AIX的Dump文件学习笔记(原创)
dump搜集

dump搜集不同机型做Force DUMP的方法:RS6000和pSeries型号众多,不同机型做Force DUMP的方法各有不同,所以有必要作一个总结。
做Force DUMP 的方法并不仅限于以下所列,这里只是列举较为便捷的方法。
注:PCI机型做Force Dump的前提是 always allow dump要设为TRUE。
MCA机型(这些机器年代久远,真正用于生产的已经非常稀少了):不管always allow dump设为何值,只要把钥匙拨到Service位置,然后按reset按钮即可。
Power5系列服务器(p510/520/550/570/575/590/595):HMC管理的服务器:在HMC图形管理界面上选Server and Partition => Server Management => 选要做DUMP的主机 => 选要做DUMP的分区 => 单击鼠标右键 => Restart Partition => 选Dump,然后按OK。
无HMC管理的服务器:方法1:在控制面板上用上下键选择02菜单,把System operating mode从Normal改为Manual,即把“N”改为“M”。
然后选择22菜单,按控制面板的回车键,面板显示A 1 0 0 3 0 2 2,用上下键再次选择22菜单,再按面板回车键。
方法2:用admin用户登录ASMI,选System Service Aids => Partition Dump => 选Partition DumpPower4系列服务器(p615/630/650/655/670/690):没有逻辑分区的机器:直接按控制面板的reset按钮。
有逻辑分区的机器:在HMC图形界面上选中需要做DUMP的分区 => 在菜单栏选Selected => Operating System Reset => 选soft reset后按yeseg:errpt命令后显示:IDENTIFIER TIMESTAMP T C RESOURCE_NAME DESCRIPTIONE87EF1BE 0810150008 P O dumpcheck The largest dump device is too small1、首先查看推荐的dump空间sysdumpdev -e2、sysdumpdev -l 看一下现在的dump配置情况,# sysdumpdev -lprimary /dev/hd6secondary /dev/sysdumpnullcopy directory /var/adm/rasforced copy flag TRUEalways allow dump FALSEdump compression OFF系统会定时检测dump device的大小,见root的cron:0 15 * * * /usr/lib/ras/dumpcheck >/dev/null 2>&1如果发现dump device空间不够大,会报错errpt,例如:837E0DE7 1112202205 P O dumpcheck The largest dump device is too small.对于这样的错误信息,一般都是主dump设备的空间太小。
了解转储(dump)设备

了解转储(dump)设备David Tansley, 系统管理员, Ace Europe2012 年7 月30 日如果发生意外,IBM AIX® 操作系统会崩溃,此时您可能希望能够自动搜集相关信息。
利用转储(dump)设备,可在这些设备上部署核心转储功能,从而准备转移到IBM 支持。
简介如果由于意外事件导致系统崩溃,则会发生核心转储。
事实上,并非总在出现系统崩溃时才发生核心转储。
然而,在本文中,假定系统崩溃是由于严重事件或用户强制性动作所引起的。
转储包含了达到崩溃时内存的内容。
就其本质而言,崩溃总是不期而至,因而当崩溃发生时,系统管理员还是应当事先做好防范措施。
能够确定崩溃的发生是否是由系统重启引起,此时在错误日志里存在具有标签为SYSDUMP的条目。
在本演示中,我使用的是AIX 7.1。
不过,我所讨论的原理也适用于AIX 5.3 和 6.1。
回页首做好准备要想防范意外的系统崩溃,需要确保具有转储设备逻辑卷(LV),用于在系统恢复时存放转储。
然而,如果转储设备不可用,那么应该指定第二转储设备来存放转储。
可能人们并不关心系统崩溃何时发生,因而也对进一步研究转储文件不感兴趣。
这完全取决于系统所有者。
但是,为保障系统正常运行,在rootvg 中包含主转储设备是很好的做法,也是很有必要的。
可为转储设备执行镜像,但是,IBM AIX 支持对此发出警告。
这是因为崩溃可能会被执行镜像或同步相关,这会导致转储设备上的镜像无效。
在某些情况下,转储文件仅会被复制到镜像转储设备(位于镜像磁盘中)的其中一个副本,当系统重启时,很可能仅恢复转储文件副本一半的内容,最好的做法是,将主转储设备放到一个非镜像的磁盘中,将第二设备放到另一个非镜像磁盘中。
然而,对rootvg 转储设备执行镜像比较常见。
只要第二转储设备不在分页空间中,或不在磁带设备之类的外部设备中,则它可以位于rootvg 内部,也可位于其外部。
回页首转储设备参考资料学习∙访问AIX 7.1 信息中心,了解更多信息。
AIX 下的 core dump 分析入门
/developerworks/cn/aix/library/0806_chench_core/ (1 of 13)2010-5-2 17:04:24
AIX 下的 core dump 分析入门
结合 core 文件以及可执行程序,来分析问题所在。
注:由于进程信号处理本质上是异步的,应用进程注册的信号处理函数中使用的例程需要保证 是异步信号安全的,例如不能使用诸如 pthread_ 开头的例程。
正常的收集过程应该如下 :
snap core 收集过程
# snapcore ./core ./a.out Core file "./core" created by "a.out" pass1() in progress ....
Calculating space required . Total space required is 14130 kbytes .. Checking for available space ... Available space is 807572 kbytes pass1 complete. pass2() in progress .... Collecting fileset information . Collecting error report of CORE_DUMP errors .. Creating readme file .. Creating archive file ... Compressing archive file .... pass2 completed. Snapcore completed successfully. Archive created in /tmp/snapcore. # cd /tmp/snapcore
使用DBX分析AIX下的 CoreDump

使用DBX分析AIX 下的CoreDumpPS:Where can you get dbx?It is part of bos.adt.debug# lslpp -w /usr/bin/dbxFile Fileset Type-------------------------------------------/usr/bin/dbx bos.adt.debug Symlink以下转自/?6141/viewspace-18882I core dump 分析入门AIX专家俱乐部E ?!CR8Z#S)[环境变量设置`#X`4\]9h|8]0;Uy%D]6sQ.i9O0 可以通过/etc/security/limits 文件对各用户的基本配置参数包括core 大小进行限制。
或者通过ulimit 更改当前环境下的core 大小限制。
AIX专家俱乐部vF?I9u:B1@]!HCc\!v_J-r)r3U0 默认情况下应用进程生成core dump 时都使用文件名core。
为了避免同一工作目录下的进程core 相互覆盖可以定义环境变量CORE_NAMING=true然后启动进程这样将生成名为core.pid.ddhhmmss 的文件。
可以使用file core 命令查看core 是哪个进程产生的。
:EvFu#O@$n*s)g0AIX专家俱乐部0U(p#k2_:J/} G"v$D.E默认情况下应用进程dump 时会包含所有的共享内存如果dump 时想排除共享内存内容可以在启动进程之前设置环境变量CORE_NOSHM=true.R1I rjg09kkS%v!@6o0 系统有一个参数fullcore 用于控制是否在程序coredump 时生成完整的core。
为避免信息丢失建议打开fullcore。
可以使用lsattr –El sys0 查询是否将fullcore 打开使用chdev -l sys0 -a fullcore=true 将fullcore 状态更改为打开。
AIX笔记

