多元统计分析论文-spss多元统计分析论文
多元统计聚类分析论文_多元统计分析论文

多元统计聚类分析论文_多元统计分析论文多元统计分析论文篇1多元统计分析课程教学探讨摘要:多元统计分析是统计学的一个重要分支,它在自然科学、社会科学、教育卫生以及经济金融等领域具有广泛的应用。
利用多元统计分析方法分析和处理实际数据、解决实际问题是统计学专业学生必备的基本能力,因此,如何进行多元统计分析课程的教学具有相当重要的意义。
本文从教学实践出发,对多元统计分析课程的教学进行了探索和实践,提出了一些教学方法。
关键词:以人为本;案例教学;软件编程;考试改革;创新教学多元统计分析是统计学中内容极其丰富、应用极其广泛的一个重要分支。
随着计算机和统计学的发展,它在自然科学、社会科学、教育卫生以及经济金融等领域中的应用越来越广泛,它已成为进行多元数据分析与处理的非常重要的工具之一。
随着社会的发展,我们常需要处理较为复杂的多维数据以及高维或超高维数据,特别地,对于统计学专业的学生,利用多元统计分析方法分析和处理日常生活中的多维数据是他们应该具备的基本能力。
因此,如何让学生很好地掌握一些基本的多元分析方法并能在实践中加以应用是我们统计学专业的教师应该思考的重要问题。
通过多年的实践教学,我们对多元统计分析课程的教学进行了探索和实践,主要在以下几个方面进行了探索和尝试。
一、转变教育观念,树立“以人为本”的教学理念教育的对象是大学生,教育的目的是以学生的终身发展为基础的。
在教学过程中,我们教师首先应转变教育观念,处处体现以学生为本的人文关怀与教育。
关注学生的思想、学生的需要以及在当今时代下学生所面临的挑战与机遇,争取成为学生的良师益友,建立良好的师生关系;通过案例教学、启发式教学等等多种教学方法,鼓励和促使学生积极参与课堂教学,变被动学习为主动学习,使学生成为课堂的主体;正视学生之间的个体差异,不歧视差生也不偏爱优等生,实施因材施教,使每个学生都得到不同程度的提高与进步。
二、注重案例教学,培养“学以致用”的学习意识三、结合软件教学,提高学生编程和数据处理能力多元分析方法分析和处理的数据是多维数据,通常维数较多,而且观测数据也较多,计算量都比较大,通常需要计算机才能实现。
论文写作中如何利用SPSS进行多元统计分析

论文写作中如何利用SPSS进行多元统计分析在当今大数据时代,统计分析成为了各个领域研究的重要工具。
而SPSS (Statistical Package for the Social Sciences)作为一款专业的统计分析软件,被广泛应用于学术研究中。
本文将从多元统计分析的角度出发,探讨如何在论文写作中充分利用SPSS进行数据分析。
一、数据准备在进行多元统计分析之前,首先需要准备好可靠的数据。
数据的质量和完整性对于分析结果的准确性至关重要。
在数据准备阶段,可以通过SPSS软件进行数据清洗、缺失值处理和异常值检测等操作,以确保数据的可靠性。
二、描述性统计分析在进行多元统计分析之前,了解数据的基本情况是必要的。
通过SPSS的描述性统计分析功能,可以获得数据的均值、标准差、最大值、最小值等统计指标。
此外,还可以通过绘制直方图、箱线图等图表来展示数据的分布情况,为后续的分析提供基础。
三、相关性分析相关性分析是多元统计分析的重要环节之一。
通过SPSS的相关性分析功能,可以计算各个变量之间的相关系数,从而了解它们之间的关系。
相关系数的取值范围为-1到1,当相关系数接近1时,表示两个变量呈正相关;当相关系数接近-1时,表示两个变量呈负相关;当相关系数接近0时,表示两个变量之间没有线性关系。
通过相关性分析,可以帮助研究者深入了解变量之间的相互作用,为后续的因果分析提供依据。
四、因素分析因素分析是一种常用的降维技术,可以将大量的变量转化为少数几个因素,从而简化数据分析的复杂度。
通过SPSS的因素分析功能,可以识别出主要的因素,并计算出各个变量对于每个因素的贡献度。
因素分析可以帮助研究者发现变量之间的内在联系,提取出潜在的因素,从而更好地理解研究对象。
五、聚类分析聚类分析是一种无监督学习的方法,可以将数据样本划分为不同的类别或群组。
通过SPSS的聚类分析功能,可以根据变量之间的相似性将样本进行分类,从而发现数据中的内在结构。
多元统计分析 课程论文.doc

HUNAN UNIVERSITY 课程论文论文题目:有关我国居民消费因素的分析指导老师:学生名字:学生学号:专业班级:经济统计学院名称: xxx学院目录概述 (1)一、引言 (2)二、数据概述系 (2)三、分析方法 (3)四、数据分析 (3)(一)相关分析 (3)(二)因子分析 (10)(三)聚类分析 (15)五、分析与建议 (18)六、心得体会 (19)参考文献 (20)有关我国居民消费因素的分析概述生活离不开消费,随着社会发展,生活水平提高,消费也在逐渐变化,并且随着经济发展,各个地区的发展水平的差异,消费也产生了不同的变化,此篇论文主要目的是利用多元统计的方法,借助spss软件,对我国31个地区的居民消费情况进行分析。
了解我国31个地区的居民消费情况与统计指标食品烟酒、衣着、居住等8个指标之间的一些联系。
并且通过因子得分,计算并排列出消费因素的综合得分,最后通过聚类分析,对我国31个地区的居民消费情况做一个大致分类,进而对各个地区分类后的情况做一个分析和总结并结合文献以及资料提出一些意见和看法。
一.引言消费在宏观经济学中,指某时期一人或一国用于消费品的总支出。
与经济活动有着密不可分的关系,消费作为社会再生产的最终阶段,是生产者生产产品的目的和导向。
如果没有了消费,生产的存在也会变得毫无意义,消费促进了生产,给生产带来了源动力。
消费者的消费需求,也推动了生产的发展。
并且消费促进了货币流通,提供了就业岗位,降低失业率,拉动了经济增长,最终有助于提高人民的生活水平。
消费是国民经济保持增长的动力,只有拉动消费需求的增长,才能促进投资,促进产业结构的调整、宏观经济的增长,满足人民的物质生活的需求,实现生活水平的提高。
故消费和生活水平有着密切的关系,从而,通过对我国居民消费水平的分析,不但可以直观了解到我国总的消费趋向,各地区不同的消费主导因素,还能客观反映我国总的生活水平也就是经济发展的大致情况。
统计年鉴中的八项指标:食品烟酒、衣着、居住、生活用及服务、交通通信、教育文化娱乐、医疗保健、其他用品及服务。
SPSS多元统计论文-回归分析

