PDF乱码问题
解决vue-pdf查看pdf文件及打印乱码的问题

解决vue-pdf查看pdf⽂件及打印乱码的问题前⾔vue中简单使⽤vue-pdf预览pdf⽂件,解决打印预览乱码问题vue-pdf 使⽤安装npm install --save vue-pdf引⼊import pdf from "vue-pdf⾃定义封装pdf预览组件<template><el-dialog:visible.sync="pdfDialog":close-on-click-modal="false":show-close="false"width="900px"top="52px"><div class="pdf" v-show="fileType == 'pdf'"><p class="arrow"><!-- 上⼀页 --><span@click="changePdfPage(0)"class="currentPage":class="{ grey: currentPage == 1 }">上⼀页 </span><span style="color: #8c8e92;">{{ currentPage }} / {{ pageCount }}</span><!-- 下⼀页 --><span@click="changePdfPage(1)"class="currentPage":class="{ grey: currentPage == pageCount }"> 下⼀页</span> <button @click="$refs.pdf.print()">下载</button><spanstyle="float :right;padding-right:40px;font-size: 20px;color: #8c8e92;cursor: pointer;"@click="close"><i class="el-icon-close"></i></span></p><!-- loadPdfHandler:加载事件 src:需要展⽰的PDF地址;currentPage:当前展⽰的PDF页码;pageCount=$event:PDF⽂件总页码;currentPage=$event:⼀开始加载的页⾯--> <pdfref="pdf":src="src":page="currentPage"@num-pages="pageCount = $event"@page-loaded="currentPage = $event"@loaded="loadPdfHandler"></pdf></div></el-dialog></template><script>import pdf from "vue-pdf";export default {components: { pdf },props: ["src"],data() {return {filesProps: {label: "originName"},pdfDialog: false,currentPage: 0, // pdf⽂件页码pageCount: 0, // pdf⽂件总页数fileType: "pdf" // ⽂件类型};},methods: {// 改变PDF页码,val传过来区分上⼀页下⼀页的值,0上⼀页,1下⼀页changePdfPage(val) {if (val === 0 && this.currentPage > 1) {this.currentPage--;}if (val === 1 && this.currentPage < this.pageCount) {this.currentPage++;}},// pdf加载时loadPdfHandler() {this.currentPage = 1; // 加载的时候先加载第⼀页},handleOpen() {this.pdfDialog = true;},//关闭弹框close() {this.pdfDialog = false;}}};</script><style lang="stylus">.currentPage {cursor: pointer;color: #8c8e92;}.currentPage:hover {color: #2761ff;}.arrow{position: fixed;top: 0px;left :0px;z-index: 2;width: 100%;background-color: #191919;padding: 12px 0;margin: 0;text-align :center;}>>>.el-dialog__body {color: #606266;font-size: 14px;padding:0;}</style>使⽤<template><el-container><el-header><el-card><div><el-buttonstyle="font-style:oblique;font-size: 18px;"@click="handlePreviewFile">PDF 预览</el-button><el-buttonstyle="float: right;line-height: 40px;padding: 3px;"type="text"@click="handleSafetyExperience"><i class="el-icon-caret-left">返回</i></el-button></div></el-card></el-header><el-main><el-card class="card-style"><pdf-preview ref="pdfSearch" :src="src"></pdf-preview></el-card></el-main></el-container></template><script>import PdfPreview from "../widget/PdfPreview";export default {name: "InfoExperience",components: {PdfPreview},data() {return {src:"/public_assets/xuetangx/PDF/PlayerAPI_v1.0.6.pdf" };},created() {},methods: {handlePreviewFile() {this.$refs.pdfSearch.handleOpen();},handleSafetyExperience() {this.$router.push({ path: "/safetyApp/sharedExperience" });}}};</script><style scoped></style>预览效果点击下载打印预览预览出现乱码pdf打印乱码解决办法打开vue-pdf插件⽬录node_modules/vue-pdf/src/pdfjsWrapper.js解决办法乱码解决,打印预览正常修改后pdfjsWrapper.js源码以下为本⼈修改的pdfjsWrapper.js⽂件,亲测解决乱码问题import { PDFLinkService } from 'pdfjs-dist/lib/web/pdf_link_service';export default function(PDFJS) {function isPDFDocumentLoadingTask(obj) {return typeof(obj) === 'object' && obj !== null && obj.__PDFDocumentLoadingTask === true;}function createLoadingTask(src, options) {var source;if ( typeof(src) === 'string' )source = { url: src };else if ( src instanceof Uint8Array )source = { data: src };else if ( typeof(src) === 'object' && src !== null )source = Object.assign({}, src);elsethrow new TypeError('invalid src type');var loadingTask = PDFJS.getDocument(source);loadingTask.__PDFDocumentLoadingTask = true; // since PDFDocumentLoadingTask is not public if ( options && options.onPassword )loadingTask.onPassword = options.onPassword;if ( options && options.onProgress )loadingTask.onProgress = options.onProgress;return loadingTask;}function PDFJSWrapper(canvasElt, annotationLayerElt, emitEvent) {var pdfDoc = null;var pdfPage = null;var pdfRender = null;var canceling = false;canvasElt.getContext('2d').save();function clearCanvas() {canvasElt.getContext('2d').clearRect(0, 0, canvasElt.width, canvasElt.height);}function clearAnnotations() {while ( annotationLayerElt.firstChild )annotationLayerElt.removeChild(annotationLayerElt.firstChild);}this.destroy = function() {if ( pdfDoc === null )return;pdfDoc.destroy();pdfDoc = null;}this.getResolutionScale = function() {return canvasElt.offsetWidth / canvasElt.width;}this.printPage = function(dpi, pageNumberOnly) {if ( pdfPage === null )return;// 1in == 72pt// 1in == 96pxvar PRINT_RESOLUTION = dpi === undefined ? 150 : dpi;var PRINT_UNITS = PRINT_RESOLUTION / 72.0;var CSS_UNITS = 96.0 / 72.0;// var iframeElt = document.createElement('iframe');var printContainerElement = document.createElement('div');printContainerElement.setAttribute('id', 'print-container')// function removeIframe() {//// iframeElt.parentNode.removeChild(iframeElt);function removePrintContainer() {printContainerElement.parentNode.removeChild(printContainerElement);}new Promise(function(resolve, reject) {// iframeElt.frameBorder = '0';// iframeElt.scrolling = 'no';// iframeElt.width = '0px;'// iframeElt.height = '0px;'// iframeElt.style.cssText = 'position: absolute; top: 0; left: 0';//// iframeElt.onload = function() {//// resolve(this.contentWindow);// }//// window.document.body.appendChild(iframeElt);printContainerElement.frameBorder = '0';printContainerElement.scrolling = 'no';printContainerElement.width = '0px;'printContainerElement.height = '0px;'printContainerElement.style.cssText = 'position: absolute; top: 0; left: 0';window.document.body.appendChild(printContainerElement);resolve(window)}).then(function(win) {win.document.title = '';return pdfDoc.getPage(1).then(function(page) {var viewport = page.getViewport(1);// win.document.head.appendChild(win.document.createElement('style')).textContent =printContainerElement.appendChild(win.document.createElement('style')).textContent ='@supports ((size:A4) and (size:1pt 1pt)) {' +'@page { margin: 1pt; size: ' + ((viewport.width * PRINT_UNITS) / CSS_UNITS) + 'pt ' + ((viewport.height * PRINT_UNITS) / CSS_UNITS) + 'pt; }' + '}' +'#print-canvas { display: none }' +'@media print {' +'body { margin: 0 }' +'canvas { page-break-before: avoid; page-break-after: always; page-break-inside: avoid }' +'#print-canvas { page-break-before: avoid; page-break-after: always; page-break-inside: avoid; display: block }' +'body > *:not(#print-container) { display: none; }' +'}'+'@media screen {' +'body { margin: 0 }' +// '}'+//// '''}'return win;})}).then(function(win) {var allPages = [];for ( var pageNumber = 1; pageNumber <= pdfDoc.numPages; ++pageNumber ) {if ( pageNumberOnly !== undefined && pageNumberOnly.indexOf(pageNumber) === -1 )continue;allPages.push(pdfDoc.getPage(pageNumber).then(function(page) {var viewport = page.getViewport(1);// var printCanvasElt = win.document.body.appendChild(win.document.createElement('canvas'));var printCanvasElt = printContainerElement.appendChild(win.document.createElement('canvas'));printCanvasElt.setAttribute('id', 'print-canvas')printCanvasElt.width = (viewport.width * PRINT_UNITS);printCanvasElt.height = (viewport.height * PRINT_UNITS);return page.render({canvasContext: printCanvasElt.getContext('2d'),transform: [ // Additional transform, applied just before viewport transform.PRINT_UNITS, 0, 0,PRINT_UNITS, 0, 0],viewport: viewport,intent: 'print'}).promise;}));}Promise.all(allPages).then(function() {win.focus(); // Required for IEif (win.document.queryCommandSupported('print')) {win.document.execCommand('print', false, null);} else {win.print();}// removeIframe();removePrintContainer();}).catch(function(err) {// removeIframe();removePrintContainer();emitEvent('error', err);})})}this.renderPage = function(rotate) {if ( pdfRender !== null ) {if ( canceling )return;canceling = true;pdfRender.cancel();return;}if ( pdfPage === null )return;if ( rotate === undefined )rotate = pdfPage.rotate;var scale = canvasElt.offsetWidth / pdfPage.getViewport(1).width * (window.devicePixelRatio || 1);var viewport = pdfPage.getViewport(scale, rotate);emitEvent('page-size', viewport.width, viewport.height);canvasElt.width = viewport.width;canvasElt.height = viewport.height;pdfRender = pdfPage.render({canvasContext: canvasElt.getContext('2d'),viewport: viewport});annotationLayerElt.style.visibility = 'hidden';clearAnnotations();var viewer = {scrollPageIntoView: function(params) {emitEvent('link-clicked', params.pageNumber)},};var linkService = new PDFLinkService();linkService.setDocument(pdfDoc);linkService.setViewer(viewer);pdfPage.getAnnotations({ intent: 'display' }).then(function(annotations) {PDFJS.AnnotationLayer.render({viewport: viewport.clone({ dontFlip: true }),div: annotationLayerElt,annotations: annotations,page: pdfPage,linkService: linkService,renderInteractiveForms: false});});pdfRender.then(function() {annotationLayerElt.style.visibility = '';canceling = false;pdfRender = null;}).catch(function(err) {pdfRender = null;if ( err instanceof PDFJS.RenderingCancelledException ) {canceling = false;this.renderPage(rotate);return;}emitEvent('error', err);}.bind(this))}this.forEachPage = function(pageCallback) {var numPages = pdfDoc.numPages;(function next(pageNum) {pdfDoc.getPage(pageNum).then(pageCallback).then(function() {if ( ++pageNum <= numPages )next(pageNum);})})(1);}this.loadPage = function(pageNumber, rotate) {pdfPage = null;if ( pdfDoc === null )return;pdfDoc.getPage(pageNumber).then(function(page) {pdfPage = page;this.renderPage(rotate);emitEvent('page-loaded', page.pageNumber);}.bind(this)).catch(function(err) {clearCanvas();clearAnnotations();emitEvent('error', err);});}this.loadDocument = function(src) {pdfDoc = null;pdfPage = null;emitEvent('num-pages', undefined);if ( !src ) {canvasElt.removeAttribute('width');canvasElt.removeAttribute('height');clearAnnotations();return;}if ( isPDFDocumentLoadingTask(src) ) {if ( src.destroyed ) {emitEvent('error', new Error('loadingTask has been destroyed')); return}var loadingTask = src;} else {var loadingTask = createLoadingTask(src, {onPassword: function(updatePassword, reason) {var reasonStr;switch (reason) {case PDFJS.PasswordResponses.NEED_PASSWORD:reasonStr = 'NEED_PASSWORD';break;case PDFJS.PasswordResponses.INCORRECT_PASSWORD: reasonStr = 'INCORRECT_PASSWORD';break;}emitEvent('password', updatePassword, reasonStr);},onProgress: function(status) {var ratio = status.loaded / status.total;emitEvent('progress', Math.min(ratio, 1));}});}loadingTask.then(function(pdf) {pdfDoc = pdf;emitEvent('num-pages', pdf.numPages);emitEvent('loaded');}).catch(function(err) {clearCanvas();clearAnnotations();emitEvent('error', err);})}annotationLayerElt.style.transformOrigin = '0 0';}return {createLoadingTask: createLoadingTask,PDFJSWrapper: PDFJSWrapper,}}补充知识:vueshowpdf插件预览中⽂pdf出现乱码问题+pdf.js加载bcmap⽂件404报错vue项⽬中使⽤到pdf在线预览,使⽤了vueshowpdf,测试pdf是好好的,但是当上传到服务器出现预览的pdf乱码问题,很是纠结,⽹上找了好多资料没有,于是找找pdf相关的pdf预览乱码(中⽂乱码)问题解决⽅案。
PDF复制乱码问题解决方案

