哈夫曼树总结习题(2学时)
数据结构-chap6 (5)哈夫曼树

构造哈夫曼树的算法 void Huffman_Tree(HuffmanTree &HT, int *w, int n){ //w 存放n 个字符的权值(均>0),构造哈夫曼树HT if (n<=1) return; m = 2* n - 1; //为哈夫曼树分配存储空间,0号单元未用 HT=(HuffmanTree)malloc((m+1) * sizeof(HTNode));
例
要传输的原文为ABACCDA
设ABCD的编码为:A(00)、 B(01) 、C(10)、 D(11) 则电文可转换为总长是14的字符串 ‘00010010101100‟
如果ABCD的编码为A(0)、B(00)、C(1)、D(01)
则电文可转换为总长是9的字符串 ‘ 000011010‟
可翻译为
要设计长短不等的编码,必须保证
任一字符的编码都不是另一个字符 的编码的前缀——前缀编码。
‘AAAA‟、„ABA‟ „BB‟等
利用二叉树来设计前缀编码
叶子结点分别表示a、b、c、d四个字符. 约定:左分支表示字符‘0’,右分支表示字符‘1’.
从根结点到叶子结点的路径上分支字符组成的字符串作为该叶子 结点字符的编码.
0 a
1 0 b
rch
夫曼树 的过程 中,新 生成的 结点
7 8 9 10 11 12 13 14 15
0 0 0 0 0 0 3 9 0 0 11 11 0 0 8 11 1 7 15 12 3 4 19 13 8 9 29 14 5 10 42 15 6 11 58 15 2 12 100 0 13 14
例:用哈夫曼算法构造 以w=(5, 29, 7, 8, 14, 23, 3, 11) 为权值的哈夫曼树
哈夫曼树最短路径长度

哈夫曼树最短路径长度
(实用版)
目录
1.哈夫曼树的概念
2.哈夫曼树的最短路径长度
3.哈夫曼树的应用
4.结论
正文
1.哈夫曼树的概念
哈夫曼树(Huffman Tree)是一种用于数据压缩的树形结构,由美国计算机科学家 David A.Huffman 在 1952 年提出。
它是一种带权路径长度最短的二叉树,权值越大的节点离根节点越远。
哈夫曼树的构造方法称为贪心算法,每次选择权值最小的两个节点进行合并,直到所有节点合并为一个树。
2.哈夫曼树的最短路径长度
哈夫曼树的最短路径长度是指从根节点到叶子节点的最短路径长度。
在哈夫曼树中,叶子节点对应着输入数据中的各个字符,而根节点对应着输出数据中的各个位。
通过哈夫曼树,可以将原始数据压缩为较短的二进制编码,从而实现数据压缩。
3.哈夫曼树的应用
哈夫曼树广泛应用于数据压缩、图像压缩、语音识别等领域。
其中,数据压缩是哈夫曼树的主要应用之一。
通过对原始数据进行哈夫曼编码,可以得到较短的二进制编码,从而实现数据压缩。
在解压缩时,只需按照哈夫曼树从根节点到叶子节点的路径进行解码,即可还原原始数据。
4.结论
哈夫曼树是一种重要的数据结构,它可以实现带权路径长度最短,从而应用于数据压缩等领域。
【算法总结】哈夫曼树

【算法总结】哈夫曼树在⼀棵树中,从任意⼀个结点到达另⼀个结点的通路被称为路径,该路径上所需经过的边的个数被称为该路径的长度。
若树中结点带有表⽰某种意义的权值,那么从根结点到达该节点的路径长度再乘以该结点权值被称为该结点的带权路径长度。
树所有的叶⼦结点的带权路径长度和为该树的带权路径长度和。
给定 n 个结点和它们的权值,以它们为叶⼦结点构造⼀棵带权路径和最⼩的⼆叉树,该⼆叉树即为哈夫曼树,同时也被称为最优树。
给定结点的哈夫曼树可能不唯⼀,所以关于哈夫曼树的机试题往往需要求解的是其最⼩带权路径长度和。
回顾⼀下我们所熟知的哈夫曼树求法(原理很容易理解,就是把⼩的往下放)。
1.将所有结点放⼊集合 K。
2.若集合 K 中剩余结点⼤于 2 个,则取出其中权值最⼩的两个结点,构造他们同时为某个新节点的左右⼉⼦,该新节点是他们共同的双亲结点,设定它的权值为其两个⼉⼦结点的权值和。
并将该⽗亲结点放⼊集合 K。
重复步骤 2 或 3。
3.若集合 K 中仅剩余⼀个结点,该结点即为构造出的哈夫曼树数的根结点,所有构造得到的中间结点(即哈夫曼树上⾮叶⼦结点)的权值和即为该哈夫曼树的带权路径和。
为了⽅便快捷⾼效率的求得集合 K 中权值最⼩的两个元素,我们需要使⽤堆数据结构。
它可以以 O(logn)的复杂度取得 n 个元素中的最⼩元素。
为了绕过对堆的实现我们使⽤标准模板库中的相应的标准模板——优先队列。
:有4 个结点 a, b, c, d,权值分别为 7, 5, 2, 4,试构造以此 4 个结点为叶⼦结点的⼆叉树。
根据给定的n个权值{w1,w2,…,wn}构成⼆叉树集合F={T1,T2,…,Tn},其中每棵⼆叉树Ti中只有⼀个带权为wi的根结点,其左右⼦树为空.在F中选取两棵根结点权值最⼩的树作为左右⼦树构造⼀棵新的⼆叉树,且置新的⼆叉树的根结点的权值为左右⼦树根结点的权值之和.在F中删除这两棵树,同时将新的⼆叉树加⼊F中.重复,直到F只含有⼀棵树为⽌.(得到哈夫曼树)利⽤语句priority_queue<int> Q;建⽴⼀个保存元素为 int 的堆 Q,但是请特别注意这样建⽴的堆其默认为⼤顶堆,即我们从堆顶取得的元素为整个堆中最⼤的元素。
数据结构哈弗曼树

