Jueyun123的统计函数C++.cpp
一次性查询出多条记录的Excel万能公式

一次性查询出多条记录的Excel万能公式不管是LOOKUP系列函数,还是INDEX+MATCH函数组合,一般的查询只能得到一条记录,但有时候我们需要查找出所有满足条件记录。
我们用INDEX+SMALL+ROW函数组合就可以完美解决这样的问题。
如下图所示,我们需要查询出所有的1班的学生,可以在F2单元格输入如下公式:=IFERROR(INDEX($B$1:$B$7,SMALL(IF($A$1:$A$7=$E$2,RO W($A$1:$A$7)),ROW(A1))),'')这是一个数组公式,因此要用CTRL+SHIFT+ENTER三键确定输入。
然后向下拖动复制至最后一行。
这个公式相当长了,可能有朋友看到这儿就蒙了,这公式也太长了吧!其实,只需一步步分析公式运行的原理,它也没有那么难。
首先,公式①:IF($A$1:$A$7=$E$2,ROW($A$1:$A$7))的意思是将A1:A7的信息逐个与E2单元格比较,如果相等则返回对应行号。
我们选中这部分公式按F9键显示匹配结果为{FALSE;2;FALSE;4;FALSE;6;FALSE}。
然后,公式②:SMALL(IF(①,ROW(A1))使用SMALL函数返回第1最小值(ROW(A1)=1),公式下拉之后,回依次返回第2最小值、第3最小值......分别对应2、4、6三个值。
然后,公式③:INDEX($B$1:$B$7,②)返回B1:B7范围对应第2、4、6行数据。
最后,用IFERROR函数屏蔽查询中的错误值IFEEOR(③,''),因为在向下拖动复制的时候,查询完所有记录之后,下面就是错误值了,影响显示效果,因此用IFEEOR函数屏蔽错误,将其变为空白。
不知道按这样说大家是否能够理解?欢迎留言讨论!。
python统计个数的函数

python统计个数的函数Python提供了许多统计个数的函数,可以方便地对数据进行分析和处理。
其中,一些常用的函数包括:1. count()函数:用于统计列表中某个元素出现的次数。
例如,对于如下列表arr:arr = [1, 2, 3, 1, 2, 1, 4, 5, 2]我们可以使用count()函数来统计元素1在列表中出现的次数:count_1 = arr.count(1)print(count_1)# 输出结果为32. len()函数:用于统计列表中元素的个数。
例如,对于如下列表arr:arr = [1, 2, 3, 1, 2, 1, 4, 5, 2]我们可以使用len()函数来统计列表中元素的个数:count = len(arr)print(count)# 输出结果为93. sum()函数:用于计算列表中元素的总和。
例如,对于如下列表arr:arr = [1, 2, 3, 1, 2, 1, 4, 5, 2]我们可以使用sum()函数来计算列表中元素的总和:sum_num = sum(arr)print(sum_num)# 输出结果为214. max()函数和min()函数:用于计算列表中元素的最大值和最小值。
例如,对于如下列表arr:arr = [1, 2, 3, 1, 2, 1, 4, 5, 2]我们可以使用max()函数和min()函数来计算列表中元素的最大值和最小值:max_num = max(arr)print(max_num)# 输出结果为5min_num = min(arr)print(min_num)# 输出结果为1总之,Python提供了许多便捷的统计个数的函数,可根据需要进行灵活应用,方便快捷地对数据进行分析和处理。
计算机二级表格函数公式大全

计算机二级表格函数公式大全以下是常见的表格函数与公式:1. 求和函数:=SUM(range),用于计算所选区域内的数值之和。
2. 平均数函数:=AVERAGE(range),用于计算所选区域内数值的平均值。
3. 最大值函数:=MAX(range),用于找出所选区域内的最大值。
4. 最小值函数:=MIN(range),用于找出所选区域内的最小值。
5. 计数函数:=COUNT(range),用于计算所选区域内的数值数量。
6. 去重函数:=UNIQUE(range),用于在所选区域内筛选出唯一值。
7. 排序函数:=SORT(range, [sort_index], [sort_order]),用于按照指定顺序对所选区域进行排序。
8. 筛选函数:=FILTER(range, condition),用于根据指定条件筛选出符合条件的数据。
9. VLOOKUP函数:=VLOOKUP(lookup_value, table_range,column_index, [range_lookup]),用于在表格中查找某个值,并返回查找到的值所在行指定列的数值。
10. HLOOKUP函数:=HLOOKUP(lookup_value, table_range,row_index, [range_lookup]),用于在表格中查找某个值,并返回查找到的值所在列指定行的数值。
11. IF函数:=IF(logical_test, [value_if_true],[value_if_false]),用于根据指定条件返回不同的值。
12. COUNTIF函数:=COUNTIF(range, criteria),用于根据指定条件计算符合条件的数值数量。
13. SUMIF函数:=SUMIF(range, criteria, [sum_range]),用于根据指定条件计算符合条件的数值之和。
