导入sql文件乱码的解决方法
oracle中文乱码解决方法

oracle中文乱码解决方法1. Oracle数据库设置数据库参数NLS_LANG为使Oracle数据库中存储与显示中文时无乱码问题,可以更改Oracle数据库的数据库参数NLS_LANG,更改该参数为中文字符集,如:simplified Chinese_China.ZHS16GBK,此参数设置会对数据库中的所有字符数据有效。
2. Oracle数据库中多个字符集混用的解决方案一般系统及数据库常用的字符集可能存在多样性,例如全角字符、英文字母、空格等,而Oracle数据库支持了多个字符集,用户可以在数据库中多个字符集混合使用。
例如,用UTF8字符集对中文、英文、全角字符编码;用UTF16字符集对Unicode字符编码;用GBK/GB2312字符集对中文字符编码。
3. 注意SQL语句及字符集的指定为了防止运行SQL语句时出现乱码,应当在SQL语句中指定运行的字符集,如:ALTER SESSION SET NLS_LANGUAGE=AMERICAN_AMERICA.AL32UTF84. 客户端应用指定编码格式对于客户端应用,如sqlplus、PL/SQL开发工具,需要在连接之前指定客户端编码格式以确保传输与显示时无乱码问题,这种解决方案比较常用,在客户端应用中设置NLS_LANG参数,让客户端的中文字符使用Unicode,例如: NLS_LANG = SIMPLIFIED CHINESE_CHINA.UTF8 即可成功连接Oracle数据库解决乱码问题。
5. 数据导入导出中文处理从其他数据库导入Oracle数据库时,应从源数据库中查找出字段编码,在导入时将字段编码转换成Oracle数据库中的字符编码,可以增加数据库中文字符的正常显示。
从Oracle数据库导出数据至其他数据库,应将 Oracle 数据库中的字符编码转换成目标数据库的编码方式,以保证导出数据无乱码状况。
6. 中文乱码的原因分析中文乱码的常见原因之一是程序的编码格式未正确设置,将GBK/GB2312等字符集与UTF-8 等Unicode字符集混用,也会出现中文乱码的情况。
启用utf8后乱码解决方法

启用utf8后乱码解决方法启用UTF-8后出现乱码可能是由于多种原因造成的,下面是一些可能的解决方法:1. 检查数据库编码设置:确保数据库、表和列的编码设置为UTF-8。
你可以使用以下命令来检查和设置编码:```sql-- 检查数据库编码SHOW VARIABLES LIKE 'character_set_database';-- 设置数据库编码为UTF-8ALTER DATABASE your_database_name CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;-- 检查表的编码SHOW FULL COLUMNS FROM your_table_name;-- 设置表的编码为UTF-8ALTER TABLE your_table_name CONVERT TO CHARACTER SETutf8mb4 COLLATE utf8mb4_unicode_ci;```2. 检查连接编码设置:确保在连接数据库时使用的编码设置为UTF-8。
你可以在连接数据库的代码中设置编码,例如在PHP中:```php$conn = new mysqli($servername, $username, $password, $dbname); $conn->set_charset('utf8'); // 设置连接编码为UTF-8```3. 检查输入输出编码设置:确保在输入和输出数据时使用的编码设置为UTF-8。
你可以在输入输出代码中设置编码,例如在PHP中:```phpheader('Content-Type: text/html; charset=utf-8'); // 设置输出编码为UTF-8echo '<meta charset="UTF-8">'; // 设置HTML文档编码为UTF-8```4. 检查文本编辑器设置:如果你在编辑器中输入了乱码,可能是由于编辑器的编码设置不正确。
SQL报错:ORA-00911:无效的字符错误

