基于Clementine数据挖掘模型评估
第5章 Clementine使用简介

第5章 Clementine使用简介5.1Clementine 概述Clementine数据挖掘平台是一个可视化的、强大的数据分析平台。
用户可以通过该平台进行与商业数据操作相关的操作。
数据流区域:它是Clementine窗口中最大的区域,这个区域的作用是建立数据流,或对数据进行操作。
选项板区域:它是在Clementine的底部,每个选项卡包含一组相关的可以用来加载到数据流区域的节点组成。
它包括:数据源、记录选项、字段选项、图形、建模和输出。
管理器:它位于Clementine的右上方,包括流、输出和模型三个管理器。
项目区域:它位于Clementine的右下方,主要对数据挖掘项目进行管理。
并且,它提供CRISP-DM和类两种视图。
另外,Clementine还包括类似于其他windows软件的菜单栏、工具栏和状态栏。
Clementine非常容易操作,包含很多经典数据挖掘算法和一些较新的数据挖掘算法通常,大多数数据挖掘工程都会经历以下过程:检查数据以确定哪些属性可能与相关状态的预测或识别有关。
保留这些属性(如果已存在),或者在必要时导出这些属性并将其添加到数据中。
使用结果数据训练规则和神经网络。
使用独立测试数据测试经过训练的系统。
Clementine的工作就是与数据打交道。
最简单的就是“三步走”的工作步骤。
首先,把数据读入Clementine中,然后通过一系列的操作来处理数据,最后把数据存入目的文件。
Clementine数据挖掘的许多特色都集成在可视化操作界面中。
可以运用这个接口来绘制与商业有关的数据操作。
每个操作都会用相应的图标或节点来显示,这些节点连接在一起,形成数据流,代表数据在操作间的流动。
Clementine用户界面包括6个区域。
数据流区域(Stream canvas):数据流区域是Clementine窗口中最大的区域,在这个区域可以建立数据流,也可以对数据流进行操作。
每次在Clementine中可以多个数据流同时进行工作,或者是同一个数据流区域有多个数据流,或者打开一个数据流文件。
数据挖掘 培训SPSS clementine11

数据准备:
© 2006 SPSS Inc.
10
课程计划
建模技术:
监督学习技术,
神经网络、归纳规则(决策树)、线性回归、Logistic 回归 Kohonen 网络、两步聚类、 K-means 聚类
非监督学习技术,
关联规则、时序探测
模型评估 如何应用 CRISP-DM 流程研究数据挖掘问题
© 2006 SPSS Inc.
11
第二章 Clementine简介
Clementine 简介
内容
熟悉 Clementine 中的工具和面板 介绍可视化编程的思想 初步了解 Clementine 的功能 课程的数据文件存放在目录―C:\培训\基础培训1‖中
目的
数据
© 2006 SPSS Inc.
在挖掘数据前,需要做什么样的数据预整理和 数据清洗?
将会使用什么样的数据挖掘技巧? 将会如何评估数据挖掘的分析结果?
© 2006 SPSS Inc.
8
CRISP-DM 过程模型
跨行业数据挖掘标准过程 (CRISP-DM)
定位是面向行业、工具导 向、面向应用 适用于大型工业和商业实 践的一般标准
13
Clementine用户界面
菜单栏 工具栏 数据流, 输出和模型 管理器
数据流区域
选项板区 项目窗口
节点
© 2006 SPSS Inc.
14
可视化编程
节点
一个图标代表在 Clementine 中进行的一个操作 一系列连接在一起的节点 包含一系列不同功能的图标
如何使用数据挖掘工具Clementine——以我国图书情报类期刊学术影响力评价为例

T k n hn s irr n nom d n Ju as A a e c a igC iee Lbaya dIfr a o o r l ’ c d mi n
I a tE au t n a n Emprc sa c mp c v l ai s A o i a Re e rh il
以我 国图书情报 类期 刊学术 影 响力评 价 为例
李 许 扬 阳 培
( 北京协 和 医学院 医学信 息研 究所 ,北 京 102) 000
( 摘 要)本文首 先简要介绍了数据挖掘工具 geel 的特 点及若干基本功能 ( l nn m te 即若干模块) ,然后 以基 于 《 中国期刊 高
D : 0.9 9 i n.0 8—0 2 .0 2. 1 0 5 OI1 3 6 s 1 0 s 8 1 2 1 O .3
[ 中图分类号]G5 . ( 215 文献标识码) [ A 文章编号]10 — 81( 1) 1 04 0 08 02 2 2 O — 1 0 6— 4
Ho t e Clme t e a Da a l n n o w o Us e n i sA t n t g To l n v
lg yce d ̄ o hns u a 2 1 e i )pbse yITC h ae vl t e cdmcipc b s g II t i e f i e or l 00vro ulhdb / ,t ppr a a dt iaae i m at yui id id n C e j n s( sn i S e e ue hr n
该软件将一系列数据处理程序或技术整合成相互独立的模块例如将聚类决策树神经网络关联规则等多种数据挖掘技术集成在直观的可视化图形界面中并采用图形用户交互式界面因此对于不谙编程但又经常面临大量数据处理任务的用户来说它的确要比excel更易用更高效而且处理方法有重用性即这次构建的数据流经保存后可在下一个类似任务中稍做修改便可使用或者一条数据流可以支持相似数据的分析不需要再翻看复杂的编程手册在excel里频繁使用各种函数整理数据等
实验一 Clementine12.0数据挖掘分析方法与应用