vi编辑器 i编辑模式 I移动到行首 a光标前一个字母 A行末 h向左移 l 向右移 k向上 j向下 x删除当前光标 dd删除整行 ctrl+f 向下翻页,ctrl+b 向上翻页图形界面安装 xmanager 然后打开软件输入命令 export DISPLAY=IP:端口即可调用修改网卡属性命令 smitty chinet修改时间和时区 smitty-->system environments-->chang / show date and time-->using system defined value-->PRCAIX关机:shutdown -F hAIX系统安装方式光盘磁带(常用) 网络安装系统启动之前先把网线,光纤拔掉,然后系统启动按1进入SMS模式,选择启动顺序,依次安装升级安装后用命令OSlevel查看是否升级成功调用配置助手的命令是# install_assist 或 # configassist查看软件包的命令:lslpp -l |grep 软件名称查看进程的命令 ps –ef |grep 进程名diag 是硬件诊断命令查看日志文件alog -o -t |more管理系统环境smit system管理语言环境smit mlang六章用户管理与安全策略查看用户ID 和组的两个命令 id+user finger+user查看用户属性的命令是 lsuser+user 或者加具体参数文件系统有 NTFS FAT16 FAT32 NFS ext2/3/4(Linux中) raw(没有格式化或格式化中取消)svmon是查看内存的增加文件读写权限:chmod 777 /file_name修改欢迎界面是在/etc/motd目录下边重置loginretrice的数值可以直接vi /etc/secrrity/lastlog 或者直接smitty user--> reset#who 查看谁在登录#ps aux |grep pts|grep –v grep 查看用户登录进程Umast权限在创建文件夹的时候文件夹权限为755 但是创建文件的时候为664(不需要执行权限)lsvg -l +vg名是查看vg信息的lsvg -p是查看PVlsvg -o是查看激活中的vglsvg –m 是查看有没有做mirrorlspv -l +pv名是查看lvlspv -p是查看pp的lslv -m 是看lp个数和pp的分布–lslv –l 是看lv在pv的分布lsps –a paging spase 分布状态lsps –s paging spase 大小quorum 是vgda可用个数为51% lsvg+vg名称如果stale pv/pp不为0的话肯定是没有同步,要去查逻辑卷删除VG的命令#reducevg –d linvg hdisk3 hdisk4导入导出VG:在exportvg之前一定要查看两边pvid号是否一致,如果不一致先更新pvid号命令:抹掉pvid:#chdev –l hdisk1 –a pv=clear重新获取pvid:#chdev –l hdisk1 –a pv=yes批量清除pvid信息#for i in 3 4 5 6 7 8 9;do chdev -l hdisk${i} -a pv=clear;done批量获取pvid信息#for I in 3 4 5 6 7 8 9;do chdev -l hdisk${i} -a pv=yes;done查看VGDA信息命令:#lqueryvg –Atp hdisk1exportvg+vg名称,可以抹掉在odm库的vg信息,在exportvg之前必须要umout 所有文件系统,而且必须varyoffvg,然后importvg -y +vg名 +pv名命令:lspv查看当前vg里边有哪几个pvlsvg -l linvg 查看 linvg有几个lv 如果有的话umount掉varyoffvg linvg 去激活vgexportvg linvg 抹掉odm库的vg信息importvg -y linvg hdisk (exportvg的那个vg里边的某个盘vmstat 1 是一秒刷新一次pageing spase将LP导入同一个VG下的其他PV中首先创建vg #smitty vg 然后add一个original vg(标准)然后把两个pv加到vg中,可以用#lsvg –l linvg 查看此vg中有没有lv 如果没有的话在其中一个pv中创建lv #smitty lv #add一个lv 创建完成后可以用#lsvg –l linvg查看lv属性可以用#lslv –l lv_linvg 查看lv分布到哪几个PV上,是怎样分布的,用#lslv –m lv_lin/vg 查看lp是怎样分布的然后用#migratelp lv_linvg/lp个数/cop个数目标pv例:#migratelp lv_linvg/1/1 hdisk9扩容LV:首先得有一个lv 用#lslv –l lv_linvg 查看 lv分布到哪几个PV上然后用#lslv –m lv_linvg 查看lp是怎样分布的,然后#smitty lvSet characteristic of a logical volume →increase the size of a logical volume→选择lv名→然后进行扩容在线转移lv:把硬盘hdisk1上的lv00转移到hdisk2上# migratepv -l lv00 hdisk1 hdisk2在线扩容lv:#lsvg –l linvg#lsvg linvg#chfs –a size=+512M /fslv_test这样扩容风险较小,#chfs –a size=-512M /fslv_test缩容也可以这样,但是有一定的风险,谨慎操作扩容VG:扩容vg之前确认要加入的pv没有其他vg占用,如果有要varyoff掉,然后exportvg擦除信息,varyoff之前要确定没有人访问,lv是close状态方法一:#smitty vg →add a pv to vg→vgname,pvname方法二:#extentvg –f linvg hdisk8扩容VG报错:#extendvg –f linvg hdisk3 报错0516-1008 rmlv: Logical volume loglv00 must be closed. If the logical volume contains a filesystem, the umount command will close the LV device.0516-884 reducevg: Unable to remove physical volume hdisk8.#chvg –t 15 linvg#lsvg linvg 看一下maxpv数量#extendvg –f linvg hdisk3文件系统满了的话进行碎片整理4k整理成1k 比如文件问3k,4k为单位那就占用了一个单位有1k是浪费了,整理成1k的话那就使用了3个单位修改换页空间属性:#smitty lvm→paging space→change ps→可以根据需求添加或减少LP如果一块硬盘坏掉,怎样解决?①去mirror,然后备份数据#smitty vg → unmirror 然后选择vgname②把lv从pv删除,然后把pv从vg删除#smitty lv →removelv 然后选择lvname 进行删除#smitty vg→set vg属性→remove pv→选择vg→选择pv 进行删除③diag点亮硬盘,确定哪一块硬盘,把硬盘拔出④把硬盘放进去,然后用#cfgmgr -v识别硬盘然后用#chdev –l pvname –a pv=yes获取pvid⑤加vg,#smitty vg→set vg属性→add一个pv⑥做mirror,#smitty vg → mirror a vg→选择vg→选择同步类型→选择pv 然后同步另:如果lv做copy(mirror)的时候首先#lslv –m lv_linvg查看一下是否有做copy 如果没有的话 #smitty lv→set lv属性→add copy lv→lvname→copy数量→选择pv→选择pv分布范围(注:如果lv分布在两个pv上的话那么range pv 一定要选择maximum) →enterMount与umont#df –g查看有哪些文件系统 mount点在哪然后确定umount哪个文件系统用#fuser –uc /inst 查看有哪些用户在用这个文件系统如果没有用户再用,然后确定不对外提供服务了,可以使用umount /inst 来umount掉如果有用户再用可以用#fuser –kuxc /inst 杀掉mount在这个目录下边的进程,然后再umount 做这些操作之前一定要确定文件系统不对外提供服务而且没有用户在使用的情况下如果paging spase在open状态下,可以用#lsps –a查看有哪些ps 然后用#swapoff /dev/paging00Mount的时候如果根目录下有几个文件系统,你只 mount了一个文件系统的话,其他文件系统是隐藏的,所以你只能看到一个,把mount的那个文件系统umount 掉才能看到其他的举例1:比如一个2G的根目录,已经使用了98%了,而我们mount 的那个文件系统才使用20%了,这个时候就需要umount掉这个mount的文件系统查看一下别的隐藏文件举例2:比如安装一个应用,安装到了vg上边,安装完成之后mount一个文件系统然后发现这个应用找不到了(其实是隐藏了)然后又安装一遍,等这个文件系统umout的时候这个应用还是可以启动,但是数据跟mount上的那个文件系统的数据不一致,所以会出现问题Mount 一个文件到一个mount点的命令首先df –g 查看有没有mount和现在mount在哪然后#mount –v jfs2 /dev/fslv00 /beth查看文件系统目录#cat /etc/filesystems创建文件系统已经mount第一种方式:首先确定要创建多大的文件系统,然后查看vg的pp size #lsvg linvg#smitty fs→add一个→选择第一项→选择第一项→然后根据提示做(选择单位大小,然后决定num,然后填写mount点,然后设置重启是不是自动启动)回车确定,然后#lsvg –l linvg查看是否已经建立成功如果建立成功的话,直接#mount /lin_test01 (这一种方式不能确定分布在哪个pv上,也不能确定是否已经做mirro等)第二种方式:首先确定要创建多大的文件系统,然后查看vg的pp size #lsvg linvg然后创建lv #smitty lvm add一个lv就可以了#lsvg –l linvg 查看lv然后#smitty fs→add一个→选择第一项→选择第二项→选择lv和填写mount 点,设置重启是不是自动启动回车确定,然后#lsvg –l linvg 查看是否已经有挂载点→然后给lv扩容,增加两个lp,#smitty lv→set属性→然后Increase size→选择增加几个lp,分布在哪个PV上,回车确定,然后查看分布在哪些pv 上lslv –m fslv_linvg,确定没问题 #mount test002查看内存的命令 #lsattr -El mem0 #prtconf 看系统配置信息cfgmgr –v 扫描所有加电的设备清除pvid信息#chdev –l hdisk1 –a pv=clear获取pvid信息#chdev –l hdisk1 –a pv=yes把硬盘hdisk1上的lv00转移到hdisk2上#migratepv –l lv00 hdisk1 hdisk2Hd4 根系统 hd5引导系统 hd6换页空间(虚拟内存)hd8日志系统网络:一般IP分为四段,一段为8位一次是128 64 32 16 8 4 2 1A类地址是1开头B类地址是10开头C类地址是100开头永久修改主机名:#chdev –l inet0 -a hostname=xxnameTCP端口监听命令#netstat –an |grep tcp |more端口记录位置#cat /etc/services更改网卡IP#smitty chinet更改网卡属性#smitty chgenet查看所有磁盘 lsdev -Cc disk 直接查看磁盘信息lsattr -El hdisk0,lssrc -a 是查看所有系统服务 refresh -g 是重启服务lssrc -t +服务名查看服务状态startsrc -s +服务名启动服务系统服务:#while true; do df –g ;sleep 5 ;echo ““;done#cd inst#vi abc.sh#!/usr/bin/kshWhile true;do df –g ;sleep 5 ;echo ““;done:wq#chmod a+x abc.sh#/abc.sh#bg 是把命令放到后台运行 fg是在前台输出,exit系统进程就会停止把命令放到后台运行且不退出的命令是#nohup ./abc.sh &#cd /inst #ls –l nohup.out可以查看跑过的nohup命令#nohup ./abc.sh 2>&1 >/dev/null & 1是标准输出2是错误输出,此命令是把错误输出到文件中去#cd /inst #vi aa.sh#!/usr/bin/kshPID=`ps -ef |grep abc.sh |grep -v grep |awk '{print $2 }'`a=`ps -ef |grep abc.sh |grep -v grep |awk '{print $2 }'|wc -l `if [ $a -ne 0 ]thenecho " abc.sh shell is active "fikill -9 $PIDa=`ps -ef |grep abc.sh |grep -v grep |awk '{print $2 }'|wc -l `if [ $a -ne 0 ]thenecho " abc.sh shell is active "elseecho "abc.sh has been killed "fi控制用户使用crontab的两个文件:/var/adm/cron/cron.deny 不允许使用cron的用户/var/adm/cron/cron.allow 允许使用cron的用户如果两个文件都存在,那么只有cron.allow文件有效,如果两个文件都不存在,那么只有root才可以用croncrontab格式:分钟小时日月份星期命令0-59 0-23 1-31 1-12 0-6(0为周日)查看crontab #crontab –l删除crontab #crontab –r编辑crontab方法一:#crontab –e方法二:# crontab –l >/tmp/crontmp# vi /tmp/crontmp# crontab /tmp/crontmp备份与恢复备份分为:系统备份,完全备份,增量备份备份软件:IBM的TSM备份软件HP的NBU备份软件备份介质:软盘,CD,磁带,等等备份系统(rootvg)的时候,可以在/etc/exclude.rootvg更改不想备份的文件,然后#smitty mksysb的时候在EXCLUDE files? 选项选成yes实验:创建一个文件系统并且挂载,然后进行备份,查看备份状态#smitty fs→add/change/show/delete file systems→Enhanced journaled file systems→add an enhanced journaled file system选择VG→选择创建单位,挂载点,选择是否重新自动挂载→创建成功#lsvg –l linvg 查看创建的文件系统是否创建成功#mount /backup#lsvg –l linvg#smitty mksysb→选择挂载点→选择是否启动exclude,选择是否 create map files然后备份备份过程共可以克隆一个会话,#cd /tmp用ls –ltr查看最新生成的文件然后#cd mksysb.13893824→#ls –ltr里边.archive.list.13893824为要备份哪些文件_mksysb.13893824里边为已经备份了哪些文件,还可以用#more /image.data查看data信息;用#wc –l backup一个目录是查看这个目录下边有多少个文件注意:#smitty mksysb只备份rootvg 如果需要备份其他vg 使用#smitty savevg #smitty vg→back up a volume guoup→就是savevg备份文件系统可以#smitty fs#dd if=/dev/fslv00 of=/inst/aa.d count=1024把fslv00前1024个字节移动到aa.d文件 aa.d必须是读写的设备管理13、设备按照读写方式一般可分为两种类型:块设备和字符设备ls -l /dev b开头的是块设备 c开头的是字符设备 d开头的是目录设备号是一个数字,由主设备号(major number)和次设备号(minor number)组成:主设备号标志这设备的类型,次设备号有相应的设备驱动程序解释,常常标志着具体的物理设备。
AIX系统日志

