统计学课件11
统计学完整全套PPT课件

模型的参数估计
阐述非线性回归模型的参数估计方 法,如最小二乘法、极大似然法等 ,并探讨其计算过程和注意事项。
模型的检验与诊断
介绍非线性回归模型的检验方法, 如拟合优度检验、参数的显著性检 验等,以及模型的诊断方法,如残 差分析、异常值识别等。
方差
各数据与平均数之差的平方的 平均数
03
标准差
方差的平方根04四源自位数间距上四分位数与下四分位数之差
偏态与峰态分析
01
02
03
偏态系数
描述数据分布偏斜程度的 统计量
峰态系数
描述数据分布尖峭或扁平 程度的统计量
正态性检验
如Jarque-Bera检验等, 用于判断数据是否服从正 态分布
03
推论性统计方法
模型评估与优化
预测结果展示与应用
通过比较模型的预测结果与实际股票价格 的差异,评估模型的预测性能,并进行优 化和改进。
将模型的预测结果进行可视化展示,为投资 者提供决策参考。
THANKS
感谢观看
统计学完整全套PPT课件
目录
• 统计学基本概念与原理 • 描述性统计方法 • 推论性统计方法 • 非参数统计方法 • 回归分析及其应用 • 时间序列分析与预测
01
统计学基本概念与原理
Chapter
统计学的定义及作用
统计学定义
统计学是一门研究如何收集、整理、分析和解释数 据的科学,它使用数学方法对数据进行建模和预测 ,以揭示数据背后的规律和趋势。
游程检验
游程检验的基本原理
以上内容仅供参考,具体细节和扩展内 容需要根据实际需求和背景知识进行补 充和完善。
统计学课件PPT课件

用直条表示频数,用横轴表示 数据范围,纵轴表示频数。
箱线图
表示一组数据的中位数、四分 位数和异常值。
散点图
表示两个变量之间的关系。
折线图
表示时间序列数据随时间的变 化趋势。
04
概率与概方法
描述随机事件发生的可能性程度,通 常用P表示。
通过实验或经验数据计算随机事件的 概率。
表示数量、大小、距离等可以量化的 数据,如年龄、收入。
统计数据的收集方法
直接观察法
通过实地考察、观测等方式收集数据, 如市场调研人员现场观察消费者行为。
实验法
通过实验设计和实验操作获取数据, 如产品测试实验。
调查法
通过问卷、访谈等方式收集数据,如 民意调查。
行政记录法
通过政府部门或企业提供的记录获取 数据,如企业财务报表。
01
单总体参数假设检 验的概念
根据单一样本数据对总体参数进 行假设检验。
02
单总体参数假设检 验的方法
如t检验、Z检验、卡方检验等。
03
单总体参数假设检 验的应用场景
如检验单个样本的平均数、比例 等是否与已知的总体参数存在显 著差异。
两总体参数的假设检验
两总体参数假设检验的概念
根据两个样本数据对两个总体的参数进行假设检验。
04
常见概率分布及其应用
二项分布
适用于独立重复试验中成功次数的概率分布, 如抛硬币、抽奖等。
正态分布
适用于许多自然现象的概率分布,如人的身 高、考试分数等。
泊松分布
适用于单位时间内随机事件的次数概率分布, 如放射性衰变、网站访问量等。
指数分布
适用于描述时间间隔或寿命的概率分布,如 电子产品寿命、等待时间等。
统计学-第11章一元线性回归学习指导
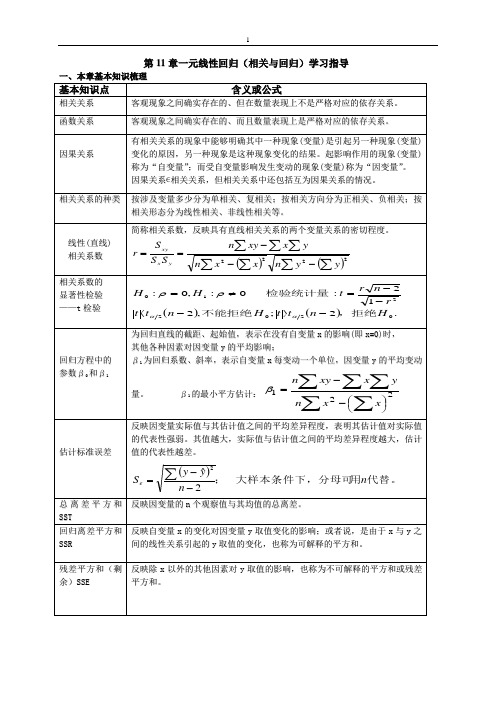
第11章一元线性回归(相关与回归)学习指导一、本章基本知识梳理基本知识点含义或公式相关关系 客观现象之间确实存在的、但在数量表现上不是严格对应的依存关系。
函数关系 客观现象之间确实存在的、而且数量表现上是严格对应的依存关系。
因果关系有相关关系的现象中能够明确其中一种现象(变量)是引起另一种现象(变量)变化的原因,另一种现象是这种现象变化的结果。
起影响作用的现象(变量)称为“自变量”;而受自变量影响发生变动的现象(变量)称为“因变量”。
因果关系∊相关关系,但相关关系中还包括互为因果关系的情况。
相关关系的种类 按涉及变量多少分为单相关、复相关;按相关方向分为正相关、负相关;按相关形态分为线性相关、非线性相关等。
线性(直线) 相关系数 简称相关系数,反映具有直线相关关系的两个变量关系的密切程度。
