R语言记录程序运行的时间
r语言时间序列预测方法

r语言时间序列预测方法
在R语言中进行时间序列预测,常用的方法有很多,以下是一些常见的预测方法:
1. ARIMA模型:这是最常用的时间序列预测模型之一。
ARIMA代表自回
归整合移动平均模型,它是用于分析和预测时间序列数据的统计模型。
在R 中,你可以使用`arima()`函数来拟合ARIMA模型。
2. 指数平滑:这种方法使用指数加权平均数来预测时间序列数据。
R中的
`forecast::HoltWinters()`函数可以用来拟合Holt-Winters模型,这是一种指数平滑方法。
3. 随机森林和梯度提升:这些机器学习方法也可以用于时间序列预测。
例如,`forecast::Prophet`在R中实现了Facebook的Prophet算法,这是一个
基于随机森林的方法。
4. 神经网络:R中的`neuralnet`包可以用来构建神经网络模型,也可以用于时间序列预测。
5. 循环神经网络(RNN):对于具有时序依赖性的数据,可以使用循环神
经网络(RNN)进行预测。
在R中,`keras`包可以用来构建和训练RNN
模型。
6. 集成方法:你也可以使用集成方法(例如bagging或boosting)来提高预测精度。
在R中,`caret`包提供了这些集成方法的实现。
以上只是一些基本的方法,具体使用哪种方法取决于你的数据和你试图解决的问题。
在选择模型时,需要考虑数据的特性(例如季节性、趋势等),以及模型的复杂性和可解释性。
r语言检验时间序列的协整关系

R语言是一种广泛应用于统计分析和数据挖掘的编程语言,它的强大之处不仅在于其功能丰富的统计包,还在于其开放源代码的特性,使得用户可以自由地扩展其功能和应用范围。
在时间序列分析领域,R语言也拥有许多优秀的包,能够帮助用户进行时间序列的建模、分析和预测。
1. 什么是时间序列的协整关系?时间序列是指一系列按照时间顺序排列的数据点,通常用于描述随时间变化的现象或变量。
在时间序列分析中,协整关系是一个重要的概念。
协整关系描述的是两个或多个时间序列之间的长期关系,即它们的线性组合是平稳的。
平稳性是时间序列分析中的一个重要性质,它意味着数据的统计特性不随时间发生显著改变。
而协整关系则表示了两个时间序列在长期内的相关性,即它们的差分是平稳的。
2. 如何使用R语言进行时间序列的协整关系检验?在R语言中,可以使用一些专门的包来进行时间序列的协整关系检验。
其中,最常用的包包括“urca”和“tseries”。
下面将以“urca”包为例,介绍如何在R语言中进行时间序列的协整关系检验。
(1)安装和加载“urca”包要使用“urca”包,首先需要先安装这个包,并且加载到R环境中。
安装“urca”包的方法是在R命令行中输入以下命令:```Rinstall.packages("urca")```加载“urca”包的方法是在R命令行中输入以下命令:```Rlibrary(urca)```(2)进行时间序列的协整关系检验在加载了“urca”包之后,就可以使用其中的函数来进行时间序列的协整关系检验了。
在“urca”包中,可以使用函数```ca.jo()```来进行时间序列的协整关系检验。
```Rca.jo(data, type="eigen", ecdet="none", K=2, spec="longrun") ```其中,参数```data```是一个包含要进行协整关系检验的时间序列数据的数据框,参数```type```指定协整关系检验的方法,参数```ecdet```指定在模型中是否包含截距,参数```K```指定模型中包含的滞后阶数,参数```spec```指定模型中包含的滞后阶数。
时间序列分析R语言程序

#例2.1绘制196 ------- 1999年中国年纱产量序列时序图(数据见附录1.2)Data1.2=read.csv("C:\\Users\\Administrator\\Desktop\\ 附录1.2.csv",header=T)#如果有标题,用T;没有标题用Fplot(Data1.2,type='o')#例2.1续tdat1.2=Data1.2[,2]a1.2=acf(tdat1.2)#例2.2绘制1962年1月至1975年12月平均每头奶牛产奶量序列时序图(数据见附录1.3)Data1.3=read.csv("C:\\Users\\Administrator\\Desktop\\ 附录 1.3.csv”,header=F)tdat1.3=as.vector(t(as.matrix(Data1.3)))[1:168]# 矩阵转置转向量plot(tdat1.3,type=T)#例2.2续acf(tdat1.3) #把字去掉pacf(tdat1.3)#例2.3绘制1949——1998年北京市每年最高气温序列时序图Data1.4=read.csv("C:\\Users\\Administrator\\Desktop\\ 附录 1.4.csv”,header=T)plot(Data1.4,type='o')##不会定义坐标轴#例2.3续tdat1.4=Data1.4[,2]a1.4=acf(tdat1.4)#例2.3续Box.test(tdat1.4,type="Ljung-Box”,lag=6)Box.test(tdat1.4,type="Ljung-Box”,lag=12)#例2.4随机产生1000个服从标准正态分布的白噪声序列观察值,并绘制时序图Data2.4=rnorm(1000,0,1)Data2.4plot(Data2.4,type=T)#例2.4续a2.4=acf(Data2.4)#例2.4续Box.test(Data2.4,type="Ljung-Box”,lag=6)Box.test(Data2.4,type="Ljung-Box”,lag=12)#例2.5对195 ——1998年北京市城乡居民定期储蓄所占比例序列的平稳性与纯随机性进行检验Data1.5=read.csv("C:\\Users\\Administrator\\Desktop\\ 附录 1.5.csv”,header=T)plot(Data1.5,type='o',xlim=c(1950,2010),ylim=c(60,100) )tdat1.5=Data1.5[,2]a1.5=acf(tdat1.5)#白噪声检验Box.test(tdat1.5,type="Ljung-Box”,lag=6)Box.test(tdat1.5,type="Ljung-Box”,lag=12)#例2.5续选择合适的ARMA模型拟合序列acf(tdat1.5)pacf(tdat1.5)#根据自相关系数图和偏自相关系数图可以判断为AR(1)模型#例2.5续P81 口径的求法在文档上#P83arima(tdat1.5,order=c(1,0,0),method="ML")# 