JAVA使用爬虫抓取网站网页内容的方法_java_脚本之家
Java-XPath解析爬取内容

Java-XPath解析爬取内容就爬取和解析内容⽽⾔,我们有太多选择。
⽐如,很多⼈都觉得Jsoup就可以解决所有问题。
⽆论是Http请求、DOM操作、CSS query selector筛选都⾮常⽅便。
关键是这个selector,仅通过⼀个表达式筛选出的只能是⼀个node。
如过我想获得⼀个text或者⼀个node的属性值,我需要从返回的element对象中再获取⼀次。
⽽我恰好接到了⼀个有意思的需求,仅通过⼀个表达式表⽰想筛选的内容,获取⼀个新闻⽹页的每⼀条新闻的标题、链接等信息。
XPath再合适不过了,⽐如下⾯这个例⼦:static void crawlByXPath(String url,String xpathExp) throws IOException, ParserConfigurationException, SAXException, XPathExpressionException {String html = Jsoup.connect(url).post().html();DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();DocumentBuilder builder = factory.newDocumentBuilder();Document document = builder.parse(html);XPathFactory xPathFactory = XPathFactory.newInstance();XPath xPath = xPathFactory.newXPath();XPathExpression expression = pile(xpathExp);expression.evaluate(html);}遗憾的是,⼏乎没有⽹站可以通过documentBuilder.parse这段代码。
网页源码爬取
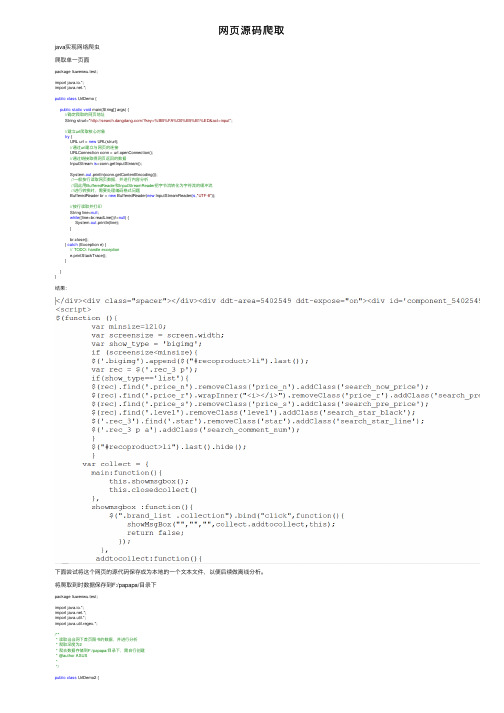
⽹页源码爬取java实现⽹络爬⾍爬取单⼀页⾯package liuwenwu.test;import java.io.*;import .*;public class UrlDemo {public static void main(String[] args) {//确定爬取的⽹页地址String strurl="/?key=%BB%FA%D0%B5%B1%ED&act=input";//建⽴url爬取核⼼对象try {URL url = new URL(strurl);//通过url建⽴与⽹页的连接URLConnection conn = url.openConnection();//通过链接取得⽹页返回的数据InputStream is=conn.getInputStream();System.out.println(conn.getContentEncoding());//⼀般按⾏读取⽹页数据,并进⾏内容分析//因此⽤BufferedReader和InputStreamReader把字节流转化为字符流的缓冲流//进⾏转换时,需要处理编码格式问题BufferedReader br = new BufferedReader(new InputStreamReader(is,"UTF-8"));//按⾏读取并打印String line=null;while((line=br.readLine())!=null) {System.out.println(line);}br.close();} catch (Exception e) {// TODO: handle exceptione.printStackTrace();}}}结果:下⾯尝试将这个⽹页的源代码保存成为本地的⼀个⽂本⽂件,以便后续做离线分析。
将爬取到时数据保存到F:/papapa/⽬录下package liuwenwu.test;import java.io.*;import .*;import java.util.*;import java.util.regex.*;/*** 读取当当⽹下⾸页图书的数据,并进⾏分析* 爬取深度为2* 爬去数据存储到F:/papapa/⽬录下,需⾃⾏创建* @author ASUS**/public class UrlDemo2 {//提取的数据存放到该⽬录下private static String savepath="F:/papapa/";//等待爬取的urlprivate static List<String> allwaiturl=new ArrayList<>();//爬取过得urlprivate static Set<String> alloverurl=new HashSet<>();//记录所有url的深度进⾏爬取判断private static Map<String, Integer> allurldepth=new HashMap<>();//爬取的深度private static int maxdepth=2;public static void main(String[] args) {//确定爬取的⽹址String strurl="/";workurl(strurl, 1);}public static void workurl(String strurl,int depth) {//判断当前url是否爬取过if(!(alloverurl.contains(strurl)||depth>maxdepth)) {//建⽴url爬取核⼼对象try {URL url = new URL(strurl);//通过url建⽴与⽹页的连接URLConnection conn = url.openConnection();//通过链接取得⽹页返回的数据InputStream is=conn.getInputStream();System.out.println(conn.getContentEncoding());//⼀般按⾏读取⽹页数据,并进⾏内容分析//因此⽤BufferedReader和InputStreamReader把字节流转化为字符流的缓冲流//进⾏转换时,需要处理编码格式问题BufferedReader br=new BufferedReader(new InputStreamReader(is,"GB2312"));//按⾏读取并打印String line=null;//正则表达式的匹配规则提取该⽹页的链接Pattern p=pile("<a .*href=.+</a>");//建⽴⼀个输出流,⽤于保存⽂件,⽂件名为执⾏时间,以防重复PrintWriter pw=new PrintWriter(new File(savepath+System.currentTimeMillis()+".txt"));while((line=br.readLine())!=null) {//编写正则,匹配超链接地址pw.println(line);Matcher m=p.matcher(line);while(m.find()) {String href=m.group();//找到超链接地址并截取字符串//有⽆引号href=href.substring(href.indexOf("href="));if(href.charAt(5)=='\"') {href=href.substring(6);}else {href=href.substring(5);}//截取到引号或者空格或者到">"结束try {href=href.substring(0,href.indexOf("\""));} catch (Exception e) {try {href=href.substring(0,href.indexOf(""));} catch (Exception e2) {href=href.substring(0,href.indexOf(">"));}}if(href.startsWith("http:")||href.startsWith("https:")){//将url地址放到队列中allwaiturl.add(href);allurldepth.put(href,depth+1);}}}pw.close();br.close();} catch (Exception e) {// TODO: handle exceptione.printStackTrace();}//将当前url归列到alloverurl中alloverurl.add(strurl);System.out.println(strurl+"⽹页爬取完成,以爬取数量:"+alloverurl.size()+",剩余爬取数量:"+allwaiturl.size()); }//⽤递归的⽅法继续爬取其他链接String nexturl=allwaiturl.get(0);allwaiturl.remove(0);workurl(nexturl, allurldepth.get(nexturl));}}控制台:本地⽬录如果想提⾼爬⾍性能,那么我们就需要使⽤多线程来处理,例如:准备好5个线程来同时进⾏爬⾍操作。
网站数据爬取方法

