mysql 5.5+版本支持emoji表情符存储方法
mysql5.5 安装详细图解
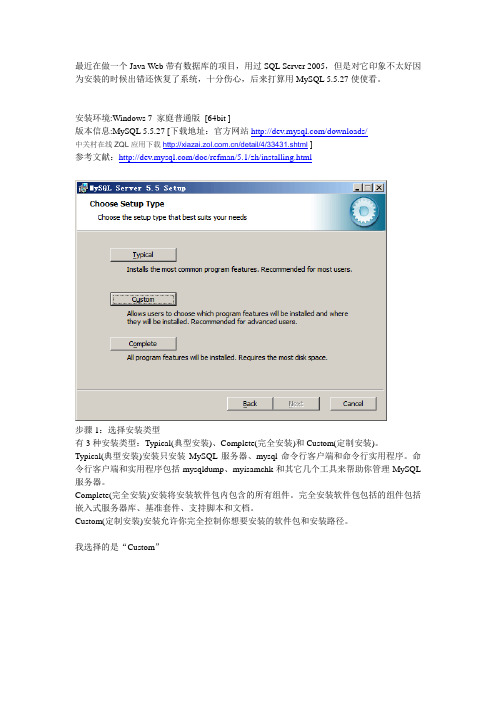
最近在做一个Java Web带有数据库的项目,用过SQL Server 2005,但是对它印象不太好因为安装的时候出错还恢复了系统,十分伤心,后来打算用MySQL 5.5.27使使看。
安装环境:Windows 7 家庭普通版[64bit ]版本信息:MySQL 5.5.27 [下载地址:官方网站/downloads/中关村在线ZQL应用下载/detail/4/33431.shtml]参考文献:/doc/refman/5.1/zh/installing.html步骤1:选择安装类型有3种安装类型:Typical(典型安装)、Complete(完全安装)和Custom(定制安装)。
Typical(典型安装)安装只安装MySQL服务器、mysql命令行客户端和命令行实用程序。
命令行客户端和实用程序包括mysqldump、myisamchk和其它几个工具来帮助你管理MySQL 服务器。
Complete(完全安装)安装将安装软件包内包含的所有组件。
完全安装软件包包括的组件包括嵌入式服务器库、基准套件、支持脚本和文档。
Custom(定制安装)安装允许你完全控制你想要安装的软件包和安装路径。
我选择的是“Custom”步骤2:定制安装对话框所有可用组件列入定制安装对话框左侧的树状视图内。
未安装的组件用红色X 图标表示;已经安装的组件有灰色图标。
要想更改组件,点击该组件的图标并从下拉列表中选择新的选项。
可以点击安装路径右侧的Change...按钮来更改默认安装路径。
选择了安装组件和安装路径后,点击Next按钮进入确认对话框。
我全都安了,没有叉。
路径改成了D:\MySQL\MySQL Server 5.5\步骤3:选择配置类型可以选择两种配置类型:Detailed Configuration(详细配置)和Standard Configuration(标准配置)。
Standard Configuration(标准配置)选项适合想要快速启动MySQL而不必考虑服务器配置的新用户。
mysqlunsigned用法

mysqlunsigned用法MySQL中Unsigned是一种数据类型修饰符,它可以用来指定一个列或变量的数据类型为无符号整数类型。
Unsigned的作用是将有符号整数的取值范围从负数扩展到正数,使得该列或变量能够表示更大的非负整数。
在MySQL中,Unsigned可以用于以下数据类型:1. TINYINT:表示一个范围为0到255的整数。
2. SMALLINT:表示一个范围为0到65535的整数。
3. MEDIUMINT:表示一个范围为0到16777215的整数。
4. INT:表示一个范围为0到4294967295的整数。
5. BIGINT:表示一个范围为0到18446744073709551615的整数。
Unsigned类型以u或U结尾,例如TINYINT UNSIGNED。
Unsigned类型在一些场景下非常有用,例如存储IP地址或者存储一些大的时间戳,因为它们都是非负整数,而且Unsigned类型的列或变量占用的存储空间比有符号整数类型的列或变量少一半,这意味着更少的磁盘空间和更快的数据读写速度。
Unsigned类型的使用也有一些限制。
首先,Unsigned类型不能存储负数,因此如果需要存储负数,应该使用有符号整数类型。
其次,如果一个Unsigned类型的列或变量被赋值了一个负数,MySQL将会将它转换为一个对应的无符号整数,这可能会导致一些意想不到的结果。
因此,在使用Unsigned类型时,应该特别小心。
下面是一个Unsigned类型的实例:CREATE TABLE test (id INT UNSIGNED NOT NULL PRIMARY KEY,name VARCHAR(50) NOT NULL);在上面的示例中,id列被指定为Unsigned类型的INT整数,因此它只能存储非负整数。
注意,在定义Unsigned类型的列或变量时,关键词UNSIGNED必须放在数据类型后面,而且不能与NOT NULL一起使用。
解决Python插入数据到MySQL时遇到的Incorrectstringvalue错误

