单词的检索与计数教材
英语六级高频词汇速查手册

英语六级高频词汇速查手册使用说明1. 本手册共分为20个单元,每个单元包含20个单词。
考生可按照单元顺序进行,也可根据自己的需求和进度进行选择。
2. 每个单词下方列出了其音标、中文释义、英文释义以及例句。
音标有助于考生正确发音,中文和英文释义帮助考生理解单词含义,例句则展示了单词在实际语境中的用法。
3. 单词按照首字母顺序排列,方便考生查找。
同时,每个单元结束后提供了单词测试,帮助考生巩固所学内容。
4. 建议考生在每个单元的过程中,充分利用单词卡片、默写、造句等方法进行巩固,以提高记忆效果。
5. 本手册可作为考生日常、复的工具书,也可作为考前冲刺的参考资料。
词汇速查以下是高频词汇速查手册的完整内容,考生可按需查找和。
1. abandon [əˈbændən]- 放弃- She abandoned her career to raise her children.2. ability [əˈbɪlɪti]- 能力- He has the ability to succeed.3. abnormal [əˈnɔːmbəl]- 异常的- An abnormal growth was detected in the tumor.4. aboard [əˈbɔːrd]- 在船(车、飞机)上- We boarded the plane and took our seats.5. abolish [əˈbɑːlɪʃ]- 废除- The government abolished slavery in the 19th century.6. n [əˈbɔːrʃn]- 流产- She had an n and never recovered from the nal trauma.7. about [əˈbaʊt]- 关于;大约- I don't know anything about the meeting.8. above [əˈbʌv]- 在...上面- The plane was flying above the clouds.9. abroad [əˈbrɔːd]- 在国外- He went abroad to study.10. absence [əˈsɛns]- 缺席;缺少- He was absent from the meeting due to illness.11. absolute [ˈæbsəluːt]- 绝对的;完全的- He has an absolute right to freedom of speech.12. absorb [əˈsɔːrb]- 吸收- The sponge absorbed water.13. abstract [ˈæbstrækt]- 抽象的;摘要- He presented an abstract of his research findings.14. absurd [əˈsɜːrd]- 荒谬的;荒唐的- The idea that the Earth is flat is absurd.15. abundance [əˈbʌndəns]- 丰富;充裕- There is an abundance of wildlife in the forest.16. abuse [əˈbjuːs]- 滥用;虐待- Drug abuse is a us problem in society.17. academic [ˌækəˈdɛmɪk]- 学术的;大学的- She is an academic specializing in English literature.18. accelerate [əkˈsɛləreɪt]- 加速- The car accelerated and left us behind.19. accent [ˈæksɛnt]- 口音;重音- He has a strong French accent.20. accept [əkˈsɛpt]- 接受- She accepted the job offer.(更多词汇请参考完整版手册)希望本《高频词汇速查手册》能帮助广大考生提高词汇水平,顺利通过考试!。
文本文件单词的检索与计数

软件综合课程设计文本文件单词的检索与计数实时监控报警系统二〇一四年六月文本文件单词的检索与计数1.问题陈述要求编程建立一个文本文件,每个单词不包含空格且不跨行,单词由字符序列构成且区分大小写;统计给定单词在文本文件中出现的总次数;检索输出某个单词出现在文本中的行号、在该行中出现的次数以及位置。
该设计要求可分为三个部分实现:其一,建立文本文件,文件名由用户用键盘输入;其二,给定单词的计数,输入一个不含空格的单词,统计输出该单词在文本中的出现次数;其三,检索给定单词,输入一个单词,检索并输出该单词所在的行号、该行中出现的次数以及在该行中的相应位置。
(1).建立文本文件(2)给定单词的计数(3)检索单词出现在文本文件中的行号、次数及其位置(4)主控菜单程序的结构①头文件包含②菜单选项包含建立文件、单词定位、单词计数、退出程序③选择1-4执行相应的操作,其他字符为非法。
2.程序代码#include<stdio.h>#include<string.h>#include<iostream>#define MaxStrSize 256 //根据用户需要自己定义大小using namespace std;typedef struct {char ch[MaxStrSize]; //ch是一个可容纳256个字符的字符数组int length;} SString;//定义顺序串类型int PartPosition (SString s1,SString s2,int k){ int i,j;i=k-1;//扫描s1的下标,因为c中数组下标是从0开始,串中序号相差1 j=0;//扫描s2的开始下标while(i<s1.length && j<s2.length){if(s1.ch[i]==s2.ch[j]){ i++;j++; //继续使下标移向下一个字符位置}else{i=i-j+1; j=0;} }if (j>=s2.length)return i-s2.length;elsereturn -1;//表示s1中不存在s2,返回-1//表示s1中存在s2,返回其起始位置} //函数结束void CreatTextFile(){SString S;char fname[10],yn;FILE *fp;printf("输入要建立的文件名:");scanf("%s",fname);fp=fopen(fname,"w");yn='n';//输入结束标志初值while(yn=='n'||yn=='N'){printf("请输入一行文本:");gets(S.ch);gets(S.ch);S.length=strlen(S.ch);fwrite(&S,S.length,1,fp);fprintf(fp,"%c",10);//是输入换行printf("结束输入吗?y or n :");yn=getchar();}fclose(fp);//关闭文件printf("建立文件结束!");}void SubStrCount(){FILE *fp;SString S,T;//定义两个串变量char fname[10];int i=0,j,k;printf("输入文本文件名:");scanf("%s",fname);fp=fopen(fname,"r");printf("输入要统计计数的单词:");cin>>T.ch;T.length=strlen(T.ch);while(!feof(fp)){ //扫描整个文本文件// fread(&S.ch,1,sizeof(S),fp);//读入一行文本 memset(S.ch,'\0',256);fgets(S.ch,100,fp);S.length=strlen(S.ch);k=0; //初始化开始检索位置while(k<S.length-1) //检索整个主串S{j=PartPosition(S,T,k);//调用串匹配函数if(j<0 ) break;else {i++;//单词计数器加1k=j+T.length;//继续下一字串的检索 }}}printf("\n单词%s在文本文件%s中共出现%d次\n",T.ch,fname,i);}//统计单词出现的个数void SubStrInd(){ FILE *fp;SString S,T; //定义两个串变量char fname[10];int i,j,k,l,m;int wz[20]; //存放一行中字串匹配的多个位置printf("输入文本文件名:");scanf("%s",fname);fp=fopen(fname,"r");printf("输入要检索的单词:");scanf("%s",T.ch);T.length=strlen(T.ch);l=0; //行计数器置0while(!feof(fp)) { //扫描整个文本文件//fread(&S,sizeof(S),1,fp); //读入一行文本memset(S.ch,'\0',256);fgets(S.ch,256,fp);S.length=strlen(S.ch);l++; //行计数器自增1k=0;//初始化开始检索位置i=0; //初始化单词计数器while(k<S.length-1) //检索整个主串S{ j=PartPosition(S,T,k); //调用串匹配函数if(j<0) break;else {i++;//单词计数器加1wz[i]=j;//记录匹配单词位置k=j+T.length;//继续下一字串检索}}if(i>0){ printf("行号:%d,次数:%d,位置分别为:",l,i);for(m=1;m<=i;m++) printf("%4d",wz[m]+1);printf("\n");}}}//检索单词出现在文本文件中的行号、次数及其位置int main(){ void CreatTextFile(),SubStrCount(),SubStrInd();int xz;do {printf("* * * * * * * * * * * * * * * * * * * ** * * * *\n");printf("*文本文件的检索、字串的统计及定位*\n");printf("* * * * * * * * * * * * * * * * * * * ** * * * *\n");printf("* 1. 建立文本文件*\n");printf("* 2. 单词字串的计数*\n");printf("* 3. 单词字串的定位*\n");printf("* 4. 退出整个程序*\n");printf("* * * * * * * * * * * * * * * * * * * ** * * * *\n");printf(" 请选择(1--4) ");scanf("%d",&xz);switch(xz) {case 1 : CreatTextFile();break;case 2 : SubStrCount();break;case 3 : SubStrInd();break;case 4 : return 0;default:printf("选择错误,重新选\n");}}while(1);}3.运行结果4.设计体会与总结我的课程设计题目是文本文件单词的检索与计数。
生物技术专业英语单词检索