原因和解决方法和上面说的一样,都是分号引起的。
乱码是需要调整字符设置与本次实验无关的但由于不影响本次实验暂不处理处理方法可参见另一篇文章
SQL报错: 911:无效的字符错误
转载自: *)ORA-00911:无效的字符错误——由编译环境下一个小错误引起。SQL执行编译时,出现了ORA-00911错误 (注意:此时出现了????乱码,是需要调整字符设置,与本次实验无关的,但由于不影响本次实验,暂不处理,处理方法可参见另一篇 文章:)
cmd命令行sql数据库中文乱码

cmd命令行sql数据库中文乱码这个问题很多人开始都会不知道,当然包括曾经的我,当用到的时候,只好求助于伟大的股沟和度娘了。
网上有设置的方法,但说明确不够详细系统,说设置字体为:Lucida Console。
问题是,在默认方式下,只有点阵字体,哪有什么Lucida Console。
所以,在自己成功设置后,拿出来和大家分享下过程,下面就让我们找出Lucida Console来设置吧。
这里需要先了解些内容:CHCPCHCP是MD DOS中的命令,用来显示或设置活动代码页编号的。
用法是:CHCP [nnn]其中nnn指定的是代码页的编号。
这个参数是可选的,在命令行下如果不指定这个代码页编号,那么默认是显示当前的代码页编号。
比如,在默认的cmd窗口中,我们输入chcp 显示的将类似:活动的代码页: 936这里的936表示当前使用的是简体中文(GB2312)编码。
UTF8你也需要了解编码的一些知识,为了完成支持UTF8的工作,你至少需要知道UTF8代码页的编号:65001。
更多关于编码的内容,这里不赘述,请自行查找相关内容。
有这两个知识点,接下来,让cmd支持UTF8就变得容易了。
1. 运行CMD;2. 输入 CHCP (没有分号)回车查看当前的编码;3. 输入CHCP 65001 回车;4. 仅如此,还是不能支持UTF8的正常显示,你还要在窗体上右键,选择属性,来设置字体;5. 操作完上面几步后,即使你原来的字体里面没有显示Lucida Console这个字体,现在应该也能看到了。
选择它。
如果原来就有,可以选上它先试试,不行在执行上述步骤(这里补充:至少我本机需要CHCP 65001下,有朋友说不要);6. 选择只应用到本窗体,确认。
这时候,你的Console里面,应该支持UTF8了。
有些朋友也想知道如何在CMD显示更多的字体,这个其实也是有办法的,只要在注册表(路径:HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\WindowsNT\CurrentVersion\Console\TrueTypeFont)中添加就好了。
关于Mysql中文乱码问题该如何解决(乱码问题完美解决方案)

关于Mysql中⽂乱码问题该如何解决(乱码问题完美解决⽅案)最近两天做项⽬总是被乱码问题困扰着,这不刚把mysql中⽂乱码问题解决了,下⾯⼩编把我的解决⽅案分享给⼤家,供⼤家参考,也⽅便以后⾃⼰查阅。
⾸先:⽤show variables like “%colla%”;show varables like “%char%”;这两条命令查看数据库与服务端的字符集设置如果查看出来都是gbk2312,或 gbk,那么就只能⽀持简体中⽂,繁体和⼀些特殊符号是不能插⼊的,我们只有修改字符集为UTF-8,修改⽅法如下:⽤记事本或UitraEdit打开mysql数据库安装⽬录下的my.ini⽂件打开,然后Ctrl+F搜索default-character-set,将后⾯的字符集修改为UTF8,注意要修改两个地⽅,⼀个事客户端的,⼀个是服务端的。
然后保存,重启mysql服务、、进去继续⽤show variables like “%colla%”;show varables like “%char%”;着两条语句查询⼀下字符集。
如图:到此就配置完成了。
注意:如果以前建有数据库没有删除的请⽤ show database 数据库名;和 show create table 表名;查看⼀下数据库和表的字符集是否为UTF8 ,因为修改my.ini⽂件,它不能修改原来数据库的的字符集。
在命令⾏下⾯可以⽤alter database 数据库名 character set “字符集”;命令来修改数据库字符集还有⼀点要注意的是,修改为UTF8以后,在命令⾏下⾯中⽂是乱码的,只输出到页⾯或控制台是正常的,这个问题我也上⽹查了⼀下,貌似命令⾏下⾯不⽀持UTF8,我也不太清楚。
当修改以后,在命令⾏下⾯如果要插⼊中⽂,可以在插⼊语句之前执⾏,set names gbk2312;就可以插⼊中⽂了,但是不能插⼊繁体和⼀些特殊符号。
以上就是这⼏天解决乱码的成果。
如何解决Sybase数据库乱码问题详解