6.7 哈夫曼树一、Huffman树二、Huffman编码6.7.1 Huffman树(最优二叉树)若干术语:路径:由一结点到另一结点间的分支所构成。
路径长度:路径上的分支数目。
例如:a→e的路径长度=2二叉树的路径长度:从二叉树根到所有叶子结点的路径长度之和。
树路径长度=8二叉树的带权路径长度:从二叉树根结点到所有叶子结点的路径长度与相应叶子结点权值的乘积之和(WPL)即树中所有叶子结点的带权路径长度之和Huffman树:带权路径长度最小的树。
Huffman常译为哈夫曼、赫夫曼、霍夫曼等树的带权路径长度如何计算?WPL = w k l k构造Huffman树的基本思想:权值大的结点用短路径,权值小的结点用长路径。
构造Huffman树的步骤(即Huffman算法):(1) 由给定的n 个权值{ w1, w2, …, w n }构造n棵二叉树的集合F = { T1, T2, …, T n} (即森林),其中每棵二叉树T i 中只有一个带权为w i 的根结点,其左右子树均空。
(2) 在F 中选取两棵根结点权值最小和次小的树分别做为左右子树构造一棵新的二叉树,且让新二叉树根结点的权值等于其左右子树的根结点权值之和。
(3) 在F 中删去这两棵树,同时将新得到的二叉树加入F中。
(4) 重复(2) 和(3) , 直到F 只含一棵树为止。
这棵树便是Huffman树。
具体操作步骤:对权值进行合并、删除与替换——在权值集合{7,5,2,4}中,总是合并当前值最小的两个权具体操作步骤:对权值进行合并、删除与替换——在权值集合{7,5,2,4}中,总是合并当前值最小的两个权Huffman树特点:肯定没有度为1的结点;一棵有n 0个叶子结点的Huffman树,共有2n0-1个结点;讨论:Huffman树有什么用?例:设有4个字符d,i,a,n,出现的频度分别为7,5,2,4,怎样编码才能使它们组成的报文在网络中传得最快?法1:等长编码令d=00,i=01,a=10,n=11,则:WPL1=2bit×(7+5+2+4)=36法2:不等长编码令d=0;i=10,a=110,n=111,则:WPL2=1bit×7+2bit×5+3bit×(2+4)=356.7.2 哈夫曼编码问题哈夫曼树可用于构造代码总长度最短的编码方案。
哈夫曼

136 题号:06004 第06章题型:单选题难易程度:适中试题:若以{4,5,6,7,8}作为权值构造哈夫曼树,则该树的带权路径长度为()。
A. 67B. 68C. 69D. 70答案:C153 题号:06021 第06章题型:选择题难易程度:较难试题:在有n个叶子结点的哈夫曼树中,其结点总数为()。
A) 不确定B) 2n C) 2n+1 D) 2n-1答案:D154 题号:06022 第06章题型:选择题难易程度:难试题:权值为{1,2,6,8}的四个结点构成的哈夫曼树的带权路径长度是()。
A) 18 B) 28 C) 19 D) 29答案:D158 题号:06026 第06章题型:选择题难易程度:适中试题: 设哈夫曼树中的叶子结点总数为m,若用二叉链表作为存储结构,则该哈夫曼树中总共有()个空指针域。
(A) 2m-1 (B) 2m (C) 2m+1 (D) 4m答案: B166 题号:06034 第06章题型:选择题难易程度:适中试题: 设一组权值集合W={2,3,4,5,6},则由该权值集合构造的哈夫曼树中带权路径长度之和为()。
(A) 20 (B) 30 (C) 40 (D) 45答案: D169 题号:06037 第06章题型:选择题难易程度:适中试题: 设某哈夫曼树中有199个结点,则该哈夫曼树中有()个叶子结点。
(A) 99 (B) 100 (C) 101 (D) 102答案: B183 题号:06051 第06章题型:选择题难易程度:适中试题: 设一组权值集合W=(15,3,14,2,6,9,16,17),要求根据这些权值集合构造一棵哈夫曼树,则这棵哈夫曼树的带权路径长度为()。
(A) 129 (B) 219 (C) 189 (D) 229答案: D188 题号:06056 第06章题型:选择题难易程度:较难9、试题:哈夫曼树指()。
(A)带权路径长度最小的二叉树(B)路长最小的二叉树(C)带权路径长度最小的树(D)路径长度最小的二叉树答案:A10、一下哪个可以构造最小生成树()(A)Prim算法(B)Dijkstra算法(C)Floyd算法(D)Huffmanmode算法答案:A。
(12)哈夫曼树及其应用(续2)

