实践练习答案-第3章创建与管理数据库
大学数据库-第3章习题解答

生产厂家的数据有:厂名、地址、向商店提供的商品价格
请设计该百货商店的概念模型,再将概念模型转换为关系模型。注意某些信息可用属性 表示,其他信息可用联系表示。 答:概念模型如图所示。
题 3.22 E-R 图
图中:
职工:职工号,姓名,住址 商品部:商品部号,名称 商品:商品代号,价格,型号,出厂价格 生产厂家:厂名,地址
〖3.19〗 请设计一个图书馆数据库,此数据库中对每个借阅 者保存记录,包括:读者号、姓名、地址、性别、 年龄、单位。对每本书,保存有:书号、书名、作 者、出版社。对每本被借出的书保存有读者号、借 出日期和应还日期。要求:给出该图书馆数据库的 E-R 图,再将其转换为关系模型。
答:该图书馆数据库的 E-R 图如图所示。 其中:
〖3.16〗 为什么要从两层 C/S 结构发展成三层 C/S 结构? 答:为了减轻两层 C/S 结构中客户机的负担,从客户机和服务器各抽一部分功能,组成应用 服务器,成为三层 C/S 结构。 〖3.17〗 叙述数据字典的主要任务。 答:数据字典的任务就是管理有关数据的信息,主要包括:描述数据库系统的所有对象,并 确定其属性;描述数据库系统对象之间的各种交叉联系;登记所有对象的完整性及安全性限 制等;对数据字典本身的维护、保护、查询与输出。 〖3.18〗 现有一个局部应用,包括两个实体“出版社”和“作者”,这两个实体是多对多的
答:概念结构设计的结果用数据库的信息模型表示。信息模型的主要特点和设计策略是:信 息模型是现实世界的一个真实模型,能真实、充分地反映现实世界,能满足用户对数据的处 理要求;信息模型应当易于理解;信息模型应当易于更改,有利于修改和扩充;信息模型易 于向特定的数据模型转换。 〖3.8〗 什么是数据抽象?试举例说明。 答:① 数据抽象就是抽取现实世界的共同特性,忽略非本质的细节,并把这些共同特性用 各种概念精确地加以描述,形成某种数据模型。
数据库原理及应用实验指导书答案

数据库原理及应用实验指导书 - 答案实验一:数据库管理系统的安装与配置问题一数据库管理系统(DBMS)是一种软件,用于管理和组织数据库。
它允许用户创建,读取,更新和删除数据库中的数据。
常见的数据库管理系统有MySQL,Oracle,SQL Server等。
问题二在实验室环境中,我们将使用MySQL作为我们的数据库管理系统。
以下是MySQL的一些常见特点: - 开源免费 - 跨平台支持 - 可扩展性强 - 有大型的用户社区和丰富的资源支持问题三MySQL的安装步骤如下: 1. 下载MySQL安装文件,可以从MySQL官方网站或者其他可信的下载源获取。
2. 运行安装程序,按照向导的指示进行安装。
3. 选择是否要安装MySQL 服务器和MySQL工具。
4. 设置密码以保护数据库的安全。
5. 完成安装程序并启动MySQL服务。
数据库是一个组织和存储数据的容器。
在关系型数据库中,数据以表的形式存储,每个表包含多个行和列。
每行代表一个记录,每列代表一个字段。
问题五关系型数据库管理系统(RDBMS)是一种DBMS,它使用结构化查询语言(SQL)来操作和处理数据。
常见的关系型数据库管理系统有MySQL,Oracle,SQL Server等。
问题六开放数据库连接(ODBC)是一种标准的数据库访问方法,它允许不同的应用程序通过统一的接口访问不同的数据库管理系统。
ODBC驱动程序充当应用程序和数据库之间的翻译器。
问题七在Windows系统中,ODBC数据源可以通过控制面板的“管理工具”来配置。
在数据源配置对话框中,可以添加,编辑和删除ODBC数据源。
在Windows系统中,可以使用ODBC接口库和ODBC驱动程序来连接和操作数据库。
具体步骤如下: 1. 加载ODBC接口库。
2. 初始化ODBC环境。
3. 建立数据库连接。
4. 执行SQL语句。
5. 关闭数据库连接。
6. 释放ODBC环境。
问题九ODBC接口库是一组API函数,用于连接和操作数据库。
数据库实训教程习题答案
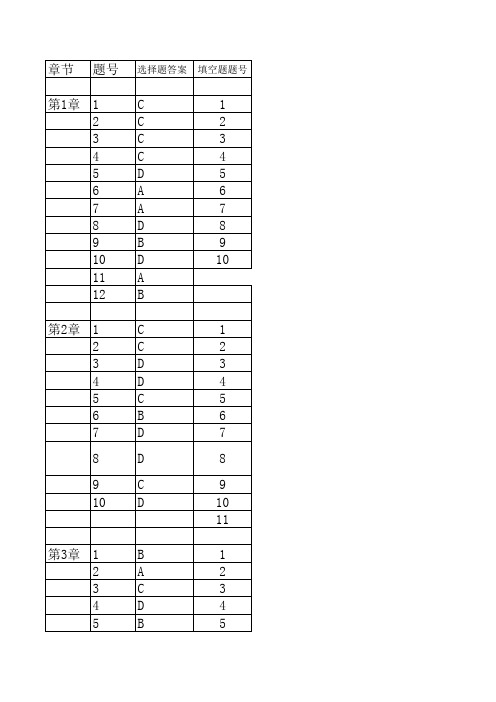
15 B
16 B
17 C
18 B
19 C
20 D
第4章 1
B
1
2
C
2
3
A
3
4
B
4
5
D
5
6
A
6
7
A
7
8
C
8
9
C
9
10 A
10
11 C
11
12 B
12
13 C
13
14 D
15 C
16 D
17 D 18 C 19 A 20 A 21 B
第5章 1
A
1
2
B
2
3
C
3
4
D
4
5
A
5
6
C
6
7
C
7
8
D
8
9
B
9
10 C
事件 插入,修改,删除
触发器只有在触发SQL语句中指定的所有操作都已成 功执行后才激发,z执行触发器而不是执行触发SQL语 句,从而替代触发语句的操作
混合 grant,deny,revoke create database,create proc,create table,create view select,insert,update sysadmin,serveradmin,diskadmin db_owner,db_securityadmin
19
20 B
20
第7章 1
C
1
2
C
2
3
C
3
4
D
4
5
A
5
6
数据库第三章习题及答案

第3章关系数据库标准语言SQL一、选择题1、SQL语言是的语言,易学习。
A.过程化 B.非过程化 C.格式化 D.导航式答案:B2、SQL语言是语言。
A.层次数据库 B.网络数据库 C.关系数据库 D.非数据库答案:C3、SQL语言具有的功能。
A.关系规范化、数据操纵、数据控制 B.数据定义、数据操纵、数据控制C.数据定义、关系规范化、数据控制 D.数据定义、关系规范化、数据操纵答案:B4、SQL语言具有两种使用方式,分别称为交互式SQL和。
A.提示式SQL B.多用户SQL C.嵌入式SQL D.解释式SQL 答案:C5、假定学生关系是S(S#,SNAME,SEX,AGE),课程关系是C(C#,CNAME,TEACHER),学生选课关系是SC(S#,C#,GRADE)。
要查找选修“COMPUTER”课程的“女”学生姓名,将涉及到关系。
A.S B.SC,C C.S,SC D.S,C,SC 答案:D6、若用如下的SQL语句创建一个student表:CREATE TABLE student(NO C(4) NOT NULL,NAME C(8) NOT NULL,SEX C(2),AGE N(2))可以插入到student表中的是。
A.(‘1031’,‘曾华’,男,23) B.(‘1031’,‘曾华’,NULL,NULL)C.(NULL,‘曾华’,‘男’,‘23’) D.(‘1031’,NULL,‘男’,23) 答案:B7、当两个子查询的结果时,可以执行并,交,差操作.A.结构完全不一致 B.结构完全一致C.结构部分一致D.主键一致答案:B第8到第10题基于这样的三个表即学生表S、课程表C和学生选课表SC,它们的结构如下:S(S#,SN,SEX,AGE,DEPT)C(C#,CN)SC(S#,C#,GRADE)其中:S#为学号,SN为姓名,SEX为性别,AGE为年龄,DEPT为系别,C#为课程号,CN为课程名,GRADE为成绩。
第3章数据管理3.2设计逻辑结构与建立数据库-高中教学同步《信息技术数据管理与分析》(教案)

