多核与多线程
了解电脑CPU的核心和线程

了解电脑CPU的核心和线程在现代计算机科技领域中,中央处理器(CPU)是电脑硬件的核心组成部分。
而在CPU中,核心和线程则是决定其性能和功能的重要因素。
本文将从根本的角度解释电脑CPU的核心和线程,帮助读者更好地了解它们的作用和关系。
一、核心的定义与功能核心是CPU的主要处理单元,它负责执行指令、运算任务和数据的处理。
每个核心都包含着算术逻辑单元(ALU)、寄存器和控制单元等组件,能够独立地执行指令和操作数据。
同时,核心也是电脑多任务处理和多线程操作的基础。
多核技术是现代CPU发展中的重要趋势之一。
通过在一个CPU芯片上集成多个核心,计算机可以同时运行多个任务,提高系统的效率和响应速度。
例如,一款四核CPU就能够同时处理四个不同的任务,从而大大加快了计算机的运行速度。
尽管核心数量的增加可以提供更高的性能,但并不是核心数量越多越好。
实际上,大部分常规应用程序并不能充分利用多核心处理器的性能优势,因此在选购计算机时,需要综合考虑核心数量和实际需求。
二、线程的概念与作用线程是一个程序执行的最小单元,它是CPU调度和执行任务的基本单位。
在多核CPU中,每个核心可以同时运行多个线程,也就是所谓的多线程操作。
多线程技术可以使计算机系统的性能得到更好的发挥。
通过并行处理多个线程,CPU可以更高效地执行多任务,提高整体的运行速度和吞吐量。
例如,在同时运行多个应用程序时,每个程序可以被分配一个单独的线程来处理,从而避免了相互之间的干扰和冲突。
此外,线程还可以用于多线程编程和并发处理。
通过合理地利用线程,可以实现更高效的程序编写和任务分配,提高应用程序的性能和用户体验。
三、核心与线程的关系核心和线程在CPU中的关系密不可分。
每个核心都能同时执行一个线程,因此多核CPU可以同时处理多个线程,实现更高效的并行处理。
然而,核心的数量并不决定线程的数量。
一个核心可以通过多线程技术同时执行多个线程,这称为超线程技术(Hyper-Threading)。
多核多线程技术综述_眭俊华

图 2 多核技术演进过程
图 3 多核 CPU 硬件体系结构
2 与多核 CPU 相关的几个问题
多核 CPU 的出现,给现有的操作系统( Operating System, OS) 、并 行 计 算 ( Parallel Computing ) 和 多 线 程 编 程 技 术 ( Multiple-Thread Programming ) 等带来了深刻的影响。
本质上,并行计算也是多核 CPU 计算机上在更高层上的 一个具体应用,因此在并行算法程序设计时,和在多核要解决同步、通信、负载 均衡和可扩展性等问题。 2. 3 多核 CPU 与软件开发
在多核 CPU 出现前,多线程技术已经出现了几十年,技 术人员很少考虑多线程设计与编程,即使程序是多线程,在单 核平台上,也只能是并发执行,而不是并行执行 ,使得单线程 和多线程的设计没有明显差异; 而且,多线程在单核平台上来 回切换所需要的时间和资源的开销,使得后者( 多线程) 在性 能上有时还比不上前者( 单线程) 。
linux cpuinfo文件详解

linux cpuinfo文件详解Linux系统下,CPU信息详解(cpuinfo,多核,多线程)问题怎么确定呢?经过查看,我的开发机器是1个物理CPU,4核8线程,Intel(R) Core(TM) i7 CPU 860 @ 2.80GHz记录一下,判断的过程和知识。
判断依据:1.具有相同core id的cpu是同一个core的超线程。
2.具有相同physical id的cpu是同一颗cpu封装的线程或者cores。
英文版:1.Physical id and core id are not necessarily consecutive but they are unique. Any cpu with the same core id are hyperthreads in the same core.2.Any cpu with the same physical id are threads or cores in the same physical socket.echo "logical CPU number:"#逻辑CPU个数cat /proc/cpuinfo | grep "processor" | wc -lecho "physical CPU number:"#物理CPU个数:cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -lecho "core number in a physical CPU:"#每个物理CPU中Core的个数:cat /proc/cpuinfo | grep "cpu cores" | uniq | awk -F: '{print $2}'#查看每个physical cpu上core id的数量,即为每个物理CPU上的core的个数cat /proc/cpuinfo | grep "core id"#是否为超线程?#如果有两个逻辑CPU具有相同的”core id”,那么超线程是打开的。
线程核核数的关系-概述说明以及解释

线程核核数的关系-概述说明以及解释1.引言1.1 概述在计算机科学领域,线程和核数都是非常重要的概念。
线程指的是在操作系统中能够独立执行的最小单位,可以理解为进程中的一个实体。
而核数是指计算机处理器中物理核的数量,它决定了计算机的并行处理能力。
本文旨在探讨线程数量与核数之间的关系,以及影响线程与核数关系的因素。
了解线程核数的关系对于编写高效的并行程序和优化计算机系统的性能至关重要。
在多线程编程中,线程的数量与核数之间是一个关键的平衡问题。
过多的线程可能会导致资源的浪费和竞争,而过少的线程可能无法充分利用计算机的处理能力。
因此,了解线程与核数之间的关系对于充分发挥计算机性能具有重要意义。
此外,影响线程与核数关系的因素也是值得探讨的。
不同的应用程序和任务对线程和核数的需求是不同的,这取决于任务的特性、并行性和计算复杂度等因素。
同时,计算机硬件的架构和操作系统的调度策略也会影响线程与核数之间的关系。
综上所述,本文将从线程的概念和核数的定义开始介绍,然后讨论线程数量与核数之间的关系,以及影响线程与核数关系的因素。
通过深入剖析这一关系,读者将能够更好地理解如何有效地利用线程和核数,并优化多线程应用程序的性能。
1.2 文章结构文章结构:本文将从以下几个方面展开讨论线程与核数之间的关系。
首先,我们会介绍线程的概念,解释它在计算机科学中的重要性。
接着,我们会对核数进行定义,详细说明它在计算机硬件中的含义与作用。
然后,我们将探讨线程数量与核数之间的关系,分析它们之间的相互影响与依赖。
最后,我们会列举影响线程与核数关系的因素,帮助读者更好地理解线程与核数之间的动态平衡关系。
通过全面了解线程与核数的关系,读者将能够更好地优化多线程程序的性能,提高计算机系统的效率。
1.3 目的本文旨在探讨线程数量与核数之间的关系,并分析影响线程与核数关系的因素。
通过深入探讨线程的概念和核数的定义,我们将详细分析线程数量与核数之间的关联,并探讨不同因素对线程与核数关系的影响。
多线程和多核的关系