网站数据爬取方法随着互联网的蓬勃发展,许多网站上的数据对于研究、分析和商业用途等方面都具有重要的价值。
网站数据爬取就是指通过自动化的方式,从网站上抓取所需的数据并保存到本地或其他目标位置。
以下是一些常用的网站数据爬取方法。
1. 使用Python的Requests库:Python是一种功能强大的编程语言,具有丰富的第三方库。
其中,Requests库是一个非常常用的库,用于发送HTTP请求,并获取网页的HTML内容。
通过对HTML内容进行解析,可以获取所需的数据。
2. 使用Python的Scrapy框架:Scrapy是一个基于Python的高级爬虫框架,可以帮助开发者编写可扩展、高效的网站爬取程序。
通过定义爬虫规则和提取规则,可以自动化地爬取网站上的数据。
3. 使用Selenium库:有些网站使用了JavaScript来加载数据或者实现页面交互。
对于这类网站,使用传统的爬虫库可能无法获取到完整的数据。
这时可以使用Selenium库,它可以模拟人为在浏览器中操作,从而实现完整的页面加载和数据获取。
4.使用API:许多网站为了方便开发者获取数据,提供了开放的API接口。
通过使用API,可以直接获取到所需的数据,无需进行页面解析和模拟操作。
5. 使用网页解析工具:对于一些简单的网页,可以使用网页解析工具进行数据提取。
例如,使用XPath或CSS选择器对HTML内容进行解析,提取所需的数据。
6.使用代理IP:一些网站为了保护自身的数据安全,采取了反爬虫措施,例如设置访问速度限制或者封锁IP地址。
为了避免被封禁,可以使用代理IP进行爬取,轮流使用多个IP地址,降低被封禁的风险。
7.使用分布式爬虫:当需要爬取大量的网站数据时,使用单机爬虫可能效率较低。
这时,可以使用分布式爬虫,将任务分发给多台机器,同时进行爬取,从而提高爬取效率。
8.设置合理的爬取策略:为了避免对网站服务器造成过大的负担,并且避免触发反爬虫机制,需要设置合理的爬取策略。
Java抓取网页内容三种方式

java抓取网页内容三种方式2011-12-05 11:23一、GetURL.javaimport java.io.*;import .*;public class GetURL {public static void main(String[] args) {InputStream in = null;OutputStream out = null;try {// 检查命令行参数if ((args.length != 1)&& (args.length != 2))throw new IllegalArgumentException("Wrong number of args");URL url = new URL(args[0]); //创建 URLin = url.openStream(); // 打开到这个URL的流if (args.length == 2) // 创建一个适当的输出流out = new FileOutputStream(args[1]);else out = System.out;// 复制字节到输出流byte[] buffer = new byte[4096];int bytes_read;while((bytes_read = in.read(buffer)) != -1)out.write(buffer, 0, bytes_read);}catch (Exception e) {System.err.println(e);System.err.println("Usage: java GetURL <URL> [<filename>]");}finally { //无论如何都要关闭流try { in.close(); out.close(); } catch (Exception e) {}}}}运行方法:C:\java>java GetURL http://127.0.0.1:8080/kj/index.html index.html 二、geturl.jsp<%@ page import="java.io.*" contentType="text/html;charset=gb2312" %> <%@ page language="java" import=".*"%><%String htmpath=null;BufferedReader in = null;InputStreamReader isr = null;InputStream is = null;PrintWriter pw=null;HttpURLConnection huc = null;try{htmpath=getServletContext().getRealPath("/")+"html\\morejava.html"; pw=new PrintWriter(htmpath);URL url = new URL("http://127.0.0.1:8080/kj/morejava.jsp"); //创建 URL huc = (HttpURLConnection)url.openConnection();is = huc.getInputStream();isr = new InputStreamReader(is);in = new BufferedReader(isr);String line = null;while(((line = in.readLine()) != null)) {if(line.length()==0)continue;pw.println(line);}}catch (Exception e) {System.err.println(e);}finally { //无论如何都要关闭流try { is.close(); isr.close();in.close();huc.disconnect();pw.close(); } catch (Exception e) {}}%>OK--,创建文件成功三、HttpClient.javaimport java.io.*;import .*;public class HttpClient {public static void main(String[] args) {try {// 检查命令行参数if ((args.length != 1) && (args.length != 2))throw new IllegalArgumentException("Wrong number of args");OutputStream to_file;if (args.length == 2)to_file = new FileOutputStream(args[1]);//输出到文件elseto_file = System.out;//输出到控制台URL url = new URL(args[0]);String protocol = url.getProtocol();if (!protocol.equals("http"))throw new IllegalArgumentException("Must use 'http:' protocol"); String host = url.getHost();int port = url.getPort();if (port == -1) port = 80;String filename = url.getFile();Socket socket = new Socket(host, port);//打开一个socket连接InputStream from_server = socket.getInputStream();//获取输入流PrintWriter to_server = new PrintWriter(socket.getOutputStream());//获取输出流to_server.print("GET " + filename + "\n\n");//请求服务器上的文件to_server.flush(); // Send it right now!byte[] buffer = new byte[4096];int bytes_read;//读服务器上的响应,并写入文件。
网络爬虫案例解析