关系模式:关系名(属性1,属性2,...)
实例:世界杯(届次,年份,地点,冠军)
3.逻辑结构设计
E-R图到关系模型的转换
实体的转换:实体→关系模式
联系的转换:
m:n联系→独立关系模式
1:n联系→独立关系模式/合并到n端实体关系模式
1:1联系→独立关系模式/合并到任意一端实体关系模式
通过小组讨论和团队协作,培养学生的团队协作能力和沟通能力。
引导学生自主学习和探索,培养学生的自主学习能力和创新精神。
情感态度与价值观目标:
激发学生对数据库学习和应用的兴趣,培养学生的信息素养和终身学习的意识。
培养学生的责任感和使命感,理解数据库技术在现代社会中的重要地位和作用。
培养学生的职业道德和规范意识,引导学生正确、合法地使用数据库技术。
准备课后反馈渠道,如电子邮件、在线论坛等,以便学生提出问题和建议。
教学媒体
教学PPT或幻灯片:用于展示课程大纲、关键概念、步骤说明、示例图(如E-R图转换为关系模型的图表)、流程图等。这些视觉元素有助于学生理解和记忆复杂的概念和过程。
数据库管理系统软件:如MySQL或Navicat for MySQL,用于演示如何在实际环境中创建、查看、修改和删除数据库及数据表,以及导入和导出数据。这些软件为学生提供了真实的操作体验。
遇到问题及时寻求帮助,与同学和教师交流。
通过实践操作,使学生掌握在MySQL控制台和Navicat for MySQL中创建和查看数据库的方法,培养学生的动手能力和实践能力。
活动四:
巩固练习
素质提升
讲解数据表创建规则:介绍创建数据表时需要注意的事项,如字段命名规则、数据类型选择等。
演示数据表操作:在Navicat for MySQL中演示如何创建、查看、修改和删除数据表。
数据库第三章习题参考答案范文大全

数据库第三章习题参考答案范文大全第一篇:数据库第三章习题参考答案3-2 对于教务管理数据库的三个基本表S(SNO,SNAME, SEX, AGE,SDEPT) SC(SNO,CNO,GRADE)C(CNO,CNAME,CDEPT,TNAME) 试用SQL的查询语句表达下列查询:⑴ 检索LIU老师所授课程的课程号和课程名。
⑵ 检索年龄大于23岁的男学生的学号和姓名。
⑶ 检索学号为200915146的学生所学课程的课程名和任课教师名。
⑷ 检索至少选修LIU老师所授课程中一门课程的女学生姓名。
⑸ 检索WANG同学不学的课程的课程号。
⑹ 检索至少选修两门课程的学生学号。
⑺ 检索全部学生都选修的课程的课程号与课程名。
⑻ 检索选修课程包含LIU老师所授课程的学生学号。
解:⑴ SELECT C#,CNAME FROM C WHERE TEACHER=’LIU’; ⑵ SELECT S#,SNAME FROM S WHERE AGE>23 AND SEX=’M’; ⑶ SELECT CNAME,TEACHER FROM SC,C WHERE SC.C#=C.C# AND S#=’200915146’ ⑷ SELECT SNAME (连接查询方式) FROM S,SC,C WHERE S.S#=SC.S# AND SC.C#=C.C# AND TEACHER=’LIU’;或:SELECT SNAME (嵌套查询方式) FROM S WHERE SEX=’F’AND S# IN (SELECT S# FROM SC WHERE C# IN (SELECT C# FROM C WHERE TEACHER=’LIU’)) 或:SELECT SNAME (存在量词方式)SEX=’F’ AND FROM S WHERE SEX=’F’ AND EXISTS(SELECT* FROM SC WHERE SC.S#=S.S# AND EXISTS(SELECT * FROM C WHERE C.C#=SC.C# AND TEACHER=’LIU’)) ⑸ SELECT C# FROM C WHERE NOT EXISTS(SELECT * FROM S,SC WHERE S.S#=SC.S# AND SC.C#=C.C# AND SNAME=’WANG)); ⑹ SELECT DISTINCT X.S# FROM SC AS X,SC AS Y WHERE X.S#=Y.S# AND X.C#!=Y.C#; ⑺ SELECT C#.CNAME FROM C WHERE NOT EXISTS (SELECT * FROM S WHERE NOT EXISTS (SELECT * FROM SC WHERE S#=S.S# AND C#=C.C#)); ⑻ SELECT DISTINCT S# FROM SC AS X WHERE NOT EXISTIS (SELECT * FROM C WHERE TEACHER=’LIU’ AND NOT EXISTS (SELECT * FROM SC AS Y WHERE Y.S#=X.S# AND Y.C#=C.C#)); 3-3 试用SQL查询语句表达下列对3.2题中教务管理数据库的三个基本表S、SC、C查询:⑴ 统计有学生选修的课程门数。
数据库答案 第三章习题参考答案

7. 找出没有使用天津产的零件的工程项目代码。 找出没有使用天津产的零件的工程项目代码。 Select jno from j where not exists (Select * from spj where spj.jno=j.jno and sno in (Select sno from s where city=‘天津’) city=‘天津了供应商 所供应的全部零件的工程号 求至少用了供应商S1所供应的全部零件的工程号 求至少用了供应商 所供应的全部零件的工程号JNO。 。 即查找:不存在这样的零件y,供应商S1供应了 供应了y,而工程x 即查找:不存在这样的零件 ,供应商 供应了 ,而工程 为选用y。 为选用 。 Select distinct jno From spj z Where not exists (select * from spj x where sno=‘S1’ and not exists (select * from spj y where y.pno=x.pno and y.jno=z.jno));
习题三
Select sno from spj Where jno=‘J1’;
第 4题
1.求供应工程 零件的供应商号码 求供应工程J1零件的供应商号码 求供应工程 零件的供应商号码SNO。 。
2.求供应工程 零件 的供应商号码 求供应工程J1零件 的供应商号码SNO。 求供应工程 零件P1的供应商号码 。 Select sno from spj Where jno=‘J1’ and pno=‘P1’;
1
3.求供应工程 零件为红色的供应商号码。 求供应工程J1零件为红色的供应商号码 求供应工程 零件为红色的供应商号码。 Select sno from spj, p Where spj.pno=p.pno and jno=‘J1’ and color=‘红 color=‘红’; 或: Select sno from spj Where jno =‘J1’ and pno in (Select pno from p where color=‘红’ ); color=‘红
数据库第三章部分习题答案

3.2 对于教学数据库的三个基本表S(S#,SNAME,AGE,SEX)SC(S#,C#,GRADE)C(C#,CNAME,TEACHER)试用SQL的查询语句表达下列查询:3.2.1检索年龄小于17岁的女学生的学号和姓名select s#,sname from Swhere age<17 and sex=F;3.2.2检索男生所学课程的课程号和课程名select c#,cname from Cwhere c# in (select distinct c#from SCwhere s# in (select s# from S where sex=M)) 3.2.3检索男生所学课程的任课老师的工号和姓名实用文档select t#,tname from Twhere t# in(select distinct t#from C实用文档where c# in(select distinct c#from SCwhere s# in(select s#from Swhere sex=1)));3.2.4检索至少选修两门课程的学生的学号select s#from SCgroup by s#having count(c#)>=2;3.2.5检索至少有学号为S2和S4所学的课程和课程名select c#,cnamefrom C实用文档where c# in((select c#from sc where s#='S2')intersect实用文档(select c# from sc where s#='S4') );3.2.6检索‘WANG’同学不学的课程号select c# from cexcept(select distinct c#from scwhere s# =(select s# from s where sname='WANG'));3.2.7检索全部学生都选修的课程号和课程名select c#,cnamefrom cwhere not exists(select s#from swhere c.c# not in (select c# from sc where sc.s#=s.s# ));实用文档3.2.8检索选修课程包含'LIU'老师所授课程的全部课程的学生的学号和姓名select s#,snamefrom s实用文档where not exists((select c#from cwhere t#=(select t#from twhere tname='LIU')) except(select c# from sc wheresc.s#=s.s#) );3.4 设有两个基本表R(A,B,C)和S(A,B,C),试用SQL查询语句表达下列关系代数表达式:① R∪S ② R∩S ③ R-S ④R×S ⑤πA,BπB,C(S)⑥π1,6(σ3=4(R×S)⑦π1,2,3(R S)⑧R÷πC(S)解:①(SELECT * FROM R)UNION(SELECT * FROM S);②(SELECT * FROM R)3=3实用文档INTERSECT(SELECT * FROM S);③(SELECT * FROM R)MINUS(SELECT * FROM S);④SELECT *实用文档FROM R, S;⑤SELECT R.A, R.B, S.CFROM R, SWHERE R.B=S.B;⑥SELECT R.A, S.CFROM R, SWHERE R.C=S.A;⑦SELECT R.* (R.*表示R中全部属性)FROM R, SWHERE R.C=S.C;⑧R÷πC(S)的元组表达式如下:{ t |(∃u)(∀v)(∃w)(R(u)∧S(v)∧R(w)∧w[1]=u[1] ∧w[2]=u[2] ∧w[3]=v[3] ∧t[1]=u[1] ∧t[2]=u[2])}据此,可写出SELECT语句:SELECT A, BFROM R RXWHERE NOT EXISTS实用文档( SELECT *FROM SWHERE NOT EXISTS( SELECT *FROM R RY实用文档WHERE RY.A=RX.A AND RY.B=RX.B ANDRY.C=S.C));3.6 试叙述SQL语言的关系代数特点和元组演算特点。
数据库原理与应用(第3版)答案

