一个简单编译器的实现
简单C语言编译器

简单C语言编译器编译器是一种将高级语言转换为机器语言的软件工具。
它是编译原理中的一个重要概念,负责将程序源代码转换成可执行文件。
在这个过程中,编译器会对源代码进行词法分析、语法分析、语义分析和代码优化等操作。
一个简单的C语言编译器包含以下主要组件:1. 词法分析器(Lexer):词法分析器将源代码分割成一个个词素(token),例如关键字、标识符、运算符和常量等。
它可以通过有限自动机(DFA)来实现,也可以使用现有的词法分析工具如Lex。
2. 语法分析器(Parser):语法分析器根据对应的语法规则,将一系列的词素组合成语法树。
它可以通过上下文无关文法(CFG)来实现,例如使用自顶向下的递归下降分析法或自底向上的移入-规约分析法。
3. 语义分析器(Semantic Analyzer):语义分析器对语法树进行语义检查,例如检查变量的声明和使用是否匹配、类型转换是否合法、函数调用是否正确等。
它还可以生成符号表,用于存储程序中的变量、函数和类型等信息。
4. 中间代码生成器(Intermediate Code Generator):中间代码生成器将语法树转换成一种中间表示形式,通常是三地址码、虚拟机指令或者抽象语法树。
该中间表示形式能够方便后续的代码优化和目标代码生成。
5. 代码优化器(Code Optimizer):代码优化器对中间代码进行优化,以提高目标代码的性能。
常见的优化技术包括常量折叠、复写传播、循环展开、函数内联等。
优化器的目标是在不改变程序行为的前提下,尽可能地减少执行时间和存储空间。
6. 目标代码生成器(Code Generator):目标代码生成器将优化后的中间代码转换成机器语言代码。
它可以根据目标平台的特点选择合适的指令集和寻址方式,并生成可以被计算机硬件执行的程序。
7. 符号表管理器(Symbol Table Manager):符号表管理器负责管理程序中的符号表,其中包含了变量、函数和类型等信息。
简单C语言编译器(编译原理)

//======================================================================================================
//词法分析函数: void scan()
//数据传递:形参fp接收指向文本文件头的文件指针;
flag=3;
else if(ch==' ')
flag=4;
else if(ch=='\n')
flag=5;
else if(ch=='?')
flag=6;
else if(feof(fp1))
flag=7;//结束
else
flag=0; //illegal character
return(flag);
else if(strcmp(ft->name,"||")==0){ft->mark_name='|';}
else if(strcmp(ft->name,"!=")==0){ft->mark_name='@';}
if(flag==1||flag==2||flag==3) {i++;buffer[i]=ch;line[i]=row;}
else if(flag==4) {i++;buffer[i]='?';line[i]=row;}
else if(flag==5) {i++;buffer[i]='~';row++;}
{
int flag;
if(ch=='!'||ch=='$'||ch=='&'||ch=='*'||ch=='('||ch==')'||ch=='-'||ch=='_'||
TINY词法分析编译程序的部分实现

TINY编译程序的部分实现TINY的程序结构很简单,它在语法上与Ada或Pascal的语法相似:仅是一个由分号分隔开的语句序列。
另外,它既无过程也无声明。
所有的变量都是整型变量,通过对其赋值可较轻易地声明变量(类似FORTRAN或BASIC)。
它只有两个控制语句:if语句和repeat语句,这两个控制语句本身也可包含语句序列。
if语句有一个可选的else部分且必须由关键字end结束。
除此之外,read语句和write语句完成输入/输出。
在花括号中可以有注释,但注释不能嵌套。
TINY的表达式也局限于布尔表达式和整型算术表达式。
布尔表达式由对两个算术表达式的比较组成,比较使用<与=比较算符。
算术表达式可以包括整型常数、变量、参数以及4个整型算符+、-、*、/,此外还有一般的数学属性。
布尔表达式可能只作为测试出现在控制语句中——而没有布尔型变量、赋值或I/O。
虽然T I N Y缺少真正程序设计语言所需要的许多特征——过程、数组和浮点值,是一些较大的省略——但它足可以用来例证编译器的主要特征了。
TINY编译器简单说明TINY编译器包括以下的C文件,(为了包含而)把它的头文件放在左边,它的代码文件放在右边:globals.h main.cutil.h util.cscan.h scan.cparse.h parse.csymtab.h symtab.canalyze.h analyze.ccode.h code.ccgen.h cgen.c除了将main.c放在globals.h的前面之外,这些文件的源代码及其行号都按顺序列在附录B中了。
任何代码文件都包含了globals.h头文件,它包括了数据类型的定义和整个编译器均使用的全程变量。
main.c 文件包括运行编译器的主程序,它还分配和初始化全程变量。
其他的文件则包含了头/代码文件对、在头文件中给出了外部可用的函数原型以及在相关代码文件中的实现(包括静态局部函数)。
使用.NET命令行编译器编译项目(如ASP.NET、C#等)

