oracle ASM实例报04031错误
oracle常见错误代码

Oracle常见错误代码的分析与解决在使用ORACLE的过程过,我们会经常遇到一些ORACLE产生的错误,对于初学者而言,这些错误可能有点模糊,而且可能一时不知怎么去处理产生的这些错误,本人就使用中出现比较频繁的错误代码一一做出分析,希望能够帮助你找到一个合理解决这些错误的方法,同时也希望你能够提出你的不同看法。
毕竟作为一种交流的手段,个人意见难免过于偏颇,而且也必定存在着不足,出错之处在所难免。
写这篇文章的目的就是想通过相互之间的交流共同促进,共同进步。
ORA-01650:unable to extend rollback segment NAME by NUM intablespace NAME产生原因:上述ORACLE错误为回滚段表空间不足引起的,这也是ORACLE数据管理员最常见的ORACLE错误信息。
当用户在做一个非常庞大的数据操作导致现有回滚段的不足,使可分配用的回滚段表空间已满,无法再进行分配,就会出现上述的错误。
解决方式:使用“ALTER TABLESPACE tablespace_name ADD DATAFILE filename SIZE size_of_file”命令向指定的数据增加表空间,根据具体的情况可以增加一个或多个表空间。
当然这与还与你主机上的裸盘设备有关,如果你主机的裸盘设备已经没有多余的使用空间,建议你不要轻意的增加回滚段表空间的大小,可使用下列的语句先查询一下剩余的tablespace空间有多少:Select user_name,sql_text from V$open_cursor where user_name=‟‟;如果多余的空间比较多,就可以适当追加一个大的回滚段给表空间使用,从而避免上述的错误。
你也可以用以下语句来检测一下rollback segment的竞争状况:Select class,count from V$waitstat where calss in(‘system undo header’,’system undo block’,’undo header’,’undo block’);和Select sum(value) from V$sysstat where name in (…db_block_gets‟,‟consistents gets‟);如果任何一个class in count/sum(value)大于1%,就应该考虑增加rollback segment。
Oracle的常见错误及解决办法
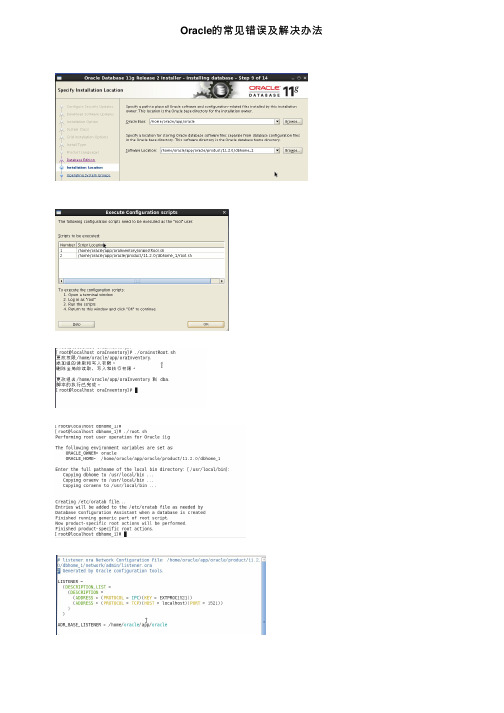
Oracle的常见错误及解决办法ORA-12528:TNS:listener: all appropriate instances are blocking new connectionsORA-12528问题是因为监听中的服务使⽤了动态服务,实例虽然启动,但没有注册到监听。
实例是通过PMON进程注册到监听上的,⽽PMON进程需要在MOUNT状态下才会启动。
所以造成了上⾯的错误。
解决这个问题,有三种⽅法:1、把监听设置为静态;2、在tnsnames.ora中追加(UR=A);3、重新启动服务;⽅法1、通过修改listener.ora的参数,把listener.ora动态注册设置为静态注册,然后重新启动监听# listener.ora Network Configuration File: $ORACLE_HOME\network\admin\listener.ora# Generated by Oracle configuration tools.LISTENER =(DESCRIPTION_LIST =(DESCRIPTION =(ADDRESS = (PROTOCOL = IPC)(KEY = EXTPROC1521))(ADDRESS = (PROTOCOL = TCP)(HOST = [IP])(PORT = 1521))))SID_LIST_LISTENER =(SID_LIST =(SID_DESC =(GLOBAL_DBNAME = [DBNAME])(ORACLE_HOME = [$ORACLE_HOME])(SID_NAME = [SID])))静态注册的风险:如果在instance运⾏中,lisener重新启动,就找不到instance了。
静态注册需要先启动lisener,再启动instance。
且静态模式下,lisener status显⽰的是unknown⽅法2、启动到nomount状态,通过修改tnsnames.ora的参数# tnsnames.ora Network Configuration File: $ORACLE_HOME\network\admin\tnsnames.ora# Generated by Oracle configuration tools.SYK =(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = [IP])(PORT = 1521))(CONNECT_DATA =(SERVER = DEDICATED)(SERVICE_NAME = SYK)(UR=A)))然后连接上数据库SQL>alter database mount;SQL>alter database open;⽅法3、重启ORACLE或者重启ORACLE服务在oracle帐户下依序执⾏如下命令:sqlplus / as sysdba;//在其它帐户(如root)下执⾏可能会报错(ORA-01031)因为这些帐户没有在dba组中shutdown immediate;startup;/s/blog_636415010100x3lc.htmloracle实例名: error while loading shared libraries: libskgxp10.so: cannot open shared object file: No such file or directory是环境变量LD_LIBRARY_PATH的问题。
Oracle数据库教程 —— 记一次ora-04030错误的处理过程

Oracle数据库教程——记一次ora-04030错误的处理过程今天客户说从数据库后台发现报错,具体如下:Errors in file/oracle/mytest/saptrace/diag/rdbms/mytest/mytest/incident/incdir_183218/mytest_j003_8103_i18 3218.trc:ORA-04030: out of process memory when trying to allocate 1052696 bytes (pga heap,log read buffer) ORA-07445: exception encountered: core dump [kgdsdst()+16] [SIGSEGV] [ADDR:0xFFFFFFFF7FFB4634] [PC:0x1081A1C90] [Address not mapped to object] []在查看的时候,并没有发现有什么语句问题的,检查系统限制如下:root@mytest# ulimit -acore file size (blocks, -c) unlimiteddata seg size (kbytes, -d) unlimitedfile size (blocks, -f) unlimitedopen files (-n) 256pipe size (512 bytes, -p) 10stack size (kbytes, -s) 8192cpu time (seconds, -t) unlimitedmax user processes (-u) 29995virtual memory (kbytes, -v) unlimited同时,报错中指出Address not mapped to object,可能存在没有足够的交换分区紧接着,又有如下报错Errors in file /oracle/mytest/saptrace/diag/rdbms/mytest/mytest/trace/mytest_psp0_27454.trc: ORA-27300: OS system dependent operation:fork failed with status: 12ORA-27301: OS failure message: Not enough spaceORA-27302: failure occurred at: skgpspawn3根据官网的介绍如下:CauseThis issue is mainly caused by lack of memory / swap. Checking the memory configuration on the server, we have found the following综合分析,报了04030的错误,而下面又分别报了27302及27301的错误。
ORA-04030错误处理方法总结