《数据库原理与应用》(第三版)习题参考答案第 1 章数据库概述1.试说明数据、数据库、数据库管理系统和数据库系统的概念。
答:数据是描述事物的符号记录。
数据库是长期存储在计算机中的有组织的、可共享的大量数据的集合。
数据库管理系统是一个专门用于实现对数据进行管理和维护的系统软件。
数据库系统是指在计算机中引入数据库后的系统,一般由数据库、数据库管理系统(及相关的实用工具)、应用程序、数据库管理员组成。
2.数据管理技术的发展主要经历了哪几个阶段?答:文件管理和数据库管理。
3.与文件管理相比,数据库管理有哪些优点?答:与文件系统管理数据相比,数据库系统管理数据带来了如下好处:将相互关联的数据集成在一起,较少的数据冗余,程序与数据相互独立,保证数据的安全可靠,最大限度地保证数据的正确性,数据可以共享并能保证数据的一致性。
4.在数据库管理方式中,应用程序是否需要关心数据的存储位置和存储结构?为什么?答:不需要。
因为数据库管理系统提供了逻辑独立性和物理独立性。
5.在数据库系统中,数据库的作用是什么?答:数据库是数据的汇集,它以一定的组织形式保存在存储介质上。
6.在数据库系统中,应用程序可以不通过数据库管理系统而直接访问数据文件吗?答:不能7.数据独立性指的是什么?它能带来哪些好处?答:数据独立性是指应用程序不会因数据的物理表示方式和访问技术的改变而改变,即应用程序不依赖于任何特定的物理表示方式和访问技术,它包含两个方面:逻辑独立性和物理独立性。
物理独立性是指当数据的存储位置或存储结构发生变化时,不影响应用程序的特性;逻辑独立性是指当表达现实世界的信息内容发生变化时,不影响应用程序的特性。
8.数据库系统由哪几部分组成,每一部分在数据库系统中的作用大致是什么?答:数据库系统一般包括数据库、数据库管理系统(及相应的实用工具)、应用程序和数据库管理员四个部分。
数据库是数据的汇集,它以一定的组织形式保存在存储介质上;数据库管理系统是管理数据库的系统软件,它可以实现数据库系统的各种功能;应用程序专指以数据库数据为基础的程序,数据库管理员负责整个数据库系统的正常运行。
第三章数据库习题答案

第三章数据库习题答案第三章数据库习题答案数据库是现代信息系统的核心组成部分,它以其高效、可靠和灵活的特性,成为许多企业和组织存储和管理数据的首选。
在学习数据库的过程中,习题是检验知识掌握程度的重要方式。
本文将为大家提供第三章数据库习题的详细答案,希望能够帮助大家更好地理解和应用数据库知识。
1. 什么是关系数据库?答:关系数据库是一种基于关系模型的数据库,它以表格的形式存储数据,表格由行和列组成,每一行表示一个记录,每一列表示一个属性。
关系数据库通过建立表之间的关系,实现数据的组织和管理。
2. 什么是关系模型?答:关系模型是一种用于描述和组织数据的模型,它基于数学集合论的概念,将数据组织成表格的形式。
关系模型通过定义表格之间的关系,实现数据的一致性和完整性。
3. 什么是主键?答:主键是关系数据库中用于唯一标识记录的属性或属性组合。
主键具有唯一性和非空性的特点,它能够确保每一条记录都能够被唯一标识。
4. 什么是外键?答:外键是关系数据库中用于建立表之间关系的属性或属性组合。
外键与其他表的主键相关联,通过外键可以实现表之间的关联和数据的一致性。
5. 什么是实体完整性?答:实体完整性是指数据库中的每一条记录都能够被唯一标识。
实体完整性通过主键来实现,它能够确保每一条记录都具有唯一性和非空性。
6. 什么是参照完整性?答:参照完整性是指数据库中的外键与其他表的主键相关联,确保数据之间的一致性和完整性。
参照完整性能够防止无效的外键值和数据的不一致。
7. 什么是范式?答:范式是一种用于设计关系数据库的规范化方法。
它通过分解表和消除冗余数据,提高数据库的一致性和性能。
常用的范式包括第一范式、第二范式和第三范式。
8. 什么是第一范式?答:第一范式是指关系数据库中的每一列都具有原子性,即每一列都不可再分。
第一范式能够消除表中的重复数据,提高数据库的一致性。
9. 什么是第二范式?答:第二范式是在第一范式的基础上,要求关系数据库中的每一条记录都能够被唯一标识。
《数据库的创建与管理》实验答案

《数据库的创建与管理》实验一、实验目的与要求1、掌握数据库的创建方法2、了解和掌握数据库维护内容、策略以及操作方法3、熟悉SQL Server 2005 Management studio管理工具二、实验平台1、操作系统:Windows XP或Windows 20032、数据库管理系统:SQL Server 2005三、实验内容1、创建数据库。
2、维护数据库:重命名数据库、扩大数据库、收缩数据库、分离、附加数据库、删除数据库。
具体内容:(1)、创建一个数据库,数据库信息为:数据库名称:图书管理系统数据文件:NAME=图书管理系统_data1FILENAME='D:\图书管理系统\图书管理系统_data1.mdf'SIZE=5MBFILEGROWTH=0注:所属主文件组(PRIMARY)日志文件:NAME=图书管理系统_log1FILENAME='D:\图书管理系统\图书管理系统_log1.ldf'SIZE=5MBFILEGROWTH=10%Create database图书管理系统On primary(NAME=图书管理系统_data1,FILENAME='D:\图书管理系统\图书管理系统_data1.mdf',SIZE=5MB,FILEGROWTH=0)Log on(NAME=图书管理系统_log1,FILENAME='D:\图书管理系统\图书管理系统_log1.ldf',SIZE=5MB,FILEGROWTH=10%)(2)、添加一个数据文件图书管理系统_data2:NAME=图书管理系统_data2FILENAME='D:\图书管理系统\图书管理系统_data2.ndf'SIZE=5MBFILEGROWTH=10%Use masterGOAlter database图书管理系统Add file(NAME=图书管理系统_data2,FILENAME='D:\图书管理系统\图书管理系统_data2.ndf',SIZE=5MB,FILEGROWTH=10%)GO(3)、以操作系统文件管理方式,查看所创建数据库的物理文件。
数据库原理习题与答案 第3章数据库系统结构

第三章.数据库系统结构(jiégòu)习题(xítí):一.选择题1.数据库技术中采用分级方法将数据库的结构划分成多个层次,是为了(w èi le)提高数据库的(1)和(2)。
(1)A.数据独立性 B.逻辑(luó jí)独立性 C.管理规范性 D.数据的共享(2)A.数据独立性 B.物理独立性 C.逻辑(luó jí)独立性 D.管理规范性2.数据库中,数据的物理独立性是指。
A.数据库与数据库管理系统的独立B.用户程序与DBMS的相互独立C.用户的应用程序与存储在磁盘上数据库中的数据是相互独立的D.应用程序与数据库中数据的逻辑结构相互独立3.数据库系统的最大特点是。
A.数据的三级抽象和二级独立性B.数据共享性C.数据的结构化D.数据独立性4.在数据库的三级模式结构中,描述数据库中全体数据的全局逻辑结构和特征的是。
A.外模式B.内模式C.存储模式D.模式5.数据库系统的数据独立性是指。
A.不会因为数据的变化而影响应用程序B.不会因为系统数据存储结构与数据逻辑结构的变化而影响应用程序C.不会因为存储策略的变化而影响存储结构D.不会因为某些存储结构的变化而影响其它的存储结构6.数据库三级模式体系结构的划分,有利于保持数据库的。
A.数据独立性B.数据(shùjù)安全性C.结构(jiégòu)规范性D.操作(cāozuò)可行性二.简答题1.试述数据库系统三级模式结构(jiégòu),这种结构的优点是什么。
2.定义并解释以下(yǐxià)术语:模式、外模式、内模式、DDL、DML。
3.什么叫数据与程序的物理独立性?什么叫数据与程序的逻辑独立性?为什么数据库系统具有数据与程序的独立性?参考答案:一.选择题4.(1)B (2)B5.C6.A7.D8.B9.A二.简答题1.数据库系统的三级模式结构由外模式、模式和内模式组成。
数据库作业第三章习题答案

数据库作业第三章习题答案数据库作业第三章习题答案数据库作业是数据库课程中非常重要的一部分,通过完成作业可以帮助学生巩固和加深对数据库知识的理解和应用。
第三章习题主要涉及数据库设计和查询语言的使用。
在本篇文章中,我们将回答第三章习题,并探讨一些相关的概念和技巧。
1. 设计一个关系模式,用于存储学生的基本信息,包括学生编号、姓名、性别、年龄和专业。
请给出该关系模式的定义。
答案:学生(学生编号,姓名,性别,年龄,专业)2. 设计一个关系模式,用于存储课程的信息,包括课程编号、课程名称和学分。
请给出该关系模式的定义。
答案:课程(课程编号,课程名称,学分)3. 设计一个关系模式,用于存储学生选课的信息,包括学生编号、课程编号和成绩。
请给出该关系模式的定义。
答案:选课(学生编号,课程编号,成绩)4. 编写一个SQL查询语句,查询学生的姓名和年龄。
答案:SELECT 姓名, 年龄 FROM 学生;5. 编写一个SQL查询语句,查询选修了某门课程的学生的姓名和成绩。
答案:SELECT 学生.姓名, 选课.成绩FROM 学生, 选课WHERE 学生.学生编号 = 选课.学生编号AND 选课.课程编号 = '某门课程编号';6. 编写一个SQL查询语句,查询某个学生的选课情况,包括课程名称和成绩。
答案:SELECT 课程.课程名称, 选课.成绩FROM 课程, 选课WHERE 课程.课程编号 = 选课.课程编号AND 选课.学生编号 = '某个学生编号';通过以上习题的回答,我们可以看到数据库设计和查询语言的基本应用。
关系模式的定义是数据库设计的基础,它描述了数据表的结构和属性。
在查询语言的使用中,我们可以通过SELECT语句来检索和过滤数据,通过WHERE子句来指定查询条件。
除了上述习题的答案,我们还可以进一步探讨数据库设计的一些原则和技巧。
例如,为了提高数据库的性能和可扩展性,我们可以使用索引来加快数据的检索速度。
教学管理数据库第3章 数据库的创建与管理—课后习题解答

