mysql体系结构【博森瑞】
MySQL数据库的体系结构介绍

MySQL数据库的体系结构介绍MySQL是一种广泛使用的关系型数据库管理系统,它被许多Web应用程序用来存储它们的数据。
MySQL数据库的体系结构可以分为以下几个主要的组件:客户端、连接器、查询缓存、分析器、优化器、执行器、存储引擎和文件系统。
在本文中,我们将详细介绍这些组件。
客户端客户端是MySQL系统的用户界面,可以让你和数据库进行交互。
大多数MySQL客户端都是基于命令行的,你可以使用命令来操作数据库。
除此之外,也有一些基于图形界面的工具,比如phpMyAdmin和MySQL Workbench等。
连接器连接器是一个组件,用于建立客户端和MySQL数据库之间的连接。
它的作用是认证用户身份、处理权限和安全等问题。
当客户端连接到MySQL服务器时,连接器会检查用户是否有足够的权限来执行请求的操作,并在需要的情况下提供额外的安全性检查。
查询缓存查询缓存是MySQL的一个组件,它用于存储查询的结果。
这意味着,如果同样的查询再次执行,MySQL会从缓存中提取结果,而不是重新执行查询。
这可以提高查询的性能,但对于大型或频繁更新的数据库来说,它可能会降低性能,因为更新操作会使缓存失效。
分析器分析器是MySQL的一个组件,它的作用是解析SQL查询语句,并确定查询的语法和语义是否正确。
如果查询存在语法错误或语义错误,分析器将无法执行该查询。
如果查询语法正确,分析器将把它传递给优化器。
优化器优化器是MySQL的一个组件,它的作用是分析查询并确定执行查询的最佳方式。
优化器会考虑使用哪个索引、是否使用连接、使用哪种连接算法等问题。
通过这些技术,优化器可以在查询中减少大量的I/O操作。
执行器执行器是MySQL的一个组件,它的作用是执行查询。
执行器将查询计划从优化器传递给存储引擎,并从存储引擎中获取查询结果。
执行器还处理锁定和事务等问题。
存储引擎存储引擎是MySQL的一个组件,它决定了如何将数据存储在磁盘上。
存储引擎可以是InnoDB、MyISAM等。
MySQL基本原理 ppt课件

15
MySQL复制原理
• MySQL Replication的基本原理是通过binlog复制应用的方式来还原数据。
• MySQL通过Server_id来识别binlog由哪台主机产生,因此即使双Master复制, 也不会出现binlog被重复应用
• 复制线程分为Slave IO和Slave SQL两个,Slave IO线程只负责注册到Master上, 读取binlog,然后解析到本地,Slave SQL线程只负责把Slave IO线程产生的可 执行SQL应用到本地。
dir=bundled –enable-assembler –enable-profiling –enable-local-in –with-readline
–with-pthread –with-embedded-server –with-client-ldflags=-all-static –with-
• MySQL结构层次 • MySQL处理流程 • 存储引擎机制
2021/3/26
MySQL基本原理 ppt课件
3
MySQL结构层次
2021/3/26
MySQL基本原理 ppt课件
4
MySQL处理流程
当客户端链接上mysql服务端时, 系统为其分配一个链接描述符thd, 用以描述客户端的所有信息,将作 为参数在各个模块之间传递。一个 典型的客户端查询在MySQL的主要 模块之间的调用关系如图所示:
wwwpenglixuncom整理课件内容概要mysql关键代码实现分析整理课件mysql体系架构存储引擎机制整理课件mysql结构层次整理课件mysql处理流程当客户端链接上mysql服务端时系统为其分配一个链接描述符thd用以描述客户端的所有信息将作为参数在各个模块之间传递
Mysql入门系列:MySQL数据目录的结构

Mysql入门系列:MySQL数据目录的结构MySQL数据目录中包含由服务器管理的所有数据库和表。
它们被组织成一个树状结构,该结构是通过UNIX 或Windows 文件系统的层次结构用简单的方式实现的:每个数据库对应该数据目录下的一个目录。
数据库中的表对应数据库目录中的文件。
数据目录还包含几个由服务器生成的状态文件,如日志文件。
这些文件提供了关于服务器运作的重要信息,对管理员是有用的,尤其是当问题出现且试图确定问题的原因时特别有用。
例如,如果某个特定的查询毁坏了数据库,您可以通过检查日志文件来识别这个讨厌的查询。
MySQL服务器怎样提供对数据的访问数据目录中的一切都由一个单个的实体进行管理,即MySQL服务器的mysqld。
客户机程序不能直接操纵数据。
而服务器提供了访问数据库的唯一的连结点,它担当着客户机程序和所需数据之间的媒介(参见图10 - 1)当启动服务器时,如果有任何请求,它都将打开日志文件,然后通过对网络连接的监听向数据目录展现网络接口。
为了访问数据,客户机建立一个到服务器的连接,然后传达作为SQL 查询的请求,以完成所期望的操作(例如,创建表、选择记录、更新记录)。
服务器执行每个操作并将结果发送回客户机。
服务器是多线程的,可以服务于多个并发的客户机的连接。
但是,由于更新操作一次只能执行一个,因此实际上这些请求是顺序化的,两个客户机决不可能在同一时刻修改同一个记录。
在正常条件下,使服务器担当数据库访问的唯一仲裁者将提供对防止各种讹误的担保,这些讹误可导致多个进程同时访问数据库的表。
然而,管理员应该知道:存在着服务器不具有对数据目录独占控制的时期:何时在单个数据目录中运行多个服务器。
通常情况下是运行一个单个的服务器来管理主机中的所有数据库,但是运行多个服务器也是可能的。
如果这样做可以提供对多个独立的数据目录的访问,则不存在交互作用的问题。
但是,有可能启动多个服务器并在相同的数据目录中指向它们。
mysql的组成结构

