 关联规则学习10. 在数据挖掘中,以下哪个技术可以用来评估数据集的密度和复杂度?A. 分形维数B. 熵C. 置换-扩散算法D. k-均值聚类11. 数据挖掘与分析技术主要涉及哪几个方面?B. 机器学习C. 深度学习D. 数据库管理12. 在数据挖掘中,以下哪个算法常用于分类和预测?A. K-均值算法B. 决策树算法C. 聚类算法D. 神经网络算法13. 数据挖掘中,用于发现数据项之间有趣关系的方法有哪几种?A. 关联规则挖掘B. 分类和预测C. 文本挖掘D. 回归分析14. 在数据挖掘中,以下哪个工具常用于数据清洗和预处理?A. ExcelB. SQLC. PythonD. R语言15. 数据挖掘与分析技术中,哪一项是用于评估模型性能的方法?A. 交叉验证B. K-折叠交叉验证C.留一法D. 自助法16. 在数据挖掘中,以下哪个技术常用于处理大规模数据集?A. 分布式计算B. 缓存技术C. 索引技术17. 数据挖掘与分析技术中,哪一项是用于描述数据集中模式和趋势的方法?A. 聚类分析B. 回归分析C. 时间序列分析D. 神经网络18. 在数据挖掘中,以下哪个步骤通常不是数据挖掘流程的第一步?A. 数据收集B. 数据清洗C. 数据转换D. 数据挖掘19. 数据挖掘与分析技术中,哪一项是用于预测未来事件的方法?A. 预测建模B. 分类C. 聚类D. 关联规则挖掘20. 在数据挖掘中,以下哪个技术常用于从大量数据中提取知识?A. 数据可视化B. 数据挖掘C. 数据分析D. 数据仓库21. 数据挖掘中常用的聚类算法有哪些?A. K-meansB. DBSCANC.层次聚类D. GMM(高斯混合模型)22. 以下哪个技术可以用来评估数据集的内在质量?B. 数据转换C. 数据验证D. 数据可视化23. 关联规则挖掘中,什么指标用于衡量规则的实用性?A. 置信度B. 支持度C. 强关联规则D. 假设检验24. 在数据挖掘中,什么是分类和预测?A. 分类是将数据划分为不同的组或类别B. 预测是根据历史数据进行趋势分析C. 分类是将数据划分为不同的组或类别D. 预测是根据历史数据进行趋势分析25. 数据挖掘中,什么技术可以用来发现数据中的异常值?A. 数据清理B. 数据转换C. 数据验证D. 数据可视化26. 以下哪个是决策树的构建方法?A. 连续属性分割B. 基于信息增益C. 基于最小描述长度D. 基于贝叶斯分类器27. 数据挖掘中,什么技术可以用来识别数据集中的模式?A. 数据清理B. 数据转换C. 数据验证28. 以下哪个技术可以用来评估模型的预测能力?A. 模型训练B. 模型评估C. 模型测试D. 模型优化29. 在关联规则挖掘中,什么指标用于衡量规则的普遍性?A. 置信度B. 支持度C. 强关联规则D. 假设检验30. 数据挖掘中,什么技术可以用来预测未来的趋势?A. 时间序列分析B. 回归分析C. 聚类分析D. 决策树31. 在数据挖掘中,以下哪个步骤不是必然发生的?A. 数据预处理B. 特征工程C. 建立模型D. 模型评估32. 以下哪个算法不是监督学习算法?A. 决策树B. 支持向量机C. 随机森林D. 神经网络33. 数据挖掘中,用于描述数据集的分布情况的统计量有哪些?A. 均值B. 中位数C. 标准差D. 四分位距34. 在数据挖掘中,以下哪个选项不是数据预处理的一部分?A. 数据清洗B. 数据转换C. 数据集成D. 数据压缩35. 在进行数据挖掘时,以下哪个因素可能影响挖掘效果?A. 数据质量B. 算法选择C. 业务理解D. 计算资源36. 数据挖掘中,以下哪个术语用来描述从大量数据中抽取出有意义的信息的过程?A. 数据挖掘B. 