[Python程序设计基础(第2版)][李东方 (10)[19页]
Python语言程序设计基础(第2版)全答案v3-20180823

Python语言程序设计基础(第2版)全答案(Ver. 2.0,2018年5月)嵩天礼欣黄天羽著(本文档由该书原作者提供,有任何修改意见请反馈:黄天羽huangtianyu@。
)目录目录 (2)第1章程序设计基本方法 (5)1.1 计算机的概念 (5)1.2 程序设计语言 (5)1.3 Python语言概述 (5)1.4 Python语言开发环境配置 (5)1.5 程序的基本编写方法 (6)1.6 Python语言的版本更迭 (6)程序练习题 (6)第2章Python程序实例解析 (7)2.1 实例1:温度转换 (7)2.2 Python程序语法元素分析 (7)2.3 实例2:Python蟒蛇绘制 (8)2.4 turtle库语法元素分析 (8)程序练习题 (9)第3章基本数据类型 (15)3.1 数字类型 (15)3.2 数字类型的操作 (15)3.3 模块1:math库的使用 (15)3.4 实例3:天天向上的力量 (16)3.5 字符串类型及其操作 (17)3.6 字符串类型的格式化 (17)3.7 实例4:文本进度条 (17)程序练习题 (18)第4章程序的控制结构 (21)4.1 程序的基本结构 (21)4.2 程序的分支结构 (21)4.3 实例5:身体质量指数BMI (21)4.4 程序的循环结构 (21)4.5 模块2:random库的使用 (22)4.6 实例6:π的计算 (22)4.7 程序的异常处理 (22)程序练习题 (23)第5章函数和代码复用 (28)5.1 函数的基本使用 (28)5.2 函数的参数传递 (28)5.3 模块3:datetime库的使用 (28)5.4 实例7:七段数码管绘制 (29)5.5 代码复用和模块化设计 (29)5.6 函数的递归 (29)5.7 实例8:科赫曲线绘制 (29)5.8 Python内置函数 (30)程序练习题 (30)第6章组合数据类型 (37)6.1 组合数据类型概述 (37)6.2 列表类型和操作 (37)6.3 实例9:基本统计值计算 (37)6.4 字典类型和操作 (38)6.5 模块4:jieba库的使用 (38)6.6 实例10:文本词频统计 (39)6.7 实例11:Python之禅 (39)程序练习题 (39)第7章文件和数据格式化 (44)7.1 文件的使用 (44)7.2 模块5:PIL库的使用 (44)7.3 实例12:图像的字符画绘制 (44)7.4 一二维数据的格式化和处理 (45)7.5 实例13:CSV格式的HTML展示 (45)7.6 高维数据的格式化 (45)7.7 模块6:json库的使用 (45)7.8 实例14:CSV和JSON格式相互转换 (46)程序练习题 (46)第8章程序设计方法论 (55)8.1 计算思维 (55)8.2 实例15:体育竞技分析 (55)8.3 自顶向下和自顶向上 (55)8.4 模块7:pyinstaller库的使用 (55)8.5 计算生态和模块编程 (56)8.6 Python第三方库的安装 (56)8.7 实例16:pip安装脚本 (56)程序练习题 (56)第9章科学计算和可视化 (66)9.1 问题概述 (66)9.2 模块8:numpy库的使用 (66)9.3 实例17:图像的手绘效果 (66)9.4 模块9:matplotlib库的使用 (66)9.5 实例18:科学坐标图绘制 (67)9.6 实例19:多级雷达图绘制 (67)程序练习题 (67)第10章网络爬虫和自动化 (70)10.1 问题概述 (70)10.2 模块10:requests库的使用 (70)10.3 模块11:beautifulsoup4库的使用 (70)10.4 实例20:中国大学排名爬虫 (70)程序练习题 (71)第1章程序设计基本方法1.1 计算机的概念[1.1]: 计算机是根据指令操作数据的设备,它的两个显著特点是功能性和可编程性。
[Python程序设计基础(第2版)][李东方 (11)[19页]
![[Python程序设计基础(第2版)][李东方 (11)[19页]](https://img.taocdn.com/s3/m/b627314d52d380eb62946da9.png)
11.1 访问SQLite数据库
SQLite是一个开源的关系型数据库,具有零配置 (Zero Configuration)、自我包含(Selfcontained)和便于传输(Easy Transfer)等 优点,由于其高度便携、使用方便、结构紧凑、 高效和可靠,因此被广泛用于移动设备嵌入式数 据库作为前端数据存储。SQLite支持规范的SQL (Structured Query Language,结构化查询 语言),可方便地支持数据库系统原型研发和移 植。
【例11-2】编写Python程序为例11-1中创建的student库的base表添加 新生学号、姓名和性别三项非空数据
import sqlite3 # 连接数据库 conn =sqlite3.connect('d:/test.db') while True:
id=input('请输入新生学号:(输入0退出程序)\n') if id=='0':
NOT NULL,
与数据库连接对象conn.execute()方法相关的常用SQL语句通式如下: ➢ 添加: INSERT INTO <表>(<字段元组>) VALUES (<数据元组>) ➢ 修改: UPDATE <表> SET <字段>=<值> ➢ 删除: DELETE FROM <表> WHERE <条件表达式>
【例11-1】在D:盘根目录下建立一个空数据库test.db,并按如图11-3所 示的表结构创建学生基本情况表base。
import sqlite3
conn = sqlite3.connect('d:/test.db')
Python程序设计与算法基础教程(第二版)微课版第三章上机实践答案