实验一Clementine12.0数据挖掘分析方法与应用一、[实验目的]熟悉Clementine12.0进行数据挖掘的基本操作方法与流程,对实际的问题能熟练利用Clementine12.0开展数据挖掘分析工作。
二、[知识要点]1、数据挖掘概念;2、数据挖掘流程;3、Clementine12.0进行数据挖掘的基本操作方法。
三、[实验内容与要求]1、熟悉Clementine12.0操作界面;2、理解工作流的模型构建方法;3、安装、运行Clementine12.0软件;4、构建挖掘流。
四、[实验条件]Clementine12.0软件。
五、[实验步骤]1、主要数据挖掘模式分析;2、数据挖掘流程分析;3、Clementine12.0下载与安装;4、Clementine12.0功能分析;5、Clementine12.0决策分析实例。
六、[思考与练习]1、Clementine12.0软件进行数据挖掘的主要特点是什么?2、利用Clementine12.0构建一个关联挖掘流(购物篮分析)。
实验部分一、Clementine简述Clementine是ISL(Integral Solutions Limited)公司开发的数据挖掘工具平台。
1999年SPSS公司收购了ISL公司,对Clementine产品进行重新整合和开发,现在Clementine已经成为SPSS公司的又一亮点。
作为一个数据挖掘平台,Clementine结合商业技术可以快速建立预测性模型,进而应用到商业活动中,帮助人们改进决策过程。
强大的数据挖掘功能和显著的投资回报率使得Clementine在业界久负盛誉。
同那些仅仅着重于模型的外在表现而忽略了数据挖掘在整个业务流程中的应用价值的其它数据挖掘工具相比,Clementine其功能强大的数据挖掘算法,使数据挖掘贯穿业务流程的始终,在缩短投资回报周期的同时极大提高了投资回报率。
为了解决各种商务问题,企业需要以不同的方式来处理各种类型迥异的数据,相异的任务类型和数据类型就要求有不同的分析技术。
设备维修信息数据挖掘

设备维修信息数据挖掘摘要随着市场竞争的日益激烈,维修售后服务成为了企业的重要竞争能力之一。
然而由于产品故障的不确定性使得备件需求难于预测,维修备件越来越多使得备件库存维护成本不断增加。
这些问题使得维修企业面临的负担加重。
因此针对产品的备件需求问题,本文利用某设备生产企业的维修数据记录,基于数据挖掘技术对不同型号的手机常见故障进行分析,从而为公司的设备储藏提供意见。
首先,本文对原始维修数据记录进行了简单分析。
在对噪声数据和“服务商代码”进行预处理之后,将数据集中的手机维修信息提取出来。
接着利用clementine12.0软件分析得知“反映问题描述”属性与手机使用时长、市场级别、服务商所在地区、产品型号相关性较强。
其次,为了分析故障与其他属性的关系,本文采用关联规则Apriori和GRI算法分析手机使用时长、产品型号分别与故障之间的关联性。
观察关联结果,发现最近买的手机(使用时间低于两个月)主要故障集中在LCD显示故障和网络故障;较早买的手机主要出现开机故障和通话故障。
但是GRI算法得出的结果支持度或置信度较低,不具有说服力。
所以本文主要利用基于协同过滤的推荐算法来分析反映问题描述属性与其他属性的关联规则,并得出了如下结果:地理位置上相近的地区,其手机常见故障也类似;不同种手机型号或不同地区的手机出现的常见故障都是:开机故障,触屏故障,按键故障和通话故障;在不同级别的市场购买手机,,其经常出现故障的手机的手机型号都是T818,T92,EG906,T912和U8。
最后,为了验证推荐算法的可信性,本文对该算法进行质量评价,利用Celmentine 将数据分为训练集和测试集,然后进行算法检验。
结果表明,推荐算法能够比较准确地得出推荐结果。
关键词:设备维修、clementine12.0软件、GRI算法、基于协同过滤的推荐算法Data mining of equipment maintenance informationAbstractAs the competition in the market is increasing, maintenance after-sale service becomes one of the important competition ability of enterprise. However, due to the uncertaint breakdown of product, the spare parts demand is difficult to predict. And with the emergence of a growing number of maintenance spare parts ,the cost of Inventory maintenance is increasing. All of these problems make maintenance enterprises are faced with the burden. Therefore, aiming at Spare parts demand for the product, we use the maintenance record of a equipment manufacturing enterprise to analyse common breakdown of different kinds of mobile phones based on data mining technology and provide equipment storage advices to the mobile phone company.First of all, the article analyses the original maintenance data records. After preprocessing the noise data and ‘Service providers code’, we extract the data set of mobile phone repair information. Then we use clementine12.0 software to analyse the correlation between the properties and learn that ‘The description of reflecting problem’ has a strong correlation with ’The usage time of mobile phone‘ , ’The market level’, ’Service area’ and ’Product model’.Then, In order to analyze the correlation between ‘The description of reflecting problem’and other attributes, We use Apriori and GRI algorithm to analyze the correlation between ’The description of reflecting problem’ and ’The usage time of mobile phone‘ , ’Product model’. Observing the correlation results,we find that the breakdown or the cellphone bought within a month is focused on the LCD display and Network fault,and the cellphone buy early appears starting up fault and communication falut mainly.However, the support or confidence of the results are so low that the results are not convincing. So we mainly use recommendation algorithm which is based on the collaborative fitering to analyse the correlation between ‘The description of reflecting proble m’and other attributes.Finally,we get the following results:1.The geographical position which is close its mobile phone common faults is similar;2. Although the product model or service area is different,the cellphone appears the same following common faults: starting up fault , touch screen fault, button fault and communication falut;3. Although the market level is different, the cellphone which appear fault usually is T818,T92,EG906,T912和U8.Finally, in order to verify the credibility of the recommendation algorithm, this article is to evaluate the quality of the algorithm.The data is divided into training set and test set used Celmentine, and then test the algorithm. The results show that, the recommendation algorithm can obtain more accurate recommendation results. Key: Equipment maintenance,Clementine12.0 software,The GRI algorithm,The recommendation algorithm which is based on the collaborative fitering目录1.挖掘目标 (7)2.分析方法与过程 (7)2.1.总体流程 (7)2.2.具体步骤 (8)2.2.1.维修数据集的特点分析 (8)2.2.2.维修数据集的预处理 (10)2.2.3.关联分析 (13)2.3.结果分析 (16)2.3.1 预处理的结果分析 (16)2.3.2手机数据集基于Clementine结果分析 (17)2.3.3 基于推荐算法的手机数据集分析 (19)2.3.4 推荐算法的评价 (25)3.结论 (26)4.参考文献 (27)5.附件 (27)1.挖掘目标本次建模目标是利用维修记录的海量真实数据,采用数据挖掘技术,分析手机各类故障与手机型号、手机各类故障与市场的相互关系,构建反映各类型号手机的常见故障评价指标体系、不同市场和地区手机质量的评价体系,为手机公司的设备储藏提供意见,同时也可为消费者提供购买意见。
基于数据挖掘的微博人气用户特征分析与研究

