Postgresql存储过程
PostgreSQL-存储过程(一)基础篇

PostgreSQL-存储过程(⼀)基础篇存储过程其实就是函数,由⼀组 sql 语句组成,实现⽐较复杂的数据库操作;存储过程是存储在数据库服务器上的,⽤户可以像调⽤ sql ⾃带函数⼀样调⽤存储过程语法解析CREATE [OR REPLACE] FUNCTION function_name (arguments)RETURNS return_datatype AS $variable_name$DECLAREdeclaration;[...]BEGIN< function_body >[...]RETURN { variable_name | value }END; LANGUAGE plpgsql;很容易理解,不多解释下⾯我对⼀张表进⾏简单操作,逐步递进的介绍存储过程的语法步骤1-基础版into 表⽰把结果赋值给后⾯的变量,该变量必须在 declare 提前声明调⽤存储过程select mycount3()步骤2-把 sql 语句赋给变量create or replace function mycount3()returns integer as $$declaremysql text;counts integer;beginmysql:='select count("CD_ID") from "CDS"';execute mysql into counts;return counts;end;$$ language plpgsql;步骤3-带变量,且 sql 语句⽤字符串拼接create or replace function mycount4(tableName text, columnName text)returns text as $$declaremysql text;beginmysql:='select count('|| quote_ident(columnName)|| ') from '|| quote_ident(tableName);return mysql;end;$$ language plpgsql;1. 函数的参数必须声明类型2. || 表⽰字符串拼接符号3. 存储过程中的对象不能直接引⽤变量,要⽤ quote_ident,它的作⽤是为字符串加上双引号4. 在 sql 语句中,⼤写,全部会变成⼩写,如果想保留⼤写,需要加双引号调⽤存储过程select mycount4('CDS', 'CD_ID');返回select count("CD_ID") from "CDS"可以看到,输⼊参数是单引号,经过 quote_ident 后,⾃动变成双引号,保留了⼤写步骤4-换⼀种拼接⽅式,并且函数体加了 if 判断create or replace function mycount4(tableName text, columnName text)returns integer as $$declaremysql text;counts integer;beginmysql:='select count("' || $2 || '") from "' || $1 || '" ';execute mysql into counts using tableName, columnName;if counts > 100 thenreturn counts;else return 1;end if;end;$$ language plpgsql;1. ⽤ using 调取变量,此时需要⾃⼰加双引号以保留⼤写2. 112 对应的是函数的参数位置,跟 using 后的顺序⽆关3. if 后⾯有个 then4. text 可变长度字符串5. 每句末尾必须带分号。
postgresql 存储过程语法

PostgreSQL存储过程语法1. 概述PostgreSQL是一个开源的关系型数据库管理系统,而存储过程是一种为了完成特定功能而封装在数据库中的一段可重复使用的代码。
存储过程在数据库服务器端执行,可以提供更高效的数据处理和业务逻辑处理能力。
本文将详细介绍PostgreSQL存储过程的语法。
2. 存储过程的创建创建存储过程前,我们首先需要理解存储过程的基本结构。
下面是一个简单的存储过程结构示例:CREATE OR REPLACE FUNCTION procedure_name() RETURNS return_type AS $$ DECLARE-- 声明局部变量variable_name datatype;BEGIN-- 逻辑处理代码-- RETURN语句可选,指定返回值END;$$ LANGUAGE plpgsql;在这个示例中,我们使用CREATE OR REPLACE FUNCTION语句来创建一个存储过程。
procedure_name是存储过程的名称,可以根据具体需求命名。
return_type是存储过程的返回值类型,可以是基本数据类型、复合数据类型或表类型。
接下来,在DECLARE关键字后面声明局部变量,用于存储过程内部的数据处理。
变量的名称可以根据实际需要命名,datatype为变量的数据类型。
在BEGIN和END之间编写存储过程的逻辑处理代码。
根据实际需求,可以使用SQL 语句、逻辑控制结构、异常处理等进行数据处理和业务逻辑控制。
最后,使用$$ LANGUAGE plpgsql;指定存储过程的语言为plpgsql,这是PostgreSQL 存储过程的默认语言。
3. 存储过程的参数存储过程可以接受输入参数和输出参数。
下面是一个接受输入参数和输出参数的存储过程示例:CREATE OR REPLACE FUNCTION procedure_name(input_param1 datatype, OUT output_pa ram1 datatype) RETURNS return_type AS $$DECLARE-- 声明局部变量variable_name datatype;BEGIN-- 逻辑处理代码-- 将结果赋给输出参数output_param1 := some_expression;-- RETURN语句可选,指定返回值END;$$ LANGUAGE plpgsql;在这个示例中,input_param1是输入参数的名称和数据类型,可以根据实际需求声明多个输入参数。
postgresql 存储过程语法

postgresql 存储过程语法PostgreSQL是一种开源的关系型数据库管理系统,它支持存储过程,存储过程是一种预定义的程序,可以在数据库中存储和执行。
存储过程可以用来执行复杂的数据操作,例如数据转换、数据验证和数据聚合等。
在本文中,我们将介绍PostgreSQL存储过程的语法。
1. 创建存储过程在PostgreSQL中,可以使用CREATE PROCEDURE语句来创建存储过程。
语法如下:CREATE PROCEDURE procedure_name (parameter_list) LANGUAGE plpgsqlAS $$-- 存储过程代码$$;其中,procedure_name是存储过程的名称,parameter_list是存储过程的参数列表,plpgsql是存储过程的语言类型,$$之间的代码是存储过程的实现代码。
例如,我们可以创建一个简单的存储过程,用于将两个数字相加:CREATE PROCEDURE add_numbers (IN a INTEGER, IN b INTEGER, OUT result INTEGER)LANGUAGE plpgsqlAS $$BEGINresult := a + b;END;$$;在上面的代码中,我们定义了一个名为add_numbers的存储过程,它有两个输入参数a和b,一个输出参数result。
存储过程的实现代码是将a和b相加,并将结果赋值给result。
2. 调用存储过程在PostgreSQL中,可以使用CALL语句来调用存储过程。
语法如下:CALL procedure_name (parameter_list);例如,我们可以调用上面创建的add_numbers存储过程:CALL add_numbers(1, 2, @result);在上面的代码中,我们将1和2作为输入参数传递给存储过程add_numbers,并将结果存储在变量@result中。
pgsql存储过程数组的用法

