第六章 最速下降法和牛顿法
牛顿法和最速下降法求解非线性方程

这是我们的题目要求非线性方程的寻优求解课题内容:求解非线性方程2()sin04xf x x=-=,分别利用最速下降法和牛顿法求解该非线性方程的非零实根的近似值。
课题要求:1、设计良好的人机交互GUI界面。
2、程序要求有注释。
3、给定误差精度,对比算法结果。
因为目标函数有两个解,一个在0附近,一个在2附近。
所以这两种方法使用时都要从0附近取一个初值计算一次得出一个解,再从2附近取一个初值计算一次得出另一个解。
两种算法都是求得解之后通过while比较误差精度,直到达到所设置的误差精度后才输出解,但这个过程中计算出来的所有解包括最终结果都会画在gui界面上,让计算过程变得直观。
两种方法除了核心计算公式不同外,其他程序基本相似,如果大家要借鉴使用,除了改动目标函数之外,还要确定合适的初值,初值的确定大家可以把目标函数解的附近取值,牛顿法解的收敛条件大家可以在网上找一下,因为如果初值给的不收敛,那么计算会出问题。
程序代码(1). 牛顿法程序clearcla %清除显示屏i=1; %迭代次数x(i)=0.3; %给定0附近的一个初值 %方程不同初值要改x(i+1)=0.2; %方程不同初值要改while abs(x(i)-x(i+1))>1*10^(-6) %比较误差精度plot(x(i+1),f(x(i+1)),'*')hold on%保持图形i=i+1;x(i+1)=x(i)-(f(x(i))/f1(x(i))); %牛顿迭代法计算公式enda1=x(end) %输出0附近的解j=1; %从2附近取一个初值y(j)=0.2; %方程不同初值要改y(j+1)=1.6; %方程不同初值要改while abs(y(j)-y(j+1))>1*10^(-6)plot(y(j+1),f(y(j+1)),'+')hold onj=j+1;y(j+1)=y(j)-(f(y(j))/f1(y(j)));enda2=y(end) %输出2附近的解x0=inline('f(x)');x1=fzero(x0,[-1,1])x2=fzero(x0,[1,2])nwc1=x1-a1 %对比系统函数fzero算法结果,计算求出解的误差nwc2=x2-a2(2)最速下降法clearclastep=0.01; %步长x=0.5; %初值为0附近 %方程不同初值要改i=0;loss=f(x);while abs(loss)>0.01 %比较误差精度plot(x,f(x),'*') %做出图形hold on%保持图形x=x-step*f1(x); %最速下降法计算公式loss =f(x) ;i=i+1;endxy=1.5; %初值为2附近时 %方程不同初值要改los=f(y);j=0;while abs(los)>0.01plot(y,f(y),'+')hold ony=y-step*f1(y);los =f(y) ;j=j+1;endyx0=inline('f(x)');x1=fzero(x0,[-1,1])x2=fzero(x0,[1,2])dwc1=x1-x %对比算法结果dwc2=x2-y(3)函数程序function a=f(x)a=sin(x)-(x.^2)/4;(4)导函数程序function b=f1(x)b=cos(x)-x/2;下面是做出的GUI界面效果图程序界面牛顿法图形最速下降法图形。
最速下降法和牛顿法求最小值点的算法及结果

1.最速下降法计算:f=(x1-1)2+5(x2-5)2(1)程序代码如下:#include<stdio.h>#include<math.h>double f1(double x,double y){double r;r=(pow(x-1,2)+5*pow((y-5),2));return r;}//最速下降法求最优解void main(){double h=3,x0=3,x1,y0=6,y1,s,r0,r1;double e0=0.000001,e1=0.000001;int k=0;s=sqrt(pow(2*x0-2,2)+pow(10*y0-50,2));printf("%d x1=%f x2=%f s=%f\n",k,x0,y0,s);while(s>e1){x1=x0;y1=y0;r0=f1(x0,y0);h=3;//一维搜索,成功失败法while(fabs(h)>e0){r1=f1((x1-h*2*(x1-1)),(y1-h*10*(y1-5)));if(r1<r0){x0=x1-h*2*(x1-1);y0=y1-h*10*(y1-5);r0=r1;h=h+h;}else if(fabs(h)>e0)h=(-1)*h/4;}s=sqrt(pow(2*x0-2,2)+pow(10*y0-50,2));k++;printf("%d x1=%f x2=%f s=%f\n",k,x0,y0,s);}printf("x1=%f x2=%f",x0,y0);}(2)初始值设为x1=3,x2=6时,运行结果如下图1-1:图1-1(3)初始值设为x1=30000,x2=60000时,运行结果如下图1-2:图1-22.牛顿法计算:f=(x1-1)2+5(x2-5)2(1)程序代码如下:#include<stdio.h>#include<math.h>double f1(double x,double y){return (pow(x-1,2)+5*pow(y-5,2)); }//牛顿法求最优解void main(){double h=3,x0=3,x1,y0=6,y1,s,r0,r1;double e0=0.000001,e1=0.000001;int k=0;s=sqrt(pow(2*x0-2,2)+pow(10*y0-50,2));printf("%d x=%f y=%f s=%f\n",k,x0,y0,s);while(s>e1){x1=x0;y1=y0;r0=f1(x0,y0);h=3;//一维搜索while(fabs(h)>e0){r1=f1((x1-h*(x1-1)),(y1-h*(y1-5)));if(r1<r0){x0=x1-h*(x1-1);y0=y1-h*(y1-5);r0=r1;h=h+h;}else if(fabs(h)>e0)h=(-1)*h/4;}s=sqrt(pow(2*x0-2,2)+pow(10*y0-50,2));k++;printf("%d x=%f y=%f s=%f\n",k,x0,y0,s);}printf("x=%f y=%f",x0,y0);}(2)初始值设为x1=3,x2=6时,运行结果如下图2-1:图2-1(3)初始值设为x1=30000,x2=60000时,运行结果如下图2-2:图2-23.