斯坦福密码课程06.2-collision-resistance-generic-birthday-attack
identity-based encryption from the weil pairing

Appears in SIAM J.of Computing,Vol.32,No.3,pp.586-615,2003.An extended abstract of this paper appears in the Proceedings of Crypto2001,volume2139of Lecture Notes in Computer Science,pages 213–229,Springer-Verlag,2001.Identity-Based Encryption from the Weil PairingDan Boneh∗Matthew Franklin†dabo@ franklin@AbstractWe propose a fully functional identity-based encryption scheme(IBE).The scheme has chosen ciphertext security in the random oracle model assuming a variant of the computational Diffie-Hellman problem.Our system is based on bilinear maps between groups.The Weil pairing onelliptic curves is an example of such a map.We give precise definitions for secure identity basedencryption schemes and give several applications for such systems.1IntroductionIn1984Shamir[41]asked for a public key encryption scheme in which the public key can be an arbitrary string.In such a scheme there are four algorithms:(1)setup generates global system parameters and a master-key,(2)extract uses the master-key to generate the private key corresponding to an arbitrary public key string ID∈{0,1}∗,(3)encrypt encrypts messages using the public key ID,and(4)decrypt decrypts messages using the corresponding private key.Shamir’s original motivation for identity-based encryption was to simplify certificate management in e-mail systems.When Alice sends mail to Bob at bob@ she simply encrypts her message using the public key string“bob@”.There is no need for Alice to obtain Bob’s public key certificate.When Bob receives the encrypted mail he contacts a third party,which we call the Private Key Generator(PKG).Bob authenticates himself to the PKG in the same way he would authenticate himself to a CA and obtains his private key from the PKG.Bob can then read his e-mail.Note that unlike the existing secure e-mail infrastructure,Alice can send encrypted mail to Bob even if Bob has not yet setup his public key certificate.Also note that key escrow is inherent in identity-based e-mail systems:the PKG knows Bob’s private key.We discuss key revocation,as well as several new applications for IBE schemes in the next section.Since the problem was posed in1984there have been several proposals for IBE schemes[11,45, 44,31,25](see also[33,p.561]).However,none of these are fully satisfactory.Some solutions require that users not collude.Other solutions require the PKG to spend a long time for each private key generation request.Some solutions require tamper resistant hardware.It is fair to say that until the results in[5]constructing a usable IBE system was an open problem.Interestingly,the related notions of identity-based signature and authentication schemes,also introduced by Shamir[41],do have satisfactory solutions[15,14].In this paper we propose a fully functional identity-based encryption scheme.The performance of our system is comparable to the performance of ElGamal encryption in F∗p.The security of our system is based on a natural analogue of the computational Diffie-Hellman assumption.Based on ∗Supported by DARPA contract F30602-99-1-0530,NSF,and the Packard Foundation.†Supported by an NSF Career Award and the Packard Foundation.this assumption we show that the new system has chosen ciphertext security in the random oracle ing standard techniques from threshold cryptography[20,22]the PKG in our scheme can be distributed so that the master-key is never available in a single location.Unlike common threshold systems,we show that robustness for our distributed PKG is free.Our IBE system can be built from any bilinear map e:G1×G1→G2between two groups G1,G2as long as a variant of the Computational Diffie-Hellman problem in G1is hard.We use the Weil pairing on elliptic curves as an example of such a map.Until recently the Weil pairing has mostly been used for attacking elliptic curve systems[32,17].Joux[26]recently showed that the Weil pairing can be used for“good”by using it for a protocol for three party one round Diffie-Hellman key exchange.Sakai et al.[40]used the pairing for key exchange and Verheul[46]used it to construct an ElGamal encryption scheme where each public key has two corresponding private keys.In addition to our identity-based encryption scheme,we show how to construct an ElGamal encryption scheme with“built-in”key escrow,i.e.,where one global escrow key can decrypt ciphertexts encrypted under any public key.To argue about the security of our IBE system we define chosen ciphertext security for identity-based encryption.Our model gives the adversary more power than the standard model for chosen ciphertext security[37,2].First,we allow the attacker to attack an arbitrary public key ID of her choice.Second,while mounting a chosen ciphertext attack on ID we allow the attacker to obtain from the PKG the private key for any public key of her choice,other than the private key for ID.This models an attacker who obtains a number of private keys corresponding to some identities of her choice and then tries to attack some other public key ID of her choice.Even with the help of such queries the attacker should have negligible advantage in defeating the semantic security of the system.The rest of the paper is organized as follows.Several applications of identity-based encryption are discussed in Section1.1.We then give precise definitions and security models in Section2.We describe bilinear maps with certain properties in Section3.Our identity-based encryption scheme is presented in Section4using general bilinear maps.Then a concrete identity based system from the Weil pairing is given in Section5.Some extensions and variations(efficiency improvements,distribution of the master-key)are considered in Section6.Our construction for ElGamal encryption with a global escrow key is described in Section7.Section8gives conclusions and some open problems.The Appendix containsa more detailed discussion of the Weil pairing.1.1Applications for Identity-Based EncryptionThe original motivation for identity-based encryption is to help the deployment of a public key infras-tructure.In this section,we show several other unrelated applications.1.1.1Revocation of Public KeysPublic key certificates contain a preset expiration date.In an IBE system key expiration can be done by having Alice encrypt e-mail sent to Bob using the public key:“bob@ current-year”. In doing so Bob can use his private key during the current year only.Once a year Bob needs to obtain a new private key from the PKG.Hence,we get the effect of annual private key expiration.Note that unlike the existing PKI,Alice does not need to obtain a new certificate from Bob every time Bob refreshes his private key.One could potentially make this approach more granular by encrypting e-mail for Bob using “bob@ current-date”.This forces Bob to obtain a new private key every day.This might be possible in a corporate PKI where the PKG is maintained by the corporation.With this approach key revocation is very simple:when Bob leaves the company and his key needs to be revoked, the corporate PKG is instructed to stop issuing private keys for Bob’s e-mail address.As a result,Bob can no longer read his email.The interesting property is that Alice does not need to communicate with any third party certificate directory to obtain Bob’s daily public key.Hence,identity based encryption is a very efficient mechanism for implementing ephemeral public keys.Also note that this approach enables Alice to send messages into the future:Bob will only be able to decrypt the e-mail on the date specified by Alice(see[38,12]for methods of sending messages into the future using a stronger security model).Managing user credentials.A simple extension to the discussion above enables us to manage user credentials using the IBE system.Suppose Alice encrypts mail to Bob using the public key:“bob@ current-year clearance=secret”.Then Bob will only be able to read the email if on the specified date he has secret clearance.Consequently,it is easy to grant and revoke user credentials using the PKG.1.1.2Delegation of Decryption KeysAnother application for IBE systems is delegation of decryption capabilities.We give two example applications.In both applications the user Bob plays the role of the PKG.Bob runs the setup algorithm to generate his own IBE system parameters params and his own master-key.Here we view params as Bob’s public key.Bob obtains a certificate from a CA for his public key params.When Alice wishes to send mail to Bob shefirst obtains Bob’s public key params from Bob’s public key certificate.Note that Bob is the only one who knows his master-key and hence there is no key-escrow with this setup.1.Delegation to a laptop.Suppose Alice encrypts mail to Bob using the current date as the IBE encryption key(she uses Bob’s params as the IBE system parameters).Since Bob has the master-key he can extract the private key corresponding to this IBE encryption key and then decrypt the message.Now,suppose Bob goes on a trip for seven days.Normally,Bob would put his private key on his laptop.If the laptop is stolen the private key is compromised.When using the IBE system Bob could simply install on his laptop the seven private keys corresponding to the seven days of the trip.If the laptop is stolen,only the private keys for those seven days are compromised.The master-key is unharmed.This is analogous to the delegation scenario for signature schemes considered by Goldreich et al.[23].2.Delegation of duties.Suppose Alice encrypts mail to Bob using the subject line as the IBE encryption key.Bob can decrypt mail using his master-key.Now,suppose Bob has several assistants each responsible for a different task(e.g.one is‘purchasing’,another is‘human-resources’,etc.).Bob gives one private key to each of his assistants corresponding to the assistant’s responsibility.Each assistant can then decrypt messages whose subject line falls within its responsibilities,but it cannot decrypt messages intended for other assistants.Note that Alice only obtains a single public key from Bob(params),and she uses that public key to send mail with any subject line of her choice.The mail can only be read by the assistant responsible for that subject.More generally,IBE can simplify security systems that manage a large number of public keys.Rather than storing a big database of public keys the system can either derive these public keys from usernames, or simply use the integers1,...,n as distinct public keys.2DefinitionsIdentity-Based Encryption.An identity-based encryption scheme E is specified by four random-ized algorithms:Setup,Extract,Encrypt,Decrypt:Setup:takes a security parameter k and returns params(system parameters)and master-key.The system parameters include a description of afinite message space M,and a description of afinite ciphertext space C.Intuitively,the system parameters will be publicly known,while the master-key will be known only to the“Private Key Generator”(PKG).Extract:takes as input params,master-key,and an arbitrary ID∈{0,1}∗,and returns a private key d.Here ID is an arbitrary string that will be used as a public key,and d is the corresponding private decryption key.The Extract algorithm extracts a private key from the given public key.Encrypt:takes as input params,ID,and M∈M.It returns a ciphertext C∈C.Decrypt:takes as input params,C∈C,and a private key d.It return M∈M.These algorithms must satisfy the standard consistency constraint,namely when d is the private key generated by algorithm Extract when it is given ID as the public key,then∀M∈M:Decrypt(params,C,d)=M where C=Encrypt(params,ID,M)Chosen ciphertext security.Chosen ciphertext security(IND-CCA)is the standard acceptable notion of security for a public key encryption scheme[37,2,13].Hence,it is natural to require that an identity-based encryption scheme also satisfy this strong notion of security.However,the definition of chosen ciphertext security must be strengthened a bit.The reason is that when an adversary attacks a public key ID in an identity-based system,the adversary might already possess the private keys of users ID1,...,ID n of her choice.The system should remain secure under such an attack.Hence,the definition of chosen ciphertext security must allow the adversary to obtain the private key associated with any identity ID i of her choice(other than the public key ID being attacked).We refer to such queries as private key extraction queries.Another difference is that the adversary is challenged on a public key ID of her choice(as opposed to a random public key).We say that an identity-based encryption scheme E is semantically secure against an adaptive chosen ciphertext attack(IND-ID-CCA)if no polynomially bounded adversary A has a non-negligible advantage against the Challenger in the following IND-ID-CCA game:Setup:The challenger takes a security parameter k and runs the Setup algorithm.It givesthe adversary the resulting system parameters params.It keeps the master-key to itself.Phase1:The adversary issues queries q1,...,q m where query q i is one of:–Extraction query ID i .The challenger responds by running algorithm Extract to gen-erate the private key d i corresponding to the public key ID i .It sends d i to theadversary.–Decryption query ID i,C i .The challenger responds by running algorithm Extract to generate the private key d i corresponding to ID i.It then runs algorithm Decrypt todecrypt the ciphertext C i using the private key d i.It sends the resulting plaintext tothe adversary.These queries may be asked adaptively,that is,each query q i may depend on the repliesto q1,...,q i−1.Challenge:Once the adversary decides that Phase1is over it outputs two equal lengthplaintexts M0,M1∈M and an identity ID on which it wishes to be challenged.The onlyconstraint is that ID did not appear in any private key extraction query in Phase1.The challenger picks a random bit b∈{0,1}and sets C=Encrypt(params,ID,M b).Itsends C as the challenge to the adversary.Phase2:The adversary issues more queries q m+1,...,q n where query q i is one of:–Extraction query ID i where ID i=ID.Challenger responds as in Phase1.–Decryption query ID i,C i = ID,C .Challenger responds as in Phase1.These queries may be asked adaptively as in Phase1.Guess:Finally,the adversary outputs a guess b ∈{0,1}and wins the game if b=b .We refer to such an adversary A as an IND-ID-CCA adversary.We define adversary A’sadvantage in attacking the scheme E as the following function of the security parameter k (k is given as input to the challenger):Adv E,A(k)= Pr[b=b ]−12 .The probability is over the random bits used by the challenger and the adversary.Using the IND-ID-CCA game we can define chosen ciphertext security for IBE schemes.As usual,we say that a function g:R→R is negligible if for any d>0we have|g(k)|<1/k d for sufficiently large k. Definition2.1.We say that the IBE system E is semantically secure against an adaptive chosen ci-phertext attack if for any polynomial time IND-ID-CCA adversary A the function Adv E,A(k)is negligible. As shorthand,we say that E is IND-ID-CCA secure.Note that the standard definition of chosen ciphertext security(IND-CCA)[37,2]is the same as above except that there are no private key extraction queries and the adversary is challenged on a random public key(rather than a public key of her choice).Private key extraction queries are related to the definition of chosen ciphertext security in the multiuser settings[7].After all,our definition involves multiple public keys belonging to multiple users.In[7]the authors show that that multiuser IND-CCA is reducible to single user IND-CCA using a standard hybrid argument.This does not hold in the identity-based settings,IND-ID-CCA,since the adversary gets to choose which public keys to corrupt during the attack.To emphasize the importance of private key extraction queries we note that our IBE system can be easily modified(by removing one of the hash functions)into a system which has chosen ciphertext security when private extraction queries are disallowed.However,the scheme is completely insecure when extraction queries are allowed.Semantically secure identity based encryption.The proof of security for our IBE system makes use of a weaker notion of security known as semantic security(also known as semantic security against a chosen plaintext attack)[24,2].Semantic security is similar to chosen ciphertext security(IND-ID-CCA)except that the adversary is more limited;it cannot issue decryption queries while attacking the challenge public key.For a standard public key system(not an identity based system)semantic security is defined using the following game:(1)the adversary is given a random public key generated by the challenger,(2)the adversary outputs two equal length messages M0and M1and receives the encryption of M b from the challenger where b is chosen at random in{0,1},(3)the adversary outputs b and wins the game if b=b .The public key system is said to be semantically secure if no polynomial time adversary can win the game with a non-negligible advantage.As shorthand we say that a semantically secure public key system is IND-CPA secure.Semantic security captures our intuition that given a ciphertext the adversary learns nothing about the corresponding plaintext.To define semantic security for identity based systems(denoted IND-ID-CPA)we strengthen the standard definition by allowing the adversary to issue chosen private key extraction queries.Similarly, the adversary is challenged on a public key ID of her choice.We define semantic security for identity based encryption schemes using an IND-ID-CPA game.The game is identical to the IND-ID-CCA game defined above except that the adversary cannot make any decryption queries.The adversary can only make private key extraction queries.We say that an identity-based encryption scheme E is semantically secure(IND-ID-CPA)if no polynomially bounded adversary A has a non-negligible advantage against the Challenger in the following IND-ID-CPA game:Setup:The challenger takes a security parameter k and runs the Setup algorithm.It givesthe adversary the resulting system parameters params.It keeps the master-key to itself.Phase1:The adversary issues private key extraction queries ID1,...,ID m.The challengerresponds by running algorithm Extract to generate the private key d i corresponding tothe public key ID i.It sends d i to the adversary.These queries may be asked adaptively.Challenge:Once the adversary decides that Phase1is over it outputs two equal lengthplaintexts M0,M1∈M and a public key ID on which it wishes to be challenged.Theonly constraint is that ID did not appear in any private key extraction query in Phase1.The challenger picks a random bit b∈{0,1}and sets C=Encrypt(params,ID,M b).Itsends C as the challenge to the adversary.Phase2:The adversary issues more extraction queries ID m+1,...,ID n.The only constraintis that ID i=ID.The challenger responds as in Phase1.Guess:Finally,the adversary outputs a guess b ∈{0,1}and wins the game if b=b .We refer to such an adversary A as an IND-ID-CPA adversary.As we did above,theadvantage of an IND-ID-CPA adversary A against the scheme E is the following function of the security parameter k:Adv E,A(k)= Pr[b=b ]−12 .The probability is over the random bits used by the challenger and the adversary.Definition2.2.We say that the IBE system E is semantically secure if for any polynomial time IND-ID-CPA adversary A the function Adv E,A(k)is negligible.As shorthand,we say that E is IND-ID-CPA secure.One way identity-based encryption.One can define an even weaker notion of security called one-way encryption(OWE)[16].Roughly speaking,a public key encryption scheme is a one-way encryption if given the encryption of a random plaintext the adversary cannot produce the plaintext in its entirety. One way encryption is a weak notion of security since there is nothing preventing the adversary from, say,learning half the bits of the plaintext.Hence,one-way encryption schemes do not generally provide secure encryption.In the random oracle model one-way encryption schemes can be used for encrypting session-keys(the session-key is taken to be the hash of the plaintext).We note that one can extend the notion of one-way encryption to identity based systems by adding private key extraction queries to the definition.We do not give the full definition here since in this paper we use semantic security as the weakest notion of security.See[5]for the full definition of identity based one-way encryption,and its use as part of an alternative proof strategy for our main result.Random oracle model.To analyze the security of certain natural cryptographic constructions Bel-lare and Rogaway introduced an idealized security model called the random oracle model[3].Roughlyspeaking,a random oracle is a function H:X→Y chosen uniformly at random from the set of all functions{h:X→Y}(we assume Y is afinite set).An algorithm can query the random oracle at any point x∈X and receive the value H(x)in response.Random oracles are used to model crypto-graphic hash functions such as SHA-1.Note that security in the random oracle model does not imply security in the real world.Nevertheless,the random oracle model is a useful tool for validating natural cryptographic constructions.Security proofs in this model prove security against attackers that are confined to the random oracle world.Notation.From here on we use Z q to denote the group{0,...,q−1}under addition modulo q.For a group G of prime order we use G∗to denote the set G∗=G\{O}where O is the identity element in the group G.We use Z+to denote the set of positive integers.3Bilinear maps and the Bilinear Diffie-Hellman AssumptionLet G1and G2be two groups of order q for some large prime q.Our IBE system makes use of a bilinear mapˆe:G1×G1→G2between these two groups.The map must satisfy the following properties: 1.Bilinear:We say that a mapˆe:G1×G1→G2is bilinear ifˆe(aP,bQ)=ˆe(P,Q)ab for all P,Q∈G1 and all a,b∈Z.2.Non-degenerate:The map does not send all pairs in G1×G1to the identity in G2.Observe that since G1,G2are groups of prime order this implies that if P is a generator of G1thenˆe(P,P)is a generator of G2.putable:There is an efficient algorithm to computeˆe(P,Q)for any P,Q∈G1.A bilinear map satisfying the three properties above is said to be an admissible bilinear map.In Section5we give a concrete example of groups G1,G2and an admissible bilinear map between them. The group G1is a subgroup of the additive group of points of an elliptic curve E/F p.The group G2is asubgroup of the multiplicative group of afinitefield F∗p2.Therefore,throughout the paper we view G1as an additive group and G2as a multiplicative group.As we will see in Section5.1,the Weil pairing can be used to construct an admissible bilinear map between these two groups.The existence of the bilinear mapˆe:G1×G1→G2as above has two direct implications to these groups.The MOV reduction:Menezes,Okamoto,and Vanstone[32]show that the discrete log problem in G1is no harder than the discrete log problem in G2.To see this,let P,Q∈G1be an instance of the discrete log problem in G1where both P,Q have order q.We wish tofind anα∈Z q such that Q=αP.Let g=ˆe(P,P)and h=ˆe(Q,P).Then,by bilinearity ofˆe we know that h=gα.By non-degeneracy ofˆe both g,h have order q in G2.Hence,we reduced the discrete log problem in G1to a discrete log problem in G2.It follows that for discrete log to be hard in G1we must choose our security parameter so that discrete log is hard in G2(see Section5).Decision Diffie-Hellman is Easy:The Decision Diffie-Hellman problem(DDH)[4]in G1is to dis-tinguish between the distributions P,aP,bP,abP and P,aP,bP,cP where a,b,c are random in Z∗q and P is random in G∗1.Joux and Nguyen[28]point out that DDH in G1is easy.To see this,observe that given P,aP,bP,cP∈G∗1we havec=ab mod q⇐⇒ˆe(P,cP)=ˆe(aP,bP).The Computational Diffie-Hellman problem(CDH)in G1can still be hard(CDH in G1is tofind abP given random P,aP,bP ).Joux and Nguyen[28]give examples of mappingsˆe:G1×G1→G2where CDH in G1is believed to be hard even though DDH in G1is easy.3.1The Bilinear Diffie-Hellman Assumption(BDH)Since the Decision Diffie-Hellman problem(DDH)in G1is easy we cannot use DDH to build cryp-tosystems in the group G1.Instead,the security of our IBE system is based on a variant of the Computational Diffie-Hellman assumption called the Bilinear Diffie-Hellman Assumption(BDH). Bilinear Diffie-Hellman Problem.Let G1,G2be two groups of prime order q.Letˆe:G1×G1→G2be an admissible bilinear map and let P be a generator of G1.The BDH problem in G1,G2,ˆe is as follows:Given P,aP,bP,cP for some a,b,c∈Z∗q compute W=ˆe(P,P)abc∈G2.An algorithm A has advantage in solving BDH in G1,G2,ˆe ifPr A(P,aP,bP,cP)=ˆe(P,P)abc ≥where the probability is over the random choice of a,b,c in Z∗q,the random choice of P∈G∗1,and the random bits of A.BDH Parameter Generator.We say that a randomized algorithm G is a BDH parameter generator if(1)G takes a security parameter k∈Z+,(2)G runs in polynomial time in k,and(3)G outputs a prime number q,the description of two groups G1,G2of order q,and the description of an admissible bilinear mapˆe:G1×G1→G2.We denote the output of G by G(1k)= q,G1,G2,ˆe .The security parameter k is used to determine the size of q;for example,one could take q to be a random k-bit prime.For i=1,2we assume that the description of the group G i contains polynomial time(in k) algorithms for computing the group action in G i and contains a generator of G i.The generator of G i enables us to generate uniformly random elements in G i.Similarly,we assume that the description of ˆe contains a polynomial time algorithm for computingˆe.We give an example of a BDH parameter generator in Section5.1.BDH Assumption.Let G be a BDH parameter generator.We say that an algorithm A has advan-tage (k)in solving the BDH problem for G if for sufficiently large k:Adv G,A(k)=Pr A(q,G1,G2,ˆe,P,aP,bP,cP)=ˆe(P,P)abc q,G1,G2,ˆe ←G(1k),P←G∗1,a,b,c←Z∗q ≥ (k) We say that G satisfies the BDH assumption if for any randomized polynomial time(in k)algorithm A we have that Adv G,A(k)is a negligible function.When G satisfies the BDH assumption we say that BDH is hard in groups generated by G.In Section5.1we give some examples of BDH parameter generators that are believed to satisfy the BDH assumption.We note that Joux[26](implicitly)used the BDH assumption to construct a one-round three party Diffie-Hellman protocol.The BDH assumption is also needed for constructions in[46,40].Hardness of BDH.It is interesting to study the relationship of the BDH problem to other hard problems used in cryptography.Currently,all we can say is that the BDH problem in G1,G2,ˆe is no harder than the CDH problem in G1or G2.In other words,an algorithm for CDH in G1or G2is sufficient for solving BDH in G1,G2,ˆe .The converse is currently an open problem:is an algorithm for BDH sufficient for solving CDH in G1or in G2?We refer to a survey by Joux[27]for a more detailed analysis of the relationship between BDH and other standard problems.We note that in all our examples(in Section5.1)the isomorphisms from G1to G2induced by the bilinear map are believed to be one-way functions.More specifically,for a point Q∈G∗1define the isomorphism f Q:G1→G2by f Q(P)=ˆe(P,Q).If any one of these isomorphisms turns out to be invertible then BDH is easy in G1,G2,ˆe .Fortunately,an efficient algorithm for inverting f Q for some fixed Q would imply an efficient algorithm for deciding DDH in the group G2.In all our examples DDH is believed to be hard in the group G2.Hence,all the isomorphisms f Q:G1→G2induced by the bilinear map are believed to be one-way functions.4Our Identity-Based Encryption SchemeWe describe our scheme in stages.First we give a basic identity-based encryption scheme which is not secure against an adaptive chosen ciphertext attack.The only reason for describing the basic scheme is to make the presentation easier to follow.Our full scheme,described in Section4.2,extends the basic scheme to get security against an adaptive chosen ciphertext attack(IND-ID-CCA)in the random oracle model.In Section4.3we relax some of the requirements on the hash functions.The presentation in this section uses an arbitrary BDH parameter generator G satisfying the BDH assumption.In Section5we describe a concrete IBE system using the Weil pairing.4.1BasicIdentTo explain the basic ideas underlying our IBE system we describe the following simple scheme,called BasicIdent.We present the scheme by describing the four algorithms:Setup,Extract,Encrypt,Decrypt. We let k be the security parameter given to the setup algorithm.We let G be some BDH parameter generator.Setup:Given a security parameter k∈Z+,the algorithm works as follows:Step1:Run G on input k to generate a prime q,two groups G1,G2of order q,and an admissible bilinear mapˆe:G1×G1→G2.Choose a random generator P∈G1.Step2:Pick a random s∈Z∗q and set P pub=sP.Step3:Choose a cryptographic hash function H1:{0,1}∗→G∗1.Choose a cryptographic hash function H2:G2→{0,1}n for some n.The security analysis will view H1,H2as random oracles. The message space is M={0,1}n.The ciphertext space is C=G∗1×{0,1}n.The system parameters are params= q,G1,G2,ˆe,n,P,P pub,H1,H2 .The master-key is s∈Z∗q.Extract:For a given string ID∈{0,1}∗the algorithm does:(1)computes Q ID=H1(ID)∈G∗1,and (2)sets the private key d ID to be d ID=sQ ID where s is the master key.Encrypt:To encrypt M∈M under the public key ID do the following:(1)compute Q ID=H1(ID)∈,(2)choose a random r∈Z∗q,and(3)set the ciphertext to beG∗1) where g ID=ˆe(Q ID,P pub)∈G∗2C= rP,M⊕H2(g rID。
斯坦福大学机器学习所有问题及答案合集