14. AVERAGEIF函数:=AVERAGEIF(range, criteria,[average_range]),用于根据指定条件计算符合条件的数值平均值。
统计数字问题c语言

统计数字问题c语言在C语言中,统计数字可以有多种方式。
下面我将从不同的角度给出一些常见的方法。
1. 统计整数个数:方法一,使用循环遍历数组或输入的数字序列,每次遇到一个整数就计数器加1。
方法二,将输入的数字序列转换为字符串,然后使用字符串处理函数(如strtok)将字符串分割成单个数字,计数器加1。
2. 统计正负数个数:方法一,使用循环遍历数组或输入的数字序列,每次判断数字的正负性,分别计数器加1。
方法二,将输入的数字序列转换为字符串,然后使用字符串处理函数将字符串分割成单个数字,判断数字的正负性,分别计数器加1。
3. 统计奇偶数个数:方法一,使用循环遍历数组或输入的数字序列,每次判断数字的奇偶性,分别计数器加1。
方法二,将输入的数字序列转换为字符串,然后使用字符串处理函数将字符串分割成单个数字,判断数字的奇偶性,分别计数器加1。
4. 统计特定数字个数:方法一,使用循环遍历数组或输入的数字序列,每次判断数字是否等于特定数字,若相等则计数器加1。
方法二,将输入的数字序列转换为字符串,然后使用字符串处理函数将字符串分割成单个数字,判断数字是否等于特定数字,若相等则计数器加1。
5. 统计数字出现频率:方法一,使用循环遍历数组或输入的数字序列,每次遇到一个数字,将其作为键值存储在一个哈希表中,并将对应的值加1。
方法二,将输入的数字序列转换为字符串,然后使用字符串处理函数将字符串分割成单个数字,将每个数字作为键值存储在一个哈希表中,并将对应的值加1。
以上是一些常见的统计数字的方法,你可以根据具体的需求选择合适的方法来实现。
需要注意的是,在实际编程过程中,还需要考虑输入数据的合法性、边界条件等情况,以保证程序的正确性和健壮性。
c 统计量 解读

C统计量是一种用于分析两个分类变量之间关系的统计量,通常用于二元分类变量。
C统计量的值介于0到1之间,越接近1表示两个变量之间的相关性越强,越接近0表示两个变量之间的相关性越弱。
C统计量的计算公式为:C = (TP / (TP + FP)) / (P1 / (P1 + P0)),其中TP表示真正例(True Positive),FP表示假正例(False Positive),P1表示正例(Positive),P0表示负例(Negative)。
具体来说,C统计量的值越大,表示两个变量之间的相关性越强,即一个变量的值越大,另一个变量的值也越大的概率越大。
相反,C 统计量的值越小,表示两个变量之间的相关性越弱,即一个变量的值越大,另一个变量的值也越大的概率越小。
需要注意的是,C统计量只适用于二元分类变量,对于多元分类变量或连续变量则需要使用其他统计方法进行相关性分析。
此外,C 统计量的计算结果也会受到样本量和数据分布的影响,因此在使用C 统计量进行数据分析时需要注意样本量和数据分布的合理性。
计数排序c语言代码

计数排序C语言代码简介计数排序是一种基于比较的整数排序算法,它的核心思想是通过确定每个元素前面有几个元素来确定它的位置。
由于计数排序不涉及元素之间的比较,所以它在某些情况下可以达到线性时间复杂度O(n)的效果。
在计数排序中,我们需要先确定待排序数组中的最大值max和最小值min,然后创建一个长度为(max-min+1)的辅助数组count,并将数组中的元素逐个进行计数。
最后,我们根据count数组的累计值得到每个元素的正确位置,并将它们按序放回原始数组中,即可完成排序。
下面是计数排序的C语言代码实现:#include <stdio.h>void countingSort(int arr[], int n) {int max = arr[0], min = arr[0];for (int i = 1; i < n; i++) {if (arr[i] > max) {max = arr[i];}if (arr[i] < min) {min = arr[i];}}int range = max - min + 1;int count[range];for (int i = 0; i < range; i++) {count[i] = 0;}for (int i = 0; i < n; i++) {count[arr[i] - min]++;}for (int i = 1; i < range; i++) {count[i] += count[i - 1];}int output[n];for (int i = n - 1; i >= 0; i--) {output[count[arr[i] - min] - 1] = arr[i];count[arr[i] - min]--;}for (int i = 0; i < n; i++) {arr[i] = output[i];}}int main() {int arr[] = {4, 2, 5, 1, 3};int n = sizeof(arr) / sizeof(arr[0]);countingSort(arr, n);printf("Sorted array: \n");for (int i = 0; i < n; i++) {printf("%d ", arr[i]);}return 0;}代码解析确定最大值和最小值首先,在实现计数排序之前,我们需要通过遍历待排序数组来确定其中的最大值和最小值。
