数据结构与算法第三版第章参考答案
数据结构第三章习题答案解析

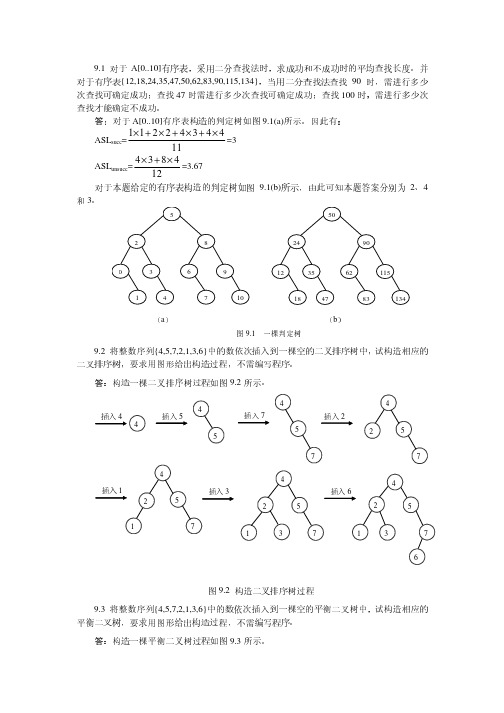
第三章习题1.按图3.1(b)所示铁道(两侧铁道均为单向行驶道)进行车厢调度,回答:⑴如进站的车厢序列为123,则可能得到的出站车厢序列是什么?⑵如进站的车厢序列为123456,能否得到435612和135426的出站序列,并说明原因。
(即写出以“S”表示进栈、以“X”表示出栈的栈操作序列)。
2.设队列中有A、B、C、D、E这5个元素,其中队首元素为A。
如果对这个队列重复执行下列4步操作:(1)输出队首元素;(2)把队首元素值插入到队尾;(3)删除队首元素;(4)再次删除队首元素。
直到队列成为空队列为止,得到输出序列:(1)A、C、E、C、C (2) A、C、E(3) A、C、E、C、C、C (4) A、C、E、C3.给出栈的两种存储结构形式名称,在这两种栈的存储结构中如何判别栈空与栈满?4.按照四则运算加、减、乘、除和幂运算(↑)优先关系的惯例,画出对下列算术表达式求值时操作数栈和运算符栈的变化过程:A-B*C/D+E↑F5.试写一个算法,判断依次读入的一个以@为结束符的字母序列,是否为形如‘序列1& 序列2’模式的字符序列。
其中序列1和序列2中都不含字符’&’,且序列2是序列1的逆序列。
例如,‘a+b&b+a’是属该模式的字符序列,而‘1+3&3-1’则不是。
6.假设表达式由单字母变量和双目四则运算算符构成。
试写一个算法,将一个通常书写形式且书写正确的表达式转换为逆波兰式。
7.假设以带头结点的循环链表表示队列,并且只设一个指针指向队尾元素结点(注意不设头指针),试编写相应的队列初始化、入队列和出队列的算法。
8.要求循环队列不损失一个空间全部都能得到利用, 设置一个标志域tag , 以tag为0或1来区分头尾指针相同时的队列状态的空与满,请编写与此结构相应的入队与出队算法。
9.简述以下算法的功能(其中栈和队列的元素类型均为int):(1)void proc_1(Stack S){ int i, n, A[255];n=0;while(!EmptyStack(S)){n++; Pop(&S, &A[n]);}for(i=1; i<=n; i++)Push(&S, A[i]);}(2)void proc_2(Stack S, int e) { Stack T; int d;InitStack(&T);while(!EmptyStack(S)){ Pop(&S, &d);if (d!=e) Push( &T, d);}while(!EmptyStack(T)){ Pop(&T, &d);Push( &S, d);}}(3)void proc_3(Queue *Q){ Stack S; int d;InitStack(&S);while(!EmptyQueue(*Q)){DeleteQueue(Q, &d);Push( &S, d);}while(!EmptyStack(S)){ Pop(&S, &d);EnterQueue(Q,d)}}实习题1.回文判断。
数据结构第三章习题答案解析

第三章习题1.按图3.1(b)所示铁道(两侧铁道均为单向行驶道)进行车厢调度,回答:⑴如进站的车厢序列为123,则可能得到的出站车厢序列是什么?⑵如进站的车厢序列为123456,能否得到435612和135426的出站序列,并说明原因。
(即写出以“S”表示进栈、以“X”表示出栈的栈操作序列)。
2.设队列中有A、B、C、D、E这5个元素,其中队首元素为A。
如果对这个队列重复执行下列4步操作:(1)输出队首元素;(2)把队首元素值插入到队尾;(3)删除队首元素;(4)再次删除队首元素。
直到队列成为空队列为止,得到输出序列:(1)A、C、E、C、C (2) A、C、E(3) A、C、E、C、C、C (4) A、C、E、C3.给出栈的两种存储结构形式名称,在这两种栈的存储结构中如何判别栈空与栈满?4.按照四则运算加、减、乘、除和幂运算(↑)优先关系的惯例,画出对下列算术表达式求值时操作数栈和运算符栈的变化过程:A-B*C/D+E↑F5.试写一个算法,判断依次读入的一个以@为结束符的字母序列,是否为形如‘序列1& 序列2’模式的字符序列。
其中序列1和序列2中都不含字符’&’,且序列2是序列1的逆序列。
例如,‘a+b&b+a’是属该模式的字符序列,而‘1+3&3-1’则不是。
6.假设表达式由单字母变量和双目四则运算算符构成。
试写一个算法,将一个通常书写形式且书写正确的表达式转换为逆波兰式。
7.假设以带头结点的循环链表表示队列,并且只设一个指针指向队尾元素结点(注意不设头指针),试编写相应的队列初始化、入队列和出队列的算法。
8.要求循环队列不损失一个空间全部都能得到利用, 设置一个标志域tag , 以tag为0或1来区分头尾指针相同时的队列状态的空与满,请编写与此结构相应的入队与出队算法。
9.简述以下算法的功能(其中栈和队列的元素类型均为int):(1)void proc_1(Stack S){ int i, n, A[255];n=0;while(!EmptyStack(S)){n++; Pop(&S, &A[n]);}for(i=1; i<=n; i++)Push(&S, A[i]);}(2)void proc_2(Stack S, int e){ Stack T; int d;InitStack(&T);while(!EmptyStack(S)){ Pop(&S, &d);if (d!=e) Push( &T, d);}while(!EmptyStack(T)){ Pop(&T, &d);Push( &S, d);}}(3)void proc_3(Queue *Q){ Stack S; int d;InitStack(&S);while(!EmptyQueue(*Q)){DeleteQueue(Q, &d);Push( &S, d);}while(!EmptyStack(S)){ Pop(&S, &d);EnterQueue(Q,d)}}实习题1.回文判断。
数据结构(第3版)习题答案

数据结构(第3版)习题答案⼗⼆五普通⾼等教育国家级本科规划教材第1章绪论⾼等学校精品资源共享课程1.1什么是数据结构?【答】:数据结构是指按⼀定的逻辑结构组成的⼀批数据,使⽤某种存储结构将这批数据存储于计算机中,并在这些数据上定义了⼀个运算集合。
1.2数据结构涉及哪⼏个⽅⾯?【答】:数据结构涉及三个⽅⾯的内容,即数据的逻辑结构、数据的存储结构和数据的运算集合。
1.3两个数据结构的逻辑结构和存储结构都相同,但是它们的运算集合中有⼀个运算的定义不⼀样,它们是否可以认作是同⼀个数据结构?为什么?【答】:不能,运算集合是数据结构的重要组成部分,不同的运算集合所确定的数据结构是不⼀样的,例如,栈与队列它们的逻辑结构与存储结构可以相同,但由于它们的运算集合不⼀样,所以它们是两种不同的数据结构。
1.4线性结构的特点是什么?⾮线性结构的特点是什么?【答】:线性结构元素之间的关系是⼀对⼀的,在线性结构中只有⼀个开始结点和⼀个终端结点,其他的每⼀个结点有且仅有⼀个前驱和⼀个后继结点。
⽽⾮线性结构则没有这个特点,元素之间的关系可以是⼀对多的或多对多的。
1.5数据结构的存储⽅式有哪⼏种?【答】:数据结构的存储⽅式有顺序存储、链式存储、散列存储和索引存储等四种⽅式。
1.6算法有哪些特点?它和程序的主要区别是什么?【答】:算法具有(1)有穷性(2)确定性(3)0个或多个输⼊(4)1个或多个输出(5)可⾏性等特征。
程序是算法的⼀种描述⽅式,通过程序可以在计算机上实现算法。
1.7抽象数据类型的是什么?它有什么特点?【答】:抽象数据类型是数据类型的进⼀步抽象,是⼤家熟知的基本数据类型的延伸和发展。
抽象数据类型是与表⽰⽆关的数据类型,是⼀个数据模型及定义在该模型上的⼀组运算。
对⼀个抽象数据类型进⾏定义时,必须给出它的名字及各运算的运算符名,即函数名,并且规定这些函数的参数性质。
⼀旦定义了⼀个抽象数据类型及具体实现,程序设计中就可以像使⽤基本数据类型那样,⼗分⽅便地使⽤抽象数据类型。
数据结构c语言版第三版习题解答

数据结构c语言版第三版习题解答数据结构 C 语言版第三版习题解答在学习计算机科学与技术的过程中,数据结构是一门非常重要的基础课程。
而《数据结构C 语言版第三版》更是众多教材中的经典之作。
其中的习题对于我们理解和掌握数据结构的概念、原理以及算法实现起着至关重要的作用。
接下来,我将为大家详细解答这本书中的一些典型习题。
首先,让我们来看一道关于线性表的习题。
题目是这样的:设计一个算法,从一个有序的线性表中删除所有其值重复的元素,使表中所有元素的值均不同。
对于这道题,我们可以采用双指针的方法来解决。
定义两个指针 p和 q,p 指向线性表的开头,q 从 p 的下一个位置开始。
当 q 所指向的元素与 p 所指向的元素相同时,我们就将 q 所指向的元素删除,并将 q 向后移动一位。
当 q 所指向的元素与 p 所指向的元素不同时,我们将 p 向后移动一位,并将 q 所指向的元素赋值给 p 所指向的位置,然后再将 q 向后移动一位。
当 q 超出线性表的范围时,算法结束。
下面是用 C 语言实现的代码:```cvoid removeDuplicates(int arr, int n) {int p = 0, q = 1;while (q < n) {if (arrp == arrq) {for (int i = q; i < n 1; i++){arri = arri + 1;}(n);} else {p++;arrp = arrq;}q++;}}```再来看一道关于栈的习题。
题目是:利用栈实现将一个十进制数转换为八进制数。
我们知道,将十进制数转换为八进制数可以通过不断除以 8 取余数的方法来实现。
而栈的特点是后进先出,正好适合存储这些余数。
以下是 C 语言实现的代码:```cinclude <stdioh>include <stdlibh>define MAX_SIZE 100typedef struct {int top;int dataMAX_SIZE;} Stack;//初始化栈void initStack(Stack s) {s>top =-1;}//判断栈是否为空int isEmpty(Stack s) {return s>top ==-1;}//判断栈是否已满int isFull(Stack s) {return s>top == MAX_SIZE 1;}//入栈操作void push(Stack s, int element) {if (isFull(s)){printf("Stack Overflow!\n");return;}s>data++s>top = element;}//出栈操作int pop(Stack s) {if (isEmpty(s)){printf("Stack Underflow!\n");return -1;}return s>datas>top;}//将十进制转换为八进制void decimalToOctal(int decimal) {Stack s;initStack(&s);while (decimal!= 0) {push(&s, decimal % 8);decimal /= 8;}while (!isEmpty(&s)){printf("%d", pop(&s));}printf("\n");}int main(){int decimal;printf("请输入一个十进制数: ");scanf("%d",&decimal);printf("转换后的八进制数为: ");decimalToOctal(decimal);return 0;}```接下来是一道关于队列的习题。
《数据结构与算法》习题与答案

《数据结构与算法》习题与答案(解答仅供参考)一、名词解释:1. 数据结构:数据结构是计算机存储、组织数据的方式,它不仅包括数据的逻辑结构(如线性结构、树形结构、图状结构等),还包括物理结构(如顺序存储、链式存储等)。
它是算法设计与分析的基础,对程序的效率和功能实现有直接影响。
2. 栈:栈是一种特殊的线性表,其操作遵循“后进先出”(Last In First Out, LIFO)原则。
在栈中,允许进行的操作主要有两种:压栈(Push),将元素添加到栈顶;弹栈(Pop),将栈顶元素移除。
3. 队列:队列是一种先进先出(First In First Out, FIFO)的数据结构,允许在其一端插入元素(称为入队),而在另一端删除元素(称为出队)。
常见的实现方式有顺序队列和循环队列。
4. 二叉排序树(又称二叉查找树):二叉排序树是一种二叉树,其每个节点的左子树中的所有节点的值都小于该节点的值,而右子树中的所有节点的值都大于该节点的值。
这种特性使得能在O(log n)的时间复杂度内完成搜索、插入和删除操作。
5. 图:图是一种非线性数据结构,由顶点(Vertex)和边(Edge)组成,用于表示对象之间的多种关系。
根据边是否有方向,可分为有向图和无向图;根据是否存在环路,又可分为有环图和无环图。
二、填空题:1. 在一个长度为n的顺序表中,插入一个新元素平均需要移动______个元素。
答案:(n/2)2. 哈希表利用______函数来确定元素的存储位置,通过解决哈希冲突以达到快速查找的目的。
答案:哈希(Hash)3. ______是最小生成树的一种算法,采用贪心策略,每次都选择当前未加入生成树且连接两个未连通集合的最小权重边。
答案:Prim算法4. 在深度优先搜索(DFS)过程中,使用______数据结构来记录已经被访问过的顶点,防止重复访问。
答案:栈或标记数组5. 快速排序算法在最坏情况下的时间复杂度为______。
数据结构教程(第三版)课后答案

