一个项目涉及到的50个Sql语句
(整理)查找某个字段最大值的记录SQL语句

查找某个字段最大值的记录 SQL语句select table_name.*from table_name,(select max(price) as price,pid from table_name group by pid) as table_name_temp where table_name_temp.price=table_name.price andtable_name_temp.pid=table_name.pid;--SQL codecreate table lk1 (uid int,pid int,price int,`time` date)engine=myisam;insert into lk1 values(1, 1, 100, '2007-07-01'),(1, 2, 150, '2007-07-02 '),(2, 1, 110, '2007-07-03 '),(3, 1, 120, '2007-07-04 '),(4, 2, 180, '2007-07-04 '),(3, 2, 170, '2007-07-04 '),(6, 3, 130, '2007-07-04 ');select*from lk1 where price in (select max(price) from lk1 group by pid) group by pid;--结果1:query result(3 records)uid pid price time311202007-07-04421802007-07-04631302007-07-04truncate table lk1;insert into lk1 values(1, 1, 200, '2007-07-01'),(1, 2, 200, '2007-07-02 '),(2, 1, 110, '2007-07-03 '),(3, 1, 120, '2007-07-04 '),(4, 2, 180, '2007-07-04 '),(3, 2, 170, '2007-07-04 '),(6, 3, 130, '2007-07-04 ');select*from lk1 where price in (select max(price) from lk1 group by pid) group by pid;--结果2:query result(3 records)uid pid price time112002007-07-01122002007-07-02631302007-07-04根据mysql的手册上面找到一个查询,修改了一下发现也可以实现,但是并不理解什么意思,不知道有没有人给解释一下SQL codeSELECT *FROM lk1 l1WHERE price = (SELECT MAX( l2.price )FROM lk1 l2WHERE l1.`pid` = l2.`pid` ) ;--SQL codecreate table lk1 (uid int,pid int,price int,`time` date)engine=myisam;insert into lk1 values(1, 1, 100, '2007-07-01'),(1, 2, 150, '2007-07-02 '),(2, 1, 110, '2007-07-03 '),(3, 1, 120, '2007-07-04 '),(4, 2, 180, '2007-07-04 '),(3, 2, 170, '2007-07-04 '),(6, 3, 130, '2007-07-04 ');select*from (select*from lk1 order by price desc) T group by pid;--结果1:query result(3 records)uid pid price time311202007-07-04421802007-07-04631302007-07-04truncate table lk1;insert into lk1 values(1, 1, 200, '2007-07-01'),(1, 2, 200, '2007-07-02 '),(2, 1, 110, '2007-07-03 '),(3, 1, 120, '2007-07-04 '),(4, 2, 180, '2007-07-04 '),(3, 2, 170, '2007-07-04 '),(6, 3, 130, '2007-07-04 ');select*from (select*from lk1 order by price desc) T group by pid;--结果2:query result(3 records)uid pid price time112002007-07-01122002007-07-02631302007-07-04insert into lk1 values(4, 3, 200, '2007-07-05 '),(5, 3, 210, '2007-07-05' );select*from (select*from lk1 order by price desc) T group by pid;--结果3:query result(3 records)uid pid price time112002007-07-01 122002007-07-02 532102007-07-05。
sql,server,2008,计算列规范