1、系统错误日志存放路径:/var/adm/ras/errlog说明:该日志记录了系统所检测到的软硬件故障和错误,尤其对系统的硬件故障有很大的参考价值,是AIX提供的最有价值的日志之一,errlog 文件用more或者其他文本的查看命令来打开我们看到的只是一对乱码,为了能够查看错误日志文件需要使用aix的errpt命令,如:errpt 列信息;errpt –a列详细信息,详细使用方法可以参考man,2、用户的登录日志存放路径:/var/adm/wtmp /var/adm/sulog说明:这些日志记录了用户登录和访问服务器的情况信息,具体的日志文件有wtmp、、sulog 等,它们记录的分别是不同的事件,wtmp记录的是历史的login和lognout信息,可以用last 命令访问。
sulog记录的是用户用su命令转变为另一用户的信息。
who、last等这些命令可以查看wtmp和sulog的内容如:Last –f wtmp我们想查看最近10次登录的用户和他们的地址,可以用如下命令:last -103、用户的失败登录日志存放路径:/etc/security/failedlogin说明:这些日志记录了用户登录和访问服务器失败的情况信息,登录失败的情况单独记录在该日志中,可以用who命令来查看。
4、集群管理软件hacmp的日志存放路径:/tmp/hacmp.out说明:HACMP是IBM提供的确保系统运行可靠性的集群套件,HACMP在每次启动和关闭时都要经历一段时间以停止服务和转换文件系统,我们可以通过对HACMP。
OUT日志文件的跟踪实时的了解HACMP在启动和关闭时的信息,如出现启动失败则可以帮助我们定位错误。
可以使用tail进行跟踪,tail –f /tmp/hacmp.out5、系统启动错误日志存放路径:/var/adm/ras/bootlog说明:该日志可以跟踪系统在Boot过程中发生的问题,包括服务器液晶板上的代码信息都有记载。
认识Dump文件

认识Dump⽂件⼀、什么是Dump⽂件⼜叫内存转储⽂件或者叫内存快照⽂件。
是⼀个进程或系统在某⼀给定的时间的快照。
⽐如在进程崩溃时或则进程有其他问题时,甚⾄是任何时候,我们都可以通过⼯具将系统或某进程的内存备份出来供调试分析⽤。
dump⽂件中包含了程序运⾏的模块信息、线程信息、堆栈调⽤信息、异常信息等数据。
⼆、分类Windows下Dump⽂件分为两⼤类:内核模式Dump和⽤户模式Dump2.1、内核模式Dump是操作系统创建的崩溃转储,最经典的就是系统蓝屏,这时候会⾃动创建内核模式的Dump。
如果你抓取整个系统的内存dump⽂件, 那么你抓取的是内核态的dump⽂件.2.2、⽤户模式Dump如果你抓⼀个进程的dump⽂件, 那么你抓取的是⽤户态的dump⽂件。
进⼀步可以分为完整Dump(Full Dump)和迷你Dump(Minidump)。
Full Dump包含了某个进程完整的地址空间数据,以及许多⽤于调试的信息Minidump随着Windows XP,微软发布了⼀组新的被称为“minidump”的崩溃转存技术。
Minidump很容易定制。
按照最常⽤的配置,⼀个minidump只包括了最必要的信息,⽤于恢复故障进程的所有线程的调⽤堆栈,以及查看故障时刻局部变量的值。
这样的dump⽂件通常很⼩(只有⼏K字节)。
所以,很容易通过电⼦⽅式发送给软件开发⼈员。
⼀旦需要,minidump甚⾄可以包含⽐原来的crash dump 更多的信息。
minidump可以定制,给我们带来了⼀个问题-保存多少应⽤程序状态信息才能既保证调试有效,⼜能够尽量保证minidump⽂件尽可能⼩?尽管调试简单的异常访问只需要调⽤堆栈和局部变量的信息,但是解决更复杂的问题需要更多的信息。
例如,我们可能需要查看全局变量的值、检查堆的完整性和分析进程虚拟内存的布局。
同时,可执⾏程序的代码段往往是多余的,开发⽤的机器上可以很容易找到这些执⾏程序。
AIX问题检测工具和技巧7

lslicense可以看当前的用户许可: # lslicense
Maximum number of fixed licenses is 32.
Floating licensing is disabled. 用SMIT可以修改用户许可数: # smit chlicense 修改后要重启系统。
# id uid=0(root) gid=0(system) groups=2(bin),3(sys),7(security),8(cron),10(audit) # su ostach $ id uid=201(ostach) gid=1(staff) $ env LOGIN=ostach LOGNAME=root MAIL=/usr/spool/mail/root
未经允许不得用于商业目的
第4页
(2)telnet 子系统
AIX 中国论坛
# telnet server1 Trying... telnet: connect: A remote host refused an attempted connect operation. 可以逐步分析原因:
2.telnet 问题
可能原因有: 没有网络连接 inetd没有运行 telnet子系统没有配置 登录慢一般是名字解析问题
(1)网络问题
# telnet server1 Trying... telnet: connect: A remote host did not respond within the timeout period. 这种情况,一般是网络问题,可能是系统自身,也可能是路由或网关问题,试试 ping 是否可行。
(3)登录慢
如果登录时间超过 2 分钟,DNS 系统可能有问题,检查运行 telnet 守护进程服务器的 /etc/resolv.conf 文件。
AIX操作系统错误日志及日常维护