ORA-04030错误处理方法总结----HRP项目研发中心(董珮)一、错误现象描述目前正在使用的为oracle 10g数据库,使用过程中报ORA-04030错误,具体错误信息是: ORA-04030: 在尝试分配...字节(...)时进程内存不足(如图所示)。
同时服务器表现为数据库无法登录,PL/SQL一直在登录页面登录,然后卡死,DOS窗口登录现象为ORA-04030:????二、错误原因分析根据异常信息,可以很容易的判断是由于内存使用过多,分配不足所致的,但是电脑本身内存并不小(4G内存,当时已使用内存仅为1.56G),经查,是因为oracle在分配内存时,设了一个默认值,而这个默认值比较小,当程序使用过程中数据库占用内存超出这个限制的时,就会出现这个错误。
值得我们注意的是max_sga_size和sga_target的设置。
max_sga_size指的是可动态分配的最大值﹐而sga_target是当前已分配的最大sga。
max_sga_size是不可以动态修改的﹐而sga_target是可动态修改﹐直到达到max_sga_size的值。
如果在实例启动时﹐max_sga_size < sga_target或max_sga_size未设定﹐则启动后max_sga_size的值会等于sga_target的值,这时如果内存占用超过sga_target,则会出现ORA-04030的错误。
三、解决方案通过调整SGA的值来解决此问题,操作前需要注意以下事项:1.查看服务器操作系统,因为32操作系统SGA上限值为1.7G,64位目前我还查到有没有确定上限值。
2.SGA、PGA的分配原则如下:OLTP:SGA=系统内存*0.56,PGA=SGA*(0.1~0.2)OLAP:SGA=系统内存*0.48,PGA=SGA*(0.45~0.65)3.记得一定要在修改SGA前备份SPFILEORCL.ORA文件,切记!!!该文件路径:10g oracle为%%\oracle\product\10.2.0\db_1\dbs\SPFILEORCL.ORA11g oracle为%%\app\Administrator\product\11.2.0\dbhome_1\database \SPFILE%ORACLE_SID%.ORA下面就可以放心的修改SGA了,修改步骤如下:1.重启服务,因为此时你的数据库已经登录不上去了,先重启一下服务释放部分内存,保证数据库能正常登录;2.调整SGA大小用DBA权限登录执行下面语句:alter system set sga_max_size=1024M scope=spfile;(以1G为例,实际情况可根据上文分配原则以及具体数据量来酌情分配)alter system set sga_target=1024M scope=spfile;(当然,该值也可以小于1024)执行之后重启ORACLE服务变更方可生效注意:如果修改之后数据库无法正常登录,报类似于“ORA-01034: ORACLE not available;ORA-27101: shared memory realm does not exist”等错误,则可能是因为你没有留意上述注意事项,将SGA值改的太大了,超过了操作系统要求上限,解决办法为还原注意事项3中的SPFILEORCL.ORA 文件,重启服务之后再重新进行SGA的调整。
ora-04030问题解决

11 0 0
5. 解决方案.
i. 调整ORACLE组件大小
SGA: 1.64G
PGA: 1.2G.
Lager_pool:初始化值64M.
1. 服务器软件环境:
i. 操作系统:windows server 2003 Enterprise SP2 . 32位. (已经设置/PAE).
ii. 物理内存: 8G.
*** 2010-10-20 10:00:55.218
----- SQL Statement (None) -----
Current SQL information unavailable - no cursor.
----- Call Stack Trace -----
Incident details in: d:\app\administrator\diag\rdbms\cmcs\cmcs\incident\incdir_35162\cmcs_ora_4968_i35162.trc
ii. cmcs_ora_1020_i35208.trc日志(详细日志见附件).
4. 错误日志.
i. RMAN错误日志(详细日志见附件alert_cmcs.log)
ORA-04030:在尝试分配1049100字节(KSFQ heap,KSFQ Buffers)时进程内存不足
Incident details in: d:\app\administrator\diag\rdbms\cmcs\cmcs\incident\incdir_35208\cmcs_ora_1020_i35208.trc
ii. 调整操作系统启动参数.
在服务器操作系统根目录下(c:\)找到BOOt.ini文件,该文件为windows的启动文件. 找到字符串/PAE ,在/PAE前串/3GB重启操作系统.
Oracle错误代码案例总结及解决方案

个人收集整理-ZQ
: 小时与日中的秒发生冲突 : 小时中的分与日中的秒发生冲突 : 分中的秒与日中的秒发生冲突 : 指定月份的日期无效 : 输入值对于日期格式不够长 : (全)年度值必须介于 和 之间,且不为 : 季度值必须介于 和 之间月份中的周值必须介于 和 之间 : 周中的日无效
: 月份中日的值必须介于 和当月最后一日之间 (判断字符型能否转换成日期型)
: 年度中的日值必须介于 和 之间(闰年为 ) : 小时值必须介于 和 之间 : 小时值必须介于 和 之间 : 分钟值必须介于 和 之间 : 秒值必须介于 和 之间 : 日中的秒值必须介于 和 之间 : 日期必须介于 和 之间 : 要求 . 或 . : 要求 . 或 . : 无效的时区 : 在要求输入数字处找到非数字字符 : 在要求输入字母处找到非字母字符 : 年度中的周值必须介于 和 之间 : 文字与格式字符串不匹配 : 数字值与格式项目的长度不匹配: 年度不支持当前日历 : 日期超出当前日历的范围 : 无效的纪元 : 日期时间类无效 : 间隔无效 : 间隔的前导精度太小 : 保留以供将来使用 : 间隔或日期时间不是相互可比较的 : 秒数必须少于 : 保留以供将来使用 : 间隔的前导精度太小 : 时区小时必须在 和 之间 : 时区分钟必须在 和 之间 : 年份必须不少于 : 内部缓冲区的字符串太长 : 在日期时间或间隔中没有找到指定的字段 : 字段必须在 和 之间 : 零点几秒必须在 和 之间
个人收集整理-ZQ
Oracle 错误代码案例总结及解决方案
常见错误: :违反唯一约束条件(主键错误) :无法连接数据库进程:无效语句 :字段名写错或是建表时最后一个字段有逗号 :缺少右括号 :无效字符:缺少逗号 :未明确定义列 :丢失或无效的选项(表名等可能有空格) :未找到关键字:缺少 : 命令未正确结束 :缺少表达式 :不是单组分组函数 :表或视图不存在:没有足够的值(一般是插入语句出现的错,插入值的数量 与字段不符) :不是 的表达式 :缺少法定参数(:做参数时,且语句为空时,报错) :数据库无法关闭及启动 :无法将值插入 :插入的值对于列过大 :中存在除数为零
ORA03114等错误

措施:如果偶尔出现,可在服务端的协议配置文件PROTOCOL.ORA中增加一行
TCP.NODELAY=YES;
如果经常出现,则为客户端与服务端字符集不一致或网络原因。
客户端的字符集在注册表里定义: HKEY__LOCAL__MACHINE/SOFTWARE/ORACLE/NLS__LANG
在客户端注册表中的TCP参数项中设置 TCPMAXDATARETRANSMITIONS=20。
2、ORA-01000
特征:达到会话允许的最大游标数
原因:达到会话允许的最大游标数
措施:有两种解决方法:
(1)在初始化文件INIT.ORA文件中增加OPEN_CURSORS的数量,一般要求大于200。
特征:当前会话无法读到以前版本的数据
原因:原因很多,主要原因有下列:回滚段太小、太少;回滚段冲突;交叉提交(FETCH_ACROSS)
措施:增加回滚段数量;
6、ORA-04031
特征:共享池内存区内存不够,或产生内存碎片
原因:当试图装载一个大包时或执行一个较大的存储过程时,而共享池没有连续的内存空间。
原因:表空间已满;存储参数不合理,NEXT太小;没有连续的区间
措施:如果表空间已满,则需为表空间增加文件;如果存储参数不合理,则需增加INITIAL和NEXT;如果没有连续的区间,需要合并空闲的表空间。
查看空间碎片用DBA_FREE_SPACE
5、ORA-01555
(2)在应用级,与开发工具有关,例如设置MAXOPEN_CURSORS等。
3、ORA-01545 来自特征:某个回滚段不可用
原因:(1)当使回滚段ONLINE时,但回滚段不可用,例如回滚段所在表空间OFFLINE;
如何解决ORA-04031错误