⽹络爬⾍案例解析⽹络爬⾍(⼜被称为⽹页蜘蛛,⽹络机器⼈,在FOAF社区中间,更经常被称为⽹页追逐者),是⼀种按照⼀定的规则,⾃动的抓取万维⽹信息的程序或者脚本,已被⼴泛应⽤于互联⽹领域。
搜索引擎使⽤⽹络爬⾍抓取Web⽹页、⽂档甚⾄图⽚、⾳频、视频等资源,通过相应的索引技术组织这些信息,提供给搜索⽤户进⾏查询。
⽹络爬⾍也为中⼩站点的推⼴提供了有效的途径,⽹站针对搜索引擎爬⾍的优化曾风靡⼀时。
⽹络爬⾍的基本⼯作流程如下:1.⾸先选取⼀部分精⼼挑选的种⼦URL;2.将这些URL放⼊待抓取URL队列;3.从待抓取URL队列中取出待抓取在URL,解析DNS,并且得到主机的ip,并将URL对应的⽹页下载下来,存储进已下载⽹页库中。
此外,将这些URL放进已抓取URL队列。
4.分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放⼊待抓取URL队列,从⽽进⼊下⼀个循环。
当然,上⾯说的那些我都不懂,以我现在的理解,我们请求⼀个⽹址,服务器返回给我们⼀个超级⼤⽂本,⽽我们的浏览器可以将这个超级⼤⽂本解析成我们说看到的华丽的页⾯那么,我们只需要把这个超级⼤⽂本看成⼀个⾜够⼤的String 字符串就OK了。
下⾯是我的代码package main.spider;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import java.io.IOException;/*** Created by 1755790963 on 2017/3/10.*/public class Second {public static void main(String[] args) throws IOException {System.out.println("begin");Document document = Jsoup.connect("/p/2356694991").get();String selector="div[class=d_post_content j_d_post_content clearfix]";Elements elements = document.select(selector);for (Element element:elements){String word= element.text();if(word.indexOf("@")>0){word=word.substring(0,stIndexOf("@")+7);System.out.println(word);}System.out.println(word);}}}我在这⾥使⽤了apache公司所提供的jsoup jar包,jsoup 是⼀款Java 的HTML解析器,可直接解析某个URL地址、HTML⽂本内容。
爬虫的四个步骤

爬虫的四个步骤爬虫技术是指利用程序自动化地浏览很多网页,并抓取它们的信息的过程。
爬虫技术在信息爬取、搜索引擎、商业竞争等领域应用广泛。
想要实现一个高效的爬虫程序,需要遵循一定的规范和流程,本文将介绍爬虫的四个步骤,它们是页面抓取、数据提取、数据存储和数据呈现。
第一步:页面抓取页面抓取是爬虫技术的第一步。
抓取的目标是将网站上的所有内容下载到本地,这些内容包括网页、图片、音频和视频等。
页面抓取是爬虫程序中最基本的过程之一,爬虫程序第一次访问目标网站时,会向目标服务器发送请求。
在拿到响应内容后,需要从中解析出有意义的信息,包括HTML源码、页面中的图片、JS文件、CSS文件等。
获取到这些信息后,需要判断响应状态码是否正常,是否符合预期,如果出现错误需要做出相应的处理。
在实现页面抓取过程中,可以使用多种语言和框架。
常用的语言有Python、Java、Node.js,常用的框架有Requests、Scrapy、Puppeteer等。
无论使用什么语言和框架,都需要注意以下几个问题:1. 多线程和协程在进行页面抓取时,需要考虑到性能和效率,如果使用单线程,无法充分利用网络资源,导致程序运行效率低下。
因此,需要采用多线程或协程的方式来处理比较复杂的任务。
多线程可以利用CPU资源,充分发挥计算机的性能。
协程可以利用异步非阻塞技术,充分利用网络资源。
2. 反爬机制在进行页面抓取时,需要考虑到反爬机制。
目标网站可能会采取一些反爬措施,如IP封禁、验证码验证等。
为了克服这些问题,需要采用相应的技术和策略,如IP代理、验证码识别等。
3. 容错处理在进行页面抓取时,需要考虑到容错处理。
爬虫程序可能会因为网络连接问题或者目标网站的异常情况导致程序运行出现异常。
因此,需要实现一些错误处理机制,如重试机制、异常捕获处理机制等。
第二步:数据提取数据提取是爬虫过程中比较重要的一步。
在页面抓取完成之后,需要将页面中有意义的信息提取出来。
java如何爬取百度百科词条内容(java如何使用webmagic爬取百度词条)