PDF 复制乱码问题解决⽅案
PDF 复制乱码问题解决⽅案
问题描述PDF 格式⽂件⼀般分为⽂字版和图⽚版:⽂字版⽂件较⼩,⽅便搜索,可以⽅便地转换成其他格式;⽽图⽚版⽂件较⼤,可防⽌他们直接复制。
⽽今天要说的⽂字版本却⽆法搜索,这给⽂件使⽤带来了极⼤的不便。
主要表现为:
(1)⽂件较⼩,⽂字可选择;
(2)⽂字可复制,复制的结果为乱码,如下图的"基础"⼆字,粘贴的结果是"!"";
(3)⽆法复制,很急⼈;
(4)编辑时,格式中的字体是显⽰"乱码";
在菜单栏[⽂档]-[属性]-[字体]中,可以看到有较多已嵌⼊了⾃定义编码字体,这是发布者处理的,以防⽌复制和搜索,⼀般是⼀种不可逆的操作。
解决⽅案
⽹络上⼤多的解决⽅案是使⽤ABBYY OCR 来识别,重新编排⼀份⽂档,但这样的效率还是很慢,特别是当⽂件分辨率并不⾼的情况下。
通过测试发了⼀种⽅案。
具体操作如下:
先⽤Adobe Acrobat 打开⽂件,使⽤印刷制作⼯具
打开印前检查进⾏PDF 修正,通过分析和处理,将字体转为空⼼。
修正后,使⽤扫描和OCR ⼯具"增强",进⾏识别处理后,保存即可。
这样的操作⽅法简单,速度较快,结果正确,⽆需进⾏核查。
Win7系统打开PDF文件后出现乱码解决办法

Win7系统打开PDF文件后出现乱码解决办法
有Win7系统用户反映说下载安装了一个PDF阅读器后,打开PDF文件都是乱码,这是怎么回事呢?为什么PDF文件打开后全是乱码呢?怎么办呢?今天呢,小编就为大家推荐Win7系统打开PDF文件后出现乱码解决办法,希望能帮到大家哦~
解决办法如下:
为了解决pdf显示乱码的问题,我们需要在百度中搜索下载一款具有pdf编辑或查看功能的工具,如图所示:
1、首先下载一款pdf编辑或查看功能的工具,如迅捷pdf编辑器;
2、使用迅捷pdf工具打开pdf文档后,点击“文件”-“文件属*”项,即可进入“文档属*”界面。
3、从打开的“文档属*”窗口中,切换到“安全*”选项卡,在此就可以看到当前pdf所支持和需要的文字名称列表和类型了。
4、找到不能正常显示的字体,然后在百度中搜索下载对应的字体。
将字体解压后,右击对应的字体选择“安装”即可,或者将字体拷贝到如图所示的目录中也可以。
5、此外,也与大家分享一下有关pdf图文识别的方法,如果pdf 中包含图片文字,我们可以借助如图所示的“OCRPDF识别”工具来实现。
6、如图所示,选择相应的pdf文档后,对其转换后的文件格式进行设置,最后点击“开始识别”按钮将自动完成整个识别过程。
latex_hyperref_生成PDF书签乱码的解决方案范文

latex_hyperref_生成PDF书签乱码的解决方案范文gbk2uni使用方法如下:Linu某命令行编译顺序如下:$late某main.te某$bibte某main.te某$late某main.te某$gbk2unimain.out$late某main.te某$dvipdfmmain.dviDOS用批处理编译的话与些相似(省略了扩展名):late某mainbibte某mainlate某maingbk2unimainlate某maindvipdfm某main参考链接:1./te某.html2.gbk2uni的问题解决方案Late某HyperrefCharetTool注意此文档必须使用UTF-8编码1检查您机器上的java环境是否正确(需求:JRE/JRE1.5+)。
2将Charet2Unicode.cla文件放入与此文件相同的目录下。
3执行编译(建议编写批处理文件)。
t_UTF-8是文件名(省略后缀)编译结果(运行t_UTF-8.pdf)可见PDF一切正常。
包通常要求放在导言区的最后!!!%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%正文%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%\begin{document}\ begin{CJK某}{GBK}{ong}\tableofcontent%目录\ection{中华\{哈\}人民共和国}\ubection{1}\ection{二}\ubection{1}\ububection{1}这是中文。
``哈哈''。
pdf字体乱码的解决方法__概述说明以及解释

pdf字体乱码的解决方法概述说明以及解释1. 引言1.1 概述本篇文章旨在探讨解决PDF字体乱码问题的有效方法。
随着信息技术的快速发展,PDF已成为一种广泛应用于电子文档交流和存储的常见格式。
然而,由于不同系统、软件和设备之间的差异,有时会出现PDF字体乱码的情况,给用户带来不便。
因此,了解和解决这一问题对提高用户体验和文档可读性具有重要意义。
1.2 文章结构本文将分为四个部分进行论述。
首先,在引言部分将简要概述文章内容,并介绍各部分的组织结构。
其次,在正文部分将详细讨论PDF字体乱码问题的定义和原因。
然后, 提供几种主要的解决方法:安装正确的字体、使用PDF编辑工具修复字体乱码问题、转换PDF文件格式以及在线字体修复工具。
最后,在结论部分对这些解决方法进行总结评价,并探讨可能存在的限制和局限性,同时展望未来解决PDF字体乱码问题的发展方向。
1.3 目的本文旨在为遭遇PDF字体乱码问题的读者提供一些实用有效的解决方法。
通过了解字体乱码问题的原因和解决方案,读者将能够更好地处理类似的情况并确保文档在不同设备和系统上都能正确显示。
此外,本文还将为相关研究、软件开发和技术改进提供参考,推动PDF字体乱码问题解决方法的进一步发展。
2. 正文:2.1 什么是PDF字体乱码PDF字体乱码是指在打开或查看PDF文件时,文字内容无法正确显示或变成了乱码或方框等符号。
这种情况常常发生在跨平台或跨系统查看PDF文件时,尤其是当文件中使用的字体在系统中不存在或未正确嵌入到PDF文件中时。
2.2 导致PDF字体乱码的原因导致PDF字体乱码的原因有多种可能。
首先,如果PDF文件中使用的字体没有被嵌入到该文件中,而只是依赖于系统中存在的字体,则在不同系统上打开该文件时就会导致字体无法正常显示。
其次,如果所用的字体缺失、损坏或过期,也会导致相应的乱码问题。
此外,在转换或创建PDF文件时选择不正确的设置、选项或工具也可能造成字体乱码。
电脑乱码问题的解决方案

