abap字符串操作语法总结
abap基本语法汇总
一数据类型和对象在ABAP中,可以使用与标准数据声明相似的语法处理数据类型,而与数据对象无关。
在程序中必须声明要使用的全部数据对象。
声明过程中,必须给数据对象分配属性,其中最重要的属性就是数据类型。
基本数据类型对算术运算的非整型结果(如分数)进行四舍五入,而不是截断。
类型 P 数据允许在小数点后有数字。
有效大小可以是从 1 到 16 字节的任何值。
将两个十进制数字压缩到一个字节,而最后一个字节包含一个数字和符号。
在小数点后最多允许 14 个数字。
确定数据对象的属性如果要查明数据对象的数据类型,或者要在程序的运行期间使用其属性,可使用 DESCRIBE 语句。
语法如下:DESCRIBE FIELD <f> [LENGTH <l>] [TYPE <t> [COMPONENTS <n>]][OUTPUT-LENGTH <o>] [DECIMALS <d>][EDIT MASK <m>].将由语句的参数指定的数据对象<f>的属性写入参数后的变量。
DESCRIBE FIELDS 语句具有下列参数:确定字段长度要确定数据对象的长度,利用DESCRIBE FIELD 语句使用 LENGTH 参数,如下所示:DESCRIBE FIELD <f> LENGTH <l>.系统读取字段<f>的长度,并将值写入字段<l>。
确定数据类型要确定字段的数据类型,利用DESCRIBE FIELD 语句使用 TYPE 参数,如下所示:DESCRIBE FIELD <f> TYPE <t> [COMPONENTS <n>].系统读取字段<f>的数据类型,然后将值写入字段<t>。
除返回预定义数据类型 C、D、F、I、N、P、T 和 X 外,该语句还返回3 s 对于带前导符号的两字节整型4 b 对于无前导符号的一字节整型4 h 对于内表4 C 对于组件中没有嵌套结构的结构4 C 对于组件中至少有一个嵌套结构的结构要确定字段的输出长度,利用 DESCRIBE FIELD 语句使用 OUTPUT-LENGTH 参数,如下所示:DESCRIBE FIELD <f> OUTPUT-LENGTH <o>.系统读取字段<f>的输出长度,并将值写入字段<o>。
ABAP语法

ABAP语法一、格式。
作用:设置或更改有效的输出格式。
注意:由Format设置的格式会影响到清淡的下一个输出操作,下一个输出命令或下一个新行。
附加ON对于转换贴切的输出格式变得更随意。
你也能设置静态的附加ON,OFF和n(对于颜色)。
1、颜色。
Format Color n [ON] or Format Color n[OFF]作用:行背景颜色。
N能有如下的价值。
OFF or COL_BACKGROUND Background (GUI-specific)1 or COL_HEADING Headers (grayish blue)2 or COL_NORMAL List body (bright gray)3 or COL_TOTAL Totals (yellow)4 or COL_KEY Key columns (bluish green)5 or COL_POSITIVE Positive threshold value (green)6 or COL_NEGATIVE Negative threshold value (red)7 or COL_GROUP Control levels (violet)清单颜色注意:每次一个新的事件(START-OF-SELECTION, TOP-OF-PAGE, ...)开始,这个系统的设置回复到COLOR 0。
附加.. INTENSIFIED和... INVERSE影响颜色的显示属性...COLOR对于线不起作用。
WRITE --- OUTPUT AS lineInclude<Line>(或更多广泛的Include<List>)对于行包含关系识别作为永恒,例如:LINE_TOP_LEFT_CORNER, LINE_BOTTOM_MIDDLE_CORNER。
Line不能有其他的显示属性。
如果像颜色(COLOR),背面VIDEO(INVERSE)或变强(INTENSIFIED)被设置,这些忽略输出。
abap 常用函数用法

abap 常用函数用法ABAP是一种功能强大的SAP开发语言,用于创建和编辑业务应用程序。
在ABAP编程中,函数是一种常用的工具,用于执行特定的任务。
本篇文章将介绍一些常用的ABAP函数及其用法。
一、字符串函数1.LEFT(string,length):返回string字符串左边的length个字符。
2.RIGHT(string,length):返回string字符串右边的length个字符。
3.MID(string,start_position,length):返回string字符串从start_position开始,length个字符的子串。
4.CONCATENATE(string1,string2,...):将多个字符串连接成一个字符串。
5.TRIM(string):去除字符串首尾的空格。
6.LOWER(string):将字符串转换为小写。
7.UPPER(string):将字符串转换为大写。
二、数值函数1.ABS(number):返回number的绝对值。
2.ROUND(number,digits):对number进行四舍五入到digits位小数。
3.FLOOR(number):对number向下取整。
4.CEILING(number):对number向上取整。
5.MOD(number1,number2):返回number1除以number2的余数。
三、日期函数1.CURDATE():返回当前日期。
2.YEAR(date):返回date日期的年份。
3.MONTH(date):返回date日期的月份。
4.DAY(date):返回date日期的天数。
5.ADD_MONTHS(date,months):将date日期增加指定的月份。
6.SUBTRACT_MONTHS(date,months):将date日期减少指定的月份。
四、其他常用函数1.ISNULL(value):检查value是否为空。
2.IS_NOT_NULL(value):检查value是否不为空。
abap find语法

abap find语法
ABAP 的 FIND 语法用于在字符串中查找子字符串,并返回子字
符串的位置。
以下是使用中文编写的 FIND 语法的示例:
FIND 子字符串 IN 目标字符串.
在上述语句中,"子字符串"是要查找的字符串,"目标字符串"是
要在其中进行查找的字符串。
如果找到了子字符串,则系统返回子字
符串在目标字符串中的位置。
示例代码:
DATA: 目标字符串 TYPE STRING,
子字符串 TYPE STRING,
位置 TYPE I.
目标字符串 = 'ABAP 是一种编程语言,用于开发企业级应用程序。
'.
子字符串 = '编程语言'.
FIND 子字符串 IN 目标字符串.
IF sy-subrc = 0.
位置 = sy-fdpos.
WRITE: '子字符串在目标字符串中的位置:', 位置.
ELSE.
WRITE: '未找到子字符串'.
ENDIF.
上述代码中,我们定义了一个目标字符串和一个子字符串,并使
用 FIND 语句在目标字符串中查找子字符串。
如果找到了子字符串,
则将子字符串在目标字符串中的位置存储在位置变量中,并输出结果。
如果没有找到子字符串,则输出 "未找到子字符串"。
这是一个简单的使用 ABAP 的 FIND 语法在字符串中查找子字符
串的示例。
在实际应用中,您可以根据具体需求进行相应的调整和扩展。
ABAP_4语法集锦(中文版)

