对应分析实验报告
对应分析实验报告

对应分析实验报告1. 引言本文旨在对进行的对应分析实验进行报告。
对应分析是一种统计方法,用于比较两个相关变量之间的关系。
本实验旨在探索两个相关变量之间的关联性,并分析其潜在的关联机制。
2. 实验设计与数据收集本实验采用了随机抽样的方法,从一个大型数据集中选择了一部分样本。
每个样本包含了两个相关变量的取值。
数据收集过程中,我们严格遵守了隐私保护原则,并且对数据进行了匿名化处理,以确保数据的安全性。
3. 数据预处理在进行对应分析之前,我们需要对数据进行预处理,以确保数据的准确性和一致性。
首先,我们对异常值进行了识别并进行了处理。
其次,对缺失值进行了填充,采用了合适的方法来保证填充后的数据与原始数据的分布一致。
4. 对应分析方法对应分析是一种多元统计方法,用于比较两个相关变量之间的关系。
它可以将两个变量的取值映射到一个低维空间中,并通过计算它们在该空间中的距离来评估它们之间的关联性。
在本实验中,我们采用了主成分分析法进行对应分析。
5. 实验结果与分析经过对应分析,我们得到了以下结果:在低维空间中,两个变量的取值分布呈现出一定的相关性。
通过对主成分的解释,我们可以推断出两个变量之间可能存在一种隐藏的关联机制。
进一步的分析表明,这种关联可能与其他变量的存在有关。
6. 结果验证与讨论为了验证对应分析结果的准确性,我们进行了交叉验证和灵敏度分析。
结果表明,对应分析的结果具有较高的稳定性和可靠性。
然而,对于关联机制的解释仍然存在一定的不确定性。
进一步的研究和实验是必要的,以揭示更深层次的关联机制。
7. 结论与展望通过本次对应分析实验,我们得到了两个相关变量之间的一些关联性信息,并对其背后的关联机制提出了一些假设。
在未来的研究中,我们将进一步探索这些假设,并采取更多的实验和统计方法来验证和解释这些关联性。
我们相信,通过不断地研究和探索,我们可以更好地了解和应用对应分析方法。
对应分析实验报告

对应分析实验报告《对应分析实验报告》摘要:本实验旨在通过对应分析的方法,探究不同变量之间的关系。
通过对实验数据的收集和分析,我们发现了变量之间的相关性,并得出了一些结论。
本文将详细介绍实验的方法、结果和结论,以及对实验过程中遇到的问题和可能的改进方案进行讨论。
引言:对应分析是一种多变量数据分析的方法,通过对数据的降维和可视化,可以帮助我们更好地理解变量之间的关系。
在本次实验中,我们选择了一组实际数据进行对应分析,希望能够揭示出其中隐藏的规律和结构。
方法:我们首先收集了一组包含多个变量的数据,然后使用对应分析的方法对数据进行处理。
具体的方法包括了数据的标准化、对应分析模型的建立和结果的解释。
我们使用了一些统计软件来进行数据处理和分析,以确保结果的准确性和可靠性。
结果:通过对应分析,我们得到了一些有意义的结果。
我们发现了一些变量之间的相关性,以及它们在对应平面上的分布情况。
通过对结果的解释,我们可以更好地理解变量之间的关系,以及它们在整体数据结构中的位置和作用。
讨论:在实验过程中,我们也遇到了一些问题和挑战。
例如,在数据收集和处理过程中可能存在一些误差,以及对对应分析模型的参数选择和解释可能存在一些困难。
针对这些问题,我们提出了一些可能的改进方案,以及对未来研究的展望。
结论:通过对应分析实验,我们得出了一些有意义的结论,并对变量之间的关系有了更深入的理解。
我们相信对应分析的方法可以在更多的领域和实际问题中得到应用,并帮助我们更好地理解数据和变量之间的关系。
同时,我们也意识到在实验过程中存在一些问题和挑战,需要进一步的研究和改进。
对应分析

