多元统计分析作业一(第三题)
《多元统计分析》习题

《多元统计分析》习题分为三部分:思考题、验证题和论文题思考题第一章绪论1﹑什么是多元统计分析?2﹑多元统计分析能解决哪些类型的实际问题?第二章聚类分析1﹑简述系统聚类法的基本思路。
2﹑写出样品间相关系数公式。
3﹑常用的距离及相似系数有哪些?它们各有什么特点?4﹑利用谱系图分类应注意哪些问题?5﹑在SAS和SPSS中如何实现系统聚类分析?第三章判别分析1﹑简述距离判别法的基本思路,图示其几何意义。
2﹑判别分析与聚类分析有何异同?3﹑简述贝叶斯判别的基本思路。
4﹑简述费歇判别的基本思路。
5﹑简述逐步判别法的基本思想。
6﹑在SAS和SPSS软件中如何实现判别分析?第四章主成分分析1﹑主成分分析的几何意义是什么?2﹑主成分分析的主要作用有那些?3﹑什么是贡献率和累计贡献率,其意义何在?4﹑为什么说贡献率和累计贡献率能反映主成分中所包含的原始变量的信息?5﹑为什么要用标准化数据去估计V的特征向量与特征值?6﹑证明:对于标准化数据有S=R。
7﹑主成分分析在SAS和SPSS中如何实现?第五章因子分析1﹑因子得分模型与主成分分析模型有何不同?2﹑因子载荷阵的统计意义是什么?3﹑方差旋转的目的是什么?4﹑因子分析有何作用?5﹑因子模型与回归模型有何不同?6﹑在SAS和SPSS中如何实现因子分析?第六章对应分析1﹑简述对应分析的基本思想。
2﹑简述对应分析的基本原理。
3﹑简述因子分析中Q型与R 型的对应关系。
4﹑对应分析如何在SAS和SPSS中实现?第七章典型相关分析1﹑典型相关分析适合分析何种类型的数据?2﹑简述典型相关分析的基本思想。
3﹑典型变量有哪些性质?4﹑典型相关系数和典型变量有何意义?5﹑典型相关分析有何作用?6 ﹑在SAS和SPSS中如何实现典型相关分析?验证题第二章聚类分析1、为了更深入了解我国人口的文化程度,现利用1990年全国人口普查数据对全国30个省、直辖市、自治区进行聚类分析。
分析选用了三个指标:(1)大学以上文化程度的人口占全部人口的比例(DXBZ);(2)初中文化程度的人都占全部人口的比例(CZBZ);(3)文盲半文盲人口占全部人口的比例(WMBZ),分别用来反映较高、中等、较低文化程度人口的状况。
应用多元统计分析试题及答案

一、填空题:1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法.2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著.3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。
通常聚类分析分为 Q型聚类和 R型聚类。
4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。
5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。
6、若()(,), Px N αμα∑=1,2,3….n且相互独立,则样本均值向量x服从的分布为_x~N(μ,Σ/n)_。
二、简答1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。
在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。
选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。
被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。
2、简述相应分析的基本思想。
相应分析,是指对两个定性变量的多种水平进行分析。
设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。
对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。
要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。
相应分析即是通过列联表的转换,使得因素 A 和因素B具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。
把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A、B的联系。
3、简述费希尔判别法的基本思想。
从k个总体中抽取具有p个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数系数:确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。
将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。
多元统计分析作业1

一、聚类分析为了研究2010年全国各地区城镇居民家庭平均每人全年消费性支出的分布规律,根据抽样调查资料进行分类处理,共抽取31个省、市、自治区的样本,每个样本有7个指标:食品、衣着、居住、家庭设备用品及服务、医疗保健、交通和通信、教育文化娱乐服务。
这7个指标反映了平均每人生活消费的支出情况,其数据资料见下表1所示。
表1定义变量及标签:设:X1:地区X2:食品支出X3:衣着支出X4:居住支出X5:家庭设备用品及服务支出X6:医疗保健支出X7:交通和通信支出X8:教育文化娱乐服务支出通过SPSS软件操作,得到如下输出结果见表2—表5所示。
表2表3表4表4给出了聚类的凝聚过程情况。
表5给出了样品聚为三类时的样品归类情况。
C A S E 0 5 10 15 20 25 Label Num +---------+---------+---------+---------+---------+甘肃 28 -+青海 29 -+新疆 31 -+河北 3 -+---+山西 4 -+ |河南 16 -+ |宁夏 30 -+ |黑龙江 8 -+ +-------+陕西 27 -+ | |云南 25 -+-+ | |西藏 26 -+ | | |广西 20 -+ +-+ |海南 21 -+ | |江西 14 -+-+ |贵州 24 -+ +-----------------------------------+ 湖北 17 -+ | | 湖南 18 -+ | | 四川 23 -+ | | 安徽 12 -+ | | 江苏 10 -+-+ | | 福建 13 -+ | | | 辽宁 6 -+ +---------+ | 吉林 7 -+ | | 山东 15 -+-+ | 重庆 22 -+ | 内蒙古 5 -+ | 天津 2 -+ | 浙江 11 -+-+ | 北京 1 -+ +-+ | 广东 19 ---+ +-------------------------------------------+ 上海 9 -----+图1图1是聚类全过程的树形图。
多元统计分析

多元统计分析习题一、填空题22121212121~(,),(,),(,),,123X N X x x x x x x ρμμμμσρ⎛⎫∑==∑=⎪⎝⎭+-1、设其中则Cov(3,)=____.10512~(,),1,,10,()()_________i i i i X N i W X X μμμ='∑=--∑ 、设则=服从。
3.__________, __________,________________。
214,1,,16(,),(,)15[4()][4()]~___________i p p X i N X A N T X A X μμμμ-=∑∑'=-- 、设是来自多元正态总体和分别为正态总体的样本均值和样本离差矩阵,则。
二、计算题123323*********(,,)~(,),(3,4,2),441,214X x x x N x x x x x x μμ-⎛⎫⎪'=∑=-∑=-- ⎪ ⎪-⎝⎭-⎛⎫+ ⎪+⎝⎭、设其中试判断与是否独立?(),123设X=x x x 的相关系数矩阵通过因子分析分解为211X h =的共性方差111X σ=的方差21X g =1公因子f 对的贡献121330.93400.1280.9340.4170.8351100.4170.8940.02700.8940.44730.8350.4470.1032013R ⎛⎫- ⎪⎛⎫⎛⎫⎪-⎛⎫ ⎪ ⎪⎪=-=-+ ⎪ ⎪ ⎪ ⎪⎝⎭ ⎪ ⎪ ⎪⎝⎭⎝⎭ ⎪ ⎪⎝⎭11262(90,58,16),82.0 4.310714.62108.946460.2,(5)( 115.6924)14.6210 3.17237.14.5X S μ--'=-⎛⎫ ⎪==-- ⎪ ⎪⎝⎭0、对某地区农村的名周岁男婴的身高、胸围、上半臂围进行测量,得相关数据如下,根据以往资料,该地区城市2周岁男婴的这三个指标的均值现欲在多元正态性的假定下检验该地区农村男婴是否与城市男婴有相同的均值。
多元统计分析课后练习答案