§. ABAP/4 DATA ELEMENT一.Data Type (数据类型)C: 字符(串), 长度为1, 最大有65535 BYTES, 初始值为: space,例: ‘M’;D: 日期, 格式为YYYYMMDD, 最大是’9999/12/31’ ,例:’1999/12/03’.F: 浮点数, 长度为8, 例如: 4.285714285714286E-01I: 整数范围 :-2^31 ~ 2^31-1N: 数值组成的字符串: 011, ‘302’.P: packed 数,用于小数点数值,例如: 12.00542;T: 时间, 格式为HHMMSS,例如: ’14:03:00’, ’21:30:39’.X: 16进制数, 例如‘1A03’.二.变量宣告变量宣告包含name, length, type, structure等,语法如下:DATA <F> [<length>] <type> [<value>] [<decimals>]其中: <f> :变量名称,最长30个字符,不可含有 + , . , : ( ) 等字符;<length><type>:变量类型及长度;<value>:初值<decimals>:小数位数Example 1:DATA: COUNTER TYPE P DECIMALS 3,NAME (10) TYPE C VALUE ‘Delta’,S_DATE TYPE D VALUE ‘19991203’.Example 2:DATA: BEGIN OF PERSON,NAME(10) TYPE C,AGE TYPE I,WEIGHT TYPE P DECIMALS 2,END OF PERSON.另外,有关DATA宣告的指令还有: CONSTANTS(宣告常数)、STATICS(临时变量宣告).三.系统专用变量说明系统内部专门创建了SYST这个STRUCTURE,里面的字段存放系统变量,常用的系统变量有:SY-SUBRC : 系统执行某指令后,表示执行成功与否的变量,’0’表示成功SY-UNAME: 当前使用者登入SAP的USERNAME;SY-DATUM: 当前系统日期;SY-UZEIT: 当前系统时间;SY-TCODE: 当前执行程序的Transaction codeSY-INDEX : 当前LOOP循环过的次数SY-TABIX: 当前处理的是internal table 的第几笔SY-TMAXL: Internal table的总笔数SY-SROWS: 屏幕总行数;SY-SCOLS: 屏幕总列数;SY-MANDT: CLIENT NUMBERSY-VLINE: 画竖线SY-ULINE: 画横线附注:1.SAP的全称是: System Application Products in Data Processing;2.ABAP/4的全称是:Advanced Business Application Programming;3.ABAP/4的路径为:Tools → ABAP/4 WorkBench→ABPA/4 Editor ;4.ABAP/4每条语句以句号结束;5.ABAP/4中象= ,>, <,+,-,*,/等符号左右都需要有至少一个空格;6.整行注释用’*’号, 注释本行后面部分用’”’号;§OUTPUTTING DATA TO SCREEN一. WRITE 语句ABAP/4用来在屏幕上输出数据的指令是WRITE指令,例如:WRITE: ‘USER NAME IS:’, SY-UNAME.二. 指定屏幕输出位置指定输出位置的语句格式为:WRITE: [AT] [ / ] [<pos>] [(<len>)] 资料项 [<par>]其中: / : 在下一行输出<pos>: 指定输出的行号;(<len>):指定输出位数(长度)<par>: 指定显示格式参数,参数有:LEFT-JUSTIFIED 资料靠左对齐CENTERED 数据靠中间对齐RIGHT-JUSTIFIED 资料靠右对齐UNDER <g> 正对在数据项<g>的下面显示NO-GAP 紧接着显示,不留空格USING EDIT MASK <m>: 使用内嵌子元显示, 如 12:03:20 USING NO EDIT MASK: 不使用内嵌子元NO-ZERO: 数字前面 0 的部分不显示NO-SIGN: 不显示正负号DECIMALS <d>: 显示 <d> 位小数EXPOENT <e>: F(浮点数)指数的值ROUND <r>: 四舍五入至小数点后<r>位CURRENCY <c>: 币别显示DD/MM/YY : 日期显示格式MM/DD/YY:YY/MM/DD:YY/DD/MMMM/DD/YYYY:DD/MM/YYYYYYYY/MM/DD:YYYY/DD/MM:例如1: WRITE: /10(6) ‘ABCDEFGHIJK’.输出结果为: ABCDEF例如2: DATA: X TYPE I VALUE ’11:20:30’,A(5) TYPE C VALUE ‘AB CDE’.WRITE: / X USING EDIT MASK ‘__:__:__’.WRITE: / X USING EDIT MASK ‘$___,___’.WRITE: / Y NO-GAP.输出结果为:11:20:30$112,030ABCDEF四.显示图标:语法: WRITE: <symbol-name> AS SYMBOL.WRITE: <icon-name> AS ICON.例如: INCLUDE <SYMBOL>.INCLUDE <ICON>.WRITE: / ‘Phone symbol:’, SYM_PHONE AS SYMBOL.WRITE: / ‘Alarm Icon:’, ICON_VOICE_OUTPUT AS ICON.要查看系统所提供有那些符号及图标,可选择’EDIT’下的’Insert Statement’,选择’Write’,接下来选择要查看的群组,如SYMBOL 或ICON, 接下来按’Display’即可.§ INTERNAL TABLE一. Internal Table 的宣告ABAP/4中的Internal Table是一种Data Structure,类似于其它语言中的STRUTURE,它可以由几个不同类型的字段(field)组成,用来表示具有不同属性的某一事物,单独一笔资料表示某个事物,多笔数据表示具有相同属性的多个事物.例如:为了存取或记录某班的同学数据,我们创建如下的internal table:DATA: BEGIN OF STUDENT OCCURS 20,STD_ID TYPE N,NAME(10) TYPE C,AGE TYPE I,BIRTH TYPE D,SCORE TYPE P DECIMALS 2,END OF STUDENT.此时我们已经创建了名叫STUDENT的internal table,并且为它预先申请了能够存放20笔数据的Buffer(当然,如果存取数据不止20笔,程序执行时,会自动申请系统Buffer)Internal table 的定义有以下几种格式:格式一. DATA: BEGIN OF <internal table> OCCURS <n>,<field 1> TYPE <type1>,[<field 2> TYPE <type 2>,<field 3> TYPE <type 3>,… ]END OF <internal table>.格式二. TYPES: BEGIN OF <work area>,<field 1> TYPE <type1>,[<field 2> TYPE <type 2>,<field 3> TYPE <type 3>,… ]END OF <work area>.TYPES <internal table> TYPE <work area> OCCURS <n>.格式三. DATA: BEGIN OF <work area>.INCLUDE STRUCTURE <table name>.DATA: END OF <work area>.DATA: <internal table> LIKE <work area> OCCURS <n>.二. APPEND LINE格式: APPEND [<work area> TO ] <internal table>.举例一. (使用work area)DATA: BEGIN OF LINE,COL1 TYPE I,COL2 TYPE I,END OF LINE.DATA ITAB LIKE LINE OCCURS 10.DO 2 TIMES.LINE-COL1 = SY-INDEX.LINE-COL2 = SY-INDEX ** 2.APPEND LINE TO ITAB.ENDDO.LOOP AT ITAB INTO LINE.WRITE: / LINE-COL1, LINE-COL2.ENDLOOP.执行结果为:1 12 4举例二. (不使用work area)DATA: BEGIN OF ITAB OCCURS 10,COL1 TYPE I,COL2 TYPE I,END OF ITAB.DO 2 TIMES.ITAB-COL1 = SY-INDEX.ITAB-COL2 = SY-INDEX ** 2.APPEND ITAB.ENDDO.LOOP AT ITAB.WRITE: / ITAB-COL1, ITAB-COL2.ENDLOOP.执行结果与举例一相同.举例三. (加入另一个Internal table的元素)格式: APPEND LINES OF <itab1> [FROM <n1> ] [TO <n2>] TO <itab2>.将<itab1>的元素加入至<itab2>中,可选取自<n1>至<n2>的范围.APPEND LINES OF ITAB TO JTAB.三. COLLECT LINECOLLECT 指令也是将元素加入Internal table中,与APPEND 的区别是: COLLECT指令在非数值字段相同的情况下,将数值字段汇总.格式: COLLECT [<work area> INTO ] <itab>DATA: BEGIN OF ITAB OCCURS 3,COL1(3) TYPE C,COL2 TYPE I,END OF ITAB.ITAB-COL1 = ‘ABC’. ITAB-COL2 = 10.COLLECT ITAB.ITAB-COL1 = ‘XYZ’. ITAB-COL2 = 20.COLLECT ITAB.ITAB-COL1 = ‘ABC’. ITAB-COL2 = 80.COLLECT ITAB.此时, internal table中放的是2笔数据, 分别为:ITAB-COL1 ITAB-COL2‘ABC’ 90‘XYZ’ 20四. INSERT LINE将元素插入在指定的internal table位置之前.格式: INSERT [<wa> INTO] [INITIAL LINE INTO ] <itab> [INDEX <idx>] 或者: INSERT LINES OF <itab1> [FROM <n1> TO <n2>] INTO <itab2> INDEX <idx>其中: <wa>即work area,工作区中的元素.[INITIAL LINE INTO] :插入一笔初始化的记录.<itab>: internal table[INDEX <idx>]: internal table 的记录号.(新加入的元素放在此记录前面)五. 读取internal table格式一:LOOP AT <itab> [INTO <wa>][FROM <n1> TO <n2>][WHERE <conditions>]<statement>ENDLOOP.格式二:READ TABLE <itab> [INTO <wa>] [INDEX <idx> / WITH KEY <conditions>]举例. (格式二)DATA: BEGIN OF ITAB OCCURS 10,COL1 TYPE I,COL2 TYPE I,END OF ITAB.DO 10 TIMES.ITAB-COL1 = SY-INDEX.ITAB-COL2 = SY-INDEX * 2.APPEND ITAB.ENDDO.READ TABLE ITAB INDEX 3.(或者: READ TABLE ITAB WITH KEY COL1 = 3.)WRITE: / ‘ITAB-COL1 = ‘, ITAB-COL1, ‘ITAB-COL2 = ‘, ITAB-COL2.执行结果同样是:ITAB-COL1 = 3ITAB-COL2 = 6.六. 修改internal table 中的值格式: MODIFY <itab> [FROM <wa>][INDEX <idx>][TRANSPORTING <f1><f2>…][WHERE <conditions>]举例一. READ TABLE ITAB INDEX 3.LINE-COL1 = 29.MODIFY ITAB FROM LINE TRANSPORTING COL1.将第三笔记录的COL1字段的值修改为29.举例二. T_SALARY – salary = 50.MODIFY T_SALARY TRANSPORTING salary WHERE birthday = ‘1999/12/06’.七. DELETE internal table中的字段格式: DELETE <itab> INDEX <idx>.或: DELETE <itab>[FROM <n1> TO <n2>] [WHERE <conditions>]八. Internal table 排序SORT <itab> [<order way>][BY <f1><f2>…]其中:<order way> 有DESCENDING 和ASCENDING, Default 为ASCENDING.<f1>: 为指定排序的字段.九. 加总SUM.总和计算存放与work area中,但只能在LOOP 中使用.例: LOOP AT ITAB INTO LINE.SUM.ENDLOOP.WRITE: / LINE-COL1, LINE-COL2.十. 初始化internal tableREFRESH <itab>. 清空<itab>中的值.CLEAR <itab>. 清空<itab>的Header Line.FREE <itab>. 释放记忆体空间.§屏幕输入命令在ABAP/4中要从屏幕输入变量, 使用的命令是 PARAMETERS 及SELECTION-OPTIONS:1. PARAMETER: 输入一个变量2. SELECTION-OPTIONS: 使用条件筛选画面来输入数据一. PARAMETERS 指令基本的输入命令, 类似如BASIC的INPUT命令, 但无法使用F格式(浮点数) 语法:PARAMETERS <p> [DEFAULT <f>] [LOWER CASE][OBLIGATORY] [AS CHECKBOX][RADIOBUTTON GROUP <rad>]Example:PARAMETERS: NAME(8),AGE TYPE I,BIRTH TYPE D.执行结果:在日期的输入格式上为 MM/DD/YY , MM/DD/YYYY, MMDDYY或MMDDYYYY , 如输入020165表 1965年02月01日, 与02/01/65的输入是一样的, 日期输入范围为公元1950年至2049年1.DEFAULT设定输入的默认值Example:PARAMETERS: COMPANY(20) DEFAULT ‘DELTA’,BIRTH TYPE D DEFAULT ‘19650201’.2. LOWER CASEABAP/4预设是将字符串输入值自动转换为大写, 加上此参数会将输入的数据转成小写,3. OBLIGATORY强制要求输入, 屏幕上会出现一个 ? , 使用者必须要输入才可.4. AS CHECKBOX输入 CHECKBOX的格式Example:PARAMETERS: TAX AS CHECKBOX DEFAULT ‘X’,NTD AS CHECKBOX.执行结果:5. RADIOBUTTON GROUP <rad>输入 RADIO BUTTON GROUP 的方式Example:PARAMETERS: BOY RADIOBUTTON GROUP SEX DEFAULT ‘X’, GIRL RADIOBUTTON GROUP SEX.执行结果:二. SELECT-OPTIONSSELECTION-OPTIONS所输入的值实际上是放在internal table中的,该Internal table 有四个字段,分别是:SIGN,OPTION,LOW,HIGH.. 条件筛选检查条件输入画面指令, 输入条件后可配合SELECT指令自TABLE读取符合条件的数据, 直接执行或放入 Internal Table中, 条件有四个参数:1. SIGN:I: 表筛选条件符合的资料E: 表筛选条件不符合的资料2. OPTION: 比较的条件符号EQ(等于),NE(不等于),GT(大于),LE(小于),CP(包含),NP(不包含)3. LOW: 最小值4. HIGH: 最大值语法:SELECT-OPTIONS <check-option> FOR <table-field> Example:TABLES SPFLI.SELECT-OPTIONS AIRLINE FOR SPFLI-CONNID.将条件的输入值存放入 AIRLINE, 筛选选择为SPFLI中的CONNID字段执行结果:可直接输入起始范围或按下选择画面, 输入完后按下左上角的执行键三. 条件输入选择画面1.自Table中选取按下输入项的右边往下箭头, 叫出Table中数据项, 选取开始和结束的范围2.Selection Options按下”Selection options”按键, , 输入Option及 Sign参数内容, 屏幕如下:3.Multi-Options输入按下最右边的Multi-Options输入键, 输入条件选取的范围, 画面如下:条件输入完后按下”Copy”按键四. 改变条件输入格式1.DEFAULT <begin> TO <end>设定开始结束范围输入默认值Example:SELECT-OPTIONS AIRLINE FOR SPFLI-CONNIDDEFAULT ‘2042’ TO ‘4555’.2.NO-EXTENSION设定不要Multi-Option输入画面3.NO INTERVALS设定不要区间范围输入画面4.LOWER CASE输入转换成大写5.OBLIGATORY强制要求输入五. 配合 SELECT 命令条件输入完后要将符合条件的数据筛选出来, 可配合使用 SELECT 指令 1.使用WHERE <条件式>Example:SELECT-OPTIONS AIRLINE FOR SPFLI-CONNID.SELECT * FROM SPFLI WHERE CONNID IN AIRLINE.WRITE: / CONNID,FROMCITY,TOCITY.ENDSELECT.2.使用CHECK参数Example:SELECT-OPTIONS AIRLINE FOR SPFLI-CONNID.SELECT * FROM SPFLI.CHECK AIRLINE.WRITE: / CONNID,FROMCITY,TOCITY.ENDSELECT.3.使用 IF … IN 叙述Example:SELECT-OPTIONS AIRLINE FOR SPFLI-CONNID.SELECT * FROM SPFLI.IF SPFLI-CONNID IN AIRLINE.WRITE: / CONNID,FROMCITY,TOCITY.ENDIFENDSELECT.六. SELECTION-SCREEN1.产生空白语法:SELECTION-SCREEN SKIP [<n>]Example:SELECTION-SCREEN SKIP 2.产生两列空白列2.产生底线语法:SELECTION-SCREEN ULINE / <pos>(length)Example:SELECTION-SCREEN ULINE /10(30).自第10格开始产生长度30的底线3.印出备注说明语法:SELECTION-SCREEN COMMENT / <pos>(length) <name>Example:REMARK = ‘Pls enter your name’.SELECTION-SCREEN COMMENT /10(30) REMARK.4. 同一列中输入数个数据项语法:SELECTION-SCREEN BEGIN OF LINE.……SELECTION-SCREEN END OF LINE.Example:SELECTION-SCREEN BEGIN OF LINE.SELECTION-SCREEN POSITION 20.PARAMETERS NAME(10).SELECTION-SCREEN POSITION 40.PARAMETERS BIRTH TYPE D.SELECTION-SCREEN END OF LINE.在20格输入NAME内容, 40格输入 BIRTH的内容5. 绘出BLOCK PANEL语法:SELECTION-SCREEN BEGIN OF BLOCK <block>[WITH FRAME [TITLE <title>].…….SELECTION-SCREEN END OF BLOCK <block>.Example:SELECTION-SCREEN BEGIN OF BLOCK RADIO WITH FRAME .PARAMETER R1 RADIOBUTTON GROUP GR1.PARAMETER R2 RADIOBUTTON GROUP GR1.PARAMETER R3 RADIOBUTTON GROUP GR1. SELECTION-SCREEN END OF BLOCK RADIO.§SQL语法我们在编写ABAP4程序的时候,经常需要从TABLE中根据某些条件读取数据,.读取数据最常用的方法就是通过SQL语法实现的.ABAP/4中可以利用SQL语法创建或读取TABLE,SQL语法分为DDL(DATA DEFINE LANGUAGE)语言和DML(DATA MULTIPULATION LANGUAGE)语言,DDL语言是指数据定义语言,例如CREATE等, DML语言是数据操作语言,例如SELECT, INSERT 等语句. SQL语句有OPEN SQL语句和NATIVE SQL语句. OPEN SQL语句不是标准SQL语句,是ABAP/4语言,利用OPEN SQL语句能在Databases 和 Command 之间产生一个BUFFER,所以它有一个语言转换的过程.而NATIVE SQL语句则是标准的SQL语句, 它直接针对Databases操作.一. OPEN SQLOPEN SQL 语句包含有: SELECT,INSERT,UPDATE,MODIFY,DELETE,OPEN CURSOR, FETCH,CLOSE CURSOR,COMMIT WORK,ROLLBACK WORK等.1. SELECT语句语法格式:SELECT <result> [INTO <target>] [FROM <source>] [WHERE <condition>] [GROUP BY <fields>] [ORDER BY <sort order>]其中: <result>指定要抓取的字段<target>将读取的记录存放在work area中<source>指定从那个TABLE中读取数据<condition>抓取资料的条件<fields>指定按那些字段分组<sort order>排序的字段及方式相关的系统变量:SY-SUBRC = 0 表示读取数据成功<> 0 表示未找到符合条件的记录SY-DBLNT: 被处理过的记录的笔数.相关的命令:EXIT. 退出循环.CHECK <logistic statement>.如果逻辑表达式成立,则继续执行,否则,开始下一次循环.◆.利用循环方式读取所有记录SELECT ….ENDSELECT.是循环方式读取记录的.例如:TABLES MARD.SELECT [DISTINCT] * FROM MARD WHERE MATNR = ‘3520421700’.<Statements>.ENDSELECT.(从MARD中抓取所有料号=3520421700的数据)◆读取一笔数据TABLES MARD.SELECT SINGLE * FROM MARD WHERE MATNR = ‘3520421700’.(从MARA中抓取一笔料号=3520421700的资料)◆将读取的记录放在work area中,并且加入Internal table 中.格式有:... INTO <work area>... INTO CORRESPONDING FIELDS OF <work area>... INTO (f1, ..., fn) 变量组.... INTO TABLE <internal table>... INTO CORRESPONDING FIELDS OF TABLE <internal table>... APPENDING TABLE <internal table>... APPENDING CORRESPONDING FIELDS OF TABLE <internal table> 举例一:TABLES MARD.DATA: BEGIN OF ITAB OCCURS 10,MATNR LIKE MARD-MATNR,WERKS LIKE MARD-WERKS,LGORT LIKE MARD-LGORT,LABST LIKE MARD-LABST,END OF ITAB.SELECT MATNR WERKS LGORT LABSTINTO CORRESPONDING FIELDS OF ITABFROM MARDWHERE MATNR = ‘3520421700’.APPEND ITAB.CLEAR ITAB.ENDSELECT.(将读取的结果放在Internal table ITAB中)举例二.TABLES MARD.SELECT MATNR MTART MAKTX INTO (t_matnr, t_mtart, maktx)FROM MARDWHERE MATNR = ‘3520421700’.<Statements>.ENDSELECT.(从MARD中抓取料号=3520421700的料号、类型和描述,放在变量t_matnr, t_mtart, maktx中)。
abap处理字符串要点掌握