sql,server,2008,计算列规范篇一:SQL Server 2008 T-SQL语句总结SQL Server 2008中T-SQL语句操作总结---【创建数据库】---(1)一个数据文件、一个日志文件create database db1on(name=RShDB_Data, ----数据库文件的逻辑名称filename='D:\RShDB_Data.mdf', ------数据库文件的物理名称(带路径)size=10MB, -----初始大小maxsize=30MB,------最大大小filegrowth=5MB -----自增长大小)log on(name=RShDB_Log,filename='D:\RShDB_Log.ldf', size=3MB,maxsize=12MB,filegrowth=2MB)(2)多个数据文件、多个日志文件create database studentson primary(name=students_data1,filename='D:\students_data1.mdf', size=5MB,maxsize=unlimited),(name=students_data2,filename='D:\students_data2.ndf', size=5MB,maxsize=20MB,filegrowth=2MB)log on(name=students_log1,filename='D:\students_log1.ldf', size=2MB,maxsize=6MB,filegrowth=10%),(name=students_log2,filename='D:\students_log2.ldf', size=3MB,maxsize=8MB,filegrowth=1MB)(3)创建具有文件组的数据库create database saleson primary(name=spri1_dat,filename='D:\spri1_dat.mdf', size=10,maxsize=50,filegrowth=10%),(name=spri2_dat,filename='D:\spri2_dat.ndf', size=10,maxsize=50,filegrowth=15%),filegroup salesGroup1(name=SGrp1Fil_dat,filename='D:\SGrp1Fil_dat.ndf', size=10,maxsize=50,filegrowth=5),(name=SGrp1Fi2_dat,filename='D:\SGrp1Fi2_dat.ndf', size=10,maxsize=50,filegrowth=5),filegroup salesGroup2(name=SGrp2Fi1_dat,filename='D:\SGrp2Fi1_dat.ndf', size=10,maxsize=50,filegrowth=5),(name=SGrp2Fi2_dat,filename='D:\SGrp2Fi2_dat.ndf', size=10,maxsize=50,filegrowth=5)log on(name=sales_log,filename='D:\sales_log.ldf',size=5,maxsize=25,filegrowth=5)总结:(i)先创建数据库文件,再创建日志文件,两者之间不需要逗号隔开,因为日志文件的创建是以log on开头,但是多个数据库文件(包括文件组)或在多个日志文件之间要用逗号隔开,(ii)create database语句中列出的第一个数据库文件将成为主要数据库文件,后缀名是mdf,其他的数据库文件均为次数据库文件,后缀名为ndf;日志文件的后缀名为ldf (iii)在指定涉及大小的参数时(如size\maxsize\filegrowth)要注意的几点:单位:如果没有指定单位只是给出数字的话,那么默认单位就为MB,比较特殊的filegrowth还可以是百分数,表示增长按发生增长时文件大小的百分比增长,总之大小不能超过maxsize就行;取值:(1)filegrowth=0说明不允许自增长;若没有指定filegrowth,那么对于数据文件来说默认都是1MB,而对于日志文件来说默认增长比例是10%,最小值为64KB;(2)maxsize不指定的话默认表示大小无限制,文件可以一直增大,直到磁盘空间满;maxsize=unlimited表示不限制增长,但这个是相对的,对于数据文件最大大小为16TB,对于日志文件最大大小为2TB;(3)size如果是在主数据库文件中未指定,那么默认使用model数据库中主数据库文件的大小,即使指定了那也不能小于model数据库中主数据库文件的大小,而在次数据库文件和日志文件中默认为1MB(4)size\maxsize都要是整数不能是小数---【修改数据库】---(1)扩大数据库空间(之前创建数据库时没有设置自增长,那么时间久了会出现这样的情况)方法一:扩大已有的数据文件或日志文件alter database studentsmodify file(name=students_data1,size=8MB)实现了对数据库students下的主数据文件students_data1由原来的5MB增大到现在的8MB的过程方法二:为数据库添加新的数据文件或日志文件alter database studentsadd file(name=students_data3,filename='D:\students_data3_ndf',size=6MB,filegrowth=0)alter database studentsadd log file(name=students_log3,filename='D:\students_log3.ldf',size=3MB,maxsize=8MB,filegrowth=1MB)篇二:SQL Server 2008中使用稀疏列和列集的方法SQL Server 2008中使用稀疏列和列集的方法如果你为INSERT 语句写了相同的触发器,那么你将看到INSERT操作出现相同的行为。
SQL语句中CASEWHEN以及CAST的运用
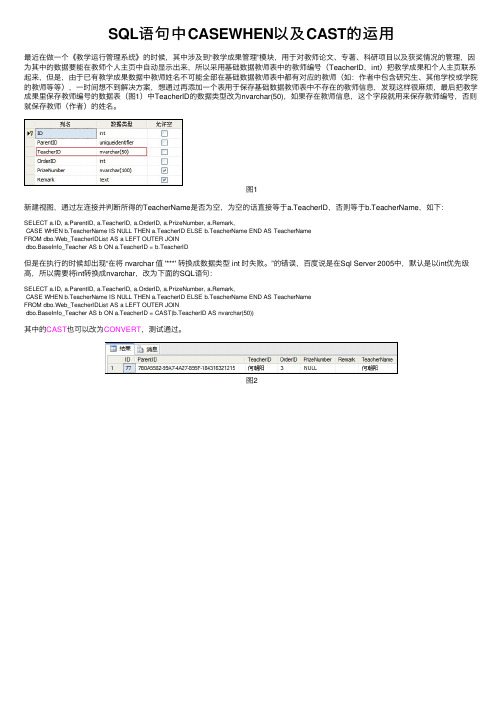
SQL语句中CASEWHEN以及CAST的运⽤最近在做⼀个《教学运⾏管理系统》的时候,其中涉及到“教学成果管理”模块,⽤于对教师论⽂、专著、科研项⽬以及获奖情况的管理,因为其中的数据要能在教师个⼈主页中⾃动显⽰出来,所以采⽤基础数据教师表中的教师编号(TeacherID,int)把教学成果和个⼈主页联系起来,但是,由于已有教学成果数据中教师姓名不可能全部在基础数据教师表中都有对应的教师(如:作者中包含研究⽣、其他学校或学院的教师等等),⼀时间想不到解决⽅案,想通过再添加⼀个表⽤于保存基础数据教师表中不存在的教师信息,发现这样很⿇烦,最后把教学成果⾥保存教师编号的数据表(图1)中TeacherID的数据类型改为nvarchar(50),如果存在教师信息,这个字段就⽤来保存教师编号,否则就保存教师(作者)的姓名。
图1新建视图,通过左连接并判断所得的TeacherName是否为空,为空的话直接等于a.TeacherID,否则等于b.TeacherName,如下:SELECT a.ID, a.ParentID, a.TeacherID, a.OrderID, a.PrizeNumber, a.Remark,CASE WHEN b.TeacherName IS NULL THEN a.TeacherID ELSE b.TeacherName END AS TeacherNameFROM dbo.Web_TeacherIDList AS a LEFT OUTER JOINdbo.BaseInfo_Teacher AS b ON a.TeacherID = b.TeacherID但是在执⾏的时候却出现“在将 nvarchar 值 '***' 转换成数据类型 int 时失败。
”的错误,百度说是在Sql Server 2005中,默认是以int优先级⾼,所以需要将int转换成nvarchar,改为下⾯的SQL语句:SELECT a.ID, a.ParentID, a.TeacherID, a.OrderID, a.PrizeNumber, a.Remark,CASE WHEN b.TeacherName IS NULL THEN a.TeacherID ELSE b.TeacherName END AS TeacherNameFROM dbo.Web_TeacherIDList AS a LEFT OUTER JOINdbo.BaseInfo_Teacher AS b ON a.TeacherID = CAST(b.TeacherID AS nvarchar(50))其中的CAST也可以改为CONVERT,测试通过。
怎么用sql语句查询一个数据库有多少张表

怎么⽤sql语句查询⼀个数据库有多少张表
今天在技术群中闲谈时忽然聊到⼀个问题,那就是当⼀个数据库中有多张表时怎么快速的获取到表的个数,从⽽给问询者⼀个准确的回答。
⼤家或许会说,这个问题和我们的数据库操作没有太⼤关系或者不是很挂钩,所以没意义记住它。
不过,⼤家要记住,对熟悉数据库的⼈来说确实如此,但是要是不懂数据库的,⽐如说你的⽼板,闲着⽆聊的时候想知道这个项⽬的数据库有多少张表,以便了解下这个项⽬的复杂度,那时⼜你该咋办了?想回答⼜不能快速回答上来,找个理由不回答⼜灭了你在⽼板⾯前的威风。
为避免这样的问题真的出现在我们可怜的码农⾝上,IT博客总结⼏种⽅法:
⼀、sql语句查询
sql server 2005
SELECT * FROM sysobjects WHERE (xtype = 'U')
查询当前数据库下所有⽤户建⽴的表
效果如下图所⽰:
解释xtype参数的含义
C = CHECK 约束
D = 默认值或 DEFAULT 约束
F = FOREIGN KEY 约束
L = ⽇志
FN = 标量函数
IF = 内嵌表函数
P = 存储过程
PK = PRIMARY KEY 约束(类型是 K)
RF = 复制筛选存储过程
S = 系统表
TF = 表函数
TR = 触发器
U = ⽤户表
UQ = UNIQUE 约束(类型是 K)
V = 视图
X = 扩展存储过程
ORACLE
select * from user_tables
⼆、视图查询
以下是sql server 2005的窗体,其余的以操作界⾯为主,同事在软件的对象管理器中也同样可以统计。
sql查询50题

