第三章_ARM9体系结构
第3章 ARM9汇编指令系统

第三章
例如
例如: LDR R8,[R10] ;R8←[R10] LDRNE R2,[R5,#960]! ;( 有 条 件 地 ) R2←[R5+960],R5←R5+960 LDR R0,localdata ;加载一个字到R0寄存 器,该字存 于localdata所指地址处 STR R5,[R7],#-8! ;R5→[R7],R7←R7-8 STRB R0,[R3,-R8 ASR #2] ;R0→[R3-R8/4], 存储R0的最低有效字节,R3和R8不变
其中:type 必须是下面所列的形式之一: SH 带符号半字(仅对LDR); H 无符号半字; SB 带符号字节(仅对LDR)。 label 程序相对偏移表达式。偏移量必须是在 当前指令的上下255字节范围内。 offset 加在Rn上的偏移量。其形式是下列两种 之一: ① #expr 是取值范围为-255~+255的整数, 经常是常量或常量表达式。 ② {-} Rm Rm是内含偏移量的寄存器,它不 能是R15。
第三章
存储器访问指令(续)
(3)LDR和STR ----双字:加载/存储两个相邻 的寄存器,64位双字。其句法有4种:
Op {cond} D Rd,[Rn] 零偏移 Op {cond} D Rd,[Rn,offset] {!} 前索引偏移 Op {cond} D Rd,label 程序相对偏移 Op {cond} D {T} Rd,[Rn],offset 后索引偏移
第三章
存储器访问指令(续)
(1) SWP:在寄存器和存储器之间 进行数据交换,其句法是: SWP {cond} {B} Rd,Rm,[Rn] 其中:B是可选后缀,若有B,则交换字 节,否则交换字。该指令作用是数据从 存储器加裁到Rd中,Rm中的内容存储 到存储器,需交换数据存储单元的首地 址在Rn中。在此,Rd和Rm可以相同, 但Rn必须与Rd、Rm不同。
arm9处理器的内部寄存器结构

arm9处理器的内部寄存器结构
ARM9处理器是一种32位的嵌入式处理器,内部包含了多种寄存器,这些寄存器扮演着不同的角色,用于存储不同类型的数据和指令,从而实现处理器的各种功能。
ARM9处理器的内部寄存器结构主要包括:
1.通用寄存器:ARM9处理器有16个32位的通用寄存器,这些寄存器不仅可以用于存储数据,还可以用于存储指令中的操作数。
通用寄存器还可以用于存储函数的参数和返回值。
2.程序计数器(PC):程序计数器是一个32位的寄存器,用于存储当前正在执行的指令的地址。
当处理器执行完一条指令后,PC会自动递增,指向下一条指令的地址。
3.状态寄存器:状态寄存器用于存储处理器的当前状态。
例如,它可以用于存储处理器的运行模式,或者存储处理器的条件码。
4.堆栈指针(SP):堆栈指针用于指向当前的堆栈顶部。
当处理器需要执行函数调用或其他需要使用堆栈的指令时,它会将数据压入堆栈中,并将堆栈指针减小。
当函数返回时,处理器会将数据从堆栈中弹出,并将堆栈指针增加。
5.链接寄存器(LR):链接寄存器用于存储函数调用的返回地址。
当函数被调用时,处理器将当前指令的地址存储在LR中。
当函数执行完毕后,处理器会将LR中的地址作为返回地址,跳转回调用函数的地方。
6.中断寄存器:中断寄存器用于存储当前中断的状态。
当处理器
接收到一个中断时,它会将当前的状态保存在中断寄存器中,并跳转到中断处理程序的地址。
总之,ARM9处理器的内部寄存器结构是非常复杂的,不同类型的寄存器扮演着不同的角色。
通过合理地利用这些寄存器,程序员可以实现各种复杂的嵌入式应用。
嵌入式系统习题查根龙

嵌入式系统温习第一章嵌入式系统基础一、嵌入式系统的概念?二、嵌入式系统的组成?3、嵌入式系统的特点?4、嵌入式系统的应用?五、嵌入式处置器的分类,常见的嵌入式处置器有哪些?六、什么是嵌入式操作系统?嵌入式操作系统有哪些类型?7、什么是实时操作系统?实时操作系统的组成和特点。
它有哪些特征?八、常见的嵌入式操作系统有哪些?九、实时操作系统常常利用的任务调试算法有哪几种?10、用什么方式解决优先级反转问题?1一、单片机是不是嵌入式系统?它与ARM嵌入式系统有何异同?1二、嵌入式系统与通用运算机之间的区别。
第二章嵌入式系统开发流程一、嵌入式系统开发进程分为哪几个阶段?每一个阶段的特点是什么?二、嵌入式软件开发流程。
3、嵌入式系统有哪几种调试方式?此刻最流行的是哪一种?利用什么接口?4、什么是板级支持包?它一般应完成哪些工作?第三章ARM的体系结构一、ARM的英文命名是什么?AMR处置器有人材特点?二、运算机中的两种典型体系结构是什么,各自的特点是什么?3、试比较RISC体系结构和CISC体系结构的特点。
4、ARM支持哪些数据类型?五、ARM处置器支持的数据类型有哪些?六、画出别离采用小端格式和大端格式寄存0x的存储器示用意。
设存储器的初始地址为0x4000。