ABAP学习笔记--处理字符串ABAP学习笔记--处理字符串一、移动字段内容1、按给定位置数移动字符串语法:SHIFT <c> [BY <n> PLACES] [<mode>].将字段<c>移动<n>个位置,如果省略BY <n> PLACES,则将<n>解释为一个位置;如果<n>是0或负数,则<c>保持不变;如果<n>超过<c>长度,则<c>用空格填充。
<n>可为变量。
<mode>可以为:LEFT 向左移动<n>个位置,右边用<n>个空格填充;RIGHT 向右移动<n>个位置,左边用<n>个空格填充;CIRCULAR 向左移动<n>个位置,以便左边<n>个字符出现在右边。
2、移动字段串到给定串语法:SHIFT <c> UP TO <str> <mode>.查找<c>字段内容直到找到字段串<str>并将字段<c>移动到字段边缘,<str>可为变量。
如果<c>中找不到<str>,则将SY-SUBRC设置为4并且不移动<c>,否则将SY-SUBRC设置为0。
<mode>内容同上。
3、根据第一个或最后一个字符移动字段串语法:SHIFT <c> LEFT DELETING LEADING <str>.SHIFT <c> RIGHT DELETING TRAILING <str>.假设左边的第一个字符或右边的最后一个字符出现在<str>中,将字段<c>向左或向右移动,字段右边或左边用空格填充,<str>可为变量。
abap 拆分字符串语法

