基于GO的图片验证码识别api调用代码实例
api keys 认证例子

api keys 认证例子
API密钥认证是一种常见的身份验证机制,用于保护对API端
点的访问。
下面我将从多个角度给出API密钥认证的例子。
1. 例如,假设我们有一个基于REST的API,它允许用户检索
其个人资料信息。
为了保护该API免受未经授权的访问,我们可以
要求每个用户在发出请求时提供其唯一的API密钥。
这个API密钥
将被包含在HTTP请求的头部或查询参数中,并且服务器将验证密钥
的有效性,以确定用户是否被授权访问其个人资料信息。
2. 另一个例子是在开发人员使用第三方API时,他们通常需要
在其应用程序中包含API密钥以便进行身份验证。
例如,Google Maps API要求开发者使用API密钥来验证其对地图服务的访问权限。
开发者需要在其应用程序中嵌入他们的API密钥,以便他们的应用
程序可以使用Google Maps API提供的功能。
3. 另一个常见的例子是在使用Amazon Web Services (AWS)
或Microsoft Azure等云服务提供商的API时,开发者需要使用他
们的API密钥来对他们的应用程序进行身份验证和授权。
这些API
密钥可以通过云服务提供商的控制台生成,并且必须被妥善保管以
防止未经授权的访问。
总的来说,API密钥认证是一种简单而有效的身份验证机制,
它确保只有经过授权的用户或应用程序可以访问受保护的API端点。
通过在每个请求中包含唯一的API密钥,并在服务器端验证密钥的
有效性,API密钥认证帮助确保API的安全性和可靠性。
基于GO的图片验证码识别api调用代码实例

基于GO的图片验证码识别api调用代码实例代码描述:基于GO的图片验证码识别api调用代码实例代码平台:聚合数据package mainimport("io/ioutil""net/http""net/url""fmt""encoding/json")//----------------------------------// 验证码识别调用示例代码-聚合数据// 在线接口文档:/docs/60//----------------------------------const APPKEY = "*******************"//您申请的APPKEYfunc main(){//1.识别验证码Request1()//2.查询验证码类型代码Request2()}//1.识别验证码func Request1(){//请求地址juheURL :="/vercode/index"//初始化参数param:=url.Values{}//配置请求参数,方法内部已处理urlencode问题,中文参数可以直接传参param.Set("key",APPKEY) //您申请到的APPKEYparam.Set("codeType","") //验证码的类型,<a href="http://www. /docs/api/id/60/aid/352" target="_blank">查询&l t;/a>param.Set("image","") //图片文件param.Set("dtype","") //返回的数据的格式,json或xml,默认为json//发送请求data,err:=Post(juheURL,param)if err!=nil{fmt.Errorf("请求失败,错误信息:\r\n%v",err)}else{var netReturn map[string]interface{}json.Unmarshal(data,&netReturn)if netReturn["error_code"].(float64)==0{fmt.Printf("接口返回result字段是:\r\n%v",netReturn["result "])}}}//2.查询验证码类型代码func Request2(){//请求地址juheURL :="/vercode/codeType"//初始化参数param:=url.Values{}//配置请求参数,方法内部已处理urlencode问题,中文参数可以直接传参param.Set("key",APPKEY) //您申请到的APPKEYparam.Set("dtype","") //返回的数据的格式,json或xml,默认为json//发送请求data,err:=Get(juheURL,param)if err!=nil{fmt.Errorf("请求失败,错误信息:\r\n%v",err)}else{var netReturn map[string]interface{}json.Unmarshal(data,&netReturn)if netReturn["error_code"].(float64)==0{fmt.Printf("接口返回result字段是:\r\n%v",netReturn["result "])}}}// get 网络请求func Get(apiURL string,params url.Values)(rs[]byte,err error){ var Url *url.URLUrl,err=url.Parse(apiURL)if err!=nil{fmt.Printf("解析url错误:\r\n%v",err)return nil,err}//如果参数中有中文参数,这个方法会进行URLEncodeUrl.RawQuery=params.Encode()resp,err:=http.Get(Url.String())if err!=nil{fmt.Println("err:",err)return nil,err}defer resp.Body.Close()return ioutil.ReadAll(resp.Body)}// post 网络请求 ,params 是url.Values类型func Post(apiURL string, params url.Values)(rs[]byte,err error){ resp,err:=http.PostForm(apiURL, params)if err!=nil{return nil ,err}defer resp.Body.Close()return ioutil.ReadAll(resp.Body)}。
python自动化实现登录获取图片验证码功能
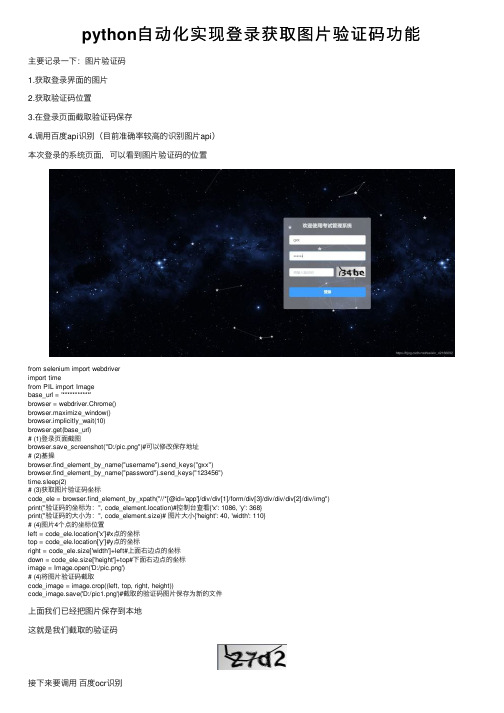
python⾃动化实现登录获取图⽚验证码功能主要记录⼀下:图⽚验证码1.获取登录界⾯的图⽚2.获取验证码位置3.在登录页⾯截取验证码保存4.调⽤百度api识别(⽬前准确率较⾼的识别图⽚api)本次登录的系统页⾯,可以看到图⽚验证码的位置from selenium import webdriverimport timefrom PIL import Imagebase_url = '***********'browser = webdriver.Chrome()browser.maximize_window()browser.implicitly_wait(10)browser.get(base_url)# (1)登录页⾯截图browser.save_screenshot("D:/pic.png")#可以修改保存地址# (2)基操browser.find_element_by_name("username").send_keys("gxx")browser.find_element_by_name("password").send_keys("123456")time.sleep(2)# (3)获取图⽚验证码坐标code_ele = browser.find_element_by_xpath("//*[@id='app']/div/div[1]/form/div[3]/div/div/div[2]/div/img")print("验证码的坐标为:", code_element.location)#控制台查看{'x': 1086, 'y': 368}print("验证码的⼤⼩为:", code_element.size)# 图⽚⼤⼩{'height': 40, 'width': 110}# (4)图⽚4个点的坐标位置left = code_ele.location['x']#x点的坐标top = code_ele.location['y']#y点的坐标right = code_ele.size['width']+left#上⾯右边点的坐标down = code_ele.size['height']+top#下⾯右边点的坐标image = Image.open('D:/pic.png')# (4)将图⽚验证码截取code_image = image.crop((left, top, right, height))code_image.save('D:/pic1.png')#截取的验证码图⽚保存为新的⽂件上⾯我们已经把图⽚保存到本地这就是我们截取的验证码接下来要调⽤百度ocr识别然后可以选择通⽤⽂字识别或者⾼精度版本,这个看个⼈选择,不过验证码识别还是选择⾼精度版本(也不⼀定识别的出来⼤家还是佛吧,测试的时候让开发把验证码去掉嘻嘻)⾃⼰去申请⼀个百度云账号,然后开通⽂字识别服务…就酱新建⼀个py⽂件#百度ocr提供了模板,我们直接复制就ok#下载通⽤⽂字识别的python sdk,⼀定要放在你写的代码的⽂件夹下⾯from aip import AipOcrfrom os import