回归分析在商品的需求量分析中的运用摘要:本文结合多元统计分析理论中关于多元线性回归分析的应用,对商品需求量与商品价格和人均月收入的关系的线性方程进行探索研究。
回归分析的基本思想是描述若干个变量间的统计关系,以研究一个或多个自变量与因变量之间的内在联系。
而回归分析研究又包括线性回归和非线性回归。
本文就是运用线性回归来分析商品需求量和商品价格,人均月收入之间的关系的。
关键词:线性回归线性方程商品需求量一.引言随着我国经济的快速发展,人们的物质生活条件越来越好,各种各样的商品出现在人们的日常生活中。
随着人们收入水平的不断变化,随着商品价格的不断变化,人们对某种商品的需求量也不同。
如果生产的商品量大于商品的需求量,则会导致资源浪费,商品的价格下降;反之如果商品的生产量少于商品的需求量,则会导致商品供应不足,价格上涨。
以上两种情况都会对经济发展造成不利的影响。
因此,对商品需求量的预测是必要的。
那么,应该如何预测商品的需求量呢?为此,本文在参阅相关文献的基础上,根据东方财富网所提供的某地1996~2995年10年间对某品牌的手表需求量和商品价格,人均月收入的数据采用线性回归的方法进行回归分析,并对模型进行检验,预测。
二.经济理论分析、所涉及的经济变量(1)经济理论分析:1.需求:是指在各种不同价格水平下,消费者愿意且能够购买的商品或服务的数量;2.需求与价格之间存在这需求规律,即“在其它条件不变的条件下,一种商品的价格上升会引起该商品的需求量减少,价格下降会引起该商品的需求量增多”;由此我们引出需求的价格弹性的概念,它是指需求量对价格变动的反应程度,是需求量变化的百分比除以价格变化 的百分比,即公式:价格变动率需求量变得率需求的价格弹性系数=3.同理,需求与收入的关系可以用需求的收入弹性分析,它表示某一商品的需求量对收入变化的反应程度,即公式: 收入变动率需求量变得率需求的收入弹性系数=(2)变量的设定:在经济生活中,我们不难发现价格和收入水平的高低对商品需求量有着直接且密切的影响,故所建立的模型是一个回归模型!其中“商品价格”与“消费者平均收入”分别是自变量x1、x2,“商品需求量”是因变量y 。
多元统计分析论文
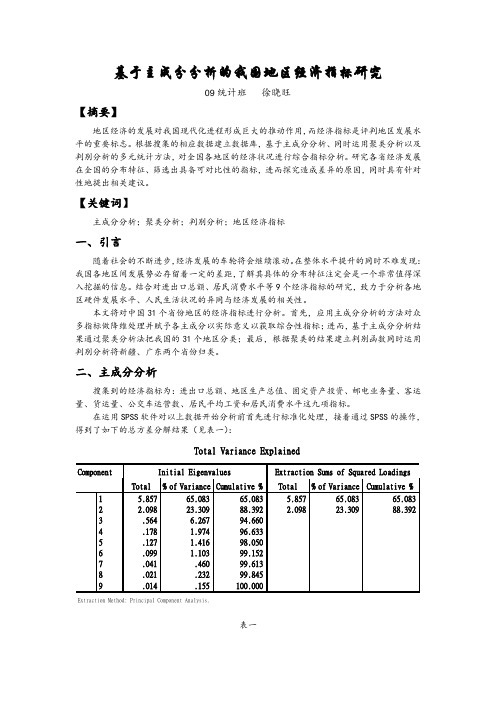
基于主成分分析的我国地区经济指标研究09统计班徐晓旺【摘要】地区经济的发展对我国现代化进程形成巨大的推动作用,而经济指标是评判地区发展水平的重要标志。
根据搜集的相应数据建立数据库,基于主成分分析、同时运用聚类分析以及判别分析的多元统计方法,对全国各地区的经济状况进行综合指标分析。
研究各省经济发展在全国的分布特征、筛选出具备可对比性的指标,进而探究造成差异的原因,同时具有针对性地提出相关建议。
【关键词】主成分分析;聚类分析;判别分析;地区经济指标一、引言随着社会的不断进步,经济发展的车轮将会继续滚动。
在整体水平提升的同时不难发现:我国各地区间发展势必存留着一定的差距,了解其具体的分布特征注定会是一个非常值得深入挖掘的信息。
结合对进出口总额、居民消费水平等9个经济指标的研究,致力于分析各地区硬件发展水平、人民生活状况的异同与经济发展的相关性。
本文将对中国31个省份地区的经济指标进行分析。
首先,应用主成分分析的方法对众多指标做降维处理并赋予各主成分以实际意义以获取综合性指标;进而,基于主成分分析结果通过聚类分析法把我国的31个地区分类;最后,根据聚类的结果建立判别函数同时运用判别分析将新疆、广东两个省份归类。
二、主成分分析搜集到的经济指标为:进出口总额、地区生产总值、固定资产投资、邮电业务量、客运量、货运量、公交车运营数、居民平均工资和居民消费水平这九项指标。
在运用SPSS软件对以上数据开始分析前首先进行标准化处理,接着通过SPSS的操作,得到了如下的总方差分解结果(见表一):表一由表一中结果可以看到保留2个主成分为宜,这2个主成分集中了原始9个变量信息的88.392%,可见效果比较好,这样原来的9个指标就可以通过这2个综合指标来反映。
此时,这2个主成分就起到了降维的作用。
通过SPSS进一步的操作还可以得到如下的主成分系数矩阵(见表二):表二由表二可以得出前2个主成分的线性组合为:Y1 = 0.852 X1 + 0.979 X2 + 0.821 X3 + 0.957 X4 + 0.885 X5 + 0.742 X6 + 0.967 X7 +0.226 X8 + 0.513 X9Y2 = 0.393 X1 - 0.113 X2 - 0.419 X3 - 0.032 X4 - 0.233 X5 - 0.483 X6 + 0.109 X7 +0.915 X8 + 0.786 X9通过对上述线性组合的观察,我们可以得出:在主成分1中进出口总额、地区生产总值、固定资产投资、邮电业务量、客运量、货运量和公交车运营数这几项指标的系数明显比主成分2的系数大,可以将Y1归类为地区经济发展中的硬件基础指标;在主成分2中平均工资和消费水平指标的系数最大,可以将Y2归类为地区经济发展中的居民生活指标。
多元统计分析论文

多元统计分析论文关于各地区固定资产投资价格指数的分析摘要:本文主要通过主成分分析、聚类分析和判别分析对全国30多个省的固定资产投资指数、建筑安装工程指数、设备工器具购置指数、其他费用指数进行分析。
关键词:主成分分析、欧氏距离、系统聚类分析、判别分析Summary:This article mainly through the principal components analysis, the cluster analysis and the distinction analysis to the national more than 30 province investment in the fixed assets indices, construction and installation the project index, the equipment labor appliance purchase index, other expense index carries on the analysis.Keywords:Principal Components Analysis、Euclidean distance、Discriminant analysis一、导言:注意微量信息引起的巨变,蝴蝶效应就是微量信息在一定条件下发生作用的过程。
在我们的经济活动中,每天的信息是大量的,这就要求我们从中发现那些对经济能产生最大影响的信息,有些是微量信息,有些是次级别的信息,本文的各地区固定资产投资价格指数就是一个非常值得深入发觉的信息。
该指数可以准确地反映固定资产投资中涉及的各类投资品和取费项目价格变动趋势和变动幅度,消除按现价计算的固定资产投资指标中的价格变动因素,真实地反映固定资产投资的规模、速度、结构和效益,为国家科学地制定、检查固定资产投资计划并提高宏观调控水平,为完善国民经济核算体系提供科学的、可靠的依据。
基于SPSS的多元回归分析模型选取的应用毕业论文