使⽤.NET命令⾏编译器编译项⽬(如、C#等)源程序最好有.csproj或.vbproj⽂件,没有的话,要花些时间调试下⾯我以做⽰例讲解⼀下:从proj我们可以获取以下有⽤信息Settings⼩节中有很多配置选项,对应⼀些编译器选项<References>⼩节中是项⽬的引⽤,第3⽅类库最好⽤绝对路径<Imports>⼩节中是要导⼊的⼀些命名空间<Files>⼩节中有项⽬的所有⽂件,选取 BuildAction = "Compile"的⽂件⽤vbc测试了⼀下,很容易,注意以下⼏项:rootnamespacereferencetargetimports加上bugreport可以将所有的源⽂件代码和bug报告输出。
不错给你⼀端编译⽰例:vbc /r:System.dll /r:System.Data.dll /r:System.Drawing.dll /r:System.Web.dll /r:System.Xml.dll/r:bin\Microsoft.ApplicationBlocks.Data.dll /r:bin\ExportTechnologies.WebControls.RTE.dll /imports:Microsoft.VisualBasic/imports:System /imports:System.Collections /imports:System.Configuration /imports:System.Data /imports:System.Drawing /imports:System.Web /imports:System.Web.UI /imports:System.Web.UI.HtmlControls /imports:System.Web.UI.WebControls /imports:MMS /rootnamespace:MMS /t:library /out:Truly.MMS.dll /bugreport:bug.log AssemblyInfo.vb Global.asax.vb HDAdd.aspx.vb HDticketLogAdd.aspx.vb MIS.vb PageBase.vb Utils.vb如果没有proj⽂件,那么可以⽤下⾯的命令获取:dir /b *.vb > filelist.txtcsc的使⽤⽅法就靠你⾃⼰去琢磨了。
编译原理自制basic

编译原理是一门研究如何将高级编程语言(也称为源代码)转换成低级编程语言(如机器代码)的学科。
在这个过程中,编译器需要经过一系列的步骤,包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等。
如果您想自制一个简单的Basic 语言的编译器,可以按照以下步骤进行:1.词法分析:这一步是将源代码分解成一系列的记号(token),如变量名、关键字、操作符等。
您可以使用正则表达式或者有限自动机等工具来实现这一步。
2.语法分析:这一步是将记号序列转换成抽象语法树(Abstract Syntax Tree, AST)。
AST 是源代码的树形表示,它可以帮助您更好地理解代码的结构。
您可以使用语法分析器生成器(如ANTLR)来生成语法分析器。
3.语义分析:这一步是检查源代码的语义是否正确,例如检查变量是否在使用前已经声明等。
您可以在AST 上实现这一步,通过遍历AST 并进行相应的检查。
4.中间代码生成:这一步是将AST 转换成中间代码,通常是三地址码。
三地址码是一种类似于汇编语言的低级代码,它由一系列的指令组成,每个指令可以有多个操作数。
您可以通过遍历AST 并生成相应的三地址码来实现这一步。
5.代码优化:这一步是对生成的中间代码进行优化,以提高生成的目标代码的效率。
您可以在这一步中对三地址码进行优化,例如常量折叠、死代码消除等。
6.目标代码生成:这一步是将优化后的中间代码转换成目标代码,通常是机器代码。
您可以使用汇编器或编译器生成器来生成目标代码。
以上是一个简单的编译器的实现过程,具体实现可以根据您的需求进行调整。
在实际应用中,编译器通常是非常复杂的软件系统,需要经过长时间的开发和测试才能保证其正确性和稳定性。
如果您只是为了学习编译原理而自制一个简单的编译器,建议您从简单开始,逐步增加功能和复杂性,以便更好地理解编译器的实现原理和工作机制。
编译器实验报告

编译器实验报告编译器实验报告引言编译器是计算机科学中的重要组成部分,它将高级语言代码转换为机器语言代码,使计算机能够理解和执行人类可读的指令。
在本次实验中,我们将设计和实现一个简单的编译器,以加深对编译原理和计算机体系结构的理解。
一、背景知识1.1 编译器的基本原理编译器主要由两个阶段组成:前端和后端。
前端负责将源代码转换为中间代码,后端则将中间代码转换为目标机器代码。
1.2 词法分析词法分析是编译器的第一个阶段,它将源代码分解为一个个词法单元,如标识符、关键字、运算符等。
词法分析器通过正则表达式和有限自动机来实现。
1.3 语法分析语法分析是编译器的第二个阶段,它将词法单元按照语法规则组织成语法树。
语法分析器通常使用上下文无关文法和递归下降分析来实现。
二、实验设计2.1 实验目标本次实验的目标是设计一个简单的编译器,能够将一种自定义的高级语言转换为目标机器代码。
我们选取了一种类C语言的语法作为实验对象。
2.2 实验流程首先,我们需要编写词法分析器,将源代码分解为词法单元。
然后,我们使用语法分析器将词法单元组织成语法树。
接下来,我们需要进行语义分析,检查代码是否符合语义规则。
最后,我们将中间代码转换为目标机器代码。
三、实验过程3.1 词法分析在词法分析阶段,我们使用正则表达式和有限自动机来实现词法分析器。
我们定义了一系列正则表达式来匹配不同的词法单元,如标识符、关键字、运算符等。
通过扫描源代码,词法分析器能够将源代码分解为一个个词法单元。
3.2 语法分析在语法分析阶段,我们使用上下文无关文法和递归下降分析来实现语法分析器。
我们定义了一系列文法规则来描述语法结构,如函数声明、条件语句、循环语句等。
语法分析器能够将词法单元组织成语法树。
3.3 语义分析在语义分析阶段,我们检查代码是否符合语义规则。
例如,我们检查变量是否声明过、函数是否调用正确等。
如果发现错误,我们将生成错误信息并终止编译过程。
3.4 代码生成在代码生成阶段,我们将中间代码转换为目标机器代码。
自己动手实现Lua 虚拟机 编译器和标准库