pathdef baiduOCR(picfile,outfile):#picfile:图⽚⽂件名 outfile:输出⽂件filename = path.basename(picfile)#图⽚名称#百度提供""" 你的 APPID AK SK """APP_ID = ''#这是你产品服务的appidAPI_KEY = ''#这是你产品服务的appkeySECRET_KEY = ''#这是你产品服务的secretkeyclient = AipOcr(APP_ID, API_KEY, SECRET_KEY)i = open(picfile, 'rb')img = i.read()print("正在识别图⽚:\t" + filename)""" 调⽤通⽤⽂字识别(⾼精度版) """message = client.basicAccurate(img)print("识别成功!")i.close()with open(outfile, 'a+') as fo:#这边是写进.txt⽂件fo.writelines("*" * 60 + '\n')#搞点花⾥胡哨的做区分fo.writelines("识别图⽚:\t" + filename + "\n" * 2)fo.writelines("⽂本内容:\n")# 输出⽂本内容for text in message.get('words_result'):#识别的内容fo.writelines(text.get('words') + '\n')fo.writelines('\n' * 2)print("⽂本导出成功!")print()if __name__ == '__main__' :outfile = 'D:/export1.txt'#保存的⽂件baiduOCR('D:/pic1.png', outfile)print('图⽚⽂本提取结束!⽂本输出结果位于 %s ⽂件中。
python 本地识别验证码代码

识别验证码通常是一个复杂的过程,因为验证码通常被设计成能够区分计算机程序和人类用户。
然而,有一些验证码可能相对容易通过机器学习或深度学习模型来识别。
下面是一个基本的例子,它使用Python的opencv库来识别验证码。
这个例子仅仅是一个简单的演示,并不能处理所有类型的验证码。
```pythonimport cv2import numpy as np# 读取图片img = cv2.imread('captcha.png', 0)# 二值化处理_, thresh = cv2.threshold(img, 127, 255, cv2.THRESH_BINARY)# 查找轮廓contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)# 遍历轮廓,尝试匹配每个字符for contour in contours:# 计算轮廓的边界框x, y, w, h = cv2.boundingRect(contour)# 提取字符图像char_img = img[y:y+h, x:x+w]# 尝试识别字符# 这里我们只是简单地将其转换为灰度图像并查找边界框gray = cv2.cvtColor(char_img, cv2.COLOR_BGR2GRAY)_, thresh = cv2.threshold(gray, 127, 255, cv2.THRESH_BINARY)contours, _ = cv2.findContours(thresh, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)if len(contours) > 0:# 如果找到轮廓,假设字符是字母或数字char = ''for cnt in contours:if cv2.contourArea(cnt) > 50:char = 'a' + str(len(char))else:char = '0' + str(len(char))print(char)```这个代码假设每个字符都是一个简单的形状,并且可以通过查找轮廓来识别。
使用Go语言进行人脸识别与人脸检测的方法与工具介绍

使用Go语言进行人脸识别与人脸检测的方法与工具介绍人脸识别与人脸检测是当今计算机视觉领域具有重要影响力的研究方向之一。
随着人工智能的发展,人脸识别与人脸检测的应用场景越来越广泛,涵盖了安全监控、人脸支付、人脸门禁等多个领域。
本文将介绍使用Go语言进行人脸识别与人脸检测的方法与工具。
首先,针对人脸识别与人脸检测任务,我们需要找到一个高效、准确的算法。
近年来,深度学习技术在人脸识别与人脸检测领域取得了巨大的突破。
目前最常用的深度学习框架之一是TensorFlow,而Go语言中有一个基于TensorFlow的开源库叫做GoCV,它提供了一系列用于图像处理与计算机视觉的工具函数和接口。
使用GoCV,我们可以轻松地进行人脸识别与人脸检测任务。
其次,人脸识别与人脸检测的方法通常分为两个步骤:人脸检测和人脸识别。
在人脸检测阶段,我们需要将输入的图像中的人脸位置标注出来;在人脸识别阶段,我们需要对标注出来的人脸进行特征提取和比对。
对于人脸检测,GoCV提供了一个名为Haar级联分类器的工具,它可以用来检测人脸的位置。
而人脸识别,则可以使用深度学习模型,例如FaceNet或VGGFace等。
这些模型可以将人脸图像转换为具有较高区分度的特征向量,并可以通过计算特征向量之间的距离来进行人脸比对。
另外,在实际的人脸识别与人脸检测应用中,我们还需要考虑一些实际问题,例如图像质量、人脸姿态、光照条件等。
对于图像质量问题,我们可以使用一些图像增强的算法,例如直方图均衡化、高斯模糊等,来提高输入图像的质量。
对于人脸姿态和光照条件问题,我们可以引入一些先进的模型,例如3D人脸姿态估计模型和光照归一化模型,来提高人脸识别与人脸检测的准确性和鲁棒性。
除了GoCV之外,还有其他一些在Go语言中进行人脸识别与人脸检测的工具和库。
例如,Pigo是一个基于Go语言的人脸检测工具,它使用了一种名为卡斯卡德级联分类器的算法来进行人脸检测。
此外,Dlib也是一个很流行的计算机视觉库,它提供了一些用于人脸识别和人脸检测的函数和模型。
go mockapi实现方式
GoMock是一个用于Go语言的mocking框架,可以帮助您模拟函数调用并验证它们的行为。
下面是一个简单的示例,演示如何使用GoMock实现mock API:首先,您需要安装GoMock:shell复制代码go get github/golang/mock/mockgen然后,假设您有一个名为api的包,其中包含一些函数和类型。
您可以使用mockgen工具生成mock的相关代码。
运行以下命令:shell复制代码mockgen -source=<source.go> -destination=**.go -package=<pkg>其中,<source.go>是包含原始代码的Go源文件,<pkg>是包名。
生成的mock代码将包含一个与原始类型对应的mock类型,以及一些用于模拟函数调用的方法。
您可以在测试中使用这些mock对象来模拟API的行为。
以下是一个简单的示例,演示如何使用GoMock模拟API的GET请求:go复制代码package mainimport ("fmt""net/http""testing""github/golang/mock/gomock""github/stretchr/testify/assert")type API struct {client *http.Client}func(a *API) GetUser(id string) (*User, error) {resp, err := a.client.Get(fmt.Sprintf("/users/%s", id))if err != nil {return nil, err}defer resp.Body.Close()// ... handle response ...}func TestAPI_GetUser(t *testing.T) {ctrl := gomock.NewController(t)defer ctrl.Finish()mockClient := NewMockClient(ctrl)api := API{client: mockClient}mockClient.EXPECT().Get("/users/123").Return(&http.Response{}, nil)user, err := api.GetUser("123")assert.NoError(t, err)assert.NotNil(t, user) // ... assert user properties ...}在上面的示例中,我们创建了一个名为API的结构体,其中包含一个client字段,该字段是http.Client类型的实例。
picgo的api请求模板

随着互联网的发展,API已经成为许多应用程序和平台之间进行数据交换和交互的重要方式。
在这个背景下,picgo作为一款流行的图像处理工具,也提供了一系列API接口供用户使用。
本文将介绍picgo的API请求模板,帮助开发者更好地了解和使用这些接口。
一、API请求的基本概念API请求是应用程序接口的请求,通过发送HTTP请求到特定的URL,可以实现与服务器之间的数据交换。
在picgo中,API请求主要用于图像处理相关的功能,如图片上传、图片缩放、图片裁剪等。