52
53
Pattern pattern = pile("(\\\\u(\\p{XDigit}{4}))");
54
Matcher matcher = pattern.matcher(str);
55
char ch;
56
while (matcher.find()) {
57
//group 6链接的一个主要内容概括...)(他的主要内容我爬不到 也不想去研究大家有好办法可以call me)
例如 互联网+这个词汇 我这里爬的互联网发展的新业态,是知识社会创新2.0推动下的互联网形态演进及其催生的经济社会发展新形态。“互联网+”是互联网思维的进一步 实践成果,推动经济形态不断地发生演变,从而带动社会经济实体的生命力,为改革、创新、发展提供广阔的网络平台。通俗的说,“互联网+”就是“互联网+各个传统行业”,但这并不是简 单的两者相加,而是利用信息通信技术以及互联网平台,让互联网与传统行业进行深度融合,创造新的发展生态。它代表一种新的社会形态,即充分发挥互联网在社会资源配置中的优化 和集成作用,将互联网的创新成果深度融合于经济、社会各域之中,提升全社会的创新力和生产力,形成更广泛的以互联网为基础设施和实现工具的经济发展新形态。2015年7月4日,国 务院印发《国务院关于积极推进“互联网+”行动的指导意见》。2016年5月31日,教育部、国家语委在京发布《中国语言生活状况报告(2016)》。“互联.....(分享自
3public static String mySplit(Page page)43 {
44
String wordname=page.getUrl().toString().split("item/")[1];
爬虫的方法和步骤

爬虫的方法和步骤在当今信息爆炸的社会中,要获取并整理特定内容的原始数据,使用爬虫成为了一种越来越流行的方法。
在这种情况下,我们希望提供一些关于爬虫的介绍,包括定义、其实现方法和步骤等。
爬虫是一种自动化程序,旨在在互联网上搜索、收集和分析信息。
爬虫程序通过互联网链接和页面之间的关系,自动地遍历和检索数据和信息。
爬虫程序可以与大量信息源进行交互,包括网站、API和数据库,并允许数据的快速收集和分析。
一.直接请求页面进行数据采集在这种情况下,爬虫程序会发送一个HTTP请求来获取特定网页的内容,然后解析返回值,处理其中的数据并挖掘出所需的信息。
HTTP请求包括URL、请求方法、HTTP头和请求正文等。
使用Python或Java等编程语言进行编程,利用第三方库如urllib库或requests库等发送HTTP请求,并对返回的应答进行解析和处理,通常使用BeautifulSoup、XPath或正则表达式库来获取和处理所需的数据信息。
二、爬虫框架这是一种将基本爬虫组件(如请求、解析和存储数据)封装为可重复使用的模块的方法。
这些模块是在不同的层次和模块中实现的,它们能够按照不同的规则组合起来调用以形成更高级别的爬虫程序。
其中比较流行的框架有Scrapy框架,它使用基于异步框架Twisted来实现并发性,并包括一些有用的固定模块,例如数据抓取、URL管理、数据处理等。
一、定义所需数据定义所需数据是爬虫的第一步。
在设计爬虫之前,以确定需要抓取的数据类型、格式、来源、数量等信息,以及需要考虑如何存储和处理采集到的数据。
二、确定数据源和爬虫方法对于某个数据源、方法、爬虫程序和其他关键因素进行评估和选择。
例如,如果我们想要查找和存储指定标记的新闻,我们就需要确定提供这些标记的新闻源,并根据需要定义爬虫程序中每个组件的实现.三、编写爬虫程序可以使用编程语言编写爬虫程序,或者在Scrapy框架下使用Python,其中包括请求管理模块、URL管理模块、页面分析模块等。
爬虫技术和网站数据抓取方法

爬虫技术和网站数据抓取方法随着互联网的发展,数据成为了一种可贵的资源,越来越多的人开始关注数据的获取和利用。
在数据的获取中,爬虫技术和网站数据抓取方法已经成为非常流行的方式之一。
本文将简单介绍爬虫技术和网站数据抓取方法,并探讨它们的应用。
一、爬虫技术1.1 爬虫的概念爬虫(Spider)是指一种在互联网上自动获取信息的程序。
它模拟浏览器行为,通过对网页中的链接进行解析和跟踪,自动获取网页中的数据。
爬虫技术主要用于数据抓取、搜索引擎、信息源汇聚等领域。
1.2 爬虫的工作原理爬虫的工作过程可以简单概括为先请求网页,再解析网页,最后抽取数据三个步骤。
首先,爬虫会发送请求到指定网页,获取网页的源代码。
然后,爬虫会对获取的网页源代码进行解析,找到网页中包含的链接和数据。
最后,爬虫会抽取有价值的数据,并进行存储和处理。
1.3 爬虫的分类根据不同的目的和需求,爬虫可以分为通用网页爬虫、数据整合爬虫、社交媒体爬虫和搜索引擎爬虫等。
通用网页爬虫:主要用于搜索引擎,通过搜索引擎抓取尽可能多的网页,并且对网页进行索引,提高搜索引擎的检索效率。
数据整合爬虫:主要用于整合互联网上的数据,如新闻、股票数据、房价数据等,以便于大众获取和使用。
社交媒体爬虫:主要用于在社交媒体平台上获取用户的信息,如微博、微信等。
搜索引擎爬虫:主要是为了让搜索引擎收录网站的数据,从而提升网站排名。
二、网站数据抓取方法2.1 网站数据抓取的目的网站数据抓取主要是为了收集和分析网站上的数据,从而了解网站的性质、变化、趋势,为网站提供参考和决策依据。
2.2 网站数据抓取的工具与技术网站数据抓取可以使用多种工具和技术,如爬虫技术、API接口、网站抓取软件等。
(1)爬虫技术爬虫技术是一种高效的网站数据抓取方式,可以快速有效地获取网站上的数据。
但是需要注意网站的反爬机制,防止被网站封禁或者被告上法庭。
(2)API接口API(Application Programming Interface)接口是一种标准化的数据交换格式,是实现不同应用程序之间的数据传递的重要方式之一。
爬虫读取数据的方法