计算机二级考试office常用函数

常用函数
sum简单求和一般1个参数
求和函数sumif 条件求和一般3个参数
sumifs多条件求和5个及5个以上
average 简单平均值一般1个参数
平均值函数averageif条件平均值一般3个参数
averageifs多条件平均值5个及5个以上
count 简单统计统计数字单元格个数一般1个参数
统计函数counta简单统计统计非空单元格个数一般1个参数countif条件统计一般2个参数
countifs 多条件统计一般4个参数
max 最大值一般1个参数
最大最小
min 最小值一般1个参数
rank.eq 排位一般3个参数
排位函数
rank.avg 平均排位一般3个参数
mid 截取一般3个参数
截取函数left 左侧截取一般2个参数
right右侧截取一般2个参数
abs 绝对值一般1个参数
int 向下取整一般1个参数
trunc 取整一般1个参数
round 四舍五入一般2个参数
if 条件函数一般3个参数
vlookup 垂直查找固定4个参数最重要的函数没有之一
now 日期和时间没有参数
today 日期函数没有参数
日期函数year 返回年份一般1个参数
month返回月份一般1个参数
weekday星期函数返回星期对应的数字
trim 删除函数一般1个参数
len 统计字符函数一般1个参数concatenate 连接函数等同于&。
c++ 排列 组合 数学库函数

C++是一种功能强大的编程语言,广泛用于计算机科学和工程领域。
在C++中,排列和组合是数学中常见的概念,它们经常被用于算法设计和数据处理中。
C++提供了一系列的数学库函数,可以方便地进行排列和组合的操作。
本文将介绍C++中排列和组合的数学库函数的使用方法和实际应用。
一、排列的概念排列是指从n个不同元素中取出m(m≤n)个元素,按照一定的顺序进行排列。
当n个元素中任选m个元素并按照一定顺序排列时,称为从n个不同元素中取出m个元素的排列数,记为A(n,m)。
在C++中,可以使用数学库函数来计算排列数。
下面是一个示例代码:```cpp#include <iostream>#include <cmath>using namespace std;int main() {int n = 5;int m = 3;int result = tgamma(n+1) / tgamma(n-m+1);cout << "A(" << n << "," << m << ") = " << result << endl;}```在这个示例代码中,使用了`<cmath>`头文件中的`tgamma()`函数来计算阶乘。
阶乘的计算是排列数的基础,而`tgamma()`函数可以计算出阶乘的值。
通过tgamma(n+1) / tgamma(n-m+1)就可以得到A(n,m)的值,即n个元素中取出m个元素的排列数。
二、组合的概念组合是指从n个不同元素中取出m(m≤n)个元素,不考虑元素的顺序。
当n个元素中任选m个元素并不考虑顺序时,称为从n个不同元素中取出m个元素的组合数,记为C(n,m)。
在C++中,同样可以利用数学库函数来计算组合数。
下面是一个示例代码:```cpp#include <iostream>#include <cmath>using namespace std;int main() {int m = 3;int result = tgamma(n+1) / (tgamma(m+1) * tgamma(n-m+1)); cout << "C(" << n << "," << m << ") = " << result << endl; return 0;}```在这个示例代码中,同样使用了`<cmath>`头文件中的`tgamma()`函数来计算阶乘。
c语言输入123输出321的程序

c语言输入123输出321的程序C语言是一种广泛应用于计算机编程领域的高级编程语言。
在C 语言中,我们可以使用多种方法来实现各种各样的功能,如输入输出、运算、逻辑判断等。
本文将介绍如何使用C语言编写一个输入123输出321的程序。
首先,我们需要了解C语言中的输入输出函数。
C语言中提供了多种输入输出函数,如printf、scanf、getchar、putchar等。
其中,printf函数可以用于输出字符串、数字、字符等,而scanf函数则可以用于从键盘上读取输入数据。
下面是一个简单的例子:#include <stdio.h>int main(){int num;printf('请输入一个整数:');scanf('%d', &num);printf('您输入的整数是:%d', num);return 0;}在上面的代码中,我们使用了printf函数输出了一个提示信息,然后使用scanf函数从键盘上读取了一个整数,并使用printf函数将其输出到屏幕上。
接下来,我们需要编写一个程序,将输入的数字倒序输出。
具体实现方法如下:#include <stdio.h>int main(){int num, a, b, c;printf('请输入一个三位数:');scanf('%d', &num);a = num / 100;b = (num % 100) / 10;c = num % 10;printf('倒序输出:%d%d%d', c, b, a);return 0;}在上面的代码中,我们首先使用scanf函数从键盘上读取了一个三位数的整数,并将其存储在变量num中。