AIX操作系统错误日志及日常维护一、系统故障记录(errorlog)errdemon 进程在系统启动时自动运行记录包括硬件软件及其他操作信息故障记录文件为/var/adm/ras/errlog 可备份下来或拷贝到别的机器上分析errpt 命令的使用(普通用户权限也可使用)#errpt |more 列出简短出错信息ERROR_ID TIMESTAMP T C RESOURCE_NAME ERROR_DESCRIPTION192ACror logging turned off038FTIMESTAMP: MMDDHHMMYY (月日时分年T 类型: P 永久; T 临时; U 未知永久性的错误应引起重视C 分类: H 硬件; S 软件; O 用户; U未知#errpt -d H 列出所有硬件出错信息#errpt -d S 列出所有软件出错信息#errpt -aj ERROR_ID 列出详细出错信息# errpt -aj 0502f666 <--- ERROR_ID用大小写均可,例:LABEL: SCSI_ERR1ID: 0502F666Date/Time: Jun 19 22:29:51Sequence Number: 95Node ID: host1Class: HType: PERMResource Name: scsi0Resource Class: adapterResource Type: hscsiLocation: 00-08VPD: <--- Virtal Product DataDevice Driver Level (00)Diagnostic Level (00)Displayable Message.........SCSIEC Level....................C25928FRU Number..................30F8834 Manufacturer................IBM97FPart Number.................59F4566Serial Number (00002849)ROS Level and ID (24)Read/Write Register Ptr (0120)DescriptionADAPTER ERRORProbable CausesADAPTER HARDWARE CABLECABLE TERMINATOR DEVICEFailure CausesADAPTERCABLE LOOSE OR DEFECTIVERecommended ActionsPERFORM PROBLEM DETERMINATION PROCEDURESCHECK CABLE AND ITS CONNECTIONSDetail DataSENSE DATA0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000 0000二、控制面板上的LED 代码.8 位代码通常系统故障灯会同时亮起某些机型还会同时显示故障设备位置代码.4 位代码通常是Exxx.3 位代码通常为0yyy 只看后3位.8 位和4位代码可查看系统服务手册 (Service Guide)3 位代码可查看系统诊断手册(Diagnostic Information for Multiple Bus System).闪动的 888, 系统崩溃硬件或软件原因造成按reset 键会显示更多内容888-102 一般为软件故障888-102-207 例外系统会产生一个dump888-102-xxx-0C9 系统正在做dump, 请等待888-102-xxx-0C0 系统dump完成可关电重启888-103 或 105硬件故障一般有 SRN 代码及位置代码三、其他用于收集系统信息的命令lsdev -C 系统设备信息#lsdev -Cc diskhdisk0 Available 00-06-00-2,0 4.5 GB 16 Bit SCSI Disk Drivehdisk1 Available 00-06-00-1,0 4.5 GB 16 Bit SCSI Disk Drivehdisk2 Defined 00-06-00-4,0 16 Bit SCSI Disk Drivelspv 查看物理卷信息#lspvhdisk0 0007821160af3d76 rootvghdisk1 000782117f571294 rootvghdisk2 0000000045c45bde datavglsvg 查看卷组信息#lsvg datavgVOLUME GROUP: datavg VG IDENTIFIER: 0000000055e2458bVG STATE: active PP SIZE: 4 megabyte(s)VG PERMISSION: read/write TOTAL PPs: 2169 (8676 megabytMAX LVs: 256 FREE PPs: 1 (4 megabytes)LVs: 3 USED PPs: 2168 (8672 megabytOPEN LVs: 2 QUORUM: 2TOTAL PVs: 1 VG DESCRIPTORS: 2STALE PVs: 0 STALE PPs: 0ACTIVE PVs: 1 AUTO ON: yesMAX PPs per PV: 2032 MAX PVs: 16#lsvg -l rootvgrootvg:LV NAME TYPE LPs PPs PVs LV STATE MOUNT POINThd5 boot 1 1 1 closed/syncd N/A...lv00 jfs 51 102 1 closed/stale /ibmcxxlv01 jfs 1 1 1 open/syncd /cics_regionslv02 jfs 4 4 1 open/syncd /var/mqmlslpp 查看文件组信息# lslpp -L |grep 23100020....100020.rte 4.3.2.7 C IBM PCI 10/100 Ethernet Adapt看某个文件组是否已安装如以太网卡驱动也用于查询补丁程序的版本lsattr 查看设备参数设置# lsattr -El ent2busio 0x7fffc00 Bus I/O address Falsebusintr 9 Bus interrupt level Falseintr_priority 3 Interrupt priority Falsetx_que_size 512 TRANSMIT queue size Truerx_que_size 256 RECEIVE queue size Truerxbuf_pool_size 384 RECEIVE buffer pool size Truemedia_speed 10_Half_Duplex Media Speed Trueuse_alt_addr no Enable ALTERNATE ETHERNET address Truealt_addr 0x000000000000 ALTERNATE ETHERNET address Trueip_gap 96 Inter-Packet Gap Truelscfg 查看VPD信息Virtual Product Data)# lscfg -vl ssa1DEVICE LOCATION DESCRIPTIONssa1 30-68 IBM SSA Enhanced RAID Adapter(14104500)Part Number.................097H0645FRU Number..................097H0645 <-- 备件号Serial Number...............C8217227EC Level....................0000F20825 Manufacturer................IBM053ROS Level and ID............7201 <-- 微码版本Loadable Microcode Level (04)Device Driver Level (00)Displayable Message.........SSA-ADAPTERDevice Specific.(Z0)........DRAM=032Device Specific.(Z1)........CACHE=0Device Specific.(Z2)........000000062955dab2Device Specific.(YL)........P2-I7 <-- 槽号不同的硬件设备有不同的VPD 所含的格式和信息都不一样通常备件号和微码版本最有参考价值注FRU(Field Replace Unit)才是真正的备件号。
Dump文件分析(转发)

Dump⽂件分析(转发)原⽂:本⽂主要介绍Dump⽂件结构,理解Dump⽂件对于分析线程⾼占⽤、死锁、内存溢出等⾼级问题有⾮常重要的指导意义。
什么是Dump⽂件Dump⽂件是进程的内存镜像。
可以把程序的执⾏状态通过调试器保存到dump⽂件中。
Dump⽂件是⽤来给程序编写⼈员调试程序⽤的,这种⽂件必须⽤专⽤⼯具软件打开。
如何⽣成Dump⽂件使⽤命令:jstack pid可以查看到当前运⾏的java进程的dump信息。
Dump⽂件结构⾸先浏览⼀下dump⽂件的⽂本内容:Full thread dump Java HotSpot(TM) 64-Bit Server VM (25.77-b03 mixed mode):"Attach Listener" #37 daemon prio=9 os_prio=0 tid=0x00007f87b42b7000 nid=0x680f waiting on condition [0x0000000000000000]ng.Thread.State: RUNNABLE"Druid-ConnectionPool-Destory-331358539" #36 daemon prio=5 os_prio=0 tid=0x00007f87a4278800 nid=0x67e4 waiting on condition [0x00007f87b8dce000] ng.Thread.State: TIMED_WAITING (sleeping)at ng.Thread.sleep(Native Method)at com.alibaba.druid.pool.DruidDataSource$DestroyConnectionThread.run(DruidDataSource.java:1724)"Druid-ConnectionPool-Create-331358539" #35 daemon prio=5 os_prio=0 tid=0x00007f87a4022000 nid=0x67e3 waiting on condition [0x00007f87ce86a000] ng.Thread.State: WAITING (parking)at sun.misc.Unsafe.park(Native Method)- parking to wait for <0x00000000b3804848> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)at com.alibaba.druid.pool.DruidDataSource$CreateConnectionThread.run(DruidDataSource.java:1629)"Abandoned connection cleanup thread" #31 daemon prio=5 os_prio=0 tid=0x00007f87e0d91800 nid=0x672b in Object.wait() [0x00007f87cd2c2000]ng.Thread.State: TIMED_WAITING (on object monitor)at ng.Object.wait(Native Method)at ng.ref.ReferenceQueue.remove(ReferenceQueue.java:143)- locked <0x00000000b422d1e8> (a ng.ref.ReferenceQueue$Lock)at com.mysql.jdbc.AbandonedConnectionCleanupThread.run(AbandonedConnectionCleanupThread.java:43)"DestroyJavaVM" #30 prio=5 os_prio=0 tid=0x00007f87e0008800 nid=0x670b waiting on condition [0x0000000000000000]ng.Thread.State: RUNNABLE"http-nio-8081-AsyncTimeout" #28 daemon prio=5 os_prio=0 tid=0x00007f87e016e800 nid=0x6727 waiting on condition [0x00007f87b94cf000]ng.Thread.State: TIMED_WAITING (sleeping)at ng.Thread.sleep(Native Method)at org.apache.coyote.AbstractProtocol$AsyncTimeout.run(AbstractProtocol.java:1211)at ng.Thread.run(Thread.java:745)"http-nio-8081-Acceptor-0" #27 daemon prio=5 os_prio=0 tid=0x00007f87e0166000 nid=0x6726 runnable [0x00007f87b95d0000]ng.Thread.State: RUNNABLEat sun.nio.ch.ServerSocketChannelImpl.accept0(Native Method)at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:422)at sun.nio.ch.ServerSocketChannelImpl.accept(ServerSocketChannelImpl.java:250)- locked <0x00000000b410d480> (a ng.Object)at .NioEndpoint$Acceptor.run(NioEndpoint.java:455)at ng.Thread.run(Thread.java:745)"http-nio-8081-ClientPoller-0" #26 daemon prio=5 os_prio=0 tid=0x00007f87e0292800 nid=0x6725 runnable [0x00007f87b96d1000]ng.Thread.State: RUNNABLEat sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:269)at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:93)at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:86)- locked <0x00000000b410d6c0> (a sun.nio.ch.Util$2)- locked <0x00000000b410d6b0> (a java.util.Collections$UnmodifiableSet)- locked <0x00000000b410d668> (a sun.nio.ch.EPollSelectorImpl)at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:97)at .NioEndpoint$Poller.run(NioEndpoint.java:793)at ng.Thread.run(Thread.java:745)"http-nio-8081-exec-10" #25 daemon prio=5 os_prio=0 tid=0x00007f87e028c000 nid=0x6724 waiting on condition [0x00007f87b97d2000]ng.Thread.State: WAITING (parking)at sun.misc.Unsafe.park(Native Method)- parking to wait for <0x00000000b410d898> (a java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject)at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)at java.util.concurrent.locks.AbstractQueuedSynchronizer$ConditionObject.await(AbstractQueuedSynchronizer.java:2039)at java.util.concurrent.LinkedBlockingQueue.take(LinkedBlockingQueue.java:442)at org.apache.tomcat.util.threads.TaskQueue.take(TaskQueue.java:103)at org.apache.tomcat.util.threads.TaskQueue.take(TaskQueue.java:31)at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)at org.apache.tomcat.util.threads.TaskThread$WrappingRunnable.run(TaskThread.java:61)at ng.Thread.run(Thread.java:745)其中每个空⾏⽤于分隔⼀个线程,每个线程的信息是以堆栈信息的⽅式展开,显⽰了⽬前正在调⽤的⽅法以及所在的代码⾏。
dump文件的函数参数

