spss中分类汇总教程
Spss软件常用菜单含义与功能介绍
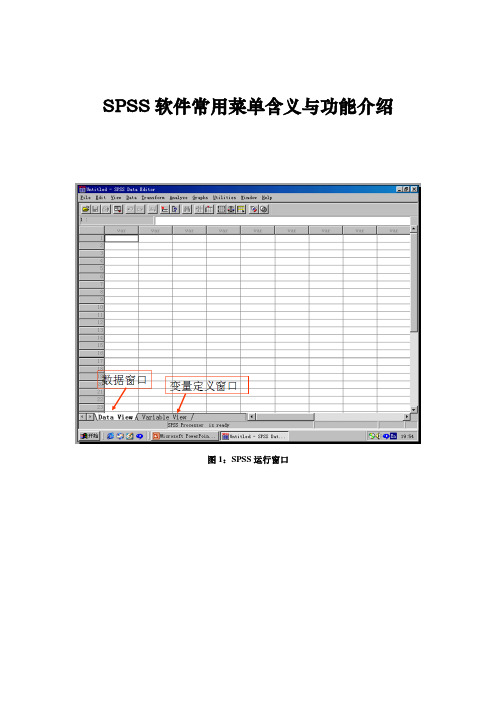
SPSS软件常用菜单含义与功能介绍图1:SPSS运行窗口1、计算产生变量根据已经存在的变量,经过函数计算后,建立新变量或替换员原量的值。
图2:计算产生变量图3:分类汇总1、描述性统计(1)频数分布分析:通过频数分布表、直方图,以及集中趋势和离散趋势的各种统计量,描述数据的分布特征。
(2)描述性统计分析:计算描述数据的集中趋势和离散趋势的各种统计量,还可以做标准化变换(变成均值为0,方差为1的数据)。
(3)探索性分析:判断数据有无离群点(outliers),极端值(extreme values);进行正态分布检验和方差齐性检验;了解数据指标之间差异的特征。
(1)双变量相关分析:分析两个变量之间是否存在相关关系。
(2)偏相关分析:剔除其他变量的影响的情况下,计算两变量之间的相关系数。
3、聚类分析与判别分析(1)系统聚类:最常用的聚类方法。
(2)判别分析:判别所研究的对象属于哪一类的统计方法。
(1)线性回归:一个因变量(dependent )与多个自变量(independents )之间存在线性数量关系。
(2)曲线拟合:可以完成11种曲线的自动拟合(根据需要进行选择),并进行参数估计与检验,绘制拟合图形等。
自变量(independent )只能选一个或者使用时间作为自变量(time: 即使用1,2,3,…,),即只能做一元函数的曲线拟合。
因变量(dependent )可以选多个,将分别做多个一元函数的拟合。
模型Models 模型名称 模型表达式Linear 线性模型 01*y b b x =+ Logarithmic对数模型01*ln y b b x =+Inverse 逆模型 01/y b b x =+ Quadratic 二次模型 2012**y b b x b x =++ Cubic 三次模型 230123***y b b x b x b x =+++Compound 复合模型 01*x y b b =Power 幂模型 10*b y b x = S S 型模型 01/b b x y e +=Growth 生长模型 01*b b x y e += Exponential 指数模型 1*0*b x y b e =LogisticLogistic 模型011/(1)b b x y e --=+一般可以先选择所有的11种模型,再根据结果选择最佳模型。
使用SPSSSPSS中文版统计软件的统计分析操作方法

使用SPSSSPSS中文版统计软件的统计分析操作方法SPSS(Statistical Package for the Social Sciences)是一种用于统计分析的软件工具,它可以帮助研究人员对数据进行处理、分析和解释。
下面将介绍SPSS中文版统计软件的常见统计分析操作方法。
一、数据导入和预处理1. 启动SPSS软件后,在主界面选择"文件"->"打开"->"数据",然后选择要导入的数据文件,如Excel或CSV格式文件。
2.在数据导入对话框中,选择正确的数据类型和分隔符,并指定变量名和数据属性。
3.完成数据导入后,可以对数据进行预处理操作,如数据清洗、变量选择、数据转换等。
二、描述统计分析1.在数据导入后,在主界面选择"统计"->"描述性统计"->"频数",然后选择要进行频数分析的变量。
2.设置所需的统计量和显示选项,如均值、标准差、最小值、最大值等,并生成描述统计表。
三、数据可视化1.在主界面选择"图表"->"柱形图",然后选择要进行柱形图分析的变量。
2.设置柱形图的样式、颜色和标题等,并生成柱形图。
3.可以根据需要选择其他类型的统计图表,如折线图、散点图、饼图等,以进行数据可视化展示。
四、假设检验1.在主界面选择"分析"->"描述统计"->"交叉表",然后选择要进行交叉表分析的变量。
2.设置所需的交叉表分析选项,如分组变量、交叉分类表等,并生成交叉表。
3.可以根据需要进行卡方检验、t检验、方差分析等假设检验方法来比较两个或多个变量之间的差异。