数据分析C. 数据可视化D. 数据建模37. 在数据挖掘中,以下哪个技术可以用来评估模型的性能?A. 交叉验证B. 超参数调整C. 误差计算D. 特征选择38. 在数据挖掘项目中,以下哪个角色通常负责监控项目的进度和资源?A. 项目经理B. 数据分析师C. 数据工程师D. 商业分析师39. 在数据挖掘中,以下哪个步骤属于数据挖掘的后续阶段?A. 数据收集B. 数据清洗C. 模型评估D. 结果解释40. 数据挖掘的目的是什么?A. 了解客户需求B. 预测未来趋势C. 提高决策效率D. 优化产品性能41. 数据挖掘中使用最频繁的算法是?A. 决策树B. 支持向量机(SVM)C. 神经网络D. 关联规则学习42. 数据挖掘中,以下哪个步骤不属于数据预处理阶段?A. 数据清洗B. 数据转换C. 数据集成D. 数据划分43. 在数据挖掘中,用于描述和评估模型预测能力的是?A. 精确率B. 召回率C. F1分数D. AUC-ROC曲线44. 以下哪个选项不属于数据挖掘中的特征工程?A. 特征选择B. 特征转换C. 特征规范化D. 特征降维45. 在数据挖掘中,以下哪个技术用于发现数据中的关联关系?A. 分类B. 聚类C. 关联规则学习D. 回归46. 数据挖掘中,用于评估模型对未知数据的预测能力的是?A. 置信区间B. 交叉验证C. 模型泛化能力D. AUC-ROC曲线47. 在数据挖掘中,以下哪个步骤属于数据挖掘的结果评估阶段?A. 数据清洗B. 模型训练C. 模型评估D. 模型部署48. 数据挖掘中,以下哪个技术可以用来评估数据集的内在质量?A. 数据可视化B. 数据质量指标计算C. 数据分布分析D. 数据相关性分析49. 在数据挖掘中,以下哪个技术可以用来预测未来的趋势和行为?A. 时间序列分析B. 回归分析C. 文本挖掘D. 机器学习二、问答题1. 什么是数据挖掘?请简要介绍数据挖掘的基本过程。
《数据挖掘》练习题(第6章)

一、填空题1、关联规则挖掘的目的是。
2项集{的支持数为,支持度为。
3、在第2题的事务数据集中,如果将最小支持数定为3,则数据集中的频繁项集有。
4、在第2题的事务数据集中,规则{牛奶,尿布}→{啤酒}的支持度为,置信度为。
5、满足最小支持度和最小信任度的关联规则称为。
6、给定一个事务数据库,关联规则挖掘间题就是通过用户指定的和来寻找强关联规则的过程。
7、关联规则挖掘问题可以划分成和两个子问题。
8、可以降低产生频繁项集的计算复杂度两种方法为:和。
9、k-候选集C产生的方法有:、和。
k10、Apriori算法有两个致命的性能瓶颈。
它们分别是:(1)(2)二、多项选择题1、设有项目集,X X是X的一个子集,则下列结论中成立的是( )1A、如果X如果频繁项目集,则X也是频繁项目集;1B、如果X如果频繁项目集,则X也是频繁项目集;1C、如果X如果非频繁项目集,则X也是非频繁项目集;1C、如果X如果非频繁项目集,则X也是非频繁项目集;1E、如果X如果频繁项目集,则X可能是频繁项目集也可能是非频繁项目集。
12、设3-项集{}a b c是频繁项目集,则下列1-项集和2-项集中,( )是频,,繁项目集。
A、{},a bB、{},b cC、{},a cD、{}aE、{}b3、设事务数据库D具有项集{}→不是强关联规则时,=,已知BC ADI A B C D,,,则下列关联规则中,( )一定不是强关联规则。
A、B ACD→E、AD BC→→D、ABC D→C、C ABD→B、CD AB4、设事务数据库D具有项集{}→不是强关联规则时,=,已知BC AD,,,I A B C D则下列关联规则中,( )一定不是强关联规则。
