回归分析案例数据
一般线性回归分析案例

一般线性回归分析案例1、案例为了研究钙、铁、铜等人体必需元素对婴幼儿身体健康的影响,随机抽取了30个观测数据,基于多员线性回归分析的理论方法,对儿童体内几种必需元素与血红蛋白浓度的关系进行分析研究。
这里,被解释变量为血红蛋白浓度(y),解释变量为钙(ca)、铁(fe)、铜(cu)。
表一血红蛋白与钙、铁、铜必需元素含量(血红蛋白单位为g;钙、铁、铜元素单位为ug)case y(g)ca fe cu1 7.00 76.90 295.30 0.8402 7.25 73.99 313.00 1.1543 7.75 66.50 350.40 0.7004 8.00 55.99 284.00 1.4005 8.25 65.49 313.00 1.0346 8.25 50.40 293.00 1.0447 8.50 53.76 293.10 1.3228 8.75 60.99 260.00 1.1979 8.75 50.00 331.21 0.90010 9.25 52.34 388.60 1.02311 9.50 52.30 326.40 0.82312 9.75 49.15 343.00 0.92613 10.00 63.43 384.48 0.86914 10.25 70.16 410.00 1.19015 10.50 55.33 446.00 1.19216 10.75 72.46 440.01 1.21017 11.00 69.76 420.06 1.36118 11.25 60.34 383.31 0.91519 11.50 61.45 449.01 1.38020 11.75 55.10 406.02 1.30021 12.00 61.42 395.68 1.14222 12.25 87.35 454.26 1.77123 12.50 55.08 450.06 1.01224 12.75 45.02 410.63 0.89925 13.00 73.52 470.12 1.65226 13.25 63.43 446.58 1.23027 13.50 55.21 451.02 1.01828 13.75 54.16 453.00 1.22029 14.00 65.00 471.12 1.21830 14.25 65.00 458.00 1.0002、回归分析表2 变量说明表输入/移去的变量a模型输入的变量移去的变量方法1 cu, fe,ca b. 输入a. 因变量: yb. 已输入所有请求的变量。
回归经典案例

回归经典案例
回归分析是一种统计学方法,用于研究变量之间的关系。
以下是一个经典的回归分析案例:
假设我们有一个数据集,其中包含一个人的身高(height)和体重(weight)信息。
我们想要研究身高和体重之间的关系,以便预测一个人
的体重。
1. 首先,我们使用散点图来可视化身高和体重之间的关系。
从散点图中可以看出,身高和体重之间存在一定的正相关关系,即随着身高的增加,体重也会增加。
2. 接下来,我们使用线性回归模型来拟合数据。
线性回归模型假设身高和体重之间的关系可以用一条直线来表示,即 y = ax + b。
其中,y 是体重,x 是身高,a 和 b 是模型参数。
3. 我们使用最小二乘法来估计模型参数 a 和 b。
最小二乘法是一种优化方法,它通过最小化预测值与实际值之间的平方误差来估计模型参数。
4. 拟合模型后,我们可以使用回归方程来预测一个人的体重。
例如,如果我们知道一个人的身高为米,我们可以使用回归方程来计算他的体重。
5. 最后,我们可以使用残差图来检查模型的拟合效果。
残差图显示了实际值与预测值之间的差异。
如果模型拟合得好,那么残差应该随机分布在零周围。
这个案例是一个简单的线性回归分析案例。
在实际应用中,回归分析可以应用于更复杂的问题,例如预测股票价格、预测疾病发病率等。
回归分析数据案例

回归分析数据案例回归分析是一种用来研究变量之间关系的统计方法,在实际情况中有很多可以应用回归分析的案例。
下面以一个销售数据案例为例,详细介绍回归分析的应用。
某电商公司想要分析广告费用与销售额之间的关系,以便确定是否需要增加广告投入来提高销售额。
公司收集了一年的数据,包括每月的广告费用和销售额。
公司使用回归分析来研究广告费用和销售额之间的关系。
首先,需要确定自变量和因变量。
在这个案例中,广告费用是自变量,销售额是因变量。
然后,利用回归模型拟合数据,得到回归方程。
假设回归方程为:销售额= β0+ β1 * 广告费用其中,β0 是截距,表示在广告费用为 0 时的销售额;β1 是斜率,表示每单位广告费用对销售额的影响。
通过计算回归方程的参数,可以得到具体的值。
接下来,用实际数据计算回归方程的参数。
假设公司收集了一年的数据,总共 12 个月的广告费用和销售额。
通过回归分析软件,可以计算得到β0 和β1 的估计值。
假设计算结果为β0= 1000,表示当广告费用为 0 时,销售额约为 1000;β1 = 2,表示每多投入 1 单位的广告费用,销售额约增加 2。
通过计算回归方程的参数,可以预测未来的销售额。
假设公司计划增加下个月的广告费用为 5000,可以利用回归方程计算出销售额的预测值。
根据回归方程:销售额 = 1000 + 2 * 5000 = 11000预测出下个月的销售额为 11000。
公司还可以利用回归方程来评估广告费用对销售额的影响。
根据回归方程的斜率β1,可以计算出每单位广告费用对销售额的影响。
在这个案例中,β1=2,说明每多投入 1 单位的广告费用,销售额平均增加 2。
通过回归分析,公司可以了解广告费用和销售额之间的关系,判断是否需要增加广告投入来提高销售额。
如果回归方程的斜率显著大于 0,说明广告费用对销售额有显著的正向影响,公司可以考虑增加广告投入。
如果回归方程的斜率接近 0 或者小于 0,说明广告费用对销售额的影响较小或者负面,公司就需要重新评估广告策略。
回归分析案例数据