7、在ARM处置器的存储空间中,有一段存储空间中存储的数据如下所示:①假设,存储空间中的数据是以大端存储的,那么地址0x8000中存储的一个字是什么?地址0x8000中存储的一个半字是什么?地址0x8003中存储的一个字节是什么?②若是,存储空间中的数据是小端存储的,上述问题的答案别离是什么?八、在ARM处置器的存储空间中,有一段存储空间中存储的数据如下所示:假设,存储空间中的数据是以小端存储的,R0中的值为0x8000。
回答以下问题:①执行完LDR R1,[R0]后,R1的值是多少?②执行完LDR R1,[R0],#4后,R1的值是多少?③执行完LDR R1,[R0,#2]后,R1的值是多少?④执行完LDMIA R0,{R1-R4}后,R0中的值如何转变?⑤执行完LDR R0,[R1,R2,LSL #3]后,R1的值如何转变?九、ARM处置器一共有几种中工作模式,别离是?那种模式下,专业寄放器最多。
ARM9寻址方式及指令集介绍

ARM9寻址方式及指令集介绍ARM9是一种32位精简指令集计算机(RISC)架构的微处理器。
在本文中,我们将介绍ARM9寻址方式和指令集的基本特点。
直接寻址是最简单的寻址方式,寻址单元根据操作码中给出的直接地址来访问内存。
例如,LDR指令将数据从内存中的特定地址加载到寄存器中。
直接寻址在寻址范围上有限制,因为地址是直接编码在指令中的。
间接寻址是通过一个保存数据的寄存器的地址来访问内存。
寄存器中的地址表示需要访问数据的内存地址。
例如,LDR指令可以使用R0寄存器中的地址来获取数据。
间接寻址使得程序可以动态地计算内存地址,提高了灵活性。
相对寻址是通过相对于当前指令地址的偏移量来访问内存。
偏移量在指令的操作码中给出,并且通常是一个8位或12位的整数。
相对寻址使得程序可以方便地访问位于当前指令之前或之后的内存位置。
基址寻址是通过一个基址寄存器和一个偏移量来访问内存,其中基址寄存器存储了起始地址,偏移量存储了与起始地址的相对位置。
例如,LDR指令可以使用R0寄存器作为基址寄存器,并使用R1作为偏移量。
基址寻址适用于访问数组或数据结构等连续的内存块。
核心寄存器寻址是指通过核心寄存器的内容来访问内存。
在ARM9架构中,核心寄存器包括程序计数器、堆栈指针和链接寄存器等。
这些寄存器具有特殊的寻址方式,允许对于特定的功能进行优化。
ARM9的指令集包括数据处理指令、分支和跳转指令、访存指令和特权指令等。
数据处理指令是最常用的指令类型,用于完成算术和逻辑操作。
例如,ADD指令将两个操作数相加,并将结果存储在目的寄存器中。
分支和跳转指令用于控制程序的流程。
例如,B指令可以根据条件跳转到指定的地址上。
访存指令用于读写内存和I/O端口。
例如,LDR指令可以将数据从内存加载到寄存器中,STR指令可以将寄存器中的数据存储到内存地址中。
特权指令用于进行特权级别的操作,例如,访问系统寄存器或控制外设。
这些指令一般只能由操作系统或系统软件使用。
ARM体系架构解析ppt课件

2)提供了较大的存储器带宽,各自有自己的
总线。
3)适合于数字信号处理.
4)大多数DSP都是哈佛结构.
5)ARM9是哈佛结构
6)取指和取数在同一周期进行,提高速度,
改进哈佛体系结构分成三个存储区:程序、数据、
程序和数据共用。
经营者提供商品或者服务有欺诈行为 的,应 当按照 消费者 的要求 增加赔 偿其受 到的损 失,增 加赔偿 的金额 为消费 者购买 商品的 价款或 接受服 务的费 用
6)将结果回写到寄存器组(res)
经营者提供商品或者服务有欺诈行为 的,应 当按照 消费者 的要求 增加赔 偿其受 到的损 失,增 加赔偿 的金额 为消费 者购买 商品的 价款或 接受服 务的费 用
流水线技术
❖
三级流水线技术
经营者提供商品或者服务有欺诈行为 的,应 当按照 消费者 的要求 增加赔 偿其受 到的损 失,增 加赔偿 的金额 为消费 者购买 商品的 价款或 接受服 务的费 用
因此,把它称为流水线工作方式。
处理器按照一系列步骤来执行每一条指令。典
型的步骤为:
1)从存储器读取指令(fetch)
2)译码以鉴别它是哪一类指令(dec)
3)从寄存器组取得所需的操作数(reg)
4)将操作数进行组合以得到结果或存储器地址(exe)
5)如果需要,则访问存储器存取数据(mem)
冯·诺依曼体系的特点
1)数据与指令都存储在同一存储区中,取指
令与取数据利用同一数据总线。
❖ 2)被早期大多数计算机所采用
❖ 3)ARM7——冯诺依曼体系
❖
结构简单,但速度较慢。取指不能同时取数据
经营者提供商品或者服务有欺诈行为 的,应 当按照 消费者 的要求 增加赔 偿其受 到的损 失,增 加赔偿 的金额 为消费 者购买 商品的 价款或 接受服 务的费 用
ARM体系结构与编程

ARM体系结构与编程
一、ARM体系结构
ARM(Advanced RISC Machine)是由英国ARM公司开发的一种低功耗、超低成本的处理器架构,是移动设备的首选处理器。
ARM架构的处理器有ARM7、ARM9、ARM11、 Cortex-A8 、Cortex-A15等,它们核心架构特点为以下几点:
1.保护模式。
ARM架构的处理器能够在用户模式和两个高级的保护模式之间来回切换。
2.对齐式存储。
ARM架构的处理器采用对齐方式,其二进制指令必须按照固定的位置排列,以便提高存储空间的利用率。