以下是一个简单的picgoAPI请求模板:```pythonimportpicgoapi_key='your_api_key'api_secret='your_api_secret'client=picgo.Client(api_key,api_secret)#发送API请求response=client.upload_image('path/to/image.jpg')#处理API响应ifresponse.status_code==200:image_id=response.json()['image_id']#执行其他操作,如缩放、裁剪等else:#处理错误情况print(f"API请求失败,状态码:{response.status_code}")print(f"详细错误信息:{response.text}")```说明:*首先需要导入picgo模块。
*然后设置API密钥和密钥对应的密钥秘钥。
*创建一个picgo客户端对象,用于发送API请求。
*使用`upload_image`方法上传图片,并获取返回的图像ID。
*根据返回的状态码和信息,处理API响应。
如果请求成功,可以执行其他操作,如缩放、裁剪等;如果请求失败,需要处理错误情况。
三、API请求的其他用法除了上述基本的用法,picgo还提供了其他一些常用的API请求方法,如缩放图片、裁剪图片、获取图像信息等。
Go-统一定义API错误码-Gin开发

Go-统⼀定义API错误码-Gin开发转载于https:///s/gTFfUN2LEcsF0Q8iQan82A改之前在使⽤ gin 开发接⼝的时候,返回接⼝数据是这样写的。
type response struct {Code int `json:"code"`Msg string `json:"msg"`Data interface{} `json:"data"`}// always return http.StatusOKc.JSON(http.StatusOK, response{Code: 20101,Msg: "⽤户⼿机号不合法",Data: nil,})这种写法 code、msg 都是在哪需要返回在哪定义,没有进⾏统⼀管理。
改之后// ⽐如,返回“⽤户⼿机号不合法”错误c.JSON(http.StatusOK, errno.ErrUserPhone.WithID(c.GetString("trace-id")))// 正确返回c.JSON(http.StatusOK, errno.OK.WithData(data).WithID(c.GetString("trace-id")))errno.ErrUserPhone、errno.OK 表⽰⾃定义的错误码,下⾯会看到定义的地⽅。
.WithID() 设置当前请求的唯⼀ID,也可以理解为链路ID,忽略也可以。
.WithData() 设置成功时返回的数据。
下⾯分享下编写的 errno 包源码,⾮常简单,希望⼤家不要介意。
errno 包源码// errno/errno.gopackage errnoimport ("encoding/json")var _ Error = (*err)(nil)type Error interface {// i 为了避免被其他包实现i()// WithData 设置成功时返回的数据WithData(data interface{}) Error// WithID 设置当前请求的唯⼀IDWithID(id string) Error// ToString 返回 JSON 格式的错误详情ToString() string}type err struct {Code int `json:"code"` // 业务编码Msg string `json:"msg"` // 错误描述Data interface{} `json:"data"` // 成功时返回的数据ID string `json:"id,omitempty"` // 当前请求的唯⼀ID,便于问题定位,忽略也可以}func NewError(code int, msg string) Error {return &err{Code: code,Msg: msg,Data: nil,}}func (e *err) i() {}func (e *err) WithData(data interface{}) Error {e.Data = datareturn e}func (e *err) WithID(id string) Error {e.ID = idreturn e}// ToString 返回 JSON 格式的错误详情func (e *err) ToString() string {err := &struct {Code int `json:"code"`Msg string `json:"msg"`Data interface{} `json:"data"`ID string `json:"id,omitempty"`}{Code: e.Code,Msg: e.Msg,Data: e.Data,ID: e.ID,}raw, _ := json.Marshal(err)return string(raw)}// errno/code.gopackage errnovar (// OKOK = NewError(0, "OK")// 服务级错误码ErrServer = NewError(10001, "服务异常,请联系管理员")ErrParam = NewError(10002, "参数有误")ErrSignParam = NewError(10003, "签名参数有误")// 模块级错误码 - ⽤户模块ErrUserPhone = NewError(20101, "⽤户⼿机号不合法")ErrUserCaptcha = NewError(20102, "⽤户验证码有误")// ...)错误码规则- 错误码需在 code.go ⽂件中定义。
记录一次谷歌人机验证码破解过程

记录⼀次⾕歌⼈机验证码破解过程前⾔ 哈喽,各位⼩伙伴,你们好呀,今天呢,咱们来说⼀下google,我们都知道,google是⽬前地表最强的搜索引擎了,我们可以借助google庞⼤的搜索资源找到⼀些⾃⼰想要的资源,可能是⼀些收费电影,可能是⼀些奇门⼩说,可能是某个⾓落的种⼦,不管怎么说,google搜索还是挺给⼒的,但是呢,有梯⼦的我们可能都遇到过,我们搜索的多了,会有这种情况 这种验证码呢,叫做ReCaptcha验证码,相对来说,是⽐较繁琐的验证码之⼀ 当然了,ReCaptcha不⽌⾕歌⼀家再⽤,国外的⽹站很多都是使⽤这种验证码,但是在国内不多,因为在国内⽐较容易被墙,所以⽤的少,但是我们是⾼端玩家,在⾃由的internet中,我们怎么可能只局限于国内,下⾯,我们就针对ReCaptcha验证码破解 ⾕歌提供的范例,实际⽹站验证码和这个⼀模⼀样 ReCaptcha验证码样式为什么使⽤第三⽅平台 嗯,看到这可能有⼈会对我不屑⼀顾,说辣鸡才会⽤第三⽅平台,要是按照技术来划分的话,我真的辣鸡,哈哈 但是这⾥要抬杠⼀下,并不是说⽤第三⽅平台就是辣鸡,我们可以想象⼀下,如果是滑动验证码,我们当然有⼀试的能⼒,python可以调⽤OpenCV,看看⽂档,当然是可以实现了,但是有个问题是,你可能针对的⼀个⽹站的滑动验证识别好了,但是可能每个⽹站的滑动验证码都不太⼀样,在⽤OpenCV识别的时候,可能就会识别率低的情况,要是在公司,⼀直完不成任务,嗯,,,等着被炒鱿鱼吧,再说,像⾕歌⼈机个⼈也解决不了,没有NB的机器学习是不可能的,所以只能⽤第三⽅平台,毕竟,完成任务才是⾸要任务为什么推荐2captcha平台 我们先说⼀下现在打码平台机制都有哪些 第⼀种呢,就是打码平台训练好各种各样的数据,⽐如,哪些是花,哪些是车,然后我们把图⽚发送给打码平台,他给我们结果,但是这样会有个问题,如果训练的不好,我们这边的结果也是很不好的,各种不准确,影响效果 第⼆种呢,就是平台雇⼈,我们把整个验证码都给打码平台,平台找⼈帮助我们点击,然后把结果给我们,我们在登录了或者做其他 我们可以看出来,肯定是第⼆种更加灵活地,现在阶段,机器再NB,⾄少在验证码上准确率还是不如⼈的 2captcha平台⽬前采⽤的就是第⼆种⽅式,赚取的是中间差价,但是识别率是我⽤过最⾼的,曾经因为选错了平台,⼀直不成功,加班加点,⿏标都被我砸坏了,唉,所以,选择⼀个合适的平台还是很重要的所需⼯具 Chromedriver:浏览器驱动,可以理解为⼀个没有界⾯的chrome浏览器 Selenium:⽤于模拟⼈对浏览器进⾏点击、输出、拖拽等操作,就相当于是个⼈在使⽤浏览器,也常常⽤来应付反爬⾍措开始⾏动 既来之则安之,选择了2captcha,就要看看⼈家的官⽹啦 打开官⽹ 嗯...纯英⽂,我也看不懂..怎么办呢,别着急,我带你们⼀步⼀步分析主要功能 登录账号 登录完成后,会⾃动跳到主页 第⼀个红⾊圈起来的地⽅表⽰剩余多少钱,没有钱的话记得要氪⾦,否则是不能⽤滴,氪⾦过程这⾥就不多做解释了哈,问题不⼤ 第⼆个红⾊圈起来的地⽅表⽰这是你的唯⼀key,每次请求要带上这个key的,所以要保管好 进⼊主题,研究⽂档 点击红⾊圈的地⽅,API,⼀般API都是⽂档,let's go En....什么玩意..