内容摘要
《自己动手实现Lua:虚拟机、编译器和标准库》这本书是一本非常有价值的读物,它向读者介 绍了如何自己动手实现Lua编程语言的虚拟机、编译器和标准库。通过阅读这本书,读者可以更 深入地了解Lua语言的底层原理和运行机制,提高自己的编程技能和解决问题的能力。这本书也 向读者展示了Lua语言在应用方面的广泛性和灵活性。如果大家对Lua语言感兴趣,并且想要更深 入地了解它的运行机制和原理,那么这本书是大家不可错过的选择。
自己动手实现Lua:虚拟机、编 译器和标准库
读书笔记
01 思维导图
03 精彩摘录 05 目录分析
目录
02 内容摘要 04 阅读感受 06 作者简介
思维导图
本书关键字分析思维导图
标准
语言
运行机制
编译器
原理
标准
了解
自己动 手
实现
实现
可以
编程
编译器
读者
大家
自己动手
通过
程序
分析
内容摘要
内容摘要
本书将为大家简要介绍《自己动手实现Lua:虚拟机、编译器和标准库》这本书。这本书主要讲 述了如何自己动手实现Lua编程语言的虚拟机、编译器和标准库。通过阅读本书,大家将了解这 本书所涉及的主题、背景以及自己动手实现Lua的意义。 在本书中,作者详细地介绍了如何从零开始实现一个完整的Lua虚拟机。Lua虚拟机是一种在计算 机上运行的软件程序,它模拟了Lua语言的运行环境。通过实现虚拟机,读者可以更好地理解Lua 语言的底层原理和运行机制。 本书所实现的虚拟机采用了基于寄存器的虚拟机设计,它将Lua代码转换为机器码并执行。虚拟 机还支持协程,这是Lua语言的重要特性之一。协程可以在程序中创建多个控制流,使程序更加 简洁、灵活。 编译器是另一个重要的主题。
编译原理课程期末总结

编译原理课程期末总结一、引言编译原理是计算机科学与技术专业必修的一门课程,主要讲授计算机程序语言的组织规则和程序的翻译方法。
本学期的编译原理课程,从基本概念开始,逐渐深入到词法分析、语法分析、语义分析和代码生成等内容。
通过学习编译原理,我对程序的编写和翻译有了更深入的理解,并且提高了编写高效程序的能力。
本文将对本学期编译原理课程的学习内容以及个人体会进行总结和归纳。
二、课程学习内容1. 基本概念在编译原理的第一节课中,老师给我们介绍了编译原理的基本概念。
编译器是将源语言程序翻译成目标语言程序的一种软件。
它包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等阶段。
我们学习了编译器的整体结构和各个阶段的作用。
2. 词法分析词法分析是编译器的第一阶段,它负责将源程序分割成一个个单词(Token)。
在本学期的编译原理课程中,我们学习了正则表达式、DFA(Deterministic Finite Automaton)和NFA(Nondeterministic Finite Automaton)的概念。
通过实践,我了解了如何用正则表达式描述词法单元的集合,并将正则表达式转化为NFA和DFA。
3. 语法分析语法分析是编译器的第二阶段,它负责将词法分析得到的单词序列解析成语法树。
在本学期的编译原理课程中,我们学习了上下文无关文法和语法分析算法。
我通过实现LL(1)语法分析器和LR(1)语法分析器,深入理解了语法分析的原理与方法。
4. 语义分析语义分析是编译器的第三阶段,它负责对语法树进行静态检查和语义处理。
在本学期的编译原理课程中,我们学习了符号表的管理和使用、类型检查和类型转换等内容。
通过实践,我掌握了如何设计和实现一个简单的语义分析器。
5. 中间代码生成中间代码生成是编译器的第四阶段,它负责将语法树转化为中间代码。
在本学期的编译原理课程中,我们学习了三地址码和四元式的表示方法,以及中间代码的生成和优化等内容。
Tiny+编译器

10. true
false
or
and
not
int
bool
string
while
do
if
then
else
end
repeat
until
read
write
11. All keywords are reserved and must be written in lowcase
12. 2.
Special symbols are the following:
17.
Identifier is letter followed by letters and digits
18. NUM=digit digit*
19. STRING=' any character except ' '
20. A STRING is enclosed in brackets '…', any character except ' can appear in a
39. 12
read‐stmt
‐> read identifier
40. 13
write‐stmt
‐> write exp
41. 14
exp
‐> arithmetic‐exp | bool‐exp | string‐exp| comparison‐exp
42. 15
comparison‐exp ‐> arithmetic‐exp comparison‐op arithmetic‐exp
30. 3
decl
‐> type‐specifier varlist
编译原理c语言编译器的设计与实现
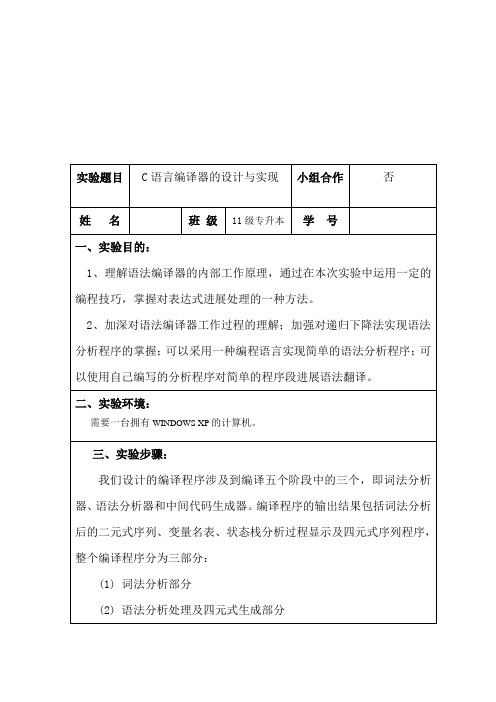
经编译程序运行后得到的输出结果如下:
1〕词法分析得出的相应的名字的号码和他的值2〕列举程序中所有的变量
3〕状态栈的移进-归约过程1.
4〕最后产生的四元式中间代码
一、实验总结:
通过此次实验,让我知道了词法分析的功能是输出把它组织成单个程序,让我理解到如何设计、编制并调试词法分析程序,加深对词法分析原理的理解;对语法规那么有明确的定义;编写的分析程序可以进展正确的语法分析;对于遇到的语法错误,可以做出简单的错误处理,给出简单的错误提示,保证顺利完成语法分析过程;实验报告要求用文法的形式对语法定义做出详细说明,说明语法分析程序的工作过程,说明错误处理的实现。
通过该实验的操作,我理解编译原理课程兼有很强的理论性和理论性,是计算机专业的一门非常重要的专业根底课程,它在系统软件中占有非常重要的地位,是计算机专业学生的一门主修课。
为了让学生可以更好地掌握编译原理的根本理论和编译程序构造的根本方法和技巧,融会贯穿本课程所学专业理论知识,进步他们的软件设计才能,。
编译原理实验报告1