sql查询50题/*⼀个项⽬涉及到的50个Sql语句问题及描述:--1.学⽣表Student(S#,Sname,Sage,Ssex) --S# 学⽣编号,Sname 学⽣姓名,Sage 出⽣年⽉,Ssex 学⽣性别--2.课程表Course(C#,Cname,T#) --C# --课程编号,Cname 课程名称,T# 教师编号--3.教师表Teacher(T#,Tname) --T# 教师编号,Tname 教师姓名--4.成绩表SC(S#,C#,score) --S# 学⽣编号,C# 课程编号,score 分数select * from Studentselect * from Courseselect * from Teacherselect * from SC*/--创建测试数据create table Student(S# varchar(10),Sname nvarchar(10),Sage datetime,Ssex nvarchar(10))insert into Student values('01' , N'赵雷' , '1990-01-01' , N'男')insert into Student values('02' , N'钱电' , '1990-12-21' , N'男')insert into Student values('03' , N'孙风' , '1990-05-20' , N'男')insert into Student values('04' , N'李云' , '1990-08-06' , N'男')insert into Student values('05' , N'周梅' , '1991-12-01' , N'⼥')insert into Student values('06' , N'吴兰' , '1992-03-01' , N'⼥')insert into Student values('07' , N'郑⽵' , '1989-07-01' , N'⼥')insert into Student values('08' , N'王菊' , '1990-01-20' , N'⼥')create table Course(C# varchar(10),Cname nvarchar(10),T# varchar(10))insert into Course values('01' , N'语⽂' , '02')insert into Course values('02' , N'数学' , '01')insert into Course values('03' , N'英语' , '03')create table Teacher(T# varchar(10),Tname nvarchar(10))insert into Teacher values('01' , N'张三')insert into Teacher values('02' , N'李四')insert into Teacher values('03' , N'王五')create table SC(S# varchar(10),C# varchar(10),score decimal(18,1))insert into SC values('01' , '01' , 80)insert into SC values('01' , '02' , 90)insert into SC values('01' , '03' , 99)insert into SC values('02' , '01' , 70)insert into SC values('02' , '02' , 60)insert into SC values('02' , '03' , 80)insert into SC values('03' , '01' , 80)insert into SC values('03' , '02' , 80)insert into SC values('03' , '03' , 80)insert into SC values('04' , '01' , 50)insert into SC values('04' , '02' , 30)insert into SC values('04' , '03' , 20)insert into SC values('05' , '01' , 76)insert into SC values('05' , '02' , 87)insert into SC values('06' , '01' , 31)insert into SC values('06' , '03' , 34)insert into SC values('07' , '02' , 89)insert into SC values('07' , '03' , 98)go--1、查询"01"课程⽐"02"课程成绩⾼的学⽣的信息及课程分数--1.1、查询同时存在"01"课程和"02"课程的情况--1.2、查询同时存在"01"课程和"02"课程的情况和存在"01"课程但可能不存在"02"课程的情况(不存在时显⽰为null)(以下存在相同内容时不再解释)--2、查询"01"课程⽐"02"课程成绩低的学⽣的信息及课程分数--2.1、查询同时存在"01"课程和"02"课程的情况--2.2、查询同时存在"01"课程和"02"课程的情况和不存在"01"课程但存在"02"课程的情况--3、查询平均成绩⼤于等于60分的同学的学⽣编号和学⽣姓名和平均成绩--4、查询平均成绩⼩于60分的同学的学⽣编号和学⽣姓名和平均成绩--4.1、查询在sc表存在成绩的学⽣信息的SQL语句。
关系数据库查询语言SQL

关系数据库查询语⾔SQL授课⽅式:以下所有的例⼦都在sql server 中进⾏现场调试其执⾏结果,或者让学⽣上讲台练习,让学⽣体会其具体的含义第四章关系数据库查询语⾔SQL(8学时)第1节关系数据库标准语⾔SQL ——查询部分⼀、SQL概述1.SQL标准SQL(Structured Query Language):结构化数据库查询语⾔。
SQL作为⼀个ANSI标准,现在最新的标准是SQL99!是介于关系代数和关系演算之间的结构化查询语⾔,功能包括数据查询(Data Query )、数据操纵(Data Manipulation)、数据定义(Data Definition)、数据控制(Data Control)2.SQL的特点1)综合统⼀SQL语⾔集数据定义语⾔DDL、数据操纵语⾔DML、数据控制语⾔DCL功能于⼀体,语⾔风格统⼀。
可独⽴完成数据库⽣命周期中的全部活动,包括:定义关系模式、建⽴数据库、插⼊数据、查询、更新、维护、数据库重构、数据库安全性控制等⼀系列操作要求,为数据库应⽤系统开发提供了良好的环境。
由于关系模型中实体间连续军⽤关系表⽰,这种数据结构单⼀性带来了数据操作的统⼀,查找、插⼊、删除、修改等每⼀种操作只需要⼀种操作符,从⽽克服了⾮关系系统由于信息表⽰⽅式多样性带来的操作复杂性。
2)⾼度⾮过程化SQL语⾔只要提出“做什么”,⽆须指明“怎么做”!!⽤户⽆须了解存取路径,存取路径的选择及SQL语句的操作过程由系统⾃动完成。
减轻了⽤户的负担,提⾼了数据独⽴性。
3)⾯向集合的操作⽅式Sql 语⾔采⽤集合操作⽅式,不仅操作对象、查询结果可以是元组集合,⽽且⼀次插⼊、删除、更新操作的对象可是元组的集合。
4)以同⼀种语法结构提供两种使⽤⽅式既是⾃含式语⾔,⼜是嵌⼊式语⾔。
⾃含式语⾔:能独⽴的⽤于联机交互的使⽤⽅式,⽤户可以在终端键盘上直接键⼊SQL 命令对数据库进⾏操作。
在SQL SERVER 2000种现场演⽰SQL语句的操作。
SQL语言查询技术