在PostgreSQL 中,存储过程是一种可重用的SQL 代码块,它可以在数据库中创建并调用。
在存储过程中,你可以使用数组来处理批量数据或进行复杂的逻辑操作。
下面是一个简单的示例,展示了如何在PostgreSQL 存储过程中使用数组:```sqlCREATE OR REPLACE FUNCTION process_array(input_array INTEGER[]) RETURNS VOID AS $$BEGIN-- 使用数组元素进行操作,例如插入到表中FOR i IN 1..array_length(input_array, 1) LOOPINSERT INTO my_table (column1) V ALUES (input_array[i]);END LOOP;END;$$ LANGUAGE plpgsql;```在上面的示例中,我们创建了一个名为`process_array` 的存储过程,它接受一个整数类型的数组`input_array` 作为参数。
在存储过程的主体部分,我们使用`FOR` 循环遍历数组的每个元素,并将其插入到名为`my_table` 的表中。
要调用这个存储过程并传递一个数组作为参数,你可以使用以下语法:```sqlSELECT process_array('{1, 2, 3, 4, 5}');```在这个例子中,我们调用`process_array` 存储过程并传递一个包含整数的数组`{1, 2, 3, 4, 5}` 作为参数。
存储过程将遍历这个数组并将每个元素插入到`my_table` 表中。
请注意,存储过程中的数组语法和操作可能会因版本而异。
确保参考PostgreSQL 的官方文档以获取更详细和最新的信息。
pg数据库存储过程写法

pg数据库存储过程写法PostgreSQL是一种功能强大的开源关系型数据库系统。
它支持存储过程,存储过程可以将SQL代码组织在一起,以便复用和封装。
在这篇文章中,我们将介绍如何使用PG数据库编写存储过程的常见方法和最佳实践。
存储过程是一组预定义的SQL语句,它们被封装在数据库服务器中,并以单个事务的方式执行。
存储过程的主要目的是提高数据库性能和安全性,简化应用程序代码,并减少网络通信的开销。
首先,我们需要创建一个包含存储过程的函数。
在PG数据库中,我们可以使用`CREATE FUNCTION`语句来创建函数。
函数的语法如下:```sqlCREATE FUNCTION function_name([参数列表])RETURNS [返回类型]LANGUAGE plpgsqlAS $$-- 存储过程的代码BEGIN-- 在这里编写SQL语句END;$$;```在这个语法中,`function_name`是函数的名称,参数列表是函数的输入参数,返回类型是函数的返回值类型。
`plpgsql`是PG数据库中的一种流行的存储过程语言,它提供了更强大的功能和灵活性。
下面是一个简单的示例,演示了如何创建一个简单的存储过程,它将接收一个整数参数并返回参数的平方值:```sqlCREATE FUNCTION square(num INT)RETURNS INTLANGUAGE plpgsqlAS $$BEGINRETURN num * num;END;$$;```在上面的示例中,`square`函数接收一个整数参数`num`,并将`num`的平方值作为返回值。
我们可以使用`SELECT`语句来测试这个存储过程:```sqlSELECT square(5);```上述查询语句将返回`25`,因为`5`的平方值是`25`。
当编写存储过程时,我们可以使用一些PL/PGSQL的特殊关键字和语句来实现更复杂的逻辑。
以下是一些常用的PL/PGSQL关键字和语句的示例:1. `DECLARE`关键字用于声明变量,它们可以在存储过程中使用。
postgresql函数(存储过程)返回多条记录的实现方式

postgresql函数(存储过程)返回多条记录的
实现方式
引言概述:
PostgreSQL是一种功能强大的关系型数据库管理系统,它提供了许多灵活的功能,其中包括函数(存储过程)返回多条记录的实现方式。
本文将介绍五种常见的实现方式,分别是游标、返回表、返回集合、返回JSON和返回记录类型。
正文内容:
1. 游标
1.1 游标的定义和使用
1.2 游标的优缺点
1.3 游标的实现方式
2. 返回表
2.1 返回表的定义和使用
2.2 返回表的优缺点
2.3 返回表的实现方式
3. 返回集合
3.1 返回集合的定义和使用
3.2 返回集合的优缺点
3.3 返回集合的实现方式
4. 返回JSON
4.1 返回JSON的定义和使用
4.2 返回JSON的优缺点
4.3 返回JSON的实现方式
5. 返回记录类型
5.1 返回记录类型的定义和使用
5.2 返回记录类型的优缺点
5.3 返回记录类型的实现方式
总结:
在本文中,我们详细介绍了五种实现方式,包括游标、返回表、返回集合、返回JSON和返回记录类型。
每种方式都有其独特的优缺点,可以根据具体的需求选择合适的方式。
游标适用于需要逐条处理结果集的情况,返回表适用于需要将结果集作为整体进行处理的情况,返回集合适用于需要返回多个值的情况,返回JSON 适用于需要将结果以JSON格式返回的情况,返回记录类型适用于需要返回多个字段的情况。
通过灵活运用这些方式,我们可以更好地实现函数(存储过程)返回多条记录的需求。
pgsql存储过程的编写