第3章数据库的创建与管理习题31.选择题(1)A(2)C(3)A(4)D(5)A(6)B(7)D(8)C(9)A(10)C(11)A(12)A2.填空题(1)文件(2)打开,关闭(3)独占,独占只读(4)常规,统计,查看和编辑数据库属性(5)数据表,设计(6)后端数据库,前端数据库(7)商品信息_2014-01-10.accdb(8)独占3.问答题(1)答:Access 2010提供了两种创建数据库的方法:一种是先创建一个空数据库,然后向其中添加表、查询、窗体和报表等对象;另一种是利用系统提供的模板来创建数据库,用户只需要进行一些简单的选择操作,就可以为数据库创建相应的表、窗体、查询和报表等对象,从而建立一个完整的数据库。
(2)答:①打开与关闭数据库对象当需要打开数据库对象时,可以在导航窗格中选择一种组织方式,然后双击对象将其直接打开。
也可以在对象的快捷菜单中选择“打开”命令打开相应的对象。
如果打开了多个对象,则这些对象都会出现在选项卡式文档窗口中,只要单击需要的文档选项卡就可以将对象的内容显示出来。
若要关闭数据库对象,可以单击相应对象文档窗口右端的“关闭”按钮,也可以右击相应对象的文档选项卡,在弹出的快捷菜单中选择“关闭”命令。
②添加数据库对象如果需要在数据库中添加一个表或其他对象,可以采用新建的方法。
如果要添加表,还可以采用导入数据的方法创建一个表。
即在“表”对象快捷菜单中选择“导入”命令,可以将数据库表、文本文件、Excel工作簿和其他有效数据源导入Access数据库中。
③复制数据库对象一般在修改某个对象的设计之前,创建一个副本可以避免因操作失误而造成损失。
一旦操作发生差错,可以使用对象副本还原对象。
例如,要复制表对象可以打开数据库,然后在导航窗格中的表对象中选中需要复制的表,单击右键,在弹出的快捷菜单中选择“复制”命令。
再单击右键,在快捷菜单中单击“粘贴”命令,即生成一个表副本。
④数据库对象的其他操作通过数据库对象快捷菜单,还可以对数据库对象实施其他操作,包括数据库对象的重命名、删除、查看数据库对象属性等。
(完整word版)数据库系统基础教程第三章答案