如何解决ORA-04031 错误翻译:Fenng文章内容1.和共享池(shared pool)相关的实例参数2.诊断ORA-04031错误3.解决ORA-04031错误• 已知的Oracle BUG• 共享池碎片o V$SQLAREA 视图o X$KSMLRU 视图• 小的共享池尺寸o 库高速缓冲(library cache)命中率o 共享池大小的计算4.对ORA-04031的高级分析诊断并解决ORA-04031错误对于大多数应用来说,共享池的大小对于Oracle性能来说都是很重要的。
共享池中保存数据字典高速缓冲和完全解析或编译的的PL/SQL块和SQL语句。
当我们在共享池中试图分配大片的连续内存失败的时候,Oracle首先刷新池中当前没使用的所有对象,使空闲内存块合并。
如果仍然没有足够大单个的大块内存满足请求,就会产生ORA-04031错误。
当这个错误出现的时候你得到的错误信息如下:Error: ORA 4031Text: unable to allocate %s bytes of shared memory (%s,%s,%s)---------------------------------------------------------------------------------------------------------------- Cause: More shared memory is needed than was allocated in the shared pool.Action: Either use the dbms_shared_pool package to pin large packages, reduce your use ofshared memory, or increase the amount of available shared memory by increasing the value ofthe init.ora parameter "shared_pool_size".1.共享池相关的实例参数在继续之前,理解下面的实例参数是很重要的:• SHARED_POOL_SIZE – 这个参数指定了共享池的大小,单位是字节。
Oracle ORA-04031 错误 说明

Oracle ORA-04031 错误说明分类:Oracle 故障解决案例Oracle 性能调优2011-06-15 14:42 364人阅读评论(0) 收藏举报在老熊的Blog上看到他们写的有关ORA-04031的文章,转到blog。
老熊的Blog:/an-ora-04031-case.htmlORA-04031这个错误,几乎每一个专业的DBA都遇到过。
这是一个相当严重的错误,Oracle进程在向SGA申请内存时,如果申请失败,则会报这个错误。
大部分情况下是在向SGA中的shared pool申请内存时失败,而少有向large pool等池中申请内存失败。
比如下面的报错:Wed Apr 27 16:00:25 2011Errors in file/oracle/app/oracle/admin/zxin/bdump/zxin1_ora_2052294.trc:ORA-04031: unable to allocate 4128 bytes of shared memory("shared pool","unknown object","sga heap(3,0)","kgllk hash table")这里很清楚地表示出来,是在向shared pool申请内存时失败。
shared pool内存申请(分配)失败,通常有如下的几种可能:(1)shared pool过小,比如在SGA Manual Management方式下,shared pool 设置过小。
比如一套数千连接的大系统,shared pool只设置了几百M。
这种情况下,要解决问题很解单,增加shared pool的大小即可。
(2)应用没有使用绑定变量,硬解析非常多,导致shared pool内存碎片严重,分配大块内存时不能获得连续的内存空间。
硬解析多的一个变种是虽然使用了绑定变量,但是由于某种原因,Cursor不能共享,导致Child Cursor非常多。
ORA-04031故障分析处理

ORA-04031故障分析处理当任何试图分配一个大的连续的共享池中的内存失败,Oracle首先会刷新掉共享池中所有目前不在使用的对象,然后使得内存块被合并在一起。
如果内存块仍然不够满足需求,那么就会出现ORA- 04031错误。
这些错误同样可能发生在ASM的实例中。
默认的共享池的大小基本能够满足大部分的环境,但是如果遇到ORA-04031错误的时候可能就需要增大。
当遇到这个错误的时候,往往会出现如下的消息显示:04031, 00000, "unable to allocate %s bytes of shared memory ("%s","%s", "%s","%s")"先来了解一下跟共享池相关的实例参数:a) SHARED_POOL_SIZE --–这个参数指定共享池的大小,以字节为单位。
b) SHARED_POOL_RESERVED_SIZE --–指定为大的连续的共享池内存请求预留的共享池的大小。
这个参数连同SHARED_POOL_RESERVED_MIN_ALLOC参数,可以用于避免消除由于共享池碎片太多导致迫使Oracle搜寻空闲的共享池空间而产生ORA-04031错误。
c) _SHARED_POOL_RESERVED_MIN_ALLOC --–这个参数用于控制预留内存的分配。
大于这个参数的内存分配可以使用预留内存的列表。
这个参数的默认值适合绝大多数的系统,如果增加这个参数值,那么Oracle将允许分配越少的预留内存列表而更多的请求共享池列表。
这个参数在Oracle8i和之后的版本都是隐含参数,但是可以通过执行如下SQL查到:select nam.ksppinm NAME,val.KSPPSTVL VALUEfrom x$ksppi nam,x$ksppsv valwhere nam.indx = val.indxand nam.ksppinm like '%shared%' order by 1;对于Oracle10g,具有一个新特性自动内存管理,允许dba保留用于分配给Oracle内存区域使用的共享内存。
Oracle错误一览表2