解决Python插⼊数据到MySQL时遇到的Incorrectstringvalue错误问题与原因使⽤python执⾏插⼊语句将数据插⼊到MySQL时抛出了以下异常pymysql.err.InternalError: (1366, "Incorrect string value: '\\xF0\\x9F\\x91\\x8D, ...' for column 'content' at row 1")以上错误是由编码问题造成的,你使⽤的数据库默认编码是utf8,可以保存1到3个字节,但是你插⼊到数据库中的字符串包含emoji表情字符(占⽤4个字节),因此会抛出Incorrect string value异常。
解决⽅法解决的⽅法主要有以下两种修改MySQL的编码格式在程序中过滤emoji表情字符修改MySQL的编码格式MySQL从5.5.3版本开始,才⽀持4个字节的utf8编码,编码名称是utf8mb4(mb4意思为max bytes 4),在MySQL中执⾏以下SQL语句可以看到utf8和utf8mb4的相关信息SELECT * FROM information_schema.CHARACTER_SETSWHERE CHARACTER_SET_NAME LIKE 'utf8%'结果如下CHARACTER_SET_NAME DEFAULT_COLLATE_NAME DESCRIPTION MAXLENutf8utf8_general_ci UTF-8 Unicode3utf8mb4utf8mb4_general_ci UTF-8 Unicode4因此,将MySQL编码改为utf8mb4就可以解决这个问题。
解决程序的编码问题需要进⾏以下⼏个操作:修改f配置找到MySQL的配置⽂件f(windows系统⼀般在MySQL的安装⽬录中,linux系统放在/etc⽬录下)修改含有utf8编码的参数为utf8mb4,如下character-set-server=utf8mb4[client]default-character-set=utf8mb4[mysql]default-character-set=utf8mb4修改保存后,重启MySQL。
一步步教会你微信小程序的登录鉴权

⼀步步教会你微信⼩程序的登录鉴权前⾔为了⽅便⼩程序应⽤使⽤微信登录态进⾏授权登录,微信⼩程序提供了登录授权的开放接⼝。
乍⼀看⽂档,感觉⽂档上讲的⾮常有道理,但是实现起来⼜真的是摸不着头脑,不知道如何管理和维护登录态。
本⽂就来⼿把⼿的教会⼤家在业务⾥如何接⼊和维护微信登录态,下⾯话不多说了,来⼀起看看详细的介绍吧。
接⼊流程这⾥官⽅⽂档上的流程图已经⾜够清晰,我们直接就该图展开详述和补充。
⾸先⼤家看到这张图,肯定会注意到⼩程序进⾏通信交互的不⽌是⼩程序前端和我们⾃⼰的服务端,微信第三⽅服务端也参与其中,那么微信服务端在其中扮演着怎样的⾓⾊呢?我们⼀起来串⼀遍登录鉴权的流程就明⽩了。
1. 调⽤wx.login⽣成codewx.login()这个API的作⽤就是为当前⽤户⽣成⼀个临时的登录凭证,这个临时登录凭证的有效期只有五分钟。
我们拿到这个登录凭证后就可以进⾏下⼀步操作:获取 openid 和 session_keywx.login({success: function(loginRes) {if (loginRes.code) {// example: 081LXytJ1Xq1Y40sg3uJ1FWntJ1LXyth}}});2. 获取openid和session_key我们先来介绍下openid,⽤过公众号的童鞋应该对这个标识都不陌⽣了,在公众平台⾥,⽤来标识每个⽤户在订阅号、服务号、⼩程序这三种不同应⽤的唯⼀标识,也就是说每个⽤户在每个应⽤的openid都是不⼀致的,所以在⼩程序⾥,我们可以⽤openid来标识⽤户的唯⼀性。
参数值appid⼩程序的appidsecret⼩程序的secretjs_code前⾯调⽤wx.login派发的codegrant_type'authorization_code'从这⼏个参数,我们可以看出,要请求这个接⼝必须先调⽤wx.login()来获取到⽤户当前会话的code。
mysql保存微信昵称特殊字符的方法

mysql保存微信昵称特殊字符的⽅法我在⽤mysql 保存微信昵称,当插⼊昵称数据的时候,报错。
于是做了如下⼯作:⼀、简介MySQL在5.5.3之后增加了这个utf8mb4的编码,mb4就是most bytes 4的意思,专门⽤来兼容四字节的unicode。
好在utf8mb4是utf8的超集,除了将编码改为utf8mb4外不需要做其他转换。
当然,为了节省空间,⼀般情况下使⽤utf8也就够了。
⼆、内容描述那上⾯说了既然utf8能够存下⼤部分中⽂汉字,那为什么还要使⽤utf8mb4呢? 原来mysql⽀持的 utf8 编码最⼤字符长度为 3 字节,如果遇到 4 字节的宽字符就会插⼊异常了。
三个字节的 UTF-8 最⼤能编码的 Unicode 字符是 0xffff,也就是 Unicode 中的基本多⽂种平⾯(BMP)。
也就是说,任何不在基本多⽂本平⾯的 Unicode字符,都⽆法使⽤ Mysql 的 utf8 字符集存储。
包括 Emoji 表情(Emoji 是⼀种特殊的 Unicode 编码,常见于 ios 和 android ⼿机上),和很多不常⽤的汉字,以及任何新增的Unicode 字符等等。
三、问题根源最初的 UTF-8 格式使⽤⼀⾄六个字节,最⼤能编码 31 位字符。
最新的 UTF-8 规范只使⽤⼀到四个字节,最⼤能编码21位,正好能够表⽰所有的 17个 Unicode 平⾯。
utf8 是 Mysql 中的⼀种字符集,只⽀持最长三个字节的 UTF-8字符,也就是 Unicode 中的基本多⽂本平⾯。
Mysql 中的 utf8 为什么只⽀持持最长三个字节的 UTF-8字符呢?我想了⼀下,可能是因为 Mysql 刚开始开发那会,Unicode 还没有辅助平⾯这⼀说呢。
那时候,Unicode 委员会还做着 “65535 个字符⾜够全世界⽤了”的美梦。
Mysql 中的字符串长度算的是字符数⽽⾮字节数,对于 CHAR 数据类型来说,需要为字符串保留⾜够的长。
java-将评论内容过滤特殊表情emoj符号,保存到mysql中