二、哈夫曼树及其应用
3.哈夫曼编码 ①等长编码:
设这4个不同的字符为A,B,C,D,则可进行 等长编码如下:
17
二、哈夫曼树及其应用
3.哈夫曼编码 ①等长编码: 设这4个不同的字符为A,B,C,D,则可进行 等长编码如下: A: 00 B: 01 C: 10 D: 11
则对于电文“ABACCDA”的二进制电码为: 00010010101100 总长为14位
共做31500 次比较
no a<90 yes no 打印"excellent" 10%的学生 3
循环一万次
i = i+1
5%的学生
15%的学生 40%的学生
打印"good" 30%的学生
学生成绩数据分布情况表
分数 学生比例数 0~59 0.05 60~69 70~79 80~89 90~100 0.15 0.40 i<=10000 0.30
哈夫曼树HT的存储结构如下(HT为HuffmanTree类型):
HT 1
7 7 0 0
2
3
4
4 5 0 0 6 6
5
3 4
11
6
7 2 5 18
7
0 1 24 6
5 6 0 0 2 5 0 0
四、构造哈夫曼树并求这 n个字符的哈夫曼编码之程序 n个字符数组的头指针HC[i](1≤i≤n)分
别指向一个字符型数组的首地址,又构 1.哈夫曼树的结点的物理结构: 成一个指针类型的一维数组;
15
40 a
30 b
5
c
10 d
15 e
12
二、哈夫曼树及其应用
2.哈夫曼树的求解过程 ③实例:已知有5个叶子结点的权值分别为:5 , 15 , 40 , 30 , 10 ;试画出一棵相应的哈夫曼树。
数据结构第六章 哈夫曼树
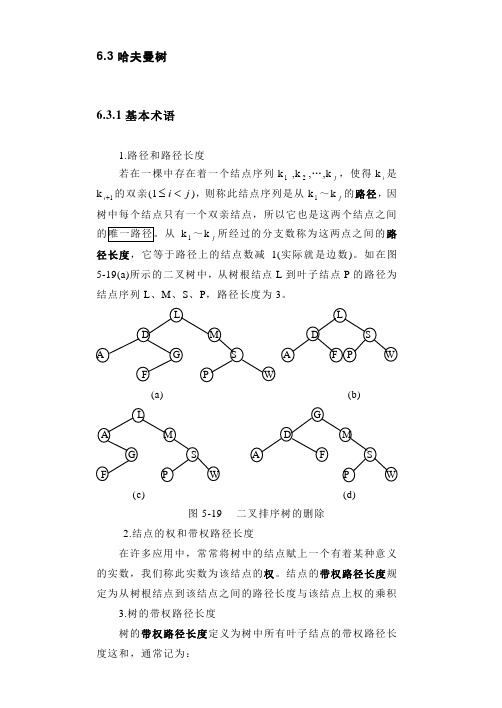
6.3哈夫曼树6.3.1基本术语1.路径和路径长度若在一棵中存在着一个结点序列k1 ,k2,…,kj,使得ki是k1+i 的双亲(1ji<≤),则称此结点序列是从k1~kj的路径,因树中每个结点只有一个双亲结点,所以它也是这两个结点之间k 1~kj所经过的分支数称为这两点之间的路径长度,它等于路径上的结点数减1(实际就是边数)。
如在图5-19(a)所示的二叉树中,从树根结点L到叶子结点P的路径为结点序列L、M、S、P,路径长度为3。
(a) (b)(c) (d)图5-19 二叉排序树的删除2.结点的权和带权路径长度在许多应用中,常常将树中的结点赋上一个有着某种意义的实数,我们称此实数为该结点的权。
结点的带权路径长度规定为从树根结点到该结点之间的路径长度与该结点上权的乘积3.树的带权路径长度树的带权路径长度定义为树中所有叶子结点的带权路径长度这和,通常记为:2 WPL = ∑=n i i i lw 1其中n 表示叶子结点的数目,i w 和i l 分别表示叶子结点i k 的权值和根到i k 之间的路径长度 。
4.哈夫曼树哈夫曼(Huffman)树又称最优二叉树。
它是n 个带权叶子结点构成的所有二叉树中,带权路径长度 WPL 最小的二叉树。
因为构造这种树的算法是最早由哈夫曼于1952年提出的,所以被称之为哈夫曼树。
例如,有四个叶子结点a 、b 、c 、d ,分别带权为9、4、5、2,由它们构成的三棵不同的二叉树(当然还有其它许多种)分别如图5-20(a)到图5-20(c)所示。
b ac a b cd d c a b d(a) (b) (c)图5-20 由四个叶子结点构成的三棵不同的带权二叉树 每一棵二叉树的带权路径长度WPL 分别为:(a) WPL = 9×2 + 4×2 + 5×2 + 2×2 = 40(b) WPL = 4×1 + 2×2 + 5×3 + 9×3 = 50(c) WPL = 9×1 + 5×2 + 4×3 + 2×3 = 37其中图5-20(c)树的WPL 最小,稍后便知,此树就是哈夫曼树。
第5章专题6哈夫曼树

数据结构(C++版)第2版
5.7 哈夫曼树及哈夫曼编码
9 4 5 2 5 0 weight parent 2 lchild -1 rchild -1
4 -1 5 -1
5 -1 4 -1 6 -1
3
1 2 3
i1
4
5
-1
-1
-1
-1
14
3
5
-1
0 -1 1 -1 4 -1
-1
3 -1 2 -1 5-1
清华大学出版社
数据结构(C++版)第2版
5.7 哈夫曼树及哈夫曼编码
哈夫曼树应用——哈夫曼编码
编码方案: A:00 B:10 C:010 D:110 E:111 F:0110 G:0111
45 0 19 0 9 A 1 10 0 1 5 0 11 B 1 26 1 15 0 7 D G 1 8 E
清华大学出版社
数据结构(C++版)第2版
5.7 哈夫曼树及哈夫曼编码
W={2,4,5 ,3} 哈夫曼树的构造过程
第1步:初始化
2 5
4
5
3
第2步:选取与合并
2
第3步:删除与加入
3 5 2 5 3
4
清华大学出版社
数据结构(C++版)第2版
5.7 哈夫曼树及哈夫曼编码
W={2,4,5 ,3} 哈夫曼树的构造过程
清华大学出版社
数据结构(C++版)第2版
5.7 哈夫曼树及哈夫曼编码
哈夫曼树应用——哈夫曼编码
编码:给每一个对象标记一个二进制位串来表示 一组对象。例:ASCII,指令系统等。
哈夫曼树经典例题