工业生物技术专业英语词汇索引来源:教材textA,B 汇编:光哥说明:分汉译英,英译汉两部分,均按序垂直排列。
地名及过长词组的部分单词未列出;由于教材的编排,部分单词重复出现;多音导致排序时“粘”“重”排到了“Z”部分。
一,汉译英二,英译汉(生长)期phase Cordial 加香料,加糖酒1,2-丙二醇1,2-propanediol pH scale pH标定1,2-乙二醇1,2-ethanediol 1,2-ethanediol 1,2-乙二醇1,3-丙二醇1,3-propanediol 1,2-propanediol 1,2-丙二醇1-丙醇1-propanol 1,3-propanediol 1,3-丙二醇2-丁醇2-butanol 1-propanol 1-丙醇3-氯-1丙醇3-chloro-1propanol 2-butanol 2-丁醇4,4-二甲基-2戊醇 4,4-dimethyl-2-pen…3-chloro-1propanol 3-氯-1丙醇4-甲基-1-戊醇4-methyl-1-pentanol 4,4-dimethyl-2-pen…4,4-二甲基-2戊醇DNA连接酶DNA ligase 4-methyl-1-pentanol 4-甲基-1-戊醇DNA序列分析DNA sequence analysis A.A.niger 黑曲霉IUPAC International Union of Pure and Chemistry abiogenesis 非生源说pH标定Ph scale absolute specificity 绝对专一性RNA聚合酶RNA polymerase acclimation time 适应期A.阿拉伯糖arabinose accounting 会计爱尔啤酒ale accumulate 积累氨基甲酸酯carbamates Acetyl coenzyme A 乙酰辅酶A氨基转移酶transaminase acetylation 乙酰化B.白兰地brandy acidity 酸度白细胞介素2 interleukin2 aconitase 顺乌头酸酶半好养的semiaerobic actinomycete 放线菌半乳糖galactose actinomycetes 放线菌半乳糖galactose activator 激活剂半乳糖醛酸羧基galacturonic acid carboxyl residues adsorption 吸附半纤维素hemicellulose Aerobic 好氧菌的半纤维素酶hemicellulase aerobic respiration 有氧呼吸棒状杆菌属Corynebacterium affinity chromatography 亲和色谱饱和的saturated agar slant 琼脂斜面菌种保持在stands at aggregate 聚集体保险insurance agitator 搅拌器苯基尿酶phenylureas alcohol 醇苯氧基乙酸phenoxyacetates aldehydes 醛边缘ledge ale 爱尔啤酒变质,腐败spoilage alfalfa 紫花苜蓿丙二醇propylene alkane 烷丙酮酸pyruvic acid amidases 酰胺酶丙酮酸的pyruvate aminotransferase 转氨酶病原性pathogenicity ampicillin resistant 抗氨苄青霉素补料的fed-batch amylase 淀粉酶不可回收的non-retractable amylase 淀粉酶不溶的insoluble amyloglucosidase 淀粉葡萄糖苷酶部分segment analyser 粗馏塔C.残余物r esidual ancestral 祖先的操纵基因operator gene anchorage 停泊处操纵子operons anhydrous ethanol 无水乙醇槽trough animal cell culture 动物细胞培养草酸的oxaloacetate anion 阴离子插入insertion antibiotic resistance 抗生素抗性插入点insertion site anti-inferon 抗干扰素插入钝化insertion inactivation antiserum 抗血清产物product apoenzyme 酶蛋白产物大量形成bulk of product formation apo-repressor 脱辅基阻遏子超滤ultrafiltration aquatic flora 水生植物群沉淀precipitation aqueous ethanol 含水酒精陈化maturation arabinose 阿拉伯糖成熟啤酒mellowed beer archaebacteria 古细菌澄清的clarified aroma 芳香除草剂herbicides aseptic 无菌的穿梭般运输shuttle assess the effect of.. 评估污染…串,簇cluster at the onset of infection 一旦感染上纯化purification at the peak of growth 在生长的最高峰醇alcohol attach 连接次级代谢产物secondary metabolites attemperation 温度调节粗馏塔purifying columns attenuated 衰减的粗馏塔analyser azeotropic 共沸混合物的簇生的clustered B.Bacillus subtilis 枯草芽孢杆菌萃取extraction backbone 骨架萃取strip bacteriophage 噬菌体D.大肠杆菌Escherichia coli baffle 挡板大麦barley barley 大麦代谢的metabolic basicity 碱度带滤板的糖化槽mash tun batch distillation 分批蒸馏贷方credit bearing 轴承单糖monosaccharide beet 甜菜单元操作unit operation berry 浆果蛋白酶protease binomial scientific names 双名制蛋白质外壳protein coat bioactive compounds 生物活性物质蛋白质修饰protein modifications biocrude 生物原料氮nitrogen biodegradation 生物降解挡板baffle biodiesel 生物柴油低温的cryogenic bioelement 生物元素电泳electrophoresis biofuels 生物燃料电子传递electron transport biogenesis 生源说淀粉starch biological oxygen demend 生物耗氧量淀粉酶amylase bioremediation 生物治理淀粉酶amylase blending 混合,调配淀粉葡萄糖苷酶amyloglucosidase blood products 血制品淀粉糖化酶giucoamylase bottom fermentation 下面发酵叠焊连接over-lapping joint brandy 白兰地丁醇butyl alcohol breakdown 分解动物界kingdom animalia Brevibacterium 短杆菌属动物细胞培养animal cell culture bulk of product formation 产物大量形成冻干lyophilization butter fat 牛脂豆科植物legumes butt-welded joint 对焊连接短杆菌属Brevibacterium butyl alcohol 丁醇对焊连接butt-welded joint by-product 副产物对数生长期exponential growth phase C.calcium 钙钝化inactive calcium phosphate 磷酸钙多孔板perforated plate calcium sulphate 硫酸钙多顺反子polycistronic cane 甘蔗多糖polysaccharide capital investment 资金总额多样性diversity carbamates 氨基甲酸酯E.二吡啶d i-pyridinium carbohydrases 糖酶二次煮出法double decoction carbohydrate 碳水化合物二甲亚砜dimethylsulfoxide carbon chain 碳链二磷酸diphosphate carbon dioxide 二氧化碳二硫物dithioates carbon dioxide evolution二氧化碳上涌二糖disaccharide Carbonic anhydrase 碳的脱水酶二氧化碳carbon dioxide casein 酪蛋白二氧化碳上涌carbon dioxide evolution cassava 木薯F.发酵废液spent culture catabolic 分解代谢的发酵罐fermenter catabolite repression 分解代谢抑制发酵罐(体积)fermenter productivity cation 阳离子发酵周期fermentation cycle cationic resin 阳离子交换树脂发芽germinate cell lines 细胞株翻译translate cell suspension 细胞悬浮液翻译后的post-translational cellobiose 纤维二塘反馈feedback cellulase 纤维素酶反式消去酶transeliminase cellulose 纤维素反应物reactant cellulose 纤维素芳香aroma cement 结合剂防冻的cryoprotective charcoal 木炭放射活性标记的radioactively labelled probe chemical bonds 化学键放线菌actinomycetes chemical equation 化学方程式放线菌actinomycete chemical oxygen demand 化学耗氧量非还原性的nonreducing chemically defined media 基本培养基非生源说abiogenesis chemo-organotrophs 有机化能营养菌非致病菌Non pathogenic cherry 樱桃废水处理waste water treatment chilling 冷却分步沉淀fractional precipitation chromatography 色谱分解dismantle chromosomal 染色体的分解breakdown circular movement 循环运动分解代谢的catabolic circulation 循环分解代谢抑制catabolite repression citric acid 柠檬酸分批蒸馏batch distillation clarified 澄清的分子式formula clinical study 临床研究风味zest cloning 克隆封闭系统closed system closed system 封闭系统孵卵incubation clump 菌团伏特加vodka cluster 串,簇符号symbol clustered 簇生的辅酶coenzyme coenzyme 辅酶辅阻遏物co-repressor coil 盘管腐蚀,腐烂decay collagenase 胶原酶附加福利fringe benefit colony hybridization 菌落原位杂交复制子replicon column 塔,柱副产物by-product common name 普通命名法富马酸fumaric acid compound 化合物G.钙 calcium compound gin 配制金酒干扰素interferon concentration 浓度甘露糖mannose conducive 有助于甘蔗cane conical bottom fermenters锥底发酵罐感染infect consensus 一致,保守高产high output constitutively 组成型高度专一吸附剂highly specific absorbent cooling coil 冷却蛇管高果糖浆high fructose corn syrup cooling jacket 冷却夹套高温分解pyrolysis co-repressor 辅阻遏物革兰阳性的Gram-positive Corynebacterium 棒状杆菌属格兰阴性的Gram negative covalent 共价的工业发酵过程industrial fermentation process covalent bonds 共价键工业级酒精industrial-quality ethanol credit 贷方工作容积operational volume cryogenic 低温的公用设施utilities cryoprotective 防冻的功能性基团functional group crystallization 结晶共沸混合物的azeotropic crystallize 结晶共价的covalent cumbersome 麻烦的共价键covalent bonds cylindro-conical 圆筒锥底的古细菌archaebacteria D.dairy industry 乳品工业谷氨酸发酵glutamic acid fermentation deacetylbaccatin 脱酰赤霉素骨架backbone deaminases 脱氨基酶固定成本fixed cost debit 收方寡糖oligosaccharide debris 碎片管理supervision decarboxylation 脱羧基罐壁vessel wall decay 腐蚀,腐烂轨道orbital decoction 煮出果胶甲基酯化酶pectin methyl esterase deductive 演绎的果胶酶pectinase dehydrogenation 脱氢果酒白兰地fruit brandy depletion of oxygen耗尽氧气果糖fructose depolymerizing 解聚酶过滤filtration depreciation 折旧H.含水酒精aqueous ethanol deproteinized 脱蛋白乳清航空燃料jet fuel desmolase 碳链裂解酶好氧菌的Aerobic determinant 决定子耗尽氧气depletion of oxygen dextrin 糊精合成synthesis dextrin 糊精核苷转移酶transglycosidase dextrinase 糊精酶核酸酶nucleases diarrhea 痢疾核酸内切酶endonuclease diesel 煤油核糖ribose dilute acid 稀酸核糖体ribosome dimethylsulfoxide 二甲亚砜黑曲霉 A.niger diphosphate 二磷酸呼吸respiration di-pyridinium 二吡啶糊化gelatinize direct operation cost 直接生产成本糊精dextrin disaccharide 二糖糊精dextrin dismantle 分解糊精酶dextrinase dissolution 解离琥珀酸succinic acid distillate 蒸馏物琥珀酰succinyl distillation 蒸馏互相拥抱,包含embraces distillation 蒸馏化合物compound distilled spirit 蒸馏酒化石燃料fossil dithioates 二硫物化学方程式chemical equation divergent 有分歧的化学耗氧量chemical oxygen demand diversity 多样性化学键chemical bonds DNA ligase DNA连接酶化学键专一性linkage specificity DNA sequence analysis DNA序列分析还原reduction double decoction 二次煮出法还原剂reducing agent drainage 排放黄单胞杆菌Xanthomonas E.electron transport 电子传递挥发性的volatile electrophoresis 电泳挥发性有机物volatile organic compound element 元素会计accounting eluate 洗出液桧属植物juniper elution 洗脱混合,调配blending embraces 互相拥抱,包含活塞流反应器plug flow reactor endonuclease 核酸内切酶J.积累accumulate endospore 内生孢子基本培养基chemically defined media end-product repression 最终产物阻遏基因定位mapping enolase 烯醇化酶基因组genome enzymatic 酶作用的激活剂activator Escherichia coli 大肠杆菌寄生虫parasites esterases 酯化酶寄主细胞host esterfy 酯化加班overtime ethylene 乙醇加仑gallons ethylene 乙二醇加香料,加糖酒Cordial Eubacteria 真细菌类甲醇methyl alcohol explant 移植甲醇基methanol group exponential growth phase 对数生长期甲基汞methylmercury extinguish 熄灭甲基转移酶transmethylase extraction萃取钾potassium F.fed-batch 补料的监视,监督surveillance feedback 反馈碱度basicity feedstocks 原料浆slurry fermentation cycle 发酵周期浆果berry fermenter 发酵罐交换型树脂resin column fermenter productivity 发酵罐(体积)胶原酶collagenase filamentous 丝状的搅拌器agitator filtration 过滤搅拌轴stirrer shaft fixed cost 固定成本搅拌装置stirring gear flat vertical paddles 平叶式搅拌桨窖kiln flavour 口味接受水体receiving water flocculate 凝聚接种seed formula 分子式接种培养物inoculated culture fossil 化石燃料结合unit fractional precipitation 分步沉淀结合剂cement fragment 片段结晶crystallize fringe benefit 附加福利结晶crystallization fructose 果糖解聚酶depolymerizing fruit brandy 果酒白兰地解离dissolution fumarase 延胡索酸酶金酒Gin fumaric acid 富马酸金属有机物organometallics functional group 功能性基团进入的酒缪incoming wash fungi 真菌浸出infusion fusion proteins 融合蛋白浸出糖化法infusion mashing G.galactose 半乳糖浸没式蛇管submerged coils galactose 半乳糖浸泡soak galacturonase 聚半乳糖醛酸酶精馏rectifying galacturonic acid carboxyl residues 半乳糖醛酸羧基精馏塔rectifier gallons 加仑精制refine gasoline 汽油精制polishing gel filtration 凝胶过滤酒花糟spent hops gelatinize 糊化聚半乳糖醛酸酶galacturonase general expenses 一般性费用聚芳香物的polyaromatic genome 基因组聚集体aggregate germinate发芽决定子determinant Gin 金酒绝对专一性absolute specificity ginseng 人参均匀混合的反应器homegeneously mixed reactor giucoamylase 淀粉糖化酶均质化homegenization glocosylation 糖苷化菌落原位杂交colony hybridization glucanase 葡聚糖酶菌丝体的mycelial glucanase 葡聚糖酶菌团clump glucanases 葡聚糖酶K.开放体系open system glucoamylase 葡萄糖淀粉酶抗氨苄青霉素ampicillin resistant glucose 葡萄糖抗干扰素anti-inferon glucose isomerase 葡萄糖异构酶抗生素抗性antibiotic resistance glutamic acid fermentation 谷氨酸发酵抗四环素基因tetracycline resistantance glycogen 糖原抗血清antiserum glycol 脂肪族二元醇类可变成本variable cost glycolysis 糖酵解可测量性scalability glycolytic pathway 糖酵解途径可诱导的inducible glycosidic linkage 糖苷键连接可转化的transformable grain solid 麦糟克隆cloning Gram negative 格兰阴性的口服疫苗oral vaccination Gram-positive 革兰阳性的口味flavour green malt 绿麦芽枯草芽孢杆菌Bacillus subtilis growth curve 生长曲线L.朗姆酒 rum growth-associated product 与生长偶联的产物酪蛋白casein guanosine 鸟嘌呤核苷冷却chilling H.having smaller mash depth 糖化缪厚度较小冷却夹套cooling jacket head 头酒冷却蛇管cooling coil heavy dependence on host cell完全依赖寄主细胞离子交换色谱ion-exchange chromatography hemicellulase 半纤维素酶李plum hemicellulose 半纤维素立体的steric hepatitis B 乙型肝炎立体异构stereochemical herbicides 除草剂利息interest high fructose corn syrup 高果糖浆痢疾diarrhea high output 高产连接attach highly specific absorbent 高度专一吸附剂连接酶ligase homegeneously mixed reactor均匀混合的反应器炼油厂oil refineries homegenization 均质化链霉菌属Streptomyces horizontal disc 水平安装的圆盘链霉素streptomycin host 寄主细胞烈性酒liqueur hybrid 杂交子临床研究clinical study hydrogen 氢磷phosphorus hydrolazate 水解物磷酸变位酶phosphomutase hydrolyze水解磷酸钙calcium phosphate hydroxyl 羟基磷酸化phosphorylation hydroxylase 羟化酶磷酸化phosphorylation hype 皮下注射磷酸转移酶transphosphorylase I.identification 识别流出,外流outflow immunoaffinity 免疫亲和流出的…run-off immunological reagent 免疫试剂流经一次single pass in the sodium form 钠型硫sulfur inactive 钝化硫酸钙calcium sulphate incoming wash 进入的酒缪绿麦芽green malt increment增加M.麻烦的cumbersome incubation 孵卵麦芽糖maltose inducible 可诱导的麦糟grain solid induction 诱导麦汁wort inductive 诱发的麦汁煮沸锅kettle industrial fermentation process 工业发酵过程煤油diesel industrial-quality ethanol 工业级酒精酶蛋白apoenzyme infect 感染酶作用的enzymatic infusion 浸出棉子糖raffinose infusion mashing 浸出糖化法免疫亲和immunoaffinity initiation 起始免疫试剂immunological reagent inoculated culture 接种培养物灭菌sterilization inorganic compound 无机化合物命名的nomenclature insertion 插入磨polish insertion inactivation 插入钝化木薯cassava insertion site 插入点木炭charcoal insoluble 不溶的木糖xylose insurance 保险木糖酶xylanase interest 利息木质素lignin interferon 干扰素木质素lignin interleukin2 白细胞介素2木质纤维素lignocellulosic intermediate compounds 中间产物木质纤维素的lignocellulosic intermediates 中间产物N.内含子i ntron intracellular growth 细胞内生长内生孢子endospore intron 内含子钠sodium ion-exchange chromatography 离子交换色谱钠型in the sodium form iron 铁耐热的thermostable isinglass 鱼胶逆转录酶reverse transcriptase isocitric acid 异柠檬酸酿酒酵母Saccharomyces cerevisiae isomer 异构体鸟嘌呤核苷guanosine isomerase异构酶尿酸盐urate isomerase 异构酶尿酸氧化酶uricase isopropyl alcohol 异丙醇柠檬酸citric acid J.jet fuel 航空燃料凝胶过滤gel filtration juniper 桧属植物凝聚flocculate K.kegged 桶装的凝乳酶rennin ketoglutarate 酮戊二酸的牛脂butter fat ketoglutaric acid 酮戊二酸农药pesticides ketones 酮浓度concentration kettle 麦汁煮沸锅浓度strength kiln 窖P.排放drainage kilobase pair 千碱基对盘管coil kingdom animalia 动物界配制金酒compound gin kingdom mycetae 真菌界喷嘴spray jet kingdom plantae 植物界皮下注射hype kingdom procaryotae 原核生物界片段fragment ctase 乳糖酶平形底发酵罐vertical bottom fermenters lactose 乳糖平叶式搅拌桨flat vertical paddles lager 贮藏啤酒评估污染…assess the effect of..on.. lauter tun 糖化槽苹果酸malic acid ledge 边缘破裂rupture leftover 剩货,残余物葡聚糖酶glucanase legumes 豆科植物葡聚糖酶glucanases ligase 连接酶葡聚糖酶glucanase ligated plasmid mixture重新连接的质粒葡萄糖glucose lignin 木质素葡萄糖淀粉酶glucoamylase lignin 木质素葡萄糖异构酶glucose isomerase lignocellulosic 木质纤维素普通命名法common name lignocellulosic 木质纤维素的Q.启动子p romoter limewater 石灰水起点start sites lipase 脂肪酶汽车燃料motor fuel lipoprotein 脂蛋白汽油gasoline liqueur 烈性酒器官培养organ culture lubrication 润滑千碱基对kilobase pair lyophilization 冻干羟化酶hydroxylase M.malic acid 苹果酸羟基hydroxyl maltose 麦芽糖亲和色谱affinity chromatography mannose 甘露糖氢hydrogen manufacturing cost 制造成本清洗rinsing mapping基因定位琼脂斜面菌种agar slant mash 糖化谬取代基命名法substitutive mash filter 糖化缪过滤器醛aldehydes mash tun 带滤板的糖化槽R.染色体的chromosomal maturation 陈化人参ginseng mellowed beer 成熟啤酒溶解性好的麦芽well-modified malt metabolic 代谢的溶质solute methanol group 甲醇基融合蛋白fusion proteins methyl alcohol 甲醇乳品工业dairy industry methylmercury 甲基汞乳清whey microbial strain 微生物菌株乳糖lactose microorganism 微生物乳糖酶lactase milky 乳状的乳状的milky mineral 无机盐化合物润滑lubrication molasses 糖蜜S.三羧酸的tricarboxylic Monera 原生生物界三羧酸循环tricarboxylic acid cycle monosaccharide 单糖三糖trisaccharide motor fuel 汽车燃料三亚甲基二醇trimethylene mycelial 菌丝体的散弹枪式克隆shotgun cloning N.neutral spirit 中性酒精色谱chromatography neutrality 中性上面发酵top fermentation neutralization 中和上清液supernatant new beer 新啤酒上行upflow nitrogen 氮生产菌种producer microorganism nomenclature 命名的生产量production volume Non pathogenic 非致病菌生产能力production capacity nonreducing 非还原性的生长曲线growth curve non-retractable 不可回收的生物柴油biodiesel nucleases 核酸酶生物耗氧量biological oxygen demend O.obligate 专性的生物活性物质bioactive compounds obscure 使模糊不清生物降解biodegradation oderless 无臭的生物燃料biofuels oil refineries 炼油厂生物元素bioelement oligosaccharide 寡糖生物原料biocrude open system 开放体系生物治理bioremediation operation cost 运行成本生源说biogenesis operational volume 工作容积剩货,残余物leftover operator gene 操纵基因石灰水limewater operons 操纵子石油petroleum oral vaccination 口服疫苗识别identification orbital 轨道使感瘟疫plague organ culture 器官培养使模糊不清obscure organic compound 有机化合物适应期acclimation time organometallics 金属有机物噬菌体bacteriophage organophosphates 有机磷收方debit outflow 流出,外流收益性profitability overhead 通常开支树脂resin overlapping 重叠的衰减的attenuated over-lapping joint 叠焊连接双名制binomial scientific names overtime 加班水解hydrolyze oxaloacetate 草酸的水解物hydrolazate Oxidase 氧化酶水平安装的圆盘horizontal disc oxidation 氧化水生植物群aquatic flora oxidizing agent 氧化剂顺乌头酸酶aconitase oxidoreductase 氧化还原酶丝状的filamentous oxygen 氧四环素敏感的tetracycline sensitive P.parasites 寄生虫四因素三水平three-level four-variable pathogen 致病菌酸度acidity pathogenicity 病原性随时间的过程图time course pathway 途径碎片debris pectin methyl esterase 果胶甲基酯化酶T.塔,重叠stack pectinase 果胶酶塔,柱column pepsin 胃蛋白酶碳的脱水酶Carbonic anhydrase perforated plate 多孔板碳链carbon chain pesticides 农药碳链裂解酶desmolase petroleum 石油碳水化合物carbohydrate pharmaceutical 制药的糖的精制sugar-refining phase (生长)期糖苷化glocosylation phenoxyacetates 苯氧基乙酸糖苷键连接glycosidic linkage phenylureas 苯基尿酶糖化saccharification phosphomutase 磷酸变位酶糖化saccharification phosphorus 磷糖化槽lauter tun phosphorylation 磷酸化糖化谬mash phosphorylation 磷酸化糖化缪过滤器mash filter plague 使感瘟疫糖化缪厚度较小having smaller mash depth plamsinogen activator 血纤维蛋白溶糖浆syrup plasmid 质粒糖酵解glycolysis plug flow reactor 活塞流反应器糖酵解途径glycolytic pathway plum 李糖酶carbohydrases polish 磨糖蜜molasses polishing 精制糖原glycogen polyaromatic 聚芳香物的甜菜beet polycistronic 多顺反子铁iron polysaccharide 多糖停泊处anchorage post-translational 翻译后的通常开支overhead potassium 钾同时进行糊精水解with simultaneous dextrin hydrolysis potassium nitrate 硝酸钾酮ketones precipitation 沉淀酮戊二酸ketoglutaric acid primary culture 原培养物酮戊二酸的ketoglutarate producer microorganism 生产菌种桶装的kegged product 产物头酒head production capacity 生产能力途径pathway production volume 生产量脱氨基酶deaminases profitability 收益性脱蛋白乳清deproteinized promoter 启动子脱辅基阻遏子apo-repressor propylene 丙二醇脱氢dehydrogenation protease 蛋白酶脱羧基decarboxylation protein coat 蛋白质外壳脱酰赤霉素deacetylbaccatin protein modifications 蛋白质修饰W.完全依赖寄主细胞heavy dependence on host cell protozoa原生动物顽强的recalcitrant pullulanase 支链淀粉酶烷alkane purification 纯化威士忌whisky purifying columns 粗馏塔微生物microorganism pyrolysis 高温分解微生物菌株microbial strain pyruvate 丙酮酸的唯一的切点single site pyruvic acid 丙酮酸胃蛋白酶pepsin R.r…and d…研究和开发温度调节attemperation radical 自由基无臭的oderless radioactively labelled probe 放射活性标记的无机化合物inorganic compound raffinose 棉子糖无机盐化合物mineral raw materials 原料无菌的aseptic reactant 反应物无水乙醇anhydrous ethanol recalcitrant 顽强的无味的tasteless receiving water 接受水体X.吸附adsorption recombinant plasmid 重组质粒烯醇化酶enolase recombinant proteins 重组蛋白稀酸dilute acid rectifier 精馏塔熄灭extinguish rectifying 精馏洗出液eluate redox 氧化还原洗脱elution reducing agent 还原剂细胞内生长intracellular growth reduction 还原细胞悬浮液cell suspension refine 精制细胞株cell lines regenerate 再生下面发酵bottom fermentation rennin 凝乳酶纤维二塘cellobiose rent 租金纤维素cellulose replicating microorganism 自身复制的微生物纤维素cellulose replicon 复制子纤维素酶cellulase repression 抑制酰胺酶amidases repressor 阻遏子限制性内切酶restriction endonuclease residual 残余物响应面分析法response surface methodology resin 树脂硝酸钾potassium nitrate resin column 交换型树脂硝酸钠sodium nitrate respiration 呼吸斜底锥顶罐sloped-bottom cone-roof tanks response surface methodology响应面分析法新啤酒new beer restriction endonuclease 限制性内切酶悬浮固形物suspended solid reverse transcriptase 逆转录酶漩涡vortex ribose 核糖血纤维蛋白溶plamsinogen activator ribosome 核糖体血制品blood products rinsing 清洗循环circulation RNA polymerase RNA聚合酶循环运动circular movement rum 朗姆酒Y.亚显微的submicroscopic run-off 流出的…延胡索酸酶fumarase rupture 破裂研究和开发r…and d…S.saccharification 糖化演绎的deductive saccharification 糖化阳离子cation Saccharomyces cerevisiae 酿酒酵母阳离子交换树脂cationic resin saturated 饱和的氧oxygen scalability 可测量性氧化oxidation sec-butyl arcohol 仲-丁醇氧化还原redox secondary metabolites 次级代谢产物氧化还原酶oxidoreductase seed 接种氧化剂oxidizing agent segment 部分氧化酶Oxidase semiaerobic 半好养的摇瓶shake flask sexual descendent 有性后代一般性费用general expenses shake flask 摇瓶一旦感染上at the onset of infection shikonin 紫草素一致,保守consensus shotgun cloning 散弹枪式克隆胰蛋白酶trypsin shuttle 穿梭般运输胰岛素trysin single pass 流经一次移植explant single site 唯一的切点移种subculturing single stranded end 粘性互补末端乙醇ethylene sloped-bottom cone-roof tanks 斜底锥顶罐乙二醇ethylene slurry 浆乙酰辅酶A Acetyl coenzyme A soak 浸泡乙酰化acetylation sodium 钠乙酰基转移酶transacetylase sodium nitrate 硝酸钠乙型肝炎hepatitis B solute 溶质异丙醇isopropyl alcohol spent culture 发酵废液异构酶isomerase spent hops 酒花糟异构酶isomerase spirit drink 蒸馏酒异构体isomer spoilage 变质,腐败异柠檬酸isocitric acid spray jet 喷嘴抑制repression stack 塔,重叠译,录下transcribe stands at 保持在阴离子anion starch 淀粉樱桃cherry start sites 起点有分歧的divergent steam-sterilized 蒸汽灭菌有机化合物organic compound stereochemical立体异构有机化能营养菌chemo-organotrophs steric 立体的有机磷organophosphates sterilization 灭菌有性后代sexual descendent still 蒸馏器有氧呼吸aerobic respiration stirrer shaft 搅拌轴有助于conducive stirring gear 搅拌装置诱导induction strength 浓度诱发的inductive Streptomyces 链霉菌属鱼胶isinglass streptomycin 链霉素与生长偶联的产物growth-associated product strip 萃取元素element subculturing 移种原核生物界kingdom procaryotae submerged coils 浸没式蛇管原料raw materials submicroscopic 亚显微的原料feedstocks substitutive 取代基命名法原培养物primary culture succinic acid 琥珀酸原生动物protozoa succinyl 琥珀酰原生生物界Monera sucrose 蔗糖原子价valence sugar-refining 糖的精制圆筒锥底的cylindro-conical sulfur 硫运行成本operation cost supernatant 上清液Z.杂交子 hybrid supervision 管理载体vector surveillance 监视,监督再生regenerate suspended solid 悬浮固形物在生长的最高峰at the peak of growth symbol 符号增加increment synthesis 合成粘性的培养物viscous culture syrup 糖浆粘性互补末端single stranded end T.tasteless 无味的折旧depreciation taxoid 紫杉烷蔗糖sucrose taxol紫杉醇真菌fungi tetracycline resistantance 抗四环素基因真菌界kingdom mycetae tetracycline sensitive 四环素敏感的真空浓缩vacuum concentration therapeutically 治疗真细菌类Eubacteria thermostable 耐热的蒸发vaporize three-level four-variable 四因素三水平蒸馏distillation time course 随时间的过程图蒸馏distillation tissue culture 组织培养蒸馏酒spirit drink top fermentation 上面发酵蒸馏酒distilled spirit total organic carbon 总有机碳蒸馏器still transacetylase 乙酰基转移酶蒸馏物distillate transaminase 氨基转移酶蒸汽灭菌steam-sterilized transcribe 译,录下支链淀粉酶pullulanase transcription 转录脂蛋白lipoprotein transeliminase 反式消去酶脂肪酶lipase transformable 可转化的脂肪族二元醇类glycol transformant 转化子直接生产成本direct operation cost transformation 转化植物界kingdom plantae transformed cells 转化的细胞酯化esterfy transgenic 转基因的酯化酶esterases transglycosidase 核苷转移酶制药的pharmaceutical translate 翻译制造成本manufacturing cost transmethylase甲基转移酶治疗therapeutically transphosphorylase 磷酸转移酶质粒plasmid tricarboxylic 三羧酸的致病菌pathogen tricarboxylic acid cycle 三羧酸循环中和neutralization trimethylene 三亚甲基二醇中间产物intermediate compounds trisaccharide 三糖中间产物intermediates trough 槽中性neutrality trypsin 胰蛋白酶中性酒精neutral spirit trysin 胰岛素仲-丁醇sec-butyl arcohol tun 装酒的大酒桶重叠的overlapping U.ultrafiltration 超滤重新连接的质粒ligated plasmid mixture unit 结合重组蛋白recombinant proteins unit operation 单元操作重组质粒recombinant plasmid upflow 上行轴承bearing urate 尿酸盐煮出decoction uricase 尿酸氧化酶贮藏啤酒lager utilities 公用设施专性的obligate V.vacuum concentration 真空浓缩转氨酶aminotransferase valence 原子价转化transformation vaporize 蒸发转化的细胞transformed cells variable cost 可变成本转化子transformant vector 载体转基因的transgenic vertical bottom fermenters 平形底发酵罐转录transcription vessel wall 罐壁装酒的大酒桶tun viscous culture 粘性的培养物锥底发酵罐conical bottom fermenters vodka 伏特加资金总额capital investment volatile 挥发性的紫草素shikonin volatile organic compound 挥发性有机物紫花苜蓿alfalfa vortex 漩涡紫杉醇taxol W.waste water treatment 废水处理紫杉烷taxoid well-modified malt 溶解性好的麦芽自身复制的微生物replicating microorganism whey 乳清自由基radical whisky 威士忌总有机碳total organic carbon with simultaneous dextrin hydrolysis同时进行糊精水解租金rent wort 麦汁阻遏子repressor X.Xanthomonas 黄单胞杆菌组成型constitutively xylanase木糖酶组织培养tissue culture xylose 木糖祖先的ancestral Z.zest 风味最终产物阻遏end-product repression IUPAC International Union of Pure and Chemistry。
c文章中单词查找课程设计