如何解决Sybase数据库乱码问题详解Sybase数据库是一种常用的关系型数据库管理系统(RDBMS),它被广泛应用于企业级应用程序的开发和管理中。
然而,在使用Sybase数据库过程中,我们有时会遇到乱码问题。
乱码是指数据库中存储的数据在显示过程中出现了不正常的字符或者无法识别的字符。
本文将详细介绍如何解决Sybase数据库乱码问题。
一、乱码问题的原因分析乱码问题的产生原因非常多样化,下面列举了一些常见的原因:1. 字符集不匹配:数据库中使用的字符集与应用程序中使用的字符集不一致会导致乱码问题。
2. 数据导入不正确:如果在导入数据时未指定正确的字符集,则可能导致数据乱码。
3. 数据存储不正确:如果数据库中存储的字符串没有使用正确的字符集,将会导致乱码问题。
4. 字符串处理不当:在应用程序中对字符串进行处理时,如果没有正确处理字符集,数据可能会出现乱码。
5. 系统环境配置问题:有时,操作系统、数据库软件或应用程序中的某些配置存在问题,也可能导致乱码问题。
二、解决乱码问题的方法针对上述原因,可以采取以下一些解决乱码问题的方法:1. 修改字符集配置:确保数据库中使用的字符集与应用程序中使用的字符集一致。
可以通过修改数据库或应用程序的配置文件来设置正确的字符集。
2. 指定正确的字符集进行导入:在导入数据时,需要指定正确的字符集,以保证数据能够正确地存储到数据库中,避免乱码问题的发生。
可以根据具体情况使用不同的导入工具或命令来完成这个操作。
3. 使用合适的数据类型:在创建数据库表时,选择合适的字符数据类型来存储字符串。
根据具体情况选择varchar、nvarchar等数据类型,并指定正确的字符集。
4. 对字符串进行正确的处理:在应用程序中,对于涉及到字符串处理的操作,需要确保使用了正确的字符集。
比如,对字符串进行拼接、截取、比较、转换等操作时,都需要注意字符集的一致性。
5. 检查系统环境配置:如果乱码问题持续存在,需要检查系统环境配置是否正确,包括操作系统、数据库软件和应用程序的相关配置。
Oracle数据库工具中文显示乱码问题的解决

Oracle 数据库工具中文显示乱码问题的解决Oracle客户端查询工具有时会有查处的结果为中文时不能正常显示,要么为乱码,要么为问号,plsql出现这种问题,以为是版本造成的,用了老的和最新的还是一样,换了另外的数据库工具也一样,但注意一点,数据其实是没有问题的,取出来显示是正常的中文,只是在工具里显示的是问号。
其实问题的原理很简单,就是字符集设置不正确造成的,但如此简单的原理在解决的过程中却会遇到很多麻烦,下面结合我遇到和解决的过程,给朋友们一点思路,说不定你们跟我的问题一样,通过这篇文章不用再折腾了,很快搞定,感觉飘飘……首先讲讲字符集的知识,Oracle字符集是一个字节数据的解释的符号集合,有大小之分,有相互的包容关系。
ORACLE支持国家语言的体系结构允许你使用本地化语言来存储,处理,检索数据。
它使数据库工具,错误消息,排序次序,日期,时间,货币,数字,和日历自动适应本地化语言和平台。
影响oracle数据库字符集最重要的参数是NLS_LANG参数。
它的格式如下:NLS_LANG = language_territory.charset它有三个组成部分(语言、地域和字符集),每个成分控制了NLS子集的特性。
其中:Language 指定服务器消息的语言,territory 指定服务器的日期和数字格式,charset 指定字符集。
如:AMERICAN _AMERICA. ZHS16GBK 。
从NLS_LANG 的组成我们可以看出,真正影响数据库字符集的其实是第三部分。
所以两个数据库之间的字符集只要第三部分一样就可以相互导入导出数据,前面影响的只是提示信息是中文还是英文。
如何查询Oracle的字符集,很多人都碰到过因为字符集不同而使数据导入失败的情况。
这涉及三方面的字符集,一是oracel server 端的字符集,二是oracle client 端的字符集;三是dmp文件的字符集。
在做数据导入的时候,需要这三个字符集都一致才能正确导入。
快速进行Access数据库转成mysql数据库及mysql导入中文数据乱码问题的解决方案

