Grep命令详解
grep参数详解

grep参数详解Grep是UNIX/Linux中最常用的命令,它是一种文本搜索工具,它可以在文件系统中快速搜索文本字符串。
Grep有许多参数,每个参数都可以改变grep的行为,因此,在使用grep时,了解这些参数是非常重要的。
在本文中,我们将详细介绍grep的参数,对一般用户和系统管理员有很大的帮助。
Grep的基本用法:Grep的基本用法是使用grep <pattern> <files>的形式,其中<pattern>表示要搜索的字符串,<files>表示要搜索的文件或目录。
Grep会隐式地把标准输入作为一个文件,这允许用户从管道中输入数据,并使用grep进行搜索,例如echohello world“ | grep world。
Grep主要参数:1. -i : 不区分大小写的搜索,即搜索的字符串无论大写或小写,grep都会返回匹配的结果。
2. -v :反搜索,即搜索的字符串不包含在搜索结果中的行,grep 就会返回这行。
3. -c :计匹配行的数量,不会返回匹配的行,只返回匹配行的数目。
4. -w :配全词搜索,即只有搜索字符串作为一个单词出现,grep 才会返回匹配的行。
5. -x :行匹配,即只有整行全部符合搜索字符串,grep才会返回匹配的行。
6. -n :索行号,即会在每一行匹配的前面显示行号。
7. -E :展正则表达式搜索,默认情况下grep只支持普通的正则表达式,-E参数支持扩展的正则表达式语法。
8. -l :出文件名,即只返回匹配文件的文件名,而不返回匹配的行。
9. -L :之,即只返会不匹配文件的文件名,而不返回不匹配的行。
10. -r :归搜索,即以当前文件夹为根,搜索其子目录。
使用Grep的实例:1.计文件中某个字符串的出现次数:grep -c hello file.txt2. 从文件中删除包含某个字符串的行:grep -v hello file.txt > file_new.txt3.文件中包含某个单词的行复制到另一个文件:grep -w hello file.txt > file_new.txt4.归搜索当前目录和其子目录的文件,找出所有包含某个字符串的文件:grep -rl hello .总结:Grep是Unix/Linux中一个非常强大的文本搜索工具,它有许多参数可以改变Grep的行为,可以帮助我们快速搜索文本字符串。
grep命令详解

grep命令详解GREP是Global search Regular Expression and Print out the line的简称,即全⾯搜索正则表达式并把⾏打印出来。
GREP是⼀种强⼤的⽂本搜索⼯具,它能使⽤正则表达式搜索⽂本,并把匹配的⾏打印出来。
1、grep命令基本⽤法grep命令是⽀持正则表达式的⼀个多⽤途⽂本搜索⼯具,grep的⼀般格式为:grep [选项] [模式] [⽂件...]grep命令由选项、模式和⽂件三部分组成,它在⼀个或多个⽂件中搜索满⾜模式的⽂本⾏,模式后的所有字符串被看做⽂件名,⽂件名可以有多个,搜索的结果被打印到屏幕,不影响原⽂件的内容。
Grep命令的选项⽤于对搜索过程进⾏补充说明。
grep命令选项及其意义:-c #只输出匹配⾏的数量-i #搜索时忽略⼤⼩写-h #查询多⽂件时不显⽰⽂件名-l #只列出符合匹配的⽂件名,⽽不列出具体的匹配⾏-n #列出所有的匹配⾏,并显⽰⾏号-s #不显⽰不存在或⽆匹配⽂本的错误信息-v #显⽰不包含匹配⽂本的所有⾏-w #匹配整词-x #匹配整⾏-r #递归搜索,不仅搜索当前⼯作⽬录,⽽且搜索⼦⽬录-q #禁⽌输出任何结果,以退出状态表⽰搜索是否成功-b #打印匹配⾏距⽂件头部的偏移量,以字节为单位-o #与-b选项结合使⽤,打印匹配的词距⽂件头部的偏移量,以字节为单位-E #⽀持扩展的正则表达式-F #不⽀持正则表达式,按照字符串的字⾯意思进⾏匹配View Codegrep命令的模式⼗分灵活,可以是字符串,也可以是变量,还可以是正则表达式。
需要说明的是,⽆论模式是何种形式,只要模式中包含空格,就需要使⽤双引号将模式引起来,如果不加双引号,空格后的单词容易被误认为是⽂件名。
⼤部分情况下,使⽤单引号将模式引起来也是可以的。
例:模式包含空格时,是否使⽤双引号的区别WORDLIST⽂件的内容:hello, caicai. world: watch, world caicaihello messagemessage world watch hello into the he shelast into.last save hello caicai, world: message.#搜索WORDLIST⽂件中包含watch字符串的⾏,不需要引号引起模式执⾏:grep watch WORDLIST结果:hello, caicai. world:watch, world caicai hello messagemessage world watch hello into the he she lastinto.#搜索WORDLIST⽂件中包含hellocaicai字符串的⾏,不⽤引号将hello caicai引起来的结果执⾏:grep hello caicaiWORDLIST结果:grep: caicai: 没有那个⽂件或⽬录#Shell将caicai解析为⽂件名,提⽰没有此⽂件的错误#下⾯给出WORDLIST⽂件中包含hello字符串的⾏WORDLIST:hello, caicai. world: watch, worldcaicai hello messageWORDLIST:message world watch hello into thehe she last into.WORDLIST:last save hello caicai, world:message.#搜索WORDLIST⽂件中包含hellocaicai字符串的⾏,⽤引号将hello caicai引起来的结果执⾏:grep "hellocaicai" WORDLIST结果:last save hellocaicai, world: message.例:grep的多⽂件查询FILE1⽂件的内容:Shanghai Jiaotong UniversityUniversity of TorontoBeijing UniversitySoutheast UniversityVictory UniversityFILE2⽂件的内容:ShanghaiTorontoBeijingNanjingMelbourne执⾏:grep Beijing FILE1FILE2结果:FILE1:BeijingUniversityFILE2:Beijing例:⽤通配表⽰多⽂件执⾏:grep Beijing FILE?结果:FILE1:BeijingUniversityFILE2:Beijing2. grep选项详解1、-c选项-c选项表⽰输出匹配字符串⾏的数量,默认情况下,grep命令打印出包含模式的所有⾏,⼀旦加上-c选项,就只显⽰包含模式⾏的数量。
grep命令实例详解 -回复