回归分析案例数据回归分析是一种常用的统计方法,用于研究自变量和因变量之间的关系。
在实际应用中,回归分析常常用来预测因变量的值,或者解释自变量对于因变量的影响程度。
本文将介绍一个回归分析案例,并使用相关数据进行分析和解释。
案例背景和问题描述:假设你是一家电子商务公司的数据分析员,你的公司销售各种产品,包括电子设备、家居用品等。
为了提高销售额,公司希望了解广告投入和销售额之间的关系。
为了解决这个问题,你收集了一年中各个季度的广告投入和销售额的数据,并准备进行回归分析。
数据收集和处理:作为数据分析员,你首先需要收集和处理数据。
你可以从公司财务部门获取广告投入和销售额的数据。
将数据整理为表格形式,以便进行分析。
这里我们使用示例数据,如下所示:季度广告投入(万元)销售额(万元)--------------------------------------------------1 10 302 12 353 8 284 15 40回归分析:数据整理完毕之后,你可以使用回归分析方法来分析广告投入和销售额的关系。
在本案例中,广告投入是自变量,销售额是因变量。
你可以使用统计软件或者编程语言进行回归分析,计算回归方程的系数和相关统计指标。
回归方程可以用来预测销售额,同时也可以解释广告投入对销售额的影响程度。
在本案例中,使用最小二乘法进行回归分析,你可以得到以下结果:回归方程:销售额 = 3.5 + 2 * 广告投入R方值:0.92解释回归方程:根据回归方程的结果,可以得出以下几点解释:1. 回归方程的截距项是3.5,表示即使没有广告投入,销售额也可以达到3.5万元。
这可能是由于公司已经积累了一定的品牌影响力,客户会主动购买产品。
2. 回归方程中广告投入的系数是2,表示每增加1万元的广告投入,销售额将增加2万元。
这说明广告投入对于销售额有显著的正向影响。
3. R方值为0.92,表示回归方程可以解释销售额变异的92%。
回归分析中的案例分析解读

回归分析是统计学中一种重要的分析方法,它用于探讨自变量和因变量之间的关系。
在实际应用中,回归分析可以帮助我们理解变量之间的相互影响,预测未来的趋势,以及解释一些现象背后的原因。
本文将通过几个实际案例,来解读回归分析在现实生活中的应用。
首先,我们来看一个销售数据的案例。
某公司想要了解广告投入对产品销量的影响,于是收集了一段时间内的广告投入和产品销量数据。
通过回归分析,他们得出了一个线性方程,表明广告投入对产品销量有显著的正向影响。
这个结论使得公司更加确定了增加广告投入的决策,并且在后续的实施中也取得了预期的销售增长。
接下来,我们来看一个医疗数据的案例。
一家医院想要探讨患者的年龄、性别、体重指数等因素对疾病治疗效果的影响。
通过回归分析,他们发现年龄和体重指数与治疗效果呈显著的负相关,而性别对治疗效果影响不显著。
这个研究结果为医院提供了重要的临床指导,使得医生们在治疗过程中更加关注患者的年龄和体重指数,以提高治疗效果。
除此之外,回归分析还可以应用在金融领域。
一家投资机构想要了解各种因素对股票价格的影响,于是收集了大量的股票市场数据。
通过回归分析,他们发现了一些关键的影响因素,比如市场指数、行业风险等,这些因素对股票价格都有一定的影响。
这些结论为投资机构提供了重要的决策参考,使得他们在投资过程中能够更加准确地评估风险和收益。
此外,回归分析还可以用于市场调研。
一家公司想要了解产品价格对销量的影响,于是进行了一次调研。
通过回归分析,他们发现产品价格与销量呈负相关关系,即产品价格越高,销量越低。
这个结论使得公司意识到自己的产品定价策略可能存在问题,于是他们调整了产品价格,并且在后续销售中取得了更好的效果。
总的来说,回归分析在实际生活中有着广泛的应用。
通过对一些案例的解读,我们可以看到回归分析在不同领域中的作用,比如市场营销、医疗、金融等。
通过回归分析,我们可以更加深入地了解变量之间的关系,从而为决策提供科学的依据。
财务回归分析案例

财务回归分析案例引言在财务领域中,回归分析是一种常用的统计方法,用于研究变量之间的关系。
通过回归分析,我们可以了解一个或多个自变量如何影响因变量,并得出模型的预测能力。
在本文中,我们将介绍一个财务回归分析的案例,以帮助读者更好地理解该方法在实际应用中的作用。
数据收集首先,我们需要收集相关的数据以进行财务回归分析。
在这个案例中,我们将使用一家零售公司的销售数据作为例子。
我们将收集以下数据:1.每个月的销售额(因变量)2.广告费用3.促销费用4.人力资源费用5.物流费用这些数据将帮助我们了解不同因素对销售额的影响,并建立一个回归模型来预测销售额。
数据处理在进行回归分析之前,我们需要对数据进行一些处理。
首先,我们需要将数据进行清洗,删除不完整或错误的数据。
然后,我们可以计算各个自变量之间的相关性,以确定是否存在多重共线性的问题。
如果存在多重共线性,我们需要考虑删除一些自变量或使用其他方法来解决该问题。
回归模型建立在确定了自变量和因变量之后,我们可以建立回归模型来分析它们之间的关系。
在本案例中,我们将使用多元线性回归模型来分析销售额与广告费用、促销费用、人力资源费用和物流费用之间的关系。
回归模型的基本形式如下:销售额= β0 + β1 * 广告费用+ β2 * 促销费用+ β3 * 人力资源费用+ β4 *物流费用+ ε其中,β0、β1、β2、β3、β4为回归系数,ε为误差项。
通过最小二乘法估计回归系数,我们可以得出模型的预测能力。
回归模型分析在得到回归模型后,我们可以进行一些分析以评估模型的有效性。
首先,我们需要评估模型的拟合程度,即模型对观察数据的解释能力。
常用的评价指标包括决定系数(R2)和调整决定系数(adj-R2)。
较高的决定系数表示模型能够较好地解释数据的变异性。
然后,我们可以通过t检验或F检验来判断自变量是否具有显著影响。
统计学上,显著性是指一个变量或模型与随机变量是显著不同的。
如果自变量的p值小于设定的显著性水平(通常为0.05),则可以得出该变量对因变量的影响是显著的。
简易回归模型案例 数据集