哈夫曼树经典例题哈夫曼树是一种经典的缩小数据存储空间的算法。
它是由David Huffman在1952年提出的,被广泛应用于数据压缩、编码和解码等领域。
本文将介绍哈夫曼树的定义、构建算法和常见的应用示例。
一、哈夫曼树的定义哈夫曼树是一种特殊的二叉树,它的构建基于一组给定的权值集合。
每个权值都与二叉树中的一个叶子节点相关联。
哈夫曼树的特点是权值较大的节点越接近于根节点,权值较小的节点越接近于叶子节点。
这种结构使得较高频率的字符具有较短的编码,而较低频率的字符具有较长的编码,从而达到压缩数据的目的。
二、哈夫曼树的构建算法哈夫曼树的构建算法主要分为以下几个步骤:1. 创建一个权值表,记录每个字符的权值。
2. 将权值表按照权值从小到大进行排序。
3. 选择权值最小的两个字符,创建一个新的内部节点,将这两个字符作为其子节点,并将其权值设为这两个字符的权值之和。
4. 将新创建的节点插入到排序后的权值表中,并删除原先两个节点。
5. 重复步骤3和步骤4,直到只剩下一个节点,即根节点为止。
三、哈夫曼树的应用示例:数据压缩数据压缩是哈夫曼树最常见的应用之一。
在压缩数据时,哈夫曼树根据字符出现的频率进行构建,将频率较高的字符用较短的编码表示,而频率较低的字符用较长的编码表示,从而达到压缩数据的目的。
举个例子,假设我们要压缩一个文本文件,其中包含6个不同的字符:A: 2次B: 3次C: 4次D: 4次E: 5次F: 6次首先,我们根据字符频率构建哈夫曼树。
按照步骤2,我们将字符按照频率从小到大排序,得到以下顺序:A, B, C, D, E, F然后,按照步骤3和步骤4,我们构建哈夫曼树的过程如下:1. 构造A和B的新节点AB,权值为2+3=5,得到新权值表:AB, C, D, E, F2. 构造AB和C的新节点ABC,权值为5+4=9,得到新权值表:ABC, D, E, F3. 构造D和E的新节点DE,权值为4+5=9,得到新权值表:ABC, DE, F4. 构造ABC和DE的新节点ABCDE,权值为9+9=18,得到新权值表:ABCDE, F5. 构造ABCDE和F的新节点全集,权值为18+6=24,得到最终的哈夫曼树。
最优二叉树(哈夫曼树)知识点

最优⼆叉树(哈夫曼树)知识点路径:在⼀棵树中从⼀个结点往下到孩⼦或孙⼦结点之间的通路结点的路径长度:从根节点到该节点的路径上分⽀的数⽬树的路径长度:树中每个结点的路径长度之和结点的权:给树中的结点赋予⼀个某种含义的值,则该值为该节点的权结点的带权路径长度:结点的路径长度乘以结点的权树的带权路径长度(WPL):树中所有叶⼦结点的带权路径长度 (Weight Path Length)最优⼆叉树(哈夫曼树):带权路径长度最⼩的⼆叉树构造哈夫曼树:给定n个权值{w1,w2,…wn},则构造出的哈夫曼树有n个叶⼦结点,构造过程如下:1.将w1,w2…wn按从⼩到⼤排序,并将他们看做n棵只有⼀个结点的树组成的森林;2.选出两个根节点权值最⼩的树合并,作为新树的左右⼦树,新树的根节点权值是左右⼦树根节点权值之和3.从森林中删除选取的两棵树,将新树加⼊森林4.重复2,3,直到只剩⼀棵树,所得即为最优⼆叉树实例如下:给定权值{5,6,2,7,9}构造哈夫曼树解:(1) 排序后为w={2,5,6,7,9}取出2,5 w={6,7,7,9}取出6,7 w={7,9,13}取出7,9 w={13,16}取出13,16上⾯的哈夫曼树的wpl=6X2+7X2+2X3+5X3+9X2=65哈夫曼树在编码中的应⽤:在通讯中,经常需要将⽂本转换成⼆进制串,即编码。
为了使电⽂代码尽可能的短,需要另经常使⽤的字符采⽤短的编码,使⽤频率⼩的字符采⽤长的编码。
同时,⼀个字符的编码不能包含另⼀个字符的编码,例如A是00,B就不能是001,使⽤哈夫曼树就可以很好的实现 ,例如A,B,C,D,E的频率分别是6,7,2,5,9 对应的哈夫曼树为:另左⼦树的路径为0,右⼦树路径为1则A:00 B:01 C:100 D:101 E:11版权声明:本⽂为博主原创⽂章,未经博主允许不得转载。
哈夫曼树的总结

哈夫曼树的总结引言哈夫曼树(Huffman Tree)是一种用于无损数据压缩的重要数据结构。
它是由美国数学家大卫·哈夫曼于1952年提出的,被广泛应用于各种领域,如文件压缩、网络传输、数据存储等。
哈夫曼树的概念哈夫曼树是一种二叉树,其中每个叶子节点代表一个字符,且树的形状是通过字符出现频率构造而成的。
哈夫曼树的特点是,出现频率高的字符位于树的较低层,频率低的字符位于树的较高层,使得出现频率高的字符用较少的编码表示,出现频率低的字符用较多的编码表示,达到数据压缩的目的。
哈夫曼编码哈夫曼树的构建过程中,每个字符的出现频率是关键。
为了压缩数据,我们需要为每个字符分配一个唯一的二进制编码。
哈夫曼编码是通过哈夫曼树来生成的,它保证了没有任何一个字符的编码是其他字符编码的前缀,因此可以方便地进行数据的解压。
构建哈夫曼树的步骤构建哈夫曼树的步骤一般如下:1.统计每个字符的出现频率。
2.将每个字符作为一个单独的树节点,构建一个森林。
3.从森林中选择出现频率最低的两棵树合并为一棵新的树,新树的权重为两棵树的权重之和。
4.将新树放回森林,重复步骤3,直到森林中只剩下一棵树,即哈夫曼树。
5.对每个叶子节点,根据路径从根节点到该叶子节点的方向,赋予唯一的二进制编码。
哈夫曼树的性质哈夫曼树具有以下几个重要的性质:1.哈夫曼树是一棵最优二叉树,即带权路径长度最短的二叉树。
2.哈夫曼树的带权路径长度是所有叶子节点的权重乘以路径长度的总和。
3.哈夫曼树的路径长度定义为从树根到叶子节点的路径上的边的数量。
4.哈夫曼树的路径长度最小,即带权路径最短,适用于数据压缩等场景。
哈夫曼树的应用哈夫曼树广泛应用于数据压缩和编码领域。
通过构建哈夫曼树和哈夫曼编码,可以实现文本、图像等数据的无损压缩。
此外,哈夫曼树还被用于文件传输、网络传输等场景,可以大大提高数据传输效率和降低带宽消耗。
总结哈夫曼树是一种重要的数据结构,通过构建哈夫曼树和哈夫曼编码,可以实现数据的无损压缩和高效传输。
哈夫曼树构造例题