03091337 李璐 03091339 宗婷婷一、上机题目:实现一个简单语言(CPL)的编译器(解释器)二、功能要求:接收以CPL编写的程序,对其进行词法分析、语法分析、语法制导翻译等,然后能够正确的执行程序。
三、试验目的1.加深编译原理基础知识的理解:词法分析、语法分析、语法制导翻译等2.加深相关基础知识的理解:数据结构、操作系统等3.提高编程能力4.锻炼独立思考和解决问题的能力四、题目说明1.数据类型:整型变量(常量),布尔变量(常量)取值范围{…, -2, -1, 0, 1, 2, …}, {true, false}2、运算表达式:简单的代数运算,布尔运算3、程序语句:赋值表达式,顺序语句,if-else语句,while语句五、环境配置1.安装Parser Generator、Visual C++;2.分别配置Parser Generator、Visual C++;3.使用Parser Generator创建一个工程编写l文件mylexer.l;编译mylexer.l,生成mylexer.h与mylexer.c;4.使用VC++创建Win32 Console Application工程并配置该项目;加入mylexer.h与mylexer.c,编译工程;执行标识符数字识别器;注意:每次修改l文件后,需要重新编译l文件,再重新编译VC工程六、设计思路及过程设计流程:词法分析LEX的此法分析部分主要利用有限状态机进行单词的识别,在分析该部分之前,首先应该对YACC的预定义文法进行解释。
在YACC中用%union扩充了yystype的内容,使其可以处理char型,int型,node型,其中Node即为定义的树形结点,其定义如下:typedef enum { TYPE_CONTENT, TYPE_INDEX, TYPE_OP } NodeEnum;/* 操作符 */typedef struct {int name; /* 操作符名称 */int num; /* 操作元个数 */struct NodeTag * node[1]; /* 操作元地址可扩展 */} OpNode;typedef struct NodeTag {NodeEnum type; /* 树结点类型 *//* Union 必须是最后一个成员 */union {int content; /* 内容 */int index; /* 索引 */OpNode op; /* 操作符对象 */};} Node;extern int Var[26];结点可以是三种类型(CONTENT,INDEX,OP)。
简单编译器实现课程设计

简单编译器实现课程设计一、课程目标知识目标:1. 学生能理解编译器的基本工作原理和组成部分;2. 学生掌握简单编译器的构建方法和步骤;3. 学生了解编程语言中的语法、词法分析过程;4. 学生掌握使用编程语言(如Python)实现简单编译器的能力。
技能目标:1. 学生能够运用所学知识,独立设计并实现一个简单的编译器;2. 学生能够运用调试工具,对编译器进行调试和优化;3. 学生能够运用所学技能,解决编译过程中遇到的问题;4. 学生能够通过小组合作,提高团队协作和沟通能力。
情感态度价值观目标:1. 学生培养对计算机科学和编程的兴趣,激发自主学习编程的热情;2. 学生认识到编译器在计算机科学中的重要性,增强对程序设计的敬畏心;3. 学生通过课程学习,培养勇于挑战困难、解决问题的信心和毅力;4. 学生在小组合作中,学会尊重他人意见,培养团队精神和协作意识。
课程性质:本课程为实践性课程,结合理论知识,让学生动手实践,实现一个简单的编译器。
学生特点:学生具备一定的编程基础,对编译原理有初步了解,具有较强的学习能力和动手能力。
教学要求:教师需引导学生掌握编译原理的基本知识,注重实践操作,培养学生解决问题的能力和团队协作能力。
通过课程学习,使学生能够将所学知识应用于实际项目中。
二、教学内容1. 编译器原理概述:介绍编译器的基本概念、工作原理和组成部分,包括词法分析、语法分析、语义分析、中间代码生成、代码优化和目标代码生成等。
教材章节:第1章 编译原理概述2. 词法分析:讲解词法分析的过程和方法,以及正则表达式和有限自动机的应用。
教材章节:第2章 词法分析3. 语法分析:介绍语法分析的方法,包括自上而下和自下而上的分析技术,以及LL(1)、LR(1)等语法分析算法。
教材章节:第3章 语法分析4. 语义分析:讲解语义分析的过程和任务,如类型检查、符号表管理等。
教材章节:第4章 语义分析5. 中间代码生成与代码优化:介绍中间代码的表示方法,以及常见的代码优化技术。
编译原理实验教案