接着,我们使用了数学运算符和取模运算符计算出了这个三位数的百位数、十位数和个位数,并将它们存储在变量a、b和c中。
计算机二级excel中常考公式及讲解

欢迎阅读计算机二级excel 中常考公式及讲解一、 常用函数1. 绝对值函数:=ABS(number):无论是直接选择一个区域还是单个选择哪几个数字,都可以直接显示出最大值或者最小值。
注:✍num_digits 表示保留的小数位数,按此位数对 number 参数进行四舍五入。
✍number 可是输入数字,也能输入单元格(图中红色为输入分数 得出的)4.取整函数:=TRUNC(number,[ Num_digits])向下取整函数:=INT(number)“,0”✍在使用函数INT时,如果遇到负数,将会如图所示,同样的,INT也能直接引用数字。
二、求和函数1.求和函数:=SUM(number1,number2,…)2.条件求和函数:=SUMIF(range, criteria, [sum_range])3.积和函数:=SUMPRODUCT(array1,array2,…)注:空白单元格将视为0,array数组参数必须具有相同三、平均数函数1.平均值函数:=AVERAGE(number1,number2,…)2.条件平均值函数:=A VERAGEIF(range,criteria,[Average_range])多条件平均值函数:=AVERAGEIFS(average_range, criteria_range1, criteria1, [criteria_range2, criteria2], ...)注:range(取值范围)criteria(条件)使用Averageif 函数时,如果对应区域大于所给区域将会默认扩展其区域。
1.计数函数=COUNT(Value1,[Value2],…)=COUNT A(Value1,[Value2],…)=COUNTIFS(criteria_range1, criteria1, [criteria_range2, criteria2]…)数时,对应区域要等于其区域。
统计总数的函数

统计总数的函数统计总数的函数是一种常见的编程函数,通常用于计算某个集合中元素的数量。
在不同的编程语言中,统计总数的函数有不同的名称和语法,但它们都具有相似的功能和用途。
下面将介绍几种常见的统计总数函数及其用法。
1. count()函数count()函数是Python中内置的一个函数,它可以用来统计一个列表、元组或字符串中某个元素出现的次数。
该函数语法如下:count(value)其中value为要统计的元素值。
例如:lst = [1, 2, 3, 4, 5, 2, 3]print(lst.count(2)) # 输出2上述代码中,count()函数统计了列表lst中值为2的元素出现了几次,并将结果输出。
2. length()函数length()函数是一种通用的统计总数函数,在多种编程语言中都有实现。
它可以用来统计一个集合(如列表、数组、字符串等)中元素的数量。
该函数语法如下:length(collection)其中collection为要统计数量的集合对象。
例如:arr = [1, 2, 3, 4, 5]print(len(arr)) # 输出5上述代码中,length()函数通过len()方法来获取列表arr中元素数量,并将结果输出。
3. size()函数size()函数是一种在C++和Java等编程语言中常用的统计总数函数,它可以用来统计一个数组或容器中元素的数量。
该函数语法如下:size(collection)其中collection为要统计数量的数组或容器对象。
例如:int arr[] = {1, 2, 3, 4, 5};cout << sizeof(arr)/sizeof(arr[0]) << endl; // 输出5上述代码中,size()函数通过sizeof()运算符获取数组arr的字节数,并除以每个元素的字节数来计算元素数量,并将结果输出。
4. count_if()函数count_if()函数是一种在C++和Python等编程语言中常用的统计总数函数,它可以用来统计满足某个条件的元素数量。
c语言求极值和统计

在C语言中,求极值和统计通常需要使用一些基本的数学和统计函数。
以下是一个简单的示例程序,用于求一组数的极值并统计其出现次数。
```c#include <stdio.h>#include <stdlib.h>#include <string.h>#define MAX_NUMBERS 100 // 假设最多有100个数// 求极值函数double find_extreme(double arr[], int n) {double min = arr[0]; // 初始假设第一个数为最小值double max = arr[0]; // 初始假设第一个数为最大值for (int i = 1; i < n; i++) {if (arr[i] < min) { // 如果当前数比最小值小,更新最小值min = arr[i];} else if (arr[i] > max) { // 如果当前数比最大值大,更新最大值max = arr[i];}}return max; // 返回最大值或最小值}// 统计函数void