多线程和多核的关系随着计算机技术的不断发展,多线程和多核成为了当前计算机领域中备受关注的两个概念。
对于计算机应用和性能优化来说,多线程和多核之间的关系十分密切。
本文将从多线程和多核的定义、特点和关系等方面进行分析和探讨。
多线程和多核的定义多线程是指在一个进程内同时运行多个独立的任务,其中每个任务称为一个线程。
多线程能够提高程序的并发性和响应速度,充分利用计算机的CPU资源,提高程序效率和性能。
多核是指一个物理处理器内部有多个处理单元,其中每个单元被称为一个核心,多核处理器可同时处理多个任务,提高系统的性能和处理速度。
多线程和多核的特点多线程和多核都是为了充分利用计算机资源,提高计算机的处理能力和性能。
但是它们的特点和优势是不同的。
具体如下:1、多线程(1)能够实现任务之间的并发执行,提高程序的响应速度和效率。
(2)能够更好地利用CPU资源,提高计算机的效率和性能。
(3)在多核计算机中尤为重要,能够更好地利用多核处理器的处理能力,进一步提高计算机的性能。
2、多核(1)能够实现同时处理多个任务,提高系统的性能和处理速度。
(2)在处理大量数据、多线程运算及计算密集型任务时,优势更明显。
(3)能够提供更高的处理能力,更好地满足计算机应用的需要。
多线程和多核的关系多线程和多核的关系主要是体现在并发性和并行性方面。
多线程能够实现并发执行多个任务,而多核则能够实现并行处理多个任务。
多线程在多核中的优势主要体现在以下几个方面:1、更好地利用多核处理器的处理能力,提高系统的性能和效率。
2、能够更好地处理多个任务之间的并发性问题,提高程序的响应速度和效率。
3、能够更好地满足计算机应用的需要,提高应用的处理能力和性能。
但是,多线程和多核的关系也存在一些问题和挑战。
具体如下:1、线程之间的调度和同步问题。
多线程在多核环境中需要更加精细地控制线程之间的调度和同步,以充分利用多核的处理能力。
2、线程间的竞争和锁问题。
多线程中存在多个线程争夺同一个资源的情况,需要更好地解决竞争和锁问题,以避免线程间的冲突和死锁。
多核VS多线程:合适的才是最好的

在进行 中 ,一 方 面 国内外 主流 的半 导 体公 司都 大 的优 势 。 争 先恐 后 地推 出 自己的多 核处 理 器产 品 ,另 一
一
步开 发线 程 级并 行性 ,最大 限度 地利 用处 理
深 圳 中微 电 科 技 有 限公 司 首 席 技 术 官 梅 器 内部 执行 资 源并 具有 最 大 的灵 活性 ,但单 核 思 行从 资 源共 享方 面 指 出两者 的差 别 , “ 核 多 线程 处理 器设 计 实 现难 度也 最 大 。相对 多线 多
们 之 间又有 什 么差 异 ?简 单地 说 ,多 核处 理器 程好 比是拼 车 ,因为要 去 较远 的不 同地方 ,效 是 集成 了多个 处理 器 核心 ,其 可 同时 执行 的任 率 反而不 好 。” 因此他认 为 多线 程在 手机 、P C
务 数是 单 核处 理器 的数 倍 ,从 而提 高 处理 器 的 等 应用 上没 有优 势 ,甚 至很 多 高端 应用 上 多线 并 行性 能 ,而 多线 程处 理 器是 在单 核 中加 入并 程其 他开 销反 而会 降低 了性能 。 行 执行 架构 以发挥 核 的最 大效 能来 提 高处 理性 尽 管 两 种 技 术 看 上 去 截 然 不 同 ,但 芯 原 能 。从 芯 片设计 的角度 来 看 ,多线 程 处理 器在 微 电子 中 国业 务和技 术 支 持高级 总监 汪洋却 认 设计 时 需要 对 内核 的微 架 构进 行调 整 ,开 发难 为 ,实 际上 多 核技 术也 是一 种 多线 程技 术 ,只 度 比多 核处 理器 要 闲难 ,因为 多核 只是 需 要处 是 在空 间上 静 态划 分 了主要 的硬 件 处理 资 源 。 理 核与 核之 间 的关 联 ,而 多线 程需 要 对核 的内 多 线程技 术 是 在开 发指 令级 并行 性 的基 础 上进 部架 构进 行调 整 。
一分钟看懂CPU多发射超标量、多线程、多核之概念和区别

【闲来无事、做做科普、反正也算是marketing job;教你一分钟看懂CPU多发射超标量/多线程/多核之概念和区别】最近在多个场合大肆宣扬多核多线程,收到对多线程表示不解的问题n多,苦思多日,终得一形象生动的模型,你肯定懂的。
因为是比喻和科普、过于严谨的技术控请勿吐槽。
处理器性能提高之公开秘笈:超标量、多线程、多核。
用于说明的生活模型:高速公路及收费站。
简单CPU的原型:单车道马路 + 单收费闸口,车辆只能一辆辆排队通过,并行度为1。
为了提高通行能力同时积极创收,相关部门运用世界顶尖CPU设计理念,对高速公路系统进行了如下拓宽改造:(1)增加车道(图示为3条车道);(2)增加收费通道(图示为2个通道);(3)每个收费通道放置多个收费员(图示每条通道有a和b两个收费窗口)。
其中(1)+(3)组合手段就是所谓的超标量结构,该图示为双发射超标量。
超标量指有多个车道,双发射是指有a和b两位收费员可以同时发卡,把两辆车送到不同车道上去。
手段(2)就是多线程的模型了,原有车道不变、只增加收费通道,这样多个车流来的时候可以同时发卡放行。
从这个比喻来看多线程显然是个非常直观和有用的办法,但为什么在CPU世界中似乎有点模糊难懂的感觉呢?那是因为CPU的指令流喜欢一个挨一个、一列纵队龟速前进,这样的话单通道多收费员还起点作用、多通道就形同虚设了。
收费员1.a和1.b会累死,而2.a和2.b则能够睡觉。
因此把车流进行整队就很重要——这就是并行编程,即要设法把一列纵队排列成多列纵队。
至于多核的概念,那就简单粗暴很多了,直接在这条马路边上进行征地拆迁、新修一条一模一样的高速公路便是,牛吧。
现在大家手机里面的多核,就是并排几条“单收费通道+多车道”的马路,车流稀少、路况不错,不过相关部门表示因为道路利用率底下、经济效益欠佳、回收投资压力巨大。
无论多核还是多线程,都有一个同样的问题需要解决,就是要把车流整成多列纵队,这样多条马路和多个收费通道的并行度才能发挥作用。
多核多线程结构线程调度策略研究