最速下降法求:f=(x1-1)2+(x2-1)2+5(x3-5)2+5(x4-5)2(1)程序代码如下:#include<stdio.h>#include<math.h>double f1(double x,double x1,double y,double y1){double r;r=(pow(x-1,2)+pow(x1-1,2)+5*pow(y-5,2)+5*pow(y1-5,2));return r;}//最速下降法求最优解void main(){//x1,x2,x3,x4分别为多项式函数中四个分量的初始值//x5,x6,x7,x8分别为对应的下一个值double d=3,x1=3,x5,x2=4,x6,x3=8,x7,x4=6,x8,s,r0,r1;double e0=0.000001,e1=0.000001;int k=0;s=sqrt(pow(2*x1-2,2)+pow(2*x2-2,2)+pow(10*x3-50,2)+pow(10*x4-50,2));printf("%d x1=%f x2=%f x3=%f x4=%f s=%f\n",k,x1,x2,x3,x4,s);while(s>e1){x5=x1;x6=x2;x7=x3;x8=x4;r0=f1(x1,x2,x3,x4);d=3;//一维搜索while(fabs(d)>e0){r1=f1((x5-d*2*(x5-1)),(x6-d*2*(x6-1)),(x7-d*10*(x7-5)),(x8-d*10*(x8-5)));if(r1<r0){x1=x5-d*2*(x5-1);x2=x6-d*2*(x6-1);x3=x7-d*10*(x7-5);x4=x8-d*10*(x8-5);r0=r1;d=d+d;}else if(fabs(d)>e0)d=(-1)*d/4;}s=sqrt(pow(2*x1-2,2)+pow(2*x2-2,2)+pow(10*x3-50,2)+pow(10*x4-50,2));k++;printf("%d x1=%f x2=%f x3=%f x4=%f s=%f\n",k,x1,x2,x3,x4,s);}printf("\nx1=%f x2=%f x3=%f x4=%f s=%f\n",x1,x2,x3,x4,s);}(2)初始值设为x1=3,x2=4,x3=8,x4=6时,运行结果如下图3-1:图3-1(3)初始值设为x1=30000,x2=40000,x3=80000,x4=60000时,运行结果如下图3-2:图3-24.牛顿法计算:f=(x1-1)2+(x2-1)2+5(x3-5)2+5(x4-5)2(1)程序代码如下:#include<stdio.h>#include<math.h>double f1(double x,double x1,double y,double y1){double r;r=(pow(x-1,2)+pow(x1-1,2)+5*pow(y-5,2)+5*pow(y1-5,2));return r;}//最速下降法求最优解void main(){//x1,x2,x3,x4分别为多项式函数中四个分量的当前值//x5,x6,x7,x8分别为多项式函数中四个分量对应的下一个值double d=3,x1=3,x5,x2=4,x6,x3=8,x7,x4=6,x8,s,r0,r1;double e0=0.000001,e1=0.000001;int k=0;s=sqrt(pow(2*x1-2,2)+pow(2*x2-2,2)+pow(10*x3-50,2)+pow(10*x4-50,2));printf("%d x1=%f x2=%f x3=%f x4=%f s=%f\n",k,x1,x2,x3,x4,s);while(s>e1){x5=x1;x6=x2;x7=x3;x8=x4;r0=f1(x1,x2,x3,x4);d=3;//一维搜索while(fabs(d)>e0){r1=f1((x5-d*(x5-1)),(x6-d*(x6-1)),(x7-d*(x7-5)),(x8-d*(x8-5)));if(r1<r0){x1=x5-d*(x5-1);x2=x6-d*(x6-1);x3=x7-d*(x7-5);x4=x8-d*(x8-5);r0=r1;d=d+d;}else if(fabs(d)>e0)d=(-1)*d/4;}s=sqrt(pow(2*x1-2,2)+pow(2*x2-2,2)+pow(10*x3-50,2)+pow(10*x4-50,2));k++;printf("%d x1=%f x2=%f x3=%f x4=%f s=%f\n",k,x1,x2,x3,x4,s);}printf("\nx1=%f x2=%f x3=%f x4=%f s=%f\n",x1,x2,x3,x4,s);}(2)初始值设为x1=3,x2=4,x3=8,x4=6时,运行结果如下图4-1:图4-1(3)初始值设为x1=30000,x2=40000,x3=80000,x4=60000时,运行结果如下图4-2:图4-25.总结(1)每一种计算最优解的方法中,如果初始值不一样,那么得到最终结果所需的步骤数不一样;比较图1-1与图1-2,在图1-1中初始值为x1=3,x2=6,得到最终结果所需步骤数为23,而在图1-2中初始值为x1=30000,x2=60000,得到最终结果所需步骤数为39;同一算法中取值越偏离最优解,所需的计算步骤越多。
非线性方程组的牛顿迭代法-最速下降法
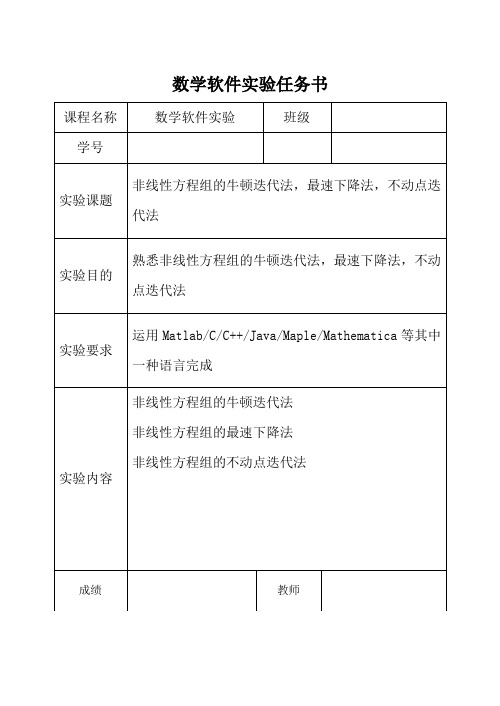