c 文章中单词查找课程设计一、教学目标本课程旨在通过文章中单词查找的学习,让学生掌握单词查找的基本方法和技巧,提高阅读理解能力。
具体目标如下:知识目标:使学生了解单词查找的重要性,理解单词查找的基本方法,掌握字典的使用技巧。
技能目标:培养学生快速准确查找文章中单词的能力,提高学生的阅读理解速度和准确度。
情感态度价值观目标:培养学生对英语阅读的兴趣,增强学生通过单词查找提高阅读理解能力的自信心。
二、教学内容本课程的教学内容主要包括单词查找的方法和技巧,以及如何通过单词查找提高阅读理解能力。
具体包括以下几个方面:1.单词查找的方法:根据文章的上下文推测单词的意思,使用字典查找单词的准确含义,通过同义词和反义词查找单词的用法。
2.单词查找的技巧:快速定位单词的位置,根据单词的前缀和后缀判断单词的意思,通过词根词缀记忆单词的含义。
3.文章阅读理解:通过单词查找提高文章阅读的速度和准确度,理解文章的主旨和细节,分析文章的结构和逻辑。
三、教学方法为了激发学生的学习兴趣和主动性,本课程将采用多种教学方法,包括讲授法、讨论法、案例分析法和实验法等。
1.讲授法:教师通过讲解单词查找的方法和技巧,使学生掌握基本的单词查找知识。
2.讨论法:学生分组讨论单词查找的案例,分享彼此的查找方法和经验,提高查找技巧。
3.案例分析法:分析文章中的单词查找实例,引导学生运用所学知识和技巧解决问题。
4.实验法:学生自主进行单词查找实验,验证所学方法和技巧的有效性,提高阅读理解能力。
四、教学资源为了支持教学内容和教学方法的实施,丰富学生的学习体验,我们将选择和准备以下教学资源:1.教材:选用权威的英语阅读教材,提供丰富的单词查找实例和练习题。
2.参考书:推荐学生阅读英语阅读参考书籍,拓展学生的阅读视野。
3.多媒体资料:利用多媒体课件和视频资料,生动形象地展示单词查找的方法和技巧。
4.实验设备:为学生提供电脑、字典等实验设备,方便学生进行单词查找实验。
ScienceDirect数据库检索与利用 ppt课件

ACS
Wiley
Springer
Polymer
Journals…
Journals…
Journals…
Cell
Other journals
登录数据库
• 通过所在机构图书馆的链接 • 在浏览器地址栏中输入: • 登录方式基于IP控制,没有并发用户限制
1ST 日程
• 了解Elsevier • Elsevier旗舰产品-SciVerse ScienceDirect • 访问SciVerse ScienceDirect • 快速掌握SciVerse ScienceDirect使用要领 • 相关资源及支持站点
Open to Accelerate Science SciVerse-ScienceDirect
爱思唯尔科技部
SciVerse平台个人统一化登录
可分别访问Hub、SD及Scopus资源 整合SD、Scopus、Scirus资源
登录账号统一
3
SciVerse Hub 基本检索
基本检索,数据来源于SD、Scopus、Scirus
Scopus中引用情况
SD中相关参考工具书
检索结果查看与处理
查找一篇参考 文献的全文
检索语言与检索技巧
AND OR AND NOT
默认算符,要求多个检索词同时出现在文章中 检索词中的任意一个或多个出现在文章中 后面所跟的词不出现在文章中
通配符 *
通配符 ?
W/n PRE/n “”
{} ()
取代单词中的任意个(0,1,2…)字母 如transplant* 可以检索到transplant, transplanted, transplanting…
• 从SciVerse ScienceDirect平台拓展至其他专业资源
统计英语词汇出现频率的书