mysql的组成结构MySQL的组成结构主要包括服务器层、存储引擎和插件。
一、服务器层服务器层是MySQL的核心组成部分,负责处理客户端的请求,协调各个模块的工作。
它包括连接器、查询缓存、分析器、优化器、执行器等几个模块。
1. 连接器连接器负责与客户端建立连接,接收客户端的请求,并进行身份验证。
一旦连接建立成功,连接器会生成一个线程,负责处理该连接的后续请求。
2. 查询缓存查询缓存模块用于缓存查询结果,当有相同的查询请求时,直接返回缓存中的结果,避免了重复执行查询操作。
但由于查询缓存的失效机制较为复杂,且随着数据的更新频繁,查询缓存的效果并不理想,因此在MySQL 8.0版本中已经被移除。
3. 分析器分析器负责对SQL语句进行解析,判断其语法是否正确,并将其转换成解析树。
同时,分析器还会进行一些语义分析,如检查表和字段是否存在、权限验证等。
4. 优化器优化器根据解析树进行优化,选择最佳的执行计划。
优化器会根据表的大小、索引情况、数据分布等因素,评估不同执行计划的成本,并选择成本最低的执行计划。
5. 执行器执行器负责执行查询计划并返回结果给客户端。
它会调用存储引擎的接口,按照查询计划的要求获取数据,并进行排序、聚合等操作。
二、存储引擎存储引擎是MySQL的另一个核心组件,负责数据的存储和检索。
MySQL支持多种存储引擎,常用的有InnoDB、MyISAM、Memory等。
1. InnoDBInnoDB是MySQL的默认存储引擎,也是最常用的存储引擎之一。
它支持事务、行级锁、外键等高级特性,具有较好的并发性能和数据恢复能力。
2. MyISAMMyISAM是MySQL的另一个常用存储引擎,它不支持事务和行级锁,但在某些特定场景下,如读密集型应用,具有较好的性能表现。
3. MemoryMemory存储引擎将数据存储在内存中,读写速度非常快,但数据的持久性较差,重启服务器后数据会丢失。
它适用于临时表、缓存表等场景。
DB2、MySQL 和 PostgreSQL 体系结构