Python程序设计与算法基础教程(第⼆版)微课版第三章上机实践答案Python程序设计与算法基础教程(第⼆版)微课版第三章上机实践答案2.Sum =0for i in range(1,101):Sum += iprint("1+2+3+...+100 = ", Sum)3.Sum =0for i in range(10,0,-1):Sum += iprint("10+9+8+...+1 = ", Sum)4.Sum =0for i in range(1,100,2):Sum += iprint("1+3+5+7+...+99 = ", Sum)5.Sum =0for i in range(2,101,2):Sum += iprint("2+4+6+8+...+100 = ", Sum)6.n =0for i in range(2000,3001):if((i %4==0and i %100!=0)or(i %400==0)):print(i, end =' ')n +=1if(n %10==0):print()7.i =1S =0for n in range(1,100):if(n %2!=0):if(i %2==0):n =-(i *2-1)else:n =( i *2-1)i +=1S += nprint("1-3+5-7+9-11+... = ", S)8.S =0for i in range(1,101):n =1.0/ iS += nprint(str.format("1+1/2+1/3+... = {0: .2f}", S))9.打印上三⾓九九乘法表:for a in range(1,10):for b in range(1, a+1):print(str.format("{0:2} * {1:2} = {2:>2}", a, b, a*b), end =' ')print()打印矩形块九九乘法表:for a in range(1,10):for b in range(1,10):print(str.format("{0:>2} * {1:1} = {2:>2}", a, b, a*b), end =' ')print()打印下三⾓九九乘法表:for a in range(1,10):for b in range(1,10):if(b < a):print(end =' ')else:print(str.format("{0:2} * {1:1} = {2:>2}", a, b, a*b), end =' ')print()10.import matha =float(input("请输⼊三⾓形的边a :"))b =float(input("请输⼊三⾓形的边b :"))c =float(input("请输⼊三⾓形的边c :"))if(a >0and b >0and c >0and a + b > c and a + c > b and b + c > a):h =1/2*(a+b+c)print(str.format("三⾓形的三条边分别为:a = {0} b = {1} c = {2}", a, b, c))print(str.format("三⾓形的周长 = {0} ⾯积 = {1}", a+b+c, math.sqrt(h *(h-a)*(h-b)*(h-c)))) else:print("⽆法构成三⾓形!")11.⽅法⼀(单分⽀语句):import mathx =float(input("请输⼊x:"))print("⽅法⼀(单分⽀语句):")if(x >=0):y =(x**2-3*x)/(x +1)+2*math.pi + math.sin(x)if(x <0):y = math.log(-5*x)+6* math.sqrt(abs(x)+pow(math.e,4))-pow((x +1),3)print(str.format("x = {0}, y = {1}", x, y))⽅法⼆(双分⽀结构):import mathx =float(input("请输⼊x:"))if(x >=0):y =(x**2-3*x)/(x +1)+2*math.pi + math.sin(x)else:y = math.log(-5*x)+6* math.sqrt(abs(x)+pow(math.e,4))-pow((x +1),3)print(str.format("x = {0}, y = {1}", x, y))⽅法三(条件运算语句):x =float(input("请输⼊x:"))y =(x**2-3*x)/(x +1)+2*math.pi + math.sin(x)if(x >=0) \else math.log(-5*x)+6* math.sqrt(abs(x)+pow(math.e,4))-pow((x +1),3)print(str.format("x = {0}, y = {1}", x, y))12.import matha =float(input("请输⼊系数a : "))b =float(input("请输⼊系数b : "))c =float(input("请输⼊系数c : "))delt = b**2-4*a*cif(a ==0and b ==0):print("此⽅程⽆解!")elif(a ==0and b !=0):print(str.format("此⽅程的解为:{0: .1f}",-c / b))elif(b**2-4*a*c ==0):print(str.format("此⽅程有两个相等虚根:{0:.1f}",-b /(2*a)))elif(delt >0):print(str.format("此⽅程有两个不等虚根: {0:.1f} 和 {1:.1f}",(-b + math.sqrt(delt))/(2*a),(-b - math.sqrt(delt))/(2*a)))else:#注意根号⾥不是b²-4ac,所以根号⾥加负号print("此⽅程有两个共轭复根: {0} 和 {1}".format(complex(-b /(2*a), math.sqrt(-delt)/(2*a)),complex(-b /(2*a),-math.sqrt(-delt)/(2*a)))) 13.