统计英语词汇出现频率的书
统计英语词汇出现频率的书有很多,下面为你介绍《英爆词汇频率统计+词根记忆高考版》。
这本书是一套关于词汇使用频率统计排名的工具书,内容包括词频、释义频率、常见发音、英美差异和使用场景分布比例等。
该系列书籍的编者是陆志晶,已出版《英爆词汇频率统计+词根记忆高考版》,后期将陆续出版四级版、六级版、专业四级版、专业八级版、托福版、雅思版、GRE版等。
《英爆词汇频率统计+词根记忆高考版》在淘宝、微信、官网等均有销售,感兴趣的话可以前往购买。
程序设计综合课程设计题目

程序设计综合课程设计题目1.运动会分数统计任务:参加运动会有n个学校,学校编号为1……n。
比赛分成m个男子项目,和w个女子项目。
项目编号为男子1……m,女子m+1……m+w。
不同的项目取前五名或前三名积分;取前五名的积分分别为:7、5、3、2、1,前三名的积分分别为:5、3、2;哪些取前五名或前三名由学生自己设定。
(m<=20,n<=20)功能要求:1)可以输入各个项目的前三名或前五名的成绩;2)能统计各学校总分,3)可以按学校编号或名称、学校总分、男女团体总分排序输出;4)可以按学校编号查询学校某个项目的情况;可以按项目编号查询取得前三或前五名的学校。
5)数据存入文件并能随时查询6)规定:输入数据形式和范围:可以输入学校的名称,运动项目的名称输出形式:有合理的提示,各学校分数为整形界面要求:有合理的提示,每个功能可以设立菜单,根据提示,可以完成相关的功能要求。
存储结构:学生自己根据系统功能要求自己设计,但是要求运动会的相关数据要存储在数据文件中。
(数据文件的数据读写方法等相关内容在c语言程序设计的书上,请自学解决)请在最后的上交资料中指明你用到的存储结构;测试数据:要求使用1、全部合法数据;2、整体非法数据;3、局部非法数据。
进行程序测试,以保证程序的稳定。
测试数据及测试结果请在上交的资料中写明;2.飞机订票系统任务:通过此系统可以实现如下功能:录入:可以录入航班情况(数据可以存储在一个数据文件中,数据结构、具体数据自定)查询:可以查询某个航线的情况(如,输入航班号,查询起降时间,起飞抵达城市,航班票价,票价折扣,确定航班是否满仓);可以输入起飞抵达城市,查询飞机航班情况;订票:(订票情况可以存在一个数据文件中,结构自己设定)可以订票,如果该航班已经无票,可以提供相关可选择航班;退票:可退票,退票后修改相关数据文件;客户资料有姓名,证件号,订票数量及航班情况,订单要有编号。
修改航班信息:当航班信息改变可以修改航班数据文件要求:根据以上功能说明,设计航班信息,订票信息的存储结构,设计程序完成功能;3.文章编辑功能:输入一页文字,程序可以统计出文字、数字、空格的个数。
高中英语单词检索词汇总表(人教版)(必修1至选修8)

adj.感激的;表示谢意的 ['greɪtfəl] n.&vt.不喜欢;厌恶 参加;加入 n.提示;技巧;尖;尖端;小费 vt.倾斜;翻倒 [tɪp] adv.第二;其次 vt.交换 n.项目;条款 n.地下人行道;<美>地铁 ['sʌbweɪ] n.电梯;升降机 ['elɪveɪtə] [swɒp] [dɪsˈlaɪk]
n.<英>卡车(=<美>truck) [ˈlɒri] n.罗丽(女名) n.休斯顿(美国城市) n.德克萨斯州(美国州名) [ˈteksəs] n.口音;腔调;重音 [ˈæksənt]
必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1 必修1
Unit 2 Unit 2 Unit 2 Unit 2 Unit 2 Unit 2 Unit 2 Unit 2 Unit 2 Unit 2 Unit 2 Unit 2 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3 Unit 3
n.伙伴;合作者;合伙人 [ˈpɑːtnə] vi.安家;定居;停留 vt.使定居;安排;解决 [ˈset(ə)l] vt.&vi.遭受;忍受;经历 [ˈsʌfə] 遭受;患病 n.孤单;寂寞 n.公路;大路;<美>高速公路 [ˈhaɪweɪ] vi.&vt.痊愈;恢复;重新获得 [rɪˈkʌvə] 对„„厌烦 vi.&vt.捆扎;包装;打行李 n.小包;包裹 [pæk] 将(东西)装箱打包 n.手提箱;衣箱 n.玛戈特(女名) n.大衣;外套 n.十几岁的青少年 与„„相处;进展 vi.&n.闲话;闲谈 相爱;爱上 adv.确实如此;正是;确切地 [ɪg'zæktli] vi.不同意 [dɪsəˈɡriː] [ˈəʊvəkəʊt] [ˈtiːneɪdʒə] [ˈsjuːtkeɪs]
英语名词词汇速查手册

英语名词词汇速查手册English Noun Vocabulary Quick Reference ManualIntroduction:The English language is enriched with a wide range of nouns that form the foundation of effective communication. From everyday objects to abstract concepts, nouns play a crucial role in expressing ideas and thoughts. This quick reference manual aims to provide a comprehensive overview of commonly used English nouns, facilitating a better understanding of their meanings and usage.Section 1: PersonNouns that refer to individuals or groups of people fall under this category.1.1 Singular Nouns- Man: A male human being.- Woman: A female human being.- Child: A young human.- Teacher: A person who imparts knowledge to others.- Doctor: A medical professional.1.2 Plural Nouns- Men: More than one male individual.- Women: More than one female individual.- Children: More than one young human.- Teachers: More than one person who imparts knowledge to others. - Doctors: More than one medical professional.Section 2: PlaceNouns that denote locations or settings are covered in this section.2.1 Common Places- Home: A place where one lives.- School: An institution for learning.- Hospital: A medical facility for patient care.- Park: An area for recreation and relaxation.- Restaurant: An establishment that serves meals.2.2 Geographical Places- Mountain: A high landform with steep sides.- River: A large flowing watercourse.- Beach: A sandy or pebbly shoreline.- Forest: An area with dense trees and vegetation.- Desert: A barren land with sparse vegetation.Section 3: ThingObjects, substances, or entities are encompassed in this section.3.1 Everyday Objects- Chair: A piece of furniture for sitting.- Table: A flat surface for various purposes.- Book: A written or printed work.- Computer: An electronic device for processing information. - Car: A motor vehicle for transportation.3.2 Abstract Concepts- Love: A deep affection or attachment.- Friendship: A mutual bond between individuals.- Knowledge: Information acquired through learning.- Happiness: A state of joy and contentment.- Success: Achievement of a desired goal.Section 4: IdeaIntangible concepts and notions belong to this section.4.1 Creativity- Art: Expression of human skill and imagination.- Music: Sounds organized in a harmonious way.- Literature: Written works of artistic value.- Poetry: Expressive writing characterized by rhythm and meter.- Dance: Movement and rhythm performed with artistic intent.4.2 Communication- Language: System of communication used by a particular group.- Conversation: Verbal exchange between individuals.- Writing: Representation of language through text.- Gesture: Body movement conveying a message.- Expression: Display of thoughts or feelings.Conclusion:This English Noun Vocabulary Quick Reference Manual aims to provide a helpful resource for individuals seeking to enhance their grasp of English nouns. Organized by categories, this manual covers a wide range of nouns, from persons and places to things and ideas. By referring to this manual, readers can deepen their understanding of English vocabulary and improve their communication skills.。
人教版(2019)必修1-选择性必修4 单词短语检索表(字母顺序版)

偶然地;意外地 (与…)相比较 相比之下 (短暂地)访问;要求某人讲话 二氧化碳 继续做,坚持干 帮助某人渡过难关 着火 (在旅馆、机场等)登记 结账离开(旅馆等) 圣诞颂歌 打扫(或清除)干净 跟随;到达;进步;赶快 患(病);染上(小病) 得出结论 (开始)掌权;上台 舒适区;舒适范围 承诺;保证(做某事等) 与……比较 集中精力于 对……关切的;为……担忧的 与…冲突或抵触 由…组成(或构成) 相反的;相对立的 adj.方便的;近便的 (使)花一大笔钱 信用卡 文化冲击 停止做(或使用、食用);剪下 日常生活 追溯到 日日夜夜;夜以继日 决定;选定 在内心深处;本质上;实际上 把…用于;献身;致力;专心 灭亡;逐渐消失 n.点心(中国食品) 向……捐赠…… 许多;很多 穿上盛装;装扮 由于;因为 在初期;早先 谋生 触电;电击 (使)从事;参与 即使;虽然 除…之外 面朝下
面朝上 逐渐消失;(身体)变得虚弱 破裂;破碎;崩溃 (逐渐)减少;消失 爱上 舒服自在;不拘束 弄懂;弄清楚;弄明白 美术(尤其绘画和雕塑) 急救 急救箱 教学卡片;识字卡 灭蚤颈圈 集中;特别关注 例如;比如 幸运曲奇 化石燃料(如煤或石油) 极冷的;冻僵的 从那时起 一般来说 参与;卷入;与…有关联 (设法)处理;完成 放出(热/光/气味/气体) 放弃;投降 让步;屈服 爆炸;走火;离开 经历;度过;通读 n.灰熊 有强烈的欲望做某事 (兴趣、想法等方面)相同 起步前的优势 (朝…)前进;(向…)去 帮助某人站起身来 以一种…的方式 独领风骚 除……以外(还) 以防;以防万一 主管;掌管 最后 处于绝望中 在手头;可供使用 作为对…的纪念 换句话说;也就是说 尤其;特别 回答;答复 作为回报;作为回应 严重受损;破败不堪 状况良好 震惊;吃惊
英语单词查询方法

英语单词查询方法一、纸质词典。
1. 牛津词典(Oxford Dictionary)- 查询方式。
- 按照字母顺序查找单词。
例如,要查找“apple”这个单词,先找到字母“a”的部分,然后在以“a”开头的单词中找到“apple”。
- 音标、词性显示。
- 音标:采用国际音标(IPA)准确标注单词发音。
例如,“apple”的音标:[ˈæpl]。
- 词性:用缩写形式标注。
名词(n.),动词(v.),形容词(adj.)等。
对于“apple”,它的词性是名词,标注为n.。
2. 朗文词典(Longman Dictionary)- 查询方式。
- 同样是按字母顺序查找。
如果查找“book”,在字母“b”的词条中找到它。
- 音标、词性显示。
- 音标:清晰准确地给出单词发音的音标。
如“book”的音标:[bʊk]。
- 词性:以缩写形式体现。
“book”可作名词(n.)和动词(v.),词典中会分别列出不同词性下的释义和用法。
二、电子词典(手机APP或电脑软件)1. 有道词典。
- 查询方式。
- 可以直接在搜索框输入要查询的单词。
如输入“cat”,很快就能显示结果。
- 音标、词性显示。
- 音标:准确显示单词音标,“cat”的音标:[kæt]。
- 词性:用缩写标注。
“cat”的词性为名词(n.),同时还会显示该单词的复数形式(cats)等相关语法信息。
2. 欧路词典。
- 查询方式。
- 支持输入单词查询,也可以使用拍照取词(在手机端)等功能。
若查询“dog”,输入后即可获取结果。
- 音标、词性显示。
- 音标:提供标准音标,“dog”的音标:[dɒg]。
- 词性:以缩写形式给出,“dog”为名词(n.),并且会给出一些常用搭配,如“a pet dog(宠物狗)”等用法示例。
学术会议录文献的检索与使用

提纲
• 会议录文献是学术文献的重要组成部分 • ISI Proceedings 的收录范围 • ISI Proceedings 的检索 • ISI Proceedings的分析与连接功能 • ISI Proceedings的检索结果处理 • 小结
标记感兴趣的记录
标记检索结果的方式 有三种: 在记录前的复选框中 做标记; 标记该页面的所有记 录; 选择某些特定的记录 范围
重新设置检 索数据库和 时间范围
Search 一般检索:
-主题 -作者或编者 -来源会议录刊名 -会议信息
作者或团体作者的检索
作者姓名的输入方式
为姓,空格后跟名的首 字母,如 Li XG
当机构名称作为文章的 作者时,则按照团体作者 处理.如Chinese Univ Hong Kong. 可使用团体作者索引查 找团体作者的准确写法
– IEEE, SPIE, ACM等协会出版的会议录
• Social Sciences & Humanities (ISSHP)包括所有的社会科学、艺术与人文领域:
– 心理学、社会学、公共卫生、管理学、经济学、艺术、历史、文学、哲学等 – 每年2,800多个会议录
ISI Proceedings: 特点
• Related Records提供与该文献相关的会议录文献
• Citing Articles (施引文献)可连接到Web of Science中检索引用该会议文献所 的期刊文献
浏览参考文献
连接到Web of Science来浏览该 文献
察看相关记录获得更多与该研究相关的信息
链接到Web of Science数据库中了解被引用情况
Thomson Scientific
基于不同策略的英文单词的词频统计和检索系统总结

基于不同策略的英文单词的词频统计和检索系统总结
基于不同策略的英文单词的词频统计和检索系统可以有效地帮助用户统计和检索英文单词。
系统的设计通常包括以下几个方面:
1. 数据预处理:系统需要对文本数据进行预处理,包括去除标点符号、转换大小写等操作,以便准确地统计词频和进行检索。
2. 词频统计:系统可以基于不同的策略进行词频统计。
一种常见的策略是统计每个单词在文本中出现的次数,从而得到单词的频率。
另一种策略是统计每个单词在文本中出现的频率百分比,以便更好地了解单词在整个文本中的重要程度。
3. 检索功能:系统可以根据用户的输入进行单词的检索。
用户可以输入单词的拼写或部分拼写进行模糊匹配,系统将返回与用户输入相似的单词,并提供其词频统计结果。
系统还可以提供基于词义的检索功能,用户可以输入单词的意思进行检索,系统将返回与用户输入意思相符的单词及其词频统计结果。
4. 可视化展示:为了更好地呈现词频统计结果,系统通常提供可视化展示功能。
可以通过柱状图、饼图等方式展示单词的词频分布,在图表中直观地显示单词的重要程度和数量。
总的来说,基于不同策略的英文单词的词频统计和检索系统能够帮助用户快速准确地统计和检索英文单词,从而提高用户对文本内容的理解和应用能力。
按词频排序的大量词汇书