()()∑∑∑∑∑∑∑---==2222y yn x xn yx xy n SS S r yx xy相关系数的 显著性检验 ——t 检验 ()().2;,212:0:,0:020221Hn t t Hn t t rn r t HH,拒绝不能拒绝检验统计量-〉-〈--=≠=ααρρ回归方程中的 参数β0和β1为回归直线的截距、起始值,表示在没有自变量x 的影响(即x =0)时,其他各种因素对因变量y 的平均影响;β1为回归系数、斜率,表示自变量x 每变动一个单位,因变量y 的平均变动量。
β1的最小平方估计:∑∑∑∑∑⎪⎭⎫ ⎝⎛--=221x x n yx xy nβ估计标准误差反映因变量实际值与其估计值之间的平均差异程度,表明其估计值对实际值的代表性强弱。
其值越大,实际值与估计值之间的平均差异程度越大,估计值的代表性越差。
()代替。
用大样本条件下,分母可;n n yyS e 2ˆ2--=∑总离差平方和S S T反映因变量的n 个观察值与其均值的总离差。
回归离差平方和S S R 反映自变量x 的变化对因变量y 取值变化的影响;或者说,是由于x 与y 之间的线性关系引起的y 取值的变化,也称为可解释的平方和。
统计学完整ppt课件完整版

假设检验中的两类错误:第一类错误 、第二类错误
假设检验的步骤:建立假设、选择检 验统计量、确定拒绝域、计算p值、 作出决策
假设检验的实例分析:单样本t检验 、双样本t检验等
方差分析(ANOVA)方法介绍
方差分析的基本原理:F分布与 方差分析的关系
多因素方差分析的实现方法: 析因设计、随机区组设计等
通过观察数据的峰度,判 断是否存在尖峰或平峰分 布
03
推论性统计方法
参数估计原理及应用
01
参数估计的基本概念: 点估计、区间估计
02
估计量的评价标准:无 偏性、有效性、一致性
03
参数估计的方法:矩估 计法、最大似然估计法
04
参数估计的应用:总体 均值的区间估计、总体 比例的区间估计等
假设检验流程与实例分析
ABCD
数据筛选与排序
介绍如何使用Excel进行数据筛选和排序,以便 更好地查看和分析数据。
函数与公式应用
分享一些常用的Excel函数和公式,以便更高效 地处理和分析数据。
案例分享:使用统计软件解决实际问题
案例一
使用SPSS进行市场调研数据分析,包 括描述性统计、交叉表分析、回归分析
等。
案例三
使用Python进行电商数据分析,包 括用户行为分析、销售预测、推荐系
据的科学。
统计学的作用
描述数据特征
推断总体参数 预测未来趋势
评估决策效果
数据类型与来源
数据类型 定量数据(连续型与离散型)
定性数据(分类数据与顺序数据)
数据类型与来源
01
数据来源
02
03
04
观察数据(实验数据与观测数 据)
统计学第十一章相对数分析

不符合以上要求时,改用二项分布或 poisson理论估计可信区间
三、样本率与总体率差别的统计意义检 验:用正态分布理论进行,P141例11-2
u p p
四、两个样本率差别的显著性检验P142 例11-3 u p1 p2
p ' P r P SMR
n i Pi
P 为标准总率 Pi为各组标准组的率 r 为被标化实际死亡数
n i Pi为预期死亡数
SMR = r 为标化死亡比
n i Pi
三、标准的选择:方法有三
1、选用一个通用的、有代表性、较稳定的、 来自数量较大的人群的年龄别人口数(或年 龄构成)或年龄别死亡率作为需要比较的各 组资料的标准。
2、标化后的率并不代表某地实际水平,只 能表明相互比较资料间的相对水平,且仅限 于采用共同标准构成的组间比较。
3、选用不同标准算得的标化率不同,但标 化率的对比趋势通常是一致的,但也有不一 致的情形出现,所以,取全国或两组合计的 人口来计算标化率比较妥。
4、如不计算标化率,而分别比较各分组的 率,也可得出正确结论,但不能比较总率的 大小
相对比型指标:
指任何两个相关联的变量A和B之比。它表示相 对于B的一个单位A有多少个单位。=A/B
常用指标:
1、对比指标:两个同类事物某种指标之比。 如性别比、某指标随时间的变化
2、关系指标:指两个有关的、但非同类事 物的数量比。如医务从员与床位比、