一、实验目的与要求1. 实验目的(1) 理解编译原理的基本概念和流程。
(2) 掌握常用的编译方法和技术。
(3) 熟练使用编译器开发工具。
2. 实验要求(1) 熟悉计算机专业基础知识。
(2) 掌握C/C++编程语言。
(3) 了解基本的编译原理。
二、实验环境1. 硬件环境(1) 计算机一台。
(2) 编译器开发工具(如GCC、Clang等)。
2. 软件环境(1) 操作系统(如Windows、Linux等)。
(2) 文本编辑器或集成开发环境(如Visual Studio、Eclipse等)。
三、实验内容1. 实验一:词法分析(1) 实现一个简单的词法分析器,识别出关键字、标识符、常量等。
(2) 分析输入的程序,输出词法分析结果。
2. 实验二:语法分析(1) 实现一个简单的语法分析器,根据给定的语法规则分析输入的程序。
(2) 分析输入的程序,输出语法分析树。
3. 实验三:语义分析(1) 实现一个简单的语义分析器,检查程序中的语义错误。
(2) 分析输入的程序,输出语义分析结果。
4. 实验四:中间代码(1) 实现一个简单的中间代码器,将转换为中间代码表示。
(2) 对输入的程序进行转换,输出中间代码。
5. 实验五:目标代码(1) 实现一个简单的目标代码器,将中间代码转换为目标代码。
(2) 对输入的中间代码进行转换,输出目标代码。
四、实验步骤与方法1. 实验一:词法分析(1) 编写词法分析器的代码。
(2) 测试并调试词法分析器。
2. 实验二:语法分析(1) 编写语法分析器的代码。
(2) 测试并调试语法分析器。
3. 实验三:语义分析(1) 编写语义分析器的代码。
(2) 测试并调试语义分析器。
4. 实验四:中间代码(1) 编写中间代码器的代码。
(2) 测试并调试中间代码器。
5. 实验五:目标代码(1) 编写目标代码器的代码。
(2) 测试并调试目标代码器。
五、实验注意事项1. 按照实验要求编写代码,注意代码规范和可读性。
北航编译技术课程设计

北航编译技术课程设计一、课程目标知识目标:1. 理解编译技术的基本概念、原理和流程;2. 掌握词法分析、语法分析、语义分析等编译技术关键环节;3. 了解优化技术及其在编译过程中的应用;4. 掌握目标代码生成与代码优化方法。
技能目标:1. 能够运用编译技术对简单程序进行词法、语法和语义分析;2. 能够编写简单的编译器,实现源代码到目标代码的转换;3. 能够运用优化技术对目标代码进行优化;4. 能够运用所学知识解决实际编译过程中的问题。
情感态度价值观目标:1. 培养学生对编译技术的兴趣,激发学习热情;2. 培养学生的团队协作意识,提高沟通与协作能力;3. 培养学生严谨、细致的学习态度,提高问题解决能力;4. 引导学生关注编译技术在计算机领域的发展趋势,增强社会责任感。
本课程针对北航高年级学生,结合编译技术课程性质,强调理论与实践相结合,注重培养学生的实际动手能力。
课程目标旨在使学生掌握编译技术的基本知识和技能,同时注重培养其情感态度价值观,使学生在掌握专业知识的基础上,具备良好的综合素质。
通过本课程的学习,为学生未来从事计算机领域的研究和工作打下坚实基础。
二、教学内容本章节教学内容主要包括以下几部分:1. 编译技术基本概念:介绍编译器的定义、编译过程、编译器的结构及各阶段的作用;2. 词法分析:讲解词法分析器的功能、词法规则、正则表达式、词法分析器的实现;3. 语法分析:阐述语法分析器的任务、语法规则、自上而下和自下而上的语法分析方法、递归下降分析法、LL(1)分析法等;4. 语义分析:介绍语义分析的作用、语义错误类型、类型检查、符号表管理等;5. 中间代码生成与优化:讲解中间代码的表示、中间代码生成方法、基本优化技术及目标代码生成;6. 目标代码生成与优化:分析目标代码生成策略、汇编代码编写、指令选择、寄存器分配、指令调度等;7. 编译器构造实践:结合实例,指导学生完成一个简单编译器的编写,巩固所学知识。
编译原理课程设计教案

编译原理课程设计教案一、课程简介1.1 课程背景编译原理是计算机科学与技术领域的基础课程,旨在培养学生对编译器设计和实现的理解。
通过本课程的学习,学生将掌握编译器的基本原理、构造方法和实现技巧。
1.2 课程目标(1)理解编译器的基本概念、工作原理和分类;(2)熟悉源程序的词法分析、语法分析、语义分析、中间代码、目标代码和优化等基本过程;(3)掌握常用的编译器构造方法和技术;(4)能够设计和实现简单的编译器。
二、教学内容2.1 词法分析(1)词法规则的定义和描述;(2)词法分析器的实现方法;(3)词法分析在编译器中的作用和重要性。
2.2 语法分析(1)语法规则的定义和描述;(2)语法分析树的构建方法;(3)常用的语法分析算法及其特点。
2.3 语义分析(1)语义规则的定义和描述;(2)语义分析的方法和技巧;(3)语义分析在编译器中的作用和重要性。
2.4 中间代码(1)中间代码的定义和表示;(2)中间代码的方法和策略;(3)中间代码在编译器中的作用和重要性。
2.5 目标代码和优化(1)目标代码的方法和技巧;(2)代码优化的方法和策略;(3)目标代码和优化在编译器中的作用和重要性。
三、教学方法3.1 讲授法通过讲解编译原理的基本概念、理论和方法,使学生掌握编译器的设计和实现技巧。
3.2 案例分析法分析实际编译器的设计和实现案例,使学生更好地理解编译原理的应用。
3.3 实验法安排实验课程,让学生动手设计和实现简单的编译器组件,提高学生的实际操作能力。
3.4 小组讨论法组织学生进行小组讨论,培养学生的团队合作精神和沟通能力。
四、教学评价4.1 平时成绩包括课堂表现、作业完成情况和小测验成绩,占总评的30%。
4.2 实验成绩包括实验报告和实验演示,占总评的30%。
4.3 期末考试包括理论知识考核和实际操作考核,占总评的40%。
五、教学资源5.1 教材推荐使用《编译原理》教材,为学生提供系统、全面的学习资料。
5.2 课件制作精美、清晰的课件,辅助课堂教学。
protobuf编译教程