基于数据挖掘的微博人气用户特征分析与研究摘要:通过网络爬虫从新浪微博站点上爬取人气百强用户信息数据,利用clementine软件的c5.0决策树模型对这些数据进行分析。
结果表明:人气用户中,娱乐明星占据着大部分,并且微博中的名人具有关注数小,被关注数大的特征。
名人效应非常显著,“非著名话唠”想要引起大家的观注依然困难。
关键词:微博;决策树;用户分析;名人效应中国分类号:tp39 文献标识码:a文章编号10053824(2013)010017020 引言微博在中国开始以不可思议的速度流行起来,并在人们的生活中扮演着越来越重要的角色,它逐渐地改变着人们的生活、思想、行为以及我们的社会文化。
针对这些变化,越来越多的专家学者将目光转向微博,开始对其特点、传播模式以及用户群展开分析研究。
目前,新浪微博用户数已超过1亿。
仅仅两年时间,新浪微博就为新浪生下了一个价值几十亿美金的“金蛋”。
那么新浪微博的用户群包括哪些人?他们当中的人气用户都是来自哪些行业?他们的空间分布又有什么特征?这些人群通过微博主要是为了了解信息,还是朋友交流?为什么他们会受到这么多的关注?给我们的社会带来什么启示?本文以新浪微博为研究对象,提取前100名人气用户数据作为分析数据,通过分析分类,挖掘用户行为特征、空间分布以及圈层特征等,找出这些问题的答案。
了解微博在社会中的作用,了解“微博人”的真实想法和思想认识,将有助于社会和相关部门更好地把控微博的舆论方向,对建设和谐社会有着积极的意义[15]。
1 研究设计1.1 样本来源研究所需的样本数据利用爬虫工具通过微博站点开放的api获取。
获取的微博人气用户数据信息主要包括:昵称、性别、地址、描述、被关注数、关注数以及微文数等属性,并以这些数据作为用户特征分析挖掘的基础。
1.2 研究方法和思路利用c5.0算法,根据用户的名人标识以及其他用户信息,分析名人的用户特征。
c5.0算法是决策树模型的经典算法之一,它的基本思想是利用信息论原理对大量样本的属性进行分析和归纳而产生树的结构或规则,其目的是使系统的熵最小,以提高算法的运算速度和精确度[67]。
【原创】数据挖掘案例——ReliefF和K-means算法的医学应用

【原创】数据挖掘案例——ReliefF和K-means算法的医学应⽤ 数据挖掘⽅法的提出,让⼈们有能⼒最终认识数据的真正价值,即蕴藏在数据中的信息和知识。
数据挖掘 (DataMiriing),指的是从⼤型数据库或数据仓库中提取⼈们感兴趣的知识,这些知识是隐含的、事先未知的潜在有⽤信息,数据挖掘是⽬前国际上,数据库和信息决策领域的最前沿研究⽅向之⼀。
因此分享⼀下很久以前做的⼀个⼩研究成果。
也算是⼀个简单的数据挖掘处理的例⼦。
1.数据挖掘与聚类分析概述数据挖掘⼀般由以下⼏个步骤:(l)分析问题:源数据数据库必须经过评估确认其是否符合数据挖掘标准。
以决定预期结果,也就选择了这项⼯作的最优算法。
(2)提取、清洗和校验数据:提取的数据放在⼀个结构上与数据模型兼容的数据库中。
以统⼀的格式清洗那些不⼀致、不兼容的数据。
⼀旦提取和清理数据后,浏览所创建的模型,以确保所有的数据都已经存在并且完整。
(3)创建和调试模型:将算法应⽤于模型后产⽣⼀个结构。
浏览所产⽣的结构中数据,确认它对于源数据中“事实”的准确代表性,这是很重要的⼀点。
虽然可能⽆法对每⼀个细节做到这⼀点,但是通过查看⽣成的模型,就可能发现重要的特征。
(4)查询数据挖掘模型的数据:⼀旦建⽴模型,该数据就可⽤于决策⽀持了。
(5)维护数据挖掘模型:数据模型建⽴好后,初始数据的特征,如有效性,可能发⽣改变。
⼀些信息的改变会对精度产⽣很⼤的影响,因为它的变化影响作为基础的原始模型的性质。
因⽽,维护数据挖掘模型是⾮常重要的环节。
聚类分析是数据挖掘采⽤的核⼼技术,成为该研究领域中⼀个⾮常活跃的研究课题。
聚类分析基于”物以类聚”的朴素思想,根据事物的特征,对其进⾏聚类或分类。
作为数据挖掘的⼀个重要研究⽅向,聚类分析越来越得到⼈们的关注。
聚类的输⼊是⼀组没有类别标注的数据,事先可以知道这些数据聚成⼏簇⽖也可以不知道聚成⼏簇。
通过分析这些数据,根据⼀定的聚类准则,合理划分记录集合,从⽽使相似的记录被划分到同⼀个簇中,不相似的数据划分到不同的簇中。
Clementine上机操作实验指导