第1章 多元正态分布1、在数据处理时,为什么通常要进行标准化处理?数据的标准化是将数据按比例缩放,使之落入一个小的特定区间。
在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权。
其中最典型的就是0-1标准化和Z 标准化。
2、欧氏距离与马氏距离的优缺点是什么?欧氏距离也称欧几里得度量、欧几里得度量,是一个通常采用的距离定义,它是在m 维空间中两个点之间的真实距离。
在二维和三维空间中的欧氏距离的就是两点之间的距离。
缺点:就大部分统计问题而言,欧氏距离是不能令人满意的。
每个坐标对欧氏距离的贡献是同等的。
当坐标表示测量值时,它们往往带有大小不等的随机波动,在这种情况下,合理的方法是对坐标加权,使变化较大的坐标比变化较小的坐标有较小的权系数,这就产生了各种距离。
当各个分量为不同性质的量时,“距离”的大小与指标的单位有关。
它将样品的不同属性之间的差别等同看待,这一点有时不能满足实际要求。
没有考虑到总体变异对距离远近的影响。
马氏距离表示数据的协方差距离。
为两个服从同一分布并且其协方差矩阵为Σ的随机变量与的差异程度:如果协方差矩阵为单位矩阵,那么马氏距离就简化为欧氏距离,如果协方差矩阵为对角阵,则其也可称为正规化的欧氏距离。
优点:它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关。
由标准化数据和中心化数据计算出的二点之间的马氏距离相同。
马氏距离还可以排除变量之间的相关性的干扰。
缺点:夸大了变化微小的变量的作用。
受协方差矩阵不稳定的影响,马氏距离并不总是能顺利计算出。
3、当变量X1和X2方向上的变差相等,且与互相独立时,采用欧氏距离与统计距离是否一致?统计距离区别于欧式距离,此距离要依赖样本的方差和协方差,能够体现各变量在变差大小上的不同,以及优势存在的相关性,还要求距离与各变量所用的单位无关。
如果各变量之间相互独立,即观测变量的协方差矩阵是对角矩阵, 则马氏距离就退化为用各个观测指标的标准差的倒数作为权数的加权欧氏距离。
多元统计学多元统计分析试题(A卷)(答案)【精选文档】

《多元统计分析》试卷1、若 且相互独立,则样本均值向量服从的分布为。
2、变量的类型按尺度划分有_间隔尺度_、_有序尺度_、名义尺度_。
3、判别分析是判别样品 所属类型 的一种统计方法,常用的判别方法有__距离判别法_、Fisher 判别法、Bayes 判别法、逐步判别法。
4、型聚类是指对_样品_进行聚类,型聚类是指对_指标(变量)_进行聚类。
5、设样品,总体,对样品进行分类常用的距离有:明氏距离,马氏距离,兰氏距离。
6、因子分析中因子载荷系数的统计意义是_第i 个变量与第j 个公因子的相关系数。
7、一元回归的数学模型是:,多元回归的数学模型是:。
8、对应分析是将 R 型因子分析和Q 型因子分析结合起来进行的统计分析方法。
9、典型相关分析是研究两组变量之间相关关系的一种多元统计方法。
1、设三维随机向量,其中,问与是否独立?和是否独立?为什么?解: 因为,所以与不独立。
把协差矩阵写成分块矩阵,的协差矩阵为因为,而,所以和是不相关的,而正态分布不相关与相互独立是等价的,所以和是独立的.2、设抽了五个样品,每个样品只测了一个指标,它们分别是1 ,2 ,4。
5 ,6 ,8。
若样本间采用明氏距离,试用最长距离法对其进行分类,要求给出聚类图. 解:样品与样品之间的明氏距离为:样品最短距离是1,故把合并为一类,计算类与类之间距离(最长距离法)得距离阵 类与类的最短距离是1。
5,故把合并为一类,计算类与类之间距离(最长距离法)得距离阵类与类的最短距离是3。
5,故把合并为一类,计算类与类之间距离(最长距离法)得距离阵分类与聚类图(略)(请你们自己做)3、设变量的相关阵为的特征值和单位化特征向量分别为一、填空题(每空2分,共40分)二、计算题(每小题10分,共40分)(1) 取公共因子个数为2,求因子载荷阵。
(2) 计算变量共同度及公共因子的方差贡献,并说明其统计意义。
解:因子载荷阵变量共同度: ===公共因子的方差贡献:统计意义(省略)(学生自己做)4、设三元总体的协方差阵为,从出发,求总体主成分,并求前两个主成分的累积贡献率。
多元统计练习题.doc
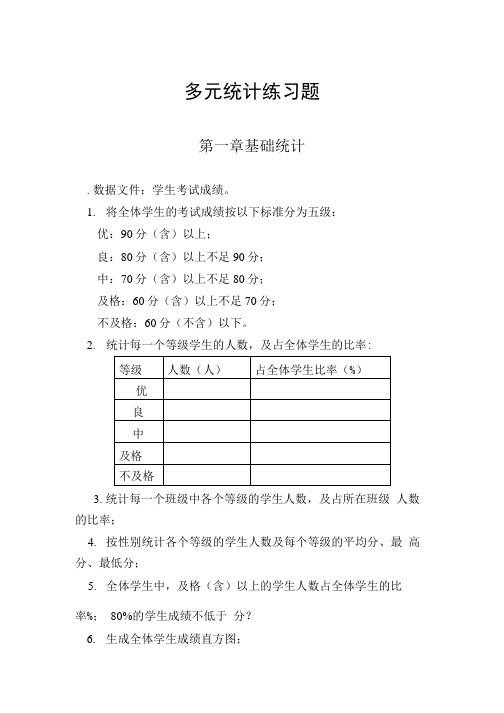
多元统计练习题第一章基础统计.数据文件:学生考试成绩。
1.将全体学生的考试成绩按以下标准分为五级:优:90分(含)以上;良:80分(含)以上不足90分;中:70分(含)以上不足80分;及格:60分(含)以上不足70分;不及格:60分(不含)以下。
2.统计每一个等级学生的人数,及占全体学生的比率:3.统计每一个班级中各个等级的学生人数,及占所在班级人数的比率;4.按性别统计各个等级的学生人数及每个等级的平均分、最高分、最低分;5.全体学生中,及格(含)以上的学生人数占全体学生的比率%;80%的学生成绩不低于分?6.生成全体学生成绩直方图;7.用P-P图或Q-Q图观察学生成绩是否来自正态分布。
并结合下一道题(8)的结果来看用P-P图或Q-Q图观察分布的局限性。
8.用K-S检验法,以0.05显著性水平,检验全体学生成绩是否来自正态总体(n或y),检验统计量值z=, 它对应的水平(近似)值Asymp. Sig =。
如果是0.1的显著性水平呢?二.数据文件:公司职工。
1.填表:2.填表:3.对全体职工按年龄(age)分组,标准如下:第1组,青年:age<35;第2 组,中年:35<age<60;第3组,老年:ageN60.填表:4.的%;中年女职工的人数为人,占全体女职工人数的%。
5.中年男办事员的平均当前薪金(salary)为元,他们中的最低受教育年限(educ)是年。
7.该公司80%的员工当前薪金(salary)不低于元。
8.如果把本文件数据看成某个正态总体的样本,试在0.05的显著性水平下检验:1)不同性别职工的平均受教育年限(educ)有无显著差异?(填y或n);检验统计量值t=,显著性值Sig.=。
2)青年职工与中年职工的平均当前薪金(salary)有无显著差异?(填y或n);检验统计量值t=,显著性值Sig.=。
3 )老、中、青三部分人平均受教育年限(educ)分别是:老年人年,中年人年,青年人年。
多元统计分析试题及答案