abap 拆分字符串语法
在ABAP(Advanced Business Application Programming)中,可以使用以下语法来拆分字符串:
abap复制代码
DATA: string_field TYPE string VALUE 'A,B,C,D,E'.
DATA: split_string TYPE TABLE OF string.
CALL FUNCTION 'CL_ABAP_SPLIT_LINE'
EXPORTING
string = string_field
IMPORTING
split_string = split_string
EXCEPTIONS
error = 1
OTHERS = 2.
在上面的示例中,我们首先定义了一个字符串变量string_field,其值为
'A,B,C,D,E'。
然后,我们定义了一个字符串表split_string,用于存储拆分后的字符串。
接下来,我们调用函数CL_ABAP_SPLIT_LINE来拆分字符串。
这个函数
将string_field拆分成多个子字符串,并将它们存储在split_string中。
请注意,上述示例中的函数CL_ABAP_SPLIT_LINE是一个自定义函数,它可能并不是ABAP 自带的标准函数。
如果您的ABAP 系统没有提供类似的函数,您可能需要自行编写代码来实现字符串的拆分功能。
ABAP中关于字符串操作的命令函数汇总

ABAP中关于字符串操作的命令函数汇总ABAP开发中经常会对字符串操作,下⾯列出⼀些相关命令/函数:
SHIFT STRING:左移字符串。
长度减1。
CONCATENATE:连接字符串。
SPLIT:拆分字符串。
SEARCH:查询字符串。
REPLACE:替换字符串。
CONDENSE:删除多余的空格。
TRANSLATE:转换字符格式,如将'ABC'转换为'ABC'
CONVERT TEXT:创建⼀个可排序的字符串。
OVERLAY:⽤⼀个字符串覆盖另⼀个字符串。
STRLEN:字符串长度。
ABS:取绝对值。
COS、SIN、TAN:取三⾓函数值。
ACOS、ASIN、ATAN:反三⾓函数。
COSH、SINH、TANH:双曲函数。
EXP:E的幂函数。
LOG:底数为E的对数。
LOG10:底数为10的对数。
SQRT:平⽅根。
SIGN:返回参数符号。
TRUNC:返回参数的整数部分。
FRAC:输⼊参数的⼩数部分。
CEIL:返回不⼩于参数的最⼩整数。
FLOOR:返回不⼤于参数的最⼩整数。
以上。
abap基本语法汇总
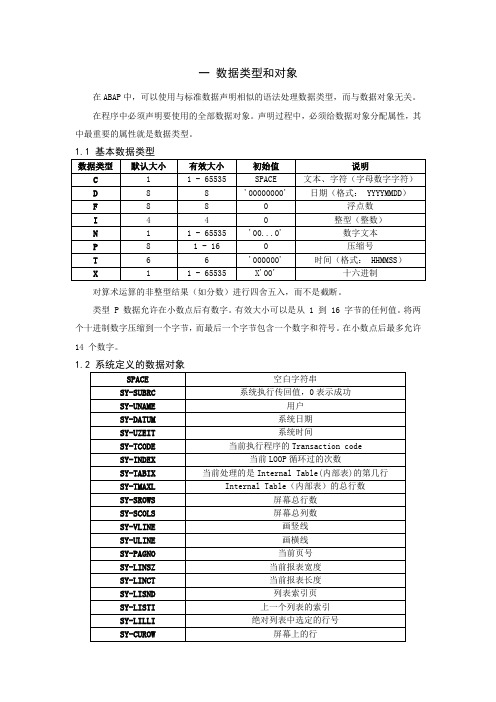
一数据类型和对象在ABAP中,可以使用与标准数据声明相似的语法处理数据类型,而与数据对象无关。
在程序中必须声明要使用的全部数据对象。
声明过程中,必须给数据对象分配属性,其中最重要的属性就是数据类型。
1.1 基本数据类型对算术运算的非整型结果(如分数)进行四舍五入,而不是截断。
类型 P 数据允许在小数点后有数字。
有效大小可以是从 1 到 16 字节的任何值。
将两个十进制数字压缩到一个字节,而最后一个字节包含一个数字和符号。
在小数点后最多允许14 个数字。
1.2 系统定义的数据对象1.3 确定数据对象的属性如果要查明数据对象的数据类型,或者要在程序的运行期间使用其属性,可使用DESCRIBE 语句。
语法如下:DESCRIBE FIELD <f> [LENGTH <l>] [TYPE <t> [COMPONENTS <n>]][OUTPUT-LENGTH <o>] [DECIMALS <d>][EDIT MASK <m>].将由语句的参数指定的数据对象<f>的属性写入参数后的变量。
DESCRIBE FIELDS 语句具有下列参数:1.3.1 确定字段长度要确定数据对象的长度,利用DESCRIBE FIELD 语句使用 LENGTH 参数,如下所示:DESCRIBE FIELD <f> LENGTH <l>.系统读取字段<f>的长度,并将值写入字段<l>。
1.3.2确定数据类型要确定字段的数据类型,利用DESCRIBE FIELD 语句使用 TYPE 参数,如下所示:DESCRIBE FIELD <f> TYPE <t> [COMPONENTS <n>].系统读取字段<f>的数据类型,然后将值写入字段<t>。
ABAP中经常会用到字符串操作—学习笔记