数据流的基本操作
向数据流区域添节点
双击选项板区中待添加的节点; 左键按住待添加节点,将其拖入数据流区域内; 先选中选项板区中待添加的节点,然后将鼠标放入数据
流区域,在鼠标变为十字形时单击数据流区域的任何空 白处。
向数据流区域删节点
左键单击待删除的节点,按键盘上的delete键删除; 右键单击待删除的节点,在快捷菜单中选择delete。
管理器窗口
管理器窗口中共包含了“流”、“输出”、“模 型”三个栏。
工程管理区
工程管理区含有两个选项栏,一个是“CRISPDM”,一个是“类”。
数据流的基本操作
生成数据流的基本过程
向数据流区域增添新的节点; 将这些节点连接到数据流中; 设定数据节点或数据流的功能; 运行数据流。
调节因子η
点击“执行”按钮,即可在管理器窗口的“模型” 标签下显示生成的K-Means模型节点。
右键单击管理器窗口“模型”标签下生成的K-Means模型节点,在快 捷菜单中选择“浏览”,打开“K-Means”对话框,在“模型”标签 下会显示划分出来的三个聚类,点击“全部展开”,则可以显示每个 簇的一些统计信息
SmallSampleComma.txt
字段实例化 将ID字段的类型修改为
无类型
字段方向
输入:输入或者预测字 段
输出:输出或者被预测 字段字段
两者:既是输入又是输 出,只在关联规则中用 到
无:建模过程中不使用 该字段
分区:将数据拆分为训 练、测试(验证)部分
字段方向设置只有在建 模时才起作用
如果数据是列界定的(字段未被分隔,但是 始于相同的位置并有固定长度),应该使用固 定文本文件导入固定文件节点
实验四 Clementine数据挖掘

实验四 数据挖掘实验指导一、目的掌握数据挖掘工具Clementine 的基本方法与操作。
二、任务利用Clementine 对药物数据进行简单的数据挖掘操作,熟悉数据挖掘的基本步骤。
三、要求了解数据挖掘的基本步骤,完成针对给定数据的决策树挖掘/关联规则分析/聚类分析,并写出实验报告。
四、实验内容利用Clementine 对Drug.txt 中药物研究数据进行决策树、关联规则分析,观察挖掘的结果,比较这些方法挖掘结果的异同,根据观察的结果写出实验报告。
注:药物研究数据来源于对治疗同一疾病病人的处方,这些病人服用不同药物,取得了相同效果。
其中所含数据项如下:Age: 年龄 Sex: 性别(M\F) Drug: 病人所服药物种类(A/B/C/X/Y) BP: 血压(High\Normal\Low)Cholesterol: 胆固醇(Normal\High) Na: 唾液中钠元素含量 K: 唾液中钾元素含量 希望通过数据挖掘发现这些处方中隐藏的规律,给出不同临床特征病人更适合服务哪种药物的建议,为未来医生填写处方提供参考。
五、实验环境1、 硬件:P4/256MB 台式计算机2、 软件:Windows 2000 Professional/SQL Server 2000/Clementine 8.1及以上3、 数据:Drugs 数据 (文件Drug.txt) 六、步骤(一) 启动clementine双击桌面数据挖掘工具“clementine 8.1” 图标或C:\Clementine 8.1\bin\Clementine.exe ,即可启动该挖掘工具,界面如图4-1所示。
主工作区结果输出区(二)数据挖掘操作1.挖掘流(stream)操作(1)新建:File菜单→New Stream命令(2)保存/另存:File菜单→Save Stream /Save Stream As…命令→指定保存位置、文件名称→保存按钮(3)打开:File菜单→Open Stream…命令→指定要打开流的位置、文件名称→打开按钮2.挖掘步骤(1)建立连接数据源1)在挖掘工具区选项卡“Sources”中将“Var. File”节点拖入到主工作区。
基于Clementine的数据挖掘技术对学科隐形关联的研究——以东华大学纺织学科为例

够从借 阅信息 中挖 掘出学科 间的关 联关 系及特点 ,以便 为 学科课程设置及 内容 调整进 行有效合 理 的建议 。这 将成 为
高校 图书馆信息服务 的一个重要课题 …。
数据挖掘 ( D a t a Байду номын сангаас i n i g) n ,是 指 从 大 量 的 结 构 化 和 非 结
为向高校师生 提供 信息 服务 的部 门,有 其 自身 特有 的信息 优势和特点 。由于 目前所有 高校都 采用 了数据 库技术 对 图 书馆进行管理 ,在 图书 的流通 过程 中 ,产生 了大量 的借 阅 数据 。学生尤其是硕 博研究 生 的借 阅书刊信息 在一定 程度
2 0 1 3年 9 月 第 3 3卷 第 9 期
・
现 代 情 报
J o u r n a l o f Mo d e m I n f o r ma i t o n
数据挖掘工具(一)Clementine