爬虫读取数据的方法
爬虫读取数据的方法有很多种,以下是一些常见的方法:
1. 直接请求数据:对于一些公开可访问的网站,可以直接使用 Python 的requests 库来发送 HTTP 请求并获取响应。
这种方法简单快捷,但需要网站提供 API 或数据接口。
2. 使用第三方库:有一些第三方库可以帮助爬虫读取数据,如BeautifulSoup、Scrapy、Selenium 等。
这些库可以解析 HTML 或 XML 结构,提取所需的数据。
3. 使用浏览器自动化工具:有些网站需要用户登录或使用 JavaScript 动态加载数据,这种情况下可以使用浏览器自动化工具(如 Selenium)模拟浏览器行为,获取网页内容。
4. 网络爬虫框架:有一些 Python 爬虫框架可以帮助简化爬虫的开发过程,如 Scrapy、PySpider 等。
这些框架提供了丰富的功能和组件,可以快速构建高效的爬虫。
5. 数据抓取:有些网站禁止爬虫抓取数据,此时可以使用一些技术手段绕过反爬虫机制,如使用代理 IP、更改 User-Agent、设置延时等。
需要注意的是,在使用爬虫读取数据时,要遵守相关法律法规和网站使用协议,尊重他人的劳动成果和隐私权。
爬虫提取数据的方法

爬虫提取数据的方法
爬虫提取数据的方法有:HTML解析、XPath或CSS选择器、API调用、正则表达式、数据库查询以及AJAX动态加载数据。
1.HTML解析:爬虫通常会下载网页的HTML源代码,然后使用HTML解析库(例如Beautiful Soup、PyQuery等)来提取所需的数据。
这些库允许您通过标签、类、属性等方式来定位和提取数据。
2.XPath或CSS选择器:XPath和CSS选择器是用于在HTML文档中定位和提取数据的强大工具。
XPath是一种用于选择HTML元素的语言,而CSS选择器是一种常用的用于选择样式表中的元素的语言。
您可以使用XPath和CSS 选择器来提取特定元素及其属性。
3.API调用:许多网站提供API(应用程序编程接口),允许开发者通过API 访问和获取数据。
使用爬虫时,您可以直接调用这些API获取数据,而无需解析HTML。
4.正则表达式:正则表达式是一种强大的文本处理工具,可以用于从HTML 源代码或文本中提取特定的模式数据。
通过编写适当的正则表达式,您可以捕获和提取所需的数据。
5.数据库查询:有些网站将其数据存储在数据库中。
爬虫可以模拟数据库查询语言(如SQL),直接向数据库发送查询请求并提取结果。
6.AJAX动态加载数据:某些网页使用AJAX技术动态加载数据。
在这种情况下,您可能需要使用模拟浏览器行为的工具(如Selenium)来处理JavaScript 渲染,并提取通过AJAX请求加载的数据。
爬虫爬取数据的方式和方法

爬虫爬取数据的方式和方法爬虫是一种自动化的程序,用于从互联网上获取数据。
爬虫可以按照一定的规则和算法,自动地访问网页、抓取数据,并将数据存储在本地或数据库中。
以下是一些常见的爬虫爬取数据的方式和方法:1. 基于请求的爬虫这种爬虫通过向目标网站发送请求,获取网页的HTML代码,然后解析HTML代码获取需要的数据。
常见的库有requests、urllib等。
基于请求的爬虫比较简单,适用于小型网站,但对于大型网站、反爬机制严格的网站,这种方式很容易被限制或封禁。
2. 基于浏览器的爬虫这种爬虫使用浏览器自动化工具(如Selenium、Puppeteer等)模拟真实用户操作,打开网页、点击按钮、填写表单等,从而获取数据。
基于浏览器的爬虫能够更好地模拟真实用户行为,不易被目标网站检测到,但同时也更复杂、成本更高。
3. 基于网络爬虫库的爬虫这种爬虫使用一些专门的网络爬虫库(如BeautifulSoup、Scrapy 等)来解析HTML代码、提取数据。
这些库提供了丰富的功能和工具,可以方便地实现各种数据抓取需求。
基于网络爬虫库的爬虫比较灵活、功能强大,但也需要一定的技术基础和经验。
4. 多线程/多进程爬虫这种爬虫使用多线程或多进程技术,同时从多个目标网站抓取数据。
多线程/多进程爬虫能够显著提高数据抓取的效率和速度,但同时也需要处理线程/进程间的同步和通信问题。
常见的库有threading、multiprocessing等。
5. 分布式爬虫分布式爬虫是一种更为强大的数据抓取方式,它将数据抓取任务分散到多个计算机节点上,利用集群计算和分布式存储技术,实现大规模、高效的数据抓取。
常见的框架有Scrapy-Redis、Scrapy-Cluster 等。
分布式爬虫需要解决节点间的通信、任务分配、数据同步等问题,同时还需要考虑数据的安全性和隐私保护问题。
网络爬虫软件的操作指引