按词频排序的大量词汇书
一、创建词汇表。
1. 收集词汇来源。
- 可以从多种渠道收集词汇,如经典的英语教材(如人教版英语教材各年级的单词汇总)、权威的英语语料库(如英国国家语料库BNC、美国当代英语语料库COCA)等。
2. 确定词频统计方法。
- 使用专门的词频统计工具,如AntConc等软件。
将收集到的文本导入工具中,就可以得到按词频排序的单词列表。
3. 添加发音和词性标注。
- 发音:
- 词性:
- 根据单词在句子中的语法功能确定词性。
例如,“run”可以是动词(v.),表示“跑;运行”,也可以是名词(n.),表示“奔跑;路程”。
同样可以参考词典进行准确标注。
二、排版示例(以部分词汇为例)
单词发音词性。
the [ðə; ðiː] art.(冠词)
be [biː] v.(动词,系动词)
and [ænd; ən(d)] conj.(连词)
a [ə; eɪ] art.(冠词)
in [ɪn] prep.(介词)
如果要制作成词汇书,还可以在单词后添加例句,以帮助更好地理解单词的用法。
例如:
单词发音词性例句。
the [ðə; ðiː] art.(冠词) The book is on the table.(书在桌子上。
)
be [biː] v.(动词,系动词) I will be there tomorrow.(我明天会在那里。
)。
oxford read and discover词汇

oxford read and discover词汇摘要:1.牛津阅读发现词汇的简介2.牛津阅读发现词汇的特点3.使用牛津阅读发现词汇的好处4.如何有效使用牛津阅读发现词汇正文:【牛津阅读发现词汇的简介】牛津阅读发现词汇是由著名的牛津大学出版社出版的一套英语词汇学习资源。
该系列词汇书以丰富的主题和详尽的解释为特点,旨在帮助英语学习者在阅读和探索的过程中提高词汇量,拓宽知识面。
【牛津阅读发现词汇的特点】牛津阅读发现词汇系列具有以下几个显著特点:1.主题丰富:该系列词汇书包含了众多主题,如科学、历史、文化等,满足了英语学习者多样化的学习需求。
2.词汇量大:每个主题的词汇书中都收录了大量的词汇,且这些词汇都是经过严格筛选的,具有较高的实用性和常见性。
3.释义详细:牛津阅读发现词汇对每个词汇的解释都十分详细,除了基本的词义之外,还包括了用法、同义词、反义词等信息,帮助学习者全面掌握词汇。
4.例句丰富:书中提供了大量的例句,让学习者在实际语境中理解和记忆词汇,提高了学习的效果。
【使用牛津阅读发现词汇的好处】使用牛津阅读发现词汇的好处有以下几点:1.提高词汇量:通过学习该系列词汇书,英语学习者可以迅速提高自己的词汇量,为阅读和写作打下坚实的基础。
2.拓宽知识面:牛津阅读发现词汇涵盖了多个领域的知识,帮助学习者在学习语言的同时,也增加了对各方面知识的了解。
3.增强阅读理解能力:书中的例句和实际语境,有助于提高学习者的阅读理解能力,使他们能够更好地理解和把握文章的内容。
4.提高写作能力:通过学习牛津阅读发现词汇,英语学习者可以丰富自己的词汇表达,使写作更具表现力和说服力。
【如何有效使用牛津阅读发现词汇】要有效使用牛津阅读发现词汇,可以采取以下几种方法:1.制定学习计划:根据自己的学习进度和需求,制定合理的学习计划,每天学习一定数量的词汇。
2.多做练习:在学习过程中,可以多做一些练习,如填空题、同义词辨析等,以巩固所学词汇。
(2016年1月完美版)(人教版)初中英语单词检索词汇总表(分教材按单元顺序)(七年级至九年级全5册)
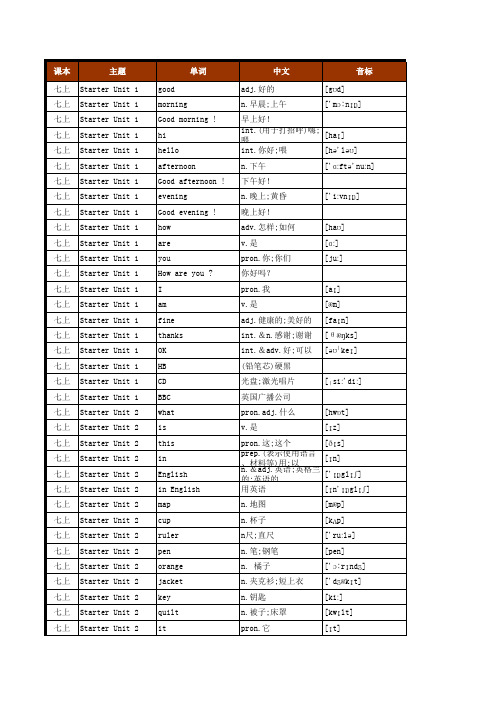
n.家;家庭 pron.那些 pron.谁;什么人 int.哦;啊 pron.这些
['fæmɪli] [ðəʊz] [huː] [əʊ] [ðiːz]
pron.,他(她、它)们 [ðeɪ] int.嗯;好吧 v.经受;经历 n.一天;一日;白天 (表示祝愿)过得愉快! int.再见 n.儿子 [sʌn] [wel] [hæv] [deɪ]
a that spell please. NBA P=parking kg=kilogram color (=colour) red yellow green blue black white purple brown the now see can say my S M L UFO CCTV name nice to meet too your Ms. his and her
单词
中文 adj.好的 n.早晨;上午 早上好! int.(用于打招呼)嗨;喂 [haɪ] int.你好;喂 n.下午 下午好! n.晚上;黄昏 晚上好! adv.怎样;如何 v.是 pron.你;你们 你好吗? pron.我 v.是 adj.健康的;美好的 int.&n.感谢;谢谢 int.&adv.好;可以 (铅笔芯)硬黑 光盘;激光唱片 英国广播公司 pron.adj.什么 v.是 pron.这;这个 [hwɒt] [ɪz] [ðɪs] [aɪ] [æm] [faɪn] [haʊ] [ɑː] [juː] [gʊd]
art.(用于单数可数名词前,表示未曾提到的)一(人、事、物) [eɪ] pron.那;那个 v.用字母拼;拼写 [ðæt] [spel]
int.(用于客气地请求或吩咐)请 (美国)全国篮球协会 停车场;停车位 千克;公斤 n.颜色 adj.&n.红色(的) adj.&n.黄色(的) adj.&n.绿色(的) adj.&n.蓝色(的) adj.&n.黑色(的) adj.&n.白色(的) adj.&n.紫色(的) [red] ['jeləʊ] [griːn] [bluː] [blæk] [hwaɪt] ['pɜːpl]
全一册英语词汇检索表