哈夫曼树构造例题【原创版】目录1.哈夫曼树的概念和基本性质2.哈夫曼树的构造方法3.哈夫曼树的应用实例正文哈夫曼树(Huffman Tree)是一种带权路径长度最短的二叉树,它是由美国计算机科学家 David A.Huffman 在 1952 年提出的。
哈夫曼树的主要应用是在数据压缩和编码领域,通过将原始数据转换成对应的哈夫曼编码,可以大大减少数据的存储空间和传输时间。
一、哈夫曼树的概念和基本性质哈夫曼树是一棵满二叉树,它的构造方法是将权值最小的两个节点合并为一个新节点,新节点的权值为两个节点权值的和。
重复这个过程,直到所有的节点都被合并为一个根节点。
哈夫曼树的基本性质包括:1.哈夫曼树是一棵满二叉树,即除了最后一层外,其他层的节点数都是满的。
2.哈夫曼树的叶节点(即最后一层的节点)对应于原始数据中的每个字符,且权值最小的叶节点在最左边。
3.哈夫曼树的每个父节点的权值等于其左右子节点权值之和。
二、哈夫曼树的构造方法构造哈夫曼树的方法可以分为两个步骤:1.根据原始数据中的字符出现频率构建一个哈夫曼树。
首先将原始数据中的每个字符作为叶子节点,权值为该字符出现的频率。
然后在这些节点中选择权值最小的两个节点合并为一个新节点,新节点的权值为两个节点权值的和。
重复这个过程,直到所有的节点都被合并为一个根节点。
2.对哈夫曼树进行编码。
从根节点到每个叶节点的路径代表一个字符的编码,其中左子节点的边表示 0,右子节点的边表示 1。
例如,如果某个字符的叶节点位于路径“001”,那么该字符的编码就是“001”。
三、哈夫曼树的应用实例哈夫曼树在数据压缩和编码领域有着广泛的应用,以下是一个简单的实例:假设有如下一段原始数据:“aaabbbccc”,对应的哈夫曼树如下:```10/a c/ /a b b c```根据哈夫曼树,我们可以得到该数据集的哈夫曼编码为:“101 102 103 11 10”。
其中,“101”代表字符“a”,“102”代表字符“b”,“103”代表字符“c”。
哈夫曼树

哈夫曼树及其应用路径长度树中一个结点到另一个结点之间的路径由这两个结点之间的分枝构成,路径上的分枝数目称为它的路径长度。
由树的定义可知,从根结点到达树的每个结点有且仅有一条路径。
我们曾规定树的根的层数为1,如果树中某个结点的层数为k ,则从树的根到该结点的路径长度为(k-1)。
例如,在图1(a )中,从根A 到结点B 、C 、D 、E 、F 、G 、H 的路径长度分别为1、1、2、2、3、3、4。
树的路径长度是从树的根结点到树的各个结点的路径长度之和,记作PL 。
例如,图1所示的3棵二叉树的路径长度分别为:PL(a) = 0+1+1+2+2+3+3+4 = 6 PL(b) = 0+1+1+2+2+2+2+3 = 13 PL(c) = 0+1+1+2+2+2+2+3 = 13由于二叉树中第k 层的结点最多为2k-1个,而树的根到第k 层的结点的路径长度为k-1,换句话说,二叉树中路径长度为k-1的这样的结点最多有2k-1个。
显然,在n 个结点的各二叉树中,完全二叉树具有最小的路径长度。
例如,图1(b )所示为完全二叉树,其路径长度是13。
但具有最小路径长度的不一定是完全二叉树。
例如,图1(c )所示为非完全二叉树,它也具有最小路径长度。
一般来说,若深度为k 的n 个结点的二叉树具有最小路径长度,那么从根结点到第k-1层具有最多的结点数2k-1-1,余下的n-2k-1+1个结点在第k 层的任一位置上。
哈夫曼树首先我们考虑带权的二叉树。
假如给定一个有n 个权值的集合{w 1,w 2,…,w n },其中wi ≥0(1≤i ≤n )。
若T 是一棵有n 个叶子的二叉树,而且将权w 1,w 2,…,w n 分别赋给T 的n 个叶子,那么我们称T 是权w 1,w 2,…,w n 的二叉树。
叶子的带权路径长度为T 的根到该叶子之间的路径长度与该叶子中权的乘积。
n 个叶子的二叉树的带权路径长度定义为:∑==ni i i l w WPL 1其中:w i 为叶子i 的权,l i 为根结点到叶子i 之间的路径长度。
数据结构实验三题目二_哈夫曼树

