数据结构 函数(精选)
数据结构

malloc函数为动态分配空间;原型为: void * malloc(int size);使用方法一般为:假设你要定义一个名为a的Node类型的指针变量,使用以下语句:Node * a=(Node *)malloc(sizeof(Node));其中(Node *)为强制转换,把返回类型void *转换为Node *,sizeof(Node)为获取Node 类型占据空间的大小,如在我机子上int类型占4字节,sizeof(int)就返回4;使用malloc需要包含#include <malloc.h>学习数据结构有什么用?计算机内的数值运算依靠方程式,而非数值运算(如表、树、图等)则要依靠数据结构。
同样的数据对象,用不同的数据结构来表示,运算效率可能有明显的差异。
程序设计的实质是对实际问题选择一个好的数据结构,加之设计一个好的算法。
而好的算法在很大程度上取决于描述实际问题的数据结构。
程序=数据结构+算法(尼克劳斯.沃尔斯)目标:“数据结构” 课程的教学目标是要求学生学会分析数据对象特征,掌握数据组织方法和计算机的表示方法,以便为应用所涉及的数据选择适当的逻辑结构、存储结构及相应算法,初步掌握算法时间空间分析的技巧,培养良好的程序设计技能。
意义1. 算法和数据结构是计算机科学的两大支柱2.数据结构是程序设计的基础程序=数据结构+算法--图灵奖获得者:Nicklaus Wirth(瑞士)数据结构是设计OS、DBMS、编译等系统程序和各种应用程序的重要基础数据结构是一门研究非数值计算的程序设计问题中计算机的操作对象以及它们之间的关系和操作的学科。
术语:数据(Data):是对信息的一种符号表示。
在计算机科学中是指所有能输入到计算机中并被计算机程序处理的符号的总称。
数据元素(Data Element):是数据的基本单位,在计算机程序中通常作为一个整体进行考虑和处理。
一个数据元素可由若干个数据项组成。
数据结构——精选推荐

数据结构1、简要回答术语:数据,数据元素,数据结构,数据类型。
A、数据(Data) :是客观事物的符号表⽰。
在计算机科学中指的是所有能输⼊到计算机中并被计算机程序处理的符号的总称。
B、数据元素(Data Element) :是数据的基本单位,在程序中通常作为⼀个整体来进⾏考虑和处理。
C、数据结构(Data Structure):是指相互之间具有⼀定联系(关系)的数据元素的集合。
D、数据类型(Data Type):是⼀个值的集合和定义在这个值集上的⼀组操作的总称。
2、数据的逻辑结构?数据的物理结构?逻辑结构与物理结构的区别和联系是什么?A、元素之间的相互联系(关系)称为逻辑结构。
四种基本类型:集合、线性结构、树型结构、图状结构或⽹状结构B、数据结构在计算机中的表⽰(⼜称映像)称为数据的物理结构,⼜称存储结构。
3、算法分析的⽬的是什么?算法分析的主要⽅⾯是什么?4、分析以下程序段的时间复杂度,请说明分析的理由或原因。
⑴Sum1( int n ){ int p=1, sum=0, m ;for (m=1; m<=n; m++){ p*=m ; sum+=p ; }return (sum) ;}⑵Sum2( int n ){ int sum=0, m, t ;for (m=1; m<=n; m++){ p=1 ;for (t=1; t<=m; t++) p*=t ;sum+=p ;}return (sum) ;}⑶递归函数fact( int n ){ if (n<=1) return(1) ;else return( n*fact(n-1)) ;}1、简述下列术语:线性表,顺序表,链表。
A、线性表(Linear List):是由n(n≧0)个数据元素(结点)a1,a2,…an组成的有限序列。
B、线性表的顺序表⽰指的是⽤⼀组地址连续的存储单元依次存储线性表的数据元素。
C、链式存储:⽤⼀组任意的存储单元存储线性表中的数据元素。
数据结构函数