( h o fCo u e ,No t we t r ol t c nia Sc o lo mp t r rh se n P ye h c I Uni e s t v r iy,Xi a 1 07 ) ’n70 2
等热点 , 分析其研 究现状 , 述 已有策略在 处理这些 问题上的优缺点 , 论 并探 讨 了可能的研 究发展方 向。
关 键 , 源划 分 线 资
A u v y ofCM T o e s r Thr a he u e Po i is S re Pr c s o e d Sc d l lc e
摘 要 片上 多核 多线程( MT 结构兼具 了片上 多 ̄I( MP) 同时多线程 ( MT) C ) C 和 s 结构的优 势, 支持片上所有处于
执行状 态的线程每 周期 并行执行 , 导致核 内与核间硬件 资源共 享和争 用问题 。该文在 阐述 C MT结构 的资源共 享特 征并 简要介绍 S MT线程调度发展状 况的基础上 , 主要 围绕 以减 少资源争 用为 目标 的线程调度 策略和资 源划分机 制
1 引言
微体 系结 构 的发 展 已经 迈人 线 程 级 并行 ( L , ra T P T ed L v l aal ) 时代 。 同时 多 线 程 ( MT, i l no s ee p rl 1的 e S Smut eu a
MutThed 结 构 和 片 上 多 处 理 ( MP, hpMut Po e— l ra) i C C i l rcs  ̄
c a a t r t fCMT r h t cu ei it o u e h rcei i o sc a c ie t r n r d c d,t e s h n,t e p e al g S T h e d s h d l o iis h rv in M i t r a c e u ep l e .An h n c d t e ,wep i r—
CPU的基础知识大全

CPU的基础知识大全中央处理器(CPU)其实是一块超大规模的集成电路,用显微镜观察一平方毫米的地方都有超密集的电路集成。
是一台电脑的运算核心和控制核心,它的功能主要是解释计算机指令以及处理各种软件数据。
下面就让小编带你去看看关于CPU 的基础知识大全吧,希望能帮助到大家!CPU 的基础知识CPU是计算机的大脑。
1、程序的运行过程,实际上是程序涉及到的、未涉及到的一大堆的指令的执行过程。
当程序要执行的部分被装载到内存后,CPU要从内存中取出指令,然后指令解码(以便知道类型和操作数,简单的理解为CPU要知道这是什么指令),然后执行该指令。
再然后取下一个指令、解码、执行,以此类推直到程序退出。
2、这个取指、解码、执行三个过程构成一个CPU的基本周期。
3、每个CPU都有一套自己可以执行的专门的指令集(注意,这部分指令是CPU提供的,CPU-Z软件可查看)。
正是因为不同CPU架构的指令集不同,使得x86处理器不能执行ARM程序,ARM程序也不能执行x86程序。
(Intel和AMD都使用x86指令集,手机绝大多数使用ARM指令集)。
注:指令集的软硬件层次之分:硬件指令集是硬件层次上由CPU 自身提供的可执行的指令集合。
软件指令集是指语言程序库所提供的指令,只要安装了该语言的程序库,指令就可以执行。
4、由于CPU访问内存以得到指令或数据的时间要比执行指令花费的时间长很多,因此在CPU内部提供了一些用来保存关键变量、临时数据等信息的通用寄存器。
所以,CPU需要提供一些特定的指令,使得可以从内存中读取数据存入寄存器以及可以将寄存器数据存入内存。
此外还需要提供加法、减、not/and/or等基本运算指令,而乘除法运算都是推算出来的(支持的基本运算指令参见ALU Functions),所以乘除法的速度要慢的多。
这也是算法里在考虑时间复杂度时常常忽略加减法次数带来的影响,而考虑乘除法的次数的原因。
5、除了通用寄存器,还有一些特殊的寄存器。
多核多线程处理器存储技术研究进展

心技术 , 多线程体系结构有望在未来 1 o年中 占支配地位[ 。 1 ]
在 2 0 年 MTE 01 AC( okh po uth eddE eu W r so nM ltrae xc — i
Hale Waihona Puke t n Arhtcuea dC mpl in会 议 上 ,ne 微 处 理 器 研 i , ci tr n o i t ) o e ao Itl
po es r r c s o .Th s p p rf s l ic s e o eo h o i a e i t ds u s ss m f e c mmo r h t c t r ft emu t c r n u t t r a r c s o . r y t n a c i h u eo h li o ea d m li h e d p o e s r e - — An e o d y e p a n o a h e e r h o h lic r n li h e d p o e s r Fi al ,a h a e o b v , d s c n l x li s t d y t e r s a c ft e mu t o e a d mu t t r a r c s o . n l - — y t t e b s fa o e t e p s i l ie in ft e me r e h i u so h u t c r n li h e d p o e s r a e s a e . h o sb ed r t so h mo y t c n q e ft em li o e a d mu t t r a r c s o r t t d o - -
高, 同时也 对存储 系统提 出了更高的要 求 。而相对增长的存储 器访 问延 迟 已经 成为影响 多核 多线 程处理 器性 能进 但
多芯CPU与迅速崛起的多线程编程