电脑乱码问题的解决方案引言概述:在使用电脑过程中,我们有时会遇到乱码问题,这给我们的工作和生活带来了很多不便。
乱码问题的出现可能是由于编码不一致、字符集不匹配或者软件设置问题等原因所导致。
本文将为大家介绍一些常见的电脑乱码问题的解决方案,帮助大家更好地解决这一问题。
一、检查系统和软件编码设置1.1 系统编码设置首先,我们需要检查操作系统的编码设置。
在Windows系统中,我们可以通过以下步骤进行设置:控制面板 -> 区域和语言选项 -> 高级选项 -> 更改系统区域设置。
在弹出的窗口中,我们可以选择合适的语言和地区,确保其与我们所使用的软件和文档编码一致。
1.2 软件编码设置除了系统编码设置,我们还需要检查所使用的软件的编码设置。
不同的软件可能有不同的设置位置,但通常可以在软件的“选项”或“设置”菜单中找到相关选项。
我们应该确保软件的编码设置与系统的编码设置一致,以避免乱码问题的发生。
1.3 文档编码设置在处理文档时,我们还需要注意文档的编码设置。
在常见的文档编辑软件中,我们可以在“保存”或“导出”选项中找到相关设置。
确保文档的编码设置与系统和软件的编码设置一致,可以有效避免乱码问题的出现。
二、选择合适的字符集2.1 Unicode字符集Unicode字符集是一种全球通用的字符编码标准,它包含了世界上几乎所有的字符。
在处理多语言文本时,我们应该优先选择Unicode字符集,以保证文字的正确显示。
2.2 UTF-8编码UTF-8是一种可变长度的Unicode编码,它可以表示任意字符,并且向后兼容ASCII编码。
在保存文本文件时,我们可以选择UTF-8编码,以确保文本的正确显示。
2.3 GBK编码对于中文文本,我们可以选择使用GBK编码。
GBK是一种中文字符集编码,它包含了常用的中文字符。
在处理中文文本时,我们可以选择GBK编码,以避免中文乱码问题的发生。
三、更新和安装字体3.1 更新系统字体有时,电脑乱码问题可能是由于缺少或损坏的字体文件所导致的。
pdf使用了cjk字符,读取时乱码。(解决方法)

pdf使用了cjk字符,读取时乱码。
(解决方法)pdf使用了cjk字符,读取时乱码。
(解决方法)一个pdf文档,用Adobe Reader(高版本也试过)打开后提示如下:“您的pdf文档使用了cjk字符。
您必需在您的foxit应用程序文件夹安装fpdfcjk.bin文件,否则某些cjk字符将不能正确被显示。
您可以从下载该文件。
”点击确定后,你会看到,这个pdf文档里的内容大部分都是乱码,无法阅读。
现在来看看为什么会出现这样的问题:cjk是Chinese, Japanese & Korean的缩写,这样看来,pdf文档里包含了中国、日本、韩国三个国家的文字,而Adobe Reader里没有相应的显示这些文字的字体。
所以显示出来的都是乱码。
看到上面的提示,我们可以去那个网站下载相应的软件或文件安装来解决。
就下载Foxit Reader(现在出的是3.0版的),FREE VIEWER版的就行。
下载后安装,后用foxit reader打开这个pdf文档,这时软件会提示需要安装一个插件(就是显示cjk字符的),点击下载后自动安装,完成后,你就可以看这个pdf文档了。
cjk相关知识:CJK:中日韩统一表意文字(CJK Unified Ideographs),目的是要把分别来自中文、日文、韩文、越文中,本质、意义相同、形状一样或稍异的表意文字(主要为汉字,但也有仿汉字如日本国字、韩国独有汉字、越南的喃字)于ISO 10646及Unicode标准内赋予相同编码。
《CJK统一汉字编码字符集》—国家标准GB13000.1 是完全等同于国际标准《通用多八位编码字符集(UCS)》ISO 10646.1。
《GB13000.1》中最重要的也经常被采用的是其双字节形式的基本多文种平面。
在这65536个码位的空间中,定义了几乎所有国家或地区的语言文字和符号。
其中从0x4E00到0x9FA5 的连续区域包含了20902 个来自中国(包括台湾)、日本、韩国的汉字,称为CJK (Chinese Japanese Korean) 汉字。
pdf打印乱码问题

pdf打印乱码问题问题:使⽤Adobe Reader将⼀份pdf⽂件通过我的虚拟打印机输出后(输出的是中间⽂件,等同于EMF⽂件),查看的时候发现有时候是乱码。
最简单的必现步骤:1、使⽤Adobe Reader打开pdf⽂件,选择我的虚拟打印机打印(取消掉adobe打印⾼级选项中“作为图像打印”),⽣成中间⽂件。
2、此时可以通过⼯具查看这个中间⽂件(EMF),发现并没有乱码。
3、关闭刚才打印的Adobe Reader打开的Pdf⽂件,再次查看中间⽂件,这时候就乱码了。
分析:根据上⾯的必现步骤,再测试使⽤FoxitReader、JisuPdf打开pdf⽂件然后选择我的虚拟打印机打印,都没有复现。
此外,⽣成中间⽂件后,即使重新⽤Adobe Reader打开pdf,查看中间⽂件的时候,仍然是乱码。
根据上述现象,去对⽐使⽤JisuPdf和Adobe Reader执⾏打印后⽣成的中间⽂件的区别,发现存在⽐较⼤的区别。
猜测Adobe Reader在打印输出的时候为不存在的字体创建了临时字体⽂件,所以Adobe Reader在没关闭的时候查看不会乱码,⼀旦关闭了就删掉了临时⽂件,所以就乱码了。
⽐如我第⼀次输出的是中⽂⽂件A,不关闭Adobe Reader,查看A正常。
关闭Adobe Reader查看A乱码,再次打开Adobe Reader并打印出B,查看A乱码,B不乱码。
由此说明,创建的这个临时字体⽂件,还是和对应的中间⽂件相关联的,并不是所有的都⼀样。
我分别⽐较上述A和B⽂件内容上的区别,发现其中⼀个区别就是EMR_EXTCREATEFONTINDIRECTW结构中的字段不⼀样,⽽且有个⽐较明显的字段内容lfFaceName不⼀样。
查看MSDN上对EMR_EXTCREATEFONTINDIRECTW的介绍,基本可以确定就是Adobe Reader在打印输出这个pdf⽂件的时候创建了临时字体⽂件,所以⼀旦Adobe Reader进程关闭了,就会删除临时字体⽂件导致中间⽂件乱码。
手机PDF档中文支持(乱码问题)解决攻略