ORA-02201: 此处不允许序列(号)ORA-02202: 此群集中不允许添加其它表ORA-02203: 不允许的INITIAL 存储选项ORA-02204: 不允许ALTER, INDEX 和EXECUTE 用于视图ORA-02205: 只有SELECT 和ALTER 权限对序列有效ORA-02206: 重复的INITRANG 选项说明ORA-02207: 无效的INITRANS 选项值ORA-02208: 重复的MAXTRANS 选项说明ORA-02209: 无效的MAXTRANS 选项值ORA-02210: 未指定ALTER TABLE 的选项ORA-02211: 无效的PCTFREE 或PCTUSED 值ORA-02212: 重复的PCTFREE 选项说明ORA-02213: 重复的PCTUSED 选项说明ORA-02214: 重复的BACKUP 选项说明ORA-02215: 重复的表空间名子句ORA-02216: 需要表空间名ORA-02217: 重复的存储选项说明ORA-02218: 无效的INITIAL 存储选项值ORA-02219: 无效的NEXT 存储选项值ORA-02220: 无效的MINEXTENTS 存储选项值ORA-02221: 无效的MAXEXTENTS 存储选项值ORA-02222: 无效的PCTINCREASE 存储选项值ORA-02223: 无效的OPTIMAL 存储选项值ORA-02224: EXECUTE 权限对于表不允许ORA-02225: 只有EXECUTE 和DEBUG 权限对过程有效ORA-02226: 无效的MAXEXTENTS 值(最大允许为: )ORA-02227: 无效的群集名ORA-02228: 重复的SIZE 说明ORA-02229: 无效的SIZE 选项值ORA-02230: 无效的ALTER CLUSTER 选项ORA-02231: 缺少或无效的ALTER DATABASE 选项ORA-02232: 无效的MOUNT 模式ORA-02233: 无效的CLOSE 模式ORA-02234: 已经记录对此表的更改ORA-02235: 此表已将更改记录在另一表中ORA-02236: 无效的文件名ORA-02237: 无效的文件大小ORA-02238: 文件名列表具有不同的文件数ORA-02239: 存在引用此序列的对象ORA-02240: 无效的OBJNO 或TABNO 值ORA-02241: 必须是EXTENTS (FILE <n> BLOCK <n> SIZE <n>,...) 格式ORA-02242: 未指定ALTER INDEX 的选项ORA-02243: ALTER INDEX 或ALTER MATERIALIZED VIEW 选项无效ORA-02244: 无效的ALTER ROLLBACK SEGMENT 选项ORA-02245: 无效的ROLLBACK SEGMENT 名ORA-02246: 缺少EVENTS 文本ORA-02247: 未指定ALTER SESSION 的选项ORA-02248: 无效的ALTER SESSION 选项ORA-02249: 缺少或无效的MAXLOGMEMBERS 值ORA-02250: 缺少或无效的约束条件名ORA-02251: 此处不允许子查询ORA-02252: 检查未正确结束的约束条件ORA-02253: 此处不允许约束条件说明ORA-02254: 此处不允许DEFAULT <表达式>ORA-02255: obsolete 7.1.5ORA-02256: 要引用的列数必须与已引用道感数匹配ORA-02257: 超出最大列数ORA-02258: 重复或冲突的NULL 和(或)NOT NULL 说明ORA-02259: 重复的UNIQUE/PRIMARY KEY 说明ORA-02260: 表只能具有一个主键ORA-02261: 表中已存在这样的唯一关键字或主键ORA-02262: 对列默认值表达式进行类型检查时, 出现ORA- ORA-02263: 需要指定此列的数据类型ORA-02264: 名称已被一现有约束条件占用ORA-02265: 无法推导引用列的数据类型ORA-02266: 表中的唯一/主键被启用的外部关键字引用ORA-02267: 列类型与引用的列类型不兼容ORA-02268: 引用的表不具有主键ORA-02269: 关键字列不能是LONG 数据类型ORA-02270: 此列列表的唯一或主键不匹配ORA-02271: 表没有这样的约束条件ORA-02272: 约束条件列不能是LONG 数据类型ORA-02273: 此唯一/主键已被某些外部关键字引用ORA-02274: 重复的引用约束条件说明ORA-02275: 此表中已经存在这样的引用约束条件ORA-02276: 默认值类型与列类型不兼容ORA-02277: 无效的序列名ORA-02278: 重复或冲突的ORDER/NOORDER 说明ORA-02279: 重复或冲突的ORDER/NOORDER 说明ORA-02280: 重复或冲突的ORDER/NOORDER 说明ORA-02281: 重复或冲突的ORDER/NOORDER 说明ORA-02282: 重复或冲突的ORDER/NOORDER 说明ORA-02283: 无法改变起始序号ORA-02284: 重复的INCREMENT BY 说明ORA-02285: 重复的START WITH 说明ORA-02286: 未指定ALTER SEQUENCE 的选项ORA-02287: 此处不允许序号ORA-02288: 无效的OPEN 模式ORA-02289: 序列(号)不存在ORA-02290: 违反检查约束条件(.)ORA-02291: 违反完整约束条件(.) - 未找到父项关键字ORA-02292: 违反完整约束条件(.) - 已找到子记录日志ORA-02293: 无法验证(.) - 违反检查约束条件ORA-02294: 无法启用(.) - 约束条件在验证过程中更改ORA-02295: 找到约束条件的多个启用/禁用子句ORA-02296: 无法启用(.) - 找到空值ORA-02297: 无法禁用约束条件(.) - 存在依赖关系ORA-02298: 无法验证(.) - 未找到父项关键字ORA-02299: 无法验证(.) - 未找到重复关键字ORA-02300: 无效的OIDGENERATORS 值ORA-02301: OIDGENERATORS 的最大数为255ORA-02302: 无效或缺少类型名ORA-02303: 无法使用类型或表的相关性来删除或取代一个类型ORA-02304: 无效的对象标识文字ORA-02305: 只有EXECUTE, DEBUG 和UNDER权限对类型有效ORA-02306: 无法创建已具有有效相关性的类型ORA-02307: 无法使用REPLACE 选项改变无效类型ORA-02308: 无效的对象类型列选项ORA-02309: 违反原子NULLORA-02310: 超出表中允许的最大列数ORA-02311: 无法使用COMPILE 选项改变具有类型或表相关性的有效类型ORA-02313: 对象类型包含不可查询的类型属性ORA-02315: 默认构造符的参数个数错误ORA-02320: 无法创建嵌套表列的存储表ORA-02322: 无法访问嵌套表列的访问表ORA-02324: THE 子查询的SELECT 列表中存在多列ORA-02327: 无法以数据类型的表达式创建索引ORA-02329: 数据类型的列不能是唯一关键字或主键ORA-02330: 不允许的数据类型说明ORA-02331: 无法创建数据类型为的列的约束条件ORA-02332: 无法对此列的属性创建索引ORA-02333: 无法对此列的属性创建约束条件ORA-02334: 无法推断列类型ORA-02335: 无效的群集列数据类型ORA-02336: 无法访问列属性ORA-02337: 不是对象类型列ORA-02338: 缺少或无效的列约束条件说明ORA-02339: 无效的列说明ORA-02340: 无效的列说明ORA-02342: 取代类型具有编译错误ORA-02344: 无法撤消执行具有表相关性的类型ORA-02345: 无法创建具有基于CURSOR 运算符的列的视图ORA-02347: 无法授权给对象表列ORA-02348: 无法创建具有嵌入LOB 的VARRAY 列ORA-02349: 无效的用户自定义类型- 类型不完整ORA-02351: 记录: 被拒绝- 表, 列上出错ORA-02352: 直接路径连接必须在同类间进行ORA-02353: 多字节字符错误ORA-02354: 字段中出现转换初始化错误ORA-02355: CONSTANT 字段中出现转换错误ORA-02356: 数据库空间耗尽。
Oracle错误代码案例总结及解决方案

Oracle错误代码案例总结及解决方案随着Oracle数据库的使用,难免会遇到一些错误代码。
本文将介绍一些常见的Oracle错误代码以及解决方案。
这个错误通常是由于输入的用户名或密码不正确造成的。
解决办法是验证用户名和密码是否正确,并确保数据库实例启动。
这个错误通常是由于在SQL查询中引用了一个不存在的列或表名造成的。
解决办法是检查查询中的列名或表名是否正确,如果需要,可以使用引号将其括起来。
这个错误通常是由于连接描述符无法被解析造成的。
解决办法是检查tnsnames.ora文件中的连接描述符是否正确,并确保listener服务正在运行。
这个错误通常是由于在数值比较中使用了无效的字符造成的。
解决办法是检查数据类型是否正确,并确保传入的值是有效的数字。
这个错误通常是由于SQL语句缺少了必要的结束符号造成的。
解决办法是确保每条SQL语句以分号结尾,并检查语法是否正确。
这个错误通常是由于插入或更新操作违反了表的完整性约束条件造成的。
解决办法是确保插入或更新的值符合表的约束条件,并确保触发器、外键等相关对象正确配置。
这个错误通常是由于在更新语句的THEN子句中没有包含所有列造成的。
解决办法是确保更新语句中的THEN子句包含所有需要更新的列。
这个错误通常是由于在SQL语句中缺少需要的表达式造成的。
解决办法是确保SQL语句中的所有操作数都是有效的,并检查语法是否正确。
这个错误通常是由于插入或更新操作违反了UNIQUE约束条件造成的。
解决办法是确保插入或更新的值不会违反UNIQUE约束条件,并确保索引、触发器等相关对象正确配置。
这个错误通常是由于读取的数据已被其他会话修改或删除造成的。
解决办法是增加undo表空间的大小,或调整事务隔离级别以减少读取之间的时间差。
总结:本文介绍了一些常见的Oracle错误代码以及解决方案,包括无效的用户名/密码、无效的标识符、无法解析指定的连接标识符、无效数字、SQL命令未正确结束、违反完整性约束条件、缺失表达式、UNIQUE约束条件违背和快照过旧等。
ASM错误