A、B ACD→E、AD BC→→C、BCD A→B、CD AB→D、ABC D5、假设关联规则{}{}→具有低可置信度,则在关联规则生成算法中,规则bed a( )应该被丢弃(剪枝)。
A、{}{}→be ad→C、{}{}cd ab→B、{}{}ad bcD、{}{}bd ae→d abc→E、{}{}三、问答题1、进行关联分析时,需要处理的两个关键问题是什么?21(1),利用Apriori算法求出所有的频繁项目集,指出其中的最大频繁项目集。
数据挖掘期末考试试题(含答案)

数据挖掘期末考试试题(含答案)题目一:数据预处理题目描述:给定一个包含缺失值的数据集,采取合适的方法对缺失值进行处理,并解释你的方法选择的原因。
答案:缺失值在数据分析中是一个常见的问题。
我选择使用均值填充的方法来处理缺失值。
这种方法将缺失的值用该特征的均值进行代替。
我选择均值填充的原因是因为这种方法简单易用,并且可以保持数据的整体分布特征。
均值填充假设缺失值与观察到值的分布相似,因此使用均值填充可以避免引入过多的噪音。
题目二:关联规则挖掘题目描述:给定一个购物篮数据集,包含多个商品的组合,使用Apriori 算法挖掘频繁项集和关联规则,并给出相关的评估指标。
答案:Apriori算法是一种常用的关联规则挖掘算法。
它通过计算支持度和置信度来挖掘频繁项集和关联规则。
首先,通过扫描数据集,计算每个项集的支持度。
然后,根据设定的最小支持度阈值,选取频繁项集作为结果。
接着,根据频繁项集,计算每个规则的置信度。
利用最小置信度阈值,筛选出高置信度的关联规则。
评估指标包括支持度、置信度和提升度。
支持度衡量一个项集在数据集中出现的频率,置信度衡量规则的可信程度,提升度衡量规则对目标项集出现的增益。
题目三:聚类算法题目描述:给定一个数据集,包含多个样本和多个特征,使用K-means算法将样本划分为K个簇,并解释评估聚类性能的指标。
答案:K-means算法是一种常用的聚类算法。
它通过迭代的方式将样本划分为K个簇。
首先,随机选择K个初始聚类中心。
然后,对于每个样本,计算其与每个聚类中心的距离,并将其划分到距离最近的簇中。
接着,更新每个簇的聚类中心,计算新的聚类中心位置。
重复以上步骤,直到聚类中心不再发生变化或达到预定的迭代次数。
评估聚类性能的指标包括簇内平方和(SSE)和轮廓系数。
簇内平方和衡量样本与其所属簇的距离之和,SSE越小表示聚类效果越好。
轮廓系数衡量样本与其所属簇以及其他簇之间的距离,值介于-1到1之间,越接近1表示聚类效果越好。
关联规则考试题

关联规则考试题
“关联规则考试题”指的是在数据挖掘或机器学习考试中,专门针对关联规则挖掘技术的练习题目。
关联规则挖掘是数据挖掘的一个重要分支,主要用于发现数据集中项之间的有趣关系。
以下是三道关于关联规则的考试题目示例:
1.题目:给定一个销售数据集,其中包含商品ID、销售数量和销售日期。
使
用关联规则挖掘算法找出最强的关联规则,并给出支持度、置信度和提升度的值。
2.题目:在一个超市的交易数据中,发现“啤酒”和“尿布”经常一起被购
买。
解释这种现象可能的原因,并给出实际生活中的一个例子。
3.题目:假设我们有一个数据集,其中包含顾客的购买历史。
我们想要使用
关联规则挖掘来找出哪些商品是互补的,即当顾客购买了其中一种商品时,很可能会购买另一种商品。
请给出一种有效的算法来实现这个目标,并解释其工作原理。
总结:“关联规则考试题”是指在数据挖掘或机器学习考试中,用于测试学生对关联规则挖掘技术的理解和应用能力的题目。
这些题目通常涉及关联规则的基本概念、算法和应用,旨在评估学生对该领域的掌握程度。