多芯CPU与迅速崛起的多线程编程摘要计算机硬件技术飞速发展,多核处理器为多核编程并行算法提供了一个很好的发展平台和契机。
人们的编程思维发生逆转,从模块到各线程间的负载平衡和扩展性,对以往习惯的设计模式进行了新一轮更替。
为了更充分地发挥硬件性能,多核编程面临着新一轮挑战。
关键词多核处理器;多核架构;“摩尔定律”;并行计算;串行算法中图分类号tp393 文献标识码a 文章编号1674-6708(2010)23-0218-022001年ibm推出了双核处理器,2006年多核处理器市场得到普及,屹今为止英特尔、amd等公司都推出了自己的多核处理器。
多核技术受到更多的关注,多核处理器技术成为未来it技术领域的主流,是全球计算机技术发展的重要方向。
1 硬件架构的发展与开发平台的进步多核处理器是多个独立cpu芯片的集成,是以cpu核为独立执行单元的体系结构。
我们可以把多核处理器看成多插槽系统,每个插槽可扩展安装一个cpu,多核封装根据设计选择是否共享cache。
多核硬件结构中,多线程(或多进程)的运用能更充分地发挥硬件性能,使cpu核每时每刻都执行线程。
多核架构具有特定的复杂性,多核cpu讲究“对称性”,联接部件涉及到处理器间的通信、协议、缓存、输入输出等。
相对于单核处理器的30亿次级计算,实施并行计算的超级计算机以百万亿次级的优势遥遥领先。
遵循“摩尔定律”的单核处理器在主频提升方面遇到的瓶颈、计算机系统性能在处理器提升方面的入不敷出都在这里得到了突破,多核技术在网络服务器、工作站、多媒体图形技术、实时嵌入式技术、安全杀毒技术等领域全面开花。
多核时代来临了,多核编程技术已经成为当今程序员必须掌握的技术。
1972年计算机开发平台就根据指令和数据流分成了四类:多指令流单数据流的misd一般只作为理论常识被认知;单指令流单数据流的sisd是我们所熟知的串行处理平台;单指令流多数据流的simd 在图形图像、数字信号和多媒体技术等方面应用较多;多指令流多数据流的mimd是当前最新多核技术的主要开发平台。
cpu核和线程的区别

cpu核和线程的区别中央处理器(CentralProcessingUnit)的缩写,即CPU,CPU是电脑中的核心配件,只有火柴盒那么大,几十张纸那么厚,但它却是一台计算机的运算核心和控制核心。
下面是店铺带来的关于cpu 核和线程的区别的内容,欢迎阅读!cpu 核和线程的区别:单核就是CPU集成了一个运算核心;双核是两个运算核心,相当于两个CPU同时工作;四核是四个运算核心,相当于四个CPU同时工作;多核:CPU最初发展的时候是一个CPU一个处理核心,CPU的性能主要靠提高核心工作频率来提高,由于物理限制,不能把CPU的核心频率无限提高,所以发展出来双核心或多核心的CPU。
相当于在一枚处理器上集成多个完整的计算引擎(内核),他们共享缓存,内存,寄存器等。
两个核心一起工作需要靠软件的支持。
软件要明白怎么把任务分给两个核心让他们一起工作,这样变相的提高了CPU的处理性能,现在新出的软件都支持多核心了。
本来是一个核心一个线程,不过INTEL发明了一个核心跑出两个线程,这叫超线程技术。
所以有双核4线程的说法。
多线程:什么是线程?每个正在系统上运行的程序都是一个进程。
每个进程包含一到多个线程。
进程也可能是整个程序或者是部分程序的动态执行。
线程是一组指令的集合,或者是程序的特殊段,它可以在程序里独立执行。
也可以把它理解为代码运行的上下文。
所以线程基本上是轻量级的进程,它负责在单个程序里执行多任务。
通常由操作系统负责多个线程的调度和执行。
什么是多线程?多线程是为了使得多个线程并行的工作以完成多项任务,以提高系统的效率。
线程是在同一时间需要完成多项任务的时候被实现的。
使用线程的好处有以下几点:·使用线程可以把占据长时间的程序中的任务放到后台去处理·用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度·程序的运行速度可能加快·在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较游泳了。
多核心性能比拼年最适合多线程工作的CPU排行

多核心性能比拼年最适合多线程工作的CPU排行随着科技的不断发展,计算机的性能要求也越来越高。
对于需要处理大量复杂任务的用户,多线程工作是必不可少的。
而多线程工作最重要的一项指标就是CPU的多核心性能。
本文将对当前市场上最适合多线程工作的CPU进行排行,并进行性能比较。
一、AMD Ryzen 9 5950X作为AMD最新推出的顶级处理器,Ryzen 9 5950X拥有16个物理核心和32个线程,采用了台积电的7nm制程工艺。
其基础频率为3.4GHz,最高可达4.9GHz。
在多线程工作中,Ryzen 9 5950X表现出色,能够处理更多的任务,同时具备较低的功耗。
它在多核心性能方面表现出色,是最适合多线程工作的CPU之一。
二、Intel Core i9-10900K作为Intel的顶级桌面处理器,Core i9-10900K拥有10个物理核心和20个线程。
尽管核心数量不及Ryzen 9 5950X,但其高频率(基础频率3.7GHz,最高可达5.3GHz)使得它在单线程性能上具有一定优势。
在多线程工作中,Core i9-10900K表现也十分出色,能够快速处理大量的任务。
对于需要兼顾单核和多核性能的用户来说,Core i9-10900K是一个不错的选择。
三、AMD Ryzen 7 5800XRyzen 7 5800X是AMD推出的中高端处理器,拥有8个物理核心和16个线程。
与Ryzen 9 5950X相比,它在核心数量和总线程数上略有落后,但在性能表现上依然出色。
Ryzen 7 5800X采用了相同的7nm制程工艺,基础频率为3.8GHz,最高可达4.7GHz。
在多线程工作中,它仍然能够胜任大多数任务,并且功耗相对较低。
对于中高端用户来说,Ryzen 7 5800X是一个性能与功耗平衡的选择。
四、Intel Core i7-10700KCore i7-10700K是Intel的中高端桌面处理器,拥有8个物理核心和16个线程。
电脑cpu的核心与线程是什么意思?