• SELECT列表项和FROM子句是每个每个 SQL查询语句所必须的,其他子句则是根 据需要可选
SELECT * FROM *
WHERE子句
• 指明查询的连接条件或筛选条件
• jsjh,jsxm,gl FROM js;WHERE gl>=10 and gl<=15; • (查询工龄在10~15之间的教师的工号、姓名、年龄)
多表查询
• 在日常中,往往要涉及多个表之间的关联 查询。SQL语言提供了连接多个表的操作, 可以在两个表之间按指定列的值将一个表 中的行与另一个表中的行连接起来,从而 大大增强其查询能力。
• 例:查询学生的学号、姓名、课程、成绩、并按学号排升序。
使用WHERE子句的筛选条件如下: SELECT Xs,xsxh,Xs,xsxh,Kc,kcmc,Cj.cj; FROM xs,cj,kc; WHERE XS,xsxh=cj.xsxh AND Cj.kcdh=kc.kcdh ORDER BY Xs.xsxh 使用FROM子句的链接条件实现如下: SELECT Xs,xsxh,Xs.xsxm,Kc ,kcmc,Cj.cj; FROM xs INNER JOIN cj INNER JOIN kc; ON Cj.kcdh=Kc.kcdh ON Xs.xsxh; ORDER BY Xs.xsxh
5.1.2SELECT-SQL查询命令
SQL语句主要内容
• • • • • • • SELECT列表项 FROM子句 INTO和TO子句 WHERE子句 GROUP BY子句 ORDER BY子句 UNION子句
SELECT列表项
FROM子句
• 用于指明查询输出的项目, • 指明被查询的自由表、数 可以是字段、表达式。 据库表或试图名,及其之 间的联接状况 • 利用表达式可以查询表中 未直接存储但可以通过计 算出来的结果 • 表达式可以为变量、常量、 函数及它们的组合,特别 是字段函数及其组合可以 实现功能十分强大的查询 和统计操作
编译原理实践yacc(sql查询语句解析)_概述说明

编译原理实践yacc(sql查询语句解析) 概述说明1. 引言1.1 概述本篇文章旨在介绍编译原理实践中使用Yacc工具对SQL查询语句进行解析的过程。
编译原理是计算机科学中的重要研究领域,主要涉及将高级语言转化为低级的机器语言,以便计算机能够理解和执行。
通过使用编译原理中的概念和技术,可以大大简化复杂语法的分析和解析过程,提高程序开发的效率。
1.2 文章结构本文共分为五个部分,每个部分都有其特定的内容和目标:- 引言:介绍本篇文章的背景和目的。
- 编译原理实践yacc:阐述编译原理及介绍Yacc工具在该领域中的应用。
- SQL查询语句解析过程:详细讲解SQL查询语句的基本结构、词法分析过程以及语法分析过程。
- Yacc工具的使用和配置:指导读者如何安装Yacc工具,并演示如何编写Yacc 源文件以及生成解析器代码并进行运行。
- 结论与展望:总结全文内容并提供未来可能的拓展方向。
1.3 目的本文目的在于通过对编译原理和Yacc工具在SQL查询语句解析中的应用进行介绍,帮助读者更好地理解编译原理的相关概念,并掌握使用Yacc工具进行语法分析和解析的方法。
通过实践演示和案例讲解,读者能够学会配置和使用Yacc 工具,并将其应用于自己感兴趣的领域。
以上为“1. 引言”部分内容的详细描述,请结合实际情况进行参考与调整。
2. 编译原理实践yacc2.1 什么是编译原理编译原理是计算机科学领域的一个重要分支,研究如何将高级程序语言转换为机器语言。
它涉及到编程语言的词法分析、语法分析和代码生成等多个方面。
通过编译原理,我们可以了解程序如何被解释和执行,从而能够更好地设计和优化程序。
2.2 Yacc介绍Yacc(Yet Another Compiler Compiler)是一款用于生成语法解析器的工具。
它是由AT&T贝尔实验室的Stephen C. Johnson在20世纪70年代开发的,并成为Unix操作系统环境下广泛使用的编译器工具之一。
深圳大学实验报告-数据库系统概论-交互式SQL语句

深圳大学实验报告课程名称:数据库系统概论实验项目名称:交互式SQL语句学院:CIE专业:IS指导教师:傅向华报告人:卢志敏学号:2006131114 班级: 3 实验时间:2008-10-20实验报告提交时间:2008-11-5教务处制一、实验目的与要求:一、实验目的通过本实验,掌握数据分析以及SQL语句的使用。
二、实验要求根据自己本学期选修课程的情况,分析学生、课程和教师之间的关系。
例如,一个学生可以选修多门课程,一门课程可以有多个学生选择,一个课程可以有多位教师讲授,一个教师也可以讲授多门课程,不同的学生可以选择不同教师的不同的课程,建立数据库并进行相关操作。
二、方法、步骤:1.利用SQL语句创建一个数据库和表,该数据库包含如下四个表:学生(学号,姓名,性别,班级,年龄,系别,籍贯,住址,电话号码)教师(教师工号,姓名,性别,系别)课程(课程号,课程名,教材,学分)(假设同一门课程只有一个课程号)选修关系(学号,课程号,教师工号,成绩)2.统计2个宿舍的学生选课情况,利用SQL语句往表中添加记录(每个表至少写出一个SQL语句);Student表:insertinto student (Sno,Sname,Ssex,Sage,Sdept,Sclass)values ('2006131145','崔元星','男',21,'IS','4')Teacher表:insertinto Teacher (Tno,Tname,Tsex,Tdept)values ('11111','傅向华','男','CS')Course表:insertinto Course (Cno,Cname,教材,Ccredit)values ('2213200104','计算机组成原理','计算机组成与结构(第四版)',4)SC表:insertinto SC (Sno,Cno,Tno,Grade)values ('2006131145','2313200501','11112','85')3.以上述数据库和记录为基础,进行如下查询,写出SQL语句和查询结果;(1)以自己的学号作为选择条件,查询自己本学期所修全部课程的课程号和课程名;(2)以自己选修课程的某位教师姓名为查询条件,查询选修该教师课程的所有学生的学号和姓名;(3 ) 查询自己选修的某位教师的某门课程的所有学生的学号,姓名以及电话号码;(4)查询自己选修的某位教师不同课程的学生人数;(5)查询不同课程成绩的最高分;(6)查询与自己同姓的所有学生的学号和姓名;(7)查询没有选修某位教师课程的学生学号和姓名;(8)查询选修了所有课程的学生学号和姓名;(9)查询至少选修了自己选修的全部课程的学生学号和姓名;(10)查询自己选修的所有课程中,超过平均成绩的课程号;4.写出如下操作的SQL语句:(1) 在学生表中添加电子邮件属性;(2) 从课程表中删除所有自己未选修的课程记录;(3)在上述表中插入自己上学期选修的一门课程的有关记录;(4)创建一个自己选课情况的视图,包括学号,姓名,课程名,教师姓名以及成绩等属性。
dbeaver 批量执行sql用法