3、计划完成指标:说明计划完成的程度, 常用实际数达到计划数的百分之几或几倍表 示。
2、分别将两县各年龄组预期死亡人数相加, 得各县预期总死亡数 nipi
《统计学》完整ppt课件

适用于等级资料或无法精确测量的数据,如医学 领域的疗效评价、心理学中的量表评分等。
3
秩和检验的优缺点
优点在于对数据分布的假设较为宽松,适用范围 广;缺点是当样本量较大时,检验效率可能降低 。
符号检验
符号检验的基本原理
通过比较样本数据的中位数或均值与某个参考值的大小关 系,判断总体分布是否存在显著差异。
推论性统计分析
介绍如何在Excel中进行推论性统计分析, 如假设检验、方差分析等。
Python编程实现统计分析案例展示
Python统计分析库介绍
数据处理与可视化
简要介绍Python中常用的统计分析库,如 NumPy、Pandas、SciPy等。
演示如何使用Python进行数据清洗、处理 及可视化,包括缺失值处理、异常值检测 等。
相关分析与回归分析
相关分析
研究两个或多个变量之间相关关系的统计分析方法,通过计算相关系数来衡量变量之间 的相关程度。
回归分析
研究因变量与一个或多个自变量之间关系的统计分析方法,通过建立回归模型来预测因 变量的取值。
04
CATALOGUE
非参数统计方法
卡方检验
卡方检验的基本原理
通过比较实际观测值与理论期望值之间的差异,判断两个或多个分 类变量之间是否存在显著关联。
03
CATALOGUE
推论性统计方法
参数估计方法
点估计
用样本统计量直接作为总体参数的估计值。
区间估计
根据样本统计量和抽样分布,构造一个包含总体参数的真值的置信区间,并给出该区间被总体参数真值覆盖的概 率。
假设检验原理及步骤
假设检验的基本原理
先对总体参数提出一个假设,然后利用样本信息判断这一假设是否合理,即判断总体参数与假设值是 否有显著差异。
统计学ppt(全)

第四节 统计学的要素和指标
一.统计学的要素 二.指标及指标体系
统计学的要素
总体(Population) 根据一定目的确定的所要研究事物的总体 2. 样本(Sample) 从总体中抽取出来的部分单位组成的集合体 3. 总体单位 组成整体的各个个体
指标及指标体系
标志与指标 2. 统计指标的特点 3. 指标的分类 统计指标体系
联系 很多统计指标的数值是从总体单位的数量标志值汇总而来的 指标与标志之间存在变换关系
统计指标的特点
同质事物的可量性 小康水平、公司绩效、满意度 量的综合性 许多个体现象的数量综合的结果 具体性
第11章 统计分析—双变量

10- 13 10-
社会 统计学
2、方差齐性检验和t检验结果 、方差齐性检验和t
F值>F 0.025 (n 1-1,n 2-1), 说明方差不齐。
10- 14 10-
P值小于给定的显著性水平α, 说明方差不齐。
P值小于给定的显著性水平α, 拒绝原假设。
社会 统计学
社会 统计学
10- 44 10-
社会 统计学
10- 45 10-
社会 统计学
【例2】“年龄段”与“忙碌程度”
10- 46 10-
社会 统计学
10- 47 10-
社会 统计学
10- 48 10-
社会 统计学
10- 49 10-
社会 统计学
斯皮尔曼等级相关系数(spearman)在这: 斯皮尔曼等级相关系数(spearman)在这: Analyze Correlate Bivariate
2、 比较重要 3、 一般 5、 很不重要 6 、说不清楚
10- 40 10-
社会 统计学
1、将被访者学历与“读书的地位”都看成 定类变量,作列联相关的检验。 2、被访者学历与“读书的地位”均为定序 量,作等级相关检验。
10- 41 10-
社会 统计学
10- 42 10-
社会 统计学
10- 43 10-
社会 统计学
二、独立样本T 检验 独立样本T
Analyze Compare Means
IndependentIndependent-Samples检验变量栏 T Test,
打开Independent-Samples T Test对 IndependentTest对
分组变量栏, 话框 只能有一个分 组变量
统计学课件ppt(全).