简易回归模型案例数据集
假设我们有一个简单的回归模型案例,我们需要一个数据集来
进行分析。
我们可以使用一个虚拟的数据集来说明这个案例。
假设
我们想要建立一个回归模型来预测学生的考试成绩(因变量)与他
们每周学习时间(自变量)之间的关系。
我们可以创建一个包含学生ID、学习时间和考试成绩的数据集。
例如,我们有10个学生的数据,他们的学习时间和考试成绩如下:
学生ID 学习时间(小时)考试成绩。
1 5 80。
2 7 85。
3 3 75。
4 6 88。
5 4 79。
6 8 92。
7 5 81。
8 7 87。
9 4 77。
10 6 89。
这个数据集包括了学生的学习时间和他们对应的考试成绩。
我们可以使用这个数据集来建立一个简单的回归模型,来预测学生的考试成绩。
在这个案例中,我们可以使用学习时间作为自变量,考试成绩作为因变量。
我们可以使用简单的线性回归模型来建立它们之间的关系,模型可以表示为,考试成绩= β0 + β1学习时间+ ε。
其中,β0是截距,β1是斜率,ε是误差项。
我们可以使用这个数据集来估计β0和β1的值,然后建立回归方程,最终用于预测学生的考试成绩。
当然,这只是一个简单的示例数据集和回归模型案例。
在实际应用中,数据集的大小和复杂度会更大,回归模型的建立也会更加细致和复杂。
但是通过这个简单的案例,我们可以初步了解回归模型的应用和建立过程。
回归分析实验案例数据

回归分析实验案例数据引言:回归分析是一种常用的统计方法,用于探索一个或多个自变量对一个因变量的影响程度。
在实际应用中,回归分析有很多种,例如简单线性回归、多元线性回归、逻辑回归等。
本文将介绍一个回归分析实验案例,并分析其中的数据。
案例背景:一家汽车制造公司对汽车的油耗进行研究。
他们收集了一些汽车的相关数据,并希望通过回归分析来探究这些数据之间的关系。
数据收集:为了进行回归分析,他们收集了以下数据:1. 汽车型号:不同汽车型号的标识符。
2. 汽车价格:每辆汽车的价格,单位为美元。
3. 汽车速度:以每小时英里的速度来衡量。
4. 引擎大小:汽车引擎的容量大小,以升为单位。
5. 油耗:每加仑汽油行驶的英里数。
数据分析:通过对收集的数据进行回归分析,可以得出以下结论:1. 汽车价格与汽车引擎大小之间存在正相关关系。
即引擎越大,汽车价格越高。
2. 汽车速度与油耗之间呈现负相关。
即速度越高,油耗越大。
3. 汽车引擎大小与油耗之间存在正相关关系。
即引擎越大,油耗越大。
结论:基于以上分析结果,可以得出以下结论:1. 汽车价格受到引擎大小的影响,即引擎越大,汽车价格越高。
这一结论可以帮助汽车制造公司在制定价格策略时做出合理的决策。
2. 汽车速度与油耗之间呈现负相关。
这一结论可以帮助消费者在购买汽车时考虑速度对油耗的影响,从而选择更经济的汽车。
3. 汽车引擎大小与油耗之间存在正相关关系。
这一结论可以帮助汽车制造公司在设计引擎时考虑油耗因素,从而提高汽车的燃油效率。
总结:回归分析是一种有效的统计方法,可以用于探索数据间的关系。
通过对汽车制造公司收集的数据进行回归分析,我们发现了汽车价格、速度和引擎大小与油耗之间的关系。
这些分析结果对汽车制造公司制定价格策略、消费者购车以及提高燃油效率都具有重要的指导意义。
回归分析中的案例分析解读(Ⅲ)

回归分析是一种统计学方法,用于研究自变量和因变量之间的关系。
它可以帮助我们理解和预测变量之间的关联性,对于数据分析和预测具有重要的作用。
在实际应用中,回归分析可以帮助我们解决许多实际问题,比如市场营销、经济预测、医疗研究等领域。
在本文中,我将通过一些案例分析来解读回归分析在实际问题中的应用。
案例一:市场营销假设我们是一家电商平台,我们希望了解用户购买行为与广告投放之间的关系。
我们收集了每位用户的购买金额作为因变量,广告投放金额作为自变量,以及其他可能影响购买行为的因素,比如用户年龄、性别、地理位置等作为控制变量。
通过回归分析,我们可以建立一个模型来预测用户购买金额与广告投放之间的关系。
通过这个模型,我们可以确定投放多少广告才能最大化用户购买金额,以及哪些因素对购买行为有显著的影响。
案例二:经济预测假设我们是一家投资公司,我们希望预测股票价格与宏观经济指标之间的关系。
我们收集了股票价格作为因变量,以及国内生产总值(GDP)、失业率、通货膨胀率等宏观经济指标作为自变量。
通过回归分析,我们可以建立一个模型来预测股票价格与宏观经济指标之间的关系。
通过这个模型,我们可以了解哪些经济指标对股票价格有显著的影响,从而更好地进行投资决策。
案例三:医疗研究假设我们是一家医药公司,我们希望了解药物剂量与治疗效果之间的关系。
我们收集了药物剂量作为自变量,治疗效果作为因变量,以及患者的年龄、性别、疾病严重程度等因素作为控制变量。
通过回归分析,我们可以建立一个模型来预测药物剂量与治疗效果之间的关系。
通过这个模型,我们可以确定最佳的药物剂量,从而更好地指导临床实践。
通过以上案例分析,我们可以看到回归分析在实际问题中的广泛应用。
它不仅可以帮助我们理解变量之间的关系,还可以帮助我们预测未来趋势和制定决策。
当然,回归分析也有一些局限性,比如对数据的假设要求较高,需要充分考虑自变量和因变量之间的因果关系等。
因此,在实际应用中,我们需要结合具体情况,慎重选择合适的回归模型,并进行充分的检验和验证。
回归分析中的案例分析解读(十)