五、回归分析1.在主界面选择"回归"->"线性",然后选择要进行回归分析的因变量和自变量。
spss第四章数据文件的操作与变换

2.选择对观测量作加权处理的方式。
.请勿对个案加权:对数据文件不作加权处理。这是系统默认状 态。
.加权个案:选择此项表示要求作加权处理。
3.当在上一步中选择了“加权个案〞选项后。从左边源变量列表框 中选择一个作为权变量的变量名,单击向右箭头按钮,送入“频率 变量〞下面的矩形框中。在此我们选择变量名“频数〞作为加权变 量。
9、平滑
4.14 替换缺失值
在分析带有缺失值的观测数据时,通常将带有缺失值的 观测量排除在分析数据范围之外,但在进展时间系列的统 计分析时,不能将带有缺失值的观测量排除在外.此时可用 替换缺失值的方法进展处理.其操作步骤如下:
替换缺失值的方法:
1、序列平均值: 用整列变量值的均值替代缺失值。如果变量值中 含有多个缺失值,那么它们都将由同一个值替换。(e414-1)
其操作步骤如下:
1. 在主菜单中单击T“转换〞,展开下拉菜单,从下拉菜单中选择“对个案 内的值计数〞 。
2. 执行“对个案内的值计数〞操作后,观测量中特定变量值出现的次数,将通 过创立一个新的变量〔称为目标变量)来保存及显示。
3.在主对话框左边的源变量列表框中选择要进展计数的变量名〔中国青 年〕,单击向一右箭头按钮,将它送入 “变量〞下方的矩形框中。
第四章 数据文件操作与变换
4·1 定义时间系列日期型变量
数据→定义日期
说明:
1、执行后,在数据窗口中为每个时间单位对应 一个新的数值变量,变量名后带 “_〞,如 YEAR_ , DAY_ , MONTH_ 等。最后还附加了一个 具有描述意义的字符变量DATE_。
2、如果在这之前已经定义了一组时间系列变量, 那么新建立的变量将全部替代原有的时间系列。
SPSS操作实验手册

SPSS试验操作指导手册(2023版)2.SPSS数据整顿2.1 SPSS数据文献旳建立SPSS数据文献旳建立可以运用【File(文献)】菜单中旳命令来实现。
详细来说, SPSS提供了四种创立数据文献旳措施:●新建数据文献【File(文献)】→【New(新建)】→【Data(数据)】命令;●直接打开已经有数据文献【File(文献)】→【Open (打开)】→【Data(数据)】命令;●使用数据库查询;【File(文献)】→【Open Database(打开数据库)】→【New Query(新建查询)】命令, 弹出【Database Wizard(数据库向导)】对话框●从文本向导导入数据文献。
【File(文献)】→【Read Text Data(打开文本数据)】命令, 弹出【Open Data(打开数据)】对话框实例分析: 股票指数旳导入文献2-1.xls是上证指数从2023年1月4日至2023年10月16 日旳数据资料, 包括了开盘价、当日最高价、当日最低价和收盘价等选项, 请将该数据导入至SPSS中。
2.2 SPSS数据文献旳属性一种完整旳SPSS文献构造包括变量名称、变量类型、变量名标签、变量值标签等内容。
注意: SPSS数据文献中旳一列数据称为一种变量, 每个变量都应有一种变量名。
SPSS数据文献中旳一行数据称为一条个案或观测量(Case)2.2.1 实例分析: 员工满意度调查表旳数据属性设计1.实例内容为了提高员工旳工作积极性, 完善企业各方面管理制度, 并到达有旳放矢旳目旳, 某企业决定对我司员工进行不记名调查, 但愿理解员工对企业旳满意状况。
请根据该企业设计旳员工满意度调查题目(行政人事管理部分)旳特点, 设计该调查表数据在SPSS旳数据属性。
2.实例操作详细环节如下文献(2-2.sav.)Step01: 打开SPSS中旳Data View窗口, 录入或导入原始调查数据。
Step02:选择菜单栏中旳【File(文献)】→【Save (保留)】命令, 保留数据文献, 以免丢失。
SPSS数据分析7

SPSS数据分析7SPSS数据分析7SPSS是一款功能强大的统计软件,可以用于数据的清洗、整理、分析和可视化。