毕业论文题目基于SPSS的多元回归分析模型选取的应用基于SPSS的多元回归分析模型选取的应用摘要本文不仅对于复杂的统计计算通过常用的计算机应用软件SPSS来实现,同时通过对两组数据的实证分析,来研究统计学中多元回归分析中的变量选取,让大家对统计学中的多元回归分析中模型的选取以及变量的选取和操作方法有更深层次的了解. 一组数据是对于淘宝交易额的未来发展趋势的研究,一组数据时对于我国财政收入的研究. 本文通过两个实证即淘宝交易额研究和财政收入研究从不同程度上对非线性回归模型和变量选取的研究运用通俗的语言和浅显的描述将SPSS在多元回归分析中的统计分析方法呈现在大家面前,让大家对多元回归分析以及SPSS软件都可以有更深一步的了解. 通过SPSS软件对数据进行分析,对数据进行处理的方法进行总结,找出SPSS对于数据处理和分析的优缺点,最后得在对变量的选取和软件的操作提出建议.关键词:统计学,SPSS,变量选取,多元回归分析AbstractThis article not only for complex statistical calculations done by the commonly used computer application software of SPSS, through the empirical analysis of the two groups of data at the same time, to study the statistics of the variables in the multivariate regression analysis, let everybody in the multiple regression analysis of statistical model selection as well as the selection of variables and operation methods have a deeper understanding. Is a set of data for the future development trend of research taobao transactions, a set of data for the research of our country's fiscal revenue. In this paper, through two empirical taobao transactions and fiscal revenue research from different degree of the study of nonlinear regression model and variable selection using a common language and plain the SPSS statistical analysis method in multiple regression analysis of present in front of everyone, let everyone to multiple regression analysis and SPSS software can have a deeper understanding. Through SPSS software to analyze data, and summarizes method of data processing, find out the advantages and disadvantages of SPSS for data processing and analysis, finally had to put forward the proposal to the operation of the selection of variables and software.Keywords: Statistical, SPSS, The selection of variables, multiple regressionanalysis目录第一章引言 (3)第二章多元回归模型的选取 (4)2.1 多元回归分析概述 (4)2.2 相关系数概述 (5)2.3 非线性回归模型概述 (5)2.4 多元线性回归模型自变量的选取 (6)第三章非线性回归模型案例:淘宝交易额模型的研究 (7)3.1 回归模型变量的确定 (7)3.1.1 数据来源 (7)3.1.2 复相关系数 (8)3.1.3 散点图看线性关系 (9)3.1.4 回归分析看拟合度 (11)3.1.5 确定回归模型变量 (11)3.2 调整后的变量的相关分析 (12)3.2.1 散点图 (12)3.2.2 计算相关系数 (14)3.3 多元线性回归分析 (16)3.4 小结 (18)第四章线性回归分析变量选取案例:财政收入模型的研究 (18)4.1 数据来源及变量选取 (18)4.2 相关分析 (20)4.2.1 散点图 (20)4.2.2 计算相关系数 (21)4.3 线性回归分析 (24)4.4 逐步回归 (26)4.5 小结 (27)第五章总结 (28)参考文献 (30)第一章引言随着社会的发展,统计的运用围越来越广泛,统计学作为高等院校经济类专业和工商管理类专业的核心课程,不管是在经济管理领域,或是在军事、医学等领域的研究中对于数量分析与统计分析都需要更高的要求,需要用到的数学知识较多,应用方面的灵活性也较强,计算量大且复杂.然而科学研究的深入,研究的对象也日益变得复杂,复杂系统的研究问题更是成为当今研究的热点. 为了更好的描述一个复杂的现象,就需要大量的数据和信息,如何高效、准确地利用已知的信息便成为当今社会研究的一项重要课题.在科学技术飞速发展的今天,统计学通过不断吸收和融合相关学科的新理论,开发应用新技术和新方法,拓展新的领域的同时不断深化和丰富了统计学传统领域的理论与方法. 在我国,社会主义市场经济体制的逐步建立,实践发展的需要对统计学提出了新的更多、更高的要求. 随着我国社会主义市场经济的成长和不断完善,统计学的潜在功能将得到更充分更完满的开掘. 从20世纪60年代开始,关于回归自变量的选择成为统计学中研究的热点问题,统计学家提出了许多回归选元的准则,并提出了许多行之有效的选元方法. 在应用回归分析去处理实际问题时,回归自变量选择是首先要解决的重要问题. 通常在做回归分析时,人们根据所研究问题的目的,结合经济理论罗列出对因变量可能有影响的的一些因素作为自变量引进回归模型,把一些对因变量影响很小的,有些甚至是没有影响的自变量,不但使得计算量变大,估计和预测的精度也下降了. 此外,如果遗漏了某些重要变量,回归方程的效果肯定不好. SPSS软件作为当今国际上运用广泛的统计分析软件,其功能齐全带有各种特点,在各个领域都得到了迅速普及,并成为各个行业提高管理水平、形成科学决策的重要手段. 然而,我国对于该软件的运用和理解始终处于早期应用阶段,无论是在功能的研究开发还是实际生活当中的运用都与西方发达国家相差甚远. 尤其是在管理决策方面,都因为没有进行深度分析而造成了浪费,要么就是利用SPSS软件进行简单分析而未进行深度开发,导致所得的信息有限、各信息间的关系不明确,最终导致管理者的判断出现偏差.基于以上背景,本文通过总结和吸取其他国外学者对统计学研究的,并结合我国的实际情况,本文采用了案例一对于网络购物这块的的研究,通过对2005年到2012年的居民消费水平,以及我国网络普及度,我国人人均纯收入以及我国的居民消费水平对淘宝网的未来发展趋势进行非线性回归模型的研究以及案例二对于我国财政收入的进行变量选取研究,通过对1992年到2012年的人均国生产总值,城镇居民家庭人均可支配收入,全社会固定投资,进出口总额,居民消费价格水平对我国财政收入的影响进行定量数据的研究. 通过对数据的选取,回归模型的确定以及软件的操作方法来告知读者如何在SPSS的操作中变量选取的原则、要求和方法.第二章多元回归模型的选取2.1 多元回归分析概述回归分析是确定两种或两种以上变数间相互依赖的定量关系的一种统计分析方法(即寻找具有相关关系的变量减的数学表达式并进行统计推断的一种统计方法). 按照其所涉及的自变量,可分为一元回归分析和多元回归分析;线性回归分析和非线性回归分析是按照自变量和因变量之间的关系划分的.而本文运用了多元线性回归分析中的方法,多元线性回归分析就是指回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系. 多元回归分析的主要容有以下几点:(1)从一组数据出发,确定某些变量之间的定量关系式,即建立数学模型并估计其中的未知参数. 估计参数的常用方法是最小二乘法;(2)对这些关系式的可信程度进行检验;(3)在许多自变量共同影响着一个因变量的关系中,判断哪些自变量的影响是显著的,哪些自变量的影响是不显著的,将影响显著的自变量选入模型中,而剔除影响不显著的变量,通常用逐步回归等方法;(4)利用所求的关系式对某一生产过程进行预测或控制.回归分析研究的主要问题是确定Y与X间的定量关系表达式,这种表达式称为回归方程;对求得的回归方程的可信度进行检验;判断自变量X对因变量Y有无影响;利用所求得的回归方程进行预测和控制. 回归分析主要应用于研究两个变量之间到底是哪个变量受哪个变量的影响,影响程度如何,通过分析现象之间相关的具体形式,确定其因果关系,并用数学模型来表现其具体关系,并根据实测数据来求解模型的各个参数,然后评价回归模型是否能够很好的拟合实测数据;如果能够很好的拟合,则可以根据自变量作进一步预测.2.2 相关系数概述相关关系是一种非确定性的关系,相关系数是研究变量之间线性相关程度的量. 相关关系是现象间客观存在的,但数值又是不严格及不完全确定的相互依存关系.1)复相关系数在一元回归分析中我们用相关系数r 来说明两变量之间线性相关的程度,在多元回归分析中,仍用它来表示y 与其他自变量之间的线性密切程度,此为复相关系数. 复相关是指因变量与多个自变量之间的相关关系. 复相关系数只是反映变量间表面的非本质的联系,因为变量很有可能受到其他变量的影响.2)偏相关系数在多变量的情况下,变量之间的相关系数是相当复杂的. 任意两个变量之间都有可能存在着相关关系,因此,只知道被解释变量与解释变量的总的相关程度是不够的. 如果需要了解某两个变量间的相关程度,就应在消除其他变量影响的情况下来计算他们的相关系数,这就是偏相关系数. 偏相关系数与复相关系数不同,复相关系数的取值在0-1之间,而偏相关系数则是有正有负,所以复相关系数与偏相关系数之间也有可能相差很大. 变量之间本存在错综复杂的关系,甚至可能使得符号也相反,但是偏相关系数才是变现变量之间的本质联系的.偏相关的主要用途:偏相关主要是用来研究自变量与因变量之间的关系的,其通过得到的自变量与因变量数据来进行计算,通过偏相关系数可以看出哪些自变量对因变量的影响更大一些,同时对于偏相关系数较小的变量,可以剔除.2.3 非线性回归模型概述非线性回归模型是指在众多的现象中,分析变量之间的关系时不符合解释变量线性和参数线性的一种模型. 在实际的经济活动中,经济变量的关系是相当复杂的,直接表示为线性关系的情况也并不多见. 但大多数的非线性关系是可以通过一些简单的数学处理,使之转化为线性关系,从而通过线性回归来进行计算. 而非线性回归模型又分为可化为线性模型的非线性回归模型和不可化为线性模型的非线性回归模型.本文研究的是可转化为线性模型的非线性回归模型,而可转化为线性模型的非线性回归模型又有好几种方法可以对变量进行转换.其有以下几种模型:1)多项式函数模型对于形如:k k x x x y ββββ+⋅⋅⋅+++=22110 ,的模型为多项式模型.令21122,,,k k k z x z x z x === ,原模型可化为线性形式k k z z z y ββββ+⋅⋅⋅+++=22110 ,那么就可以用多元线性回归分析的方法进行处理了.2)指数函数模型对于形如:k x k x x e e e y ββββ+⋅⋅⋅+++=21210 ,的模型为指数函数模型. 令k x k x x e z e z e z =⋅⋅⋅==,,,2121 ,原模型可化为线性形式k k z z z y ββββ+⋅⋅⋅+++=22110 ,那么就可以用多元线性回归分析的方法进行处理了.3)双曲线模型;4)半对数模型和双对数模型等.本文将对指数函数型非线性模型进行案例说明,所以对于其他类型的非线性回归模型的道理是一致的,在这里就不进行一一解释.2.4 多元线性回归模型自变量的选择在多元线性回归模型中自变量的选择实质上就是模型的选择. 现设一切可供选择的变量是t 个 ,它们组成的回归模型称为全模型(记:1+=t m ),在获得n 组观测数据后,我们有模型:⎩⎨⎧+=),0(~2n n I N X Y σεεβ , 其中:Y 是1⨯n 的观测值,β是1⨯m 未知参数向量,X 是m n ⨯结构矩阵,并假定X 的秩为m .现从t x x x ,,,21 这t 个变量中选t '变量,不妨设t x x x ',,,21 ,那么对全模型中的参数β和结构矩阵X 可作如下的分块(记:1+'=t p ):()'=q p βββ, , ()q p X X X = .我们称下面的回归模型为选模型:⎩⎨⎧+=),0(~2n p p I N X Y σεεβ ,其中:Y 是1⨯n 的观测值,p β是1⨯p 未知参数向量, p X 是p n ⨯结构矩阵,并假定p X 的秩为p .自变量的选择可以看成是这样的两个问题,一是究竟是用全模型还是用选模型,二是若用选模型,则究竟应包含多少变量最适合. 然而自变量的选择与相关系数,回归分析都有密切的关系,自变量的选择需要通过一系列的验证,剔除之后才能得到最好的变量从而得到最好的回归模型. 下面我们用两个案例来对多元回归模型的选取来进行解释和探讨.第三章 非线性回归模型案例:淘宝交易额研究3.1 回归模型变量的确定3.1.1数据来源为研究淘宝网未来发展趋势,从新浪官方微博淘宝数据魔方中获得淘宝2009年聚划算中购物群众的年龄比例作为定性数据,进行研究年龄对淘宝购物的影响. 并在新浪财经网上获得淘宝网自2003年到2012年的淘宝交易额以及淘宝注册人数的数据. 在中商情报局里获得我国近网络普及度等数据并从国家统计年鉴中选取统计指标居民消费水平.淘宝注册人数(1x )在一定程度上反应了网络购物的群众的人数,反应了当今社会网络购物的普遍性. 同时淘宝的注册人数也展现了人们对网络购物的认可度,换言之也就是说接受了网络购物并会在网上进行消费,是对网络购物很大程度上的支持. 我国网络普及度(2x )是指我国近几年网络在我国普及的围,这一块更好的反映了网络对居民网络消费的影响,因为网络是网络消费的必要条件. 我国网络普及度反映的是在我国日趋发展的经济下,人们对网络的接受程以及信任程度也是直接影响到淘宝的网络购物.居民消费水平(3x )主要通过消费的物质产品和劳务的数量和质量来反映. 居民消费水平的提高也能很好的展现在网络消费上作出的贡献.第二产业增加值(4x )是指采矿业,制造业,电力、煤气及水的生产和供应业,建筑业. 而制造业的发展也相继影响着产品的销售,所以在这里采用第二产业对淘宝交易额的影响. 通过对以上这三个定量数据的研究来其与淘宝交易额的关系,从而研究淘宝未来的发展趋势以及优劣态. 原始数据如下:表3.1为消除数据之间因单位不同产生的量纲的影响,对数据进行标准化得如下数据得到表3.23.1.2 复相关系数对表3.2 的数据进行复相关系数的研究,看变量之间的复相关关系,得到如下表3.3的复相关系数表:表3.3表3.3中有带“**”号的结果表明有关的两变量在0.01的显著性水平下显著相关,由上图可知,y 与1x 的相关系数为0.987>0,表示变量之间存在线性关系,其相关系数检验对应的概率P 值为0.000,低于显著性水平0.05,说明淘宝交易额与淘宝注册人数之间相关性显著. y 与2x e 的相关系数为0.923>0,表示变量之间存在线性关系,其对应P 值为0.000,小于显著性水平0.05,说明淘宝交易额与我国网络普及度之间相关性显著.y 与3x 的相关系数为0.963>0,表示变量之间存在线性关系,其对应P 值为0.000,小于显著性水平0.05,说明淘宝交易额与居民消费水平之间相关性显著. y 与4x e 的相关系数为0.919>0,表示变量之间存在线性关系,其对应P 值为0.000,小于显著性水平0.05,说明我国第二产业增加值与居民消费水平之间相关性显著.综上所述通过SPSS 得出的相关系数的矩阵得到为:=1yx r 0.987 ,=2yx r 0.923 ,=3yx r 0.963 ,=4yx r 0.919 .虽然变量都通过了检验,但是可以看到2yx r 和4yx r 较另外两个复相关系数较低,因此对变量进行散点图的分析来了解自变量与因变量的相关关系.3.1.3 散点图看线性关系对y 与各个变量作出散点图(1)淘宝注册人数1x 与淘宝网交易总额y 的相关性散点图:图3.1(2)网络普及度2x 与淘宝网交易总额y 的散点图:图3.2(3)我国居民消费水平3x 与淘宝交易额y 的散点图:图3.3(4)第二产业增加值4x 对淘宝交易额y 的散点图:图3.4图3.2和3.4分别是自变量2x 和4x 与因变量的相关系数图,可以看出自变量2x 和因变量y 之间呈明显的指数线性关系,而变量4x 也是同样与因变量y 之间呈明显的指数线性关系.他们之间是非线性回归模型的关系. 所拟合的效果不理想所以我们还需要对数据进行进一步的处理和分析,得到确切的答案.3.1.4 回归分析看拟合度对数据进行回归分析:表3.4表3.4是自变量与因变量得到的回归分析,可知,因变量y 与常数项和自变量1x ,2x ,3x ,4x 的回归的标准化回归系数分别为0.01,0.660,-0.229,1.439,-0.899.而通过P 检验可以看到由上表 2.4可以看出常数项以及各自变量的P 值分别为:0.906,0.000,0.018,0.000及0.000. 可以看出原始变量所得到的P 值并没有全部通过检验. 说明常数项对因变量影响不显著. 对数据进行t 值检验,在给定的05.0=α,自由度9211=-=n 的临界值时,查表得=9025.0t 2.262,其常数项的t 值为0.123小于2.262,说明常数项不显著. 综上所述,可以初步得到一个模型为:4321899.0439.1229.0660.001.0x x x x y -+-+= .3.1.5确定回归模型变量综上通过散点图、复相关系数以及回归分析可以知道由于自变量2x 和4x 与因变量y 之间是非线性关系,是呈指数线性关系为研究之间线性关系,所以得到的模型的拟合程度并不是很理想.因此对自变量2x 和4x 进行取e 的对数即2x e 和4x e 来对变量进行研究看拟合效果得到下表.表3.5下面对表3.5进行变量分析与研究,通过对非线性模型中的变量的研究来了解多元回归分析中变量的选取与使用,同时对自变量进一步进行分析.3.2 调整后变量的相关分析3.2.1 散点图对y与各个变量作出散点图x与淘宝网交易总额y的相关性散点图:(1)淘宝注册人数1图3.5(2)e的网络普及度次方2x e与淘宝网交易总额y的相关性检验:图3.6x与淘宝交易额y的相关性检验:(3)我国居民消费水平3图3.7(4)e的第二产业增加值的次方4x e对淘宝交易额y的影响:图3.8由以上四个散点图可知,其所有的点均落在了左上至右下的一条直线上,表明了数据之间存在显著相关关系. 所以我们还需要对数据进行进一步的分析,得到确切的答案.3.2.2 计算相关系数(1)复相关系数r 是用来衡量回归直线对于观察值配合的密切程度,即用来衡量因变量y 与自变量1x ,2x e ,3x ,4x e 之间相关的密切程度. 以下是用SPSS 对数据进行相关性分析,得到如下的相关系数图表3.6图中有带“**”号的结果表明有关的两变量在0.01的显著性水平下显著相关,由上图可知,y 与1x 的相关系数为0.987>0,表示变量之间存在线性关系,其相关系数检验对应的概率P 值为0.000,低于显著性水平0.05,说明淘宝交易额与淘宝注册人数之间相关性显著. y 与2x e 的相关系数为0.979>0,表示变量之间存在线性关系,其对应P 值为0.000,小于显著性水平0.05,说明淘宝交易额与我国网络普及度之间相关性显著.y 与3x 的相关系数为0.963>0,表示变量之间存在线性关系,其对应P 值为0.000,小于显著性水平0.05,说明淘宝交易额与居民消费水平之间相关性显著. y 与4x e 的相关系数为0.997>0,表示变量之间存在线性关系,其对应P 值为0.000,小于显著性水平0.05,说明我国第二产业增加值与居民消费水平之间相关性显著.综上所述通过SPSS 得出的相关系数的矩阵得到为:=1yx r 0.987 ,=2yx r 0.979 ,=3yx r 0.963 ,=4yx r 0.997 .由以上数据可以看出,各列之间存在正相关关系. 即淘宝网注册人数1x 、e 的我国网络普及度2x e 、我国居民消费水平3x 、e 的我国第二产业增加值次方4x e 与淘宝交易总额y 存在显著的相关关系.(2)计算偏相关系数:下面是用SPSS 作出的偏相关系数:① 消除我国网络普及度、第二产业增加值和居民消费水平的影响后,计算淘宝注册人数与淘宝交易额的偏相关系数为:表3.7由上可知,淘宝注册人数与淘宝交易额的偏相关系数为0.795.②消除淘宝交易额、第二产业增加值和居民消费水平的影响后,我国网络普及度和淘宝交易额的偏相关系数为:表3.8由上可知我国网络普及度与淘宝交易额的偏相关系数为0.733.③消除淘宝注册人数、第二产业增加值和我国网络普及度的影响后,我国居民消费水平和淘宝交易额的偏相关系数:表3.9由上可知,我国居民消费水平和淘宝交易额的偏相关系数为-0.932.④消除淘宝注册人数、我国网络普及度和居民消费水平的影响后,计算第二产业增加值与淘宝交易额的偏相关系数:表3.10由上可知,e的第二产业增加值次方与淘宝交易额的偏相关系数为0.946.⑤下表为各个变量之间的偏相关系数表,为方便,这里直接变各变量之间的偏相关系数:r y 1x 2x e3x 4x e y 0.795 0.773 -0.9320.946 1x 0.795 -0.611 0.758 -0.592x e0.773 -0.611 0.702 -0.521 3x-0.932 0.758 0.702 0.818 4x e 0.946 -0.59 -0.521 0.818表3.11这里我们对变量2x 和4x 采用的是其指数幂,是因为在对变量的相关性进行检验时,通过散点图可以看出2x 和4x 与因变量之间呈的是指数线性关系,是非线性关系所以对数据进行了处理,因为原始变量之间存在的非线性关系得出的结果不具有代表性. 可以通过散点图看到从以上的偏相关系数来看,如果2x e ,3x 和4x e 保持不变,y 与1x 之间存在相关关系,当1x ,3x 和4x e 的保持不变时,2x e 和y 之间存在相关关系,其他关系同上,在这里就不进行一一解释.我们也可以通过以上的偏相关系数表可以看出各个自变量之间也存在一定的偏相关关系,但是相对于自变量与因变量之间的偏相关关系较小,说明这些变量之间的选择比较显著.但是其关系强度较前者略低,所以经过以上系数得到的偏相关系数可以看出,其相关程度较原关系的强度低,应采用原数据的自变量和因变量. 即所采用的自变量和因变量保持不变.通过复相关系数的计算和偏相关系数的计算结果可以看出,复相关系数的取值在0-1之间,偏相关系数的取值在-1到1之间,由上数据便可看出偏相关系数与复相关系数之间的差距相差甚大,有的甚至改变了符号. 从上可以看出通过复相关系数不能很好的确定变量之间的相关关系,不能明确的解释变量,而偏回归系数可以看出变量是否符合要求. 从下面的回归分析中继续对变量进行研究.3.3 多元线性回归分析对数据进行回归分析,得到如下结果:表3.12复相关系数为1,判定系数为0.999,调整系数为0.999,估计值的标准误差为0.03296.表3.13由上面结果的看其显著性检验结果为,回归平方和为9.993,残差平方和0.007,总平方和10.000, F 统计量的值为2.299E3,对应的概率P 值为0.000,小于显著性水平0.05,即:淘宝交易总额y 与淘宝网注册人数1x 、e 的我国网络普及度次方2x e 、我国居民消费水平3x 和e 的我国第二产业增加值次方4x e 之间存在线性关系,所以可认为所建立的回归方程有效.表3.14由上表可知,因变量y 与常数项和自变量1x ,2x e ,3x ,4x e 的回归的标准化回归系数分别为-1.119,0.244,0.107,-0.321,0.615. 3个回归系数B 的显著性水平均小于0.05,这里可以认为自变量1x ,2x e ,3x ,4x e 对因变量y 有显著性影响. 于是得到回归方程为:42615.0321.0107.0244.0119.131x x e x e x y +-++-= , 由上图可知对数据进行t 值检验,在给定的05.0=α,自由度9211=-=n 的临界值时,查表得=9025.0t 2.262,因为1x ,2x e ,3x ,4x e 的参数对应的t 统计量的绝对值均大于2.262,这说明%5的显著性水平下,斜率系数均显著不为0,表明淘宝网注册人数1x ,e 的我国网络普及度次方2x e ,我国居民消费水平3x ,e 的我国第二产业增加值次方4x e 等变量联合起来对该商品的消费支出有显著的影响.P 检验:由上表可以看出各自变量以及常数项的P 值分别为:0.00,0.018,0.039,0.001及0.000,可以看出其P 值均小于0.05,均通过检验综上所述,四个自变量对因变量都有显著性影响,并都通过了检验可以得到最优方程式为:。
多元统计分析课程论文