SN Book Unit Word Part of Speech 13B Unit 1and23B Unit 1ball33B Unit 1black43B Unit 1blue53B Unit 1colour63B Unit 1find73B Unit 1green83B Unit 1matter93B Unit 1mix103B Unit 1red113B Unit 1white123B Unit 1yellow133B Unit 2candy143B Unit 2ice cream153B Unit 2lemon163B Unit 2how173B Unit 2orange183B Unit 2sour193B Unit 2sweet203B Unit 2taste213B Unit 3bike223B Unit 3bus233B Unit 3can243B Unit 3car253B Unit 3hear263B Unit 3listen273B Unit 3plane283B Unit 3ship293B Unit 3train303B Unit 3sound313B Unit 3monster323B Unit 3worry333B Unit 4bear353B Unit 4elephant 363B Unit 4like373B Unit 4lion383B Unit 4man 393B Unit 4monkey 403B Unit 4our413B Unit 4panda 423B Unit 4strong 433B Unit 4tiger 443B Unit 4hat453B Unit 4old463B Unit 5fun473B Unit 5lovely 483B Unit 5play 493B Unit 5robot 503B Unit 5sorry 513B Unit 5super 523B Unit 5toy bear 533B Unit 5kite543B Unit 6about 553B Unit 6biscuit 563B Unit 6bread 573B Unit 6have 583B Unit 6breakfast 593B Unit 6child 603B Unit 6egg613B Unit 6juice 623B Unit 6milk 633B Unit 6some 643B Unit 6too653B Unit 6water 663B Unit 7at home 673B Unit 7come in693B Unit 7paint 703B Unit 7read 713B Unit 7sing 723B Unit 7skate 733B Unit 7sleep 743B Unit 7swim 753B Unit 7work 763B Unit 7worker 773B Unit 7hobby 783B Unit 8blow 793B Unit 8cake 803B Unit 8card 813B Unit 8cut823B Unit 8birthday 833B Unit 8dear 843B Unit 8for853B Unit 8how old 863B Unit 8noodle 873B Unit 8to883B Unit 8together 893B Unit 8wish 903B Unit 9animal 913B Unit 9bye 923B Unit 9cow 933B Unit 9farm 943B Unit 9gate 953B Unit 9grass 963B Unit 9great 973B Unit 9horse 983B Unit 9litter 993B Unit 9pig 1003B Unit 9sheep 1013B Unit 9stone1023B Unit 9throw 1033B Unit 10arm 1043B Unit 10head 1053B Unit 10body 1063B Unit 10cartoon 1073B Unit 10foot 1083B Unit 10hand 1093B Unit 10leg1103B Unit 11cup 1113B Unit 11day 1123B Unit 11do1133B Unit 11flower 1143B Unit 11frame 1153B Unit 11idea 1163B Unit 11love 1173B Unit 11photo 1183B Unit 11tea 1193B Unit 12afraid(of) 1203B Unit 12bad 1213B Unit 12go1223B Unit 12house 1233B Unit 12little 1243B Unit 12make 1253B Unit 12now 1263B Unit 12there 1273B Unit 12very 1284A Unit 1meet 1294A Unit 1new 1304A Unit 1morning 1314A Unit 1classmate 1324A Unit 1her 1334A Unit 1name 1344A Unit 1sit1354A Unit 1afternoon1384A Unit 2fast1394A Unit 2fly1404A Unit 2draw1414A Unit 2write1424A Unit 2jump1434A Unit 2welcome 1444A Unit 2woof1454A Unit 2but1464A Unit 3happy 1474A Unit 3sad1484A Unit 3tired1494A Unit 3hungry 1504A Unit 3full1514A Unit 3thirsty 1524A Unit 3bird1534A Unit 3see1544A Unit 3bottle 1554A Unit 3drink1564A Unit 4any1574A Unit 4cousin 1584A Unit 4family 1594A Unit 4parent 1604A Unit 4grandparent 1614A Unit 4son1624A Unit 4grandfather 1634A Unit 4uncle1644A Unit 4aunt1654A Unit 4that1664A Unit 5T-shirt 1674A Unit 5brown 1684A Unit 5shorts 1694A Unit 5ride1724A Unit 5shirt 1734A Unit 5tooth 1744A Unit 5sharp 1754A Unit 5help 1764A Unit 5 a pair of 1774A Unit 5get out 1784A Unit 6nurse 1794A Unit 6fireman 1804A Unit 6teacher 1814A Unit 6doctor 1824A Unit 6bus driver 1834A Unit 6kid1844A Unit 6so1854A Unit 6fire1864A Unit 6people 1874A Unit 6job1884A Unit 6play with 1894A Unit 7school 1904A Unit 7office 1914A Unit 7busy 1924A Unit 7computer 1934A Unit 7many 1944A Unit 7library 1954A Unit 7playground 1964A Unit 7classroom 1974A Unit 7toilet 1984A Unit 7animal 1994A Unit 7forest 2004A Unit 7pupil 2014A Unit 7try2024A Unit 7first2034A Unit 7climb trees2054A Unit 8tomato 2064A Unit 8soup2074A Unit 8potato 2084A Unit 8carrot 2094A Unit 8thirty2104A Unit 8fish2114A Unit 8meat2124A Unit 8rice2134A Unit 8glasses 2144A Unit 8want2154A Unit 8together 2164A Unit 8magic 2174A Unit 9need2184A Unit 9where 2194A Unit 9in2204A Unit 9box2214A Unit 9give2224A Unit 9plate2234A Unit 9on2244A Unit 9table2254A Unit 9lunch2264A Unit 9under 2274A Unit 9beside 2284A Unit 9kitchen 2294A Unit 9floor2304A Unit 9angry2314A Unit 10around 2324A Unit 10home 2334A Unit 10street 2344A Unit 10park2354A Unit 10near2364A Unit 10behind 2374A Unit 10supermarket2384A Unit 10restaurant 2394A Unit 10live 2404A Unit 10old2414A Unit 10eat2424A Unit 10nice 2434A Unit 10food 2444A Unit 10a lot of 2454A Unit 11shape 2464A Unit 11picture 2474A Unit 11square 2484A Unit 11circle 2494A Unit 11star 2504A Unit 11rectangle 2514A Unit 11triangle 2524A Unit 11today 2534A Unit 11well 2544A Unit 12weather 2554A Unit 12rainy 2564A Unit 12cloudy 2574A Unit 12windy 2584A Unit 12sunny 2594A Unit 12Sunday 2604A Unit 12cloud 2614A Unit 12rain 2624A Unit 12sun 2634A Unit 12wind 2644B Unit 1touch 2654B Unit 1feel 2664B Unit 1soft 2674B Unit 1hard 2684B Unit 1thick 2694B Unit 1thin 2704B Unit 1blind 2714B Unit 1noise2724B Unit 1young 2734B Unit 2smell 2744B Unit 2strawberry 2754B Unit 2or2764B Unit 2watermelon 2774B Unit 2grape 2784B Unit 2fox2794B Unit 2round 2804B Unit 2purple 2814B Unit 2wait2824B Unit 2minute 2834B Unit 2get2844B Unit 2those 2854B Unit 3rise2864B Unit 3shadow 2874B Unit 3noon 2884B Unit 3high2894B Unit 3sky2904B Unit 3everning 2914B Unit 3again 2924B Unit 3night2934B Unit 3moon 2944B Unit 3him2954B Unit 3stop2964B Unit 3at noon 2974B Unit 3go down 2984B Unit 3at night 2994B Unit 3take a walk 3004B Unit 4subject 3014B Unit 4lesson 3024B Unit 4Chinese 3034B Unit 4Maths 3044B Unit 4English 3054B Unit 4science3064B Unit 4PE3074B Unit 4Music3084B Unit 4Art3094B Unit 4timetable 3104B Unit 4from3114B Unit 4 a.m.3124B Unit 4p.m.3134B Unit 4break3144B Unit 4from…to…3154B Unit 4sport3164B Unit 5football3174B Unit 5club3184B Unit 5join3194B Unit 5tell3204B Unit 5about3214B Unit 5basketball 3224B Unit 5volleyball 3234B Unit 5us3244B Unit 5table tennis 3254B Unit 5play football 3264B Unit 5play basketball 3274B Unit 5play volleyball 3284B Unit 6wonderful 3294B Unit 6violin3304B Unit 6guitar3314B Unit 6whose3324B Unit 6piano3334B Unit 6city3344B Unit 6bag3354B Unit 6glod3364B Unit 6all3374B Unit 6play the violin 3384B Unit 6play the guitar 3394B Unit 7o'clock3414B Unit 7time3424B Unit 7half3434B Unit 7wash3444B Unit 7dinner3454B Unit 7start3464B Unit 7catch3474B Unit 7get up3484B Unit 7bursh…teeth 3494B Unit 7half past 3504B Unit 7have breakfast 3514B Unit 7go to school 3524B Unit 7wash…face 3534B Unit 7have lunch 3544B Unit 7have dinner 3554B Unit 7go to bed 3564B Unit 8week3574B Unit 8Monday3584B Unit 8with3594B Unit 8Tuesday3604B Unit 8Wednesday 3614B Unit 8Thursday 3624B Unit 8Friday3634B Unit 8game3644B Unit 8Saturday 3654B Unit 8Sunday3664B Unit 8clock3674B Unit 8play chess 3684B Unit 8at the weekend 3694B Unit 8(be) late for 3704B Unit 9China3714B Unit 9talk3724B Unit 9May3734B Unit 9June3754B Unit 9February 3764B Unit 9March 3774B Unit 9April3784B Unit 9July3794B Unit 9August 3804B Unit 9September 3814B Unit 9October 3824B Unit 9November 3834B Unit 9December 3844B Unit 9email 3854B Unit 9hat3864B Unit 9wear3874B Unit 9yours 3884B Unit 9every year 3894B Unit 10garden 3904B Unit 10plant3914B Unit 10leaf3924B Unit 10water 3934B Unit 10them3944B Unit 10grow3954B Unit 10seed3964B Unit 10every day 3974B Unit 11song3984B Unit 11zoo3994B Unit 11cinema 4004B Unit 11museum 4014B Unit 11also4024B Unit 11have a party 4034B Unit 12ugly4044B Unit 12duckling 4054B Unit 12duck4064B Unit 12river4074B Unit 12baby4094B Unit 12quack4104B Unit 12back4114B Unit 12away4124B Unit 12swan4134B Unit 12into4145A Unit 1future4155A Unit 1want4165A Unit 1pilot4175A Unit 1teach4185A Unit 1cook4195A Unit 1taxi driver 4205A Unit 1job4215A Unit 1singer4225A Unit 1fall4235A Unit 1lifeguard 4245A Unit 1save4255A Unit 1become 4265A Unit 1(be)good at 4275A Unit 2by4285A Unit 2walk4295A Unit 2Ms4305A Unit 2journey4315A Unit 2primary school 4325A Unit 2underground 4335A Unit 2station4345A Unit 2take4355A Unit 2after4365A Unit 2hour4375A Unit 2bus stop 4385A Unit 2by bus4395A Unit 2far from 4405A Unit 2on foot4415A Unit 2by bike4435A Unit 2get off 4445A Unit 3party 4455A Unit 3when 4465A Unit 3begin 4475A Unit 3bring 4485A Unit 3thing4495A Unit 3favourite 4505A Unit 3interesting 4515A Unit 3hat4525A Unit 3have fun 4535A Unit 4usually 4545A Unit 4often 4555A Unit 4visit4565A Unit 4sometimes 4575A Unit 4always 4585A Unit 4never 4595A Unit 4play sport 4605A Unit 4go shopping 4615A Unit 5clever 4625A Unit 5same 4635A Unit 5class4645A Unit 5both4655A Unit 5cross4665A Unit 5carry4675A Unit 5heavy 4685A Unit 5different 4695A Unit 5bored 4705A Unit 5word 4715A Unit 5easy4725A Unit 5say4735A Unit 5then4745A Unit 5ask4755A Unit 5answer4765A Unit 5soon4775A Unit 5each other 4785A Unit 5make phone calls 4795A Unit 6life4805A Unit 6living room 4815A Unit 6bedroom4825A Unit 6model plane 4835A Unit 6kitchen4845A Unit 6bathroom4855A Unit 6their4865A Unit 6light4875A Unit 6watch4885A Unit 6TV4895A Unit 6before4905A Unit 6bedtime4915A Unit 6do…homework 4925A Unit 6turn off4935A Unit 6watch TV4945A Unit 6tell a story 4955A Unit 7beach4965A Unit 7enjoy4975A Unit 7sunshine4985A Unit 7collect4995A Unit 7shell5005A Unit 7sea5015A Unit 7letter5025A Unit 7put5035A Unit 7know5045A Unit 7year5055A Unit 7on holiday 5065A Unit 7have a good time 5075A Unit 8outing5085A Unit 8map5095A Unit 8hill5115A Unit 8diamond 5125A Unit 8another 5135A Unit 8lake5145A Unit 8funny 5155A Unit 8hole5165A Unit 8key5175A Unit 8think5185A Unit 8at the top of 5195A Unit 8get through 5205A Unit 9post office 5215A Unit 9quite5225A Unit 9along 5235A Unit 9turn5245A Unit 9left5255A Unit 9straight 5265A Unit 9right5275A Unit 9between 5285A Unit 9flower shop 5295A Unit 9hospital 5305A Unit 9toy shop 5315A Unit 9road5325A Unit 9get to 5335A Unit 10blow5345A Unit 10gently 5355A Unit 10softly 5365A Unit 10strongly 5375A Unit 10happily 5385A Unit 10windmill 5395A Unit 10move 5405A Unit 10slowly 5415A Unit 10quickly 5425A Unit 10sound 5435A Unit 10wind-bell5455A Unit 10paper5465A Unit 10quiet5475A Unit 11tap5485A Unit 11use5495A Unit 11vegetable 5505A Unit 11clothes5515A Unit 11farmer5525A Unit 11useful5535A Unit 11drop5545A Unit 11up5555A Unit 11shine5565A Unit 11over5575A Unit 11mountain 5585A Unit 11tree5595A Unit 11ground5605A Unit 11inside5615A Unit 11grow crop 5625A Unit 11put out fires 5635A Unit 12fire5645A Unit 12burn5655A Unit 12hurt5665A Unit 12must5675A Unit 12careful5685A Unit 12safety5695A Unit 12smoke5705A Unit 12match5715A Unit 12heat5725A Unit 12hate5735A Unit 12burn down 5745A Unit 12be careful with 5755A Unit 12not … at all 5765B Unit 1tidy5775B Unit 1mess5795B Unit 1sock5805B Unit 1yours 5815B Unit 1cap5825B Unit 1mine5835B Unit 1crayon 5845B Unit 1umbrella 5855B Unit 1nail5865B Unit 1drop5875B Unit 1stick5885B Unit 1second 5895B Unit 1hers5905B Unit 1theirs 5915B Unit 1tidy up 5925B Unit 1(be)full of 5935B Unit 1 a few 5945B Unit 2why5955B Unit 2because 5965B Unit 2study 5975B Unit 2dining room 5985B Unit 2wild goose 5995B Unit 2change 6005B Unit 2place 6015B Unit 2twice 6025B Unit 2every 6035B Unit 2north 6045B Unit 2south 6055B Unit 2enough 6065B Unit 2then6075B Unit 2all day 6085B Unit 3future 6095B Unit 3stand 6105B Unit 3machine 6115B Unit 3will6125B Unit 3exercise 6135B Unit 3early6145B Unit 3easily6155B Unit 3hard6165B Unit 3more6175B Unit 3in the future 6185B Unit 3in front of 6195B Unit 3take a photo 6205B Unit 3wear glasses 6215B Unit 3do exercise 6225B Unit 3(be) weak in 6235B Unit 3not…any more 6245B Unit 4storybook 6255B Unit 4buy6265B Unit 4story6275B Unit 4dictionary 6285B Unit 4magazine 6295B Unit 4newspaper 6305B Unit 4week6315B Unit 4student 6325B Unit 4poster6335B Unit 4best6345B Unit 4writer6355B Unit 4over there 6365B Unit 4do a survey 6375B Unit 4act…out 6385B Unit 5weekend 6395B Unit 5stay6405B Unit 5film6415B Unit 5boat6425B Unit 5plan6435B Unit 5tomorrow 6445B Unit 5build6455B Unit 5next6465B Unit 5swing6475B Unit 5cry6485B