Exercise 3.1.1Answers for this exercise may vary because of different interpretations.Some possible FDs:Social Security number → nameArea code → stateStreet address, city, state → zipcodePossible keys:{Social Security number, street address, city, state, area code, phone number}Need street address, city, state to uniquely determine location. A person couldhave multiple addresses. The same is true for phones. These days, a person couldhave a landline and a cellular phoneExercise 3.1.2Answers for this exercise may vary because of different interpretationsSome possible FDs:ID → x-position, y-position, z-positionID → x-velocity, y-velocity, z-velocityx-position, y-position, z-position → IDPossible keys:{ID}{x-position, y-position, z-position}The reason why the positions would be a key is no two molecules can occupy the same point.Exercise 3.1.3aThe superkeys are any subset that contains A1. Thus, there are 2(n-1) such subsets, since each of the n-1 attributes A2 through A n may independently be chosen in or out.Exercise 3.1.3bThe superkeys are any subset that contains A1 or A2. There are 2(n-1) such subsets when considering A1 and the n-1 attributes A2 through A n. There are 2(n-2) such subsets when considering A2 and the n-2 attributes A3 through A n. We do not count A1 in these subsets because they are already counted in the first group of subsets. The total number of subsets is 2(n-1) + 2(n-2).Exercise 3.1.3cThe superkeys are any subset that contains {A1,A2} or {A3,A4}. There are 2(n-2) such subsets when considering {A1,A2} and the n-2 attributes A3 through A n. There are 2(n-2) – 2(n-4) such subsets when considering {A3,A4} and attributes A5 through A n along with the individual attributes A1 and A2. We get the 2(n-4) term because we have to discard the subsets that contain the key {A1,A2} to avoid double counting. The total number of subsets is 2(n-2) +2(n-2) – 2(n-4).Exercise 3.1.3dThe superkeys are any subset that contains {A1,A2} or {A1,A3}. There are 2(n-2) such subsets when considering {A1,A2} and the n-2 attributes A3 through A n. There are 2(n-3) such subsets when considering {A1,A3} and the n-3 attributes A4 through A n We do not count A2 in these subsets because they are already counted in the first group of subsets. The total number of subsets is 2(n-2) + 2(n-3).Exercise 3.2.1aWe could try inference rules to deduce new dependencies until we are satisfied we have them all. A more systematic way is to consider the closures of all 15 nonempty sets of attributes.For the single attributes we have {A}+ = A, {B}+ = B, {C}+ = ACD, and {D}+ = AD. Thus, the only new dependency we get with a single attribute on the left is C→A.Now consider pairs of attributes:{AB}+ = ABCD, so we get new dependency AB→D. {AC}+ = ACD, and AC→D is nontrivial. {AD}+= AD, so nothing new. {BC}+ = ABCD, so we get BC→A, and BC→D. {BD}+ = ABCD, giving us BD→A and BD→C. {CD}+ = ACD, giving CD→A.For the triples of attributes, {ACD}+ = ACD, but the closures of the other sets are each ABCD. Thus, we get new dependencies ABC→D, ABD→C, and BCD→A.Since {ABCD}+ = ABCD, we get no new dependencies.The collection of 11 new dependencies mentioned above are:C→A, AB→D, AC→D, BC→A, BC→D, BD→A, BD→C, CD→A, ABC→D, ABD→C, and BCD→A.Exercise 3.2.1bFrom the analysis of closures above, we find that AB, BC, and BD are keys. All other sets either do not have ABCD as the closure or contain one of these three sets.Exercise 3.2.1cThe superkeys are all those that contain one of those three keys. That is, a superkeythat is not a key must contain B and more than one of A, C, and D. Thus, the (proper) superkeys are ABC, ABD, BCD, and ABCD.Exercise 3.2.2ai) For the single attributes we have {A}+ = ABCD, {B}+ = BCD, {C}+ = C, and {D}+ = D. Thus, the new dependencies are A→C and A→D.Now consider pairs of attributes:{AB}+ = ABCD, {AC}+ = ABCD, {AD}+ = ABCD, {BC}+ = BCD, {BD}+ = BCD, {CD}+ = CD. Thus the new dependencies are AB→C, AB→D, AC→B, AC→D, AD→B, AD→C, BC→D and BD→C.For the triples of attributes, {BCD}+ = BCD, but the closures of the other sets are each ABCD. Thus, we get new dependencies ABC→D, ABD→C, and ACD→B.Since {ABCD}+ = ABCD, we get no new dependencies.The collection of 13 new dependencies mentioned above are:A→C, A→D, AB→C, AB→D, AC→B, AC→D, AD→B, AD→C, BC→D, BD→C, ABC→D, ABD→C and ACD→B.ii) For the single attributes we have {A}+ = A, {B}+ = B, {C}+ = C, and {D}+ = D. Thus, there are no new dependencies.Now consider pairs of attributes:{AB}+ = ABCD, {AC}+ = AC, {AD}+ = ABCD, {BC}+ = ABCD, {BD}+ = BD, {CD}+ = ABCD. Thus the new dependencies are AB→D, AD→C, BC→A and CD→B.For the triples of attributes, all the closures of the sets are each ABCD. Thus, we get new dependencies ABC→D, ABD→C, ACD→B and BCD→A.Since {ABCD}+ = ABCD, we get no new dependencies.The collection of 8 new dependencies mentioned above are:AB→D, AD→C, BC→A, CD→B, ABC→D, ABD→C, ACD→B and BCD→A.iii) For the single attributes we have {A}+ = ABCD, {B}+ = ABCD, {C}+ = ABCD, and {D}+ = ABCD. Thus, the new dependencies are A→C, A→D, B→D, B→A, C→A, C→B, D→B and D→C.Since all the single attributes’ closures are ABCD, any superset of the singleattributes will also lead to a closure of ABCD. Knowing this, we can enumerate the restof the new dependencies.The collection of 24 new dependencies mentioned above are:A→C, A→D, B→D, B→A, C→A, C→B, D→B, D→C, AB→C, AB→D, AC→B, AC→D, AD→B, AD→C, BC→A, BC→D, BD→A, BD→C, CD→A, CD→B, ABC→D, ABD→C, ACD→B and BCD→A.Exercise 3.2.2bi) From the analysis of closures in 3.2.2a(i), we find that the only key is A. All other sets either do not have ABCD as the closure or contain A.ii) From the analysis of closures 3.2.2a(ii), we find that AB, AD, BC, and CD are keys.All other sets either do not have ABCD as the closure or contain one of these four sets.iii) From the analysis of closures 3.2.2a(iii), we find that A, B, C and D are keys. All other sets either do not have ABCD as the closure or contain one of these four sets.Exercise 3.2.2ci) The superkeys are all those sets that contain one of the keys in 3.2.2b(i). The superkeys are AB, AC, AD, ABC, ABD, ACD, BCD and ABCD.ii) The superkeys are all those sets that contain one of the keys in 3.2.2b(ii). The superkeys are ABC, ABD, ACD, BCD and ABCD.iii) The superkeys are all those sets that contain one of the keys in 3.2.2b(iii). The superkeys are AB, AC, AD, BC, BD, CD, ABC, ABD, ACD, BCD and ABCD.Exercise 3.2.3aSince A1A2…A n C contains A1A2…A n, then the closure of A1A2…A n C contains B. Thus it follows that A1A2…A n C→B.Exercise 3.2.3bFrom 3.2.3a, we know that A1A2…A n C→B. Using the concept of trivial dependencies, we can show that A1A2…A n C→C. Thus A1A2…A n C→BC.Exercise 3.2.3cFrom A1A2…A n E1E2…E j, we know that the closure contains B1B2…B m because of the FD A1A2…A n→B1B2…B m. The B1B2…B m and the E1E2…E j combine to form the C1C2…C k. Thus the closure ofA1A2…A n E1E2…E j contains D as well. Thus, A1A2…A n E1E2…E j→D.Exercise 3.2.3dFrom A1A2…A n C1C2…C k, we know that the closure contains B1B2…B m because of the FD A1A2…A n→B1B2…B m. The C1C2…C k also tell us that the closure of A1A2…A n C1C2…C k contains D1D2…D j. Thus, A1A2…A n C1C2…C k→B1B2…B k D1D2…D j.Exercise 3.2.4aIf attribute A represented Social Security Number and B represented a person’s name,then we would assume A→B but B→A would not be valid because there may be many peoplewith the same name and different Social Security Numbers.Exercise 3.2.4bLet attribute A represent Social Security Number, B represent gender and C represent name. Surely Social Security Number and gender can uniquely identify a person’s name (i.e.AB→C). A Social Security Number can also uniquely identify a person’s name (i.e. A→C). However, gender does not uniquely determine a name (i.e. B→C is not valid).Exercise 3.2.4cLet attribute A represent latitude and B represent longitude. Together, both attributes can uniquely determine C, a point on the world map (i.e. AB→C). However, neither A nor B can uniquely identify a point (i.e. A→C and B→C are not valid).Exercise 3.2.5Given a relation with attributes A1A2…A n, we are told that there are no functional dependencies of the form B1B2…B n-1→C where B1B2…B n-1 is n-1 of the attributes from A1A2…A n and C is the remaining attribute from A1A2…A n. In this case, the set B1B2…B n-1 and any subset do not functionally determine C. Thus the only functional dependencies that we can make are ones where C is on both the left and right hand sides. All of these functional dependencies would be trivial and thus the relation has no nontrivial FD’s.Exercise 3.2.6Let’s prove this by using the contrapositive. We wish to show that if X+ is not a subset of Y+, then it must be that X is not a subset of Y.If X+ is not a subset of Y+, there must be attributes A1A2…A n in X+ that are not in Y+. If any of these attributes were originally in X, then we are done because Y does not contain any of the A1A2…A n. However, if the A1A2…A n were added by the closure, then we must examine the case further. Assume that there was some FD C1C2…C m→A1A2…A j where A1A2…A j is some subset of A1A2…A n. It must be then that C1C2…C m or some subset of C1C2…C m is in X. However, the attributes C1C2…C m cannot be in Y because we assumed that attributes A1A2…A n are only in X+ and are not in Y+. Thus, X is not a subset of Y.By proving the contrapositive, we have also proved if X ⊆ Y, then X+⊆ Y+.Exercise 3.2.7The algorithm to find X+ is outlined on pg. 76. Using that algorithm, we can prove that (X+)+ = X+. We will do this by using a proof by contradiction.Suppose that (X+)+≠ X+. Then for (X+)+, it must be that some FD allowed additional attributes to be added to the original set X+. For example, X+→ A where A is some attribute not in X+. However, if this were the case, then X+ would not be the closure of X. The closure of X would have to include A as well. This contradicts the fact that we weregiven the closure of X, X+. Therefore, it must be that (X+)+ = X+ or else X+ is not the closure of X.Exercise 3.2.8aIf all sets of attributes are closed, then there cannot be any nontrivial functional dependencies. Suppose A1A2...A n→B is a nontrivial dependency. Then {A1A2...A n}+ contains B and thus A1A2...A n is not closed.Exercise 3.2.8bIf the only closed sets are ø and {A,B,C,D}, then the following FDs hold:A→B A→C A→DB→A B→C B→DC→A C→B C→DD→A D→B D→CAB→C AB→DAC→B AC→DAD→B AD→CBC→A BC→DBD→A BD→CCD→A CD→BABC→DABD→CACD→BBCD→AExercise 3.2.8cIf the only closed sets are ø, {A,B} and {A,B,C,D}, then the following FDs hold:A→BB→AC→A C→B C→DD→A D→B D→CAC→B AC→DAD→B AD→CBC→A BC→DBD→A BD→CCD→A CD→BABC→DABD→CACD→BBCD→AExercise 3.2.9We can think of this problem as a situation where the attributes A,B,C represent cities and the functional dependencies represent one way paths between the cities. The minimal bases are the minimal number of pathways that are needed to connect the cities. We do not want to create another roadway if the two cities are already connected.The systematic way to do this would be to check all possible sets of the pathways. However, we can simplify the situation by noting that it takes more than two pathways to visit the two other cities and come back. Also, if we find a set of pathways that is minimal, adding additional pathways will not create another minimal set.The two sets of minimal bases that were given in example 3.11 are:{A→B, B→C, C→A}{A→B, B→A, B→C, C→B}The additional sets of minimal bases are:{C→B, B→A, A→C}{A→B, A→C, B→A, C→A}{A→C, B→C, C→A, C→B}Exercise 3.2.10aWe need to compute the closures of all subsets of {ABC}, although there is no need to think about the empty set or the set of all three attributes. Here are the calculations for the remaining six sets:{A}+=A{B}+=B{C}+=ACE{AB}+=ABCDE{AC}+=ACE{BC}+=ABCDEWe ignore D and E, so a basis for the resulting functional dependencies for ABC is: C→A and AB→C. Note that BC->A is true, but follows logically from C->A, and therefore may be omitted from our list.Exercise 3.2.10bWe need to compute the closures of all subsets of {ABC}, although there is no need to think about the empty set or the set of all three attributes. Here are the calculations for the remaining six sets:{A}+=AD{B}+=B{C}+=C{AB}+=ABDE{AC}+=ABCDE{BC}+=BCWe ignore D and E, so a basis for the resulting functional dependencies for ABC is: AC→B.Exercise 3.2.10cWe need to compute the closures of all subsets of {ABC}, although there is no need tothink about the empty set or the set of all three attributes. Here are the calculationsfor the remaining six sets:{A}+=A{B}+=B{C}+=C{AB}+=ABD{AC}+=ABCDE{BC}+=ABCDEWe ignore D and E, so a basis for the resulting functional dependencies for ABC is: AC→B and BC→A.Exercise 3.2.10dWe need to compute the closures of all subsets of {ABC}, although there is no need tothink about the empty set or the set of all three attributes. Here are the calculationsfor the remaining six sets:{A}+=ABCDE{B}+=ABCDE{C}+=ABCDE{AB}+=ABCDE{AC}+=ABCDE{BC}+=ABCDEWe ignore D and E, so a basis for the resulting functional dependencies for ABC is: A→B, B→C and C→A.Exercise 3.2.11For step one of Algorithm 3.7, suppose we have the FD ABC→DE. We want to use Armstrong’s Axioms to show that ABC→D and ABC→E follow. Surely the functional dependencies DE→D and DE→E hold because they are trivial and follow the reflexivity property. Using the transitivity rule, we can derive the FD ABC→D from the FDs ABC→DE and DE→D. Likewise, we can do the same for ABC→DE and DE→E and derive the FD ABC→E.For steps two through four of Algorithm 3.7, suppose we have the initial set ofattributes of the closure as ABC. Suppose also that we have FDs C→D and D→E. Accordingto Algorithm 3.7, the closure should become ABCDE. Taking the FD C→D and augmenting both sides with attributes AB we get the FD ABC→ABD. We can use the splitting method in stepone to get the FD ABC→D. Since D is not in the closure, we can add attribute D. Taking the FD D→E and augmenting both sides with attributes ABC we get the FD ABCD→ABCDE.Using again the splitting method in step one we get the FD ABCD→E. Since E is not in the closure, we can add attribute E.Given a set of FDs, we can prove that a FD F follows by taking the closure of the left side of FD F. The steps to compute the closure in Algorithm 3.7 can be mimicked by Armstrong’s axioms and thus we can prove F from the given set of FDs using Armstrong’s axioms.Exercise 3.3.1aIn the solution to Exercise 3.2.1 we found that there are 14 nontrivial dependencies, including the three given ones and eleven derived dependencies. They are: C→A, C→D,D→A, AB→D, AB→ C, AC→D, BC→A, BC→D, BD→A, BD→C, CD→A, ABC→D, ABD→C, and BCD→A.We also learned that the three keys were AB, BC, and BD. Thus, any dependency above that does not have one of these pairs on the left is a BCNF violation. These are: C→A, C→D,D→A, AC→D, and CD→A.One choice is to decompose using the violation C→D. Using the above FDs, we get ACD and BC as decomposed relations. BC is surely in BCNF, since any two-attribute relation is. Using Algorithm 3.12 to discover the projection of FDs on relation ACD, we discover that ACD is not in BCNF since C is its only key. However, D→A is a dependency that holds in ABCD and therefore holds in ACD. We must further decompose ACD into AD and CD. Thus, the three relations of the decomposition are BC, AD, and CD.Exercise 3.3.1bBy computing the closures of all 15 nonempty subsets of ABCD, we can find all thenontrivial FDs. They are B→C, B→D, AB→C, AB→D, BC→D, BD→C, ABC→D and ABD→C. From the closures we can also deduce that the only key is AB. Thus, any dependency above that does not contain AB on the left is a BCNF violation. These are: B→C, B→D, BC→D andBD→C.One choice is to decompose using the violation B→C. Using the above FDs, we get BCD and AB as decomposed relations. AB is surely in BCNF, since any two-attribute relation is. Using Algorithm 3.12 to discover the projection of FDs on relation BCD, we discover that BCD is in BCNF since B is its only key and the projected FDs all have B on the left side. Thus the two relations of the decomposition are AB and BCD.Exercise 3.3.1cIn the solution to Exercise 3.2.2(ii), we found that there are 12 nontrivial dependencies, including the four given ones and the eight derived ones. They are AB→C, BC→D, CD→A, AD→B, AB→D, AD→C, BC→A, CD→B, ABC→D, ABD→C, ACD→B and BCD→A.We also found out that the keys are AB, AD, BC, and CD. Thus, any dependency above that does not have one of these pairs on the left is a BCNF violation. However, all of the FDs contain a key on the left so there are no BCNF violations.No decomposition is necessary since all the FDs do not violate BCNF.Exercise 3.3.1dIn the solution to Exercise 3.2.2(iii), we found that there are 28 nontrivial dependencies, including the four given ones and the 24 derived ones. They are A→B, B→C, C→D, D→A, A→C, A→D, B→D, B→A, C→A, C→B, D→B, D→C, AB→C, AB→D, AC→B, AC→D,AD→B, AD→C, BC→A, BC→D, BD→A, BD→C, CD→A, CD→B, ABC→D, ABD→C, ACD→B and BCD→A.We also found out that the keys are A,B,C,D. Thus, any dependency above that does nothave one of these attributes on the left is a BCNF violation. However, all of the FDs contain a key on the left so there are no BCNF violations.No decomposition is necessary since all the FDs do not violate BCNF.Exercise 3.3.1eBy computing the closures of all 31 nonempty subsets of ABCDE, we can find all the nontrivial FDs. They are AB→C, DE→C, B→D, AB→D, BC→D, BE→C, BE→D, ABC→D, ABD→C, ABE→C, ABE→D, ADE→C, BCE→D, BDE→C, ABCE→D, and ABDE→C. From the closures we canalso deduce that the only key is ABE. Thus, any dependency above that does not contain ABE on the left is a BCNF violation. These are: AB→C, DE→C, B→D, AB→D, BC→D, BE→C, BE→D, ABC→D, ABD→C, ADE→C, BCE→D and BDE→C.One choice is to decompose using the violation AB→C. Using the above FDs, we get ABCDand ABE as decomposed relations. Using Algorithm 3.12 to discover the projection of FDs on relation ABCD, we discover that ABCD is not in BCNF since AB is its only key and the FD B→D follows for ABCD. Using violation B→D to further decompose, we get BD and ABC as decomposed relations. BD is in BCNF because it is a two-attribute relation. Using Algorithm 3.12 again, we discover that ABC is in BCNF since AB is the only key and AB→Cis the only nontrivial FD. Going back to relation ABE, following Algorithm 3.12 tells us that ABE is in BCNF because there are no keys and no nontrivial FDs. Thus the three relations of the decomposition are ABC, BD and ABE.Exercise 3.3.1fBy computing the closures of all 31 nonempty subsets of ABCDE, we can find all the nontrivial FDs. They are: C→B, C→D, C→E, D→B, D→E, AB→C, AB→D, AB→E, AC→B, AC→D, AC→E, AD→B, AD→C, AD→E, BC→D, BC→E, BD→E, CD→B, CD→E, CE→B, CE→D, DE→B,ABC→D, ABC→E, ABD→C, ABD→E, ABE→C, ABE→D, ACD→B, ACD→E, ACE→B, ACE→D, ADE→B, ADE→C, BCD→E, BCE→D, CDE→B, ABCD→E, ABCE→D, ABDE→C and ACDE→B. From the closures we can also deduce that the keys are AB, AC and AD. Thus, any dependency above that does not contain one of the above pairs on the left is a BCNF violation. These are: C→B, C→D,C →E,D →B, D →E, BC →D, BC →E, BD →E, CD →B, CD →E, CE →B, CE →D, DE →B, BCD →E, BCE →D and CDE →B.One choice is to decompose using the violation D →B. Using the above FDs, we get BDE and ABC as decomposed relations. Using Algorithm 3.12 to discover the projection of FDs on relation BDE, we discover that BDE is in BCNF since D, BD, DE are the only keys and all the projected FDs contain D, BD, or DE in the left side. Going back to relation ABC,following Algorithm 3.12 tells us that ABC is not in BCNF because since AB and AC are its only keys and the FD C →B follows for ABC. Using violation C →B to further decompose, we get BC and AC as decomposed relations. Both BC and AC are in BCNF because they are two-attribute relations. Thus the three relations of the decomposition are BDE, BC and AC.Exercise 3.3.2Yes, we will get the same result. Both A →B and A →BC have A on the left side and part ofthe process of decomposition involves finding {A}+to form one decomposed relation and Aplus the rest of the attributes not in {A}+as the second relation. Both cases yield the same decomposed relations.Exercise 3.3.3Yes, we will still get the same result. Both A →B and A →BC have A on the left side andpart of the process of decomposition involves finding {A}+to form one decomposedrelation and A plus the rest of the attributes not in {A}+as the second relation. Both cases yield the same decomposed relations.Exercise 3.3.4This is taken from Example 3.21 pg. 95.Suppose that an instance of relation R only contains two tuples.The projections of R onto the relations with schemas {A,B} and {B,C} are:If we do a natural join on the two projections, we will get:The result of the natural join is not equal to the original relation R.Exercise 3.4.1aThis is the initial tableau:→A.Since there is not an unsubscripted row, the decomposition for R is not lossless for this set of FDs.We can use the final tableau as an instance of R as an example for why the join is not lossless. The projected relations are:The joined relation is:The joined relation has three more tuples than the original tableau.Exercise 3.4.1bThis is the initial tableau:This is the final tableau after applying FDs AC→E and BC→DSince there is an unsubscripted row, the decomposition for R is lossless for this set of FDs.Exercise 3.4.1cThis is the initial tableau:This is the final tableau after applying FDs A→D, D→E and B→D.Since there is an unsubscripted row, the decomposition for R is lossless for this set of FDs.Exercise 3.4.1dThis is the initial tableau:This is the final tableau after applying FDs A→D, CD→E and E→DSince there is an unsubscripted row, the decomposition for R is lossless for this set of FDs.Exercise 3.4.2When we decompose a relation into BCNF, we will project the FDs onto the decomposed relations to get new sets of FDs. These dependencies are preserved if the union of these new sets is equivalent to the original set of FDs.For the FDs of 3.4.1a, the dependencies are not preserved. The union of the new sets of FDs is CE→A. However, the FD B→E is not in the union and cannot be derived. Thus the two sets of FDs are not equivalent.For the FDs of 3.4.1b, the dependencies are preserved. The union of the new sets of FDs is AC→E and BC→D. This is precisely the same as the original set of FDs and thus the two sets of FDs are equivalent.For the FDs of 3.4.1c, the dependencies are not preserved. The union of the new sets of FDs is B→D and A→E. The FDs A→D and D→E are not in the union and cannot be derived. Thus the two sets of FDs are not equivalent.For the FDs of 3.4.1d, the dependencies are not preserved. The union of the new sets of FDs is AC→E. However, the FDs A→D, CD→E and E→D are not in the union and cannot be derived. Thus the two sets of FDs are not equivalent.Exercise 3.5.1aIn the solution to Exercise 3.3.1a we found that there are 14 nontrivial dependencies. They are: C→A, C→D, D→A, AB→D, AB→ C, AC→D, BC→A, BC→D, BD→A, BD→C, CD→A,ABC→D, ABD→C, and BCD→A.We also learned that the three keys were AB, BC, and BD. Since all the attributes on the right sides of the FDs are prime, there are no 3NF violations.Since there are no 3NF violations, it is not necessary to decompose the relation.Exercise 3.5.1bIn the solution to Exercise 3.3.1b we found that there are 8 nontrivial dependencies. They are B→C, B→D, AB→C, AB→D, BC→D, BD→C, ABC→D and ABD→C.We also found out that the only key is AB. FDs where the left side is not a superkey or the attributes on the right are not part of some key are 3NF violations. The 3NF violations are B→C, B→D, BC→D and BD→C.Using algorithm 3.26, we can decompose into relations using the minimal basis B→C andB→D. The resulting decomposed relations would be BC and BD. However, none of these two sets of attributes is a superkey. Thus we add relation AB to the result. The final set of decomposed relations is BC, BD and AB.Exercise 3.5.1cIn the solution to Exercise 3.3.1c we found that there are 12 nontrivial dependencies. They are AB→C, BC→D, CD→A, AD→B, AB→D, AD→C, BC→A, CD→B, ABC→D, ABD→C, ACD→B and BCD→A.We also found out that the keys are AB, AD, BC, and CD. Since all the attributes on the right sides of the FDs are prime, there are no 3NF violations.Since there are no 3NF violations, it is not necessary to decompose the relation.Exercise 3.5.1dIn the solution to Exercise 3.3.1d we found that there are 28 nontrivial dependencies. They are A→B, B→C, C→D, D→A, A→C, A→D, B→D, B→A, C→A, C→B, D→B, D→C, AB→C,AB→D, AC→B, AC→D, AD→B, AD→C, BC→A, BC→D, BD→A, BD→C, CD→A, CD→B, ABC→D,ABD→C, ACD→B and BCD→A.We also found out that the keys are A,B,C,D. Since all the attributes on the right sidesof the FDs are prime, there are no 3NF violations.Since there are no 3NF violations, it is not necessary to decompose the relation.Exercise 3.5.1eIn the solution to Exercise 3.3.1e we found that there are 16 nontrivial dependencies. They are AB→C, DE→C, B→D, AB→D, BC→D, BE→C, BE→D, ABC→D, ABD→C, ABE→C, ABE→D, ADE→C, BCE→D, BDE→C, ABCE→D, and ABDE→C.We also found out that the only key is ABE. FDs where the left side is not a superkey or the attributes on the right are not part of some key are 3NF violations. The 3NFviolations are AB→C, DE→C, B→D, AB→D, BC→D, BE→C, BE→D, ABC→D, ABD→C, ADE→C, BCE→D and BDE→C.Using algorithm 3.26, we can decompose into relations using the minimal basis AB→C,DE→C and B→D. The resulting decomposed relations would be ABC, CDE and BD. However,none of these three sets of attributes is a superkey. Thus we add relation ABE to the result. The final set of decomposed relations is ABC, CDE, BD and ABE.Exercise 3.5.1fIn the solution to Exercise 3.3.1f we found that there are 41 nontrivial dependencies. They are: C→B, C→D, C→E, D→B, D→E, AB→C, AB→D, AB→E, AC→B, AC→D, AC→E, AD→B, AD→C, AD→E, BC→D, BC→E, BD→E, CD→B, CD→E, CE→B, CE→D, DE→B, ABC→D, ABC→E,ABD→C, ABD→E, ABE→C, ABE→D, ACD→B, ACD→E, ACE→B, ACE→D, ADE→B, ADE→C, BCD→E, BCE→D, CDE→B, ABCD→E, ABCE→D, ABDE→C and ACDE→B.We also found out that the keys are AB, AC and AD. FDs where the left side is not a superkey or the attributes on the right are not part of some key are 3NF violations. The3NF violations are C→E, D→E, BC→E, BD→E, CD→E and BCD→E.Using algorithm 3.26, we can decompose into relations using the minimal basis AB→C, C→D, D→B and D→E. The resulting decomposed relations would be ABC, CD, BD and DE. Since relation ABC contains a key, we can stop with the decomposition. The final set of decomposed relations is ABC, CD, BD and DE.Exercise 3.5.2aThe usual procedure to find the keys would be to take the closure of all 63 nonempty subsets. However, if we notice that none of the right sides of the FDs contains。
数据库技术基础练习题答案