第七章 函数
6.4 函数的调用
调用形式
函数名(实参表); 说明:
实参与形参个数相等,类型一致,按顺序一一对应 实参表求值顺序,因系统而定(Turbo C 自右向左)
7.2 函数的定义
一般格式
函数返回值类型 缺省int型 无返回值void
合法标识符
现代风格:
函数类型 函数名(形参类型说明表) { 说明部分 语句部分 } 例例 有参函数(现代风格) 有参函数(现代风格) 例 无参函数 例 空函数 int int max(int x, y) max(int x,int y) printstar( ) dummy( ) { {int int z; z; { printf(“********** \n”); } { } z=x>y?x:y; z=x>y?x:y; 或 return(z); return(z); printstar(void ) 函数体为空 } } { printf(“**********\n”); }
函数体
第七章 函数
函数传统风格和例子
传统风格:
函数类型 函数名(形参表) 形参类型说明 { 说明部分 语句部分 }
例 有参函数(传统风格) int max(x,y) int x,y; { int z; z=x>y?x:y; return(z); }
第七章 函数
7.3 函数的返回值
例 无返回值函数 void swap(int x,int y ) 返回语句 { int temp; 形式: return(表达式); temp=x; 或 return 表达式; x=y; y=temp; 或 return; } 功能:使程序控制从被调用函数返回到调用函数中, 同时把返值带给调用函数 说明:
数据结构知识点归纳总结(经典)

数据结构知识点归纳总结(经典)1. 简介数据结构是计算机科学中的一个重要概念,它用于组织和存储数据,以便于操作和管理。
数据结构能够帮助我们更有效地处理和分析大量的数据。
2. 常见的数据结构以下是一些常见的数据结构类型:2.1 数组(Array)数组是一种连续存储数据元素的数据结构,可以按照索引访问元素。
它具有固定大小,可以用于存储相同类型的元素。
2.2 链表(Linked List)链表是一种通过指针将元素连接起来的数据结构。
它可以包含不同类型的元素,并且具有动态分配内存的能力。
2.3 栈(Stack)栈是一种具有后进先出(LIFO)特性的数据结构。
它只能在栈顶进行插入和删除操作。
2.4 队列(Queue)队列是一种具有先进先出(FIFO)特性的数据结构。
它可以在队尾插入元素,在队头删除元素。
2.5 树(Tree)树是一种非线性的数据结构,它由节点和边构成。
树的一个节点可以有多个子节点,但每个节点只有一个父节点。
2.6 图(Graph)图是一种由节点和边构成的数据结构。
节点之间的边可以表示节点之间的关系。
2.7 哈希表(Hash Table)哈希表是一种以键-值对形式存储数据的数据结构。
它使用哈希函数将键映射到存储位置,以实现快速的查找操作。
3. 常见的数据结构操作数据结构不仅仅是存储数据,还包括对数据的操作。
以下是一些常见的数据结构操作:- 插入元素:向数据结构中添加新元素。
- 删除元素:从数据结构中删除指定元素。
- 查找元素:在数据结构中查找指定元素。
- 遍历元素:按照特定的顺序访问数据结构中的所有元素。
- 排序元素:对数据结构中的元素进行排序。
- 合并结构:将两个或多个数据结构合并成一个。
- 分割结构:将一个数据结构分割成两个或多个。
4. 数据结构的应用数据结构在计算机科学中有广泛的应用,包括但不限于以下领域:- 数据库系统- 图像处理- 网络通信- 操作系统- 算法设计和分析5. 总结数据结构是计算机科学中的重要概念,它为我们处理和管理大量数据提供了有效的方式。
算法与数据结构 调和函数

算法与数据结构调和函数调和函数是一种在算法和数据结构中经常出现的数学函数。
它由数学家欧拉发现,是一种几何级数的求和形式。
在计算机科学中,调和函数在许多算法和数据结构中扮演了重要角色,例如计算凸包、最小生成树和多项式求逆等问题。
调和函数的定义如下:H(n) = 1 + 1/2 + 1/3 + ··· + 1/n其中n是一个正整数。
可以看到,调和函数是一个无限级数,每个项都是分数1/i,其中i表示1到n中的整数。
当n趋向于无穷大时,调和函数趋向于无穷大,但以相对较缓慢的速度增长。
调和函数在算法和数据结构中的应用非常广泛。
其中最重要的应用之一是计算凸包。
在几何中,凸包是一个凸多边形,它包含平面上的所有给定点。
计算凸包需要找到点集中的极值点,而这些极值点可以使用调和函数来计算。
具体地,给定一些点,首先我们计算所有点到x轴的投影,然后将它们按照从左到右的顺序排序。
然后我们将投影转换为高度为1/Hi的矩形,其中Hi是第i个点之前的点到x轴的距离。
调和函数H(n)可以用于计算Hi。
除了计算凸包,调和函数还可以用于计算最小生成树。
最小生成树是一个连通图的子图,它包含所有节点并且权重最小。
在计算最小生成树时,我们需要用到Prim算法或者Kruskal算法。
这些算法通常涉及到对边进行排序,并找到一组边,使它们依次加入生成树中。
对于每个新节点,我们需要将它与前面的节点进行比较,以确定其权重。
这里调和函数又可以用于计算每个节点相邻的边的平均权值。
最后,调和函数还可以用于多项式求逆。
多项式求逆是计算一个多项式的逆多项式,即另一个多项式q,满足p(x)q(x) = 1。
调和函数可以用于计算多项式q的系数,从而实现多项式求逆。
总之,调和函数是一种在算法和数据结构中非常重要的数学函数。
它可以用于许多问题,其中包括计算凸包、最小生成树和多项式求逆等。
因此,掌握调和函数的概念和应用是非常有必要的。
数据结构