数学软件实验任务书实验一 非线性方程组的牛顿迭代法 1 实验原理对于非线性方程11221212(,,,)(,,,)(,,,)n n n n f x x x f x x x f f x x x ⎛⎫ ⎪ ⎪= ⎪ ⎪⎝⎭ 在x (k )处按照多元函数的泰勒展开,并取线性项得到 ()()()()(1)()1111()()()()(1)()()122()()()()(1)()1(,,,)(,,,)()0(,,,)k k k k k k n n k k k k k k k n n n k k k k k k n n n nn f x x x x x f x x x x x f x f x x x x x +++⎛⎫⎛⎫- ⎪ ⎪- ⎪ ⎪'+= ⎪ ⎪ ⎪ ⎪ ⎪ ⎪-⎝⎭⎝⎭ 其中1111()n n n n f f x x f x f f x x ∂∂⎛⎫ ⎪∂∂ ⎪' ⎪= ⎪∂∂ ⎪ ⎪∂∂⎝⎭(1)()()()()()1111(1)()()()()()()1221(1)()()()()()1(,,,)(,,,)[()](,,,)k k k k k k n n k k k k k k k n n n k k k k k k n n n n n x x f x x x x x f x x x f x x x f x x x ++-+⎛⎫⎛⎫⎛⎫ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪'=- ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭⎝⎭ 2 数据来源计算非线性方程组22220.50440x x y x y ⎧--+=⎨+-=⎩ 初值取11x y ⎡⎤⎡⎤=⎢⎥⎢⎥⎣⎦⎣⎦3 实验步骤步骤一:编写牛顿迭代法的基本程序。
打开Editor 编辑器,输入以下语句:function [x,n,data]=new_ton(x0,tol)if nargin==1tol=1e-10;endx1=x0-f1(x0)/df1(x0);MATLAB 241 数值分析与应用n=1;%迭代过程while (norm(x1-x0)>tol)x0=x1;x1=x0-f1(x0)/df1(x0);n=n+1;%data 用来存放中间数据data(:,n)=x1;endx=x1;以文件名new_ton.m保存。
机器学习算法系列最速下降法牛顿法拟牛顿法

机器学习算法系列最速下降法牛顿法拟牛顿法最速下降法(Gradient Descent)最速下降法是一种常用的优化算法,用于求解无约束的最小化问题。
其原理是通过不断迭代更新参数的方式来逼近最优解。
在最速下降法中,每次迭代的方向是当前位置的负梯度方向,即沿着目标函数下降最快的方向前进。
具体地,对于目标函数f(x),在当前位置x_k处的梯度为g_k=▽f(x_k),则下一次迭代的位置x_{k+1}可以通过以下公式计算:x_{k+1}=x_k-α*g_k其中,α 是一个称为学习率(learning rate)的参数,用于控制每次迭代的步长。
最速下降法的优点是简单易实现,收敛速度较快。
然而,它也有一些缺点。
首先,最速下降法的收敛速度依赖于学习率的选择,过小的学习率会导致收敛速度过慢,而过大的学习率可能会导致跳过最优解。
其次,最速下降法通常会在目标函数呈现弯曲或者高度相关的情况下表现不佳,很难快速收敛到最优解。
牛顿法(Newton's Method)牛顿法是一种通过二阶导数信息来优化的算法,可以更快地收敛到目标函数的最优解。
在牛顿法中,每次迭代的位置x_{k+1}可以通过以下公式计算:x_{k+1}=x_k-(H_k)^{-1}*▽f(x_k)其中,H_k是目标函数f(x)在当前位置x_k处的黑塞矩阵。
黑塞矩阵描述了目标函数的二阶导数信息,可以帮助更准确地估计参数的更新方向。
牛顿法的优点是收敛速度较快,特别是对于目标函数呈现弯曲或者高度相关的情况下,相较于最速下降法可以更快地达到最优解。
然而,牛顿法也有一些缺点。
首先,计算黑塞矩阵的代价较高,尤其是当参数较多时。
其次,黑塞矩阵可能不可逆或者计算代价较大,这时可以通过使用拟牛顿法来避免。
拟牛顿法(Quasi-Newton Method)拟牛顿法是一类基于牛顿法的优化算法,通过估计黑塞矩阵的逆来逼近最优解,从而避免了计算黑塞矩阵的代价较高的问题。
在拟牛顿法中,每次迭代的位置x_{k+1}可以通过以下公式计算:x_{k+1}=x_k-B_k*▽f(x_k)其中,B_k是一个对黑塞矩阵逆的估计。
最速下降法

0 为一维搜索最佳步长,应满足极值必要条件
0Байду номын сангаас0 f x1 min f x f x
min 2 4 25 2 100 min
2 2
0 8 2 4 5000 2 100 0
解 取初始值
x 0 2, 2
T
则初始点处函数值及梯度分别为
f x0 104 2 x1 4 f x0 50 x2 x0 100 沿负梯度方向进行一维搜索,有
x1 x 0 0f x 0 2 4 2 4 0 2 0 100 2 100 0
从直观上看在远离极小点的地方每次迭代可能使目标函数有较大的下降但是在接近极小点的地方由于锯齿现象从而导致每次迭代行进距离缩短因而收敛速度不快
最速下降法
1 无约束多变量问题最优化
考虑无约束问题
min
f (X) X E n
其中函数f (X)具有一阶连续偏导数。 在处理这类问题时,总希望从某一点出发,选择一个目
其中 d ( k ) 是从 x ( k ) 出发的搜索方向,这里取在点x ( k ) 处的最速 下降方向,即
d ( k ) f ( x ( k ) )
k 是从 x ( k )出发沿方向 d ( k )进行一维搜索的步长,即 k 满足
f ( x ( k ) k d ( k ) ) min f ( x ( k ) d ( k ) )
x 0
*
f
* x 0
0
T
根据一元函数极值的必要条件
和复合函数求导公式可得:
最速下降法和牛顿法

f ( x ) ≈ P( x ) = f x
由 P′( x ) = 0 ,即
( )
(k )
+ f ′ x (k ) x − x (k ) +
( )(
)
f ′′ x (k ) x − x (k ) 2
( )(
)
2
f ′ x (k ) +
( )
f ′′ x (k ) × 2 × x − x (k ) = 0 , 2
T
3
[ 0, 2] itrcount= H= 4 0 g= -4 -2 t= x= 5/18 1 0 2
10/9 5/9 看看前后梯度是否正交,g0'*g1=-8.881784e-016 itrcount= 2 H= 4 0 0 2 g= 4/9 -8/9 t= 5/12 x= 25/27 25/27 看看前后梯度是否正交,g0'*g1=1.387779e-016 itrcount= 3 H= 4 0 0 2 g= -8/27 -4/27 t= 5/18 x= 245/243 235/243 看看前后梯度是否正交,g0'*g1=7.979728e-017
T
0 2
1 1 看看前后梯度是否正交,g0'*g1=0.000000e+000
例子 2: 试用最速下降法求下列函数的极小点,已知 ε = 0.1 :