回归分析是统计学中一种重要的分析方法,用于探究自变量和因变量之间的关系。
在实际应用中,回归分析常常用于预测、解释和控制变量。
本文将通过几个实际案例,对回归分析进行深入解读和分析。
案例一:销售数据分析某电商平台想要分析不同广告投放对销售额的影响,他们收集了一段时间内的广告投放数据和销售额数据。
为了进行分析,他们利用回归分析建立了一个模型,以广告费用作为自变量,销售额作为因变量。
通过回归分析,他们发现广告费用与销售额之间存在着显著的正相关关系,即广告费用的增加会带动销售额的增加。
通过该分析,电商平台可以更好地制定广告投放策略,优化营销预算,提高销售效益。
案例二:医疗数据分析一家医疗机构收集了一组患者的基本信息、生活习惯以及健康指标等数据,希望通过回归分析来探究生活习惯对健康指标的影响。
他们建立了一个回归模型,以吸烟、饮酒、饮食习惯等自变量,健康指标作为因变量。
通过回归分析,他们发现吸烟和饮酒对健康指标有负向影响,而良好的饮食习惯与健康指标呈正相关关系。
这些发现可以帮助医疗机构更好地进行健康干预和宣教,促进患者的健康改善。
案例三:金融数据分析一家金融机构收集了一段时间内的股票价格、市场指数等数据,希望通过回归分析来探究市场指数对股票价格的影响。
他们建立了一个回归模型,以市场指数作为自变量,股票价格作为因变量。
通过回归分析,他们发现市场指数与股票价格存在着较强的正相关关系,即市场指数的波动会对股票价格产生显著影响。
这些结果可以帮助金融机构更好地进行投资策略的制定和风险控制。
通过以上案例分析,我们可以看到回归分析在不同领域的应用。
回归分析不仅可以帮助人们理解变量之间的关系,还可以用于预测和控制变量。
在实际应用中,我们需要注意回归分析的假设条件、模型选择和结果解释等问题,以确保分析的准确性和可靠性。
在回归分析中,我们需要注意变量选择、模型拟合度和结果解释等问题。
另外,回归分析也有一些局限性,比如无法确定因果关系、对异常值敏感等问题。
回归分析数据案例

回归分析数据案例回归分析是一种常用的统计方法,用于探究变量之间的关系。
在实际应用中,回归分析可以帮助我们理解和预测变量之间的相互影响,为决策提供依据。
下面,我们通过一个实际的数据案例来介绍回归分析的应用。
案例背景:某公司想要了解员工的工作满意度与工作绩效之间的关系,以便更好地管理和激励员工。
为了达到这个目的,他们进行了一项调查,收集了员工的工作满意度得分和工作绩效得分。
数据收集:在这个案例中,我们收集了100名员工的工作满意度得分和工作绩效得分。
工作满意度得分是基于员工对工作的满意程度进行评分,分数范围为1-10分;工作绩效得分是基于员工在工作中的表现进行评分,分数范围为1-100分。
数据分析:为了探究工作满意度与工作绩效之间的关系,我们进行了回归分析。
首先,我们绘制了工作满意度得分和工作绩效得分的散点图,发现两者呈现一定的线性关系。
接下来,我们利用回归分析模型进行了拟合,得到了回归方程,Y = 0.8X + 20。
这个回归方程告诉我们,工作满意度每提高1分,工作绩效就会提高0.8分。
结论:通过回归分析,我们发现员工的工作满意度与工作绩效之间存在一定的正向关系,即工作满意度提高,工作绩效也会相应提高。
这为公司提供了重要的管理启示,他们可以通过提升员工的工作满意度来促进工作绩效的提升,从而实现组织的发展目标。
总结:回归分析是一种强大的工具,可以帮助我们理解变量之间的关系,为决策提供支持。
在实际应用中,我们需要收集准确的数据,进行严谨的分析,才能得出可靠的结论。
希望本文的案例分析能够帮助大家更好地理解回归分析的应用,为实际问题的解决提供参考。
通过以上案例分析,我们可以看到回归分析在实际工作中的应用价值。
希望这个案例能够帮助大家更好地理解回归分析的概念和方法,为实际问题的解决提供参考。
同时也提醒大家在进行回归分析时,要注意数据的准确性和分析方法的严谨性,才能得出可靠的结论。
感谢大家的阅读!。
商务数据分析教学案例-回归分析案例