/*文件名:algo2-1.cpp*/#include <stdio.h>#include <malloc.h>#define MaxSize 50typedef char ElemType;typedef struct{ElemType elem[MaxSize];int length;} SqList;void InitList(SqList *&L){L=(SqList *)malloc(sizeof(SqList));L->length=0;}void DestroyList(SqList *L){free(L);}int ListEmpty(SqList *L){return(L->length==0);}int ListLength(SqList *L){return(L->length);}void DispList(SqList *L){int i;if (ListEmpty(L)) return;for (i=0;i<L->length;i++)printf("%c",L->elem[i]);printf("\n");}int GetElem(SqList *L,int i,ElemType &e) {if (i<1 || i>L->length)return 0;e=L->elem[i-1];return 1;}int LocateElem(SqList *L, ElemType e) {int i=0;while (i<L->length && L->elem[i]!=e) i++;if (i>=L->length)return 0;elsereturn i+1;}int ListInsert(SqList *&L,int i,ElemType e){int j;if (i<1 || i>L->length+1)return 0;i--; /*将顺序表位序转化为elem下标*/ for (j=L->length;j>i;j--) /*将elem[i]及后面元素后移一个位置*/ L->elem[j]=L->elem[j-1];L->elem[i]=e;L->length++; /*顺序表长度增1*/return 1;}int ListDelete(SqList *&L,int i,ElemType &e){int j;if (i<1 || i>L->length)return 0;i--; /*将顺序表位序转化为elem下标*/ e=L->elem[i];for (j=i;j<L->length-1;j++)L->elem[j]=L->elem[j+1];L->length--;return 1;}/*文件名:algo2-2.cpp*/#include <stdio.h>#include <malloc.h>typedef char ElemType;typedef struct LNode /*定义单链表结点类型*/{ElemType data;struct LNode *next;} LinkList;void InitList(LinkList *&L){L=(LinkList *)malloc(sizeof(LinkList)); /*创建头结点*/L->next=NULL;}void DestroyList(LinkList *&L){LinkList *p=L,*q=p->next;while (q!=NULL){free(p);p=q;q=p->next;}free(p);}int ListEmpty(LinkList *L){return(L->next==NULL);}int ListLength(LinkList *L){LinkList *p=L;int i=0;while (p->next!=NULL){i++;p=p->next;}return(i);}void DispList(LinkList *L){LinkList *p=L->next;while (p!=NULL){printf("%c",p->data);p=p->next;}printf("\n");}int GetElem(LinkList *L,int i,ElemType &e) {int j=0;LinkList *p=L;while (j<i && p!=NULL){j++;p=p->next;}if (p==NULL)return 0;else{e=p->data;return 1;}}int LocateElem(LinkList *L,ElemType e){LinkList *p=L->next;int n=1;while (p!=NULL && p->data!=e){p=p->next;n++;}if (p==NULL)return(0);elsereturn(n);}int ListInsert(LinkList *&L,int i,ElemType e){int j=0;LinkList *p=L,*s;while (j<i-1 && p!=NULL){j++;p=p->next;}if (p==NULL) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{s=(LinkList *)malloc(sizeof(LinkList)); /*创建新结点*s*/s->data=e;s->next=p->next; /*将*s插入到*p之后*/p->next=s;return 1;}}int ListDelete(LinkList *&L,int i,ElemType &e){int j=0;LinkList *p=L,*q;while (j<i-1 && p!=NULL){j++;p=p->next;}if (p==NULL) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{q=p->next; /*q指向要删除的结点*/p->next=q->next; /*从单链表中删除*q结点*/free(q); /*释放*q结点*/return 1;}}/*文件名:algo2-3.cpp*/#include <stdio.h>#include <malloc.h>typedef char ElemType;typedef struct DNode /*定义双链表结点类型*/{ElemType data;struct DNode *prior; /*指向前驱结点*/struct DNode *next; /*指向后继结点*/} DLinkList;void InitList(DLinkList *&L){L=(DLinkList *)malloc(sizeof(DLinkList)); /*创建头结点*/ L->prior=L->next=NULL;}void DestroyList(DLinkList *&L){DLinkList *p=L,*q=p->next;while (q!=NULL){free(p);p=q;q=p->next;}free(p);}int ListEmpty(DLinkList *L){return(L->next==NULL);}int ListLength(DLinkList *L){DLinkList *p=L;int i=0;while (p->next!=NULL){i++;p=p->next;}return(i);}void DispList(DLinkList *L){DLinkList *p=L->next;while (p!=NULL){printf("%c",p->data);p=p->next;}printf("\n");}int GetElem(DLinkList *L,int i,ElemType &e) {int j=0;DLinkList *p=L;while (j<i && p!=NULL){j++;p=p->next;}if (p==NULL)return 0;else{e=p->data;return 1;}}int LocateElem(DLinkList *L,ElemType e) {int n=1;DLinkList *p=L->next;while (p!=NULL && p->data!=e){n++;p=p->next;}if (p==NULL)return(0);elsereturn(n);}int ListInsert(DLinkList *&L,int i,ElemType e){int j=0;DLinkList *p=L,*s;while (j<i-1 && p!=NULL){j++;p=p->next;}if (p==NULL) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{s=(DLinkList *)malloc(sizeof(DLinkList)); /*创建新结点*s*/s->data=e;s->next=p->next; /*将*s插入到*p之后*/if (p->next!=NULL) p->next->prior=s;s->prior=p;p->next=s;return 1;}}int ListDelete(DLinkList *&L,int i,ElemType &e){int j=0;DLinkList *p=L,*q;while (j<i-1 && p!=NULL){j++;p=p->next;}if (p==NULL) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{q=p->next; /*q指向要删除的结点*/if (q==NULL) return 0; /*不存在第i个结点*/p->next=q->next; /*从单链表中删除*q结点*/if (p->next!=NULL) p->next->prior=p;free(q); /*释放*q结点*/return 1;}}void Sort(DLinkList *&head) /*双链表元素排序*/{DLinkList *p=head->next,*q,*r;if (p!=NULL) /*若原双链表中有一个或以上的数据结点*/{r=p->next; /*r保存*p结点后继结点的指针*/p->next=NULL; /*构造只含一个数据结点的有序表*/p=r;while (p!=NULL){r=p->next; /*r保存*p结点后继结点的指针*/q=head;while (q->next!=NULL && q->next->data<p->data) /*在有序表中找插入*p的前驱结点*q*/q=q->next;p->next=q->next; /*将*p插入到*q之后*/if (q->next!=NULL) q->next->prior=p;q->next=p;p->prior=q;p=r;}}}/*文件名:algo2-4.cpp*/#include <stdio.h>#include <malloc.h>typedef char ElemType;typedef struct LNode /*定义单链表结点类型*/{ElemType data;struct LNode *next;} LinkList;void InitList(LinkList *&L){L=(LinkList *)malloc(sizeof(LinkList)); /*创建头结点*/L->next=L;}void DestroyList(LinkList *&L){LinkList *p=L,*q=p->next;while (q!=L){free(p);p=q;q=p->next;}free(p);}int ListEmpty(LinkList *L){return(L->next==L);}int ListLength(LinkList *L){LinkList *p=L;int i=0;while (p->next!=L){i++;p=p->next;}return(i);}void DispList(LinkList *L){LinkList *p=L->next;while (p!=L){printf("%c",p->data);p=p->next;}printf("\n");}int GetElem(LinkList *L,int i,ElemType &e){int j=0;LinkList *p;if (L->next!=L) /*单链表不为空表时*/ {if (i==1){e=L->next->data;return 1;}else /*i不为1时*/{p=L->next;while (j<i-1 && p!=L){j++;p=p->next;}if (p==L)return 0;else{e=p->data;return 1;}}}else /*单链表为空表时*/return 0;}int LocateElem(LinkList *L,ElemType e){LinkList *p=L->next;int n=1;while (p!=L && p->data!=e){p=p->next;n++;}if (p==L)return(0);elsereturn(n);}int ListInsert(LinkList *&L,int i,ElemType e){int j=0;LinkList *p=L,*s;if (p->next==L || i==1) /*原单链表为空表或i==1时*/ {s=(LinkList *)malloc(sizeof(LinkList)); /*创建新结点*s*/s->data=e;s->next=p->next; /*将*s插入到*p之后*/p->next=s;return 1;}else{p=L->next;while (j<i-2 && p!=L){j++;p=p->next;}if (p==L) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{s=(LinkList *)malloc(sizeof(LinkList)); /*创建新结点*s*/s->data=e;s->next=p->next; /*将*s插入到*p之后*/p->next=s;return 1;}}}int ListDelete(LinkList *&L,int i,ElemType &e){int j=0;LinkList *p=L,*q;if (p->next!=L) /*原单链表不为空表时*/{if (i==1) /*i==1时*/{q=L->next; /*删除第1个结点*/L->next=q->next;free(q);return 1;}else /*i不为1时*/{p=L->next;while (j<i-2 && p!=L){j++;p=p->next;}if (p==L) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{q=p->next; /*q指向要删除的结点*/p->next=q->next; /*从单链表中删除*q结点*/free(q); /*释放*q结点*/return 1;}}}else return 0;}/*文件名:algo2-5.cpp*/#include <stdio.h>#include <malloc.h>typedef char ElemType;typedef struct DNode /*定义双链表结点类型*/{ElemType data;struct DNode *prior; /*指向前驱结点*/struct DNode *next; /*指向后继结点*/} DLinkList;void InitList(DLinkList *&L){L=(DLinkList *)malloc(sizeof(DLinkList)); /*创建头结点*/ L->prior=L->next=L;}void DestroyList(DLinkList *&L){DLinkList *p=L,*q=p->next;while (q!=L){free(p);p=q;q=p->next;}free(p);}int ListEmpty(DLinkList *L){return(L->next==L);}int ListLength(DLinkList *L){DLinkList *p=L;int i=0;while (p->next!=L){i++;p=p->next;}return(i);}void DispList(DLinkList *L){DLinkList *p=L->next;while (p!=L){printf("%c",p->data);p=p->next;}printf("\n");}int GetElem(DLinkList *L,int i,ElemType &e){int j=0;DLinkList *p;if (L->next!=L) /*双链表不为空表时*/ {if (i==1){e=L->next->data;return 1;}else /*i不为1时*/{p=L->next;while (j<i-1 && p!=L){j++;p=p->next;}if (p==L)return 0;else{e=p->data;return 1;}}else /*双链表为空表时*/return 0;}int LocateElem(DLinkList *L,ElemType e){int n=1;DLinkList *p=L->next;while (p!=NULL && p->data!=e){n++;p=p->next;}if (p==NULL)return(0);elsereturn(n);}int ListInsert(DLinkList *&L,int i,ElemType e){int j=0;DLinkList *p=L,*s;if (p->next==L) /*原双链表为空表时*/{s=(DLinkList *)malloc(sizeof(DLinkList)); /*创建新结点*s*/s->data=e;p->next=s;s->next=p;p->prior=s;s->prior=p;return 1;}else if (i==1) /*原双链表不为空表但i=1时*/ {s=(DLinkList *)malloc(sizeof(DLinkList)); /*创建新结点*s*/s->data=e;s->next=p->next;p->next=s; /*将*s插入到*p之后*/s->next->prior=s;s->prior=p;return 1;}else{p=L->next;while (j<i-2 && p!=L)p=p->next;}if (p==L) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{s=(DLinkList *)malloc(sizeof(DLinkList)); /*创建新结点*s*/s->data=e;s->next=p->next; /*将*s插入到*p之后*/if (p->next!=NULL) p->next->prior=s;s->prior=p;p->next=s;return 1;}}}int ListDelete(DLinkList *&L,int i,ElemType &e){int j=0;DLinkList *p=L,*q;if (p->next!=L) /*原双链表不为空表时*/{if (i==1) /*i==1时*/{q=L->next; /*删除第1个结点*/L->next=q->next;q->next->prior=L;free(q);return 1;}else /*i不为1时*/{p=L->next;while (j<i-2 && p!=NULL){j++;p=p->next;}if (p==NULL) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{q=p->next; /*q指向要删除的结点*/if (q==NULL) return 0; /*不存在第i个结点*/p->next=q->next; /*从单链表中删除*q结点*/if (p->next!=NULL) p->next->prior=p;free(q); /*释放*q结点*/return 1;}}}else return 0; /*原双链表为空表时*/}/*文件名:algo3-1.cpp*/#include <stdio.h>#include <malloc.h>#define MaxSize 100typedef char ElemType;typedef struct{ElemType elem[MaxSize];int top; /*栈指针*/} SqStack;void InitStack(SqStack *&s){s=(SqStack *)malloc(sizeof(SqStack));s->top=-1;}void ClearStack(SqStack *&s){free(s);}int StackLength(SqStack *s){return(s->top+1);}int StackEmpty(SqStack *s){return(s->top==-1);}int Push(SqStack *&s,ElemType e){if (s->top==MaxSize-1)return 0;s->top++;s->elem[s->top]=e;return 1;}int Pop(SqStack *&s,ElemType &e){if (s->top==-1)return 0;e=s->elem[s->top];s->top--;return 1;}int GetTop(SqStack *s,ElemType &e){if (s->top==-1)return 0;e=s->elem[s->top];return 1;}void DispStack(SqStack *s){int i;for (i=s->top;i>=0;i--)printf("%c ",s->elem[i]);printf("\n");}/*文件名:algo3-2.cpp*/#include <stdio.h>#include <malloc.h>typedef char ElemType;typedef struct linknode{ElemType data; /*数据域*/ struct linknode *next; /*指针域*/} LiStack;void InitStack(LiStack *&s){s=(LiStack *)malloc(sizeof(LiStack));s->next=NULL;}void ClearStack(LiStack *&s){LiStack *p=s->next;while (p!=NULL){free(s);s=p;p=p->next;}int StackLength(LiStack *s){int i=0;LiStack *p;p=s->next;while (p!=NULL){i++;p=p->next;}return(i);}int StackEmpty(LiStack *s){return(s->next==NULL);}void Push(LiStack *&s,ElemType e){LiStack *p;p=(LiStack *)malloc(sizeof(LiStack));p->data=e;p->next=s->next; /*插入*p结点作为第一个数据结点*/ s->next=p;}int Pop(LiStack *&s,ElemType &e){LiStack *p;if (s->next==NULL) /*栈空的情况*/return 0;p=s->next; /*p指向第一个数据结点*/e=p->data;s->next=p->next;free(p);return 1;}int GetTop(LiStack *s,ElemType &e){if (s->next==NULL) /*栈空的情况*/return 0;e=s->next->data;return 1;}void DispStack(LiStack *s)LiStack *p=s->next;while (p!=NULL){printf("%c ",p->data);p=p->next;}printf("\n");}/*文件名:algo3-3.cpp*/#include <stdio.h>#include <malloc.h>#define MaxSize 5typedef char ElemType;typedef struct{ElemType elem[MaxSize];int front,rear; /*队首和队尾指针*/} SqQueue;void InitQueue(SqQueue *&q){q=(SqQueue *)malloc (sizeof(SqQueue));q->front=q->rear=0;}void ClearQueue(SqQueue *&q){free(q);}int QueueEmpty(SqQueue *q){return(q->front==q->rear);}int QueueLength(SqQueue *q){return (q->rear-q->front+MaxSize)%MaxSize; }int enQueue(SqQueue *&q,ElemType e){if ((q->rear+1)%MaxSize==q->front) /*队满*/ return 0;q->rear=(q->rear+1)%MaxSize;q->elem[q->rear]=e;return 1;}int deQueue(SqQueue *&q,ElemType &e)if (q->front==q->rear) /*队空*/return 0;q->front=(q->front+1)%MaxSize;e=q->elem[q->front];return 1;}/*文件名:algo3-4.cpp*/#include <stdio.h>#include <malloc.h>typedef char ElemType;typedef struct qnode{ElemType data;struct qnode *next;} QNode;typedef struct{QNode *front;QNode *rear;} LiQueue;void InitQueue(LiQueue *&q){q=(LiQueue *)malloc(sizeof(LiQueue));q->front=q->rear=NULL;}void ClearQueue(LiQueue *&q){QNode *p=q->front,*r;if (p!=NULL) /*释放数据结点占用空间*/ {r=p->next;while (r!=NULL){free(p);p=r;r=p->next;}}free(q); /*释放头结点占用空间*/ }int QueueLength(LiQueue *q){int n=0;QNode *p=q->front;while (p!=NULL){n++;p=p->next;}return(n);}int QueueEmpty(LiQueue *q){if (q->rear==NULL)return 1;elsereturn 0;}void enQueue(LiQueue *&q,ElemType e){QNode *s;s=(QNode *)malloc(sizeof(QNode));s->data=e;s->next=NULL;if (q->rear==NULL) /*若链队为空,则新结点是队首结点又是队尾结点*/ q->front=q->rear=s;else{q->rear->next=s; /*将*s结点链到队尾,rear指向它*/q->rear=s;}}int deQueue(LiQueue *&q,ElemType &e){QNode *t;if (q->rear==NULL) /*队列为空*/return 0;if (q->front==q->rear) /*队列中只有一个结点时*/{t=q->front;q->front=q->rear=NULL;}else /*队列中有多个结点时*/{t=q->front;q->front=q->front->next;}e=t->data;free(t);return 1;}/*文件名:algo4-1.cpp*/#include <stdio.h>#define MaxSize 100 /*最多的字符个数*/typedef struct{ char ch[MaxSize]; /*定义可容纳MaxSize个字符的空间*/ int len; /*标记当前实际串长*/} SqString;void StrAssign(SqString &str,char cstr[]) /*str为引用型参数*/{int i;for (i=0;cstr[i]!='\0';i++)str.ch[i]=cstr[i];str.len=i;}void StrCopy(SqString &s,SqString t) /*s为引用型参数*/{int i;for (i=0;i<t.len;i++)s.ch[i]=t.ch[i];s.len=t.len;}int StrEqual(SqString s,SqString t){int same=1,i;if (s.len!=t.len) /*长度不相等时返回0*/same=0;else{for (i=0;i<s.len;i++)if (s.ch[i]!=t.ch[i]) /*有一个对应字符不相同时返回0*/same=0;}return same;}int StrLength(SqString s){return s.len;}SqString Concat(SqString s,SqString t){SqString str;int i;str.len=s.len+t.len;for (i=0;i<s.len;i++) /*将s.ch[0]~s.ch[s.len-1]复制到str*/str.ch[i]=s.ch[i];for (i=0;i<t.len;i++) /*将t.ch[0]~t.ch[t.len-1]复制到str*/str.ch[s.len+i]=t.ch[i];return str;}SqString SubStr(SqString s,int i,int j){SqString str;int k;str.len=0;if (i<=0 || i>s.len || j<0 || i+j-1>s.len){printf("参数不正确\n");return str; /*参数不正确时返回空串*/ }for (k=i-1;k<i+j-1;k++) /*将s.ch[i]~s.ch[i+j]复制到str*/ str.ch[k-i+1]=s.ch[k];str.len=j;return str;}SqString InsStr(SqString s1,int i,SqString s2){int j;SqString str;str.len=0;if (i<=0 || i>s1.len+1) /*参数不正确时返回空串*/{printf("参数不正确\n");return s1;}for (j=0;j<i-1;j++) /*将s1.ch[0]~s1.ch[i-2]复制到str*/ str.ch[j]=s1.ch[j];for (j=0;j<s2.len;j++) /*将s2.ch[0]~s2.ch[s2.len-1]复制到str*/ str.ch[i+j-1]=s2.ch[j];for (j=i-1;j<s1.len;j++) /*将s1.ch[i-1]~s.ch[s1.len-1]复制到str*/ str.ch[s2.len+j]=s1.ch[j];str.len=s1.len+s2.len;return str;}SqString DelStr(SqString s,int i,int j){int k;SqString str;str.len=0;if (i<=0 || i>s.len || i+j>s.len+1) /*参数不正确时返回空串*/{printf("参数不正确\n");return str;}for (k=0;k<i-1;k++) /*将s.ch[0]~s.ch[i-2]复制到str*/str.ch[k]=s.ch[k];for (k=i+j-1;k<s.len;k++)/*将s.ch[i+j-1]~ch[s.len-1]复制到str*/ str.ch[k-j]=s.ch[k];str.len=s.len-j;return str;}SqString RepStr(SqString s,int i,int j,SqString t){int k;SqString str;str.len=0;if (i<=0 || i>s.len || i+j-1>s.len) /*参数不正确时返回空串*/{printf("参数不正确\n");return str;}for (k=0;k<i-1;k++) /*将s.ch[0]~s.ch[i-2]复制到str*/ str.ch[k]=s.ch[k];for (k=0;k<t.len;k++) /*将t.ch[0]~t.ch[t.len-1]复制到str*/ str.ch[i+k-1]=t.ch[k];for (k=i+j-1;k<s.len;k++) /*将s.ch[i+j-1]~ch[s.len-1]复制到str*/ str.ch[t.len+k-j]=s.ch[k];str.len=s.len-j+t.len;return str;}void DispStr(SqString str){int i;if (str.len>0){for (i=0;i<str.len;i++)printf("%c",str.ch[i]);printf("\n");}}/*文件名:algo4-2.cpp*/#include <stdio.h>#include <malloc.h>typedef struct snode{char data;struct snode *next;} LiString;void StrAssign(LiString *&s,char t[]){int i;LiString *r,*p;s=(LiString *)malloc(sizeof(LiString));s->next=NULL;r=s;for (i=0;t[i]!='\0';i++){p=(LiString *)malloc(sizeof(LiString));p->data=t[i];p->next=NULL;r->next=p;r=p;}}void StrCopy(LiString *&s,LiString *t){LiString *p=t->next,*q,*r;s=(LiString *)malloc(sizeof(LiString));s->next=NULL;s->next=NULL;r=s;while (p!=NULL) /*将t的所有结点复制到s*/ {q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}}int StrEqual(LiString *s,LiString *t){LiString *p=s->next,*q=t->next;while (p!=NULL && q!=NULL && p->data==q->data) {p=p->next;q=q->next;}if (p==NULL && q==NULL)return 1;elsereturn 0;}int StrLength(LiString *s){int i=0;LiString *p=s->next;while (p!=NULL){i++;p=p->next;}return i;}LiString *Concat(LiString *s,LiString *t){LiString *str,*p=s->next,*q,*r;str=(LiString *)malloc(sizeof(LiString));str->next=NULL;r=str;while (p!=NULL) /*将s的所有结点复制到str*/{q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}p=t->next;while (p!=NULL) /*将t的所有结点复制到str*/{q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}return str;}LiString *SubStr(LiString *s,int i,int j){int k;LiString *str,*p=s->next,*q,*r;str=(LiString *)malloc(sizeof(LiString));str->next=NULL;r=str;if (i<=0 || i>StrLength(s) || j<0 || i+j-1>StrLength(s)){printf("参数不正确\n");return str; /*参数不正确时返回空串*/ }for (k=0;k<i-1;k++)p=p->next;for (k=1;k<=j;k++) /*将s的第i个结点开始的j个结点复制到str*/ {q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}return str;}LiString *InsStr(LiString *s,int i,LiString *t){int k;LiString *str,*p=s->next,*p1=t->next,*q,*r;str=(LiString *)malloc(sizeof(LiString));str->next=NULL;r=str;if (i<=0 || i>StrLength(s)+1) /*参数不正确时返回空串*/{printf("参数不正确\n");return str;}for (k=1;k<i;k++) /*将s的前i个结点复制到str*/{q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}while (p1!=NULL) /*将t的所有结点复制到str*/{q=(LiString *)malloc(sizeof(LiString));q->data=p1->data;q->next=NULL;r->next=q;r=q;p1=p1->next;}while (p!=NULL) /*将*p及其后的结点复制到str*/{q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}return str;}LiString *DelStr(LiString *s,int i,int j){int k;LiString *str,*p=s->next,*q,*r;str=(LiString *)malloc(sizeof(LiString));str->next=NULL;r=str;if (i<=0 || i>StrLength(s) || j<0 || i+j-1>StrLength(s)){printf("参数不正确\n");return str; /*参数不正确时返回空串*/ }for (k=0;k<i-1;k++) /*将s的前i-1个结点复制到str*/{q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}for (k=0;k<j;k++) /*让p沿next跳j个结点*/p=p->next;while (p!=NULL) /*将*p及其后的结点复制到str*/ {q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}return str;}LiString *RepStr(LiString *s,int i,int j,LiString *t){int k;LiString *str,*p=s->next,*p1=t->next,*q,*r;str=(LiString *)malloc(sizeof(LiString));str->next=NULL;r=str;if (i<=0 || i>StrLength(s) || j<0 || i+j-1>StrLength(s)){printf("参数不正确\n");return str; /*参数不正确时返回空串*/ }for (k=0;k<i-1;k++) /*将s的前i-1个结点复制到str*/{q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}for (k=0;k<j;k++) /*让p沿next跳j个结点*/p=p->next;while (p1!=NULL) /*将t的所有结点复制到str*/{q=(LiString *)malloc(sizeof(LiString));q->data=p1->data;q->next=NULL;r->next=q;r=q;p1=p1->next;}while (p!=NULL) /*将*p及其后的结点复制到str*/ {q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}return str;}void DispStr(LiString *s){LiString *p=s->next;while (p!=NULL){printf("%c",p->data);p=p->next;}printf("\n");}/*文件名:algo7-1.cpp*/#include <stdio.h>#include <malloc.h>#define MaxSize 100typedef char ElemType;typedef struct node{ElemType data; /*数据元素*/struct node *lchild; /*指向左孩子*/struct node *rchild; /*指向右孩子*/} BTNode;void CreateBTNode(BTNode *&b,char *str) /*由str串创建二叉链*/ {BTNode *St[MaxSize],*p=NULL;int top=-1,k,j=0;char ch;b=NULL; /*建立的二叉树初始时为空*/ch=str[j];while (ch!='\0') /*str未扫描完时循环*/{switch(ch){case '(':top++;St[top]=p;k=1; break; /*为左结点*/case ')':top--;break;case ',':k=2; break; /*为右结点*/default:p=(BTNode *)malloc(sizeof(BTNode));p->data=ch;p->lchild=p->rchild=NULL;if (b==NULL) /*p指向二叉树的根结点*/b=p;else /*已建立二叉树根结点*/{switch(k){case 1:St[top]->lchild=p;break;case 2:St[top]->rchild=p;break;}}}j++;ch=str[j];}}BTNode *FindNode(BTNode *b,ElemType x) /*返回data域为x的结点指针*/{BTNode *p;if (b==NULL)return NULL;else if (b->data==x)return b;else{p=FindNode(b->lchild,x);if (p!=NULL)return p;elsereturn FindNode(b->rchild,x);}}BTNode *LchildNode(BTNode *p) /*返回*p结点的左孩子结点指针*/{return p->lchild;}BTNode *RchildNode(BTNode *p) /*返回*p结点的右孩子结点指针*/{return p->rchild;}int BTNodeDepth(BTNode *b) /*求二叉树b的深度*/{int lchilddep,rchilddep;if (b==NULL)return(0); /*空树的高度为0*/ else{lchilddep=BTNodeDepth(b->lchild); /*求左子树的高度为lchilddep*/rchilddep=BTNodeDepth(b->rchild); /*求右子树的高度为rchilddep*/return (lchilddep>rchilddep)? (lchilddep+1):(rchilddep+1);}}void DispBTNode(BTNode *b) /*以括号表示法输出二叉树*/{if (b!=NULL){printf("%c",b->data);if (b->lchild!=NULL || b->rchild!=NULL){printf("(");DispBTNode(b->lchild);if (b->rchild!=NULL) printf(",");DispBTNode(b->rchild);printf(")");}}}int BTWidth(BTNode *b) /*求二叉树b的宽度*/{struct{int lno; /*结点的层次编号*/BTNode *p; /*结点指针*/} Qu[MaxSize]; /*定义顺序非循环队列*/int front,rear; /*定义队首和队尾指针*/int lnum,max,i,n;front=rear=0; /*置队列为空队*/if (b!=NULL){rear++;Qu[rear].p=b; /*根结点指针入队*/Qu[rear].lno=1; /*根结点的层次编号为1*/while (rear!=front) /*队列不为空*/{front++;b=Qu[front].p; /*队头出队*/lnum=Qu[front].lno;if (b->lchild!=NULL) /*左孩子入队*/{rear++;Qu[rear].p=b->lchild;Qu[rear].lno=lnum+1;}if (b->rchild!=NULL) /*右孩子入队*/{rear++;Qu[rear].p=b->rchild;Qu[rear].lno=lnum+1;}}max=0;lnum=1;i=1;while (i<=rear){n=0;while (i<=rear && Qu[i].lno==lnum){n++;i++;}lnum=Qu[i].lno;if (n>max) max=n;}return max;}elsereturn 0;}int Nodes(BTNode *b) /*求二叉树b的结点个数*/{int num1,num2;if (b==NULL)。
数据结构第三版第九章课后习题参考答案
}
}
设计如下主函数:
void main()
{ BSTNode *bt;
KeyType k=3;
int a[]={5,2,1,6,7,4,8,3,9},n=9;
bt=CreatBST(a,n);
//创建《教程》中图 9.4(a)所示的二叉排序树
printf("BST:");DispBST(bt);printf("\n");
#define M 26 int H(char *s)
//求字符串 s 的哈希函数值
{
return(*s%M);
}
构造哈希表 void Hash(char *s[]) //
{ int i,j;
char HT[M][10]; for (i=0;i<M;i++)
//哈希表置初值
HT[i][0]='\0'; for (i=0;i<N;i++) { j=H(s[i]);
//求每个关键字的位置 求 // s[i]的哈希函数值
while (1)
不冲突时 直接放到该处 { if (HT[j][0]=='\0') //
,
{ strcpy(HT[j],s[i]);
break;
}
else
//冲突时,采用线性线性探测法求下一个地址
j=(j+1)%M;
}
} for (i=0;i<M;i++)
printf("%2d",path[j]);
printf("\n");
}
else { path[i+1]=bt->key;
数据结构与算法分析课后习题答案