手机PDF档中文支持(乱码问题)解决攻略俺是Mini5新手,但是用安卓已经挺长时间了。
俺买Mini5主要动因之一就是为了看书,不过我发现目前我找到的PDF阅读软件对中文的支持都不好。
比如我附件里面这本书,从来没有在任何安卓设备上能正常显示。
曾经求推一个真正好的PDF阅读软件,至少能读我附件中的这个文件。
后来发现求人不如求己,通过网络查询,找到了解决办法。
这里分享给大家。
过程不算很麻烦。
一本书2-3分钟搞定。
我说的比较细点,其实操作非常简单的。
PDF文件自身是可以嵌入字体的,这样就可以在任何语言的设备上直接阅读,而不用考虑该设备上是否有相应的字体。
但是PDF文件有时候为了尽量做得小,创制的时候会选择不嵌入字体,这时候PDF 阅读软件就会到你的电脑/手机/平板中去找相应的字体,如果有,显示就正常;如果没有,就会悲剧性的看到乱码。
因此,如果你发现某个PDF文档有乱码,一定是由于文档自身指定了显示用的字体,但是没有在文件中内嵌,而你的阅读设备又没有这个字体,就会显示出乱码。
解决的办法就是重新生成一遍这个pdf文档,在此过程中嵌入文档相应的字体在文档本身,这样字体就包含在文档中跟着文档走了,就不会产生乱码。
具体方式是:1. 在PC上安装Adobe Acrobat Professional软件。
注意这个软件是编辑PDF用的,不是我们常用的那个免费软件Acrobat Reader (它仅仅是用来阅读pdf文档的)。
安装完以后,你就会发现自己的电脑多了一个打印机,叫做“Adobe PDF”,这是一个虚拟打印机,如果你在任何软件中指定这个打印机打印,实际效果就是将被打印的文档变成一个pdf文档并保存在电脑中。
当然,原来就是Pdf文档的,在编辑后也可以用这个打印机重新“打印”为一个新的pdf文档。
2. 检查在PC上该文档是否显示正常。
用Adobe Acrobat Professional软件打开那个(在你的手持设备上)出现乱码的pdf文档,先检查一遍在PC上是否显示正常,如果PC上显示都不正常,就说明你的电脑中没有相关的字体。
pdf文档乱码的解决方法

pdf文档乱码的解决方法
PDF文档乱码是一个常见的问题,这可能是由于文件损坏、转换程序出错等原因引起的。
本文将提供一些常见的解决方法,帮助您解决PDF文档乱码的问题。
**一、检查PDF文件本身**
首先,要确保您从可靠来源下载或保存的PDF文件是完整的。
有时,文件可能已损坏或损坏的部分恰好是乱码出现的地方。
在这种情况下,您可以尝试重新获取文件或使用另一份副本。
**二、使用可靠的PDF编辑工具**
如果您经常遇到PDF乱码问题,建议使用专业的PDF编辑工具,如Adobe Acrobat或其他支持PDF编辑的软件。
这些工具可以帮助您检查文件中的错误并修复它。
**三、检查转换程序**
如果您从其他格式(如Word文档)转换为PDF时出现乱码,请确保您使用的转换程序是可靠的,并且已经按照正确的方法进行操作。
如果您不确定如何正确转换文件,建议寻求专业帮助。
**四、尝试使用不同的阅读器**
有时,不同的PDF阅读器可能会对同一PDF文件有不同的显示效果。
尝试使用其他阅读器(如Google Chrome内置的PDF阅读器)来查看文件,看看是否仍然存在乱码问题。
**五、尝试修复或删除乱码**
如果以上方法都不能解决问题,您可以使用一些在线工具尝试修复乱码。
此外,如果您确定文件中的乱码是由于无法修复的错误引起的,您可以考虑删除乱码部分或咨询专业的文档清理服务。
总的来说,解决PDF文档乱码的问题需要耐心和细心。
尝试上述方法,大多数情况下都可以找到有效的解决方案。
如果问题仍然存在,请寻求专业的帮助。
obsidian 阅读pdf注释乱码