数据挖掘工具(一)SPSS Clementine18082607 洪丹Clementine是ISL(Integral Solutions Limited)公司开发的数据挖掘工具平台。
1999年SPSS公司收购了ISL公司,对Clementine产品进行重新整合和开发,现在Clementine已经成为SPSS公司的又一亮点。
作为一个数据挖掘平台, Clementine结合商业技术可以快速建立预测性模型,进而应用到商业活动中,帮助人们改进决策过程。
强大的数据挖掘功能和显著的投资回报率使得Clementine在业界久负盛誉。
同那些仅仅着重于模型的外在表现而忽略了数据挖掘在整个业务流程中的应用价值的其它数据挖掘工具相比, Clementine其功能强大的数据挖掘算法,使数据挖掘贯穿业务流程的始终,在缩短投资回报周期的同时极大提高了投资回报率。
近年来,数据挖掘技术越来越多的投入工程统计和商业运筹,国外各大数据开发公司陆续推出了一些先进的挖掘工具,其中spss公司的Clementine软件以其简单的操作,强大的算法库和完善的操作流程成为了市场占有率最高的通用数据挖掘软件。
本文通过对其界面、算法、操作流程的介绍,具体实例解析以及与同类软件的比较测评来解析该数据挖掘软件。
1.1 关于数据挖掘数据挖掘有很多种定义与解释,例如“识别出巨量数据中有效的、新颖的、潜在有用的、最终可理解的模式的非平凡过程。
” 1、大体上看,数据挖掘可以视为机器学习和数据库的交叉,它主要利用机器学习界提供的技术来分析海量数据,利用数据库界提供的技术来管理海量数据。
2、数据挖掘的意义却不限于此,尽管数据挖掘技术的诞生源于对数据库管理的优化和改进,但时至今日数据挖掘技术已成为了一门独立学科,过多的依赖数据库存储信息,以数据库已有数据为研究主体,尝试寻找算法挖掘其中的数据关系严重影响了数据挖掘技术的发展和创新。
尽管有了数据仓库的存在可以分析整理出已有数据中的敏感数据为数据挖掘所用,但数据挖掘技术却仍然没有完全舒展开拳脚,释放出其巨大的能量,可怜的数据适用率(即可用于数据挖掘的数据占数据库总数据的比率)导致了数据挖掘预测准确率与实用性的下降。
SPSS_Clementine_数据挖掘入门

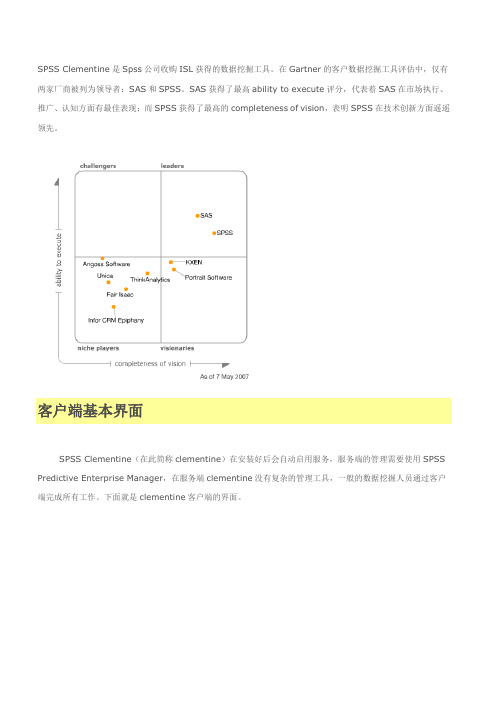
目录SPSS Clementine数据挖掘入门(1) (2)客户端基本界面 (3)项目区 (3)工具栏 (3)源工具(Sources) (3)记录操作(Record Ops)和字段操作(Field Ops) (4)图形(Graphs) (4)输出(Output) (4)模型(Model) (4)数据流设计区 (4)管理区 (5)Outputs (5)Models (5)SPSS Clementine数据挖掘入门(2) (6)1.定义数据源 (6)2.理解数据 (8)3.准备数据 (9)4.建模 (13)5.模型评估 (14)6.部署模型 (15)SPSS Clementine数据挖掘入门(3) (17)分类 (20)决策树 (20)Naïve Bayes (23)神经网络 (24)回归 (26)聚类 (27)序列聚类 (30)关联 (31)SPSS Clementine数据挖掘入门(1)SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具。
在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS。
SAS获得了最高ability to execute评分,代表着SAS在市场执行、推广、认知方面有最佳表现;而SPSS获得了最高的completeness of vision,表明SPSS在技术创新方面遥遥领先。
客户端基本界面SPSS Clementine(在此简称clementine)在安装好后会自动启用服务,服务端的管理需要使用SPSS Predictive Enterprise Manager,在服务端clementine没有复杂的管理工具,一般的数据挖掘人员通过客户端完成所有工作。
下面就是clementine客户端的界面。
一看到上面这个界面,我相信只要是使用过SSIS+SSAS部署数据挖掘模型的,应该已经明白了六、七分。
是否以跃跃欲试了呢,别急,精彩的还在后面^_’项目区顾名思义,是对项目的管理,提供了两种视图。
SPSS+Clementine8.1(英文版)数据挖掘平台入门操作指南