绪 论
CUIT
李
数据对象 (Data Object)
性质相同的数据元素的集合,是数据的子集, 例如整数。
莉
丽
数 据 结 构
数据结构 (Data Structure)
作为一个概念是指:相互之间存在一种或多种 特定关系的数据元素的集合。数据元素之间的相互 关系称为结构。有下列四种基本结构:
之
(1)集合
数 据 结 构
例3:
多叉路口交通灯的管理问题 这类交通、道路的问题数据模型是一种 称为“图”的数据结构。
C
之
绪 论
CUIT
D B
李
A
(a) 五叉路口
E
莉
丽
数 据 结 构
结论:
之
综合上面三个例子,描述这类非数值计算性问 题的数学模型不再是数学方程,而是诸如表、树和 图之类的数据结构。
绪 论
数 据 结 构
这个关系不是线性的,从一个棋盘可以派生出几个格 局,如下图: * * * * *
(a) 棋盘格式示例
之
*
*
*
*
绪 论
CUIT
* * * *
* * * *
* *
(b)井字棋对弈树的局部
李
莉
丽
“树根”是对奕开始之前的棋盘格局,而所有的 “叶子”是可能出现的结局,对奕的过程就是从树 根沿树叉到达某个叶子的过程。 --“树”这种数据 模型也是一种数据结构。
李
莉
丽
数 据 结 构
1. 4
算法:
算法与算法分析
是对特定问题求解步骤的一种描述,是指令的 有限序列,其中每一条指令是一个或多个操作。 一个算法就是一个有穷规则的集合,规则规 定了解决某特定问题的运算序列。
数据结构题——精选推荐

数据结构题第六章树和⼆叉树简答题1、有⼀棵树的括号表⽰为A(B,C(E,F(G)),D),回答下⾯的问题:这棵树的根结点是谁?这棵树的叶⼦结点是什么?结点C的度是多少?这棵树的度是多少?这棵树的深度是多少?结点C的孩⼦结点是哪些?结点C的双亲结点是谁?2、若⼀棵度为4的树中度为1,2,3,4的结点个数分别是4,3,2,2,则该树中叶⼦结点的个数是多少?总结点个数是多少?3、⼀棵⾼度为h的完全k次数,如果按照层次⾃上向下、⾃左向右的顺序从1开始对全部结点编号,试问:最多有多少个结点?最少有多少个结点?编号为q的结点的第i个孩⼦结点的编号是多少?4、若⼀棵⼆叉树具有10个度为2的结点,5个度为1的结点,则度为0的结点个数为结点的总个数为5、⼀棵完全⼆叉树有1001个结点,其中叶⼦结点的个数为6、⼀棵⾼度为h的完全⼆叉树⾄少有个结点。
7、⼀棵⾼度为5的完全⼆叉树⾄多有个结点。
8、设⾼度为h的⼆叉树上只有度为0和度为2的结点,则此类⼆叉树⾄少包含个结点。
9、⼀个具有1025个结点的⼆叉树的⾼度h为10、在⼀棵完全⼆叉树中,结点个数为n,则编号最⼤的分⽀结点的编号为11、⼀棵⼆叉树的先序遍历为ABCDEF,中序遍历为CBAEDF,则后序遍历为12、⼀棵⼆叉树的先序遍历为ABCDEFG,它的中序遍历可能为A.CABDEFGB. ABCDEFGC.DACEFBGD.ADCFEGB思考:⼆叉树的先序和中序遍历相同的条件是?⼆叉树的后序和中序遍历相同的条件是?13、⼀棵⼆叉树的后序遍历为DABEC,中序遍历为DEBAC,则先序遍历为14、⼀棵⼆叉树的先序遍历为EFHIGJK,中序遍历为HFIEJKG,则该⼆叉树根结点的右孩⼦为16、根据使⽤频率为5个字符设计的赫夫曼编码不可能的是A.111,110,10,01,00B.000,001,010,011,1C.100,11,10,1,0D.001,000,01,11,1017、根据使⽤频率为5个字符设计的赫夫曼编码不可能的是A. 000,001,010,011,1B.0000,0001,001,01,1C. 000,001,01,10,11D.00,100,101,110,11118、设有13个值,⽤它们组成⼀棵赫夫曼树,则该赫夫曼树共有个结点。
头文件btree.h中定义数据结构并声明用于完成基本运算的函数。对应基本运算的函数