ABAP中经常会用到字符串操作—学习笔记字符串首字符索引为0;Character Fields:C,N,D,T,string(CNDT =>C N Data Time)1.字符串连接CONCATENATE dobj1 dobj2 ...INTO result[IN{BYTE|CHARACTER}MODE][SEPARATED BY sep].2.字符串分隔,split一个string的部分到一个内表或一系列的变量SPLIT dobj AT sep INTO{{result1 result2 ...}|{TABLE result_tab}}[IN{BYTE|CHARACTER}MODE].3.字符串查找,在一个字符串中查找模式串(FIND or SEARCH)FIND sub_stringIN SECTION[OFFSET off][LENGTH len]OF dobj --> 灰色部分用来缩小目的串被查找的范围[IN{BYTE|CHARACTER}MODE][{RESPECTING|IGNORING}CASE][MATCH OFFSET moff ][MATCH LENGTH mlen ].FIND'knows'IN SECTION OFFSET5OF'Everybody knows this is nowhere' MATCH OFFSET moff " => moff = 10MATCH LENGTH mlen. "=> mlen=5在字符串dobj中查找patternSEARCH dobj FOR pattern[IN{BYTE|CHARACTER}MODE][STARTING AT p1][ENDING AT p2][ABBREVIATED][AND MARK].if sy-subrc =0.then SY-FDPOS =返回pattern在dobj中的位置About pattern:'pat'-忽略尾部空格'.pat.'-不忽略尾部空格'*pat'-以pat结尾'pat*'-以pat开始单词是指:用空格,;:?!()/+=分隔的字串4.字符串替换REPLACE SECTION[OFFSET off][LENGTH len]OF dobj WITH new[IN{BYTE|CHARACTER}MODE].REPLACE[{FIRST OCCURRENCE}|{ALL OCCURRENCES}OF] [SUBSTRING] sub_stringIN[SECTION[OFFSET off][LENGTH len]OF] dobj WITH new [IN{BYTE|CHARACTER}MODE][{RESPECTING|IGNORING}CASE][REPLACEMENT COUNT rcnt][REPLACEMENT OFFSET roff][REPLACEMENT LENGTH rlen].eg:DATA: text1 TYPE string VALUE'xababx'.REPLACE'ab'IN text1 WITH'xx'.--> xxxabx5.去前导0(Remove leading zero)SHIFT dobj LEFT DELETING LEADING'0'.FM : CONVERSION_EXIT_ALPHA_OUTPUT增前导0(Add leading zero)DATA v_s(5).UNPACK'123'to v_s.==> v_s ='00123'FM: CONVERSION_EXIT_ALPHA_INPUTSHIFT dobj[{BY num PLACES}|{UP TO sub_string}][LEFT|RIGHT][CIRCULAR]SHIFT dobj{LEFT DELETING LEADING}|{RIGHT DELETING TRAILING}pattern. [IN{BYTE|CHARACTER}MODE].6.字符串的长度,内表的行数STRLEN( dobj)字符串的长度LINES( itab )内表的行数7.删字符串中的空格:CONDENSE text[NO-GAPS].8.大小写转换,字符变换TRANSLATE text{TO{UPPER|LOWER}CASE}|{USING pattern}. eg:text= `Barbcbdbarb`.TRANSLATE text USING'ABBAabba'.=>'Abracadabra'9.CONVERT转换CONVERT DATE dat [TIME tim [DAYLIGHT SAVING TIME dst]]INTO TIME STAMP time_stamp TIME ZONE tz.CONVERT TIME STAMP time_stamp TIME ZONE tzINTO[DATE dat][TIME tim][DAYLIGHT SAVING TIME dst].CONVERT TEXT text INTO SORTABLE CODE hex.10.覆盖OVERLAY text1 WITH text2 [ONLY pattern].如果不指定后面的ONLY pattern,text1中的空格会被text2中的对应字符替代如果指定只有匹配的字符才会被替代,注意大小写敏感11.模式匹配CO/CN contains only or notCA/NA contains any or not anyCS/NS contains string or notCP/NP contains pattern or not注意:a).CO,NO,CA,NA比较时区分大小写,并且尾部空格也在比较的范围之内data: s1(10)value'aabb'.if s1 co'ab'==>falseif s1 co'ab '==>trueCS,NS,CP,NP不区分大小写和尾部空格b).对于CP,NP*= \s?+= \s# 换码字符,用于匹配*,+这样的字符###*#+#___ 比较结尾空格#[a-z]在CP,NP中强制区分大小写c).比较结束后,如果结果为真,sy-fdpos将给出s2在s1中的偏移量信息12.特殊字符在字符串中加入回车换行或TAB字符,在其他语言可以使用$13$10这样的ASCII 码进行插入.但在ABAP中要使用sap的类CL_ABAP_CHAR_UTILITIES.里面有字符常量:CR_LF,HORIZONTAL_TAB,NEWLINE等等.13.字符串位操作DATA: v_s(10)value'abcd'.v_s+0(1)='b'.v_s+2(*)='12'.=> v_s ='bb12'.。
ABAP学习(1):基本语法介绍