Use of uninitialized value $related_alias in concatenation (.) or string at /u01/app/11.2.0/grid/lib/asmcmdbase.pm line 1955, <STDIN> line 19.
节点2:写入
create spfile='+CRS' FROM PFILE='/home/grid/initasm.ora';
写入的文件默认目录:
+CRS/urp-cluster/asmparameterfile
最后重新启动所有数据库
su - grid
conn / as sysasm
ile/registry.253.848668091
最后Z执行:
重启crs
root@rac1:~# crsctl stop crs -f
root@rac:~# crsctl start crs
ORA-04031: unable to allocate 4064 bytes of shared memory ("shared pool","unknown object","sga heap(1,0)","kglsim heap") (DBD ERROR: OCIStmtExecute/Describe)
*.memory_target = 4G #添加参数
典型案例:深入剖析ORA-04031的前世今生

典型案例:深入剖析ORA-04031的前世今生李磊云和恩墨技术专家每一个接触过Oracle 数据库的人想必听到Ora-04031 都会有一种捶胸顿足的感觉,至少在两年前的我是这样子的。
都说Ora-04031 和 Ora-01555 等是 Oracle 的经典错误,之所以成为经典,可能就是因为它们会经常出现,却又不是那么好解决的缘故吧。
今天我就跟大家分享一个我工作当中的4031案例,解读一下4031的前世今生,希望通过今天晚上的交流,当我们再次遇见4031错误时不再像之前那么恐惧。
本次跟大家分享的这个案例是去年我在某电力公司驻场的时候,某天下午刚回到住处就收到手机报警短信,说 pmdb1 库有4031报错(因为该客户使用了 zabbix 监控,所以手机可以收到数据库的所有警告和错误),于此同时开发人员打来电话说应用日志里面有4031错误,我立马赶回办公室,处理这个棘手的4031错误。
在继续下面的内容之前我先介绍一下本次案例中这套数据库的情况。
这是一个运行在AIX 上的一套双节点RAC,数据库的版本为11.2.0.3.0,库的数据数据量不是很大,在80G左右,但是是一个非常重要的业务系统的中间库。
以我这几年的工作经验来说,当我们遇到 Oracle 报错时,通常都会从数据库的 alert 日志看起,结合与错误相关的 trace 文件以及发生错误时的一些系统状态、数据库状态等获取相关信息,综合上面的信息来判断该报错。
本次对4031错误的分析也是一样。
哪么我首先来查看了数据库的 alert 日志,果不其然,日志里面有大量的4031错误,记录如下所示:经历过 Ora-04031 错误的 DBA 都知道,如果数据库遇到了4031错误,可能会导致很多会话都会抛出4031错误,严重的会导致整个数据库不能运行任何SQL 语句,即使是一条非常简单的语句,更有甚者还会导致数据宕机。
而一提到数据库宕机相信可能会让很多 DBA 都胆战心惊,这里我先用一句话简单的总结一下4031错误的原因,让大家对4031先有一个初步的认识。
ORA-04031故障分析处理

ORA-04031故障分析处理当任何试图分配一个大的连续的共享池中的内存失败,Oracle首先会刷新掉共享池中所有目前不在使用的对象,然后使得内存块被合并在一起。
如果内存块仍然不够满足需求,那么就会出现ORA- 04031错误。
这些错误同样可能发生在ASM的实例中。
默认的共享池的大小基本能够满足大部分的环境,但是如果遇到ORA-04031错误的时候可能就需要增大。
当遇到这个错误的时候,往往会出现如下的消息显示:04031, 00000, "unable to allocate %s bytes of shared memory ("%s","%s", "%s","%s")"先来了解一下跟共享池相关的实例参数:a) SHARED_POOL_SIZE --–这个参数指定共享池的大小,以字节为单位。
b) SHARED_POOL_RESERVED_SIZE --–指定为大的连续的共享池内存请求预留的共享池的大小。
这个参数连同SHARED_POOL_RESERVED_MIN_ALLOC参数,可以用于避免消除由于共享池碎片太多导致迫使Oracle搜寻空闲的共享池空间而产生ORA-04031错误。
c) _SHARED_POOL_RESERVED_MIN_ALLOC --–这个参数用于控制预留内存的分配。
大于这个参数的内存分配可以使用预留内存的列表。
这个参数的默认值适合绝大多数的系统,如果增加这个参数值,那么Oracle将允许分配越少的预留内存列表而更多的请求共享池列表。
这个参数在Oracle8i和之后的版本都是隐含参数,但是可以通过执行如下SQL查到:select nam.ksppinm NAME,val.KSPPSTVL VALUEfrom x$ksppi nam,x$ksppsv valwhere nam.indx = val.indxand nam.ksppinm like '%shared%' order by 1;对于Oracle10g,具有一个新特性自动内存管理,允许dba保留用于分配给Oracle内存区域使用的共享内存。
ORA-04031 ERROR