网络爬虫软件的操作指引第一章:网络爬虫软件的介绍及应用范围网络爬虫软件是一种用来自动化地从互联网中收集信息的工具。
它可以模拟人类浏览器的行为,自动访问网页并提取所需的数据。
网络爬虫广泛应用于各个领域,包括搜索引擎、数据挖掘、舆情分析、网络监控等等。
第二章:网络爬虫软件的安装及配置2.1 下载网络爬虫软件根据你的需求选择合适的网络爬虫软件,如Python中的Scrapy、Java中的Jsoup等。
在官方网站或开源社区下载软件的压缩文件。
2.2 解压缩及安装将压缩文件解压到你希望安装的目录下。
按照官方文档的指引进行安装,通常只需运行一个安装脚本或配置环境变量即可。
2.3 配置网络爬虫软件打开网络爬虫软件的配置文件,根据你的需求进行修改。
配置文件中通常包含了各种参数设置,如爬取速度、请求头模拟、代理IP等。
根据实际情况进行配置,以便实现最佳效果。
第三章:编写爬虫程序3.1 确定目标网站确定你想要爬取的目标网站,并进行分析。
了解网站的结构、URL规则、数据位置等,以便在后续编写程序时能够顺利获取所需数据。
3.2 编写爬虫程序根据目标网站的分析结果,使用你选择的网络爬虫软件编写爬虫程序。
程序的主要任务是发送HTTP请求、解析网页内容并提取所需数据。
具体的编写方法请参考网络爬虫软件的官方文档或教程。
3.3 调试及测试在编写完成后,进行程序的调试和测试。
确保程序能够正确地获取所需数据,并遵守网站的规则和限制。
如果出现错误,根据错误信息进行排查和修复。
第四章:爬取数据及后续处理4.1 运行爬虫程序将编写好的爬虫程序运行起来,开始爬取目标网站的数据。
根据网络爬虫软件的指示,程序将自动发送请求、解析内容并保存数据。
4.2 数据清洗与处理爬取得到的数据通常需要进行清洗和处理,以便后续的分析和使用。
根据数据的特点,运用相应的数据处理工具进行数据清洗、去重、格式转换等操作。
4.3 数据存储根据数据的种类和规模,选择合适的数据存储方式。
java网络爬虫,乱码问题终于完美解决

java⽹络爬⾍,乱码问题终于完美解决第⼀次写爬⾍,被乱码问题困扰两天,试了很多⽅法都不可以,今天随便⼀试,居然好了。
在获取⽹页时创建了⼀个缓冲字节输⼊流,问题就在这个流上,添加标红代码即可BufferedReader in = null;in = new BufferedReader(new InputStreamReader(connection.getInputStream(),"utf-8"));附上代码,以供参考。
1public String sendGet(String url) {2 Writer write = null;3// 定义⼀个字符串⽤来存储⽹页内容4 String result = null;5// 定义⼀个缓冲字符输⼊流6 BufferedReader in = null;7try {8// 将string转成url对象9 URL realUrl = new URL(url);10// 初始化⼀个链接到那个url的连接11 URLConnection connection = realUrl.openConnection();12// 开始实际的连接13 connection.connect();14// 初始化 BufferedReader输⼊流来读取URL的响应15 in = new BufferedReader(new InputStreamReader(16 connection.getInputStream(),"utf-8"));17// ⽤来临时存储抓取到的每⼀⾏的数据18 String line;1920 File file = new File(saveEssayUrl, fileName);21 File file2 = new File(saveEssayUrl);2223if (file2.isDirectory() == false) {24 file2.mkdirs();25try {26 file.createNewFile();27 System.out.println("********************");28 System.out.println("创建" + fileName + "⽂件成功!!");2930 } catch (IOException e) {31 e.printStackTrace();32 }3334 } else {35try {36 file.createNewFile();37 System.out.println("********************");38 System.out.println("创建" + fileName + "⽂件成功!!");39 } catch (IOException e) {40 e.printStackTrace();41 }42 }43 Writer w = new FileWriter(file);4445while ((line = in.readLine()) != null) {46// 遍历抓取到的每⼀⾏并将其存储到result⾥⾯47// line = new String(line.getBytes("utf-8"),"gbk");48 w.write(line);49 w.write("\r\n");50 result += line;51 }52 w.close();53 } catch (Exception e) {54 System.out.println("发送GET请求出现异常!" + e);55 e.printStackTrace();56 }57// 使⽤finally来关闭输⼊流58finally {59try {60if (in != null) {61 in.close();62 }6364 } catch (Exception e2) {65 e2.printStackTrace();66 }67 }68return result;69 }。
爬虫获取数据的基本流程

爬虫获取数据的基本流程
爬虫获取数据的基本流程如下:
1. 确定目标:确定需要抓取数据的网站或页面。
2. 发起请求:使用爬虫程序向目标网站发送HTTP请求,请求页面的内容。
3. 获取页面内容:获取目标网站返回的页面内容,可以使用网络请求库(如 requests)来发送请求,获取并保存页面的HTML源码。
4. 解析页面:使用HTML解析库(如 BeautifulSoup)对获取到的HTML源码进行解析,提取出需要的数据。
5. 数据处理:对提取到的数据进行清洗和处理,如去除不需要的标签、格式化数据等。
6. 存储数据:将处理后的数据存储到数据库、文件或其他的存储介质中。
7. 循环抓取:根据需求,循环发起请求、获取和解析页面,直至获取到目标数据或完成所有抓取任务。
8. 反爬策略:针对可能存在的反爬措施,可使用代理、模拟登录、设置请求头等方式进行处理,确保正常抓取数据。
9. 监控和异常处理:设置异常处理机制,监控爬虫运行情况,及时发现并处理可能出现的错误和异常,保证爬虫的稳定性和可靠性。
10. 定期更新:根据目标网站数据的更新频率,定期运行爬虫程序,更新抓取到的数据。
以上是爬虫获取数据的基本流程,具体实现过程中还需要根据目标网站的特点和需求进行相应的优化和调整。
爬虫的流程