ABAP学习(1):基本语法介绍ABAP学习ABAP学习基本资料整理。
ABAP基本语法ABAP中不区分⼤⼩写,例如:Type 和type表⽰⼀个意思。
1基本数据类型ABAP基本数据类型:I : 整形数据;C:字符型数据;N:只包含数字的字符串;P:包装数据类型;F:浮点类型;D:⽇期类型;T:时间类型;X:⼗六进制数据。
F和P类型都保存浮点数,P的精度⽐F更⾼,⼀般使⽤P类型。
⽰例:"整型DATA:num1 type I."字符型DATA:num2(3) type C."数字字符型DATA:num3(4) type N."包装类型,decimals指定⼩数位数,只有P类型可⽤DATA:num4(10) type P DECIMALS 4."浮点型DATA:num5 type F."⽇期型DATA:num6 type D."时间型DATA:num7 type T."16进制型DATA:num8(10) type X."字符串DATA:num9 type string."C,N,X,P可以使⽤length定义长度DATA:num10 TYPE C LENGTH 14."赋值操作"move to 语句"MOVE 1333 TO num1.num1 = 1234567890.num2 = 'abc'.num3 = '0010'.num4 = '1.23456789'.num5 = '12.3456789'.num6 = sy-datum.num7 = sy-uzeit.num8 = 1234567890.write :/ 'num1=',num1,'num2=',num2,'num3=',num3,'num4=',num4,'num5=',num5,'num6=',num6,'num7=',num7,'num8=',num8."字符串转I,"不能有汉字,不能是科学计数法"num9 = '1.23300000E+2'.num9 = '12.33334'.num1 = num9.WRITE:/ 'num1',num1."字符串转Cnum9 = '中'.num2 = num9.WRITE:/ 'num2',num2."字符串转N,会将⼩数点去掉num9 = '22.33'.num3 = num9.WRITE:/ 'num3',num3."字符串转P,num9 = '12.3456'.num4 = num9.WRITE:/ 'num4',num4."字符串转F,会变成科学计数法显⽰num9 = '12.34567'.num5 = num9.WRITE:/ 'num5',num5."字符串转D,MMDDYYYY"输出:09302018num9 = '20180930'.num6 = num9.WRITE:/ 'num6',num6."字符串转T,hhmmssnum9 = '014423'.num7 = num9.WRITE:/ 'num7',num7."字符串转X,长度超过20位,截取前20字符num9 = '123456789012345678901234'.num8 = num9.WRITE:/ 'num8',num8."科学计数法转换DATA:str TYPE char25 VALUE '4.3999999999999997E-2'. DATA:m_str LIKE CHA_CLASS_DATA-SOLLWERT. DATA:c_str(16) TYPE C.DATA:c_num(16) TYPE P DECIMALS 3.MOVE str to m_str."科学计数法字符串转换成数字CALL FUNCTION'QSS0_FLTP_TO_CHAR_CONVERSION' EXPORTINGI_NUMBER_OF_DIGITS = 3I_FLTP_VALUE = m_strI_VALUE_NOT_INITIAL_FLAG = 'X'I_SCREEN_FIELDLENGTH = 16 IMPORTINGE_CHAR_FIELD = c_str.IF sy-subrc = 0.WRITE:/ c_str.c_num = c_str.WRITE:/ c_num.ENDIF."不⽤function转换,QSOLLWERTE作为中间数据"将科学计数法字符串转换为其他数据DATA:mid_str TYPE QSOLLWERTE.mid_str = str.c_num = mid_str.View Code2 type定义数据类型语法结构:Types :<类型名> type <数据类型>Types :<类型名> like <数据对象或数据类型>定义结构体Types: begin of <结构名>,<资料名> type <数据类型>,…………end of <结构名>.Data: begin of <结构名>,<资料名> type <数据类型>,…………end of <结构名>."******************************************************************"type定义数据类型"******************************************************************TYPES: length TYPE I.TYPES: str(20) TYPE C.TYPES: BEGIN OF person,Name(10) type C,Age type I,END OF person.3变量声明相关语法:data: <变量名> type <数据类型> [value <值>] 。
ABAP语法基础篇(3)——赋值

ABAP语法基础篇(3)——赋值三、赋值在 ABAP/4中,可以在声明语句和操作语句中给数据对象赋值。
在声明语句中,将初始值赋给声明的数据对象。
为此,可以在DATA 、常量或 STATICS 语句中使⽤ VALUE 参数。
要在操作语句中给数据对象赋值,可以使⽤:MOVE语句和WRITE TO语句,对应于赋值运算符=3.1⽤MOVE赋值3.1.1 基本赋值操作要将值(⽂字)或源字段的内容赋给⽬标字段,可以使⽤MOVE语句或赋值运算符=。
MOVE语句的语法如下所⽰:MOVE <f1> TO <f2>.MOVE语句将源字段<f1>的内容传送给⽬标字段<f2>。
<f1>可以是任何数据对象。
<f2>必须是变量,不能是⽂字或常量。
传送后,<f1>的内容保持不变。
赋值运算符=的语法如下所⽰:<f2> = <f1>.MOVE语句和赋值运算符功能相同。
3.1.2 ⽤指定偏移量赋值可以在每条 ABAP/4 语句中为基本数据类型指定偏移量和长度。
在这种情况下,MOVE语句语法如下:MOVE <f1>[+<o1>][(<l1>)] TO <f2>[+<o2>][(<l2>)].将字段<f1>从<o1>+1位置开始且长度为<l1>的段内容赋给字段<f2>,覆盖从<o2>+1位置开始且长度为<l2>的段。
在MOVE语句中,所有偏移量和长度指定都可为变量。
3.1.3 在字符串组件之间赋值描述的MOVE语句赋值⽅法适⽤于基本数据对象和结构化数据对象。
另外,还有⼀种MOVE语句变体,允许将源字段串组件内容复制到⽬标字段串组件中。
语法如下:MOVE-CORRESPONDING <string1> TO <string2>.该语句将字段串<string1>组件的内容赋给有相同名称的字段串<string2>组件。
abap cp用法

在ABAP(Advanced Business Application Programming)编程语言中,CP(Character Format)是一种格式化字符串的指令。
它可以用于将数字、日期等数据类型格式化为特定的字符串表示形式。
CP指令的语法如下:CP <length> <option> <format> <field>其中:<length> 指定输出字符串的长度。
<option> 指定输出字符串的选项,可以是以下之一:A:自动调整输出字符串的长度,在必要时添加空格。
E:使用科学计数法表示数字。
F:固定点表示法表示数字。
N:数字表示法表示数字。
P:使用百分比表示法表示数字。
S:使用标准表示法表示数字。
<format> 指定输出字符串的格式,可以是以下之一:B:二进制格式。
D:日期格式。
I:整数格式。
P:百分比格式。
S:标准格式。
X:十六进制格式。
<field> 指定要格式化的字段名或变量名。
以下是一个示例,演示如何使用CP指令将一个整数格式化为标准格式的字符串:DATA: lv_number TYPE i VALUE 12345.WRITE: / 'The formatted number is:', lv_number.WRITE: / 'The formatted string is:', cp 10 'S' lv_number.输出结果将是:The formatted number is: 12345The formatted string is: 12,345。
abap replace用法

abap replace用法ABAPReplace是一种字符串函数,它可以在字符串中查找并替换子字符串。
以下是使用ABAP Replace的常见用法:1. 替换字符串中的子字符串使用ABAP Replace可以轻松地替换字符串中的子字符串。
例如,要将字符串“Hello World”中的“World”替换为“ABAP”,可以使用以下代码:```DATA: lv_string TYPE string,lv_new_string TYPE string.lv_string = 'Hello World'.lv_new_string = REPLACE( val = lv_stringsub = 'World'with = 'ABAP' ).```2. 删除字符串中的子字符串ABAP Replace还可以用于删除字符串中的子字符串。
例如,要删除字符串“ABAP is awesome”中的“ is awesome”,可以使用以下代码:```DATA: lv_string TYPE string,lv_new_string TYPE string.lv_string = 'ABAP is awesome'.lv_new_string = REPLACE( val = lv_stringsub = ' is awesome'with = '' ).```3. 替换字符串中的特定字符使用ABAP Replace还可以替换字符串中的特定字符。
例如,要将字符串“ABAP is awesome”中的所有空格替换为下划线,可以使用以下代码:```DATA: lv_string TYPE string,lv_new_string TYPE string.lv_string = 'ABAP is awesome'.lv_new_string = REPLACE( val = lv_stringsub = ' 'with = '_' ).```4. 替换字符串中的多个子字符串ABAP Replace也可以用于替换字符串中的多个子字符串。
SAP-ABAP语法整理