dump文件的函数参数一、什么是dump文件?dump文件是程序在运行过程中,将内存中的数据以二进制的形式保存到磁盘上的一种文件格式。
它包含了程序在运行过程中的所有内存信息,包括变量的值、函数的调用栈、堆栈信息等。
通过分析dump文件,可以了解程序在运行过程中的状态,帮助程序员快速定位和解决问题。
二、为什么需要使用dump文件?在程序开发过程中,经常会遇到各种各样的bug和崩溃问题。
当程序出现崩溃时,我们通常无法立即找到问题的原因,这时候使用dump文件就非常有帮助了。
通过分析dump文件,可以还原出程序在崩溃时的内存状态,帮助我们定位问题所在。
三、如何生成dump文件?生成dump文件的方法有很多种,下面介绍两种常用的方法:1. 使用操作系统提供的工具:在Windows操作系统中,可以通过配置系统参数或使用命令行工具来生成dump文件。
例如,在Windows 7及以上版本中,可以通过配置系统参数来指定在程序崩溃时自动生成dump文件。
2. 使用调试工具:在程序调试过程中,可以使用调试工具生成dump文件。
例如,在Visual Studio中,可以通过在代码中插入调试断点或使用异常处理机制来生成dump文件。
dump文件的函数参数是指在生成dump文件时,对相关函数的调用所传递的参数信息。
这些参数信息对于分析问题和定位错误非常重要。
下面介绍几个常见的dump文件函数参数:1. 栈指针(Stack Pointer):栈指针是指向程序当前栈帧的指针,它指向了当前函数的返回地址和函数的局部变量。
通过栈指针,可以获取函数的调用栈信息,从而了解函数的调用关系和参数传递。
2. 堆指针(Heap Pointer):堆指针是指向堆内存区域的指针,堆内存是动态分配的内存,例如通过malloc()函数分配的内存。
通过堆指针,可以获取堆内存的状态信息,帮助我们分析内存泄漏等问题。
3. 函数参数(Function Arguments):函数参数是指函数在调用时传递的参数值。
aix sysdump

AIX中The largest dump device is too small的处理在errpt中出现E87EF1BE 0926082807 P O dumpcheck The largest dump device is too small.信息.断定为存放dump文件的lg_dumplv容量不够.需要扩容.扩容步骤如下:1.查看lg_dumplv大小的估计值#sysdumpdev -e0453-041 Estimated dump size in bytes: 1287651328即1.2G2.现在lg_dumplv大小#lslv lg_dumplv其中PP SIZE: 256 megabyte(s)PPs: 4经计算,现在容量为1G.需要扩容0.2G3.查看lg_dumplv所在的vg的容量是否够用#lsvg rootvg其中PP SIZE: 256 megabyte(s)TOTAL PPs: 1092 (279552 megabytes)FREE PPs: 826 (211456 megabytes)经计算,vg剩余容量为206.5G,因为根盘做了镜像.故,可用剩余容量为103G左右.因pp size为256m,故扩容2pps,即0.5G(其实扩1个pp也可以.2个放心点.)4.扩容操作extendlv lg_dumplv 25.检查当前lg_dumplv的大小.#lslv lg_dumplv其中PP SIZE: 256 megabyte(s)PPs: 6即,现在容量为1.5G.6.使用dumpcheck命令查看,是否还出现errpt信息#/usr/lib/ras/dumpcheck#errpt不出现,则为成功.注:在AIX 系统中的lg_dumplv 逻辑卷是用于存放系统dump 的区域。
在安装系统时是否创建该逻辑卷与服务器的内存配置有关。
若服务器的内存小于4GB时, 那么在安装 AIX 5.2 或 5.3时,系统就不会自动创建它。
Dump文件数据存储格式(一)

Dump⽂件数据存储格式(⼀)我们已经了解了什么是Dump⽂件,它保存了什么数据,有什么作⽤,但它是如何存储的,数据格式是怎样的呢。
下⾯简单说⼀下。
⼀、总体结构⼆、⽂件头⾸先⽂件的最开始的32个字节是Dump⽂件的⽂件头,这⾥包含了Dump⽂件标识、格式版本、校验和、时间戳和⼀些标志,数据结构如下typedef struct _MINIDUMP_HEADER {ULONG32 Signature;ULONG32 Version;ULONG32 NumberOfStreams;RVA StreamDirectoryRva;ULONG32 CheckSum;union {ULONG32 Reserved;ULONG32 TimeDateStamp;};ULONG64 Flags;} MINIDUMP_HEADER, *PMINIDUMP_HEADER上⾯的结构包含了很多信息,总共32个字节,存放在⽂件的最开始的位置,下⾯分别说下各成员:Signature---⽂件标识4个字节,存放内容是"MDMP"字符串的ASSIC码。
可以简单的读取⽂件的头4个字节是否等于"MDMP"来判断⼀个⽂件是否是Dump⽂件。
Version---Dump格式的版本低两字节是MiniDump的版本号,⾼两字节是⼀个特定整形值NumberofStreams----⽂件⾥内存数据流的计数也就是MiniDump⽬录表的元素个数。
dump⽂件是以流的形式保存内存数据,各个流的类型不⼀样。
StreamDirectoryRVA流⽬录表的⽂件偏移地址,从⽂件最开始处也就是地址0开始,那么要寻址流⽬录:0+StreamDirectoryRva(字节)CheckSum⽂件校验和,可以为0TimeDataStamp时间戳,⽂件的修改时间Flags⼀个或多个MINIDUMP_TYPE的枚举值组成的标志,说明本⽂件⾥包含了哪些信息。
IBM AIX 持续可用性dumpctrl

IBM AIX 持续可用性: 第 3 部分多年以来,AIX 操作系统一直包含由IBM 技术支持的许多可靠性特性,现在通过应用更先进的技术进一步提高了AIX 的可靠性。
其中一些新特性包括对POWER6 存储键的内核支持、并行更新、动态跟踪和增强的软件初次故障数据捕捉等等。
错误检查Run-Time Error CheckingRun-Time Error Checking(RTEC)让服务人员能够使用产品二进制代码中内置的调试功能。
RTEC 提供强大的初次故障数据捕捉和二次故障数据捕捉错误探测特性。
基本的RTEC 框架是在AIX V5.3 TL3 中引入的,现在已经增加了更多的特性。
RTEC 特性包括Consistency Checker 和Xmalloc Debug 特性。
这些特性一般可以通过errctrl 命令调整。
一些特性还有专门针对给定子系统的属性或命令,比如sodebug 命令与新的套接字调试功能相关联。
AIX 出版物中描述了增强的套接字调试功能,可以在以下站点上找到:/infocenter/pserIEs/v5r3/index.jsp内核堆栈溢出探测从AIX V5.3 TL5 开始,内核提供用来探测堆栈溢出的增强的逻辑。
所有运行的AIX 代码都维护一个称为堆栈的内存区,堆栈用来存储执行代码所需的数据。
在代码运行时,堆栈会增长和收缩。
堆栈可能增长到超过其最大的范围并覆盖其它数据。
这些问题很难解决。
AIX V5.3 TL5 引入了一个异步的运行时检查功能,用来检查特定的内核堆栈是否溢出。
探测到溢出时的默认操作是在AIX 错误日志中记录错误。
堆栈溢出运行时错误检查特性由ml.stack_overflow 组件控制。
AIX V6.1 改进了内核堆栈溢出探测,支持用同步溢出探测功能保护某些堆栈。
另外,在启用恢复框架时,以前属于重大问题的某些内核堆栈溢出现在是完全可恢复的。
内核非执行(no-execute)探测非执行探测也是在AIX V5.3 TL5 中引入的,可以为不应该作为可执行代码的各种内核数据区设置这种保护。
AIX常用命令知识