问题是如果直接用它来把ACCESS文件导入MYSQL会出现乱码。所以我试下以下方法,虽然麻烦点,但是还可是可行。
5.1 用Access-to-MySQL Pro来把数据库导出为*.sql 文件。
A) 运行Access-to-MySQL Pro的时候选ADVANCE MODE,下一步;
B) 选择STORE into dump file, 就是保存为l;
有可能会出现错误提示音,不管他,等它再次出现提示符的时候,导入成功。我用这种方法导入一个50M的文件没有问题,只是提示音响了十分钟。
可以在phpMyAdmin下查看数据是否正确,如果没有乱码就OK了。
二、关于数据导入mysql时的乱码的解决方案
C) 选择目标MYSQL的版本,选默认值,下一步;
D) 这下要选MS ACCESS USER-LEVElL SECURITY FILE,这个文件一般在你的OFFICE安装目录下。我的是在G:\Program Files\Microsoft Office\Office\SYSTEM.MDW , 用户名填 ADMIN , 下一步;
CREATE TABLE `userinfo` (
`id` INT NOT NULL AUTO_INCREMENT,
`name` VARCHAR(50),
'pwd' VARCHAR(20),
PRIMARY KEY (`id`)
Mysql中文乱码问题完美解决方案

转载:Mysql中文乱码的解决方法第一种方法,很精辟的总结:经常更换虚拟主机,而各个服务商的MYSQL版本不同,当导入数据后,总会出现乱码等无法正常显示的问题,查了好多资料,总结出自己的一点技巧:WINDOWS 下导入应该这样使用MYSQL的命令在DOS 命令下进入mysql的bin目录下,输入mysql -uroot -p密码数据库名称<要恢复的数据库, 例如我们要把D盘的一个名称为test.sql的数据库恢复到本地的test2这个数据库,那么就这样: mysql -uroot -p密码test2以前的国外主机用的Mysql是4.x系列的,感觉还比较好,都无论GBK和UTF-8都没有乱码,没想到新的主机的Mysql是5.0版本的,导入数据后,用Php读出来全是问号,乱码一片,记得我以前也曾经有过一次切换出现乱码的经验,原因肯定是Mysql版本之间的差异问题。
只好查资料,发现了一个解决方法,就是在mysql_connect后面加一句SET NAMES UTF8,即可使得UTF8的数据库消除乱码,对于GBK的数据库则使用SET NAMES GBK,代码如下:$mysql_mylink = mysql_connect($mysql_host, $mysql_user, $mysql_pass);mysql_query("SET NAMES 'GBK'");数据库字符集为utf-8连接语句用这个mysql_query("SET NAMES 'UTF8'");mysql_query("SET CHARACTER SET UTF8");mysql_query("SET CHARACTER_SET_RESULTS=UTF8'");还有个方法就是,如果你自己的机器的话,可以更改MYSQL字符集,一般在MYSQ4和MYSQL5这两个版本中有效。
plsql中文乱码问题解决