在进行SPSS数据分析时,一般需要经过以下步骤:数据导入、数据清洗、数据整理、数据分析和结果解读。
下面将逐步介绍这些步骤。
首先,将数据导入SPSS软件中。
SPSS支持多种数据格式,如Excel、CSV等。
打开SPSS软件后,点击菜单栏的“File”选项,选择“Open”,导入数据文件。
接下来,进行数据整理。
数据整理主要包括数据排序、合并和拆分等操作。
在菜单栏上选择“Data”选项,然后选择“Sort Cases”可以对数据进行排序。
在“Sort Cases”对话框中,我们可以选择按照一些或多个变量进行排序。
此外,我们还可以使用“Data”选项下的“Merge Files”进行数据的合并,使用“Split File”进行数据的拆分,具体操作根据实际需求进行选择。
然后,进行数据分析。
SPSS提供了丰富的统计方法和分析工具,可以根据不同的研究目的和数据类型进行选择。
常见的数据分析方法包括描述统计分析、相关分析、方差分析、回归分析、因子分析等。
点击菜单栏上的“Analyze”选项,可以选择相应的分析方法和工具,并设置相应的参数。
在设置参数时,需要注意选择适当的检验方法和统计指标。
最后,进行结果解读。
通过SPSS进行数据分析后,会得到相应的结果报告和图表。
在结果解读时,需要结合具体的研究问题和数据分析方法来进行解读。
要注意关注显著性水平、效应大小和置信区间等指标,判断结果的可靠性和实际意义。
此外,还可以使用SPSS提供的图表和可视化工具来展示数据分析的结果,更直观地呈现研究的结论。
综上所述,SPSS数据分析主要包括数据导入、数据清洗、数据整理、数据分析和结果解读等步骤。
通过SPSS软件的功能和工具,可以实现对数据的全面分析和解读,为研究者提供科学的数据支持,帮助做出准确的决策和结论。
分类汇总使用方法

分类汇总使用方法一、数据清洗在进行分类汇总之前,需要对数据进行清洗和预处理,以保证数据的准确性和一致性。
数据清洗主要包括以下几个方面:1.缺失值处理:检查数据中的缺失值,并选择合适的处理方法,如填充缺失值或删除含有缺失值的记录。
2.异常值处理:识别数据中的异常值,并采取相应的处理方法,如将异常值替换为合理值或删除含有异常值的记录。
3.特征工程:通过特征选择、特征构造等方法,对数据进行变换和增强,以提高分类汇总的效果。
二、特征选择在进行分类汇总时,需要选择与目标变量相关的特征,以提取分类所需的特征信息。
特征选择的方法包括:1.基于统计的特征选择:根据特征与目标变量之间的相关性、方差等统计指标,选择最重要的特征。
2.基于模型的特征选择:通过训练分类模型,并根据模型的特征权重或特征贡献度来选择最重要的特征。
3.集成方法特征选择:将多个特征选择方法结合使用,以提高特征选择的准确性和稳定性。
三、分类方法选择根据数据的特点和分类任务的要求,选择合适的分类方法。
常见的分类方法包括:1.决策树分类:通过构建决策树来对数据进行分类。
2.朴素贝叶斯分类:基于贝叶斯定理和特征之间独立假设的分类方法。
3.支持向量机分类:在数据空间中找到一个超平面,将不同类别的数据分隔开。
4.神经网络分类:通过训练神经网络来对数据进行分类。
5.集成方法分类:将多个分类方法结合使用,以提高分类的准确性和稳定性。
四、训练模型根据选择的分类方法,使用训练数据集对模型进行训练。
在训练过程中,需要对模型进行参数调整和优化,以提高模型的准确性和稳定性。
同时,需要注意防止过拟合和欠拟合问题。
五、评估模型使用测试数据集对训练好的模型进行评估,以检验模型的分类性能。
评估指标包括准确率、精度、召回率、F1值等。
通过对模型的评估结果进行分析,可以发现模型存在的问题和改进的方向。
六、部署应用将训练好的模型部署到实际应用中,用于对新的数据进行分类预测。
在部署过程中,需要考虑模型的实时性、可扩展性和安全性等方面的问题。
SPSS数据录入(一)

精选课件
14
录入数据的第一步是定义变量属性,随后才能进行 数据录入。
(一)单选题的录入 单选题的录入可以采用字符直接录入、字符代码+值 标签、数值代码+值标签三种方式。