1、ST05是用于在开发ABAP程序时,对应事务码取得的字段是“数据结构”而不是“透明表”的时候,通过ST05的“SQL跟踪”来获得相关“Select”的语句;一般查看“REC”列耗时比较多的“Select”语句;2、跟踪时如果有涉及到“数量”这类有对数据表进行更新或插入操作的,则直接去查Update 和Insert的SQL语句;3、在跟踪后,直接双击“对象名”列的名称,点选“表格”转到“SE11”的表字段表;4、ABAP程序开头的Tables:“数据表名”,只有在屏幕中有用到的表,才需要声明;在程序中用到的表则不需要进行在Tables内声名;5、抓SAP“文本”字段的数据,要先自定义变量,然后通过SE37的函数“FUNCTION ‟ZREAD_TEXT‟”取回文本数据;6、新建的ABAP程序,在测试运行的时候要先进行“激活”,才能测试运行;7、SE93:把ABAP写好的程序指定一个事务码执行;8、abap引号内的字符‟‟必须要是大写;9、ABAP select 里面的语句,不能像mssql有那么丰富的函数使用,需要导到内表后再对数据进行操作;10、‟EQ‟是单个数据值,‟BT‟是between区间的意思。
11、在写select inner join 里面,要注意是否需要加上销售组织的条件;on 条件1 and 销售组织条件。
12、SELECTION-SCREEN,里面有两个子项,PARAMETERS和select-options。
PARAMETERS 一般是用于必输项的屏幕参数设置,如果这个参数不是必输项的,就要用select-options。
在select ...where条件里,用PARAMETERS的条件语法是“数据字段= 屏幕字段”;而select-options的条件语法是“数据字段in 屏幕字段”。
13、在where判断一个日期型数据是空,不是DEAKT = ‟‟,也不是DEAKT is initial,而应该写成DEAKT = ‟00000000‟ (8个0)。
ABAP中的字符串操作

ABAP中的字符串操作1,连接字符串:将⼏个字符串连接起来,形成⼀个新的字符串,可以使⽤CONCATENATE语句,SEPARATED BY⽤于指定⼀个字符(串)作为分隔符,在构成新字符串时插⼊s1...sn之间。
语法:CONCATENATE s1 ... sn INTO s_dest [SEPARATED BY sep].其中s_dest也可以是s1...sn中的某个变量。
简单实例:REPORT z_string_con.DATA: s1(9) TYPE c VALUE 'FName',s2(10) TYPE c VALUE 'SName',s3(20),sep(1) TYPE c VALUE '.'.CONCATENATE s1 s2 INTO s3.WRITE / s3.CONCATENATE s1 s2 INTO s3 SEPARATED BY sep.WRITE / s3.输出结果如下:FNameSNameFName.SName注意所有字符串操作将忽略s1...sn中的尾部空格2,拆分字符串:使⽤SPLIT语句将字符串拆分成多个⼩串。
语法:SPLIT s_source AT sep INTO s1 ... sn.在源字符串中搜索分隔符(串)sep,根据该分隔符将源字符串拆分成各个⼩串,然后放到⽬标字段s1 ... sn中,但是⼦字符串中不包括分隔符。
语法:SPLIT s_source AT sep INTO TABLE itab.若源字符串能够拆分的⼦串多过指定数⽬,则使⽤内表操作,该形式根据⼦串数⽣成n⾏的内表简单实例:REPORT z_string_split.DATA: text TYPE string,itab TYPE TABLE OF string.text = 'YOU ARE GOOD BOY'.SPLIT text AT space INTO TABLE itab.LOOP AT itab INTO text.WRITE / text.ENDLOOP.space其实就是text字字符串中的空格,语句LOOP AT⽤于循环出内表的每⼀⾏数据输出结果:YOUAREGOODBOY3,查找⼦串模式:在⼀个字符串中找到⼀个⼦字符串,使⽤SEARCH语句。
ABAP字符串操作截取字符长度取位数

ABAP字符串操作截取字符长度取位数ABAP字符串操作ABAP對字串的操作⽅法與其他語⾔的操作有較⼤差別,以下是較常⽤的對字串操作的⽅法:1. 字串的連接:CONCATENATEDATA: t1 TYPE c LENGTH 10 VALUE 'We', t2 TYPE c LENGTH 10 VALUE 'have', t3 TYPE c LENGTH 10 VALUE 'all', t4 TYPE c LENGTH 10 VALUE 'the', t5 TYPE c LENGTH 10 VALUE 'time', t6 TYPE c LENGTH 10 VALUE 'in', t7 TYPE c LENGTH 10 VALUE 'the', t8 TYPE c LENGTH 10 VALUE 'world', result TYPE string.CONCATENATE t1 t2 t3 t4 t5 t6 t7 t8 INTO result. "直接連接CONCATENATE t1 t2 t3 t4 t5 t6 t7 t8 INTO result SEPARATED BY space. "⽤空格將每個字串連接2. 拆分字串: SPLITDATA: str1 TYPE string, str2 TYPE string,str3 TYPE string,itab TYPE TABLE OF string,text TYPE string.text = `What a drag it is getting old`.SPLIT text AT space INTO: str1 str2 str3,TABLE itab.3. 去除多余的空格:CONDENSEDATA: BEGIN OF sentence, word1 TYPE c LENGTH 30 VALUE 'She',word2 TYPE c LENGTH 30 VALUE 'feeds',word3 TYPE c LENGTH 30 VALUE 'you',word4 TYPE c LENGTH 30 VALUE 'tea',word5 TYPE c LENGTH 30 VALUE 'and',word6 TYPE c LENGTH 30 VALUE 'oranges',END OF sentence,text TYPE string.text = sentence.CONDENSE text.“在每個連接串中間會有⼀個空格 CONDENSE text No-GAPS. "在後⾯加⼊NO-GAPS後,所有空格都會去除。
abap代码中 concatenate into的含义