MySQL实例与DB2数据库相似。
MySQL和PostgreSQL数据库可以几乎每周都进行特性修改,但是DB2中的特性实现和修改要经过非常仔细的计划,这是因为有众多的业务依赖于使用DB2产品。请注意,在本文中我们使用MySQL 5.1、PostgreSQL 8.0.3和DB2 V8.2进行比较,所以在阅读本文时请考虑到这一点。
在默认情况下分配一个缓冲池,并可以使用CREATE BUFFERPOOL命令添加其他缓冲池。默认的页大小在创建数据库时决定,可以是4、8、16或32K。
数据库连接
客户机使用CONNECT或USE语句连接数据库,这时要指定数据库名,还可以指定用户id和密码。使用角色管理数据库中的用户和用户组。
客户机使用connect语句连接数据库,这时要指定数据库名,还可以指定用户id和密码。使用角色管理数据库中的用户和用户组。
图1、图2和图3是MySQL、PostgreSQL和DB2的体系结构图。我们在阅读一些文档之后竭尽我们的能力绘制出MySQL和PostgreSQL的体系结构图。如果您发现不符合实际情况的地方,请告诉我们,我们会进行纠正。
MySQL
MySQL使用一种基于线程的体系结构,而PostgreSQL和DB2采用基于进程的体系结构。正如在图1中看到的,一个MySQL实例可以管理许多数据库。一个实例中的所有MySQL数据库共享一个公用的系统编目,INFORMATION_SCHEMA。
图4. DB2数据库管理器(实例)和数据库共享内存体系结构
特性对比
表1对比了MySQL、PostgreSQL和DB2特性。这不是一个完整的列表,但是对比了最常用的特性。
表1. MySQL、PostgreSQL和DB2特性对比
MySQL基础架构-架构详解
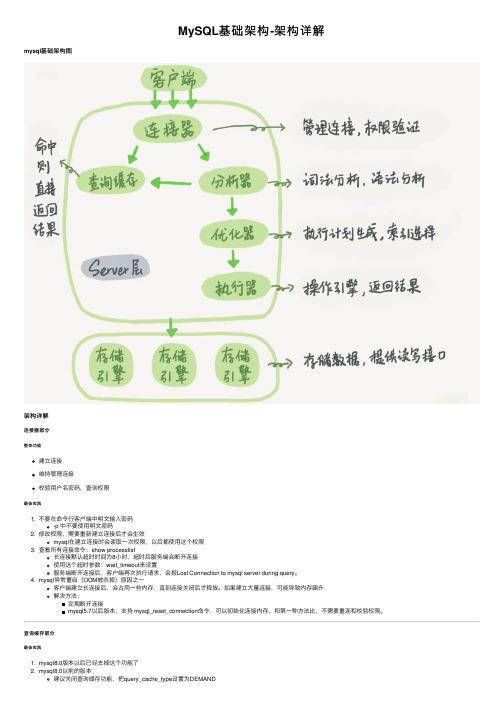
MySQL基础架构-架构详解mysql基础架构图架构详解连接器部分整体功能建⽴连接维持管理连接校验⽤户名密码,查询权限最佳实践1. 不要在命令⾏客户端中明⽂输⼊密码-p 中不要使⽤明⽂密码2. 修改权限,需要重新建⽴连接后才会⽣效mysql在建⽴连接时会读取⼀次权限,以后都使⽤这个权限3. 查看所有连接命令:show processlist长连接默认超时时间为8⼩时,超时后服务端会断开连接使⽤这个超时参数:wait_timeout来设置服务端断开连接后,客户端再次执⾏请求,会报Lost Connection to mysql server during query。
4. mysql异常重启(OOM被杀掉)原因之⼀客户端建⽴长连接后,会占⽤⼀些内存,直到连接关闭后才释放。
如果建⽴⼤量连接,可能导致内存飙升解决⽅法:定期断开连接mysql5.7以后版本,⽀持 mysql_reset_connection命令,可以初始化连接内存,和第⼀种⽅法⽐,不需要重连和校验权限。
查询缓存部分最佳实践1. mysql8.0版本以后已经去掉这个功能了2. mysql8.0以前的版本建议关闭查询缓存功能,把query_cache_type设置为DEMAND在需要使⽤缓存的表中,select语句中加⼊ SQL_CACHE即可select SQL_CACHE * from 表名3. 查询结果返回时,会校验权限分析器部分分析器部分主要做两件事:1. 词法分析:解析关键词,校验表名是否存在,列是否存在等等2. 语法分析:判断是否符合mysql的语法规则最佳实践1. 出现语法错误时,会返回you have an error in your SQL syntax错误,这个错误提⽰第⼀个出现错误的地⽅,所以检查紧跟use near后⾯的语句即可优化器部分优化器做两类事:1. 选择索引2. 确定表关联的顺序⽬的都是优化执⾏性能执⾏器部分执⾏器先校验是否有权限如果有权限,按照表定义中的引擎,使⽤这个引擎提供的接⼝如果没有索引:1. 调⽤引擎提供的取表第⼀⾏,判断是否符合条件,符合条件加⼊结果集2. 调⽤引擎提供的下⼀⾏接⼝,继续判断;直到最后⼀⾏3. 将结果集返回给客户端如果有索引:1. 调⽤满⾜条件的第⼀⾏接⼝2. 循环取满⾜条件的下⼀⾏接⼝最佳实践1. 慢查询⽇志中有⼀个rows_examined字段,这个字段是在执⾏器每调⽤⼀次引擎接⼝的时候就加⼀,但是每调⽤⼀次接⼝,实际在引擎中扫描的⾏数是不确定的,所以实际扫描⾏数和这个字段并不完全⼀致。
mysql原理课件ppt

MySQL查询处理
将SQL查询语句分解为单词和符号,识别关键字、标识符、操作符等。
词法分析
语法分析
语义分析
根据语法规则将词法分析的结果构建成一颗解析树。
检查解析树中的语义是否合法,例如检查表和列是否存在,数据类型是否匹配等。
03
02
01
生成多种可能的执行计划
查询优化器会根据统计信息和系统配置生成多种可能的执行计划。
使用SSD硬盘,配置RAID,调整磁盘I/O参数等。
表空间优化
合理规划表空间大小和使用方式,避免空间不足或浪费。
操作系统优化
调整操作系统的参数,如内存分配、进程调度等,以提高MySQL服务器的性能。
MySQL配置优化
根据服务器硬件和业务需求,调整MySQL的配置参数,如缓冲区大小、连接数等。
数据库复制
数据仓库
MySQL可以与移动应用配合使用,提供后端数据库服务。
移动应用
MySQL可以用于存储和管理物联网设备生成的数据。
物联网(IoT)
MySQL数据库系统架构
InnoDB是MySQL的默认存储引擎,支持事务处理、行级锁定和外键约束。
InnoDB
MyISAM
Memory
CSV
MyISAM是MySQL早期版本的默认存储引擎,不支持事务处理,但具有较高的读性能。
详细描述
总结词:MySQL高可用性解决方案是通过多种技术手段来提高数据库的可用性和可靠性,包括主从复制、集群、分片等技术。
MySQL性能优化
优化数据存储
选择合适的数据类型,减少数据冗余,合理组织数据结构。
文件系统优化
使用高性能的文件系统,如XFS或EXT4,并合理配置文件系统参数。
MySQL Cluster体系结构概述