利用回归分析法预测店铺销售额回归分析法通常适用于那些超过20家连锁店的连锁企业来分析商圈的潜在需求量的情况。
虽然它使用的逻辑与类比分析法有些相似,但它是根据统计数据而非主观判断来预测新店的销售额的。
其最初的步骤与类比分析法相同,后来就与类比分析法不一样了。
它并不是通过店址分析员的主观经验来比较现有和潜在销售点的特征,而是采用了一个数据等式方法来解决问题。
步骤一: 选择合适的衡量指标和变量。
用来预测销售业绩的变量包括人口统计数据和每个店铺商圈的消费者生活习惯、商业环境、商店形象、物业条件、竞争状况等多种因素。
店铺形态不同,则变量也不同。
例如,在预测一家新的珠宝首饰店的销售额时,家庭收入可能是一个重要的因素,而在预测麦当劳店的销售额时,每个家庭的学龄儿童数将是一个合适的指标。
步骤二: 解这个回归方程,并用结果预测新销售点的业绩。
店铺业绩衡量指标和预测变量数据将被用于回归方程的计算。
回归分析的结论是一个方程式,方程式的变量已被指定。
下面用一个简单的例子来说明回归分析过程。
表1提供了10个假设的家居用品店的数据(这个例子已被大大简化了。
因为回归分析至少需要20家店铺。
而且,例子中只使用了一个变量: 3000米距离内的人口数。
通常分析会同时使用若千个预测变量)。
表1 10个家居用品店的年销售额、周围3000米内的人口数我们可以根据表1-5中的年销售额和人口数据描绘回归线,回归线可以根据最能体现销售额和人口关系的点描绘出来,具体而言,回归线是根据数值来划分的,这样就可以使每个点到回归线的距离的平方值最小,这些点距高回归线越近,则销售额预测就越准。
通过这条回归线,可以发现销售额随人口的增长而增长。
假设距离商店0~3000米范围内的人数为40000人。
为了估算销售额,可以从横轴上标40000人处引出一条垂直线与回归线相交,从交点处画出一条与横轴平行的线,与纵轴相交,则可得到预计销售额为366 万美元。
回归线是根据下列方程式推导出的:销售额=a+b1x1式中,a--回归模型中的一个常量,a也是回归线与纵轴交点;b1--回归模型中表示销售额与预测变量间关系的一个系数,也是这条回归线的斜率;x1--预测变量(0-3000 米范国内的人口数) 。
案例一(回归分析)

方差来源 平方和 自由度 均方 F 值 p 值
回归分析 1
2805999928059999478.4294 3.26E-21
残差
33
1935458 58650.24
总计
34
29995457
表三 回归模型系数表
Coefficients 标准误差 t Stat P-value
研究思路
本案例拟运用逐步回归方法建立回归模型。在实际问题中, 人们总是希望从 对因变量 y 有影响的诸多变量中选择一些变量作为自变量, 应用多元回归分析 的方法建立“最优”回归方程以便对因变量进行预报或控制。所谓“最优”回归 方程, 主要是指希望在回归方程中包含所有对因变量 y 影响显著的自变量而不 包含对 y 影响不显著的自变量的回归方程。逐步回归分析正是根据这种原则提出 来的一种回归分析方法。它的主要思路是在考虑的全部自变量中按其对 y 的作用 大小, 显著程度大小或者说贡献大小, 由大到小地逐个引入回归方程, 而对那 些对 y 作用不显著的变量可能始终不被引人回归方程。另外, 己被引人回归方程 的变量在引入新变量后也可能失去重要性, 而需要从回归方程中剔除出去。引人 一个变量或者从回归方程中剔除一个变量都称为逐步回归的一步, 每一步都要 进行 F 检验, 以保证在引人新变量前回归方程中只含有对 y 影响显著的变量, 而 不显著的变量已被剔除。逐步回归分析的实施过程是每一步都要对已引入回归方 程的变量计算其偏回归平方和, 然后选一个偏回归平方和最小的变量, 在预先 给定的 F 水平下进行显著性检验, 如果显著则该变量不必从回归方程中剔除, 这时方程中其它的几个变量也都不需要剔除(因为其它的几个变量的偏回归平方 和都大于最小的一个更不需要剔除)。相反, 如果不显著, 则该变量要剔除, 然 后按偏回归平方和由小到大地依次对方程中其它变量进行 F 检验。将对 y 影响不 显著的变量全部剔除, 保留的都是显著的。接着再对未引人回归方程中的变量分 别计算其偏回归平方和, 并选其中偏回归平方和最大的一个变量, 同样在给定 F 水平下作显著性检验, 如果显著则将该变量引入回归方程, 这一过程一直继
多元回归分析案例数据

多元回归分析案例数据多元回归分析是一种统计分析方法,它可以用来研究多个自变量对因变量的影响。
在实际应用中,多元回归分析可以帮助我们理解不同因素之间的关系,预测因变量的数值,并进行因素的影响比较等。
本文将通过一个实际案例来介绍多元回归分析的应用,以及如何利用案例数据进行多元回归分析。
案例背景。
假设我们是一家电子产品公司的市场营销部门,我们想要了解电子产品销售额与广告投入、产品定价和季节因素之间的关系。
为了实现这一目标,我们收集了一年的销售数据,并记录了每个月的广告投入、产品定价和销售额等信息。
数据分析。
首先,我们需要对收集的数据进行分析和处理。
我们可以利用统计软件,如SPSS、R或Python等,对数据进行多元回归分析。
在进行分析前,我们需要对数据进行数据清洗,包括缺失值处理、异常值处理等。
接下来,我们可以建立多元回归模型,以销售额作为因变量,广告投入、产品定价和季节因素作为自变量,进行回归分析。
模型解释。
通过多元回归分析,我们可以得到各个自变量对销售额的影响程度,以及它们之间的相互影响关系。
比如,我们可以得出广告投入每增加一单位,销售额增加的数量;产品定价每增加一单位,销售额的变化情况;季节因素对销售额的影响等。
这些信息可以帮助我们更好地理解销售额的变化规律,为市场营销策略的制定提供依据。
结果预测。
除了对现有数据进行分析外,多元回归分析还可以用来进行结果预测。
通过建立的回归模型,我们可以输入不同的自变量数值,预测对应的销售额。
这对于制定销售计划、预测市场需求等方面具有重要意义。
结论。
通过对多元回归分析案例数据的分析,我们可以得出不同自变量对销售额的影响程度和影响关系,为市场营销决策提供科学依据。
同时,多元回归分析还可以用来进行结果预测,帮助我们更好地制定营销策略和销售计划。
因此,多元回归分析在实际应用中具有重要的意义,可以帮助企业更好地理解市场和预测销售情况。
在本文中,我们通过一个实际案例介绍了多元回归分析的应用,以及如何利用案例数据进行多元回归分析。
统计学案例——相关回归分析