pgsql存储过程的编写PostgreSQL是一种开源的对象关系型数据库管理系统,有时候也需要使用存储过程来完成某些业务逻辑。
本文将介绍如何编写pgsql存储过程。
一、什么是存储过程存储过程是一组预编译的SQL语句的集合。
一个存储过程通常可接受输入参数,执行一些操作,然后将结果返回给调用方。
存储过程可以很好地封装、保护并简化数据库操作,能够提高数据库执行效率和数据的安全性。
二、存储过程的优点1.提高执行效率存储过程中的SQL语句已经经过预编译,可以直接在数据库中执行,因此执行速度更快。
2.减少网络流量存储过程可以在服务器端执行,仅将查询结果返回给客户端。
相对于客户端发送多条SQL语句而言,可以减少网络流量。
3.实现业务逻辑封装存储过程可以把业务逻辑封装起来,客户端可以通过存储过程调用实现数据库中复杂的业务逻辑。
4.提高数据安全性存储过程可以对表进行一定程度的保护,只有授权的用户才能访问数据。
CREATE [ OR REPLACE ] PROCEDURE procedure_name ( [ parameter_namedata_type [ = default_value ] ][ , ... ] )[ LANGUAGE language_name ] [ AS ]' function_body '存储过程的语法包括存储过程的名称、参数名称、参数数据类型、缺省值和语言。
其中REPLACE为可选项,如果指定,则会替换掉已存在的同名存储过程;如果不指定,则在同名存储过程存在时会报错。
四、实例说明假设有一张学生成绩表(student)和一张课程表(course),每门课程均有5个成绩,我们需要编写一个存储过程,可以根据某个学生的学号(student_id)和课程号(course_id)查询其某门课程的最高分数(max_score)、最低分数(min_score)和平均分数(average_score)。
PostgreSQL存储过程

PostgreSQL存储过程PostgreSQL存储过程⼏年前写过很多,但是⼏年不碰⼜陌⽣了,今天给客户写了⼀个存储过程,查了⼀些资料,记录⼀下:--创建测试表create table student (id integer, name varchar(64));create table employees (id integer, age integer);--table_new 需要在外部创建create table table_new (id integer, name varchar(64), age integer);--插⼊测试数据insert into student select generate_series(1, 100), 'lili_'||cast(random()*100as varchar(2));insert into employees select generate_series(1, 50), random()*100;select count(*) from student;select count(*) from employees;--存储过程create or replace function P_DWA_ERP_LEDGER_JQ_MONTH_NEW( v_mouth varchar(8), out v_retcode text, out v_retinfo text, out v_row_num integer) AS$BODY$declarebegininsert into table_new(id, name, age) select t.id, , m.age from student t, employees m where t.id=m.id;GET DIAGNOSTICS V_ROW_NUM := ROW_COUNT;-- 执⾏成功后的返回信息V_RETCODE :='SUCCESS';V_RETINFO :='结束';--异常处理EXCEPTIONWHEN OTHERS THENV_RETCODE :='FAIL';V_RETINFO := SQLERRM;end;$BODY$language plpgsql;--调⽤存储过程select*from P_DWA_ERP_LEDGER_JQ_MONTH_NEW('12');--查看结果select count(*) from table_new;delete from table_new;vacuum table_new;create or replace function test() returns integerAS$BODY$declarev_mouth varchar(8);v_retcode text;v_retinfo text;v_row_num integer;beginv_mouth :=12;select*from P_DWA_ERP_LEDGER_JQ_MONTH_NEW(v_mouth) into v_retcode, v_retinfo, v_row_num;raise notice 'P_DWA_ERP_LEDGER_JQ_MONTH_NEW result is: %, %, %, %', v_mouth, v_retcode, v_retinfo, v_row_num;return0;end;$BODY$language plpgsql;select test();⼀、写法⽰例/blog/2194815PostgreSQL的存储过程简单⼊门存储过程事物PL/pgSQL - SQL存储过程语⾔postgreSQL存储过程写法⽰例结构PL/pgSQL是⼀种块结构的语⾔,⽐较⽅便的是⽤pgAdmin III新建Function,填⼊⼀些参数就可以了。
PGSQL存储过程学习

PGSQL存储过程学习
PostgreSQL是现在被用来建立web应用程序的非常流行的开源数据库。
PostgreSQL具有高可扩展性、可靠性、安全性和全面的SQL支持,可以帮助开发人员编写出高效的数据库应用程序。
此外,它还具有一系列的开发功能,比如存储过程。
存储过程可以帮助开发人员解决一些难以实现的功能,这些功能可以在表中不断重复,从而提高程序的性能。
存储过程有两种:内联和外联。
内联存储过程是指SQL语句被包含在查询中,并在每次查询时运行。
外联存储过程是指建立在数据库结构上的一组特定指令,它们耦合在一起以执行一定的任务。
它们可以通过SQL操作和程序来调用。
存储过程用于加快SQL查询的执行速度,可以处理复杂的计算,也可以用于定制数据库应用。
PostgreSQL的存储过程可以用PL/pgSQL编写。
PL/pgSQL是一种嵌入式的语言,可以用来编写数据库存储过程,包括基本的数据运算,循环和判断。
它可以与SQL语句结合使用,可以在带有结果集的函数中使用。
要创建一个存储过程,首先要创建一个函数。
函数的定义有四部分,即函数名、形参定义、函数体和返回类型。
函数名用于标识函数,在函数体中,可以定义变量、定义循环和条件语句,定义操作,并且还可以调用数据库函数和结构。
postsql 存储过程语法

postsql 存储过程语法PostgreSQL存储过程语法PostgreSQL是一种功能强大的开源关系型数据库管理系统,支持存储过程。
存储过程是一段预编译的代码块,可以在数据库中被调用和执行。
本文将介绍PostgreSQL存储过程的语法和使用方法。
1. 创建存储过程在PostgreSQL中,可以使用CREATE PROCEDURE语句来创建存储过程。
语法如下:CREATE PROCEDURE procedure_name ([参数列表])LANGUAGE language_nameAS$$-- 存储过程的代码块$$;其中,procedure_name为存储过程的名称,参数列表是可选的,用于指定存储过程的输入参数。
language_name是存储过程所使用的编程语言,通常为plpgsql。
2. 存储过程的输入参数在存储过程中,可以定义输入参数来接收外部传入的值。
参数可以是任何有效的数据类型。
下面是一个例子:CREATE PROCEDURE get_employee_details (IN employee_id INT) LANGUAGE plpgsqlAS$$BEGIN-- 存储过程的代码块END;$$;3. 存储过程的输出参数除了输入参数,存储过程还可以定义输出参数来返回结果。
输出参数必须使用OUT关键字声明,并且在存储过程的代码块中进行赋值。
下面是一个例子:CREATE PROCEDURE get_employee_details (IN employee_id INT, OUT employee_name VARCHAR)LANGUAGE plpgsqlAS$$BEGINSELECT name INTO employee_name FROM employees WHERE id = employee_id;END;$$;4. 调用存储过程在PostgreSQL中,可以使用CALL语句来调用存储过程。
postgre 存储过程