⽅法⼀(for循环):n =int(input("请输⼊⾮负整数n:"))while(n <0):n =int(input("请输⼊⾮负整数n:"))S =1if(n ==0):print("0! = 1")if(n >0):for i in range(n,0,-1):S *= iprint(str.format("{0}! = {1}", n, S))⽅法⼆(while循环):n =int(input("请输⼊⾮负整数n:"))while(n <0):n =int(input("请输⼊⾮负整数n:"))S =1if(n ==0):print("0! = 1")if(n >0):m = nwhile(m !=0):S *= mm -=1print(str.format("{0}! = {1}", n, S))14.a = random.randint(0,100)b = random.randint(0,100)S = a*bprint(str.format("整数1 = {0},整数2 = {1}", a, b))if(a < b):a, b = b, awhile(a%b !=0):a,b = b,a%bprint("最⼤公约数 = {0},最⼩公倍数 = {1}".format(b, S/b))满怀希望就会所向披靡。
python程序设计基础第二版董付国课件

06
常用库函数介绍与实践应用举例
数学计算相关库函数
math库
提供了一系列数学函数,如三角函数 、指数函数、对数函数等,用于进行 基本的数学计算。
scipy库
基于numpy库,提供了许多用于科学 和技术计算的函数和工具,如优化、 线性代数、积分、插值、特殊函数等 。
日期时间处理相关库函数
datetime库
用于将表达式的值赋给变量, 包括简单赋值、增量赋值等。
成员运算符
用于判断一个值是否属于某个 序列或集合,包括in和not in
两种。
身份运算符
用于比较两个对象的身份是否 相同,包括is和is not两种。
03
控制结构与函数设计
条件语句与分支结构
if语句
根据条件判断执行不同代码块, 可通过elif实现多分支结构。
卸载包
使用`pip uninstall package_name`命令卸载包。
pip概述
pip是Python的包管理工具,用 于安装、升级和卸载Python包。 它可以从Python Package Index (PyPI)下载并安装包。
查看已安装包
使用`pip list`命令查看已安装的 所有包及其版本信息。
提供了日期和时间处理的类,包括日期、时间、日期时间、时间差 等,支持日期和时间的算术运算和格式化输出。
time库
提供了时间相关的函数,如获取当前时间、格式化时间、睡眠等。
calendar库
提供了与日历相关的功能,如获取某年某月的日历、判断某年是否为 闰年等。
正则表达式库re模块使用
re库
Python标准库中的正则表达式库,提供了正则表达式的匹配、 搜索、替换等功能。
[Python程序设计基础(第2版)][李东方 (8)[47页]
![[Python程序设计基础(第2版)][李东方 (8)[47页]](https://img.taocdn.com/s3/m/143b63835022aaea998f0fef.png)
【例8-5】 用grid()方法排列标签,效果如图8-6所示。设想有一个3×4 的表格,起始行、列序号均为0。将标签lbred置于第2列第0行;将标签 lbgreen置于第0列第1行;将标签lbblue置于第1列起跨2列第2行,占 20像素宽
import tkinter root = () lbred = bel(root, text="Red",
# 创建一个320×240的窗体
8.1.2 tkinter常用控件
【例8-2】 标签及其常见属性示例
import tkinter root=() lb=bel(root,text='我是一个标签',\
bg='#d3fbfb',\ fg='red',\ font=('华文新魏',32),\ width=20,\ height=2,\ relief=tkinter.SUNKEN) lb.pack() root.mainloop()
8.1.3 控件布局 控件的布局通常有pack()、grid()和place()三种方法。 1.pack()方法 方法pack()是一种简单的布局方法,如果用不加参数的默认方式,将按布 局语句的先后,以最小占用空间的方式自上而下地排列控件实例,并且保 持控件本身的最小尺寸。 【例8-3】 用pack()方法不加参数排列标签。为看清楚各控件实例所占用 的空间大小,文本使用了不同长度的中英文,并设置 relief=tkinter.GROOVE的凹陷边缘属性
2.grid()方法 方法grid()是基于网格的布局。先虚拟一个二维表格,再在该表格中布局 控件实例。由于在虚拟表格的单元格中所布局的控件实例大小不一,单 元格也没有固定或均一的大小,因此其仅用于布局的定位。grid()方法与 pack()方法不能混合使用。 方法grid()常用的布局参数如下。
《PYTHON程序设计基础》习题答案与分析

Python程序设计基础习题答案与分析程昱第1章基础知识1.1简单说明如何选择正确的Python版本。
答:在选择Python的时候,一定要先考虑清楚自己学习Python的目的是什么,打算做哪方面的开发,有哪些扩展库可用,这些扩展库最高支持哪个版本的Python,是Python2.x还是Python3.x,最高支持到Python2.7.6还是Python2.7.9。
这些问题都确定以后,再做出自己的选择,这样才能事半功倍,而不至于把大量时间浪费在Python的反复安装和卸载上。
同时还应该注意,当更新的Python版本推出之后,不要急于更新,而是应该等确定自己所必须使用的扩展库也推出了较新版本之后再进行更新。
尽管如此,Python3毕竟是大势所趋,如果您暂时还没想到要做什么行业领域的应用开发,或者仅仅是为了尝试一种新的、好玩的语言,那么请毫不犹豫地选择Python3.x系列的最高版本(目前是Python3.4.3)。
1.2为什么说Python采用的是基于值的内存管理模式?Python采用的是基于值的内存管理方式,如果为不同变量赋值相同值,则在内存中只有一份该值,多个变量指向同一块内存地址,例如下面的代码。