概率论
样本数据 统计数据 总体数据 描述统计学 推断统计学
总体内在的 数量规律性
一、描述统计学和推断统计学
描述统计和推断统计是统计方法的两个 组成部分。描述统计是整个统计的基础, 推断统计是现代统计学的主要内容,已经 成为统计学的核心内容。
二、理论统计学和应用统计学
• 1.理论统计学(Theoretical Statistics)指 统计学的数学原理,它主要研究统计学的 一般理论和统计方法的数学理论。它是统 计方法的理论基础。 • 2.应用统计学(Applied Statistics)研究如 何应用统计方法去解决实际问题。 如:生物统计学、卫生统计学、人口统 计学、农业统计学、管理统计学、社会统 计学
一、描述统计学和推断统计学
• 1.描述统计学(Descriptive Statistics)研究如何取 得反映客观现象的数据,并通过图表形式,对所收 集的数据进行加工处理和显示,进而通过综合、概 括与分析得出反映客观现象的规律性数量特征。 (数据的收集、加工处理、显示以及数据分布特征 的概括与分析) • 2.推断统计学(Inferential Statistics)研究如何根据 样本数据去推断总体数量特征的方法,它是在对样 本数据进行描述的基础上,对统计总体的未知数量 特征作出以概率形式表述的推断。(举例说明,全 校某次英语四级考试的通过率,通过抽样调查100人) (抽样估计、假设检验、回归分析)
医学统计学第11讲 二项分布及其应用一二

死亡 数 X 0
1
2
3
生存数 不同死亡数的概率
nX
3
C30 0.800.23 0.23
死亡 0个
2
C310.810.22 3 0.8 0.22
死亡 1个
C32 0.820.21
死亡
1
3 0.82 0.2 2个
0
C33 0.830.20 0.83
p
p
1
n
样本率的 总体均数
样本率的总体标准差,又称样本率的标准 误,反映样本率的抽样误差的大小。
当π未知时,常以样本率p来估计:
p X n
p 1 p
sp
n
例:已知某地钩虫感染率为6.7%,如 果随机抽查该地150人,记样本钩虫感 染率为p,求p的抽样误差σp。
本例n=150,π=0.067
p
(1 )
n
0.067(1 0.067) 0.020 2% 150
累计概率
从阳性率为π的总体中随机抽取n个个体,则
①结果A最多有K次发生的概率:
K
P(X k) P(X k) k 0
P(X 0) P(X 1)
为了解这些随机现象的规律性,在 相同条件下进行多次试验。发现其 共同特点:
(1)对立性 ( A, A) (2)独立性
应用条件
(3)重复性 ( p, q 1 p)
满足这些条件的n次重复独立试验为n重贝 努利试验,简称贝努利(Bernoulli)试验 或贝努利试验模型。
二项分布的定义
任意一次试验中,只有事件A发生和不发生两种 结果,发生的概率分别是: 和1- 若在相同的条件下,进行n次独立重复试验,用X 表示这n次试验中事件A发生的次数,那么X服从 二项分布,记做 XB(n,),也叫Bernoulli分布。
统计学__第11章 时间序列分析