3.浮点处理单元。
ARM架构的处理器具有浮点数处理功能,使数值运算能够高效率地完成。
4.多级缓存。
ARM架构的处理器将原始数据复制到不同级别的快速缓存中,以便快速访问。
二、ARM程序的编程
1、ARM程序的编写
ARM程序的编写可以使用C语言编写,程序开发者需要掌握ARM架构各种中央处理器扩展指令集的使用方法,以便获得更好的效率。
2、编译ARM程序
ARM程序的编译是使用GNU的gcc编译器进行的,它可以将C语言编写的程序编译成ARM架构的机器码,并可以在ARM架构的处理器上运行。
3、调试ARM程序
ARM程序的调试使用GDB程序调试,它可以提供丰富的调试工具,可以跟踪程序执行的步骤,提供全面的程序反馈信息,可以帮助开发者快速定位程序运行出错的地方。
三、总结。
ARM体系结构

ARM9TDMI处理器一个显著的特点是采用 指令和数据分离访问的方式,即采用了指令 缓存(I-Cache)和数据缓存(D-Cache)。 这样可以把指令访问和数据访问单独安排1级 流水线。
2015/9/28
9
ARM9处理能力的提高是通过增加时钟频率和减少指令执行周期实 现的。 (1)时钟频率的提高 ARM9采用了五级流水线,而ARM7采用的是三级流水线,ARM9增 加的流水线设计提高了时钟频率和并行处理能力。五级流水线能够将各 条指令处理分配到5个时钟周期内,在每个时钟周期内同时有5条指令在 执行。在同样的加工工艺下,ARM9 TDMI处理器的时钟频率是ARM7 TDMI的2倍左右。 (2)指令周期的改进 指令周期的改进有助于处理器性能的提高。性能提高的幅度依赖于 代码执行时指令的重叠。 ① load指令和store指令 指令周期数改进最明显的是load指令和store指令。 ② 互锁(interlock)技术 当指令需要的数据因为以前的指令没有执行完,将产生管道互锁。管
操作系统的保护模式 指令或数据预取操作中止时的模 式,该模式下实现虚拟存储器或 存储器保护 当执行未定义的指令时进入该模 式 响应普通中断时的处理模式
未定义模式 IRQ模式
Und Irq
FIQ模式
Fiq
响应快速中断时的处理模式
2015/9/28
21
处理器工作模式
ARM微处理器的运行模式可以通过软件改变,也可以通 过外部中断或异常处理改变。 大多数的应用程序运行在用户模式下,当处理器运行在 用户模式下时,某些被保护的系统资源是不能被访问的。 除用户模式以外,其余的6种模式称为非用户模式或特 权模式; 除去用户模式和系统模式以外的5种又称为异常模式, 常用于处理中断或异常,以及访问受保护的系统资源等情 况。
ARM9系统的硬件设计

ARM9系统的硬件设计ARM9系统的硬件设计指的是基于ARM9内核的嵌入式系统的硬件组成和设计方法。
ARM9是英国ARM公司推出的第九代32位内核处理器,被广泛应用于移动设备、嵌入式系统、消费电子产品等领域。
下面将详细介绍ARM9系统的硬件设计内容。
一、ARM9系统硬件设计的基本原则1.系统性能和功耗平衡:硬件设计要充分考虑系统性能和功耗之间的平衡,尽量在不影响系统性能的情况下降低功耗。
2.硬件模块化设计:将整个系统划分为多个模块,每个模块负责特定的功能,便于维护和升级。
3.充分利用硬件资源:合理利用硬件资源,提高系统的性能和效率。
4.合理布局和连接:设计时应合理布局硬件组件和引脚连接,减少信号干扰和传输延迟。
5.异常处理:系统设计要考虑到异常情况的处理,保证系统的稳定性和可靠性。
二、ARM9系统硬件设计的基本组成1.处理器:ARM9内核的处理器是系统的核心部件,负责执行指令和控制系统运行。
2.存储器:包括RAM、ROM和闪存等,用于存储指令和数据,RAM用于存储工作数据,ROM和闪存用于存储软件和操作系统。
3.外设接口:包括串口、并口、USB接口等,用于与外部设备通信。
4.时钟和定时器:时钟提供系统的时序和时基,定时器用于定时和计数。
5.中断控制器:用于处理外部中断和异常,保证系统的正常运行。
6.显示控制器:用于控制和管理显示设备,如LCD显示屏。
7.输入输出设备:如触摸屏、键盘、鼠标等,用于用户与系统的交互。
8.电源管理:包括电源管理单元和电源管理软件,用于控制和管理系统的电源消耗。
三、ARM9系统硬件设计的关键技术1.PCB设计:根据系统需求和硬件组件的布局,设计合适的PCB板,保证信号传输的稳定和可靠。
2.时钟设计:根据系统需求设计合适的时钟方案,保证系统的协调和同步。
3.内存管理:根据系统的存储需求,选择适当的存储器类型和容量,合理划分存储区域。
4.性能优化:通过合理的硬件配置和系统参数调整,提高系统的运行速度和性能。
第三节ARM体系结构
一般的通用寄存器
寄存器类别 寄存器在汇编中的名称
用户
系统
R0(a1)
R1(a2)
R2(a3)其中R0~R7为
R3(a4)
未R分4(v1) 组的寄存器,也
通用寄存器 和程序计数
器
就R是5(v2) 说对于任何处理 R6(v3)
器R模7(v4) 式,这些寄存器 都对应于相同的32位 R8(v5)