MySQL Cluster 体系结构概述MySQL Cluster的高可用特性目录1前言 (1)2引入MYSQL (1)3高可用性系统架构 (2)4系统配置示例 (2)5同步复制 (3)6故障检测 (3)通信中断 (4)心跳故障 (4)网络分区 (4)确定故障顺序 (5)7节点恢复 (5)单节点恢复 (5)多节点恢复 (5)8系统恢复 (6)局部检查点 (6)全局检查点 (6)系统恢复 (6)复制和分区透明 (6)9故障案例 (6)10MYSQL服务器节点故障 (7)存储节点故障 (7)管理服务器节点崩溃 (7)连接失败 (7)磁盘故障 (7)11结论 (7)关于MYSQL (8)1前言这篇文献是介绍MySQL Cluster的高可用性和可靠性,MySQL是一个内存集群的分布式数据库管理系统。
该系统建立在一个无共享体系结构上,包括了故障转移,节点恢复,数据同步和无单点故障等高级特性。
此文献描述了一个不同的应用场景,系统架构和使用方法,用于提供高可用性能。
2引入MySQLMySQL Cluster 通过使用无单节点故障的分布式节点结构来得以达到高达99.999%的可用率。
该系统包括了多个分布于各设备和区域的节点,保证了持续可用,以防节点和网络故障。
MySQL Cluster使用一种由一系列存储节点组成的存储引擎,这些存储节点可以存储那些使用标准的SQL访问MySQL服务器的获得的数据。
MySQL Cluster包括三种节点(如图1):图1:节点系统1.存储节点(SN)式系统的主要节点。
所有数据可以被存储在存储节点上。
数据在存储节点之间进行复制传递,以防止在在一个或者多个节点出现故障的情况下数据依然可用。
存储节点能够处理所有数据。
2.管理服务器节点(MSN)处理系统的配置和用于改变该系统的安装。
通常只有一个管理服务器节点被使用,但也有可能运行几个。
管理服务器节点仅用于在启动和系统重新配置,这意味着存储节点是可操作的,而不管理节点。
mysql表结构定义-概述说明以及解释

mysql表结构定义-概述说明以及解释1.引言1.1 概述概述部分是文章引言的开头,主要介绍文章将要涉及的主题和要解决的问题。
在这篇关于"mysql表结构定义"的文章中,概述部分应该简要介绍MySQL表结构在数据库设计和管理中的重要性,并引出接下来要探讨的主题,即MySQL表结构的基本组成和定义规范。
此外,还可以提及MySQL表结构对于数据存储和查询的影响,以及在实际应用中常见的问题和解决方案,为读者带来一个整体的概念。
1.2 文章结构文章结构是指文章的组织和排列方式,包括标题、章节、段落、图表等元素的排列顺序和关系。
一个良好的文章结构能够提高文章的可读性和逻辑性,使读者更容易理解文章的内容和主题。
在撰写文章时,我们需要考虑如何合理地组织和排列文章的内容,使之呈现出清晰的逻辑结构和连贯的表达方式。
一般而言,一篇文章的结构可以分为引言、正文和结论三个部分。
引言部分主要介绍文章的主题和背景,概述文章的内容和目的,引起读者的兴趣;正文部分是文章的核心内容,主要阐述作者的观点和论述,提供论据和例证支持,展开对主题的分析和讨论;结论部分总结全文内容,回顾文章的主要论点和结论,展望未来可能的发展方向或讨论问题。
在文章撰写过程中,作者应根据文章的主题和内容确定适合的结构和排列方式,合理安排各个部分的内容,确保整篇文章通顺、连贯、逻辑明晰。
文章结构的设置应当符合读者阅读习惯和逻辑思维方式,便于读者理解和吸收文章的信息。
同时,作者也可以根据需要在文章中加入标题、小标题、引言、转折等元素,增强文章结构和表达的层次感,使文章更加有条理和丰富多样。
1.3 目的在本文中,我们旨在探讨MySQL表结构定义的重要性以及其基本组成和定义规范。
通过深入理解MySQL表结构的相关知识,我们可以更好地设计和管理数据库,提高数据存储的效率和安全性。
此外,我们还将分析MySQL表结构的应用场景,展望未来在数据库设计和管理领域的发展方向。
mysql原理知识点总结

mysql原理知识点总结一、MySQL的体系结构MySQL的体系结构是指其内部结构和组成部分。
MySQL的体系结构主要包括服务器层、存储引擎层和插件层。
服务器层负责连接处理、安全认证、SQL解析和执行、查询缓存等功能;存储引擎层负责数据的存储和读写操作;插件层负责提供扩展性特征,支持插件化的存储引擎和功能插件。
MySQL的服务器层采用了多层架构,包括连接管理器、查询缓存、解析器、优化器、执行器等。
其中,连接管理器负责连接的创建和断开;查询缓存负责缓存查询的结果,减少数据库的负载;解析器负责解析语句,将语句转化为内部数据结构;优化器负责生成执行计划,选择最优的执行路径;执行器负责执行SQL语句,返回结果给客户端。
MySQL的存储引擎层是它的核心组件,负责数据的存储和读写操作。
MySQL支持多种存储引擎,包括InnoDB、MyISAM、Memory、CSV等。
不同的存储引擎具有各自的特点和适用场景,例如InnoDB支持事务和行级锁,适合于高并发和数据一致性要求高的场景;MyISAM不支持事务和行级锁,但对于读操作效率高,适合于读写比例低的场景;Memory存储引擎是将数据存储在内存中,读写效率极高,但数据不具有持久性。
MySQL的插件层支持扩展性特征,允许存储引擎和功能插件的动态加载和卸载。
这种模块化的设计使得MySQL能够针对不同的需求进行定制,具有良好的可扩展性。
二、MySQL的数据存储机制MySQL的数据存储机制包括数据文件、日志文件、索引文件和临时文件。
数据文件存储数据表的实际数据,通常以.ibd为后缀名;日志文件包括重做日志和归档日志,重做日志负责数据的持久化,用于数据的恢复,归档日志负责记录所有的数据库操作,以确保数据库的一致性;索引文件存储表的索引数据,用于加速检索操作;临时文件用于存储临时数据,例如排序和连接操作的中间结果。
MySQL的数据存储采用了页式存储的方式,数据文件被划分为一个个的数据页,每个数据页默认大小为16KB。
超详细的MySQL工作原理体系结构