X 1的共性方差h12 =
X 1的方差σ
11
= ___1 注(0.128+0.872)___,
公因子f1对X的贡献g12 = 1.743
备注(0.934^2+(-0.417)^2+0.835^2)__。
5、 设 X i , i = 1,⋯ ,16是 来 自 多 元 正 态 总 体 N p ( µ , Σ ), X 和 A分 别 为 正 态 总 体 N p ( µ , Σ ) 的 样 本 均 值 和 样 本 离 差 矩 阵 ,则 T 2 = 15[4( X − µ )]′ A − 1[4( X − µ )] ~ ___________ 。
2、假设检验问题:H 0 : µ = µ0,H1 : µ ≠ µ0 ⎛ −8.0 ⎞ 经计算可得:X − µ0 = ⎜ 2.2 ⎟ , ⎜ ⎟ ⎜ −1.5 ⎟ ⎝ ⎠ ⎛ 4.3107 −14.6210 8.9464 ⎞ −1 −1 ⎜ S = (23.13848) −14.6210 3.172 −37.3760 ⎟ ⎜ ⎟ ⎜ 8.9464 −37.3760 35.5936 ⎟ ⎝ ⎠ 构造检验统计量:T 2 = n( X − µ0 )′S −1 ( X − µ0 ) = 6 × 70.0741 = 420.445 由题目已知F0.01 (3,3) = 29.5,由是 3× 5 F0.01 (3,3) = 147.5 3 所以在显著性水平α = 0.01下,拒绝原设 H 0
⎛ 16 −4 2 ⎞ 1、设X = ( x1 , x2 , x3 ) ~ N 3 ( µ , Σ), 其中µ = (1,0, − 2)′, Σ = ⎜ −4 4 −1⎟ , ⎜ ⎟ ⎜ 2 −1 4 ⎟ ⎝ ⎠ ⎛x −x ⎞ 试判断x1 + 2 x3与 ⎜ 2 3 ⎟ 是否独立? ⎝ x1 ⎠
多元统计分析作业一第三题

多元统计分析作业一(第三题)
课程名称:多元统计回归分析
实验项目:边远及少数民族聚居区和会经济发展水平实验类型:验证性
学生学号:
学生姓名:
学生班级:
课程教师:
实验日期: 2016-03-28
)做出统计判断,最后对统计判断作出具体的解释
模块可以完成多元正态分布有关均值与方差的检验。
依次点选
、第三产业比重、人均消费支出、人口自然增长率及文盲半文盲
,由此我们可以知道边远及少数民族聚居区社会经济发展水平与全国平均发展水平中的人均消费存在显著差别,即全国的平均人均消费大于边远及少数民族聚居区人均消费,相差值为
均大于显著性水平
发展水平与全国平均发展水平中的人均
盲半文盲等指标无明显差别。
注:验证性实验仅上交电子文档,设计性试验需要同时上交电子与纸质文档进行备份存档。
应用多元统计分析试题及答案
一、填空题:1、多元统计分析是运用数理统计方法来研究解决多指标问题的理论和方法.2、回归参数显著性检验是检验解释变量对被解释变量的影响是否著.3、聚类分析就是分析如何对样品(或变量)进行量化分类的问题。
通常聚类分析分为 Q型聚类和 R型聚类。
4、相应分析的主要目的是寻求列联表行因素A 和列因素B 的基本分析特征和它们的最优联立表示。
5、因子分析把每个原始变量分解为两部分因素:一部分为公共因子,另一部分为特殊因子。
6、若()(,), Px N αμα∑=1,2,3….n且相互独立,则样本均值向量x服从的分布为_x~N(μ,Σ/n)_。
二、简答1、简述典型变量与典型相关系数的概念,并说明典型相关分析的基本思想。
在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数。
选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对,如此下去直到两组之间的相关性被提取完毕为止。
被选出的线性组合配对称为典型变量,它们的相关系数称为典型相关系数。
2、简述相应分析的基本思想。
相应分析,是指对两个定性变量的多种水平进行分析。
设有两组因素A和B,其中因素A包含r个水平,因素B包含c个水平。
对这两组因素作随机抽样调查,得到一个rc的二维列联表,记为。
要寻求列联表列因素A和行因素B的基本分析特征和最优列联表示。
相应分析即是通过列联表的转换,使得因素 A 和因素B具有对等性,从而用相同的因子轴同时描述两个因素各个水平的情况。
把两个因素的各个水平的状况同时反映到具有相同坐标轴的因子平面上,从而得到因素A、B的联系。
3、简述费希尔判别法的基本思想。
从k个总体中抽取具有p个指标的样品观测数据,借助方差分析的思想构造一个线性判别函数系数:确定的原则是使得总体之间区别最大,而使每个总体内部的离差最小。
将新样品的p 个指标值代入线性判别函数式中求出 值,然后根据判别一定的规则,就可以判别新的样品属于哪个总体。
多元统计分析

多元统计分析多元统计分析习题集(⼀)⼀、填空题1.若()(,),(1,2,,)p X N n αµα∑= 且相互独⽴,则样本均值向量X 服从的分布是____________________。
2.变量的类型按尺度划分为___________、____________、_____________。
3.判别分析是判别样品_____________的⼀种⽅法,常⽤的判别⽅法有_____________、_____________、_____________、_____________。
4.Q 型聚类是指对_____________进⾏聚类,R 型聚类指对_____________进⾏聚类。
5.设样品12(,,,),(1,2,,)i i i ip X X X X i n '== ,总体(,)p X N µ∑ ,对样品进⾏分类常⽤的距离有____________________、____________________、____________________。
6.因⼦分析中因⼦载荷系数ij a 的统计意义是_________________________________。
7.主成分分析中的因⼦负荷ij a 的统计意义是________________________________。
8.对应分析是将__________________和__________________结合起来进⾏的统计分析⽅法。
9.典型相关分析是研究__________________________的⼀种多元统计分析⽅法。
⼆、计算题 1.设3(,)X N µ∑ ,其中410130002?? ?∑= ? ??,问1X 与2X 是否独⽴?12(,)X X '与3X 是否独⽴?为什么?2.设抽了5个样品,每个样品只测了⼀个指标,它们分别是1,2,4.5,6,8。
若样品间采⽤绝对值距离,试⽤最长距离法对其进⾏分类,要求给出聚类图。
多元统计分析方法练习题