DIAGNOSING AND RESOLVING ORA-04031 ERRORWhen any attempt to allocate a large piece of contiguous memory in the shared pool fails Oracle first flushes all objects that are not currently in use from the pool and the resulting free memory chunks are merged. If there is still not a single chunk large enough to satisfy the request the ORA-04031 error is returned. NOTE: These errors can occur on an ASM instance as well. The default shared_pool_size should be sufficient in most environments, but can be increased if you are experiencing ORA-04031 errors.The message that you will get when this error appears is the following:04031, 00000, "unable to allocate %s bytes of shared memory(\"%s\",\"%s\",\"%s\",\"%s\")"// *Cause: More shared memory is needed than was allocated in the shared// pool.// *Action: If the shared pool is out of memory, either use the // dbms_shared_pool package to pin large packages,// reduce your use of shared memory, or increase the amount of// available shared memory by increasing the value of the// INIT.ORA parameters "shared_pool_reserved_size" and// "shared_pool_size".// If the large pool is out of memory, increase the INIT.ORA// parameter "large_pool_size".1. Instance parameters related with the Shared PoolBefore continuing, understanding the following instance parameters will be essential:SHARED_POOL_SIZE - This parameter specifies the size of the shared pool in bytes and can accepta numerical values or a number followed by the suffix "K" or "M"where "K" means "multiply by 1000"and "M" means "multiply by 1000000"∙SHARED_POOL_RESERVED_SIZE - It specifies the shared pool space which is reserved for large contiguous requests for shared pool memory. This parameter along with theSHARED_POOL_RESERVED_MIN_ALLOC parameter, can be used to avoid the occurrence of this error from situations where shared poolfragmentation forces Oracle to search for and freechunks of unused pool to satisfy the current request.Ideally, this parameter should be large enough to satisfy any request scanning for memory on the reserved list without flushing objects from the shared pool. Since the operating system memory may constraint the size of the shared pool, in general, you should set this parameter to 10% of the SHARED_POOL_SIZE parameter.∙SHARED_POOL_RESERVED_MIN_ALLOC - The value of this parameter controls allocation of reserved memory. Memory allocation larger than this value can allocate space from the reserved list if a chunk of memory of sufficient size is not found on the shared pool free lists. The default value is adequate for most systems. If you increase the value, then the Oracle server will allow fewerallocations from the reserved list and will request more memory from the shared pool list. This parameter is hidden in Oracle 8i and higer, but it can be found by executing the following SQL statement:select nam.ksppinm NAME,val.KSPPSTVL VALUEfrom x$ksppi nam,x$ksppsv valwhere nam.indx = val.indxand nam.ksppinm like '%shared%'order by 1;NOTE: This parameter was obsoleted with 8i. The parameter can still be modified via the underscore parameter_SHARED_POOL_RESERVED_MIN_ALLOC.10g Note:In Oracle 10g a new feature called "automatic memory management" allows the dba to reserve a pool of shared memory that is used to allocate the shared pool, the buffer cache, the java pool and the large pool.In general, when the database needs to allocate a large object into the shared pool and cannot find contiguous space available, it will automatically increase the shared pool size using free space from other SGA structure.Since the space allocation is automatically managed by Oracle, the probability of getting ora-4031 errors may be greatly reduced.Automatic Memory Management is enabled when the parameterSGA_TARGET is greater than zero and the current setting can be obtained quering the v$sga_dynamic_components view.It is not possible restrict the size of shared pool if usingSGA_TARGET. If you want to exercise more control on shared pool size, please dont use SGA_TARGET parameter.Please refer to the 10g Administration Manual for furtherreference.2. Diagnosing error ORA-04031:Note:Most common ORA-4031 occurrences are related to the SHARED POOL SIZE, therefore the diagnostic steps provided in this article will mostly address issues related to the shared pool. For other areas like large_pool or java_pool where the memory allocation algorith is simpler, normally the error is caused by an undersized structure.ORA-04031 error can be due to either an inadequeate sizing of the SHARED POOL size or due to heavy fragmentation leading the database to not finding large enough chuncks of memory. NOTE: There have been many reports where the default size for shared_pool_size on an ASM instance is too small. If you experience ORA-04031 error on your ASM instance, increase the shared_pool_size parameter to 50M. If the problem persists, then increase the parameter again in increments of 10M until you stop seeing the error.Inadequate Sizing:The first thing is determining if the ORA-04031 error is a result of lack of contiguous space in the library cache by verifying the following from V$SHARED_POOL_RESERVED:REQUEST_FAILURES is > 0 and LAST_FAILURE_SIZE is <SHARED_POOL_RESERVED_MIN_ALLOCorREQUEST_FAILURES is 0 and LAST_FAILURE_SIZE is <SHARED_POOL_RESERVED_MIN_ALLOCIf this is the case, consider loweringSHARED_POOL_RESERVED_MIN_ALLOC toallow the database putting more objects into the shared poolreserved space and then increase theSHARED_POOL_SIZE if the problem is not resolved.NOTE: A bug was discoverd where LAST_FAILURE_SIZE can be wrong in cases where multiple pools are used. The value in LAST_FAILURE_SIZE can be a sum of failure sizes across all pools. This is fixed as of 9.2.0.7, 10.1.0.4, and 10.2.x.Fragmentation:If this is not the case, then you must determine if the ORA-04031 was a result of fragmentation in the library cache or in the shared pool reserved space by following this rule:REQUEST_FAILURES is > 0 and LAST_FAILURE_SIZE is >SHARED_POOL_RESERVED_MIN_ALLOC.To resolve this consider increasingSHARED_POOL_RESERVED_MIN_ALLOC to lowerthe number of objects being cached into the shared pool reserved space andincrease SHARED_POOL_RESERVED_SIZE and SHARED_POOL_SIZE toincrease theavailable memory in the shared pool reserved space.Another consideration: - Pre-9i, changingOPTIMIZER_MAX_PERMUTATIONS to 2000 can reduce shared pool space pressure3. Resolving error ORA-04031:Oracle BUGsOracle recommends to apply the latest patchser available for your platform. Most of the ORA-4031 errors related to BUGs can be avoided by applying these patchsets. The following table summarize the most common BUGs related with this error, possible workaround and the patchset that fixes the problem.ORA-4031 when compiling Java code:If you run out of memory while compiling a java code (within loadjava or deployejb), you should see an error:A SQL exception occurred while compiling: : ORA-04031: unable toallocate bytes of shared memory ("shared pool","unknownobject","joxlod: init h", "JOX: ioc_allocate_pal")The solution is to shut down the database and set JAVA_POOL_SIZE to a larger value. The mention of "shared pool" in the error message is a misleading reference to running out of memory in the "Shared Global Area". It does not mean you should increase yourSHARED_POOL_SIZE. Instead, you must increase your JAVA_POOL_SIZE, restart your server, and try again.See Bug 2736601Small shared pool sizeIn many cases, a small shared pool can be the cause of the ORA-04031 error.The following information will help you to adjust the size of the shared pool:o Library Cache Hit RatioThe hit ratio helps to measure the usage of the shared poolbased on how many times a SQL/PLSQL statement needed to beparsed instead of being reused. The following SQL statementhelp you to calculate the library cache hit ratio:SELECT SUM(PINS) "EXECUTIONS",SUM(RELOADS) "CACHE MISSES WHILE EXECUTING"FROM V$LIBRARYCACHE;If the ratio of misses to executions is more than 1%, thentry to reduce the library cache misses by increasing theshared pool size.o Shared Pool Size CalculationTo calculate the size of the shared pool that best fits toyour current workload, please refer to:Note 1012046.6: HOW TO CALCULATE YOUR SHARED POOL SIZE.Shared Pool Fragmentation:Every time a SQL or PL/SQL statement needs to be executed the parse representation is loaded in the library cache requiring a specific amount of free contiguous space. The first resource where the database scans is the free memory available in the shared pool. Once the free memory is exhausted, the database looks for reusing an already allocated piece not in use. If a chunk with the exact size is not available, the scan continues looking for space based on the following criteria:- The chunk size is larger than the required size- The space is contiguous- The chunk is available (not in use)Then that chunk is split and the remaining free space is added to the appropriate free space list. When the database is operating in this way for a certain period of time the shared pool structure will be fragmented.When the shared pool is suffering fragmentation ORA-04031 errors (when the database cannot find a contiguous piece of free memory) may occur. Also as a concequence , the allocation of a piece of free space takes more time an the performance may be affected (the "chunk allocation" is protected by a single latch called "shared pool latch" which is held during the whole operation). However, ORA-4031 errors don't always affect the performance of the database.If the SHARED_POOL_SIZE is large enough, most ORA-04031 errors area result of dynamic sql fragmenting the shared pool. This can becaused by:o Not sharing SQLo Making unnecessary parse calls (soft)o Not using bind variablesTo reduce fragmentation you will need to address one or more of the causes described before. In general to reduce fragmentation you must analyze how the application is using the shared pool and maximize the use of sharable cursors.Please refer to Note 62143.1, which describes these options in greater detail. This note contains as well further detail on how the shared pool works.The following views will