数据结构与算法分析课后习题答案[篇一:《数据结构与算法》课后习题答案]>2.3.2 判断题2.顺序存储的线性表可以按序号随机存取.〔√〕4.线性表中的元素可以是各种各样的,但同一线性表中的数据元素具有相同的特性,因此属于同一数据对象.〔√〕6.在线性表的链式存储结构中,逻辑上相邻的元素在物理位置上不一定相邻.〔√〕8.在线性表的顺序存储结构中,插入和删除时移动元素的个数与该元素的位置有关.〔√〕9.线性表的链式存储结构是用一组任意的存储单元来存储线性表中数据元素的.〔√〕2.3.3 算法设计题1.设线性表存放在向量a[arrsize]的前elenum个分量中,且递增有序.试写一算法,将x 插入到线性表的适当位置上,以保持线性表的有序性,并且分析算法的时间复杂度.[提示]直接用题目中所给定的数据结构〔顺序存储的思想是用物理上的相邻表示逻辑上的相邻,不一定将向量和表示线性表长度的变量封装成一个结构体〕,因为是顺序存储,分配的存储空间是固定大小的,所以首先确定是否还有存储空间,若有,则根据原线性表中元素的有序性,来确定插入元素的插入位置,后面的元素为它让出位置,〔也可以从高下标端开始一边比较,一边移位〕然后插入x ,最后修改表示表长的变量.int insert <datatype a[],int *elenum,datatype x> /*设elenum为表的最大下标*/ {if <*elenum==arrsize-1> return 0; /*表已满,无法插入*/else {i=*elenum;while <i=0 a[i]x>/*边找位置边移动*/{a[i+1]=a[i];i--;}a[i+1]=x;/*找到的位置是插入位的下一位*/ <*elenum>++;return 1;/*插入成功*/}}时间复杂度为o<n>.2.已知一顺序表a,其元素值非递减有序排列,编写一个算法删除顺序表中多余的值相同的元素.[提示]对顺序表a,从第一个元素开始,查找其后与之值相同的所有元素,将它们删除;再对第二个元素做同样处理,依此类推.void delete<seqlist *a>{i=0;while<ia-last>/*将第i个元素以后与其值相同的元素删除*/{k=i+1;while<k=a-lasta-data[i]==a-data[k]>k++;/*使k指向第一个与a[i]不同的元素*/ n=k-i-1;/*n表示要删除元素的个数*/for<j=k;j=a-last;j++>a-data[j-n]=a-data[j]; /*删除多余元素*/a-last= a-last -n;i++;}}3.写一个算法,从一个给定的顺序表a中删除值在x~y<x=y>之间的所有元素,要求以较高的效率来实现.[提示]对顺序表a,从前向后依次判断当前元素a-data[i]是否介于x 和y之间,若是,并不立即删除,而是用n记录删除时应前移元素的位移量;若不是,则将a-data[i]向前移动n位.n用来记录当前已删除元素的个数.void delete<seqlist *a,int x,int y>{i=0;n=0;while <ia-last>{if <a-data[i]=x a-data[i]=y>n++; /*若a-data[i] 介于x和y之间,n 自增*/ else a-data[i-n]=a-data[i];/*否则向前移动a-data[i]*/i++;}a-last-=n;}4.线性表中有n个元素,每个元素是一个字符,现存于向量r[n]中,试写一算法,使r中的字符按字母字符、数字字符和其它字符的顺序排列.要求利用原来的存储空间,元素移动次数最小.[提示]对线性表进行两次扫描,第一次将所有的字母放在前面,第二次将所有的数字放在字母之后,其它字符之前.int fch<char c> /*判断c是否字母*/{if<c=ac=z||c=ac=z> return <1>;elsereturn <0>;}int fnum<char c> /*判断c是否数字*/{if<c=0c=9>return <1>;elsereturn <0>;}void process<char r[n]>{low=0;high=n-1;while<lowhigh> /*将字母放在前面*/{while<lowhighfch<r[low]>> low++;while<lowhigh!fch<r[high]>> high--;if<lowhigh>{k=r[low];r[low]=r[high];r[high]=k;}}low=low+1;high=n-1;while<lowhigh> /*将数字放在字母后面,其它字符前面*/{while<lowhighfnum<r[low]>> low++;while<lowhigh!fnum<r[high]>> high--;if<lowhigh>{k=r[low];r[low]=r[high];r[high]=k;}}}5.线性表用顺序存储,设计一个算法,用尽可能少的辅助存储空间将顺序表中前m个元素和后n个元素进行整体互换.即将线性表:〔a1, a2, … , am, b1, b2, … , bn〕改变为:〔b1, b2, … , bn , a1, a2, … , am〕.[提示]比较m和n的大小,若mn,则将表中元素依次前移m次;否则,将表中元素依次后移n次.void process<seqlist *l,int m,int n>{if<m=n>for<i=1;i=m;i++>{x=l-data[0];for<k=1;k=l-last;k++>l-data[k-1]=l-data[k];l-data[l-last]=x;}else for<i=1;i=n;i++>{x=l-data[l-last];for<k=l-last-1;k=0;k- ->l-data[k+1]=l-data[k];l-data[0]=x; }}6.已知带头结点的单链表l中的结点是按整数值递增排列的,试写一算法,将值为x 的结点插入到表l中,使得l仍然递增有序,并且分析算法的时间复杂度.linklist insert<linklist l, int x>{p=l;while<p-next xp-next-data>p=p-next;/*寻找插入位置*/ s=<lnode *>malloc<sizeof<lnode>>; /*申请结点空间*/ s-data=x;/*填装结点*/s-next=p-next;p-next=s; /*将结点插入到链表中*/ return<l>;}7.假设有两个已排序〔递增〕的单链表a和b,编写算法将它们合并成一个链表c而不改变其排序性.linklist bine<linklist a, linklist b>{c=a;rc=c;pa=a-next; /*pa指向表a的第一个结点*/pb=b-next; /*pb指向表b的第一个结点*/free<b>; /*释放b的头结点*/while <pa pb> /*将pa、pb所指向结点中,值较小的一个插入到链表c的表尾*/if<pa-datapb-data>{rc-next=pa;rc=pa;pa=pa-next;}else{rc-next=pb;rc=pb;pb=pb-next;}if<pa> rc-next=pa;else rc-next=pb;/*将链表a或b中剩余的部分到链表c的表尾*/return<c>;}8.假设长度大于1的循环单链表中,既无头结点也无头指针,p为指向该链表中某一结点的指针,编写算法删除该结点的前驱结点.[提示]利用循环单链表的特点,通过s指针可循环找到其前驱结点p 与p的前驱结点q,然后可删除结点*p.viod delepre<lnode *s>{lnode *p, *q;p=s;while <p-next!=s>{q=p;p=p-next;}q-next=s;free<p>;}9.已知两个单链表a和b分别表示两个集合,其元素递增排列,编写算法求出a和b的交集c,要求c同样以元素递增的单链表形式存储.[提示]交集指的是两个单链表的元素值相同的结点的集合,为了操作方便,先让单链表c带有一个头结点,最后将其删除掉.算法中指针p 用来指向a中的当前结点,指针q用来指向b中的当前结点,将其值进行比较,两者相等时,属于交集中的一个元素,两者不等时,将其较小者跳过,继续后面的比较.linklist intersect<linklist a, linklist b>{lnode *q, *p, *r, *s;linklist c;c= <lnode *>malloc<sizeof<lnode>>;c-next=null;r=c;p=a;q=b;while <p q >if <p-dataq-data> p=p-next;else if <p-data==q-data>{s=<lnode *>malloc<sizeof<lnode>>;s-data=p-data;r-next=s;r=s;p=p-next;q=q-next;}else q=q-next;r-next=null;c=c-next;return c;}10.设有一个双向链表,每个结点中除有prior、data和next域外,还有一个访问频度freq域,在链表被起用之前,该域的值初始化为零.每当在链表进行一次locata<l,x>运算后,令值为x的结点中的freq 域增1,并调整表中结点的次序,使其按访问频度的非递增序列排列,以便使频繁访问的结点总是靠近表头.试写一个满足上述要求的locata<l,x>算法.[提示]在定位操作的同时,需要调整链表中结点的次序:每次进行定位操作后,要查看所查找结点的freq域,将其同前面结点的freq域进行比较,同时进行结点次序的调整. typedef struct dnode[篇二:数据结构课后习题答案]lass=txt>高等学校精品资源共享课程绪论第 1 章1.1 什么是数据结构?[答]:数据结构是指按一定的逻辑结构组成的一批数据,使用某种存储结构将这批数据存储于计算机中,并在这些数据上定义了一个运算集合. 1.2 数据结构涉与哪几个方面?[答]:数据结构涉与三个方面的内容,即数据的逻辑结构、数据的存储结构和数据的运算集合.1.3 两个数据结构的逻辑结构和存储结构都相同,但是它们的运算集合中有一个运算的定义不一样,它们是否可以认作是同一个数据结构?为什么?[答]:不能,运算集合是数据结构的重要组成部分,不同的运算集合所确定的数据结构是不一样的,例如,栈与队列它们的逻辑结构与存储结构可以相同,但由于它们的运算集合不一样, 所以它们是两种不同的数据结构.1.4 线性结构的特点是什么?非线性结构的特点是什么?[答]:线性结构元素之间的关系是一对一的,在线性结构中只有一个开始结点和一个终端结点,其他的每一个结点有且仅有一个前驱和一个后继结点.而非线性结构则没有这个特点,元素之间的关系可以是一对多的或多对多的. 1.5 数据结构的存储方式有哪几种?[答]:数据结构的存储方式有顺序存储、链式存储、散列存储和索引存储等四种方式. 1.6 算法有哪些特点?它和程序的主要区别是什么?[答]:算法具有〔1〕有穷性〔2〕确定性〔3〕0 个或多个输入〔4〕1 个或多个输出〔5〕可行性等特征.程序是算法的一种描述方式,通过程序可以在计算机上实现算法. 1.7 抽象数据类型的是什么?它有什么特点?[答]:抽象数据类型是数据类型的进一步抽象,是大家熟知的基本数据类型的延伸和发展. 抽象数据类型是与表示无关的数据类型,是一个数据模型与定义在该模型上的一组运算.对一个抽象数据类型进行定义时,必须给出它的名字与各运算的运算符名,即函数名,并且规定这些函数的参数性质.一旦定义了一个抽象数据类型与具体实现,程序设计中就可以像使用基本数据类型那样,十分方便地使用抽象数据类型.抽象数据类型的设计者根据这些描述给出操作的具体实现,抽象数据类型的使用者依据这些描述使用抽象数据类型. 1.8 算法的时间复杂度指的是什么?如何表示?[答]:算法执行时间的度量不是采用算法执行的绝对时间来计算的,因为一个算法在不同的机器上执行所花的时间不一样,在不同时刻也会由于计算机资源占用情况的不同,使得算法在同一台计算机上执行的时间也不一样,另外,算法执行的时间还与输入数据的状态有关,所以对于算法的时间复杂性,采用算法执行过程中其基本操作的执行次数,称为计算量来度量.算法中基本操作的执行次数一般是与问题规模有关的,对于结点个数为 n 的数据处理问题,用 t<n>表示算法基本操作的执行次数.为了评价算法的执行效率,通常采用大写 o 符号表示算法的时间复杂度,大写 o 符号给出了函数 f 的一个上限.其它义如下:3十二五普通高等教育国家级本科规划教材高等学校精品资源共享课程定义:f <n>=o <g <n>> 当且仅当存在正的常数 c 和 n0,使得对于所有的n≥n0,有f <n> ≤c g<n>.上述定义表明,函数 f 顶多是函数 g 的 c 倍,除非 n 小于 n0.因此对于足够大的 n <如n≥n0>, g 是 f 的一个上限〔不考虑常数因子 c〕.在为函数 f 提供一个上限函数 g 时,通常使用比较简单的函数形式.比较典型的形式是含有 n 的单个项〔带一个常数系数〕.表 1-1 列出了一些常用的 g 函数与其名称.对于表1-1 中的对数函数 logn,没有给出对数基,原因是对于任何大于 1 的常数 a 和 b 都有 logan =logbn/logba,所以 logan 和 logbn 都有一个相对的乘法系数 1/logba, 其中 a 是一个常量.表 1-1 常用的渐进函数1.9 [答]:算法的空间复杂度是指算法在执行过程中占用的额外的辅助空间的个数.可以将它表示为问题规模的函数,并通过大写o符号表示空间复杂度.1.10 对于下面的程序段,分析带下划线的语句的执行次数,并给出它们的时间复杂度 t<n>.〔1〕 i++ ;〔2〕 for<i=0;in;i++>if <a[i]x> x=a[i];〔3〕for<i=0;in;i++>for<j=0;jn;j++>;〔4〕for <i=1;i=n-1;i++>{ k=i;for<j=i+1;j=n;j++>if<a[j]a[j+1]> k=j; t=a[k]; a[k]=a[i]; a[i]=t; }〔5〕for<i=0;in;i++>for<j=0;jn;j++>{++x;s=s+x;}[答]:〔1〕o〔1〕;〔2〕o〔n〕;〔3〕o〔n2〕;〔4〕o〔n2〕;〔5〕o〔n2〕4第 2 章线性表与其顺序存储2.1 选择题〔1〕表长为 n 的顺序存储的线性表,当在任何位置上插入或删除一个元素的概率相等时, 插入一个元素所需移动元素的平均个数为〔为〔 a 〕.a.〔n?1〕/2 e.n/2b.n f.<n+1>/2c.n+1d.n?1g.<n?2>/2〔2〕设栈 s 和队列 q 的初始状态为空,元素 e1、e2、e3、e4、e5 和 e6 依次通过栈 s, 一个元素出栈后即进入队列 q,若 6 个元素出队的序列为 e2、e4、e3、e6、e5 和 e1,则栈 s 的容量至少应该为〔 c 〕.a.6〔 b 〕.a.不确定b.n?i+1c.id.n?i〔4〕在一个长度为 n 的顺序表中删除第 i 个元素〔1=i=n〕时,需向前移动〔 a 〕个元素.a.n?i间复杂度为〔 a 〕.a.o<n>b.o<1>c.o<n2>〕.d.?+*abcd d.o<n3>〔6〕表达式 a*<b+c>?d 的后缀表达式是〔 bb.n?i+1c.n?i?1d.i〔5〕若长度为 n 的线性表采用顺序存储结构存储,在第 i 个位置上插入一个新元素的时b.4c.3d.2〔3〕设栈的输入序列为 1、2、3… n,若输出序列的第一个元素为 n,则第 i 个输出的元素为e 〕,删除一个元素所需移动元素的平均个数a.abcd*+? b.abc+*d? c.abc*+d? 〔7〕队列是一种特殊的线性表,其特殊性在于〔 c 〕.a.插入和删除在表的不同位置执行 b.插入和删除在表的两端位置执行 c.插入和删除分别在表的两端执行 d.插入和删除都在表的某一端执行〔8〕栈是一种特殊的线性表,具有〔 b 〕性质.a.先进先出b.先进后出c.后进后出d.顺序进出〔9〕顺序循环队列中〔数组的大小为 n〕,队头指示 front 指向队列的第 1 个元素,队尾指示 rear 指向队列最后元素的后 1 个位置,则循环队列中存放了 n??? 1 个元素,即循环队列满〕. 的条件为〔 ba.<rear+1>%n=front?1 c.<rear>%n=frontb.<rear+1>%n=front d.rear+1=front〔10〕顺序循环队列中〔数组的大小为 6〕,队头指示 front 和队尾指示 rear 的值分别为 3 和 0,当从队列中删除 1 个元素,再插入 2 个元素后,front 和 rear 的值分别为〔 d 〕.a.5 和 1b.2 和 4c.1 和 5d.4 和 22.2 什么是顺序表?什么是栈?什么是队列?5[答]:当线性表采用顺序存储结构时,即为顺序表.栈是一种特殊的线性表,它的特殊性表现在约定了在这种线性表中数据的插入与删除操作只能在这种线性表的同一端进行〔即栈顶〕, 因此,栈具有先进后出、后进先出的特点.队列也是一种特殊的线性表,它的特殊性表现在约定了在这种线性表中数据的插入在表的一端进行,数据的删除在表的另一端进行,因此队列具有先进先出,后进后出的特点.2.3 设计一个算法,求顺序表中值为 x 的结点的个数. [答]:顺序表的存储结构定义如下〔文件名 seqlist.h〕: #include stdio.h #define n 100 typedef int datatype; typedef struct {datatype data[n]; int length; } seqlist;/*预定义最大的数据域空间*/ /*假设数据类型为整型*//*此处假设数据元素只包含一个整型的关键字域*/ /*线性表长度*//*预定义的顺序表类型*/算法 countx〔l,x〕用于求顺序表 l 中值为 x 的结点的个数. int countx<seqlist *l,datatype x> {int c=0; int i;for <i=0;il-length;i++>if <l-data[i]==x> c++; return c; }2.4 设计一个算法,将一个顺序表倒置.即,如果顺序表各个结点值存储在一维数组 a 中,倒置的结果是使得数组 a 中的 a[0]等于原来的最后一个元素,a[1] 等于原来的倒数第 2 个元素,…,a 的最后一个元素等于原来的第一个元素.[答]:顺序表的存储结构定义同题 2.3,实现顺序表倒置的算法程序如下: void verge<seqlist *l> {int t,i,j; i=0;j=l-length-1; while <ij>{ t=l-data[i];l-data[i++]=l-data[j]; l-data[j--]=t; } }2.5 已知一个顺序表中的各结点值是从小到大有序的,设计一个算法,插入一个值为 x 的结点, 使顺序表中的结点仍然是从小到大有序.[答]:顺序表的定义同题 2.3,实现本题要求的算法程序如下:6void insertx<seqlist *l,datatype x> {int j;if <l-lengthn> { j=l-length-1;while <j=0 l-data[j]x>{ l-data[j+1]=l-data[j];j--; } l-data[j+1]=x; l-length++; } }2.6 将下列中缀表达式转换为等价的后缀表达式.<1> 5+6*7 <2> <5-6>/7 <3> 5-6*7*8 <4> 5*7-8 <5> 5*<7-6>+8/9 <6> 7*<5-6*8>-9 [答]:<7> 5+6*7 <8> <5-6>/7 <9> 5-6*7*8 <10>5*7-8 <11>5*<7-6>+8/9 <12>7*<5-6*8>-9后缀表达式:5 6 7*+ 后缀表达式:5 6-7/ 后缀表达式:5 6 7*8*- 后缀表达式:5 7* 8- 后缀表达式:5 7 6-*8 9/+ 后缀表达式:7 5 6 8*-*9-2.7 循环队列存储在一个数组中,数组大小为 n,队首指针和队尾指针分别为 front 和 rear,请写出求循环队列中当前结点个数的表达式.[答]:循环队列中当前结点个数的计算公式是:<n+rear-front>%n2.8 编号为 1,2,3,4 的四列火车通过一个栈式的列车调度站,可能得到的调度结果有哪些?如果有 n 列火车通过调度站,请设计一个算法,输出所有可能的调度结果. [答]:方法一:算法思想:逐次输出所有可能,用回溯法.即:总体:对原始序列中的每一个元素,总是先入栈,后出栈1.入栈后的操作:a.该元素出栈;b.下一个元素入栈;2.出栈后的操作:a.〔栈中其他元素〕继续出栈;b. 〔原始序列中〕下一个数入栈;注意:回溯法,关键在于回溯,即在某分支结点 x:处理 x 的一个子分支,再退回分支 x, 接着处理 x 的下一个子分支,若所有 x 的子分支处理完,再退回上一层分支节点.所谓"退回〞,7[篇三:数据结构课后习题答案]下列概念:数据、数据元素、数据项、数据对象、数据结构、逻辑结构、存储结构、抽象数据类型.答案:数据:是客观事物的符号表示,指所有能输入到计算机中并被计算机程序处理的符号的总称.如数学计算中用到的整数和实数,文本编辑所用到的字符串,多媒体程序处理的图形、图像、声音、动画等通过特殊编码定义后的数据.数据项:是组成数据元素的、有独立含义的、不可分割的最小单位.例如,学生基本信息表中的学号、##、性别等都是数据项.数据结构:是相互之间存在一种或多种特定关系的数据元素的集合.换句话说,数据结构是带"结构〞的数据元素的集合,"结构〞就是指数据元素之间存在的关系.逻辑结构:从逻辑关系上描述数据,它与数据的存储无关,是独立于计算机的.因此,数据的逻辑结构可以看作是从具体问题抽象出来的数学模型.存储结构:数据对象在计算机中的存储表示,也称为物理结构.抽象数据类型:由用户定义的,表示应用问题的数学模型,以与定义在这个模型上的一组操作的总称.具体包括三部分:数据对象、数据对象上关系的集合和对数据对象的基本操作的集合.2.试举一个数据结构的例子,叙述其逻辑结构和存储结构两方面的含义和相互关系. 答案:例如有一张学生基本信息表,包括学生的学号、##、性别、籍贯、专业等.每个学生基本信息记录对应一个数据元素,学生记录按顺序号排列,形成了学生基本信息记录的线性序列.对于整个表来说,只有一个开始结点<它的前面无记录>和一个终端结点<它的后面无记录>,其他的结点则各有一个也只有一个直接前趋和直接后继.学生记录之间的这种关系就确定了学生表的逻辑结构,即线性结构.这些学生记录在计算机中的存储表示就是存储结构.如果用连续的存储单元<如用数组表示>来存放这些记录,则称为顺序存储结构;如果存储单元不连续,而是随机存放各个记录,然后用指针进行,则称为链式存储结构.即相同的逻辑结构,可以对应不同的存储结构.3.简述逻辑结构的四种基本关系并画出它们的关系图.答案:〔1〕集合结构数据元素之间除了"属于同一集合〞的关系外,别无其他关系.例如,确定一名学生是否为班级成员,只需将班级看做一个集合结构.〔2〕线性结构数据元素之间存在一对一的关系.例如,将学生信息数据按照其入学报到的时间先后顺序进行排列,将组成一个线性结构.〔3〕树结构数据元素之间存在一对多的关系.例如,在班级的管理体系中,班长管理多个组长,每位组长管理多名组员,从而构成树形结构.〔4〕图结构或网状结构数据元素之间存在多对多的关系.例如,多位同学之间的朋友关系,任何两位同学都可以是朋友,从而构成图形结构或网状结构.其中树结构和图结构都属于非线性结构.四类基本逻辑结构关系图4.存储结构由哪两种基本的存储方法实现?答案:〔1〕顺序存储结构顺序存储结构是借助元素在存储器中的相对位置来表示数据元素之间的逻辑关系,通常借助程序设计语言的数组类型来描述.〔2〕链式存储结构顺序存储结构要求所有的元素依次存放在一片连续的存储空间中,而链式存储结构,无需占用一整块存储空间.但为了表示结点之间的关系,需要给每个结点附加指针字段,用于存放后继元素的存储地址.所以链式存储结构通常借助于程序设计语言的指针类型来描述.5.选择题〔1〕在数据结构中,从逻辑上可以把数据结构分成〔〕.a.动态结构和静态结构 b.紧凑结构和非紧凑结构c.线性结构和非线性结构d.内部结构和外部结构答案:c〔2〕与数据元素本身的形式、内容、相对位置、个数无关的是数据的〔〕.a.存储结构b.存储实现c.逻辑结构d.运算实现答案:c〔3〕通常要求同一逻辑结构中的所有数据元素具有相同的特性,这意味着〔〕.a.数据具有同一特点b.不仅数据元素所包含的数据项的个数要相同,而且对应数据项的类型要一致c.每个数据元素都一样d.数据元素所包含的数据项的个数要相等答案:b〔4〕以下说法正确的是〔〕.a.数据元素是数据的最小单位b.数据项是数据的基本单位c.数据结构是带有结构的各数据项的集合d.一些表面上很不相同的数据可以有相同的逻辑结构答案:d解释:数据元素是数据的基本单位,数据项是数据的最小单位,数据结构是带有结构的各数据元素的集合.〔5〕算法的时间复杂度取决于〔〕.a.问题的规模答案:d解释:算法的时间复杂度不仅与问题的规模有关,还与问题的其他因素有关.如某些排序的算法,其执行时间与待排序记录的初始状态有关.为此,有时会对算法有最好、最坏以与平均时间复杂度的评价.〔6〕以下数据结构中,〔〕是非线性数据结构a.树 b.字符串 c.队列 d.栈答案:a6.试分析下面各程序段的时间复杂度.〔1〕x=90; y=100;while<y0>if<x100>{x=x-10;y--;}else x++;答案:o<1>解释:程序的执行次数为常数阶.b.待处理数据的初态 d.a和b c.计算机的配置〔2〕for <i=0; in; i++>for <j=0; jm; j++>a[i][j]=0;答案:o<m*n>解释:语句a[i][j]=0;的执行次数为m*n.〔3〕s=0;for i=0; in; i++>for<j=0; jn; j++>s+=b[i][j];sum=s;2答案:o<n>解释:语句s+=b[i][j];的执行次数为n.〔4〕i=1;while<i=n>i=i*3;答案:o<log3n>解释:语句i=i*3;的执行次数为 ?log3n?.〔5〕x=0;for<i=1; in; i++>for <j=1; j=n-i; j++>x++;2答案:o<n>解释:语句x++;的执行次数为n-1+n-2+??+1= n<n-1>/2.〔6〕x=n; //n1y=0;while<x≥<y+1>* <y+1>>y++;答案:o<>解释:语句y++;的执行次数为 ?n?. 2第2章线性表1.选择题〔1〕顺序表中第一个元素的存储地址是100,每个元素的长度为2,则第5个元素的地址是〔〕.a.110b.108 c.100 d.120答案:b解释:顺序表中的数据连续存储,所以第5个元素的地址为:100+2*4=108.〔2〕在n个结点的顺序表中,算法的时间复杂度是o<1>的操作是〔〕.a.访问第i个结点〔1≤i≤n〕和求第i个结点的直接前驱〔2≤i≤n〕b.在第i个结点后插入一个新结点〔1≤i≤n〕c.删除第i个结点〔1≤i≤n〕d.将n个结点从小到大排序答案:a解释:在顺序表中插入一个结点的时间复杂度都是o<n2>,排序的时间复杂度为o<n2>或o<nlog2n>.顺序表是一种随机存取结构,访问第i个结点和求第i个结点的直接前驱都可以直接通过数组的下标直接定位,时间复杂度是o<1>.〔3〕向一个有127个元素的顺序表中插入一个新元素并保持原来顺序不变,平均要移动的元素个数为〔〕.a.8 b.63.5 c.63d.7答案:b解释:平均要移动的元素个数为:n/2.〔4〕存储的存储结构所占存储空间〔〕.a.分两部分,一部分存放结点值,另一部分存放表示结点间关系的指针b.只有一部分,存放结点值c.只有一部分,存储表示结点间关系的指针d.分两部分,一部分存放结点值,另一部分存放结点所占单元数答案:a〔5〕线性表若采用链式存储结构时,要求内存中可用存储单元的地址〔〕.a.必须是连续的 b.部分地址必须是连续的c.一定是不连续的 d.连续或不连续都可以答案:d〔6〕线性表L在〔〕情况下适用于使用链式结构实现.a.需经常修改L中的结点值B.需不断对L进行删除插入c.L中含有大量的结点D.L中结点结构复杂答案:b。
数据结构实用教程(第三版)课后答案