将上面的nls_lang配置到plsql中去。
第三种
解决PL/SQL和TOAD中文乱码问题:
regedit->hkey_local_machine->software->oracle->home0->NLS_LANG value:AMERICAN_AMERICA.WE8ISO8859P1”
select * from nls_session_parameters;
1.设置本地客户端编码:
进入 我的电脑,属性,高级,环境变量,
添加2项: LANG=zh_CN.GBK
NLS_LANG="SIMPLIFIED CHINESE_CHINA.ZHS16GBK" (我只配置了这一行就成功了,
select * from nls_instance_parameters;
st where t.PARAMETER =''NLS_LANGUAGE''
or t.PARAMETER =''NLS_CHARACTERSET'';
解决plsql客户端中文乱码,三种解决方法:
第一种:
在pls暗中文件下面生成一个.bat
查看数据库服务器和客户端的字符集有没有不同的:
代码如下:
select * from nls_database_parameters;
在环境变量中——“系统环境”中配置
第二种
2.更加直接的方法就是在plsql的安装文件下创建一个txt文件,文件名称为: nls_lang
代码如下: set nls_lang=simplified chinese_china.ZHS16GBK
在SQLServer中使用SQL语句插入或更新数据出现乱码或问号的解决方法
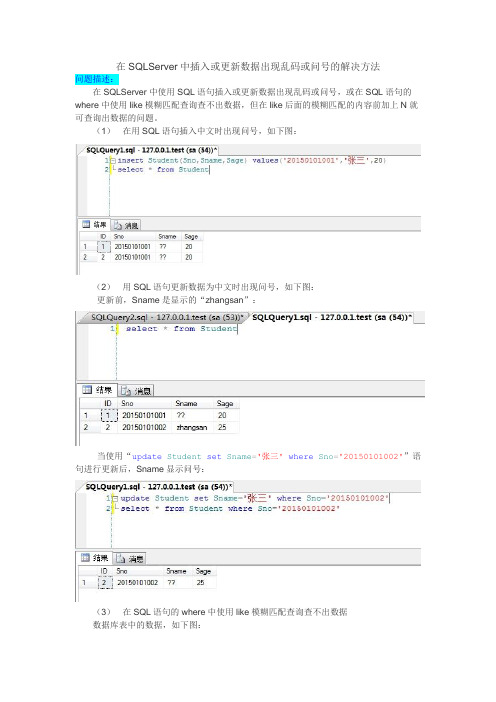
在SQLServer中插入或更新数据出现乱码或问号的解决方法问题描述:在SQLServer中使用SQL语句插入或更新数据出现乱码或问号,或在SQL语句的where中使用like模糊匹配查询查不出数据,但在like后面的模糊匹配的内容前加上N就可查询出数据的问题。
(1)在用SQL语句插入中文时出现问号,如下图:(2)用SQL语句更新数据为中文时出现问号,如下图:更新前,Sname是显示的“zhangsan”:当使用“update Student set Sname='张三'where Sno='20150101002'”语句进行更新后,Sname显示问号:(3)在SQL语句的where中使用like模糊匹配查询查不出数据数据库表中的数据,如下图:使用like模糊匹配查询查不出数据,如下图:但在like后面的模糊匹配的内容前加上N就可查询出数据,如下图:问题产生的原因:由于数据库属性的排序规则设置不正确。
解决方法:方法一:手动修改(设置数据库的排序规则)具体步骤:选中要修改的数据库-->右键-->属性-->弹出数据库属性对话框-->选项-->把排序规则设置成:Chinese_PRC_90_CI_AS-->确定。
(1)选中要修改的数据库→右键→属性:(2)弹出数据库属性对话框→选项→把排序规则设置成:Chinese_PRC_90_CI_AS→确定注意事项:在修改数据库排序规则时首先要确定修改的数据库没有被使用,否则会失败!如下图所示失败提示:方法二:使用SQL语句修改在查询分析器中输入下面的SQL语句执行即可:USE masterGOALTER DATABASE数据库名COLLATE排序规则如要修改test数据库的排序规则,则可:USE masterGOALTER DATABASE test COLLATE Chinese_PRC_90_CI_AS注意事项:在修改数据库排序规则时首先要确定修改的数据库没有被使用,否则会失败!如下图所示失败提示:当在修改数据库排序规则时要修改的数据库被使用从而导致排序规则修改失败时的处理方法:重启数据库服务:选中数据库服务器→右键→重新启动即可:排序规则术语:什么是排序规则呢?排序规则是根据特定语言和区域设置标准指定对字符串数据进行排序和比较的规则。
在SQLServer中使用SQL语句插入或更新数据出现乱码或问号的解决方法