grep命令實例详解-回复grep命令实例详解grep命令是在Linux和Unix系统中用于在文件中查找指定模式的工具。
它是一种强大而灵活的搜索工具,可以根据正则表达式匹配文本内容,并输出符合条件的行。
本文将逐步回答“grep命令实例详解”的主题,介绍grep命令的基本语法和常用选项,并提供一些实际使用场景的示例。
一、基本语法和选项grep命令的基本语法为:`grep [OPTIONS] PATTERN [FILE...]`其中,OPTIONS是可选的参数,PATTERN是要查找的模式,FILE是要查找的文件。
如果没有指定文件名,grep命令将从标准输入中读取数据。
常用的grep选项如下:- `-i`:忽略大小写;- `-v`:反向匹配,输出不包含指定模式的行;- `-r`:递归地搜索匹配指定模式的文件;- `-l`:仅输出包含匹配模式的文件名;- `-n`:输出匹配行以及行号;- `-c`:仅输出匹配模式的行数;二、实例演示下面将通过一些实例来演示grep命令的应用场景及其使用方法。
1. 在文件中查找指定字符串假设我们有一个名为example.txt的文件,内容如下:This is an exampleof how grep commandcan be used tosearch for specificpatterns in files.我们可以使用下面的命令来查找文件中包含字符串“example”的行:`grep "example" example.txt`命令的输出如下:This is an example2. 忽略大小写进行搜索如果我们希望忽略大小写进行搜索,可以使用选项`-i`:`grep -i "example" example.txt`命令的输出如下:This is an example3. 反向匹配,输出不包含指定模式的行如果我们希望查找不包含指定模式的行,可以使用选项`-v`:`grep -v "example" example.txt`命令的输出如下:of how grep commandcan be used tosearch for specificpatterns in files.4. 递归搜索匹配指定模式的文件如果我们希望递归地搜索整个目录及子目录中匹配指定模式的文件,可以使用选项`-r`:`grep -r "example" /path/to/directory`命令将在指定目录下查找包含字符串“example”的所有文件,并输出包含匹配内容的行。
linux grep命令详解 正则

linux grep命令详解正则【实用版】目录1.Linux grep 命令简介2.grep 命令的基本语法3.正则表达式在 grep 命令中的应用4.grep 命令的选项与参数5.grep 命令的实例分析正文【1.Linux grep 命令简介】grep(全局正则表达式打印,global regular expression print)是 Linux 系统中一个强大的文本搜索工具,它可以使用正则表达式搜索文本文件中的内容,然后将匹配的行输出。
grep 命令在日常的文本处理、日志分析等场景中都有着广泛的应用。
【2.grep 命令的基本语法】grep 的基本语法如下:```grep "pattern" file```其中,"pattern" 是要搜索的正则表达式,file 是要搜索的文件。
【3.正则表达式在 grep 命令中的应用】正则表达式是一种用来描述字符或字符串模式的文本字符串。
在grep 命令中,正则表达式用于精确地匹配搜索内容。
正则表达式可以使用一些特殊符号来表示字符集、量词等。
例如:- `.` 匹配任意字符- `*` 匹配零个或多个前面的字符- `+` 匹配一个或多个前面的字符- `?` 匹配前面的字符零次或一次- `{n}` 匹配前面的字符 n 次- `{n,}` 匹配前面的字符 n 次或多次- `{n,m}` 匹配前面的字符 n 到 m 次【4.grep 命令的选项与参数】grep 命令除了基本的搜索功能外,还提供了许多选项与参数来满足不同场景的需求。
常用的选项与参数如下:- -i:忽略大小写- -n:显示匹配行的行号- -v:反转匹配,输出不匹配的行- -r:递归查找目录下的所有文件- -w:只匹配整个单词- -c:显示匹配的行数而非具体内容【5.grep 命令的实例分析】假设我们有一个名为 sample.txt 的文件,内容如下:```appleorangebananagrapelemon```我们可以使用 grep 命令来搜索包含字母 "a" 的行:```grep "a" sample.txt```输出结果为:```appleorangebanana```如果我们想要忽略大小写进行搜索,可以使用 -i 选项:```grep -i "a" sample.txt```输出结果不变。
grep命令用法详解

grep命令用法详解```grep [options] pattern [files]```其中,`options`是可选的命令行选项,`pattern`是要搜索的文本模式,`files`是要搜索的文件名(可以是一个或多个文件,也可以使用通配符)。
下面是一些常见的`grep`命令选项:- `-c`:只输出匹配行的数量,不输出匹配的文本。
- `-i`:忽略大小写进行匹配。
- `-n`:输出匹配行的行号。
- `-v`:反转匹配,即输出不匹配指定模式的行。
- `-E`:使用正则表达式进行匹配。
- `-F`:使用固定字符串进行匹配,不支持正则表达式的元字符。
以下是一些`grep`命令的使用示例:1. 在当前目录下的所有`*.cpp`文件中查找包含`hello world`字符串的行:```grep "hello world" *.cpp```2. 在`file.txt`文件中查找包含`error`字符串的行,并输出行号:```grep -n "error" file.txt```3. 在`file.txt`文件中查找不包含`error`字符串的行:```grep -v "error" file.txt```4. 在`file.txt`文件中使用正则表达式查找以`abc`开头的行:```grep -E "abc.*" file.txt```5. 在`file.txt`文件中使用固定字符串查找以`abc`开头的行:```grep -F "abc" file.txt```通过以上介绍,你应该对`grep`命令的用法有了更深入的了解。
它是一个非常实用的工具,可以帮助你快速查找文本中的特定模式。
grep命令的参数-i,表示模式匹配时区分大小写

一、grep命令的基本概念grep命令是Linux系统中常用的文本搜索工具,用于在文件或标准输入中搜索指定的模式,并将匹配的行打印出来。
它可以根据用户提供的正则表达式进行模式匹配,从而达到快速定位目标文本内容的目的。
grep命令的参数很多,其中-i参数表示模式匹配时不区分大小写。
二、grep命令的常见用法grep命令通常用于查找包含特定字符或模式的行,并将其输出到标准输出。
其基本用法如下:```grep [option] pattern [file]```其中,option是命令的参数,pattern是要匹配的模式,file是要进行搜索的文件。
三、-i参数的作用在使用grep命令进行模式匹配时,默认情况下是区分大小写的,也就是说大写和小写字母是不同的。
而使用了-i参数之后,grep命令将不再区分大小写,即不管是大写还是小写都可以匹配到相应的内容。
四、使用实例假设有一个文件test.txt,内容如下:```Hello, world!hello, world!HELLO, WORLD!```我们希望查找包含hello的行,可以使用以下命令:```grep -i "hello" test.txt```使用了-i参数之后,不再区分大小写,上述命令将匹配到所有包含hello的行,输出如下:```Hello, world!hello, world!```如果不使用-i参数,则只会匹配到第二行。
五、-i参数的注意事项使用-i参数可以方便地进行不区分大小写的模式匹配,但也要注意一些问题。
如果模式本身包含了大小写字母,那么-i参数将不再起作用,需要注意模式的书写方式。
另外,使用-i参数可能会对性能产生一定影响,因为要进行更多的匹配工作。
六、总结grep命令是Linux系统中非常常用的文本搜索工具,而-i参数可以方便地进行不区分大小写的模式匹配,提高了搜索的灵活性和通用性。
在实际使用过程中,合理地应用-i参数可以提高工作效率,但也需要注意一些使用注意事项。
grep命令详解