超详细的MySQL工作原理体系结构了解MySQL(超详细的MySQL工作原理体系结构)•1.MySQL体系结构•2.MySQL内存结构•3.MySQL文件结构•4.innodb体系结构一、了解MySQL前你需要知道的引擎是什么:MySQL中的数据用各种不同的技术存储在文件(或者内存)中。
这些技术中的每一种技术都使用不同的存储机制、索引技巧、锁定水平并且最终提供广泛的不同的功能和能力。
通过选择不同的技术,你能够获得额外的速度或者功能,从而改善你的应用的整体功能。
当我们理解了引擎这个概念,自然而然就知道引擎层的作用就提供各种不同引擎给你选择,然后用你选出来的引擎去处理sql语句二、MySQL体系结构MySQL 最重要、最与众不同的特性是它的存储引擎架构,这种架构的设计将查询处理(Query Processing)及其他系统任务(Server Task)和数据的存储/提取相分离。
这种处理和存储分离的设计可以在使用时根据性能、特性,以及其他需求来选择数据存储的方式。
由图,可以看出MySQL最上层是连接组件。
下面服务器是由连接池、管理工具和服务、SQL接口、解析器、优化器、缓存、存储引擎、文件系统组成。
•用户:进行数据库连接的人。
•支持接口:是第三方语言提供和数据库连接的接口,常见的有jdbc,odbc,c的标准api函数等等。
•管理工具和服务:系统管理和控制工具,例如备份恢复、Mysql 复制、集群等(见图)•连接层:提供与用户的连接服务,用于验证登录服务。
—> 连接池:由于每次建立建立需要消耗很多时间,连接池的作用就是将这些连接缓存下来,下次可以直接用已经建立好的连接,提升服务器性能。
•服务层:完成大多数的核心服务功能。
有sql接口,解析器parser,优化器optimizer,查询缓存 cache/buffer 。
—>SQL接口:接受用户的SQL命令,并且返回用户需要查询的结果。
比如select * from就是调用SQL Interface—>解析器: SQL命令传递到解析器的时候会被解析器验证和解析。
MySQL高级【三】MySQL体系结构和存储引擎

MySQL⾼级【三】MySQL体系结构和存储引擎MySQL的体系结构概览整个MySQL Server由以下组成:Connection Pool : 连接池组件Management Services & Utilities : 管理服务和⼯具组件SQL Interface : SQL接⼝组件Parser : 查询分析器组件Optimizer : 优化器组件Caches & Buffers : 缓冲池组件Pluggable Storage Engines : 存储引擎File System : ⽂件系统连接层最上层是⼀些客户端和链接服务,包含本地sock 通信和⼤多数基于客户端/服务端⼯具实现的类似于 TCP/IP的通信。
主要完成⼀些类似于连接处理、授权认证、及相关的安全⽅案。
在该层上引⼊了线程池的概念,为通过认证安全接⼊的客户端提供线程。
同样在该层上可以实现基于SSL的安全链接。
服务器也会为安全接⼊的每个客户端验证它所具有的操作权限。
服务层第⼆层架构主要完成⼤多数的核⼼服务功能,如SQL接⼝,并完成缓存的查询,SQL的分析和优化,部分内置函数的执⾏。
所有跨存储引擎的功能也在这⼀层实现,如过程、函数等。
在该层,服务器会解析查询并创建相应的内部解析树,并对其完成相应的优化如确定表的查询的顺序,是否利⽤索引等,最后⽣成相应的执⾏操作。
如果是 select 语句,服务器还会查询内部的缓存,如果缓存空间⾜够⼤,这样在解决⼤量读操作的环境中能够很好的提升系统的性能。
引擎层存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API和存储引擎进⾏通信。
不同的存储引擎具有不同的功能,这样我们可以根据⾃⼰的需要,来选取合适的存储引擎。
存储层数据存储层,主要是将数据存储在⽂件系统之上,并完成与存储引擎的交互。
优势:和其他数据库相⽐,MySQL 的架构可以在多种不同场景中应⽤并发挥良好作⽤,主要体现在存储引擎上,插件式的存储引擎架构,将查询处理和其他的系统任务以及数据的存储提取分离,这种架构可以根据业务的需求和实际需要选择合适的存储引擎。
MySQL体系结构