极大似然估计ar1=arima(tdat1.5,order=c(1,0,0),method="ML") summary(ar1)ev=ar1$residualsacf(ev)pacf(ev)#参数的显著性检验t1=0.6914/0.0989p1=pt(t1,df=48,lower.tail=F)*2#ar1的显著性检验t2=81.5509/ 1.7453p2=pt(t2,df=48,lower.tail=F)*2#残差白噪声检验Box.test(ev,type="Ljung-Box”,lag=6,fitdf=1)Box.test(ev,type="Ljung-Box”,lag=12,fitdf=1)#例2.5续P94预测及置信区间predict(arima(tdat1.5,order=c(1,0,0)),n.ahead=5)tdat1.5.fore=predict(arima(tdat1.5,order=c(1,0,0)),n.ahea d=5)U=tdat1.5.fore$pred+1.96*tdat1.5.fore$seL=tdat1.5.fore$pred-1.96*tdat1.5.fore$seplot(c(tdat1.5,tdat1.5.fore$pred),type="l”,col=1:2)lines(U,co l=”blue”,lty=”dashed”)lines(L,col=”blue”,lty=”dashed”)#例3.1.1例3.5 例3.5续#方法一plot.ts(arima.sim(n=100,list(ar=0.8)))#方法二x0=runif(1)x=rep(0,1500)x[1]=0.8*x0+rnorm(1) for(i in 2:length(x)) {x[i]=0.8*x[i-1]+rnorm(1)} plot(x[1:100],type=T) acf(x)pacf(x)##拟合图没有画出来x[1]=x1x[2 ]=-x1-0.5*x0+rnorm(1)for(i in 3:length(x)){x[i]=-x[i-1]-0.5*x[i-2]+rnorm(1)} plot(x[1:100],type=T)acf(x)pacf(x)#例3.1.2x0=runif(1)x=rep(0,1500)x[1]=-1.1*x0+rnorm(1) for(i in 2:length(x)) #均值和方差smu=mean(x) svar=var(x){x[i]=-1.1*x[i-1]+rnorm(1)} plot(x[1:100],type=T) acf(x) pacf(x) #例3.2求平稳AR (1)模型的方差例3.3 mu=0 mvar=1/(1-0.8A2) #书上51 页#总体均值方差#例3.1.3方法一plot.ts(arima.sim(n=100,list(ar=c(1,-0.5)))) #方法二x0=runif(1)x1=runif(1)x=rep(0,1500)x[1]=x1x[2]=x1-0.5*x0+rnorm(1)for(i in 3:length(x)){x[i]=x[i-1]-0.5*x[i-2]+rnorm(1)}plot(x[1:100],type=T)acf(x)pacf(x) cat("population mean and var are”,c(mu,mvar),"\n")#样本均值方差cat("sample mean and var are”,c(mu,mvar),"\n")#例题3.4svar=(1+0.5)/((1-0.5)*(1-1-0.5)*(1+1-0.5))#例题3.6 MA模型自相关系数图截尾和偏自相关系数图拖尾#3.6.1法:x=arima.sim(n=1000,list(ma=-2))plot.ts(x,type='l')acf(x)#例3.1.4x0=runif(1)x1=runif(1)x=rep(0,1500)x[1]=x1x[2]=x1+0.5*x0+rnorm(1)for(i in 3:length(x)){x[i]=x[i-1]+0.5*x[i-2]+rnorm(1)} plot(x[1:100],type=T)acf(x)pacf(x) pacf(x)法二x=rep(0:1000)for(i in 1:1000){x[i]=rnorm[i]-2*rnorm[i-1]} plot(x,type=T)acf(x)pacf(x)#3.6.2法一:又一个式子x0=runif(1)x1=runif(1)x=rep(0,1500) x=arima.sim(n=1000,list(ma=-0.5)) plot.ts(x,type='l')acf(x)pacf(x)法二x=rep(0:1000)for(i in 1:1000){x[i]=rnorm[i]-0.5*rnorm[i-1]}plot(x,type='l')acf(x)pacf(x)##错误于rnorm[i]:类别为'closure'的对象不可以取子集#3.6.3法^:x=arima.sim(n=1000,list(ma=c(-4/5,16/25)))plot.ts(x,type=T)acf(x)pacf(x)法二:x=rep(0:1000)for(i in 1:1000) {x[i]=rnorm[i]-4/5*rnorm[i-1]+16/25*rnorm[i-2]} plot(x,type='l')acf(x)pacf(x)##错误于x[i] = rnorm[i] - 4/5 * rnorm[i - 1] + 16/25 * rnorm[i - 2] :##更换参数长度为零#例3.6续根据书上64页来判断#例3.7拟合ARMA ( 1,1)模型,x(t)-0.5x(t-1)=u(t)-0.8*(u-1),并直观观察该模型自相关系数和偏自相关系数的拖尾性。
r语言实现贝叶斯时间序列

在R语言中,可以使用不同的包来实现贝叶斯时间序列模型。
下面是一个简单的例子,展示了如何使用bsts包来实现贝叶斯结构时间序列模型(Bayesian Structural Time Series Model):
首先,确保安装了bsts包。
如果尚未安装,可以使用以下命令进行安装:
接下来,可以使用以下示例代码来实现贝叶斯结构时间序列模型:
在这个示例中,我们首先生成了一个示例的时间序列数据y。
然后,我们使用bsts 包中的函数构建了一个贝叶斯结构时间序列模型,并对其进行了拟合。
最后,我们打印了模型的摘要信息,并进行了结果的可视化。
请注意,这只是一个简单的贝叶斯时间序列模型的示例,可以根据的具体数据和需求进行调整和修改。
如果需要更复杂的模型或对模型进行更深入的调整和分析,可能需要更多的参数设置和模型定制。
时间序列:R语言ARMA-GARCH模型

时间序列:R语⾔ARMA-GARCH模型ARMA:
#读⼊数据,并绘制时序图
d<-read.table("C:/Users/haha/Desktop/R/zuoye/1.txt")
x<-ts(log(d),start = 1)
1: x的时间序列图:
x<-ts(log(d),start = 1)
plot(x)
2:
从上图可以看出x.dif序列值在0的附近波动,没有存在显著地波动起伏⼤的情况,基本为平稳特征.