dbeaver 批量执行sql用法1. 引言1.1 概述在进行数据库管理和操作时,批量执行SQL语句是一项非常常见且重要的需求。
通过批量执行SQL,我们可以高效地完成大量数据库操作,节省了人工逐个执行的时间和劳动力。
而dbeaver作为一款功能强大且流行的开源数据库工具,提供了批量执行SQL的功能,能够帮助用户快速、便捷地处理大规模数据库操作任务。
1.2 文章结构本文将详细介绍dbeaver批量执行SQL的用法,包括软件概述、需求背景、功能和优势等方面。
随后会给出使用dbeaver批量执行SQL的方法步骤,并结合实例演示讲解注意事项和常见问题解答。
最后,文章会进行总结并给出对工作的启示以及展望未来。
1.3 目的本文旨在帮助读者深入了解dbeaver批量执行SQL的用法,并掌握相关技巧与注意事项。
通过学习本文,读者能够熟练使用dbeaver进行高效、准确地批量执行SQL语句,并在实际工作中更好地应用这一技术。
同时,本文也将指出一些使用过程中可能遇到的问题,并给出相应解决方案和优化建议,提高工作效率和数据操作的质量。
2. dbeaver 批量执行sql用法:2.1 dbeaver简介:DBeaver是一款强大的开源数据库管理工具,支持多种数据库系统,如MySQL、Oracle、PostgreSQL等。
它提供了丰富的功能和工具,方便开发人员和数据库管理员进行数据库管理和操作。
2.2 批量执行sql的需求背景:在某些情况下,我们需要对数据库中的多条SQL语句进行批量执行,以实现一次性操作多个数据表或记录。
这样可以提高工作效率,减少手动操作的时间和精力消耗。
2.3 dbeaver批量执行sql的功能和优势:DBeaver提供了强大且灵活的批量执行sql的功能,具有以下优势:1. 执行速度快:通过批量处理模式,可以一次性提交多个SQL语句到数据库并执行,从而减少了与数据库服务器之间的通信次数,大大缩短了执行时间。
教学管理系统数据库ER图及SQL语句

教学管理系统一、系统功能需求学校教务管理系统是针对学校的大量信息处理工作而开发的管理软件,完成的主要功能如下:(1) 学生基本信息管理:能够对学生基本信息进行输入、删除、修改。
学生基本信息包括:学号、姓名、性别、出生日期、入学成绩、所在系号。
(2) 系部基本信息管理:系部的基本信息输入、修改、删除。
系部基本信息包括:系号、系名称、系的简介。
(3) 课程信息管理:课程信息的输入、修改、删除。
课程信息包括:课程号、课程名称、任课教师号、学时、学分、上课时间、上课地点、考试时间.(4) 教职工信息管理:教职工信息的输入、修改、删除。
教职工信息包括:职工号、姓名、性别、出身年月、所在系号、职称、技术专长。
(5)选课管理:学号、学生、课程号、课程名称、上课教师姓名、系号每学期所选课程的学分不能超过15分。
学生可以同时选修一门或多门课程。
可以同时为多个学生选修某一门或某几门课程。
可以删除和修改选课信息。
(6)成绩管理可以按课程输入和修改成绩,也可以按学生输入和修改成绩.(7)信息查询可以按学号、姓名、系号查询学生基本信息。
可以按职工号、姓名、系号查询教职工基本信息。
可以按系号、系名称查询系的基本信息。
可以按课程号、课程名称、上课教师姓名查询课程基本信息。
按学号、课程号、课程名称、上课教师姓名、系号查询学生成绩,内容包括课程基本情况.若查询涉及多门课程,则按课程分组.每门课程按总评成绩从高分到低分给出选修该门课程的所有学生的成绩(平时成绩、考试成绩和总评成绩).(8)统计报表a、成绩报表:内容包括课程基本信息(课程号、课程名称、任课教师号、学时、学分),选课学生名单(学号、姓名、性别),每个学生的平时成绩、考试成绩和总评成绩。
能按课程号、课程名称、教师姓名输出对应课程的成绩报表。
b、能够根据课程、授课教师统计成绩〉=90分、〉=80分、>=70分、>=60分及不及格学生的人数及比例。
二、任务描述1、根据需求描述,完成数据概念模型设计,画出E-R图;2、优化E—R图,给出数据逻辑模型;3、将逻辑模型转换成物理模型并创建数据库和数据表。
kotlin select sql语句

kotlin select sql语句全文共四篇示例,供读者参考第一篇示例:Kotlin是一种新兴的编程语言,它被广泛用于Android应用程序开发。
在Kotlin中使用SQL语句来操作数据库是非常常见的,因为SQL是一种用于管理和操作关系数据库的标准语言。
在本文中,我们将重点介绍如何在Kotlin中使用SQL语句执行select查询操作。
让我们先了解一下什么是select查询。
select查询是SQL中最常见的查询类型,它用于从数据库中检索数据。
select查询通过指定要检索的列和行来过滤数据库中的数据,并返回满足条件的数据集。
使用select查询时,你可以按照指定的条件筛选出符合条件的数据,并将其显示在结果集中。
在Kotlin中执行select查询的方法与在其他编程语言中执行select查询的方法类似。
下面是一个简单的示例,演示如何在Kotlin 中使用SQL语句执行select查询:```import java.sql.Connectionimport java.sql.DriverManagerimport java.sql.ResultSetval sql = "SELECT * FROM mytable"val resultSet: ResultSet = statement.executeQuery(sql)while (resultSet.next()) {val id = resultSet.getInt("id")val name = resultSet.getString("name")println("id: id, name: name")}connection.close()}```在上面的示例中,我们首先建立了与数据库的连接,并创建了一个Statement对象。
然后,我们定义了一个SQL查询语句,SELECT * FROM mytable,该语句表示检索mytable表中的所有列和行。
数据库查询优化-20条必备sql优化技巧