SPSS Clementine8.1(英文版)数据挖掘平台入门操作指南一、基本操作1.工作区简介1)可视化界面操作:管理器数据流区域项目区选项板区2.基本符号1)收藏夹用于存放常用的节点。
2)数据源用来将数据读进Clementine系统的节点。
3)记录选项用来在数据记录上进行操作的节点。
4)字段选项用来在数据字段上进行操作的节点。
5)图在建模之前和之后用来可视化数据的节点。
6) 建模在Clementine 系统中可用的代表有效算法的节点。
7)输出用来给出Clementine数据的各种输出、图表和模型结果。
3.基本操作1)向数据流中增加数据流节点从节点选项板中向数据流增加节点有三种方式:●在选项板上双击一个节点,自动将它连接到当前的数据流上●将一个节点从选项板拖放到数据流区域中●在选项板上点击一个节点,然后在数据流区域中点击一下向数据流区域增加节点以后,双击这个节点来显示它的对话框。
2)删除节点●点击数据流中的节点并按Delete键●或者单击鼠标右键从菜单中选择“Delete”3)在数据流中连接节点●通过双击鼠标左键来增加和连接节点●使用鼠标中间键来连接节点(如果鼠标没有中间键,可通过按住Alt键后单击鼠标左键来完成)●手工连接节点a)选择一个节点并单击鼠标右键打开内容菜单b)从菜单中选择“Connect”c)一个连接符号将同时出现在开始节点上和鼠标上,点击数据流区域上的第二个节点将两个节点连接在一起如果试图做下列任何类型的连接,将会收到一个错误信息:a)导向一个来源节点的连接b)从一个最终节点导出的连接c)一个超过其输入连接最大值的节点d)连接两个已被连接的节点e)循环(数据返回一个它已经经过的节点)4)绕开一个节点●在数据区域上,使用鼠标中间键来双击想要绕开的节点●或者按住Alt键后双击鼠标左键来完成5)在当前连接中增加节点●使用鼠标中间键,点击连接箭头不放,并拖到想要插入的节点上●或者按住Alt键后,使用鼠标左键点击连接箭头,并拖到想要插入的节点上来完成●选择一个节点,从主菜单中选择:Edit→Note→Disconnect6)执行数据流●从工具菜单中选择Execute●点击工具栏上的执行按钮用户可以执行整个数据流或者只是执行数据流的一部分a)单击鼠标右键选择一个最终节点,可以执行一个简单的数据流b)单击鼠标右键选择任何一个非最终节点,可执行所选节点后的所有操作7)删除节点间的连接●在连接箭头的头部单击鼠标右键打开内容菜单,从菜单中选择“Delete Connection”选择一个节点并按F3键,来删除该节点所有的连接4.基本流程数据流:通过一系列节点来执行数据的过程称为一个数据流。
A006-H-黄莉莉_基于客户价值的客户细分与流失

图 2-2 客户流失预测体系 足够,将数据分区,重新组成三组样本,分别用于训练、 检测、验证,得到的模型结果更加具有可推敲性; 步骤 4:数据预处理 主要包括缺失值处理、异常值处理、数据标准化/规范化、转化生成新变 量等。 缺失值处理 在原始数据中,有些变量发现存在缺失的现象,为确保模型结果的有效性,丢弃缺失部分 变量值的样本,不参与模型的建设。 异常值处理 在原始数据中,许多样本的工作城市、工作省份、工作国家三者地理位置是相互矛盾,由 于筛选难度及成本较大,可挖掘得到的信息较少,所以丢弃这三个变量;另外, “平均折扣
关键词: 关键词: 客户价值,客户细分 页,共 20 页
太普华南杯数据挖掘竞赛论文报告
Customer segmentation based on customer value and loss
Abstract
With the increasing competition in the aviation market, how to maintain the attendance of air transport is the secret of success of the airline. This article is based on the means of data mining, the use of Clementine and spss two data processing software, to get an analysis of customer segmentation and loss which's based on customer value . First, based on the analysis of the direct or indirect association of the respective data indicators, and with the selective extraction of the value of the variable, we create customer value evaluation system; Next, the partition of the sample, respectively, for training, detection, authentication functions; then preprocessed data. Modeling stage, the first to figure out the weight of seven variables in the calculation of customer value system based on principal component analysis, and get the evaluation model of customer value, then we can compare customer value by real number .By the scatter ,it finds that the main customer groups is the second value customers and low-value customers, prospects scarce, almost no value customers. Then, with the hierarchical clustering method, using a two-step clustering algorithm to segment customers into 3 classes, and so we find out the consumption characteristics of the various types of customers. Finally, we use C & R Tree and Bayesian network to find out the decision-making and predict customer churn. And we figure out that a discount is the most important influencing factors of customer churn and get a customer churn prediction model. Comprehensive analysis, combined with customer characteristics and customer churn model, we targeted service strategies for different types of customer base, and hope that eventually transformed toward the direction of the value customers.
ClementineC5.0模型预测CDMA客户流失