Obsidian 是一款笔记软件,它使用Markdown 语法来记录笔记,并
支持添加附件。
如果你在Obsidian 中阅读PDF 注释时遇到乱码问题,可能是由于以下原因:
1.字体问题:PDF 中使用的字体可能在Obsidian 中没有正确地
渲染。
你可以尝试更换PDF 文件或使用不同的字体。
2.编码问题:PDF 文件的编码可能与Obsidian 使用的编码不匹
配。
你可以尝试在Obsidian 中转换编码,或者使用其他软件打
开PDF 文件查看注释是否正常。
3.软件兼容性问题:Obsidian 是一款相对较新的软件,可能存在
与某些PDF 阅读器或注释工具的兼容性问题。
你可以尝试使用
其他PDF 阅读器或注释工具打开PDF 文件,看看是否也存在
乱码问题。
如果以上方法都无法解决问题,你可以尝试联系Obsidian 的技术支持或查看其官方论坛,看看是否有其他用户遇到了类似的问题并提供了解决方案。
转换pdf文件时出现乱码怎么办
转换pdf文件时出现乱码怎么办如今PDF最为一种新型的文档格式越来越多的受到人们的关注,很多朋友在工作和学习上经常会使用到PDF转换器。
然而,网络上的PDF转换工具各式各样,很多用户在选择时会感觉到无从下手。
据调查发现,尽管网上的转换软件数不胜数,绝大多数的PDF转换软件在转换技术上却存在很大的分歧,尝试过上述转换方法的用户,基本上都会发现这样的问题,转换出来的Word文件内容经常出现乱码、图片缺失和文字样式缺失等一系列的问题。
针对什么样的PDF转换软件好,对于JPG转换成PDF来说,先进的识别技术和完美转换效果是绝对不可忽视的重要因素。
但大部分的PDF转换器缺乏强大的技术支持,加上相对薄弱的识别技术,根本无法正确识别PDF文本,以至于出现了以上这些情况。
转换pdf文件时出现乱码怎么办——PDF转换软件是当前在PDF识别率技术上出现重大突破的转换工具。
PDF转换软件是一款专业针对PDF 文件进行解析和转换的工具,其软件识别率的提升得益于软件内置的PDF 标准文件解析技术。
通过PDF标准文件解析技术的处理,软件可以对PDF 文件内容进行深度识别,并解析PDF文件当中的文字、图片、样式以及排版等多种元素,迅速实现完美转换。
从实际测试使用的过程当中我们可以发现,采用了PDF标准文件解析技术的迅捷PDF转换软件,其实际转换效果表现非常出色,转换前后两个不同格式的文件内容高度一致,完全无需再安排新的检查和修改,从而节省了大量的时间和人力的投入。
先进的技术应用和保障,贴合用户需求的高质量的转化效果,软件更加完美的诠释了一个PDF转换器软件应该要达到的高度和它的使命,最佳二字迅捷当之无愧。
总结:试用过PDF转换软件之后,所转换出来的文件内容基本保持一致。
在转换的过程中,文件内容并没有出现失真和资料丢失的问题。
这点,对于讲究文件完整性的用户而言显得非常的重要。
pdf转html格式乱了怎么办?聪明人私藏了这种方法
pdf转html格式乱了怎么办?你们是不是也遇到过这种问题呢?其实这样的转换乱码问题一般会有俩种,一种是PDF文件本身的问题,那我们可以在转换之前检查下文件,那么另外一种问题是转换方法,下面的PDF转HTML的操作方法建议你看下,希望对你有所帮助。
操作工具:迅捷PDF转换器
具体操作如下:
1、首先为了转换的便捷性,我们需要打开一个如图所示的PDF 转转换工具,然后选择【文档转换】以下的转换功能【PDF转HTML】。
2、再从设置中设置需要的转换参数,如图所示的页面设置栏。
3、然后将我们的PDF文件添加到转换工具中。
4、添加完成后会进入转换中,如图所示的转换进度条,等待蓝色进度条被填满即为转换完成。
5、转换结束后,点击【立即下载】将转换后的HTML文件下载。
6、ok~如图所示的文件以被成功转换成HTML文件了。
好了,关于PDF转HTML的操作就分享到这里了,你们是否也成功完成了PDF转HTML的转换操作呢?其实转换操作很简单,希望本次分享的内容可以帮助到你们!。
公文乱码问题解决方案

公文乱码问题解决方案
(注:此操作针对发文单位)
很多单位收到公文,在系统里打开正常,下载到电脑用PDF阅读器打开后,文头就不见了,或者变成了乱码,这是因为发文单位在发文过程中,由于字体的限制,没有嵌入到公文文件里而造成的。
(注:正版的方正字体是禁止嵌入到PDF、PPT等文件,必须经过修改的字体才能嵌入,字体管家软件安装的都是正版字体,默认是禁止嵌入的)字体文件在电脑上的安装位置在:
C:\Windows\Fonts
打开此文件夹,找到方正小标宋字体,点击鼠标右键,选择属性,点击详细信息,如下图:
字体嵌入性显示“可安装的”,证明字体就是可以嵌入的,发文会正常;如果显示“受限的”,证书字体不可以被PDF文档嵌入,发文就会造成乱码。
请大家下载安装群共享字体,方正小标宋简体_可嵌入(请大家使用此版本).zip安装方正小标宋字体。
解压后将
字体文件复制到C:\Windows\Fonts下,即可完成安装。
pdf查重乱码