完全看不懂,别慌,往下滑 滑到rates,我们知道,⾕歌⼈机是ReCaptcha,但是三个呢,到底是哪个呢,我就来带⼤家看看 ⾸先点击ReCaptcha(oldmethod),这个是⽼的⽅法,咱也不知道唉,所以就先看看这个吧,从浅到深嘛,这⾥呢,我都直接翻译了⼀下,⽅便我们观看 Look,⼈家也说了,旧⽅法解决ReCaptcha准确率⽐较低,建议使⽤新⽅法,那我们就点击新⽅法去看看 我们找到了,这种属于ReCaptcha v2验证码,确实和⾕歌⼈机挺⼀样的,我们来看⼀下⽂档是怎么写的 然后找到id=g-recaptcha-response的textarea标签,将display:none 这个css删除 将给我们字符串添加到textarea输⼊框点击提交,就完成了 是不是很简单,我们也来试⼀下 打开⾕歌的⽰例样式 我们打开开发者⼯具,搜索data-sitekey,可以看到,真的有⼀个 我们赋值⼀下这个data-sitekey,并且⽤代码获取到最后的结果 然后我们找到 id=g-recaptcha-response 的textarea标签,将他的display属性删除 但是有点不太对 我们的 2captcha的⽰例的 我们可以看到,2captcha是个删除display之后,textarea框是直接展⽰出来的,但是我们删除display之后,基本没⽤丝毫动静,这... 别着急,⼈家都想到了,我们往下滑滑 既然我们不能直接显⽰出来textarea,那就说明我们是隐式的ReCaptcha验证码,其实他的原理呀,也挺简单 如果你学过⼀些前端,会些js,你可能就会想到,虽然我看不到这个textarea,但是通过js我们仍然能更改textarea的数据,只是说,我们⿏标点击不了⽽已,⼈家也说了,看第⼀个红圈的位置,通过此js,我们我们就可以把向2captcha获取的值赋值上,第⼆个圈js是提交表单,其实就是我们⼈点击提交⽽已,只不过是js代码帮我们完成了,这样,我们也完成了⼀个偷天换⽇⼩试⽜⼑ 好嘞,我们就先来⼿动搞⼀下,在上述中,我们已经根据data-sietkey拿到了最后的结果,显然,我们只能通过js完成,那么,我们就试⼀下 通过上述gif看到,我们通过js,确实绕过了点击车辆识别了,其他识别,确实⽅便, 但是我们不可能通过⼈每次这样搞呀,但是因为牵扯到了执⾏js,所以只能使⽤selenium,所以,我们来看⼀下selenium上的效果吧 Look,这样,我们就针对⾕歌⼈机(ReCaptcha)验证码,完成了⾃动登录,如果爬取国外的某某⽹站时,如果遇到了ReCaptcha,我相信⼀定会对你有帮助 完整代码import timefrom selenium import webdriverfrom selenium.webdriver.chrome.webdriver import WebDriverimport requests# 常量driver: WebDriverUSER = {}API_KEY = "xxxxxxxxxxxxxxx"# 初始化def init():global driverdriver = webdriver.Chrome("chromedriver.exe", desired_capabilities=None)def open_google():driver.get("https:///recaptcha/api2/demo")data_sitekey = driver.find_element_by_xpath('//*[@id="recaptcha-demo"]').get_attribute("data-sitekey")# iframe_src = driver.find_element_by_xpath('//*[@id="recaptcha-demo"]/div/div/iframe').get_attribute("src")# iframe_k = url_params_format(iframe_src).get("k")print(data_sitekey)page_url = "https:///recaptcha/api2/demo"# print(iframe_k)u1 = f"https:///in.php?key={API_KEY}&method=userrecaptcha&googlekey={data_sitekey}&pageurl={page_url}&json=1&invisible=1" r1 = requests.get(u1)print(r1.json())rid = r1.json().get("request")u2 = f"https:///res.php?key={API_KEY}&action=get&id={int(rid)}&json=1"time.sleep(25)while True:print(u2)r2 = requests.get(u2)print(r2.json())if r2.json().get("status") == 1:form_tokon = r2.json().get("request")breaktime.sleep(5)wirte_tokon_js = f'document.getElementById("g-recaptcha-response").innerHTML="{form_tokon}";'submit_js = 'document.getElementById("recaptcha-demo-form").submit();'driver.execute_script(wirte_tokon_js)time.sleep(1)driver.execute_script(submit_js)if__name__ == '__main__':init()open_google()Code 谢谢观看,谢谢⽀持。
使用Go语言进行图像识别与处理的方法与工具介绍

使用Go语言进行图像识别与处理的方法与工具介绍Go语言(Golang)作为一种开源编程语言,已经在图像识别和处理领域得到广泛应用。
它的高性能、并发性、简洁的语法以及开发便捷性使得它成为图像处理的强大工具。
本文将介绍使用Go语言进行图像识别与处理的方法和常用工具。
首先,我们来介绍一些常用的Go语言图像处理库。
这些库提供了丰富的函数和工具,方便我们进行图像处理的开发和优化。
1. GoCV:GoCV是一个基于OpenCV的图像处理库,它提供了一个简单易用的接口,能够在Go语言中进行图像处理和计算机视觉任务。
GoCV支持各种图像处理功能,包括图像滤波、边缘检测、图像分割等。
同时,它还支持机器学习和深度学习功能,可以进行人脸识别、目标检测等高级图像处理技术。
2. imaging:imaging是一个轻量级的Go语言图像处理库,它提供了一系列简单易用的函数,可以进行图像缩放、裁剪、旋转和滤镜等常见的图像处理操作。
imaging适用于对图像进行简单处理和操作的场景,它的代码简洁,易于理解和扩展。
除了图像处理库,Go语言还有一些优秀的图像识别和机器学习库,可以帮助我们进行图像识别任务。
1. GoTensor:GoTensor是一个强大的张量处理库,它提供了丰富的张量操作函数,可以进行矩阵运算、卷积和池化等常用的图像处理操作。
GoTensor支持GPU 加速,可以大幅提升图像处理和神经网络训练的速度。
2. gocv-text:gocv-text是一个基于GoCV的OCR(光学字符识别)库,它可以识别图片中的文字并输出识别结果。
gocv-text支持多种语言的文字识别,可以应用于自动化文本处理、图像检索和机器人视觉等场景。
一旦选定了适合自己需求的图像处理库,我们就可以开始进行图像处理的开发了。
下面是使用Go语言进行图像处理的一般步骤:1. 读取图像:使用图像处理库提供的函数,将图像从文件或者网络中读取到内存中。
读取后的图像可以表示为二维的像素矩阵。
用于验证码图片识别的类(C#源码)
⽤于验证码图⽚识别的类(C#源码)最近写了⼏个⽹站的验证码图⽚⾃动识别程序,尽管每个⽹站的验证码图⽚都不相同,识别的⽅法有所差别。
但写得多了,也总结出不少相同之处。
今天抽空封装出⼀个基础类来,发现可以很好地重复利⽤,编写不同的验证码识别程序,效率提⾼了不少。
好东东不能独享,现放出来供⼤家共同研究,请⽹友们妥善⽤之。
封装后的类使⽤很简单,针对不同的验证码,相应继承修改某些⽅法,即可简单⼏句代码就可以实现图⽚识别了:GrayByPixels(); //灰度处理GetPicValidByValue(128, 4); //得到有效空间Bitmap[] pics = GetSplitPics(4, 1); //分割string code = GetSingleBmpCode(pics[i], 128); //得到代码串具体使⽤,请参见我做的例⼦:(例⼦说明:使⽤进程投票,可⾃动清除Alert弹出窗⼝,可⾃动换IP,ADSL⽤户⾃⾏修改Restart.bat中第三⾏内容)using System;using System.Collections.Generic;using System.Text;using System.Collections;using System.Drawing;using System.Drawing.Imaging;using System.Runtime.InteropServices;namespace BallotAiying2{class UnCodebase{public Bitmap bmpobj;public UnCodebase(Bitmap pic){bmpobj = new Bitmap(pic); //转换为Format32bppRgb}///<summary>///根据RGB,计算灰度值///</summary>///<param name="posClr">Color值</param>///<returns>灰度值,整型</returns>private