《统计学》案例——相关回归分析案例一质量控制中的简单线性回归分析1、问题的提出某石油炼厂的催化装置通过高温及催化剂对原料的作用进行反应,生成各种产品,其中液化气用途广泛、易于储存运输,所以,提高液化气收率,降低不凝气体产量,成为提高经济效益的关键问题。
通过因果分析图和排列图的观察,发现回流温度是影响液化气收率的主要原因,因此,只有确定二者之间的相关关系,寻找适当的回流温度,才能达到提高液化气收率的目的。
经认真分析仔细研究,确定了在保持原有轻油收率的前提下,液化气收率比去年同期增长1个百分点的目标,即达到12.24%的液化气收率。
2、数据的收集序号回流温度(℃)液化气收率(%)序号回流温度(℃)液化气收率(%)1 2 3 4 5 6 7 8 9 10 11 12 13 14 1536 39 43 43 39 38 43 44 37 40 34 39 40 41 4413.1 12.8 11.3 11.4 12.3 12.5 11.1 10.8 13.1 11.9 13.6 12.2 12.2 11.8 11.116 17 18 19 20 21 22 23 24 25 26 27 28 29 3042 43 46 44 42 41 45 40 46 47 45 38 39 44 4512.3 11.9 10.9 10.4 11.5 12.5 11.1 11.1 11.1 10.8 10.5 12.1 12.5 11.5 10.9目标值确定之后,我们收集了某年某季度的回流温度和液化气收率的30组数据(如上表),进行简单直线回归分析。
3.方法的确立设线性回归模型为εββ++=x y 10,估计回归方程为x b b y10ˆ+= 将数据输入计算机,输出散点图可见,液化气收率y 具有随着回流温度x 的提高而降低的趋势。
因此,建立描述y 和x 之间关系的模型时,首选直线型是合理的。
从线性回归的计算结果,可以知道回归系数的最小二乘估计值b 0=21.263和b 1=-0.229,于是最小二乘直线为x y229.0263.21ˆ-= 这就表明,回流温度每增加1℃,估计液化气收率将减少0.229%。
回归分析案例
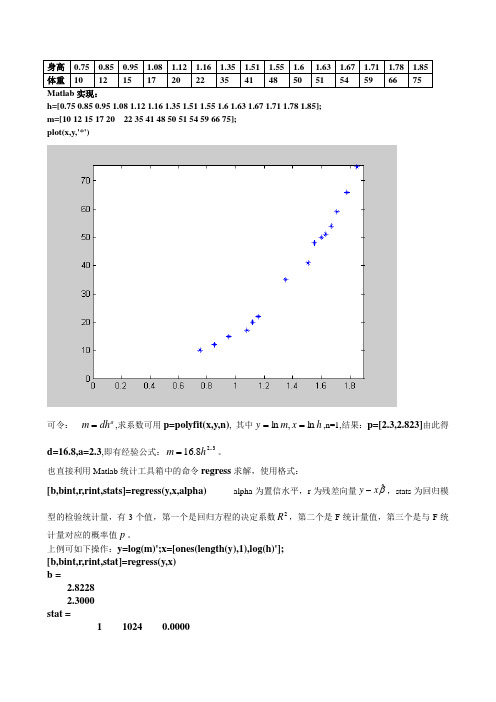
身高 0.75 0.85 0.95 1.08 1.12 1.16 1.35 1.51 1.55 1.6 1.63 1.67 1.71 1.78 1.85 体重 101215172022354148505154596675Matlab 实现:h=[0.75 0.85 0.95 1.08 1.12 1.16 1.35 1.51 1.55 1.6 1.63 1.67 1.71 1.78 1.85]; m=[10 12 15 17 20 22 35 41 48 50 51 54 59 66 75]; plot(x,y,'*')可令:adh m =,求系数可用p=polyfit(x,y,n), 其中h x m y ln ,ln ==,n=1,结果:p=[2.3,2.823]由此得d=16.8,a=2.3,即有经验公式:3..28.16h m =。
也直接利用Matlab 统计工具箱中的命令regress 求解,使用格式:[b,bint,r,rint,stats]=regress(y,x,alpha) alpha 为置信水平,r 为残差向量βˆx y -,stats 为回归模型的检验统计量,有3个值,第一个是回归方程的决定系数2R ,第二个是F 统计量值,第三个是与F 统计量对应的概率值p 。
上例可如下操作:y=log(m)';x=[ones(length(y),1),log(h)'];[b,bint,r,rint,stat]=regress(y,x)b =2.82282.3000 stat =1 1024 0.0000残差分析:rcoplot(r,rint)----------------------------------------------------------------------------------------------------------------------------------例2:施肥效果分析(1992建模赛题)磷肥施用量 0244973 98 147 196 245 294 342 土豆产量 33.46 32.47 36.06 37.96 41.04 40.09 41.26 42.17 40.36 42.73 磷肥施用量 0244973 98 147 196 245 294 342 土豆产量33.46 34.76 36.0637.9641.0440.0941.2642.1740.3642.73氮肥施用量 0244973 98 147 196 245 294 342 土豆产量33.46 34.76 36.0637.9641.0440.0941.2642.1740.3642.73对于磷肥-----土豆:可选择函数xbea y -+=1 或威布尔函数 0,≥-=-x Be A y cx对于氮肥-----土豆:可选择函数0,2210≥++=x x b x b b y2)模型的参数估计:可如下操作:x=[0 34 67 101 135 202 259 336 404 471]';y=[15.18 21.36 25.72 32.29 34.03 39.45 43.15 43.46 40.83 30.75]';X=[ones(length(y),1),x,x.^2];[b,bint,r,rint,stat]=regress(y,X)b =14.74160.1971-0.0003stat =0.9863 251.7971 0.0000 即20003.01971.07416.14x x y -+=拟合曲线图:3) 显著性检验: (仅以氮肥-----土豆模型为例说明)A):回归方程的显著性检验:检验的概率p=0,说明方程是高度显著的.B):回归系数的的显著性检验:对1β: 0:110=βH 检验统计量 =T 对2β: 0:220=βH检验统计量 =T -1004341.84343142都有 8945.1)7(05.0=>t T ,所以,均应拒绝原假设,认为系数)2,1(=i i β显著地不为0.4)残差诊断:标准化残差图如下12345678910标准化残差基本上均匀分布于-2至2之间,可以认为模型拟合是合理的.------------------------------------------------------------------------------------------------------------------------------ 案例:牙膏的销售量某牙膏制造企业要求销售部门根据市场调查,找出公司生产的牙膏销售量与销售价格、广告投入等之间的关系,从而预测出在不同价格和广告费用下的销售量。
回归分析实验案例数据1