头文件btree.h中定义数据结构并声明用于完成基本运算的函数。
对应基本运算的函数1.引言1.1 概述在计算机科学领域,数据结构是研究数据组织、存储和管理的方法。
它是计算机程序设计的基础,对于解决复杂的问题和优化算法至关重要。
本文主要讨论的是一个名为btree.h的头文件中所定义的数据结构,以及在该头文件中声明的用于完成基本运算的函数。
这些基本运算函数可以对该数据结构进行插入、删除、搜索等操作,为处理数据提供了方便和高效。
首先,在头文件btree.h中,我们定义了一种名为B树的数据结构。
B树是一种自平衡的二叉查找树,它在处理大量数据时具有出色的性能。
B树通常用于在数据库和文件系统中存储和管理数据。
其次,我们在头文件中声明了一些用于完成基本运算的函数。
这些函数包括插入数据、删除数据、搜索数据等操作。
通过这些函数的使用,我们可以在B树中灵活地操作数据,实现快速的查找、插入和删除。
本文的目的是介绍头文件btree.h中所定义的数据结构和基本运算函数的使用方法,以及它们在实际应用中的意义和优势。
通过深入了解和熟练掌握这些内容,读者可以在自己的程序中更好地利用B树这种数据结构,提高数据处理的效率和准确性。
接下来,将在文章的第2部分探讨头文件btree.h的定义,以及在第3部分总结整篇文章的内容以及展望未来可能的研究方向。
通过进行系统和全面的分析,读者将能够更好地理解并运用该头文件中定义的数据结构和函数。
1.2 文章结构本文的目的是介绍头文件btree.h中定义的数据结构以及声明用于完成基本运算的函数。
文章主要分为以下几个部分:1. 引言:在引言部分,将对本文的整体内容进行概述,介绍头文件btree.h 的目的和作用,以及本文的结构和目的。
2. 正文:正文部分主要包括两个小节。
2.1 头文件btree.h 的定义:在这一小节中,将详细介绍头文件btree.h 的定义,包括其中定义的数据结构以及相关的宏定义和全局变量。
数据结构reverse函数

数据结构reverse函数数据结构是计算机科学中非常重要的一个概念,它是指一组数据元素以及定义在此数据元素上的一组操作。
在实际应用中,我们经常需要对数据结构进行操作,其中一个常见的操作就是反转(reverse)。
反转是指将数据结构中的元素按照相反的顺序重新排列。
例如,对于一个数组[1, 2, 3, 4, 5],反转后的结果是[5, 4, 3, 2, 1]。
反转操作在很多场景下都有重要的应用,比如字符串反转、链表反转等。
在实现数据结构的反转操作时,我们可以使用reverse函数。
reverse 函数是一种通用的函数,可以用于不同类型的数据结构,比如数组、链表等。
它的作用是将数据结构中的元素按照相反的顺序重新排列。
下面我们以数组为例,来介绍如何实现一个reverse函数。
首先,我们需要定义一个数组,并初始化它的元素。
假设我们的数组为arr,初始元素为[1, 2, 3, 4, 5]。
接下来,我们可以使用两个指针来实现数组的反转。
一个指针指向数组的第一个元素,另一个指针指向数组的最后一个元素。
然后,我们交换这两个指针所指向的元素,并将两个指针向中间移动,重复这个过程,直到两个指针相遇为止。
具体的实现代码如下:```void reverse(int[] arr) {int left = 0;int right = arr.length - 1;while (left < right) {int temp = arr[left];arr[left] = arr[right];arr[right] = temp;left++;right--;}}```通过调用reverse函数,我们可以将数组[1, 2, 3, 4, 5]反转为[5, 4, 3, 2, 1]。
除了数组,我们还可以使用类似的方法来实现其他数据结构的反转操作。
比如,对于链表,我们可以使用三个指针来实现反转。
一个指针指向当前节点,一个指针指向前一个节点,一个指针指向后一个节点。
Python数据结构概述