f ( x ) = 2( x1 − 1) + ( x2 − 1)
2
2
初始解: x = (0,0) 程序运行结果: gfun = [ 4*x1-4] [ 2*x2-2] Hfun = [ 4, 0]
P k = −∇f X k
( )
( )
在射线 X 上做直线搜索,以确定搜索步长 tk 。 满足条件:
最速下降法和牛顿法

最速下降法和牛顿法【引言】在数学和计算机领域中,最速下降法和牛顿法都是经典的优化算法。
它们在不同的问题中有着不同的应用,但它们都是以误差最小化为目标,寻找最优解的算法。
本文将对这两个算法进行详细介绍,以帮助读者更好地理解它们的应用和优缺点。
【正文一:最速下降法】最速下降法,又称为梯度下降法,是一种基于梯度的优化算法。
在寻找某个函数的最小值时,最速下降法的思路是从任何一个点出发,按照函数梯度的反方向移动,直到到达最小值处为止。
因此,最速下降法的关键就是确定每一步移动的方向和步长。
最速下降法的优点是简单易懂,可以用于解决大多数的优化问题。
在逃避局部最优解的情况下,其效果非常好。
然而,最速下降法也有缺点。
由于只是按照梯度的反方向移动,可能会产生震荡现象,从而导致计算速度缓慢等问题。
【正文二:牛顿法】与最速下降法不同,牛顿法是一种利用二阶导数信息,在每个迭代步骤中更新预测的最优解的优化算法。
它可以更快地收敛于函数的极小值点。
在求解非线性方程组、多项式拟合和机器学习等问题时,牛顿法是一种有效的优化算法。
与最速下降法相比,牛顿法的优点是其快速收敛和高效性。
但是,缺点是它需要耗费更多的时间和计算能力来求解每一步迭代。
在某些情况下,由于Hessian矩阵可能不可逆或昂贵,因此此算法的实现可能具有挑战性。
【正文三:最速下降法 VS 牛顿法】最速下降法和牛顿法各有优缺点,它们在不同的问题中应用广泛。
在求解凸优化问题时,最速下降法的效果比较好,在处理大量数据时,牛顿法更加高效。
在实际应用中,可以根据具体问题的不同,选择合适的优化算法。
【结尾】综上所述,最速下降法和牛顿法是经典的优化算法,它们在各自的领域都有着广泛的应用。
两种算法都有其优点和缺点,要选择哪一种算法取决于具体问题和可行性的考虑。
本文的介绍,希望能够帮助读者更好地理解这两种算法,并在实际问题中正确应用它们。
广义牛顿法

特点:恒定步长为1。 为解决收敛性的问题,采用广义牛顿法(采用一维搜索 来确定步长因子)。
广义牛顿法
牛顿法在充分接近极小点时,是二阶收敛
的.如果初始点远离极小点时,就不能保持 收敛性.改进. 引进一维搜索.
求单变量极值问题 min f ( x k z k ) f ( x k k z k );
1 1 2 1 1 1 2 令z [ f ( x )] f ( x ) 0 x z 2 2
1 1
0 4 2 1 100 2 50
2 2 ,
T
求• min f ( x1 z 1 ) f ( x1 1 z 1 ),得1 1,
0
其中方向z k同上
步骤: 1、取初始点x1 E n , 允许误差 0, k : 1; 2、检验是否满足收敛性判别准则: f ( x k ) .是, 终止, 否,转3。 3、令z [ f ( x )] f ( x );
k 2 k k 1
4、求单变量极值问题 min f ( x k z k ) f ( x k k z k );
k i
不失一般性,设点列x ki 1 收敛到y 2 , 又因为f ( x k )单调下降有下界且连续,所以收敛,
再证f x ( y1 )=0。用反证法。 若f x ( y1 ) 0,则 f x ( y1 ) 0.对于充分小的,
f ( y1-[ f xx ( y1 )]1 f x ( y1 )T ) =f ( y )-f x ( y )[ f xx ( y )]
1 1 2 1 1 1 2 令z [ f ( x )] f ( x ) 0 x z 2 2
最优化算法(牛顿、拟牛顿、梯度下降)
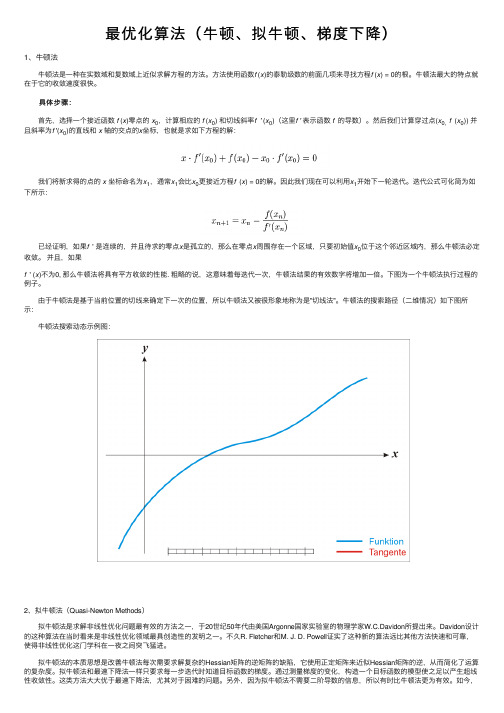
最优化算法(⽜顿、拟⽜顿、梯度下降)1、⽜顿法 ⽜顿法是⼀种在实数域和复数域上近似求解⽅程的⽅法。
⽅法使⽤函数f (x)的泰勒级数的前⾯⼏项来寻找⽅程f (x) = 0的根。
⽜顿法最⼤的特点就在于它的收敛速度很快。
具体步骤: ⾸先,选择⼀个接近函数f (x)零点的x0,计算相应的f (x0) 和切线斜率f ' (x0)(这⾥f ' 表⽰函数f 的导数)。
然后我们计算穿过点(x0, f (x0)) 并且斜率为f '(x0)的直线和x 轴的交点的x坐标,也就是求如下⽅程的解: 我们将新求得的点的x 坐标命名为x1,通常x1会⽐x0更接近⽅程f (x) = 0的解。
因此我们现在可以利⽤x1开始下⼀轮迭代。
迭代公式可化简为如下所⽰: 已经证明,如果f ' 是连续的,并且待求的零点x是孤⽴的,那么在零点x周围存在⼀个区域,只要初始值x0位于这个邻近区域内,那么⽜顿法必定收敛。
并且,如果f ' (x)不为0, 那么⽜顿法将具有平⽅收敛的性能. 粗略的说,这意味着每迭代⼀次,⽜顿法结果的有效数字将增加⼀倍。
下图为⼀个⽜顿法执⾏过程的例⼦。
由于⽜顿法是基于当前位置的切线来确定下⼀次的位置,所以⽜顿法⼜被很形象地称为是"切线法"。
⽜顿法的搜索路径(⼆维情况)如下图所⽰: ⽜顿法搜索动态⽰例图:2、拟⽜顿法(Quasi-Newton Methods) 拟⽜顿法是求解⾮线性优化问题最有效的⽅法之⼀,于20世纪50年代由美国Argonne国家实验室的物理学家W.C.Davidon所提出来。
Davidon设计的这种算法在当时看来是⾮线性优化领域最具创造性的发明之⼀。
不久R. Fletcher和M. J. D. Powell证实了这种新的算法远⽐其他⽅法快速和可靠,使得⾮线性优化这门学科在⼀夜之间突飞猛进。
拟⽜顿法的本质思想是改善⽜顿法每次需要求解复杂的Hessian矩阵的逆矩阵的缺陷,它使⽤正定矩阵来近似Hessian矩阵的逆,从⽽简化了运算的复杂度。
最速下降法

随着人工智能、模糊控制、模式识别、人工网络等新技术的应用和发展。
可以让它们与广义预测控制相结合,建立高精度、多模态的预测模型。
使广义预测控制在异常情况下可以稳定运行,推进广义预测控制的进一步发展。
2.2.1最速下降法最速下降法是无约束最优化中是比较有效的方法,它是以d}=一可(x})作为下降方向的算法。
其迭代格式为xx+i=xx一。
*Of (xk)上式中,一般通过精确线搜索准则求得步长因子。