MySQL体系结构MySQL 体系结构及存储引擎体系结构MySQL体系结构连接者:不同语⾔的代码程序和mysql的交互(SQL交互)1、连接池管理、缓冲⽤户的连接,线程处理等需要缓存的需求2、管理服务和⼯具组件系统管理和控制⼯具,例如备份恢复、Mysql复制、集群等3、sql接⼝接受⽤户的SQL命令,并且返回⽤户需要查询的结果4、查询解析器 SQL命令传递到解析器的时候会被解析器验证和解析(权限、语法结构)5、查询优化器 SQL语句在查询之前会使⽤查询优化器对查询进⾏优化select id,name from user where age = 40;a、这个select 查询先根据where 语句进⾏选取,⽽不是先将表全部查询出来以后再进⾏age过滤b、这个select查询先根据id和name进⾏属性投影,⽽不是将属性全部取出以后再进⾏过滤c、将这两个查询条件联接起来⽣成最终查询结果6、缓存如果查询缓存有命中的查询结果,查询语句就可以直接去查询缓存中取数据7、插⼊式存储引擎存储引擎说⽩了就是如何管理操作数据(存储数据、如何更新、查询数据等)的⼀种⽅法。
因为在关系数据库中数据的存储是以表的形式存储的,所以存储引擎也可以称为表类型(即存储和操作此表的类型)说明:在Oracle 和SQL Server等数据库中,所有数据存储管理机制都是⼀样的。
⽽MySql数据库提供了多种存储引擎。
⽤户可以根据不同的需求为数据表选择不同的存储引擎,⽤户也可以根据⾃⼰的需要编写⾃⼰的存储引擎。
甚⾄⼀个库中不同的表使⽤不同的存储引擎,这些都是允许的。
存储引擎MyISAM存储引擎由于该存储引擎不⽀持事务、也不⽀持外键,所以访问速度较快。
因此当对事务完整性没有要求并以访问为主的应⽤适合使⽤该存储引擎。
InnoDB存储引擎mysql 5.5版本以后默认的存储引擎由于该存储引擎在事务上具有优势,即⽀持具有提交、回滚及崩溃恢复能⼒等事务特性,所以⽐MyISAM存储引擎占⽤更多的磁盘空间。
MySQL概述与技术结构