在SQLServer中使用SQL语句插入或更新数据出现乱码或问号的解决方法在SQLServer中插入或更新数据出现乱码或问号的解决方法问题描述:在SQLServer中使用SQL语句插入或更新数据出现乱码或问号,或在SQL语句的where中使用like模糊匹配查询查不出数据,但在like后面的模糊匹配的内容前加上N就可查询出数据的问题。
(1)在用SQL语句插入中文时出现问号,如下图:(2)用SQL语句更新数据为中文时出现问号,如下图:更新前,Sname是显示的“zhangsan”:当使用“update Student set Sname='张三'where Sno='20150101002'”语句进行更新后,Sname显示问号:(3)在SQL语句的where中使用like模糊匹配查询查不出数据数据库表中的数据,如下图:使用like模糊匹配查询查不出数据,如下图:但在like后面的模糊匹配的内容前加上N就可查询出数据,如下图:问题产生的原因:由于数据库属性的排序规则设置不正确。
解决方法:方法一:手动修改(设置数据库的排序规则)具体步骤:选中要修改的数据库-->右键-->属性-->弹出数据库属性对话框-->选项-->把排序规则设置成:Chinese_PRC_90_CI_AS-->确定。
(1)选中要修改的数据库→右键→属性:(2)弹出数据库属性对话框→选项→把排序规则设置成:Chinese_PRC_90_CI_AS→确定注意事项:在修改数据库排序规则时首先要确定修改的数据库没有被使用,否则会失败!如下图所示失败提示:方法二:使用SQL语句修改在查询分析器中输入下面的SQL语句执行即可:USE masterGOALTER DATABASE数据库名COLLATE排序规则如要修改test数据库的排序规则,则可:USE masterGOALTER DATABASE test COLLATE Chinese_PRC_90_CI_AS注意事项:在修改数据库排序规则时首先要确定修改的数据库没有被使用,否则会失败!如下图所示失败提示:当在修改数据库排序规则时要修改的数据库被使用从而导致排序规则修改失败时的处理方法:重启数据库服务:选中数据库服务器→右键→重新启动即可:排序规则术语:什么是排序规则呢?排序规则是根据特定语言和区域设置标准指定对字符串数据进行排序和比较的规则。
exp、imp导入数据乱码、plsql中文乱码,显示问号

1.登陆plsql,执行sql语句,输出的中文标题显示成问号????;条件包含中文,
则无数据输出
2.输入sql语句select * from V$NLS_PARAMETERS查看字符集,查看第一
行value值是否为简体中文
3.进入注册表,依次单击HKEY_LOCAL_MACHINE --->SOFTWARE --->
ORACLE--->home(小编安装的是Oracle 11g,这里显示成
KEY_OraDb11g_home1),找到NLS_LANG,查看数值数据是否为:SIMPLIFIED CHINESE_CHINA.ZHS16GBK
4.如果以上设置都没有问题,那就要查看下环境变量的设置,查看是否有变量
NLS_LANG,没有则新建该变量
5.新建变量,设置变量名:NLS_LANG,变量值:SIMPLIFIED
CHINESE_CHINA.ZHS16GBK,确定即可
6.退出plsql,重新登陆plsql。
输入sql语句,执行,中文标题终于正常显示,
也有数据输出了
注册表,NLS_LANG值与环境变量中的NLS_LANG值保持一致。
MYSQL数据库中文乱码问题

collation server utf8_general_ci utf8_general_ci
从这里可以看到character全部变成utf8了。
有人要问,为什么都要改成utf8呢?改成GB2312不行吗?
character set database utf8 utf8
character set results utf8 utf8
character set server utf8 utf8
character set system utf8 utf8
collation connection utf8_general_ci utf8_general_ci
这样我们就把服务器和数据库的编码改为了GBK。
现在我们就可以插入中文字符串了,但是为什么有时间还是会显示
Exception in thread "main" com.mysql.jdbc.MysqlDataTruncation: Data truncation: Data too long for column 'name' at row 1
二.在linux上导出
如果用mysqldump导出出现了乱码也没有关系,可以运行iconv来转换一下
iconv -c -f UTF-8 -t GB2312 库文件名 > 新的gb2312的库文件名
综上所述,你要注意:
1。尽量在需要导入的库文件的开头加入SET NAMES 'gb2312';告诉mysql你要导入的是一个gb2312的文件;
(3)数据库连接串中指定字符集
PL_SQL汉字乱码和汉字查询不识别问题(已解决)