grep命令详解1.简介:grep (global search regular expression(RE) and print out the line,全⾯搜索正则表达式并把⾏打印出来)是⼀种强⼤的⽂本搜索⼯具,它能使⽤正则表达式搜索⽂本,并把匹配的⾏打印出来。
grep的⼯作⽅式是这样的,它在⼀个或多个⽂件中搜索字符串模板。
如果模板包括空格,则必须被引⽤,模板后的所有字符串被看作⽂件名。
搜索的结果被送到标准输出,不影响原⽂件内容。
grep可⽤于shell脚本,因为grep通过返回⼀个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的⽂件不存在,则返回2。
我们利⽤这些返回值就可进⾏⼀些⾃动化的⽂本处理⼯作。
2.命令格式:grep [option] pattern file3.命令参数:-a --text #不要忽略⼆进制的数据。
-A<显⽰⾏数> --after-context=<显⽰⾏数> #除了显⽰符合范本样式的那⼀列之外,并显⽰该⾏之后的内容。
-b --byte-offset #在显⽰符合样式的那⼀⾏之前,标⽰出该⾏第⼀个字符的编号。
-B<显⽰⾏数> --before-context=<显⽰⾏数> #除了显⽰符合样式的那⼀⾏之外,并显⽰该⾏之前的内容。
-c --count #计算符合样式的列数。
-C<显⽰⾏数> --context=<显⽰⾏数>或-<显⽰⾏数> #除了显⽰符合样式的那⼀⾏之外,并显⽰该⾏之前后的内容。
-d <动作> --directories=<动作> #当指定要查找的是⽬录⽽⾮⽂件时,必须使⽤这项参数,否则grep指令将回报信息并停⽌动作。
-e<范本样式> --regexp=<范本样式> #指定字符串做为查找⽂件内容的样式。
grep命令详解

grep命令详解linux grep 命令详解1.作⽤Linux系统中grep命令是⼀种强⼤的⽂本搜索⼯具,它能使⽤正则表达式搜索⽂本,并把匹配的⾏打印出来。
grep全称是Global Regular Expression Print,表⽰全局正则表达式版本,它的使⽤权限是所有⽤户。
2.格式grep [OPTIONS] PATTERN [FILE...]3.主要参数[options]主要参数:-a或--tt 不要忽略⼆进制的数据。
-A<显⽰列数>或--after-context=<显⽰列数> 除了显⽰符合范本样式的那⼀列之外,并显⽰该列之后的内容。
-b或--byte-off 在显⽰符合范本样式的那⼀列之前,标⽰出该列第⼀个字符的位编号。
-B<显⽰列数>或--before-context=<显⽰列数> 除了显⽰符合范本样式的那⼀列之外,并显⽰该列之前的内容。
-c或--count 计算符合范本样式的列数。
-C<显⽰列数>或--context=<显⽰列数>或-<显⽰列数> 除了显⽰符合范本样式的那⼀列之外,并显⽰该列之前后的内容。
-d<进⾏动作>或--directories=<进⾏动作> 当指定要查找的是⽬录⽽⾮⽂件时,必须使⽤这项参数,否则grep指令将回报信息并停⽌动作。
-e<范本样式>或--regexp=<范本样式> 指定字符串做为查找⽂件内容的范本样式。
-E或--extended-regexp 将范本样式为延伸的普通表⽰法来使⽤。
-f<范本⽂件>或--=<范本⽂件> 指定范本⽂件,其内容含有⼀个或多个范本样式,让grep查找符合范本条件的⽂件内容,格式为每列⼀个范本样式。
-F或--fixed-regexp 将范本样式视为固定字符串的列表。
-G或--basic-regexp 将范本样式视为普通的表⽰法来使⽤。
grep命令参数详解
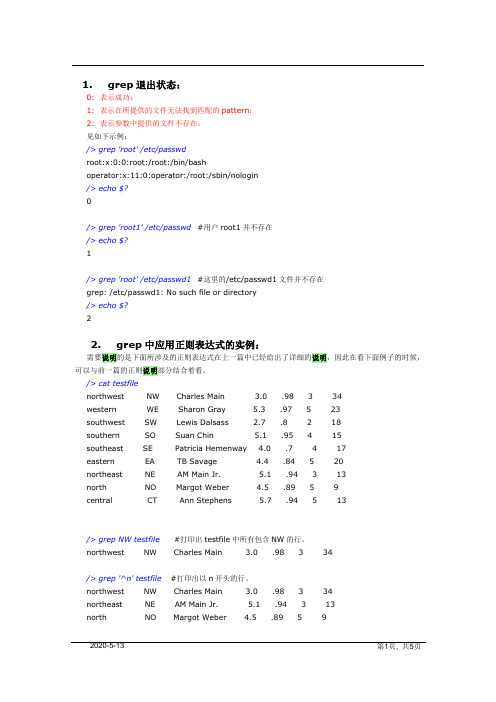
1. grep退出状态:0:表示成功;1:表示在所提供的文件无法找到匹配的pattern;2:表示参数中提供的文件不存在。
见如下示例:/> grep 'root' /etc/passwdroot:x:0:0:root:/root:/bin/bashoperator:x:11:0:operator:/root:/sbin/nologin/> echo $?/> grep 'root1' /etc/passwd#用户root1并不存在/> echo $?1/> grep 'root' /etc/passwd1#这里的/etc/passwd1文件并不存在grep: /etc/passwd1: No such file or directory/> echo $?22. grep中应用正则表达式的实例:需要说明的是下面所涉及的正则表达式在上一篇中已经给出了详细的说明,因此在看下面例子的时候,可以与前一篇的正则说明部分结合着看。
/> cat testfilenorthwest NW Charles Main 3.0 .98 3 34western WE Sharon Gray 5.3 .97 5 23southwest SW Lewis Dalsass 2.7 .8 2 18southern SO Suan Chin 5.1 .95 4 15southeast SE Patricia Hemenway 4.0 .7 4 17eastern EA TB Savage 4.4 .84 5 20northeast NE AM Main Jr. 5.1 .94 3 13north NO Margot Weber 4.5 .89 5 9central CT Ann Stephens 5.7 .94 5 13/> grep NW testfile#打印出testfile中所有包含NW的行。
grep命令参数及用法