Unit 5until6495B Unit 5see a film 6505B Unit 5row a boat 6515B Unit 6holiday6525B Unit 6clear6535B Unit 6seafood 6545B Unit 6hotel6555B Unit 6island6565B Unit 6butterfly 6575B Unit 6how long 6585B Unit 6go swimming 6595B Unit 6in the south of 6605B Unit 6all year round 6615B Unit 7meet6625B Unit 7school gate 6635B Unit 7art room 6645B Unit 7hall6655B Unit 7finally6665B Unit 7meeting room 6675B Unit 7show6685B Unit 7project6695B Unit 7board6705B Unit 8which6715B Unit 8trousers 6725B Unit 8size6735B Unit 8sweater 6745B Unit 8coat6755B Unit 8shoe6765B Unit 8emperor 6775B Unit 8only6785B Unit 8nod6795B Unit 8smile6815B Unit 8keep6825B Unit 8laugh6835B Unit 8try…on6845B Unit 8put …on6855B Unit 8keep quiet 6865B Unit 8have a look 6875B Unit 9ill6885B Unit 9wrong6895B Unit 9headache6905B Unit 9fever6915B Unit 9should6925B Unit 9medicine6935B Unit 9rest6945B Unit 9toothache6955B Unit 9toothless6965B Unit 9present6975B Unit 9world6985B Unit 9dentist6995B Unit 9have a headache 7005B Unit 9have a fever 7015B Unit 9have a cold 7025B Unit 9have a rest 7035B Unit 9get well7045B Unit 9have a toothache 7055B Unit 9have a meeting 7065B Unit 9pull…out7075B Unit 10invention7085B Unit 10watch7095B Unit 10anywhere7105B Unit 10travel7115B Unit 10invent7125B Unit 10something 7135B Unit 10myself7155B Unit 10far away from 7165B Unit 11festival7175B Unit 11important7185B Unit 11call7195B Unit 11dumpling7205B Unit 11relative7215B Unit 11red packet7225B Unit 11firework7235B Unit 11monster7245B Unit 11end7255B Unit 11village7265B Unit 11last7275B Unit 11firecracker7285B Unit 11mooncake7295B Unit 11at the end of 7305B Unit 12giant7315B Unit 12wall7325B Unit 12kind7335B Unit 12through7345B Unit 12no entry7355B Unit 12(be) kind to 7365B Unit 12knock down 7376A Unit 1(be)born7386A Unit 1catch7396A Unit 1cute7406A Unit 1fly7416A Unit 1grow up7426A Unit 1handsome7436A Unit 1junior high school 7446A Unit 1month7456A Unit 1pretty7466A Unit 1turtle7476A Unit 10air7496A Unit 10balloon 7506A Unit 10clean7516A Unit 10dirty7526A Unit 10everywhere 7536A Unit 10factory 7546A Unit 10fresh7556A Unit 10hurt7566A Unit 10keep…alive 7576A Unit 10plant7586A Unit 10plant trees 7596A Unit 10smoke 7606A Unit 11cool7616A Unit 11cut…down 7626A Unit 11have to 7636A Unit 11look for 7646A Unit 11match7656A Unit 11miss7666A Unit 11wood7676A Unit 12Earth7686A Unit 12forest7696A Unit 12glass7706A Unit 12land7716A Unit 12ocean7726A Unit 12own7736A Unit 12part7746A Unit 12pick up 7756A Unit 12plastic bag 7766A Unit 12recycle 7776A Unit 12rubbish 7786A Unit 12shopping bag 7796A Unit 12sick7806A Unit 12so many 7816A Unit 2countryside7836A Unit 2everyone 7846A Unit 2famous7856A Unit 2pick7866A Unit 2spend7876A Unit 2summer holiday 7886A Unit 3 a little7896A Unit 3chicken7906A Unit 3chocolate 7916A Unit 3cola7926A Unit 3fish and chips 7936A Unit 3fruit7946A Unit 3hamburger 7956A Unit 3healthy7966A Unit 3pie7976A Unit 3pizza7986A Unit 3sandwich 7996A Unit 3unhealthy 8006A Unit 3vegetable 8016A Unit 3yesterday 8026A Unit 4daughter 8036A Unit 4dig8046A Unit 4make noise 8056A Unit 4neighbour 8066A Unit 4noisy8076A Unit 4owl8086A Unit 4son8096A Unit 5blue whale 8106A Unit 5die8116A Unit 5drive away 8126A Unit 5go for a walk 8136A Unit 5hundred8146A Unit 5in danger 8156A Unit 5in the past8176A Unit 5rhino8186A Unit 5send8196A Unit 5South China tiger 8206A Unit 5take care of 8216A Unit 5thousand8226A Unit 5way8236A Unit 5wild8246A Unit 6country8256A Unit 6e-friend8266A Unit 6grade8276A Unit 6hobby8286A Unit 6other8296A Unit 6team8306A Unit 6would like8316A Unit 6yourself8326A Unit 7asleep8336A Unit 7boring8346A Unit 7brave8356A Unit 7exciting8366A Unit 7fairest8376A Unit 7fall asleep8386A Unit 7kill8396A Unit 7mirror8406A Unit 7next time8416A Unit 7once upon a time 8426A Unit 7police8436A Unit 7policeman8446A Unit 7princess8456A Unit 7queen8466A Unit 7shall8476A Unit 8ant8486A Unit 8anything8496A Unit 8bee8506A Unit 8car museum 8516A Unit 8dancer8526A Unit 8finger8536A Unit 8insect8546A Unit 8insect museum 8556A Unit 8kind8566A Unit 8many kinds of 8576A Unit 8model car 8586A Unit 8science museum 8596A Unit 9building8606A Unit 9capital8616A Unit 9east8626A Unit 9in the east of 8636A Unit 9in the north of 8646A Unit 9most8656A Unit 9north8666A Unit 9palace8676A Unit 9South8686A Unit 9sushi8696A Unit 9tourist8706A Unit 9west8716B Unit 1centimetre 8726B Unit 1enjoy oneself 8736B Unit 1fan8746B Unit 1fantastic8756B Unit 1get…in8766B Unit 1go fishing 8776B Unit 1kilogram8786B Unit 1taller8796B Unit 1theatre8806B Unit 1themselves 8816B Unit 1weigh8826B Unit 10adult8836B Unit 10blow off8846B Unit 10fairy tale 8856B Unit 10scarf8866B Unit 10stronger 8876B Unit 10take off 8886B Unit 10than8896B Unit 10well-known 8906B Unit 11bright8916B Unit 11jack-o'-lantern 8926B Unit 11laugh at 8936B Unit 11turkey8946B Unit 11Western 8956B Unit 12bigger8966B Unit 12bullet8976B Unit 12excited8986B Unit 12forever8996B Unit 12hit9006B Unit 12lazy9016B Unit 12look out of 9026B Unit 12one by one 9036B Unit 12pea9046B Unit 12pod9056B Unit 12roof9066B Unit 12see the world 9076B Unit 12yard9086B Unit 2broom9096B Unit 2by hand 9106B Unit 2digital9116B Unit 2drive9126B Unit 2fairy9136B Unit 2film9146B Unit 2in a short time 9156B Unit 2life9166B Unit 2photographer 9176B Unit 2poor9186B Unit 2right away9196B Unit 2street cleaner 9206B Unit 2street sweeper 9216B Unit 2sweep9226B Unit 2wife9236B Unit 2wish9246B Unit 2writer9256B Unit 3 a piece of9266B Unit 3better and better 9276B Unit 3carry9286B Unit 3dinosaur9296B Unit 3even9306B Unit 3head teacher 9316B Unit 3have a picnic9326B Unit 3mountain9336B Unit 3online9346B Unit 3PS9356B Unit 3space9366B Unit 4all the time9376B Unit 4artist9386B Unit 4brush9396B Unit 4carefully9406B Unit 4Chinese ink painting 9416B Unit 4ink9426B Unit 4oil9436B Unit 4oil painting9446B Unit 4on the left9456B Unit 4on the right9466B Unit 4paints9476B Unit 4powerful9486B Unit 4unhappy9496B Unit 5 a long time ago 9506B Unit 5at work9516B Unit 5craft9526B Unit 5craftsman9536B Unit 5crown9546B Unit 5easily9556B Unit 5glue9566B Unit 5himself9576B Unit 5model house 9586B Unit 5saw9596B Unit 5say to oneself 9606B Unit 5scissors9616B Unit 5still9626B Unit 5tape9636B Unit 5tool9646B Unit 6fit9656B Unit 6high jump9666B Unit 6long jump9676B Unit 6long race9686B Unit 6short race9696B Unit 6swimming cap 9706B Unit 6swimming goggles 9716B Unit 6swimming pool 9726B Unit 6swimsuit9736B Unit 6warm-up9746B Unit 6win9756B Unit 7ago9766B Unit 7bell9776B Unit 7gatekeeper9786B Unit 7neck9796B Unit 7praise9806B Unit 7praise…for9816B Unit 8follow9826B Unit 8get lost9836B Unit 8in the middle 9846B Unit 8look out9856B Unit 8lost9866B Unit 8may9876B Unit 8middle9886B Unit 8no smoking9896B Unit 8no swimming9906B Unit 8on the way9916B Unit 8path9926B Unit 8sign9936B Unit 8some time9946B Unit 8special9956B Unit 8worry9966B Unit 9can9976B Unit 9cloth9986B Unit 9envelope9996B Unit 9pen holder10006B Unit 9piece10016B Unit 9plastic10026B Unit 9reuse10036B Unit 9rubber10046B Unit 9rubbish bin10056B Unit 9throw away10066B Unit 9truck10076B Unit 9vase10087A Unit 1actor n. 10097A Unit 1actress n. 10107A Unit 1address n. 10117A Unit 1age n. 10127A Unit 1art n. 10137A Unit 1complete v./a. 10147A Unit 1completely adv. 10157A Unit 1country n. 10167A Unit 1dream n. 10177A Unit 1elder a. 10187A Unit 1email n./v. 10197A Unit 1engineer n.10207A Unit 1everyone pron. 10217A Unit 1favourite a. 10227A Unit 1flat n. 10237A Unit 1friendly a. 10247A Unit 1German a. 10257A Unit 1Germany n. 10267A Unit 1grammar n. 10277A Unit 1hobby n. 10287A Unit 1Japan n. 10297A Unit 1Japanese n. 10307A Unit 1mountain n. 10317A Unit 1scientist n. 10327A Unit 1sound n./v. 10337A Unit 1star n. 10347A Unit 1subject n. 10357A Unit 1US n. 10367A Unit 1world n. 10377A Unit 1yourself pron. 10387A Unit 2article n. 10397A Unit 2band n. 10407A Unit 2bell n. 10417A Unit 2break n. 10427A Unit 2daily a. 10437A Unit 2end v./n. 10447A Unit 2Geography n. 10457A Unit 2grade n. 10467A Unit 2guitar n. 10477A Unit 2market n. 10487A Unit 2never adv. 10497A Unit 2practice n. 10507A Unit 2ride v. 10517A Unit 2ring v. 10527A Unit 2seldom adv. 10537A Unit 2so conj.10547A Unit 2together adv. 10557A Unit 2usually adv. 10567A Unit 3away adv. 10577A Unit 3burn v. 10587A Unit 3catch v. 10597A Unit 3Earth n. 10607A Unit 3energy n. 10617A Unit 3fact n. 10627A Unit 3few a. 10637A Unit 3field n. 10647A Unit 3forest n. 10657A Unit 3ground n. 10667A Unit 3importance n. 10677A Unit 3important a. 10687A Unit 3into prep. 10697A Unit 3kill v. 10707A Unit 3kilometre n. 10717A Unit 3land n. 10727A Unit 3large a. 10737A Unit 3must modal v. 10747A Unit 3own a. 10757A Unit 3part n. 10767A Unit 3pattern n. 10777A Unit 3pollute v. 10787A Unit 3pollution n. 10797A Unit 3problem n. 10807A Unit 3protect v. 10817A Unit 3provide v. 10827A Unit 3quiz n. 10837A Unit 3report n. 10847A Unit 3river n. 10857A Unit 4Australia n. 10867A Unit 4autumn n. 10877A Unit 4blow v.10887A Unit 4bright a. 10897A Unit 4brightly adv. 10907A Unit 4cloudy a. 10917A Unit 4dry a. 10927A Unit 4during prep. 10937A Unit 4everything pron. 10947A Unit 4foggy a. 10957A Unit 4footprint n. 10967A Unit 4grandparent n. 10977A Unit 4heavy a. 10987A Unit 4kick v. 10997A Unit 4picnic n. 11007A Unit 4rainy a. 11017A Unit 4relative n. 11027A Unit 4season n. 11037A Unit 4shine v. 11047A Unit 4snowy a. 11057A Unit 4spend v. 11067A Unit 4spring n. 11077A Unit 4stormy a. 11087A Unit 4strongly adv. 11097A Unit 4summer n. 11107A Unit 4sunny a. 11117A Unit 4town n. 11127A Unit 4trip n. 11137A Unit 4wet a. 11147A Unit 4windy a. 11157A Unit 4winter n. 11167A Unit 5able a. 11177A Unit 5breathe v. 11187A Unit 5camera n. 11197A Unit 5diary n. 11207A Unit 5garden n. 11217A Unit 5if conj.11227A Unit 5leave v. 11237A Unit 5machine n. 11247A Unit 5nervous a. 11257A Unit 5ourselves pron. 11267A Unit 5postcard n. 11277A Unit 5return v. 11287A Unit 5rock n. 11297A Unit 5space n. 11307A Unit 5spaceship n. 11317A Unit 5spacesuit n. 11327A Unit 5tie v. 11337A Unit 5weak a. 11347A Unit 5without prep. 11357A Unit 5work v. 11367A Unit 6across prep. 11377A Unit 6area n. 11387A Unit 6Asia n. 11397A Unit 6beauty n. 11407A Unit 6bridge n. 11417A Unit 6building n. 11427A Unit 6centre n. 11437A Unit 6direction n. 11447A Unit 6dumpling n. 11457A Unit 6guide n. 11467A Unit 6just adv. 11477A Unit 6light n. 11487A Unit 6modern a. 11497A Unit 6natural a. 11507A Unit 6outside prep. 11517A Unit 6pond n. 11527A Unit 6sightseeing n. 11537A Unit 6snack n. 11547A Unit 6temple n. 11557A Unit 6traditional a.11567A Unit 7amazed a. 11577A Unit 7amazing a. 11587A Unit 7another pron. 11597A Unit 7ant n. 11607A Unit 7attend v. 11617A Unit 7bee n. 11627A Unit 7bored a. 11637A Unit 7boring a. 11647A Unit 7butterfly n. 11657A Unit 7disappear v. 11667A Unit 7excited a. 11677A Unit 7exciting a. 11687A Unit 7fair n. 11697A Unit 7headline n. 11707A Unit 7information n. 11717A Unit 7launch v. 11727A Unit 7power n. 11737A Unit 7recent a. 11747A Unit 7recently adv. 11757A Unit 7rocket n. 11767A Unit 7skill n. 11777A Unit 7surprised a. 11787A Unit 7surprising a. 11797A Unit 7teach v. 11807A Unit 8ago adv. 11817A Unit 8anything pron. 11827A Unit 8doorbell n. 11837A Unit 8everywhere adv. 11847A Unit 8follow v. 11857A Unit 8free a. 11867A Unit 8front a. 11877A Unit 8granddaughter n. 11887A Unit 8grandson n. 11897A Unit 8hardly adv.11907A Unit 8inside adv. 11917A Unit 8interview v. 11927A Unit 8magazine n. 11937A Unit 8model n. 11947A Unit 8newspaper n. 11957A Unit 8over adv. 11967A Unit 8push v. 11977A Unit 8really adv. 11987A Unit 8sentence n. 11997A Unit 8should modal v. 12007A Unit 8silver n. 12017A Unit 8something pron. 12027A