PL_SQL汉字乱码和汉字查询不识别问题(已解决)
PL/SQL 汉字乱码和汉字查询不识别问题(已解决)
原因分析:本机字符集设置的问题,即PL/SQL所在的终端的字符集设置与Oracle服务器端的字符集设置不统一;
处理方式:
1. 查询Oracle服务器端的字符集设置。
可以通过“SELECT * FROM v$nls_parameters;”获取服务端的字符集设置,如下图:s
2. 设置本地的字符集设置;打开系统”环境变量“设置窗口,查看NLS_LANG变量,若存在则直接参照服务端的设置调整变量值,否则,新建该变量并参照赋值。
特别说明,我将变量值与服务器设置(SIMPLIFIED CHINESE_CHINA.AL32UTF8)统一后问题问题得以解决,而当我把变量值设置为(SIMPLIFIED CHINESE_CHINA.ZHS16GBK)时,问题同样得到了解决。
3. 补充说明,在环境变量配置为AL32UTF8之后,在正常的执行
数据操作(DML)时正常。
但在执行创建表(含汉字备注)脚本的时候,出现“非法字符”的提示,调整为ZHS16GBK后恢复正常。
sqlite中文乱码问题原因分析及解决

sqlite中⽂乱码问题原因分析及解决在VC++中通过sqlite3.dll接⼝对sqlite数据库进⾏操作,包括打开数据库,插⼊,查询数据库等,如果操作接⼝输⼊参数包含中⽂字符,会导致操作异常。
例如调⽤sqlite3_open打开数据库⽂件,如果⽂件路径出现中⽂,就会导致打开失败。
sqlite3_exec执⾏sql语句,如果包含中⽂对应字符就会变成乱码。
这是由于sqlite数据库使⽤的是UTF-8编码⽅式,⽽传⼊的字符串是ASCII编码或Unicode编码,导致字符串格式错误。
解决⽅案是在调⽤sqlite接⼝之前,先将字符串转换成UTF-8编码,以下提供各种字符串编码转换函数。
复制代码代码如下://UTF-8转Unicodestd::wstring Utf82Unicode(const std::string& utf8string){int widesize = ::MultiByteToWideChar(CP_UTF8, 0, utf8string.c_str(), -1, NULL, 0);if (widesize == ERROR_NO_UNICODE_TRANSLATION){throw std::exception("Invalid UTF-8 sequence.");}if (widesize == 0){throw std::exception("Error in conversion.");}std::vector<wchar_t> resultstring(widesize);int convresult = ::MultiByteToWideChar(CP_UTF8, 0, utf8string.c_str(), -1, &resultstring[0], widesize);if (convresult != widesize){throw std::exception("La falla!");}return std::wstring(&resultstring[0]);}//unicode 转为 asciistring WideByte2Acsi(wstring& wstrcode){int asciisize = ::WideCharToMultiByte(CP_OEMCP, 0, wstrcode.c_str(), -1, NULL, 0, NULL, NULL);if (asciisize == ERROR_NO_UNICODE_TRANSLATION){throw std::exception("Invalid UTF-8 sequence.");}if (asciisize == 0){throw std::exception("Error in conversion.");}std::vector<char> resultstring(asciisize);int convresult =::WideCharToMultiByte(CP_OEMCP, 0, wstrcode.c_str(), -1, &resultstring[0], asciisize, NULL, NULL);if (convresult != asciisize){throw std::exception("La falla!");}return std::string(&resultstring[0]);}//utf-8 转 asciistring UTF_82ASCII(string& strUtf8Code){string strRet("");//先把 utf8 转为 unicodewstring wstr = Utf82Unicode(strUtf8Code);//最后把 unicode 转为 asciistrRet = WideByte2Acsi(wstr);return strRet;}/////////////////////////////////////////////////////////////////////////ascii 转 Unicodewstring Acsi2WideByte(string& strascii){int widesize = MultiByteToWideChar (CP_ACP, 0, (char*)strascii.c_str(), -1, NULL, 0);if (widesize == ERROR_NO_UNICODE_TRANSLATION){throw std::exception("Invalid UTF-8 sequence.");}if (widesize == 0){throw std::exception("Error in conversion.");}std::vector<wchar_t> resultstring(widesize);int convresult = MultiByteToWideChar (CP_ACP, 0, (char*)strascii.c_str(), -1, &resultstring[0], widesize);if (convresult != widesize){throw std::exception("La falla!");}return std::wstring(&resultstring[0]);}//Unicode 转 Utf8std::string Unicode2Utf8(const std::wstring& widestring){int utf8size = ::WideCharToMultiByte(CP_UTF8, 0, widestring.c_str(), -1, NULL, 0, NULL, NULL);if (utf8size == 0){throw std::exception("Error in conversion.");}std::vector<char> resultstring(utf8size);int convresult = ::WideCharToMultiByte(CP_UTF8, 0, widestring.c_str(), -1, &resultstring[0], utf8size, NULL, NULL); if (convresult != utf8size){throw std::exception("La falla!");}return std::string(&resultstring[0]);}//ascii 转 Utf8string ASCII2UTF_8(string& strAsciiCode){string strRet("");//先把 ascii 转为 unicodewstring wstr = Acsi2WideByte(strAsciiCode);//最后把 unicode 转为 utf8strRet = Unicode2Utf8(wstr);return strRet;}。
解决mysql数据库数据迁移达梦数据乱码问题