管理 (svc) 操作系下统保访护问代码用户模系统式复位的和寄软件存中器断响就应比时进较入方此模式
中止 (abt) 未定义 (und)
用或于存支储便 可持器虚 保,以拟护而使内存且用和操这/ 作个在A系模RM统式7TD的访MI一问没有些一大用特 些处权 受任 控务 的 支软持件硬仿资件真协源处。理器的 未定义指令异常响应时进入此模式
各模式下实际访问的寄存器
用户
系统
管理
中止
未定义
RR00
在汇编语言中寄存
R1
器R0~R13为保存数据
R2
或地址值的通用寄存器。
R3
它们是完全通用的寄存器, R4
不会被体系结构作为特殊
R5
用途,并且可用于任何使
R6
用通用寄存器的指令。
R7
R8
R9
R10
R11
R12
R13
RR1133__ssvc
R13_abt
SSPPSSRR__fifqiq
ARM状态各模式下可以访问的寄存器
寄存器类别 寄存器在汇编中的名称
通用寄存器和 程序计数器
状态寄存器
R0 R1 R2 R3 R4 R5 R6 R7 R8 R9 R10 R11 R12 R13(SP) R14(LR) R15(PC) CPSR SPSR
ARM9嵌入式系统设计基础教程课程设计

ARM9嵌入式系统设计基础教程课程设计课程背景随着科技的发展和人们对生活质量要求的提高,嵌入式技术(Embedded System)在各行各业中得到了越来越广泛的应用。
嵌入式系统作为一种特殊的计算机系统,已经在家电、汽车、医疗、工业控制等领域崭露头角。
ARM9嵌入式系统是目前应用最广泛的一种嵌入式系统,其性能稳定、易于开发、兼容性强等优点让它成为众多企业和开发者的首要选择。
本课程以ARM9嵌入式系统为主要研究对象,旨在教授ARM9嵌入式系统设计基础知识,为学生提供嵌入式系统开发的技术支持和实践操作经验。
教学目标1.掌握ARM9嵌入式系统设计的基础知识,包括ARM体系结构、ARM处理器、电路设计等;2.学习嵌入式系统开发所需的编程语言和工具,包括C语言、汇编语言和keil MDK等;3.学习ARM9嵌入式系统中常用的外设,包括串口、SPI、I2C等;4.掌握基本的嵌入式系统开发流程和调试方法。
教学内容第一章 ARM体系结构1.ARM体系结构概述2.ARM的寄存器组织与功能3.ARM的指令系统4.ARM的异常处理第二章 ARM处理器1.ARM的微架构和流水线结构2.ARM的存储访问方式3.ARM的中断和异常处理4.ARM的外设接口和总线控制器第三章嵌入式系统开发工具1.keil MDK介绍2.C语言编程基础3.汇编语言编程基础4.嵌入式系统的调试方法第四章 ARM9嵌入式系统外设的设计和应用1.串口应用2.SPI应用3.I2C应用4.中断应用实验环节1.ARM9嵌入式系统的基本操作2.嵌入式系统空中升级功能设计3.基于keil MDK的ARM9单片机系统串口通信模块驱动程序设计4.基于keil MDK的ARM9单片机系统SPI通信模块驱动程序设计5.基于keil MDK的ARM9单片机系统I2C通信模块驱动程序设计实际效果学生通过本课程的学习和实践,在ARM9嵌入式系统设计方面获得了基本的理论知识和实践经验,能够独立完成基于ARM9嵌入式系统的嵌入式系统设计开发,为企业和个人发展奠定了扎实的技术基础。
ARM体系结构

ARM体系结构
ARM作为一种微处理器体系结构,具有广泛应用范围、高性价比、低功耗等优势,在晶体管规模以及架构方面有着很大的节省,因而受到了越来越多应用者的青睐。
ARM体系结构包括处理器(Processor)、片外存储器(External Memory)、I/O接口(Input/Output Interface)、外围器件(Peripheral Devices)、软件支持(Software Support)等内容。
从处理器来说,ARM体系结构提供了一系列非常细分的机型,它们有不同的特性和操作速度,可以满足不同的性能需求,而且这些机型一般都有较高的可缩放性,所以在产品设计的过程中可以根据实际要求选择合适的特性和速度。
从片外存储器来说,ARM体系结构支持使用不同类型的存储器,比如SRAM、DRAM、Flash等,可以根据应用性能和耗电量的需求,来选择合适的存储器以满足不同应用场景的需求,而且存储器容量也比较可观,一般可以满足大部分应用场景的要求。
从I/O接口来说,ARM体系结构支持多种接口,如USB、I2C、SPI、UART等,通过这些接口可以与周边的外设进行连接,而这些接口的功耗和速度也比较低。
《嵌入式系统设计》教学大纲