*,当然也不排除可以利用非精确线搜索准则来求得步长因子。
*。
不管最速下降法采取何种线搜索准则,它均具有全局收敛性,但是这也不能直接就认为最速下降算法就是一个良好的优化算法。
在实际试验中,有很多优化问题利用最速下降法并不是下降的特快,反而下将的十分缓慢。
这是因为出现了锯齿现象:就是在计算过程中,最速下降法开始几步还是挺快的,但是当目标函数f (x)的等高线接近于一个球的时候,就出现了类似锯齿现象,前进十分缓慢,降低了算法的效能。
2.2.12.2.2牛顿法牛顿法也是无约束最优化问题中的一种经典算法,它是利用目标函数.f (x)的二次泰勒展开式,并将二次泰勒展开式进行极小化。
其迭代格式为x}+}=xA十d}(2-5)其中步长因子。
、=l} d、为02f (x} )d + Of (xA ) = 0的解。
当目标函数f(x)是正定二次函数的时候,牛顿法可以一步达到最优解;当目标函数f (x)是非二次函数的时候,牛顿法经过有限次迭代之后就不能确保求得目标函数f (x)的最优解。
我们知道目标函数f (x)在极小点附近是很接近于二次函数的,所以,假如初始点非常靠近无约束最优化问题((1-1)的最优解x的时候,并且}Z.f (x.)正定的时候,那么牛顿法就会有很快的收敛速度,而由此算法产生的点列也具有了超线性收敛速度,同时还在一定条件下具有二次收敛性;假如初始点与无约束最优化问题(1-1)的最优解x’相距比较远的时候,这时的}Z.}(x})就不一定是正定的了,也就存在了一个问题,那就是此时的牛顿方向就不一定是下降方向,有可能是上升方向,此时由此算法产生的点列可能也就不收敛于无约束最优化问题((1-1)的最优解了。
本章要点最速下降法的基本思想及特点牛顿方向Newton法

例4.1 用最速下降法求函数 f (x1, x2)=x12+4x22 的极小点,(迭代两次), 并验证相邻两个搜索方向是正交的。初始点取为x(0)=[1,1]T 。
x1
因而由上述定理知: x1
0 0 || x1 || 0
x1
即只需迭代一步就到了极小点,这表明最速下降法用于等值线为圆的目标 函数时,从任意初始点出发,只需迭代一步就到了极小点。
(2)当 1 2 时, 等值线为椭圆。此时对于一般的初始点将产生锯齿现象。
(3)当 1 2
d kT g k d k g k
当且仅当dk=-gk时, (dk)Tgk 最小,从而-gk是最速下降方向。
最速下降法的迭代格式为:
x( k 1) x( k ) tk f ( x( k ) )
(二)算法
开始
给定x(0) , M , 1 , 2 , 令 k=0 计算f( x(k ) ) ||f( x(k ) )|| < 1 否 k>M 是 是
而采用固定步长λ的方法,称为固定步长最速下降法。只要λ充分小,总有:
f x k f xk 1 f xk f x k
f xk
但λ到底取多大,没有统一的标准, λ取小了,收敛太慢,而λ取大了, 又会漏掉极小点。——不精确线搜索解决这个问题
x1 x0 0f x0 1.919877 0.3071785 10
f ( x1 ) 3.686164.
2
T
然后再从 x1开始新的迭代,经过10次迭代,得最优解 x* (0, 0)T 计算中可 以发现,开始几次迭代,步长比较大,函数值下将降较快但当接进最优点 时,步长很小,目标函数值下降很慢。如果不取初点为 x0 (2, 2)T 而取 x0 (100,0)T 虽然后一初点较前一初点离最优点 x* (0, 0)T 远,但迭代中 不会出现上面的锯齿现象。这时:
机器学习算法系列(25):最速下降法、牛顿法、拟牛顿法

作为指导。
3.2 DFP算法
DFP算法是以William C.Davidon、Roger Fletcher、Michael J.D.Powell三个人人的名字的首首字⺟母命 名的,它由Davidon于1959年年首首先提出,是最早的拟牛牛顿法。该算法的核心心是:通过迭代的方方
,求λ k,使 f(x ( k ) + λ kp k) = minλ ≥ 0 f(x ( k ) + λp k) 4. 置x ( k + 1 ) = x ( k ) + λ kp k,计算f(x ( k + 1 ) )当 | | f(x ( k + 1 ) ) − f(x ( k ) ) | | < ξ或 | | x ( k = 1 ) − x ( k ) | | < ξ,停止止迭代,令x ∗ = x ( k + 1 ) 5. 否则,置k = k + 1,转到步骤3。 当目目标函数是凸函数时,梯度下降法的解释全局最优解。一一般情况下,其解不不保证是全局最优 解。梯度下降法的收敛速度也未必是很快的。
3.1 拟牛牛顿条件
设经过k + 1次迭代后得到X k + 1,此时将目目标函数f(X)在X k + 1附近作泰勒勒展开,取二二阶近似,得到 1 f( X) ≈ f( X k + 1 ) + ∇ f( X k + 1 ) · ( X − X k + 1 ) + · ( X − X k + 1 ) T · ∇ 2 f( X k + 1 ) · ( X − X k + 1 ) 2 在两边同时作用用一一个梯度算子子 ∇ ,可得 ∇ f( X) ≈ ∇ f ( X k + 1 ) + H k + 1 · ( X − X k + 1 ) 取X = X k并整理理,可得 g k + 1 − g k ≈ H k + 1 · (X k + 1 − X k ) 若引入入记号s k = X k + 1 , y k = g k + 1 − g k则可以改写成
最速下降法与牛顿法结合求无约束最优值(mtlab动画演示)

最速下降法与牛顿法结合求无约束最优值(mtlab动画演示)2009-04-05 9:54最速下降法能找出全局最优点,但在接近最优点的区域内就会陷入“齿型”迭代中,使其每进行一步迭代都要花掉非常久的时间,这样长久的等待是无法忍受的,不信你就在我那个程序的第一步迭代中把精度取得很小如:0.000000001等,其实我等过一个钟都没有什么结果出来。
再者我们考究一下牛顿迭代法求最优问题,牛顿法相对最速下降法的速度就快得多了,而且还有一个好处就是能高度逼近最优值,而不会出现死等待的现象。
如后面的精度,你可以取如:0.0000000000001等。
但是牛顿法也有缺点,就是要求的初始值非常严格,如果取不好,逼近的最优解将不收敛,甚至不是最优解。
就算收敛也不能保证那个结就是全局最优解,所以我们的出发点应该是:为牛顿法找到一个好的初始点,而且这个初始点应该是在全局最优点附近,这个初始点就能保证牛顿法高精度收敛到最优点,而且速度还很快。