java-将评论内容过滤特殊表情emoj符号,保存到mysql中正常操作评论,保存时,若评论内容含有特殊表情符号,后台将报错如下:Illegal mix of collations (utf8_general_ci,IMPLICIT) and (utf8mb4_general_ci,COERCIBLE) for operation '='; nested exception is java.sql.SQLException: Illegal mix of collations (utf8_general_ci,IMPLICIT) and (utf8mb4_general_ci,COERCIBLE) for operation '='后来查阅资料,找到⽅法将其评论内容中特殊符号过滤掉,然后保存。
废话不多说,直接上代码:1/**2 * 检测是否有emoji字符3 * @param source4 * @return⼀旦含有就抛出5*/6public static boolean containsEmoji(String source) {7if (StringUtils.isBlank(source)) {8return false;9 }1011int len = source.length();1213for (int i = 0; i < len; i++) {14char codePoint = source.charAt(i);1516if (isEmojiCharacter(codePoint)) {17//do nothing,判断到了这⾥表明,确认有表情字符18return true;19 }20 }2122return false;23 }2425private static boolean isEmojiCharacter(char codePoint) {26return (codePoint == 0x0) ||27 (codePoint == 0x9) ||28 (codePoint == 0xA) ||29 (codePoint == 0xD) ||30 ((codePoint >= 0x20) && (codePoint <= 0xD7FF)) ||31 ((codePoint >= 0xE000) && (codePoint <= 0xFFFD)) ||32 ((codePoint >= 0x10000) && (codePoint <= 0x10FFFF));33 }3435/**36 * 过滤emoji 或者其他⾮⽂字类型的字符37 * @param source38 * @return39*/40public static String filterEmoji(String source) {4142if (!containsEmoji(source)) {43return source;//如果不包含,直接返回44 }45//到这⾥铁定包含46 StringBuilder buf = null;4748int len = source.length();4950for (int i = 0; i < len; i++) {51char codePoint = source.charAt(i);5253if (isEmojiCharacter(codePoint)) {54if (buf == null) {55 buf = new StringBuilder(source.length());56 }5758 buf.append(codePoint);59 } else {60 }61 }6263if (buf == null) {64return source;//如果没有找到 emoji表情,则返回源字符串65 } else {66if (buf.length() == len) {//这⾥的意义在于尽可能少的toString,因为会重新⽣成字符串67 buf = null;68return source;69 } else {70return buf.toString();71 }72 }7374 } Java Code。
mysql中Incorrectstringvalue乱码问题解决方案

mysql中Incorrectstringvalue乱码问题解决⽅案mysql中Incorrect string value乱码问题解决⽅案你是否遇到过类似以下错误?java.sql.SQLException: Incorrect string value: '\xF0\x9F\x92\x9C' for column 'content' at row 1.产⽣这种异常的原因在于,mysql中的utf8编码最多会⽤3个字节存储⼀个字符,如果⼀个字符的utf8编码占⽤4个字节(最常见的就是ios中的emoji表情字符),那么在写⼊数据库时就会报错。
mysql从5.5.3版本开始,才⽀持4字节的utf8编码,编码名称为utf8mb4(mb4的意思是max bytes 4),这种编码⽅式最多⽤4个字节存储⼀个字符。
要想证明这个问题,可以执⾏以下sql:select * frominformation_schema.CHARACTER_SETSwhere CHARACTER_SET_NAME like 'utf8%'结果如图:因此,要解决上述异常的发⽣,需要使⽤utf8mb4编码。
解决数据库编码后,还需要解决客户端Connection连接对象使⽤的编码问题。
调⽤创建的Connection对象执⾏以下sql:conn.createStatement().execute("SET names 'utf8mb4'");如果项⽬中使⽤了DataSource数据源,只需要对数据源进⾏相关配置即可,这⾥以apache的DBCP数据源为例讲解,在spring框架下配置如下:<!-- 数据源 --><bean id="dataSource" class="mons.dbcp.BasicDataSource"><property name="driverClassName" value="com.mysql.jdbc.Driver"></property><property name="url" value="jdbc:mysql://${${data-source.prefix}.data-source.host-name}:3306/${${data-source.prefix}.data-source.db-name}?characterEncoding=utf8&autoReconnect=true&failOverReadOnly=false&maxReconnec <property name="username" value="${${data-source.prefix}ername}" /><property name="password" value="${${data-source.prefix}.data-source.password}" /><property name="maxActive" value="150" /><property name="maxIdle" value="2" /><property name="testOnBorrow" value="true" /><property name="testOnReturn" value="true" /><property name="testWhileIdle" value="true" /><property name="validationQuery" value="select 1" /><!-- 此配置⽤于在创建Connection对象时执⾏指定的初始化sql --><property name="connectionInitSqls"><list><value>set names 'utf8mb4'</value></list></property></bean>以下解释引⽤⾃mysql参考⼿册:SET NAMES 'charset_name'SET NAMES显⽰客户端发送的SQL语句中使⽤什么字符集。
mysql字符集查看、修改utf8mb4