3.对x.dif序列adf单位根检验:
从x.dif的adf单位根检验p=0.01⼩于显著⽔平a=0.05,故拒绝原假设,所有x.dif是平稳序列.
4.
从上图可以看出x.dif的ACF,PACF是均显⽰不截尾的性质(PACF:lag12,14; ACF:lag:4,12 在2倍标准差外),故认为可以尝试使⽤模型ARMA(1,1)
5: 系统⾃动定阶:
为避免错估模型采⽤,auto.arima⾃动定价模型
定阶模型是ARIMA(1,1,1),其中p=1,d=1,q=1
也就是d=1是需要⼀阶差分后,序列才平稳,然后对它进⾏⾃回归模型是ARMA(1,1).既最后得到模型为x.dif序列的ARMA(1,1)模型6:
7: 进⾏⽩噪声检验:
8:
GARCH:
ARCH效应检验的两种⽅法:LM检验(拉格朗⽇检验)
拟合garch(1,1):。
时间序列分析及应用R语言第二版课程设计 (2)

时间序列分析及应用R语言第二版课程设计
一、课程介绍
本课程主要介绍时间序列分析的基本概念、方法和应用,以及R语言在时间序
列分析中的实践应用。
通过本课程的学习,学生将了解时间序列数据的特征和性质,掌握基本的时间序列模型、预测方法和验证技巧,了解常见的时间序列分析问题和解决方案,并能够使用R语言进行时间序列数据的处理、建模和预测。
二、教学内容
本课程的教学内容包括以下部分:
1.时间序列分析基础概念
•时间序列的定义及特征
•时间序列的基础统计量和时间序列图
•时间序列的平稳性、白噪声和自相关性检验
2.常见时间序列模型
•ARIMA模型的基本原理和模型参数估计
•季节性时间序列模型及其应用
•非线性时间序列模型和ARCH/GARCH模型
3.时间序列预测与验证
•简单时间序列预测方法和移动平均预测法
•ARIMA模型预测和模型误差的检验
•时间序列交叉验证和预测效果评估
4.R语言在时间序列分析中的应用
•R语言环境的配置和基础语法
•R语言中时间序列数据的读取、处理和转换
1。
r语言arima函数用法

r语言arima函数用法一、概述Arima函数是R语言中用于时间序列分析的一个功能强大的函数。
它可以用来估计和预测时间序列数据,包括季节性和趋势性成分。
本文主要介绍Arima函数的用法,包括参数设置、模型识别、模型估计、模型检验和预测等方面。
二、参数设置Arima函数的参数包括x、order、seasonal和include.mean。
其中,x表示输入的时间序列数据,通常为一个向量或矩阵;order指定AR、差分和MA的阶数,格式为c(p, d, q),其中p代表AR阶数,d代表差分阶数,q代表MA阶数;seasonal指定季节性的阶数,格式为c(P, D, Q, m),其中P代表季节AR阶数,D 代表季节差分阶数,Q代表季节MA阶数,m代表季节周期;include.mean指定是否包括常数项,默认为TRUE。
三、模型识别在使用Arima函数之前,首先需要对时间序列数据进行模型识别。
模型识别主要包括确定AR和MA的阶数以及季节性的阶数。
常用的方法包括自相关函数ACF和偏自相关函数PACF的观察,以及模型选择准则AIC和BIC的比较。
•自相关函数ACF:用来检测时间序列数据的自相关性。
如果ACF在k阶后截尾,则说明可以考虑AR(k)模型。
•偏自相关函数PACF:用来检测时间序列数据的偏自相关性。
如果PACF在k 阶后截尾,则说明可以考虑MA(k)模型。
•模型选择准则AIC和BIC:用来比较不同模型的拟合程度。
AIC和BIC值越小,模型的拟合程度越好。
四、模型估计模型估计是指根据已有的时间序列数据,估计ARIMA模型的参数。
在估计过程中,需要设置初始值,然后通过迭代方法求解模型的参数估计值。
在R语言中,使用Arima函数可以很方便地进行模型估计。
五、模型检验模型检验是指对估计得到的模型参数进行检验,判断模型是否合理。
常用的检验方法包括残差自相关图、残差正态性检验、白噪声检验等。
•残差自相关图:用来检测模型残差序列的自相关性。
时间序列分析及应用R语言第二版课程设计

时间序列分析及应用R语言第二版课程设计一、课程背景时间序列分析是统计学中重要的分支之一,是许多领域中应用广泛的数据分析方法。
具体地说,时间序列分析用于研究随时间而变化的数据,例如经济、金融、天气等等,这些数据收集自一定时间内的某个特定过程或现象。
其中,时间序列模型也是对这些数据的预测与分析的基础。
本课程侧重介绍时间序列数据的描述和建模方法,包括平稳性检验、ARIMA模型、季节性调整、傅里叶变换等等,并通过R语言进行实际应用。
另外,本课程还将介绍一些纯时间序列模型、时间序列预测和动态因素模型,旨在帮助学员掌握时间序列分析和建模手段,从而运用到具体的数据分析问题当中。
二、教学目标1.理解时间序列的基本概念和特性;2.掌握主要的时间序列建模方法,包括平稳性检验、ARIMA模型、季节性调整、傅里叶变换等等;3.对时间序列模型进行建模和分析,实现对现实数据的预测和分析;4.运用R语言进行实际数据分析,并深入理解时间序列数据分析及应用。
三、教学内容与安排1. 时间序列基础•时间序列概念和特性介绍;•时间序列的统计描述方法;•时间序列的可视化方法。
2. 时间序列建模•平稳性检验;•ARIMA模型;•季节性调整;•傅里叶变换。
3. 时间序列模型•纯时间序列模型;•时间序列预测;•动态因素模型。
4. 数据分析与R语言应用•基于R语言的时间序列分析;•多个时间序列数据的分析;•实践案例应用。
四、教学方法本课程以理论授课和实际案例演示为主,并结合实际场景应用,注重理论与实践相结合,学习者将在优秀的教师的指导下,通过实际操作演示案例的方式,逐步掌握时间序列分析的方法和应用技巧。
五、考核方式本课程的考核方式主要采用以下方式:1.实践案例演示;2.课堂测验。
六、参考教材与学习资料1.Brockwell P.J. and Davis R.A. (2006), Introductionto Time Series and Forecasting. 2nd ed., Springer;2.Shumway, R.H. and Stoffer, D.S. (2006) Time SeriesAnalysis and Its Applications: With R Examples. Springer.七、适用人群本课程适合以下人员学习:•经济、金融、统计学、数学、物理等等各个学科中的学生和从业人员;•对时间序列分析和建模感兴趣的个人。
R语言是什么R语言简介

R语⾔是什么R语⾔简介⽬录1、什么是R语⾔?2、R语⾔能⼲什么?3、R语⾔有什么优势?补充5、为什么使⽤R ?6、R语⾔学习路线图7、R语⾔参考资料R是由Ross Ihaka和Robert Gentleman在1993年开发的⼀种编程语⾔,R拥有⼴泛的统计和图形⽅法⽬录。
它包括机器学习算法、线性回归、时间序列、统计推理等。
⼤多数R库都是⽤R编写的,但是对于繁重的计算任务,最好使⽤C、c++和Fortran代码。
R不仅在学术界很受欢迎,很多⼤公司也使⽤R编程语⾔,包括Uber、⾕歌、Airbnb、Facebook等。