AIX 常用命令知识(自整理)lsvg –o rootvg# lspv hdisk0$ lspv hdisk0PHYSICAL VOLUME: hdisk0 VOLUME GROUP: rootvg PV IDENTIFIER: 007857f365c430ec VG IDENTIFIER 007857f3a79852ee PV STATE: activeSTALE PARTITIONS: 0 ALLOCATABLE: yesPP SIZE: 8 megabyte(s) LOGICAL VOLUMES: 8 TOTAL PPs: 516 (4128 megabytes) VG DESCRIPTORS: 2FREE PPs: 90 (720 megabytes)USED PPs: 426 (3408 megabytes)FREE DISTRIBUTION: 23..38..00..00..29USED DISTRIBUTION: 81..65..103..103..74# oslevel$ oslevel4.3.2.0# oslevel –rssaxlate –l hdisk3lsattr –El hdisk0lsattr -El proc0lscfg –vl fsc0lscfg –vl pdisk*errpt –aj 粘贴错误码errclear 0 (记得备份)cp /var/adm/errlog /home/ww/err/errlogerrclear 0lsdev -Cc adapterprtconfbosboot –ad /dev/hdisk0bootlist –m normal –obootlist -m normal hdisk0 hdisk1 rmt0 fd查看安装媒体内容:installp -q -d /dev/cdrom –lduerrpt |morefind / -name core –printcp file1 file1.030807ps aux |headpmcycles -msync CommandUpdates the i-node table and writes buffered files to the hard disk#sync;sync;synccrontab –l 查看crontab –e 修改(vi)crontab –r 删除有系统的,也可以编辑自己需要的有时系统也自动生成,如电源故障报警系统生成的,改正错误后应该删掉。
dump文件分析2篇

dump文件分析2篇第一篇:Windows dump文件分析Windows dump文件是一种用来记录系统崩溃信息的文件。
当Windows操作系统遇到蓝屏或其他严重错误时,会自动生成一个dump文件,其中包含系统状态和运行时数据,这对于问题诊断和修复非常重要。
在本文中,我们将介绍如何分析Windows dump文件,以帮助用户解决系统故障和崩溃问题。
一、获取dump文件通常,当Windows发生蓝屏或停机错误时,会在系统重启时自动生成一个dump文件,将其保存在C:\Windows\Minidump文件夹中。
如果用户没有设置该文件夹位置,则dump文件通常位于系统根目录的MEMORY.DMP文件中。
如果没有自动创建dump文件,则可以手动启用Windows内存转储(crash dump)功能,以生成dump文件。
二、分析dump文件通过分析Windows dump文件,我们可以得到以下信息:1、错误代码:告诉我们这次崩溃的是哪种类型的问题。
例如,错误代码0x0000007B表示硬盘损坏或驱动程序异常。
2、异常地址:崩溃时发生错误的代码位置,帮助我们确定问题来自哪个程序或驱动程序。
3、堆栈跟踪:程序崩溃时调用栈的状态。
从最后一个函数返回地址开始,逐个跟踪函数调用过程,以确定程序崩溃的原因。
以下是我们分析dump文件的步骤:1、使用Debugging Tools for Windows工具(例如WinDbg)打开dump文件。
2、在WinDbg中输入“!analyze -v”命令,以查看错误代码和异常地址。
3、使用“kb”命令查看堆栈跟踪,确定哪个驱动程序或应用程序导致崩溃。
4、在Google或Microsoft的搜索引擎中,输入发生错误代码的十六进制值,以查找可能的解决方案和修复。
例如,如果错误代码为0x0000007B,则可能是硬件设备或磁盘问题。
5、根据分析结果采取相应措施。
例如,更新所有驱动程序、检查硬件问题或升级操作系统。
dump参数

dump参数dump参数是指在计算机编程中,用于将数据从内存中转储到外部存储介质的一种操作。
它常用于调试和分析程序运行时的数据状态,对于程序员来说是一项非常重要的工具。
下面将从不同的角度来探讨dump参数的作用和使用。
一、dump参数的基本概念和作用在计算机编程中,dump参数是指通过将内存中的数据转储到外部存储介质上,以便于程序员在调试和分析程序运行时的数据状态。
通过使用dump参数,可以将程序在运行过程中的数据状态保存下来,以便于后续的分析和调试工作。
dump参数通常被用于查找程序中的bug,分析程序的性能问题以及进行内存泄漏的检测等。
在不同的编程语言和操作系统中,dump参数的使用方法可能会有所不同。
下面以C语言为例,介绍一下在Linux系统中如何使用dump 参数。
1. 在程序中添加dump参数的代码在C语言中,可以使用库函数如`glibc`中的`abort()`函数来生成dump文件。
当程序运行到某个特定的条件下时,可以调用`abort()`函数来生成dump文件。
例如,可以在程序中添加一个断言,当断言条件不满足时,调用`abort()`函数来生成dump文件。
2. 编译程序时添加相应的选项在Linux系统中,可以通过在编译程序时添加相应的选项来生成dump文件。
例如,可以使用`gcc`编译器的`-g`选项来生成带有调试信息的可执行文件。
然后,当程序运行到某个特定的条件下时,可以使用`gdb`调试工具来生成dump文件。
3. 使用调试工具生成dump文件除了在程序中添加dump参数的代码和编译程序时添加相应的选项外,还可以使用调试工具来生成dump文件。
例如,在Linux系统中,可以使用`gdb`调试工具来生成dump文件。
首先,需要启动`gdb`调试工具并加载可执行文件。
然后,可以使用`generate-core-file`命令来生成dump文件。
三、dump参数的应用场景dump参数在程序开发和调试过程中有着广泛的应用场景。
AIX的系统dump 工具学习笔记

AIX的系统dump 工具学习笔记(一)关于system dump facility在sg247199一书9.3进行了描述,因为BJCCPC基础操作系统对system dump提出一些要求,所以临上轿抓过来看看。
当系统非正常停机,dump对系统做了一个快照,dump数据首先写到主dump设备,如果主设备不可用,再写到次设备。
Dump也可以由用户发起,并写到指定设备。
一、配置System Dump设备系统安装完成后,默认的dump设备/dev/hd6,同时也是默认的交换区设备。
次设备是/dev/sysdumpnull,系统重启时,/dev/hd6中的内容从/dev/hd6拷贝到/var/adm/ras。
1、sysdumpdev列出当前的dump配置#sysdumpdev -lprimary /dev/hd6secondary /dev/sysdumpnullcopy directory /var/adm/rasforced copy flag TRUEalways allow dump FALSEdump compression OFFdump设备可以配置在磁带或其它的逻辑卷上,如果次dump设备是共享的,那么主dump设备必须是专用的。
注:(1)如果系统内存大小大于或等于4GB,缺省的dump设备是/dev/lg_dumplv,该设备是专门为dump而设置的。
(2)不要用镜像的或有拷贝的lv做dump设备,否则dump将失败,而且没有错误信息。
不要用软盘设备作为dump设备。
2、修改System Dump设备(1)用sysdumpdev永久修改主dump设备# sysdumpdev -P -p /dev/dumpdevprimary /dev/dumpdevsecondary /dev/sysdumpnullcopy directory /var/adm/rasforced copy flag TRUEalways allow dump TRUEdump compression ON注:如果将主dump不在rootvg上,那么无法复制从交换区拷贝(2)用sysdumpdev永久修改备dump设备# sysdumpdev -P -s /dev/rmt0primary /dev/hd6secondary /dev/rmt0copy directory /var/adm/rasforced copy flag TRUEalways allow dump FALSEdump compression OFF(3)用sysdumpdev临时修改主dump设备用sysdumpdev临时修改主dump设备,下次重启时恢复原设置。
有关aio引起AIX宕机的core_dump分析