HUNAN UNIVERSITY 课程论文论文题目:有关我国居民消费因素的分析指导老师:学生名字:学生学号:专业班级:经济统计学院名称:xxx学院目录12...2.. .3. .. (3).. 310.15.18....19....20....有关我国居民消费因素的分析概述生活离不开消费,随着社会发展,生活水平提高,消费也在逐渐变化,并且随着经济发展,各个地区的发展水平的差异,消费也产生了不同的变化,此篇论文主要目的是利用多元统计的方法,借助spss软件,对我国31 个地区的居民消费情况进行分析。
了解我国31 个地区的居民消费情况与统计指标食品烟酒、衣着、居住等 8 个指标之间的一些联系。
并且通过因子得分,计算并排列出消费因素的综合得分,最后通过聚类分析,对我国31 个地区的居民消费情况做一个大致分类,进而对各个地区分类后的情况做一个分析和总结并结合文献以及资料提出一些意见和看法。
一 .引言消费在宏观经济学中,指某时期一人或一国用于消费品的总支出。
与经济活动有着密不可分的关系,消费作为社会再生产的最终阶段,是生产者生产产品的目的和导向。
如果没有了消费,生产的存在也会变得毫无意义,消费促进了生产,给生产带来了源动力。
消费者的消费需求,也推动了生产的发展。
并且消费促进了货币流通,提供了就业岗位,降低失业率,拉动了经济增长,最终有助于提高人民的生活水平。
消费是国民经济保持增长的动力,只有拉动消费需求的增长,才能促进投资,促进产业结构的调整、宏观经济的增长,满足人民的物质生活的需求,实现生活水平的提高。
故消费和生活水平有着密切的关系,从而,通过对我国居民消费水平的分析,不但可以直观了解到我国总的消费趋向,各地区不同的消费主导因素,还能客观反映我国总的生活水平也就是经济发展的大致情况。
统计年鉴中的八项指标:食品烟酒、衣着、居住、生活用及服务、交通通信、教育文化娱乐、医疗保健、其他用品及服务。
囊括了居民消费的全部项目,居民日常消费可以清楚地从数据中了解到。
多元统计分析论文范文精选3篇(全文)