数据库查询优化-20条必备sql优化技巧0、序⾔本⽂我们来谈谈项⽬中常⽤的 20 条 MySQL 优化⽅法,效率⾄少提⾼ 3倍!具体如下:1、使⽤ EXPLAIN 分析 SQL 语句是否合理使⽤ EXPLAIN 判断 SQL 语句是否合理使⽤索引,尽量避免 extra 列出现:Using File Sort、Using Temporary 等。
2、必须被索引重要SQL必须被索引:update、delete 的 where 条件列、order by、group by、distinct 字段、多表 join 字段。
3、联合索引对于联合索引来说,如果存在范围查询,⽐如between、>、<等条件时,会造成后⾯的索引字段失效。
对于联合索引来说,要遵守最左前缀法则:举列来说索引含有字段 id、name、school,可以直接⽤ id 字段,也可以 id、name 这样的顺序,但是 name; school 都⽆法使⽤这个索引。
所以在创建联合索引的时候⼀定要注意索引字段顺序,常⽤的查询字段放在最前⾯。
4、强制索引必要时可以使⽤ force index 来强制查询⾛某个索引: 有的时候MySQL优化器采取它认为合适的索引来检索 SQL 语句,但是可能它所采⽤的索引并不是我们想要的。
这时就可以采⽤ forceindex 来强制优化器使⽤我们制定的索引。
5、⽇期时间类型对于⾮标准的⽇期字段,例如字符串的⽇期字段,进⾏分区裁剪查询时会导致⽆法识辨,依旧⾛全表扫描。
尽管 TIMESTAMEP 存储空间只需要 datetime 的⼀半,然⽽由于类型 TIMESTAMP 存在性能问题,建议你还是尽可能使⽤类型 DATETIME。
(TIMESTAMP ⽇期存储的上限为2038-01-19 03:14:07,业务⽤ TIMESTAMP 存在风险;)6、禁⽌使⽤ SELECT *SELECT 只获取必要的字段,禁⽌使⽤ SELECT *。
【原创】最简单的SQL语句

【67】SQL最好的汽车手自一体,最好的系统手自一体,最好的程序员不但善于运用框架、平台中现有的技术减少开发工作量提升系统稳定性,同时,当框架、平台无法满足需求时,还会用Notepad写代码,手工写SQL,命令行下的基本调试。
一、基本DDL语句,必须会手写。
(1)INSERT INTO订单商品表(商品ID,数量)VALUES(’A47’,’2012-10-01’)这是最简单的语句,同时又是其他操作的数据来源,基础中的基础,所以一定要会。
(2)SELECT 商品ID,数量FROM 订单商品表WHERE订单日期>=’2012-10-01’最灵活最常用的那20%,就是这个SELECT语句。
(3)UPDATE 订单商品表SET数量=数量+(100.0) WHERE数量IS NOT NULL,UPDATE语句使用原则:(1)不要在生产库中使用,这个原则同样适用于下面的DELETE语句,否则造成的损失可能导致公司破产。
(2)UPDATE语句也可以多表关联操作(JOIN),但不建议使用。
张三曾经在一个著名大型数据库的新版本上执行了一个关联语句,结果就造成了数据库实例停止服务,这充分说明了那80%不常用的功能真的很脆弱,想让自己的作品天长地久的运行下去,就尽量用大道边上的功能,知道回字的四种写法并不意味着自己水平比别人高,会写繁体字却是有文化的表现。
(4)DELETE FROM 订单表WHERE订单日期>=’2012-10-01’这里的表名和字段名都是中文只是为了看得更清楚,并不是倡导这么做,当然,公司规范要求用中文的话,没有任何问题的。
二、常用的关键字,排名不分先后,尽量熟练应用之,至少要知道是干啥的。
(10)ISNULL(NVL、COALESCE)、IS、NOT、NULL,关于空值的处理。
空值是数据库和代码中都有的内容,都是需要特殊处理的一个特殊数据。
“空不异色,色不异空”,圣人不我欺。
(20)LENGTH(LEN),判断字段值得长度,注意NULL和空格等不可见的值。
SQL语句练习题

SQL语句练习题S Q L语言一、选择题1.S Q L语言是()的语言,容易学习。
A.过程化B.非过程化C.格式化D.导航式2. S Q L语言的数据操纵语句包括S E L E C T、I N S E R T、U PD A T E、D E L E T E等。
其中最重要的,也是使用最频繁的语句是()。
A.S E L E C TB.I N S E R TC.U P D A T ED.D E L E T E3.在视图上不能完成的操作是()。
A.更新视图B.查询C.在视图上定义新的表D.在视图上定义新的视图4.S Q L语言集数据查询、数据操纵、数据定义和数据控制功能于一体,其中,C R E A T E、D R O P、A L T E R语句是实现哪种功能()。
A.数据查询B.数据操纵C.数据定义D.数据控制5.S Q L语言中,删除一个视图的命令是()。
A.D E L E T EB.D R O PC.C L E A RD.R E M O V E6.在S Q L语言中的视图V I E W是数据库的()。
A.外模式B.模式C.内模式D.存储模式7.下列的S Q L语句中,()不是数据定义语句。
A.C R E A T E T A B L EB.D R O P V I E WC.C R E A T E V I E WD.G R A N T8.若要撤销数据库中已经存在的表S,可用()。
A.D E L E T E T A B L E SB.D E L E T E SC.D R O P T A B L E SD.D R O P S9.若要在基本表S中增加一列C N(课程名),可用()。
A.A D D T A B L E S(C N C H A R(8))B.A D D T A B L E S A L T E R(C N C H A R(8))C.A L T E R T A B L E S A D D(C N C H A R(8))D.A L T E R T A B L E S(A D D C N C H A R(8))10.学生关系模式S(S#,S n a m e,S e x,A g e),S的属性分别表示学生的学号、姓名、性别、年龄。
sql 的编码格式-概述说明以及解释