int GetGrayNumColor(System.Drawing.Color posClr){return (posClr.R * 19595 + posClr.G * 38469 + posClr.B * 7472) >> 16;}///<summary>///灰度转换,逐点⽅式///</summary>public void GrayByPixels(){for (int i = 0; i < bmpobj.Height; i++){for (int j = 0; j < bmpobj.Width; j++){int tmpValue = GetGrayNumColor(bmpobj.GetPixel(j, i));bmpobj.SetPixel(j, i, Color.FromArgb(tmpValue, tmpValue, tmpValue));}}}///<summary>///去图形边框///</summary>///<param name="borderWidth"></param>public void ClearPicBorder(int borderWidth){for (int i = 0; i < bmpobj.Height; i++){for (int j = 0; j < bmpobj.Width; j++){if (i < borderWidth || j < borderWidth || j > bmpobj.Width - 1 - borderWidth || i > bmpobj.Height - 1 - borderWidth)bmpobj.SetPixel(j, i, Color.FromArgb(255, 255, 255));}}}///<summary>///灰度转换,逐⾏⽅式///</summary>public void GrayByLine(){Rectangle rec = new Rectangle(0, 0, bmpobj.Width, bmpobj.Height);BitmapData bmpData = bmpobj.LockBits(rec, ImageLockMode.ReadWrite, bmpobj.PixelFormat);// PixelFormat.Format32bppPArgb);// bmpData.PixelFormat = PixelFormat.Format24bppRgb;IntPtr scan0 = bmpData.Scan0;int len = bmpobj.Width * bmpobj.Height;int[] pixels = new int[len];Marshal.Copy(scan0, pixels, 0, len);//对图⽚进⾏处理int GrayValue = 0;for (int i = 0; i < len; i++){GrayValue = GetGrayNumColor(Color.FromArgb(pixels[i]));pixels[i] = (byte)(Color.FromArgb(GrayValue, GrayValue, GrayValue)).ToArgb(); //Color转byte }bmpobj.UnlockBits(bmpData);}///<summary>///得到有效图形并调整为可平均分割的⼤⼩///</summary>///<param name="dgGrayValue">灰度背景分界值</param>///<param name="CharsCount">有效字符数</param>///<returns></returns>public void GetPicValidByValue(int dgGrayValue, int CharsCount){int posx1 = bmpobj.Width; int posy1 = bmpobj.Height;int posx2 = 0; int posy2 = 0;for (int i = 0; i < bmpobj.Height; i++) //找有效区{for (int j = 0; j < bmpobj.Width; j++){int pixelValue = bmpobj.GetPixel(j, i).R;if (pixelValue < dgGrayValue) //根据灰度值{if (posx1 > j) posx1 = j;if (posy1 > i) posy1 = i;if (posx2 < j) posx2 = j;if (posy2 < i) posy2 = i;};};};// 确保能整除int Span = CharsCount - (posx2 - posx1 + 1) % CharsCount; //可整除的差额数if (Span < CharsCount){int leftSpan = Span / 2; //分配到左边的空列,如span为单数,则右边⽐左边⼤1if (posx1 > leftSpan)posx1 = posx1 - leftSpan;if (posx2 + Span - leftSpan < bmpobj.Width)posx2 = posx2 + Span - leftSpan;}//复制新图Rectangle cloneRect = new Rectangle(posx1, posy1, posx2 - posx1 + 1, posy2 - posy1 + 1);bmpobj = bmpobj.Clone(cloneRect, bmpobj.PixelFormat);}///<summary>///得到有效图形,图形为类变量///</summary>///<param name="dgGrayValue">灰度背景分界值</param>///<param name="CharsCount">有效字符数</param>///<returns></returns>public void GetPicValidByValue(int dgGrayValue){int posx1 = bmpobj.Width; int posy1 = bmpobj.Height;int posx2 = 0; int posy2 = 0;for (int i = 0; i < bmpobj.Height; i++) //找有效区{for (int j = 0; j < bmpobj.Width; j++){int pixelValue = bmpobj.GetPixel(j, i).R;if (pixelValue < dgGrayValue) //根据灰度值{if (posx1 > j) posx1 = j;if (posy1 > i) posy1 = i;if (posx2 < j) posx2 = j;if (posy2 < i) posy2 = i;};};};//复制新图Rectangle cloneRect = new Rectangle(posx1, posy1, posx2 - posx1 + 1, posy2 - posy1 + 1);bmpobj = bmpobj.Clone(cloneRect, bmpobj.PixelFormat);}///<summary>///得到有效图形,图形由外⾯传⼊///</summary>///<param name="dgGrayValue">灰度背景分界值</param>///<param name="CharsCount">有效字符数</param>///<returns></returns>public Bitmap GetPicValidByValue(Bitmap singlepic, int dgGrayValue){int posx1 = singlepic.Width; int posy1 = singlepic.Height;int posx2 = 0; int posy2 = 0;for (int i = 0; i < singlepic.Height; i++) //找有效区{for (int j = 0; j < singlepic.Width; j++){int pixelValue = singlepic.GetPixel(j, i).R;if (pixelValue < dgGrayValue) //根据灰度值{if (posx1 > j) posx1 = j;if (posy1 > i) posy1 = i;if (posx2 < j) posx2 = j;if (posy2 < i) posy2 = i;};};};//复制新图Rectangle cloneRect = new Rectangle(posx1, posy1, posx2 - posx1 + 1, posy2 - posy1 + 1);return singlepic.Clone(cloneRect, singlepic.PixelFormat);}///<summary>///平均分割图⽚///</summary>///<param name="RowNum">⽔平上分割数</param>///<param name="ColNum">垂直上分割数</param>///<returns>分割好的图⽚数组</returns>public Bitmap [] GetSplitPics(int RowNum,int ColNum){if (RowNum == 0 || ColNum == 0)return