ClementineC5.0模型预测CDMA客户流失摘要:该文针对目前电信行业中一个日益严峻的问题:客户离网进行研究,通过收集客户的基本数据、消费数据和缴费行为等数据,建立客户流失预测模型,进行客户流失分析及预测。
通过对大量相关技术和统计方法的研究,最终确定了clementine的C5.0模型作为电信客户流失的预测模型。
此模型对客户流失预测有较高的准确性,为电信经营分析系统作了有益的尝试与探索。
关键词:数据挖掘;客户流失;统计分析;C5.0模型;CDMA 客户1概述以中国电信云南某公司的项目支撑为基础,从统计数据来看,维持5%的老用户增长,给电信公司带来的利润将远远超过85%,而要想把一位非电信用户发展成客户,其成本将比保留一位老客户的成本高得多,统计数据表明成本是4倍左右,此时,客户对电信的忠实程序也将发生强烈的变化,由此给企业造成的损失将大大增加。
从项目的实施情况来看,为了保证成功向客户推销运营商的产品,多数人都只愿意向老客户推销。
因为由此付出的代价比用户要小得多,成功率也要高得多。
通过这些数据我们可以看到防范老客户的流失相比发2研究现状及C5.0模型特点在我们国内,很多运营商为了应对市场的竞争,多数都己经建立了“电信经营分析系统”,这在一定程序上为深层次的数据分析提供了良好的数据处理分析平台。
而目前国内在数据利用上确远远不及国外的层次深,国内的数据应用主要集中在固定报表处理、查询分析和个人的主观探索,在更高领域的应用如数据挖掘还不太成熟,更谈不上深层次的应用。
而这些在国外,很多知名的电信运营商却已经能够很好地利用数据挖掘技术,以便通过建立客户流失的模型,提升利润空间及对一些流失概率比较高的客户进行有针对的保留工作,这样做的目的可能有效地控制入网用户的流失。
Clementine作为一个数据挖掘软件,给运营商创造了很好的数据处理应用平台,在此平台下,运营商可以有效地使用一些商业技术准确、快捷地建立预测的模型,而后把由此模型生成的数据使用在推销应用领域。
Clementine_数据挖掘入门
SPSS Clementine是Spss公司收购ISL获得的数据挖掘工具。
在Gartner的客户数据挖掘工具评估中,仅有两家厂商被列为领导者:SAS和SPSS。
SAS获得了最高ability to execute评分,代表着SAS在市场执行、推广、认知方面有最佳表现;而SPSS获得了最高的completeness of vision,表明SPSS在技术创新方面遥遥领先。
客户端基本界面SPSS Clementine(在此简称clementine)在安装好后会自动启用服务,服务端的管理需要使用SPSS Predictive Enterprise Manager,在服务端clementine没有复杂的管理工具,一般的数据挖掘人员通过客户端完成所有工作。
下面就是clementine客户端的界面。
一看到上面这个界面,我相信只要是使用过SSIS+SSAS部署数据挖掘模型的,应该已经明白了六、七分。
是否以跃跃欲试了呢,别急,精彩的还在后面^_’项目区顾名思义,是对项目的管理,提供了两种视图。
其中CRISP-DM (Cross Industry Standard Process for Data Mining,数据挖掘跨行业标准流程)是由SPSS、DaimlerChrysler(戴姆勒克莱斯勒,汽车公司)、NCR(就是那个拥有Teradata的公司)共同提出的。
Clementine里通过组织CRISP-DM的六个步骤完成项目。
在项目中可以加入流、节点、输出、模型等。
工具栏工具栏总包括了ETL、数据分析、挖掘模型工具,工具可以加入到数据流设计区中,跟SSIS中的数据流非常相似。
Clementine中有6类工具。
源工具(Sources)相当SSIS数据流中的源组件啦,clementine支持的数据源有数据库、平面文件、Excel、维度数据、SAS数据、用户输入等。
记录操作(Record Ops)和字段操作(Field Ops)相当于SSIS数据流的转换组件,Record Ops是对数据行转换,Field Ops是对列转换,有些类型SSIS的异步输出转换和同步输出转换(关于SSIS异步和同步输出的概念,详见拙作:/esestt/archive/2007/06/03/769411.html)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于Clementine的数据挖掘模型评估
摘要:本文采用clementine数据挖掘工具生成了某商业银行的客户响应具体模型,并评估了所生成的模型。
通过分析报告和评估图的方式,最终比较了决策表、神经网络和决策树c5.0算法预测的效果。
关键词:数据挖掘;clementine;模型评估;c5.0
中图分类号:tp311.13
目前,银行的数据库和数据仓库中都收集和存储了大量有关客户的宝贵数据,它们涵盖了从客户基本资料、购买记录以及客户反馈等多个环节。
利用这些数据,进一步分析、挖掘出大量隐藏在其中的有用信息,可以帮助银行更好地做到客户关系管理,实现crm的功能和目标。
在分析当前客户关系管理中数据挖掘的应用的基础上,以某商业银行的crm系统开发为背景,建立客户响应预测模型,生成商业银行的客户响应具体模型,分析维度表中的相关变量对目标变量(客户是否响应)的影响。
最终对所生成的模型进行评估,比较不同算法预测的效果。
1clementine软件
clementine(ibm spss modeler)最早属英国isl(integral solutions limited)公司的产品,后被spss公司收购。
2009年,spss被ibm公式收购。
自2000年以来,kdnuggets公司面向全球开展“最近12个月你使用的数据挖掘工具”的跟踪调查,clementine
一直列居首位。
clementine具有分类、预测、聚类、关联分析等数据挖掘的全部分析方法。
这些分析方法经过组合,或单独使用,可用于研究客户响应问题。
其crisp-dm标准能够帮助用户规范数据挖掘的整个过程。
clementine的操作与数据分析的一般流程相吻合。