1.Postgresql存储过程PostgreSQL的存储过程基本语法结构如下:CREATE OR REPLACE FUNCTION 函数名(参数1,[整型int4, 整型数组_int4, …])RETURNS 返回值类型AS$BODY$DECLARE变量声明BEGIN函数体END;$BODY$LANGUAGE ‘plpgsql' VOLATILE;2. MySql存储过程MySQL中存储过程的建立以关键字create procedure开始,后面紧跟存储过程的名称和参数。
MySQL的存储过程名称不区分大小写,例如PROCE1()和proce1()代表同一个存储过程名。
存储过程名不能与MySQL数据库中的内建函数重名。
MySQL存储过程的参数一般由3部分组成。
第一部分可以是in、out或inout。
in表示向存储过程中传入参数;out表示向外传出参数;inout表示定义的参数可传入存储过程,并可以被存储过程修改后传出存储过程,存储过程默认为传入参数,所以参数in可以省略。
第二部分为参数名。
第三部分为参数的类型,该类型为MySQL数据库中所有可用的字段类型,如果有多个参数,参数之间可以用逗号进行分割。
MySQL存储过程的语句块以begin开始,以end结束。
语句体中可以包含变量的声明、控制语句、SQL查询语句等。
由于存储过程内部语句要以分号结束,所以在定义存储过程前应将语句结束标志“;”更改为其他字符,并且该字符在存储过程中出现的几率也应该较低,可以用关键字delimiter更改。
例如:mysql>delimiter //存储过程创建之后,可用如下语句进行删除,参数proc_name指存储过程名。
drop procedure proc_nameDELIMITER $$USE `test`$$DROP PROCEDURE IF EXISTS `p_create_table`$$CREATE DEFINER=`root`@`localhost` PROCEDURE `p_create_table`() BEGINDECLARE tableName VARCHAR(100);DECLARE table_name VARCHAR(100);DECLARE monthInt INT DEFAULT 1;DECLARE monthStr VARCHAR(16);DECLARE tableHeader VARCHAR(16);DECLARE tableBody VARCHAR(255);DECLARE dropTableStr VARCHAR(255);DECLARE sqlStr VARCHAR(1000);SET tableName = CONCAT('test_',DATE_FORMAT(NOW(),'%Y'));SET tableHeader = 'CREATE TABLE ';SET tableBody = '(`id` INT(11) NOT NULL AUTO_INCREMENT,`name` VARCHAR(10),PRIMARY KEY (`id`)) ENGINE=INNODB DEFAULT CHARSET=utf8;';WHILE monthInt<= 12 DOIF monthInt< 10 THENSET monthStr = CONCAT('0',monthInt);ELSESET monthStr = CONCAT(monthInt);END IF;SET table_name = CONCAT(tableName,monthStr);SET dropTableStr = CONCAT('DROP TABLE IF EXISTS ',table_name );SET sqlStr = CONCAT(tableHeader,table_name,tableBody);SELECT dropT ableStr INTO @dropT ableStr;SELECT sqlStr INTO @sqlStr;BEGINPREPARE stepDropExistTable FROM @dropTableStr;EXECUTE stepDropExistTable;PREPARE stepCreateTbale FROM @sqlStr;EXECUTE stepCreateTbale;END;SET monthInt = monthInt + 1;END WHILE;END$$DELIMITER ;create function 函数([函数参数[,….]])Returns 返回类型BeginIf(Return (返回的数据)ElseReturn (返回的数据)end if;end;。
postgre sql procedure 参数-概述说明以及解释