数据结构实用教程 (第三版) 课后答案file:///D|/-------------------上架商品---------------/数据结构实用教程 (第三版) 课后答案 (徐孝凯著) 清华大学出版社/第一章绪论.txt第一章绪习题一一、单选题1.一个数组元数a[i]与( A )的表示等价。
A *(a+i)B a+iC *a+iD &a+i2.对于两个函数,若函数名相同,但只是( C) 不同则不是重载函数。
A 参数类型B 参数个数C 函数类型3.若需要利用形参直接访问实参,则应把形参变量说明为 (B) 参数。
A 指针B 引用C 值4.下面程序段的复杂度为 (C )。
for(int i=0;i<m;i++)for(int j=0;j<n;j++)a[i][j]=i*j;A O(m2)B O(n2)C O(m*n)D O(m+n)5.执行下面程序段时,执行S语句的次数为 (D )。
for(int i=1;i<=n;i++)for(int j=1; j<=i;j++)S;A n2B n2/2C n(n+1)D n(n+1)/26.下面算法的时间复杂度为( B) 。
int f(unsigned int n){if(n==0||n==1) return 1;Else return n*f(n-1);}A O(1)B O(n)C O(n2)D O(n!)二、填空题1.数据的逻辑结构被除数分为集合结构、线性结构、树型结构和图形结构四种。
2.数据的存储结构被分为顺序结构、链接结构、索引结构和散列结构四种。
3.在线性结构、树型结构和图形结构中,前驱和后继结点之间分别存在着 1对1 、 1对N 和M对N 的关系。
4.一种抽象数据类型包括数据和操作两个部分。
5.当一个形参类型的长度较大时,应最好说明为引用,以节省参数值的传输时间和存储参数的空间。
6.当需要用一个形参访问对应的实参时,则该形参应说明为引用。
数据结构(c语言版)第三版习题解答

A.n− i B.n− i+1 C.n− i− 1 D.i (5)若长度为n的线性表采用顺序存储结构存储,在第i个位置上插入一个新元素的时 间复杂度为( A )。
定义:f (n)=O (g (n)) 当且仅当存在正的常数c和n0,使得对于所有的n≥n0,有f (n) ≤c g(n)。
2
上述定义表明,函数f顶多是函数g的c倍,除非n 小于n0。因此对于足够大的n (如n≥n0), g是f 的一个上限(不考虑常数因子c)。在为函数f 提供一个上限函数g 时,通常使用比较 简单的函数形式。比较典型的形式是含有n的单个项(带一个常数系数)。表1-1列出了一些 常用的g函数及其名称。对于表1-1中的对数函数logn,没有给出对数基,原因是对于任何大 于1的常数a和b都有logan =logbn/logba,所以logan和logbn都有一个相对的乘法系数1/logba, 其中a是一个常量。
void verge(seqlist *L)
{int t,i,j; i=0; j=L->length-1; while (i<j) { t=L->data[i]; L->data[i++]=L->data[j]; L->data[j-的,设计一个算法,插入一个值为x的结点,
数据结构
(C语言版)(第3版)
习题解析
揭安全 李云清 杨庆红 编著
江西师范大学计算机信息工程学院
联系方式:jieanquan@
2012年12月
1
第1章 绪论
数据结构教程(第三版)课后答案