grep命令参数及用法1. 简介:grep 是一种强大的命令行工具,用于在文件中查找特定字符串。
grep 命令可以用来在文件中查找一个或多个匹配字符串,并将包含该字符串的所有行打印出来。
grep 命令是 Linux 系统中的一个常用命令,可以在终端中使用。
2. 命令格式grep [option] pattern [file…]3. 参数- -i:忽略大小写。
- -v:仅显示不匹配的行。
- -n:在输出中显示行号。
- -r:递归查找子目录。
- -c:仅显示匹配行的数目。
- -o:仅显示匹配的字符串,而不是整行。
- -w:指定字符串为单词,即仅匹配整个单词,而不是部分单词。
- -e:指定要查找的字符串。
- -f:从指定文件中读取要查找的字符串。
- --color=auto:将匹配的字符串高亮显示。
- --exclude=pattern:排除匹配的文件。
- --include=pattern:仅包含匹配的文件。
- --exclude-dir=pattern:排除匹配的子目录。
- --include-dir=pattern:仅包含匹配的子目录。
- --group-separator:在输出中使用指定的分隔符。
- --no-group-separator:在输出中不使用分隔符。
- --null:在输出中使用 null 作为行分隔符。
- --max-count:仅显示前几个匹配项。
4. 实例4.1 在文件中查找特定字符串命令:grep 'string' file说明:在文件 file 中查找包含‘string’ 子字符串的行,并将其输出到屏幕上。
例子:在文件 example.txt 中查找‘apple’:```grep 'apple' example.txt```4.2 忽略大小写4.3 显示匹配行的行号4.4 仅显示包含字符串的行数4.6 将查找结果输出到文件4.8 配合使用多个参数例子:在目录 /var/log 中递归查找所有包含‘error’ 子字符串的日志并显示行号:```grep -rni 'error' /var/log```5. 总结grep 命令是 Linux 系统中非常常用的命令之一,通过使用它,你可以很方便地在文件中查找特定字符串,并将结果输出到屏幕上。
grep命令实例详解

grep命令實例详解grep命令是在Unix和类Unix操作系统中使用的强大的文本搜索工具。
它可以用来在文件中查找匹配特定模式的文本行,并将匹配的行打印出来。
下面我将从不同的角度详细解释grep命令的使用实例。
1. 基本用法:grep命令的基本语法是,grep [选项] 模式文件名。
例如,我们要在文件file.txt中查找包含单词"apple"的行,可以使用以下命令:grep "apple" file.txt.这将输出所有包含"apple"的行。
2. 忽略大小写:默认情况下,grep是区分大小写的。
如果我们希望忽略大小写进行搜索,可以使用选项"-i"。
例如,我们要在文件file.txt中查找包含单词"apple"的行,不区分大小写,可以使用以下命令:grep -i "apple" file.txt.3. 输出行号:如果我们希望在输出结果中显示匹配行的行号,可以使用选项"-n"。
例如,我们要在文件file.txt中查找包含单词"apple"的行,并显示行号,可以使用以下命令:grep -n "apple" file.txt.4. 反向匹配:如果我们希望找到不包含指定模式的行,可以使用选项"-v"。
例如,我们要在文件file.txt中查找不包含单词"apple"的行,可以使用以下命令:grep -v "apple" file.txt.5. 使用正则表达式:grep支持使用正则表达式进行模式匹配。
正则表达式是一种强大的模式匹配工具,可以实现更灵活的搜索。
例如,我们要在文件file.txt中查找以字母开头的行,可以使用以下命令:grep "^[a-zA-Z]" file.txt.这将输出所有以字母开头的行。
linux grep指令参数

linux grep指令参数
grep是一个在文本文件中搜索特定模式的命令行工具。
以下是grep的一些常用参数:
•-i:忽略大小写。
•-v:反转匹配,即显示不匹配指定模式的行。
•-r或-R:递归搜索,会搜索指定目录下所有文件。
•-l:仅显示包含匹配行的文件名。
•-n:显示匹配行的行号。
•-c:计数,只输出匹配的行数。
•-w:整词匹配,只匹配整个单词。
•-o:仅输出匹配的部分,而不是整行。
•-A num:显示匹配行之后的num行。
•-B num:显示匹配行之前的num行。
•-C num或--context=num:显示匹配行前后的num行。
•--color=always或--color=auto:高亮显示匹配的文本。
这些参数可以组合使用,例如:
bash复制代码
grep -i -c 'pattern' *.txt # 在当前目录下的所有txt文件中搜索pattern,忽略大小写,并统计匹配的行数上述内容仅供参考,建议查阅相关技术文档或咨询专业人士以获取准确的信息。
grep命令实例详解 -回复

grep命令實例详解-回复grep命令实例详解grep命令是Linux系统中用于搜索指定模式或关键字的功能强大的命令。
它能够递归地搜索文件和文件夹,并快速返回所有匹配的结果。
本文将详细介绍grep命令的使用方法,以及几个实例来帮助读者更好地理解和掌握这个命令。
1. grep命令的基本用法grep命令的基本用法是:grep [选项] 模式文件名其中,选项和模式是可选的,文件名是要搜索的文件或文件夹的名称。
下面是一些常用的选项:- -i:忽略大小写;- -r:递归搜索子文件夹;- -v:返回不匹配的结果。
这些选项可以根据实际需要进行组合使用,以满足不同的搜索需求。
2. 实例1:简单搜索文件中的关键字假设有一个名为example.txt的文件,内容如下:This is an example file.It contains some text.We will use grep to search for a keyword.现在我们想要搜索文件中包含关键字"example"的行。
执行以下命令:grep "example" example.txt命令的输出结果如下:This is an example file.可以看到,grep命令成功地找到了包含关键字"example"的行,并返回了匹配的结果。
3. 实例2:搜索多个文件grep命令不仅可以搜索单个文件,还可以搜索多个文件。
假设有两个文件example.txt和another.txt,内容和上面的示例相同。
我们可以使用以下命令来搜索两个文件:grep "example" example.txt another.txt输出结果如下:example.txt: This is an example file.another.txt: This is an example file.可以看到,grep命令找到了包含关键字"example"的行,并返回了匹配的结果。
详解grep命令