Python数据结构概述近年来,数据结构的应用场景越来越广泛,尤其是在计算机领域。
而Python作为一种高级编程语言,也有其独特的数据结构实现方法。
本文将对Python数据结构进行概述。
一、Python数据类型在Python中,有许多数据类型,如数字、字符串、列表、元组、字典和集合等。
其中最基本的数据类型为数字类型,Python支持int、float和complex三种类型的数字。
而对于字符串类型,Python字符串可以使用单引号或双引号来定义,如:str1 = 'hello world'str2 = "hello world"Python的列表数据类型是其中的一种,它是一种有序的数据结构,可以存储不同类型的元素,如:list1 = [1, 'hello', 3.14, ['a', 'b', 'c']]Python中的元组也是一种有序的数据结构,与列表类似,但不同之处在于元组是不可变的,如:tuple1 = (1, 'hello', 3.14, ['a', 'b', 'c'])Python的字典数据类型也是一种非常常用的数据结构,它是由键值对构成的,如:dict1 = {'name': 'Bob', 'age': 18, 'score': {'English': 90, 'Math': 85, 'Physics': 80}}Python也提供了集合数据类型,它是无序的,并且不允许出现重复的元素,如:set1 = set([1, 2, 3, 4, 5])二、Python数据结构常用函数Python提供了许多对数据结构进行操作的函数,掌握这些函数可以帮助我们更加方便地使用Python数据结构。
结构——精选推荐

设哈希(Hash )表的地址范围为0~17,哈希函数为:H (K )=K MOD 16。
K 为关键字,用线性探测法再散列法处理冲突,输入关键字序列:(10,24,32,17,31,30,46,47,40,63,49)造出Hash 表,试回答下列问题:(1) 画出哈希表的示意图;(2) 若查找关键字63,需要依次与哪些关键字进行比较?(3) 若查找关键字60,需要依次与哪些关键字比较?(4) 假定每个关键字的查找概率相等,求查找成功时的平均查找长度。
解: (1)画表如下:然后顺移,与46,47,32,17,63相比,一共比较了6次!(3)查找60,首先要与H(60)=60%16=12号单元内容比较,但因为12号单元为空(应当有空标记),所以应当只比较这一次即可。
(4) 对于黑色数据元素,各比较1次;共6次;对红色元素则各不相同,要统计移位的位数。
“63”需要6次,“49”需要3次,“40”需要2次,“46”需要3次,“47”需要3次,所以ASL=1/11(6+2+3×3)=17/11=1.5454545454≈1.55(1) 已知二叉树的二叉链表存储表示,指出建立如图所示树的结构时输入的字符序列。
typedef struct BiTNode{ char data;struct BiTNode *lchild,*rchild;} BiTNode;void CreateBiTree( BiTNode *T){ char ch;scanf(&ch);if(ch= =… …) T=NULL;else{ T=(BiTNode *)malloc(sizeof(BiTNode));while (T==NULL)T=(BiTNode *)malloc(sizeof(BiTNode));T –>data=ch;CreateBiTree(T –>lchild);CreateBiTree(T –>rchildd);(2) 设有一组关键字{9,01,23,14,55,20,84,27},采用哈希函数:H (key )=key mod 7 ,表长为10,用开放地址法的二次探测再散列方法Hi=(H(key)+di) mod 10(di=12,22,32,…,)解决冲突。
数据结构代码汇总简版

数据结构代码汇总数据结构代码汇总概述本文档旨在汇总和介绍常见的数据结构代码示例。
数据结构是计算机科学的重要基础,能够帮助我们有效地存储和组织数据。
有了良好的数据结构代码,我们可以提高程序的执行效率,并简化问题的解决过程。
本文档将介绍以下几种常见的数据结构及其相应的代码示例:1. 数组(Array)2. 链表(Linked List)3. 栈(Stack)4. 队列(Queue)5. 树(Tree)6. 图(Graph)7. 哈希表(Hash Table)数组(Array)数组是一组具有相同数据类型的元素按照连续的内存位置存储的数据结构。
以下是数组的示例代码:```python定义一个整型数组arr = [1, 2, 3, 4, 5]输出数组中的元素for i in arr:print(i)```链表(Linked List)链表是一种线性数据结构,由节点组成,每个节点包含数据和指向下一个节点的指针。
以下是链表的示例代码:```python定义一个链表的节点类class Node:def __init__(self, data):self.data = dataself.next = None定义一个链表类class LinkedList:def __init__(self):self.head = None在链表末尾添加一个节点def append(self, data):new_node = Node(data)if self.head is None:self.head = new_node else:curr = self.headwhile curr.next:curr = curr.next curr.next = new_node 遍历并打印链表中的节点值def display(self):curr = self.headwhile curr:print(curr.data)curr = curr.next创建一个链表对象并添加节点ll = LinkedList()ll.append(1)ll.append(2)ll.append(3)打印链表中的节点值ll.display()```栈(Stack)栈是一种后进先出(LIFO)的数据结构,只能在栈顶进行元素的插入和删除。
数据结构1