clementine 形象地将各个环节表示成若干个节点,将数据分析过程看作是数据在各个节点之间的流动,并通过图形化的“数据流”方式,直观表示整个数据挖掘。
操作使用clementine的目标:建立数据流,即根据数据挖掘的实际需要,选择节点,依次连接节点建立数据流,不断修改和调整流中节点的参数,执行数据流,最终完成相应的数据挖掘任务。
clementine软件是按照crisp-dm标准过程来进行项目管理的。
一共包括6个部分:business understanding(商业理解)、data understanding(数据理解)、data preparation(数据准备)、modeling(建模)、evaluation(模型评估)和deployment(结果部署)。
为了方便管理,整个项目开发的过程中,在每个阶段生成的结果,例如模型、数据、报告等,都可以存储到相应的阶段中。
clementine软件支持非常多的数据挖掘分析算法和建模,其中包括了c5.0、apriori、c&r tree、神经网络、logistic等算法。
通过使用clementine软件,能够使整个分析过程更得直观、简单。
另外,clementine软件对其它功能的支持包括:
(1)数据源:这个内容包含了对数据源的支持,能够支持多种
格式的数据文件,如access数据库、sql server数据库、excel
文件、spss文件、sas文件等。
(2)记录选项:此项用来处理数据记录,包括:抽样、平衡、合并、选择、排序、汇总、区分、追加等功能。
(3)字段选项:此项用来处理属性字段,包括:字段类型定义、字段空值填充、字段过滤、新字段生成、重分类等功能。
(4)图形选项:其中包括histogram(柱状图)、evaluation(评估图)、distribution(分类图)、plot(聚类图)等分析图形。
(5)输出选项:其中包括excel文件、报告、表格、数据库等结果输出方式。
2建立模型
以某商业银行为例,该银行举办一系列金融产品的促销活动,不同阶层的客户对此活动的响应可能不同,比如性别、年龄、家庭和收入等因素会对此类产品的购买力产生不同程度的影响。
通过选择神经网络、决策表和c5.0算法三种方法来建立预测模型,预测各因素对此类促销活动的响应程度。
银行希望通过为每个客户提供最合适的报价,以在未来的商业竞争中取得更大的收益。
该商业银行客户响应预测模型的数据流中,包括若干包含每位客户的相关人口统计和金融信息的字段,这些字段可用于构建或“训练”依据特定特征针对不同组预测响应率的模型。
通过clementine挖掘软件,根据在决策列表节点中指定的设置运行默认的挖掘任务。
尝试使用不同的建模方法,从菜单中选择相
应的操作,完成替代模型的创建。
通过将一项挖掘任务的结果反馈给另一项挖掘任务,这些最新模型将同时包含高响应率段和低响应率段。
3模型评估
模型建立后,就需要检验训练出来的模型,这个就是模型评估阶段,也是数据挖掘中一步重要的工作。
在确定挖掘目标和数据准备阶段的时候有两个原则:所建立的预测模型要有可评估性和可实现性。
3.1模型评价标准
在数据建模的过程中,通常需要使用多种不同的数据挖掘方法。
为了能够挑选出最好的预测模型,这里介绍一些参考标准:
(1)预测准确率的高低决定了模型的质量。
准确率分为两种,即所有记录的准确率和流失响应预测的准确率。
因为通常响应用户更受关注,所以关心的重点是响应用户预测的准确率。
在输出的分析报告中比较正确率和错误率,正确率越高,预测结果越准确。
(2)评估图中的响应图通常是从100%附近开始,逐渐下降直到它们达到了图表右端整体响应率为止(总的成功数/总的记录数)。
对于一个好的模型来说,这条线在左端将从100%附近或恰好在100%上开始,当用户向右移动时能够保持一个较高的稳定状况,然后在图表右端突然急剧地下降到整体响应率。
对没有提供任何信息的模型来说,整个图像中曲线将一直在整体响应率附近围绕。
(如果已经选择了include baseline,一条水平的等于整体响应率的线将被
显示在图表中作为参照)。
3.2测试数据集的选择
为了能够得到比较精确的测试结果,尽量选择没有参加过建模的数据进行模型的评估测试。
要使得测试结果比较好,进行测试的数据建议采用建立预测模型的。
然而,在实际的数据中应用模型时,经常会产生很大的偏差结果。
因此,进行评估测试要选择未参加建模的数据。
此外,测试的准确率包括两种:响应用户预测的准确率和所有记录的准确率。
因此,测试数据一般使用混合测试数据集,包括响应和未响应的。
3.3模型评估比较
通过采用三种算法建模:决策表(decision list)、神经网络(neural net)、决策树c5.0。
下面对这三种方式进行比较分析。
预测模型评估所用样本的检验集数据来验证模型的情况。
(1)分析报告的对比:
决策表建模的分析结果中,正确率为11.68%。
神经网络建模的分析结果中,正确率为92.02%。
决策树c5.0建模的分析结果中,正确率为92.86%。
比较分析结果发现,c5.0的正确率较高,神经网络其次,决策表的正确率较低。
(2)评估图对比:
根据模型评价标准和三种模型建模的评估图,比较发现c5.0模型的预测效果较好,决策表模型的预测效果较差。
综合以上两种评估,可以看出c5.0预测效果好一些。
通过以上的内容,我们评估了所生成的模型,通过分析报告和评估图的方式,比较了决策表、神经网络和决策树c5.0算法预测的效果。
对于所使用的测试数据集而言,发现使用c5.0算法的预测效果较好,其次是神经网络,使用决策表的预测效果较差。
参考文献:
[1]颜昌沁,胡建华,周海河.基于clementine神经网络的电信客户流失模型应用[j].电脑应用技术,2009(1).
[2]赵伦,侯波,颜昌沁.利用clementine c5.0模型预测cdma客户流失[j].电脑知识与技术,2011(20).
[3]薛薇,陈欢歌.clementine数据挖掘方法及应用[m].电子工业出版社,2010,9.
[4]薛薇,陈欢歌.基于clementine的数据挖掘[m].中国人民大学出版社,2012,3.
[5]熊平.数据挖掘算法与clementine实践[m].清华大学出版社,2011,4.。