⽤R进⾏数据分析需要⼀系列步骤:编程、转换、发现、建模和交流结果R 语⾔是为数学研究⼯作者设计的⼀种数学编程语⾔,主要⽤于统计分析、绘图、数据挖掘。
如果你是⼀个计算机程序的初学者并且急切地想了解计算机的通⽤编程,R 语⾔不是⼀个很理想的选择,可以选择 Python、C 或Java。
R 语⾔与 C 语⾔都是贝尔实验室的研究成果,但两者有不同的侧重领域,R 语⾔是⼀种解释型的⾯向数学理论研究⼯作者的语⾔,⽽ C 语⾔是为计算机软件⼯程师设计的。
R 语⾔是解释运⾏的语⾔(与 C 语⾔的编译运⾏不同),它的执⾏速度⽐ C 语⾔慢得多,不利于优化。
但它在语法层⾯提供了更加丰富的数据结构操作并且能够⼗分⽅便地输出⽂字和图形信息,所以它⼴泛应⽤于数学尤其是统计学领域。
1、什么是R语⾔?R是⽤于统计分析、绘图的语⾔和操作环境。
R是属于GNU系统的⼀个⾃由、免费、开源的软件,它是⼀个⽤于统计计算和统计制图的优秀⼯具。
R语⾔是主要⽤于统计分析、绘图的语⾔和操作环境。
R本来是由来⾃新西兰奥克兰⼤学的Ross Ihaka和Robert Gentleman 开发。
(也因此称为R)现在由“R开发核⼼团队”负责开发。
R是基于S语⾔的⼀个GNU项⽬,所以也可以当作S语⾔的⼀种实现,通常⽤S 语⾔编写的代码都可以不作修改的在R环境下运⾏。
时间序列建模的完整教程用R语言
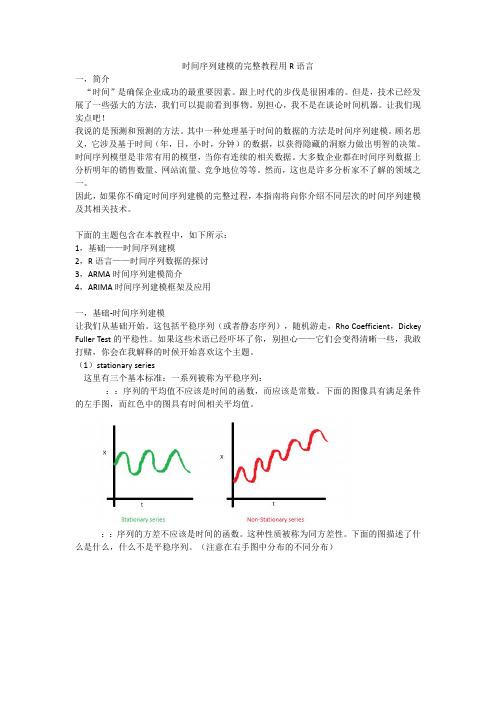
如果我们尝试绘制这个图表,它会看起来像这样:
你注意到 MA 和 AR 模型的区别了吗?在 MA 模型中,噪声/冲击随时间迅速消失。AR 模型对冲击具有持久的影响。 AR 模型与 MA 模型的区别 AR 和 MA 模型之间的主要区别是基于~时间序列对象在不同时间点之间的相关性。 X (T) 和 X( T-N)之间的相关性,对于 n 阶的 MA 总是为零。这直接源于 MA 模型中 x( t)和 x
/WOP/RandomWalk.html
想象一下,你坐在另一个房间里,看不到那个女孩。你想预测女孩的位置随着时间的推移。 你会有多精确?当然,随着女孩的位置变化,你会变得越来越不准确。在 T=0,你完全知 道那个女孩在哪里。下一次,她只能移动到 8 个方格,因此你的概率下降到 1/8,而不是 1, 而且它一直在下降。现在让我们来尝试一下这个时间序列。
时间序列建模的完整教程用 R 语言 一,简介 “时间”是确保企业成功的最重要因素。跟上时代的步伐是很困难的。但是,技术已经发 展了一些强大的方法,我们可以提前看到事物。别担心,我不是在谈论时间机器。让我们现 实点吧! 我说的是预测和预测的方法。 其中一种处理基于时间的数据的方法是时间序列建模。 顾名思 义,它涉及基于时间(年,日,小时,分钟)的数据,以获得隐藏的洞察力做出明智的决策。 时间序列模型是非常有用的模型, 当你有连续的相关数据。 大多数企业都在时间序列数据上 分析明年的销售数量、网站流量、竞争地位等等。然而,这也是许多分析家不了解的领域之 一。 因此, 如果你不确定时间序列建模的完整过程, 本指南将向你介绍不同层次的时间序列建模 及其相关技术。 下面的主题包含在本教程中,如下所示: 1,基础——时间序列建模 2,R 语言——时间序列数据的探讨 3,ARMA 时间序列建模简介 4,ARIMA 时间序列建模框架及应用 一,基础-时间序列建模 让我们从基础开始。这包括平稳序列(或者静态序列),随机游走,Rho Coefficient,Dickey Fuller Test 的平稳性。如果这些术语已经吓坏了你,别担心——它们会变得清晰一些,我敢 打赌,你会在我解释的时候开始喜欢这个主题。 (1)stationary series 这里有三个基本标准:一系列被称为平稳序列: ::序列的平均值不应该是时间的函数,而应该是常数。下面的图像具有满足条件 的左手图,而红色中的图具有时间相关平均值。
时间序列分析及应用R语言第二版教学设计 (2)

时间序列分析及应用R语言第二版教学设计一、前言时间序列数据已经在各个领域得到了广泛的应用,例如金融领域的股票预测、气象领域的天气预测等等。
R语言是一种功能强大且易于使用的编程语言,在时间序列分析中具有很大的优势。
本教学设计旨在向学生介绍时间序列分析的基本知识和R语言的应用。
二、教材及参考书目教材•Brockwell, P. J., & Davis, R. A. (2002). Introduction to Time Series and Forecasting (2nd ed.). Springer.参考书目•Hyndman, R. J., & Athanasopoulos, G. (2018). Forecasting: principles and practice (2nd ed.). OTexts.•Cowpertwt, P. S. P., & Metcalfe, A. V. (2009). Introductory Time Series with R (1st ed.). Springer.•Shumway, R. H., & Stoffer, D. S. (2017). Time Series Analysis and Its Applications: With R Examples (4th ed.). Springer.三、教学目标•理解时间序列的基本概念和性质,能够进行时间序列的可视化和数据处理。
•掌握时间序列模型的建立和评估方法,能够应用ARIMA、季节性ARIMA和指数平滑等方法进行时间序列预测。
•熟悉R语言在时间序列分析中的应用,能够进行时间序列建模和预测。
四、教学内容第一章:时间序列预备知识1.1 时间序列概述1.2 常见时间序列模型1.3 时间序列的可视化和数据处理第二章:时间序列分析基本方法2.1 平稳时间序列模型2.2 自回归模型2.3 移动平均模型第三章:ARIMA模型3.1 ARIMA模型介绍3.2 ARIMA模型求解方法3.3 ARIMA模型的评估和预测第四章:季节性ARIMA模型4.1 季节性ARIMA模型介绍4.2 季节性ARIMA模型求解方法4.3 季节性ARIMA模型的评估和预测第五章:指数平滑法5.1 简单指数平滑法5.2 带趋势的指数平滑法5.3 季节性指数平滑法第六章:R语言在时间序列分析中的应用6.1 R语言基础知识6.2 时间序列数据的导入和可视化6.3 时间序列模型的建立和预测五、教学方法本教学设计主要采用理论授课和实例演示相结合的教学方法。
r语言面板数据时间效应

r语言面板数据时间效应1.引言1.1 概述面板数据是一种在时间序列和横截面数据之间提供了更多信息的独特数据类型。
它包含了多个观察单元(个体、公司、地区等)在不同时间点上的多个观测值。
由于面板数据同时具有时间序列和横截面的特征,它可以用来研究时间和个体之间的关系,比单纯的时间序列或横截面数据更加有优势。
面板数据的分析中一个重要的考虑因素是时间效应。
时间效应也被称为时间固定效应,它反映了不同时间点上的数据观测之间的差异。
时间效应可以来自各种原因,例如季节性变化、经济周期、政策变化等。
研究时间效应有助于我们理解观测数据在时间上的演变和变化趋势,从而提供更准确的分析和预测。
R语言作为一种强大的数据分析和统计建模工具,在面板数据分析中也得到了广泛的应用。