CS 229机器学习(问题及答案)斯坦福大学目录(1) 作业1(Supervised Learning) 1(2) 作业1解答(Supervised Learning) 5(3) 作业2(Kernels, SVMs, and Theory)15(4) 作业2解答(Kernels, SVMs, and Theory)19(5) 作业3(Learning Theory and UnsupervisedLearning)27 (6) 作业3解答(Learning Theory and Unsupervised Learning)31 (7) 作业4(Unsupervised Learning and Reinforcement Learning)39 (8) 作业4解答(Unsupervised Learning and Reinforcement Learning)44(9) Problem Set #1: Supervised Learning 56(10) Problem Set #1 Answer 62(11) Problem Set #2: Problem Set #2: Naive Bayes, SVMs, and Theory 78 (12) Problem Set #2 Answer 85CS229Problem Set#11 CS229,Public CourseProblem Set#1:Supervised Learning1.Newton’s method for computing least squaresIn this problem,we will prove that if we use Newton’s method solve the least squares optimization problem,then we only need one iteration to converge toθ∗.(a)Find the Hessian of the cost function J(θ)=1T x(i)−y(i))2.2P i=1(θm(b)Show that thefirst iteration of Newton’s method gives usθ⋆=(X T X)−1X T~y,thesolution to our least squares problem.2.Locally-weighted logistic regressionIn this problem you will implement a locally-weighted version of logistic regression,wherewe weight different training examples differently according to the query point.The locally-weighted logistic regression problem is to maximizeλℓ(θ)=−θTθ+Tθ+2mw(i)hy(i)log hθ(x(i))+(1−y(i))log(1−hθ(x(i)))i. Xi=1The−λTθhere is what is known as a regularization parameter,which will be discussed2θin a future lecture,but which we include here because it is needed for Newton’s method to perform well on this task.For the entirety of this problem you can use the valueλ=0.0001.Using this definition,the gradient ofℓ(θ)is given by∇θℓ(θ)=XT z−λθwhere z∈R m is defined byz i=w(i)(y(i)−hθ(x(i)))and the Hessian is given byH=XT DX−λIwhere D∈R m×m is a diagonal matrix withD ii=−w(i)hθ(x(i))(1−hθ(x(i)))For the sake of this problem you can just use the above formulas,but you should try toderive these results for yourself as well.Given a query point x,we choose compute the weightsw(i)=exp2τ2CS229Problem Set#12(a)Implement the Newton-Raphson algorithm for optimizingℓ(θ)for a new query pointx,and use this to predict the class of x.T he q2/directory contains data and code for this problem.You should implementt he y=lwlr(X train,y train,x,tau)function in the lwlr.mfile.This func-t ion takes as input the training set(the X train and y train matrices,in the formdescribed in the class notes),a new query point x and the weight bandwitdh tau.G iven this input the function should1)compute weights w(i)for each training exam-p le,using the formula above,2)maximizeℓ(θ)using Newton’s method,andfinally3)o utput y=1{hθ(x)>0.5}as the prediction.W e provide two additional functions that might help.The[X train,y train]=load data;function will load the matrices fromfiles in the data/folder.The func-t ion plot lwlr(X train,y train,tau,resolution)will plot the resulting clas-s ifier(assuming you have properly implemented lwlr.m).This function evaluates thel ocally weighted logistic regression classifier over a large grid of points and plots ther esulting prediction as blue(predicting y=0)or red(predicting y=1).Dependingo n how fast your lwlr function is,creating the plot might take some time,so wer ecommend debugging your code with resolution=50;and later increase it to atl east200to get a better idea of the decision boundary.(b)Evaluate the system with a variety of different bandwidth parametersτ.In particular,tryτ=0.01,0.050.1,0.51.0,5.0.How does the classification boundary change whenvarying this parameter?Can you predict what the decision boundary of ordinary(unweighted)logistic regression would look like?3.Multivariate least squaresSo far in class,we have only considered cases where our target variable y is a scalar value.S uppose that instead of trying to predict a single output,we have a training set withm ultiple outputs for each example:{(x(i),y(i)),i=1,...,m},x(i)∈R n,y(i)∈R p.Thus for each training example,y(i)is vector-valued,with p entries.We wish to use a linearmodel to predict the outputs,as in least squares,by specifying the parameter matrixΘiny=ΘT x,whereΘ∈R n×p.(a)The cost function for this case isJ(Θ)=12m p2(Θi=1j=1T x(i))j−y(ji)X X(Θ.W rite J(Θ)in matrix-vector notation(i.e.,without using any summations).[Hint: Start with the m×n design matrixX=—(x(1))T——(x(2))T—...—(x(m))T—2CS229Problem Set#13 and the m×p target matrixY=—(y(1))T——(y(2))T—...—(y(m))T—and then work out how to express J(Θ)in terms of these matrices.](b)Find the closed form solution forΘwhich minimizes J(Θ).This is the equivalent tothe normal equations for the multivariate case.(c)Suppose instead of considering the multivariate vectors y(i)all at once,we instead(i)compute each variable yj separately for each j=1,...,p.In this case,we have a p individual linear models,of the form(i)T(i),j=1,...,p. yj=θj x(So here,eachθj∈R n).How do the parameters from these p independent least squares problems compare to the multivariate solution?4.Naive BayesI n this problem,we look at maximum likelihood parameter estimation using the naiveB ayes assumption.Here,the input features x j,j=1,...,n to our model are discrete,b inary-valued variables,so x j∈{0,1}.We call x=[x1x2···x n]T to be the input vector.For each training example,our output targets are a single binary-value y∈{0,1}.Our model is then parameterized by φj|y=0=p(x j=1|y=0),φj|y=1=p(x j=1|y=1),andφy=p(y=1).We model the joint distribution of(x,y)according top(y)=(φy)y(1−φy)1−yp(x|y=0)=nYp(x j|y=0)j=1=nYx j(1−φj|y=0)1−x(φj|y=0)j j=1p(x|y=1)=nYp(x j|y=1)j=1=nYx j(1−φj|y=1)1−x(φj|y=1)j j=1(i),y(i);ϕ)in terms of the(a)Find the joint likelihood functionℓ(ϕ)=log Q i=1p(xmodel parameters given above.Here,ϕrepresents the entire set of parameters {φy,φj|y=0,φj|y=1,j=1,...,n}.(b)Show that the parameters which maximize the likelihood function are the same as3CS229Problem Set#14those given in the lecture notes;i.e.,thatm(i)φj|y=0=P j=1∧yi=11{x(i)=0}mP i=11{y(i)=0} m(i)φj|y=1=P j=1∧yi=11{x(i)=1}mP i=11{y(i)=1}φy=P(i)=1}mi=11{y.m(c)Consider making a prediction on some new data point x using the most likely classestimate generated by the naive Bayes algorithm.Show that the hypothesis returnedby naive Bayes is a linear classifier—i.e.,if p(y=0|x)and p(y=1|x)are the classp robabilities returned by naive Bayes,show that there exists someθ∈R n+1sucht hatT x1p(y=1|x)≥p(y=0|x)if and only ifθ≥0.(Assumeθ0is an intercept term.)5.Exponential family and the geometric distribution(a)Consider the geometric distribution parameterized byφ:p(y;φ)=(1−φ)y−1φ,y=1,2,3,....Show that the geometric distribution is in the exponential family,and give b(y),η,T(y),and a(η).(b)Consider performing regression using a GLM model with a geometric response vari-able.What is the canonical response function for the family?You may use the factthat the mean of a geometric distribution is given by1/φ.(c)For a training set{(x(i),y(i));i=1,...,m},let the log-likelihood of an examplebe log p(y(i)|x(i);θ).By taking the derivative of the log-likelihood with respect toθj,derive the stochastic gradient ascent rule for learning using a GLM model withgoemetric responses y and the canonical response function.4CS229Problem Set#1Solutions1CS229,Public CourseProblem Set#1Solutions:Supervised Learning1.Newton’s method for computing least squaresIn this problem,we will prove that if we use Newton’s method solve the least squares optimization problem,then we only need one iteration to converge toθ∗.(a)Find the Hessian of the cost function J(θ)=1T x(i)−y(i))2.2P i=1(θmAnswer:As shown in the class notes∂J(θ)∂θj=mXT x(i)−y(i))x(i)(θj. i=1So∂2J(θ)∂θj∂θk==m∂X T x(i)−y(i))x(i)(θ∂θkj i=1mX(i)(i)T X)jkx j x k=(Xi=1Therefore,the Hessian of J(θ)is H=X T X.This can also be derived by simply applyingrules from the lecture notes on Linear Algebra.(b)Show that thefirst iteration of Newton’s method gives usθ⋆=(X T X)−1X T~y,thesolution to our least squares problem.Answer:Given anyθ(0),Newton’s methodfindsθ(1)according toθ(1)=θ(0)−H−1∇θJ(θ(0))=θ(0)−(X T X)−1(X T Xθ(0)−X T~y)=θ(0)−θ(0)+(X T X)−1X T~y=(XT X)−1X T~y.Therefore,no matter whatθ(0)we pick,Newton’s method alwaysfindsθ⋆after oneiteration.2.Locally-weighted logistic regressionIn this problem you will implement a locally-weighted version of logistic regression,where we weight different training examples differently according to the query point.The locally- weighted logistic regression problem is to maximizeλℓ(θ)=−θTθ+Tθ+2mw(i)hy(i)log hθ(x(i))+(1−y(i))log(1−hθ(x(i)))i. Xi=15CS229Problem Set#1Solutions2 The−λTθhere is what is known as a regularization parameter,which will be discussedθ2in a future lecture,but which we include here because it is needed for Newton’s method to perform well on this task.For the entirety of this problem you can use the valueλ=0.0001.Using this definition,the gradient ofℓ(θ)is given by∇θℓ(θ)=XT z−λθwhere z∈R m is defined byz i=w(i)(y(i)−hθ(x(i)))and the Hessian is given byH=XT DX−λIwhere D∈R m×m is a diagonal matrix withD ii=−w(i)hθ(x(i))(1−hθ(x(i)))For the sake of this problem you can just use the above formulas,but you should try toderive these results for yourself as well.Given a query point x,we choose compute the weightsw(i)=exp2τ2CS229Problem Set#1Solutions3theta=zeros(n,1);%compute weightsw=exp(-sum((X_train-repmat(x’,m,1)).^2,2)/(2*tau));%perform Newton’s methodg=ones(n,1);while(norm(g)>1e-6)h=1./(1+exp(-X_train*theta));g=X_train’*(w.*(y_train-h))-1e-4*theta;H=-X_train’*diag(w.*h.*(1-h))*X_train-1e-4*eye(n);theta=theta-H\g;end%return predicted yy=double(x’*theta>0);(b)Evaluate the system with a variety of different bandwidth parametersτ.In particular,tryτ=0.01,0.050.1,0.51.0,5.0.How does the classification boundary change whenv arying this parameter?Can you predict what the decision boundary of ordinary(unweighted)logistic regression would look like?Answer:These are the resulting decision boundaries,for the different values ofτ.tau = 0.01 tau = 0.05 tau = 0.1tau = 0.5 tau = 0.5 tau = 5For smallerτ,the classifier appears to overfit the data set,obtaining zero training error,but outputting a sporadic looking decision boundary.Asτgrows,the resulting deci-sion boundary becomes smoother,eventually converging(in the limit asτ→∞to theunweighted linear regression solution).3.Multivariate least squaresSo far in class,we have only considered cases where our target variable y is a scalar value. Suppose that instead of tryingto predict a single output,we have a training set with7CS229Problem Set#1Solutions4multiple outputs for each example:{(x(i),y(i)),i=1,...,m},x(i)∈R n,y(i)∈R p.Thus for each training example,y(i)is vector-valued,with p entries.We wish to use a linearmodel to predict the outputs,as in least squares,by specifying the parameter matrixΘiny=ΘT x,whereΘ∈R n×p.(a)The cost function for this case isJ(Θ)=12m p2 X X T x(i))j−y(j=1ji)(Θi=1.W rite J(Θ)in matrix-vector notation(i.e.,without using any summations).[Hint: Start with the m×n design matrixX=—(x(1))T——(x(2))T—...—(x(m))T—and the m×p target matrixY=—(y(1))T——(y(2))T—...—(y(m))T—and then work out how to express J(Θ)in terms of these matrices.] Answer:The objective function can be expressed asJ(Θ)=12tr T(XΘ−Y)(XΘ−Y).To see this,note thatJ(Θ)===1tr T(XΘ−Y)(XΘ−Y)212X i T(XΘ−Y)XΘ−Y)ii12X i X(XΘ−Y)2ijj=12m p2i)(Θi=1j=1T x(i))j−y j(X X(Θ8CS229Problem Set#1Solutions5(b)Find the closed form solution forΘwhich minimizes J(Θ).This is the equivalent tothe normal equations for the multivariate case.Answer:First we take the gradient of J(Θ)with respect toΘ.∇ΘJ(Θ)=∇Θ1tr(XΘ−Y)T(XΘ−Y)2=∇ΘT X T XΘ−ΘT X T Y−Y T XΘ−Y T T1trΘ21=∇ΘT X T XΘ)−tr(ΘT X T Y)−tr(Y T XΘ)+tr(Y T Y)tr(Θ21=tr(Θ2∇ΘT X T XΘ)−2tr(Y T XΘ)+tr(Y T Y)12T XΘ+X T XΘ−2X T Y=X=XT XΘ−X T YSetting this expression to zero we obtainΘ=(XT X)−1X T Y.This looks very similar to the closed form solution in the univariate case,except now Yis a m×p matrix,so thenΘis also a matrix,of size n×p.(c)Suppose instead of considering the multivariate vectors y(i)all at once,we instead(i)compute each variable y j separately for each j=1,...,p.In this case,we have a p individual linear models,of theform(i)T(i),j=1,...,p. y j=θxj(So here,eachθj∈R n).How do the parameters from these p independent least squares problems compareto the multivariate solution?Answer:This time,we construct a set of vectors~y j=(1)jyy(2)j...