/* c1.h (程序名) */#include<string.h>#include<ctype.h>#include<malloc.h> /* malloc()等*/#include<limits.h> /* INT_MAX等*/#include<stdio.h> /* EOF(=^Z或F6),NULL */#include<stdlib.h> /* atoi() */#include<io.h> /* eof() */#include<math.h> /* floor(),ceil(),abs() */#include<process.h> /* exit() *//* 函数结果状态代码*/#define TRUE 1#define FALSE 0#define OK 1#define ERROR 0#define INFEASIBLE -1/* #define OVERFLOW -2 因为在math.h中已定义OVERFLOW的值为3,故去掉此行*/ typedef int Status; /* Status是函数的类型,其值是函数结果状态代码,如OK等*/ typedef int Boolean; /* Boolean是布尔类型,其值是TRUE或FALSE *//* c1-1.h 采用动态分配的顺序存储结构*/typedef ElemType *Triplet; /* 由InitTriplet分配三个元素存储空间*//* Triplet类型是ElemType类型的指针,存放ElemType类型的地址*//* bo1-1.c 抽象数据类型Triplet和ElemType(由c1-1.h定义)的基本操作(8个) */ Status InitTriplet(Triplet *T,ElemType v1,ElemType v2,ElemType v3){ /* 操作结果:构造三元组T,依次置T的三个元素的初值为v1,v2和v3 */*T=(ElemType *)malloc(3*sizeof(ElemType));if(!*T)exit(OVERFLOW);(*T)[0]=v1,(*T)[1]=v2,(*T)[2]=v3;return OK;}Status DestroyTriplet(Triplet *T){ /* 操作结果:三元组T被销毁*/free(*T);*T=NULL;return OK;}Status Get(Triplet T,int i, ElemType *e){ /* 初始条件:三元组T已存在,1≤i≤3。
getelem函数

getelem函数
Getelem函数是一种常用的数据结构操作函数,它可以用来获取某个
数据结构中指定位置的元素。
在编程中,我们经常需要对数据结构进
行操作,而getelem函数就是其中一个重要的操作函数。
getelem函数的使用非常简单,只需要传入数据结构和要获取的元素
位置即可。
例如,如果我们要获取一个数组中第三个元素的值,可以
使用以下代码:
int arr[] = {1, 2, 3, 4, 5};
int elem = getelem(arr, 2);
这段代码中,getelem函数会返回数组arr中第二个位置的元素,也
就是数字3。
通过这种方式,我们可以方便地获取数据结构中任意位置的元素。
除了数组,getelem函数还可以用于其他类型的数据结构,比如链表、栈、队列等。
无论是哪种数据结构,getelem函数的作用都是相同的,即获取指定位置的元素。
在实际编程中,getelem函数的使用非常广泛。
它可以用来实现各种
算法和数据结构,比如排序、查找、遍历等。
例如,在快速排序算法中,我们需要不断地获取数组中的元素进行比较和交换,而getelem
函数就是实现这一功能的重要工具之一。
总之,getelem函数是一种非常实用的数据结构操作函数,它可以方
便地获取任意位置的元素。
在编程中,我们经常需要使用它来实现各
种算法和数据结构,因此掌握getelem函数的使用方法是非常重要的。
算法与数据结构实验 调和函数