R语言提供了许多面板数据分析的函数和包,可以帮助研究人员更好地理解和利用面板数据中的时间效应。
通过使用R语言进行面板数据分析,我们可以更准确地估计时间效应的影响,从而得出更准确的结论。
本篇文章将介绍面板数据的基本概念和特点,并探讨R语言在面板数据分析中的应用。
首先,我们将详细介绍面板数据的基本概念和分类。
然后,我们将介绍R语言中常用的面板数据分析函数和包,并演示其在实际研究中的应用。
最后,我们将总结面板数据分析中的时间效应研究结果,并展望未来的研究方向。
通过本文的阅读,读者将对面板数据的时间效应有更深入的认识,并能够熟练运用R语言进行面板数据的时间效应分析。
这将为相关学术研究和实际应用提供一定的参考和指导。
1.2文章结构1.2 文章结构本文将按照以下顺序讨论面板数据时间效应的研究问题。
首先,在引言部分概述了本文的研究背景和目的。
接下来,在正文部分,我们将介绍面板数据的基本概念和特征,包括它的定义、分类以及常见的面板数据模型。
随后,我们将详细探讨R语言在面板数据分析中的应用,包括数据预处理、面板数据模型估计和时间效应分析等方面。
这一部分将给读者提供一些基本的工具和方法,帮助他们在实际研究中使用R进行面板数据时间效应的分析。
R语言时间序列中文教程

R语言时间序列中文教程2012特别声明:R语言是免费语言,其代码不带任何质量保证,使用R语言所产生的后果由使用者负全责。
前言R语言是一种数据分析语言,它是科学的免费的数据分析语言,是凝聚了众多研究人员心血的成熟的使用范围广泛全面的语言,也是学习者能较快受益的语言。
在R语言出现之前,数据分析的编程语言是SAS。
当时SAS的功能比较有限。
在贝尔实验室里,有一群科学家讨论提到,他们研究过程中需要用到数据分析软件。
SAS的局限也限制了他们的研究。
于是他们想,我们贝尔实验室的研究历史要比SAS长好几倍,技术力量也比SAS强好几倍,且贝尔实验室里并不缺乏训练有素的专业编程人员,那么,我们贝尔实验室为什么不自己编写数据分析语言,来满足我们应用中所需要的特殊要求呢?于是,贝尔实验室研究出了S-PLUS语言。
后来,新西兰奥克兰大学的两位教授非常青睐S-PLUS的广泛性能。
他们决定重新编写与S-PLUS相似的语言,并且使之免费,提供给全世界所有相关研究人员使用。
于是,在这两位教授努力下,一种叫做R的语言在奥克兰大学诞生了。
R基本上是S-PLUS的翻版,但R是免费的语言,所有编程研究人员都可以对R语言做出贡献,且他们已经将大量研究成果写成了R命令或脚本,因而R语言的功能比较强大,比较全面。
研究人员可免费使用R语言,可通过阅读R语言脚本源代码,学习其他人的研究成果。
笔者曾有幸在奥克兰大学受过几年熏陶,曾经向一位统计系的老师提请教过一个数据模拟方面的问题。
那位老师只用一行R语句就解答了。
R语言的强大功能非常令人惊讶。
为了进一步推广R语言,为了方便更多研究人员学习使用R语言,我们收集了R语言时间序列分析实例,以供大家了解和学习使用。
当然,这是非常简单的模仿练习,具体操作是,用复制粘贴把本材料中R代码放入R的编程环境;材料中蓝色背景的内容是相关代码和相应输出结果。
经过反复模仿,学习者便能熟悉和学会。
需要提醒学习者的是:建议学习者安装了R语言编程,再继续阅读本材料;执行R 命令时,请删除命令的中文注解,没使用过在命令中加入中文;如果学习者是初次接触R或者Splus,建议先阅读<<R语言样品比较应用举例>>,如果学习者比较熟悉R语言,还可以阅读优秀时间序列读物Ecomometrics in R,也可以上QuickR 网站。
r程序使用方法

R程序使用方法R是一种数据统计和分析的编程语言,可以通过编写R程序来进行数据分析、统计建模等工作。
以下是R程序的使用方法:1. 安装R:首先需要在计算机上安装R软件,可以从R官网下载最新版本的R 安装包。
2. 启动R:安装完成后,可以启动R控制台或RStudio集成开发环境(IDE)。
3. 编写代码:使用R语言编写数据分析、统计建模等代码,可以参考如下示例:```# 读取数据data <- read.csv("data.csv")# 数据清洗clean_data <- na.omit(data)# 数据分析summary(clean_data)plot(clean_data$x, clean_data$y)# 统计建模model <- lm(y ~ x, data = clean_data)summary(model)```4. 运行代码:在R控制台或RStudio中,可以直接运行代码,或者将代码保存为.R文件后运行。
5. 查看结果:运行完代码后,可以在控制台或IDE中查看输出结果,也可以将结果保存为图表、报告等形式。
6. 了解R基本语法:要编写R程序,需要了解R的基本语法,包括变量、运算、条件判断、循环等语句。
在编写代码时,需要注意语法的正确性和规范性,这样可以提高代码的可读性和易维护性。
7. 学习R函数库:R拥有大量的函数库,包括数据导入、数据清洗、数据分析、统计建模等方面,可以通过调用函数库中的函数来完成相应的任务。
在使用函数库时,需要先安装相应的包,并了解每个函数的参数和用法。
8. 调试R程序:在编写R程序时,难免会遇到一些错误和问题,需要进行调试。
R提供了一些调试工具,例如debug()函数、traceback()函数等,可以帮助我们定位和解决问题。
9. 参考R文档:R拥有广泛的文档和社区支持,可以通过官方文档、Stack Overflow等网站学习和解决问题。
R语言时间序列作业

2016年第二学期时间序列分析及应用R 语言课后作业 第三章 趋势3.4(a) data(hours);plot(hours,ylab='Monthly Hours',type='o') 画出时间序列图(b) data(hours);plot(hours,ylab='Monthly Hours',type='l')type='o' 表示每个数据点都叠加在曲线上;type='b' 表示在曲线上叠加数据点,但是该数据点附近是断开的;type='l' 表示只显示各数据点之间的连接线段;type='p' 只想显示数据点。