(m)yj,j=1,...,p.Then our j-th linear model can be solved by the least squares solutionθj=(XT X)−1X T~y j.If we line up ourθj,we see that we have the following equation:[θ1θ2···θp]=(X T X)−1X T~y1(X T X)−1X T~y2···(X T X)−1X T~y p=(XT X)−1X T[~y1~y2···~y p]=(XT X)−1X T Y=Θ.Thus,our p individual least squares problems give the exact same solution as the multi- variate least squares. 9CS229Problem Set#1Solutions64.Naive BayesI n this problem,we look at maximum likelihood parameter estimation using the naiveB ayes assumption.Here,the input features x j,j=1,...,n to our model are discrete,b inary-valued variables,so x j∈{0,1}.We call x=[x1x2···x n]T to be the input vector.For each training example,our output targets are a single binary-value y∈{0,1}.Our model is then parameterized by φj|y=0=p(x j=1|y=0),φj|y=1=p(x j=1|y=1),andφy=p(y=1).We model the joint distribution of(x,y)according top(y)=(φy)y(1−φy)1−yp(x|y=0)=nYp(x j|y=0)j=1=nYx j(1−φj|y=0)1−x(φj|y=0)j j=1p(x|y=1)=nYp(x j|y=1)j=1=nY x j(1−φj|y=1)1−x(φj|y=1)jj=1m(i),y(i);ϕ)in terms of the(a)Find the joint likelihood functionℓ(ϕ)=log Qi=1p(xmodel parameters given above.Here,ϕrepresents the entire set of parameters {φy,φj|y=0,φj|y=1,j= 1,...,n}.Answer:mY p(x(i),y(i);ϕ) ℓ(ϕ)=logi=1mYp(x(i)|y(i);ϕ)p(y(i);ϕ) =logi=1(i);ϕ)m nY Y(i)p(y(i);ϕ) =log j|yp(xi=1j=1(i);ϕ)m nX Xlog p(y(i);ϕ)+(i)=j|ylog p(xi=1j=1m"Xy(i)logφy+(1−y(i))log(1−φy) =i=1nX j=1(i)(i)+xlogφj|y(i)+(1−x j)log(1−φj|yj(i))(b)Show that the parameters which maximize the likelihood function are the same as10CS229Problem Set#1Solutions7those given in the lecture notes;i.e.,thatm(i)φj|y=0=P(i)=0}i=11{x j=1∧ymP i=11{y(i)=0} m(i)φj|y=1=P(i)=1}i=11{x j=1∧ymPi=11{y(i)=1} m(i)=1}φy=Pi=11{y.mA nswer:The only terms inℓ(ϕ)which have non-zero gradient with respect toφj|y=0 are those which includeφj|y(i).Therefore,∇φj|y=0ℓ(ϕ)=∇φj|y=0mX i=1(i)(i)(i))x j)log(1−φj|yjlogφj|y(i)+(1−xj)log(1−φj|y=∇φj|y=0mi=1(i)X(i)=0} xjlog(φj|y=0)1{y=(i)(i)=0}+(1−xj)log(1−φj|y=0)1{ym111{y(i)=0}CS229Problem Set#1Solutions8To solve forφy,mi=1y(i)logφy+(1−y(i))log(1−φy) X∇φyℓ(ϕ)=∇φym1−φy1p(y=1|x)≥p(y=0|x)if and only ifθ≥0.(Assumeθ0is an intercept term.)Answer:p(y=1|x)≥p(y=0|x)≥1⇐⇒p(y=1|x)p(y=0|x)⇐⇒Qj=1p(x j|y=1)≥1np(y=1)p(y=0)Q j=1p(x j|y=0)n⇐⇒Qj≥1 nx j(1−φj|y=0)1−xφyj=1(φj|y=0)Qjn j=1(φj|y=1)x j(1−φj|y=1)1−x(1−φy)n+(1−x j)log1−φj|y=0x j logφj|y=0≥0,12CS229Problem Set#1Solutions9 whereθ0=nlog1−φj|y=01y log(1−φ)−log1−φThenb(y)=1η=log(1−φ)T(y)=ya(η)=log1−φφCS229Problem Set#1Solutions10ℓi(θ)=log"exp T x(i)·y(i)−log T x(i)!!#θT x(i)eθ1−eθ=log exp T x(i)·y(i)−log T x(i)−1θ1e−θ∂∂θj=θT x(i)·y(i)+log T x(i)−1e−θT x(i)e−θ(i)(i)jy(−x(i)+ℓi(θ)=x j)e−θT x(i)−1(i)(i)−=x j y1(i)T x(i)xj1−e−θ=y(i)−1T x(i)CS229Problem Set#21 CS229,Public CourseProblem Set#2:Kernels,SVMs,and Theory1.Kernel ridge regressionIn contrast to ordinary least squares which has a cost functionJ(θ)=12mXT x(i)−y(i))2,(θi=1we can also add a term that penalizes large weights inθ.In ridge regression,our least s quares cost is regularized by adding a termλkθk2,whereλ>0is afixed(known)constant (regularization will be discussed at greater length in an upcoming course lecutre).The ridger egression cost function is thenJ(θ)=12mXT x(i)−y(i))2+(θi=1λkθk2.2(a)Use the vector notation described in class tofind a closed-form expreesion for thevalue ofθwhich minimizes the ridge regression cost function.(b)Suppose that we want to use kernels to implicitly represent our feature vectors in ahigh-dimensional(possibly infinite dimensional)ing a feature mappingφ, the ridge regression cost function becomesJ(θ)=12mXTφ(x(i))−y(i))2+(θi=1λkθk2.2Making a prediction on a new input x new would now be done by computingθTφ(x new).S how how we can use the“kernel trick”to obtain a closed form for the predictiono n the new input without ever explicitly computingφ(x new).You may assume thatt he parameter vectorθcan be expressed as a linear combination of the input feature vectors;i.e.,θ=P (i))for some set of parametersαi.mi=1αiφ(x[Hint:You mayfind the following identity useful:(λI+BA)−1B=B(λI+AB)−1.If you want,you can try to prove this as well,though this is not required for theproblem.]2.ℓ2norm soft margin SVMsIn class,we saw that if our data is not linearly separable,then we need to modify our support vector machine algorithm by introducing an error margin that must be minimized.Specifically,the formulation we have looked at is known as theℓ1norm soft margin SVM.In this problem we will consider an alternative method,known as theℓ2norm soft margin SVM.This new algorithm is given by the following optimization problem(notice that theslack penalties are now squared):.min w,b,ξ12+Ck wk2P i=1ξ2m2is.t.y(i)(w T x(i)+b)≥1−ξi,i=1,...,m15CS229Problem Set#22(a)Notice that we have dropped theξi≥0constraint in theℓ2problem.Show that thesenon-negativity constraints can be removed.That is,show that the optimal value ofthe objective will be the same whether or not these constraints are present.(b)What is the Lagrangian of theℓ2soft margin SVM optimization problem?(c)Minimize the Lagrangian with respect to w,b,andξby taking the following gradients:∇w L,∂L∂b,and∇ξL,and then setting them equal to0.Here,ξ=[ξ1,ξ2,...,ξm]T.(d)What is the dual of theℓ2soft margin SVM optimization problem?3.SVM with Gaussian kernelC onsider the task of training a support vector machine using the Gaussian kernel K(x,z)=exp(−kx−zk2/τ2).We will show that as long as there are no two identical points in thet raining set,we can alwaysfind a value for the bandwidth parameterτsuch that the SVMa chieves zero training error.(a)Recall from class that the decision function learned by the support vector machinecan be written asf(x)=mXαi y(i)K(x(i),x)+b. i=1A ssume that the training data{(x(1),y(1)),...,(x(m),y(m))}consists of points whicha re separated by at least a distance ofǫ;that is,||x(j)−x(i)||≥ǫfor any i=j.F ind values for the set of parameters{α1,...,αm,b}and Gaussian kernel widthτs uch that x(i)is correctly classified,for all i=1,...,m.[Hint:Letαi=1for all ia nd b=0.Now notice that for y∈{−1,+1}the prediction on x(i)will be correct if|f(x(i))−y(i)|<1,sofind a value ofτthat satisfies this inequality for all i.](b)Suppose we run a SVM with slack variables using the parameterτyou found in part(a).Will the resulting classifier necessarily obtain zero training error?Why or whynot?A short explanation(without proof)will suffice.(c)Suppose we run the SMO algorithm to train an SVM with slack variables,underthe conditions stated above,using the value ofτyou picked in the previous part,and using some arbitrary value of C(which you do not know beforehand).Will thisnecessarily result in a classifier that achieve zero training error?Why or why not?Again,a short explanation is sufficient.4.Naive Bayes and SVMs for Spam ClassificationI n this question you’ll look into the Naive Bayes and Support Vector Machine algorithmsf or a spam classification problem.However,instead of implementing the algorithms your-s elf,you’ll use a freely available machine learning library.There are many such librariesa vailable,with different strengths and weaknesses,but for this problem you’ll use theW EKA machine learning package,available at /ml/weka/.WEKA implements many standard machine learning algorithms,is written in Java,andhas both a GUI and a command line interface.It is not the best library for very large-scaledata sets,but it is very nice for playing around with many different algorithms on mediumsize problems.You can download and install WEKA by following the instructions given on the websiteabove.To use it from the command line,youfirst need to install a java runtime environ-ment,then add the weka.jarfile to your CLASSPATH environment variable.Finally,you16CS229Problem Set#23 can call WEKA using the command:java<classifier>-t<training file>-T<test file>For example,to run the Naive Bayes classifier(using the multinomial event model)on ourprovided spam data set by running the command:java weka.classifiers.bayes.NaiveBayesMultinomial-t spam train1000.arff-T spam test.arffT he spam classification dataset in the q4/directory was provided courtesy of ChristianS helton(cshelton@).Each example corresponds to a particular email,and eachf eature correspondes to a particular word.For privacy reasons we have removed the actualw ords themselves from the data set,and instead label the features generically as f1,f2,etc.H owever,the data set is from a real spam classification task,so the results demonstrate thep erformance of these algorithms on a real-world problem.The q4/directory actually con-t ains several different trainingfiles,named spam train50.arff,spam train100.arff,etc(the“.arff”format is the default format by WEKA),each containing the correspondingn umber of training examples.There is also a single test set spam test.arff,which is ah old out set used for evaluating the classifier’s performance.(a)Run the weka.classifiers.bayes.NaiveBayesMultinomial classifier on the datasetand report the resulting error rates.Evaluate the performance of the classifier usingeach of the different trainingfiles(but each time using the same testfile,spam test.arff).Plot the error rate of the classifier versus the number of training examples.(b)Repeat the previous part,but using the weka.classifiers.functions.SMO classifier,which implements the SMO algorithm to train an SVM.How does the performanceof the SVM compare to that of Naive Bayes?5.Uniform convergenceIn class we proved that for anyfinite set of hypotheses H={h1,...,h k},if we pick the hypothesis hˆthat minimizes the training error on a set of m examples,then with probabilityat least(1−δ),12kε(hˆ)≤ε(h i)min log,+2r2mδiwhereε(h i)is the generalization error of hypothesis h i.Now consider a special case(oftenc alled the realizable case)where we know,a priori,that there is some hypothesis in ourc lass H that achieves zero error on the distribution from which the data is drawn.Thenw e could obviously just use the above bound with min iε(h i)=0;however,we can prove ab etter bound than this.(a)Consider a learning algorithm which,after looking at m training examples,choosessome hypothesis hˆ∈H that makes zero mistakes on this training data.(By ourassumption,there is at least one such hypothesis,possibly more.)Show that withprobability1−δε(hˆ)≤1m logkδ.N otice that since we do not have a square root here,this bound is much tighter.[Hint: C onsider the probability that a hypothesis with generalization error greater thanγmakes no mistakes on the training data.Instead of the Hoeffding bound,you might alsofind the following inequality useful:(1−γ)m≤e−γm.]17CS229Problem Set#24(b)Rewrite the above bound as a sample complexity bound,i.e.,in the form:forfixedδandγ,forε(hˆ)≤γto hold with probability at least(1−δ),it suffices that m≥f(k,γ,δ)(i.e.,f(·)is some function of k,γ,andδ).18CS229Problem Set#2Solutions1 CS229,Public CourseProblem Set#2Solutions:Kernels,SVMs,and Theory1.Kernel ridge regressionIn contrast to ordinary least squares which has a cost functionJ(θ)=12mXT x(i)−y(i))2,(θi=1we can also add a term that penalizes large weights inθ.In ridge regression,our least s quares cost is regularized by adding a termλkθk2,whereλ>0is afixed(known)constant (regularization will be discussed at greater length in an upcoming course lecutre).The ridger egression cost function is thenJ(θ)=12mX T x(i)−y(i))2+(θi=1λkθk2.2(a)Use the vector notation described in class tofind a closed-form expreesion for thevalue ofθwhich minimizes the ridge regression cost function.Answer:Using the design matrix notation,we can rewrite J(θ)asJ(θ)=12(Xθ−~y)T(Xθ−~y)+T(Xθ−~y)+λθTθ.Tθ.2Then the gradient is∇θJ(θ)=XT Xθ−X T~y+λθ.Setting the gradient to0gives us0=XT Xθ−X T~y+λθθ=(XT X+λI)−1X T~y.(b)Suppose that we want to use kernels to implicitly represent our feature vectors in ahigh-dimensional(possibly infinite dimensional)ing a feature mappingφ, the ridge regression cost function becomesJ(θ)=12mX Tφ(x(i))−y(i))2+(θi=1λkθk2.2Making a prediction on a new input x new would now be done by computingθTφ(x new).S how how we can use the“kernel trick”to obtain a closed form for the predictiono n the new input without ever explicitly computingφ(x new).You may assume that the parameter vectorθcan beexpressed as a linear combination of the input featurem(i))for some set of parametersαi.vectors;i.e.,θ=P i=1αiφ(x19。
格密码学课程六