实验课程案例数据1香烟消费数据:一个国家保险组织想要研究在美国所有50个州和哥伦比亚特区的香烟消费模式,表1给出了研究中所选的变量,表2给出了1970年的数据。
讨论下列问题:表1. 香烟消费数据的变量表2. 香烟消费数据(1970年)州年龄HS 收入黑人比例女性比例价格销量AL2741.3294826.251.742.789.8AK22.966.74644345.741.8121.3AZ26.358.13665350.838.5115.2AR29.139.9287818.351.538.8100.3CA28.162.64493750.839.7123CO26.263.93855350.731.1124.8CT29.1564917651.545.5120DE26.854.6452414.351.341.3155DC28.455.2507971.153.532.6200.4FL32.352.6373815.351.843.8123.6GA25.940.6335425.951.435.8109.9HI2561.9462314836.782.1ID26.459.532900.350.133.6102.4IL28.652.6450712.851.541.4124.8IN27.252.93772 6.951.332.2134.6IO28.8593751 1.251.438.5108.5KA28.759.93853 4.85138.9114KY27.538.531127.250.930.1155.8LA24.842.2309029.851.439.3115.9ME2854.733020.351.338.8128.5MD27.152.3430917.851.134.2123.5MA2958.54340 3.152.241124.3MI26.352.8418011.25139.2128.6MN26.857.638590.95140.1104.3MS25.141262636.851.637.593.4MO29.448.8378110.351.836.8121.3MT27.159.235000.35034.7111.2NB28.659.33789 2.751.234.7108.1NV27.865.24563 5.749.344189.5NH2857.637370.351.134.1265.7NJ30.152.5470110.851.641.7120.7NM23.955.23077 1.950.741.790NY30.352.7471211.952.241.7119NC26.538.5325222.25129.4172.4ND26.450.330860.449.538.993.8OH27.753.240209.151.538.1121.6OK29.451.63387 6.751.339.8108.4OR29603719 1.35129157PA30.750.2397185244.7107.3RI29.246.43959 2.750.940.2123.9SC24.837.8299030.550.934.3103.6SD27.453.331230.350.338.592.7TN28.141.8311915.851.641.699.8TX26.447.4360612.55142106.4UT23.167.332270.650.636.665.5VT26.857.134680.251.139.5122.6V A26.847.8371218.550.630.2124.3WA27.563.54053 2.150.340.396.7WV3041.63061 3.951.641.6114.5WI27.254.53812 2.950.940.2106.4WY27.262.938150.85034.4132.2(1)在销量关于6个自变量的回归模型中,检验假设“不需要女性比例这一变量”;(2)在上面的模型中,检验假设“不需要女性比例和HS这两个变量”;(3)计算收入变量回归系数的95%的置信区间;(4)去掉收入这个变量后拟合回归方程,其他变量对于销量的解释比例是多少?(5)用价格、年龄和收入作自变量拟合模型,它们对销量的解释比例是多少?(6)仅用收入作自变量拟合模型,它们对销量的解释比例是多少?。
回归分析案例数据