电脑cpu的核心与线程是什么意思?你说的核心与线程是常说的某CPU有4核心8线程中的意义吧,这个就要分开讲讲:CPU核心随着工艺的局限和频率的难以提升,CPU的性能不能再是无限制的往高频率的方向发展了,开始转向多核心的方向,简单地说,就是在一个物理内核里并列几个功能相同的核心,它们可以并行执行不同的任务进程,打个比方说,以前是一个人上夜班,现在是四个人上夜班,这就是所谓的CPU核心。
各个CPU核心都具有固定的逻辑结构,如一级缓存、二级缓存、执行单元、指令级单元和总线接口等逻辑单元等,CPU核心的进步对普通消费者而言,就是能以较低的价格买到性能较强的CPU。
但是,在多核CPU中,并不是所有的核心都是在全速满负载工作,可能有时内核会有所闲置,这样就有了Intel的超线程和AMD的多线程技术,把这些闲置资源利用起来。
线程严格来说,线程(Thread)是操作系统能够进行运算调动的最小单位,作为进程中的实际运作单位,一个进程中可以并发多个线程,每条线程并行执行不同的任务。
多线程指的是在一个CPU核心上执行多个线程,或者多个任务,虽然在同一核心但是它们之间完全分离。
多线程可以用Temporal MultiThreading时间多线程和Simulate MultiThreading同步多线程来实现,具体细节这里就不讲了。
Windows 10下CPU的负载相当平均对于单一核心而言,它能每秒钟处理成千上万条指令,但是在某一时刻只能够对一条指令进行处理,超/多线程技术能够在软件层变成将它变成两个逻辑处理器,同步并行处理更多指令和数据,它就是一种可以将CPU内部暂时闲置处理资源充分“调动”起来的技术。
我们对比测试过Core i7-6700K和Core i5-7600K,他们主要区别就在于超线程的有无和L3缓存的大小了,至于Skylake与Kaby Lake架构是没有性能上的差别的。
可以看到有超线程的Core i7-6700K其多线程性能比Core i5-7600K好19%左右。
多线程与多核编程

第13章 多线程与多核编程多任务的并发执行会用到多线程(multithreading ),而CPU 的多核(mult-core )化又将原来只在巨型机中才使用的并行计算(parallel computing )带入普通PC 应用的多核程序设计(multi-core programming )中。
13.1 进程与线程进程(process )是执行中的程序,线程(thread )是一种轻量级的进程。
13.1.1 进程与多任务现代的操作系统都是多任务(multitask )的,即可同时运行多个程序。
进程(process )是位于内存中正被CPU 运行的可执行程序。
参见图15-1。
图15-1 程序与进程目前的主流计算机采用的都是冯·诺依曼(John von Neumann )体系结构——存储程序计算模型,程序(program )就是在内存中顺序存储并以线性模式在CPU 中串行执行的指令序列。
对于传统的单核CPU 计算机,多任务操作系统的实现是通过CPU 分时(time-sharing )和程序并发(concurrency )完成的。
即在一个时间段内,操作系统将CPU 分配给不同的程序,虽然每一时刻只有一个程序在CPU 中运行,但是由于CPU 的速度非常快,在很短的时间段中可在多个进程间进行多次切换,所以用户的感觉就像多个程序在同时执行,我们称之为多任务的并发。
13.1.2 进程与线程程序一般包括代码段、数据段和堆栈,对具有GUI (Graphical User Interfaces ,图形用户界面)的程序还包含资源段。
进程(process )是应用程序的执行实例,即正在被执行的程序。
每个进程都有自己的虚拟地址空间,并拥有操作系统分配给它的一组资源,包括堆栈、寄存器状态等。
线程(thread )是CPU 的调度单位,是进程中的一个可执行单元,是一条独立的指令执行路径。
线程只有一组CPU 指令、一组寄存器和一个堆栈,它本身没有其他任何资源,而是与拥有它的进程共享几乎一切,包括进程的数据、资源和环境变量等。
CPU多核性能及超线程技术详解

CPU多核性能及超线程技术详解如今,计算机技术的迅速发展推动了处理器性能的持续提升。
而在处理器设计中,多核心和超线程技术作为两个重要的方向,对于提升CPU性能起到了举足轻重的作用。
本文将详细讨论多核性能和超线程技术,并探究它们对计算机性能的贡献。
一、多核性能的原理及优势多核技术是在一个芯片上集成多个处理器核心,将原本单一的处理器拆分成多个独立的核心。
这些核心可以同时执行不同的指令,充分利用处理器的资源。
多核性能的提升主要基于以下两个原理:1.并发处理能力增强:多核处理器拥有多个独立的核心,能够并发地执行多个任务。
当一个任务正在等待某个资源(例如内存或者I/O设备)时,其他核心可以继续执行其他任务,从而提高系统的整体吞吐量。
2.负载均衡:多核处理器可以将任务分配给不同的核心处理,实现负载均衡。
这种均衡可以保证每个核心都得到充分利用,防止某一个核心过载,而另一个核心处于闲置状态。
多核性能的优势主要体现在以下几个方面:1.多线程应用的加速:多核技术可以充分利用并发性,对于多线程应用程序的性能提升尤为明显。
在多核处理器上,每一个线程都可以运行在一个独立的核心上,实现并行处理,从而大大缩短了程序的执行时间。
2.运算能力的提升:多核处理器的核心数量增多,意味着能够同时处理更多的指令。
对于需要大量计算的任务,如图形渲染和科学计算等,多核处理器能够显著加速计算速度。
3.能源效率的提高:相较于单核处理器,多核处理器在相同计算能力下能够以较低的时钟频率运行,从而降低功耗。
这使得多核处理器在能耗方面更加高效,有助于节省电力。
二、超线程技术的原理及优势超线程技术是一种利用处理器的硬件资源并行执行多个线程的方法。
在超线程技术下,单个物理核心可以模拟出多个逻辑核心,每个逻辑核心都能够独立地执行指令。
这使得处理器能够在同一个时钟周期内同时执行多个线程,从而提高了系统的并发性能。
超线程技术的原理和优势可以归结如下:1.资源利用率提升:超线程技术能够将一个物理核心模拟为多个逻辑核心,每个逻辑核心都具备自己的寄存器和计算单元。
揭密多线程和多核技术