count_numbers(double arr[], int n) {int count[n] = {0}; // 初始化计数数组为0for (int i = 0; i < n; i++) { // 遍历数组中的每个数count[arr[i]]++; // 统计每个数的出现次数}for (int i = 0; i < n; i++) { // 输出每个数的出现次数printf("%f: %d\n", arr[i], count[arr[i]]);}}int main() {double numbers[MAX_NUMBERS]; // 存储一组数的数组int n; // 数组中元素的个数printf("请输入一组数(最多不超过%d个):\n", MAX_NUMBERS);scanf("%lf%*c", numbers); // 从标准输入中读取一组数,不包括结尾的换行符n = sizeof(numbers) / sizeof(numbers[0]); // 计算数组中元素的个数if (n > MAX_NUMBERS) { // 如果输入的数超过最大值,输出错误信息并退出程序printf("输入的数超过最大值!\n");return 1;}// 求极值并统计出现次数double extreme = find_extreme(numbers, n);printf("极值为:%f\n", extreme);count_numbers(numbers, n);return 0;}```这个程序首先定义了一个`find_extreme`函数,用于求一组数的极值。
计算机二级excel中常考公式及讲解
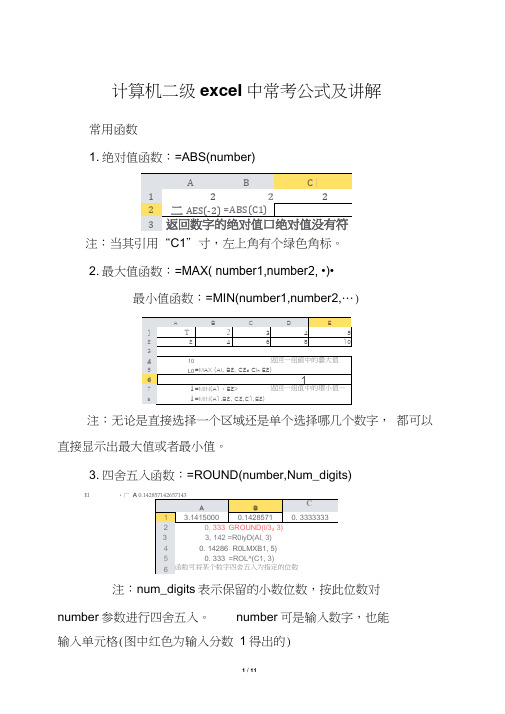
计算机二级exceI中常考公式及讲解常用函数1. 绝对值函数:=ABS(number)注:当其引用“C1”寸,左上角有个绿色角标。
2. 最大值函数:=MAX( number1,number2, •)•最小值函数:=MIN(number1,number2,…)注:无论是直接选择一个区域还是单个选择哪几个数字,都可以直接显示出最大值或者最小值。
3. 四舍五入函数:=ROUND(number,Num_digits)El •广A注:num_digits表示保留的小数位数,按此位数对number参数进行四舍五入。
number可是输入数字,也能输入单元格(图中红色为输入分数1得出的)34. 取整函数:=TRUNC(number,[ Num_digits])向下取整函数:=INT(number)B *T 11W|・]・醫粘贴3* jB II!" | 岸*辜|善去国」星査用暮相:H * A d | 雯.*4 a .00 *・0罗单元格携A3 -注:其中TRUNC 中还能选择日期,选择后默认把常规变 为自定义(如表格中的红框框,其中43118为常规状态下的” =TRUNC(A2,1”而框框中黑色字体的 “201軒1月18日 为输入公式后的自定义下的导出值)其中 ” =TRUNC( number,] Num_digits])中的[Num_digits]默认为0,当只想取整数部分时, 可入图片黄色 区域,不输入卫”。
在使用函数INT 时,如果遇到负数,将会如图所示, 同样的,INT 也能直接引用数字。
求和函数1. 求和函数:=SUM(number1,number2,…)2.条件求和函数:=SUMIF (range, criteria, [sum_range])A B C D E112345A B C D E F G 2]3579L23二53246810I3pD 94246810严□5S=SL1IIF (Al A,>3")12345G 7半省略第三个第数时,则条件区域就是实际求和区域・27 =SiyiF |.:A1:E3, *>3^, C1:E3)123百56a J89 IC3 E5-9-W多条件求和函数:二SUMIFSSum_rangecriteria_rangelcriteria][criteria_rang^,23riteria2J …)注:range (取值范围)criteria(条件)使用条件求和函数SUMIF第三个参数的时,默认[sum_range ]区域的左上角第一个就为前面一个取值范围的左上角,并且默认扩展其区域(如图上,我们在F1G3中输入任何数字都会被加入到A7的数值中,即完整的应该为=SUMIF(A1:E3,">3",C1:G3)。
统计条件不重复项的函数

统计条件不重复项的函数
1. 使用集合(Set),集合是一种无序且不包含重复元素的数
据结构。
我们可以遍历给定的条件列表,将每个元素添加到集合中,由于集合的特性,重复的元素不会被重复添加。
最后,我们可以返
回集合的大小作为不重复项的数量。
2. 使用字典(Dictionary),字典是一种键值对的数据结构,
其中键是唯一的。
我们可以遍历给定的条件列表,将每个元素作为
字典的键,值可以是任意非重要的占位值。
由于字典的键是唯一的,重复的元素将会被自动去重。
最后,我们可以返回字典的键的数量
作为不重复项的数量。
3. 使用列表和循环,我们可以创建一个空列表,然后遍历给定
的条件列表。
对于每个元素,我们可以检查它是否已经在列表中存在,如果不存在,则将其添加到列表中。
最后,我们可以返回列表
的长度作为不重复项的数量。
这些方法在不同的编程语言中都可以实现。
下面是一个使用Python语言实现的示例代码,它使用集合来统计不重复项的数量:
python.