数据结构教程(第三版)课后答案/*文件名:algo2-1.cpp*/#include <stdio.h>#include <malloc.h>#define MaxSize 50typedef char ElemType; typedef struct{ElemType elem[MaxSize];int length;} SqList;void InitList(SqList *&L) {L=(SqList *)malloc(sizeof(SqList));L->length=0;}void DestroyList(SqList *L) {free(L);}int ListEmpty(SqList *L) {return(L->length==0); }int ListLength(SqList *L) {return(L->length);}void DispList(SqList *L) {int i;if (ListEmpty(L)) return;for (i=0;i<L->length;i++)printf("%c",L->elem[i]);printf("\n");}int GetElem(SqList *L,int i,ElemType &e) {if (i<1 || i>L->length)return 0;e=L->elem[i-1];return 1;}int LocateElem(SqList *L, ElemType e){int i=0;while (i<L->length && L->elem[i]!=e) i++; if (i>=L->length)return 0;elsereturn i+1;}int ListInsert(SqList *&L,int i,ElemType e) {int j;if (i<1 || i>L->length+1)return 0;i--; /*将顺序表位序转化为elem下标*/for (j=L->length;j>i;j--) /*将elem[i]及后面元素后移一个位置*/ L->elem[j]=L->elem[j-1];L->elem[i]=e;L->length++; /*顺序表长度增1*/return 1;}int ListDelete(SqList *&L,int i,ElemType &e){int j;if (i<1 || i>L->length)return 0;i--; /*将顺序表位序转化为elem下标*/e=L->elem[i];for (j=i;j<L->length-1;j++)L->elem[j]=L->elem[j+1];L->length--;return 1;}/*文件名:algo2-2.cpp*/#include <stdio.h>#include <malloc.h>typedef char ElemType; typedef struct LNode /*定义单链表结点类型*/ {ElemType data;struct LNode *next; } LinkList;void InitList(LinkList *&L) {L=(LinkList *)malloc(sizeof(LinkList)); /*创建头结点*/L->next=NULL;}void DestroyList(LinkList *&L){LinkList *p=L,*q=p->next;while (q!=NULL){free(p);p=q;q=p->next;}free(p);}int ListEmpty(LinkList *L) {return(L->next==NULL); }int ListLength(LinkList *L) {LinkList *p=L;int i=0;while (p->next!=NULL){i++;p=p->next;}return(i);}void DispList(LinkList *L) {LinkList *p=L->next;while (p!=NULL){printf("%c",p->data);p=p->next;}printf("\n");}int GetElem(LinkList *L,int i,ElemType &e) {int j=0;LinkList *p=L;while (j<i && p!=NULL){j++;p=p->next;}if (p==NULL)return 0;else{e=p->data;return 1;}}int LocateElem(LinkList *L,ElemType e){LinkList *p=L->next;int n=1;while (p!=NULL && p->data!=e){p=p->next;n++;}if (p==NULL)return(0);elsereturn(n);}int ListInsert(LinkList *&L,int i,ElemType e) {int j=0;LinkList *p=L,*s;while (j<i-1 && p!=NULL){j++;p=p->next;}if (p==NULL) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{s=(LinkList *)malloc(sizeof(LinkList)); /*创建新结点*s*/ s->data=e;s->next=p->next; /*将*s插入到*p之后*/p->next=s;return 1;}}int ListDelete(LinkList *&L,int i,ElemType &e){int j=0;LinkList *p=L,*q;while (j<i-1 && p!=NULL){j++;p=p->next;}if (p==NULL) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{q=p->next; /*q指向要删除的结点*/p->next=q->next; /*从单链表中删除*q结点*/free(q); /*释放*q结点*/return 1;}}/*文件名:algo2-3.cpp*/#include <stdio.h>#include <malloc.h>typedef char ElemType; typedef struct DNode /*定义双链表结点类型*/ { ElemType data;struct DNode *prior; /*指向前驱结点*/struct DNode *next; /*指向后继结点*/ } DLinkList;void InitList(DLinkList *&L) {L=(DLinkList *)malloc(sizeof(DLinkList)); /*创建头结点*/L->prior=L->next=NULL; }void DestroyList(DLinkList *&L) {DLinkList *p=L,*q=p->next;while (q!=NULL){free(p);p=q;q=p->next;}free(p);}int ListEmpty(DLinkList *L) { return(L->next==NULL); }int ListLength(DLinkList *L) {DLinkList *p=L;int i=0;while (p->next!=NULL){i++;p=p->next;}return(i);}void DispList(DLinkList *L) { DLinkList *p=L->next;while (p!=NULL){printf("%c",p->data);p=p->next;}printf("\n");}int GetElem(DLinkList *L,int i,ElemType &e) {int j=0;DLinkList *p=L;while (j<i && p!=NULL){j++;p=p->next;}if (p==NULL)return 0;else{e=p->data;return 1;}}int LocateElem(DLinkList *L,ElemType e) {int n=1;DLinkList *p=L->next;while (p!=NULL && p->data!=e){n++;p=p->next;}if (p==NULL)return(0);elsereturn(n);}int ListInsert(DLinkList *&L,int i,ElemType e) {int j=0;DLinkList *p=L,*s;while (j<i-1 && p!=NULL){j++;p=p->next;}if (p==NULL) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{s=(DLinkList *)malloc(sizeof(DLinkList)); /*创建新结点*s*/ s->data=e;s->next=p->next; /*将*s插入到*p之后*/if (p->next!=NULL) p->next->prior=s;s->prior=p;p->next=s;return 1;}}int ListDelete(DLinkList *&L,int i,ElemType &e){int j=0;DLinkList *p=L,*q;while (j<i-1 && p!=NULL){j++;p=p->next;}if (p==NULL) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{q=p->next; /*q指向要删除的结点*/if (q==NULL) return 0; /*不存在第i个结点*/p->next=q->next; /*从单链表中删除*q结点*/if (p->next!=NULL) p->next->prior=p;free(q); /*释放*q结点*/return 1;}}void Sort(DLinkList *&head) /*双链表元素排序*/{DLinkList *p=head->next,*q,*r;if (p!=NULL) /*若原双链表中有一个或以上的数据结点*/{r=p->next; /*r保存*p结点后继结点的指针*/p->next=NULL; /*构造只含一个数据结点的有序表*/p=r;while (p!=NULL){r=p->next; /*r保存*p结点后继结点的指针*/q=head;while (q->next!=NULL && q->next->data<p->data) /*在有序表中找插入*p 的前驱结点*q*/q=q->next;p->next=q->next; /*将*p插入到*q之后*/if (q->next!=NULL) q->next->prior=p;q->next=p;p->prior=q;p=r;}}}/*文件名:algo2-4.cpp*/#include <stdio.h>#include <malloc.h>typedef char ElemType;typedef struct LNode /*定义单链表结点类型*/ { ElemType data;struct LNode *next;} LinkList;void InitList(LinkList *&L) {L=(LinkList *)malloc(sizeof(LinkList)); /*创建头结点*/ L->next=L;}void DestroyList(LinkList *&L){LinkList *p=L,*q=p->next;while (q!=L){free(p);p=q;q=p->next;}free(p);}int ListEmpty(LinkList *L) { return(L->next==L); }int ListLength(LinkList *L) { LinkList *p=L;int i=0;while (p->next!=L){i++;p=p->next;}return(i);}void DispList(LinkList *L) { LinkList *p=L->next;while (p!=L){printf("%c",p->data);p=p->next;}printf("\n");}int GetElem(LinkList *L,int i,ElemType &e) {int j=0;LinkList *p;if (L->next!=L) /*单链表不为空表时*/{if (i==1){e=L->next->data;return 1;}else /*i不为1时*/{p=L->next;while (j<i-1 && p!=L){j++;p=p->next;}if (p==L)return 0;else{e=p->data;return 1;}}}else /*单链表为空表时*/return 0;}int LocateElem(LinkList *L,ElemType e){LinkList *p=L->next;int n=1;while (p!=L && p->data!=e){p=p->next;n++;}if (p==L)return(0);elsereturn(n);}int ListInsert(LinkList *&L,int i,ElemType e) {int j=0;LinkList *p=L,*s;if (p->next==L || i==1) /*原单链表为空表或i==1时*/{s=(LinkList *)malloc(sizeof(LinkList)); /*创建新结点*s*/ s->data=e;s->next=p->next; /*将*s插入到*p之后*/p->next=s;return 1;}else{p=L->next;while (j<i-2 && p!=L){j++;p=p->next;}if (p==L) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{s=(LinkList *)malloc(sizeof(LinkList)); /*创建新结点*s*/ s->data=e;s->next=p->next; /*将*s插入到*p之后*/p->next=s;return 1;}}}int ListDelete(LinkList *&L,int i,ElemType &e) {int j=0;LinkList *p=L,*q;if (p->next!=L) /*原单链表不为空表时*/{if (i==1) /*i==1时*/{q=L->next; /*删除第1个结点*/L->next=q->next;free(q);return 1;}else /*i不为1时*/{p=L->next;while (j<i-2 && p!=L){j++;p=p->next;}if (p==L) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{q=p->next; /*q指向要删除的结点*/p->next=q->next; /*从单链表中删除*q结点*/free(q); /*释放*q结点*/return 1;}}}else return 0;}/*文件名:algo2-5.cpp*/#include <stdio.h>#include <malloc.h>typedef char ElemType; typedef struct DNode /*定义双链表结点类型*/ { ElemType data;struct DNode *prior; /*指向前驱结点*/struct DNode *next; /*指向后继结点*/ } DLinkList;void InitList(DLinkList *&L) {L=(DLinkList *)malloc(sizeof(DLinkList)); /*创建头结点*/L->prior=L->next=L;}void DestroyList(DLinkList *&L) { DLinkList *p=L,*q=p->next;while (q!=L){free(p);p=q;q=p->next;}free(p);}int ListEmpty(DLinkList *L) { return(L->next==L);}int ListLength(DLinkList *L){DLinkList *p=L;int i=0;while (p->next!=L){i++;p=p->next;}return(i);}void DispList(DLinkList *L){DLinkList *p=L->next;while (p!=L){printf("%c",p->data);p=p->next;}printf("\n");}int GetElem(DLinkList *L,int i,ElemType &e) {int j=0;DLinkList *p;if (L->next!=L) /*双链表不为空表时*/{if (i==1){e=L->next->data;return 1;}else /*i不为1时*/{p=L->next;while (j<i-1 && p!=L){j++;p=p->next;}if (p==L)return 0;else{e=p->data;return 1;}}}else /*双链表为空表时*/return 0;}int LocateElem(DLinkList *L,ElemType e) {int n=1;DLinkList *p=L->next;while (p!=NULL && p->data!=e){n++;p=p->next;}if (p==NULL)return(0);elsereturn(n);}int ListInsert(DLinkList *&L,int i,ElemType e){int j=0;DLinkList *p=L,*s;if (p->next==L) /*原双链表为空表时*/{s=(DLinkList *)malloc(sizeof(DLinkList)); /*创建新结点*s*/ s->data=e;p->next=s;s->next=p;p->prior=s;s->prior=p;return 1;}else if (i==1) /*原双链表不为空表但i=1时*/{s=(DLinkList *)malloc(sizeof(DLinkList)); /*创建新结点*s*/ s->data=e;s->next=p->next;p->next=s; /*将*s插入到*p之后*/s->next->prior=s;s->prior=p;return 1;}else{p=L->next;while (j<i-2 && p!=L){ j++;p=p->next;}if (p==L) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{s=(DLinkList *)malloc(sizeof(DLinkList)); /*创建新结点*s*/ s->data=e;s->next=p->next; /*将*s插入到*p之后*/if (p->next!=NULL) p->next->prior=s;s->prior=p;p->next=s;return 1;}}}int ListDelete(DLinkList *&L,int i,ElemType &e) {int j=0;DLinkList *p=L,*q;if (p->next!=L) /*原双链表不为空表时*/{if (i==1) /*i==1时*/{q=L->next; /*删除第1个结点*/L->next=q->next;q->next->prior=L;free(q);return 1;}else /*i不为1时*/{p=L->next;while (j<i-2 && p!=NULL){j++;p=p->next;}if (p==NULL) /*未找到第i-1个结点*/return 0;else /*找到第i-1个结点*p*/{q=p->next; /*q指向要删除的结点*/if (q==NULL) return 0; /*不存在第i个结点*/ p->next=q->next; /*从单链表中删除*q结点*/ if (p->next!=NULL) p->next->prior=p;free(q); /*释放*q结点*/return 1;}}}else return 0; /*原双链表为空表时*/}/*文件名:algo3-1.cpp*/#include <stdio.h>#include <malloc.h>#define MaxSize 100typedef char ElemType; typedef struct{ElemType elem[MaxSize];int top; /*栈指针*/} SqStack;void InitStack(SqStack *&s) {s=(SqStack *)malloc(sizeof(SqStack));s->top=-1;}void ClearStack(SqStack *&s) { free(s);}int StackLength(SqStack *s) { return(s->top+1);}int StackEmpty(SqStack *s) {return(s->top==-1);}int Push(SqStack *&s,ElemType e) { if (s->top==MaxSize-1)return 0;s->top++;s->elem[s->top]=e;return 1;}int Pop(SqStack *&s,ElemType &e) {if (s->top==-1)return 0;e=s->elem[s->top];s->top--;return 1;}int GetTop(SqStack *s,ElemType &e){if (s->top==-1)return 0;e=s->elem[s->top];return 1;}void DispStack(SqStack *s) {int i;for (i=s->top;i>=0;i--)printf("%c ",s->elem[i]);printf("\n");}/*文件名:algo3-2.cpp*/#include <stdio.h>#include <malloc.h> typedef char ElemType; typedef struct linknode { ElemType data; /*数据域*/struct linknode *next; /*指针域*/ } LiStack;void InitStack(LiStack *&s) {s=(LiStack *)malloc(sizeof(LiStack));s->next=NULL;}void ClearStack(LiStack *&s) {LiStack *p=s->next;while (p!=NULL){free(s);s=p;p=p->next;}}int StackLength(LiStack *s) {int i=0;LiStack *p;p=s->next;while (p!=NULL){i++;p=p->next;}return(i);}int StackEmpty(LiStack *s) { return(s->next==NULL); }void Push(LiStack *&s,ElemType e) {LiStack *p;p=(LiStack *)malloc(sizeof(LiStack));p->data=e;p->next=s->next; /*插入*p结点作为第一个数据结点*/ s->next=p;}int Pop(LiStack *&s,ElemType &e){LiStack *p;if (s->next==NULL) /*栈空的情况*/return 0;p=s->next; /*p指向第一个数据结点*/e=p->data;s->next=p->next;free(p);return 1;}int GetTop(LiStack *s,ElemType &e){if (s->next==NULL) /*栈空的情况*/return 0;e=s->next->data;return 1;}void DispStack(LiStack *s){LiStack *p=s->next;while (p!=NULL){printf("%c ",p->data);p=p->next;}printf("\n");}/*文件名:algo3-3.cpp*/#include <stdio.h>#include <malloc.h>#define MaxSize 5typedef char ElemType; typedef struct {ElemType elem[MaxSize];int front,rear; /*队首和队尾指针*/} SqQueue;void InitQueue(SqQueue *&q) {q=(SqQueue *)malloc (sizeof(SqQueue)); q->front=q->rear=0;}void ClearQueue(SqQueue *&q) {free(q);}int QueueEmpty(SqQueue *q) {return(q->front==q->rear); }int QueueLength(SqQueue *q) {return (q->rear-q->front+MaxSize)%MaxSize;}int enQueue(SqQueue *&q,ElemType e){if ((q->rear+1)%MaxSize==q->front) /*队满*/return 0;q->rear=(q->rear+1)%MaxSize;q->elem[q->rear]=e;return 1;}int deQueue(SqQueue *&q,ElemType &e){if (q->front==q->rear) /*队空*/return 0;q->front=(q->front+1)%MaxSize;e=q->elem[q->front];return 1;}/*文件名:algo3-4.cpp*/ #include <stdio.h> #include <malloc.h> typedef char ElemType; typedef struct qnode {ElemType data;struct qnode *next; } QNode;typedef struct{QNode *front;QNode *rear;} LiQueue;void InitQueue(LiQueue *&q){q=(LiQueue *)malloc(sizeof(LiQueue)); q->front=q->rear=NULL; }void ClearQueue(LiQueue *&q){QNode *p=q->front,*r;if (p!=NULL) /*释放数据结点占用空间*/ {r=p->next;while (r!=NULL){free(p);p=r;r=p->next;}}free(q); /*释放头结点占用空间*/ }int QueueLength(LiQueue *q){int n=0;QNode *p=q->front;while (p!=NULL){n++;p=p->next;}return(n);}int QueueEmpty(LiQueue *q) {if (q->rear==NULL)return 1;elsereturn 0;}void enQueue(LiQueue *&q,ElemType e){QNode *s;s=(QNode *)malloc(sizeof(QNode));s->data=e;s->next=NULL;if (q->rear==NULL) /*若链队为空,则新结点是队首结点又是队尾结点*/ q->front=q->rear=s;else{q->rear->next=s; /*将*s结点链到队尾,rear指向它*/ q->rear=s;}}int deQueue(LiQueue *&q,ElemType &e){QNode *t;if (q->rear==NULL) /*队列为空*/return 0;if (q->front==q->rear) /*队列中只有一个结点时*/ {t=q->front;q->front=q->rear=NULL;}else /*队列中有多个结点时*/{t=q->front;q->front=q->front->next;}e=t->data;free(t);return 1;}/*文件名:algo4-1.cpp*/#include <stdio.h>#define MaxSize 100 /*最多的字符个数*/ typedef struct{ char ch[MaxSize]; /*定义可容纳MaxSize个字符的空间*/int len; /*标记当前实际串长*/ } SqString;void StrAssign(SqString &str,char cstr[]) /*str为引用型参数*/ { int i;for (i=0;cstr[i]!='\0';i++)str.ch[i]=cstr[i];str.len=i;}void StrCopy(SqString &s,SqString t) /*s为引用型参数*/ {int i;for (i=0;i<t.len;i++)s.ch[i]=t.ch[i];s.len=t.len;}int StrEqual(SqString s,SqString t){int same=1,i;if (s.len!=t.len) /*长度不相等时返回0*/same=0;else{for (i=0;i<s.len;i++)if (s.ch[i]!=t.ch[i]) /*有一个对应字符不相同时返回0*/ same=0;}return same;}int StrLength(SqString s) {return s.len;}SqString Concat(SqString s,SqString t){SqString str;int i;str.len=s.len+t.len;for (i=0;i<s.len;i++) /*将s.ch[0],s.ch[s.len-1]复制到str*/ str.ch[i]=s.ch[i];for (i=0;i<t.len;i++) /*将t.ch[0],t.ch[t.len-1]复制到str*/ str.ch[s.len+i]=t.ch[i];return str;}SqString SubStr(SqString s,int i,int j) {SqString str;int k;str.len=0;if (i<=0 || i>s.len || j<0 || i+j-1>s.len){printf("参数不正确\n");return str; /*参数不正确时返回空串*/}for (k=i-1;k<i+j-1;k++) /*将s.ch[i],s.ch[i+j]复制到str*/str.ch[k-i+1]=s.ch[k];str.len=j;return str;}SqString InsStr(SqString s1,int i,SqString s2){int j;SqString str;str.len=0;if (i<=0 || i>s1.len+1) /*参数不正确时返回空串*/{printf("参数不正确\n");return s1;}for (j=0;j<i-1;j++) /*将s1.ch[0],s1.ch[i-2]复制到str*/str.ch[j]=s1.ch[j];for (j=0;j<s2.len;j++) /*将s2.ch[0],s2.ch[s2.len-1]复制到str*/ str.ch[i+j-1]=s2.ch[j];for (j=i-1;j<s1.len;j++) /*将s1.ch[i-1],s.ch[s1.len-1]复制到str*/str.ch[s2.len+j]=s1.ch[j];str.len=s1.len+s2.len;return str;}SqString DelStr(SqString s,int i,int j) {int k;SqString str;str.len=0;if (i<=0 || i>s.len || i+j>s.len+1) /*参数不正确时返回空串*/ {printf("参数不正确\n");return str;}for (k=0;k<i-1;k++) /*将s.ch[0],s.ch[i-2]复制到str*/str.ch[k]=s.ch[k];for (k=i+j-1;k<s.len;k++)/*将s.ch[i+j-1],ch[s.len-1]复制到str*/ str.ch[k-j]=s.ch[k];str.len=s.len-j;return str;}SqString RepStr(SqString s,int i,int j,SqString t){int k;SqString str;str.len=0;if (i<=0 || i>s.len || i+j-1>s.len) /*参数不正确时返回空串*/{printf("参数不正确\n");return str;}for (k=0;k<i-1;k++) /*将s.ch[0],s.ch[i-2]复制到str*/str.ch[k]=s.ch[k];for (k=0;k<t.len;k++) /*将t.ch[0],t.ch[t.len-1]复制到str*/str.ch[i+k-1]=t.ch[k];for (k=i+j-1;k<s.len;k++) /*将s.ch[i+j-1],ch[s.len-1]复制到str*/ str.ch[t.len+k-j]=s.ch[k];str.len=s.len-j+t.len;return str;}void DispStr(SqString str) {int i;if (str.len>0){for (i=0;i<str.len;i++)printf("%c",str.ch[i]);printf("\n");}}/*文件名:algo4-2.cpp*/#include <stdio.h>#include <malloc.h>typedef struct snode{char data;struct snode *next;} LiString;void StrAssign(LiString *&s,char t[]) { int i;LiString *r,*p;s=(LiString *)malloc(sizeof(LiString));s->next=NULL;r=s;for (i=0;t[i]!='\0';i++){p=(LiString *)malloc(sizeof(LiString));p->data=t[i];p->next=NULL;r->next=p;r=p;}}void StrCopy(LiString *&s,LiString *t) { LiString *p=t->next,*q,*r;s=(LiString *)malloc(sizeof(LiString));s->next=NULL;s->next=NULL;r=s;while (p!=NULL) /*将t的所有结点复制到s*/{q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}}int StrEqual(LiString *s,LiString *t) { LiString *p=s->next,*q=t->next;while (p!=NULL && q!=NULL && p->data==q->data) {p=p->next;q=q->next;}if (p==NULL && q==NULL)return 1;elsereturn 0;}int StrLength(LiString *s){int i=0;LiString *p=s->next;while (p!=NULL){i++;p=p->next;}return i;}LiString *Concat(LiString *s,LiString *t) { LiString *str,*p=s->next,*q,*r;str=(LiString *)malloc(sizeof(LiString)); str->next=NULL;r=str;while (p!=NULL) /*将s的所有结点复制到str*/ {q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}p=t->next;while (p!=NULL) /*将t的所有结点复制到str*/ {q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}return str;}LiString *SubStr(LiString *s,int i,int j) {int k;LiString *str,*p=s->next,*q,*r;str=(LiString *)malloc(sizeof(LiString));str->next=NULL;r=str;if (i<=0 || i>StrLength(s) || j<0 || i+j-1>StrLength(s)){printf("参数不正确\n");return str; /*参数不正确时返回空串*/}for (k=0;k<i-1;k++)p=p->next;for (k=1;k<=j;k++) /*将s的第i个结点开始的j个结点复制到str*/ {q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}return str;}LiString *InsStr(LiString *s,int i,LiString *t) {int k;LiString *str,*p=s->next,*p1=t->next,*q,*r;str=(LiString *)malloc(sizeof(LiString));str->next=NULL;r=str;if (i<=0 || i>StrLength(s)+1) /*参数不正确时返回空串*/ {printf("参数不正确\n");return str;}for (k=1;k<i;k++) /*将s的前i个结点复制到str*/{q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}while (p1!=NULL) /*将t的所有结点复制到str*/{q=(LiString *)malloc(sizeof(LiString));q->data=p1->data;q->next=NULL;r->next=q;r=q;p1=p1->next;}while (p!=NULL) /*将*p及其后的结点复制到str*/{q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}return str;}LiString *DelStr(LiString *s,int i,int j) {int k;LiString *str,*p=s->next,*q,*r;str=(LiString *)malloc(sizeof(LiString));str->next=NULL;r=str;if (i<=0 || i>StrLength(s) || j<0 || i+j-1>StrLength(s)) {printf("参数不正确\n");return str; /*参数不正确时返回空串*/}for (k=0;k<i-1;k++) /*将s的前i-1个结点复制到str*/{q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}for (k=0;k<j;k++) /*让p沿next跳j个结点*/p=p->next;while (p!=NULL) /*将*p及其后的结点复制到str*/{q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}return str;}LiString *RepStr(LiString *s,int i,int j,LiString *t) { int k;LiString *str,*p=s->next,*p1=t->next,*q,*r;str=(LiString *)malloc(sizeof(LiString));str->next=NULL;r=str;if (i<=0 || i>StrLength(s) || j<0 || i+j-1>StrLength(s)) {printf("参数不正确\n");return str; /*参数不正确时返回空串*/}for (k=0;k<i-1;k++) /*将s的前i-1个结点复制到str*/{q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}for (k=0;k<j;k++) /*让p沿next跳j个结点*/p=p->next;while (p1!=NULL) /*将t的所有结点复制到str*/ {q=(LiString *)malloc(sizeof(LiString));q->data=p1->data;q->next=NULL;r->next=q;r=q;p1=p1->next;}while (p!=NULL) /*将*p及其后的结点复制到str*/ {q=(LiString *)malloc(sizeof(LiString));q->data=p->data;q->next=NULL;r->next=q;r=q;p=p->next;}return str;}void DispStr(LiString *s) {LiString *p=s->next;while (p!=NULL){printf("%c",p->data);p=p->next;}printf("\n");}/*文件名:algo7-1.cpp*/#include <stdio.h>#include <malloc.h>#define MaxSize 100typedef char ElemType;typedef struct node{ElemType data; /*数据元素*/struct node *lchild; /*指向左孩子*/struct node *rchild; /*指向右孩子*/} BTNode;void CreateBTNode(BTNode *&b,char *str) /*由str串创建二叉链*/ { BTNode *St[MaxSize],*p=NULL;int top=-1,k,j=0;char ch;b=NULL; /*建立的二叉树初始时为空*/ch=str[j];。
数据结构与算法第3章课后答案