2
The Micciancio-Voulgaris Algorithm for CVP
The MV algorithm solves CVP on any n-dimensional lattice in 2O(n) time (for simplicity, we ignore polynomial factors in the input length). It is based around the (closed) Voronoi cell of the lattice, which, to recall, is the set of all points in Rn that are as close or closer to the origin than to any other lattice point: ¯ (L) = {x ∈ Rn : x ≤ x − v ∀ v ∈ L \ {0}}. V We often omit the argument L when it is clear from context. From the definition it can be seen that for any ¯ consists of all the shortest elements of t + L. For any lattice point v, define coset t + L, the set (t + L) ∩ V the halfspace Hv = {x : x ≤ x − v } = {x : 2 x, v ≤ v, v }. ¯ is the intersection of Hv over all v ∈ L \ {0}. The minimal set V of lattice vectors It is easy to see that V ¯ such that V = v∈V Hv is called the set of Voronoi-relevant vectors; we often call them relevant vectors for short. The following characterizes the relevant vectors of a lattice: Fact 2.1 (Voronoi). A nonzero lattice vector v ∈ L \ {0} is relevant if and only if ±v are the only shortest vectors in the coset v + 2L. Corollary 2.2. An n-dimensional lattice has at most 2(2n − 1) ≤ 2n+1 relevant vectors. Proof. Every relevant vector belongs to some nonzero coset of L/2L, of which there exactly 2n − 1. By the above, there are at most two relevant vectors in each such coset. 2
椭圆曲线密码ppt课件