精选课件
15
(二)多选题的录入
1.多重二分法(Multiple Dichotomy Method) 所谓多重二分法,是在编码的时候,对应每一个选项都要定义
一、常用基本概念 (1)spss算术表达式 spss算术表达式是由常量、spss变
量名、spss的算术运算符、圆括号等组成的式子。 (2)spss函数 spss提供了多达70多种函数,分为八大类:
算术函数、统计函数、分布函数、逻辑函数、字符串函数、 日期时间函数、缺失值函数和其它函数。 (3)spss条件表达式 通过spss的算术表达式和函数可以对 所有记录计算一个结果,如果仅希望对部分记录进行计算, 则应当利用spss的条件表达式指定对那些记录进行计算。
精选课件
5
1.1 数据格式概述
1.1.1 统计软件中数据的录入格式 (1)不同观测对象的数据不能在同一记录中出现,即同一
观测数据应当独占一行。 (2)每一个观测量指标或影响因素只能占据一列的位置,
即同一指标的数量观测值都应当录入到同一个变量中去。
即:一个观测占一行,一个变量占一列
精选课件
6
1.1.2 变量属性介绍
一个变量,有几个选项就有几个变量,这些变量均为二分类, 他们各自代表对一个选项的选择结果。P16 H3b 2.多重分类法(Multiple Category Method) 多重分类法,也是利用多个变量对一个多选题的答案进行定义, 应该用多少个变量,由被访者实际可能给出的最多答案数而 定。P16 H4
《用SPSS作聚类分析》课件

《用SPSS作聚类分析》 PPT课件
欢迎来到《用SPSS作聚类、SPSS的应用以及结果分析。让我们一起开始这个有趣而有深度的数据 挖掘之旅吧!
什么是聚类分析?
聚类分析是一种数据分析方法,将相似的事物归类到同一组,帮助我们找到 数据中的规律和模式。
SPSS聚类分析的基本步骤
1
数据准备
选取要分析的数据并进行预处理,
聚类方法选择
2
如缺失值填充。
根据需求选择合适的聚类方法,如
层次聚类、K-Means聚类或模糊聚 类。
3
变量选择
选择对聚类分析有影响的变量并进
行预处理。
聚类分析运行
4
对选取的变量运行聚类分析,并选
择最优的聚类数。
5
结果分析
分析聚类结果,命名聚类结果,并 可视化展示。
为什么要进行聚类分析?
聚类分析能够帮助我们发现数据中隐藏的规律和模式,为决策提供科学依据,优化业务流程,提 高效率。
参考文献
贺志鹏. 数据挖掘与SPSS实战[M].
清华大学出版社, 2009.
Mirkin B. Clustering: A Data Recovery Approach[M].
CRC Press, 1996.
SPSS聚类分析具体操作步骤-spss如何聚类

单击“方法”按钮弹出对话框
• 下拉框指定的是小类之间的距离计算方法7种供用 户选择
13
• 度量标准 计算样本距离的方法
14
点击“继续”接下来指定SPSS分析图形输出
属性图以树的形式展现 聚类分析的每一次合并 过程。冰柱图通过表格 中的冰柱显示。 可以指定并主图的输出 方向,纵向和横向
15
显示凝聚状态表,单击“统计量”
• 点间距离有很多定义方式。最简单的是欧式距离,还有其 他的距离。
• 当然还有一些和距离相反但起同样作用的概念,比如相似 性等,两点越相似度越大,就相当于距离越短。
• 由一个点组成的类是最基本的类;如果每一类都由一个点 组成,那么点间的距离就是类间距离。但是如果某一类包 含不止一个点,那么就要确定类间距离,
4
SPSS中聚类分析分类
(一)按分类对象 对变量的聚类称为R型聚类 对观测值聚类称为Q型聚类 这两种聚类在数学上是对称的,没有什么不同。
(二)按聚类的方法分类 分层聚类或系统聚类分析 快速聚类分析 两步聚类分析:新型的
5
事先不用确定分多少类:分层聚类
分层聚类或系统聚类(hierarchical cluster)。开始 时,有多少点就是多少类。
1
聚类分析概述
(一)概念 • (1)聚类分析是统计学中研究“物以类聚”的一种
方法,属多元统计分析方法.