有关aio引起AIX宕机的core_dump分析2008.03.27前些日子,客户的S7A主机发生了几次宕机,产生了CORE_DUMP文件,下面是利用crash命令分析宕机原因的过程pwd/# hostnames7a01# cd /var/adm/ras# ls -l 查看core文件名称total 395133-rw-rw-r-- 1 root system 4226 Apr 02 2003 BosMenus.log-rw-r--r-- 1 root system 2 Jan 07 2000 SRCSemID-rw------- 1 root system 8192 May 20 13:35 bootlog-rw-r--r-- 1 root system 8388 Apr 02 2003 bosinst.data-rw-rw-r-- 1 root system 16384 Apr 02 2003 bosinstlog--w------- 1 root system 2 May 16 15:47 bounds-rw-r--r-- 1 bin bin 197206 Jan 01 1970 codepoint.cat-rw--w--w- 1 root system 16384 May 20 15:52 conslog--w------- 1 root system 21 May 16 15:47 copyfilename-rw-r--r-- 1 root system 57078 Apr 02 2003 devinst.log-rw-r--r-- 1 root system 83319 May 20 14:00 diag_log-rw------- 1 root system 8192 May 16 15:49 dumpsymplog-rw-r--r-- 1 root system 151552 May 20 15:52 errlog-rw-r--r-- 1 root system 151552 Apr 22 2004 errlog0422.log-r--r--r-- 1 bin bin 103968 Jan 07 2000 errtmplt-rw-r--r-- 1 root system 7949 Apr 02 2003 image.data-rw-r--r-- 1 root system 8192 May 20 13:21 nimlog-rw-rw-rw- 1 root system 1334264 Jan 20 2000 trcfile-rw------- 1 root system 200136704 May 16 15:47 vmcore.0# crash vmcore.0 开打vmcore.0文件Using /unix as the default namelist file.2 dump routines failed. The following were recorded:0x0141cbe8 failed with rc=140x01422764 failed with rc=14> stat 查看宕机时的状态sysname: AIXnodename: s7a01release: 3version: 4machine: 000AAD014C00time of crash: Tue May 16 15:05:18 TAIST 2006age of system: 22 hr., 51 min.xmalloc debug: disabledabend code: 300 查看错误代码,这个代码很关键csa: 0x2ff3b400exception struct:dar: 0x00000000dsisr: 0x00000000:srv: 0x00000000dar2: 0x00000000dsirr: 0x00000000: (errno) "Error 0"> trace -mSkipping first MSTMST STACK TRACE:0x2ff3b400 (excpt=00000004:0a000000:00000000:00000004:00000106) (intpri=11) IAR: .compare_and_swap+2c (0000a4ec): stw r9,0x0(r4)LR: .[aiopin:untie_knot]+a8 (0143d7a8)2ff3a2e0: .[aio.ext:qlioreq]+b0 (014376ec)2ff3a340: .[aio.ext:listio]+128 (01438f5c)2ff3b3c0: .sys_call_ret+0 (00003a6c)0001113a: lasttocentry+fead9 (00348001)0452-771: Cannot read return address at address 0x01892c0b.> le 0000a4ecNo loader entry found for module address 0x0000a4ecNo loader entry found for module named '0000a4ec'> le 0143d7a8LoadList entry at 0x04ea7980Module *start:0x00000000_0143bef0 Module filesize:0x00000000_0000228cModule *end:0x00000000_0143e17c*data:0x00000000_0143dbe8 data length:0x00000000_00000594Use-count:0x0001 load_count:0x0000 *file:0x00000000flags:0x00000262 TEXT DATAINTEXT DATA DATAEXISTS*exp:0x04ed8000 *lex:0x00000000 *deferred:0x00000000 expsize:0x6e6c732f Name: /usr/lib/drivers/aiopinndepend:0x0001 maxdepend:0x0001*depend[00]:0x05039280*le_next: 04ea7680> le 014376ecLoadList entry at 0x04ea7680Module *start:0x00000000_014348c0 Module filesize:0x00000000_00007624Module *end:0x00000000_0143bee4*data:0x00000000_0143a4c0 data length:0x00000000_00001a24Use-count:0x0003 load_count:0x0001 *file:0x00000000flags:0x00000272 TEXT KERNELEX DATAINTEXT DATA DATAEXISTS*exp:0x051e3000 *lex:0x00000000 *deferred:0x00000000 expsize:0x6c696263 Name: /etc/drivers/aio.extndepend:0x0002 maxdepend:0x0002*depend[00]:0x04ea7980*depend[01]:0x05039280*le_next: 04edb700> le 01438f5cLoadList entry at 0x04ea7680Module *start:0x00000000_014348c0 Module filesize:0x00000000_00007624 Module *end:0x00000000_0143bee4*data:0x00000000_0143a4c0 data length:0x00000000_00001a24Use-count:0x0003 load_count:0x0001 *file:0x00000000flags:0x00000272 TEXT KERNELEX DATAINTEXT DATA DATAEXISTS*exp:0x051e3000 *lex:0x00000000 *deferred:0x00000000 expsize:0x6c696263 Name: /etc/drivers/aio.extndepend:0x0002 maxdepend:0x0002*depend[00]:0x04ea7980*depend[01]:0x05039280*le_next: 04edb700经查,宕机跟Name: /usr/lib/drivers/aiopin有关,> errpt 查看宕机时产生的错误日志LAST ERRORS READ BY ERRDEMON (MOST RECENT LAST):Tue May 16 15:05:18 TAIST: DSI_PROC data storage interrupt : processor Resource Name: SYSVMM0a000000 00000000 00000004 00000086LAST 3 ERRORS READ BY ERRDEMON (MOST RECENT FIRST):> od vmmerrlog 9 rpco proc - 0SLT ST PID PPID PGRP UID EUID TCNT NAME0 a 0 0 0 0 0 1 swapperFLAGS: swapped_in no_swap fixed_pri kprocLinks: *child:0xe20030c0 *siblings:0x00000000 *uinfo:0x50004020(0x0038) *ganchor:0x00000000 *pgrpl:0x00000000 *ttyl:0x00000000Dispatch Fields: pevent:0x00000000 *synch:0xfffffffflock:0x00000000 lock_d:0x00000000Thread Fields: *threadlist:0xe6000000 threadcount:1active:1 suspended:0 local:0 terminating:0Scheduler Fields: fixed pri: 16 repage:0x00000000 scount:0 sched_pri:0 *sched_next:0x00000000 *sched_back:0x00000000 cpticks:3087msgcnt:0 majfltsec:0Misc: adspace:0x0003c00f kstackseg:0x00000000 xstat:0x0000*p_ipc:0x00000000 *p_dblist:0x00000000 *p_dbnext:0x00000000Signal Information:pending:hi 0x00000000,lo 0x00000000sigcatch:hi 0x00000000,lo 0x00000000 sigignore:hi 0xffffffff,lo 0xfff7ffff Statistics: size:0x00000000(pages) audit:0x00000000accounting page frames:0 page space blocks:0Number of virtual pages in use :0pctcpu:0 minflt:1987 majflt:7> thread - 0SLT ST TID PID CPUID POLICY PRI CPU EVENT PROCNAME0 s 3 0 unbound FIFO 10 78 swappert_flags: wakeonsig kthreadLinks: *procp:0xe2000000 *uthreadp:0x2ff3b400 *userp:0x2ff3b6e0 *prevthread:0xe6000000 *nextthread:0xe6000000, *stackp:0x00000000*wchan1(real):0x00000000 *wchan2(VMM):0x00000000 *swchan:0x00000000 wchan1sid:0x00000000 wchan1offset:0x00000000pevent:0x00000000 wevent:0x00000001 *slist:0x00000000Dispatch Fields: *prior:0xe6000000 *next:0xe6000000polevel:0x0000000a ticks:0x0c0f *synch:0xffffffff result:0x00000000*eventlst:0x00000000 *wchan(hashed):0x00000000 suspend:0x0001thread waiting for: event(s)Scheduler Fields: cpuid:0xffffffff scpuid:0xffffffff pri: 16 policy:FIFO affinity:0x0001 affinity_ts:0x3b6e31e cpu:0x0078 run_queue:34a900lpri: 0 wpri:127 time:0x00 sav_pri:0x10Misc: lockcount:0x00000000 ulock:0x00000000 *graphics:0x00000000 dispct:0x00031718 fpuct:0x00000001 boosted:0x0000userdata:0x00000000fsflags: 00000000 adsp_flags: 0000Signal Information: cursig:0x00 *scp:0x00000000pending:hi 0x00000000,lo 0x00000000 sigmask:hi 0x00000000,lo 0x00000000 > q#lslpp -w /usr/lib/drivers/aiopin 查看相关的文件集File Fileset Type----------------------------------------------------------------------------/usr/lib/drivers/aiopin bos.rte.aio File# lslpp -ah bos.rte.aio 查看这个文件集的版本为4.3.3.1Fileset Level Action Status Date Time----------------------------------------------------------------------------Path: /usr/lib/objreposbos.rte.aio4.3.3.0 COMMIT COMPLETE 01/01/70 08:29:524.3.3.1 COMMIT COMPLETE 01/07/00 09:57:114.3.3.1 APPLY COMPLETE 01/07/00 09:55:52Path: /etc/objreposbos.rte.aio4.3.3.0 COMMIT COMPLETE 01/01/70 08:29:524.3.3.1 COMMIT COMPLETE 01/07/00 09:57:114.3.3.1 APPLY COMPLETE 01/07/00 09:55:53经查,宕机跟bos.rte.aio有关,在IBM网站上查到如下内容IY05599: AIO CRASH IN COMPARE_AND_SWAP 00/01/14 PTF PECHANGE APAR statusClosed as program error.Error descriptionWhen the parameter passed to the compare_and_swap() expectedto be a pointer to an integer, but the code passed an integer.I/O on this address (small integer) caused the system crashedwith DSI.Local fixProblem summary*************************************************************** *USERS AFFECTED: ** All users with the following filesets at these levels ** bos.rte.aio 4.3.3.1.