null;int singW = bmpobj.Width / RowNum;int singH = bmpobj.Height / ColNum;Bitmap [] PicArray=new Bitmap[RowNum*ColNum];Rectangle cloneRect;for (int i = 0; i < ColNum; i++) //找有效区{for (int j = 0; j < RowNum; j++){cloneRect = new Rectangle(j*singW, i*singH, singW , singH);PicArray[i*RowNum+j]=bmpobj.Clone(cloneRect, bmpobj.PixelFormat);//复制⼩块图}}return PicArray;}///<summary>///返回灰度图⽚的点阵描述字串,1表⽰灰点,0表⽰背景///</summary>///<param name="singlepic">灰度图</param>///<param name="dgGrayValue">背前景灰⾊界限</param>///<returns></returns>public string GetSingleBmpCode(Bitmap singlepic, int dgGrayValue){Color piexl;string code = "";for (int posy = 0; posy < singlepic.Height; posy++)for (int posx = 0; posx < singlepic.Width; posx++){piexl = singlepic.GetPixel(posx, posy);if (piexl.R < dgGrayValue) // Color.Black )code = code + "1";elsecode = code + "0";}return code;}}}。
golang 验证参数

golang 验证参数在Go语言中,你可以使用类型断言或自定义验证函数来验证参数。
下面是一个示例,演示了如何使用类型断言来验证参数:```gopackage mainimport ("fmt")func validateInt(i interface{}) error {_, ok := i.(int)if !ok {return ("invalid type: %T", i)}return nil}func main() {var i interface{} = 42err := validateInt(i)if err != nil {(err) // 输出: "invalid type: 42 of type int"} else {("参数验证通过")}i = "hello"err = validateInt(i)if err != nil {(err) // 输出: "invalid type: hello of type string"} else {("参数验证通过")}}```在上面的示例中,`validateInt`函数接受一个空接口类型的参数,并使用类型断言将其转换为`int`类型。
如果转换成功,则表示参数是一个有效的整数,函数返回`nil`。
如果转换失败,则表示参数的类型不正确,函数返回一个错误。
在`main`函数中,我们使用一个整数和一个字符串作为参数,分别调用`validateInt`函数进行验证。
根据验证结果,我们打印相应的消息。
请注意,这只是一个简单的示例,用于演示如何使用类型断言进行参数验证。
在实际开发中,你可能需要根据具体的需求和参数类型进行更复杂的验证。
Django-实现图片验证码

Django-实现图⽚验证码Django实现图⽚验证码Python⽣成随机验证码,需要使⽤PIL模块.pip3 install pillow1、基本使⽤1. 1 创建图⽚from PIL import Imageimg = Image.new(mode='RGB', size=(120, 30), color=(255, 255, 255))# 在图⽚查看器中打开# img.show()# 保存在本地with open('code.png','wb') as f:img.save(f,format='png')1、2 创建画笔from PIL import Imagefrom PIL import ImageDrawimg = Image.new(mode="RGB", size=(120, 30), color=(255,255,255))draw = ImageDraw.Draw(img, mode="RGB")1、3 画点from PIL import Imagefrom PIL import ImageDrawimg = Image.new(mode="RGB", size=(120, 30), color=(255,255,255))draw = ImageDraw.Draw(img, mode="RGB")# 第⼀个参数:表⽰坐标# 第⼆个参数:表⽰颜⾊draw.point([100,20], fill="red")draw.point([50,10], fill=(255, 135, 255))with open("code.png",'wb') as f:img.save(f,format="png")1、4 画线from PIL import Imagefrom PIL import ImageDrawimg = Image.new(mode="RGB", size=(120, 30), color=(255,255,255))draw = ImageDraw.Draw(img, mode="RGB")# 第⼀个参数:表⽰起始坐标和结束坐标# 第⼆个参数:表⽰颜⾊draw.line((10, 10, 10, 30), fill="red")draw.line((10, 10, 30, 10), fill=(255, 135, 255))with open("code.png",'wb') as f:img.save(f,format="png")1、5 画圆from PIL import Imagefrom PIL import ImageDrawimg = Image.new(mode="RGB", size=(150, 150), color=(255,255,255))draw = ImageDraw.Draw(img, mode="RGB")# 第⼀个参数:表⽰起始坐标和结束坐标(圆要画在中间)# 第⼆个参数:表⽰开始⾓度# 第三个参数:表⽰结束⾓度# 第四个参数:表⽰颜⾊draw.arc((50, 50, 100, 100), 0, 360, fill="red")with open("code.png",'wb') as f:img.save(f,format="png")1、6 写⽂本from PIL import Imagefrom PIL import ImageDrawimg = Image.new(mode="RGB", size=(120, 30), color=(255,255,255))draw = ImageDraw.Draw(img, mode="RGB")# 第⼀个参数:表⽰起始坐标# 第⼆个参数:表⽰写⼊内容# 第三个参数:表⽰颜⾊draw.text([20, 10], "python", fill="red")with open("code.png",'wb') as f:img.save(f,format="png")1、7设置特殊字体from PIL import Image, ImageDraw, ImageFontimg = Image.new(mode="RGB", size=(120, 30), color=(255,255,255))draw = ImageDraw.Draw(img, mode="RGB")# 第⼀个参数:表⽰字体路径# 第⼆个参数:表⽰字体⼤⼩font = ImageFont.truetype("kumo.ttf", 25)# 第⼀个参数:表⽰起始坐标# 第⼆个参数:表⽰写⼊内容# 第三个参数:表⽰颜⾊# 第四个参数:表⽰字体draw.text([30, 0], "python", fill="red", font=font)with open("code.png",'wb') as f:img.save(f,format="png")2 应⽤2.1 应⽤⽅法import randomfrom io import BytesIOfrom PIL import Image, ImageDraw, ImageFontdef check_code(width=120, height=30, char_length=5, font_file='kumo.ttf', font_size=28):f = BytesIO()img = Image.new(mode='RGB', size=(width, height),color=(random.randint(50, 250), random.randint(50, 255), random.randint(50, 255)))draw = ImageDraw.Draw(img, mode='RGB')char_list = []# 画字for i in range(char_length):char = random.choice([chr(random.randint(65, 