postgre sql procedure 参数-概述说明以及解释1.引言1.1 概述在使用PostgreSQL数据库时,存储过程(Procedure)是一种非常常见的数据库对象。
它允许我们将一系列的SQL语句打包成一个可重复执行的程序单元,以便在应用程序中进行调用和使用。
而存储过程的参数正是其中非常重要的组成部分。
参数可以理解为存储过程的输入和输出,用于在调用存储过程时向其传递数据或从中获取数据。
参数的定义和使用方法对于存储过程的正确调用和执行起着至关重要的作用。
本文将深入探讨PostgreSQL存储过程中参数的相关知识。
首先,我们将介绍参数的定义和作用,包括如何在存储过程中声明参数以及参数的不同类型和作用范围。
其次,我们将详细解释参数的使用方法,包括如何在存储过程中传递参数的值、如何在存储过程中使用参数进行业务逻辑处理以及如何返回参数的值。
最后,我们将讨论参数的一些限制和注意事项,帮助读者避免在存储过程中出现常见的错误和局限性。
通过深入学习存储过程中参数的相关知识,读者将能够更好地理解存储过程的运作机制,灵活运用参数实现各种复杂的业务逻辑需求。
同时,掌握参数的定义和使用方法也将提高应用程序的性能和安全性。
下面,我们将逐一介绍参数的定义和作用、参数的使用方法以及参数的限制和注意事项等内容,帮助读者全面掌握存储过程中参数的重要性和应用技巧。
1.2 文章结构本文将分为引言、正文和结论三个部分来探讨postgre sql procedure 的参数。
在引言部分,我们将简要介绍postgre sql procedure的概述,说明其在数据库管理中的重要性和应用场景。
同时,我们将阐述本文的目的,即详细讨论postgre sql procedure参数的定义、作用和使用方法。
正文部分将分为三个小节。
首先,在2.1节中,我们将深入探讨参数的定义和作用,解释参数在postgre sql procedure中的作用和用途。
postgresql存储过程动态更新数据
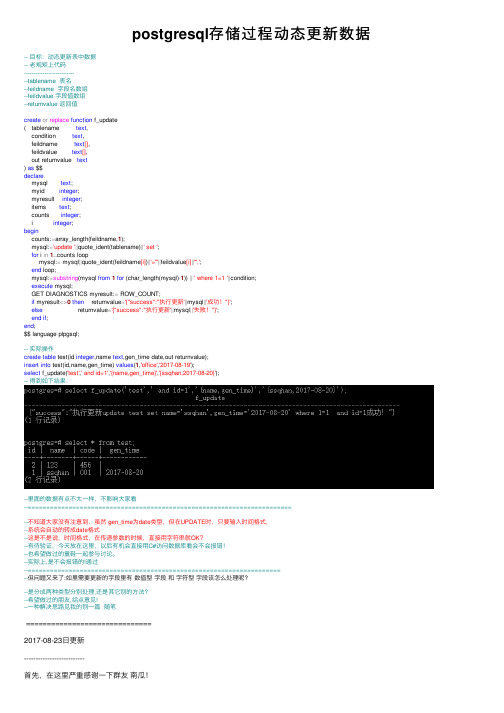
postgresql存储过程动态更新数据-- ⽬标:动态更新表中数据-- ⽼规矩上代码-----------------------------tablename 表名--feildname 字段名数组--feildvalue 字段值数组--returnvalue 返回值create or replace function f_update( tablename text,condition text,feildname text[],feildvalue text[],out returnvalue text) as $$declaremysql text;myid integer;myresult integer;items text;counts integer;i integer;begincounts:=array_length(feildname,1);mysql:='update '||quote_ident(tablename)||' set ';for i in1..counts loopmysql:= mysql||quote_ident(feildname[i])||'='''||feildvalue[i]||''',';end loop;mysql:=substring(mysql from1for (char_length(mysql)-1)) ||' where 1=1 '||condition;execute mysql;GET DIAGNOSTICS myresult:= ROW_COUNT;if myresult<>0then returnvalue='{"success":"执⾏更新'||mysql||'成功!"}';else returnvalue='{"success":"执⾏更新'||mysql||'失败!"}';end if;end;$$ language plpgsql;-- 实际操作create table test(id integer,name text,gen_time date,out returnvalue);insert into test(id,name,gen_time) values(1,'office','2017-08-19');select f_update('test',' and id=1','{name,gen_time}','{ssqhan,2017-08-20}');-- 得到如下结果:--⾥⾯的数据有点不太⼀样,不影响⼤家看--=======================================================================--不知道⼤家没有注意到,虽然 gen_time为date类型,但在UPDATE时,只要输⼊时间格式,--系统会⾃动的转成date格式--这是不是说,时间格式,在传递参数的时候,直接⽤字符串就OK?--有待验证,今天放在这⾥,以后有机会直接⽤C#访问数据库看会不会报错!--也希望做过的童鞋⼀起参与讨论。
POSTGRESQL存储过程实战