⑴ 密钥生成
• 用户随机地选择一个整数d作为自己的秘密的解 密钥,2≤d≤p-2 。
• 计算y=αd mod p,取y为自己的公开的加密钥。 • 由公开钥y 计算秘密钥d,必须求解离散对数,
由于上述运算是定义在模p有限域上的,所以称为 离散对数运算。
③从x计算y是容易的。可是从y计算x就困难得多, 利用目前最好的算法,对于小心选择的p将至少 需用O(p ½)次以上的运算,只要p足够大,求解 离散对数问题是相当困难的。
篮球比赛是根据运动队在规定的比赛 时间里 得分多 少来决 定胜负 的,因 此,篮 球比赛 的计时 计分系 统是一 种得分 类型的 系统
要小,所以ELGamal密码的加解密速度比RSA稍快。 ②随机数源
由ELGamal密码的解密钥d和随机数k都应是高质量 的随机数。因此,应用ELGamal密码需要一个好的随机 数源,也就是说能够快速地产生高质量的随机数。 ③大素数的选择
为了ELGamal密码的安全,p应为150位(十进制数) 以上的大素数,而且p-1应有大素因子。
三、椭圆曲线密码
2、椭圆曲线
②定义逆元素
设P(x1 ,y1)和Q(x2 ,y2)是解点,如果 x1=x2 且y1=-y2 ,则
P(x1 ,y1)+Q(x2 ,y2)=0 。
这说明任何解点R(x ,y)的逆就是
R(x ,-y)。
注意:规定无穷远点的逆就是其自己。
O(∞,∞)=-O(∞,∞)
篮球比赛是根据运动队在规定的比赛 时间里 得分多 少来决 定胜负 的,因 此,篮 球比赛 的计时 计分系 统是一 种得分 类型的 系统
三、椭圆曲线密码
讲义+#9——卡雷尔例程序四则

|《斯坦福大学开放课程:编程方法》专译组
4
清洁工卡雷尔(CleanupKarel)程序代码 /* * File: CleanupKarel.java * ----------------------* Karel starts at (1, 1) facing East and cleans up any * beepers scattered throughout his world. */ import stanford.karel.*; public class CleanupKarel extends SuperKarel { /* Cleans up a field of beepers, one row at a time */ public void run() { cleanRow(); while (leftIsClear()) { repositionForRowToWest(); cleanRow(); if (rightIsClear()) { repositionForRowToEast(); cleanRow(); } else { /* * In rows with an even number of streets, we want * Karel's left to be blocked after he cleans the last * row, so we turn him to the appropriate orientation. */ turnAround(); } } }
|《斯坦福大学开放课程:编程方法》专译组 5
private void repositionForRowToEast() { turnRight(); move(); turnRight(); } }
生命密码二阶课程