protobuf编译教程protobuf(Protocol Buffers)是一种轻量级的数据序列化格式,由Google开发,用于结构化数据的存储和交换。
它具有高效、可扩展和跨语言的特点,支持多种编程语言。
本文将详细介绍protobuf 的编译过程,以帮助读者快速上手并充分利用这一工具。
一、安装protobuf编译器首先,我们需要安装protobuf编译器,可以从Google的官方仓库中下载最新的编译器版本。
protobuf的编译器支持多个操作系统,包括Windows、Linux和MacOS。
1.1 下载编译器:进入Google的protobuf官方仓库(1.2 安装编译器:解压下载的二进制文件,并将可执行文件所在的路径添加到系统的PATH环境变量中,以便在命令行中可以直接使用protobuf编译器。
二、编写.proto文件protobuf使用.proto文件来定义数据结构和消息格式,类似于定义一个类或者接口。
在这里,我们将演示一个简单的示例,以更好地理解.proto文件的编写。
2.1 定义消息类型:打开一个文本编辑器,创建一个名为example.proto的文件,并在文件中编写以下内容:syntax = "proto3";message Person {string name = 1;int32 age = 2;repeated string hobbies = 3;}在这个示例中,我们定义了一个名为Person的消息类型,其中包含name、age和hobbies三个字段。
2.2 语法说明:- "syntax = proto3"指定protobuf使用proto3版本的语法。
- "message Person"定义了一个名为Person的消息类型。
- "string name = 1"定义了一个名为name的字符串字段,并将字段标识符设置为1。
编译原理编译器综合实验报告

编译原理编译器综合实验报告
本次综合实验的目标是设计和实现一个简单的编译器,用于将一种高级程序语言转化为等效的目标代码。
该编译器的设计基于编译原理的相关知识和技术。
在实验中,我们首先进行了语法分析的设计与实现。
通过使用自顶向下的递归下降方法,我们构建了一个语法分析器,该分析器能够识别源代码中的语法结构,并生成相应的语法树。
为了提高语法分析的效率,我们还使用了一些常见的优化技术,如LL(1)文法的设计和FIRST集合的计算。
接下来,我们进行了语义分析的设计与实现。
在语义分析阶段,我们对语法树进行了类型检查和语义检查。
通过遍历语法树,我们检查了变量的声明和使用情况,以及表达式的合法性。
同时,我们还进行了符号表的设计与管理,用于记录变量和函数的相关信息。
我们进行了中间代码生成的设计与实现,在中间代码生成阶段,我们将语法树转化为一种中间表示形式,以方便后续的优化和目标代码生成。
为了提高中间代码的质量,我们使用了一些常见的优化技术,如常量折叠和公共子表达式消除。
我们进行了目标代码生成的设计与实现,在目标代码生成阶段,我们将中间代码转化为目标代码,以便于在特定的硬件平台上执行。
为了生成高效的目标代码,我们使用了一些常见的优化技术,如寄存器分配和指令选择。
通过本次综合实验,我们深入了解了编译器的各个阶段,了解了
编译原理的基本原理和技术。
同时,我们也学会了如何设计和实现一个简单的编译器,并通过实践掌握了相关的编程技能。
这对我们进一步学习和研究编译原理以及相关领域的知识具有重要意义。
编译器是如何工作的_编译器的工作过程详解

编译器是如何工作的_编译器的工作过程详解编译器介绍简单讲,编译器就是将一种语言(通常为高级语言)翻译为另一种语言(通常为低级语言)的程序。
一个现代编译器的主要工作流程:源代码(source code)预处理器(preprocessor)编译器(compiler)目标代码(object code)链接器(Linker)可执行程序(executables)编译器的种类编译器可以生成用来在与编译器本身所在的计算机和操作系统(平台)相同的环境下运行的目标代码,这种编译器又叫做本地编译器。
另外,编译器也可以生成用来在其它平台上运行的目标代码,这种编译器又叫做交叉编译器。
交叉编译器在生成新的硬件平台时非常有用。
源码到源码编译器是指用一种高级语言作为输入,输出也是高级语言的编译器。
例如:自动并行化编译器经常采用一种高级语言作为输入,转换其中的代码,并用并行代码注释对它进行注释(如OpenMP)或者用语言构造进行注释(如FORTRAN 的DOALL指令)。
编译器工作原理编译是从源代码(通常为高级语言)到能直接被计算机或虚拟机执行的目标代码(通常为低级语言或机器语言)的翻译过程。
然而,也存在从低级语言到高级语言的编译器,这类编译器中用来从由高级语言生成的低级语言代码重新生成高级语言代码的又被叫做反编译器。
也有从一种高级语言生成另一种高级语言的编译器,或者生成一种需要进一步处理的的中间代码的编译器(又叫级联)。
典型的编译器输出是由包含入口点的名字和地址,以及外部调用(到不在这个目标文件中的函数调用)的机器代码所组成的目标文件。
一组目标文件,不必是同一编译器产生,但使用的编译器必需采用同样的输出格式,可以链接在一起并生成可以由用户直接执行的EXE,所以我们电脑上的文件都是经过编译后的文件。
编译器的工作过程源码要运行,必须先转成二进制的机器码,这是编译器的任务。
比如,下面这段源码(假定文件名叫做test.c)。
编译原理课程设计报告-简单文法的编译器的设计与实现