mysql字符集查看、修改utf8mb4⼀、查看字符集1.查看MYSQL数据库服务器和数据库字符集⽅法⼀:show variables like '%character%';⽅法⼆:show variables like 'collation%';mysql> show variables like '%character%';+--------------------------+--------------------------------------+| Variable_name | Value |+--------------------------+--------------------------------------+| character_set_client | utf8 || character_set_connection | utf8 || character_set_database | utf8 || character_set_filesystem | binary || character_set_results | utf8 || character_set_server | utf8 || character_set_system | utf8 || character_sets_dir | /usr/local/mysql5535/share/charsets/ |+--------------------------+--------------------------------------+8 rows in set (0.00 sec)utf8mb4 已成为 MySQL 8.0 的默认字符集,在MySQL 8.0.1及更⾼版本中将 utf8mb4_0900_ai_ci 作为默认排序规则。
新项⽬只考虑 utf8mb4UTF-8 编码是⼀种变长的编码机制,可以⽤1~4个字节存储字符。
详解MySQL查询时区分字符串中字母大小写的方法

详解MySQL查询时区分字符串中字母⼤⼩写的⽅法如果你在mysql有唯⼀约束的列上插⼊两⾏值'A'和'a',Mysql会认为它是相同的,⽽在oracle中就不会。
就是mysql默认的字段值不区分⼤⼩写?这点是⽐较令⼈头痛的事。
直接使⽤客户端⽤sql查询数据库。
发现的确是⼤⼩不敏感。
通过查询资料发现需要设置collate(校对)。
collate规则:*_bin: 表⽰的是binary case sensitive collation,也就是说是区分⼤⼩写的*_cs: case sensitive collation,区分⼤⼩写*_ci: case insensitive collation,不区分⼤⼩写关于字符集与校验规则,mysql能:1、使⽤字符集来存储字符串,⽀持多种字符集;2、使⽤校验规则来⽐较字符串,同种字符集还能使⽤多种校验规则来⽐较;3、在同⼀台服务器、同⼀个数据库或者甚⾄在同⼀个表中使⽤不同字符集或校对规则来混合组合字符串;4、可以在任何级别(服务器、数据库、表、字段、字符串),定义不同的字符集和校验规则。
强制区分⼤⼩写可以通过binary关键字,⽅法有两种:第⼀种:让mysql查询时区分⼤⼩写select * from usertable where binary id='AAMkADExM2M5NjQ2LWUzYzctNDFkMC1h';第⼆种:在建表时加以标识create table `usertable`(`id` varchar(32) binary,PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;或CREATE TABLE `usertable` (`id` varchar(32) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '',PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;在mysql中,存在⼤⼩写问题的地⽅还有:(1) 关键字:不区分⼤⼩写 select * fRom table_name 和 select * from table_name 效果是⼀样的(2) 标⽰符(如数据库名称和表名称):不区分⼤⼩写。
【记录】mysql中建表utf8和utf8mb4区别?timestamp和datetime区别?

【记录】mysql中建表utf8和utf8mb4区别?timestamp和datetime区别?mysql中建表utf8和utf8mb4区别?1:utf8 是 Mysql 中的⼀种字符集,只⽀持最长三个字节的 UTF-8字符,也就是 Unicode 中的基本多⽂本平⾯2:要在 Mysql 中保存 4 字节长度的 UTF-8 字符,需要使⽤ utf8mb4 字符集,但只有 5.5.33:版本以后的才⽀持(查看版本: select version();)。
我觉得,为了获取更好的兼容性,应该总是使⽤ utf8mb4 ⽽⾮ utf8.4:对于 CHAR 类型数据,utf8mb4 会多消耗⼀些空间,根据 Mysql 官⽅建议,使⽤ VARCHAR 替代 CHAR。
为了获取更好的兼容性,应该总是使⽤ utf8mb4 ⽽⾮ utf8,事实上,最新版的phpmyadmin默认字符集就是utf8mb4。
诚然,对于 CHAR 类型数据,使⽤utf8mb4 存储会多消耗⼀些空间。
那么utf8mb4⽐utf8多了什么的呢?多了emoji编码⽀持.如果实际⽤途上来看,可以给要⽤到emoji的库或者说表,设置utf8mb4.⽐如评论要⽀持emoji可以⽤到.建议普通表使⽤utf8 如果这个表需要⽀持emoji就使⽤utf8mb4timestamp和datetime区别?1 区别1.1 占⽤空间类型占据字节表⽰形式datetime8 字节yyyy-mm-dd hh:mm:sstimestamp4 字节yyyy-mm-dd hh:mm:ss1.2 表⽰范围类型表⽰范围datetime'1000-01-01 00:00:00.000000' to '9999-12-31 23:59:59.999999'timestamp'1970-01-01 00:00:01.000000' to '2038-01-19 03:14:07.999999'timestamp翻译为汉语即"时间戳",它是当前时间到 Unix元年(1970 年 1 ⽉ 1 ⽇ 0 时 0 分 0 秒)的秒数。
MySQL微信Eomji表情支持问题