POSTGRESQL存储过程实战转了N多的SQL语句,可是⾃⼰⽤时,却到处是坑啊,啊,啊想写⼀个获取表中最新ID值.上代码CREATE TABLE department(ID INT PRIMARY KEY NOT NULL,d_code VARCHAR(50),d_name VARCHAR(50) NOT NULL,d_parentID INT NOT NULL DEFAULT0);--insert into department values(1,'001','office');--insert into department values(2,'002','office',1);下⾯要写个存储过程,以获取表中ID的最⼤值:drop function f_getNewID(text,text);create or replace function f_getNewID(myTableName text,myFeildName text) returns integer as $$declaremysql text;myID integer;beginmysql:='select max( $1 ) from $2';execute mysql into myID using myFeildName,myTableName;if myID is null or myID=0then return1;else return myID+1;end if;end;$$ language plpgsql;--⼤家可以试⼀下,上⾯这个是会报错的--select f_getNewID('department','ID');--出错!看了官⽅⽂档,⼈家就是这么⽤的:EXECUTE'SELECT count(*) FROM mytable WHERE inserted_by = $1 AND inserted <= $2'INTO cUSING checked_user, checked_date;你确定你看清楚了确定你读完读懂了说明书--这个看了?---------------------------------------EXECUTE'SELECT count(*) FROM '|| quote_ident(tabname)||' WHERE inserted_by = $1 AND inserted <= $2'INTO cUSING checked_user, checked_date;--这个看了?---------------------------------------EXECUTE'UPDATE tbl SET '|| quote_ident(colname)||' = '|| quote_literal(newvalue)||' WHERE key = '|| quote_literal(keyvalue);--=============================--好吧,我改------------------------------------------------------drop function f_getNewID(text,text);create or replace function f_getNewID(myTableName text,myFeildName text) returns integer as $$declaremysql text;myID integer;beginmysql:='select max('|| quote_ident(myFeildName)||') from '|| quote_ident(myTableName);execute mysql into myID;--using myTableName,myFeildName;if myID is null or myID=0then return1;else return myID+1;end if;end;$$ language plpgsql;--==============================--漂亮,成功了!--But Why?--注意对象(表名、字段名等)是不可以直接⽤变量的,要⽤ quote_ident()-------------------------------------------------------postgres=# select f_getnewid('department','ID');--错误: 字段 "ID" 不存在--第1⾏select max("ID") from department^--查询: select max("ID") from department--背景: 在EXECUTE的第10⾏的PL/pgSQL函数f_getnewid(text,text)--===============================--什么情况,ID怎么会有双引号,引号,号,号------------------------------------------------------------这⾥要感谢⼤神:权宗亮@飞象数据--改成这样:postgres=# select f_getnewid('department','id');f_getnewid------------2(1⾏记录)----终于成功了!⼤⼩写还有区别吗 --but why? --当在命令⾏输⼊CREATE TABLE role(ID INT PRIMARY KEY NOT NULL,r_name VARCHAR(50) NOT NULL,r_paretnID INT NOT NULL DEFAULT0);--结果在pgAdmin⾥看到的却是⼩写的--同样,如果是在QUERY TOOLS 下⽤这样的语句创建还是所有的字体名为⼩写--如果我就想⼤写怎么办--要这样写CREATE TABLE "RoleUPER"("ID" INT PRIMARY KEY NOT NULL,r_name VARCHAR(50) NOT NULL,"r_paretnID" INT NOT NULL DEFAULT0);--再⽤⼤象看看--可以了!总结⼀下:1、存储过程(FUNCITON)变量可以直接⽤ || 拼接。
postgresqlprocedure存储过程
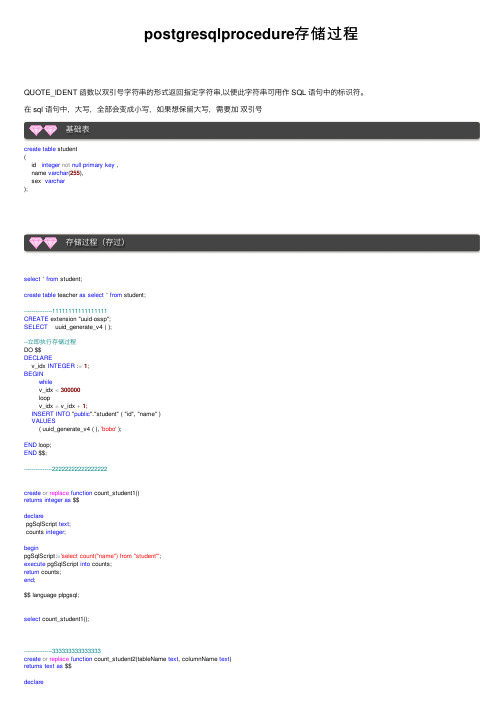
postgresqlprocedure存储过程QUOTE_IDENT 函数以双引号字符串的形式返回指定字符串,以便此字符串可⽤作 SQL 语句中的标识符。
在 sql 语句中,⼤写,全部会变成⼩写,如果想保留⼤写,需要加双引号基础表create table student(id integer not null primary key ,name varchar(255),sex varchar);存储过程(存过)select*from student;create table teacher as select*from student;---------------11111111111111111CREATE extension "uuid-ossp";SELECT uuid_generate_v4 ( );--⽴即执⾏存储过程DO $$DECLAREv_idx INTEGER :=1;BEGINwhilev_idx <300000loopv_idx = v_idx +1;INSERT INTO "public"."student" ( "id", "name" )VALUES( uuid_generate_v4 ( ), 'bobo' );END loop;END $$;---------------22222222222222222create or replace function count_student1()returns integer as $$declarepgSqlScript text;counts integer;beginpgSqlScript:='select count("name") from "student"';execute pgSqlScript into counts;return counts;end;$$ language plpgsql;select count_student1();---------------333333333333333create or replace function count_student2(tableName text, columnName text)returns text as $$declarepgSqlScript text;counts integer;beginpgSqlScript:='select count('|| quote_ident(columnName) ||') from '|| quote_ident(tableName); return pgSqlScript;end;$$ language plpgsql;select count_student2('student','name');---------------4444444444444444drop function count_student3;create or replace function count_student3(tableName text, columnName text)returns integer as $$declarepgSqlScript text;counts integer;beginpgSqlScript:='select count('|| quote_ident(columnName) ||') from '|| quote_ident(tableName); execute pgSqlScript into counts;if counts >100thenreturn counts;elsereturn0;end if;end;$$ language plpgsql;select count_student3('student','name');---------------555555555555555create or replace function count_student5()returns integer as $$declarepgSqlScript text;myid integer;myname varchar;beginpgSqlScript:='select id,name from student order by "id" asc ';execute pgSqlScript into myid,myname;-- 可以同时赋多个值,但只会塞⼊最后⼀⾏数据raise notice 'result is %' , myname; --打印语句return myid;end;$$ language plpgsql;select count_student5();select id,name from student order by id;delete from teacher;select*from teacher;select*from student;insert into teacher select*from student;update teacher T1 set name = from student T2 where T1.id = T2.id;游标使⽤CREATE OR REPLACE FUNCTION cursor_demo()RETURNS refcursor AS--返回⼀个游标$BODY$declare--定义变量及游标unbound_refcursor refcursor; --游标t_accid varchar; --变量t_accid2 int; --变量begin--函数开始open unbound_refcursor for execute'select name from cities_bak'; --打开游标并注⼊要搜索的字段的记录loop --开始循环fetch unbound_refcursor into t_accid; --将游标指定的值赋值给变量if found then--任意的逻辑raise notice '%-',t_accid;elseexit;end if;end loop; --结束循环close unbound_refcursor; --关闭游标raise notice 'the end of msg...'; --打印消息return unbound_refcursor; --为函数返回⼀个游标exception when others then--抛出异常raise exception 'error-----(%)',sqlerrm;--字符“%”是后⾯要显⽰的数据的占位符end; --结束$BODY$LANGUAGE plpgsql; --规定语⾔select cursor_demo();--调⽤总结⼀下:定义变量是在begin前变量赋值时使⽤:=select 中赋值使⽤into1、存储过程(FUNCITON)变量可以直接⽤ || 拼接。
postgre sql存储过程编写