help you to identify non-sharable versions of SQL/PLSQL text in the shared pool:o V$SQLAREA ViewThis view keeps information of every SQL statement and PL/SQL block executed in the database. The following SQL can show you statements with literal values or candidates to include bind variables:SELECT substr(sql_text,1,40) "SQL",count(*) ,sum(executions) "TotExecs"FROM v$sqlareaWHERE executions < 5GROUP BY substr(sql_text,1,40)HAVING count(*) > 30ORDER BY 2;Note: The number "30" in the having section of the statement can be adjusted as needed to get more detailed information.o X$KSMLRU ViewThere is a fixed table called x$ksmlru that tracksallocations in the shared pool that cause other objects in the shared pool to be aged out. This fixed table can be used to identify what is causing the large allocation.If many objects are being periodically flushed from theshared pool then this will cause response time problems and will likely cause library cache latch contention problems when the objects are reloaded into the shared pool.One unusual thing about the x$ksmlru fixed table is that the contents of the fixed table are erased whenever someoneselects from the fixed table. This is done since the fixed table stores only the largest allocations that have occurred.The values are reset after being selected so that subsequent large allocations can be noted even if they were not quiteas large as others that occurred previously. Because of this resetting, the output of selecting from this table should be carefully kept since it cannot be retrieved back after the query is issued.To monitor this fixed table just run the following:SELECT * FROM X$KSMLRU WHERE ksmlrsiz > 0;This view can only be queried by connected as the SYS.o X$KSMSP View (Similar to Heapdump Information)Using this view you will be able to find out how the free space is currently allocated, which will be helpful to undrestand the level of fragmentation of the shared pool. As it was described before, the first place to find a chunck big enough for the cursor allocation is the free list. The following SQL shows the chunks available in the free list:select '0 (<140)' BUCKET, KSMCHCLS, KSMCHIDX,10*trunc(KSMCHSIZ/10) "From",count(*) "Count" , max(KSMCHSIZ) "Biggest",trunc(avg(KSMCHSIZ)) "AvgSize", trunc(sum(KSMCHSIZ))"Total"from x$ksmspwhere KSMCHSIZ<140and KSMCHCLS='free'group by KSMCHCLS, KSMCHIDX, 10*trunc(KSMCHSIZ/10)UNION ALLselect '1 (140-267)' BUCKET, KSMCHCLS,KSMCHIDX,20*trunc(KSMCHSIZ/20) ,count(*) , max(KSMCHSIZ) ,trunc(avg(KSMCHSIZ)) "AvgSize", trunc(sum(KSMCHSIZ))"Total"from x$ksmspwhere KSMCHSIZ between 140 and 267and KSMCHCLS='free'group by KSMCHCLS, KSMCHIDX, 20*trunc(KSMCHSIZ/20)UNION ALLselect '2 (268-523)' BUCKET, KSMCHCLS, KSMCHIDX,50*trunc(KSMCHSIZ/50) ,count(*) , max(KSMCHSIZ) ,trunc(avg(KSMCHSIZ)) "AvgSize", trunc(sum(KSMCHSIZ)) "Total"from x$ksmspwhere KSMCHSIZ between 268 and 523and KSMCHCLS='free'group by KSMCHCLS, KSMCHIDX, 50*trunc(KSMCHSIZ/50) UNION ALLselect '3-5 (524-4107)' BUCKET, KSMCHCLS, KSMCHIDX,500*trunc(KSMCHSIZ/500) ,count(*) , max(KSMCHSIZ) ,trunc(avg(KSMCHSIZ)) "AvgSize", trunc(sum(KSMCHSIZ)) "Total"from x$ksmspwhere KSMCHSIZ between 524 and 4107and KSMCHCLS='free'group by KSMCHCLS, KSMCHIDX, 500*trunc(KSMCHSIZ/500) UNION ALLselect '6+ (4108+)' BUCKET, KSMCHCLS, KSMCHIDX,1000*trunc(KSMCHSIZ/1000) ,count(*) , max(KSMCHSIZ) ,trunc(avg(KSMCHSIZ)) "AvgSize", trunc(sum(KSMCHSIZ)) "Total"from x$ksmspwhere KSMCHSIZ >= 4108and KSMCHCLS='free'group by KSMCHCLS, KSMCHIDX, 1000*trunc(KSMCHSIZ/1000);Note:The information available in this view is the same that is generated as part of a HEAPDUMP level 2.Also be aware that running this query too often is likely to cause other memory issues in the shared pool.There is also a port specific bug filed on HP and 10g where running queries on x$ksmsp will hang the database.If the result of the above query shows that must of the space available is on the top part of the list (meaning available only in very small chuncks). It is very likely that the error is due to a heavy fragmentation.You can also use this view as follows to review overall memory usage in the SGASQL> SELECT KSMCHCLS CLASS, COUNT(KSMCHCLS) NUM,SUM(KSMCHSIZ) SIZ,To_char( ((SUM(KSMCHSIZ)/COUNT(KSMCHCLS)/1024)),'999,999.00')||'k' "AVG SIZE"FROM X$KSMSP GROUP BY KSMCHCLS;CLASS NUM SIZ AVG SIZE-------- ---------- ---------- ------------R-free 12 8059200 655.86k <= Reserved ListR-freea 24 960 .04k <= Reserved Listfree 331 151736448 447.67k <= Free Memoryfreeabl 4768 7514504 1.54k <= Memory for user / systemprocessingperm 2 30765848 15,022.39k <= Memory allocated to the systemrecr 3577 3248864 .89k <= Memory for user / system processinga) if free memory (SIZ) is low (less than 5mb or so) you mayneed to increase the shared_pool_size andshared_pool_reserved_size.b) if perm continually grows then it is possible you areseeing system memory leak.c) if freeabl and recr are always huge, this indicates thatyou have lots of cursor info stored that is not releasing.d) if free is huge but you are still getting 4031 errors, (youcan correlate that with the reloads and invalids causingfragmentation)4. ORA-04031 error and Large PoolThe Large pool is an optional memory area that can be configured to provide large memory allocations for one of the following operations :∙ session memory for the multi-threaded server and the Oracle XA interface.∙ The memory ( Buffers ) for Oracle backup and restore operations and for I/O server processes.∙ Parallel Execution messaging buffers.The Large pool does not have a LRU list. It is different from reserved space in the shared pool, which uses the same LRU list as other memory allocated from the shared pool.Chunks of memory are never aged out of the large pool,memory has to be explicitly allocated and freed by each session.If there is no free memory left when a request is made then an ORA-4031 will be signalled similar to this :ORA-04031: unable to allocate XXXX bytes of shared memory("large pool","unknown object","session heap","frame")Few things can be checked when this error occurs:1- Check V$SGASTAT and see how much memory is used and free using the following SQL statement:SELECT pool,name,bytes FROM v$sgastat where pool = 'largepool';2- You can also take a heapdump level 32 to dump the large pool heap and check free chunks sizes.Memory is allocated from the large pool in chunks of LARGE_POOL_MIN_ALLOC bytes to help avoid fragmentation. Any request to allocate a chunk size less LARGE_POOL_MIN_ALLOC will be allocated with size ofLARGE_POOL_MIN_ALLOC. In general you may see more memory usage when using Large Pool compared to Shared Pool.Usually to resolve an ORA-4031 in the large pool the LARGE_POOL_SIZE size must be increased.5. ORA-04031 and SHARED POOL FLUSHINGThere are several technics to increase cursor sharability so that shared pool fragmentation is reduce as well as likeability of ORA-4031 errors. The best way is by modifying the application to use bind variables. Another workaround when the application cannot be modified is usingCURSOR_SHARING to a value different of EXACT (Be aware that this may cause changes in execution plan, so it is advisable to test the application first). When none of the above techniques can be used and fragmentation is considearble heavy in the system, flushing the shared pool might help alliviating the fragmentation. However some considerations must be taken into account:Flushing the shared pool will cause that all the cursor that are not in use are removed from the library cache. Thereforejust after the shared pool flusing is issued, most of the SQLand PL/SQL cursors will have to be hard parsed. This willincrease the CPU usage of the system and will also increasethe latch activity.∙When applications don't use bind variables and have heavy possibilities of many users doing frequen similar operations(like in OLTP systems) it is common that soon after the flushis issued the fragmentation is back in place. So be advicethat flushing the shared pool is not always the solution fora bad application.∙For large shared pool flushing the shared pool may cause a halt of the system, specially when the instance is very active.It is recommended to flush the shared pool during off-peakhours.6. Advanced analysis to ORA-04031errorIf none of the techniques provided cannot resolve the occurence of ORA-04031 errors, additional tracing may be needed to get a snapshot of the shared pool when the problem is in place.Modify the init.ora paramater to add the following events toget a trace file with additional information about theproblem:event = "4031 trace name errorstack level 3"event = "4031 trace name HEAPDUMP level 3"Note:This parameter will take not effect unless the instanceis bounced.Starting with 9.2.0.5, instead of requesting heapdump level1,2 , 3 or 32 you can use level those same levels plus(536870912).This will generate the 5 largest subheaps AND the 5 largestheap areas within each of those.If the problem is reproducible, the event can be set atsession level using the following statement before theexecution of the faulty SQL statement:SQL> alter session set events '4031 trace name errorstacklevel 3';SQL> alter session set events '4031 trace name HEAPDUMP level536870915';This trace file should be sent to Oracle Support for troubleshooting.Important Note:In Oracle 9.2.0.5 and Oracle 10g releases a trace file is generated BY DEFAULT every time an ORA-4031 error occurs, and can be located in the user_dump_dest directory. If your database version is oneof these, you don't need to follow the steps described before to generate additional tracing.RELATED DOCUMENTSNote 396940.1FAQ: ORA-4031Note 1012046.6How to Calculate Your Shared Pool SizeNote 62143.1Understanding and Tuning the Shared PoolNote 61623.1Resolving Shared Pool Fragmentation In Oracle7Note 1012049.6Tuning Library Cache Latch ContentionNote 105813.1SCRIPT. TO SUGGEST MINIMUM SHARED POOL SIZENote 316138.1ORA-4031 / Continuos Growth of 'miscellaneous' in v$sgastat when STATISTICS_LEVEL is set to TYPICAL or ALLNote 367392.1ORA-4031 with calls to ksfd_alloc_sgabuffer,ksfd_alloc_contig_buffer, ksfd_get_contig_buffer。
Oracle数据库发生ORA-04031错误原因浅析及处理