数据库编码问题一、我输入的中文编码是urf8的,建的库是urf8的,但是插入MySQL总是乱码,一堆”???????????????????????”。
可以使用以下的方式试试决解:原url地址是jdbc:mysql://localhost:3306/数据库名改为jdbc:mysql://localhost:3306/数据库名?useUnicode=true&characterEncoding=UTF-8二、报错:Incorrect string value: ‘\xF0\x9F…’ for column ‘XXX’ at row 1做有关微信公众账号的项目时,报Incorrect string value: ‘\xF0\x9F\x98\x92’ for column ‘NIKENAME’ at row 1,而所有的字符编码都是utf8,使用的数据库是mysql,在测试环境用得好好的,部署到线上后(使用的集群是阿里巴巴的,数据库服务器也是使用它们的,mysql 服务器版本是5.5.18),就报这个错了,并且这个错,时而出现,时而不出现Emoji表情字符现在在APP已经广泛支持了。
但是MySQL的UTF8编码对Emoji字符的支持却不是那么好。
所以我们经常会遇到这样的异常:Java.sql.SQLException: Incorrect string value: '\xF0\x9F\x98\x8E' for column 'nick' at row 1原因是Mysql里UTF8编码最多只能支持3个字节,而Emoji表情字符使用的UTF8编码,很多都是4个字节,有些甚至是6个字节。
解决的方案有两种:1.使用utf8mb4的mysql编码来容纳这些字符。
2.过滤掉这些特殊的表情字符。
方法1:使用utf8mb4的mysql编码来容纳这些字符注意:要使用utf8mb4类型,首先要保证Mysql版本要不低于MySQL 5.5.3。
mysql 特殊字符转移方法

mysql 特殊字符转移方法(实用版3篇)目录(篇1)1.MySQL 概述2.特殊字符的定义与作用3.MySQL 中特殊字符的转移方法a.使用转义字符b.使用预处理语句c.使用函数4.实际案例与应用5.总结正文(篇1)【1.MySQL 概述】MySQL 是一款广泛应用于各类项目的开源关系型数据库管理系统。
它基于 Structured Query Language(SQL)进行数据操作,具有高性能、易使用、成本低等优点。
在 MySQL 中,数据以表格的形式存储,每个表格包含若干个字段和记录。
【2.特殊字符的定义与作用】特殊字符是指在 MySQL 中具有特殊含义或者用途的字符。
例如,单引号(")、双引号(")、反斜杠()、美元符号($)等。
这些特殊字符在SQL 语句中可能会引起歧义或者错误,因此需要进行适当的转义。
【3.MySQL 中特殊字符的转移方法】在 MySQL 中,特殊字符的转移方法主要有以下几种:a.使用转义字符在 SQL 语句中,可以使用反斜杠()对特殊字符进行转义。
例如,如果要在查询结果中显示一个包含双引号的字符串,可以使用如下 SQL 语句:```sqlSELECT "这是一段"文字"```此时,查询结果将会正确显示为:这是一段"文字"。
b.使用预处理语句预处理语句是 MySQL 中一种强大的功能,可以防止 SQL 注入攻击。
通过预处理语句,可以将特殊字符与 SQL 语句分离,从而避免歧义。
例如:```sqlSET @name = "这是一段"文字";SELECT @name;```查询结果将会正确显示为:这是一段"文字"。
c.使用函数MySQL 提供了许多内置函数,可以用于处理特殊字符。
例如,使用`REPLACE()`函数可以替换字符串中的特殊字符。
例如:```sqlSELECT REPLACE("这是一段"文字", """, "");```查询结果将会正确显示为:这是一段文字。
mysql utf8默认排序规则