生命密码二阶课程(总10页) -CAL-FENGHAI.-(YICAI)-Company One1-CAL-本页仅作为文档封面,使用请直接删除生命密码二阶1生命密码的意义:对于管理者来说,对人的选,用,驭,留或者是选,驭,用,留都是至关重量,对于普通人来说,了解自己和别人的性格特性,更好的与人沟通和相处,每一种性格的人,在遇到同样的一件事情的时候,都会是不同的行为表现方式,当你理解这一切之后,你就会坦然的接受自己和别人的不足,不再会责怪自己;同样你也会发现自己和别人一些潜在的特质,并将它发挥出来,提高自己,让自己信心百倍。
首先,我们将会引入生命密码二阶课程中最为关键的一个密码图,李小龙的生日是1940年11月27日,他的生命密码三角形如下所示:在所有的生日年份中有一个特殊就是2000年,2+0=0,0+0=5,而不是0,切记三角形外的小圆圈内的数字必须是3, 6, 9,如果不是的话,肯定是计算错误。
现在来简单的介绍一下如何利用年月日生日计算上面的三角形生命密码图谱,首先按照图示把李小龙的生日年份日1940年11月27日,按照上面的位置填写好,从左往右开始计算,首先是27,把它们相加至个位2+7=9,然后是11,1+1=2, 19 (1+9=10, 1+0=1), 40,4+0=4,把9, 2, 1, 4 依次写在三角形内,继续 (9+2=11, 1+1=2), 1+4=5, 2+5=7,当把三角形内的数据加完之后,我们就开始计算三角形外的数字,左半部分,最下面一行的9,2分别左半部分第二行的2相加,2+2=4, (9+2=11, 1+1=2), 4+2=6, 右半部分也是同理可以得到6, 9, 6的结果。
最上面的3, 9, 3的结果是如何计算的呢?和我们刚才描述的左右部分的数字加成有所不一样,第二行的2, 5 分别与最上面7相加,结果不在同侧,而在相反的一侧,2+7=9, 2是左边的数字,而9却在右边,同理5+7=12, 1+2=3, 在左侧。
凯撒加解密c 课程设计

凯撒加解密c 课程设计一、课程目标知识目标:1. 学生能理解凯撒加解密的基本原理,掌握其加密与解密的方法。
2. 学生能够运用所学知识,对简单的凯撒密码进行加密与解密。
3. 学生了解密码学在历史与现代通讯中的重要性。
技能目标:1. 学生通过实际操作,培养逻辑思维能力和问题解决能力。
2. 学生学会运用数学方法分析问题,提高数学运用能力。
3. 学生在小组合作中,提高沟通与协作能力。
情感态度价值观目标:1. 学生培养对密码学的兴趣,激发探究精神。
2. 学生在解密过程中,体验成功解决问题的喜悦,增强自信心。
3. 学生认识到信息安全的重要性,树立正确的网络安全意识。
分析课程性质、学生特点和教学要求:本课程为数学学科拓展课程,结合五年级学生的认知水平,注重培养学生的逻辑思维能力和实际操作能力。
在教学过程中,充分考虑学生的好奇心和求知欲,通过生动有趣的案例,引导学生主动参与课堂,提高学习积极性。
同时,注重培养学生的团队合作精神,使学生在互动交流中共同成长。
将目标分解为具体的学习成果:1. 学生能够独立完成凯撒加解密的操作。
2. 学生能够解释凯撒加解密原理,并运用到实际问题中。
3. 学生在小组合作中,能够主动承担责任,与组员共同解决问题。
4. 学生在课堂中积极参与讨论,分享学习心得,提升网络安全意识。
二、教学内容本章节教学内容以密码学基础知识为主,结合五年级数学课程,围绕凯撒加解密方法展开。
1. 导入:通过介绍密码学在历史和现代的应用,激发学生对密码学的兴趣。
2. 基本概念:- 加密与解密的定义- 凯撒加解密的基本原理3. 教学主体内容:- 凯撒密码的加密方法- 凯撒密码的解密方法- 案例分析:实际操作凯撒加解密4. 教学拓展内容:- 密码学在其他领域的应用- 现代加密技术简介教学大纲安排如下:第一课时:- 导入:密码学应用介绍- 基本概念:加密与解密定义,凯撒加解密原理第二课时:- 教学主体内容:凯撒密码加密方法- 实践操作:学生尝试对简单文本进行加密第三课时:- 教学主体内容:凯撒密码解密方法- 实践操作:学生尝试对已加密文本进行解密第四课时:- 教学拓展内容:密码学在现代的应用- 案例分析:学生分组讨论并分享凯撒加解密案例教学内容与教材关联性:本教学内容与教材中关于逻辑思维、问题解决、数学运用等相关章节相结合,确保学生在掌握基础知识的同时,提高综合运用能力。
斯坦福大学公开课:机器学习课程note1翻译分析解析
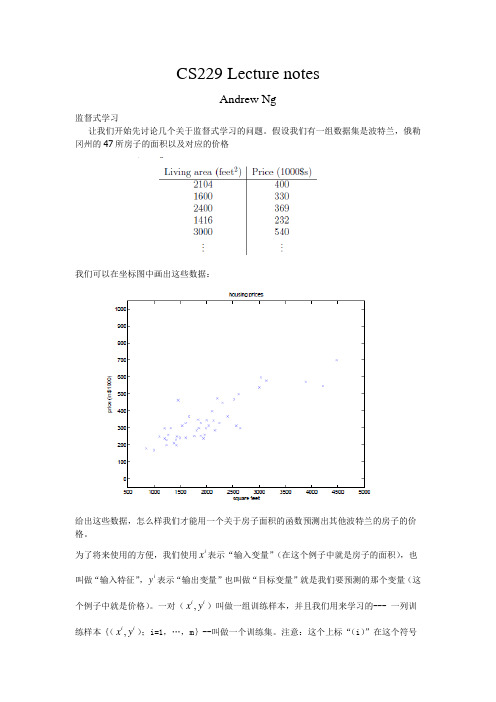
CS229 Lecture notesAndrew Ng监督式学习让我们开始先讨论几个关于监督式学习的问题。
假设我们有一组数据集是波特兰,俄勒冈州的47所房子的面积以及对应的价格我们可以在坐标图中画出这些数据:给出这些数据,怎么样我们才能用一个关于房子面积的函数预测出其他波特兰的房子的价格。
为了将来使用的方便,我们使用i x表示“输入变量”(在这个例子中就是房子的面积),也叫做“输入特征”,i y表示“输出变量”也叫做“目标变量”就是我们要预测的那个变量(这x y)叫做一组训练样本,并且我们用来学习的--- 一列训个例子中就是价格)。
一对(,i ix y);i=1,…,m}--叫做一个训练集。
注意:这个上标“(i)”在这个符号练样本{(,i i表示法中就是训练集中的索引项,并不是表示次幂的概念。
我们会使用χ表示输入变量的定义域,使用表示输出变量的值域。
在这个例子中χ=Y=R为了更正式的描述我们这个预测问题,我们的目标是给出一个训练集,去学习产生一个函数h :X → Y 因此h(x)是一个好的预测对于近似的y 。
由于历史性的原因,这个函数h 被叫做“假设”。
预测过程的顺序图示如下:当我们预测的目标变量是连续的,就像在我们例子中的房子的价格,我们叫这一类的学习问题为“回归问题”,当我们预测的目标变量仅仅只能取到一部分的离散的值(就像如果给出一个居住面积,让你去预测这个是房子还是公寓,等等),我们叫这一类的问题是“分类问题”PART ILinear Reression为了使我们的房子问题更加有趣,我们假设我们知道每个房子中有几间卧室:在这里,x 是一个二维的向量属于2R 。
例如,1i x 就是训练集中第i 个房子的居住面积, 2i x 是训练集中第i 个房子的卧室数量。
(通常情况下,当设计一个学习问题的时候,这些输入变量是由你决定去选择哪些,因此如果你是在Portland 收集房子的数据,你可能会决定包含其他的特征,比如房子是否带有壁炉,这个洗澡间的数量等等。
斯坦福大学 CS229 机器学习notes12