附录B习题第一章1- 1设20~60岁的男子大脑莹量与头颅长度(Y, cm)服从二元正态分布.已知X与Y的相关系数为;X的均数和标准差分别为:和。
试写出X与Y的二元正态分布函数。
并绘制二元正态分布的正态曲面。
1- 2已知成年女子的胸围、腰围和臀围服从三元正态分布,均数分别为:,八协方差矩阵为:‘30.530、25.536 39.859J9.532 20.703 27.363,试写出相应的三元正态分布函数。
1- 3证明,若变量心花服从二元正态分布MN(从 of;心 b;; p),对州內作线性变换:则Z],®亦服从二元正态分布。
并分别求出乙]也2的均数.方差及石与6的相关系数。
1-4就例资料,图示二元分布的90%参考值范囲。
1-5设S和R分别是随机向量X的方差-协方差矩阵和相关系数矩阵,证明:|S|二佝込2…%)岡.第二幸2-1对20名健康女性的汗水进行测量和化脸,数据如下,其中.Xi为排汗董,X2为汗水中钾的含量,X3为汗水中钠的含量。
试检验,样本是否来自Uo‘ =(4,50,10)的总体。
试验者X, X2X3试验者Xi <2 X31・ 2.3. 4.5. 6.7. 8・9. 10.11. 12.13. 14.15. 16.17. 18.19.20.资料来濂:王学仁.王松桂.《实用多元统计分析》,上海科学技术出版社.1232- 2以两均向量比较为例,证明,队数据阵作线性变换,不改变假设检验的结果。
2-3脸证:当m=1时,Hotel I ing T?检验与t检验等价。
状况有无差别。
男生女生编号编号身高体重胸国身高体莹胸国1 12 23 34 45 56 67 78 89 910 101112为了解某溶栓药对脑梗塞患者血压的影响,观察10名患者,分别与疗前、溶后5分钟、10 分钟.20分钟测定患者的收缩压(X,mmHg)和舒张压(Y,mniHg),结果如下表,问该溶栓药对血压有无影响?1 175 115 175 110 170 110 170 902 136 93 130 90 135 95 135 973 142 89 138 99 138 99 142 1084 180 100 180 100 180 100 180 905 170 90 170 80 180 70 170 706 125 70 114 67 111 64 112 687 140 100 140 90 140 90 140 908 150 70 144 81 166 87 151 919 150 98 150 98 150 98 143 8310 105 75 113 75 113 75 113 75许料来源:陈清棠,九五攻关项目。
多元统计试题及答案

从这个矩阵可以看出,G5,G6的相关性最大,因此将G5,G6在水平0.89上合成一个新类G8={5,6},计算G8与G7,G3,G4,之间的最长距离,得到:
在第二个相关距离作为新的一行一列,得到:
③在第二步的基础上,再将其余的 个自变量分别加入到此模型中,拟合各个模型并计算偏F统计量值,与 比较决定是否又新变量引入,如果有新的变量引入,还需要检验原模型中的老变量是否因为这个新变量的引入而不再显著,那样就应该被删除。
重复以上的步骤,直到没有新的变量能进入模型,同时在模型中的老变量都不能被剔除,则结束选择过程,最后,一个模型即为所求的最优回归模型。
六、在作判别分析时,如何检验判别效果的优良性?(8分)
解答:
当一个判别准则提出以后,还要研究其优良性,即要考察误判概率.一般使用以训练样本为基础的回代估计法与交叉确认估计法
八、因子模型 中,因子载荷 、变量共同度以及公共因子 的方差贡献的统计意义是什么?在实际应用中,一般怎样选择公共因子?(10分)
试用最长距离法对这六个样品进行聚类,并画出谱系图。(10分)
解答:首先将6个样品的各自看成一类,即:
Gi=(i),i=1,2,3,4,5,6
将相关系数矩阵记为R0,则:
从这个矩阵可以看出,G1,G2的相关性最大,因此将G1,G2在水平0.92上合成一个新类G7={1,2},计算G7与G3,G4,G5,G6之间的最长距离,得到:
利用P值法作显著性检验十分方便,这里的P值是 ,定显著性水平α.,若 ,则拒绝 ,反之接受 .
⑷回归分析和相关分析的区别和联系?
相关分析和回归分析都是对客观事物数量依存关系的分析,均有一元和多元,线性与非线性之分,在应用中相互结合与渗透,但仍有差别,主要是:
多元统计分析课后练习答案