在市场销售流行的游戏机。 为了取得成 万个产品 ( 不仅包括 R I 这 S 的设计,还 尽可能 限制 第三方厂家获取 关键的设 功, 该公司采用 r 以游戏销售和附件的 加上L ts 、 例如 , 使用在编程过程中能对 o 自己的标 牌) 这些 冒牌产品 计信启 。 u 。 版税来补 贴机 器成本的业 式。同 后来通过 灰色市场 以低价销 售 ,使到 位流进 行AE 加密的 F G 务模 S P A解决 方案 , 时 , 了防止第三方厂家复制或利用逆 市场竞争增加 , 为 价格下降 ; 而且 由 F产 在制造环节 中减小设计泄漏的风险。 向工程技术破解其产品 , 从而制造出兼 品无法胜过竞争对手 ( 尽管是 自己设计 保护 I 另一种途径是考虑为设 P的
利用以S AM为基础的F G R P A没计和开
基于闪存的 F G P A
针 对设计的实现 来小心地选择技术是
使用市场上最 安全的可编程逻辑 保 护这种可贵资产 免受不道德竞争对
发MP 播放器。 3 作为一个家电品牌, S 技 术来减低针对物理层面的潜在攻击 , 手攻击的第一道防线 。 RI 圄
但 成 本和 功 率 敏 感的 设 计都 受 到 极 能 够均 匀地 分 布到 4个 处理 器 ,那 器 都 有 具 大程 度 的限制 。幸运 的是 , 事实 上所 么 每个 处理 器只需 在 2 0MHz下运 体的职责 , 5 有 电 脑设 备 都 有 某种 程 度 的 多任 务 行 。如 果每 个 2 O 5 MHz的处 理 器只 并 可 根 据 协同。 至少 在某 些时 间 , 有两 个或 有 1 会 GHz 理 器的 四分之 一大 小 , 处 或 具 体 任 务
类 问题 时 应清 楚掌握 最关键 的步 骤 ,
以便保护知识产权。
浅谈多核CPU、多线程、多进程

浅谈多核CPU、多线程、多进程1.CPU发展趋势核⼼数⽬依旧会越来越多,依据摩尔定律,由于单个核⼼性能提升有着严重的瓶颈问题,普通的桌⾯PC有望在2017年末2018年初达到24核⼼(或者16核32线程),我们如何来⾯对这突如其来的核⼼数⽬的增加?编程也要与时俱进。
笔者⽃胆预测,CPU各个核⼼之间的⽚内总线将会采⽤4路组相连:),因为全相连太过复杂,单总线⼜不够给⼒。
⽽且应该是⾮对称多核处理器,可能其中会混杂⼏个DSP处理器或流处理器。
2.多线程与并⾏计算的区别(1)多线程的作⽤不只是⽤作并⾏计算,他还有很多很有益的作⽤。
还在单核时代,多线程就有很⼴泛的应⽤,这时候多线程⼤多⽤于降低阻塞(意思是类似于while(1){if(flag==1)break;sleep(1);}这样的代码)带来的CPU资源闲置,注意这⾥没有浪费CPU资源,去掉sleep(1)就是纯浪费了。
阻塞在什么时候发⽣呢?⼀般是等待IO操作(磁盘,数据库,⽹络等等)。
此时如果单线程,CPU会⼲转不⼲实事(与本程序⽆关的事情都算不⼲实事,因为执⾏其他程序对我来说没意义),效率低下(针对这个程序⽽⾔),例如⼀个IO操作要耗时10毫秒,CPU就会被阻塞接近10毫秒,这是何等的浪费啊!要知道CPU是数着纳秒过⽇⼦的。
所以这种耗时的IO操作就⽤⼀个线程Thread去代为执⾏,创建这个线程的函数(代码)部分不会被IO操作阻塞,继续⼲这个程序中其他的事情,⽽不是⼲等待(或者去执⾏其他程序)。
同样在这个单核时代,多线程的这个消除阻塞的作⽤还可以叫做“并发”,这和并⾏是有着本质的不同的。
并发是“伪并⾏”,看似并⾏,⽽实际上还是⼀个CPU在执⾏⼀切事物,只是切换的太快,我们没法察觉罢了。
例如基于UI的程序(俗话说就是图形界⾯),如果你点⼀个按钮触发的事件需要执⾏10秒钟,那么这个程序就会假死,因为程序在忙着执⾏,没空搭理⽤户的其他操作;⽽如果你把这个按钮触发的函数赋给⼀个线程,然后启动线程去执⾏,那么程序就不会假死,继续相应⽤户的其他操作。
多核多线程
1、CMP的概念:单芯片多处理器、片上多核处理器。
单芯片多处理器(Chip Multiprocessors,简称CMP),CMP是由美国斯坦福大学提出的,其将大规模并行处理器中的SMP(对称多处理器)集成到同一芯片内,各个处理器并行执行不同的进程。
片上多核处理器(Chip Multi-Processor,CMP)就是将多个计算内核集成在一个处理器芯片中,从而提高计算能力。
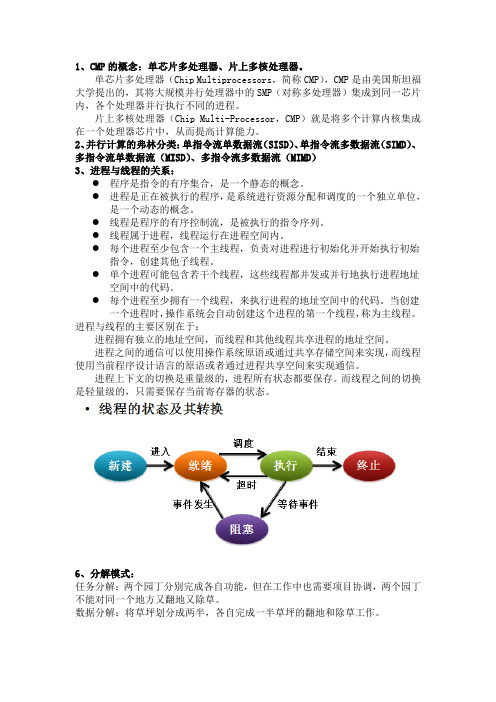
2、并行计算的弗林分类:单指令流单数据流(SISD)、单指令流多数据流(SIMD)、多指令流单数据流(MISD)、多指令流多数据流(MIMD)3、进程与线程的关系:●程序是指令的有序集合,是一个静态的概念。
●进程是正在被执行的程序,是系统进行资源分配和调度的一个独立单位,是一个动态的概念。
●线程是程序的有序控制流,是被执行的指令序列。
●线程属于进程,线程运行在进程空间内。
●每个进程至少包含一个主线程,负责对进程进行初始化并开始执行初始指令,创建其他子线程。
●单个进程可能包含若干个线程,这些线程都并发或并行地执行进程地址空间中的代码。
●每个进程至少拥有一个线程,来执行进程的地址空间中的代码。
当创建一个进程时,操作系统会自动创建这个进程的第一个线程,称为主线程。
进程与线程的主要区别在于:进程拥有独立的地址空间,而线程和其他线程共享进程的地址空间。
进程之间的通信可以使用操作系统原语或通过共享存储空间来实现,而线程使用当前程序设计语言的原语或者通过进程共享空间来实现通信。
进程上下文的切换是重量级的,进程所有状态都要保存。
而线程之间的切换是轻量级的,只需要保存当前寄存器的状态。
6、分解模式:任务分解:两个园丁分别完成各自功能,但在工作中也需要项目协调,两个园丁不能对同一个地方又翻地又除草。
数据分解:将草坪划分成两半,各自完成一半草坪的翻地和除草工作。
数据流分解:一个园丁承担准备工具任务,他要完成为割草机加油,清扫剪刀等工作。
直到这些准备工作就绪后,其他工作才能开始。
Python并行计算专题