回归分析案例数据回归分析是一种统计方法,用于研究和预测变量之间的关系。
在实际应用中,回归分析可用于解释和预测因变量与自变量之间的关系,并对未来数据进行预测。
本文将通过一个回归分析案例来说明如何使用回归分析来分析数据。
案例描述:假设某公司想要了解广告支出与销售额之间的关系。
他们收集了过去12个月的数据,其中包含每个月的广告支出和销售额。
现在他们想利用这些数据来建立一个回归模型,以预测未来的销售额。
数据分析过程:1. 数据收集和准备首先,我们需要收集并整理数据。
数据应包括广告支出和销售额这两个变量的观测值。
确保数据的准确性和完整性,并进行必要的清洗和处理。
2. 数据可视化为了更好地理解数据之间的关系,我们可以使用数据可视化工具(如散点图)绘制广告支出与销售额之间的关系图。
通过观察图形,可以初步判断变量之间的关系。
3. 建立回归模型将收集到的数据用来建立回归模型。
在这个案例中,我们可以使用简单线性回归模型,因为只有一个自变量(广告支出)和一个因变量(销售额)。
通过最小二乘法,选择最佳拟合线,并确定回归方程。
4. 模型评估建立回归模型后,需要对模型进行评估。
常用的评估指标包括残差分析、决定系数(R²)、假设检验等。
这些指标可以帮助我们评估模型的拟合程度、预测能力和统计显著性。
5. 预测未来销售额利用建立好的回归模型,我们可以估计未来的销售额。
通过输入未来的广告支出值,模型可以给出对应的销售额的预测值。
6. 模型应用和调整建立好的回归模型可以应用于实际业务场景中。
然而,模型的应用过程中可能会遇到一些约束条件和限制,如广告预算、市场竞争等。
在实际应用中,需要不断地调整和改进模型,以适应不断变化的环境。
总结:回归分析是一种常用的统计方法,可用于解释和预测变量之间的关系。
本文通过一个案例说明了回归分析的数据分析过程,并介绍了回归模型的建立、评估和应用。
通过回归分析,我们可以更好地理解数据之间的关系,并利用模型对未来进行预测和决策。
回归分析案例
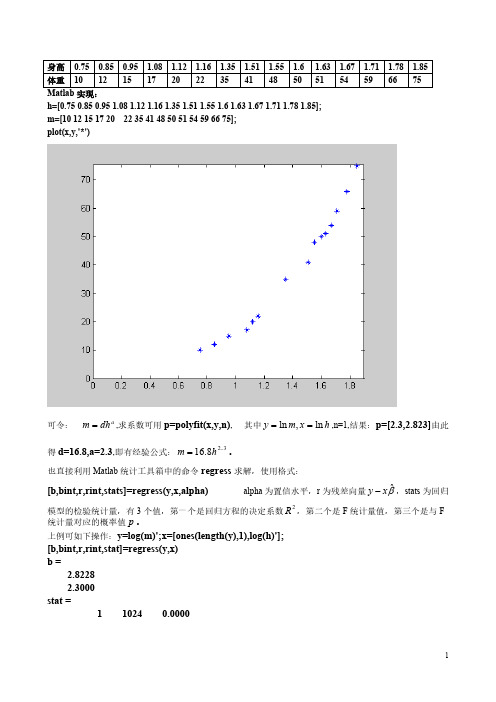
身高0.750.850.95 1.08 1.12 1.16 1.35 1.51 1.55 1.6 1.63 1.67 1.71 1.78 1.85体重101215172022354148505154596675Matlab 实现:h=[0.75 0.85 0.95 1.08 1.12 1.16 1.35 1.51 1.55 1.6 1.63 1.67 1.71 1.78 1.85];m=[10 12 15 17 20 22 35 41 48 50 51 54 59 66 75];plot(x,y,'*')可令:,求系数可用p=polyfit(x,y,n), 其中,n=1,结果:p=[2.3,2.823]由此a dh m =h x m y ln ,ln ==得d=16.8,a=2.3,即有经验公式:。
3..28.16hm =也直接利用Matlab 统计工具箱中的命令regress 求解,使用格式:[b,bint,r,rint,stats]=regress(y,x,alpha)alpha 为置信水平,r 为残差向量,stats 为回归βˆx y -模型的检验统计量,有3个值,第一个是回归方程的决定系数,第二个是F 统计量值,第三个是与F2R 统计量对应的概率值。
p 上例可如下操作:y=log(m)';x=[ones(length(y),1),log(h)'];[b,bint,r,rint,stat]=regress(y,x)b =2.82282.3000stat =1 1024 0.0000残差分析:rcoplot(r,rint)----------------------------------------------------------------------------------------------------------------------------------例2:施肥效果分析(1992建模赛题)磷肥施用量(吨/公顷)与土豆产量:磷肥施用量024497398147196245294342土豆产量33.4632.4736.0637.9641.0440.0941.2642.1740.3642.73y(0)、y(24)是病态数据,以线性插值代替:磷肥施用量024497398147196245294342土豆产量33.4634.7636.0637.9641.0440.0941.2642.1740.3642.73氮肥施用量(吨/公顷)与土豆产量:氮肥施用量024497398147196245294342土豆产量33.4634.7636.0637.9641.0440.0941.2642.1740.3642.731)模型选择:对于磷肥-----土豆:可选择函数或威布尔函数 xbea y -+=10,≥-=-x Be A y cx对于氮肥-----土豆:可选择函数,2210≥++=x x b x b b y2)模型的参数估计:可如下操作:x=[0 34 67 101 135 202 259 336 404 471]';y=[15.18 21.36 25.72 32.29 34.03 39.45 43.15 43.46 40.83 30.75]';X=[ones(length(y),1),x,x.^2];[b,bint,r,rint,stat]=regress(y,X)b =14.74160.1971-0.0003stat =0.9863 251.79710.0000即20003.01971.07416.14x x y -+=拟合曲线图:3) 显著性检验: (仅以氮肥-----土豆模型为例说明)A):回归方程的显著性检验:检验的概率p=0,说明方程是高度显著的.B):回归系数的的显著性检验:对: 1β0:110=βH 检验统计量 2539.10825802353=T 对: 2β0:220=βH 检验统计量 -1004341.84343142=T 都有 ,所以,均应拒绝原假设,认为系数显著地不为0.8945.1)7(05.0=>t T )2,1(=i i β4)残差诊断:标准化残差图如下12345678910标准化残差基本上均匀分布于-2至2之间,可以认为模型拟合是合理的.------------------------------------------------------------------------------------------------------------------------------案例:牙膏的销售量某牙膏制造企业要求销售部门根据市场调查,找出公司生产的牙膏销售量与销售价格、广告投入等之间的关系,从而预测出在不同价格和广告费用下的销售量。