第1章 多元正态分布1、在数据处理时,为什么通常要进行标准化处理数据的标准化是将数据按比例缩放,使之落入一个小的特定区间;在某些比较和评价的指标处理中经常会用到,去除数据的单位限制,将其转化为无量纲的纯数值,便于不同单位或量级的指标能够进行比较和加权;其中最典型的就是0-1标准化和Z 标准化;2、欧氏距离与马氏距离的优缺点是什么欧氏距离也称欧几里得度量、欧几里得度量,是一个通常采用的距离定义,它是在m 维空间中两个点之间的真实距离;在二维和三维空间中的欧氏距离的就是两点之间的距离;缺点:就大部分统计问题而言,欧氏距离是不能令人满意的;每个坐标对欧氏距离的贡献是同等的;当坐标表示测量值时,它们往往带有大小不等的随机波动,在这种情况下,合理的方法是对坐标加权,使变化较大的坐标比变化较小的坐标有较小的权系数,这就产生了各种距离;当各个分量为不同性质的量时,“距离”的大小与指标的单位有关;它将样品的不同属性之间的差别等同看待,这一点有时不能满足实际要求;没有考虑到总体变异对距离远近的影响;马氏距离表示数据的协方差距离;为两个服从同一分布并且其协方差矩阵为Σ的随机变量与的差异程度:如果协方差矩阵为单位矩阵,那么马氏距离就简化为欧氏距离,如果协方差矩阵为对角阵,则其也可称为正规化的欧氏距离;优点:它不受量纲的影响,两点之间的马氏距离与原始数据的测量单位无关;由标准化数据和中心化数据计算出的二点之间的马氏距离相同;马氏距离还可以排除变量之间的相关性的干扰; 缺点:夸大了变化微小的变量的作用;受协方差矩阵不稳定的影响,马氏距离并不总是能顺利计算出;3、当变量X1和X2方向上的变差相等,且与互相独立时,采用欧氏距离与统计距离是否一致统计距离区别于欧式距离,此距离要依赖样本的方差和协方差,能够体现各变量在变差大小上的不同,以及优势存在的相关性,还要求距离与各变量所用的单位无关;如果各变量之间相互独立,即观测变量的协方差矩阵是对角矩阵, 则马氏距离就退化为用各个观测指标的标准差的倒数作为权数的加权欧氏距离;4、如果正态随机向量12(,,)p X X X X '=的协方差阵为对角阵,证明X 的分量是相互独立的随机变量;解: 因为12(,,)p X X X X '=的密度函数为 又由于21222p σσσ⎛⎫ ⎪ ⎪= ⎪ ⎪ ⎪⎝⎭Σ 则1(,...,)p f x x则其分量是相互独立;5.1y 和2y 是相互独立的随机变量,且1y ~)1,0(N ,2y ~)4,3(N ;(a )求21y 的分布;(b )如果⎥⎦⎤⎢⎣⎡-=2/)3(21y y y ,写出y y '关于1y 与2y 的表达式,并写出y y '的分布;(c )如果⎥⎦⎤⎢⎣⎡=21y y y 且y ~∑),(μN ,写出∑-'1y y 关于1y 与2y 的表达式,并写出∑-'1y y 的分布;解:a 由于1y ~)1,0(N ,所以1y ~)1(2χ;b 由于1y ~)1,0(N ,2y ~)4,3(N ;所以232-y ~)1,0(N ;故2221)23(-+='y y y y ,且y y '~)2(2χ 第2章 均值向量和协方差阵的检验1、略2、试谈Wilks 统计量在多元方差分析中的重要意义;3、题目此略多元均值检验,从题意知道,容量为9的样本 ,总体协方差未知假设H0:0μμ= , H1:0μμ≠ n=9 p=5检验统计量/n-1)()(0102μμ-'-=-X S X n T 服从P,n-1的2T 分布 统计量2T 实际上是样本均值与已知总体均值之间的马氏距离再乘以nn-1,这个值越大,相等的可能性越小,备择假设成立时,2T 有变大的趋势,所以拒绝域选择2T 值较大的右侧部分,也可以转变为F 统计量零假设的拒绝区域 {n-p/n-1p}2T >,()p n p F α-1/102T >F5,45μ0= 2972 ’样本均值 ’样本均值-μ0’= Inter-Item Covariance Matrix人均GDP 元 三产比重% 人均消费元 人口增长% 文盲半文盲% 人均GDP 元三产比重%人均消费元人口增长%文盲半文盲%协方差的逆矩阵计算:2T=9s^-1 ’F统计量=> 拒绝零假设,边缘及少数民族聚居区的社会经济发展水平与全国平均水平有显着差异;4、略第3章聚类分析1.、聚类分析的基本思想和功能是什么聚类分析的基本思想是研究的样品或指标之间存着程度不同的相似性,于是根据一批样品的多个观测指标,具体找出一些能够度量样品或指标之间的相似程度的统计量,以这些统计量作为划分类型的依据,把一些相似程度较大的样品聚合为一类,把另外一些彼此之间相似程度较大的样品又聚合为另外一类,直到把所有的样品聚合完毕,形成一个有小到大的分类系统,最后再把整个分类系统画成一张分群图,用它把所有样品间的亲疏关系表示出来;功能是把相似的研究对象归类;2、试述系统聚类法的原理和具体步骤;系统聚类是将每个样品分成若干类的方法,其基本思想是先将各个样品各看成一类,然后规定类与类之间的距离,选择距离最小的一对合并成新的一类,计算新类与其他类之间的距离,再将距离最近的两类合并,这样每次减少一类,直至所有的样品合为一类为止;具体步骤:1、对数据进行变换处理;不是必须的,当数量级相差很大或指标变量具有不同单位时是必要的2、构造n个类,每个类只包含一个样本;3、计算n个样本两两间的距离ijd;4、合并距离最近的两类为一新类;5、计算新类与当前各类的距离,若类的个数等于1,转到6;否则回4;6、画聚类图;7、决定类的个数,从而得出分类结果;3、试述K-均值聚类的方法原理;K-均值法是一种非谱系聚类法,把每个样品聚集到其最近形心均值类中,它是把样品聚集成K 个类的集合,类的个数k可以预先给定或者在聚类过程中确定,该方法应用于比系统聚类法大得多的数据组;步骤是把样品分为K个初始类,进行修改,逐个分派样品到期最近均值的类中通常采用标准化数据或非标准化数据计算欧氏距离重新计算接受新样品的类和失去样品的类的形心;重复这一步直到各类无元素进出;4、试述模糊聚类的思想方法;模糊聚类分析是根据客观事物间的特征、亲疏程度、相似性,通过建立模糊相似关系对客观事物进行聚类的分析方法,实质是根据研究对象本身的属性构造模糊矩阵,在此基础上根据一定的隶属度来确定其分类关系;基本思想是要把需要识别的事物与模板进行模糊比较,从而得到所属的类别;简单地说,模糊聚类事先不知道具体的分类类别,而模糊识别是在已知分类的情况下进行的;模糊聚类分析广泛应用在气象预报、地质、农业、林业等方面;它有两种基本方法:系统聚类法和逐步聚类法;该方法多用于定性变量的分类;5、略第4章判别分析1、应用判别分析应该具备什么样的条件答:判别分析最基本的要求是,分组类型在两组以上,每组案例的规模必须至少在一个以上,解释变量必须是可测量的,才能够计算其平均值和方差;对于判别分析有三个假设:1每一个判别变量不能是其他判别变量的线性组合;有时一个判别变量与另外的判别变量高度相关,或与其的线性组合高度相关,也就是多重共线性;2各组变量的协方差矩阵相等;判别分析最简单和最常用的的形式是采用现行判别函数,他们是判别变量的简单线性组合,在各组协方差矩阵相等的假设条件下,可以使用很简单的公式来计算判别函数和进行显着性检验;3各判别变量之间具有多元正态分布,即每个变量对于所有其他变量的固定值有正态分布,在这种条件下可以精确计算显着性检验值和分组归属的概率;2、试述贝叶斯判别法的思路;答:贝叶斯判别法的思路是先假定对研究的对象已有一定的认识,常用先验概率分布来描述这种认识,然后我们取得一个样本,用样本来修正已有的认识先验概率分布,得到后验概率分布,各种统计推断都通过后验概率分布来进行;将贝叶斯判别方法用于判别分析,就得到贝叶斯判别;3、试述费歇判别法的基本思想;答:费歇判别法的基本思想是将高维数据点投影到低维空间上来,然而利用方差分析的思想选出一个最优的投影方向;因此,严格的说费歇判别分析本身不是一种判别方法,只是利用费歇统计量进行数据预处理的方法,以使更有利于用判别分析方法解决问题;为了有利于判别,我们选择投影方向a 应使投影后的k个一元总体能尽量分开同一总体中的样品的投影值尽量靠近;k要做到这一点,只要投影后的k个一元总体均值有显着差异,即可利用方差分析的方法使组间平方和尽可能的大;则选取投影方向a使Δa达极大即可;4、什么是逐步判别分析答:具有筛选变量能力的判别方法称为逐步判别分析法;逐步判别分析法就是先从所有因子中挑选一个具有最显着判别能力的因子,然后再挑选第二个因子,这因子是在第一因子的基础上具有最显着判别能力的因子,即第一个和第二个因子联合起来有显着判别能力的因子;接着挑选第三个因子,这因子是在第一、第二因子的基础上具有最显着判别能力的因子;由于因子之间的相互关系,当引进了新的因子之后,会使原来已引入的因子失去显着判别能力;因此,在引入第三个因子之后就要先检验已经引入的因子是否还具有显着判别能力,如果有就要剔除这个不显着的因子;接着再继续引入,直到再没有显着能力的因子可剔除为止,最后利用已选中的变量建立判别函数;5、简要叙述判别分析的步骤及流程答:1研究问题:选择对象,评估一个多元问题各组的差异,将观测个体归类,确定组与组之间的判别函数;2设计要点:选择解释变量,样本量的考虑,建立分析样本的保留样本;3假定:解释变量的正态性,线性关系,解释变量间不存在多重共线性,协方差阵相等;4估计判别函数:联立估计或逐步估计,判别函数的显着性;5使用分类矩阵评估预测的精度:确定最优临界得分,确定准则来评估判对比率,预测精确的统计显着性;6判别函数的解释:需要多少个函数;评价单个函数主要从判别权重、判别载荷、偏F值几个方面;评价两个以上的判别函数,分为评价判别的函数和评价合并的函数;7判别结果的验证:分开样本或交叉验证,刻画组间的差异;6、略第5章主成分分析1、主成分的基本思想是什么在对某一事物进行实证研究时,为更全面、准确地反映事物的特征及其发展规律,往往考虑与其有关的多个指标,在多元统计中也称为变量;一方避免遗漏重要信息而考虑尽可能多的指标看,另一方面考虑指标的增多,又难以避免信息重叠;希望涉及的变量少,而得到的信息量有较多;主成分的基本思想是研究如何通过原来的少数几个线性组合来解释原来变量绝大多数信息的一种多元统计方法;研究某一问题涉及的众多变量之间有一定的相关性,必然存在着支配作用的公共因素;通过对原始变量相关矩阵或协方差矩阵内部结构关系的研究,利用原始变量的线性组合形成几个无关的综合指标主成分来代替原来的指标;通常数学上的处理就是将原来P个指标作线性组合,作为新的综合指标;最经典的做法就是用F1选取的第一个线性组合,即第一个综合指标的方差来表达,即VarF1越大,表示F1包含的信息越多;因此在所有的线性组合中选取的F1应该是方差最大的,故称F1为第一主成分,如果第一主成分不足以代表原来P个指标的信息,再考虑选取F2即选第二个线性组合,为了有效地反映原来信息,F1已有的信息就不需要再出现在F2中,用数学语言表达就是要求CovF1,F2=0则称F2为第二主成分,依此类推可以构造出第三、第四······,第P个主成分;2、主成分在应用中的主要作用是什么作用:利用原始变量的线性组合形成几个综合指标主成分,在保留原始变量主要信息的前提下起到降维与简化问题的作用,使得在研究复杂问题时更容易抓住主要矛盾;通过主成分分析,可以从事物之间错综复杂的关系中找出一些主要成分,从而能有效利用大量数据进行定量分析,解释变量之间的内在关系,得到对事物特征及其发展规律的一些深层次的启发,把研究工作引向深入;主成分分析能降低所研究的数据空间的维数,有时可通过因子载荷aij的结论,弄清X变量间的某些关系,多维数据的一种图形表示方法,用主成分分析筛选变量,可以用较少的计算量来选择,获得选择最佳变量子集合的效果;3.由协方差阵出发和由相关阵出发求主成分有什么不同1由协方差阵出发设随即向量X=X1,X2,X3,……Xp’的协方差矩阵为Σ,1≥2≥……≥p为Σ的特征值,γ1,γ2,……γp为矩阵A各特征值对应的标准正交特征向量,则第i个主成分为Yi=γ1iX1+γ2iX2+……+γpiXp,i=1,2,……,p此时VARYi=i,COVYi,Yj=0,i≠j我们把X1,X2,X3,……Xp的协方差矩阵Σ的非零特征根1≥2≥……≥p>0向量对应的标准化特征向量γ1,γ2,……γp分别作为系数向量,Y1=γ1’X, Y2=γ2’X,……, Yp=γp’X分别称为随即向量X的第一主成分,第二主成分……第p主成分;Y的分量Y1,Y2,……,Yp依次是X的第一主成分、第二主成分……第p主成分的充分必要条件是:1Y=P’X,即P为p阶正交阵,2Y的分量之间互不相关,即DY=diag1,2,……,p,3Y的p个分量是按方差由大到小排列,即1≥2≥……≥p;2由相关阵出发对原始变量X进行标准化,Z=Σ^1/2^-1X-μ covZ=R原始变量的相关矩阵实际上就是对原始变量标准化后的协方差矩阵,因此,有相关矩阵求主成分的过程与主成分个数的确定准则实际上是与由协方差矩阵出发求主成分的过程与主成分个数的确定准则相一致的;λi,γi 分别表示相关阵R的特征根值与对应的标准正交特征向量,此时,求得的主成分与原始变量的关系式为:Yi=γi’Z=γi’Σ^1/2^-1X-μ在实际研究中,有时单个指标的方差对研究目的起关键作用,为了达到研究目的,此时用协方差矩阵进行主成分分析恰到好处;有些数据涉及到指标的不同度量尺度使指标方差之间不具有可比性,对于这类数据用协方差矩阵进行主成分分析也有不妥;相关系数矩阵计算主成分其优势效应仅体现在相关性大、相关指标数多的一类指标上;避免单个指标方差对主成分分析产生的负面影响,自然会想到把单个指标的方差从协方差矩阵中剥离,而相关系数矩阵恰好能达到此目的;4、略第6章 因子分析1、因子分析与主成分分析有什么本质不同答:1因子分析把诸多变量看成由对每一个变量都有作用的一些公共因子和一些仅对某一个变量有作用的特殊因子线性组合而成,因此,我们的目的就是要从数据中探查能对变量起解释作用的公共因子和特殊因子,以及公共因子和特殊因子的线性组合;主成分分析则简单一些,它只是从空间生成的角度寻找能解释诸多变量绝大部分变异的几组彼此不相关的新变量2因子分析中,把变量表示成各因子的线性组合,而主成分分析中,把主成分表示成各变量的线性组合3主成分分析中不需要有一些专门假设,因子分析则需要一些假设,因子分析的假设包括:各个因子之间不相关,特殊因子之间不相关,公共因子和特殊因子之间不相关;4在因子分析中,提取主因子的方法不仅有主成分法,还有极大似然法等,基于这些不同算法得到的结果一般也不同;而主成分分析只能用主成分法提取;5主成分分析中,当给定的协方差矩阵或者相关矩阵的特征根唯一时,主成分一般是固定;而因子分析中,因子不是固定的,可以旋转得到不同的因子;6在因子分析中,因子个数需要分析者指定,结果随指定的因子数不同而不同;在主成分分析中,主成分的数量是一定的,一般有几个变量就有几个主成分; 7与主成分分析相比,由于因子分析可以使用旋转技术帮助解释因子,在解释方面更加有优势;而如果想把现有的变量变成少数几个新的变量新的变量几乎带有原来所有变量的信息来进行后续的分析,则可以使用主成分分析;2、因子载荷ij a 的统计定义是什么它在实际问题的分析中的作用是什么答:1因子载荷ij a 的统计定义:是原始变量i X 与公共因子j F 的协方差,i X 与j F ),...,2,1;,...,2,1(m j p i ==都是均值为0,方差为1的变量,因此ij a 同时也是i X 与j F 的相关系数;(2)记),,...,2,1(...222212m j a a a g pjj j j =+++=则2j g 表示的是公共因子j F 对于X 的每一分量),...,2,1(p i X i =所提供的方差的总和,称为公共因子j F 对原始变量X 的方贡献,它是衡量公共因子相对重要性的指标;2j g 越大,表明公共因子j F 对i X 的贡献越大,或者说对X 的影响作用就越大;如果因子载荷矩阵对A 的所有的),...,2,1(2m j g j =都计算出来,并按大小排序,就可以依此提炼出最有影响的公共因子;3、略第7章 对应分析1、试述对应分析的思想方法及特点;思想:对应分析又称为相应分析,也称R —Q 分析;是因子分子基础发展起来的一种多元统计分析方法;它主要通过分析定性变量构成的列联表来揭示变量之间的关系;当我们对同一观测数据施加R 和Q 型因子分析,并分别保留两个公共因子,则是对应分析的初步;对应分析的基本思想是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来;它最大特点是能把众多的样品和众多的变量同时作到同一张图解上,将样品的大类及其属性在图上直观而又明了地表示出来,具有直观性;另外,它还省去了因子选择和因子轴旋转等复杂的数学运算及中间过程,可以从因子载荷图上对样品进行直观的分类,而且能够指示分类的主要参数主因子以及分类的依据,是一种直观、简单、方便的多元统计方法;特点:对应分析的基本思想是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来;它最大特点是能把众多的样品和众多的变量同时作到同一张图解上,将样品的大类及其属性在图上直观而又明了地表示出来,具有直观性;另外,它还省去了因子选择和因子轴旋转等复杂的数学运算及中间过程,可以从因子载荷图上对样品进行直观的分类,而且能够指示分类的主z |Uz |V 要参数主因子以及分类的依据,是一种直观、简单、方便的多元统计方法;2、试述对应分析中总惯量的意义;总惯量不仅反映了行剖面集定义的各点与其重心加权距离的总和,同时与2x 统计量仅相差一个常数,而2x 统计量反映了列联表横联与纵联的相关关系,因此总惯量也反映了两个属性变量各状态之间的相关关系;对应分析就是在对总惯量信息损失最小的前提下,简化数据结构以反映两属性变量之间的相关关系;3、略第8章 典型相关分析1、试述典型相关分析的统计思想及该方法在研究实际问题中的作用;答: 典型相关分析是研究两组变量之间相关关系的一种多元统计方法;用于揭示两组变 量之间的内在联系;典型相关分析的目的是识别并量化两组变量之间的联系;将两组变量相 关关系的分析转化为一组变量的线性组合与另一组变量线性组合之间的相关关系;基本思想:1在每组变量中找出变量的线性组合,使得两组的线性组合之间具有最大的相关系数; 即:XX 1, X 2, , , X p 、XX 1, X 2, , , X q 是两组相互关联的随机变量,分别在两组变量中选取若干有代表性的综合变量 U i 、Vi,使是原变量的线性组合;U i a 1X 1 a 2 X 2..... a P X P ≡ a ‘XV i b 1Y 1 b 2 Y 2 .... b q Y q ≡ b‘Y 在 D aX D bX 1 的条件下,使得 aX , bX 达到最大;2选取和最初挑选的这对线性组合不相关的线性组合,使其配对,并选取相关系数最大的一对;(3)如此继续下去,直到两组变量之间的相关性被提取完毕为此;其作用为:进行两组变量之间的相关性分析,用典型相关系数衡量两组变量之间的相关性;2、简述典型相关分析中冗余分析的内容及作用;答:典型型冗余分析的作用即分析每组变量提取出的典型变量所能解释的该组样本总方差的比 例,从而定量测度典型变量所包含的原始信息量;第一组变量样本的总方差为 t r R 11 p ,第二组变量样本的总方差为 t r R 22 q ;*A ˆz和*B ˆz 是样本典型相关系数矩阵,典型系数向量是矩阵的行向量, Z z z **A ˆU ˆ=,Z z z **B ˆV ˆ= 前 r 对典型变量对样本总方差的贡献为则第一组样本方差由前 r 个典型变量解释的比例为:第二组样本方差由前 r 个典型变量解释的比例为:3、典型变量的解释有什么具体方法实际意义是什么答:主要使用三种方法:1典型权重标准相关系数:传统的解释典型函数的方法包括观察每个原始变量在它的典型变量中的典型权重,即标准化相关系数Standardized Canonical Coefficients 的符号和大小;有较大的典型权重,则说明原始变量对它的典型变量的贡献较大,反之则相反;原始变量的典型权重有相反的符号说明变量之间存在一种反面关系,反之则有正面关系;但是这种解释遭到了很多批评;这些问题说明在解释典型相关的时候应慎用典型权重;(2)典型载荷结构系数:由于典型载荷逐步成为解释典型相关分析结果的基础;典型载荷分析,即典型结构分析Canonical Structure Analyse,是原始变量自变量或者因变量与它的典型变量间的简单线性相关系数;典型载荷反映原始变量与典型变量的共同方差,它的解释类似于因子载荷,就是每个原始变量对典型函数的相对贡献;(3)典型交叉载荷交叉结构系数:它的提出时作为典型载荷的替代,也属于典型结构分析;计算典型交叉载荷包括每个原始因变量与自变量典型变量直接相关,反之亦然;交叉载荷提供了一个更直接地测量因变量组与自变量组之间的关系的指标;实际意义:即使典型相关系数在统计上是显着的,典型根和冗余系数大小也是可接受的,研究者仍需对结果做大量的解释;这些解释包括研究典型函数中原始变量的相对重要性;4.、略。
多元统计分析试题