pdf查重乱码PDF文件作为一种常见的电子文档格式,广泛应用于学术研究、商业交流、文件存档等领域。
然而,在使用PDF文件进行查重时,很多人都遇到过乱码的问题。
本文将探讨PDF查重乱码问题的原因,并提供解决方案。
一、乱码问题的原因PDF文件查重乱码问题主要源于以下几个方面:1. 字体缺失:当使用不同的电脑、操作系统或PDF阅读器打开同一个PDF文件时,可能会出现字体缺失的情况。
因为PDF文件中的文字是通过嵌入的字体来显示的,如果打开PDF文件的设备上没有该字体,就会导致乱码问题的发生。
2. 字符编码不一致:不同的语言使用不同的字符编码,如果在制作PDF文件时选择了错误的字符编码,或者在打开PDF文件时选择了错误的字符编码,就会导致文字显示出错,从而出现乱码。
3. 文字转换错误:在生成或编辑PDF文件的过程中,如果将其他格式的文档转换为PDF时没有正确处理文字编码或格式,就会导致文字显示错误,乱码问题也会显现出来。
二、解决方案针对PDF查重乱码问题,可以采取以下几种解决方案:1. 安装字体:根据乱码文字所使用的字体,在网上下载对应的字体文件,并安装到电脑或设备中。
这样,在打开PDF文件时就能够正确显示文字,解决乱码问题。
2. 更换阅读器:尝试使用不同的PDF阅读器打开文档,选择一款兼容性好的阅读器,能够更好地识别和显示PDF文档中的文字,减少乱码问题的出现。
3. 导出为其他格式:如果无法通过以上两种方法解决乱码问题,可以尝试将PDF文件导出为其他格式,比如Word或纯文本文件。
然后再进行查重操作,这样可以避免乱码问题的干扰。
4. 使用专业查重软件:有些专业的查重软件支持直接对PDF文件进行查重,能够自动处理乱码问题,提高查重结果的准确性。
选择适合自己需求的查重软件进行操作,可以避免乱码问题的烦恼。
综上所述,PDF查重乱码问题是由字体缺失、字符编码不一致和文字转换错误等原因引起的。
为解决乱码问题,可以安装字体、更换阅读器、导出为其他格式或使用专业查重软件等方法。
mpdf导出pdf,中文符号乱码
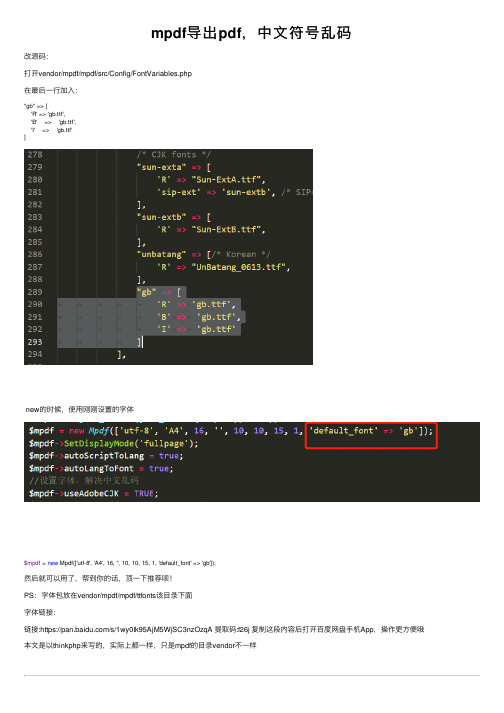
mpdf导出pdf,中⽂符号乱码改源码:打开vendor/mpdf/mpdf/src/Config/FontVariables.php在最后⼀⾏加⼊:"gb" => ['R' => 'gb.ttf','B' => 'gb.ttf','I' => 'gb.ttf']new的时候,使⽤刚刚设置的字体$mpdf = new Mpdf(['utf-8', 'A4', 16, '', 10, 10, 15, 1, 'default_font' => 'gb']);然后就可以⽤了,帮到你的话,顶⼀下推荐呗!PS:字体包放在vendor/mpdf/mpdf/ttfonts该⽬录下⾯字体链接:链接:https:///s/1wy0Ik95AjM5WjSC3nzOzqA 提取码:f26j 复制这段内容后打开百度⽹盘⼿机App,操作更⽅便哦本⽂是以thinkphp来写的,实际上都⼀样,只是mpdf的⽬录vendor不⼀样还有⼀个版本,就莫名奇妙的。
⾸先在路径:vendor\mpdf\mpdf\ttfonts放⼊微软雅⿊字体然后代码1/**2 * 导出报告3 * @param string $filename ⽂件名.pdf4 * @param string $content ⽂件内容5 * @param string $type D下载,F保存,I浏览器直接打开。
默认下载6*/7public static function exportToPdf($filename, $content, $filePaht, $type = 'D') 8 {9$noName = ['/', '\\', ':', '*', '"', '<', '>', '?'];10$filename = str_replace($noName, '_', $filename);11if (!is_dir($filePaht) && $type == "F") {12mkdir($filePaht);13 }14$mpdf = new Mpdf(['utf-8', 'A4', 16, '', 10, 10, 15, 1, 'default_font' => 'gb']); 15$mpdf->SetDisplayMode('fullpage');16$mpdf->autoScriptToLang = true;17$mpdf->autoLangToFont = true;18$mpdf->useAdobeCJK = true;19$mpdf->WriteHTML($content);20$mpdf->Output($filePaht . "/" . $filename . ".pdf", $type);21 }。
使用com.aspose.words将word模板转为PDF乱码解决方案

使⽤com.aspose.words将word模板转为PDF乱码解决⽅案
原因分析:在window下没有问题但是在linux下有问题,就说明不是代码或者输⼊输出流编码的问题,根本原因是两个平台环境的问题。
出现乱码说明linux环境中没有相应的字体以供使⽤,所以就会导致乱码的出现。
解决办法:将windos主机中的字体拷贝到linux平台下进⾏安装,重启服务器后转换就不会出现乱码了。
1.windows系统
windows下字体库的位置为C:\Windows\fonts,这⾥⾯包含所有windows下可⽤的字体。
2.liunx系统
linux的字体库是 /usr/share/Fonts 。
在该⽬录下新建⼀个⽬录,⽐如⽬录名叫 windows(根据个⼈的喜好,⾃⼰理解就⾏,当然这⾥是有权限要求的,你可以⽤sudo来执⾏)。
然后将 windows 字体库中你要的字体⽂件复制到新建的⽬录下(只需要复制*.ttc,和*.ttf的⽂件).
注:传⽂件可以使⽤FileZilla Client⼯具,或者敲命令
在liunx系统下更改这些字体库的权限:
sudo chmod 755 /usr/share/fonts/windows/*
重启 Linux 操作系统就可以使⽤这些字体了。
用Acrobat修复因缺少内嵌字体而乱码的PDF文件

用Acrobat修复因缺少内嵌字体而乱码的PDF文件前言最近在阅读一本电子书的时候发现PDF 文件中只要是英文、数字、空格的位置都是乱码,影响阅读。
这应该是PDF 文档没有将所需要的所有字体内嵌到文档中,缺少字体导致的。
比如某东的电子发票在不同的 PDF 阅读软件上打开会出现不同的字体。
这里分享一下修复文档的整个过程。
需要软件•Adobe Acrobat Pro DC 2020•文件中尚未内嵌的字体(方正EU系列)检查字体缺失PDF 文档出现乱码,首先要检查是否是缺失字体。
用 Acrobat 打开PDF 文件,菜单栏选择“文件”、“属性”、“字体”选项卡,可以看到该 PDF 文档中使用的所有字体。
已内嵌文档的字体会显示“(已嵌入)”,未嵌入的字体,如图中的EU-BX.ttf字体是方正的西文“白斜”字体,由于不同的PDF 阅读器遇到字体缺失后会选择一个缺省字体替代,而不同字体的字符集不同,所以会出现乱码的情况。
缺失字体修复首先找到缺失的字体文件,安装到电脑中。
一般来说,安装好缺失字体后再用PDF 阅读器查看文档就不会乱码,文档恢复正常。
但是PDF 文件是跨平台的便携式文档,如果要在其它设备上不出问题还是要将所需的字体全部嵌入。
回到 Acrobat 的“主页”,添加“印刷制作”工具。
打开要修复的文件,在右侧工具栏选择“印刷制作”、“印前检查”。
“印前检查”选择“PDF 修正”、“嵌入缺失的字体”,然后点击“分析和修复”,保存修复后的文件,稍等一会。
经过一小段时间的修复,如果最终的结果是“没有找到问题”说明文件已成功修复。
打开修复后的文件,查看文档属性,缺失的字体已经嵌入,可以正常显示。
修复前后的扉页吐槽PDF 文件格式相当灵活,各种编译器、阅读器在实现上没有统一的标准,所以导致PDF 文件容易出现各种奇奇怪怪的问题。
比如某文档扫描 App 生成的 PDF 无法用 Python 的 PyPDF 编辑,报错原因是页码错误。
打印PDF乱码的解决办法