多元统计分析论文范文精选3篇多元统计分析法是证券投资中非常重要的分析方法,它的理论内容包含了多个方面的理论方法,每个理论分析方法对证券投资有着不同的分析作用,应该对每个分析方法进行认真研究得出相关的结论,再应用到实际经济生活中。
1聚类分析在证券投资中的应用(1)定义:聚类分析是依据研究对象的特征对其进行分类、减少研究对象的数目,也叫分类分析和数值分析,是一种统计分析技术。
(2)在证券投资中应用聚类分析,是基于证券投资的各种基本特点而决定的。
证券投资中包含着非常多的动态的变化因素,要认真分析证券投资中各种因素的动态变化情况,找出合适的方法对这种动态情况进行把握规范处理,使投资分析更加的准确、精确。
1)弥补影响股票价格波动因素的不确定性证券市场受到非常多方面的影响,具有很大的波动性和不稳定性,这种波动性也造成了证券市场极不稳定的进展状态,这些状态的好坏对证券市场投资者和小股民有着非常重要的影响。
聚类分析的方法是建立在基础分析之上的,立足基础进展长远,并对股票的基本层面的因素进行量化分析,并认真分析掌握结果再应用于证券投资实践中,从股票的基本特征出发,从深层次挖掘股票的内在价值,并将这些价值发挥到最大的效用。
影响证券投资市场波动的因素非常多,通过聚类分析得出的数据更加的全面科学,对于投资者来说这些数据是进行理性投资必不可少的参考依据。
2)聚类分析深层次分析了与证券市场相关的行业和公司的成长性聚类分析是一种非常专业的投资分析方法,它善于利用证券投资过程中出现的各种数据来对证券所涉及的各种行业和公司进行具体的行业分析,这些数据所产生额模型是证券投资者进行证券投资必不可少的依据。
而所谓成长性是一种是一个行业和一个公司进展的变化趋势,聚类分析通过各种数据总结归纳出某个行业的进展历史和未来进展趋势,并不断的进行自我检测和自我更新。
并且,要在实际生活中更好的利用这种分析方法进行分析研究总结,就要有各种准确的数据来和不同成长阶段的不同参数,但是,猎取这种参数比较困难,需要在证券市场实际交易和对行业和公司的不断调查研究中才能得出正确的数据。
多元统计分析spss分析论文

用聚类分析法分析细菌性食物中毒学号:1110110047姓名:何昌业摘要:探讨我国细菌性食物中毒的发生规律,为预防细菌性食物中毒的发生提供参考。
将收集的1994—2003年766起细菌性食物中毒案件的发生情况利用SPSS软件进行聚类分析,按其中毒发生情况将全部23种细菌中毒情况分为4类。
本文选取了细菌性食物中毒的报道起数、中毒人数、死亡人数的统计量作为研究数据。
各项数据均来自于万方数据搜索。
分析结果表明:细菌性食物中毒有其规律性,根据其内在的特点,采取相应的预防措施,将有助于预防其发生.关键词:食物中毒细菌性食物中毒聚类分析引言:随着生活水平的不断提高,我们的食物也越来越丰富,但随之食物中毒的情况也越来越多.其中细菌性食物中毒比较常见,对人们生活习惯影响较大。
因此,本文对1994—2003年766起细菌性食物中毒案件的具体情况进行聚类分析。
首先对引起细菌性食物中毒的细菌进行聚类,将全部细菌分为4类,然后对中毒人数、死亡人数、中毒原因等进行分析。
通过本文的分析研究,可以清楚地了解细菌性食物中毒的分布情况,以及发生中毒的原因,最终对细菌性食物中的预防起指导作用.2 聚类分析的原理与方法2.1主要思想及原理主要思想:先将待聚类的n个样品(或者变量)各自看成一类,共有n类;然后按照实现选定的方法计算每两类之间的聚类统计量,即某种距离(或者相似系数),将关系最为密切的两类合为一类,其余不变,即得到n—1类;再按照前面的计算方法计算新类与其他类之间的距离(或相似系数),再将关系最为密切的两类并为一类,其余不变,即得到n—2类;如此下去,每次重复都减少一类,直到最后所有的样品(或者变量)都归为一类为止。
聚类分析的原理:直接比较样本中各事物之间的性质,,将性质相近的归为一类,而将性质差别比较大的分在不同类。
也就是说,同类事物之间的性质差异小,类与类之间的事物性质相差较大。
其中欧式距离在聚类分析中用得最广,它的表达式如下:其中Xik表示第i个样品的第k个指标的观测值,Xjk表示第j个样品的第k个指标的观测值,dij为第i个样品与第j个样品之间的欧氏距离。
spss多元统计分析论文