图例7 一、循环变动及其测定目的二、循环变动的测定方法(一)直接法(二)剩余法循环变动分析循环变动分析-意义循环变动分析―形式直接法剩余法操作步骤用移动平均法,得到TC的估计,由Y/TC,得到仅含<a name=baidusnap0></a>季节</B>变动的序列,计算季节</B>指数对原序列建立趋势方程,得趋势项T 的估计值原始序列Y/TS得CI的数据对CI进行移动平均得到C的估计注:剔除趋势求季节</B>指数,如果没有特别要求就先采用移动平均法求其趋势,然后求季指回总目录回本章目录平稳时间序列概述平稳时间序列定义常见时间序列模型严平稳回总目录回本章目录平稳时间序列所谓平稳时间序列,指如果序列二阶矩有限 , 且满足如下条件:对任意整数为常数;对任意整数自协方差函数仅与时间间隔有关,和起止时刻无关。
即则称序列为宽平稳(或协方差平稳,二阶矩平稳)序列当时,自协方差函数就是方差回总目录回本章目录平稳序列图形上来看就是: (1)序列围绕常数的长期均值波动,称为是均值回复(Meaning Reversion) (2)在每一时刻,方差对均值的偏离基本相同,波动程度大致相等。
回总目录回本章目录最简单的宽平稳序列是白噪声,常记为,它是构成其他序列的基石,一般白噪声的定义如下:对任意对任意对不同的时刻自回归模型(AR:Auto-regressive);滑动平均模型(MA:Moving-Average);自回归滑动平均模型(ARMA:Auto-regressive Moving-Average)。
回总目录回本章目录常见时间序列模型 P阶自回归模型AR(P)模型回总目录回本章目录其中称为自回归系数,为白噪声序列上式称为是p阶自回归模型,简记为AR(p) 当满足一定条件时,序列是平稳的零均值时间序列满足如下形式 q阶滑动平均模型MA(q)模型回总目录回本章目录其中称为滑动平均系数,为白噪声序列上式称为是q阶滑动平均模型,简记为MA(q) 当阶数q有限时,序列是平稳的零均值时间序列满足如下形式自回归滑动平均模型(ARMA)模型回总目录回本章目录其中称为自回归系数,称为滑动平均系数,为白噪声序列上式称为是p阶自回归模型-q阶滑动平均模型,简记为AMMA(p,q). 当p=0, AMMA(p,q)--MA(q) 一般ARMA模型的数学形式为当满足一定条件时,序列是平稳的.从以上定义中可以看出,AR模型和MA模型即为ARMA模型的特例当q=0, AMMA(p,q)--MA(p) 回总目录回本章目录 ARMA模型的识别相关函数定阶法信息准则定阶法严平稳回总目录回本章目录相关函数定阶法采用ARMA模型对现有的数据进行建模,首要的问题是确定模型的阶数,即相应的p,q的值,对于ARMA模型的识别主要是通过序列的自相关函数以及偏自相关函数进行的。
《统计学》完整ppt课件

.
3. 数据的四个等级 定类数据 也称定名数据,这种数据只对事物的某
种属性和类别进行具体的定性描述。
例如,对人口按性别划分为男性和女性 两类。
定类数据
能够进行的唯一运算是计数,即计算每一 个类型的频数或频率(即比重)。
定序数据,也称序列数据,是对事物所具 有的属性顺序进行描述。
.
(二)数据分类的原则
互斥原则:每一个数据只能划归到某一类型中,而 不能既是这一类,又是那一类 。 穷尽原则:所有被观察的数据都可被归属到适当的 类型中,没有一个数据无从归属。
(三)数据的类型
1. 定性数据和定量数据 定性数据:用文字描述的 。 如在本章的“统计引例”中消费者对永美所提供服 务的总体评价等都属于文字描述的定性数据。
.