sql 的编码格式-概述说明以及解释1.引言1.1 概述SQL(结构化查询语言)是用于管理和操作关系型数据库的编程语言。
在进行SQL编码时,正确的编码格式对于保证数据的完整性、准确性和安全性至关重要。
本文将详细介绍SQL编码格式的定义、常见的SQL编码格式以及SQL编码格式的重要性。
在编写SQL语句时,需要按照一定的格式和规范来编码,以保证语句的可读性和易维护性。
SQL编码格式主要包括缩进、换行、大小写、注释等方面的规范。
首先,缩进在SQL编码中起到了对语句进行层级划分的作用,使得代码结构清晰可见。
通过缩进,可以清晰地区分出SELECT语句、FROM子句、WHERE子句等不同的部分。
其次,换行在SQL编码中能够使得复杂的SQL语句更易理解。
将不同的子句和关键字放在不同的行上,可以使得语句的层次更加明确,也便于注释和修改。
同时,对于SQL关键字和标识符的大小写,也需要遵循一定的编码规范。
一般来说,SQL关键字建议使用大写,而表名、列名等标识符则建议使用小写。
这样可以增加代码的可读性,并且能够避免与关键字冲突的问题。
此外,在SQL编码时添加注释是十分重要的。
注释能够增加代码的可维护性和可读性,帮助其他人更好地理解意图和功能。
注释可以在语句的前面或是行内进行添加,以帮助开发人员更好地理解该段代码的作用和目的。
综上所述,SQL编码格式在数据库开发中起到了至关重要的作用。
通过正确的缩进、换行、大小写和注释等编码格式,可以使得SQL语句更加易读、易懂,提高代码的可维护性和可读性。
在后续的章节中,本文将进一步讨论常见的SQL编码格式以及SQL编码格式的重要性。
1.2 文章结构本文主要以SQL 的编码格式为主题进行探讨和研究。
为了更好地阐述SQL 编码格式的定义、常见的格式以及其重要性,本文将从以下几个方面进行分析。
首先,将介绍SQL 编码格式的定义。
我们将解释什么是SQL 编码格式,它是一种用于编写SQL 语句的规范和约定。
SQL数据库完全操作手册

SQL数据库完全操作手册SQL是Structured Quevy Language(结构化查询语言)的缩写。
SQL是专为数据库而建立的操作命令集,是一种功能齐全的数据库语言。
在使用它时,只需要发出“做什么”的命令,“怎么做”是不用使用者考虑的。
SQL功能强大、简单易学、使用方便,已经成为了数据库操作的基础,并且现在几乎所有的数据库均支持SQL。
##1 二、SQL数据库数据体系结构SQL数据库的数据体系结构基本上是三级结构,但使用术语与传统关系模型术语不同.在SQL中,关系模式(模式)称为“基本表”(base table);存储模式(内模式)称为“存储文件"(stored file);子模式(外模式)称为“视图"(view);元组称为“行”(row);属性称为“列”(column).名称对称如^00100009a^:##1 三、SQL语言的组成在正式学习SQL语言之前,首先让我们对SQL语言有一个基本认识,介绍一下SQL 语言的组成:1。
一个SQL数据库是表(Table)的集合,它由一个或多个SQL模式定义.2.一个SQL表由行集构成,一行是列的序列(集合),每列与行对应一个数据项。
3。
一个表或者是一个基本表或者是一个视图。
基本表是实际存储在数据库的表,而视图是由若干基本表或其他视图构成的表的定义。
4。
一个基本表可以跨一个或多个存储文件,一个存储文件也可存放一个或多个基本表.每个存储文件与外部存储上一个物理文件对应。
5。
用户可以用SQL语句对视图和基本表进行查询等操作。
在用户角度来看,视图和基本表是一样的,没有区别,都是关系(表格).6。
SQL用户可以是应用程序,也可以是终端用户。
SQL语句可嵌入在宿主语言的程序中使用,宿主语言有FORTRAN,COBOL,PASCAL,PL/I,C和Ada语言等。
SQL用户也能作为独立的用户接口,供交互环境下的终端用户使用。
##1 四、对数据库进行操作SQL包括了所有对数据库的操作,主要是由4个部分组成:1.数据定义:这一部分又称为“SQL DDL”,定义数据库的逻辑结构,包括定义数据库、基本表、视图和索引4部分.2.数据操纵:这一部分又称为“SQL DML”,其中包括数据查询和数据更新两大类操作,其中数据更新又包括插入、删除和更新三种操作。
SQL语言基础培训

SQL语言基本使用培训大纲工程中心项目实施部2008年一. SQL语言简介SQL (Structured Query Language,结构查询语言)是一个功能强大的数据库语言,SQL通常用于与数据库的通讯。
ANSI(美国国家标准学会)声称,SQL是关系型数据库管理系统的标准语言。
SQL语句通常用于完成一些数据库的操作任务,比如从数据库中更新数据,或者从数据库中检索数据。
二. 功能简介DML (Data Manipulation Language,数据操作语言)---用于检索或者修改数据。
DDL (Data Definition Language,数据定义语言)---用于定义数据的结构,如创建、修改或者删除数据库对象。
DCL (Data Control Language,数据控制语言)---用于定义数据库用户的权限。
(这里不作介绍)DML 语言主要涉及的语句为SELECT ,UPDATE ,INSERT ,DELETE 。
DDL 语言主要涉及的语句为:CREATE ,DROP ,ALTER 。
DCL 语言主要涉及的语句为GRANT ,REVOKE 。
二. 功能简介三.DDL介绍1.建表主语句:create table table_name(column1 datatype[not null],column2 datatype[not null],...)说明:datatype--是字段的属性。
not null --可不可以允许字段有空值存在的。
Eg:Create Table DZ(ID number(2),address varchar2(100));删除表语句:DROP Table table_nameEg: Drop table DZ;2. 更改表结构--说明:增加一个字段alter table table_nameadd column_name datatypeEg:Alter Table DZ add JLX varchar2(50);--说明:删除一个字段alter table table_namedrop column column_nameEg:Alter Table DZ drop column JLX;--说明:为一个字段重命名alter table table_namerename column old_column_name to new_column_name Eg:Alter Table DZ rename column JLX to STREET;--说明:修改一个字段类型alter table表名modify字段名数据类型Eg:alter table dz modify street varchar2(200);3.建立索引create index index_name on table_name(column_name)说明:对某个表的字段建立索引以增加查询时的速度。
结构化查询语言(SQL)