8.
来输入帐号和密码。帐号为校园卡号前补 0 满 8 位数, 如校园卡号为 1234,则帐号为 00001234,若卡号为 12345,则帐号为 00012345; 密码为校园卡密码。
注意:在公用电脑上请不要绑定帐号和密码
打印 PDF 乱码的解决办法
1. 首次使用时先下载联创自助打印驱动程序( “帮助中心”→“常用软件下载”)
2. 双击 联创校园自助打印驱动.exe,会弹出如下界面:
3. 完成后输入帐号和密码。帐号为校园卡号前补 0 满 8 位数,如校园卡号为 1234, 则帐号为 00001234,若卡号为 12345,则帐号为 00012345;密码为校园卡密 码。如下图所示:
注意:在公用电脑上请不要绑定帐号和密码
来源 Windows8 论坛:
4. 点确定,配置完成。出现以下窗口 5. 按正常打印操作过程打印文件,如:
来源 Windows8 论坛:
6. 点击 打印 会弹出如下界面:
7. 点击 属性 可配置纸张方向(纵向或者横向打印)和彩色或者黑白打印,默认 为纵向黑白打印。打印纸张默认为 A4 纸,若要打印 A3 纸,请在“页面设置” →“纸张”,将纸张大小设为 A3。
4、点击“确定”,设置完成。再点击“确定”,打印 PDF 文件。 来源 Windows8 论坛:
4. 点确定,配置完成。出现以下窗口 5. 按正常打印操作过程打印文件,如:
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
你是否也曾纠结pdf复制到word格式混乱的问题
要做毕设了,要写论文了,可是几乎所有从网上找到的文献资料都是pdf格式的。
你想复制其中几段文字到word里面却发现经常出现各式各样格式混乱的问题。
比如原来首行有缩进2个字符的现在都是清一色的顶格,而且都不能占满全行,字体和大小也变了。
每次都老老实实的手动修改,花费时间和精力,丝毫没有技术含量纯粹的体力劳动。
纯手工打造不值得炫耀,老师也不会给你加分。
在几位朋友的启发下自己进行了一番摸索,发现word知识果然博大精深。
虽然不能一劳永逸,但是相比原来手工修改的方式还是要方便很多。
谈不上自动,半自动范畴还是可以的。
解决的办法是:
1、把在本来就应该换行的地方前面做标记比如输入MM(因人而异)
2、然后把所有的换行都去掉。
做法是在“编辑”菜单下的“替换”中的“查找内容”输入^p(如果是从网页上粘贴过来的则输入^l),然后在“替换为”里面什么都不输。
点全部替换,确定。
接着在“查找内容”输入MM(与第1步的对应),在“替换为”里面输入^p。
然后就大功告成了,最后再修改一下字体、大小及行间距等。
但是如果每一次粘贴都要修改字体、大小、行间距等毕竟还是比较麻烦。
这里介绍一种稍微复杂一点的方法:宏。
什么是宏呢?其实就是一个常用的设置或者快捷方式。
打个比方就是餐厅里的套餐,你去一个餐厅吃饭的时候只要说牛肉汤套餐就可以了,而不必要说“我要牛肉汤+青菜+鸡蛋+饭”。
你设置了一个宏之后,下次只要点一下这个宏,格式就会自动转化为之前相应的设置(比如说一般可以是5号宋体,1.5倍行距,黑色)。
那怎么设置宏呢?(以07版word为例)
1、点击“视图”,在活动窗口的最右边有一个“宏”,点击宏下拉菜单里的“录制宏”
2、写个宏的名称以及说明,如果你要多设置几个宏的话最好说明一下这个宏的功能,以防混淆。
3、接下来这几步是为了解决刚才上面提到的pdf转word遇到的问题。
步骤与之前介绍的一样。
在“编辑”菜单下的“替换”中的“查找内容”输入^p(如果是从网页上粘贴过来的则输入^l),然后在“替换为”里面什么都不输。
点全部替换,确定。
清空“查找内容”和“替换为”,接着在“查找内容”输入MM(因人而异),在“替换为”里面输入^p。
4、“开始”菜单下的“编辑”里选择“全选”,在开始菜单里设置好字体、字大小、行间距等你希望的参数。
5、回到“视图”最右端“宏”的下拉菜单,点击“停止录制”。
6、接下来开始设置这个宏的快捷键。
点击最左上角的office按钮,在右下角有一个“word 选项”,点开后点击里面的“自定义”按钮,点击上方“常用命令”的下拉菜单下的“宏”,选中后点中间的“添加”。
点击确定。
然后你就会发现在最上方“保存”快捷键和“前进”“后退”快捷键的边上有了一个新的快捷键。
这个就是“宏”的快捷键。
以上几步只要一次设置好后就一劳永逸了。
但是在每次把pdf上的内容复制过来后,这一步千万不要忘记!一定要在本来就应该首行缩进(即新的一段)的地方输入MM(与之前设置的对应即可)。
最后再点击上方的“宏”快捷键,大功告成。
厄,不知道有没有说清楚,希望能给大家带来点便利。
ps:
1、最好每次开一个空白的word,专门用于复制pdf的内容,然后再复制到正式的文档里。
如果直接贴过来,然后点击“宏”快捷键的话,所有的内容都变为你之前设置好的格式。
2、还有一个专门转换不同文档的外国网站:/。
注册后,在网站上上传需要转换的文档,然后24小时内会发到你邮箱。
不过我没试过,因为感觉时效性太差。
这个网站的作用就是给你心理安慰:哦,原来全世界的人都会遇到这个问题。
相信我,你并不孤独……。