爬虫的流程
爬虫的基本流程包括以下几个步骤:
1. 获取目标网站:首先需要确定需要爬取的目标网站,并通过URL获取网站的源代码。
2. 解析网页:对获取到的网页源代码进行解析,提取出需要的信息。
常用的网页解析方式有正则表达式、XPath、CSS选择器等。
3. 存储数据:将获取到的信息存储到本地或远程数据库中。
常用的数据库包括MySQL、MongoDB等。
4. 处理异常:在爬取的过程中,可能会出现各种异常,如请求超时、页面404等,需要进行相应的异常处理。
5. 爬虫策略:为了防止被目标网站屏蔽,需要设置合理的爬取策略,包括爬虫频率、爬虫速度等。
6. 监控反爬措施:一些网站会采取反爬虫措施,如验证码、IP 封禁等,需要及时监控并进行相应的应对措施。
7. 数据分析:对获取到的数据进行分析,包括数据清洗、统计分析等,为后续的应用提供数据支持。
以上就是一个简单的爬虫流程,不同的场景和需求会有相应的差异,需要根据实际情况进行调整。
爬取数据的方法

爬取数据的方法一、确定爬取目标在开始爬取数据之前,需要确定所要爬取的目标。
可以通过搜索引擎、社交媒体等渠道获取相关信息,并分析目标网站的页面结构和数据格式。
二、选择合适的爬虫框架爬虫框架是实现网络爬虫的重要工具,常用的有Scrapy、BeautifulSoup、Requests等。
选择合适的框架可以提高开发效率和代码可维护性。
三、编写爬虫程序1. 发送请求获取页面内容使用框架提供的网络请求方法,发送HTTP请求获取目标网站的HTML内容。
可以设置请求头部信息,模拟浏览器行为,避免被网站识别为机器人并被封禁。
2. 解析页面内容使用框架提供的解析HTML的方法,将HTML内容转换为可操作的Python对象。
可以使用XPath或CSS选择器等方式定位所需数据,并进行提取和清洗。
3. 存储数据将提取到的数据存储到本地文件或数据库中。
建议使用关系型数据库或NoSQL数据库进行存储,并设置合适的索引以提高查询效率。
四、处理反爬机制为了防止被网站识别为机器人并被封禁,需要采取一些措施处理反爬机制。
可以使用代理IP、设置请求头部信息、使用验证码识别等方式。
五、定期更新爬虫程序由于网站的页面结构和数据格式可能会发生变化,需要定期更新爬虫程序以适应变化。
同时也需要注意遵守网站的robots.txt协议,避免对网站造成不必要的负担。
六、注意法律风险在进行数据爬取时,需要注意相关法律法规,避免侵犯他人隐私和知识产权等问题。
如果涉及到敏感信息或商业机密,建议咨询相关专业人士并获得授权后再进行爬取。
七、总结数据爬取是一项复杂而又有趣的工作,需要具备一定的编程技能和分析能力。
通过选择合适的框架和采取合理的策略,可以高效地获取所需数据,并为后续分析和应用提供支持。
爬虫(爬虫原理与数据抓取)

爬⾍(爬⾍原理与数据抓取)通⽤爬⾍和聚焦爬⾍根据使⽤场景,⽹络爬⾍可分为通⽤爬⾍和聚焦爬⾍两种.通⽤爬⾍通⽤⽹络爬⾍是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。
主要⽬的是将互联⽹上的⽹页下载到本地,形成⼀个互联⽹内容的镜像备份。
通⽤搜索引擎(Search Engine)⼯作原理通⽤⽹络爬⾍从互联⽹中搜集⽹页,采集信息,这些⽹页信息⽤于为搜索引擎建⽴索引从⽽提供⽀持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。
第⼀步:抓取⽹页搜索引擎⽹络爬⾍的基本⼯作流程如下:1. ⾸先选取⼀部分的种⼦URL,将这些URL放⼊待抓取URL队列;2. 取出待抓取URL,解析DNS得到主机的IP,并将URL对应的⽹页下载下来,存储进已下载⽹页库中,并且将这些URL放进已抓取URL队列。
3. 分析已抓取URL队列中的URL,分析其中的其他URL,并且将URL放⼊待抓取URL队列,从⽽进⼊下⼀个循环....搜索引擎如何获取⼀个新⽹站的URL:1. 新⽹站向搜索引擎主动提交⽹址:(如百度)2. 在其他⽹站上设置新⽹站外链(尽可能处于搜索引擎爬⾍爬取范围)3. 搜索引擎和DNS解析服务商(如DNSPod等)合作,新⽹站域名将被迅速抓取。
但是搜索引擎蜘蛛的爬⾏是被输⼊了⼀定的规则的,它需要遵从⼀些命令或⽂件的内容,如标注为nofollow的链接,或者是Robots协议。
Robots协议(也叫爬⾍协议、机器⼈协议等),全称是“⽹络爬⾍排除标准”(Robots Exclusion Protocol),⽹站通过Robots协议告诉搜索引擎哪些页⾯可以抓取,哪些页⾯不能抓取,例如:淘宝⽹:腾讯⽹:第⼆步:数据存储搜索引擎通过爬⾍爬取到的⽹页,将数据存⼊原始页⾯数据库。
其中的页⾯数据与⽤户浏览器得到的HTML是完全⼀样的。
搜索引擎蜘蛛在抓取页⾯时,也做⼀定的重复内容检测,⼀旦遇到访问权重很低的⽹站上有⼤量抄袭、采集或者复制的内容,很可能就不再爬⾏。
爬虫获取数据的基本流程