一、填空题(30分):1、多元正态分布检验用到的三大分布为、、o2、若X〜N〃(4,Z),则AX + d~o (服从什么分布)3、常用的聚类方法有、动态聚类、等。
4、我们将变量的类型按照尺度可分为、、三类。
5、统计距离公式为o6、相似系数一般有、两种测度。
7、常用的多元数据图表示法有、、o二、计算证明题(30分):1、设抽取5个样本,每个样本只检测一个指标,他们是13, 14, 15.5, 19, 21o试用最短距离法对5个样本进行分类并画出谱系图。
71° 1 12、试验证函数/(X,九2,*3)=即+6刍+-玉工2,其中0<XI < 1,0<犬2 <2,0<工3 <一为随3机向量X=(X1,X2,X3)'的密度函数。
113、证明Gov(X,5y)= Cw(X,y)B'。
15《多元统计分析》简答题1、试简单比较一元正态总体单样本均值检验和多元正态总体均值检验。
(方差或协差阵未知时,应包括所用到的统计量,有何联系等内容)34一元正态总体样本均值的检验(方差未知时):当〃未知时,用S2 =-^—Y(X i-X)2(3.2)作为/的估计量,用统寸量:;在4 册(3.3)S来做检验。
当假设成立时,统计量/服从自由度为〃-1的,分布,从而否定域为111> %2 5 T),%2(〃—1)为自由度为〃T的,分布上的。
/2分位点。
这里我们应该注意数(33)式可以表示为t2 = 丁) = X -^\S2Y\X -//)(3.4)对于多元变量而言,可以将,分布推广为下面将要介绍的Hotelling T~分布。
多元正态总体均值检验:(-)协差阵E未知时均值向量的检验"(): JI =% (%为已知向量)H}: "No假设“。
成立,检验统计量为(〃:1):〃 + 1尸〜尸(p,〃— p)(3.7)(〃一1)〃其中,T2 =(n- 1)LV^(X-Ji()ys-1 V^(x-ji())J给定检验水平a,查产分布表,使定[-〃二二a,可[5-l)p J确定出临界值尸a,再用样本值计算出72,若〃二〃-屑〉(〃-1)〃则否定“。
(完整word版)多元统计分析习题