Unit 8soon adv. 12037A Unit 8space n. 12047A Unit 8stamp n. 12057A Unit 8UK n. 12067A Unit 8unusual a. 12077B Unit 1care n. 12087B Unit 1careful a. 12097B Unit 1cheerful a. 12107B Unit 1encourage v. 12117B Unit 1forget v. 12127B Unit 1hard-working a. 12137B Unit 1joke n. 12147B Unit 1laugh v. 12157B Unit 1member n. 12167B Unit 1miss v. 12177B Unit 1paragraph n. 12187B Unit 1patient a. 12197B Unit 1person n. 12207B Unit 1probably adv. 12217B Unit 1remain v. 12227B Unit 1smart a. 12237B Unit 1smell v.12247B Unit 1strict a. 12257B Unit 1successful a. 12267B Unit 1support v. 12277B Unit 2address n. 12287B Unit 2coast n. 12297B Unit 2date n. 12307B Unit 2Europe n. 12317B Unit 2European a. 12327B Unit 2excellent a. 12337B Unit 2finish v. 12347B Unit 2flag n. 12357B Unit 2France n. 12367B Unit 2French a. 12377B Unit 2greeting n. 12387B Unit 2lie v. 12397B Unit 2lift n. 12407B Unit 2perfect a. 12417B Unit 2possible a. 12427B Unit 2prefer v. 12437B Unit 2receive v. 12447B Unit 2receiver n. 12457B Unit 2ski v. 12467B Unit 2south n. 12477B Unit 2stairs n. 12487B Unit 2step n. 12497B Unit 2store n. 12507B Unit 2tick v. 12517B Unit 2tower n. 12527B Unit 2wine n. 12537B Unit 3act v. 12547B Unit 3airport n. 12557B Unit 3allow v. 12567B Unit 3anywhere adv. 12577B Unit 3apologize v.12587B Unit 3apology n. 12597B Unit 3appear v. 12607B Unit 3bark v. 12617B Unit 3blind a. 12627B Unit 3bottom n. 12637B Unit 3climb v. 12647B Unit 3dark a. 12657B Unit 3final a. 12667B Unit 3finally adv. 12677B Unit 3helpful a. 12687B Unit 3lead v. 12697B Unit 3mean v. 12707B Unit 3nothing pron. 12717B Unit 3pet n. 12727B Unit 3programme n. 12737B Unit 3radio n. 12747B Unit 3towel n. 12757B Unit 3wake v. 12767B Unit 4against prep. 12777B Unit 4branch n. 12787B Unit 4carry v. 12797B Unit 4convenient a. 12807B Unit 4dig v. 12817B Unit 4discuss v. 12827B Unit 4discussion n. 12837B Unit 4disease n. 12847B Unit 4example n. 12857B Unit 4fight v. 12867B Unit 4furniture n. 12877B Unit 4gas n. 12887B Unit 4harmful a. 12897B Unit 4hole n. 12907B Unit 4imagine v. 12917B Unit 4major a.12927B Unit 4oxygen n. 12937B Unit 4pine n. 12947B Unit 4produce v. 12957B Unit 4save v. 12967B Unit 5add v. 12977B Unit 5bank n. 12987B Unit 5bit n. 12997B Unit 5change n. 13007B Unit 5chemical n. 13017B Unit 5continue v. 13027B Unit 5drop n./v. 13037B Unit 5experiment n. 13047B Unit 5form v. 13057B Unit 5fresh a. 13067B Unit 5journey n. 13077B Unit 5on prep. 13087B Unit 5pipe n. 13097B Unit 5quantity n. 13107B Unit 5return v. 13117B Unit 5salt n. 13127B Unit 5through prep. 13137B Unit 5valuable a. 13147B Unit 5value n. 13157B Unit 5voice n. 13167B Unit 6anyone pron. 13177B Unit 6battery n. 13187B Unit 6connect v. 13197B Unit 6conversation n. 13207B Unit 6cook v./n. 13217B Unit 6cooker n. 13227B Unit 6electricity n. 13237B Unit 6foolish a. 13247B Unit 6fridge n. 13257B Unit 6lock v.。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
内江师范学院计算机科学学院数据结构课程设计报告课题名称:文本文件单词的检索与计数姓名:学号:专业班级:软件工程系(院):计算机科学学院设计时间:20XX 年X 月X日设计地点:成绩:1.课程设计目的(1).训练学生灵活应用所学数据结构知识,独立完成问题分析,结合数据结构理论知识,编写程序求解指定问题。
(2).初步掌握软件开发过程的问题分析、系统设计、程序编码、测试等基本方法和技能;(3).提高综合运用所学的理论知识和方法独立分析和解决问题的能力;(4).训练用系统的观点和软件开发一般规范进行软件开发,巩固、深化学生的理论知识,提高编程水平,并在此过程中培养他们严谨的科学态度和良好的工作作风。
2.课程设计任务与要求:文本文件单词的检索与计数软件任务:编写一个文本文件单词的检索与计数软件, 程序设计要求:1)建立文本文件,文件名由用户键盘输入2)给定单词的计数,输入一个不含空格的单词,统计输出该单词在文本中的出现次数要求:(1)、在处理每个题目时,要求从分析题目的需求入手,按设计抽象数据类型、构思算法、通过设计实现抽象数据类型、编制上机程序和上机调试等若干步骤完成题目,最终写出完整的分析报告。
前期准备工作完备与否直接影响到后序上机调试工作的效率。
在程序设计阶段应尽量利用已有的标准函数,加大代码的重用率。
(2)、设计的题目要求达到一定工作量(300行以上代码),并具有一定的深度和难度。
(3)、程序设计语言推荐使用C/C++,程序书写规范,源程序需加必要的注释;(4)、每位同学需提交可独立运行的程序;(5)、每位同学需独立提交设计报告书(每人一份),要求编排格式统一、规范、内容充实,不少于8页(代码不算);(6)、课程设计实践作为培养学生动手能力的一种手段,单独考核。
3.课程设计说明书一需求分析3.1 串模式匹配算法的设计要求在串的基本操作中,在主串中查找模式串的模式匹配算法——即求子串位置的函数Index(S,T),是文本处理中最常用、最重要的操作之一。
所谓子串的定位就是求子串在主串中首次出现的位置,又称为模式匹配或串匹配。
模式匹配的算法很多,在这里只要求用最简单的朴素模式匹配算法。
该算法的基本思路是将给定子串与主串从第一个字符开始比较,找到首次与子串完全匹配的子串为止,并记住该位置。
但为了实现统计子串出现的个数,不仅需要从主串的第一个字符位置开始比较,而且需要从主串的任一给定位置检索匹配字符串,所以,首先要给出两个算法:1.标准的朴素模式匹配算法2.给定位置的匹配算法3.2 文本文件单词的检索与计数的设计要求要求编程建立一个文本文件,每个单词不包含空格且不跨行,单词由字符序列构成且区分大小写;统计给定单词在文本文件中出现的总次数;检索输出某个单词出现在文本中的行号、在该行中出现的次数以及位置。
该设计要求可分为三个部分实现:其一,建立文本文件,文件名由用户用键盘输入;其二,给定单词的计数,输入一个不含空格的单词,统计输出该单词在文本中的出现次数;其三,检索给定单词,输入一个单词,检索并输出该单词所在的行号、该行中出现的次数以及在该行中的相应位置。
1.建立文本文件2.给定单词的计数3.检索单词出现在文本文件中的行号、次数及其位置4.主控菜单程序的结构二概要设计2.1建立文本文件定义一个串变量,定义文本文件,输入文件名,打开该文件,循环读入文本行,写入文本文件,关闭文件。
2.2给定单词的计数逐行扫描文本文件。
匹配一个,计数器加1,直到整个文件扫描结束;然后输出单词的次数2.3检索单词出现在文本文件中的行号、次数及其位置逐行扫描文本文件。
扫描一个单词,单词数加1,匹配一个,计数器加1,输出该单词数,行数到底,以此,行数加1,单词数清零,直到整个文件扫描结束;然后输出单词的次数,行号,第几个单词。
三详细设计朴素模式匹配算法该算法的基本思想是:设有三个指针——i,j,k,用i指示主串S每次开始比较的位置;指针j,k分别指示主串S和模式串T中当前正在等待比较的字符位置;一开始从主串S的第一个字符(i=0;j=1)和模式T的第一个字符(k=0)比较,若相等,则继续逐个比较后续字符(j++,k++)。
否则从主串的下一个字符(i++)起再重新和模式串(j=0)的字符开始比较。
依此类推,直到模式T中的所有字符都比较完,而且一直相等,则称匹配成功,并返回位置i;否则返回-1,表示匹配失败。
顺序串的模式匹配算法如下:int index(SString S, SString T){ //求子串T在主串S中首次出现的位置int i,j,k,m,n;m=T.length; //模式串长度赋mn=S.length; //目标串长度赋nfor (i=0; i<=n-m; i++){j=0; k=i; // 目标串起始位置i送入kwhile (j<=m && s.ch[k]==t.ch[j]){k++; j++;} //继续下一个字符的比较if (j==m) //若相等,则说明找到匹配的子串,返回匹配位置i,//否则从下一个位置重新开始比较return i;} //endforreturn -1;} //endIndex给定位置的串匹配算法该算法要求从串S1(为顺序存储结构)中第k个字符起,求出首次与字符串S2相同的子串的起始位置。
该算法与上面介绍的模式匹配算法类似,只不过上述算法的要求是从主串的第一个字符开始,该算法是上述算法的另一种思路:从第k个元素开始扫描S1,当其元素值与S2的第一个元素的值相同时,判定它们之后的元素值是否依次相同,直到S2结束为止。
若都相同,则返回当前位置值;否则继续上述过程,直至S1扫描完为止,其实现算法如下:Int PartPosition(SString S1, SString S2, int k){int i, j;i=k-1; //扫描s1的下标,因为c中数组下标是从0开始,串中序号相差1j=0; //扫描s2的开始下标while (i<s1.length && j<s2.length)if (s1.ch[i]==s2.ch[j]){ i++; j++; //继续使下标移向下一个字符位置}else{ i=i-j+1; j=0;//使i下标回溯到原位置的下一个位置,使j指向s2的第一个字符,再重新比较} if (j>=s2.length)return i- s2.length; //表示s1中存在s2,返回其起始位置elsereturn -1; //表示s1中不存在s2,返回-1} //函数结束说明:以上两个算法可统一为一个算法,即在子串定位算法Index(S,T)的参数中增加一个起始位置参数即可。
建立文本文件建立文件的实现思路是:(1)定义一个串变量;(2)定义文本文件;(3)输入文件名,打开该文件;(4)循环读入文本行,写入文本文件,其过程如下:While ( 不是文件输入结束) {读入一文本行至串变量;串变量写入文件;输入是否结束输入标志;}(5)关闭文件。
给定单词的计数该功能需要用到前一节中设计的模式匹配算法,逐行扫描文本文件。
匹配一个,计数器加1,直到整个文件扫描结束;然后输出单词出现的次数。
其实现过程如下:(1)输入要检索的文本文件名,打开相应的文件;(2)输入要检索统计的单词;(3)循环读文本文件,读入一行,将其送入定义好的串中,并求该串的实际长度,调用串匹配函数进行计数。
具体描述如下:While (不是文件结束) {读入一行并到串中;求出串长度;模式匹配函数计数;}(4)关闭文件,输出统计结果。
检索单词出现在文本文件中的行号、次数及其位置这个设计要求与上一个类似,但要相对复杂一些。
其实现过程描述如下:(1)输入要检索的文本文件名,打开相应的文件;(2)输入要检索统计的单词;(3)行计数器置初值0;(4)while (不是文件结束) {读入一行到指定串中;求出串长度;行单词计数器置0;调用模式匹配函数匹配单词定位、该行匹配单词计数;行号计数器加1;If (行单词计数器!=0)输出行号、该行有匹配单词的个数以及相应的位置;}运行主控程序主控菜单程序的结构要求内容如下:(1)头文件包含;(2)菜单选项包括:1.建立文件2.单词计数3.单词定位4.退出程序(3)选择1——4执行相应的操作,其他字符为非法。
四调试分析与测试结果4.1未输入文件前的页面4.2输入文本文件4.3文本单词汇总4.4 单词定位五用户手册该软件界面简洁,操作简单,运行程序后根据提示就可完成相关操作。
六附录(源程序清单)#include <stdio.h>#include <stdlib.h>#include <string.h>#define LIST_INIT_SIZE 500 /*线性表存储空间的初始分配量*/#define LISTINCREMENT 10 /*线性表存储空间的分配增量*/#define FILE_NAME_LEN 20 /*文件名长度*/#define WORD_LEN 20 /*单词长度*/#define MaxStrSize 256#define llength 110 /*规定一行有110个字节*/#define MaxStr 258#define WORD 21typedef struct {char ch[MaxStr]; /* ch是一个可容纳256个字符的字符数组 */ int length;} string; /* 定义顺序串类型 */typedef struct {char word[WORD]; /*存储单词,不超过20个字符*/ int count; /*单词出现的次数*/} elem_type;typedef struct{elem_type *elem; /*存储空间基址*/int length; /*当前长度*/int listsize; /*当前分配的存储容量*/} sqlist;int sqlist_init(sqlist *sq, elem_type *et){sq->elem = et;sq->length = 0;return 0;}int sqlist_add(sqlist *sq, elem_type *et, char *word){int i;int j;for (i = 0; i < sq->length; i++){/*当前单词与加入的单词相同,直接统计,不做插入 */if (strcmp(et[i].word, word) == 0){et[i].count++;return 0;}if (strcmp(et[i].word, word) > 0){break;}}if (sq->length == LIST_INIT_SIZE){printf("空间不足,单词[%s]插入失败\n", word);return 0;}for (j = sq->length; j > i; j--){memcpy(et+j, et+j-1, sizeof(elem_type));}sq->length++;strcpy(et[i].word, word);et[i].count = 1;return 0;}int sqlist_count(sqlist *sq, elem_type *et){int i, j = 0;for(i=0;i<sq->length;i++)j=j+et[i].count;return j;}int creat_text_file(){elem_type w;sqlist s;char file_name[FILE_NAME_LEN + 1],yn;FILE *fp;printf("输入要建立的文件名:");scanf("%s",file_name);fp=fopen(file_name,"w");yn='n'; /* 输入结束标志初值 */while(yn=='n'||yn=='N'){printf("请输入一行文本:");gets(w.word);gets(w.word);s.length=strlen(w.word);fwrite(&w,s.length,1,fp);fprintf(fp,"%c",10); /* 是输入换行 */printf("结束输入吗?y or n :");yn=getchar();}fclose(fp); /* 关闭文件 */printf("建立文件结束!\n");return 0;}int substrsum(){char file_name[FILE_NAME_LEN + 1];char word[WORD_LEN+1];FILE *fp;int i;int j,q=0;int w,x,y=0;elem_type et[LIST_INIT_SIZE];sqlist sq;sqlist_init(&sq, et);printf("请输入文件名:");scanf("%s", file_name);fp = fopen(file_name, "r");if (fp == NULL){printf("打开文件失败!\n");return 0;}while (fscanf(fp, "%s", word) != EOF){sqlist_add(&sq, et, word);}fclose(fp);printf(">>>>>>>>>>>>>>>>单词<<<>>>>个数<<<<<<<<<<<\n");for (i = 0; i < sq.length; i++){x=strlen(et[i].word);for(w=x-1;w>=0;w--)if(et[i].word[w]<65||(et[i].word[w]>90&&et[i].word[w]<97)||et[i].word[w]>122) {et[i].word[w]=' ';}for(w=0;w<x;w++)if (et[i].word[w]==' ')y++;if(y==x){et[i].count=0;y=0;}else y=0;if(et[i].count!=0)printf("%20s%10d\n", et[i].word, et[i].count);else q++;}j=sqlist_count(&sq, et);printf("\n>>>>>>>>>>>>>>>>>>%s的单词总数为%d个\n",file_name,j); printf("\n>>>>>>>>>>>>>>>>>>%s的非单词个数为%d种\n",file_name,q); printf("\n");return 0;}int partposition (string s1,string s2,int k){ int i,j;i=k-1;/* 扫描s1的下标,因为c中数组下标是从0开始,串中序号相差1 */j=0; /* 扫描s2的开始下标 */while(i<s1.length && j<s2.length){if(s1.ch[i]==s2.ch[j]){ i++;j++; /* 继续使下标移向下一个字符位置 */}else{i=i-j+1; j=0;} }if (j>=s2.length)return i-s2.length;elsereturn -1; /* 表示s1中不存在s2,返回-1 *//* 表示s1中存在s2,返回其起始位置 */} /* 函数结束 */int substrcount(){FILE *fp;string s,t; /* 定义两个串变量 */char fname[10];int i=0,j,k;printf("输入文本文件名:");scanf("%s",fname);fp=fopen(fname,"r");printf("输入要统计计数的单词:");scanf("%s",t.ch);t.length=strlen(t.ch);while(!feof(fp)){memset(s.ch,'\0',110);fgets(s.ch,110,fp);s.length=strlen(s.ch);k=0; /* 初始化开始检索位置 */while(k<s.length-1) /* 检索整个主串S */{j=partposition(s,t,k); /* 调用串匹配函数 */if(j<0 ) break;else {i++; /* 单词计数器加1 */k=j+t.length; /* 继续下一字串的检索 */ }}}printf("\n单词%s在文本文件%s中共出现%d次\n",t.ch,fname,i);return 0;}/* 统计单词出现的个数 */int substrint(){FILE *fp;string s,t; /* 定义两个串变量 */char fname[10];int i,j,k,l,m;int wz[20]; /* 存放一行中字串匹配的多个位置 */printf("输入文本文件名:");scanf("%s",fname);fp=fopen(fname,"r");printf("输入要检索的单词:");scanf("%s",t.ch);t.length=strlen(t.ch);l=0; /* 行计数器置0 */while(!feof(fp)){ /* 扫描整个文本文件 */memset(s.ch,'\0',110);fgets(s.ch,110,fp);s.length=strlen(s.ch);l++; /* 行计数器自增1 */k=0; /* 初始化开始检索位置 */i=0; /* 初始化单词计数器 */while(k<s.length-1) /* 检索整个主串S */{j=partposition(s,t,k); /* 调用串匹配函数 */if(j<0) break;else{i++; /* 单词计数器加1 */wz[i]=j; /* 记录匹配单词位置 */k=j+t.length; /* 继续下一字串检索 */}}if(i>0){printf("行号:%d,次数:%d,起始位置分别为:",l,i);for(m=1;m<=i;m++)printf("第%4d个字符",wz[m]+1);}printf("\n");}printf("\n本软件自定义110个字节为一行\n\n");return 0;} /* 检索单词出现在文本文件中的行号、次数及其位置 */int substrio(){int substrcount(),substrint();char t;//while(1)//{printf("===============================================\n");printf("||文本文件单词字串的定位统计及定位||\n");printf("||================================||\n");printf("|| a. 单词出现次数 ||\n");printf("|| ||\n");printf("|| ||\n");printf("|| b. 单词出现位置 ||\n");printf("|| ||\n");printf("====================================\n");printf("请输入a或b:");scanf("%c%*c",&t);switch(t){case 'a': substrcount();break;case 'b': substrint();break;default: return 0;}//}return 0;}int main(void){int creat_text_file(),substrsum(),substrio();int a;int t = 1;while(t){printf("*************************************\n");printf("******文本文件单词的检索与计数 ******\n");printf("*************************************\n");printf("**1.建立文本文档 **\n");printf("**2.文本单词汇总 **\n");printf("**3.单词定位 **\n");printf("**4.退出 **\n");printf("*************************************\n");printf("请选择(1~4):");scanf("%d%*c",&a);switch(a){case 1: creat_text_file();break;case 2: substrsum();break;case 3: substrio();break;case 4: return 0;default:printf("选择错误,重新选 \n");}}return 0;}七课程设计心得经过几周的奋斗,这次数据结构的课程设计终于做完了。