– 例如:细分市场、消费行为划分
• 聚类分析是建立一种分类,是将一批样本(或变量) 按照在性质上的“亲疏”程度,在没有先验知识的 情况下自动进行分类的方法.其中:类内个体具有 较高的相似性,类间的差异性较大.
• 比如学生成绩数据就可以对学生按照理科或文科 成绩(或者综合考虑各科成绩)分类,
SPSS数据整理

例6 :在cars.sav文件
• 标出美国产的汽车马力在135以下的 • 注意:
– Count 在标示数据的过程中,不能对同时满足 多个取值条件的记录进行标示,只能对满足某 一个条件的变量进行标示。
四、变量的重新赋值
• 选Transform菜单的Recode命令项, • 该过程用于将原变量按照某种一一对应的 关系生成新变量,可以将新值赋给原变量 也可以生成一个新变量。 • 两种选择:一是对变量自身重新赋值(Into Same Variables...),一是对其它变量或 新生成的变量进行赋值(Into Different Variables...)。
例4:cars data.sav
•选择 Analyze all cases, do not create groups, 并对“origin”变量进行频数分析 •选择 compare groups,将根据所选变量的不同值 对原始数据进行分组,从而得到拆分数 据。并对“origin”变量进行频数分析 •选择organize output by groups ,根据所选变量的 不同值对原始数据进行分组,并将分析结果 单独保存
结果
• 原文件中的行变成新文件中的列,原文件中 的列变成新文件中的行;
• 原文件中的变量变成新文件中的个案,原文 件中的个案变成新文件中的变量 • 原文件中未被选定的变量将在新文件中丢失
3 数据的分组汇总
选Data菜单的Aggregate...命令项
• 类组(Break Group): 分类变量的不同取值 将原始数据分成若干组.如: origin=1、2、3 分别代表美国、欧洲和日本,分成三个类 组 • 源变量(Source Variable):每个类组对应的 原有数据。
SPSS19.0经典教程

• 1.实例内容 为了提高员工的工作积极性,完善公司各方面 管理制度,并达到有的放矢的目的,某公司决定对 本公司员工进行不记名调查,希望了解员工对公司 的满意情况。请根据该公司设计的员工满意度调查 题目(行政人事管理部分)的特点,设计该调查表 数据在 的数据属性。
2. 实例操作
具体步骤如下。 Step01:打开 中的 窗口,录入或导入 原始调查数据。 Step02:选择菜单栏中的【 (文件)】→【 = (保存)】命令,保存数据文件,以免丢失。 Step03:单 中的【 (变量视图)】 选项卡,按窗口提示进行数据属性的定义,如变量 名称、标签、标签值等。
2.实例内容:地区生产总值分析
地区生产总值是指某地区在一定时间内的国内生产总 值,它可以作为衡量该地区经济发展的重要综合指 标。随书光盘中的数据 P. 列出了 年我国部 分省份的地区生产总值及第一产业、第二产业和第 三产业的生产总值,请根据这些数据分析不同省份 经济发展状况的差异性。
Step01:选定对话框 打开 软件,选择菜单栏中的【 →【 (排序个案)】命令,弹出【 序个案)】对话框。
3. 实例结果
2.3
SPSS数据文件的整理
• 通常情况下,刚刚建立的数据文件并不能立即进行 统计分析,这是因为收集到的数据还是原始数据, 还不能直接利用分析。此时,需要对原始数据进行 进一步的加工、整理,使之更加科学、系统和合 理。这项工作在数据分析中称之为统计整理。 • 【Data(数据)】菜单中的命令主要用于实现数据文 件的整理功能。
2.3.1 观测量排序: 地区生产总值分析
SPSS操作详解 Step01:打开观测量排序对话框 打开 软件,选择菜单栏中的【 (文件)】→ 【 (数据)】→【 (排序个案)】命令,弹出 【 (排序个案)】对话框。
SPSS Modeler数据挖掘操作之分类汇总

多重分类汇总设置
5
本例的第二个操作目标术语 多重分类汇总问题。
其中第一个分组变量为流失, 第二个分组变量为套餐类型, 汇总变量为基本费用,如图 所示
运行结果如下
6
将【表】节点添加到数据流中并运行,可以看到汇总后的结果
SPSS Modeler数据挖掘操作之 分类汇总
分类汇总说明
1
数据的分类汇总:首先根据指定的分组变量将数据分成若干组;然后在各个 组内计算汇总变量的基本描述统计量
在【记录选项】选项卡中的【汇总】节点可实现数据的分类汇总
数据说明
2
本例以虚拟的电信客户数据为例,说明分类汇总的具体操作: 操作目标如下:
一、分别计算未流失客户和流失客户的基本费用的均值和标准差 二、分别针对未流失客户和流失客户群,计算选用不同套餐类型的客户,其基本费用的
均值和标准差
基本操作简介
3
一、选择【Stastistics文件】节点,添加到数据流区,并读入 Telephone.sav文件数据。
二、选择【记录选项】中的【汇总】节点,将其添加到数据流中,右击鼠标, 选择弹出的【编辑】选项进行参数设置,如下
SPSS中使用分类汇总求标准差

在变量摘要框中选择睡眠时间。
然后点击函数。
在菜单中有很多的函件运算就可以得到所需要的数据了。
有的时候我们会碰到一组数据比如某一年有多少的样本我们就需要对它做一下分类汇总如何来做呢
SPSS中使用分类汇总求标准差
有的时候我们会碰到一组数据,比如某一年有多少的样本,我们就需要对它做一下分类汇总,如何来做呢?下面跟随小编的步伐开始吧!