>>>x=3>>>id(x)10417624>>>y=3>>>id(y)10417624>>>y=5>>>id(y)10417600>>>id(x)10417624>>>x=[1,2,3,1,1,2]>>>id(x[0])==id(x[3])==id(x[4])True1.3解释Python中的运算符“/”和“//”的区别。
答:在Python2.x中,“/”为普通除法,当两个数值对象进行除法运算时,最终结果的精度与操作数中精度最高的一致;在Python3.x中,“/”为真除法,与除法的数学含义一致。
Python基础教程第2章(共133张)

*
乘法运算
2*2的结果是4
/
除法运算
4/2的结果是2
%
求模运算
10 % 3的结果是1
**
幂运算。x**y返回x的y次幂 2**3的结果是8 Nhomakorabea//
整除运算,即返回商的整数 9//2的结果 4
部分
第21页,共133页。
2.赋值运算符
位运算符 = += -= *= /= %= **= //=
直接赋值 加法赋值 减法赋值 乘法赋值 除法赋值 取模赋值 幂赋值 整除赋值
第37页,共133页。
【例2-13】 嵌套if语句(yǔjù)的例子
: eval(str) 参数str是待计算的Python表达式字符串。
第11页,共133页。
【例2-4】
a = "1"; b = int(a)+1; print(b);
第12页,共133页。
【例2-5】
a = "1+2"; print(eval(a)); 运行(yùnxíng)结果为3。
第13页,共133页。
位“与”操作。只要两个表达式的某位都为 1,则结果的该位为 1;
否则,结果的该位为 0
|
按位或运算, 运算符查看两个表达式的二进制表示法的值,并执行按
位“或”操作。只要两个表达式的某位有一个为 1,则结果的该位为
1;否则,结果的该位为 0
^
按位异或运算。异或的运算法则为:0异或0=0,1异或0=1,0异或1=1,
2.3.1 赋值语句
2.3.2 条件分支语句 3.3.3 循环语句 2.3.4 try-except语句
第32页,共133页。
Python程序设计基础习题答案与分析

《P y t h o n程序设计基础》习题答案与分析(总16页)--本页仅作为文档封面,使用时请直接删除即可----内页可以根据需求调整合适字体及大小--Python程序设计基础习题答案与分析程昱第1章基础知识简单说明如何选择正确的Python版本。
答:在选择Python的时候,一定要先考虑清楚自己学习Python的目的是什么,打算做哪方面的开发,有哪些扩展库可用,这些扩展库最高支持哪个版本的Python,是Python 还是Python ,最高支持到Python 还是Python 。
这些问题都确定以后,再做出自己的选择,这样才能事半功倍,而不至于把大量时间浪费在Python的反复安装和卸载上。
同时还应该注意,当更新的Python版本推出之后,不要急于更新,而是应该等确定自己所必须使用的扩展库也推出了较新版本之后再进行更新。
尽管如此,Python 3毕竟是大势所趋,如果您暂时还没想到要做什么行业领域的应用开发,或者仅仅是为了尝试一种新的、好玩的语言,那么请毫不犹豫地选择Python 系列的最高版本(目前是Python )。
为什么说Python采用的是基于值的内存管理模式Python采用的是基于值的内存管理方式,如果为不同变量赋值相同值,则在内存中只有一份该值,多个变量指向同一块内存地址,例如下面的代码。
>>> x = 3>>> id(x)>>> y = 3>>> id(y)>>> y = 5>>> id(y)>>> id(x)>>> x = [1, 2, 3, 1, 1, 2]>>> id(x[0])==id(x[3])==id(x[4])True解释Python中的运算符“/”和“ else:print(x)except BaseException:print('You must input an integer.')2)Python 代码:import typesx = input('Please input an integer of more than 3 digits:') if type(x) != :print 'You must input an integer.'elif len(str(x)) != 4:print 'You must input an integer of more than 3 digits.' else:print x......(map(str,result)))2)Python 代码x = input('Please input an integer less than 1000:')t = xi = 2result = []while True:if t==1:breakif t%i==0:(i)t = t/ielse:i+=1print x,'=','*'.join(map(str,result))编写程序,至少使用2种不同的方法计算100以内所有奇数的和。
Python程序设计实例教程 第2版 项目6 面向对象程序设计基础

• 类是实现代码复用和设计复用的一个重要方法,封装、继承、多态是面向对象程序设计的三 个要素。
这个成员,但在对象外部可以通过“对象名._类名__xxx”这样的特殊方式来访问。 ➢ __xxx__:系统预定义的特殊成员。
❖ 注意:Python中不存在严格意义上的私有成员。
9
6.2.2 数据成员
• 数据成员用来描述类或对象的某些特征和属性,例如一本书的作者、书号、 出版社、定价等。数据成员可以大致分为两类:属于对象的数据成员和属于 类的数据成员。
• 公有方法通过对象名直接调用,私有方法不能通过对象名直接调用,只能在其他 实例方法中通过前缀self进行调用或在外部通过特殊的形式来调用。
>>> a._A__value 0
# 在外部访问对象的私有数据成员
8
6.2.1 私有成员与公有成员
在Python中,以下划线开头的变量名和方法名有特殊的含义,尤其是在类的 定义中。
➢ _xxx:单下划线开头,表示受保护成员。 ➢ __xxx:双下划线开头,表示私有成员,只有类对象自己能访问,子类对象不能直接访问到
• 从形式上看,在定义类的成员时,如果成员名以两个下划线开头但是不以两 个下划线结束则表示是私有成员,否则就不是私有成员。