Python并⾏计算专题⽬录最近⼯作中经常涉及到Python并⾏计算的内容,所以今天做⼀期专题的知识整理。
本⽂将涉及以下三块内容:1. 多核/多线程/多进程的概念区分,2. Python多线程,多进程的使⽤⽅式,3. Python进程池的管理⽅案多核/多线程/多进程⼀般⽽⾔,计算机可以并⾏执⾏的线程数量就是CPU的物理核数,因为CPU只能看到线程(线程是CPU调度分配的最⼩单位)。
然⽽,由于超线程技术的存在,现在的CPU可以在每个内核上运⾏更多的线程,因此,现代计算机可以并⾏执⾏的线程数量往往是CPU物理核数的两倍或更多进程是操作系统资源分配(内存,显卡,磁盘等)的最⼩单位,线程是执⾏调度(即CPU资源调度)的最⼩单位(CPU看到的都是线程⽽不是进程)。
⼀个进程可以有⼀个或多个线程,线程之间共享进程的资源。
如果计算机有多个内核,且计算机中的总的线程数量⼩于逻辑核数,那线程就可以并⾏运⾏在不同的内核中。
如果是单核多线程,那多线程之间就不是并⾏的关系,它们只是通过分时的⽅式,轮流使⽤单个内核的计算资源,营造出⼀种“并发”执⾏的假象。
由于线程切换需要耗费额外的资源,因此如果多线程协同处理的是同⼀个计算任务,那么该任务的完成速度是不如单线程从头算到尾的针对计算密集型的任务,我们使⽤与逻辑内核数相同的线程数就可以最⼤化地利⽤计算资源(线程数少了会引起内核资源的闲置,线程数多了则会消耗不必要的资源在分时切换上)。
如果是IO密集型任务,我们就需要创建更多的线程,因为当⼀个线程已经算好结果,在等待IO写⼊时,我们就可以让另⼀个线程去使⽤此时空闲的内核资源,在这个场景下线程间切换的代价是⼩于内核资源闲置的代价的在上⼀段中,我们讨论的⼀直都是线程,那么什么时候我们应该使⽤更多的进程呢?回顾之前提到过的进程的特点:进程是操作系统资源分配的最⼩单位因此,是否使⽤多进程,这取决于你是否想要,并且是否能够发挥某⼀系统资源IO性能的最⼤值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
{
c=_getch(); //选择输入;
if(c=='1') //这个if就是第一段程序的总体了,可以与下个else if比较发现仅少了 #pragma omp parallel for 语句;
This handle must have the PROCESS_QUERY_INFORMATION access right. For more information, see Process Security and Access Rights.
for(int k=0;k<10000;k++);
}
int main(int argc, char* argv[])
{
int k[num];
char c='0';
printf("请选择想执行的程序:\n1.单线程示例程序\n2.多线程示例程序\n3.退出\n注:这两段程序相同所不同的是第二段为多线程程序,计算性能应从电脑提示程序已经开始时计算!\n请输入:");//这个for是整个循环主题了,也就是程序的框架;但是这个for不是最耗性能的,所以不用多线程化;
#pragma omp parallel for //就多了这么一句,在我的电脑上就快了75%;
for ( int j = 0; j < num; j++ )
{
k[j]=j;
printf("%d ",k[i]); 很显然,这是一个经典的单线程程序,其中的for(int p=0;p<10000;p++)cout(p); 是一个内嵌了提高程序复杂性的函数的大循环,主要是为了提高程序的额外开销,以便于我们能够明显的观察到多线程程序与单线程程序之间的性能差异。整个for程序执行的流程如下所示: j=0 -> k[j]=j -> 进行复杂运算 -> j!=j++并继续下一个循环num-1?:退出循环并顺序显示k[num]中的内容 有一点需要注意的是,由于单线程的程序是顺序执行的,所以上面这个程序第二个for语句其实是可以不必使用的,可以将它内嵌入第一个for语句中: for ( int j = 0; j < num; j++ )
BOOL GetProcessAffinityMask(
HANDLE hProcess,
PDWORD_PTR lpProcessAffinityMask,
PDWORD_PTR lpSystemAffinityMask
);
Parameters
hProcess
[in] Handle to the process whose affinity mask is desired.
{
printf("1\n第一段程序已经开始了,该段程序是单线程程序\n");
for ( int j = 0; j < num; j+or(int p=0;p<10000;p++)cout(p); //开始做无用功!既进行很大的for循环,又调用函数,主要目的就是让它耗时间;
} else if(c=='2') //第二段主程序;
{
printf("2\n第二段程序已经开始了,该段程序和第一段程序相同,只是多了#pragma omp parallel for,我们可以仔细观察它们的区别\n");
for(int p=0;p<10000;p++)cout(p);
}
for(int i=0;i<num;i++)
printf("%d ",k[i]);
printf("\n第二段程序已经结束\n请输入:");
}
for(int i=0;i<num;i++) //顺序输出0-99;
printf("%d ",k[i]);
printf("\n第一段程序已经结束\n请输入:");
{
k[j]=j;
for(int p=0;p<10000;p++)cout(p); //进行很大的for循环,又调用函数,主要目的就是让它耗时间; printf("%d ",k[i]);