mysql utf8默认排序规则MySQL UTF8 默认排序规则在MySQL数据库中,UTF8是一种广泛使用的字符编码,用于存储和处理多种语言的文本数据。
在默认情况下,MySQL使用的UTF8编码具有默认的排序规则。
本文将介绍MySQL UTF8编码的默认排序规则及其相关内容。
## 什么是UTF8编码?UTF8(Unicode Transformation Format 8-bit)是一种用于编码Unicode字符的可变长度字符编码。
它可以表示Unicode标准中的所有字符,包括全球各种文字、标点符号和特殊符号。
UTF8编码使用1到4个字节表示不同的字符。
对于ASCII字符,它使用1个字节表示,而对于非ASCII字符,它使用2到4个字节不等。
## MySQL中的UTF8编码在MySQL中,UTF8编码分为两种形式:utf8和utf8mb4。
utf8mb4是utf8的超集,支持更多的字符。
MySQL 5.5.3及以上版本推荐使用utf8mb4编码,可以支持存储Emoji表情等特殊字符。
## MySQL UTF8排序规则排序规则决定了如何对存储在UTF8编码下的字符串进行排序。
在MySQL中,默认的UTF8排序规则是根据字符的二进制值来排序的。
具体来说,MySQL使用的是一种称为`utf8_general_ci`的排序规则。
- `utf8`表示使用UTF8编码;- `general`表示是一般性的排序规则,不区分大小写和重音符号;- `ci`表示不区分大小写(case-insensitive)。
这意味着在默认情况下,MySQL对于包含相同字符的不同大写或小写形式以及重音符号的不同形式的字符将被视为相等。
## utf8_bin排序规则除了默认的`utf8_general_ci`规则外,MySQL还提供了一个更严格的排序规则,称为`utf8_bin`。
`utf8_bin`排序规则是基于二进制值的排序,不区分大小写和重音符号,也不将相同字符的不同形式视为相等。
mysql设置了utf8mb4,为什么还有utf8mb4_general_ci和utf8m。。。

mysql设置了utf8mb4,为什么还有utf8mb4_general_ci和utf8m。
前段时间,遇到⼀个mysql的问题,我仔细看看报错信息,应该是MySQL数据库报出来的,⼤意是说:collation不兼容,⼀个是 utf8mb4_0900_ai_ci,另⼀个是utf8mb4_general_ci。
utf8mb4_general_ci这玩意⼉我见过,是针对utf8mb4编码的collation,但是utf8mb4_0900_ai_ci是啥,我也没见过。
于是我问他,这玩意⼉从哪⾥出来的?他说:“我也不知道,我完全没见过啊。
再说,我数据库编码已经是utf8mb4了,怎么还会有这么多名堂?”看他着急⼜不知所措的样⼦,我便花了点时间来研究,还真学到点新知识。
⽽且我也发现,有许多程序员天真的以为“⽤了UTF8就等于做了国际化了,不⽤再担⼼编码问题”。
看来,这个话题还真值得多讲讲。
⾸先从utf8mb4_0900_ai_ci这个诡异的名字说起。
Unicode编码的诞⽣,是为了解决之前各国的计算机⽂字编码⾃成⼀体的问题。
不同国家采⽤不同的编码,⾃⼰⽤还算正常,但是跨⽂化交流必然会出问题,更⽆法解决“在同⼀篇⽂档⾥⼜要显⽰中⽂⼜要显⽰韩⽂还要显⽰⽇⽂”之类的问题。
有了Unicode,地球上所有的⽂字都有独⼀⽆⼆的编码(Code Point,也就是为它分配的码值,或者说“逻辑代号”),前述问题就解决了。
但是Unicode(有个相关的名字是UCS,Universal Coded Character Set,⼆者基本等价)只确定了码值,或者说,只分配了逻辑代号。
⾄于这些逻辑代号在实际使⽤中如何存储,如何传输,那是另⼀个问题。
⽽UTF-8,就是解决存储和传输等问题的“实际⽅案”。
实际上,UTF的全名是Unicode Transformation Format,也就是“Unicode变换格式”。
这⾥的“变换”,基本可以类⽐为:要告诉别⼈明天早上九点来开会,到底是发邮件呢,还是打电话呢,还是写纸条呢,还是直接去敲门打招呼呢?。
MySQL5.5版本新特性介绍

提高性能和可扩展性
MySQL5.5 引入了一种可重构 InnoDB,这种结构包含许多性能和扩展性特征。在 InnoDB 中增加 以下增强性能,可延伸 MySQL5.5 的性能和可扩展性: 提高了 Windows 系统下的系统性能和可扩展性——一直以来,MySQL 数据库一直能在基于 UNIX 的平台中良好地运行。现在,随着越来越多的开发者开始在 Windows 系统中构建和开发应用 程序, MySQL 数据库开始逐渐从 Windows 平台下的桌面开发向产品数据中心转变。实际上, Windows 是目前应用最普遍的 MySQL 应用平台,MySQL 5.5 包含了诸多针对 Widows 平台的专用 改 进 措 施 , 这 些 措 施 增强 了 系 统 和 应 用 的 性 能和 可 扩 展 性 , 可 应 对 高并 发 数 和 用 户 负 载。
© 2010, Oracle Corporation and/or its affiliates 3
MySQL5.5 针对 Windows 系统所作的改进主要包括: 现在,MySQL 使用 Windows 系统原生的同步基元实现互斥和加锁算法。 现在,MySQL 使用 Windows 原生的独立操作而不是代理线程,实现和释放读/写专用锁定。 现在,MySQL 默认使用 Windows 原生的操作系统的内存分配程序。 现在,Windows 系统中的 MySQL 的输入/输出线程最大处理能力已经与其它平台的最大处理 能力相同。 其它平台上所作的既有优化措施现在已经移植到 Windows 平台中的 MySQL。 清理了许多 Windows 平台下特有的漏洞。
http:/
© 2010, Oracle Corporation and/or its affiliates
MySQL数据库字符集与排序规则解析