postgre sql存储过程编写
PostgreSQL存储过程是一段可重用的代码,可以执行一系列SQL语句、控制结构和逻辑,可以用于复杂的数据处理、数据转换、逻辑控制等。
下面是一个简单的存储过程示例:
CREATE OR REPLACE FUNCTION get_customer_order_count(customer_id INTEGER)
RETURNS INTEGER AS
DECLARE
order_count INTEGER;
BEGIN
SELECT COUNT(*) INTO order_count FROM orders WHERE customer_id = 1;
RETURN order_count;
END;
LANGUAGE plpgsql;
这个存储过程接受一个customer_id参数,返回该客户的订单数量。
实现过程中,使用了DECLARE定义变量、SELECT INTO读取数据、RETURN返回结果等PL/pgsql语法。
在创建存储过程时,可以使用CREATE FUNCTION或CREATE PROCEDURE 语句,指定存储过程的名称、参数、返回值类型、语言等信息。
存储过程的执行可以使用CALL或SELECT语句调用。
在实际开发中,存储过程可以应用于事务管理、数据更新、复杂查询、数据清洗等场景中,可以提高系统性能和稳定性。
postgresql 存储过程高级写法

存储过程是在数据库中存储、编译并可以在需要时执行的一组SQL 语句的代码块。
在PostgreSQL 中,存储过程可以使用PL/pgSQL(一种过程化语言)进行编写。
以下是PostgreSQL 存储过程的一些高级写法示例:### 1. 基本结构```plpgsqlCREATE OR REPLACE FUNCTION my_function(param1 type1, param2 type2)RETURNS returnType AS $$DECLARE--声明变量variable1 type1;variable2 type2;BEGIN--主体代码RETURN result; --返回结果END;$$ LANGUAGE plpgsql;```### 2. 条件语句```plpgsqlIF condition THEN--处理逻辑ELSIF condition THEN--处理逻辑ELSE--处理逻辑END IF;```### 3. 循环语句```plpgsqlFOR record_variable IN query LOOP--处理逻辑END LOOP;```### 4. 异常处理```plpgsqlBEGIN--主体代码EXCEPTIONWHEN division_by_zero THEN--处理除零异常WHEN others THEN--处理其他异常END;```### 5. 动态SQL```plpgsqlEXECUTE 'SELECT column_name FROM table_name WHERE id = $1' INTO variable USING parameter;```### 6. 返回表```plpgsqlCREATE OR REPLACE FUNCTION get_data()RETURNS TABLE(column1 type1, column2 type2) AS $$BEGINRETURN QUERY SELECT column1, column2 FROM your_table;END;$$ LANGUAGE plpgsql;```### 7. 使用`RETURN NEXT` 迭代返回结果```plpgsqlCREATE OR REPLACE FUNCTION get_numbers(max_number INT)RETURNS SETOF INT AS $$DECLAREcounter INT := 1;BEGINWHILE counter <= max_number LOOPRETURN NEXT counter;counter := counter + 1;END LOOP;RETURN;END;$$ LANGUAGE plpgsql;```### 8. 使用`RETURN QUERY` 返回查询结果```plpgsqlCREATE OR REPLACE FUNCTION get_data_by_condition(condition TEXT)RETURNS TABLE(column1 type1, column2 type2) AS $$BEGINRETURN QUERY EXECUTE 'SELECT column1, column2 FROM your_table WHERE ' || condition;END;$$ LANGUAGE plpgsql;```请注意,这些只是一些PL/pgSQL 的高级写法示例,实际的存储过程实现取决于您的具体需求。
pgsql存储过程介绍

pgsql存储过程介绍虽然现在postgresql的使用率不错,但是现在关于它的教程还是很少,而教程中对于存储过程的讲解也不详细,今天就自己的使用经验说一说。
创建存储过程很简单,create or replace function test(),当然,你如果这样写:create function test()也可以,但如果test()已存在就会报错,第一种写法是创建或覆盖,就是无论有没有都创建test()。
这个是不带参数的,那如果带参数的存储过程呢?这样:create or replace function test(name varchar),存储过程参数的数据类型要放在参数名的后面,现在来创建一个简单的存储过程。
create or replace function test(name varchar) returns varhcar as$$declarestr varchar;str2 varchar;beginstr = name;str2 = name || ' is ' || $1;return str2;end$$language plpgsql;执行它:select test('postgresql'),返回的是一个字符串’postgresql is postgresql',这里对这个存储过程介绍一下,首先returns varchar定义一个返回类型,说明返回varchar类型的数据,$$符号把存储过程包围起来,更便于存储过程的识别,declare是声明变量,而函数体都在begin和end之间,name是代表参数name,而$1也是代表name,它是指存储过程的第一个参数,$2是指第二个参数,在存储过程里,字符串的相加用的||,中间要用空格,如果是常量,那要用两个'来包含起来,如果我需要字符',那怎么办?那还是用两个'包含起来,注意,'是关键符号,所以要用两个'来表示一个',所以用四个'可以表示一个'字符。
数据库PostgreSQL掌握存储过程的创建执行删除操作