学年第一学期 吉林财经大学2012-2013学年第一学期多元统计分析多元统计分析描述统计实验报告描述统计实验报告系别:工商管理系系别:工商管理系专业:人力资源管理专业:人力资源管理学号:********** 姓名:张晓宇姓名:张晓宇城镇人均生活收入及消费支出分析一、城镇人均生活收入及消费支出分析 随着经济的发展,我国城镇居民的收入水平和消费水平的结构也发生了很大变化,居民生活水平的提高和消费的增加对于实现国民经济又好又快发展、正确处理好内需和外需的关系至关重要。
系至关重要。
二、数据来源说明1、城镇居民家庭基本情况. 数据来源于《2008中国中国统计统计年鉴》。
2、下表是要进行处理的31个省市的城镇居民消费相关的原始数据,数据来源于《2008中国统计年鉴》。
各地区城镇居民家庭平均每人生活消费支出(2007) 单位: 元地 区城镇人均生活消费支出消费支出居民人均收入食品食品 衣着衣着 家庭设备家庭设备 医疗医疗保健保健全 国2415.47 3587.04 835.48 167.34 126.07 191.51 北 京5681.09 8275.47 1836.31 451.63 303.46 575.80 天 津3261.91 6227.94 1133.62 265.16 122.41 263.24 河 北2246.29 3801.82 685.98 167.75 115.82 166.34 山 西2039.80 3180.92 659.02 227.43 98.26 142.66 内蒙古内蒙古 2378.60 3341.88 726.06 184.07 97.95 232.76 辽 宁2740.97 4090.40 866.55 242.96 112.15 267.86 吉 林2398.45 3641.13 818.37 189.90 105.11 256.28 黑龙江黑龙江 2365.23 3552.43 747.54 198.85 79.26 253.84 上 海7807.08 9138.65 2824.99 417.57 481.04 549.44 江 苏3658.19 5813.23 1283.17 222.59 199.48 232.30 浙 江5819.70 7334.81 2001.40 368.52 288.02 459.39 安 徽2050.09 2969.08 697.37 138.18 116.76 165.02 福 建3217.66 4834.75 1310.07 213.26 167.33 162.26 江 西2111.73 3459.53 777.45 130.06 105.68 159.14 山 东2867.30 4368.33 916.49 197.11 158.71 221.80 河 南1875.98 3261.03 596.73 159.46 104.75 140.55 湖 北2099.64 3419.35 686.75 144.26 134.17 172.44 湖 南2444.90 3389.62 918.18 137.66 129.51 196.54 广 东3421.56 5079.78 1498.49 151.11 148.10 197.00 广 西1917.97 2770.48 752.23 79.91 110.09 123.91 海 南1759.26 3255.53 768.24 75.15 87.85 110.92 重 庆1600.58 2873.83 577.76 113.27 117.24 159.68 四 川1816.09 3002.38 675.71 132.85 112.21 160.31 贵 州1167.92 1984.62 392.85 88.56 64.91 76.76 云 南1597.26 2250.46 530.84 93.61 83.75 138.16 西 藏1435.41 2435.02 500.57 175.18 117.00 54.37 陕 西1938.60 2260.19 612.12 138.33 94.88 195.61 甘 肃1365.33 2134.05 381.12 97.23 77.78 127.35 青 海 1657.87 2358.37 450.66 160.51 90.12 192.77 宁 夏1824.87 2760.14 523.86 159.10 104.32 187.60 新 疆 1696.40 2737.28 494.47 182.85 70.79 189.69 三、家庭总收入分析1、城镇家庭总收入单线图,城镇家庭总收入逐年增加。
多元统计分析论文

多元统计分析论文多元统计分析是一种统计方法,用于分析多个自变量与一个或多个因变量之间的关系。
该方法可以帮助研究者探索自变量之间的相互作用,并确定它们与因变量之间的关系。
本文将通过一个案例研究来说明多元统计分析的应用。
假设我们想研究工资水平与教育程度、工作经验和性别之间的关系。
我们收集了200个参与者的数据,其中包括他们的工资水平(因变量),教育程度、工作经验和性别(自变量)。
我们将使用多元线性回归分析来检验这些自变量对工资水平的影响。
我们首先进行数据的描述性统计分析,以了解各个变量的分布和关系。
我们发现工资水平的平均值为5000美元,标准差为1000美元。
教育程度的平均值为12年,标准差为3年。
工作经验的平均值为5年,标准差为2年。
性别中,男性占60%,女性占40%。
接下来,我们进行多元线性回归分析。
我们将工资水平作为因变量,教育程度、工作经验和性别作为自变量。
我们的回归模型如下所示:工资水平=β0+β1*教育程度+β2*工作经验+β3*性别+ε在这个模型中,β0是截距,β1、β2和β3是回归系数,ε是误差项。
回归系数表示自变量对因变量的影响,正值表示正相关,负值表示负相关。
通过进行多元线性回归分析,我们得到了以下结果:教育程度对工资水平有显著影响(β1=1000,p<0.001),工作经验对工资水平也有显著影响(β2=500,p<0.01),性别对工资水平的影响不显著(β3=200,p>0.05)。
由此可见,教育程度和工作经验对工资水平具有显著影响,教育程度每增加1年,工资水平平均增加1000美元;工作经验每增加1年,工资水平平均增加500美元。
而性别对工资水平的影响不显著,即性别不是工资水平的显著预测因素。
在多元统计分析中,我们还可以使用其他方法,如多元方差分析、聚类分析、主成分分析等。
这些方法可以根据研究问题和数据类型的不同,来解读和分析自变量与因变量之间的关系。
总结而言,多元统计分析是一种强大的方法,可以帮助研究者探索多个自变量与因变量之间的关系。
应用多元统计分析论文

河北省十一城市综合实力统计分析摘要:本文根据中国城市经济发展研究中心提出的城市综合经济实力和区域的概念,并利用2009年各城市社会经济发展状况的截面数据,就山东省11市的经济数据进行分析。
首先建立了评价的指标体系,其次,分别采用主成分分析法和聚类分析法对山东省根据行政区域划分的11个市的综合经济实力进行了全面的评价和比较,并在此基础上提出了促进山东各市经济协调发展、共同进步的相关措施。
关键词:城市经济主成分分析聚类分析一、引言在区域经济发展中,城市处于核心和龙头的地位,提高城镇化水平、加快城市化进程是解决当前和未来一系列问题的关键。
山东经济发展显示出不平衡的态势,鲁东的少数几个城市GDP几乎占据全省三分之二[1]。
很显然,山东省各市的城市化水平也存在显著差异, 青岛、济南等的城市化水平始终走在全省乃至全国前列,泰安和滨州则相对落后。
随着黄河三角洲经济一体化进程的加快,山东作为沿海省份必须清楚的看到发展差异并找出差异形成的原因,通过核心城市的优先发展带动区域经济和社会的快速发展,是现实提出的急需解决的问题。
为此,本文在参阅相关文献的基础上,根据中国城市经济发展研究中心提出的城市综合经济实力以及区域的概念,根据区域的行政划分,从山东省11个市出发,利用2009年各城市社会经济发展状况的截面数据,首先建立了评价指标体系,其次,分别采用主成分分析法和聚类分析法对山东省11个市的综合经济实力进行了综合的评价和排位,并在此基础上提出了促进山东省各市经济协调发展、共同进步的相关措施。
面对区域差距带来的影响,山东省应该继续加大固定资产投资的力度,在制定区域发展策略时应该加强区域间的交流和合作,促进各地区优势互补,共同发展。
同时,也要积极鼓励引进外资和开拓国际市场,加快与国际经济的接轨和融合。
另外,还要继续扩大中心城市的规模,在积极建设环渤海产业带的同时,不断加强鲁西和鲁中产业带的建设,提高中心城市的综合竞争力,扩大其对周围地区的辐射和带动作用,最终逐步缩小区域差距,促进各地区和谐发展、共同繁荣。
应用多元统计分析论文

应用多元统计分析论文本篇论文介绍了应用多元统计分析的相关内容。
在引言部分,我们将简要介绍本篇论文的主题和目的,解释多元统计分析在研究中的重要性,并概述论文的结构。
多元统计分析是一种统计方法,用于分析多个变量之间的关系和相互影响。
在研究领域中,多元统计分析被广泛应用,可以帮助研究者理解和解释复杂的数据结构和关系。
它能够帮助研究者发现变量之间的模式、趋势和相关性,从而得出更准确的结论。
本论文旨在探讨如何应用多元统计分析方法来分析特定数据集,并得出相关结论。
我们将介绍所采用的多元统计分析方法和技术,并具体说明它们对于研究结果的解释和解读的意义。
接下来的章节将依次介绍多元统计分析的相关概念、数据集的描述和预处理、统计模型的建立和分析方法的应用。
最后,我们将总结研究结果,并讨论其对研究领域的意义和可能的应用价值。
通过本篇论文的详细介绍和分析,读者将能够了解多元统计分析的基本原理和应用方法,以及如何运用这些方法来解读和分析特定领域的研究数据。
本论文的目的是为学术研究者和相关领域的专业人士提供一个有益的参考,帮助他们在研究中更好地使用多元统计分析方法,并取得可靠的研究成果。
请继续阅读下面的章节,以了解更多关于应用多元统计分析的内容。
研究背景多元统计分析是一个广泛应用于各个学科领域的研究方法。
选择进行多元统计分析研究的原因可以有很多,首先,通过多元统计分析,我们可以从多个变量的角度来探索和解释问题。
这能够使我们更全面地了解现象背后的本质,并且提供更深入的洞察。
在相关的研究领域和现有的研究成果方面,多元统计分析已经被广泛应用于社会科学、医学、教育、经济学等等领域。
许多研究已经表明,多元统计分析是一种有效的研究方法,可以帮助研究者发现变量之间的关系和相互影响。
然而,尽管多元统计分析已经被广泛应用,仍然存在一些研究空白需要填补。
例如,某些特定领域可能缺乏基于多元统计分析的研究,或者现有研究可能只关注了特定方面而忽略了其他重要变量。
多元统计分析课程论文

《应用多元统计分析》期末论文农村居民生活消费分析——2014年我国农村居民消费分析目录摘要 .......................................................................... 错误!未定义书签。
一、引言 (2)二、因子分析法 (2)2.1统计思想 (2)2.2因子的确定 (3)2.3分析过程 (4).................................................................................. 错误!未定义书签。
.................................................................................. 错误!未定义书签。
.................................................................................. 错误!未定义书签。
三、聚类分析法 (8)3.1系统聚类法的思想 (9)3.2系统聚类 (9)四、影响农村居民消费因素 (9)4.1收入影响 (10)4.2消费环境影响 (10)4.3消费观念影响 (10)五、参考文献 (11)六、附录: (11)农村居民生活消费分析——2014年我国农村居民消费分析摘要:本文综合了因子分析与聚类分析,先进行因子分析, 再用因子分析的结果进行聚类分析。
在2014 年农村居民消费结构的数据基础上, 本文较多运用了31个省份的因子得分,计算出单因子情况下31个省份的得分和31个省份在八项消费产生的3个因子上的综合得分, 再把该得分作为31个省份的属性, 采用离差平方和(ward)方法进行聚类, 最后将城市分为三层,对整体进行综合评价和说明。
关键词:因子分析;聚类分析;综合评价2014年我国农村居民消费分析一、引言由于我国国土辽阔,自然条件差异很大,经济发展极不平衡,一些地区、一些乡村、一些居民群体的生活目前与小康指标仍有差距,有的甚至还没有解决温饱问题。
多元统计分析原理与基于spss的应用