Oracle数据库发生ORA-04031错误原因浅析及处理凌玥;张建清;吴越
【期刊名称】《黑龙江科技信息》
【年(卷),期】2016(000)021
【摘要】Oracle数据库介绍;ORA-4031错误信息产生原因的分析及处理;共享池空间不够产生的原因分析及调整等.
【总页数】1页(P178)
【作者】凌玥;张建清;吴越
【作者单位】南京邮电大学,江苏南京210000;中国电信股份有限公司无锡分公司,江苏无锡214000;中兴通讯股份有限公司,江苏南京210000
【正文语种】中文
【相关文献】
1.产前检查处理中容易发生的医疗错误和防治要点 [J], 郭玉娜;程蔚蔚
2.计划生育处理中容易发生的医疗错误及防范措施 [J], 方爱华
3.Oracle数据库系统常见错误的信息及故障处理 [J], 闫军;唐晓梅;王建华
4.地面测报程序使用中容易发生的一些错误及处理方法 [J], 李春学;
5.第二届高校出版社学术著作评奖参评图书编校错误举例及错误原因浅析 [J], 周月梅
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
环境:oracle 11.2.0.3 rac ,AIX6.1第一节点ASM实例报04031,赶到单位检查日志:ORA-04031: unable to allocate 3896 bytes of shared memory ("shared pool","select name_kfgrp, number_kf...","sga heap(1,0)","kglsim object batch")登录ASM实例,检查SGASQL> select bytes,name,pool from v$sgastat where name like '%free memory%';60501728 free memory shared pool未发现异常设置事件检查TRACESQL >alter session set events '4031 trace name heapdump level 536870914';SQL >alter session set events '4031 trace name context off;检查TRACE文件1、Memory Utilization of Subpool 1中未发现异常2、LIBRARY CACHE STATISTICS--SQL AREA reload较高,其他正常。
MOS上记录了一个11.2.0.3的BUG:Oracle Server - Enterprise Edition - Version 11.2.0.3 and laterInformation in this document applies to any platform.Symptoms11.2.0.3.0 ASM instance crash after giving the following errors:-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Tue Mar 27 14:09:16 2012Errors in file /app/oracle/diag/asm/+asm/+ASM1/trace/+ASM1_ora_2966.trc (incident=206840):ORA-04031: unable to allocate 3896 bytes of shared memory ("shared pool","DECLAREhdl number; blk_nu...","sga heap(1,0)","kglsim object batch")Incident details in: /app/oracle/diag/asm/+asm/+ASM1/incident/incdir_206840/+ASM1_ora_2966_i206840.trc ... <the above repeat massively>Tue Mar 27 15:11:28 2012DDE: Problem Key 'ORA 4031' was completely flood controlled (0x6)Further messages for this problem key will be suppressed for up to 10 minutesTue Mar 27 15:15:25 2012Errors in file /app/oracle/diag/asm/+asm/+ASM1/trace/+ASM1_ora_2967.trc (incident=211937):ORA-00600: internal error code, arguments: [ksxp_rm_check0], [0xFFFFFFFF79122998], [0], [0x517854080], [], [], [], [], [], [], [], []Incident details in: /app/oracle/diag/asm/+asm/+ASM1/incident/incdir_211937/+ASM1_ora_2967_i211937.trc WARNING: ASM communication error: op 0 state 0x0 (15055)ERROR: direct connection failure with ASMNOTE: Deferred communication with ASM instanceErrors in file /app/oracle/diag/asm/+asm/+ASM1/trace/+ASM1_ora_21400.trc:ORA-15055: unable to connect to ASM instanceORA-00600: internal error code, arguments: [ORA_NPI_ERROR], [600], [ORA-00600: internal error code, arguments: [ksxp_rm_check0],[0xFFFFFFFF79122998], [0], [0x517854080], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], [], []CauseNon-published Bug:12925089 which fix is included starting 11.2.0.4根据ID 1370925.1推荐ASM配置:ReferencesNOTE:437924.1 - ASM & Shared Pool (ORA-4031)NOTE:1363369.1 - Things to Consider Before Upgrading to 11.2.0.3 Grid Infrastructure/ASMHdr: 13605735 11.2.0.3 PCW 11.2.0.3 PRODID-5 PORTID-46Abstract: SET ASM MEMORY_TARGET TO BE AT LEAST 1536M WHILE UPGRADING TO 11.2.0.3*** 01/18/12 02:34 pm REQUEST TEXT ***In 11.2.0.3, init.ora parameter "processes" will be default to "available CPUcores * 80 + 40". As the default value for "memory_target" is based on"processes", it can be insufficient if there's large number of CPU cores orlarge number of diskgroups which could cause issues, it's recommended toincrease the value of memory_max_target and memory_target while/beforeupgrading to 11.2.0.3 to the minimal of 1536m or the default.*** 01/18/12 02:34 pm BUSINESS NEED ****** 01/19/12 01:42 am ****** 02/03/12 02:18 pm ****** 02/03/12 02:18 pm RESPONSE ***ER is forwarded for further consideration修改相关参数bjschxdbcx01:/u01/app/grid/diag/asm/+asm/+ASM1/trace$vmstatSystem configuration: lcpu=40 mem=81920MB ent=10.00kthr memory page faults cpu----- ----------- ------------------------ ------------ -----------------------r b avm fre re pi po fr sr cy in sy cs us sy id wa pc ec6 1 9409443 1227672 0 0 0 215 399 0 4608 71811 23295 6 2 89 2 1.37 13.71.修改PROCESSES=CPU.CORE*80+402.metalink推荐memory_max_target = 4096m ,memory_target = 1536m3.修改_library_cache_advice=falseSQL> alter system set "_library_cache_advice"=false scope = spfile;System altered.SQL> alter system set memory_max_target = 4096m scope=spfile;System altered.SQL> alter system set memory_target = 1536m scope=spfile;System altered.SQL> alter system set processes = 32402 scope = spfile;System altered.--重启第一节点集群后现象消失crsctl stop cluster -n bjschxdbcx01crsctl start cluster -n bjschxdbcx01。