points(y=hours,x=time(hours),pch=as.vector(season(hours)))3.10(a)TimeM o n t h l y H o u r s1983198419851986198739.039.540.040.541.041.5TimeM o n t h l y H o u r s1983198419851986198739.039.540.040.541.041.5TimeM o n t h l y H o u r s1983198419851986198739.039.540.040.541.041.5J A SO N D J FM A M J J AS O N DJ F M AM J J A S O N DJ F MA M JJA S ON DJ FM AMJ JA S ONDJ F M AM Jdata(hours);hours.lm=lm(hours~time(hours)+I(time(hours)^2));summary(hours.lm) 用最小二乘法拟合二次趋势,结果显示如下: Call:lm(formula = hours ~ time(hours) + I(time(hours)^2))Residuals:Min 1Q Median 3Q Max -1.00603 -0.25431 -0.02267 0.22884 0.98358Coefficients:Estimate Std. Error t value Pr(>|t|) (Intercept) -5.122e+05 1.155e+05 -4.433 4.28e-05 *** time(hours) 5.159e+02 1.164e+02 4.431 4.31e-05 *** I(time(hours)^2) -1.299e-01 2.933e-02 -4.428 4.35e-05 *** ---Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1Residual standard error: 0.423 on 57 degrees of freedomMultiple R-squared: 0.5921, Adjusted R-squared: 0.5778 F-statistic: 41.37 on 2 and 57 DF, p-value: 7.97e-12(b)plot(y=rstudent(hours.lm),x=as.vector(time(hours)),type='l',ylab='Standardized Residuals')points(y=rstudent(hours.lm),x=as.vector(time(hours)),pch=as.vector(season(hour s)))标准残差的时间序列,应用月度绘图标志。
R语言 时间序列有关各种函数总结

一、基础篇1、安装程序包install.packages('程序包名字')例:install.packages('TSA') //安装TSA程序包注:直接输入install.packages() 可弹出程序包窗口,若未选择镜像,会先弹出镜像窗口,选择镜像后再弹出程序包窗口2、加载程序包library(程序包名字)例:library(TSA) 加载TSA程序包注:程序包名字前后不需要打引号3、加载程序包内数据data(数据名)例:data(larain) //加载larain数据注:加载之后才可以使用此数据,否则会提示数据不存在4、构建时间序列时间序列名字=ts(数据名,freq=单位时间内的数据个数,start=第一个数据对应的时间)例:a=ts(larain,freq=12,start=2000) //将larain转化成从2000年1月开始的月度数据注:freq=4表示季度数据,12表示月度数据;start可以等于一个数,表示年份,即数据是从该年第一月开始的,也可以等于c(年份,月份),表示从某年某月开始5、从TXT文档读取单变量数据数据名=scan('文件名字.txt')例:a=scan('file1.txt') //读取file1中的变量,并命名为a注:读取的文档需放到工作目录之下6、从TXT文档读取多变量数据数据名=read.table('文件名字.txt',header=T/F)attach(数据名字)例:a= read.table ('file2.txt', header=F) //将file2中数据命名为a,系统自带列标V1,V2……attach(a) //打开a,之后可以直接调用a中各变量V1 //输出a中第一列数据注:读取的文档需放到工作目录之下,header=T表示文档中第一行是各列数据的名字,第二行开始是数据,header=F表示系统会自动给各列数据命名,调用数据之前必须先打开它7、从CSV格式的表格文件中读取数据数据名=read.csv('文件名字.csv',header=T/F)attach(数据名)例:a=read.csv('file3.csv', header=T) //将file3中数据命名为a,第一行为各列数据的名字attach(a) //打开a,之后可以直接调用a中各变量X //输出a中第一列数据(假如表中第一列第一行为X)注:读取的文件需放到工作目录之下,header参数含义同上,调用数据之前也必须先打开8、导出数据write.table (需要导出的数据名,file ="生成的文件名.txt",sep="数据分隔符号",s =T/F,s =T/F, quote =T/F)例:write.table (larain, file ="file4.txt",s =F, s =F, quote =F)//将larain导出到file4文档中,没有分隔符,行标不导出,列标也不导出,数据不加引号注:生成的文件在工作目录下,sep参数在多列数据导出时,可以用到来间隔各列数据,如果是单列数据,可以省略。
Qt编写软件运行时间记录(开源)

Qt编写软件运⾏时间记录(开源)#ifndef SAVERUNTIME_H#define SAVERUNTIME_H#include <QObject>#include <QDateTime>class QTimer;#ifdef quc#if (QT_VERSION < QT_VERSION_CHECK(5,7,0))#include <QtDesigner/QDesignerExportWidget>#else#include <QtUiPlugin/QDesignerExportWidget>#endifclass QDESIGNER_WIDGET_EXPORT SaveRunTime : public QObject#elseclass SaveRunTime : public QObject#endif{Q_OBJECTpublic:static SaveRunTime *Instance();explicit SaveRunTime(QObject *parent = 0);private:static QScopedPointer<SaveRunTime> self;QString path; //⽇志⽂件路径QString name; //⽇志⽂件名称int lastID;int saveInterval;QDateTime startTime;QString logFile;QTimer *timerSave;private:void getDiffValue(const QDateTime &startTime, const QDateTime &endTime, int &day, int &hour, int &minute);signals:public slots:void start(); //启动服务void stop(); //停⽌服务void initLog(); //初始化⽇志⽂件void appendLog(); //追加⼀条记录到⽇志⽂件void saveLog(); //保存运⾏时间到⽇志⽂件void setPath(const QString &path);void setName(const QString &name);void