2008级数据结构实验报告实验名称:实验三树学生姓名:班级:班内序号:学号:日期: 20013年11月26日1.实验要求实验目的通过选择下面两个题目之一进行实现,掌握如下内容:掌握二叉树基本操作的实现方法了解赫夫曼树的思想和相关概念学习使用二叉树解决实际问题的能力实验内容利用二叉树结构实现赫夫曼编/解码器。
基本要求:1.初始化(Init):能够对输入的任意长度的字符串s进行统计,统计每个字符的频度,并建立赫夫曼树2.建立编码表(CreateTable):利用已经建好的赫夫曼树进行编码,并将每个字符的编码输出。
3.编码(Encoding):根据编码表对输入的字符串进行编码,并将编码后的字符串输出。
4.译码(Decoding):利用已经建好的赫夫曼树对编码后的字符串进行译码,并输出译码结果。
5.打印(Print):以直观的方式打印赫夫曼树(选作)6.计算输入的字符串编码前和编码后的长度,并进行分析,讨论赫夫曼编码的压缩效果。
2. 程序分析哈夫曼树结点的储存结构除了二叉树所有的双亲域parents,左子树域lchild,右子树域rchild。
还需要有字符域word,权重域weight,编码域code。
其中由于编码是一串由0和1组成的字符串,所以code是一个字符数组。
进行哈夫曼编码首先要对用户输入的信息进行统计,将每个字符作为哈夫曼树的叶子结点。
统计每个字符出现的次数(频度)作为叶子的权重,统计次数可以根据每个字符不同的ASCII 码。
并根据叶子结点的权重建立一个哈夫曼树。
建立每个叶子的编码从根结点开始,规定通往左子树路径记为0,通往右子树路径记为 1.由于编码要求从根结点开始,所以需要前序遍历哈夫曼树,故编码过程是以前序遍历二叉树为基础的。
同时注意递归函数中能否直接对结点的编码域进行操作。
编码信息只要遍历字符串中每个字符,从哈夫曼树中找到相应的叶子结点,取得相应的编码。
最后再将所有找到的编码连接起来即可。
哈夫曼树学习资料

哈夫曼树1、(哈夫曼(Huffman)树又称最优二叉树或最优搜索树,是一类带权路径长度最短的树。
)★什么是哈夫曼树?为了说明清楚,我们先举一个具体的实例。
★例:将学生的百分制成绩表转换为五分制成绩,大于或等于90分者表为"A",80~90分为"B",70~79分为"C",60~69为"D",小于60分为"E"。
★转换过程的程序用分支结构是很容易实现的。
如果每次的输入量很大,则应考虑程序的操作时间。
判定过程如下图所示(一种分支结构)★如按此过程判断,则5%的数据需1次比较,15%的数据需2次比较,40%的数据需3次比较,40%的数据需4次比较,因此10000个数据比较的次数为10000(5%+2×15%+3×40%+4×40%)=31500次★也即按如上图所示的分支结构与程序段,则10 000个数据需执行判断31500次。
如果换一种分支结构,如下图所示,则需比较的次数应为10000(3×20%+2×80%)=22000次,很明显,两种判断方法的效率是不一样的。
那么能不能找到一种效率最高的判定方法呢?哈夫曼树就是一种最优的搜索方法。
另一种分支结构★为了引入哈夫曼树,先介绍二叉树路径长度的概念。
★树中一个结点到另一个结点之间的路径长度是这两个结点之间的分支所构成的路径上的分支数。
★由树的定义可知,从根结点到达树的每个结点有且仅有一种路径。
我们规定根的层数为1,如果树中某个结点的层次为k,则从根到该点的路径长度为(k-1)。
★如下图为三棵二叉树,其中图(a)所示的二叉树中,从根A到B,C,D,E,F,G,H,I的路径长度分别为1,1,2,2,3,3,4,4。
三棵二叉树★树的路径长度是从树的根结点到树的各个结点的路径长度之和,记作TL,例如上图所示的三棵二叉树的路径长度分别为:TL(a)=0+1+1+2+2+3+3+4+4=20TL(b)=0+1+1+2+2+2+2+3+3=16TL(c)=0+1+1+2+2+2+2+3+3=16★若将上述概念推广到一般情况,考虑带权的结点,则某结点的带权路径长度是指该结点的路径长度与该结点上权的乘积,二叉树的带权路径长度是指所有带权叶子结点的带权路径长度之和。
哈夫曼树

说明:对于给定的字符集,可能存在多种编码方案,但应 选择最优的。
Slide. 3.7 - 22
3.字符集的平均编码长度 设文件的字符集由 n 个不同字符构成C={c1,c2,,…cn},每个字符 cj的频度(出现比率)为fj,码长为lj ,则∑fj · lj表示编码后的文 件总长。 通过对定义在相同字符集上的大量文件进行统计分析,得出每 个字符cj 的概率(出现比率)pj,此时的∑pj · lj表示平均码长。 把使得∑fj · lj或∑pj · lj最小的前缀编码称为最优的前缀码。 字符 a b 概率 0.45 0.13 等长 000 001 变长 0 101 c 0.12 010 100 d e f 平均 0.16 0.09 0.05 码长 011 100 101 3 = log2|C| 111 1101 1100 2.24 =∑pj · lj
Slide. 3.7 - 5
3. 扩充二叉树的加权路径长 叶结点的加权路径长: 设每个叶结点 j 对应一个实数w j (称为叶结点的权值), l j 是从根到叶结点 j 的路长,则 wj · l j个称为叶结点 j 的加权路长。 扩充二叉树的加权路长: WPL = ∑wj · l j称为扩充二叉树的加权路长。
1
2
double weight ; /* 权值 */
int lchild ; /* 左孩子链 */ int rchild ; /* 右孩子链 */
int parent; /* 双亲链 */
}HTNODE ,*HuffmanTree;
m=(2n-1)-1 HuffmanT HT;
HT=(HuffmanTree)malloc((m+1)*sizeo f(HTNODE));//0号单元未用 /* huffman树的三叉链表表示 */
哈夫曼树例题