详解grep命令1、grep命令⾏的⼀般语法格式为:grep 【OPTIONS】 PATTERN INPUT_FILE_NAMESgrep是⼀种匹配尽可能多的⼀种匹配模式,“贪婪模式”PATTERN部分表⽰正则表达式正则表达式⼜由普通字符和元字符组成,元字符的依据分类也可以分为:次数限制元字符:*表⽰任意多次;表⽰⼀次或者零次+表⽰⼤于或者等于⼀次{}表⽰指定范围次数,{n,m}{n,}{,m}{n,n}位置锚定元字符:^表⽰必定以其后⾯所跟字符开头$表⽰必定⼀起前⾯所跟字符结尾\<\>表⽰单词边界字符字符类和中括号表达式中括号正则表达式是使⽤"["和"]"包围的字符列表。
它能匹配该列表中的任意单个字符。
如果列表中的第⼀个字符是"^",则表⽰不匹配该列表中的任意单个字符。
例如,'[0123456789]'能匹配任意数字。
中括号中可以使⽤连字符"-"连接两个字符表⽰"范围"。
例如,C字符集下的"[a-d]"等价于"[abcd]"。
⼤多数字符集规则和字典排序规则⼀样,这意味着"[a-d]"不等价于"[abcd]",⽽是等价于"[aBbCcDd]"。
可以设置环境变量"LC_ALL"的值为C使得采取C字符集的排序规则。
最后,预定义了⼏个特定名称的字符类,它们都使⽤中括号包围。
如下:'[:alnum:]'匹配⼤⼩写字母和数字。
等价于字符类'[:alpha:]'与字符类'[:digit:]'的和。
'[:alpha:]'字母字符类。
匹配⼤⼩写字母。
等价于字符类'[:lower:]'和字符类'[:upper:]'的和。
grep指令用法

grep指令用法grep指令用法简介grep是一个在Unix、Linux和类Unix系统中常用的命令,用于搜索文本文件中的匹配行。
它是全称为“global/regular expression/print”的缩写,意为全局/正则表达式/打印。
用法一:基本搜索简单的用法是在命令行中输入grep,后接要搜索的关键词以及要搜索的文件名。
例如:grep keyword filename这将在给定的文件中搜索所有包含关键词的行,并将它们显示在屏幕上。
如果要搜索多个文件,只需要在文件名之后加上更多的文件名。
用法二:显示匹配行的行数使用-c选项可以显示匹配行的行数。
例如:grep -c keyword filename这将输出匹配行的数量,而不是实际的匹配行。
这在统计匹配行数或判断一个文件中是否包含关键词时很有用。
用法三:忽略大小写默认情况下,grep是区分大小写的。
如果要忽略大小写进行搜索,可以使用-i选项。
例如:grep -i keyword filename这将搜索文件中包含关键词的行,无论其大小写如何。
用法四:递归搜索通过使用-r选项,grep可以递归搜索指定目录及其子目录中的文件。
例如:grep -r keyword directory这将搜索指定目录下的所有文件,并显示包含关键词的行。
用法五:使用正则表达式grep支持使用正则表达式进行高级搜索。
可以在搜索模式中使用通配符、字符类和其他正则表达式元字符。
例如,grep '' filename将匹配包含”keyword”后跟任意字符然后是”d”的行。
用法六:选项的组合使用可以同时使用多个选项进行更复杂的搜索。
例如,grep -i -r'keyword' directory将忽略大小写地递归搜索指定目录及其子目录中的文件,并显示匹配的行。
用法七:将匹配行输出到文件通过使用>运算符,可以将grep命令的输出重定向到文件中。
grep命令详解

grep命令详解grep⽤法详解:grep与正则表达式⾸先要记住的是: 正则表达式与通配符不⼀样,它们表⽰的含义并不相同!正则表达式只是⼀种表⽰法,只要⼯具⽀持这种表⽰法,那么该⼯具就可以处理正则表达式的字符串。
vim、grep、awk 、sed 都⽀持正则表达式,也正是因为由于它们⽀持正则,才显得它们强⼤;在以前上班的公司⾥,由于公司是基于web的服务型⽹站(nginx),对正则的需求⽐较⼤,所以也花了点时间研究正则,特与⼤家分享下:1基础正则表达式grep ⼯具,以前介绍过。
grep -[acinv] '搜索内容串' filename-a 以⽂本⽂件⽅式搜索-c 计算找到的符合⾏的次数-i 忽略⼤⼩写-n 顺便输出⾏号-v 反向选择,即找没有搜索字符串的⾏其中搜索串可以是正则表达式!1搜索有the的⾏,并输出⾏号$grep -n 'the' regular_express.txt搜索没有the的⾏,并输出⾏号$grep -nv 'the' regular_express.txt2 利⽤[]搜索集合字符[] 表⽰其中的某⼀个字符,例如[ade] 表⽰a或d或ewoody@xiaoc:~/tmp$ grep -n 't[ae]st' regular_express.txt8:I can't finish the test.9:Oh! the soup tast e good!可以⽤^符号做[]内的前缀,表⽰除[]内的字符之外的字符。
⽐如搜索oo前没有g的字符串所在的⾏. 使⽤'[^g]oo' 作搜索字符串woody@xiaoc:~/tmp$ grep -n '[^g]oo' regular_express.txt2:apple is my favorite foo d.3:Foo tball game is not use feet only.18:google is the best too ls for search keyword.19:go ooo oogle yes![] 内可以⽤范围表⽰,⽐如[a-z] 表⽰⼩写字母,[0-9] 表⽰0~9的数字, [A-Z] 则是⼤写字母们。
grep命令参数详解

grep命令参数详解grep命令是Linux系统中非常常用的文本搜索工具,可以根据指定的模式在文件中搜索匹配的行,并将其输出。
grep命令的参数众多,灵活运用这些参数可以提高搜索的效率和准确性。
本文将详细介绍grep命令的各个参数及其用法,以帮助读者更好地掌握该命令。
1. -i, --ignore-case: 忽略大小写使用这个参数后,grep命令将忽略搜索模式和文件内容的大小写差异。
这样可以更全面地搜索目标内容,无论目标是大写、小写还是混合大小写形式。
2. -v, --invert-match: 取反匹配在默认情况下,grep命令会输出匹配到的行。
而使用-v参数后,grep命令将输出未匹配到的行。
这对于筛选出不符合要求的行非常有用。
3. -r, --recursive: 递归搜索当需要搜索某个目录及其子目录下的所有文件时,可以使用-r参数。
这样grep命令将会递归地搜索目录下的所有文件,并输出匹配到的行。
4. -l, --files-with-matches: 仅输出文件名有时候我们只想知道哪些文件中包含了匹配的内容,而不需要具体的匹配行。
使用-l参数后,grep命令将仅输出包含匹配内容的文件名。
5. -c, --count: 统计匹配行数若只关心匹配行的数量,可以使用-c参数。
grep命令将输出匹配到的行数,而不显示具体的匹配内容。
6. -n, --line-number: 显示行号使用-n参数后,grep命令将在匹配行前显示行号。
这样可以更方便地定位到目标内容所在的行。
7. -w, --word-regexp: 完整匹配单词使用-w参数可以保证匹配模式与单词边界完全匹配。
这样可以避免出现模糊匹配的情况。
8. -A, --after-context: 显示匹配行后的内容使用-A参数后,grep命令将会输出匹配行后的若干行内容。
这对于查看上下文非常有帮助,可以更好地理解匹配内容的语境。
9. -B, --before-context: 显示匹配行前的内容与-A参数相反,使用-B参数后,grep命令将会输出匹配行前的若干行内容。
(31)grep命令详解:查找文件内容