setSaveInterval(int saveInterval);};#endif// SAVERUNTIME_H#include "saveruntime.h"#include "qmutex.h"#include "qapplication.h"#include "qtimer.h"#include "qfile.h"#include "qtextstream.h"#include "qstringlist.h"#include "qdebug.h"#ifdef Q_OS_WIN#define NEWLINE "\r\n"#else#define NEWLINE "\n"#endifQScopedPointer<SaveRunTime> SaveRunTime::self;SaveRunTime *SaveRunTime::Instance(){if (self.isNull()) {QMutex mutex;QMutexLocker locker(&mutex);if (self.isNull()) {self.reset(new SaveRunTime);}}return self.data();}SaveRunTime::SaveRunTime(QObject *parent) : QObject(parent){path = qApp->applicationDirPath();QString str = qApp->applicationFilePath();QStringList list = str.split("/");name = list.at(list.count() - 1).split(".").at(0);saveInterval = 1 * 60 * 1000;startTime = QDateTime::currentDateTime();timerSave = new QTimer(this);timerSave->setInterval(saveInterval);connect(timerSave, SIGNAL(timeout()), this, SLOT(saveLog()));}void SaveRunTime::start(){timerSave->start();initLog();appendLog();saveLog();}void SaveRunTime::stop(){timerSave->stop();}void SaveRunTime::getDiffValue(const QDateTime &startTime, const QDateTime &endTime, int &day, int &hour, int &minute) {qint64 sec = startTime.secsTo(endTime);day = hour = minute = 0;int seconds = 0;while (sec > 0) {seconds++;if (seconds == 60) {minute++;seconds = 0;}if (minute == 60) {hour++;minute = 0;}if (hour == 24) {day++;hour = 0;}sec--;}}void SaveRunTime::initLog(){//判断当前年份的记事本⽂件是否存在,不存在则新建并且写⼊标题//存在则⾃动读取最后⼀⾏的id号记事本⽂件格式内容//编号开始时间结束时间已运⾏时间//1 2016-01-01 12:33:33 2016-02-05 12:12:12 day: 0 hour: 0 minute: 0logFile = QString("%1/%2_runtime_%3.txt").arg(path).arg(name).arg(QDate::currentDate().year());QFile file(logFile);if (file.size() == 0) {if (file.open(QFile::WriteOnly | QFile::Text)) {QString strID = QString("%1\t").arg("编号");QString strStartTime = QString("%1\t\t").arg("开始时间");QString strEndTime = QString("%1\t\t").arg("结束时间");QString strRunTime = QString("%1").arg("已运⾏时间");QString line = strID + strStartTime + strEndTime + strRunTime;QTextStream stream(&file);stream << line << NEWLINE;file.close();lastID = 0;}} else {if (file.open(QFile::ReadOnly)) {QString lastLine;while (!file.atEnd()) {lastLine = file.readLine();}file.close();QStringList list = lastLine.split("\t");lastID = list.at(0).toInt();}}lastID++;}void SaveRunTime::appendLog(){logFile = QString("%1/%2_runtime_%3.txt").arg(path).arg(name).arg(QDate::currentDate().year());QFile file(logFile);//写⼊当前⾸次运⾏时间if (file.open(QFile::WriteOnly | QFile::Append | QFile::Text)) {QString strID = QString("%1\t").arg(lastID);QString strStartTime = QString("%1\t").arg(startTime.toString("yyyy-MM-dd HH:mm:ss"));QString strEndTime = QString("%1\t").arg(QDateTime::currentDateTime().toString("yyyy-MM-dd HH:mm:ss"));int day, hour, minute;getDiffValue(startTime, QDateTime::currentDateTime(), day, hour, minute);QString strRunTime = QString("%1 天 %2 时 %3 分").arg(day).arg(hour).arg(minute);QString line = strID + strStartTime + strEndTime + strRunTime;QTextStream stream(&file);stream << line << NEWLINE;file.close();}}void