爬虫获取数据的基本流程1.确定需求:首先,需要明确所需获取的数据的目标网站和数据类型。
根据需求的不同,可以选择爬取整个网站的所有信息,或者只爬取特定页面的特定数据。
2. 确认可用性:在进行爬虫之前,需要确保目标网站允许爬取其内容。
有些网站可能会有限制爬取的条件,例如robots.txt文件中的规定,或者网站本身的访问限制。
4. 编写代码:使用编程语言编写爬虫代码,实现获取数据的功能。
一般会使用网络请求库(如Python中的requests库)发送HTTP请求,获取网页内容,然后使用解析库(如BeautifulSoup)对网页进行解析,提取出需要的数据。
5.发送请求:使用网络请求库发送HTTP请求,获取网页的内容。
可以选择使用GET请求或POST请求,根据目标网站的要求来确定。
7.数据存储:将获取到的数据存储到本地文件或数据库中,以备后续处理和分析。
可以以文本文件、CSV文件、JSON文件或数据库等形式进行存储。
8.设置延时和异常处理:为了避免对目标网站造成过大的访问压力,需要设置适当的延时,以模拟正常的人类访问行为。
同时,还需要处理可能出现的异常情况,如网络连接错误、网页解析错误等。
9.遍历页面:如果需要获取多个页面的数据,可以使用循环或递归的方式遍历页面。
可以根据网页的URL规律进行自动化生成,然后再逐个获取数据。
10.定期更新:定期运行爬虫程序,以获取最新的数据。
可以使用定时任务或者监控机制来实现定期运行。
总结:爬虫获取数据的基本流程包括确定需求、确认可用性、分析网页结构、编写代码、发送请求、解析内容、数据存储、设置延时和异常处理、遍历页面和定期更新。
通过以上流程,可以顺利获取目标网站的数据,并进行后续的处理和分析。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
9
HttpClient client = new HttpClient();
10
String response = null ;
11
12
String keyword = null ;
13
PostMethod postMethod = new PostMethod(url);
14
// try {
15
16
68 69
.getOutputStream());
70
out.write(strPostRequest);
71
out.flush();
72 73
out.close();
74
}
// 读取内容
BufferedReader rd = new BufferedReader( new InputStreamReader(
56 57
System.setProperty( ".client.defaultReadTimeout" , "5000" );
58
try {
59
URL newUrl = new URL(strUrl);
60 61
HttpURLConnection hConnect = (HttpURLConnection) newUrl
33
.getBytes( "ISO‐8859‐1" ), "gb2312" );
34
//这里要注意下 gb2312要和你抓取网页的编码要一样
35
36
String p = response.replaceAll( "//&[a‐zA‐Z]{1,10};" , "" )
37
.replaceAll( "<[^>]*>" , "" ); //去掉网页中带有html语言的标签
27
28
// 以上部分是带参数抓取,我自己把它注销了.大家可以把注销消掉研究下
29
try {
30
int statusCode = client.executeMethod(postMethod);
31
32
response = new String(postMethod.getResponseBodyAsString()
hConnect.getInputStream()));
int ch;
for ( int length = 0 ; (ch = rd.read()) > ‐ 1
&& (maxLength <= 0 || length < maxLength); length++)
buffer.append(( char ) ch);
38
System.out.println(p);
39
40
} catch (Exception e) {
41
e.printStackTrace();
42
}
43
44
return response;
45
}
46
// 第二种方法
47 48
// 这种方法是JAVA自带的URL来抓取网站内容
49
public String getPageContent(String strUrl, String strPostRequest,
// if (param != null)
17
// keyword = new String(param.getBytes("gb2312"), "ISO‐8859‐1");
18
// } catch (UnsupportedEncodingException e1) {
19
20
// // TODO Auto‐generated catch block
return buffer.toString().trim();
} catch (Exception e) {
// return "错误:读取网页失败!";
//
return null ;
}
}
然后写个测试类:
?
1
public static void main(String[] args) {
2
String url = "" ;
21
// e1.printStackTrace();
22
// }
23
24
// NameValuePair[] data = { new NameValuePair("keyword", keyword) };
25
// // 将表单的值放入postMethod中
26
// postMethod.setRequestBody(data);
3
4
//但是要用到以下包:commons‐codec‐1.4.jar
5
// commons‐httpclient‐3.1.jar
6
// commons‐logging‐1.0.4.jar
7
8
public static String createhttpClient(String url, String param) {
本文实例讲述了JAVA使用爬虫抓取网站网页内容的方法。分享给大家供大家参考。具体如下: 最近在用JAVA研究下爬网技术,呵呵,入了个门,把自己的心得和大家分享下 以下提供二种方法,一种是用apache提供的包.另一种是用JAVA自带的. 代码如下:
?
1
// 第一种方法
2
//这种方法是用apache提供的包,简单方便
50
int maxLength) {
51
52
// 读取结果网页
53
StringBuffer buffer = new StringBuffer();
54
55
ห้องสมุดไป่ตู้ 55
System.setProperty( ".client.defaultConnectTimeout" , "5000" );
}
呵呵,看看控制台吧,是不是把网页的内容获取了
3
4
String keyword = "脚本之家" ;
5
createhttpClient p = new createhttpClient();
6
String response = p.createhttpClient(url, keyword);
7
8
// 第一种方法
// p.getPageContent(url, "post", 100500);//第二种方法
String s = buffer.toString();
s.replaceAll( "//&[a‐zA‐Z]{1,10};" , "" ).replaceAll( "<[^>]*>" , ""
System.out.println(s);
rd.close();
hConnect.disconnect();
62
.openConnection();
63
// POST方式的额外数据
64 65
if (strPostRequest.length() > 0 ) {
66
hConnect.setDoOutput( true );
67
OutputStreamWriter out = new OutputStreamWriter(hConnect