解决mysql数据库数据迁移达梦数据乱码问题受到领导的嘱托,接⼿了⼀个java项⽬,要进⾏重构,同时了项⽬的整体建设要满⾜信创的要求。
那么⾸先就要满⾜两点:1,使⽤国产数据库达梦8替换mysql数据库2,使⽤⾦蝶中间件替换tomcat进⾏容器部署在不懈的努⼒下,我已在本地的搭建和安装完成达梦8(dm8)数据库,也完成了代码框架更改数据库源,替换达梦数据库的demo验证⼯作。
driverClassName: dm.jdbc.driver.DmDriverurl: jdbc:dm://10.0.3.132:5236/XC-SERVICE?zeroDateTimeBehavior=convertToNull&useUnicode=true&characterEncoding=utf-8username: XC-SERVICEpassword: 123456789现在代码也能正常运⾏了。
除了部分sql脚本要进⾏规范外,也没有什么其它问题了。
现在最重要的事情来了,就是把数据进⾏迁移也就是将mysql的库迁移到dm8当中。
迁移的⽅式,采⽤达梦⾃带的数据库迁移⼯具达梦⾃带数据库迁移⼯具数据表结构和数据迁移后效果迁移完成后,会惊奇的发现,数据表结构倒是没有什么问题,但是中⽂数据全是乱码。
尝试了很多⽅法,百度了⼏圈,都没有找到解决⽅案,后来没有办法,只有去达梦的论坛上⾯去找解决⽅案。
终于,我找到了,⼀个很神奇的解决⽅式,解决数据迁移后乱码的问题。
使⽤数据迁移⼯具,进⾏数据源配置的时候,选择指定驱动。
url地址进⾏指定:jdbc:mysql://10.0.3.131:3306/sys-service?useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=Asia/Shanghai同时指定maven下载到本地的驱动。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
方法一: 通过增加参数 –default-character-set = utf8 解决乱码问题
mysql -u root -p password < path_to_import_file –default-character-set = utf8
方法二: 在命令行导入乱码解决
1. use database_name;
2. set names utf8; (或其他需要的编码)
3. source example.sql (sql文件存放路径)
方法三: 直接粘贴sql文件里的代码
1. 打开SQLyog客户端软件;
2. 定位到SQL编辑器,然后用记事本打开刚刚导出的SQL文件;
3. 复制文件中所有SQL语句到SQL编辑器当中,执行这些SQL代码;
方法四: 用记事本或其他文本工具改变SQL文件的编码格式(若方法三不行,那就尝试方法四)
1. 用记事本(或UE)打开刚才的导出的SQL文件;
2. 另存此文件——打开另存为对话框,选择对话框中的编码格式为UNICODE编码;
3. 保存文件,然后CTRL+A,全选;
4. 复制里面的SQL语句到SQLyog中的“SQL编码器”当中,再执行一次SQL语句;
5. 执行完成后切记刷新一次,查看中文的数据表,乱码消除,大功告成;