MySQL数据库字符集与排序规则解析在使用MySQL数据库进行开发和运维的过程中,字符集与排序规则是非常重要的概念。
正确设置字符集和排序规则,可以保证数据库的正常运行和数据的完整性。
本文将对MySQL数据库的字符集与排序规则进行详细解析,并提供一些常见问题的解决方案和最佳实践。
一. 什么是字符集(Character Set)和排序规则(Collation)?MySQL支持多种字符集和排序规则。
字符集用于确定字符的表示方法,而排序规则用于确定字符的比较和排序规则。
1. 字符集(Character Set)字符集是一组可供数据库使用的字符和符号的集合。
它定义了字符如何表示和存储。
MySQL提供了多种字符集,常用的字符集包括:- utf8:Unicode字符集,支持多种语言,最常用的字符集。
- utf8mb4:支持更广泛的Unicode字符集,包括Emoji等特殊符号。
- latin1:西欧字符集,包括英文、法文、西班牙文等。
- gbk:中文字符集,支持中文和一些特殊符号。
2. 排序规则(Collation)排序规则用于对字符进行比较和排序。
它决定了字符的顺序和比较的结果。
MySQL中排序规则的名称一般由字符集名和排序规则名组成。
常见的排序规则包括:- utf8_general_ci:utf8字符集的默认排序规则,不区分大小写。
- utf8_bin:utf8字符集的大小写敏感排序规则,区分大小写。
- latin1_general_ci:latin1字符集的默认排序规则,不区分大小写。
- gbk_chinese_ci:gbk字符集的中文排序规则,支持中文按拼音排序。
二. 字符集和排序规则设置方法在MySQL中,可以通过以下几种方式设置字符集和排序规则。
1. 数据库级别设置可以在创建数据库的时候指定字符集和排序规则。
例如:```CREATE DATABASE mydb CHARACTER SET utf8 COLLATE utf8_general_ci; ```这样,创建的`mydb`数据库的字符集就是utf8,排序规则为utf8_general_ci。
MySQL数据库原理设计与应用考试题

MySQL数据库原理设计与应用考试题一、单选题(共30题,每题1分,共30分)1、使用mysqldump命令时,()选项表示导出xml格式的数据。
A、#REF!B、#REF!C、#REF!D、#REF!正确答案:D2、下面关于“CREATE VIEW v_goods AS SELECT id, name FROM goods”描述错误的是()。
A、创建v_goods的用户默认为当前用户B、视图算法由MySQL自动选择C、视图的安全控制默认为DEFINERD、以上说法都不正确正确答案:D3、InnoDB表的自动增长字段值为1和2,那么删除2后,重启服务器,再次插入记录,自动增长字段的值为()。
A、1B、2C、3D、4正确答案:B4、以下不属于MySQL安装时自动创建的数据库是()。
A、mysqlB、information_schemaC、sysD、mydb正确答案:D5、下面对“ORDER BY pno,level”描述正确的是()。
A、先按level全部升序后,再按pno升序B、先按level升序后,相同的level再按pno升序C、先按pno全部升序后,再按level升序D、先按pno升序后,相同的pno再按level升序正确答案:D6、以下选项中,运算优先级别最低的是()。
A、位运算符B、算术运算符C、赋值运算符D、逻辑运算符正确答案:C7、命令行客户端工具的选项中,()用于指定连接的端口号。
A、-pB、-uC、-PD、-h正确答案:C8、下列mysql数据库中用于保存用户名和密码的表是()。
A、dbB、columns_privC、tables_privD、user正确答案:D9、以下可以创建外键约束的表是()。
A、MyISAM表B、InnoDB表C、MEMORY表D、以上答案全部正确正确答案:B10、下面关于MySQL安装目录描述错误的是()。
A、lib目录用于存储一系列的库文件B、include目录用于存放一些头文件C、bin目录用于存放一些课执行文件D、以上答案都不正确正确答案:D11、以下选项中,不属于MySQL特点的是()。
MySql_5.5安装图解说明(超详细)

MySql5.5安装详细说明打开MySql5.5安装文件开始:点击Next打上勾,再点击Next点击Custom,说明如下:Typical(典型安装)Installs the most common program features.Recommended for most users.意思是:安装最常用的程序功能。
建议大多数用户使用。
Custom(自定义安装)Allows uers to choose which program features will be installed and where they will be installed.Recommended for advanced users.意思是:允许用户选择安装的程序功能和安装的位置,建议高级用户使用。
Complete(完全安装)All program features will be installed.Requires the most disk space.意思是:将安装所有的程序功能,需要最多的磁盘空间。
这里就要详细说明一下:点一下Developer Components左边的+按钮,会看到带的图标,这代表这里的内容不会被安装到本地硬盘上。
带有图标的都是默认安装到本地硬盘上的。
Developer Components(开发者部分):用左键单击向下的小箭头选择Entire feature will be installed on local hard drive。
意思是:即此部分,以及下属子部分内容全部安装在本地硬盘上。
MySQL Server(mysql服务器):照上面的做。
Client Programs(mysql客户端程序) :照上面的做。
Documentation(文档) :照上面的做。
Server data files(服务器数据文件):照上面的做。
Debug Symbols(调试符号):照上面的做。
这样操作,以保证安装所有文件,如果是图标的就不用去管它,操作完再点击Next。
Shein公司面试题