数据库技术基础练习题答案第1章绪论一、选择题1.数据模型的三个组成部分是数据结构、数据操作和(C)A.数据安全性控制B.数据一致性规则C.数据完整性约束D.数据处理逻辑2.位于用户和数据库之间的一层数据管理软件是(C)A.D B SB.D BC.D B M SD.M I S3.在数据库系统中,数据独立性是指(C)A.用户与计算机系统的独立性B.数据库与计算机的独立性C.数据与应用程序的独立性D.用户与数据库的独立性4.D B的三级模式结构中最接近外部存储器的是(D)A.子模式B.外模式C.概念模式D.内模式5.数据库三级模式体系结构的划分,有利于保持数据库的(A)A.数据独立性B.数据安全性C.结构规范化D.设备独立性6.子模式D D L用来描述数据库(C)A.总体逻辑结构B.物理存储结构C.局部逻辑结构D.概念结构7.在D B S中,D B M S和O S之间的关系是(A)A.D B M S调用O SB.相互调用C.O S调用D B M SD.并发运行8.数据库中全体数据的整体逻辑结构描述称为(A)A.模式B.内模式C.外模式D.子模式9.文件系统所具有的数据独立性是(D)A.系统独立性B.物理独立性C.逻辑独立性D.设备独立性10.在信息世界中将现实世界的事物在某一方面的特性称为(C)A.实体B.实体值C.属性D.信息11.数据存储结构与应用程序之间的独立性称为数据的(B)A.结构独立性B.物理独立性C.逻辑独立性D.分布独立性12.在数据库方式下的数据管理,占据中心位置的是(A)A.数据B.程序C.软件D.磁盘13.下述各项中,属于数据库系统的特点的是(C)A.存储量大B.存取速度快C.数据独立性D.操作方便14.文件系统与数据库系统相比较,其缺陷主要表现在数据联系弱、数据冗余和(C)A.数据存储量低B.处理速度慢C.数据不一致D.操作烦琐二、填空题1.D B S的全局结构体现了D B S的模块功能结构。
实践练习答案-第3章创建与管理数据库
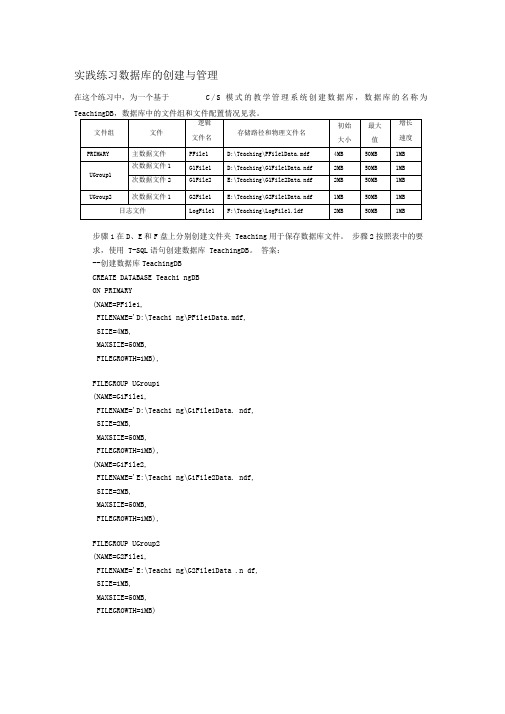
实践练习数据库的创建与管理在这个练习中,为一个基于C/S模式的教学管理系统创建数据库,数据库的名称为步骤1在D、E和F盘上分别创建文件夹 Teaching用于保存数据库文件。
步骤2按照表中的要求,使用 T-SQL语句创建数据库 TeachingDB。
答案:--创建数据库TeachingDBCREATE DATABASE Teachi ngDBON PRIMARY(NAME=PFile1,FILENAME='D:\Teachi ng\PFile1Data.mdf,SIZE=4MB,MAXSIZE=50MB,FILEGROWTH=1MB),FILEGROUP UGroup1(NAME=G1File1,FILENAME='D:\Teachi ng\G1File1Data. ndf,SIZE=2MB,MAXSIZE=50MB,FILEGROWTH=1MB),(NAME=G1File2,FILENAME='E:\Teachi ng\G1File2Data. ndf,SIZE=2MB,MAXSIZE=50MB,FILEGROWTH=1MB),FILEGROUP UGroup2(NAME=G2File1,FILENAME='E:\Teachi ng\G2File1Data .n df,SIZE=1MB,MAXSIZE=50MB,FILEGROWTH=1MB)LOG ON(NAME=LogFile1,FILENAME='F:\Teachi ng\LogFile1」df, SIZE=2MB, MAXSIZE=50MB, FILEGROWTH=1MB) GO步骤3通过T-SQL 语句修改文件组 UGroup1的属性,将其配置为默认文件组。
答案:--将UGroup1修改为默认文件组 ALTER DATABASE Teachi ngDBMODIFY FILEGROUP UGroup1 DEFAULT GO步骤4通过数据库属性对话框中的【文件】页添加一个日志文件,逻辑文件名为 LogFile2,存储路径为 F:\Teaching ,初始大小为1MB ,最大值为50MB ,增长速度为1MB 。
国家开放大学《数据库应用技术》章节测试参考答案