1.已知n=4,p=3的一个样本数据阵143X =626,X S 833534ρ⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦计算,,v,2.已知23514241130010322X ⎡⎤⎢⎥⎢⎥⎢⎥=⎢⎥⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦,用最短、最长、中间距离法聚类,并画出聚类树形图3.已知52=22⎡⎤∑⎢⎥⎣⎦,要求: ①求特征根12λλ, ②求特征向量12μμ,③构造主成分12,F F④计算1F 的方差Var(F 1)和2F 的方差Var(F 2)⑤计算()()()()11122122,,,,;;;F X F X F X F X ρρρρ4.设有12,G G 两个总体,从中分别抽取容量为3的样品如下:要求:(1)样本的均值向量()()12,XX 及离差阵12,S S(2)假定()()12==∑∑∑,用12,S S 联合估计∑(3)已知待判样品(27)X T=,分别用距离判别法、Fisher 判别法、Bayes 判别法判定X 的归属。
5.设111=n 个和122=n 个的观测值分别取自两个随机变量1X 和2X 。
假定这两个变量服从二元正态分布,且有相同的协方差阵。
样本均值向量和联合协方差阵为:⎥⎦⎤⎢⎣⎡--=111X ,⎥⎦⎤⎢⎣⎡=122X ,⎥⎦⎤⎢⎣⎡--=∑8.41.11.13.7。
新样品⎥⎦⎤⎢⎣⎡=21X ,要求用Bayes 法和Fisher 进行判别分析。
6.已知2变量协方差阵⎥⎦⎤⎢⎣⎡=∑3224,要求:(1)求∑的特征根及其对应的单位特征向量;(2)组建主成分1F 、2F ;(3)验证j j F Var λ=)(;(4)计算11x F ρ、21x F ρ。
7、试分析某海运学院100名新生的性别与来自的区域有无相关关系。
(20.05(1) 3.84χ=)8、已知4个样品3个数据的数据如下:44068644363X ⎡⎤⎢⎥⎢⎥=⎢⎥⎢⎥⎣⎦,试求均值向量X 、协方差阵∑、相关阵R 。
9、已知随机向量X=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡321x x x ,具有均值向量826X ⎡⎤⎢⎥=⎢⎥⎢⎥⎣⎦和协方差阵,⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡--=∑411161113。
多元统计学多元统计分析试题(A卷)(答案)