我们打开一组数据,对40年龄的人进行分类汇总。
我们点击编辑——分类汇总。
SPSS分类汇总
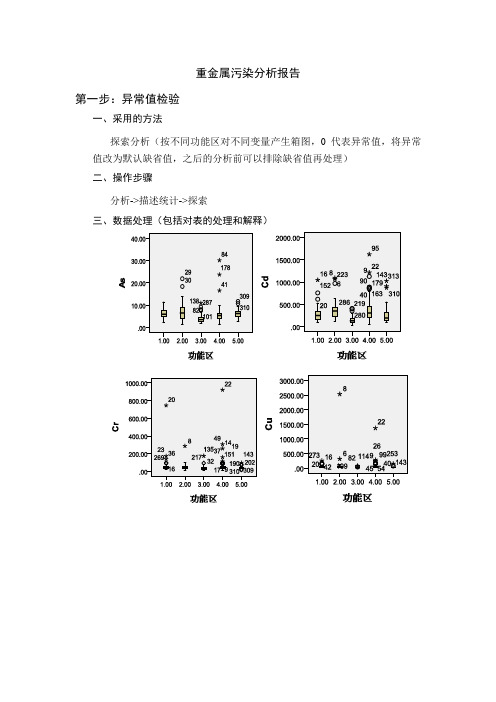
重金属污染分析报告第一步:异常值检验一、采用的方法探索分析(按不同功能区对不同变量产生箱图,0代表异常值,将异常值改为默认缺省值,之后的分析前可以排除缺省值再处理)二、操作步骤分析->描述统计->探索三、数据处理(包括对表的处理和解释)对于箱图中有0的序列号,找到该序列号,将异常值改为默认缺省值,在对缺省值进行均值替换。
As:29,30,82,138,309;Cd:6,20,152,280;Cr:32,309;Cu:20;Hg:157;Ni:20,138,319;Pb:144,221;Zn:23,31。
第二步:异常值替换一、采用的方法替换缺失值二、操作步骤转换->替换缺失值三、结果分析表格 1 结果变量结果变量被替换的缺失值数非缺失值的个案数有效个案数创建函数第一个最后一个1 Cd_1 4 1 319 319 SMEAN(Cd)2 Cr_1 2 1 319 319 SMEAN(Cr)3 Cu_1 1 1 319 319 SMEAN(Cu)4 Hg_1 1 1 319 319 SMEAN(Hg)5 Ni_1 3 1 319 319 SMEAN(Ni)6 Pb_1 2 1 319 319 SMEAN(Pb)7 Zn_1 2 1 319 319 SMEAN(Zn)8 As_1 5 1 319 319 SMEAN(As) 第三步:不同功能区的污染程度(法一:分类汇总)一采用的方法分类汇总(统计不同功能区不在金属标准范围的百分比)二、操作步骤数据->分类汇总三、结果分析表格 2 不同区域重金属污染程度As Cd Cr Cu Hg Ni Pb Zn生活区68.272.745.577.365.92559.161.4工业区63.986.141.794.47544.480.677.8山区18.231.822.727.336.418.221.218.2交通区51.47936.282.658.719.666.772.5公园绿地区74.354.325.768.66011.44051.4从表二可以看出在山区重金属污染程度都是最少的,其中在工业区的Cd,Cu,Hg,Ni,Pb,Zn含量最多。
SPSS操作步骤汇总

SPSS学习第一章数据文件的建立数据编码Type:Numeric:数值型 string:字符串型Missing:Measure:scale定量变量 nominal定性变量根据已有的变量建立新变量1、对于数据进行重新编码Transform—recode into different variables—选择input variable output variable –定义新变量的名称—change—开始定义新旧变量—continue2、通过SPSS函数建立新变量Transform—compute variable –从function group中选择公式范围下面选择具体的公式—if中设置要改变—continue—OK(可以对变量进行各种计算)第二章清除数据与基本统计分析1、对不合理的数据检查并清理检查:analysis-description statistic-frequencies—选入要检查的数据—OK结果:频数统计表—看是否有错误—missing system清理:1.对系统缺失值的清理Data—select case—if condition is satisfied—if—function group(missing)--下面选(missing)--continue—output(delete unselected cases)--OK—对num为哪一位的进行修改2.对sex=3的清理(直接就清除了)Data—select case—if condition is satisfied—if—sex调入再输入=3—continue-- output(delete unselected cases)--OK—对num为哪一位的进行修改2. 对相关变量间逻辑性检查和清理Data—select case—if condition is satisfied—if—输入表达式(前后逻辑不相符合的表达式)-- continue-- output(delete unselected cases)--OK—对num 为哪一位的进行修改3.