*************************************************************** *PROBLEM DESCRIPTION: ** When the parameter passed to the compare_and_swap()* expected to be a pointer to an integer, but the code* passed an integer. I/O on this address (small* integer) caused the system crashed with DSI.*************************************************************** *RECOMMENDATION: ** Apply apar IY05599*************************************************************** Problem conclusionCorrected the parameter passed to compare_and_swap calls.Temporary fixCommentsAPAR informationAPAR number IY05599Reported component name AIX 4.3.0Reported component ID 5765C3403Reported release 430Status CLOSED PERPE YesPEHIPER NoHIPERSubmitted date 1999-11-02Closed date 1999-11-08Last modified date 2000-10-17APAR is sysrouted FROM one or more of the following:APAR is sysrouted TO one or more of the following:Fix informationFixed component name AIX 4.3.0Fixed component ID 5765C3403Applicable component levelsR430 PSY U467596 UP99/12/21 I 1000现在确定,这台机器需要打相关补丁才能彻底解决宕机.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
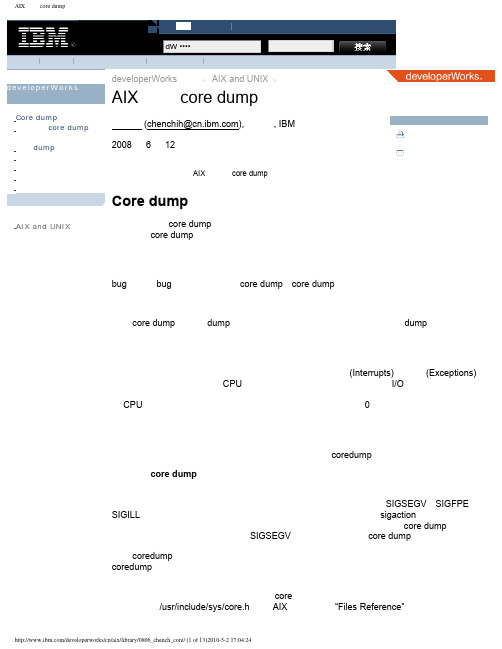
AIX的Dump文件学习笔记(原创)DUMP文件概述为了增强故障分析能力,IBM的服务器增加了对设备故障当前环境的保存功能,就是保存一份设备故障时的内存、CPU寄存器、IO等设备的数据和状态信息,如果系统并没有停住,只是某个程序死掉,会产生CORE DUMP,在当前目录下产生一个CORE文件。
而如果操作系统死掉,则产生System DUMP或者System Crash,通常会引起系统停机。
DUMP的记录如下图所示。
作为一般客户通常只需要收集DUMP信息,并反馈给IBM工程师即可。
当发生系统DUMP时,机器将会被宕下来。
可能的原因包括:系统在进行内核操作时发生了未知的意外或者不能对其进行正常处理,都会引起DUMP。
也可以由系统管理员发出命令,强制系统DUMP。
当系统进行DUMP时,DUMP管理设施自动将内核相关的数据(kernel segment0及其他由内核或者内核扩展程序记录在主DUMP表中的内存块)复制到主DUMP设备。
可以把DUMP理解为系统当时的一个快照,供以后分析,分析DUMP可以在其他机器上进行,但需要复制一份此机器的内核程序,即unix_mp或unix_mp64.没有对应于DUMP的内核程序是午饭进行DUMP分析的。
DUMP的生成过程CORE DUMP的生成过程在进程运行出现异常行为时,例如无效地址访问、浮点异常、指令异常等,将导致系统转入内核态进行异常处理(即中断处理),向相应的进程发出特定信号例如SIGSEGV、SIGFPE、SIGILL 等。
如果应用进程注册了相应信号的处理函数(例如可通过sigaction 注册信号处理函数),则调用相应处理函数进行处理(应用程序可以选择记录信息后生成core dump 并退出);否则将采取默认动作,例如SIGSEGV 的默认动作是生成core dump 并退出程序。
进程coredump 的时候,操作系统会将进程终止并释放其占用的资源,正常情况下,应用进程coredump 不会对系统本身的运行造成危害。
当然如果系统中存在与此进程相关的其他进程,则这些进程会受到影响,至于后果则视其对此异常的具体处理而定。
由于相关指令已经包含在可执行文件中,core 文件一般只包含进程异常时相关的内存信息。
其格式可参考/usr/include/sys/core.h 或者AIX 帮助文档的“Files Reference”章节。
我们一般需要结合core 文件以及可执行程序,来分析问题所在注:由于进程信号处理本质上是异步的,应用进程注册的信号处理函数中使用的例程需要保证是异步信号安全的,例如不能使用诸如pthread_ 开头的例程。
系统dump 生成过程系统异常dump 的具体过程与应用进程类似,但由于更接近底层,为了避免问题所在的资源(例如文件系统)正好包含在生成dump 需要使用的资源中,造成dump 无法生成,操作系统一般会用最简单的方式来生成dump。
例如系统内存小于4G 的情况下,一般直接将dump 生成在pagingspace 中;大于4G 时,会建专门的lg_dumplv 逻辑卷(裸设备),默认的dump设备/dev/hd6,次设备是/dev/sysdumpnull保存dump 信息。
在系统重启的时候,如果设置的DUMP 转存目录(文件系统中的目录)有足够空间,它将会转存成一个文件系统文件,缺省情况下,是/var/adm/ras/ 下的vmcore* 这样的文件。
下面是常见的转储设备大小规则当服务器的内存大于4GB时,在安装AIX时,就会为系统dump 创建一专用区域,该逻辑卷名就是lg_dumplv. 其缺省大小是按以下规则分配的:4GB < = 服务器的内存〈12GB lg_dump 的大小为1GB12GB < = 服务器的内存〈24GB lg_dump 的大小为2GB24GB < = 服务器的内存〈48GB lg_dump 的大小为3GB48GB < = 服务器的内存lg_dump 的大小为4GB系统dump 一般可以通过升级微码、提高系统补丁级别、升级驱动等方式解决。
环境变量设置可以通过/etc/security/limits 文件对各用户的基本配置参数包括core 大小进行限制。
或者通过ulimit 更改当前环境下的core 大小限制。
默认情况下,应用进程生成core dump 时都使用文件名core。
为了避免同一工作目录下的进程core 相互覆盖,可以定义环境变量CORE_NAMING=true,然后启动进程,这样将生成名为core.pid.ddhhmmss 的文件。
可以使用file core 命令查看core 是哪个进程产生的。
默认情况下,应用进程dump 时会包含所有的共享内存,如果dump 时想排除共享内存内容,可以在启动进程之前设置环境变量CORE_NOSHM=true.系统有一个参数fullcore 用于控制是否在程序coredump 时生成完整的core。
为避免信息丢失,建议打开fullcore。
可以使用lsattr –El sys0 查询是否将fullcore 打开,使用chdev -l sys0 -a fullcore=true 将fullcore 状态更改为打开。
如果想让系统DUMP后自动重新启动,(对于远程管理员比较有用,否则管理员必须到现场按开关重新启动计算机,可以执行lsattr –El sys0 查看autorestart是否为true,使用chdev -l sys0 -a autorestart=true 将autorestart状态更改为打开。
两者都可以通过smit chgsys的smit菜单来修改DUMP文件管理由于DUMP文件较为复杂而且一般都交给IBM工程师进行分析,在次本文不做讨论,下文主要探讨DUMP文件的管理。
查看当前DUMP设备的配置信息#sysdumpdev -lprimary /dev/lg_dumplv ##主DUMP设备secondary /dev/sysdumpnull ##次DUMP设备copy directory /var/adm/ras ##DUMP文件拷贝目录forced copy flag TRUE ##是否进行提示将DUMP文件复制到外设always allow dump FALSE ##总是进行DUMPdump compression ON ##是否启用DUMP文件压缩type of dump traditional注意1.旧版本的AIX “always allow dump”可能默认为关闭;为方便系统crash 时问题定位,建议打开。
当该选项设置为true时,当按下服务器reset 按钮或者预先设定的DUMP键盘序列的时候系统会自动生成DUMP。
打开命令#sysdumpdev -KP关闭命令#sysdumpdev -kP或者使用smitty -> System Environments-> Change / Show Characteristics of System Dump 菜单设置。
2.当系统重启的时候,如果设置了force copy flag为true,可以有提示让你将dump复制到外置介质,例如磁带。
这样磁盘目录不够的时候,也有机会保留(往往DUMP设备与系统交换分区共用同一逻辑卷,而系统启动后,交换区将被覆盖)一份系统DUMP。
3.如果想允许DUMP文件进行压缩,则使用下列命令打开命令#sysdumpdev -CP关闭命令#sysdumpdev -cPsysdump命令使用示例创建DUMP设备#mklv -y dumplv -t sysdump rootvg 10将逻辑卷hd7 临时指派为主要转储设备:#sysdumpdev -p /dev/hd7估计需要的转储设备大小:#sysdumpdev -e 或者 smit dump_estimate将磁带设备rmt0 临时指派为辅助转储设备:#sysdumpdev -s /dev/rmt0显示先前的转储的统计信息:#sysdumpdev -L永久地将主要转储设备的数据库对象更改到/dev/newdisk1,输入:#sysdumpdev -P -p /dev/newdisk1确定是否存在新的系统转储,输入:#sysdumpdev -z如果最近发生了系统转储,则会出现与下列相似的输出:4537344 /dev/hd7将远程转储文件/var/adm/ras/systemdump(在主机mercury 上)指派给主要转储设备,输入:#sysdumpdev -p mercury:/var/adm/ras/systemdump在主机名和文件名之间必须输入冒号:。
指定系统崩溃后转储要复制到其上的目录(如果转储设备是/dev/hd6),输入:#sysdumpdev -d /tmp/dump这会在系统崩溃后试图将转储从/dev/hd6 复制到/tmp/dump。
如果在复制过程中出现了错误,那么系统继续引导,但是丢失了转储。
指定系统崩溃后转储所要复制其上的目录,如果转储设备是/dev/hd6,输入:#sysdumpdev -D /tmp/dump这会在崩溃后尝试将转储从/dev/hd6 复制到/tmp/dump 目录。
如果复制失败,那么会提示您一个菜单以允许手工将转储复制到某个外部介质。
-c 指定不压缩转储。
-c 标志只适用于AIX 4.3.2 和以后的版本。
-C 指定所有将来的转储在其写入转储设备之前将其压缩。
-C 标志只适用于AIX 4.3.2 和以后的版本。
-d Directory 指定系统引导时转储所复制到的目录。
如果引导时复制失败,那么 -d 标志会忽略系统转储。
-D Directory 指定系统引导时转储所复制到的目录。
如果引导时复制失败,那么使用 -D 标志允许您将转储复制到外部的介质。
注:使用 -d Directory 或 -D Directory 标志时,会检测下列的错误情况:∙目录不存在。
∙目录不在本地日志文件系统里。
∙目录不在 rootvg 卷组中。
-e 估计当前运行的系统的转储大小(以字节表示)。
如果压缩转储,那么所显示的大小是压缩之后大小的估计值。
-i 表示从系统函数调用 sysdumpdev 命令。
只有系统实用程序才使用该标志。
如果不是自动IBM 函数的函数已经修改了有效值,那么 -i 标志就不会作请求的更改;也就是说,-i 标志不会覆盖先前的更改。
-I 重新设置先前更改的指示信息。
指定 -I 标志后,用 -i 标志就允许更改。
-k 如果您的机器有钥匙方式开关,那么在用复位按钮或转储键控序列强制转储前,钥匙需要处于服务位置。