《嵌入式系统原理与设计》教学大纲课程名称:嵌入式系统设计,EmbeddedSystemDesign课程性质:专业必修课学分:2总学时:38其中,理论学时:26实验(上机)学时:12适用专业:电子信息工程先修课程:单片原理与接口技术,C语言程序设计,操作系统一、教学目的与要求独第一章嵌入式系统基础(2学时)第一节嵌入式系统概念一、嵌入式的定义二、嵌入式系统的组成三、嵌入式系统的特点四、嵌入式系统的应用五、实时系统第二节嵌入式系统处理器一、嵌入式处理器分类二、微控制器三、嵌入式微处理器四、DSP处理器五、片上系统六、典型的嵌入式处理器第三节嵌入式操作系统一、操作系统的概念和分类二、实时操作系统三、常见的嵌入式操作系统第四节实时操作系统的内核123121234第二章本章重点:1、嵌入式软件开发流程2、板级支持包本章难点:1、嵌入式系统的调试2、板级支持包本章教学要求:1、熟悉嵌入式软件开发特点2、掌握嵌入式软件开发流程3、掌握嵌入式系统的调试4、正确理解板级支持包第三章ARM体系结构(9学时)第一节ARM体系结构概述一、ARM体系结构特点二、ARM处理器结构三、ARM处理器内核四、ARM处理器核第二节编程模型一、数据类型本章重点:1、编程模型2、ARM的寻址方式3、ARM指令集本章难点:1、ARM的寻址方式2、ARM指令集3、ARM920T核本章教学要求:1、熟悉ARM的体系结构2、掌握编程模型3、正确理解ARM基本寻址方式4、掌握ARM指令集5、熟悉ARM内核第四章ARM硬件设计基础(9学时)第一节ARM开发环境简介一、RealViewMDK开发工具简介二、RealViewMDK集成开发环境简介第二节基于ARM的汇编语言程序设计本章实验:汇编语言和C语言程序设计(3学时)本章重点:1、ARM汇编语言2、基于ARM的硬件启动程序3、基于ARM的C语言与汇编语言混合编程本章难点:1、汇编语言程序设计2、C语言与汇编语种汇合编程本章教学要求:1、了解RealViewMDK开发环境2、掌握基于ARM的汇编语言程序设计3、熟悉硬件启动程序4、正确理解C语言与汇编语言混合编程5、了解印制电路板第五章基于S3C2410的系统硬件设计(12学时)第一节S3C2410简介一、S3C2410A的特点二、存储器控制器三、NANDFlash控制器二、键盘和LED控制的编程实例第八节LCD一、LCD显示原理二、S3C2410A的LCD控制器三、LCD显示的编程实例第九节触摸屏一、触摸屏工作原理二、S3C2410A的触摸屏接口三、触摸屏编程实例第十节音频录放一、音频录放的实现原理二、S3C2410A的I2S总线接口三、音频录放的编程实例第十一节USB设备数据收发一、USB接口及编程简介二、S3C2410A的USB设备控制器三、USB设备的收发数据编程本章实验:I/O接口(3学时)触摸屏控制(3学时)1、2、1、2123第六章一、设备文件二、设备驱动三、控制方式第四节Linux的使用一、Linux常用命令二、vi编辑器的使用三、make工具和gcc编译器本章重点:1、Linux操作系统的基本结构与特点2、Linux设备管理本章难点:1、Linux的内核结构2、Linux设备管理本章教学要求:1、掌握Linux操作系统的基本结构与特点2、熟悉Linux操作系统的使用第七章嵌入式Linux软件设计(2学时)第一节Bootloader引导程序一、Bootloader的启动过程1、2、1、2、驱动程序开发和应用程序开发本章教学要求:1、掌握BootLoader引导程序的2、掌握Linux的移植3、正确理解基于Linux操作系统驱动程序和应用程序的开发第八章图形用户接口MiniGUI(1学时)第一节MiniGUI简介一、MiniGUI的功能特色二、MiniGUI的技术优势第二节MiniGUI在Linux下运行环境的建立一、MiniGUI在Linux下的运行环境二、安装资源文件三、配置安装MiniGUI库文件第三节MiniGUI在DVFB上的仿真应用第四节在Linux下S3C2410FrameBuffer的启动一、FrameBuffer简介二、FrameBuffer驱动的添加三、FrameBuffer设备文件的添加四、FrameBuffer测试程序的编写121、212341、课程总评成绩由平时成绩(30%)和其末考试成绩(70%)组成,其中平时成绩包括作业、实验报告和考勤以及期中考试成绩和单元测验。
arm内核全解析_arm内核体系结构分类介绍

arm内核全解析_arm内核体系结构分类介绍ARM处理器是英国Acor n有限公司设计的低功耗成本的第一款RISC微处理器。
全称为Ad vanced RISC Machine。
ARM处理器本身是32位设计,但也配备16位指令集,一般来讲比等价32位代码节省达35%,却能保留32位系统的所有优势。
ARM内核特点ARM处理器为RISC芯片,其简单的结构使ARM内核非常小,这使得器件的功耗也非常低。
它具有经典RISC的特点:* 大的、统一的寄存器文件;* 简单的寻址模式;* 统一和固定长度的指令域,3地址指令格式,简化了指令的译码。
编译开销大,尽可能优化,采用三地址指令格式、较多寄存器和对称的指令格式便于生成优化代码;* 单周期操作,ARM指令系统中的指令只需要执行简单的和基本的操作,因此其执行过程在一个机器周期内完成;* 固定的32位长度指令,指令格式固定为32位长度,这样使指令译码结构简单,效率提高;* 采用指令流水线技术。
ARM内核体系结构ARM架构自诞生至今,已经发生了很大的演变,至今已定义了7种不同的版本:V1版架构:该架构只在原型机ARM1出现过,其基本性能包括基本的数据处理指令(无乘法)、字节、半字和字的Load/Store指令、转移指令,包括子程序调用及链接指令、软件中断指令、寻址空间64MB。