多元统计分析原理与基于SPSS的应用1. 引言多元统计分析是统计学中的重要分支,用于研究多个变量之间的关系和模式。
在实际应用中,SPSS是一个流行的统计分析软件,提供了丰富的功能和工具,可以用于多元统计分析。
本文将介绍多元统计分析的原理,并探讨如何利用SPSS进行实际应用。
2. 多元统计分析概述多元统计分析是一种从多个维度考察数据的统计方法。
它可以帮助研究者发现多个变量之间的模式和关联,从而提供更深入的分析和理解。
常见的多元统计分析方法包括:主成分分析、因子分析、聚类分析、判别分析等。
2.1 主成分分析(PCA)主成分分析是一种减少数据集维度的方法,它可以将大量的变量转化为少数几个主成分。
通过主成分分析,可以发现数据中的主要模式和结构,从而简化数据集和分析过程。
2.2 因子分析因子分析是一种确定变量之间潜在关系的方法。
它可以帮助研究者发现共同的因素或维度,并解释变量之间的相关性。
因子分析可用于降维或构造新的变量,进而减少数据集的复杂性。
2.3 聚类分析聚类分析是一种将观测对象分组或分类的方法。
它可以通过计算对象之间的相似性或距离,将它们划分为不同的类别。
聚类分析可帮助研究者发现数据中的隐藏结构,并进行进一步的分析和解释。
2.4 判别分析判别分析是一种预测变量类别的方法。
它可以根据已知类别的样本数据,建立预测模型并进行分类。
判别分析可用于识别不同群体或类别之间的差异,并进行进一步的推断和预测。
3. 多元统计分析的应用场景多元统计分析可以应用于各种领域,如市场调研、社会科学、医学研究等。
以下是一些常见的应用场景:•市场调研:通过主成分分析和因子分析,可以帮助企业确定消费者需求和消费行为的主要影响因素。
•社会科学:聚类分析可用于对人群进行社会分类,从而提供对人群特征和行为的深入理解。
•医学研究:判别分析可以应用于医学诊断,预测患者是否患有某种疾病或疾病的严重程度。
4. 基于SPSS的多元统计分析应用示例SPSS是一款功能强大的统计分析软件,提供了多种多元统计分析方法和工具。
多元统计分析聚类分析多元统计聚类分析论文

多元统计分析聚类分析多元统计聚类分析论文多元统计分析论文—论科研经费与效益的关系[摘要]研究多元统计分析的理论,利用主成分分析和聚类分析的方法对区域经济指标体系进行分析和综合,找出实质体的数量特征和内在统计规律性。
通过实际的历史数据进行演算,证实与当时的客观实际情况相吻合,为决策部门衡量本地区的经济发展,制定科学决策提供了有利的支持。
[关键词]多元统计分析;主成分分析;聚类分析;因子分析;Study on the theory of multivariate statistical analysis, using the methods of principal component analysis and cluster analysis on the index system of regional economyFor analysis and synthesis, to find out the essence of the number of features and the internal statistical regularity. Through the historical data of calculus, that is consistent with the actual circumstances, to measure the local area for the decision-making department of economic development, and provide beneficial support to make scientific decision.1.引言在日常生活中,我们常常遇到一些计算量大,分析工作复杂度高的数据分析工作,为了能够更加简便的进行数据分析,在此给大家介绍几种多元统计分析的方法。
本文主要运用了聚类分析法,因子分析法,主成分分析法对科研经费与效益的关系进行统计分析。
多元统计论文

多元统计论文
以下是一些多元统计的论文主题:
1. "基于多元统计方法的市场营销策略分析"
这篇论文可以探讨如何利用多元统计方法来分析市场营销策
略的有效性,包括聚类分析、主成分分析和多元回归分析等方法。
2. "社交媒体数据的多元统计分析和预测"
这篇论文可以研究如何利用多元统计方法来分析社交媒体数据,包括情感分析、主题建模和时间序列分析等方法,以预测用户行为和趋势。
3. "多元统计分析在医学研究中的应用"
这篇论文可以探讨多元统计方法在医学研究中的应用,包括
多因素分析、系统评价和生存分析等方法,以帮助研究人员发现与健康和疾病相关的关联因素。
4. "多元统计分析在金融风险管理中的应用"
这篇论文可以研究多元统计方法在金融风险管理中的应用,
包括方差-协方差矩阵估计、因子分析和条件风险价值等方法,以帮助金融机构评估资产组合的风险。
5. "多元统计分析在教育评估中的应用"
这篇论文可以探讨如何利用多元统计方法来评估教育项目的
效果,包括相关性分析、多元方差分析和线性混合模型等方法,以帮助教育决策者做出更好的决策。
这些主题只是多元统计论文的一小部分,你可以根据自己的兴趣和专业选择适合的主题。
多元统计分析论文