(31)grep命令详解:查找⽂件内容1.grep命令⽤于不需要列出⽂件的全部内容,⽽是从⽂件中找到包含指定信息的那些⾏。
grep命令能够在⼀个或多个⽂件中,搜索某⼀特定的字符模式(也就是正则表达式),此模式可以是单⼀的字符、字符串、单词或句⼦。
正则表达式是描述⼀组字符串的⼀个模式,正则表达式的构成模仿了数学表达式,通过使⽤操作符将较⼩的表达式组合成⼀个新的表达式。
正则表达式可以是⼀些纯⽂本⽂字,也可以是⽤来产⽣模式的⼀些特殊字符。
为了进⼀步定义⼀个搜索模式,grep 命令⽀持如表 1 所⽰的这⼏种正则表达式的元字符(也就是通配符)。
c* 将匹配 0 个(即空⽩)或多个字符 c(c 为任⼀字符)。
. 将匹配任何⼀个字符,且只能是⼀个字符。
[xyz] 匹配⽅括号中的任意⼀个字符。
[^xyz] 匹配除⽅括号中字符外的所有字符。
^ 锁定⾏的开头。
$ 锁定⾏的结尾。
需要注意的是,在基本正则表达式中,如通配符 *、+、{、|、( 和 )等,已经失去了它们原本的含义,⽽若要恢复它们原本的含义,则要在之前添加反斜杠\,如 \*、\+、\{、\|、\( 和 \)。
grep 命令是⽤来在每⼀个⽂件或中(或特定输出上)搜索特定的模式,当使⽤ grep 时,包含指定字符模式的每⼀⾏内容,都会被打印(显⽰)到屏幕上,但是使⽤ grep 命令并不改变⽂件中的内容。
grep 命令的基本格式如下: [root@localhost ~]# grep [选项] 模式⽂件名 这⾥的模式,要么是字符(串),要么是正则表达式。
grep 命令常⽤选项及含义 -c 仅列出⽂件中包含模式的⾏数。
-i 忽略模式中的字母⼤⼩写。
-l 列出带有匹配⾏的⽂件名。
-n 在每⼀⾏的最前⾯列出⾏号。
-v 列出没有匹配模式的⾏。
-w 把表达式当做⼀个完整的单字符来搜寻,忽略那些部分匹配的⾏。
注意,如果是搜索多个⽂件,grep 命令的搜索结果只显⽰⽂件中发现匹配模式的⽂件名;⽽如果搜索单个⽂件,grep 命令的结果将显⽰每⼀个包含匹配模式的⾏。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Grep命令详解grep [ -E | -F ] [ -i ] [ -h ] [ -s ] [ -v ] [ -w ] [ -x ] [ -y ] [ [ [ -b ] [ -n ] ] | [ -c | -l | -q ] ] [ -p [ Separator ] ] { [ -e PatternList ... ] [ -f PatternFile ... ] | PatternList ... } [ 文件... ]描述grep命令用于搜索由Pattern参数指定的模式,并将每个匹配的行写入标准输出中。
这些模式是具有限定的正则表达式,它们使用ed或egrep命令样式。
grep命令使用压缩的不确定算法。
如果在File参数中指定了多个名称,grep命令将显示包含匹配行的文件的名称。
对shell 有特殊含义的字符($, *, [, |, ^, (, ), \ ) 出现在Pattern参数中时必须带双引号。
如果Pattern参数不是简单字符串,通常必须用单引号将整个模式括起来。
在诸如[a-z], 之类的表达式中,-(减号)cml 可根据当前正在整理的序列来指定一个范围。
整理序列可以定义等价的类以供在字符范围中使用。
如果未指定任何文件,grep 会假定为标准输入。
注意:1.行被限制为2048个字节。
2.段落(使用-p标志时)长度当前被限制为5000个字符。
3.请不要对特殊文件运行grep命令,这样做可能产生不可预计的结果。
4.输入行不应包含空字符。
5.输入文件应该以换行符作为结束。
6.正则表达式不会对换行符进行匹配。
7.虽然一些标志可以同时被指定,但其中的某些标志会覆盖其它标志。
例如,-l选项将优先于所有其它标志。
另外,如果您同时指定了-E和-F标志,则后指定的那个会有优先权。
标志-b在每行之前添加找到该行时所在的块编号。
使用这个标志有助于通过上下文来找到磁盘块号码。
-b标志不能用于来自标准输入和管道的输入。
-c仅显示匹配行的计数。
-E将每个指定模式视作扩展的正则表达式(ERE)。
ERE 的空值将匹配所有的行。
注:带有-E标志的grep命令等价于egrep 命令,只不过它们的错误和使用信息不同以及-s 标志的作用不同。
-e PatternList指定一个或多个搜索模式。
其作用相当于一个简单模式,但在模式以-(减号)开始的情况下,这将非常有用。
模式之间应该用换行符分隔。
连续使用两个换行符或者在引号后加上换行符("\n) 可以指定空模式。
除非同时指定了-E或-F标志,否则每个模式都将被视作基本正则表达式(BRE)。
grep可接受多个-e和-f标志。
在匹配行时,所有指定的模式都将被使用,但评估的顺序没有指定。
-F将每个指定的模式视作字符串而不是正则表达式。
空字符串可匹配所有的行。
注:带有-F标志的grep命令等价于fgrep 命令,只不过它们的错误和使用信息不同以及-s 标志具有不同的作用。
-f PatternFile指定包含搜索模式的文件。
模式之间应该用换行符加以分隔,空行将被认为是空模式。
每种模式都将被视作基本的正则表达式(BRE),除非同时指定了-E或-F标志。
-h禁止在匹配行后附加包含此行的文件的名称。
当指定多个文件时,将禁止文件名。
-i在进行比较时忽略字母的大小写。
-l仅列出(一次)包含匹配行的文件的名称。
文件名之间用换行符加以分隔。
如果搜索到标准输入,将返回(标准输入)的路径名。
-l标志同-c和-n标志的任意组合一起使用时,其作用类似于仅使用了-l标志。
-n在每一行之前放置文件中相关的行号。
每个文件的起始行号为1,在处理每个文件时,行计数器都将被复位。
-p[ Separator]显示包含匹配行的整个段落。
段落之间将按照Separator参数指定的段落分隔符加以分隔,这些分隔符是与搜索模式有着相同格式的模式。
包含段落分隔符的行将仅用作分隔符,它们不会被包含在输出中。
缺省的段落分隔符是空白行。
-q禁止所有写入到标准输出的操作,不管是否为匹配行。
如果选择了输入行,则以零状态退出。
-q标志同-c和-l、-n标志的任意组合一起使用时,其作用类似于仅使用了-q标志。
-s禁止通常因为文件不存在或不可读取而写入的错误信息。
其它的错误信息并未被禁止。
-v显示所有与指定模式不匹配的行。
-w执行单词搜索。
-x显示与指定模式精确匹配而不含其它字符的行。
-y当进行比较时忽略字符的大小写。
PatternList指定将在搜索中使用的一个或多个模式。
这些模式将被视作如同是使用-e标志指定的。
File指定将对其进行模式搜索的文件的名称。
如果未给出File变量,将使用标准输入。
退出状态此命令返回下列出口值:找到匹配项。
1未找到匹配项。
>1发现语法错误,或者文件不可访问(即使找到了匹配项)。
示例1.若使用包含以下模式匹配字符的模式:*, ^, ?, [, ], \(, \), \{ 和\}请输入:grep "^[a-zA-Z]" pgm.s这将显示pgm.s 中第一个字符为字母的所有行。
2.若显示所有与模式不匹配的行,请输入:grep -v "^#" pgm.s这将显示pgm.s 中首字母不是#(井字符)的所有行。