• Python并没有对私有成员提供严格的访问保护机制,通过一种特殊形式“对 象名._类名__xxx”也可以在外部程序中访问私有成员,但这会破坏类的封装 性,不建议这样做。
7
Python语言程序设计基础(第2版)第四章课后习题答案
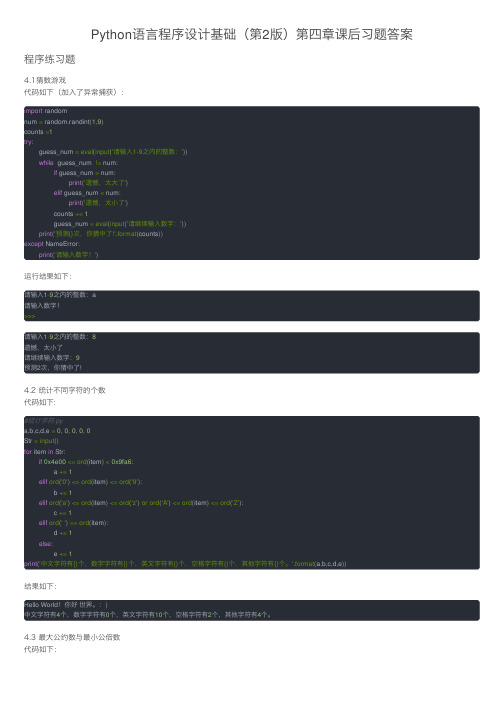
Python语⾔程序设计基础(第2版)第四章课后习题答案程序练习题4.1猜数游戏代码如下(加⼊了异常捕获):import randomnum = random.randint(1,9)counts =1try:guess_num =eval(input('请输⼊1-9之内的整数:'))while guess_num != num:if guess_num > num:print('遗憾,太⼤了')elif guess_num < num:print('遗憾,太⼩了')counts +=1guess_num =eval(input('请继续输⼊数字:'))print('预测{}次,你猜中了!'.format(counts))except NameError:print('请输⼊数字!')运⾏结果如下:请输⼊1-9之内的整数:a请输⼊数字!>>>请输⼊1-9之内的整数:8遗憾,太⼩了请继续输⼊数字:9预测2次,你猜中了!4.2 统计不同字符的个数代码如下:#统计字符.pya,b,c,d,e =0,0,0,0,0Str =input()for item in Str:if0x4e00<=ord(item)<0x9fa6:a +=1elif ord('0')<=ord(item)<=ord('9'):b +=1elif ord('a')<=ord(item)<=ord('z')or ord('A')<=ord(item)<=ord('Z'):c +=1elif ord(' ')==ord(item):d +=1else:e +=1print('中⽂字符有{}个,数字字符有{}个,英⽂字符有{}个,空格字符有{}个,其他字符有{}个。
[Python程序设计基础(第2版)][李东方 (12)[25页]
![[Python程序设计基础(第2版)][李东方 (12)[25页]](https://img.taocdn.com/s3/m/55d9bad7d0d233d4b14e69a9.png)
12.1.3 编辑操作和写入
1.赋值 Excel的单元格除可以赋值为字符串、整数和浮点数之外,还可以接
收日期、百分数、公式等赋值,例如:
ws['A1'] = datetime.datetime(2016, 9, 18)
# 需预先
import datetime
ws['B1'] = '0.15%'
# 需打开后手工转为数字
ws['C1'] = '0000001234'
# 自动判别为字符格式
ws['D1'] = '=SUM(D2:D10)'
12.1.2 数据的读取
使用openpyxl,可以直接访问活动工作表的单元格, 例如:
cell_A4=ws['A4']
这里,cell_A4对象实例的类型是单元格,其值为 cell_A4.value。
也可以直接以行、列定位访问单元格,读取数据或赋 值,例如:
cell_B4= ws.cell(row=4, column=2, value='上海市')
由于Excel文件具有独占性,因此只能访问不会同时被其他程序打开的.xlsx文件。 对于新创建的空工作簿应创建新的工作表,例如: ws1 = wb.create_sheet("Mysheet") 或 ws1 = wb.create_sheet("Mysheet", 0) # 将其放在所有工作表的首位
>>> tuple(ws.rows) ((<Cell Sheet.A1>, <Cell Sheet.B1>, <Cell Sheet.C1>), (<Cell Sheet.A2>, <Cell Sheet.B2>, <Cell Sheet.C2>), (<Cell Sheet.A3>, <Cell Sheet.B3>, <Cell Sheet.C3>), (<Cell Sheet.A4>, <Cell Sheet.B4>, <Cell Sheet.C4>), (<Cell Sheet.A5>, <Cell Sheet.B5>, <Cell Sheet.C5>), (<Cell Sheet.A6>, <Cell Sheet.B6>, <Cell Sheet.C6>), (<Cell Sheet.A7>, <Cell Sheet.B7>, <Cell Sheet.C7>), (<Cell Sheet.A8>, <Cell Sheet.B8>, <Cell Sheet.C8>), (<Cell Sheet.A9>, <Cell Sheet.B9>, <Cell Sheet.C9>))
教学课件 Python语言程序设计基础(第2版) 嵩天

程序设计语言
程序设计语言概述
程序设计语言包括编译执行和解释执行两种方式
程序设计语言是计算机能够理解和识别用户操作意 图的一种交互体系,它按照特定规则组织计算机指 令,使计算机能够自动进行各种运算处理。按照程 序设计语言规则组织起来的一组计算机指令称为计 算机程序。
程序设计语言概述
Python语言版本更迭
Python语言的版本更迭
更高级别的3.0系列不兼容早期2.0系列 2008年至今,版本更迭带来大量库函数的升 级替换,Python语言的版本更迭痛苦且漫长 到今天,Python 3.x系列已经成为主流
本章小结
本章具体讲解了计算机的基本定义、计算机的 功能性和可编程性、程序设计语言分类、编译 和 解 释 、 Python 语 言 的 历 史 和 发 展 、 配 置 Python开发环境等内容,最后给出了Python版 本的主要区别供参考。
Python语言的优势
跨平台 + 开源
/
目前有93561个开源库,覆盖各类计算问题
例5: from random import random rnd = random()*10 print(rnd)
Python语言的优势
Python语言的优势:面向过程 + 面向对象
Python语言的优势
脚本语言 + 语句执行
例1:
print(“Hello World!大家好!")