第 3 章特殊线性表——栈、队列和串(2005-07-14) -第 3 章特殊线性表——栈、队列和串课后习题讲解1. 填空⑴设有一个空栈,栈顶指针为1000H,现有输入序列为1、2、3、4、5,经过push,push,pop,push,pop,push,push后,输出序列是(),栈顶指针为()。
【解答】23,1003H⑵栈通常采用的两种存储结构是();其判定栈空的条件分别是(),判定栈满的条件分别是()。
【解答】顺序存储结构和链接存储结构(或顺序栈和链栈),栈顶指针top= -1和top=NULL,栈顶指针top等于数组的长度和内存无可用空间⑶()可作为实现递归函数调用的一种数据结构。
【解答】栈【分析】递归函数的调用和返回正好符合后进先出性。
⑷表达式a*(b+c)-d的后缀表达式是()。
【解答】abc+*d-【分析】将中缀表达式变为后缀表达式有一个技巧:将操作数依次写下来,再将算符插在它的两个操作数的后面。
⑸栈和队列是两种特殊的线性表,栈的操作特性是(),队列的操作特性是(),栈和队列的主要区别在于()。
【解答】后进先出,先进先出,对插入和删除操作限定的位置不同⑹循环队列的引入是为了克服()。
【解答】假溢出⑺数组Q[n]用来表示一个循环队列,front为队头元素的前一个位置,rear为队尾元素的位置,计算队列中元素个数的公式为()。
page: 2The Home of jetmambo - 第 3 章特殊线性表——栈、队列和串【解答】(rear-front+n)% n【分析】也可以是(rear-front)% n,但rear-front的结果可能是负整数,而对一个负整数求模,其结果在不同的编译器环境下可能会有所不同。
⑻用循环链表表示的队列长度为n,若只设头指针,则出队和入队的时间复杂度分别是()和()。
【解答】O(1),O(n)【分析】在带头指针的循环链表中,出队即是删除开始结点,这只需修改相应指针;入队即是在终端结点的后面插入一个结点,这需要从头指针开始查找终端结点的地址。
《数据结构与算法》课后习题答案

2.3 课后习题解答2.3.2 判断题1.线性表的逻辑顺序与存储顺序总是一致的。
(×)2.顺序存储的线性表可以按序号随机存取。
(√)3.顺序表的插入和删除操作不需要付出很大的时间代价,因为每次操作平均只有近一半的元素需要移动。
(×)4.线性表中的元素可以是各种各样的,但同一线性表中的数据元素具有相同的特性,因此属于同一数据对象。
(√)5.在线性表的顺序存储结构中,逻辑上相邻的两个元素在物理位置上并不一定相邻。
(×)6.在线性表的链式存储结构中,逻辑上相邻的元素在物理位置上不一定相邻。
(√)7.线性表的链式存储结构优于顺序存储结构。
(×)8.在线性表的顺序存储结构中,插入和删除时移动元素的个数与该元素的位置有关。
(√)9.线性表的链式存储结构是用一组任意的存储单元来存储线性表中数据元素的。
(√)10.在单链表中,要取得某个元素,只要知道该元素的指针即可,因此,单链表是随机存取的存储结构。
(×)11.静态链表既有顺序存储的优点,又有动态链表的优点。
所以它存取表中第i个元素的时间与i无关。
(×)12.线性表的特点是每个元素都有一个前驱和一个后继。
(×)2.3.3 算法设计题1.设线性表存放在向量A[arrsize]的前elenum个分量中,且递增有序。
试写一算法,将x 插入到线性表的适当位置上,以保持线性表的有序性,并且分析算法的时间复杂度。
【提示】直接用题目中所给定的数据结构(顺序存储的思想是用物理上的相邻表示逻辑上的相邻,不一定将向量和表示线性表长度的变量封装成一个结构体),因为是顺序存储,分配的存储空间是固定大小的,所以首先确定是否还有存储空间,若有,则根据原线性表中元素的有序性,来确定插入元素的插入位置,后面的元素为它让出位置,(也可以从高下标端开始一边比较,一边移位)然后插入x ,最后修改表示表长的变量。
int insert (datatype A[],int *elenum,datatype x) /*设elenum为表的最大下标*/ {if (*elenum==arrsize-1) return 0; /*表已满,无法插入*/else {i=*elenum;while (i>=0 && A[i]>x) /*边找位置边移动*/{A[i+1]=A[i];i--;}A[i+1]=x; /*找到的位置是插入位的下一位*/(*elenum)++;return 1; /*插入成功*/}}时间复杂度为O(n)。
数据结构(C语言版)第三版习题答案