3.若显示文件file1 中与abc 或xyz 字符串匹配的所有行,请输入:grep -E "abc|xyz" file14.若在名为test2 的文件中搜索$(美元符号),请输入:grep \\$ test2为了强制shell 将\$(单反斜杠和美元符号)传递给grep命令,必须要使用\\(双反斜杠)。
\(单反斜杠)字符可通知grep命令将其后的字符(本例中为$)视作原义字符而不是表达式字符。
如果使用fgrep命令,则可以不必使用反斜杠之类的转义字符在Unix中经常会用到grep去选取所需要的信息,用好grep有时可以到达意想不到的效果。
Grep : g (globally) search for a re (regular expression ) and p (print ) the results.1、参数:-I :忽略大小写-c :打印匹配的行数-l :从多个文件中查找包含匹配项-v :查找不包含匹配项的行-n:打印包含匹配项的行和行标2、RE(正则表达式)\ 忽略正则表达式中特殊字符的原有含义^ 匹配正则表达式的开始行$ 匹配正则表达式的结束行\< 从匹配正则表达式的行开始\>; 到匹配正则表达式的行结束[ ] 单个字符;如[A] 即A符合要求[ - ] 范围;如[A-Z]即A,B,C一直到Z都符合要求. 所有的单个字符* 所有字符,长度可以为0# cat zhao.conf(显示我们所查文件的内容)48 Dec 3BC1997 LPSX 68.00 LVX2A 138483 Sept 5AP1996 USP 65.00 LVX2C 18947 Oct 3ZL1998 LPSX 43.00 KVM9D 512219 dec 2CC1999 CAD 23.00 PLV2C 68484 nov 7PL1996 CAD 49.00 PLV2C 234487 may 5PA1998 USP 37.00 KVM9D 644471 May 7Zh1999 UDP 37.00 KV30D 643# grep -c "48" zhao.conf(统计所有以“48”字符开头的行有多少)# grep -i "May" zhao.conf(不区分大小写查找“May”所有的行)487 may 5PA1998 USP 37.00 KVM9D 644471 May 7Zh1999 UDP 37.00 KV30D 643# grep -n "48" zhao.conf(显示行号;显示匹配字符“48”所在的行的行号)1:48 Dec 3BC1997 LPSX 68.00 LVX2A 1382:483 Sept 5AP1996 USP 65.00 LVX2C 1895:484 nov 7PL1996 CAD 49.00 PLV2C 2346:487 may 5PA1998 USP 37.00 KVM9D 644# grep -ni "may" zhao.conf(显示行号;显示匹配字符“may”所在的行的行号,不区分大小写)# grep -v "48" zhao.conf(显示输出没有字符“48”所有的行)47 Oct 3ZL1998 LPSX 43.00 KVM9D 512219 dec 2CC1999 CAD 23.00 PLV2C 68471 May 7Zh1999 UDP 37.00 KV30D 643# grep "471" zhao.conf(显示输出字符“471”所在的行)471 May 7Zh1999 UDP 37.00 KV30D 643# grep "48>" zhao.conf(精确显示输出字符“48”所在的行)48 Dec 3BC1997 LPSX 68.00 LVX2A 138# grep "48<tab>" zhao.conf(显示输出以字符“48”开头,并在字符“48”后是一个tab键所在的行注:tab键,安一下tab键即可;和精确显示输出的结果是相同的)48 Dec 3BC1997 LPSX 68.00 LVX2A 138# grep "48[34]" zhao.conf(显示输出以字符“48”开头,第三个字符是“3”或是“4”的所有的行)483 Sept 5AP1996 USP 65.00 LVX2C 189484 nov 7PL1996 CAD 49.00 PLV2C 234# grep '48[34]' zhao.conf(注意使用单引号(‘’)和使用双引号(“”)在Solaris8中输出的结果是一样的;即:单引号、和双引号是通用的,只要你养成一种习惯就好)483 Sept 5AP1996 USP 65.00 LVX2C 189484 nov 7PL1996 CAD 49.00 PLV2C 234# grep "^[^48]" zhao.conf(显示输出行首不是字符“48”的行)219 dec 2CC1999 CAD 23.00 PLV2C 68# grep "[Mm]ay" zhao.conf(设置大小写查找:显示输出第一个字符以“M”或“m”开头,以字符“ay”结束的行)487 may 5PA1998 USP 37.00 KVM9D 644471 May 7Zh1999 UDP 37.00 KV30D 643# cat zhao.conf(再次显示我们所使用的文件的内容)48 Dec 3BC1997 LPSX 68.00 LVX2A 138483 Sept 5AP1996 USP 65.00 LVX2C 18947 Oct 3ZL1998 LPSX 43.00 KVM9D 512219 dec 2CC1999 CAD 23.00 PLV2C 68484 nov 7PL1996 CAD 49.00 PLV2C 234487 may 5PA1998 USP 37.00 KVM9D 644471 May 7Zh1999 UDP 37.00 KV30D 643# grep "K...D" zhao.conf(显示输出第一个字符是“K”,第二、三、四是任意字符,第五个字符是“D”所在的行)47 Oct 3ZL1998 LPSX 43.00 KVM9D 512487 may 5PA1998 USP 37.00 KVM9D 644471 May 7Zh1999 UDP 37.00 KV30D 643# grep "[A-Z][A-Z][A-Z][9]D" zhao.conf(显示输出第一个字符的范围是“A-D”,第二个字符的范围是“A-D”,第三个字符的范围是“A-D”,第四个字符是“9”,第五个字符的是“D”,所有的行:已知所查字符串的长度为5位)47 Oct 3ZL1998 LPSX 43.00 KVM9D 512487 may 5PA1998 USP 37.00 KVM9D 644# grep "5..1998" zhao.conf487 may 5PA1998 USP 37.00 KVM9D 644# grep "[35]..1998" zhao.conf(显示输出第一个字符是“3”或“5”,第二、三个字符是任意,以1998结尾的所有行;已知所查字符串的长度是7位)47 Oct 3ZL1998 LPSX 43.00 KVM9D 512487 may 5PA1998 USP 37.00 KVM9D 644## grep "4{2,}" zhao.conf(模式出现几率查找:显示输出字符“4”至少重复出现两次的所有行)487 