例2:
sum = 99999 * 99999 print(sum)
Python语言的优势
例3: months="JanFebMarAprMayJunJulAugSepOctNovDec" n=4 monthAbbrev = months[(n-1)*3:(n-1)*3+3] print(monthAbbrev)
#Python程序语言设计基础(第二版)程序练习题

#Python程序语⾔设计基础(第⼆版)程序练习题Python程序语⾔设计基础(第⼆版)程序练习题3.1 重量计算,⽉球上物体的体重是在地球上的16.5%,假如你在地球上每年增长0.5kg,编写程序输出未来10年你在地球和⽉球上的体重状况。
current_weight = float(input('当前体重kg:'))for i in range(1,11):current_weight += 0.5moon_weight = current_weight*16.5/100print('第{:d}年,地球体重{:.2f}kg,⽉球体重{:.2f}kg'.format(i,current_weight,moon_weight))运⾏结果:当前体重kg:50第1年,地球体重50.50kg,⽉球体重8.33kg第2年,地球体重51.00kg,⽉球体重8.41kg第3年,地球体重51.50kg,⽉球体重8.50kg第4年,地球体重52.00kg,⽉球体重8.58kg第5年,地球体重52.50kg,⽉球体重8.66kg第6年,地球体重53.00kg,⽉球体重8.74kg第7年,地球体重53.50kg,⽉球体重8.83kg第8年,地球体重54.00kg,⽉球体重8.91kg第9年,地球体重54.50kg,⽉球体重8.99kg第10年,地球体重55.00kg,⽉球体重9.07kg3.2 天天向上续。
尽管每天坚持,但⼈的能⼒发展并不是⽆限的,它符合特定模型。
假设能⼒增长符合如下带有平台期的模型:以7天为周期,连续学习3天能⼒值不变,从第四天开始⾄第七天每天能⼒增长为前⼀天的1%。
如果7天中有1天间断学习则周期从头计算。
请编写程序回答,如果初始能⼒值为1,连续学习365天后能⼒值是多少?initial_value = 1for i in range(365):if i%7 in [4,5,6,0]:initial_value = initial_value*(1+0.01)print('{:.5f}'.format(initial_value))运⾏结果:8.00142天天向上续。
《Python程序设计基础》习题答案与分析

Python程序设计基础习题答案与分析程昱第1章基础知识1.1 简单说明如何选择正确的P ytho n版本。
答:在选择Pyt hon的时候,一定要先考虑清楚自己学习Pyth on的目的是什么,打算做哪方面的开发,有哪些扩展库可用,这些扩展库最高支持哪个版本的Py thon,是Pytho n 2.x还是Pyt hon 3.x,最高支持到P y thon 2.7.6还是Pyt hon 2.7.9。
这些问题都确定以后,再做出自己的选择,这样才能事半功倍,而不至于把大量时间浪费在Pyth on的反复安装和卸载上。
同时还应该注意,当更新的Py thon版本推出之后,不要急于更新,而是应该等确定自己所必须使用的扩展库也推出了较新版本之后再进行更新。
尽管如此,Python 3毕竟是大势所趋,如果您暂时还没想到要做什么行业领域的应用开发,或者仅仅是为了尝试一种新的、好玩的语言,那么请毫不犹豫地选择P y thon 3.x系列的最高版本(目前是Pyt hon 3.4.3)。
1.2 为什么说Py thon采用的是基于值的内存管理模式?Python采用的是基于值的内存管理方式,如果为不同变量赋值相同值,则在内存中只有一份该值,多个变量指向同一块内存地址,例如下面的代码。
>>> x = 3>>> id(x)10417624>>> y = 3>>> id(y)10417624>>> y = 5>>> id(y)10417600>>> id(x)10417624>>> x = [1, 2, 3, 1, 1, 2]>>> id(x[0])==id(x[3])==id(x[4])True1.3 解释Pyth o n中的运算符“/”和“//”的区别。
《Python程序设计基础(第2版)》教学大纲(参考)

《Python程序设计基础》教学大纲院(系、部):教研室:日期:2018年3月20日目录一、课程简介 (1)二、教学目的和要求 (1)三、教学中应注意的问题 (1)四、教学内容 (2)五、教学课时分配 (9)六、教材与参考书目 (10)一、课程简介课程名称:Python程序设计基础课程编号:课程性质:必修适用专业:非计算机专业前导课程:无考核方式:考试建议学时:48+16二、教学目的和要求通过本课程的学习,使得学生能够理解Python的编程模式,熟练运用Python 列表、元组、字典、集合等基本数据类型以及相关列表推导式、切片等特性来解决实际问题,熟练掌握Python分支结构、循环结构、函数设计以及类的设计与使用,熟练使用正则表达式处理字符串,熟练使用Python读写文本文件与二进制文件,了解Python程序的调试方法,熟练运用Python编写面向对象程序,掌握使用Python操作SQLite数据库的方法,掌握Python+pandas进行数据处理的基本用法,掌握使用Python+matplotlib进行数据可视化的用法,同时还应培养学生的代码优化与安全编程意识。