统计描述正态分布统计描述1、正态性检验:Analysis—nonparametric tests—legacy dialogs—1-sample K-S—one-sample Kolomogorov Smirnov test –normal—ok/2、统计描述:Analysis—descriptives--time选入—options—ok3、按照男女统计描述:data—split file –compare group –sex调入—okAnalysis-descriptive statistic –descriptive—time 调入—options选择—OK非正态分布资料统计描述1、正态性检验nonparametric2、Analysis—descriptive statistics—frequencies 选入-- statistics选择—OK第三章T检验1、单样本t检验正态性检验—analyze—compare means—one-sample t test—test value选择要对比的数值—OK2、配对样本t检验建立数据文档—两列(前和后)--正态性检验—analysis- compare means—paired sample t test –调入—ok3、两独立样本t检验(正态性检验的时候采用分开组,其他都要合并在一起)建立数据库—第一列(group)第二列(数值)-- data—split file –compare group—调入group—ok-正态性检验—OK-- data—split file—选择analysis all—analyze—compare means—independent sample t test—选入,分组—OK结果分方差齐与否第四章方差分析(前提正态)1、单因素方差分析(就是平常的三个组比较)建立数据库—第一列(group)第二列(数值)- data—split file –compare group—调入group—ok-正态性检验—OK-- data—split file—选择analysis all--analyze—compare means—one-way-anova—数据调入dependent list—分组调入factor------options—descriptive基本统计描述—homogeneity of variance做方差齐性分析—OK2、方差分析两两比较analyze—compare means—one-way-anova---数据调入dependent list—分组调入factor—点post hoc—选择SNK LSD3、随机区组设计方差分析建立数据库—第一列(group)第二列(block)第三列(数值)--按照group split开,进行正态性检验—OK—general liner model—univairate—数值调入dependent variable—group和block调入fixed factor—model—custom—build terms(main effects)再把group和block调入model下的矩形框---continue—OK如果区组间无差别,组间进行两两比较。
SPSS统计分析分解

SPSS统计分析分解SPSS(Statistical Package for the Social Sciences)是一种用于统计分析和数据管理的软件工具,被广泛应用于社会科学、市场研究、健康科学和其他领域的研究中。
SPSS可以进行各种统计分析,包括描述性统计、推断统计、回归分析、方差分析、因子分析、聚类分析等。
在本文中,我们将详细介绍SPSS的统计分析功能以及如何使用它进行数据分析。
首先,SPSS可以进行描述性统计,包括计算均值、标准差、最小值、最大值和频数等。
用户可以通过简单的几步操作生成一个包含所有这些统计量的报告。
描述性统计可以帮助用户对数据进行初步的了解,识别异常值和缺失数据,并提供基本的数据概述。
其次,SPSS可以进行推断统计分析,包括参数估计、假设检验和置信区间等。
参数估计可以帮助用户对总体参数进行估计,如总体均值、总体比例等。
常用的假设检验方法包括t检验、方差分析和卡方检验等。
用户可以使用SPSS的“分析”菜单下的各种统计分析选项进行推断统计分析。