定量数据:用数字描述的。
如企业的净资产额、净利润额等。 2. 离散型数据和连续型数据
变量 若我们所研究现象的属性和特征的具体表现在 不同时间、不同空间或不同单位之间可取不同 的数值,则可称这种数据为变量。
离散型变量:数据只能取整数。 类型 如一家公司的职工人数。
连续型变量的数据可以取介于两个数 值之间的任意数值。
(一)普查、抽样、统计报表制度和重点调查
1.普查 特点:工作量大,时间性强,需要大量人力和财力。 任务:搜集重要的国情国力和资源状况的全面资
料,为政府制定规划、方针政策提供依据。
方式:建立专门机构,配备专门人员调查。
利用基层单位原始记录和核算资料进行调查。
也称比率数据,是比定距数据更高一级的 定量数据。它不仅可以进行加减运算,而 且还可以作乘除运算。
如产量、产值、固定资产投资额、居民 货币收入和支出、银行存款余额等。
《统计学》全套课件 PPT

第三节 统计学中的基本概念
二、标志与变异、变量 、变量值
1 标志概念与分类 标志:是说明总体单位特征的名称。可分为品质标志(财院每一 个学生性别、民族等)和数量标志(如财院每一个学生月生活 费、考试分数等等)。数量标志的具体表现是标志值
2 不变标志与可变标志概念 不变标志 可变标志
第三节 统计学中的基本概念
第二节 统计的工作过程与研究方法
一、统计工作过程
*统计设计
*统计调查 *统计整理 *统计分析
第二节 统计的工作过程与研究方法
.四个阶段关系 统计设计:是对社会经济现象的定性认识(如有哪些统计指标,哪些表
格),定量认识的准备(统计指标数值,表格内指标数值) 统计调查:搜集资料
基础环节,是个体特征过渡到总体特征的定量认 识过程
变量概念:就是可变的数量标志(成绩) 变量值概念:变量的数值表现(标志值)
变量分类:连续变量(在一定区间内可任意取值的变量,其数值
是连续不断的,相邻两个数值可作无限分割,可取无限个数值, 如110米跨栏成绩、人体测量的身高、体重等等)与离散变量(可 按一定顺序一一列举其数值的变量,其数值表现为断开的,如财 院所属系数、教师人数、教室数等等)确定性和随机性变量.
以各部分数值与总体数值对比得到的比重或比率。它表明总体 内部的构成状况,说明各部分在总体中的地位。其计算公式为: 结构相对指标=总体某一部分数值/总体的全部数值 3.比例相对指标是指同一总体内不同部分指标数对比得到的相对指 标,用以分析总体各部分之间的比例关系,其计算公式为: 比例相对指标=总体中某一部分数值/总体中另一部分数值
二、研究对象
任何现象都有质与量的统一体,统计研究的 是社会经济现象总体的数量方面,即社会经济 现象的规模、水平、结构、速度、比例关系、
贾俊平版统计学课件 第11章

从相关矩阵可以看出,在不良贷款与其他几个变量的关 系中,与贷款余额的相关系数最大,而与固定资产投资额的 相关系数最小。
11.1.3 相关系数的显著性检验
1. r 的抽样分布
回归模型
1、回答“变量之间是什么样的关系?” 2、方程中运用 1 个数值型因变量(响应变量) 被预测的变量 1 个或多个数值型或分类型自变量 (解释变量) 用于预测的变量 3、主要用于预测和估计
11.2.1 一元线性回归模型
1.回归模型(regression model)
y 0 1 x
i 1 i 1 i 1
n
n
n
相关系数的取值范围及意义
1. r 的取值范围为[-1,1]. 2. r 1 ,称完全相关,即存在线性函数关系. r =1,称完全正相关. r =-1,称完全负相关. 3. r =0,称零相关,即不存在线性相关关系.
4. r <0,称负相关.
5. r >0,称正相关. 6. r 愈大,表示相关关系愈密切.
t 0.05 (23) 2.069
2
由于
t 7.5344 t 0.05 (23) 2.069
2
因此,拒绝 H 0,认为 x 和 y 的相关系数 0 ,即不良贷 款与贷款余额之间的线性相关关系显著.