三、教学中应注意的问题Python编程模式中非常重要的一条是代码简单化、问题简单化,同时应保证代码具有较强的可读性。
在教学过程中,尽量避免在Python程序中带有其他编程语言的痕迹,要尽量从最简单的角度去思考和解决问题、实现自己的想法和思路,尽量多使用Python内置函数、标准库对象和合适的扩展库对象,保证代码的优雅、简洁,让代码更加Pythonic。
使用Python编程解决问题应充分借鉴和使用成熟的标准库和扩展库,尽量避免自主编写完整的业务逻辑,部分具体操作完全可以使用扩展库来实现,大幅度提高开发效率。
例如:如果需要进行排序则直接使用内置函数或方法进行排序,切不可再使用选择法排序、冒泡法排序或堆排序等排序算法来编写代码实现;计算最大公约数应习惯于使用math标准库的gcd()函数;对数据进行随机乱序应使用random标准库中的shuffle()函数;从给定数据集中随机选择元素应使用random标准库中的choice()函数;等等。
Python程序设计与算法基础教程(第2版)第4章 常用内置数据类型

12.3.hex() #结果:'0x1.899999999999ap+3' float.hex(12.3) #结果:'0x1.899999999999ap+3'
fromhex(string)
十六进制字符串转换为浮 点数
float.fromhex('0xFF') #结果:255.0
• 浮点数的运算
is_integer()
• 【例4.3】int对象方法示例
>>> i = -10
>>> bin(i)
#数值转换为二进制字符串。输出:'-0b1010‘
'-0b1010'
>>> i.bit_length(), int.bit_length(i) #返回i的二进制位数。输出:(4, 4)
(4, 4)
int类型(任意精度整数)(3)
>>> complex
#输出:<class 'complex'>
• complex对象属性和方法
>>> c = complex(4, 5)
>>> c
#输出:(4+5j)
属性/方法
说明
示例
real
复数的实部
>>> (1+2j)g
• 整数的运算 • 算术运算、位运算、内置函数、math模块 中的数学运算函数
• 【例4.4】整数运算示例(int_ops.py)
import sys a = int(sys.argv[1]) b = int(sys.argv[2]) sum = a + b print(a, ' + ', b, ' = ', sum)
Python基础学习笔记

Python 基础学习笔记基于《 Python 语言程序设计基础(第 2 版)》第一部分初识 Python 语言第 1 章程序设计基本方法1.1 计算机的概念计算机是根据指令操作数据的设备,具备功能性和可编程性两个基本特性。
计算机技术发展阶段:1.第一阶段: 1946-1981 年,“计算机系统结构阶段”。
2.第二阶段: 1982-2007 年,“计算机网络和视窗阶段”。
3.第三阶段: 2008 年至今,“复杂信息系统阶段”。
4.第四阶段:月 20 年后某个时期开始,“人工智能阶段”。
1.2 程序设计语言1.2.1 程序设计语言概述机器语言:直接使用二进制代码表达指令,可被计算机硬件直接识别和执行。
不同计算机结构的机器指令不同。
汇编语言:使用助记符对应机器语言中的指令,可直接操作计算机硬件。
不同计算机结构的汇编指令不同。
机器语言和汇编语言都直接操作计算机硬件并基于此设计,统称“低级语言”。
高级语言:用更接近自然语言的方式描述计算问题。
代码只与编程语言有关,与计算机结构无关。
1.2.2 编译和解释高级语言按执行方式可分为采用编译执行的静态语言和采用解释执行的脚本语言。
编译是将源代码转换成目标代码的过程。
解释是将源代码逐条转换成目标代码同时逐条运行目标代码的过程。
1.2.3 计算机编程我学习 Python 的原因:1.通过编程实现自动化,提高效率。
2.通过编程了解一个新的广阔世界。
学习一门编程语言(重点在于练习)1.掌握该语言的语法2.结合问题设计程序结构3.掌握解决问题的能力1.3Python 语言概述1.3.1 Python 语言的发展Python 语言是一个语法简洁、跨平台、可扩展的开源通用脚本语言。
Python 语言诞生于 1990 年,创世人为 Guido 。
2000 年 10 月, Python 2.0 正式发布, 2010 年, Python 2.x 系列发布最后一版(2.7 )。
2008 年 12 月, Python 3.0 正式发布,解释器内部采用完全面向对象的方式实现,代价是 3.x 系列版本无法向下兼容 2.x 系列的既有语法。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
创建正则表达式对象p:
p=pile('''[0-9a-zA-Z\_] #匹配1个数字、字母或下画线
AA?