通过解决这些题目,学生可以加深对关联规则挖掘的理解,并提高在实际问题中应用该技术的能力。
数据挖掘考试题目——关联分析知识讲解

数据挖掘考试题目——关联分析一、10个选择1.以下属于关联分析的是()A.CPU性能预测B.购物篮分析C.自动判断鸢尾花类别D.股票趋势建模2.维克托▪迈尔-舍恩伯格在《大数据时代:生活、工作与思维的大变革》一书中,持续强调了一个观点:大数据时代的到来,使我们无法人为地去发现数据中的奥妙,与此同时,我们更应该注重数据中的相关关系,而不是因果关系。
其中,数据之间的相关关系可以通过以下哪个算法直接挖掘()A.K-means B.Bayes NetworkC.C4.5 D.Apriori3.置信度(confidence)是衡量兴趣度度量()的指标。
A.简洁性B.确定性C.实用性D.新颖性4.Apriori算法的加速过程依赖于以下哪个策略()A.抽样B.剪枝C.缓冲D.并行5.以下哪个会降低Apriori算法的挖掘效率()A.支持度阈值增大B.项数减少C.事务数减少D.减小硬盘读写速率6.Apriori算法使用到以下哪些东东()A.格结构、有向无环图B.二叉树、哈希树C.格结构、哈希树D.多叉树、有向无环图7.非频繁模式()A.其置信度小于阈值B.令人不感兴趣C.包含负模式和负相关模式D.对异常数据项敏感8.对频繁项集、频繁闭项集、极大频繁项集的关系描述正确的是()[注:分别以1、2、3代表之]A.3可以还原出无损的1 B.2可以还原出无损的1C.3与2是完全等价的D.2与1是完全等价的9.Hash tree在Apriori算法中所起的作用是()A.存储数据B.查找C.加速查找D.剪枝10.以下不属于数据挖掘软件的是()A.SPSS Modeler B.WekaC.Apache Spark D.Knime二、10个填空1.关联分析中表示关联关系的方法主要有:和。
2.关联规则的评价度量主要有:和。
3.关联规则挖掘的算法主要有:和。
4.购物篮分析中,数据是以的形式呈现。
5.一个项集满足最小支持度,我们称之为。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据挖掘考试题目——关联分析
一、10个选择
1.以下属于关联分析的是()
A.CPU性能预测B.购物篮分析
C.自动判断鸢尾花类别D.股票趋势建模
2.维克托▪迈尔-舍恩伯格在《大数据时代:生活、工作与思维的大变革》一书中,持续强调了一个观点:大数据时代的到来,使我们无法人为地去发现数据中的奥妙,与此同时,我们更应该注重数据中的相关关系,而不是因果关系。
其中,数据之间的相关关系可以通过以下哪个算法直接挖掘()
A.K-means B.Bayes Network
C.C4.5 D.Apriori
3.置信度(confidence)是衡量兴趣度度量()的指标。
A.简洁性B.确定性
C.实用性D.新颖性
4.Apriori算法的加速过程依赖于以下哪个策略()
A.抽样B.剪枝
C.缓冲D.并行
5.以下哪个会降低Apriori算法的挖掘效率()
A.支持度阈值增大B.项数减少
C.事务数减少D.减小硬盘读写速率
6.Apriori算法使用到以下哪些东东()
A.格结构、有向无环图B.二叉树、哈希树
C.格结构、哈希树D.多叉树、有向无环图
7.非频繁模式()
A.其置信度小于阈值B.令人不感兴趣
C.包含负模式和负相关模式D.对异常数据项敏感
8.对频繁项集、频繁闭项集、极大频繁项集的关系描述正确的是()[注:分别以1、2、3代表之]
A.3可以还原出无损的1 B.2可以还原出无损的1