国家开放大学《数据库应用技术》章节测试参考答案第一章 数据库系统概述1.下列不属于数据库管理数据特点的是()a. 应用程序与数据的物理存储紧密相关b. 最大限度的保证数据的正确性c. 数据可以共享并能保证数据的一致性d. 相互关联的数据集合2.使用数据库管理数据可以实现程序与数据的相互独立。
(√)3.数据库管理系统是一个系统软件,这个软件主要负责将磁盘上的数据库文件读入到内存中。
(×)4.下列属于数据动态特征的是()a. 数据的主键约束b. 数据的取值范围约束c. 数据所包含的属性d. 插入数据5.下列关于概念层数据模型的说法,正确的是a. 概念层数据模型要能够方便地在计算机上实现b. 概念层数据模型与具体的数据库管理系统相关c. 概念层数据模型是从计算机实现的角度进行建模d. 概念层数据模型要真实地模拟现实世界6.概念层数据模型描述的是数据的组织方式。
(×)7.在E/R图中,联系用()描述a. 矩形框b. 菱形框c. 圆角矩形d. 三角形8.一名教师可以教多门课程,一门课程可以被多个教师讲授,则教师与课程之间的联系是a. 一对一b. 多对多c. 多对一d. 一对多9.E-R图中的“E”表示的是实体。
(√)10.下列关于关系数据模型的说法,正确的是a. 关系数据模型采用的是导航式的数据访问方式b. 关系数据模型采用的是简单二维表结构c. 关系数据模型是一种概念层数据模型d. 关系数据模型只能表达实体,不能表达实体之间的联系11.关系数据模型允许一个属性包含更小的属性。
(×)12.下列关于数据库三级模式中“模式”的说法,错误的是a. 外模式的信息全部来自于模式b. 模式应该包含全体用户的数据需求c. 模式是对整个数据库的底层表示d. 关系数据库中的表对应三级模式中的模式13.下列用于描述数据的物理存储的是a. 内模式b. 外模式c. 模式d. 模式间的映像14.数据库三级模式中的模式是面向全体用户的数据需求设计的。
数据库第三章课后习题解答