V2版架构:该版架构对V1版进行了扩展,如ARM2与ARM3(V2a版)架构,增加的功能包括乘法和乘加指令、支持协处理器操作指令、快速中断模式、SWP/SWPB的最基本存储器与寄存器交换指令、寻址空间64MB。
V3版架构:该版对ARM体系结构作了较大的改动,把寻址空间增至32位(4G B),增加了当前程序状态寄存器CPSR和程序状态保存寄存器 SPSR以便于异常处理。
增加了中止和未定义2种处理器模式。
ARM6就采用该版结构。
指令集变化包括增加了M RS/MSR指令,以访问新增的CPSR /SPSR寄存器、增加了从异常处理返回的指令功能。
arm9嵌入式系统组成结构
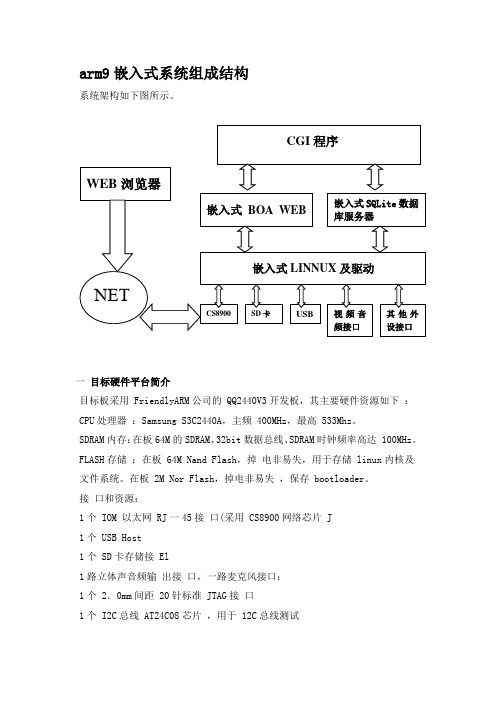
arm9嵌入式系统组成结构系统架构如下图所示。
一目标硬件平台简介目标板采用 FriendlyARM公司的 QQ2440V3开发板,其主要硬件资源如下:CPU处理器:Samsung S3C2440A,主频 400MHz,最高 533Mhz。
SDRAM内存:在板64M的SDRAM、32bit数据总线、SDRAM时钟频率高达 100MHz。
FLASH存储:在板 64M Nand Flash,掉电非易失,用于存储 linux内核及文件系统。
在板 2M Nor Flash,掉电非易失,保存 bootloader。
接口和资源:1个 IOM 以太网 RJ一45接口(采用 CS8900网络芯片 J1个 USB Host1个 SD卡存储接 El1路立体声音频输出接口,一路麦克风接口;1个 2.0mm间距 20针标准 JTAG接口1个 I2C总线 AT24C08芯片,用于 12C总线测试系统时钟源:12M无源晶振。
实时时钟:内部实时时钟(带后备锂电池 )。
软件资源方面。
该开发板提供移植好的 bootloader(vivi】和 linux系统。
本文采用的交叉编译器为:arnl—linux—gcc一3.4.1编译内核使用;alTll—linux—gcc一2.95.3编译 vivi用:yaffs文件系统映象制作工具 mkyaffsimage。
其中,应用程序使用 3.4.1或 2.95.3均可。
二、嵌入式 web服务器 BOA的移植、配置目前,应用较多的嵌入式web服务器有 httpd、thttpd、BOA等,就众多选择而言,BOA不但支持一般的静态页面,还支持认证和 CGI。
其中认证机制显著提高系统的安全性,而 CGI程序是实现动态页面的主要手段,通过 CGI程序,就可以启动新进程,操作硬件资源以及访问数据库。
三、CGI编程规范CGI全称是“公共网关接口”(Comnlon Gateway Interface)。
是一种 web 服务器浏览进行“交谈”的一种工具。
ARM9常识知识的笔记

ARM处理器特点:1支持Thumb和ARM双指令集,能很好地兼容8位/16位器件。
Thumb指令集比通常的8位和16位CISC/RISC处理器具有更好代码密度。
2指令采用的3级、5级流水技术。
4支持大端格式和小端格式两种方法存储数据。
5支持字节、半字、和字这3种数据类型。
6 体积小,成本低,性能高ARM工作状态:1、32位ARM状态、2、16位Thumb状态ARM处理器七种运行模式:用户、快中断、中断、管理、(指令预取)中止、系统和未定义(除用户模式外,其余6种模式称为非用户模式,或特权模式;除去用户模式和系统模式外,其余5种模式又称为异常模式)。
R13为堆栈指针SP,R14为链接寄存器LR,R15为程序计数器PC,R16状态寄存器CPSR ARM(嵌入式)系统(从模块结构上看)三大组成部分:硬件、软件、开发平台。
嵌入式系统概念:以应用为中心,以计算机技术为基础,软硬件可裁剪,适应应用系统对功能、可靠性、成本、体积、功耗严格要求的专用计算机系统。
嵌入式开发环境主要组件:●宿主机●目标机●基于JTAG的ICD仿真器、或调试监控软件、或在线仿真器ICE●运行于宿主机的交叉编译器和链接器、以及开发工具链或软件开发环境●嵌入式操作系统常见的嵌入式系统:移动电话、数码照相机、MP4、数字电视的机顶盒、微波炉、汽车内部的喷油控制系统、防抱死制动系统。
4种电源管理模式:1正常模式:正常运行模式2慢速模式:不加PLL的低时钟频率模式3空闲模式:只停止CPU的时钟4掉电模式:切断所有外设和内核的电源RAM=SRAM+DRAM边界对齐方式:字对齐、半字对齐、字节对齐名词解释:ROM:Read Only Memory是只能读出事先所存的数据的固态半导体存储器,其特性是一旦存储资料就无法改变或删除。
ARM:Advanced RISC Machines先进精简指令集。
ARM公司1991年成立于英国剑桥,是专门从事基于RISC技术芯片设计开发公司,主要出售芯片设计技术的授权。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ADD
SUB
CMP
ADD
SUB
ADD
ARM的三级流水线(例如ARM7TDMI)
ARM流水线的级数