MySQL overview and application framework1 Introduction to MySQLMySQL is a relational database management system, which is developed by MySQL AB of Sweden and belongs to Oracle. MySQL is one of the most popular relational database management systems. In terms of Web applications, MySQL is one of the best RDBMS (Relational Database Management System) applications.MySQL is a relational database management system. Relational databases store data in different tables instead of putting all data in a large warehouse, which increases speed and flexibility.The SQL language used by MySQL is the most commonly used standardized language for accessing databases. MySQL software adopts the dual authorization policy, which is divided into community version and commercial version. Because of its small size, fast speed, low total cost of ownership, especially the open source, MySQL is generally selected as the website database for the development of small, medium and large websites.2. MySQL logical architectureMySQL's logical architecture can be roughly divided into three layers: the client layer, the server layer, and the storage engine layer.(1) Layer 1: client (server layer)It mainly deals with connection processing, authorization authentication, security assurance, etc.(2) Layer 2: Server layerIt covers most of MySQL's core service functions, including query parsing, analysis, optimization, caching and all built-in functions (such as date, time, math and encryption functions). Stored procedures, triggers, views and other cross storage engine functions are also implemented in this layer.Server layer basic components:Connector: We use the database. The first step is to connect to the database. The connector is responsible for establishing a connection with the client, obtaining permissions, maintaining and managing the connection query cache: when executing the query statement, it will first query the cache to verify whether the SQL has been executed. If there is a SQL cache, it will be directly returned to the client. If there is no hit, the subsequent operations will be executed; (MySQL 8.0 is deleted)Analyzer: If the cache is not hit, the SQL statement will go through the analyzer, which is mainly divided into two steps: lexical analysis and syntax analysis. First, see what the SQL statement needs to do, and then check whether the SQL statement syntax is correct; Optimizer: the optimizer optimizes queries, including rewriting queries, determining the read/write order of tables, selecting appropriate indexes, and generating execution plans. The main operations of the optimizer include: deciding which index to use when there are multiple indexes in a table; When a statement has multiple table joins, determine the join order of each table;Executor: Before execution, the user will be checked for permission. If there is no permission, an error message will be returned. If there is permission, the engine interface will be called according to the execution plan, and the result will be returned.(3) Layer 3: storage engine layerIt is mainly responsible for data storage and extraction. The server layer interacts with the storage engine layer through APIs. The server communicates with the storage engine through APIs. These interfaces mask the differences between different storage engines, making the differences transparent to the upper layer query process. In addition to the InnoDB defined by the foreign key, the storage engine will not parse SQL, and different storage engines will not communicate with each other, but simply respond to the request of the upper layer server.3 MySQL statement execution process(1) The execution process of the query statement is as follows:Permission verification, query cache, analyzer, optimizer, permission verification, executor, engine. First, check the permission. If there is no permission, an error is returned; If the cache is enabled, it will check whether the cache has the corresponding result of the sql (the cache storage form is key vlaue, where key is the executed sql and value is the corresponding value). If the cache is enabled and there is a mapping of the sql, the result will be returned directly; Lexical analysis and grammatical analysis. Extract the table name and query criteria, and check whether the syntax is incorrect; The optimizer generates execution plans, selects indexes, and selects the optimal execution scheme; Then come to the executor, open the table to call the storage engine interface, judge whether the query conditions are met line by line, put them in the result set, and finally return them to the client; If an index is used, the filtered rows will also be filtered according to the index.(2) Update statement execution processThe execution process of the update statement is as follows: analyzer, permission verification, executor, engine, redo log (prepare status), binlog, and redo log (commit status). The cache will be used if there is a cache. Get the query results, update the contents, and then call the engine interface to write the updated data. The Innodb engine saves the data in memory and records the redo log. At this time, the redo log enters the prepare state. After receiving the notification, the actuator records the binlog, calls the engine interface, and submits the redo log to the commit status. Update completed.4 Differences between MySQL and SQL Server(1) Open sourceMySQL is an open source relational database management system (RDBMS); SQL Server is not open source, but commercial.(2) ProcedureMySQL is mainly programmed in C and C++programming languages. SQL Server is mainly programmed in C++, but there are some parts in C language.(3) Use platformSQL Server only supports Linux and Windows platforms, mainly for Net application or Windows project. In contrast, MySQL supports many platforms, mainly for PHP projects or applications.(4) GrammarMySQL syntax is relatively complex; SQL Server syntax is simpler and easier to use.(5) Execute QueryIn MySQL, once the query is executed, you cannot cancel the query halfway. In SQL Server, queries can be canceled halfway after execution.(6) Storage EngineIn MySQL, there are multiple storage engines that allow developers to use engines for tables more flexibly based on performance. InnoDB is a popular storage engine. SQL Server can only use one or only one storage engine.(7) BackupWhen using MySQL, developers must back up data by extracting all data into SQL statements. Due to the execution of multiple SQL statements, data recovery is time-consuming. SQL Server does not block the database when backing up data, which enables users to back up and restore large amounts of data without spending additional time and effort.(8) SecurityBoth enterprise database systems are designed as binary collections. MySQL enables developers to operate database files through binary files at runtime. It even allows other processes to access and manipulate database files at runtime. However, SQL Server does not allow any process to access or manipulate its database files or binaries. It requires users to execute specific functions or operation files by running instances. Therefore, hackers cannot directly access or manipulate data. Design rules make SQL Server more secure than MySQL.(9) Supported programming languagesMySQL and SQL Server both support multiple programming languages. They all support PHP, C++, Python, Visual Basic, etc. But MySQL also supports Perl, Scheme, Haskel, Eiffel and other programming languages. MySQL is more popular because it supports many programming languages.(10) FilteringMySQL allows users to filter out tables, rows and users in various ways, but it requires users to filter out tables, rows or users according to individual databases. When filtering data, developers must run multiple queries to filter database tables separately. SQL Server uses row based filtering, and row based filtering options filter the data on the database by database. The filtered data is stored in a separate distribution database.5 Index functionAn index is a special file (the index on the InnoDB data table is a component of the table space). It contains reference pointers to all records in the data table. Indexes are not universal. Indexes can speed up data retrieval operations, but slow down data modification operations. The index must be refreshed every time the data record is modified. In order to remedy this defect to some extent, many SQL commands have a DELAY_ KEY_ WRITE items. This option temporarily prevents MySQL from refreshing the index after inserting a new record and modifying an existing record. The index will be refreshed after all records are inserted/modified. When many new records need to be inserted into a data table, DELAY_ KEY_ The WRITE option will be very useful. In addition, the index also takes up considerable space on the hard disk. Therefore, you should only index the data columns that are most frequently queried and sorted. Note that if a data column contains a lot of duplicate content, indexing it will not have much practical effect.(1) Index of InnoDB data tableCompared with InnoDB data tables, indexes are much more important to InnoDB data tables. On the InnoDB data table, the index will not only play a role in searching data records, but also be the basis of the data row level locking mechanism. "Data row level locking" meansthat the individual records being processed are locked during the execution of transaction operations to prevent other users from accessing them. This locking will affect (but not limited to) the SELECT, LOCKINSHAREMODE, SELECT, FORUPDATE commands, and INSERT, UPDATE, and DELETE commands. For efficiency reasons, data row level locking of InnoDB data tables actually occurs on their indexes, not on the data tables themselves. Obviously, the data row level locking mechanism can only work when the relevant data table has a suitable index for locking.(2) RestrictionsIf there is an inequality sign (WHERE colon!=) in the query condition of the WHERE clause, MySQL cannot use the index. Similarly, if a function (WHERE DAY (column)=) is used in the query condition of the WHERE clause, MySQL cannot use the index. In JOIN operations (when data needs to be extracted from multiple data tables), MySQL can only use indexes when the data types of primary keys and foreign keys are the same.If the comparison operators LIKE and REGEXP are used in the query conditions of the WHERE clause, MySQL can use the index only if the first character of the search template is not a wildcard. For example, if the query condition is LIKE 'abc%', MySQL will use the index; If the query condition is LIKE '% abc', MySQL will not use the index.In the ORDER BY operation, MySQL uses indexes only when the sort condition is not a query condition expression. (Even so, in queries involving multiple data tables, even if indexes are available, those indexes have little effect in speeding up ORDER BY.). If a data column contains many duplicate values, even if it is indexed, it will not work well. For example, if a data column contains only "0/1" or "Y/N" equivalents, it is unnecessary to create an index for it.6 Index Category(1) General IndexThe task of a normal index (an index defined by the keyword KEY or INDEX) is to speed up data access. Therefore, indexes should be created only for the data columns in the query condition (WHERE column=) or sort condition (ORDER BY column) that most often occur. Whenever possible, you should select the most tidy and compact data column (such as an integer type data column) to create an index.(2) IndexA normal index allows the indexed data column to contain duplicate values. For example, because a person may have the same name, the same name may appear twice or more times in the same Employee Profile data table. If it can be determined that a data column will only contain different values, the keyword UNIQUE should be used to define it as an index when creating an index for this data column. The advantages of this approach are: First, it simplifies MySQL's management of the index, which makes the index more efficient; Second, when a new record is inserted into the data table, MySQL will automatically check whether the value of this field of the new record has appeared in this field of a record; If yes, MySQL will refuse to insert that new record. In other words, indexes can ensure the uniqueness of data records. In fact, on many occasions, people create indexes not to improve access speed, but to avoid duplication of data.(3) Primary indexIt has been repeatedly emphasized that an index must be created for the primary key field, which is called the "primary index". The difference between primary indexes is that the formeris defined with PRIMARY instead of UNIQUE.(4) Foreign Key IndexIf you define a foreign key constraint for a foreign key field, MySQL will define an internal index to help you manage and use the foreign key constraint in the most efficient way. (5) Composite indexIndexes can cover multiple data columns, such as INDEX (columnA, columnB) indexes. The feature of this index is that MySQL can selectively use one such index. If the query operation only needs to use an index on the columnA data column, you can use the composite index INDEX (columnA, columnB). However, this usage only applies to data column combinations that rank first in a composite index. For example, INDEX (A, B, C) can be used as an index of A or (A, B), but not B, C or (B, C).。
MySQL数据库文件的结构及存储引擎