C.3与2是完全等价的D.2与1是完全等价的
9.Hash tree在Apriori算法中所起的作用是()
A.存储数据B.查找
C.加速查找D.剪枝
10.以下不属于数据挖掘软件的是()
A.SPSS Modeler B.Weka
C.Apache Spark D.Knime
二、10个填空
1.关联分析中表示关联关系的方法主要有:和。
2.关联规则的评价度量主要有:和。
3.关联规则挖掘的算法主要有:和。
4.购物篮分析中,数据是以的形式呈现。
5.一个项集满足最小支持度,我们称之为。
6.一个关联规则同时满足最小支持度和最小置信度,我们称之为。
7.在回归与相关分析中,因变量值随自变量值的增大(减小)而减小(增大)的现象叫做。
8.极大频繁项集不能无损还原出频繁项集,是因为它不包含频繁项集的信息。
9.经典的Apriori算法是逐层扫描的,也就是说它是 (选:深度/宽度)优先的。
10.数据挖掘大概步骤包括:输入数据→预处理→挖掘→后处理→输出知识。
其中,输出的知识可以有很多种表示形式,两种极端的形式是:①内部结构难以被理解的黑匣子,比如说人工神经网络训练得出的网络;②模式结构清晰的匣子,这种结构容易被人理解,比如说决策树产生的树。
那么,关联分析中输出的知识的表示形式主要是 (选:黑匣子/清晰结构)。
三、10个判断
()1.啤酒与尿布的故事是聚类分析的典型实例。
()2.Apriori算法是一种典型的关联规则挖掘算法。
()3.支持度是衡量关联规则重要性的一个指标。
()4.可信度是对关联规则的准确度的衡量。
()5.给定关联规则A→B,意味着:若A发生,B也会发生。
()6.频繁闭项集可用来无损压缩频繁项集。
()7.关联规则可以用枚举的方法产生。
()8.Apriori算法产生的关联规则总是确定的。
()9.不满足给定评价度量的关联规则是无趣的。
()10.对于项集来说,置信度没有意义。
四、5个简答
1.简述关联规则产生的两个基本步骤。
2.Apriori算法是从事务数据库中挖掘布尔关联规则的常用算法,该算法利用频繁项集性质的先验知识,从候选项集中找到频繁项集。
请简述Apriori算法的基本原理。
3.简述Apriori算法的优点和缺点。
4.针对Apriori算法的缺点,可以做哪些方面的改进?
5.强关联规则一定是有趣的吗?为什么?
数据挖掘考试题目+参考答案
一、10个选择
1.以下属于关联分析的是( B )
A.CPU性能预测B.购物篮分析
C.自动判断鸢尾花类别D.股票趋势建模
2.维克托▪迈尔-舍恩伯格在《大数据时代:生活、工作与思维的大变革》一书中,持续强调了一个观点:大数据时代的到来,使我们无法人为地去发现数据中的奥妙,与此同时,我们更应该注重数据中的相关关系,而不是因果关系。
其中,数据之间的相关关系可以通过以下哪个算法直接挖掘( D )
A.K-means B.Bayes Network
C.C4.5 D.Apriori
3.置信度(confidence)是衡量兴趣度度量( B )的指标。
A.简洁性B.确定性
C.实用性D.新颖性
4.Apriori算法的加速过程依赖于以下哪个策略( B )
A.抽样B.剪枝
C.缓冲D.并行
5.以下哪个会降低Apriori算法的挖掘效率( D )
A.支持度阈值增大B.项数减少
C.事务数减少D.减小硬盘读写速率
6.Apriori算法使用到以下哪些东东( C )
A.格结构、有向无环图B.二叉树、哈希树
C.格结构、哈希树D.多叉树、有向无环图
7.非频繁模式( D )
A.其置信度小于阈值B.令人不感兴趣
C.包含负模式和负相关模式D.对异常数据项敏感