• • • • ARM9 流水线增加到5级,增加了存储器访问段和回写段,使ARM9处理能力平均可达到1.1 Dhrystone,指令吞吐量增加了约13%。 随着流水线深度(级数)的增加,每一段的工作量被削减了,这使得处理器可以工作在更高的频 率,同时改进了性能; 负面作用是增加了系统的延时,即内核在执行一条指令前,需要更多的周期来填充流水线; 流水线级数的增加也意味着在某些段之间会产生数据相关;
– 提高了最大时钟频率
ARM9TDMI数据通道 (1)
ARM9TDMI 数据通道 (2)
结果 DINFWD
MU 逻辑
B 寄存器 Bank Imm BDATA 移位器
A
乘法器
ALU
PSR
ADATA
锁存
锁存
ARM9TDMI 处理器结构示意图
第三节 ARM920T的体系结构简介
ARM9系列微处理器包含ARM920T、ARM922T和ARM940T几种类型,可以在 高性能和低功耗特性方面提供最佳的性能。采用5级整数流水线,指令执行 效率更高。提供1.1MIPS/MHz的哈佛结构。支持数据Cache和指令Cache,具 有更高的指令和数据处理能力。 支持32位ARM指令集和16位Thumb指令集。 支持32位的高速AMBA总线接口。全性能的MMU,支持Windows CE、Linux、 Palm OS等多种主流嵌入式操作系统。MPU支持实时操作系统。 ARM920T处理器核在ARM9TDMI处理器内核基础上,增加了分离式的指令 Cache和数据Cache,并带有相应的存储器管理单元I-MMU和D-MMU、写缓冲器 及AMBA接口等,如图3.1.2所示。
乘数 An-1An 00 01 进位Cin 0 0 操作 S->2, Cout=“0” S+B->2, Cout=“0”
10
11
0
0
S+2×B->2, Cout=“0”
S-B->2, Cout=“1”
00
01 10 11
1
1 1 1
S+B->2, Cout=“0”
S+2×B->2, Cout=“0” S-B->2, Cout=“1” S->2, Cout=“1”
这里S为低二位乘以被乘数的部分积、B为被乘数、Cin为低二位乘以被乘数时产生 的进位。Cout为当前二位乘以被乘数时产生的进位,在下二位乘以被乘数时,传递 给Cin。 被乘数(B) 10110110 乘数 10110101
右移3
in[0] in[1] in[2] in[3]
右移2
右移1
不移位
in[3] 左移1 左移2
图3.1.2
ARM920T内核结构
第四节 ARM9体系结构的重要特性
• • • • • • • • • 流水线技术 总线技术 Cache技术 协处理器 异常与中断 工作模式 寄存器组 ARM体系结构的命名规则 JTAG调试接口
3.4.1 ARM的流水线技术
取指
译码
执行
周期1 时 间 周期2
周期3
预取 译码 执行 (Fetch) (Decode) (Execute) 预取 译码 执行 访存 写入 (Fetch) (Decode) (Execute) (Memory) (Write) 预取 (Fetch) 预取 (Fetch) 发送 译码 执行 访存 写入 (Issue) (Decode) (Execute) (Memory) (Write) 预取 (Fetch) 发送 译码 (Issue) (Decode) 转换 执行 访存 写入 (Snny) (Execute) (Memory) (Write)
ARM7
ARM9
ARM10 ARM11
ARM9TDMI
Instruction Fetch
ARM or Thumb Inst Decode Reg Reg Decode Read
Shift + ALU
Memory Access
Reg Write
FETCH
DECODE
EXECUTE
MEMORY
WRITE
A操作数锁存
反相ALeabharlann B操作数锁存反相B
XOR门
XOR门
功能
逻辑功能运算器
加法器
C 输入 C 进位位 V 溢出
逻辑/算术
结果多路器 N 符号位 零检测
Z 为零标志
结果
ALU 逻辑框图
高速乘法器
下面我们以两位乘法器为例。所谓的两位乘法器是指把乘数每两位分成一段,根据该段 值,通过硬件实现被乘数与该段值的相乘。规则如下:
• 5 级流水线
• 实现了以下改进: – 改进 CPI(Cycles Per Instruction)
ARM9系列与ARM7TDMI的比较. ARM9TDMI上100条指令平均需176周期,CPI为1.760 。 ARM7TDMI上100条指令平均需224.1个周期,CPI为2.241。 因此在ARM9TDMI上花费的时间平均是ARM7TDMI上的79%,或者说在 同频率下,ARM9TDMI的性能是ARM7TDMI的127%
协处理器