多元统计分析论文本文主要介绍多元统计分析论文的背景和重要性,并概述了该大纲的目的和结构。
多元统计分析是一种重要的统计方法,用于研究多个变量之间的关系和影响。
在许多领域,如社会科学、经济学、医学等,多元统计分析被广泛应用于数据分析和决策支持。
该大纲旨在帮助读者了解多元统计分析论文的基本要素和结构。
它将包括以下几个部分:引言:介绍多元统计分析论文的背景和重要性,概述该大纲的目的和结构。
文献综述:回顾相关领域的研究成果和知识,介绍已有的多元统计分析方法和应用案例。
研究问题和假设:明确研究中要解决的问题和所提出的假设。
数据收集和变量选择:描述数据收集的方法和过程,并讨论变量的选择和测量。
多元统计分析方法:介绍常用的多元统计分析方法,如多元方差分析、线性回归、因子分析等。
结果分析与讨论:展示并解释多元统计分析的结果,讨论研究发现的实际意义。
结论和建议:总结研究的主要发现,提出对进一步研究的建议。
参考文献:列出引用的文献和资料。
通过阅读该大纲,读者将能够了解如何撰写一篇结构合理、内容详实的多元统计分析论文,并能够应用多元统计分析方法进行数据分析和解释研究结果。
确定该论文研究的核心问题,包括研究对象和相关变量。
本章将详细介绍多元统计分析的相关方法,包括因子分析、聚类分析和回归分析等。
对每种方法的原理、步骤和适用场景进行全面介绍。
因子分析因子分析是一种常用的多元统计分析方法,用于探索变量之间的内在关系。
它可以揭示出变量背后的共性因素,并将多个变量综合为少数几个主成分。
原理因子分析基于统计模型,通过对观测数据进行因子提取和旋转,找出能够解释数据方差的主成分。
这些主成分代表了原始变量的共同变异。
步骤因子分析一般包括以下步骤:数据准备:收集所需的原始数据,并进行预处理,如缺失值处理和标准化等。
因子提取:使用合适的因子提取方法,如主成分分析或主因子分析,将原始变量转化为主成分或因子。
因子旋转:通过旋转因子矩阵,使得因子之间更易解释和理解。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
因子分析和聚类分析在全国省会城市经济实力分析中的应用摘要:本文利用SPSS中的因子分析和聚类分析功能对全国26个省会城市经济实力进行分析。
先用因子分析,再对因子分析的结果进行聚类分析。
本文选取2012年上半年26个省会城市的9个经济指标,通过因子分析提取两个因子计算出26个省会城市的综合得分函数,再根据因子分析得出的得分函数对这些城市进行聚类分析,分类结果为:然后再对分类后的城市进行分析说明,最后针对分类的结果进而得出经济综合实力的结论。
关键词:因子分析聚类分析 SPSS 经济实力一、引言城市的发展是经济发展和社会进步的重要标志。
目前,我国正处于加快推进现代化的历史阶段。
现代城市既要有发达的经济,也要有发达的文明。
文明城市是指在全面建设小康社会、推进社会主义现代化建设新的发展阶段,物质文明、政治文明与精神文明协调发展,经济和社会事业全面进步,精神文明建设取得显著成就,市民整体素质和城市文明程度较高的城市。
文明城市,是反映一个地区现代文明程度、城市综合竞争实力的重要标志。
创建文明城市对经济社会发展所产生的现实意义和深远影响,已经远远超出了原来一般意义上的群众性精神文明建设活动。
我们要从战略高度来看待创建文明城市的重要意义,提高对创建文明城市重要性的认识。
随着改革开放的脚步,全国各地经济都有着飞速的发展,人们越来越关注各个省会城市经济实力。
经济是衡量一个地区综合实力的重要指标,而依照经济实力对城市进行分类可以看出一个地区综合实力以及发展潜力,利用经济分类,我们也可以得出该地区的发展状况,以及在哪些方面做得不够,哪些方面可以得到改进。
基于以上原因,本文运用SPSS 对全国26个省会城市,合肥, 武汉, 长沙, 郑州, 南昌, 太原, 西安, 福州, 石家庄, 沈阳, 哈尔滨, 长春, 南京, 杭州, 济南, 南宁, 成都, 贵阳, 昆明, 兰州, 西宁, 银川, 海口, 广州, 乌鲁木齐, 呼和浩特2012年上半年的9类经济指标进行因子分析,聚类分析。
根据这两种分析的结果,对该26个省会城市进行2012上半年的经济分类。
这样能让广大人们群众更清楚的认识此26个省会城市的经济状况,上级部门也可以通过这些分类对这26个地区下达给类发展命令,让这26个城市在经济上能更进一步。
选取的这九个经济指标是地区生产总值(X1),社会消费品零售总额(X2),规模以上工业增加值(x3),出口总额(x4),固定资产投资(x5),人民币储蓄存款余额(x6),地方财政收入(x7),农民人均现金收入(x8),城镇居民人均收入(x9)。
二、模型假设1、假设经济指标数据真实、准确;2、假设选取的经济指标能基本上全面反映城市的经济信息;3、假设各个经济指标信息之间存在重叠;4、假设特殊因子),0(~2σεN 。
三、符号说明四、模型分析与建立4.1 模型分析4.1.1 因子分析(1)因子分析基本思想因子分析的基本思想是通过变量(或样品)的相关系数矩阵(对样品是相似系数矩阵)内部结构的研究,找出能控制所有变量(或样品)的少数几个随机变量去描述多个变量(或样品)之间的相关(相似)关系,但在这里,这少数几个随机变量是不可观测的,通常成为因子。
然后根据相关性(或相似性)的大小把变量(或样品)分组,使得同组内的变量(或样品)之间相关性(或相似性)较高,但不同组的变量相关性(或相似性)较低。
从全部计算过程来看做R型因子分析与作Q型因子分析都是一样的,只不过出发点不同,R型从相关系数矩阵出发,Q型从相似系数矩阵出发都是对同一批观测数据,可以根据其所要求的母的决定用哪一类型的因子分析。
(2)因子分析模型1.基本概念因子分析是一种通过显在变量测评潜在变量测评,通过具体指标测评抽象因子的分析方法,最早是由心理学家Chales Spearman在1904年提出的,他的基本思想是将实测的多个指标,用少数几个潜在的指标(因子)的线性组合表示。
因子主要应用到两个方面:一是寻求基本结构,简化观测系统;二是对变量或样本进行分类。
2.统计原理因子分析的核心是用奇偶少的相互独立的因子反映原有变量的绝大部分信息,可以通过下面的数学模型来表示。
设原有p 个变量p x x x x ,,,,321 ,且每个变量(或经标准化处理后)的均值为0,标准差均为1。
现将每个原有变量用k (p k <)个因子k f f f f ,,,,321 的线性组合来表示,即有⎪⎪⎪⎩⎪⎪⎪⎨⎧+++++=+++++=+++++=+++++=pk pk p p p k k k k k k f a f a f a f a x f a f a f a f a x f a f a f a f a x f a f a f a f a x p εεεε332213333323213223232221211313212111113121 (4.1) 式(4.1 )便是因子分析的数学模型,也可用矩阵的形式表示为ε+=AF X .其中F 称为因子,由于它们出现在每个原有变量的线性表达式中,因此又称为公共因子。
因子可理解为高维空间中互相垂直的k 个坐标轴;A 称为因子载荷矩阵,ij a (k j p i ,2,1;,,2,1== ) 称为因子载荷,是第i 个原有变量在第j 个因子上的负荷。
如果把变量i x 看成k 维因子空间的一个变量,则ij a 表示i x 在坐标轴j f 上的投影,相当于多元线性回归模型中的标准化回归系数;ε称为特殊因子,表示了原有变量不能被因子解释的部分,其均值为0,相当于多元线性回归模型中的残差。
由式(4.1) 可知因子是不可见的。
•因子载荷在因子不相关的前提下,因子载荷ij a 是变量i x 与因子j f 的相关系数,反映了变量i x 与因子j f 的相关程度。
因子载荷ij a 值小于等于1,绝对值越接近1,表明因子j f 与变量i x 的相关系数越强。
同时,因子载荷ij a 也反映了因子j f 对解释变量i x 的重要作用和程度。
•变量共同度变量共同度也即变量方差,变量i x 的共同度2i h 的数学定义为∑==kj ij ia h 122(4.2) 式(4.2)表明,变量i x 的共同度是因子载荷矩阵A 中第i 行元素的平方和。
在变量i x 标准化时,由于变量i x 的方差可以表示成122=+i i h ε,因此原有变量i x 的方差可由两个部分解释:第一部分为变量共同度2i h ,是全部因子对变量i x 方差解释说明的比例,体现了因子全体对变量i x 的解释贡献程度。
变量共同度2i h 越接近1,说明因子全体解释说明了变量i x 的较大部分方差,如果用因子全体刻画变量i x ,则变量i x 的信息丢失较少;第二部分为特殊因子i ε的平方,反应了变量i x 方差中不能由因子全体解释说明的比例,2i ε越小则说明变量i x 的信息丢失越少。
总之,变量i x 的共同度刻画了因子全体对变量i x 信息解释的程度,是评价变量i x 信息丢失程度的重要指标。
如果大多数原有变量的变量共同度均较高(如高于0.8),则说明提取的因子能够反映原有变量的大部分(80%以上)信息,仅有较少的信息丢失,因子分析的效果较好。
因此,变量共同度是衡量因子分析效果的重要依据。
•因子的方差贡献因子i f 的方差贡献的数学定义为∑==pi ij ja S 122(4.3) 式(4.3)表明,因子j f 的方差贡献是因子载荷阵A 中第j 列元素的平方和。
因子j f 的方差贡献反映了因子j f 对原有变量总方差的解释能力。
该值越高,说明相应因子的重要性越高。
因此,因子的方差贡献和方差贡献率事衡量因子重要性的关键指标。
4.1.2 聚类分析(1)系统聚类的基本思想系统聚类方法的基本思想是首先定义样品间的距离(或相似系数)和类与类之间的距离。
初始将n 个样品看成n 类(每一类包含一个样品),这是类间的距离与样品间的距离是等价的,然后将距离最近的两类合并成为新类,并计算新类与其他类的类间距离,再按最小距离准则并类。
这样每侧缩小一类,直到所有的样品都并成一类为止。
(2)聚类分析计算方法系统聚类法的聚类原则决定于样品间的距离(或相似系数)及类间距离的定义,类间距离的不同定义就产生了不同的系统聚类分析方法。
1、最短距离法A. 类与类之间的距离定义为两类中相距最近的样品之间的距离,即列为p G 和q G 之间的距离pq D 定义为pq D =ijd Q P G j G i min ,∈∈B. 当某步骤类p G 和类q G 合并为和r G 后,按最短距离法计算新类r G 与其他类k G 的类间距离,其递推公式为:{}()q p k D D D qk pk rk ,,,min ≠=2、最长距离法A . 类与类之间的距离定义为两类中相距最远的样品之间的距离,即列为p G 和q G 之间的距离pq D 定义为pq D =ijd Q P G j G i max ,∈∈B . 当某步骤类p G 和类q G 合并为和r G 后,按最长距离法计算新类r G 与其他类k G 的类间距离,其递推公式为:{}()q p k D D D qk pk rk ,,,max ≠=3、中间距离法A. 如果类与类之间的距离既不采用两同类之间的最近距离,也不采用最远的距离,而是采用介于这两者间的距离,这种方法称为中间距离法。
B. 当某步骤类p G 和类q G 合并为和r G 后,按中间距离法计算新类r G 与其他类k G 的类间距离,其递推公式为()⎪⎭⎫ ⎝⎛≠≤≤-++=q p k D D D D pq qk pk rk,,041,212222ββ4、重心法A. 如果将两类间的距离定义为两类中心间的距离,这种方法称为重心法。
B. 当某步骤类p G 和类q G 合并为和r G 后,它们所包含的样品个数分别为q p n n ,和r n ,并定义样品间的距离为欧式距离,按重心法计算新类r G 与其他类k G 的类间距离,其递推公式为: ()q p k D n n n n D n n D n n D pq rq r p qkrq pkrp rk,,2222≠-+=5、类平均法A .用两类样品两辆之间平方距离的平均作为类之间的距离,这种方法叫作类平均法B .当某步骤类p G 和类q G 合并为和r G 后,它们所包含的样品个数分别为q p n n ,和r n ,按类平均法计算新类r G 与其他类k G 的类间距离,其递推公式为:()q p k D n n D n n D qk rq pk rp rk ,,222≠+=6、可变类平均法可变类平均法是将合并后的新类r G 与其他类k G 的距离平方公式进一步推广为:()()q p k D D n n D n n D pq qk r q pk r p rk ,,12222≠+⎥⎦⎤⎢⎣⎡+-=ββ7、可变法纪McQuitty 相似分析法当某步骤类p G 和类q G 合并为和r G 后,可变法把r G 与其他类k G 的距离平方公式进一步定义为:[]()q p k D D D D pq qk pk rk ,,212222≠++-=ββ,若,0=β则把此方法称为McQuitty 相似分析法三8、离差平方和法 (Ward 法)A . Ward 法是先将n 个样品各自成一类,每次选择使所有类的总离差平方和增加最小的两类进行合并,直至所有样品合并为一类为止。