表11-3 各相关系数显著性检验的t 统计量值
11.2 一元线性回归
11.2.1 一元线性回归模型 11.2.1 参数的最小二乘估计
相关系数的性质
性质 1 : r 具有对称性。即 x 与 y 之间的相关系数和 y 与 x 之间 的相关系数相等,即rxy= ryx 性质 2 : r 数值大小与 x 和 y 原点及尺度无关 ,即改变 x 和 y 的 数据原点及计量尺度,并不改变r数值大小 性质3:仅仅是x与y之间线性关系的一个度量,它不能用 于描述非线性关系。这意味着, r=0只表示两个变量之间 不存在线性相关关系,并不说明变量之间没有任何关系 性质 4 : r 虽然是两个变量之间线性关系的一个度量,却不 一定意味着x与y一定有因果关系
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
即该企业下年度利润预测值为17百万元。
第十一章 统计预测
11.3.3季节预测
季节预测法就是通过分析反映现象季节 变动的时间数列,建立季节变动模型,进 而预测其未来发展的规模、水平和状态。
第十一章 统计预测
1、按月(季)平均法
按月(季)平均法就是不考虑长期趋势的影 响,根据最近3年或三年以上各月(季)资料,采用 同期平均法测定各月(季)度的平均值,将各月 (季)平均值与历年总的月(季)平均值相比或 相减 ,求得季节比率或季节变差, 结合已知年度 的预测值来推测预测年的月(季)预测值。
1 MAE n ei
第十一章 统计预测
11.4.2 均方误差
均方误差( MSE)是预测误差平方的平均 数,
MSE
1 n
ei 2
第十一章 统计预测
11.4.3 均方根误差
均方根误差( RMSE)是均方误差的平方根, 其计算公式为:
RMSE ei 2 n
第十一章 统计预测
第五节 EXCEL在统计 预测中的运用
解得:
An B t y
At bt2=ty
B nty t y
nt2 t 2
A y B t
n
n
第十一章 统计预测
将上表中有关数据代入参数公式得: A lg a =1.10415,B lg b =0.0728, 所以,a 11.0053,b 1.1825
则指数曲线趋势方程为:2008年该公司的销 售额的预测值是:yˆ 11.0053 (1.1825 )13(亿元)
11.3.1 趋势预测
趋势预测法是根据某个现象的时间数列 资料,在假定过去的发展趋势及规律性在 今后仍然存在的条件下予以外推,借以预 测出下一时期或以后若干期该现象的规模 水平的预测方法。
第十一章 统计预测
11.3.1 趋势预测
1、直线趋势预测模型 当某现象时间数列的各期观测值大致成等差
形式变动时,现象的发展趋势是直线型的,我们 可以利用直线趋势模型进行外推预测。
此外,还可按预测的数值形态分为点预测和区 间预测,按预测对象的时态分为静态预测和动态 预测等。
第十一章 统计预测
• 11.1.3 统计预测的原则和步骤
• 1、统计预测的原则:连贯性原则,类推性原则。 • 2、统计预测的步骤:
(1)确定预测目的 (2)收集整理资料。 (3)选择预测方法。 (4)评价预测结果。 (5)提出预测报告。
EXCEL 在统计预测中有着广泛运用,在这里 仅通过EXCEL在指数平滑预测中的运用,介绍其 一般操作方法。
第十一章 统计预测
用EXCEL进行预测,具体操作步骤如下: 第一步,选择“工具”菜单中的“数据分析”命令,此时弹出数据 分析对话框。在“分析工具”列表框中,选择“移动平均”工具 。
第二步,在输入框中指定输入参数。在输入区域框中指定统计 数据所在区域;因指定的输入区域包含标志行,所以选中标志位于第一 行复选框;在“间隔”框内键入移动平均项数。
707.7×0.2=781(万元)
第十一章 统计预测
11.2.3 专家预测法
• 1、个人判断法 个人判断法是预测者根据所掌握的资料,凭借自己的
知识与经验,对预测目标作出符合客观实际的估计与判断。 • 2、集体判断法
集体判断法是在个人判断法的基础上,通过一次或多 次会议进行集体分析判断,将专家个人的见解综合起来, 寻求较为一致的结论的预测方法。 • 3、德尔菲法
德尔菲法是由各专家在互相保密的情况下,用书面形 式独立地回答预测者提出的问题,经过多次的反馈、修改, 逐步使各专家的意见趋向一致,最后由预测者综合确定预 测结论的一种预测方法。
第十一章 统计预测
第三节 定量预测法
• 11.3.1 • 11.3.2 • 11.3.3
趋势预测 回归预测 季节预测
第十一章 统计预测
年 份 1998 1999 2000
年次(t)
1
2
3
工业增加值 52
57
60
(亿元)
2001 4 68
2002 5 80
2003 6 84
2004 7 91
2005 8
106
2006 9
118
第十一章 统计预测
解:在本例中,我们用三点法估计参数建立预测模型。 三点法是根据预测对象时间数列资料求出三个具有代表性 的点,用来估计抛物线预测模型中的参数。