思路概括如下:1。
用最速下降法在大范围找到一个好的初始点给牛顿法:(最速下降法在精度不是很高的情况下逼近速度也是蛮快的)2。
在最优点附近改用牛顿法,用最速下降法找到的点为牛顿法的初始点,提高逼近速度与精度。
3。
这样两种方法相结合,既能提高逼近的精度,还能提高逼近的速度,而且还能保证是全局最优点。
这就充分吸收各自的优点,扬长避短。
得到理想的结果了。
ticclc;clear;syms x1 x2G=[];G=input('请输入想x1^2,x2^2,x1*x2,x1,x2,常系数,如[1,2,3,4,5,6] 系数向量=:');a=G(1,1);b=G(1,2);c=G(1,3);d=G(1,4);e=G(1,5);g=G(1,6);f=a*x1^2+b*x2^2+c*x1*x2+d*x1+e*x2+g;%画出原始图像figure;x11=-100:0.5:100;x22=x11;[x11,x22]=meshgrid(x11,x22);f11=a.*x11.^2+b*x22.^2+c*x11.*x22+d.*x11+e.*x22+g;surf(f11),grid on,hold on;%画出原始图像df1=diff(f,x1);df2=diff(f,x2);%对函数进行求一阶导DF=[df1;df2];df11=diff(df1,x1);df12=diff(df1,x2);df21=diff(df2,x1);df22=diff(df2,x2);%这里进行求函数二阶导数DEE=[df11,df12;df21,df22];x=input('请输入x的初始值为x=[x1,x2],x=:');x=x';E=input('请输入你所要求的最速下降法的精度数(一般取3~5)E=:'); %这里进行一些相关初始值的计算T=[];d=T;T(:,1)=subs(DF,[x1,x2],[x(1),x(2)]);TH=subs(DEE,[x1,x2],[x(1),x(2)]);%这里进行一些相关初始值的计算disp('由于你输入的初始值,这里将开始最速下降法搜寻:');for k=1:100000d(:,1)=-T(:,1);%d(k)是x(k+1)=x(k)+A(k)*d(k)A(1)=(T(:,1)'*T(:,1))/(T(:,1)'*TH*T(:,1));TH=subs(DEE,[x1,x2],[x(1,k),x(2,k)]);T(:,k)=subs(DF,[x1,x2],[x(1,k),x(2,k)]);d(:,k+1)=-T(:,k);A(k)=(T(:,k)'*T(:,k))/(T(:,k)'*TH*T(:,k));KLJ(:,k)=norm(T(:,k));GG(k)=subs(f,[x1,x2],[x(1,k),x(2,k)]);if norm(T(:,k))<Edisp('有这里你就进入牛顿法求最优了');disp(' ');disp('FX就是最速下的解 ')FX=subs(f,[x1,x2],[x(1,k),x(2,k)])disp(' ');disp('对应的x值为 ');x(:,k)break;endx(:,k+1)=x(:,k)+A(k)*d(:,k);endtoc%画出最速下降迭代点最终停留位置figure;plot3(x11,x22,f11,'r'),grid on;for tk=1:kh1=line( 'Color' ,[0 1 0], 'Marker' , '.' , 'MarkerSize' ,20, 'EraseMode' , 'xor' );set(h1, 'xdata' ,x(1,tk), 'ydata' ,x(2,tk), 'zdata' , GG(tk)); drawnow; % 刷新屏幕pause(0.1);endfop1=getframe(gcf)image(fop1.cdata)%画出最速下降迭代点最终停留位置ticY=x(:,k);EE=input('请输入牛顿最终的精度系数EE=:');TT(:,1)=subs(DF,[x1,x2],[Y(1),Y(2)]);THH=subs(DEE,[x1,x2],[Y(1),Y(2)]);aa=1;disp('程序可以运行到这里');for kk=1:10000dd(:,kk)=-inv(THH)*TT(:,kk);Y(:,kk+1)=Y(:,kk)+ aa*dd(:,kk);THH=subs(DEE,[x1,x2],[Y(1,kk),Y(2,kk)]);TT(:,kk+1)=subs(DF,[x1,x2],[Y(1,kk+1),Y(2,kk+1)]);PP=norm(TT(:,kk));GG1(kk)=subs(f,[x1,x2],[Y(1,kk),Y(2,kk)]);if PP<EEdisp('到这里您已经得到全局最优解了');FXX=subs(f,[x1,x2],[Y(1,kk),Y(2,kk)])disp(' ');disp('对应的x值为: ');Y(:,kk)break;endendFXX=subs(f,[x1,x2],[Y(1,kk),Y(2,kk)])toc%画出最终极值点停留位置figure;plot3(x11,x22,f11,'r'),grid on;for J=1:kkh2=line( 'Color' ,[0 1 0], 'Marker' , '.' , 'MarkerSize' ,40, 'EraseMode' , 'xor' );set(h2, 'xdata' ,Y(1,J), 'ydata' ,Y(2,J), 'zdata' , GG1(1,J));pause(0.1);fop=getframe(gcf);image(fop.cdata);enddisp('现在程序已经结束了');%画出最终极值点停留位置转自《研学论坛》。
梯度下降法和牛顿法的异同

梯度下降法和牛顿法的异同
梯度下降法和牛顿法都属于最优化算法。
它们都被广泛用于优化算法中,尤其是机器学习中的优化问题。
这两种算法对求解问题的极小值有着重要的作用,它们都是基于损失函数的梯度确定update规则的迭代方式。
但是,梯度下降法和牛顿法有一定的不同:
首先,两种算法的更新规则是不同的。
梯度下降法用的是梯度下降的方法,即根据最新的梯度值,以当前位置为基准,沿着此方向寻找梯度最低点,即下降最小值点;而牛顿法则需要计算平均梯度以及拟合函数的矩阵,即当前位置的Hessian矩阵,然后根据它们来更新参数。