SaveRunTime::saveLog(){//每次保存都是将之前的所有⽂本读取出来,然后替换最后⼀⾏即可logFile = QString("%1/%2_runtime_%3.txt").arg(path).arg(name).arg(QDate::currentDate().year());QFile file(logFile);//如果⽇志⽂件不存在,则初始化⼀个⽇志⽂件if (file.size() == 0) {initLog();appendLog();return;}if (file.open(QFile::ReadWrite)) {//⼀⾏⾏读取到链表QStringList content;while (!file.atEnd()) {content.append(file.readLine());}//重新清空⽂件file.resize(0);//如果⾏数⼩于2则返回if (content.count() < 2) {file.close();return;}QString lastLine = st();QStringList list = lastLine.split("\t");//计算已运⾏时间int day, hour, minute;getDiffValue(startTime, QDateTime::currentDateTime(), day, hour, minute);QString strRunTime = QString("%1 天 %2 时 %3 分").arg(day).arg(hour).arg(minute);//重新拼接最后⼀⾏list[2] = QDateTime::currentDateTime().toString("yyyy-MM-dd HH:mm:ss");list[3] = strRunTime;lastLine = list.join("\t");//重新替换最后⼀⾏并写⼊新的数据content[content.count() - 1] = lastLine;QTextStream stream(&file);stream << content.join("") << NEWLINE;file.close();}}void SaveRunTime::setPath(const QString &path) {if (this->path != path) {this->path = path;}}void SaveRunTime::setName(const QString &name) {if (this->name != name) {this->name = name;}}void SaveRunTime::setSaveInterval(int saveInterval) {if (this->saveInterval != saveInterval) {this->saveInterval = saveInterval;timerSave->setInterval(saveInterval);}}。
R语言日期的表示和运算(详细总结)

4、把日期值输出为字符串today <- Sys.Date()format(today, "%Y年%m月%d日")[1] "2014年10月29日"5、计算日期差由于日期内部是用double存储的天数,所以是可以相减的。
today <- Sys.Date()gtd <- as.Date("2011-07-01")today - gtdTime difference of 1216 days用difftime()函数可以计算相关的秒数、分钟数、小时数、天数、周数difftime(today, gtd, units="weeks") #还可以是“secs”, “mins”, “hours”, “days”Time difference of 173.7143 weeks#日期型数据在R中自带的日期形式为:as.Date();以数值形式存储;对于规则的格式,则不需要用format指定格式;如果输入的格式不规则,可以通过format 指定的格式读入;标准格式:年-月-日或者年/月/日;如果不是以上二种格式,则会提供错误;as.Date('23-2013-1')错误于charTo按照Date(x) : 字符串的格式不够标准明确> as.Date('23-2013-1',format='%d-%Y-%m')[1] "2013-01-23"格式意义%d月份中当的天数%m月份,以数字形式表示%b月份,缩写%B月份,完整的月份名,指英文%y年份,以二位数字表示%Y年份,以四位数字表示#其它日期相关函数weekdays()取日期对象所处的周几;months()取日期对象的月份;quarters()取日期对象的季度;#POSIX类The POSIXct class stores date/time values as the number of seconds since January 1, 1970, while the POSIXlt class stores them as a list with elements for second, minute, hour, day, month, and year, among others.POSIXct 是以1970年1月1号开始的以秒进行存储,如果是负数,则是1970年以前;正数则是1970年以后。
as.date的用法 -回复

as.date的用法-回复as.date是R语言中的一个函数,用于将字符型或数字型数据转换成日期型数据。
在R语言中,日期数据是以“年-月-日”的形式存储的。
as.date函数的语法格式如下:as.date(x, format = "Y-m-d")其中,x表示要转换的数据,format表示转换后的日期格式,"Y-m-d"表示年-月-日的格式。
在本文中,我们将详细介绍as.date函数的用法,并给出一些示例来帮助您更好地理解和使用这个函数。
首先,我们来了解一下R语言中的日期数据类型。
R语言中有两种常见的日期数据类型,一种是Date类型,另一种是POSIXct类型。
Date类型表示一个固定的日期,没有具体的时间信息。
POSIXct类型表示一个日期和时间,包括年、月、日、时、分、秒等详细信息。
在使用as.date函数时,可以根据需要选择转换成Date类型还是POSIXct 类型。
接下来,我们来看一些使用as.date函数的示例。
首先,我们来将字符型的日期数据转换成Date类型的日期数据。
假设有一个字符向量dates,其中包含几个日期字符串,例如"2022-09-15"和"2022-09-16"。
我们可以使用as.date函数将这些日期字符串转换成Date类型的日期数据,示例如下:Rdates <- c("2022-09-15", "2022-09-16")dates_as_date <- as.Date(dates, format = "Y-m-d")这样,dates_as_date就是转换后的Date类型的日期数据。
接下来,我们来将数字型的日期数据转换成Date类型的日期数据。
假设有一个数字向量dates,其中包含几个日期的数字,例如20220915和20220916。