90)), str(random.randint(1, 9)), chr(random.randint(97, 122)), ]) font = ImageFont.truetype("blog/static/fonts/"+font_file, font_size)draw.text([i * 24, 0], char, (random.randint(200, 255), random.randint(0, 50), random.randint(0, 50)),font=font)char_list.append(char)def rndColor():"""⽣成随机颜⾊:return:"""return (random.randint(0, 255), random.randint(10, 255), random.randint(64, 255))# 写⼲扰点for i in range(40):draw.point([random.randint(0, width), random.randint(0, height)], fill=rndColor())# 写⼲扰圆圈for i in range(40):draw.point([random.randint(0, width), random.randint(0, height)], fill=rndColor())x = random.randint(0, width)y = random.randint(0, height)draw.arc((x, y, x + 4, y + 4), 0, 90, fill=rndColor())# 画⼲扰线for i in range(5):x1 = random.randint(0, width)y1 = random.randint(0, height)x2 = random.randint(0, width)y2 = random.randint(0, height)draw.line((x1, y1, x2, y2), fill=rndColor())img.save(f, "png")data = f.getvalue()s_code = ''.join(char_list)return data,s_code2.2 调⽤⽅法def get_valid_img(request):'''登录和注册的验证码:param request::return:'''data,s_code = check_code()request.session["valid_code"] = s_code return HttpResponse(data)。
python3图片验证码识别种类最多第三方模块-MuggleOCR
python3图⽚验证码识别种类最多第三⽅模块-MuggleOCR pip install muggle_ocrpip install muggle_ocr -i --trusted-host 案例1导⼊包import time# 1. 导⼊包import muggle_ocr"""使⽤预置模型,预置模型包含了[ModelType.OCR, ModelType.Captcha] 两种其中 ModelType.OCR ⽤于识别普通印刷⽂本, ModelType.Captcha ⽤于识别4-6位简单英数验证码"""# 打开印刷⽂本图⽚with open(r"test1.png", "rb") as f:ocr_bytes = f.read()# 打开验证码图⽚with open(r"test2.jpg", "rb") as f:captcha_bytes = f.read()# 2. 初始化;model_type 可选: [ModelType.OCR, ModelType.Captcha]sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.OCR)# ModelType.Captcha 可识别光学印刷⽂本for i in range(5):st = time.time()# 3. 调⽤预测函数text = sdk.predict(image_bytes=ocr_bytes)print(text, time.time() - st)# ModelType.Captcha 可识别4-6位验证码sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.Captcha)for i in range(5):st = time.time()# 3. 调⽤预测函数text = sdk.predict(image_bytes=captcha_bytes)print(text, time.time() - st)"""使⽤⾃定义模型⽀持基于 https:///kerlomz/captcha_trainer 框架训练的模型训练完成后,进⼊导出编译模型的[out]路径下, 把[graph]路径下的pb模型和[model]下的yaml配置⽂件放到同⼀路径下。
Go语言技术中的图像识别与处理算法实践

Go语言技术中的图像识别与处理算法实践图像识别与处理在现代技术发展中扮演着重要的角色,它不仅应用于计算机视觉、人工智能等领域,还广泛应用于医疗、安防、交通、娱乐等众多领域。
而Go语言作为一种简洁、高效、易学的编程语言也得到了越来越多开发者的青睐。
本文将介绍如何利用Go语言的技术和一些常用的图像处理算法来实现图像识别与处理。
一、图像识别算法实践1. 图像分类图像分类是图像识别中最常见的任务之一。
它的目标是将输入的图像分成不同的类别。
利用Go语言,我们可以使用一些机器学习库来实现图像分类。
例如,可以使用GoCV库结合经典的图像分类算法如卷积神经网络(CNN)来实现图像分类。
首先,需要加载已经训练好的CNN模型,可以选择使用已经训练好的模型也可以自己进行训练。
然后,对需要识别的图像进行预处理,例如调整图像的大小、归一化等。
最后,通过将图像输入到CNN模型中,得到其分类结果。
GoCV库提供了快速、便捷的接口来实现这些功能。
2. 目标检测目标检测是识别图像中特定对象的任务。
与图像分类不同,目标检测不仅需要识别对象的类别,还需要找到对象所在的位置。
在Go语言中,可以使用深度学习库如GoCV或TFGo来实现目标检测。
目标检测的实现可以分为两个主要步骤:首先,使用预训练的目标检测模型对图像进行处理,并通过模型输出的边界框来确定目标的位置;然后,根据目标的位置,在图像上绘制矩形框来标识目标。
借助GoCV库和相应的目标检测模型,我们能够方便地实现目标检测功能。
二、图像处理算法实践1. 图像滤波图像滤波是图像处理中的一种重要技术,常用于去噪、平滑、锐化等操作。
Go 语言提供了一些图像处理库,如GoCV和GIFT,可以帮助我们实现各种图像滤波操作。
例如,可以使用高斯滤波器对图像进行平滑处理。
高斯滤波器通过对图像进行卷积操作,移除图像中的高频噪声,使图像变得更加平滑。
在Go语言中,我们可以利用相应的图像处理库来实现高斯滤波器的卷积操作。
使用Go语言进行高效的图像识别与分类

使用Go语言进行高效的图像识别与分类Go语言是一种简洁、高效的编程语言,越来越多的开发者将其用于图像识别和分类任务。
使用Go语言进行高效的图像识别与分类,可以提高处理速度、减少资源消耗,并且能够轻松应对大规模图像处理需求。
本文将介绍如何使用Go语言进行高效的图像识别与分类,并分享一些实用的技巧和工具。
首先,要进行图像识别与分类,首要的是选择适合的机器学习库或框架。
Go语言生态系统中拥有一些优秀的图像处理库,例如GoCV,它是针对计算机视觉的开源项目,可以帮助我们实现图像的读取、处理、分析和生成。
另外,Go语言还提供了一些常用且强大的机器学习库,如Gorgonia和TFGo等,这些库提供了丰富的机器学习算法和模型,可用于图像识别与分类任务。
其次,为了提高图像处理的速度和效率,我们可以利用Go语言的并发特性。
并发是Go语言的核心特性之一,通过使用goroutine和channel,我们可以并行地处理多个图像,从而加快处理速度。
例如,在图像识别任务中,我们可以使用多个goroutine同时处理不同的图像,然后通过channel将结果收集起来,以提高整体的处理速度。
另外,图像特征提取是图像识别与分类中非常重要的一步。
在Go语言中,我们可以使用一些常用的图像特征提取方法,如颜色直方图、纹理特征和形状特征等。
通过提取图像的特征,我们可以将图像转化为更容易处理的数值向量,然后使用机器学习算法进行分类。
在Go语言中,我们可以借助上述提到的机器学习库,快速构建图像分类模型,并实现高效的图像分类。
此外,为了让图像识别与分类更加准确,我们还可以使用预训练的模型。
预训练的模型是一种已经在大规模图像数据集上进行训练的模型,具有较高的识别准确率。
在Go语言中,我们可以使用一些已经训练好的深度学习模型,如ResNet和VGG等。
这些模型已经在著名的图像数据集上进行了训练,并且可以应用于各种图像识别和分类任务中。
最后,为了便于管理和扩展,在图像识别与分类任务中,我们可以将代码组织为模块化的结构。
hcaptcha的例子

hcaptcha的例子
hCaptcha是一种人机验证工具,类似于Google的reCAPTCHA。
它的主要目的是确保网站上的用户是真实的人类而不是自动化程序
或机器人。
hCaptcha通过向用户展示一些任务或问题来验证其身份,这些任务可能包括识别图像中的物体、解决简单的数学问题或者选