此外,由于梯度下降更新规则的简单性,梯度下降法更加容易理解和实现,而牛顿法由于需要计算Hessian矩阵对算法计算量有更大的要求,而且对初值设置和特征选择也有更高的要求;因此梯度下降法比牛顿法更容易实现和更新,而且也更容易训练,但是牛顿法可以收敛得更快,但是如果初值和特征选择不合理,会影响牛顿法的训练效果。
此外,两种算法的对策略也有所不同,梯度下降法的更新规则是每一次更新量小,每次迭代量也相对较小,迭代次数更多,而牛顿法每次更新量较大,迭代次数更少。
不同的策略使得它们收敛的特性也不一样,梯度下降法的收敛慢,而牛顿法的收敛速度快。
总的来说,梯度下降法和牛顿法都属于最优化算法,它们都用了梯度确定update规则,但是在更新规则,对待策略和精度上,两种方法有一定的不同。
最速下降法 牛顿法

1.最速下降法最速下降法迭代公式是)(min )(0k k k k k p x f p x f ααα+=+≥ 计算步骤如下:(1)给定初点0x ,允许误差ε>0,令k=0。
(2)计算搜索方向)(k k x g g =(3)若ε≤k g ,则 kx x =*,停止;否则令k k g p -= ,由一维搜索步长 kα ,使得)(min )(0k k k k k p x f p x f ααα+=+≥(4)令k k k k p x x α+=+1 ,k=k+1,转步骤(2)。
用最速下降法求min f=(x1-4)^4+(x2+2)^2+1,初始点是(1,-3)%允许误差e%zk 是给定初点%z 是找到的最优点%k 是迭代次数%选用步长公式)'()'(Hg g g g t =;syms x1 x2f=(x1-4)^4+(x2+2)^2+1;%目标函数e=1.0e-4;df_dx1=diff(f,x1);df_dx2=diff(f,x2);f1=[df_dx1;df_dx2];flag=1;k=0;zk=[1;-3];while flagg=subs(f1,[x1;x2],zk); %梯度g(zk)norm_g=norm(g);if norm_g<=e%如果g的模小于允许误差,则已找到最优点 flag=0;z=zk;zuiyou_f=subs(f,[x1;x2],z);disp('极小点是')zdisp('最小值是')zuiyou_fdisp('迭代次数')kbreakelse%g的模不小于允许误差的情况 k=k+1;p=-g; %负梯度h=jacobian(f1);H=subs(h,[x1;x2],zk); %Hesse 矩阵 H (xk ) t=(g'*g)/(g'*H*g); %t 是搜索步长 zk=zk+t*p;endend2.牛顿法已知目标函数)(x f 及其梯度)(x g ,Hesse 矩阵)(x G ,终止限 ε 。
007最速下降和牛顿法-PPT文档资料

内容提要
最速下降法 针对二次函数的收敛速度分析 收敛图示/香蕉函数 Newton法 实用Newton法 BB算法 一个有研究价值的例子 Matlab程序示例
steepest-descent direction
梯度 g= 4u’u u-4Au
Hessian矩阵 4u’u *I+8uu’-4A 改进幂法? 思路一 Since A ≈uu’ (4u’u+4uu’) d = -g 用秩一求逆公式 u+=u + d 思路二 (12u’uu’u -4u’Au)/u’u * d=-g
Matlab程序示例 计算 Min ||A-X||F S.t. Rank(X)=1 X≥0
X = max(0,u1) *S(1,1)*max(0,-v1)'; temp3 = norm(A-X,'fro'); X = max(0,-u1) *S(1,1)*max(0,-v1)'; temp4 = norm(A-X,'fro') ; fval1 = min([temp1 temp2 temp3 temp4]);
m=10 n=20 残差 14.38 CPU 58.032s
function fval=opt_3(A) %直接调用无约束优化函数fminunc [m n]=size(A); [U,S,V] = svd(A); S11 = S(1,1); x=fminunc((x) myfun_3(x,A,S11),ones(n+m)); fval = myfun_3(x,A,S11); fval = sqrt(fval); function F = myfun_3(x,A,S11) [m n]=size(A); F=0; for i=1:m for j=1:n F = F+(A(i,j)-x(i)^2*S11*x(m+j)^2)^2; end end
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
所求稳定点;否则,转(3)。
(3) 计算 H (x ) 1 和下降方向 pk 。
(4) 沿 p k 方向进行一维搜索,决定步长 k :
f
x k k pk
min f ( x k pk ) 0
(5) 令 xk1 = x k k pk , k k 1,返回(2)。
f ( x k )T pk 0
(4)
即可保证 f ( x) f ( x k pk ) f ( x k ) 。此时,若取
x k1 x k p k
(5)
就一定能使目标函数得到改善。
建模方法与应用
6.1 最速下降法
现在考察不同的方向 p k ,假设 p k 的模不为零,并设 f (x k ) 0(否
x x 点处的梯度方向,仅在 点的一个小邻域内才具有最速的
性质,而对于整个优化过程来说,那就是另外一回事了。由上
x2
x 0 (1,1)
1
x1
例可以看出,当二次函数的等值线为同心椭圆时,采用梯度法 其搜索路径呈直角锯齿状;最初几步函数值变化显著,但是迭 代到最优点附近时,函数值的变化程度非常小。因此,梯度法
用一维搜索法、微分法,也可以利用试算法,或者根据某些函数确定最佳步长,则只能选用前两种方法。
建模方法与应用
6.1 最速下降法
一般地,若 f (x k ) 2 ,则 x k 即为近似极小点;否则求步
长 k 并计算 xk1 = x k k f ( x k ) 。如此反复,直到达到要求
建模方法与应用
6.1 最速下降法
为了得到下一个近似点,在选定搜索方向之后,还要确定
步长 。的计算可以采用试算法,即首先选取一个 值进 行试算,看它是否满足不等式 f ( x k1 ) f ( x k pk ) f ( x k ) ; 如果满足就迭代下去,否则缩小 使不等式成立。由于采用 负梯度方向,满足该不等式的 总是存在的。