3-3 习题33.4 在SQL Server中,创建一个名为students且包含有下列几个属性的表。
SNO char(10);NAME varchar(10);SEX char(1);BDATE datetime;DEPT varchar(10);DORMITORY varchar(10).要求:1.采用两种形式创建表,即用SQL语句和用图形界面的形式来创建。
2.定义必要的约束,包括主键SNO,NAME值不允许为空,且SEX取值为0或1。
【解答】·进入SQL查询分析器建立查询,创建students表的SQL语句如下,操作如图3.17所示。
use mydb /* 假设在mydb库中建表*/create table students(SNO char(10) not NULL primary key,NAME varchar(10) not NULL,SEX char(1) not NULL check(sex='0' or sex='1'),BDATE datetime,DEPT varchar(10),DORMITORY varchar(10))- 1-图3.17 用SQL语句创建students表·进入企业管理器用基本操作创建students表。
用右键单击“mydb”数据库,从弹出的菜单中选择“新建”,再从其下一级菜单中选择“表”。
或者,用右键单击“mydb”数据库下一级的“表”,从弹出的菜单中选择“新建表”。
然后,在弹出的窗体中,把students表所包含的字段逐一输入,每个字段都要指明列名、数据类型、长度和是否允许空值、是否主键等内容,如图3.18所示。
图3.18用基本操作创建students表其中,SEX字段取值为0或1,需要建立约束。
操作是用右键单击SEX字段,从弹出的菜单中选择“CHECK约束”,再从弹出的“属性”窗体中,选择“CHECK约束”卡,在约束表达式框中输入约束表达式,如图3.19所示。
数据库原理第三章课后习题答案

第三章作业一、试述SQL特点SQL集数据查询、数据操纵、数据定义和数据控制功能于一体,其主要特点包括以下几部分。
1.综合统一2.高度非过程化3.面向集合的操作方式4.以同一种语法结构提供多种使用方式5.语言简洁,易学易用二、设有两个关系S(A,B,C,D)和T(C,D,E,F),写出与下列查询等价的SQL表达式(1)select A,B,S.C, S.D,E,Ffrom S,Twhere S.C=T.C(2)select * from S,Twhere S.C=T.C三、设关系RA B C10 NULL 2020 30 NULL写出查询语句SELECT * FROM R WHERE X的查询结果,其中X分别为1.1 A IS NULL;1.2 A>8 AND B<20;1.3 A>8 OR B<20;1.4 C+10>25;1.5 EXISTS (SELECT B FROM R WHERE A=10);use Rcreate table R(A tinyint primary key,B tinyint,C tinyint)1.11.21.31.41.5四、基于教材中的学生-课程数据库,用SQL完成如下查询:2.1 创建一张新表,记录每个学生的学号、选课门数和总学分数。
格式如下SCC(sno, totalCourse, totalCredit)并插入每个学生相应的数据。
create table SCC( sno char(10),totalcourse tinyint,totalcredit int)insertinto SCC(sno,totalcourse,totalcredit)select sc.sno,count(distinct o)as totalcourse,sum(ccredit)as totalcredit from sc,student,coursegroup by sc.snoselect*from SCC2.2、查询缺考和不及格课程多于3门的学生的学号和姓名select sc.sno,snamefrom student,scwhere exists(select snofrom scwhere grade<60 or grade=nullgroup by snohaving count(grade)>3)2.3 查询每个学生超过他自己选修课程平均成绩的课程号(写出3种以上类型的方法)(1)select cnofrom sc,(select sno,avg(grade)from sc group by sno)as avg_sc(avg_sno,avg_grade)where sc.sno=avg_sc.avg_sno and sc.grade>=avg_sc.avg_grade(2)select sno,cnofrom sc xwhere grade>=(select avg(grade)from sc ywhere y.sno=x.sno);2.4 查询同时选修了“数据库”和“数据结构”的学生的学号和姓名(写出5种以上类型方法)(1)select sno,snamefrom student,coursewhere cname='数据库'and sno in(select snofrom scwhere cname='数据结构')(2)select sc.sno,snamefrom student,course,scwhere student.sno=sc.sno and o=o and cname='数据库'intersectselect sc.sno,snamefrom student,course,scwhere student.sno=sc.sno and o=o and cname='数据结构';五、在上机实践过程中遇到过什么问题?解决方案是什么?。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实践练习数据库的创建与管理
在这个练习中,为一个基于C/S模式的教学管理系统创建数据库,数据库的名称为TeachingDB,数据库中的文件组和文件配置情况见表。
步骤1 在D、E和F盘上分别创建文件夹Teaching用于保存数据库文件。
步骤2 按照表中的要求,使用T-SQL语句创建数据库TeachingDB。
答案:
--创建数据库TeachingDB
CREATE DATABASE TeachingDB
ON PRIMARY
(NAME=PFile1,
FILENAME='D:\Teaching\PFile1Data.mdf',
SIZE=4MB,
MAXSIZE=50MB,
FILEGROWTH=1MB),
FILEGROUP UGroup1
(NAME=G1File1,
FILENAME='D:\Teaching\G1File1Data.ndf',
SIZE=2MB,
MAXSIZE=50MB,
FILEGROWTH=1MB),
(NAME=G1File2,
FILENAME='E:\Teaching\G1File2Data.ndf',
SIZE=2MB,
MAXSIZE=50MB,
FILEGROWTH=1MB),
FILEGROUP UGroup2
(NAME=G2File1,
FILENAME='E:\Teaching\G2File1Data.ndf',
SIZE=1MB,
MAXSIZE=50MB,
FILEGROWTH=1MB)
LOG ON
(NAME=LogFile1,
FILENAME='F:\Teaching\LogFile1.ldf',
SIZE=2MB,
MAXSIZE=50MB,
FILEGROWTH=1MB)
GO
步骤3 通过T-SQL语句修改文件组UGroup1的属性,将其配置为默认文件组。
答案:
--将UGroup1修改为默认文件组
ALTER DATABASE TeachingDB
MODIFY FILEGROUP UGroup1 DEFAULT
GO
步骤 4 通过数据库属性对话框中的【文件】页添加一个日志文件,逻辑文件名为LogFile2,存储路径为F:\Teaching,初始大小为1MB,最大值为50MB,增长速度为1MB。
答案:
在【对象资源管理器】窗口中展开【数据库】节点,在数据库TeachingDB上单击鼠标右键,在弹出的快捷菜单中选择【属性】命令弹出【数据库属性】对话框。
切换到【文件】页,单击右下角的【添加】按钮添加一个文件并配置文件的属性如图所示。
单击【确定】按钮管理【数据库属性】对话框。
步骤5 目前,数据库的大小为12MB,通过将文件组UGroup1中的两个数据文件分别收缩到1MB大小的方式使数据库收缩到10MB大小,使用T-SQL语句实现以上的要求。
答案:
--收缩数据库文件
USE TeachingDB
GO
DBCC SHRINKFILE('G1File1',1) GO
DBCC SHRINKFILE('G1File2',1) GO。