CS229Lecture notesAndrew NgPart XIIIReinforcement Learning and ControlWe now begin our study of reinforcement learning and adaptive control.In supervised learning,we saw algorithms that tried to make their outputs mimic the labels y given in the training set.In that setting,the labels gave an unambiguous“right answer”for each of the inputs x.In contrast,for many sequential decision making and control problems,it is very difficult to provide this type of explicit supervision to a learning algorithm.For example, if we have just built a four-legged robot and are trying to program it to walk, then initially we have no idea what the“correct”actions to take are to make it walk,and so do not know how to provide explicit supervision for a learning algorithm to try to mimic.In the reinforcement learning framework,we will instead provide our al-gorithms only a reward function,which indicates to the learning agent when it is doing well,and when it is doing poorly.In the four-legged walking ex-ample,the reward function might give the robot positive rewards for moving forwards,and negative rewards for either moving backwards or falling over. It will then be the learning algorithm’s job tofigure out how to choose actions over time so as to obtain large rewards.Reinforcement learning has been successful in applications as diverse as autonomous helicopterflight,robot legged locomotion,cell-phone network routing,marketing strategy selection,factory control,and efficient web-page indexing.Our study of reinforcement learning will begin with a definition of the Markov decision processes(MDP),which provides the formalism in which RL problems are usually posed.12 1Markov decision processesA Markov decision process is a tuple(S,A,{P sa},γ,R),where:•S is a set of states.(For example,in autonomous helicopterflight,S might be the set of all possible positions and orientations of the heli-copter.)•A is a set of actions.(For example,the set of all possible directions in which you can push the helicopter’s control sticks.)•P sa are the state transition probabilities.For each state s∈S and action a∈A,P sa is a distribution over the state space.We’ll say more about this later,but briefly,P sa gives the distribution over what states we will transition to if we take action a in state s.•γ∈[0,1)is called the discount factor.•R:S×A→R is the reward function.(Rewards are sometimes also written as a function of a state S only,in which case we would have R:S→R).The dynamics of an MDP proceeds as follows:We start in some state s0, and get to choose some action a0∈A to take in the MDP.As a result of our choice,the state of the MDP randomly transitions to some successor states1,drawn according to s1∼P s0a0.Then,we get to pick another action a1.As a result of this action,the state transitions again,now to some s2∼P s1a1.We then pick a2,and so on....Pictorially,we can represent this process as follows:s0a0−→s1a1−→s2a2−→s3a3−→...Upon visiting the sequence of states s0,s1,...with actions a0,a1,...,our total payoffis given byR(s0,a0)+γR(s1,a1)+γ2R(s2,a2)+···.Or,when we are writing rewards as a function of the states only,this becomesR(s0)+γR(s1)+γ2R(s2)+···.For most of our development,we will use the simpler state-rewards R(s), though the generalization to state-action rewards R(s,a)offers no special difficulties.3 Our goal in reinforcement learning is to choose actions over time so as to maximize the expected value of the total payoff:E R(s0)+γR(s1)+γ2R(s2)+···Note that the reward at timestep t is discounted by a factor ofγt.Thus,to make this expectation large,we would like to accrue positive rewards as soon as possible(and postpone negative rewards as long as possible).In economic applications where R(·)is the amount of money made,γalso has a natural interpretation in terms of the interest rate(where a dollar today is worth more than a dollar tomorrow).A policy is any functionπ:S→A mapping from the states to the actions.We say that we are executing some policyπif,whenever we are in state s,we take action a=π(s).We also define the value function for a policyπaccording toVπ(s)=E R(s0)+γR(s1)+γ2R(s2)+··· s0=s,π].Vπ(s)is simply the expected sum of discounted rewards upon starting in state s,and taking actions according toπ.1Given afixed policyπ,its value function Vπsatisfies the Bellman equa-tions:Vπ(s)=R(s)+γ s ∈S P sπ(s)(s )Vπ(s ).This says that the expected sum of discounted rewards Vπ(s)for starting in s consists of two terms:First,the immediate reward R(s)that we get rightaway simply for starting in state s,and second,the expected sum of future discounted rewards.Examining the second term in more detail,we[Vπ(s )].This see that the summation term above can be rewritten E s ∼Psπ(s)is the expected sum of discounted rewards for starting in state s ,where s is distributed according P sπ(s),which is the distribution over where we will end up after taking thefirst actionπ(s)in the MDP from state s.Thus,the second term above gives the expected sum of discounted rewards obtained after thefirst step in the MDP.Bellman’s equations can be used to efficiently solve for Vπ.Specifically, in afinite-state MDP(|S|<∞),we can write down one such equation for Vπ(s)for every state s.This gives us a set of|S|linear equations in|S| variables(the unknown Vπ(s)’s,one for each state),which can be efficiently solved for the Vπ(s)’s.1This notation in which we condition onπisn’t technically correct becauseπisn’t a random variable,but this is quite standard in the literature.4We also define the optimal value function according toV ∗(s )=max πV π(s ).(1)In other words,this is the best possible expected sum of discounted rewards that can be attained using any policy.There is also a version of Bellman’s equations for the optimal value function:V ∗(s )=R (s )+max a ∈A γ s ∈SP sa (s )V ∗(s ).(2)The first term above is the immediate reward as before.The second term is the maximum over all actions a of the expected future sum of discounted rewards we’ll get upon after action a .You should make sure you understand this equation and see why it makes sense.We also define a policy π∗:S →A as follows:π∗(s )=arg max a ∈A s ∈SP sa (s )V ∗(s ).(3)Note that π∗(s )gives the action a that attains the maximum in the “max”in Equation (2).It is a fact that for every state s and every policy π,we haveV ∗(s )=V π∗(s )≥V π(s ).The first equality says that the V π∗,the value function for π∗,is equal to the optimal value function V ∗for every state s .Further,the inequality above says that π∗’s value is at least a large as the value of any other other policy.In other words,π∗as defined in Equation (3)is the optimal policy.Note that π∗has the interesting property that it is the optimal policy for all states s .Specifically,it is not the case that if we were starting in some state s then there’d be some optimal policy for that state,and if we were starting in some other state s then there’d be some other policy that’s optimal policy for s .Specifically,the same policy π∗attains the maximum in Equation (1)for all states s .This means that we can use the same policy π∗no matter what the initial state of our MDP is.2Value iteration and policy iterationWe now describe two efficient algorithms for solving finite-state MDPs.For now,we will consider only MDPs with finite state and action spaces (|S |<∞,|A |<∞).The first algorithm,value iteration ,is as follows:51.For each state s,initialize V(s):=0.2.Repeat until convergence{For every state,update V(s):=R(s)+max a∈Aγ s P sa(s )V(s ).}This algorithm can be thought of as repeatedly trying to update the esti-mated value function using Bellman Equations(2).There are two possible ways of performing the updates in the inner loop of the algorithm.In thefirst,we canfirst compute the new values for V(s)for every state s,and then overwrite all the old values with the new values.This is called a synchronous update.In this case,the algorithm can be viewed as implementing a“Bellman backup operator”that takes a current estimate of the value function,and maps it to a new estimate.(See homework problem for details.)Alternatively,we can also perform asynchronous updates. Here,we would loop over the states(in some order),updating the values one at a time.Under either synchronous or asynchronous updates,it can be shown that value iteration will cause V to converge to V∗.Having found V∗,we can then use Equation(3)tofind the optimal policy.Apart from value iteration,there is a second standard algorithm forfind-ing an optimal policy for an MDP.The policy iteration algorithm proceeds as follows:1.Initializeπrandomly.2.Repeat until convergence{(a)Let V:=Vπ.(b)For each state s,letπ(s):=arg max a∈A s P sa(s )V(s ).}Thus,the inner-loop repeatedly computes the value function for the current policy,and then updates the policy using the current value function.(The policyπfound in step(b)is also called the policy that is greedy with re-spect to V.)Note that step(a)can be done via solving Bellman’s equations as described earlier,which in the case of afixed policy,is just a set of|S| linear equations in|S|variables.After at most afinite number of iterations of this algorithm,V will con-verge to V∗,andπwill converge toπ∗.6Both value iteration and policy iteration are standard algorithms for solv-ing MDPs,and there isn’t currently universal agreement over which algo-rithm is better.For small MDPs,policy iteration is often very fast and converges with very few iterations.However,for MDPs with large state spaces,solving for Vπexplicitly would involve solving a large system of lin-ear equations,and could be difficult.In these problems,value iteration may be preferred.For this reason,in practice value iteration seems to be used more often than policy iteration.3Learning a model for an MDPSo far,we have discussed MDPs and algorithms for MDPs assuming that the state transition probabilities and rewards are known.In many realistic prob-lems,we are not given state transition probabilities and rewards explicitly, but must instead estimate them from data.(Usually,S,A andγare known.) For example,suppose that,for the inverted pendulum problem(see prob-lem set4),we had a number of trials in the MDP,that proceeded as follows:s(1)0a (1) 0−→s(1)1a (1) 1−→s(1)2a (1) 2−→s(1)3a (1) 3−→...s(2)0a (2) 0−→s(2)1a (2) 1−→s(2)2a (2) 2−→s(2)3a (2) 3−→......Here,s(j)i is the state we were at time i of trial j,and a(j)i is the cor-responding action that was taken from that state.In practice,each of the trials above might be run until the MDP terminates(such as if the pole falls over in the inverted pendulum problem),or it might be run for some large butfinite number of timesteps.Given this“experience”in the MDP consisting of a number of trials, we can then easily derive the maximum likelihood estimates for the state transition probabilities:P sa(s )=#times took we action a in state s and got to s#times we took action a in state s(4)Or,if the ratio above is“0/0”—corresponding to the case of never having taken action a in state s before—the we might simply estimate P sa(s )to be 1/|S|.(I.e.,estimate P sa to be the uniform distribution over all states.) Note that,if we gain more experience(observe more trials)in the MDP, there is an efficient way to update our estimated state transition probabilities7 using the new experience.Specifically,if we keep around the counts for both the numerator and denominator terms of(4),then as we observe more trials, we can simply keep accumulating those puting the ratio of these counts then given our estimate of P sa.Using a similar procedure,if R is unknown,we can also pick our estimate of the expected immediate reward R(s)in state s to be the average reward observed in state s.Having learned a model for the MDP,we can then use either value it-eration or policy iteration to solve the MDP using the estimated transition probabilities and rewards.For example,putting together model learning and value iteration,here is one possible algorithm for learning in an MDP with unknown state transition probabilities:1.Initializeπrandomly.2.Repeat{(a)Executeπin the MDP for some number of trials.(b)Using the accumulated experience in the MDP,update our esti-mates for P sa(and R,if applicable).(c)Apply value iteration with the estimated state transition probabil-ities and rewards to get a new estimated value function V.(d)Updateπto be the greedy policy with respect to V.}We note that,for this particular algorithm,there is one simple optimiza-tion that can make it run much more quickly.Specifically,in the inner loop of the algorithm where we apply value iteration,if instead of initializing value iteration with V=0,we initialize it with the solution found during the pre-vious iteration of our algorithm,then that will provide value iteration with a much better initial starting point and make it converge more quickly.。
精品课件-应用密码学-第5章 非对称密码(3)

2020/11/19
15
1155
图5-1 y2≡x3+x+6所表示的曲线 图5-4 y2≡x3+x+6 (mod 11)所表示的曲线
通过比较y2≡x3+x+6在平面的曲线(见图5-1所示)和y2≡x3+x+6 ( mod 11) 在平面上的点(如图5-4所示),直观感觉没有太多的联系。
P +Q+ R1=O。则P+Q =- R1=R,如图5-2。
2020/11/19
2020/11/219020/11/
图5-2 R=P+Q示意图 2020/11/19
8
8 88
点P的倍点定义为:过P点做椭圆曲线的切线,设与椭圆曲线交于R1, 则 P+P+ R1=O, 故2P=- R1=R。如图5-3。
2020/11/19
5
5 55
本章的介绍以第一种椭圆曲线为主,如图5-1是y2≡x3+x+6所表示的曲线,该图 可以用matlab实现。显然该曲线关于x轴对称。
图5-1 y2≡x3+x+6所表示的 曲线
2020/11/19
2020/11/219020/11/
2020/11/19
6
6 66
2.椭圆曲线的加法
2020/11/19
2020/11/19
2020/11/19
20
2200
- ④ 计算点:(x1,y1)=kP - ⑤ 计算点:(x2,y2)=kQ,如果x2=0,则返回第③步 - ⑥ 计算:c=mx2 - ⑦ 传送加密数据(x1,y1,c)给B
(4)解密过程
当实体B解密从A收到的密文(x1,y1,c)时,执行步骤:
《密码学》课程教学大纲

《密码学》课程教学大纲Cryprtography课程代码:课程性质:专业方向理论课/必修适用专业:信息安全开课学期:5总学时数:56总学分数:3.5编写年月:2006年6月修订年月:2007年7月执笔:李锋一、课程的性质和目的本课程是信息与计算科学专业信息安全方向的主要专业方向课。
其主要目的研究实现是让学生学习和了解密码学的一些基本概念,理解和掌握一些常用密码算法的加密和解密原理,认证理论的概念以及几种常见数字签名算法和安全性分析。
本课程涉及分组加密、流加密、公钥加密、数字签名、哈希函数、密钥建立与管理、身份识别、认证理论与技术、PKI技术等内容。
要求学生掌握密码学的基本概念、基本原理和基本方法。
在牢固掌握密码学基本理论的基础上,初步具备使用C或C++语言编写基本密码算法(SHA-1、DES、A ES、RC5等)的能力,要求学生通过学习该课程初步掌握密码学的理论和实现技术,使当代大学生适应社会信息化的要求,能利用密码技术服务于社会。
二、课程教学内容及学时分配第1章密码学概论(2学时)要求深刻理解与熟练掌握的重点内容有:1.信息安全的基本概念,2. 密码学的基本概念,3.与密码学有关的难解数学问题。
要求一般理解与掌握的内容有:信息安全的基本内容、密码体制分类、密码学的发展历史。
重点:密码体制的分类。
难点:密码体制的攻击类型理解。
第2章古典密码体制(2学时)本章主要了解1949年之前的古典密码体制,掌握不同类型的加密方式,并了解和认识无条件安全及古典密码的破译。
本章知识点:代换密码(分类和举例)、置换密码(列置换密码、周期置换密码)、古典密码的破译、无条件安全的一次一密体制。
要求学生能够使用C、C++编写Caesar 密码算法,练习最基本或最简单的加密模式。
为进一步加强对加密算法的理解,课堂上演示实现的Caesar密码。
第3章现代分组密码(10学时)要求掌握分组密码概述,主要使用的结构及模式,详细学习DES、IDEA、RC5、AES算法的流程,特别是如何实现这些算法,并了解每个算法的安全性及其效率。
凯撒密码——精选推荐