相同时,其发展趋势为指数曲线型,可配合指数 曲线趋势方程进行预测。指数曲线预测模型为:
yˆ abt
式中,yˆ 为预测值, t 为时间变量, a 、 b 为参数。
第十一章 统计预测
例 某公司1996-2006年商品销售额如表,试建立 指数曲线趋势模型,并预测第2008年的销售额。
解:根据最小平方法的原理有:
当数列总项数9≦<15时,假设R,S,T分别表示时间 数列初期、中期和近期各取3项数据的加权平均数,权数由 远及近依次取1、2、3,则:
R
1 6
( y1
2y2
3y3 )
1 6
(52
2
57
3
60)
57.67
1
1
S 6 ( yd1 2 yd 3yd1) 6 (68 2 80 3 84) 80
第十一章 统计预测
下面举例说明长期趋势剔法预测。 例 某商业企业某种商品销售资料如下表所示(见表2、3、4
行),试用长期趋势剔除法预测第四年各月的销售量。
表 某商业企业商品销售季节变动分析(单位:千件)
第十一章 统计预测
长期趋势剔除法季节预测计算表
第十一章 统计预测
长期趋势剔除法季节预测计算表
T
1 6 ( yn2
2 yn1
3yn )
1 (91 6
2 106 3118)
109.5
第十一章 统计预测
a R 7 b 6c 57.67 7 4.3898 6 0.3983 45.0373
3
3
b T R 3n 5 c 109.5 57.67 3 9 5 0.3983 4.3898
第十一章 统计预测ቤተ መጻሕፍቲ ባይዱ
第十一章 统计预测
用综合意见法,可作如下预测: 经理人员预测值=760×0.5+840×0.3+
960×0.2=824(万元) 管理部门预测值=720×0.3+755×0.4+
792×0.3=773.6(万元) 销售人员预测值=675×0.3+708×0.3+
737×0.4=707.7(万元) 下年度销售额预测值=824×0.4+773.6×0.4+
润 yˆ (单位:百万元)存在线性相关关系,其回归方程
为 量
yˆ 6.763 1.231
x1=14、x 2
x1 0.0688 x2 ,并知下年度两种产品计划产 =15,试据此资料预测下年度的利润额。
解:将 x1 =14 、x2 =15代入回归方程得:
yˆ 6.7631.2318 0.06888 17 (百万元)
• 第十一章 统计预测
• 学习目标
•
知识目标:
•
了解统计预测的基本原理和种类,掌握统计
预测的基本概念、步骤和方法。
•
能力目标:
•
能够针对微观现象的特点,选择适当的统计
预测方法,正确的进行预测分析
第十一章 统计预测
• 第一节 统计预测概述 • 第二节 定性预测法 • 第三节 定量预测法 • 第四节 预测误差分析 • 第五节 EXCEL在统计预测中的运用
第十一章 统计预测
11.3.2 回归预测
1、回归预测的条件和步骤 回归预测法是在分析研究变量之间的
相关关系的基础上,建立回归模型 ,然后 根据自变量的已知数值来推测因变量数值 的一种预测方法。按自变量的不同,回归 预测模型可分为一元回归、多元回归和自 回归三种。
第十一章 统计预测
2、一元线性回归预测 当某种现象(因变量)发展只受一个主
要因素(自变量)影响,并表现为显著线 性相关时,则可建立一元线性回归模型进 行预测。一元线性回归模型的建立,以及 利用一元线性回归模型进行预测,在第十 章已作介绍,这里不在赘述。
第十一章 统计预测
3、多元线性回归预测
当某种现象的发展受两个或两个以上的 主要
因素影响,且表现为显著线性相时,应当建立多 元线性回归模型进行预测。
n3 3
93
3
c 2R T 2S 257.67 109.5 2 80 0.3983
n 32
(9 3)2
则该二次抛物线为: yˆ 45.0373 4.3898 t 0.3983 t2
该地区2007与2008年的工业生产总值的预测值为:
yˆ2007 45.0373 4.3898 10 0.3983 10 2 128 .77(亿元) yˆ2008 45.0373 4.3898 11 0.3983 112 141 .52(亿元)
第十一章 统计预测
2、长期趋势剔除法
长期趋势剔除法就是先测定并剔除现象的季
节变动,用其结果数据建立趋势方程预测出现象 各期趋势值后,再考虑季节变动因素,推算各期 预测值。这种方法的数学模型是:
Tˆ b0 b1t
yt (b0 b1t)St*
为趋势式方中程:T参ˆ, y数t ,依S次t* 为为t预期测的期趋的势季值节和指预数测。值;b0 ,b1
第三步,在输出选项框内指定输出选项。可以选择输出到当前 工作表的某个单元格区域、新工作表或是新工作簿。
多元线性回归预测模型为:
yˆ b0 b1x1 b2 x2 bn xn
式中 x1, x2 , , xn 是各期的自变量,共有n个,
为常b量0 因素,
估计的参数。
b1,b2为,各,b自n 变量的系数,即要
下面以二元线性回归预测为例讲述。