数据库系统原理实验报告一、存储过程实验1. 实验目的(1)掌握存储过程的创建操作。
(2)掌握存储过程的执行操作。
(3)掌握存储过程的删除操作。
2. 实验内容(1)创建带输入参数的存储过程。
(2)执行所创建的存储过程。
(3)删除所有新创建的存储过程。
3. 示例例1:Create or replace function loop1() returns void as $$ DECLAREi int :=1;BEGINLOOPINSERT INTO employee_1511630117values(i);i:=i+1;exit when i>10;END LOOP;END;$$ language plpgsql;select loop1()例2:Create function sales_tax(subtotal real) returns real as $$ beginreturn subtotal *0.06;end;$$language plpgsql;select sales_tax(0.8);例3:Create or replace function select_test() returns table (no char(6)) as $$BEGINreturn QUERYselect departmentid from employee_1511630117;END;$$ language plpgsql;select * from select_test();select select_test();drop function select_test()4. 实验步骤对应于employee数据库(1)创建一个无参存储过程,查询雇员的编号,姓名,性别,出生日期;create or replace function EmployeeInfo() returnstable(employeeid char(6),name char(10),birthday date,sex bit(1)) as $$beginreturn queryselect employee_1511630117.employeeid,employee_, employee_1511630117.birthday,employee_1511630117.sexfrom employee_1511630117;end ;$$language plpgsql;select * from EmployeeInfo();(2)创建一个带参的存储过程,根据传入的employeeid查询employee表中的其他信息create or replace function emp_info(idt char(6)) returnstable(id char(6),name char(10),birth date,sex bit(1)) as $$beginreturn queryselect employee_1511630117.employeeid,employee_, employee_1511630117.birthday,employee_1511630117.sexfrom employee_1511630117where idt = employeeid;end;$$ language plpgsql;select * from emp_info('1002');(3)创建一个带参数的存储过程,根据输入的employeeid,departmentid 查询雇员的其他信息create or replace function Emp_Info2(idt char(6),departmentidt char(3))returns table(id char(6),name char(10),sex bit(1),department char(3)) as $$beginreturn queryselectemployee_1511630117.employeeid,employee_,employee_ 1511630117.sex,employee_1511630117.departmentidfrom employee_1511630117where idt = employeeid anddepartmentidt=employee_1511630117.departmentid;end;$$ language plpgsql;查询:select * from emp_info2('1001','1');(4)删除创建的存储过程drop function employeeInfo();5.实验过程中遇到的问题、解决办法及心得体会。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
用PL/pgSQL写postgreSQL的存储过程
一、存储过程结构:
Create or replace function 过程名(参数名参数类型,…..) returns 返回值类型as $body$
//声明变量
Declare
变量名变量类型;
如:
flag Boolean;
变量赋值方式(变量名类型:=值;)
如:
Str text :=值; / str text; str :=值;
Begin
函数体;
End;
$body$
Language plpgsql;
二、变量类型:
除了postgresql内置的变量类型外,常用的还有 RECORD ,表示一条记录
三、连接字符:
Postgresql存储过程中的连接字符不再是“+”,而是使用“||”。
四、控制结构:
1、if 条件(五种形式)
IF ... THEN
IF ... THEN ... ELSE
IF ... THEN ... ELSE IF
IF ... THEN ... ELSIF ... THEN ... ELSE
IF ... THEN ... ELSEIF ... THEN ... ELSE(注:ELSEIF 是 ELSIF 的别名)
2、循环
使用LOOP,EXIT,CONTINUE,WHILE,和 FOR 语句,可以控制PL/pgSQL 函数重复一系列命令。
1)、LOOP
[ <<label>> ]
LOOP
statements
END LOOP [ label ];
LOOP 定义一个无条件的循环,无限循环,直到由EXIT或者RETURN语句终止。
可选的label可以由 EXIT 和 CONTINUE 语句使用,用于在嵌套循环中声明应该应用于哪一层循环。
2)、EXIT
EXIT [ label ] [ WHEN expression ];
如果没有给出label,那么退出最内层的循环,然后执行跟在 END LOOP 后面的语句。
如果给出label,那么它必须是当前或者更高层的嵌套循环块或者语句块的标签。
然后该命名块或者循环就会终止,而控制落到对应循环/块的 END 语句后面的语句上。
如果声明了WHEN,循环退出只有在expression为真的时候才发生,否则控制会落到 EXIT 后面的语句上。
EXIT 可以用于在所有的循环类型中,它并不仅仅限制于在无条件循环中使用。
在和 BEGIN 块一起使用的时候,EXIT 把控制交给块结束后的下一个语句。
例如:
Loop 循环
If … then 条件判断
Exit ; 条件成立,则退出循环。
End if;
End loop;
3)、CONTINUE
CONTINUE [ label ] [ WHEN expression ];
如果没有给出label,那么就开始最内层的循环的下一次执行。
也就是说,控制传递回给循环控制表达式(如果有),然后重新计算循环体。
如果出现了label,它声明即将继续执行的循环的标签。
如果声明了 WHEN,那么循环的下一次执行只有在expression为真的情况下才进行。
否则,控制传递给 CONTINUE 后面的语句。
CONTINUE 可以用于所有类型的循环;它并不仅仅限于无条件循环。
例如:
LOOP
一些计算
EXIT WHEN count > 100;
CONTINUE WHEN count < 50;
一些在count 数值在 [50 .. 100] 里面时候的计算
END LOOP;
4)、WHILE
[ <<label>> ]
WHILE expression LOOP
statements
END LOOP [ label ];
只要条件表达式为真,WHILE语句就会不停在一系列语句上进行循环. 条件是在每次进入循环体的时候检查的.
例如:
WHILE amount_owed > 0 AND gift_certificate_balance > 0 LOOP
-- 可以在这里做些计算
END LOOP;
WHILE NOT BOOLEAN_expression LOOP
-- 可以在这里做些计算
END LOOP;
5)、FOR (整数变种)
[ <<label>> ]
FOR name IN [ REVERSE ] expression .. expression LOOP
statements
END LOOP [ labal ];
这种形式的FOR对一定范围的整数数值进行迭代的循环。
变量name会自动定义为integer类型并且只在循环里存在。
给出范围上下界的两个表达式在进入循环的时候计算一次。
迭代步进值总是为 1,但如果声明了REVERSE就是 -1。
一些整数FOR循环的例子∶
FOR i IN 1..10 LOOP 表示1循环到10
这里可以放一些表达式
RAISE NOTICE 'i IS %', i;
END LOOP;
FOR i IN REVERSE 10..1 LOOP
这里可以放一些表达式
END LOOP;
如果下界大于上界(或者是在 REVERSE 情况下是小于),那么循环体将完
全不被执行。
而且不会抛出任何错误。
3、异常捕获
EXCEPTION
WHEN 错误码(如:STRING_DATA_RIGHT_TRUNCATION:字串数据右边被截断)
THEN
/**后台打印错误信息*/
RAISE NOTICE '错吴信息';
附件含有实例代码。