《多元统计分析》试卷1、若),2,1(),,(~)(n N X p =∑αμα 且相互独立,则样本均值向量X 服从的分布为2、变量的类型按尺度划分有_间隔尺度_、_有序尺度_、名义尺度_.3、判别分析是判别样品 所属类型 的一种统计方法,常用的判别方法有__距离判别法_、Fisher 判别法、Bayes 判别法、逐步判别法。
4、Q 型聚类是指对_样品_进行聚类,R 型聚类是指对_指标(变量)_进行聚类。
5、设样品),2,1(,),,('21n i X X X X ip i i i ==,总体),(~∑μp N X ,对样品进行分类常用的距离有:明氏距离,马氏距离2()ijd M =)()(1j i j i x x x x -∑'--,兰氏距离()ij d L6、因子分析中因子载荷系数ij a 的统计意义是_第i 个变量与第j 个公因子的相关系数。
7、一元回归的数学模型是:εββ++=x y 10,多元回归的数学模型是:εββββ++++=p p x x x y 22110。
8、对应分析是将 R 型因子分析和Q 型因子分析结合起来进行的统计分析方法。
9、典型相关分析是研究两组变量之间相关关系的一种多元统计方法。
一、填空题(每空2分,共40分)二、计算题(每小题10分,共40分)1、设三维随机向量),(~3∑μN X ,其中⎪⎪⎪⎭⎫ ⎝⎛=∑200031014,问1X 与2X 是否独立?),(21'X X 和3X 是否独立?为什么?解: 因为1),cov(21=X X ,所以1X 与2X 不独立。
把协差矩阵写成分块矩阵⎪⎪⎭⎫⎝⎛∑∑∑∑=∑22211211,),(21'X X 的协差矩阵为11∑因为12321),),cov((∑='X X X ,而012=∑,所以),(21'X X 和3X 是不相关的,而正态分布不相关与相互独立是等价的,所以),(21'X X 和3X 是独立的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
课程名称:多元统计回归分析
实验项目:边远及少数民族聚居区和会经济发展水平实验类型:验证性
学生学号:
学生姓名:
学生班级:
课程教师:
实验日期: 2016-03-28 (6212.01 , 32.87, 2972, 9.5, 15.78)
μ
μ
)做出统计判断,最后对统计判断作出具体的解释
模块可以完成多元正态分布有关均值与方差的检验。
依次点选
lMultivariate……进入
ββXε
01
、第三产业比重、人均消费支出、人口自然增长率及文盲半文盲
0.05的水平下,
,由此我们可以知道边远及少数民族聚居区社会经济发展水平与全国平均发展水平中的人均消费存在显著差别,即全国的平均人均消费大于边远及少数民族聚居区人均消费,相差值为
文盲半文盲等指标无明显差别。
0.01的水平下,
均大于显著性水平
发展水平与全国平均发展水平中的人均
盲半文盲等指标无明显差别。
注:验证性实验仅上交电子文档,设计性试验需要同时上交电子与纸质文档进行备份存档。