def count_unique_items(condition_list):
unique_items = set()。
for item in condition_list:
unique_items.add(item)。
return len(unique_items)。
请注意,以上只是其中一种实现方式,根据具体的需求和编程语言,可能会有其他更适合的实现方法。
希望以上的解答能够满足你的需求。
unordered_set的count函数

unordered_set的count函数在C++的标准库中,`std::unordered_set` 是一个无序集合容器,其中的元素是唯一的且无序排列。
`count` 函数是用于计算指定元素在`std::unordered_set` 中出现的次数的成员函数。
然而,由于`std::unordered_set` 的性质,每个元素在集合中要么存在(出现1次),要么不存在。
以下是`count` 函数的基本用法:```cpp#include <iostream>#include <unordered_set>int main() {std::unordered_set<int> mySet = {1, 2, 3, 4, 5};// 使用count 函数检查元素是否存在int elementToFind = 3;if (mySet.count(elementToFind) > 0) {std::cout << "Element " << elementToFind << " is present in the set." << std::endl;} else {std::cout << "Element " << elementToFind << " is not present in the set." << std::endl;}return 0;}```在上述示例中,`count` 函数被用于检查集合中是否存在特定的元素(在此例中是数字3)。
如果元素存在,则`count` 返回1,否则返回0。
请注意,由于`std::unordered_set` 中的元素是唯一的,`count` 函数的返回值最多为1。
numpy统计个数函数count

numpy统计个数函数countcount函数的语法如下:参数说明:-a:数组,可以是一维或多维数组。
- axis:用于指定沿着哪个维度进行统计,默认为None,表示对整个数组进行统计。
- dtype:用于指定返回的结果类型,默认为None,表示返回整数类型。
- keepdims:用于指定返回结果是否保留原数组中的维度信息,默认为False,表示不保留。
下面是count函数的一些应用示例:1.统计整个数组中满足条件的元素个数```pythonimport numpy as nparr = np.array([1, 2, 3, 4, 5, 6])count = np.count(arr)print(count) # 输出结果:6```2.统计数组中满足条件的元素的个数(多维数组)```pythonimport numpy as nparr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])count = np.count(arr)print(count) # 输出结果:9```3.沿着指定的维度统计数组中满足条件的元素个数```pythonimport numpy as nparr = np.array([[1, 2, 3], [4, 0, 6], [7, 8, 0]])count = np.count(arr, axis=1)print(count) # 输出结果:[3 2 2]```在上面的示例中,count函数分别统计了整个数组、二维数组以及沿着指定维度的元素个数。
结果分别保存在变量count中,并通过print函数进行打印。
需要注意的是,在count函数中,满足条件的元素是指不为0的元素。
如果想要统计满足其他条件的元素个数,可以通过非0运算来实现,例如:np.count_nonzero(arr)。
此外,还可以使用sum函数来实现统计满足条件的元素个数的功能。
多条件统计个数函数

多条件统计个数函数
多条件统计个数函数是一种在数据分析和计算机编程中常用的
函数,用于按照多个条件对数据进行筛选和统计。
该函数可用于对大量数据进行快速的分类和汇总,从而便于进行数据分析和决策。
在使用多条件统计个数函数时,需要指定一个或多个条件,以便对数据进行筛选和统计。
这些条件可以基于数据的属性、数值范围、文本内容等。
例如,可以按照地区、年龄、性别等条件对数据进行分类和汇总,以便了解不同群体的特征和趋势。
多条件统计个数函数通常包括多个参数,其中最重要的是条件参数和计数参数。
条件参数用于指定筛选数据的条件,计数参数用于指定需要统计的数据项。
例如,可以使用COUNTIF函数来统计符合特定条件的数据项的数量,或使用SUMIF函数来计算符合条件的数据项的总和。
在实际应用中,多条件统计个数函数可用于各种领域,包括金融、市场营销、医疗保健等。
例如,可以利用该函数对投资组合进行风险分析,或根据客户购买行为进行市场营销策略的制定。
总之,多条件统计个数函数是一种强大的数据分析工具,可以为决策者提供有价值的信息和见解。
无论是在企业管理还是个人数据分析中,都可以发挥重要的作用。
- 1 -。
多条件统计个数的函数

多条件统计个数的函数条件统计是指根据特定条件对数据进行分类并计算各类别下的个数。
这种统计方法可以帮助我们更好地了解数据的分布情况,并且可以为后续的分析和决策提供参考。
在本篇文章中,我们将介绍多条件统计个数的函数以及如何使用它来实现条件统计。
count(data, condition)其中,data表示需要进行统计的数据集,condition表示数据分类所依据的条件。
函数的返回结果是一个字典,字典的键为各个类别,键值为对应类别下的个数。
例如,假设我们有一个列表data=[1, 2, 3, 4, 5, 6, 7, 8, 9, 10],我们可以使用count函数来统计data中小于等于5的数和大于5的数的个数:count(data, lambda x: x <= 5) # 返回结果为{'小于等于5': 5, '大于5': 5}上述例子中,我们使用了一个lambda表达式作为条件来进行分类,lambda表达式x: x <= 5表示小于等于5的数作为一类,大于5的数作为另一类。