#后面跟A或 AA
(0*)$
#由若干个0结尾
''',re.I|re.X) #忽略大小写、忽略空格并允许当中整行加注释
10.2.1 匹配与搜索
匹配与搜索函数通常有match()、search()和findall(),它们的 作用和用法相似,通常有两种使用方法。 ① 作为正则表达式编译对象p的方法使用:
import re
p=pile('^[a-zA-Z0-9]{1,10}@[a-zA-Z0-9]{1,10}.(com|org)$',re.I)
re.match(pattern, string[,flag]) re.search(pattern, string[,flag]) re.findall(pattern, string[,flag])
【例10-1】 假定某E-mail地址由三部分构成:英文字母或数字(1~10 个字符)、“@”、英文字母或数字(1~10个字符)、“.”,最后以com 或org结束,其正则表达式为:'^[a-zA-Z0-9]{1,10}@[a-zA-Z09]{1,10}.(com|org)$'是否符合设定规则。
第10章 正则表达式的应用
本章教学目标:
理解正则表达式的基本语法规则。 学会用re库的内置函数进行匹配、搜索、分组、 替换等字符串操作。 了解和体验简单爬虫自动获取网页资源的方法。
10.1 正则表达式
正则表达式(regular expression)是由一些特 定字符及其组合所组成的字符串表达式,用来对 目标字符串进行过滤操作。
(1)数字和字符 用'\d'可以匹配一个数字,用'\w'可以匹配一个字符(包括数 字)。例如:
'11\d'可匹配'114',但不能匹配'11A' '\d\d\d'可匹配'021' '\w\w\d'可匹配'sp3'
(2)任意单个字符 用'.'可以匹配任意单个字符,例如:'py.'可以匹配'py2'、'py3'、'py!'等。 (3)多个字符 用'*'表示任意个字符(包括0个),用'+'表示至少1个字符,用'? '表示0个或1个字符,用 '{n}'表示n个字符,用'{n,m}'表示n-m个字符,例如,在正则表达式'd{3}\s+\d{3,8}'中, '\d{3}'匹配3位数字,'\s'匹配1个空格,而'\s+'表示至少有1个空格(包括制表位空格), '\d{3,8}'表示3~8位数字。这样,该正则表达式即可匹配带区号并以任意个空格隔开的电话 号码。 (4)字符范围 用'[]'表示字符范围,1组方括号只能表示1个字符,例如,'[0-9a-zA-Z\_]'可匹配1个数字、 字母或下画线。'P|p'可匹配'P'或'p','[P|p]ython'可匹配'Python'或'python'。 (5)开头和结尾 用'^'表示行的开头,用'^\d'表示必须以数字开头。用'$'表示行的结束,用'\d$'表示必须以数 字结束。例如,'py'可以匹配'python',但加上表示开头和结尾的符号,'^py$'就只能匹配整 行完整的'py',而对于'python'则无法匹配了。 (6)特殊字符 特殊字符通常指非字母、非数字字符。例如,换行符'\n'、回车符'\r'、空白符'\s'、制表位符 '\t'等。 为避免与语法表达式中符号的歧义,要用'\'转义或加r前缀统一转义。建议使用r前缀,就可以 不用考虑转义的问题了。 例如,常见的用'-'隔开区号的电话号码, 可用正则表达式'\d{3}\-\d{3,8}'或r'd{3}d{3,8}'匹配。 (7)汉字 匹配汉字的正则表达式为:' [\u4e00-\u9fa5] '。在支持Unicode编码的系统中,也可以直接 用汉字精确匹配
p.match(string[,pos[endpos]]) p.search (string[,pos[endpos]]) p.findall(string[,pos[endpos]])
若非指定,则pos和endpos的默认值分别为0和len(string),即 从头到尾。 ② 不使用正则表达式编译对象而直接调用:
10.2 re模块的内置函数
Python处理正则表达式的标准库是re pile()函数通常包括pattern(正则表达
式)和flag(匹配模式,可选)参数。
flag的常见取值如下: re.I:忽略大小写。 re.L:使用当前本地化语言字符集中定义的\w、\W、\b、\B、\s、\S(用于 多语言操作系统)。 re.M:多行模式,使'^'和'$'作用于每行的开始和结尾。 re.S:用'.'所匹配的任意字符包括换行符。 re.U:使用Unicode字符集中定义的\w、\W、\b、\B、\s、\S、\d、\D。 re.X:忽略空格,并允许用'#'添加注释。
正则表达式是用基本符号,以单个字符、字符集 合、字符范围、字符间的组合等形式组成模板, 然后用这个模板与所搜索的字符串进行匹配。
利用正则表达式对字符串的匹配通常分为精确匹 配和贪婪匹配两种。
表10-1 正则表达式的常见基本符号
10.1.1 精确匹配
在正则表达式中,如果直接给出字符,则为精确 匹配
10.1.2 贪婪匹配
贪婪匹配是一种尽可能多地匹配字符的匹配模式 贪婪匹配是正字表达式默认的匹配方式
当需要对数字字符串'6540000'进行匹配时,根据其以数字开头和若干 个0结尾的特点可写出正则表达式'^(\d+)(0*)$',但实际上该表达式 等效于'^(\d+)$',因为默认的贪婪匹配模式直接把后面的'0'作为数字 全部匹配了,对'6540123'照样可以匹配,无法精确表达以若干个0结 尾的含义。这时,必须用'?'使得'\d+'采用非贪婪匹配模式,并限定0 的位数,用正则表达式'^(\d+?)(0{4})$'才能把后面的'0'全部匹配出 来。