• 协处理器的应答信号中: ● nCPI为ARM处理器至CPn协处理器信号,该信号低电压有效代表“协处理 器指令”,表示ARM处理器内核标识了1条协处理器指令,希望协处理器去执 行它。 ● CPA为协处理器至ARM处理器内核信号,表示协处理器不存在,目前协处 理器无能力执行指令。 ● CPB为协处理器至ARM处理器内核信号,表示协处理器忙,还不能够开始 执行指令。 协处理器也采用流水线结构,为了保证与ARM处理器内核中的流水线同步,在 每一个协处理器内需有1个流水线跟随器(Pipeline Follower),用来跟踪ARM 处理器内核流水线中的指令。由于ARM的Thumb指令集无协处理器指令,协 处理器还必须监视TBIT信号的状态,以确保不把Thumb指令误解为ARM指 令。 协处理器也采用Load/Store结构,用指令来执行寄存器的内部操作,从存储 器取数据至寄存器或把寄存器中的数保存至存储器中,以及实现与ARM处理 器内核中寄存器之间的数据传送。而这些指令都由协处理器指令来实现。
3.4.2 AMBA总线
• 高级微控制器总线协议(AMBA)是1996年提出的,被ARM处理器做为片上总线 结构; ARM处理器内核可以通过先进的微控制器总线架构AMBA(Advanced Microcontroller Bus Architecture)来扩展不同体系架构的宏单元及I/O部 件。AMBA已成为事实上的片上总线OCB(On Chip Bus)标准。 • 最初的AMBA总线包含ARM系统总线(ASB)和ARM外设总线(APB);AMBA有AHB (Advanced High-performance Bus,先进高性能总线)、ASB(Advanced System Bus,先进系统总线)和APB(Advanced Peripheral Bus,先进外围 总线)等三类总线。 • ARM高性能总线(AHB)是新的标准,可以支持64位和128位宽度的ARM总线; • ASB是目前ARM常用的系统总线,用来连接高性能系统模块,支持突发(Burst) 方式数据传送。 • AHB不但支持突发方式的数据传送,还支持分离式总线事务处理,以进一步提 高总线的利用效率。特别在高性能的ARM架构系统中,AHB有逐步取代ASB的趋 势,例如在ARM1020E处理器核中。 • APB为外围宏单元提供了简单的接口,也可以把APB看作ASB的余部。
ARM9嵌入式系统设计基础
—基于S3C2410A与μC/OS-II
第三章 ARM9体系结构
徐卓镛
1 ARM9体系结构简介
2 ARM9TDMI
3
ARM920T的体系结构简介
4 ARM9TDMI体系结构的重要特性
第一节 ARM9体系结构简介
• 一个典型的ARM体系结构方框图如图3.1.1所示, 包含有32位ALU、31个32位通用寄存器及6位状 态寄存器、32×8位乘法器、32×32位桶形移位 寄存器、指令译码及控制逻辑、指令流水线和数 据/地址寄存器等。
图2.7.1 一个基于AMBA的典型系统
3.4.3 Cache和紧耦合器
• 冯诺伊曼结构数据和指令共用一个缓存;哈佛体系结构 有独立的指令和数据缓存; • Cache改善了系统的整体性能,但也使程序的执行时间 变得不可预测,对实时系统而言,代码执行的确定性— —装载和存储指令或数据的时间必须是可预测的; • ARM采用紧耦合器TCM实现可预测,TCM紧靠内核,保证 取指或数据操作的时钟周期数。TCM位于存储器的地址 映射中,可作为快速存储器访问; • 结合Cache和TCM,ARM既能改善性能,又能够获得可预 测的实时响应;
AMBA总线
• AMBA通过测试接口控制器TIC(Test Interface Controller)提供了模块测 试的途径,允许外部测试者作为ASB总线的主设备来分别测试AMBA上的各个模 块。 • AMBA中的宏单元也可以通过JTAG方式进行测试。虽然AMBA的测试方式通用性 稍差些,但其通过并行口的测试比JTAG的测试代价也要低些。
3.4.4 协处理器
为了便于片上系统SoC的设计,ARM可以通过协处理器(CP)来支持 一个通用指令集的扩充,通过增加协处理器来增加系统的功能。
• 协处理器可以附属于ARM处理器,一个协处理器通过扩展指令或提供配臵寄 存器来扩展内核处理功能; • 协处理器可以通过一组专门的、提供load-store类型接口的ARM指令来访问。 如协处理器15(CP15),用于控制Cache、TCM和存储器管理;在逻辑上, ARM可以扩展16个(CP15~CP0)协处理器,其中:CP15作为系统控制, CP14作为调试控制器,CP7~4作为用户控制器,CP13~8和CP3~0保留。每 个协处理器可有16个寄存器。例如MMU和保护单元的系统控制都采用CP15协 处理器;JTAG调试中的协处理器为CP14,即调试通信通道DCC(Debug Communication Channel)。 • 协处理器也能通过提供一组专门的新指令来扩展指令集,如,处理向量浮点 运算的指令集; • 这些指令在ARM流水线的译码阶段被处理,如果在译码阶段发现是一条协处 理器指令,则把它送给相应的协处理器。如果该协处理器不存在,或不认识 该指令,则ARM认为发生未定义指令异常; • ARM处理器内核与协处理器接口有以下4类。 ① 时钟和时钟控制信号:MCLK、nWAIT、nRESET; ② 流水线跟随信号:nMREQ、SEQ、nTRANS、nOPC、TBIT; ③ 应答信号:nCPI、CPA、CPB; ④ 数据信号:D[31:0]、DIN[31:0]、DOUT[31:0]。