圆的问题,不管初始近似点选在哪里,
负梯度方向总是直接指向圆心,即圆
心为极值点。这样,只要一次迭代即
x1 能达到最优。
x0
图 12
建模方法与应用
6.1 最速下降法
[例] 试用梯度法求
f ( x) 4x1 6x2 2x12 2x1x2 2x22 的极大点。
解:该二次函数的绝对最优解
x
(
1 3
8 H (x) 4
4 8 是正定矩阵
取 x 0 (5,2)T ,则:
f
(
x0
)
48 36
,
H
(x
0
)
8 4
4 8
,
H
(
x
0
)
1
1 6
1 12
1 12
1 6
x1
x0
H ( x 0 )1f
(x0)
5 2
1 6
1 12
1 12
1 6
48 36
0 0
因 f ( x1 ) (0,0)T ,故 x1 (0,0)T 为 f (x) 的极小点,极小值
(
2,2)
2 0
0 2
2 2
16
2
x x 1 0
=
0
f
(
x
0
)
=
00
1 2
22
11
f ( x1 ) 2 [ (0)2 (0)2 ]2 0
建模方法与应用
6.1 最速下降法
x2
图 12 展示了该例的迭代过程,即
极小点 x1
从 x 0 (0,0) 经过负梯度方向一步到达
极小点 x1 (1,1) 。其实,对于等值线为
此时,按式(7)求得的极小点,只是 f (x) 的近似极小点。在
这种情况下,常按下式选取搜索方向:
pk H ( x k )1f ( x k )
(8)
x k1 = x k k p k
(9)
k: min f ( x k k P k )
(10)
按照这种方式求函数 f (x) 极小点的方法称为牛顿法,式
另一种方法是通过在 x k 负梯度方向上的一维搜索,来确
定使得 f ( x k1 ) f ( x k p k ) 最小的,这种梯度法就是所谓的
最速下降法。
建模方法与应用
6.1 最速下降法
2.基本步骤
给定一个初始近似点 x 0 及其精度 0,若 f (x0 ) 2 ,则 x 0 即为近似
极小点;若 f (x0 ) 2 ,求步长0 并计算 x1= x0 0 f (x0 ) 。求步长可以
与一维问题类似,在局部,用一个二次函数近似代替目标
函数 f (x) ,然后用近似函数的极小点作为 f (x) 的近似极小
点。
若非线性目标函数 f (x) 具有二阶连续偏导, x k 为 f (x)
的一个近似极小点,在 x k 点取 f (x) 的二阶泰勒展开,即:
f (x) f ( x k ) f ( x k )T
xk1 ,在 x k 点沿方向 p k 作射线 x x k + pk , ( 0)称为步长。现 将 f (x) 在 x k 处作泰勒展开,有:
f ( x) f ( x k pk ) f ( x k ) f ( x k )T p k o()
其中 o()是 的高阶无穷小。对于充分小的 ,只要
0
)
3 1
1
1
,
H (x0
) 1
1 2
1 2
1 2
3 2
x1
x0
H ( x 0 )1f
(x0)
0 0
1 2
1 2
1 2
3 2
2
0
1 1
因 f ( x1 ) (0,0)T ,故 x1 (1,1)T 为 f (x) 的极小点,极小值是
“-1”。
建模方法与应用
6.2 Newton型 法
即
x x k H ( x k )1f ( x k )
(7)
如果 f (x) 是二次函数,则其海赛矩阵为常数,式(6)是
精确的。在这种情况下,从任意一点出发,用式(7)只要一
步即可求出 f (x) 的极小点(假设海赛矩阵正定)。
建模方法与应用
6.2 Newton型 法
如果 f (x) 不是二次函数,式(6)仅是一个近似表达式。
f ( x(k ) )T f ( x(k ) )
= f ( x(k ) )T H ( x(k ) )f ( x(k ) ) ,可见最佳步长不仅与梯度有关,而且
与海赛矩阵有关。
建模方法与应用
6.1 最速下降法
[例] 试用梯度法求 f ( x) (x1 1)2 (x2 1)2 的极小点, 0.1。
则 x k 是稳定点);那么,使式(4)成立的 p k 有无穷多个,为了使目标
函数能得到尽量大的改善,必须寻求能使 f ( x k )T pk 取最小值的 p k 。 由 于 f ( x k )T pk = f ( x k ) pk cos , 当 p k 与 f ( x k ) 反 向 ( 即 cos1800 1)时,f ( x k )T pk 取最小值。 pk f ( x k ) 被称为负梯 度方向,在 x k 的某一小的邻域内,负梯度方向是使函数值下降最快的 方向。
是“0”。
建模方法与应用
6.2 Newton型 法
[例]
试用牛顿法求
f (x)
x 3 2
21
1 2
x22
x1 x2
2x1的极小
值。
解:
f ( x) (3x1 x2 2, x2 x1 )T
H
(
x)
3 1
1
1
是正定矩阵
取 x 0 (0,0)T ,则:
f
(
x
0
)
2
0
,
H
(
x
建模方法与应用
6.1 最速下降法
有 f ( x1 ) 2(1 2)2 2(1 2) 4
令函数 f ( x1 ) 对 的导数为零,可求得最佳步长
1
1 4
于是有
x1
(1
2,1)
(
1 2
,1)
,同理可进行后续的各步迭代。
第二次迭代: f ( x1 ) (0,1) , 2
1 4
,
x2
(
1 2
解:取初始近似点 x 0 (0,0)T , f ( x 0 ) (2,2)T
f ( x (0) ) 2 [ (2)2 (2)2 ]2 8
2 0 H (x) 0 2
f ( x(0) )T f ( x(0) )
(
2,
2)
2 2
81
0 = f ( x(0) )T H ( x(0) )f ( x(0) )
2.阻尼 Newton 法
在上面介绍的 Newton 法中,步长 k 总是取为 1。在阻尼 Newton
法中,每一步迭代沿方向
pk H ( x k )1f ( x k )
进行一维搜索来决定 k ,即取 k ,使得
f
x k k pk
min f ( x k pk ) 0
从而使用下面的迭代公式
xk1 = x k k H ( x k )1f ( x k )
来代替(8)-(10). 阻尼 Newton 法保持了 Newton 收敛速度快的优点,又不要
求初始点选的很好,因而在实际应用中取得较好的效果。
建模方法与应用
6.2 Newton型 法
阻尼 Newton 法的计算步骤
(1) 给的初始点 x 0 ,精度 0 ,令 k 0 。