结构化查询语言(SQL)SQL概述SQL的内容在笔试和上机考试中均占到大约30%的比例,此外它还是查询和视图的基础,因此是学习的重点也是难点。
SQL是结构化查询语言Structure Query Language的缩写。
SQL包含了查询功能、数据定义、数据操纵和数据控制功能,在VFP中没有提供数据控制功能。
SQL主要特点1.SQL是一种一体化语言.2.SQL是一种高度非过程化的语言。
3.SQL语言非常简洁。
4.SQL语言可直接以命令方式交互使用,也可嵌入到程序设计语言中以程序方式使用。
查询功能SELECT命令的特点:1.可以自动打开数据库、表文件加以查询,而不需要事先用OPEN DATABASE或USE命令打开。
2.可以直接选取数据表中的数据,而不需要事先用SET RELATION命令建立关联。
3.当需要的索引文件不存在时,会自动建立暂存索引文件,以支持快速搜索技术(Rushmore)来查询。
4.其查询结果可输出到文件、表、屏幕或报表上,还可以转换成统计图表。
命令格式:SELECT —- FROM -— WHERE可与 LIST FIELDS—— FOR ——对照学习。
关系操作:投影,选择,联接.说明:功能强大,语法灵活;要处理的数据表无须事先打开,通过FROM子句指明并打开。
1.SELECT 短语:说明要查询的数据;对应的关系操作为投影,类似于FIELDS 子句。
2.FROM 短语:说明要查询的数据来自哪个或哪些表,可对单个表或多个表进行查询;3.WHERE 短语:说明查询条件;对应的关系操作为选择,类似于FOR子句。
如是多表查询还可能过该子句指明联接条件,进行联接.4.GROUP BY 短语:用于对查询结果进行分组,可利用它进行分组汇总;类似于TOTAL命令。
5.HAVING 短语:跟随GROUP BY 使用,它用来限定分组必须满足的条件;6.ORDER BY 短语:用于对查询的结果进行排序;类似于SORT命令。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
/*标题:一个项目涉及到的50个Sql语句(整理版)作者:爱新觉罗.毓华(十八年风雨,守得冰山雪莲花开)时间:2010-05-10地点:重庆航天职业学院说明:以下五十个语句都按照测试数据进行过测试,最好每次只单独运行一个语句。
问题及描述:--1.学生表Student(Sid,Sname,Sage,Ssex) --Sid 学生编号,Sname 学生姓名,Sage 出生年月,Ssex 学生性别--2.课程表Course(Cid,Cname,Tid) --Cid --课程编号,Cname 课程名称,Tid 教师编号--3.教师表Teacher(Tid,Tname) --Tid 教师编号,Tname 教师姓名--4.成绩表SC(Sid,Cid,score) --Sid 学生编号,Cid 课程编号,score 分数*/--创建测试数据create table Student(Sid varchar(10),Sname nvarchar(10),Sage datetime,Ssex nvarchar(10))insert into Student values('01' , N'赵雷' , '1990-01-01' , N'男') insert into Student values('02' , N'钱电' , '1990-12-21' , N'男') insert into Student values('03' , N'孙风' , '1990-05-20' , N'男') insert into Student values('04' , N'李云' , '1990-08-06' , N'男') insert into Student values('05' , N'周梅' , '1991-12-01' , N'女') insert into Student values('06' , N'吴兰' , '1992-03-01' , N'女') insert into Student values('07' , N'郑竹' , '1989-07-01' , N'女') insert into Student values('08' , N'王菊' , '1990-01-20' , N'女') create table Course(Cid varchar(10),Cname nvarchar(10),Tid varchar(10)) insert into Course values('01' , N'语文' , '02')insert into Course values('02' , N'数学' , '01')insert into Course values('03' , N'英语' , '03')create table Teacher(Tid varchar(10),Tname nvarchar(10))insert into Teacher values('01' , N'张三')insert into Teacher values('02' , N'李四')insert into Teacher values('03' , N'王五')create table SC(Sid varchar(10),Cid varchar(10),score decimal(18,1)) insert into SC values('01' , '01' , 80)insert into SC values('01' , '02' , 90)insert into SC values('01' , '03' , 99)insert into SC values('02' , '01' , 70)insert into SC values('02' , '02' , 60)insert into SC values('02' , '03' , 80)insert into SC values('03' , '01' , 80)insert into SC values('03' , '02' , 80)insert into SC values('03' , '03' , 80)insert into SC values('04' , '01' , 50)insert into SC values('04' , '02' , 30)insert into SC values('04' , '03' , 20)insert into SC values('05' , '01' , 76)insert into SC values('05' , '02' , 87)insert into SC values('06' , '01' , 31)insert into SC values('06' , '03' , 34)insert into SC values('07' , '02' , 89)insert into SC values('07' , '03' , 98)go--1、查询"01"课程比"02"课程成绩高的学生的信息及课程分数--1.1、查询同时存在"01"课程和"02"课程的情况select a.* , b.score [课程'01'的分数],c.score [课程'02'的分数]from Student a , SC b , SC cwhere a.Sid = b.Sid and a.Sid = c.Sid and b.Cid ='01'and c.Cid ='02' and b.score > c.score--1.2、查询同时存在"01"课程和"02"课程的情况和存在"01"课程但可能不存在"02"课程的情况(不存在时显示为null)(以下存在相同内容时不再解释)select a.* , b.score [课程"01"的分数],c.score [课程"02"的分数]from Student aleft join SC b on a.Sid = b.Sid and b.Cid ='01'left join SC c on a.Sid = c.Sid and c.Cid ='02'where b.score >isnull(c.score,0)--2、查询"01"课程比"02"课程成绩低的学生的信息及课程分数--2.1、查询同时存在"01"课程和"02"课程的情况select a.* , b.score [课程'01'的分数],c.score [课程'02'的分数]from Student a , SC b , SC cwhere a.Sid = b.Sid and a.Sid = c.Sid and b.Cid ='01'and c.Cid ='02' and b.score < c.score--2.2、查询同时存在"01"课程和"02"课程的情况和不存在"01"课程但存在"02"课程的情况select a.* , b.score [课程"01"的分数],c.score [课程"02"的分数]from Student aleft join SC b on a.Sid = b.Sid and b.Cid ='01'left join SC c on a.Sid = c.Sid and c.Cid ='02'where isnull(b.score,0) < c.score--3、查询平均成绩大于等于60分的同学的学生编号和学生姓名和平均成绩select a.Sid , a.Sname , cast(avg(b.score) as decimal(18,2)) avg_scorefrom Student a , sc bwhere a.Sid = b.Sidgroup by a.Sid , a.Snamehaving cast(avg(b.score) as decimal(18,2)) >=60order by a.Sid--4、查询平均成绩小于60分的同学的学生编号和学生姓名和平均成绩--4.1、查询在sc表存在成绩的学生信息的SQL语句。
select a.Sid , a.Sname , cast(avg(b.score) as decimal(18,2)) avg_score from Student a , sc bwhere a.Sid = b.Sidgroup by a.Sid , a.Snamehaving cast(avg(b.score) as decimal(18,2)) <60order by a.Sid--4.2、查询在sc表中不存在成绩的学生信息的SQL语句。