Shein公司⾯试题1.在python3环境下运⾏以下代码,输出是什么?print(round(1.5))print(round(2.5))print(round(101,-1))回顾:round()是python内置函数,round函数很简单,对浮点数进⾏近似取值,保留⼏位⼩数,⽐如:>>>round(10.0/3,2)3.33>>> round(20/7)3第⼀个参数是⼀个浮点数,第⼆个参数是保留的⼩数位数,可选,如果不写的话默认保留到整数。
区别:在python2.7的doc中,round()的最后写着,“Values are rounded to the closest multiple of 10 to the power minus ndigits; if two multiples are equally close,rounding is done away from 0.” 保留值将保留到离上⼀位更近的⼀端(四舍六⼊),如果距离两端⼀样远,则保留到离0远的⼀边。
所以round(0.5)会近似到1,⽽round(-0.5)会近似到-1。
但是到了python3.5的doc中,⽂档变成了“values are rounded to the closest multiple of 10 to the power minus ndigits; if two multiples are equally close, rounding is done toward the even choice.” 如果距离两边⼀样远,会保留到偶数的⼀边。
⽐如round(0.5)和round(-0.5)都会保留到0,⽽round(1.5)会保留到2。
所以如果有项⽬是从py2迁移到py3的,可要注意⼀下round的地⽅(当然,还要注意/和//,还有print,还有⼀些⽐较另类的库)答:2,2,1002.写出下⾯程序的输出结果:def ChangeInt(a):a=10nfoo=2ChangeInt(nfoo)print(nfoo)def ChangeList(a):a[0]=10IstFoo=[2]ChangeList(IstFoo)print(IstFoo)答:2,103.使⽤列表推导优化以下代码:result=[]for x in range(10):result.append(x**2)print(result)答:result=[x**2 for x in range(10)]print(result)4.python中如何拷贝⼀个对象?答:(1)浅拷贝:使⽤copy.copy,它可以进⾏对象的浅拷贝(shallow copy),它复制了对象,但对于对象中的元素,依然使⽤引⽤(换句话说修改拷贝对象元素,则被拷贝对象元素也被修改)(2)深拷贝:使⽤copy.deepcopy,它可以进⾏深拷贝,不仅拷贝了对象,同时也拷贝了对象中的元素,获得了全新的对象,与被拷贝对象完全独⽴,但这需要牺牲⼀定的时间和空间。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
开发移动应用时,emoji表情在mysql默认情况下是不能存储的。
出现如下错误:
Incorrect string value: '\xF0\x9F\x92\x94' for column 'name' at row 1
让mysql支持emoji表情存储的方法如下:
1、升级mysql 5.5以上版本;
2、服务——>mysql右键,找到my.ini的路径;
3、修改my.ini
[mysqld]
character-set-server=utf8mb4
[mysql]
default-character-set=utf8mb4
4、打开mysql command line client,或在安装目录bin中打开mysql.exe;
输入以下命令,用于修改环境变量:
set character_set_client = utf8mb4;
set character_set_connection = utf8mb4;
set character_set_database = utf8mb4;
set character_set_results = utf8mb4;
set character_set_server = utf8mb4;
5、在服务中,重启Mysql服务;
6、登陆MYSQL,show variables like 'character%'; 可以查看编码是否已经修改成功。
7、将已经建好的表也转换成utf8mb4
alter ta开发移动应用时,emoji表情在mysql默认情况下是不能存储的。
出现如下错误:
Incorrect string value: '\xF0\x9F\x92\x94' for column 'name' at row 1
让mysql支持emoji表情存储的方法如下:
1、升级mysql 5.5以上版本;
2、服务——>mysql右键,找到my.ini的路径;
3、修改my.ini
[mysqld]
character-set-server=utf8mb4
[mysql]
default-character-set=utf8mb4
4、打开mysql command line client,或在安装目录bin中打开mysql.exe;
输入以下命令,用于修改环境变量:
set character_set_client = utf8mb4;
set character_set_connection = utf8mb4;
set character_set_database = utf8mb4;
set character_set_results = utf8mb4;
set character_set_server = utf8mb4;
5、在服务中,重启Mysql服务;
6、登陆MYSQL,show variables like 'character%'; 可以查看编码是否已经修改成功。
7、将已经建好的表也转换成utf8mb4
alter table TABLE_NAME convert to character set utf8mb4 collate utf8mb4_bin; (将TABLE_NAME替换成你的表名)
8、在代码中,连接数据库成功后,执行"set names utf8mb4"
修改成功!
在sql cmd窗口执行以下插入语句:
insert into Table (a) values (''牛仔帽
如果执行成功,就大功告成了!注意,在mysql客户端软件navicat的查询窗口运行是不能通过的,可能是navicat软件的支持问题。
ble TABLE_NAME convert to character set utf8mb4 collate utf8mb4_bin; (将TABLE_NAME替换成你的表名)
8、在代码中,连接数据库成功后,执行"set names utf8mb4"
修改成功!
在sql cmd窗口执行以下插入语句:
insert into Table (a) values ('牛仔帽')
如果执行成功,就大功告成了!注意,在mysql客户端软件navicat的查询窗口运行是不能通过的,可能是navicat软件的支持问题。