abap代码中concatenate into的含义摘要:1.ABAP代码简介2.CONCATENATE INTO语句的作用3.CONCATENATE INTO的实际应用4.结论正文:ABAP是SAP系统中的编程语言,被广泛应用于企业信息化建设。
在ABAP代码中,CONCATENATE INTO语句是一种常用的字符串操作功能,主要用于将多个字符串连接在一起。
本文将详细介绍CONCATENATE INTO的含义、应用及其在实际编程中的实用性。
在ABAP中,CONCATENATE INTO语句的作用是将两个或多个字符串连接在一起。
它的语法格式如下:```CONCATENATE INTO <目标字段> <源字段1> <分隔符1> <源字段2> <分隔符2> ...```其中,<目标字段>表示要将字符串连接后的结果存储的字段;<源字段1>、<源字段2>等表示要连接的字符串字段;<分隔符1>、<分隔符2>等表示字符串之间的分隔符,可以省略。
举个例子,假设我们有一个名为`VBELN`的字段,需要将两个字符串`A`和`B`连接在一起,可以使用以下代码:```CONCATENATE INTO VBELN A "," B.```这条代码将把字符串A和B连接在一起,并将结果存储在VBELN字段中。
CONCATENATE INTO语句在实际编程中的应用非常广泛,例如在数据处理、报表生成、邮件发送等方面。
掌握这项技能对于ABAP开发者来说非常有用。
总之,ABAP代码中的CONCATENATE INTO语句是一种强大的字符串操作功能,可以方便地将多个字符串连接在一起。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ABAP 字符串操作语法总结CONCATENATE:合并字符串.CONCATENATE f1 … fn INTO g [SEPARATED BY h].1* CONCATENATE合并字符串2DATA: c1(10) TYPE c VALUE 'Sum',3c2(3) TYPE c VALUE 'mer',4c3(5) TYPE c VALUE 'holi ',5c4(10) TYPE c VALUE 'day',6c5(30) TYPE c ,7sep(3) TYPE c VALUE ' - '.8CONCATENATE c1 c2 c3 c4 INTO c5.9WRITE c5.10CONCATENATE c1 c2 c3 c4 INTO c5 SEPARATED BY sep. 11WRITE / c5.--------------------------------------------------------输出结果:SummerholidaySum - mer - holi - day--------------------------------------------------------SPLIT: 字符串拆分.SPLIT f AT g INTO h1 … hn.SPLIT f AT g INTO TABLE itable.1* splitting strings2DATA: string10(60) TYPE c ,3p1(20) TYPE c VALUE '++++++++++++++++++++', 4p2(20) TYPE c VALUE '++++++++++++++++++++', 5p3(20) TYPE c VALUE '++++++++++++++++++++', 6p4(20) TYPE c VALUE '++++++++++++++++++++', 7del10(3) TYPE c VALUE '***'.8 string10 = ' Part 1 *** Part 2 *** Part 3 *** Part 4 *** Part 5'. 9WRITE string10.10SPLIT string10 AT del10 INTO p1 p2 p3 p4.11WRITE / p1.12WRITE / p2.13WRITE / p3.14WRITE / p4.--------------------------------------------------------输出结果:Part 1 *** Part 2 *** Part 3 *** Part 4 *** Part 5Part 1Part 2Part 3Part 4 *** Part 5--------------------------------------------------------SHIFT:字符串整体或者字串进行转移.如果SHIFT 操作的对象是C类型,则所有字节都会向前移动一位,最后一位用空格代替;如果SHIFT操作的对象是String类型,则所有字符都会向前移动一位,最后一位删除;SHIFT c <LEFT/RIGHT/CIRCULAR>.SHIFT c BY n PLACES.SHIFT c UP TO c1.1* SHIFT c BY n PLACES 用法.2DATA: t1(10) TYPE c VALUE 'abcdefghij',3string1 LIKE t1.45 string1 = t1.6WRITE string1.7SHIFT string1.8WRITE / string1.9 string1 = t1.10SHIFT string1 BY3 PLACES LEFT.11WRITE / string1.12 string1 = t1.13SHIFT string1 BY3 PLACES RIGHT.14WRITE / string1.15 string1 = t1.16SHIFT string1 BY3 PLACES CIRCULAR.17WRITE / string1.-------------------------------------------------------- 输出结果:abcdefghij “string1bcdefghijdefghijabcdefgdefghijabc--------------------------------------------------------1* SHIFT c UP TO c12DATA: t2(10) TYPE c VALUE 'abcdefghij',3string2 LIKE t2,4str2(2) TYPE c VALUE 'ef'.56 string2 = t2.7WRITE string2.8SHIFT string2 UP TO str2.9WRITE / string2.10 string2 = t2.11SHIFT string2 UP TO str2 LEFT.12WRITE / string2.13 string2 = t2.14SHIFT string2 UP TO str2 RIGHT.15WRITE / string2.16 string2 = t2.17SHIFT string2 UP TO str2 CIRCULAR.18WRITE / string2.--------------------------------------------------------输出结果:abcdefghijefghijefghijabcdefefghijabcd--------------------------------------------------------移除字符串左/右边的子字符串:SHIFT c LEFT DELETEING LEADING c1.SHIFT c RIGHT DELETEING TRAILING c1.1* SHIFT c LEFT/RIGHT DELETEING LEADING c1 2DATA: t3(14) TYPE c VALUE 'abcdefghij',3string3 LIKE t3,4str3(6) TYPE c VALUE 'ghijkl'.56 string3 = t3.7WRITE string3.8SHIFT string3 LEFT DELETING LEADING space. 9WRITE / string3.10 string3 = t3.11SHIFT string3 RIGHT DELETING TRAILING str3. 12WRITE / string3.--------------------------------------------------------输出结果:abcdefghijabcdefghijabcdef--------------------------------------------------------CONDENSE:重新整合分配字符串.CONDENSE c <NO-GAPS>.1* condensing strings2DATA: string9(25) TYPE c VALUE ' one two three four', 3len9 TYPE i.45 len9 = strlen( string9 ).6WRITE: string9, '!'.7WRITE: / 'Length: ', len9.8CONDENSE string9.9 len9 = strlen( string9 ).10WRITE: string9, '!'.11WRITE: / 'Length: ', len9.12CONDENSE string9 NO-GAPS.13 len9 = strlen( string9 ).14WRITE: string9, '!'.15WRITE: / 'Length: ', len9.--------------------------------------------------------输出结果:one two three four !Length: 25 one two three four !Length: 18 onetwothreefour !Length: 15--------------------------------------------------------TRANSLATE:实现字符串转换.TRANSLATE c TO UPPER CASE.TRANSLATE c TO LOWER CASE.TRANSLATE c USING c1.1* translating signs2DATA: t5(10) TYPE c VALUE 'AbCdEfGhIj',3string5 LIKE t5,4rule5(20) TYPE c VALUE 'AxbXCydYEzfZ'.56 string5 = t5.7WRITE string5.8TRANSLATE string5 TO UPPER CASE. "#EC SYNTCHAR 9WRITE / string5.10 string5 = t5.11TRANSLATE string5 TO LOWER CASE. "#EC SYNTCHAR 12WRITE / string5.13 string5 = t5.14TRANSLATE string5 USING rule5. "#EC SYNTCHAR15WRITE / string5.----------------------------------------------输出结果:AbCdEfGhIjABCDEFGHIJabcdefghijxXyYzZGhIj----------------------------------------------TRANSLATE c … FROM CODE PAGE g1 … TO CODE PAGE g2. OVERLAY:参考字符串对空白字符进行填充.OVERLAY c with c1.REPLACE:字符串按条件取代.REPLACE f … WITH g … INTO h.1* replacing values2DATA: t4(10) TYPE c VALUE 'abcdefghij',3string4 LIKE t4,4str41(4) TYPE c VALUE 'cdef',5str42(4) TYPE c VALUE 'klmn',6str43(2) TYPE c VALUE 'kl',7str44(6) TYPE c VALUE 'klmnop',8len4 TYPE i VALUE 2.910 string4 = t4.11WRITE string4.12REPLACE str41 WITH str42 INTO string4.13WRITE / string4.14 string4 = t4.15REPLACE str41 WITH str42 INTO string4 LENGTH len4. 16WRITE / string4.17 string4 = t4.18REPLACE str41 WITH str43 INTO string4.19WRITE / string4.20 string4 = t4.21REPLACE str41 WITH str44 INTO string4.22WRITE / string4.----------------------------------------------输出结果:abcdefghijabklmnghijabklmnefghabklghijabklmnopgh--------------------------------------------------------SERACH:搜索指定字符串. 通过SY_SUBRC取值得到查询结果. SERACH f FOR g.[ABBREVIATED] : 从指定字符串中按顺序搜索相匹配字符串abbreviated [STARTING AT n1 ]:从字符串第n1个字符串开始搜索[ENDING AT n2 ]:搜索到字符串第n2个字符为止[AND MARK]:从指定字符串中模糊搜索相匹配字符串1*searching strings2DATA string7(30) TYPE c VALUE 'This is a little sentence.'.3WRITE: / 'Searched', 'SY-SUBRC', 'SY-FDPOS'.45ULINE /1(26).6SEARCH string7 FOR'X'.7WRITE: / 'X', sy-subrc UNDER 'SY-SUBRC',8sy-fdpos UNDER 'SY-FDPOS'.9SEARCH string7 FOR'itt '.10WRITE: / 'itt ', sy-subrc UNDER 'SY-SUBRC',11sy-fdpos UNDER 'SY-FDPOS'.12SEARCH string7 FOR'.e .'.13WRITE: / '.e .', sy-subrc UNDER 'SY-SUBRC',14sy-fdpos UNDER 'SY-FDPOS'.15SEARCH string7 FOR'*e'.16WRITE: / '*e ', sy-subrc UNDER 'SY-SUBRC',17sy-fdpos UNDER 'SY-FDPOS'.18SEARCH string7 FOR's*'.19WRITE: / 's* ', sy-subrc UNDER 'SY-SUBRC',20sy-fdpos UNDER 'SY-FDPOS'.----------------------------------------------输出结果:Searched SY-SUBRC SY-FDPOS--------------------------------------------X 4 0itt 0 11.e . 0 15*e 0 10s* 0 17----------------------------------------------1*2DATA: string8(30) TYPE c VALUE 'This is a fast first example.',3pos8 TYPE i,4off8 TYPE i.56WRITE / string8.7SEARCH string8 FOR'ft' ABBREVIATED.8WRITE: / 'SY-FDPOS:', sy-fdpos.9 pos8 = sy-fdpos + 2.10SEARCH string8 FOR'ft' ABBREVIATED STARTING AT pos8 AND MARK. 11WRITE / string8.12WRITE: / 'SY-FDPOS:', sy-fdpos.13 off8 = pos8 + sy-fdpos - 1.14WRITE: / 'Off:', off8.----------------------------------------------输出结果:This is a fast first example.SY-FDPOS: 10This is a fast FIRST example.SY-FDPOS: 4Off: 15----------------------------------------------SERACH itab FOR g.[ABBREVIATED] : 从内表中按顺序逐行搜索相匹配字符串[STARTING AT line1 ]:从字符串第n1个字符串开始搜索[ENDING AT line2 ]:搜索最大范围到内表中具体某行[AND MARK]:从内表中模糊搜索相匹配字符串。