择相关的图像等。
以下是一些hCaptcha的例子:
1. 图像识别,hCaptcha可能会要求用户在一系列图片中选择
特定的物体,比如要求用户点击所有包含车辆的图像,以确认用户
是真实的人类而不是自动化程序。
2. 文字识别,用户可能需要输入显示在图像中的文字,以证明
他们是真实的人类。
3. 数学问题,hCaptcha可能会要求用户解决简单的数学问题,比如计算两个数字的和或者差,以验证其身份。
4. 图像标记,用户可能需要在一组图像中标记出特定的物体或
区域,以证明其是真实的人类。
这些例子展示了hCaptcha如何通过不同类型的任务来验证用户的身份,以确保网站的安全性和防止恶意机器人的访问。
通过这种方式,hCaptcha既保护了网站的安全性,又确保了用户体验的流畅性。
Go语言的图形图像处理与图像识别

Go语言的图形图像处理与图像识别引言•Go语言的发展和应用•图形图像处理和图像识别的重要性•本文的目的和结构什么是图形图像处理和图像识别图形图像处理•图形图像处理的定义•图形图像处理在计算机视觉和计算机图形学中的应用•条件图形变换和几何图形变换图像识别•图像识别的定义•图像识别在机器学习和人工智能中的应用•图像特征提取和目标分类Go语言在图形图像处理中的应用图形图像处理库•Go语言的图像处理库和工具•常用的图像处理操作•图像缩放、裁剪和旋转•图像滤波和增强•图像压缩和解压缩图像识别算法库•Go语言的机器学习和图像识别算法库•常用的图像特征提取和目标分类算法•Haar特征和级联分类器•SURF特征和Bag of Words模型•CNN卷积神经网络和深度学习使用Go语言进行图形图像处理图像处理示例•使用Go语言进行图像缩放、裁剪和旋转•使用Go语言进行图像滤波和增强•使用Go语言进行图像压缩和解压缩图像识别示例•使用Go语言进行图像特征提取和目标分类•使用Go语言实现Haar特征和级联分类器•使用Go语言实现SURF特征和Bag of Words模型•使用Go语言实现CNN卷积神经网络和深度学习Go语言在图形图像处理中的优势并发和并行计算•Go语言的并发和并行计算模型•并发和并行计算在图像处理中的应用垃圾回收和内存管理•Go语言的垃圾回收和内存管理机制•垃圾回收和内存管理对图形图像处理的影响跨平台支持•Go语言的跨平台支持特性•跨平台支持对图形图像处理的影响结论•总结Go语言在图形图像处理和图像识别中的应用•强调Go语言的优势和未来发展前景•提出未来研究方向和挑战。
golangimage图片处理示例

golangimage图⽚处理⽰例本⽂实例讲述了golang image图⽚处理⽅法。
分享给⼤家供⼤家参考,具体如下:golang处理图⽚挺简单的,我是过功能挺简单的,没有过⼀个缩略图⽅法.复制代码代码如下:package mainimport ("fmt""os""image""image/color""image/draw""image/jpeg")func main() {f1, err := os.Open("1.jpg")if err != nil {panic(err)}defer f1.Close()f2, err := os.Open("2.jpg")if err != nil {panic(err)}defer f2.Close()f3, err := os.Create("3.jpg")if err != nil {panic(err)}defer f3.Close()m1, err := jpeg.Decode(f1)if err != nil {panic(err)}bounds := m1.Bounds()m2, err := jpeg.Decode(f2)if err != nil {panic(err)}m := image.NewRGBA(bounds)white := color.RGBA{255, 255, 255, 255}draw.Draw(m, bounds, &image.Uniform{white}, image.ZP, draw.Src)draw.Draw(m, bounds, m1, image.ZP, draw.Src)draw.Draw(m, image.Rect(100, 200, 300, 600), m2, image.Pt(250, 60), draw.Src)err = jpeg.Encode(f3, m, &jpeg.Options{90})if err != nil {panic(err)}fmt.Printf("ok\n")}希望本⽂所述对⼤家Go语⾔程序设计有所帮助。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于GO的图片验证码识别api调用代码实例
代码描述:基于GO的图片验证码识别api调用代码实例
代码平台:聚合数据
package main
import(
"io/ioutil"
"net/http"
"net/url"
"fmt"
"encoding/json"
)
//----------------------------------
// 验证码识别调用示例代码-聚合数据
// 在线接口文档:/docs/60
//----------------------------------
const APPKEY = "*******************"//您申请的APPKEY
func main(){
//1.识别验证码
Request1()
//2.查询验证码类型代码
Request2()
}
//1.识别验证码
func Request1(){
//请求地址
juheURL :="/vercode/index"
//初始化参数
param:=url.Values{}
//配置请求参数,方法内部已处理urlencode问题,中文参数可以直接传参param.Set("key",APPKEY) //您申请到的APPKEY
param.Set("codeType","") //验证码的类型,<a href="http://www. /docs/api/id/60/aid/352" target="_blank">查询&l t;/a>
param.Set("image","") //图片文件
param.Set("dtype","") //返回的数据的格式,json或xml,默认为json
//发送请求
data,err:=Post(juheURL,param)
if err!=nil{
fmt.Errorf("请求失败,错误信息:\r\n%v",err)
}else{
var netReturn map[string]interface{}
json.Unmarshal(data,&netReturn)
if netReturn["error_code"].(float64)==0{
fmt.Printf("接口返回result字段是:\r\n%v",netReturn["result "])
}
}
}
//2.查询验证码类型代码
func Request2(){
//请求地址
juheURL :="/vercode/codeType"
//初始化参数
param:=url.Values{}
//配置请求参数,方法内部已处理urlencode问题,中文参数可以直接传参
param.Set("key",APPKEY) //您申请到的APPKEY
param.Set("dtype","") //返回的数据的格式,json或xml,默认为json
//发送请求
data,err:=Get(juheURL,param)
if err!=nil{
fmt.Errorf("请求失败,错误信息:\r\n%v",err)
}else{
var netReturn map[string]interface{}
json.Unmarshal(data,&netReturn)
if netReturn["error_code"].(float64)==0{
fmt.Printf("接口返回result字段是:\r\n%v",netReturn["result "])
}
}
}
// get 网络请求
func Get(apiURL string,params url.Values)(rs[]byte,err error){ var Url *url.URL
Url,err=url.Parse(apiURL)
if err!=nil{
fmt.Printf("解析url错误:\r\n%v",err)
return nil,err
}
//如果参数中有中文参数,这个方法会进行URLEncode
Url.RawQuery=params.Encode()
resp,err:=http.Get(Url.String())
if err!=nil{
fmt.Println("err:",err)
return nil,err
}
defer resp.Body.Close()
return ioutil.ReadAll(resp.Body)
}
// post 网络请求 ,params 是url.Values类型
func Post(apiURL string, params url.Values)(rs[]byte,err error){ resp,err:=http.PostForm(apiURL, params)
if err!=nil{
return nil ,err
}
defer resp.Body.Close()
return ioutil.ReadAll(resp.Body)
}。