MySQL数据库文件的结构1.数据文件1)MyISAM表:有三个相关的文件,数据文件.MYD,索引文件.MYI,目标文件(定义文件).frm2)BDB表:包含两个文件,一个.db数据文件和一个.frm目标文件3)InnoDB表:有自己的目标文件.frm,但实际的数据存放在上一级目录中,与数据库属于同一级目录2.日志文件出错日志:在目录C:\Program Files\MySQL\MySQL Server 5.0\data\下, .err文件3.数据库备份与恢复最简单和直观的方法:使用官方的Mysql Administrator GUI工具1)BACKUP /RESTORBACKUP TABLE sales to 'c:\\temp';RESTOR TABLE sales from 'c:\\temp';2)对MyISAM表,可直接拷贝三个相关文件(MyISAM表是独立于平台的,可直接转移到其他机器上)3)mysqldump备份备份mysqldump test sales > c:\temp\backupsales2006_05_05.sql恢复mysqldump test < c:\temp\backupsales2006_05_05.sql4)select into备份备份表select * from sales into outfile 'c:\\temp\\sales.dat'恢复表load data infile 'c:\\temp\\sales.dat' into table sales5)mysqlhotcopy备份mysqlhotcopy databasename backup_directory_path6)数据库复制技术(...)InnoDB概述InnoDB给MySQL提供了具有提交,回滚和崩溃恢复能力的事务安全(ACID兼容)存储引擎。
MySQL架构介绍

MySQL架构介绍
一、目录结构
•/var/lib/mysql/:MySQL数据库文件的存放路径;
•/usr/share/mysql:配置文件目录;
•/usr/bin:MySQL命令的存放目录;
•/etc/init.d/mysql:启停相关脚本
二、分层结构
MySQL分为四层,从上到下依次为:
•连接层:为应用程序提供连接服务的,比如JDBC;
•服务层:这一层名堂很多,首先是有连接池,然后有sql接口,解析器,优化器等东西;
•引擎层:真正负责mysql数据的存储和读取的部分,提供了很多可拔插式的存储引擎,常用的有MyIsam和InnoDB;
•存储层:MySQL中存储的数据最终都要存在硬盘上,文件存储层就是将数据存储到文件系统,并完成与存储引擎的交互。
上面提到了可拔插式,意思就是,你要给手机充电,你可以放在无线充上,也可以用充电头充,也可以用充电宝充。
实现相同的功能,你可以选择不同的实现方式,并且这些实现方式之间互不关联互不影响。
三、innoDB和MyIsam对比
扫描二维码。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
缓存磁盘上的数据,方便快速地读取,并且在对磁盘文件 进行修改之前在这里缓存.
重做日志缓冲
1-6
Copyright © Bosenrui, 2015. All rights reserved.
Innodb的后台线程
1-7
Copyright © Bosenrui, 2015. All rights reserved.
Mysql体系结构组成部分
组成部分: 1.连接池组件 2.管理服务和工具组件 3.Sql接口组件 4.查询分析器组件 5.优化器组件 6.缓冲组件 7.插件式存储引擎(与其他数据库的主要区别) 8.物理文件
1-3
Copyright © Bosenrui, 2015. All rights reserved.
后台线程的主要作用: 刷新内存池中的数据,保证缓冲池中的内存缓存是最近最新的 数据。 将已修改的数据文件刷新到磁盘文件,同时保证在数据库发生 异常情况下,innodb能恢复到正常运行状态。 注:4个IO线程包括: Insert buffer thread,redo log thread,read/write thread Master thread,page cleaner thread ,Purge thread Lock monitor thread,error monitor thread
Mysql 体系结构 博森瑞
1-1
Copyright © Bosenrui, 2015. All rights reserved.
分层设计 引入存储引擎设计 Myisam innodb memory
1-2
Copyright © Bosenrui, 2015. All rights reserved.
Innodb内存结构
1-4
Copyright © Bosenrui, 2015. All rights reserved.
内存剖析
1-5
Copyright © Bosenrui, 2015. All rights reserved.
Innodb内部有多个内存块,这些内存块组成了一个大的内存 池。 内存池工作如下: 维护所有进程/线程需要访问的多个内部数据结构.
1-8
Copyright © Bosenrui, 2015. All rights reserved.
Innodb的逻辑存储
1-9
Copyright © Bosenrui, 2015. All rights reservБайду номын сангаасd.