下面是一个实现多条件统计个数的函数的示例代码:def count(data, *conditions):result = {}for condition in conditions:result[condition.__name__] = len(list(filter(condition, data)))return result上述代码中,count函数接受一个数据集data和多个条件conditions,利用循环遍历conditions中的条件,然后使用filter函数筛选满足条件的数据,再使用len函数计算筛选后的数据个数。
最后,将条件的名字作为键,对应的个数作为键值,构建一个字典并返回。
使用多条件统计个数的函数非常简单,只需要将数据集和条件作为参数传入函数即可。
下面是一个示例代码:data = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]# 统计data中偶数和奇数的个数result = count(data, lambda x: x % 2 == 0, lambda x: x %2 != 0)print(result) # 输出结果为{'偶数': 5, '奇数': 5}# 统计data中小于等于5的数和大于5的数的个数result = count(data, lambda x: x <= 5, lambda x: x > 5)print(result) # 输出结果为{'小于等于5': 5, '大于5': 5}上述例子中,我们分别统计了data中偶数和奇数的个数,以及小于等于5的数和大于5的数的个数。
按条件统计个数函数

按条件统计个数函数
按条件统计个数函数是一种常见的数据处理函数,它可以根据给定的条件从数据集中筛选出符合条件的数据,并计算其数量。
这种函数在数据分析、统计学和机器学习等领域都有广泛的应用。
通常,按条件统计个数函数需要至少两个参数:一个是数据集,另一个是条件。
数据集可以是数组、列表、数据框或数据表等数据结构,而条件则可以是一个函数、一个逻辑表达式或一个向量。
在R语言中,按条件统计个数函数非常常见,其中最常用的函数包括`sum()`、`mean()`、`median()`、`table()`和`count()`等。
这些函数可以接受不同的参数类型,如逻辑向量、字符向量、数字向量等。
例如,下面的代码演示了如何使用`sum()`函数计算一个向量中大于10的元素的个数:
```
x <- c(5, 8, 15, 4, 12, 20, 3)
sum(x > 10)
```
输出结果为:
```
[1] 3
```
这说明在向量x中,有3个元素大于10。
除了基本的按条件统计个数函数之外,还有许多其他的函数可以用来处理数据。
例如,`dplyr`包中的`filter()`和`count()`函数可以非常方便地进行数据筛选和统计;`tidyr`包中的`gather()`和
`spread()`函数可以用来进行数据的长宽格式转换等。
在实际的数据处理中,我们经常会用到按条件统计个数函数。
因此,熟练掌握这些函数的使用方法非常重要。
c++中count的用法

c++中count的用法摘要:1.C++中count 的用法概述2.count 函数的语法和参数3.count 函数的使用示例4.count 函数的返回值和注意事项正文:【1.C++中count 的用法概述】在C++编程语言中,count 函数是一种用于计算数组或容器中特定元素出现次数的实用函数。
count 函数可以用于统计数组或容器中的数字、字符、对象等元素的出现次数,从而为程序员提供有关数据分布的信息。
【2.count 函数的语法和参数】count 函数的语法如下:```cpptemplate <class T>std::size_t count(const T& container);```其中,T 表示容器的类型,container 表示需要统计的容器。
count 函数的参数是一个常量引用,表示要统计的容器。
当调用count 函数时,需要将容器作为参数传递。
【3.count 函数的使用示例】下面是一个使用count 函数的示例,该示例统计一个整数数组中数字1 的出现次数:```cpp#include <iostream>#include <vector>int main() {std::vector<int> nums = {1, 2, 3, 1, 4, 1, 5};std::size_t count_result = count(nums, 1);std::cout << "数字1 在数组中出现的次数为:" << count_result << std::endl;return 0;}```【4.count 函数的返回值和注意事项】count 函数的返回值是容器中特定元素出现的次数。
如果容器为空,则返回0。
在使用count 函数时,需要注意以下几点:1.count 函数只能用于统计容器中的元素,不能用于修改容器的元素。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Sum=getSum(Dat,Count);
Average=getAverage(Dat,Count);
cout<<endl;
cout<<"-----------------------------------------------------"<<endl;
showDat(Dat,Count);
for(i=0,sum=0;i<n;i++)
{
sum+=dat[i];
}
aver=sum/n;
return aver;
}
//float
for(i=0;i<n;i++)
{
cout<<" Data["<<i<<" is used for jump to next line when has showed 6 line here
if(!(i % MAX_LINE)) cout<<endl;
{
int i;
float s;
for(i=0,s=0;i<n;i++)
{