} 这样可以减少程序额外开销,但是对于多线程程序来说,这点开销是必须的,如果输出必须是顺序的话,那我们有必要控制它的输出顺序,否则将会出现乱序输出--尽管结果是正确的,但是输出的顺序却是我们不想看到的。当然,第二个for语句所增加的开销,远远比不上并行程序运行时所节约的开销。我们使用Intel的openmp技术来创建多线程的程序,因为openmp技术够直观,也很容易去分析与理解,所以我们无需去调用底层API就能够轻易的实现多线程编程。要使用openmp技术就要安装Intel编译器及下面的openmp组件,Intel编译器可以很好的与Visual Stdio整合在一起,起码要求是你的计算机上必须安装了Visual C++6.0。当然,安装完之后我们必须进行一些设置,以Visual Stdio 2008为例,如果我们想要使用openmp技术的话,我们须在VC项目下右边的“资源管理器”中点“属性”--“C/C++”--“语言”--有个“openmp支持”选项,选“是(/openmp)”即可。另外我们必须在程序中插入<omp.h>的头文件。 做完了最基本的设置之后,我们就可以开始改程序了: #pragma omp parallel for //就多了这么一句,在我的电脑上就快了75%;
多核平台下的多线程编程示例zz2008-07-15 10:41PC时代引来了多核平台,在硬件性能不断提升的情况下,我们有没有做好迎接它的准备?在单核时代,程序是单线程运行,由于Intel引入了超线程的技术,使我们还在单核时代就领略了将会在多核平台下成为主流的多线程编程技术。但是有一个显而易见的问题:如果没有软件的支持,那么多核平台将无法发挥它的优势,那么我们转变到多核平台所需要的代价将变得没有意义。所以,幸运的是,多线程编程技术出现在了多核平台之前,并且早已为多核平台打下了基础,而且芯片公司也早已预见到了这种软硬必须同步发展的必要性。Intel在其最新的编译器中,已经为软件多线程编程提供了多种方案;当然,本篇只是一篇多线程编程的实验结论,并不是探求多线程编程技术理论的文章,所以不想对其深入探讨。本篇所作的实验是在Intel Core2 Quad Q6600 2.4G四核处理器平台下的试验性程序,其编程平台选用的是Microsoft Visual Stdio 2008专业版+Intel C++编译器10.1。 首先我们先来看一段例程: for ( int j = 0; j < num; j++ )
{
k[j]=j;
for(int p=0;p<10000;p++)cout(p); //进行很大的for循环,又调用函数,主要目的就是让它耗时间;
}
for(int i=0;i<num;i++) //顺序输出0-99;
如题
提问者: wdh128b - 一级最佳答案MSDN:
GetProcessAffinityMask
The GetProcessAffinityMask function retrieves the process affinity mask for the specified process and the system affinity mask for the system.
} else //稍微做的正规点,就加了这么一句;
printf("无该选项,请重新选过!\n请输入:");
}
return 0;
多核多线程编程中,怎么获得线程在哪个cpu核上运行?
悬赏分:20 - 解决时间:2009-5-13 18:59
for ( int j = 0; j < num; j++ )
{
k[j]=j;
for(int p=0;p<10000;p++)cout(p);
}
for(int i=0;i<num;i++)
printf("%d ",k[i]); 这就可以了,我们发现,仅仅只是多了一条“#pragma omp parallel for”而已,但是就多了这么一句,就是程序在我的计算机上快了近75%(估测,非精确计算)。原先程序使用了近32秒,但是现在程序仅用了8秒,这证明了程序运行确实是大幅提高了性能。那我们该着么理解这仅多出来的一条语句呢?很简单,这显然是编译器控制指令,它会在程序编译的时候自动分析for语句,将它拆成多个线程来运行。这样做的好处是我们能够很简单的就创建多线程程序而无需去了解其底层的运行机制,但是它也有一些局限性,使得我们不得不考虑以下几个问题: 1.对for语句我们必须使用for(i=xxx;x<或>xxx;i的运算法则不能含有变量)其中xxx为固定的常数的形式的循环才能够使用#pragma omp parallel for (当然sections结构也可以进行拆分),也就是说在需要进行多线程化的循环必须是定长的、可预见的,当然使用低层API我们可以动态的创建线程,也就不存在定长循环的问题。 2.对所要拆分线程的for语句,规定不得存在迭代相关性。因为创建线程后线程之间是独立运行的,如果线程之间存在相关性,将会使得程序产生混乱的运行结果。当然使用底层的API我们可以更有效的控制和操作各个线程的合作与运行,但是在openmp就无法实现了。如果要进行多线程化的循环出现了迭代相关性,那我们必须重新设计for循环,以等效的无相关性的循环代替它,但是代价就是提高了程序的复杂性。 3.数据竞争。我们必须保证,各个线程之间不会对同一个外部或公共变量进行操作(哪怕是读操作都是危险的),在此情况下,Intel提供了两种方案:一种是尽可能的使用私有或局部变量;一种是获取公共变量的副本。 总之,openmp的编程技术确实是非常的方便与美妙,只要我们在程序设计的时候遵守了以上几个法则即可。当然,openmp的功能要远为强大的多,包括更复杂的线程分配方案、更复杂的操作等,但是却能很简单的应用。不过对本例来说还用不着那些技术,仅 #pragma omp parallel for就足亦。下面我将这次试验的源代码完整的贴上来,以使各位能够更全面的来了解一下程序的结构://多线程试验程序#include "stdafx.h"