在给定权值为w 1 ,w 2…w n的n 个叶结点所构成的所有扩充二元树中,WPL = ∑wj ·l j最小的称为huffman树哈夫曼树的构造算法:1 由给定的n 个权值{w0, w1, w2, …, wn-1},构造具有n 棵扩充二元树的森林F = { T0, T1, T2, …, Tn-1 },其中每棵扩充二叉树Ti 只有一个带权值wi 的根结点, 其左、右子树均为空。
2重复以下步骤, 直到F 中仅剩下一棵二元树为止:①在F 中选取两棵根结点的权值最小的扩充二元树, 做为左、右子树构造一棵新的二元树,且置新的二元树的根结点的权值为其左、右子树上根结点的权值之和。
②在F 中删去这两棵二元树。
③把新的二元树加入F。
*/#include<stdio.h>#define n 5#define m 2*n-1typedef struct {double weight;int lchild;int rchild;int parent;}HTNODE;/*静态三叉链表表示,又是游标表示即使用整型变量标记/指向节点*/typedef HTNODE HuffmanT[m];/*初始值,依据教材的例子,存放相应数据P116*/void InitHT(HuffmanT T){/*每个节点就是一个树,因此是森林F,共有n棵二叉树*/T[0].weight = 0.12;T[0].parent=-1;T[0].lchild=-1;T[0].rchild=-1;/*书中代码从1开始,不良习惯!*/T[1].weight = 0.40;T[1].parent=-1;T[1].lchild=-1;T[1].rchild=-1;T[2].weight = 0.15;T[2].parent=-1;T[2].lchild=-1;T[2].rchild=-1;T[3].weight = 0.08;T[3].parent=-1;T[3].lchild=-1;T[3].rchild=-1;T[4].weight = 0.25;T[4].parent=-1;T[4].lchild=-1;T[4].rchild=-1;/*可以只存放前5个节点,后面的是为了与结果比较*/T[5].weight = 0;T[5].parent=-1;T[5].lchild=-1;T[5].rchild=-1;T[6].weight = 0;T[6].parent=-1;T[6].lchild=-1;T[6].rchild=-1;T[7].weight = 0;T[7].parent=-1;T[7].lchild=-1;T[7].rchild=-1;T[8].weight = 0;T[8].parent=-1;T[8].lchild=-1;T[8].rchild=-1;/*打印HuffmanT[m]数组元素,每个元素是一个哈夫曼树的结构体*/void PrintHT(HuffmanT T){int i;for(i=0;i<m;i++)if(T[i].weight!=0)printf("%d weight %3.2f parent %d lchild %d rchild %d\n",i, T[i].weight, T[i].parent,T[i].lchild,T[i].rchild);}/*选取两个最小的权值节点,注意指针变量p1,p2的使用:比较自然*/void SelectMin(HuffmanT T, int nn, int* p1, int* p2){int i,j,temp;for(i=0;i<=nn;i++)/*找到第一个没有合并的节点,取其位置i为*p1的初始值*/if(T[i].parent == -1){*p1=i;break;}for(j=i+1;j<=nn;j++)/*找到在i的后面,第二个没有合并的节点,取其位置j 为*p2的初始值*/if(T[j].parent==-1){*p2=j;break;}for(i=0;i<=nn;i++)/*将位置*p1的权值依次与所有节点比较大小,得到最小的*/if((T[*p1].weight >T[i].weight)/*取较小的*/&&(T[i].parent==-1)/*没有合并或者合并后双亲指针为空的节点*/&&(*p2!=i))/*? 与p2不同,取最小的两个节点! 正是因此,导致左右孩子错误?*/*p1=i;for(j=0;j<=nn;j++)/*同上*/if((T[*p2].weight>T[j].weight)&&(T[j].parent==-1)&&(*p1!=j))*p2=j;/*书中没有此判断代码!确保左子树的权值小于右子树*/if(T[*p1].weight>T[*p2].weight){temp = *p1;*p1=*p2;*p2=temp;}}/*第四版的教材,国家级精品课程还是这样,可怜中国IT,更可悲中国GIS!*/ void CreateHT(HuffmanT T){int i,p1,p2;InitHT(T);/*初始化*/PrintHT(T);/*打印初始化后情况*/for(i=n;i<m;i++){SelectMin(T,i-1,&p1,&p2);/*选择两个最小权值,i-1 所以SelectMin函数内部循环取等*/T[p1].parent = T[p2].parent = i+1;/*新节点的双亲指针,从n+1开始存放,与P118终态一致*/T[i].lchild = p1+1;/*新节点的左孩子指针*/T[i].rchild = p2+1;/*新节点的右孩子指针*/T[i].parent = -1;/*新节点的双亲指针,可省*/T[i].weight = T[p1].weight + T[p2].weight;/*新节点的权值*/printf("===================%d===================\n",i);PrintHT(T);/*打印每次合并的情况*/}}int main(void){HuffmanT T;printf("Huffman Tree initlization status\n");CreateHT(T);printf("Huffman Tree result status\n");PrintHT(T);//getch();return 0;}。
数据结构课堂练习2_data(答案).

课堂练习(2)
(答案)
选择题:二叉排序树?堆?哈夫曼树?
30 15 25
10 52 23
74 63 4 6 7
15 8
12
18
3 26
4
2 2
12 36 27 40 31 98
二叉排序树
65
哈夫曼树
堆
81 73 55 49 56
选择题
1.对二叉搜索树进行中序遍历,得到的结点序列是 A.按关键字递增有序 B.按关键字递减有序 C.无序序列 D.有时有序,有时无序 2.堆是满足一定条件的 A.栈 C.队列 。 B.线性表 D.完全二叉树 最小的二 。
解答题
8.关键字序列{92,37,86,32,12,57,25},利用堆排 序法建立小根堆,画出: (1) 建立的初始堆 (2) 输出第一个最小关键字后重建的堆。 解:(1) 建立的初始堆 (2) 输出第一个最小关键字后重建的堆
12 25 32 25
32
57
92
37
57
86
92
37
86
编程题
1. 设二叉排序树中的各结点值(data)互不相同,用递归算法编写一个按从大 到小次序打印输出二叉排序树中各结点值的函数。 设函数原型为:void PrintBST(BTreeNode *BT) 结点结构定义如下: typedef struct node { ElemType data; struct node *left; struct node *right; }BTreeNode;
void x_PrintBST(BTreeNode *BT, ElemType x) { if(BT!=NULL){ PrintBST (BT->left); if(BT->data>=x) cout<<BT->data<<" "; PrintBST (BT->right); } }
北邮数据结构实验三题目2哈夫曼树