may 5PA1998 USP 37.00 KVM9D 644# grep "9{3,}" zhao.conf(模式出现几率查找:显示输出字符“9”至少重复出现三次的所有行)219 dec 2CC1999 CAD 23.00 PLV2C 68471 May 7Zh1999 UDP 37.00 KV30D 643# grep "9{2,3}" zhao.conf(模式出现几率查找:显示输出字符“9”重复出现的次数在一定范围内(重复出现2 次或3次)所有行)48 Dec 3BC1997 LPSX 68.00 LVX2A 138483 Sept 5AP1996 USP 65.00 LVX2C 18947 Oct 3ZL1998 LPSX 43.00 KVM9D 512219 dec 2CC1999 CAD 23.00 PLV2C 68484 nov 7PL1996 CAD 49.00 PLV2C 234487 may 5PA1998 USP 37.00 KVM9D 644471 May 7Zh1999 UDP 37.00 KV30D 643grep用法大全linux指令2009-09-14 10:26 阅读154 评论0 字号:大大中中小小Grep : g (globally) search for a re (regular expression ) and p (print ) the results.1、参数:-I :忽略大小写-c :打印匹配的行数-l :从多个文件中查找包含匹配项-v :查找不包含匹配项的行-n:打印包含匹配项的行和行标2、RE(正则表达式)\ 忽略正则表达式中特殊字符的原有含义^ 匹配正则表达式的开始行$ 匹配正则表达式的结束行\< 从匹配正则表达式的行开始\> 到匹配正则表达式的行结束[ ] 单个字符;如[A] 即A符合要求[ - ] 范围;如[A-Z]即A,B,C一直到Z都符合要求. 所有的单个字符* 所有字符,长度可以为03、举例# ps -ef | grep in.telnetdroot 19955 181 0 13:43:53 ? 0:00 in.telnetd# more size.txt size文件的内容b124230b034325a081016m7187998m7282064a022021a061048m9324822b103303a013386b044525m8987131B081016M45678B103303BADc2345# more size.txt | grep '[a-b]' 范围;如[A-Z]即A,B,C一直到Z都符合要求b124230b034325a081016a022021a061048b103303a013386b044525# more size.txt | grep '[a-b]'*b124230b034325a081016m7187998m7282064a022021a061048m9324822b103303a013386b044525m8987131B081016M45678B103303BADc2345# more size.txt | grep '' 单个字符;如[A] 即A符合要求b124230b034325b103303b044525# more size.txt | grep '[bB]'b124230b034325b103303b044525B081016B103303BADc2345# grep 'root' /etc/grouproot::0:rootbin::2:root,bin,daemonsys::3:root,bin,sys,admadm::4:root,adm,daemonuucp::5:root,uucpmail::6:roottty::7:root,tty,admlp::8:root,lp,admnuucp::9:root,nuucpdaemon::12:root,daemon# grep '^root' /etc/group 匹配正则表达式的开始行root::0:root# grep 'uucp' /etc/groupuucp::5:root,uucpnuucp::9:root,nuucp# grep '\<uucp' /etc/groupuucp::5:root,uucp# grep 'root$' /etc/group 匹配正则表达式的结束行root::0:rootmail::6:root# more size.txt | grep -i 'b1..*3' -i :忽略大小写b124230b103303B103303# more size.txt | grep -iv 'b1..*3' -v :查找不包含匹配项的行b034325a081016m7187998m7282064a022021a061048m9324822a013386b044525B081016M45678BADc2345# more size.txt | grep -in 'b1..*3'1:b1242309:b10330315:B103303# grep '$' /etc/init.d/nfs.server | wc -l128# grep '\$' /etc/init.d/nfs.server | wc –l 忽略正则表达式中特殊字符的原有含义15# grep '\$' /etc/init.d/nfs.servercase "$1" in>/tmp/sharetab.$$[ "x$fstype" != xnfs ] && \echo "$path\t$res\t$fstype\t$opts\t$desc" \>>/tmp/sharetab.$$/usr/bin/touch -r /etc/dfs/sharetab /tmp/sharetab.$$/usr/bin/mv -f /tmp/sharetab.$$ /etc/dfs/sharetabif [ -f /etc/dfs/dfstab ] && /usr/bin/egrep -v '^[ ]*(#|$)' \if [ $startnfsd -eq 0 -a -f /etc/rmmount.conf ] && \if [ $startnfsd -ne 0 ]; thenelif [ ! -n "$_INIT_RUN_LEVEL" ]; thenwhile [ $wtime -gt 0 ]; dowtime=`expr $wtime - 1`if [ $wtime -eq 0 ]; thenecho "Usage: $0 { start | stop }"# more size.txtthe test filetheir are filesThe end# grep 'the' size.txtthe test filetheir are files# grep '\<the' size.txttheir are files# grep 'the\>' size.txtthe test file# grep '\<the\>' size.txtthe test file# grep '\<[Tt]he\>' size.txtthe test file1 双引号引用在grep命令中输入字符串参数时,最好将其用双引号括起来2 grep选项常用的g r e p选项有:-c 只输出匹配行的计数。