s+=dat[i];
}
return s;
}
float getAverage(const float dat[],const float &n)
{
int i;
float sum,aver;
float getAverage(const float dat[],const float &n);
float main()
{
float Dat[MAX_COUNT];
float dtDat[MAX_COUNT];
float Count;
float Average;
float Sum;
void showAbsolateError(const float dat[],float datb[],const float &n,const float &aver);
void showMeasurementError(const float dat[],const float &n,const float &aver);
return -1;
}
return ste;
}
float getData(float dat[],const float &n)
{
int i=0;
if((n > MAX_COUNT) || n<= 1) return 0;
cout<<"Please input the data here:"<<endl;
cout<<"> The sum of all data is ["<<Sum<<"]"<<endl;
cout<<"> The average of all data is ["<<Average<<"]"<<endl;
cout<<"-----------------------------------------------------";
for(i=0;i<n;i++)
{
datb[i]=dat[i]-aver;
cout<<" dtData["<<i<<"]="<<datb[i];
//This part is used for deal jump to next line when line is full
showMeasurementError(Dat,Count,Average);
cout<<"-----------------------------------------------------"<<endl;
StandardErr=getStandardError(dtDat,Count);
if(!(i % MAX_LINE)) cout<<endl;
}
cout<<endl;
}
void showMeasurementError(const float dat[],const float &n,const float &aver)
{
int i;
cout<<endl;
cout<<" Input 1 to exit"<<endl;
int x=0;
while(x!=1)
cin>>x;
}
void showDat(const float dat[],const float n)
{
int i,j;
cout<<endl;
cout<<" These data you have inputed is:"<<endl;
while(i<n)
{
cout<<endl<<"Data["<<i<<"]=";
cin>>dat[i];
cout<<endl<<" Data["<<i<<"="<<dat[i];
i++;
}
cout<<endl;
return n;
}
float getSum(const float dat[],const float &n)
//作者:Jueyun123
//2012年制作
#include <iostream.h>
#include <math.h>
#define MAX_COUNT 100
#define MAX_LINE 6
void showDat(const float dat[],const float n);
cout<<"-----------------------------------------------------"<<endl;
showAbsolateError(Dat,dtDat,Count,Average);
cout<<"-----------------------------------------------------"<<endl;
cout<<" Please input the AMOUNT of the DATAs"<<endl;
cin>>Count;
if(getData(Dat,Count)==0)
{
cout<<" Get datas FAILED!"<<endl;
return -1;
float getStandardError(const float dtDat[],const float &n);
float getData(float dat[],const float &n);
float getSum(const float dat[],const float &n);
cout<<"The Measurement Error is";
cout<<endl;
}
float getStandardError(const float dtDat[],const float &n)
{
int i;
float s=0;
float ste=0;
if(n<=1) return -1;
}
cout<<endl;
}
void showAbsolateError(const float dat[],float datb[],const float &n,const float &aver)
{
int i;
cout<<endl;
cout<<" The ABSOLATE ERROR is :"<<endl;
cout<<"> The STANDARD ERROR is "<<StandardErr<<endl;
cout<<"-----------------------------------------------------"<<endl;
cout<<"> There are ["<<Count<<"] DATA in the count"<<endl;