精神成就事业,态度决定一切。
附录习题参考答案习题1参考答案1.1.选择题(1). A. (2). A. (3). A. (4). B.C. (5). A. (6). A. (7). C. (8). A. (9). B. (10.) A.1.2.填空题(1). 数据关系(2). 逻辑结构物理结构(3). 线性数据结构树型结构图结构(4). 顺序存储链式存储索引存储散列表(Hash)存储(5). 变量的取值范围操作的类别(6). 数据元素间的逻辑关系数据元素存储方式或者数据元素的物理关系(7). 关系网状结构树结构(8). 空间复杂度和时间复杂度(9). 空间时间(10). Ο(n)1.3 名词解释如下:数据:数据是信息的载体是计算机程序加工和处理的对象包括数值数据和非数值数据数据项:数据项指不可分割的、具有独立意义的最小数据单位数据项有时也称为字段或域数据元素:数据元素是数据的基本单位在计算机程序中通常作为一个整体进行考虑和处理一个数据元素可由若干个数据项组成数据逻辑结构:数据的逻辑结构就是指数据元素间的关系数据存储结构:数据的物理结构表示数据元素的存储方式或者数据元素的物理关系数据类型:是指变量的取值范围和所能够进行的操作的总和算法:是对特定问题求解步骤的一种描述是指令的有限序列1.4 语句的时间复杂度为:(1) Ο(n2)(2) Ο(n2)(3) Ο(n2)(4) Ο(n-1)(5) Ο(n3)1.5 参考程序:main(){int XYZ;scanf("%d %d%d"&X&YZ);if (X>=Y)if(X>=Z)if (Y>=Z) { printf("%d %d%d"XYZ);}else{ printf("%d %d%d"XZY);}else{ printf("%d %d%d"ZXY);}else if(Z>=X)if (Y>=Z) { printf("%d %d%d"YZX);}else{ printf("%d%d%d"ZYX);}else{ printf("%d%d%d"YXZ);}}1.6 参考程序:main(){int in;float xa[]p;printf("\nn=");scanf("%f"&n);printf("\nx=");scanf("%f"&x);for(i=0;i<=n;i++)scanf("%f "&a[i]);p=a[0];for(i=1;i<=n;i++){ p=p+a[i]*x;x=x*x;}printf("%f"p)'}习题2参考答案2.1选择题(1). C. (2). B. (3). B. (4). B. 5. D. 6. B. 7. B. 8. A. 9. A. 10. D.2.2.填空题(1). 有限序列(2). 顺序存储和链式存储(3). O(n) O(n)(4). n-i+1 n-i(5). 链式(6). 数据指针(7). 前驱后继(8). Ο(1) Ο(n)(9). s->next=p->next; p->next=s ;(10). s->next2.3. 解题思路:将顺序表A中的元素输入数组a若数组a中元素个数为n将下标为012...(n-1)/2的元素依次与下标为nn-1...(n-1)/2的元素交换输出数组a的元素参考程序如下:main(){int in;float ta[];printf("\nn=");scanf("%f"&n);for(i=0;i<=n-1;i++)scanf("%f "&a[i]);for(i=0;i<=(n-1)/2;i++){ t=a[i]; a[i] =a[n-1-i]; a[n-1-i]=t;} for(i=0;i<=n-1;i++)printf("%f"a[i]);}2.4 算法与程序:main(){int in;float ta[];printf("\nn=");scanf("%f"&n);for(i=0;i<n;i++)scanf("%f "&a[i]);for(i=1;i<n;i++)if(a[i]>a[0]{ t=a[i]; a[i] =a[0]; a[0]=t;}printf("%f"a[0]);for(i=2;i<n;i++)if(a[i]>a[1]{ t=a[i]; a[i] =a[1]; a[1]=t;}printf("%f"a[0]);}2.5 算法与程序:main(){int ijkn;float xta[];printf("\nx=");scanf("%f"&x);printf("\nn=");scanf("%f"&n);for(i=0;i<n;i++)scanf("%f "&a[i]); // 输入线性表中的元素for (i=0; i<n; i++) { // 对线性表中的元素递增排序k=i;for (j=i+1; j<n; j++) if (a[j]<a[k]) k=j; if (k<>j) {t=a[i];a[i]=a[k];a[k]=t;}}for(i=0;i<n;i++) // 在线性表中找到合适的位置if(a[i]>x) break;for(k=n-1;k>=i;i--) // 移动线性表中元素然后插入元素xa[k+1]=a[k];a[i]=x;for(i=0;i<=n;i++) // 依次输出线性表中的元素printf("%f"a[i]);}2.6 算法思路:依次扫描A和B的元素比较A、B当前的元素的值将较小值的元素赋给C如此直到一个线性表扫描完毕最后将未扫描完顺序表中的余下部分赋给C即可C的容量要能够容纳A、B两个线性表相加的长度有序表的合并算法:void merge (SeqList ASeqList BSeqList *C){ int ijk;i=0;j=0;k=0;while ( i<=st && j<=st )if (A.data[i]<=B.data[j])C->data[k++]=A.data[i++];elseC->data[k++]=B.data[j++];while (i<=st )C->data[k++]= A.data[i++];while (j<=st )C->data[k++]=B.data[j++];C->last=k-1;}2.7 算法思路:依次将A中的元素和B的元素比较将值相等的元素赋给C如此直到线性表扫描完毕线性表C就是所求递增有序线性表算法:void merge (SeqList ASeqList BSeqList *C){ int ijk;i=0;j=0;k=0;while ( i<=st)while(j<=st )if (A.data[i]=B.data[j])C->data[k++]=A.data[i++];C->last=k-1;}习题3参考答案3.1.选择题(1). D (2). C (3). D (4). C (5). B (6). C (7). C (8). C (9). B (10).AB (11). D (12). B (13). D (14). C (15). C (16). D(17). D (18). C (19). C (20). C 3.2.填空题(1) FILOFIFO(2) -13 4 X * + 2 Y * 3 / -(3) stack.topstack.s[stack.top]=x(4) p>llink->rlink=p->rlinkp->rlink->llink=p->rlink(5) (R-F+M)%M(6) top1+1=top2(7) F==R(8) front==rear(9) front==(rear+1)%n(10) N-13.3 答:一般线性表使用数组来表示的线性表一般有插入、删除、读取等对于任意元素的操作而栈只是一种特殊的线性表栈只能在线性表的一端插入(称为入栈push)或者读取栈顶元素或者称为"弹出、出栈"(pop)3.4 答:相同点:栈和队列都是特殊的线性表只在端点处进行插入删除操作不同点:栈只在一端(栈顶)进行插入删除操作;队列在一端(top)删除一端(rear)插入3.5 答:可能序列有14种:ABCD; ACBD; ACDB; ABDC; ADCB; BACD; BADC; BCAD; BCDA; BDCA; CBAD; CBDA; CDBA; DCBA3.6 答:不能得到435612最先出栈的是4则按321的方式出不可能得到1在2前的序列可以得到135426按如下方式进行push(1)pop()push(2)push(3)pop()push(4)push(5)pop()pop()pop()push(6)pop()3.7 答:stack3.8 非递归:int vonvert (int noint a[]) //将十进制数转换为2进制存放在a[] 并返回位数{int r;SeStack s*p;P=&s;Init_stack(p);while(no){push(pno%2);no/=10;}r=0;while(!empty_stack(p)){pop(pa+r);r++;}return r;}递归算法:void convert(int no){if(no/2>0){Convert(no/2);Printf("%d"no%2);}elseprintf("%d"no);}3.9 参考程序:void view(SeStack s){SeStack *p; //假设栈元素为字符型char c;p=&s;while(!empty_stack(p)){c=pop(p);printf("%c"c);}printf("\n");}3.10 答:char3.11 参考程序:void out(linkqueue q){int e;while(q.rear !=q.front ){dequeue(qe);print(e); //打印}}习题4参考答案4.1 选择题:(1). A (2). D (3). C (4). C (5). B (6). B (7). D (8). A (9). B (10). D 4.2 填空题:(1)串长相等且对应位置字符相等(2)不含任何元素的串(3)所含字符均是空格所含空格数(4) 10(5) "hello boy"(6) 13(7) 1066(8)模式匹配(9)串中所含不同字符的个数(10) 364.3 StrLength (s)=14StrLength (t)=4SubStr( s87)=" STUDENT"SubStr(t21)="O"StrIndex(s"A")=3StrIndex (st)=0StrRep(s"STUDENT"q)=" I AM A WORKER"4.4 StrRep(s"Y""+");StrRep(s"+*""*Y");4.5 空串:不含任何字符;空格串:所含字符都是空格串变量和串常量:串常量在程序的执行过程中只能引用不能改变;串变量的值在程序执行过程中是可以改变和重新赋值的主串与子串:子串是主串的一个子集串变量的名字与串变量的值:串变量的名字表示串值的标识符4.6int EQUAl(ST){char *p*q;p=&S;q=&T;while(*p&&*q){if(*p!=*q)return *p-*q;p++;q++;}return *p-*q;}4.7(1)6*8*6=288(2)1000+47*6=1282(3)1000+(8+4)*8=1096(4)1000+(6*7+4)*8=13684.8习题5参考答案5.1 选择(1)C(2)B(3)C(4)B(5)C(6)D(7)C(8)C(9)B(10)C (11)B(12)C(13)C(14)C(15)C(16)B5.2 填空(1)1(2)1036;1040(3)2i(4) 1 ; n ; n-1 ; 2(5)2k-1;2k-1(6)ACDBGJKIHFE(7)p!=NULL(8)Huffman树(9)其第一个孩子; 下一个兄弟(10)先序遍历;中序遍历5.3叶子结点:C、F、G、L、I、M、K;非终端结点:A、B、D、E、J;各结点的度:结点: A B C D E F G L I J K M度: 4 3 0 1 2 0 0 0 0 1 0 0树深:4无序树形态如下:二叉树形态如下:5.5二叉链表如下:三叉链表如下:5.6先序遍历序列:ABDEHICFJG中序遍历序列:DBHEIAFJCG后序遍历序列:DHIEBJFGCA5.7(1) 先序序列和中序序列相同:空树或缺左子树的单支树;(2) 后序序列和中序序列相同:空树或缺右子树的单支树;(3) 先序序列和后序序列相同:空树或只有根结点的二叉树5.8这棵二叉树为:先根遍历序列:ABFGLCDIEJMK后根遍历序列:FGLBCIDMJKEA层次遍历序列:ABCDEFGLIJKM5.10证明:设树中结点总数为n叶子结点数为n0则n=n0 + n1 + ...... + nm (1)再设树中分支数目为B则B=n1 + 2n2 + 3n3 + ...... + m nm (2)因为除根结点外每个结点均对应一个进入它的分支所以有n= B + 1 (3)将(1)和(2)代入(3)得n0 + n1 + ...... + nm = n1 + 2n2 + 3n3 + ...... + m nm + 1 从而可得叶子结点数为:n0 = n2 + 2n3 + ...... + (m-1)nm + 15.11由5.10结论得n0 = (k-1)nk + 1又由 n=n0 + nk得nk= n-n0代入上式得n0 = (k-1)(n-n0)+ 1叶子结点数为:n0 = n (k-1) / k5.12int NodeCount(BiTree T){ //计算结点总数if(T)if (T-> lchild==NULL )&&( T --> rchild==NULL )return 1;elsereturn NodeCount(T-> lchild ) +Node ( T --> rchild )+1; elsereturn 0;}void ExchangeLR(Bitree bt){/* 将bt所指二叉树中所有结点的左、右子树相互交换 */ if (bt && (bt->lchild || bt->rchild)) {bt->lchild<->bt->rchild;Exchange-lr(bt->lchild);Exchange-lr(bt->rchild);}}/* ExchangeLR */5.14int IsFullBitree(Bitree T){/* 是则返回1否则返回0*/Init_Queue(Q); /* 初始化队列*/flag=0;In_Queue(QT); /* 根指针入队列按层次遍历*/while(!Empty_Queue (Q)){Out_Queue(Qp);if(!p) flag=1; /* 若本次出队列的是空指针时则修改flag值为1若以后出队列的指针存在非空则可断定不是完全二叉树 */else if (flag) return 0; /*断定不是完全二叉树 */ else{In_Queue(Qp->lchild);In_Queue(Qp->rchild); /* 不管孩子是否为空都入队列*/}}/* while */return 1; /* 只有从某个孩子指针开始之后所有孩子指针都为空才可断定为完全二叉树*/}/* IsFullBitree */转换的二叉树为:5.16对应的森林分别为:5.17typedef char elemtype;typedef struct{ elemtype data;int parent;} NodeType;(1) 求树中结点双亲的算法:int Parent(NodeType t[ ]elemtype x){/* x不存在时返回-2否则返回x双亲的下标(根的双亲为-1 */for(i=0;i<MAXNODE;i++)if(x==t[i].data) return t[i].parent; return -2;}/*Parent*/(2) 求树中结点孩子的算法:void Children(NodeType t[ ]elemtype x){for(i=0;i<MAXNODE;i++){if(x==t[i].data)break;/*找到x退出循环*/}/*for*/if(i>=MAXNODE) printf("x不存在\n"); else {flag=0;for(j=0;j<MAXNODE;j++)if(i==t[j].parent){ printf("x的孩子:%c\n"t[j].data);flag=1;}if(flag==0) printf("x无孩子\n");}/*Children*/5.18typedef char elemtype;typedef struct ChildNode{ int childcode;struct ChildNode *nextchild;}typedef struct{ elemtype data;struct ChildNode *firstchild;} NodeType;(1) 求树中结点双亲的算法:int ParentCL(NodeType t[ ]elemtype x){/* x不存在时返回-2否则返回x双亲的下标 */for(i=0;i<MAXNODE;i++)if(x==t[i].data) {loc=i;/*记下x的下标*/break;}if(i>=MAXNODE) return -2; /* x不存在 *//*搜索x的双亲*/for(i=0;i<MAXNODE;i++)for(p=t[i].firstchild;p!=NULL;p=p->nextchild) if(loc==p->childcode)return i; /*返回x结点的双亲下标*/}/* ParentL */(2) 求树中结点孩子的算法:void ChildrenCL(NodeType t[ ]elemtype x){for(i=0;i<MAXNODE;i++)if(x==t[i].data) /*依次打印x的孩子*/{flag=0; /* x存在 */for(p=t[i].firstchild;p;p=p->nextchild){ printf("x的孩子:%c\n"t[p-> childcode].data);flag=1;}if(flag==0) printf("x无孩子\n");return;}/*if*/printf("x不存在\n");return;}/* ChildrenL */5.19typedef char elemtype;typedef struct TreeNode{ elemtype data;struct TreeNode *firstchild; struct TreeNode *nextsibling; } NodeType;void ChildrenCSL(NodeType *telemtype x){ /* 层次遍历方法 */Init_Queue(Q); /* 初始化队列 */In_Queue(Qt);count=0;while(!Empty_Queue (Q)){Out_Queue(Qp);if(p->data==x){ /*输出x的孩子*/p=p->firstchild;if(!p) printf("无孩子\n");else{ printf("x的第%i个孩子:%c\n"++countp->data);/*输出第一个孩子*/p=p->nextsibling; /*沿右分支*/while(p){printf("x的第%i个孩子:%c\n"++countp->data);p=p-> nextsibling;}}return;}if(p-> firstchild) In_Queue(Qp-> firstchild);if(p-> nextsibling) In_Queue(Qp-> nextsibling);}}/* ChildrenCSL */5.20(1) 哈夫曼树为:(2) 在上述哈夫曼树的每个左分支上标以1右分支上标以0并设这7个字母分别为A、B、C、D、E、F和H如下图所示:则它们的哈夫曼树为分别为:A:1100B:1101C:10D:011E:00F:010H:111习题6参考答案6.1 选择题(1)C (2)A (3)B(4)C(5)B______条边(6)B(7)A(8)A(9)B(10)A(11)A(12)A(13)B(14)A(15)B(16)A(17)C 6.2 填空(1) 4(2) 1对多 ; 多对多(3) n-1 ; n(4) 0_(5)有向图(6) 1(7)一半(8)一半(9)___第i个链表中边表结点数___(10)___第i个链表中边表结点数___(11)深度优先遍历;广度优先遍历(12)O(n2)(13)___无回路6.3(1)邻接矩阵:(2)邻接链表:(3)每个顶点的度:顶点度V1 3V2 3V3 2V4 3V5 36.4(1)邻接链表:(2)逆邻接链表:(3)顶点入度出度V1 3 0V2 2 2V3 1 2V4 1 3V5 2 1V6 2 36.5(1)深度优先查找遍历序列:V1 V2 V3 V4 V5; V1 V3 V5 V4 V2; V1 V4 V3 V5 V2 (1)广度优先查找遍历序列:V1 V2 V3 V4 V5; V1 V3 V2 V4 V5; V1 V4 V3 V2 V56.6有两个连通分量:6.7顶点(1)(2)(3)(4)(5)Low Close Cost VexLow CloseCost VexLow CloseCost VexLow CloseCost VexLow CloseCost VexV10 00 00 00 00 0V21 00 00 00 00 0V31 01 00 00 00 0V43 02 12 10 10 1V5∞ 05 13 22 30 3U{v1} {v1v2} {v1v2v3} {v1 v2 v3 v4} {v1 v2 v3 v4 v5} T {} { (v1 v2) } {(v1 v2) (v1 v3) } {(v1 v2) (v1 v3) (v2 v4) } {(v1 v2) (v1v3)(v2v4)(v4v5) }最小生成树的示意图如下:6.8拓扑排序结果: V3--> V1 --> V4 --> V5 --> V2 --> V66.9(1)建立无向图邻接矩阵算法:提示:参见算法6.1因为无向图的邻接矩阵是对称的所以有for (k=0; k<G ->e; k++) /*输入e条边建立无向图邻接矩阵*/{ scanf("\n%d%d"&i&j);G ->edges[i][j]= G ->edges[j][i]=1;}(2)建立无向网邻接矩阵算法:提示:参见算法6.1初始化邻接矩阵:#define INFINITY 32768 /* 表示极大值*/for(i=0;i<G->n;i++)for(j=0;j<G->n;j++) G->edges[i][j]= INFINITY;输入边的信息:不仅要输入边邻接的两个顶点序号还要输入边上的权值for (k=0; k<G ->e; k++) /*输入e条边建立无向网邻接矩阵*/{ scanf("\n%d%d%d"&i&j&cost); /*设权值为int型*/G ->edges[i][j]= G ->edges[j][i]=cost;/*对称矩阵*/}(3)建立有向图邻接矩阵算法:提示:参见算法6.16.10(1)建立无向图邻接链表算法:typedef VertexType char;int Create_NgAdjList(ALGraph *G){ /* 输入无向图的顶点数、边数、顶点信息和边的信息建立邻接表 */scanf("%d"&n); if(n<0) return -1; /* 顶点数不能为负 */G->n=n;scanf("%d"&e); if(e<0) return =1; /*边数不能为负 */G->e=e;for(m=0;m< G->n ;m++)G-> adjlist [m].firstedge=NULL; /*置每个单链表为空表*/for(m=0;m< G->n;m++)G->adjlist[m].vertex=getchar(); /*输入各顶点的符号*/for(m=1;m<= G->e; m++){scanf("\n%d%d"&i&j); /* 输入一对邻接顶点序号*/if((i<0 || j<0) return -1;p=(EdgeNode*)malloc(sizeof(EdgeNode));/*在第i+1个链表中插入一个边表结点*/ p->adjvex=j;p->next= G-> adjlist [i].firstedge;G-> adjlist [i].firstedge=p;p=(EdgeNode*)malloc(sizeof(EdgeNode));/*在第j+1个链表中插入一个边表结点*/ p->adjvex=i;p->next= G-> adjlist [j].firstedge;G-> adjlist [j].firstedge=p;} /* for*/return 0; /*成功*/}//Create_NgAdjList(2)建立有向图逆邻接链表算法:typedef VertexType char;int Create_AdjList(ALGraph *G){ /* 输入有向图的顶点数、边数、顶点信息和边的信息建立逆邻接链表 */scanf("%d"&n); if(n<0) return -1; /* 顶点数不能为负 */G->n=n;scanf("%d"&e); if(e<0) return =1; /*弧数不能为负 */G->e=e;for(m=0;m< G->n; m++)G-> adjlist [m].firstedge=NULL; /*置每个单链表为空表*/for(m=0;m< G->n;m++)G->adjlist[m].vertex=getchar(); /*输入各顶点的符号*/for(m=1;m<= G->e ; m++){scanf("\n%d%d"&t&h); /* 输入弧尾和弧头序号*/if((t<0 || h<0) return -1;p=(EdgeNode*)malloc(sizeof(EdgeNode));/*在第h+1个链表中插入一个边表结点*/ p->adjvex=t;p->next= G-> adjlist [h].firstedge;G-> adjlist [h].firstedge=p;} /* for*/return 0; /*成功*/}//Create_AdjList6.11void Create_AdjM(ALGraph *G1MGraph *G2){ /*通过无向图的邻接链表G1生成无向图的邻接矩阵G2*/G2->n=G1->n; G2->e=G1->e;for(i=0;i<G2->n;i++) /* 置G2每个元素为0 */for(j=0;j<G2->n;j++) G2->edges[i][j]= 0;for(m=0;m< G1->n;m++)G2->vexs[m]=G1->adjlist[m].vertex; /*复制顶点信息*/num=(G1->n/2==0?G1->n/2:G1->n/2+1); /*只要搜索前n/2个单链表即可*/for(m=0;m< num;m++){ p=G1->adjlist[m].firstedge;while(p){ /* 无向图的存储具有对称性*/G2->edges[m][ p->adjvex ]= G2->edges[p->adjvex ] [m] =1;p==p->next;}}/* for */}/*Create_AdjM */void Create_AdjL(ALGraph *G1MGraph *G2){ /*通过无向图的邻接矩阵G1生成无向图的邻接链表G2*/G2->n=G1->n; G2->e=G1->e;for(i=0;i<G1->n;i++) /* 建立每个单链表 */{ G2->vexs[i]=G1->adjlist[i].vertex;G2->adjlist[i].firstedge=NULL;for(j=i; j<G1->n; j++) /*对称矩阵只要搜索主对角以上的元素即可*/{ if(G1->edges[i][j]== 1){ p=(EdgeNode*)malloc(sizeof(EdgeNode));/*在第i+1个链表中插入一个边表结点*/p->adjvex=j;p->next= G-> adjlist [i].firstedge;G-> adjlist [i].firstedge=p;p=(EdgeNode*)malloc(sizeof(EdgeNode));/*在第j+1个链表中插入一个边表结点*/p->adjvex=i;p->next= G-> adjlist [j].firstedge;G-> adjlist [j].firstedge=p;}/*if*/}/* for*/}/* for*/}/* Create_AdjL */6.13(1) 邻接矩阵中1的个数的一半;(2) 若位于[i-1j-1]或[j-1i-1]位置的元素值等于1则有边相连否则没有(3) 顶点i的度等于第i-1行中或第i-1列中1的个数6.14(1) 邻接链表中边表结点的个数的一半;(2) 若第i-1(或j-1)个单链表中存在adjvex域值等于j-1(或i-1)的边表结点则有边相连否则没有(3) 顶点i的度等于第i-1个单链表中边表结点的个数提示:参见算法6.2 和6.3习题 7参考答案7.1 选择题(1)C (2)C (3) C (4)B (5) A (6)A (7) D (8)B (9)D (10) B(11)B (12)A (13)C (14)C (15)A (16)D (17)C (18)BC (19)B (20)A7.2 填空题(1) O(n)O(log2n)(2) 12485log2(n+1)-1(3)小于大于(4)增序序列(5)m-1(6) 70; 342055(7) n/m(8)开放地址法链地址法(9)产生冲突的可能性就越大产生冲突的可能性就越小(10)关键码直接(11)②①⑦(12) 1616821(13)直接定址法数字分析法平方取中法折叠法除留余数法随机数法(14)开放地址法再哈希法链地址法建立一个公共溢出区(15)装满程度(16)索引快(17)哈希函数装填因子(18)一个结点(19)中序(20)等于7.3 一棵二叉排序树(又称二叉查找树)或者是一棵空树或者是一棵同时满足下列条件的二叉树:(1)若它的左子树不空则左子树上所有结点的键值均小于它根结点键值(2)若它的右子树不空则右子树上所有结点的键值均大于它根结点键值(3)它的左、右子树也分别为二叉排序树7.4 对地址单元d=H(K)如发生冲突以d为中心在左右两边交替进行探测按照二次探测法键值K的散列地址序列为:do=H(K)d1=(d0+12)mod md2=(d0-12)mod md3=(d0+22)mod md4=(d0-12)mod m......7.5 衡量算法的标准有很多时间复杂度只是其中之一尽管有些算法时间性能很好但是其他方面可能就存在着不足比如散列查找的时间性能很优越但是需要关注如何合理地构造散列函数问题而且总存在着冲突等现象为了解决冲突还得采用其他方法二分查找也是有代价的因为事先必须对整个查找区间进行排序而排序也是费时的所以常应用于频繁查找的场合对于顺序查找尽管效率不高但却比较简单常用于查找范围较小或偶而进行查找的情况7.6此法要求设立多个散列函数Hii=1...k当给定值K与闭散列表中的某个键值是相对于某个散列函数Hi的同义词因而发生冲突时继续计算该给定值K在下一个散列函数Hi+1下的散列地址直到不再产生冲突为止7.7散列表由两个一维数组组成一个称为基本表另一个称为溢出表插入首先在基本表上进行;假如发生冲突则将同义词存人溢出表7.8 结点个数为n时高度最小的树的高度为1有两层它有n-1个叶结点1个分支结点;高度最大的树的高度为n-l有n层它有1个叶结点n-1个分支结点7.9 设顺序查找以h为表头指针的有序链表若查找成功则返回结点指针p查找失败则返回null值pointer sqesrearch(pointer hint xpointerp){p=null;while(h)if(x>h->key)h=h->link;else{if(x==h->key)p=h;return(p);}}虽然链表中的结点是按从小到大的顺序排列的但是其存储结构为单链表查找结点时只能从头指针开始逐步进行搜索故不能用折半(二分)查找7.10 分析:对二叉排序树来讲其中根遍历序列为一个递增有序序列因此对给定的二叉树进行中根遍历如果始终能保证前一个值比后一个值小则说明该二叉树是二叉排序树int bsbtr (bitreptr T) /*predt记录当前结点前趋值初值为-∞*/{ if (T==NULL) return(1);else{b1=bsbtr(T->lchild);/*判断左子树*/if (!b1|| (predt>=T->data)) return(0);*当前结点和前趋比较*/ predt=T->data;/*修改当前结点的前趋值*/return(bsbtr(T->rchild));/*判断右子树并返回最终结果*/}}7.11 (1)使用线性探查再散列法来构造散列表如表下所示散列表───────────────────────────────地址 0 1 2 3 4 5 6 7 8 9 10───────────────────────────────数据 33 1 13 12 34 38 27 22───────────────────────────────(2)使用链地址法来构造散列表如下图(3)装填因子a=8/11使用线性探查再散列法查找成功所需的平均查找次数为Snl=0.5(1+1/(1-a))=0.5*(1+1/(1-8/11))=7/3使用线性探查再散列法查找不成功所需的平均查找次数为:Unl=0.5(1+1/(1-a)2)=0.5*(1+1/(1-8/11)2)=65/9 使用链地址法查找成功所需的平均查找次数为:Snc=l+a/2=1+8/22=15/11使用链地址法查找不成功所需的平均查找次数为: 'Unl=a+e-a=8/1l+e-8/117.12 分析:在等查区间的上、下界处设两个指针由此计算出中间元素的序号当中间元素大于给定值X时接下来到其低端区间去查找;当中间元素小于给定值X时接下来到其高端区间去查找;当中间元素等于给定值X时表示查找成功输出其序号Int binlist(sqtable Aint stkeytype X) /*t、s分别为查找区间的上、下界*/{ if(s<t) return(0);/*查找失败*/else{ mid=(S+t)/2;switCh(mid){case x<A.item[midJ.key: return(binlist(Asmid-lX));/*在低端区间上递归*/case x==A.item[mid].key: return(mid);/+查找成功*/ case x>A.item[mid].key: return(amid+ltX));/*在高端区间上递归*/}}}int sqsearch0 (sqtable Akeytype X) /*数组有元素n个*/{ i=l;A.item[n+1].key=X;/t设置哨兵*/while (A.item[n+1].key!=X) i++;return (i% (n/1));/*找不到返回0找到返回其下标*/}查找成功平均查找长度为:(1+2+3+...+n)/n:(1+n)/2查找不成功平均查找长度为:n+17.14散列函数:H(key)=100+(key个位数+key十位数) mod l0;形成的散列表:100 101 102 103 104 105 106 107 108 10998 75 63 46 49 79 61 53 17查找成功时的平均长度为:(1+2+1+1+5+1+1+5+5+3)/10=2.5次由于长度为10的哈希表已满因此在插人第11个记录时所需作的比较次数的期望值为10查找不成功时的平均长度为10习题 8参考答案8.1 选择题(1)B (2)A (3)D (4)C (5)B (6)A (7)B (8)C (9)A (10)C(11)D (12)C (13) C (14)D (15)C (16)B (17) D (18)C (19)B (20)D8.2填空题(1)快速归并(2) O(log2n)O(nlog2n)(3)归并(4)向上根结点(5) 1918162030(6)(7)4913275076386597(8)88(9)插入选择(每次选择最大的)(10)快速归并(11)O(1)O(nlog2n)(12)稳定(13)3(14)(15205040)(15)O(log2n)(16)O(n2)(17)冒泡排序快速排序(18)完全二叉树n/2(19)稳定不稳定(20)24(2015)8.3. 假定给定含有n个记录的文件(r1f2...rn)其相应的关键字为(k1k2...kn)则排序就是确定文件的一个序列rrr2...rn使得k1'≤k2'≤...≤kn'从而使得文件中n个记录按其对应关键字有序排列如果整个排序过程在内存中进行则排序叫内部排序假设在待排序的文件中存在两个或两个以上的记录具有相同的关键字若采用某种排序方法后使得这些具有相同关键字的记录在排序前后相对次序依然保持不变则认为该排序方法是稳定的否则就认为排序方法是不稳定的8.4.稳定的有:直接插入排序、二分法插入排序、起泡排序、归并排序和直接选择排序8.5.初始记录序列按关键字有序或基本有序时比较次数为最多8.6.设5个元素分别用abcde表示取a与b、c与d进行比较若a>bc>d(也可能是a<bc<d此时情况类似)显然此时进行了两次比较取b与d再比较若b>d则a>b>d若b<d则有c>d>b此时已进行了3次比较要使排序比较最多7次可把另外两个元素按折半检索排序插入到上面所得的有序序列中此时共需要4次比较从而可得算法共只需7次比较8.7.题目中所说的几种排序方法中其排序速度都很快但快速排序、归并排序、基数排序和Shell排序都是在排序结束后才能确定数据元素的全部序列而排序过程中无法知道部分连续位置上的最终元素而堆排序则是每次输出一个堆顶元素(即最大或最少值的元素)然后对堆进行再调整保证堆顶元素总是当前剩下元素的最大或最小的从而可知欲在一个大量数据的文件中如含有15000个元素的记录文件中选取前10个最大的元素可采用堆排序进行8.8.二分法排序8.9.void insertsort(seqlist r)  ;{ //对顺序表中记录R[0一N-1)按递增序进行插入排序&NBSP;int ij;  ;for(i=n-2;i>=0; i--) //在有序区中依次插入r[n-2]..r[0]  ;if(r[i].key>r[i+1].key) //若不是这样则r[i]原位不动 ;{  ;r[n]=r[i];j=i+l;//r[n]是哨兵 ;do{ //从左向右在有序区中查找插入位置 ;r[j-1]= r[j];//将关键字小于r[i].key的记录向右移 ;j++;  ;}whle(r[j].key r[j-1]=r[n];//将引i)插入到正确位置上 ;}//endif ;}//insertsort.  ;8.10.建立初始堆:[937 694 863 265 438 751 742129075 3011]&NBSP;&NBSP;第一次排序重建堆:[863 694 751 765 438 301 742 129 075]9378.11.在排序过程中每次比较会有两种情况出现若整个排序过程至少需作t次比较则显然会有2^t个情况由于n个结点总共有n!种不同的排列因而必须有n!种不同的比较路径于是: 2t≥n!即t≥log2n!因为log2nl=nlog2n-n/ln2+log2n/2+O(1)故有log2n!≈nlog2n从而t≧nlog2n得证8.12.依据堆定义可知:序列(1)、(2)、(4)是堆(3)不是堆从而可对其调整使之为如下的大根堆(1009580604095821020)8.13.第一趟:[265 301] [129 751] [863 937] [694 742] [076 438]&NBSP; &NBSP;第二趟:[129 265 301 751] [694 742 863 937] [076 438]&NBSP;&NBSP;第三趟:[129 265 301 694 742 751 863 937] [076 438]&NBSP;&NBSP;第四趟:[076 129 265 301 438 694 742 751 863 937]&NBSP;8.14.(1)归并排序:(1829) (2547) (1258) (1051)(18252947) (10125158)(1012182529475158)(2)快速排序:(1018251229585147)(1018251229475158)(1012182529475158)(3)堆排序:初始堆(大顶堆):(58 47512918122510)第一次调整:(51 472529181210)(58)第二次调整:(47 2925101812)(5158)第三次调整:(29 18251012)(475158)第四次调整:(25 181210)(29475158)第五次调整:(18 1012)(2529475158)第六次调整:(12 10) (182529475158)第七次调整:(10 12182529475158)8.15.(1)直接插入排序序号 1 2 3 4 5 6 7 8 9 10 11 12 关键字 83 40 63 13 84 35 96 57 39 79 61 151=2 40 83 [63 13 84 35 96 57 39 79 61 15] 1=3 40 63 83 [13 84 35 96 57 39 79 61 15] 1=4 13 40 63 83 [84 3 5 96 57 39 79 61 15] I=5 13 40 63 83 84 [35 96 57 39 79 61 15] I=6 13 35 40 63 83 84 [96 57 39 79 61 15] 1=7 13 35 40 63 83 84 96 [57 39 79 61 15] 1=8 13 35 40 57 63 83 84 96 [ 39 79 61 15] 1=9 13 35 39 40 57 63 83 84 96 [79 61 15] I=10 13 35 39 40 57 63 79 83 84 96 [61 15] I=11 13 35 39 40 57 61 63 79 83 84 96 [15] 1=12 13 15 35 39 40 57 61 63 79 83 84 96 (2)直接选择排序序号 1 2 3 4 5 6 7 8 9 10 11 12 关键字 83 40 63 13 84 35 96 57 39 79 61 15i=1 13 [ 40 63 83 84 35 96 57 39 79 61 15] i=2 13 15 [63 83 84 35 96 57 39 79 61 40] i=3 13 15 35 [83 84 63 96 57 39 79 61 40] i=4 13 15 35 39 [84 63 96 57 83 79 61 40] i=5 13 15 35 39 40 [63 96 57 83 79 61 84] i=6 13 15 35 39 40 57 [96 63 83 79 61 84] i=7 13 15 35 39 40 57 61 [63 83 79 96 84] i=8 13 15 35 39 40 57 61 63 [83 79 96 84] i=9 13 15 35 39 40 57 61 63 79 183 96 84] i=10 13 15 35 39 40 57 61 63 79 83 [96 84] i=11 13 15 35 39 40 57 61 63 79 83 84 [96] (3)快速排序关键字 83 40 63 13 84 35 96 57 39 79 61 15 第一趟排序后 [15 40 63 13 61 35 79 57 39] 83 [96 84] 第二趟排序后 [13] 15 [63 40 61 35 79 57 39] 83 84 [96] 第三趟排序后 13 15 [39 40 61 35 57] 63 [79] 83 84 96 第四趟排序后 13 15 [35] 39 [61 40 57] 63 79 83 84 96第五趟排序后 13 15 35 39 [57 40] 61 63 79 83 84 96 第六趟排序后 13 15 35 39 40 [57] 61 63 79 83 84 96 第七趟排序后 13 15 35 39 40 57 61 63 79 83 84 96 (4)堆排序关键字 83 40 63 13 84 35 96 57 39 79 61 15排序成功的序列 96 84 83 79 63 61 57 40 39 35 15 13(5)归并排序关键字 83 40 63 13 84 35 96 57 39 79 61 15 第一趟排序后 [40 83] [13 63] [3584] [57 96] [39 79] [15 61]第二趟排序后 [13 40 63 83] [35 57 84 96] [15 39 61 79] 第三趟排序后 [13 35 40 57 63 83 84 96]] [15 39 61 79] 第四趟排序后 13 15 35 39 40 57 61 63 79 83 84 96。
数据结构(第3版)习题答案