8.对频繁项集、频繁闭项集、极大频繁项集的关系描述正确的是( B )[注:分别以1、2、3代表之]
A.3可以还原出无损的1 B.2可以还原出无损的1
C.3与2是完全等价的D.2与1是完全等价的
9.Hash tree在Apriori算法中所起的作用是( C )
A.存储数据B.查找
C.加速查找D.剪枝
10.以下不属于数据挖掘软件的是( C )
A.SPSS Modeler B.Weka
C.Apache Spark D.Knime
二、10个填空
1.关联分析中表示关联关系的方法主要有:项集和关联规则。
2.关联规则的评价度量主要有:支持度和置信度。
3.关联规则挖掘的算法主要有: Apriori 和 FP-Growth 。
4.购物篮分析中,数据是以不对称二元变量的形式呈现。
5.一个项集满足最小支持度,我们称之为频繁项集。
6.一个关联规则同时满足最小支持度和最小置信度,我们称之为强规则。
7.在回归与相关分析中,因变量值随自变量值的增大(减小)而减小(增大)的现象叫做负相关。
8.极大频繁项集不能无损还原出频繁项集,是因为它不包含频繁项集的支持度信息。
9.经典的Apriori算法是逐层扫描的,也就是说它是宽度 (选:深度/宽度)优先的。
10.数据挖掘大概步骤包括:输入数据→预处理→挖掘→后处理→输出知识。
其中,输出的知识可以有很多种表示形式,两种极端的形式是:①内部结构难以被理解的黑匣子,比如说人工神经网络训练得出的网络;②模式结构清晰的匣子,这种结构容易被人理解,比如说决策树产生的树。
那么,关联分析中输出的知识的表示形式主要是清晰结构 (选:黑匣子/清晰结构)。
三、10个判断
(✘)1.啤酒与尿布的故事是聚类分析的典型实例。
(✔)2.Apriori算法是一种典型的关联规则挖掘算法。
(✔)3.支持度是衡量关联规则重要性的一个指标。
(✔)4.可信度是对关联规则的准确度的衡量。
(✘)5.给定关联规则A→B,意味着:若A发生,B也会发生。
(✔)6.频繁闭项集可用来无损压缩频繁项集。
(✔)7.关联规则可以用枚举的方法产生。
(✔)8.Apriori算法产生的关联规则总是确定的。
(✘)9.不满足给定评价度量的关联规则是无趣的。
(✔)10.对于项集来说,置信度没有意义。
四、5个简答
1.简述关联规则产生的两个基本步骤。
答:关联规则产生的两个基本步骤为:①根据给定的支持度从项集中产生频繁项集;②根据给定的置信度从频繁项集中产生关联规则。
2.Apriori算法是从事务数据库中挖掘布尔关联规则的常用算法,该算法利用频繁项集性质的先验知识,从候选项集中找到频繁项集。
请简述Apriori算法的基本原理。
答:关联规则的产生并不依赖于Apriori算法,Apriori算法用来加速规则的产生过程。
Apriori算法的加速过程依赖于这样一个先验原理:“频繁项集的子集是频繁的”。
3.简述Apriori算法的优点和缺点。
答:Apriori算法的优点:结构简单、易于理解。
Apriori算法的缺点:产生大量的候选项集,I/O开销较大。
4.针对Apriori算法的缺点,可以做哪些方面的改进?
答:Apriori算法的缺点主要是产生的候选项集较多,从而导致I/O开销较大。
由此,可以将庞大的数据集划分为可以装进内存的数据块,利用“频繁项集至少在一个分区中是频繁的”原理合并各个数据块产生的频繁项集得到最终的频繁项集。
5.强关联规则一定是有趣的吗?为什么?
答:不一定。
因为:规则的评价标准有很多,可以是客观的也可以是主观的。
另外,强规则也可能是负相关的,即因变量值随自变量值的增大(减小)而减小(增大)的现象。