算法与数据结构实验:调和函数一、介绍调和函数是离散数学和算法与数据结构中的重要概念之一。
在数据结构中,调和函数用于计算一些操作的平均时间复杂度。
在本文中,我们将深入探讨调和函数的概念、性质和应用。
二、调和函数的定义调和函数又称平均阻塞时间函数,是一种将函数与级数联系起来的数学概念。
对于正整数 n,调和函数 H(n) 的定义如下:H(n) = 1/1 + 1/2 + 1/3 + … + 1/n调和函数的值随着 n 的增加而增加,但增速逐渐减慢。
事实上,调和函数是发散的,也就是说,它的值可以无限增加,但增速越来越慢。
三、调和函数的性质1.渐近性质:调和函数的渐近增长速度与自然对数函数 ln(n) 相同。
换句话说,当 n 趋向于无穷大时,调和函数 H(n) 的增长速度与 ln(n) 几乎相同。
2.上下界性质:调和函数的上下界可以用自然对数函数来确定。
具体而言,调和函数 H(n) 的下界是 ln(n),而上界是 ln(n) + 1。
3.近似性质:当 n 很大时,调和函数的值可以用自然对数函数来近似表示。
这是因为自然对数函数的增长速度比调和函数更慢,所以在实际应用中,我们可以使用自然对数函数来近似计算调和函数的值。
四、调和函数的应用调和函数在算法与数据结构中有广泛的应用。
以下是一些常见的应用场景:1. 平均时间复杂度分析在算法设计和分析中,我们经常需要评估某个操作的平均时间复杂度。
如果我们知道该操作在不同输入规模下的执行时间,我们可以使用调和函数来计算平均时间复杂度。
具体而言,如果一个操作在输入规模为 n 的情况下执行的时间复杂度是O(H(n)),那么它的平均时间复杂度就可以用调和函数来表示。
2. 算法优化调和函数的性质可以帮助我们优化算法的执行效率。
由于调和函数随着 n 的增加而增长缓慢,我们可以利用这一性质来设计更具效率的算法。
例如,当我们需要处理大规模的数据时,可以尽量避免使用具有较高调和函数值的操作,从而提高算法的执行效率。
数据结构精选考研试题

数据结构精选考研试题[注]:编写程序可选用任一种高语言,算法描述可采用类语言,必要时加上注释一、回答下列问题:[20分]1、算法的定义和性质2、为什么说数组与广义表是线性表的推广?3、什么是结构化程序设计?4、哈希方法的基本思想5、给出一不稳定排序方法名称与实例二、构造结果:[24分](1)确定某:=某+1语句在下面程序段中的频率,要求写出分析过程。
fori:=1tondoforj:=1toIdofork:=1tojdo某:=某+1(2)画出对长度为8的有序表进行折半查找的判定树,并求其在等概率时查找成功的平均查找长度。
(3)已知一棵二叉树如右图,给出对这棵二叉树进行前序、中序、后序遍历的结果序列.(4)假设用于通讯的电文仅由8个字母组成,字母在电文中出现的频率分别为{2,3,5,7,11,4,13,15},试为这8个字母设计哈夫曼编码.(5)在地址空间为0~15的散列区中,对以下关键字序列构G造哈希表,关键字序列为(Jan,Feb,Mar,Apr,May,Jun,JulAug,Sep,Oct,Nov,Dec),H(某)=[i/2],其中i为关键字中第一字母在字母表中的序号。
要求用线性探测开放定址法处理冲突,并求出在等概率情况下查找成功的平均查找长度。
(6)构造有7个元素组成的线性表一实例,是进行快速排序时比较次数最少的初始排序。
三、写一算法,完成对这棵二叉树的左右子树的交换,设二叉树以二叉链表作存储结构。
[15分]四、编写一非递归算法,对一棵二叉排序树实现中序遍历。
[15分]五、编写程序,完成下列功能:[15分]1.读入整数序列,以整数0作为序列的结束标志(0不作为序列元素),建立一个单链表。
2.实现单链表原地逆转,即单链表中结点指针方向反转,反转操作不使用额外的链表结点,可使用临时工作单元。
例:输入序列为:1,8,4,3,0六、给出有向图G的邻接表表示。
找出其一棵最小生成树。
[11分][注]:编写程序可选用任一种高语言,算法描述可采用类语言,必要时加上注释一、回答下列问题:[20分]1、算法的定义和性质2、为什么说数组与广义表是线性表的推广?3、什么是结构化程序设计?4、哈希方法的基本思想5、给出一不稳定排序方法名称与实例二、构造结果:[24分](1)确定某:=某+1语句在下面程序段中的频率,要求写出分析过程。
数据结构——精选推荐