提供全套毕业论文,各专业都有课程设计报告设计题目:简单文法的编译器的设计与实现班级:计算机1206组长学号:20123966组长姓名:指导教师:设计时间:2014年12月摘要编译原理是计算机科学与技术专业一门重要的专业课, 它具有很强的理论性与实践性,目的是系统地向学生介绍编译系统的结构、工作原理以及编译程序各组成部分的设计原理和实现技术,在计算机本科教学中占有十分重要的地位。
计算机语言之所以能由单一的机器语言发展到现今的数千种高级语言,就是因为有了编译技术。
编译技术是计算机科学中发展得最迅速、最成熟的一个分支,它集中体现了计算机发展的成果与精华。
本课设是词法分析、语法分析、语义分析的综合,外加上扩展任务中间代码的优化和目标代码的生成,主要是锻炼学生的逻辑思维能力,进一步理解编译原理的方法和步骤。
关键词:编译原理,前端,目标代码,后端目录摘要 (3)1. 概述 (6)2. 课程设计任务及要求 (8)2.1 设计任务 (8)2.2 设计要求 (9)3. 算法及数据结构 (10)3.1算法的总体思想 (10)3.2 词法分析器模块 (11)3.2.1 功能 (11)3.2.2 数据结构 (11)3.2.3 算法 (12)3.3 语法分析器模块 (13)3.3.1功能 (13)3.3.2 数据结构 (13)3.3.3算法 (14)3.4 中间代码产生器模块 (24)3.4.1 功能 (24)3.4.2 数据结构 (24)3.4.3 算法 (25)3.5 优化器模块 (27)3.5.1 功能 (27)3.5.2 数据结构 (27)3.5.3 算法 (28)3.6 目标代码生成器模块 (30)3.6.1功能 (30)3.6.2 数据结构 (30)3.6.3 算法 (31)4. 程序设计与实现 (32)4.1 程序流程图 (32)4.2 程序说明 (33)4.3 实验结果 (35)5. 结论 (42)6. 参考文献 (43)7. 收获、体会和建议 (44)1 概述在计算机上执行一个高级语言程序一般要分为两步;第一步,用一个编译程序把高级语言翻译成机器语言程序;第二步,运行所得的机器语言程序求得计算结果。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于flex与bison的一个简单编译器的研究与实践[摘要]编译是程序执行过程中一个重要的步骤,分为词法分析、语法分析、语义分析、中间代码生成、中间代码优化、机器代码生成、机器代码优化几个步骤。
本文使用flex与bison 工具,编写了简洁的代码,实现了对一个简单语言的简单程序的词法分析、语法分析,最后生成了相应的抽象语法树。
得出了flex与bison是编写词法分析器和语法分析器的有效工具的结论。
[关键词] 编译抽象语法树词法语法程序目录摘要第一章绪论1.1 为什么要用编译器1.2 编译步骤第二章简单编译器的研究与实现2.1 简单编译器的结构2.2 词法分析2.3 语法分析2.4 语义分析第三章实验结果全文总结第一章绪论1.1 为什么要用编译器在计算机中,程序可以用不同的语言来编写,比如C,C++,汇编语言,机器代码等。
计算机能够直接识别的只有机器代码,因此需要编译器来将其他语言编译成机器代码,或者将一种语言编译成另一种语言[1]。
编译器是一个计算机程序(或一系列程序),它能将用程序语言写的源代码编译成计算机能够识别的目标代码,后者往往是二进制代码[2]。
近年来基本的编译器设计都没多大的改变,而且它们正迅速地成为计算机科学课程中的中心一环。
[5]1.2 编译步骤1.2.1 预处理一个较为复杂的程序可能被分割为多个模块,并存放于对应的源文件中。
预处理器是一个程序,它把源程序拼接在一起,并把宏转化为源语言的语句[3]。
1.2.2 词法分析经过预处理的源程序会作为输入传递给编译器,词法分析是编译的第一个步骤。
词法分析器以字符流的形式读入源程序,将它们组织成有意义的单词(token)[3]。
flex是一种词法分析工具,它基于lex做了改进,能够更快地生成C语言词法分析程序。
1.2.3 语法分析语法分析是编译的第二个步骤。
在这个步骤中,根据语言的语法识别词法分析后得到的字符流,生成语法树。
为了能够为应用程序提供清晰简洁的接口,隐藏复杂的底层信息,抽象语法树仅仅设计了有实际意义的节点。
Bison是一种语法分析工具,它基于YACC做了改进,能够自动生成C语言语法分析程序。
第二章简单编译器的研究与实践2.1 简单编译器的结构2.1.1 编译器的功能本文将实现一个能将某些具有代表性的程序片段转换成三地址代码的编译器。
例如:程序片段:a=1;b=10;While (a<b) a=a+1;b=a+b;三地址代码:100:a=1101: b=10102: if a<b goto 104103: goto 107104: t1=a+1105: a=t1106: goto 102107: t2=a+b;108:b=t2;2.1.2 本语言的词法和语法语言的最小单元成为词素,词素包括数字的字面值、运算符和关键字等[3]。
本语言的终结符有标识符(以字母开头,可以包含字母或数字)、正整数、运算符、while关键字、符号。
本语言的语法规则定义如下:program →stmt | program stmtstmt →while_stmt | assign_stmtwhile_stmt →WHILE ( bool_expr ) stmtassign_stmt →ID = expr;bool_stmt →expr > expr | expr < expr | expr == exprexpr →primary_expr + expr | primary_expr - exprprimary_expr →ID | NUMBER每一条推导式中→代表“具有以下形式”,左边是要定义的语法成分,右边是相应的词素构成,|表示或者,大写的单词表示终结符。
2.1.3 简单编译器的结构简单编译器包括词法分析程序、语法分析程序、符号表管理程序和中间代码生成程序。
分别实现将字符流转化为单词符号流,用单词符号流构建抽象语法树,管理语法分析过程中向符号表中增改信息的功能。
2.1.4 程序编写和连接本文借助flex工具生成词法分析器,bison工具生成语法分析器,用C语言编写程序,所有程序在同一目录下,用gcc编译连接。
2.2 词法分析2.2.1 为什么使用flex词法分析通常所做的就是在输入中寻找字符的模式(pattern),而一种简洁明了的模式的描述方式就是正则表达式(regular expression)。