凯撒密码凯撒密码的原理与实现1.实验⽬的及内容:熟悉古典密码算法:凯撒密码算法和维吉尼亚密码算法的编程实现,加强对密码学的理解。
2. 实验内容凯撒密码(caeser)是罗马扩张时期朱利斯?凯撒(Julius Caesar)创造的,⽤于加密通过信使传递的作战命令。
它将字母表中的字母移动⼀定位置⽽实现加密。
古罗马随笔作家修托尼厄斯在他的作品中披露,凯撒常⽤⼀种“密表”给他的朋友写信。
这⾥所说的密表,在密码学上称为“凯撒密表”。
⽤现代的眼光看,凯撒密表是⼀种相当简单的加密变换,就是把明⽂中的每⼀个字母⽤它在字母表上位置后⾯的第三个字母代替。
古罗马⽂字就是现在所称的拉丁⽂,其字母就是我们从英语中熟知的那26个拉丁字母。
因此,凯撒密表就是⽤d代a,⽤e代b,……,⽤z代w。
这些代替规则也可⽤⼀张表格来表⽰,所以叫“密表”。
当偏移量是3的时候,所有的字母A将被替换成D,B变成E,以此类推。
使⽤时,加密者查找明⽂字母表中需要加密的消息中的每⼀个字母所在位置,并且写下密⽂字母表中对应的字母。
需要解密的⼈则根据事先已知的密钥反过来操作,得到原来的明⽂。
例如:明⽂:THE QUICK BROWN FOX JUMPSOVER THE LAZY DOG密⽂:WKH TXLFN EURZQ IRA MXPSVRYHU WKH ODCB GRJ恺撒密码的加密、解密⽅法还能够通过同余数的数学⽅法进⾏计算。
⾸先将字母⽤数字代替,A=0,B=1,...,Z=25。
此时偏移量为n的加密⽅法即为:E (x)= (x+n) mod 2解密就是:D (x)=(x-n) mod 2利⽤加解密技术可以保证信息处理、通信中的信息安全。
对于双⼯信道(即可以双向传输信息的信道),每端都需要⼀个完整的编/译码系统。
试为这样的信息收发站编写⼀个凯撒密码的编/译码系统。
3.需求分析⼀个完整的系统应具有以下功能:(1) I:初始化(Initialization)。
第二讲:密码学基础

9世纪的科学家阿尔·金迪在《关于破译加密信 息的手稿》
“如果我们知道一条加密信息所使用的语言,那么破 译这条加密信息的方法就是找出同样的语言写的一篇 其他文章,大约一页纸长,然后我们计算其中每个字 母的出现频率。我们将频率最高的字母标为1号,频率 排第2的标为2号,第三标为3号,依次类推,直到数完 样品文章中所有字母。然后我们观察需要破译的密文, 同样分类出所有的字母,找出频率最高的字母,并全 部用样本文章中最高频率的字母替换。第二高频的字 母用样本中2号代替,第三则用3号替换,直到密文中 所有字母均已被样本中的字母替换。”
2020/3/10
6
保密系统模型
非法接入者
搭线信道 (主动攻击)
C’
搭线信道
m‘
(被动攻击)
密码分析员
m
信源 M
c 加E密k器1 (m)
m
m 解密D器k2 (c)
接收者
k1
密钥源 K1
密钥信道
k2
密钥源 K2
2020/3/10
7
保密系统应当满足的要求
系统即使达不到理论上是不可破的,即
pr{m’=m}=0,也应当为实际上不可破的。就
如果列读的顺序再变一下,352146得密文
பைடு நூலகம்
“mtohmoerCmreowoo”
很容易破解
多轮简单分栏变换加密技术
▪ 简单分栏变换加密变换多次,从而增加复 杂性
明文“Comehometomorrow”
第一列 第二列 第三列 第四列 第五列 第六列
C
o
m
e
h
o
m
e
t
o
m
o
密码培训教程

对称密码
1. 对称密码 :加密密钥与解密密钥相同。 2. 优点是:
• 安全性高 • 加解密速度快 3. 缺点是: • 随着网络规模的扩大,密钥管理成为一
个难点;
• 无法解决消息确认问题;(不过可以采 用一些业务方法弥补,如:商户号终端 号等方式但对内部人员无效)
• 缺乏自动检测密钥泄露的能力。 举例:21.80.66.254 /usr/btssrc/twb/encrypt
非对称密码
1. 非对称密码 :加密密钥与解密密钥不同 , 而且解密密钥不能根据加密密钥计算出来。
2. 优点是:不需要安全信道来传送密钥 。
3. 缺点是:算法复杂,加解密速度慢,一般 比单钥密码慢1000倍。
攻击分类
被动攻击
主动攻击
窃听 获取消息内容 流量分析
中断
修改
伪造
破坏可用性 破坏完整性 破坏真实性
• 传统密码学的缺陷: 1、受限制,只能在一个组织内使用。大家必须知道相应 的加解密算法。 2、对人要求过高,一旦一个用户离开组织就会使保密荡 然无存。(这就是为什么风语者中:为什么要保护密码员, 为什么当密码员被抓的时候,宁可杀死他也不能落到敌人 手里的原因。) 3、受限制的密码算法不可能进行质量控制或者标准化。
2. 保证交易信息在传输、交换过程中的完整性。 3. 安全的密钥管理。这是保证上述两点的必要
条件。
银行网络解决之道
• 建立基于硬件加密设备的安全体系,是 解决银行卡网络系统安全的有效办法。
• 现在的银行卡网络安全系统采用的是基 于DES/3DES算法的对称密码体制。
DES算法
• DES算法来自IBM。
加密方式:软件加密
• 缺点Байду номын сангаас安全性差、速度慢、造价高。
密码学课程SPOC教学模式的实践探究

密码学课程SPOC教学模式的实践探究作者:张姗姗来源:《电脑知识与技术》2022年第32期摘要:针对密码学能够保障信息安全的专业特色及疫情期间线上教学的需求,结合SPOC 模式的专属性、重组性等特点,提出密码学课程SPOC教学模式的总体规划,首先分析了该教学模式的特色,接着阐述了具体的实施策略,并通过设计RSA加密方案的SPOC模式教学过程,体现多角度促进混合式教学的教学成效。
关键词:密码学;SPOC;教学模式;密码方案;教学成效中图分类号:TP311 文献标识码:A文章编号:1009-3044(2022)12-0150-031 引言MOOC(Massive Open Online Courses),简称为慕课[1-2],是具有分享协作精神的个人或组织发布在互联网上的大规模免费开放课程,倡导的是一种全新的知识传播模式和学习方式,其理念的核心在于“以学生为中心”,具有大规模、开放访问等特点。
国内外高校在2013年陆续推出自己的MOOC平台,但因其制作成本高及学习管理方面存在较大挑战,故可将MOOC优质资源与面对面的课堂教学有机结合起来,即采用SPOC ( Small Private Online Courses )模式[3]。
針对在校注册学生,在本地自制或借助已有MOOC资源,按照课程大纲要求来重新组合设计,重组教学资源,促进混合式教学,为疫情期间的“停课不停学”保驾护航,也为后续的线下教学提供新的教学方式。
随着计算机和通信网络的迅速发展,信息的安全性已受到人们的普遍重视。
信息安全不仅仅局限于政治和军事外交等领域,已与人们的生活息息相关,没有信息安全就没有国家安全,而密码学能够为信息安全提供强有力技术保障[4-6]。
密码学作为安全类专业的基础课[7-10],目前大多仍是传统授课模式,教学内容偏理论,缺少实践案例教学设置,没能发挥学生的专业特长;教学方法满堂灌,“PPT+粉笔”式教学缺少新意,学生主观能动性没有得以充分调动;考核形式单一化,一考定输赢已经不适合素质教育的要求,且学生自我要求有待重塑。
斯坦福监狱实验

• 津巴多的模拟监狱应该不会发生什么骇人听闻的事情,毕 竟这批所谓的看守和囚犯都是通过心理测试证明是“正常 的、心理健康的”好人。津巴多也在1996年多伦多举行的 讨论会上坦诚,在实验进行之前,觉得有可能只是无聊的 两个星期。
• 实验开始的相遇是尴尬,毕竟对于看守和囚犯双方而言, 都需要时间进入角色。无聊的时光如何打发?于是这群耳 濡目染于当时美国反越战学潮的学生囚犯开始挑战权威: 撕掉缝制于衣服身上的编号,把自己锁在牢房内不理会看 守的命令,并取笑看守。
莱分校助理教授的职务,正准备动身,分身无暇的她只好拒绝了津巴 多邀请其参与斯坦福监狱试验的研究项目。 • 但她还是答应了津巴多帮忙做一些访谈。她在试验进行了大约一周之 后的周四晚上来到了斯坦福监狱。一开始的印象是平静,与其中一名 看守进行了交谈之后,她的感觉是这是一位礼貌、友好和让人愉快的 好人。 • 而这位昵称John Wayne的看守,是斯坦福监狱最“臭名昭著”的狱警。 尽管耳闻John Wayne的作为,Christina见到了John Wayne之后却感到 非常震惊(absolutely stunned):与传闻相反,John Wayne是一个绝 对的好人。但直到她开始试验观察时,看到的却是完全不同的一个人: 他戴着黑色的墨镜,手持警棍,身穿制服,放声嚎叫,痛骂犯人,让 犯人报数时表现出一种粗暴的态度。 • 当时正当洗浴时间。洗浴房在监狱外,看守把犯人用脚镣锁成一列, 每个人都戴上头套,完全看不到环境的情况。再把他们带到洗浴房。 津巴多通过观察窗看着发生在监狱的情形,兴奋地对他的女友说: “快来看,看一下现在要发生什么!”“看到没有,这场景是太棒 了!”但Christina却把头转过去,不忍再看,心里充盈着一种冰凉而 作呕的感觉:如此残暴的场景让她感觉到一种女性置身于男权世界所 产生的无力感。
Lecture02-古典密码

=(9,8,8,24)
=(JIIY)
解密:
K 1 23 20 5 1 2 11 18 1 2 20 6 25 25 2 22 25
P CK 1
23 20 5 1 2 11 18 1 mod 26 (9 8 8 24 ) 2 20 6 25 25 2 22 25
• “China”经仿射加密变换成“RAHQD”
解密:
17 19 236 2 C 0 19 19 7 H 15 7 19 86 mod 26 8 I 16 19 221 13 N 3 19 26 0 A
使用密钥的单表代替加密
• 设密钥为:spectacular。 • 明文:
ABCDEFGHIJKLMNOPQRSTUVWXYZ
• 对应的密文:spectaulrbdfghijkmnoqvwxyz • 如果明文为“China”,则对应的密文为: • elrhs
仿射加密
• 加密:
y f ( x) k1 x k 2 (mod 26)
• 原始消息“China”得到恢复
单表代替密码的特点:
• 密钥量很小,不能抵抗穷尽搜索攻击 • 没有将明文字母出现的概率掩藏起来,很容易 受到频率分析的攻击
频率分析攻击
图3-3 一个长的英文文本中各字母出现的相对频率
常见的双字母组合:TH、HE、IN、ER、RE、AN、ON、EN、 AT; 常见的三字母组合:THE、ING、AND、HER、ERE、ENT、 THA、NTH、WAS、ETH、FOR、DTH等。