十二五普通高等教育国家级本科规划教材第1章绪论高等学校精品资源共享课程什么是数据结构【答】:数据结构是指按一定的逻辑结构组成的一批数据,使用某种存储结构将这批数据存储于计算机中,并在这些数据上定义了一个运算集合。
数据结构涉及哪几个方面【答】:数据结构涉及三个方面的内容,即数据的逻辑结构、数据的存储结构和数据的运算集合。
两个数据结构的逻辑结构和存储结构都相同,但是它们的运算集合中有一个运算的定义不一样,它们是否可以认作是同一个数据结构为什么【答】:不能,运算集合是数据结构的重要组成部分,不同的运算集合所确定的数据结构是不一样的,例如,栈与队列它们的逻辑结构与存储结构可以相同,但由于它们的运算集合不一样,所以它们是两种不同的数据结构。
线性结构的特点是什么非线性结构的特点是什么【答】:线性结构元素之间的关系是一对一的,在线性结构中只有一个开始结点和一个终端结点,其他的每一个结点有且仅有一个前驱和一个后继结点。
而非线性结构则没有这个特点,元素之间的关系可以是一对多的或多对多的。
数据结构的存储方式有哪几种【答】:数据结构的存储方式有顺序存储、链式存储、散列存储和索引存储等四种方式。
算法有哪些特点它和程序的主要区别是什么【答】:算法具有(1)有穷性(2)确定性(3)0 个或多个输入(4)1 个或多个输出(5)可行性等特征。
程序是算法的一种描述方式,通过程序可以在计算机上实现算法。
抽象数据类型的是什么它有什么特点【答】:抽象数据类型是数据类型的进一步抽象,是大家熟知的基本数据类型的延伸和发展。
抽象数据类型是与表示无关的数据类型,是一个数据模型及定义在该模型上的一组运算。
对一个抽象数据类型进行定义时,必须给出它的名字及各运算的运算符名,即函数名,并且规定这些函数的参数性质。
一旦定义了一个抽象数据类型及具体实现,程序设计中就可以像使用基本数据类型那样,十分方便地使用抽象数据类型。
抽象数据类型的设计者根据这些描述给出操作的具体实现,抽象数据类型的使用者依据这些描述使用抽象数据类型。
算法数数据结构 第3版 绪论课后答案
算法与数据结构---C语言描述(第三版)第1章绪论1、解释以下概念:逻辑结构,存储结构,操作,数据结构,数据结构的表示,数据结构的实现,抽象数据类型,算法,算法的时间代价,算法的空间代价,大O表示法,贪心法,回溯法,分治法。
答:(1)逻辑结构(数学模型):①指数据元素之间地逻辑关系。
②具体解释:指数学模型(集合,表,树,和图)之间的关系。
③描述方式:B = <K,R>, K是节点的有穷集合,R是K上的一个关系。
(2)存储结构(物理结构):数据的逻辑结构在计算机存储器中的映射(或表示)。
(3) 操作(行为):指抽象数据类型关心的的各种行为在不同的存储结构上的具体算法(或程序)。
(4) 数据结构:①传统观念:数据结构是计算机中表示(存储)的、具有一定逻辑关系和行为特征的一组数据。
②根据面向对象的观点:数据结构是抽象数据类型的物理实现。
(5) 数据结构的表示:(6) 数据结构的实现:(7) 抽象数据类型:(8) 算法:是由有穷规则构成(为解决某一类问题)的运算序列。
-算法可以有若干输入(初始值或条件)。
-算法通常又有若干个输出(计算结果)。
-算法应该具有有穷性。
一个算法必须在执行了有穷步之后结束。
-算法应该具有确定性。
算法的每一步,必须有确切的定义。
-算法应该有可行性。
算法中国的每个动作,原则上都是能够有机器或人准确完成的。
(9) 算法的时间代价:(10) 算法的空间代价:(11) 大O表示法:-更关注算法复杂性的量级。
-若存在正常数c和n0,当问题的规模n>=c*f(n), 则说改算法的时间(或空间)代价为O(f(n))(12) 贪心法:当追求的目标是一个问题的最优解是,设法把整个问题的求解工作分成若干步来完成。
在其中的每一个阶段都选择都选择从局部来看是最优的方案,以期望通过各个阶段的局部最有选择达到整体的最优。
例如:着色问题:先用一种颜色尽可能多的节点上色,然后用另一种颜色在为着色节点中尽可能多的节点上色,如此反复直到所有节点都着色为止;(13) 回溯法有一些问题,需要通过彻底搜索所有的情况寻找一个满足某些预定条件的最优解。
数据结构与算法分析c第三版答案

数据结构与算法分析c第三版答案【篇一:数据结构第三章习题答案】txt>#include iostream#include stringusing namespace std;bool huiwen(string s){int n=s.length();int i,j;i= 0;j=n-1;while(ij s[i]==s[j]){ i++;j--;}if(i=j) return true;else return false;}int main(){string s1;cins1;couthuiwen(s1);return 0;}=============(2)设从键盘输入一整数的序列:a1, a2, a3,…,an,试编写算法实现:用栈结构存储输入的整数,当ai≠-1时,将ai进栈;当ai=-1时,输出栈顶整数并出栈。
算法应对异常情况(入栈满等)给出相应的信息。
#include iostreamusing namespace std;#define overflow -2#define ok 1#define error 0typedef int selemtype;typedef int status;typedef struct{selemtype a[5];int top;} sqstack;status initstack(sqstack s){s.top=0;return ok;}status push(sqstack s,selemtype e){if (s.top4){coutoverlow!endl;return error;}else s.a[s.top++]=e;return ok;}status pop(sqstack s,selemtype e){if (s.top==0) {coutunderflowendl; return error;}e=s.a[--s.top];couteendl;return ok;}int main(){sqstack s;initstack(s);int n,x,e1;coutn=?endl;cinn;for(int i=0;in;i++){ cinx;if(x!=-1 )push(s,x);else pop(s,e1); }return 0;}============(3)假设以i和o分别表示入栈和出栈操作。
数据结构与算法 智慧树网课章节测试答案

1、选择题:在数据结构中,从逻辑上可以把数据结构分成()。
选项:A:紧凑结构和非紧凑结构B:线性结构和非线性结构C:内部结构和外部结构D:动态结构和静态结构答案: 【线性结构和非线性结构】2、选择题:在数据结构中,从存储结构上可以将之分为()。
选项:A:动态结构和静态结构B:顺序存储和非顺序存储C:紧凑结构和非紧凑结构D:线性结构和非线性结构答案: 【顺序存储和非顺序存储】3、选择题:某算法的时间复杂度是O(n^2),表明该算法的()。
选项:A:执行时间与n^2成正比B:选择题规模是n^2C:执行时间等于n^2D:选择题规模与n^2成正比答案: 【执行时间与n^2成正比】4、选择题:在下面的程序段中,x=x+1;的语句频度为()。
for( i=1;i<=n;i++) for( j=1;j<=n;j++) x=x+1;选项:A:O(2n)B:O(n)C:O(n^2)D:O(log2n)答案: 【O(n^2)】5、选择题:以下数据结构中,()是非线性数据结构。
选项:A:树B:字符串C:队D:栈答案: 【树】6、选择题:顺序存储,存储章的地址()。
选项:A:一定连续B:一定不连续C:不一定连续D:部分连续,部分不连续答案: 【一定连续】7、选择题:评价一个算法性能好坏的重要标准是( )。
选项:A:算法的正确性B:算法易于调试C:算法的时间和空间复杂度D:算法易于理解答案: 【算法的时间和空间复杂度】8、选择题:若需要利用形式参数直接访问修改实参值,则应将形参说明为()参数。
选项:A:值参数B:实地址C:指针D:地址参数答案: 【指针】9、选择题:顺序存储方式的优点是存储密度大,且插入、删除运算效率高。
选项:A:对B:错答案: 【错】10、选择题:数据结构中评价算法的两个重要指标是算法的时间复杂度和空间复杂度。
选项:A:对B:错答案: 【对】1、选择题:下述哪一条是顺序存储结构的优点()。
选项:A:可方便地用于各种逻辑结构的存储表示B:插入运算方便C:删除运算方便D:存储密度大答案: 【存储密度大】3、选择题:设某顺序表中第一个元素的地址是se(下标从1开始),每个结点占m个章,则第i个结点的地址为()。
数据结构(第3版)习题答案

(7)队列是一种特殊的线性表,其特殊性在于(C)。
A.插入和删除在表的不同位置执行B.插入和删除在表的两端位置执行
C.插入和删除分别在表的两端执行D.插入和删除都在表的某一端执行
(8)栈是一种特殊的线性表,具有(B)性质。
A.先进先出
B.先进后出
C.后进后出
D.顺序进出
(9)顺序循环队列中(数组的大小为n),队头指示front指向队列的第1个元素,队尾
注意:回溯法,关键在于回溯,即在某分支结点X:处理X的一个子分支,再退回分支X,
接着处理X的下一个子分支,若所有X的子分支处理完,再退回上一层分支节点。所谓“退回”,
7
十二五普通高等教育国家级本科规划教材
高等学校精品资源共享课程
实际上就是恢复。
程序代码:(2_8_1.c)
#include <stdio.h>
第2章
线性表及其顺序存储
2.1选择题
(1)表长为n的顺序存储的线性表,当在任何位置上插入或删除一个元素的概率相等时,
插入一个元素所需移动元素的平均个数为(
为(A)。
E
),删除一个元素所需移动元素的平均个数
A.(n−1)/2
E.n/2
B.n
F.(n+1)/2
C.n+1
G.(n−2)/2
D.n−1
(2)设栈S和队列Q的初始状态为空,元素e1、e2、e3、e4、e5和e6依次通过栈S,
if (L->data[i]==x) c++;
return c;
}
2.4设计一个算法,将一个顺序表倒置。即,如果顺序表各个结点值存储在一维数组a中,倒
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
【解答】略。
4.运算是数据结构的一个重要方面。试举例说明两个数据结构的逻辑结构和存储方式完全相同,只是对于运算的定义不同,使得两个结构具有显著不同的特性。
【解答】比如顺序栈和循环队列,二者的逻辑结构都是线性结构,都采用顺序存储方式存储,但它们的运算不同,栈限定元素的插入和删除在栈顶进行,队列限定元素在队尾插入、在队首删除,因此它们是截然不同的数据结构。
4.算法的优劣与描述算法的语言无关,但与所用计算机的性能有关。(×)
5.算法必须有输出,但可以没有输人。(√)
三、筒答题
1.常见的逻辑结构有哪几种,各自的特点是什么?常用的存储结构有哪几种,各自的特点是什么?
【答】常见的四种逻辑结构:
①集合结构:数据元素之间是“属于同一个集合”
②线性结构:数据元素之间存在着一对一的关系
5.分析下列程序段中带标号“#’’语句的执行频度(n为正整数)。
(1) j=1;k=0;
while(j<=n-1)
{j++;
k+=j;/*#*/
【解答】n-1
(2)i=0;s=0;n=100;
do{i++;
s+=10*i;/*#*/
}while!(i<n&&s <n);
【解答】1
(3)k=0;
for(i=0;i<n;i++)
}
[解答] 1000
6.写出下列各程序段关于n的时间复杂度。
(1)a=1;m=1;
while(a<n)
{m+= a;
a*=3;
}
[解答]O(n)
(2)设n是偶数。
for(i=1,s=0;i<=n;i++)
for(j=2*i;j<=n;j++)
s++;
[解答]O(n2)
(3)for(i=1;i<=n-1;i++)
③树结构:数据元素之间存在着一对多的关系
④结构:数据元素之间存在着多对多的关系。
常见的四种存储结构有:
①顺序存储:把逻辑上相邻的元素存储在物理位置相邻的存储单元中。顺序存储结构是一种最基本的存储表示方法,通常借助于程序设计语言中的数组来实现。
②链接存储:对逻辑上相邻的元素不要求物理位置相邻的存储单元,元素间的逻辑关系通过附设的指针域来表示。
D.同一个算法,实现语言的级别越高,执行效率就越低
5.在发生非法操作时,算法能够作出适当处理的特性称为(B)。
A.正确性B.健壮性C.可读性D.可移植性
二、判断题
1.数据的逻辑结构是指数据的各数据项之间的逻辑关系。(√)
2.顺序存储方式的优点是存储密度大,且插人、删除运算效率高。(×)
3.数据的逻辑结构说明数据元素之间的次序关系,它依赖于数据的存储结构。(×)
for(j=i;j<n;j++)
k++;/*#*/
【解答】n(n+1)/2
(4) a=1;b =0;
while(a+b<=n)
{if( a<b)a++;/*#*/
elseb++;
}
[解答]n
(5)x=91;y=100;
while(y>0)
{if (x>100){x-=10; y--;}/*#*/
else x++;
3.采用顺序存储结构表示数据时,相邻的数据元素的存储地址(A)。
A.一定连续B.一定不连续
C.不一定连续D.部分连续,部分不连续
4.下面关于算法说法正确的是பைடு நூலகம்D)。
A.算法的时间复杂度一般与算法的空间复杂度成正比
B.解决某问题的算法可能有多种,但肯定采用相同的数据结构
C.算法的可行性是指算法的指令不能有二义性
main()
{s=0;
scanf(”%f" ,&x);
for(k=n; k>=1;k--)
{scanf ("% f”,&a);
s=s*x+a;
}
printf(”P(x,n)=%f”,s);
}
④分析:该算法仅使用了n次乘法和n次加法,来完成一元n次多项式的求值问题,具有较好的时间和空间性能。
{k=i;
for(j=i+1;j<=n;j++)
if(R[j]>R[j+1])k=j;
t=R[k];R[k]=R[i];R[i]=t;
}
[解答]O(n2)
7.计算一元n次多项式P( x,n)=a0+alx+a2x2+..+anxn“的值,输人x,n,a0,al,…,an,输出多项式P(x,n)的值。设计算法求解,请选择合适的输人、输出格式,要求算法具有较好的时间性能。
③索引存储:通过建立索引表存储结点信息的方法,其中索引表一般存储结点关键字和一个地点信息,可通过该地址找到结点的其他信息。
④散列存储:根据结点的关键字直接计算出该结点的存储地址的方法。
2.简述算法和程序的区别。
【解答】一个算法若用程序设计语言来描述,则它就是一个程序。算法的含义与程序十分相似,但又有区别。一个程序不一定满足有穷性。例如,操作系统,只要整个系统不遭破坏,它将永远不会停止,即使没有作业需要处理,它仍处于动态等待中。因此,操作系统不是一个算法。另一方面,程序中的指令必须是机器可执行的,而算法中的指令则无此限制。算法代表了对问题的解,而程序则是算法在计算机上的特定的实现。
【解答】
①将一元n次多项式做如下改写:
P( x,n)=a0+alx+a2x2+..+anxn
=a0+x(al+a2x+..+anxn-1)
=……
=a0+x(al+x(a2+x(a3+..x(an-1+xan)…))))
②按指数递减次序输人各系数,即输人次序为an,an-1,…,a2,a0
③算法如下:
习题参考答案
一.选择题
1.从逻辑上可以把数据结构分为(C)两大类。
A.动态结构、静态结构B.顺序结构、链式结构
C.线性结构、非线性结构D.初等结构、构造型结构
2.在下面的程序段中,对x的斌值语句的频度为(C)。
for( t=1;k<=n;k++)
for(j=1;j<=n; j++)
x=x十1;
A. O(2n)B.O(n)C.O(n2).D.O(1og2n)