Flex会把所有的正则表达式翻译成一种高效的内部格式(确定性有穷自动机,DFA),使它几乎可以同时处理所有需要匹配的模式,因此它的速度可以成百倍地提高[4]。
另外,flex版本的词法分析器比相应的手写的C代码更简短,因此也更容易调试。
2.2.2 flex代码及含义首先包括进由bison产生的头文件,其中有对关键字、终结符的枚举。
然后将字符流组织成有意义的单词(token),再返回给yylex()函数。
在yyparse()运行过程中会多次调用yylex()函数来获取单词(token)。
%option noyywrap nodefault yylineno%{#include <stdio.h>#include <stdlib.h>#include "headfile.h"#include "parser.tab.h"%}%%"while" {return WHILE;}[a-zA-Z][a-zA-Z0-9]* {yylval.s=yytext;return ID;}[0-9]+ {yylval.i=atoi(yytext);return NUMBER;}"==" {return EQUAL;}"\n"|" " {} ";"|"+"|"-"|"*"|"/"|"("|")"|">"|"<"|"=" {yylval.s=yytext;return yytext[0];}%%2.2.3 词法分析部分总结Flex根据所提供的lexer.l文件,自动生成yy.lexer.c文件,编译成功后得到相应的yy.lexer.exe可执行文件,后续进行语法分析时会调用该文件中的内容,使输入字符串以单词符号流的形式进入语法分析器。
2.3 语法分析2.3.1 为什么使用bisonBison基于所给的语法来生成可以识别这个语法中有效语句的语法分析器[4],它基于2.1.2中所给的语法来识别语法上的正确输入。
通过在识别之后加入一些语句进行抽象语法树的生成,就可以实现语法分析的整个过程并为目标代码的生成提供接口。
Bison所生成的代码也将比手写的代码简短、易于调试。
2.3.2 抽象语法树的相关定义抽象语法树使用同一节点类型以便管理,同时定义了根据不同输入数据建立节点的函数:pastnode newAstnode(){pastnode a=(pastnode)malloc(sizeof(_astnode));if(a==NULL){printf("run out of memory.\n");exit (0);}memset(a,0,sizeof(_astnode));return a;}pastnode newNum(int num){pastnode a=newAstnode();a->nodetype="number";a->value=num;return a;}pastnode newId(char* string){pastnode a=newAstnode();a->nodetype="id";a->string=string;return a;}pastnode newExpr(int oper,pastnode l,pastnode r){ pastnode a=newAstnode();a->nodetype="expression";a->value=oper;a->l=l;a->r=r;return a;}pastnode newStmt(pastnode l,pastnode r){pastnode a=newAstnode();a->nodetype="statement";a->l=l;a->r=r;return a;}pastnode newAssign(char* string,pastnode r){ pastnode a=newAstnode();a->nodetype="assign";pastnode l=newId(a->string);a->l=l;a->r=r;return a;}pastnode newWhile(pastnode l,pastnode r){ pastnode a=newAstnode();a->nodetype="while";a->l=l;a->r=r;return a;}2.3.3 打印语法树打印语法树时,先查看该节点的节点类型,根据类型选择不同的打印方式,再进行对左右子数的递归调用。
int showAst(pastnode a,int layer){int i;for (i=1;i<=layer;i++){printf(" ");}if (a->nodetype=="number"){printf ("number:%d",a->value);printf("\n");return 0;}if (a->nodetype=="id"){printf ("id:%s",a->string);printf("\n");return 0;}if(a->nodetype=="expression"){if (a->value==EQUAL) {printf("== expression:\n");}else printf("%c expression:\n",a->string);if (a->l!=NULL) showAst(a->l,layer+1);if (a->r!=NULL) showAst(a->r,layer+1);return 0;}if(a->nodetype=="statement"){printf("statement:\n");if (a->l!=NULL) showAst(a->l,layer+1);if (a->r!=NULL) showAst(a->r,layer+1);return 0;}if(a->nodetype=="assign"){printf("assign statement:\n");if (a->l!=NULL) showAst(a->l,layer+1);if (a->r!=NULL) showAst(a->r,layer+1);return 0;}if(a->nodetype=="while"){printf("while statement:\n");showAst(a->l,layer+1);showAst(a->r,layer+1);return 0;}}2.3.4 Bison代码及含义Bison代码首先定义了联合类型表示终结符或非终结符可以为哪些类型,然后就是语法分析部分,大括号内是相应的建立节点的语句,当整个程序执行完时,一棵抽象语法树就建成了。