北京邮电大学信息与通信工程学院
{ while (*s!='\0') { int parent=m-1;//根结点 while(HTree[parent].LChild!=-1)//从根节点开始直到终端结点结束循环 { if (*s=='0') parent=HTree[parent].LChild; else parent=HTree[parent].RChild;
第 4页
北京邮电大学信息与通信工程学院
k++; l=1; HTree[k].c=ctemp; HTree[k].weight=l; } } delete []temp;//释放动态内存空间 Creat();//创建哈夫曼数的数组 CodeTable();//创建哈夫曼编码表 } 时间复杂度:n
2 创建哈夫曼树动态数组 算法步骤: ①根据权重数组初始化哈夫曼树; ②选取权值最小的两个结点作为左右子树,构成一个新的二叉树,其根结点的权值取 左右子树权值之和; ③删除这两棵子树,将新构成的树加入到 T 中,重复②③直至 T 中只含有一棵树。
*d+=HcodeTable[i].code[j]; sum+=1; }
s++; n++; break; } } } cout<<"压缩比为:"<<sum/(8*n)<<endl; } 时间复杂度:n
7 解码函数 算法步骤: ①从根节点开始进行解码,如果字符为 0,则为左孩子,1,则为右孩子; ②编码匹配编码表中对应的数据,进行解码。 源代码: void Huffman::Decode(char *s,char *d)
第 1页
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
F1= A 7
B2
C4
D5
E9
F2= A 7
6
B2
C4
B2
C4
D5
E9
11
6
F3= A 7
6 D D5 5
E9
B2
C4
B2
C4
接上页:
F4=
16
A
7A
7 E
9
B2
11 E9
6 D5
C4
F5=
27
16
11
A 7 E169
6 11 D 5
A
EB 2 6 CD 45
7
9
2B C4
根的权值为27
WPL=7*2+2*3+4*3+5*2+9*2=60
2. 掌握二叉树的ADT定义,特点,结点的形态,性质,存 储结构(二叉链表) 掌握二叉树的遍历,线索的方法 掌握遍历算法的应用 掌握二叉树与树和森林的转换 掌握Huffman树概念,构造和编码
3. Huffman编码
(1) 等长编码 A B C D
00 01 10 11 两位一分进行译码
(2) 不等长编码:出现多的字符采用短码,总长短了!
但出现二义性! A B C D
0 00 1 11
(3) 前缀编码:一个字符的编码都不是另一个字符的编
码的前缀.
用二叉树实现: 左分支0;右分支1
0
1
C
96
WPL=0.23*2+0.11*3+……
42
54
23
19 29
29
11
8
14
15
5
3
7
8
Huffman编码
0.05: 0110
0.29: 10
0.07: 1110
0.08: 1111
0.14: 110
0.23: 00
0.03: 0111
0.11: 010
作业:
本章小结
1. 掌握树的定义,表示形式和术语(二叉树通用) 掌握树的存储结构(孩子-兄弟表示) 掌握树与二叉树的转换 了解树的ADT定义与树和森林遍历
量某螺钉直d-径σ,方d法与标d+准σ的比较,判定树? 概率
5% 10% 50% 25% 10%
最大的
最靠近
>d
根判断
=d
>d+ σ
> d- σ
50%
25%
10%
5%
10% WPL=5%*3+10%*3+50%*2+25%*2+10%*2=?
2. Huffman树的构造(自底向上) W={7,2,4,5,9}
W={7,2,4,5,9}
B2
A
E
7
9
2B
D5 C4
C4
D5
7A
E9
WPL1=∑wklk =7*2+5*2+2*3 +4*3+9*2 =60
WPL2=∑wklk =7*4+9*4+5*3 +4*2+2*1 =89
在解决某些判定问题时,利用Huffman树可得
到最佳判定算法
例如,某厂生产螺钉,要求直径为d,误差σ.现测
两个结论:
(1) 在Huffman树中没有度为1的结点.
(2) 一棵有n个叶子结点的Huffman树共有2n-1个 结点.证明设?总结点数为m个,叶子n个,度为1的n1个,度
为2的n2个
m=n+n1+n2 由性质3 n=n2+1 所以 n2=n-1 m=n+n1+n2 =n+n1+n-1 =2n+n1-1 有(1)得 n1=0 所以 m=2n+0-1=2n-1
Huffman 树形态不 唯一!
构造过程(Huffman算法) (1) n个权值构成n棵独立二叉树的森林F={T1,…Tn} (2)在森林中选出两棵根权值最小的二叉树作为 左右子树,构造二叉树,根权值为左右子树的和 (3) 在F中删除这两棵,新构成的添加到F中 (4)重复(2)和(3),直到F中含一棵二叉树为止.
Байду номын сангаас
0
1
A
B
A: 00 B: 01 C: 1
(4) Huffman编码:设计Huffman树而得到的编码.
例如:有8种字符,概率如下: 设计Huffman编码 {0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11}
解:同时扩大100倍,得权值集合: {5,29,7,8,14,23,3,11}
6.6 Huffman树
• 基本概念 • 构造 • 编码
1. 基本概念
• 路径:从一个结点到另一个结点之间的分支. • 路径长度:路径上分支数目. • 结点的路径长度:从根结点到该结点的路径长度. • 树的路径长度:树中每个结点的路径长度之和.
完全二叉树这种长度最短的二叉树. • 结点的带权路径长度:该结点的路径长度*结点的权值 • 树的带权路径长度:树中所有叶子结点的带权路径长度 之和.记作:WPL=∑wklk 例如 • 最优二叉树:在所有含n个叶子结点、并带相同权值