回归分析是SPSS中最常用的统计分析方法之一、它可以通过建立一个数学模型来探究自变量与因变量之间的关系。
在SPSS中,用户可以使用“回归”选项来进行线性回归、多元回归、逐步回归等分析。
用户可以通过回归分析来预测因变量的取值,并评估自变量对因变量的解释力。
方差分析是一种用于比较三个或多个组之间差异的统计方法。
在SPSS中,用户可以使用“方差分析”选项来进行单因素方差分析、多因素方差分析等。
方差分析可以帮助用户确定不同组之间是否存在显著差异,并识别出哪些因素对于差异的解释较为重要。
因子分析是一种用于探索变量之间的潜在结构的统计方法。
在SPSS 中,用户可以使用“因子分析”选项进行因子提取和旋转。
因子分析可以帮助用户确定变量之间的相关模式,并将其转化为更少和更有意义的几个综合因子。
聚类分析是一种将观测单位划分为不同群组的统计方法。
在SPSS中,用户可以使用“聚类分析”选项进行层次聚类、K均值聚类等。
分类汇总的参数设置_SPSS 统计分析从入门到精通_[共2页]
![分类汇总的参数设置_SPSS 统计分析从入门到精通_[共2页]](https://img.taocdn.com/s3/m/7136cac114791711cc7917fe.png)
SPSS统计分析从入门到精通●如果个案满足条件则包括:只对满足指定条件的观测量才计算新变量,选中此项激活其他参数选项。
条件表达式在下面的编辑框内进行输入和编辑,操作方式与图3-35中的计算表达式编辑方法相同。
●对于那些不满足此处指定条件表达式的观测量,对应的新变量都取系统缺失值。
3.结果显示在图3-35中单击“确定”按钮运行,在当前数据集生成的新变量如图3-38所示。
图3-38 计算新变量的结果显示其中,新变量计算表达式为:月结余=月工资+月奖金+其他收入−支出,且只对“月份>2”的观测量才按此表达式进行计算,其他情况下新变量都取系统缺失值。
3.2 分类汇总分类汇总就是按指定的分类变量对观测量进行分组,然后计算各分组内的某些变量的描述统计量。
汇总结果可以生成新的数据文件,在新文件中对指定分类变量的每个值产生一个观测记录,如果分组变量只有两个值,那么新的汇总文件中将只包含两个观测记录。
本节就用一个简单的实例来介绍如何对数据进行分类汇总。
3.2.1 数据描述本节使用某小学10~13岁儿童的身高和体重数据,数据来自随盘文件“Chapter 03\儿童的身高和体重数据.sav”,本数据曾在第3.1.2节使用,数据格式如图3-4所示。
下面以性别和年龄为指定的分类变量,对儿童的身高和体重进行汇总。
3.2.2 分类汇总的参数设置依次单击菜单“数据→分类汇总…”,打开的主设置界面如图3-39所示,在此设置分类汇总的变量、保存等选项。
1.主界面设置在左侧的变量列表中选中性别和年龄变量,单击“分组变量”左侧的按钮,将其指定为分组变量;在左侧的变量列表选中身高和体重变量,单击“变量摘要”左侧的按钮,将其指定为汇总变量;单击选中“个案数”复选框。
下面介绍各设置选项的含义。
①“分组变量”列表:用于从左侧的变量列表中选入汇总的分类变量。
②“变量摘要”列表:用于从左侧的变量列表中选入汇总变量(要在各分组内进行描述的变58。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
spss教程:分类汇总
按照某种分类变量进行分类计算,对原始数据分类,做出表格形式,便于直观地观察数据大致分布情况。
方法/步骤
1.调出相关窗口,分类变量是“户口状况”,汇总变量为“人均面积”、“计划
面积”。
分类变量可以多个,称为“多重分类汇总”,第一个分类变量称为“主分类变量”,依次称为“第二、第三分类变量”。
2.按钮“函数”表示计算哪些汇总变量,系统默认均值,用户可自己定义。
3.“变量名与标签”:重新命名汇总结果中的变量名和标签,系统有默认的命名,
见图片。
“保存”:将最后的汇总结果保存在何处。
我此处选择的是第二种,即“将汇总结果保存在一个数据编辑窗口中”。
“个案数”:保存各分类组的个案数,系统默认变量名“N_BREAK”。
4.选择第二种保存方式,结果展示见图片。
“个案数”分别是2825、168。
对
于系统缺失值,spss自动剔除含缺失值的样本,所以平均值的计算不受缺失样本量的影响。
END
经验内容仅供参考,如果您需解决具体问题(尤其法律、医学等领域),建议您详细咨询相关领域专业人士。