第1章绪论在线测试第一题、单项选择题(每题1分,5道题共5分)1、具有线性结构的数据结构是________.A、图B、树C、线性表D、集合2、计算机算法是指________A、计算方法和运算结果B、调度方法C、解决某一问题的有限指令系列D、排序方法3、设n为正整数。
确定下面程序段的时间复杂度:k=0; for(i=1;i<=n;i++){ for(j=i;j<=n;j++) @ k++; }A、nB、lognC、nlognD、n^24、设n为正整数。
确定下面程序段的时间复杂度:i=1; k=0; while(i<=n-1){ k+=10*i; i++; }A、1B、nC、nlognD、n^25、在线性结构中,除第一个以外的其余结点有________个前驱结点。
A、0B、1C、任意多D、第二题、多项选择题(每题2分,5道题共10分)1、计算机算法必须具备输入、输出和________等特性。
A、确定性B、稳定性C、可行性D、有穷性E、易读性F、可扩充性2、根据元素之间关系的不同特性,通常可有下列基本结构________。
A、集合B、线性结C、树结构D、图结构3、一个"好"的算法应达到的目标有________。
A、正确性B、健壮性C、高时间效率D、可读性E、低存储率F、输入G、输出4、从逻辑上可以把数据结构分为________。
A、顺序结构B、链式结构C、线性结构D、非线性结构E、动态结构F、静态结构5、下列说法中,不正确的是________。
A、数据是数据元素的基本单位B、数据元素是数据中不可分割的最小标识单位C、数据元素可由若干个数据项组成D、数据项可由若干个数据元素组成第三题、判断题(每题1分,5道题共5分)1、数据元素是数据的不可分割的最小单位。
正确错误2、数据对象一定是有限集。
正确错误3、数据的物理结构是指数据和关系在计算机内的实际存储形式。
正确错误4、算法原地工作的含义是指运行时不需要任何临时的辅助空间。
数据结构——精选推荐
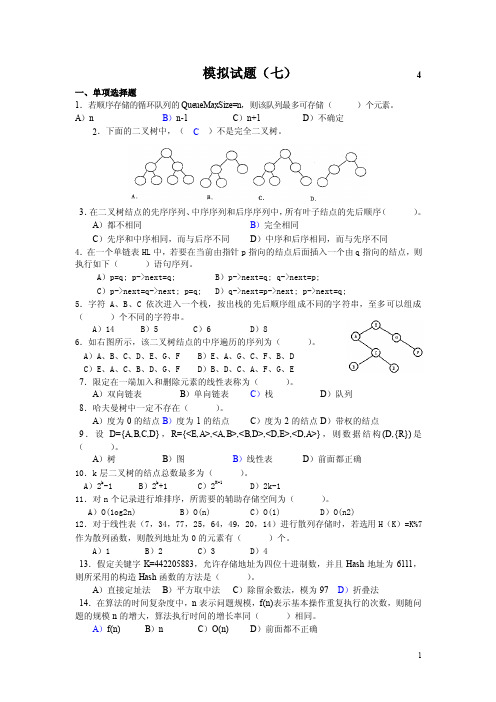
模拟试题(七)4一、单项选择题1.若顺序存储的循环队列的QueueMaxSize=n,则该队列最多可存储()个元素。
A)n B)n-1 C)n+1 D)不确定2.下面的二叉树中,(C)不是完全二叉树。
3.在二叉树结点的先序序列、中序序列和后序序列中,所有叶子结点的先后顺序()。
A)都不相同B)完全相同C)先序和中序相同,而与后序不同D)中序和后序相同,而与先序不同4.在一个单链表HL中,若要在当前由指针p指向的结点后面插入一个由q指向的结点,则执行如下()语句序列。
A)p=q; p->next=q; B)p->next=q; q->next=p;C)p->next=q->next; p=q; D)q->next=p->next; p->next=q;5.字符A、B、C依次进入一个栈,按出栈的先后顺序组成不同的字符串,至多可以组成()个不同的字符串。
A)14 B)5 C)6 D)86.如右图所示,该二叉树结点的中序遍历的序列为()。
A)A、B、C、D、E、G、F B)E、A、G、C、F、B、DC)E、A、C、B、D、G、F D)B、D、C、A、F、G、E7.限定在一端加入和删除元素的线性表称为()。
A)双向链表B)单向链表C)栈D)队列8.哈夫曼树中一定不存在()。
A)度为0的结点B)度为1的结点C)度为2的结点 D)带权的结点9.设D={A,B,C,D},R={<E,A>,<A,B>,<B,D>,<D,E>,<D,A>},则数据结构(D,{R})是()。
A)树B)图B)线性表D)前面都正确10.k层二叉树的结点总数最多为()。
A)2k-1 B)2k+1 C)2K-1D)2k-111.对n个记录进行堆排序,所需要的辅助存储空间为()。
A)O(1og2n) B)O(n) C)O(1) D)O(n2)12.对于线性表(7,34,77,25,64,49,20,14)进行散列存储时,若选用H(K)=K%7作为散列函数,则散列地址为0的元素有()个。