实验七对应分析一、实验目的1、了解对应分析的原理,巩固课堂所学的理论知识;2、会用SPSS操作,完成对应分析。
二、实验要求1.利用购买商品房的客户背景资料和房屋购买情况的数据(对应分析(买房).sav),分析不同客户对互相购买的偏好.2.某生产纯水的企业为其产品命名,决定对选定的备选名称方案进行品牌测试,采用问卷调查的方式对消费者进行名称联想调查,以便最终确定产品品牌名称。
调查数据表如下是通过对应分析说明选定的品牌在消费者的心目中是否达到了预期效果。
三、实验内容问题1实验步骤:1、打开数据集,点“分析”——“降维”——“对应分析”2、将x5键入到行,点击“定义范围”,设置最小值为1,最大值为6,点击“更新”,再点击“继续将x10键入到列,点击“定义范围”,设置最小值为1,最大值为11,点击“更新”,再点击“继续”3、点击“模型”,看到解的维数默认为2,即公共因子数为2,距离度量中卡方是检验收入和户型之间是否相关,原假设为不相关(注:这里一般拒绝原假设,否则没有必要做对应分析)4、点“继续”,点击“统计量”5、点击“继续”,点击“绘制”,“双标图”必选,“行点”“列点”可选可不选6、点击“确定”,得输出结果,以及对实验结果的分析:从对应表中,我们可以看到,调查的对象有一共719个,而家庭年收入在10000~25000元的家庭购买房屋的有355人,在719个对象中,购买两室一厅、三室一厅、三室两厅的居多,这就可以给房屋工商提供初步的判断:两室一厅、三室一厅、三室两厅的销售市场要比其他的大,可以作多一些的投资。
我们可以了解到惯量就是特征值,奇异值是惯量的特征值,而通过摘要,我们可以看到第一个维度的方差贡献率为0.658,前两个维度的方差贡献率为0.804>0.80,信息量损失很小。
概述行点中可以的懂得信息:维中的得分就是载荷系数,则可以知道对应分析的模型:点对维惯量中的数据表述各个指标对公因子的影响度,如:0.045指5000元以下的指标对公因子的影响度,0.476指5000元以下的指标对公因子的影响度。
分析父亲受教育程度和本人受教育程度的关系
学生实验报告学生实验报告(经管类专业用)一、实验目的及要求:1、目的用SPSS软件对所给数据进行对应分析,分别分析父亲受教育程度和孩子受教育程度的关系;母亲受教育程度和孩子受教育程度的关系及父亲受教育程度与母亲受教育程度之间的关系。
2、内容及要求用SPSS软件对所给数据进行对应分析,分别分析父亲受教育程度和孩子受教育程度的关系;母亲受教育程度和孩子受教育程度的关系及父亲受教育程度与母亲受教育程度之间的关系。
二、仪器用具:三、实验方法与步骤:打开GSS93 subset.sav。
四、实验结果与数据处理:一、本人受教育程度和父亲受教育程度的对应分析操作步骤如下:分析父亲受教育程度和本人受教育程度的关系;母亲受教育程度和本人受教育程度之间的关系以及父亲、母亲受教育程度之间的关系一,父亲受教育程度和本有受教育程度的关系对所给SPSS数据中变量padeg与变量degree进行对应分析,依次点选“分析”,“降维”,“对应分析…”进入“对应分析”对话框。
数据集中所有的变量标签均已出现在左边的窗口中,将degree变量选入右侧行变量的小窗口中,此时窗口显示的degree变量形如:degree(??),同时,其下方的定义范围按钮被激活,点击该按钮,进入“行变量的分类全距”对话框,在该对话框中需要确定Degreeyo变量的取值范围,在最小值与最大值处分别填上0和9,按右侧的更新按钮,可以看到degree的取值0~9已出现在“类别约束”框架左侧的窗口中,该框架的作用是对degree的各状态加以限定条件,保持默认值“无”,即对degree的取值不加以限定条件。
点击“继续”按钮,回到“对应分析”对话框,可以看到此时行变量degree 的显示变为degree(0 9).按照同样的方法,把padeg选为列变量敲定其取值范围为0~9,点击OK按键运行,则可以得出输出结果如下五部分。
Active Margin 193 632 75 206 99 1205其中,输出的第一部分Correspondence Table 表是由原始数据按Degree 与Race 分类的列联表,可以看到观测总数n=1499而不是原始数据观测个数1500,这是因为原始数据中有1条记录有缺失。
spss对应分析实验报告

SPSS对应分析实验报告1. 引言本实验旨在使用SPSS软件对一组数据进行对应分析,以探究不同变量之间的相关性。
对应分析是一种多元统计方法,用于研究两个变量之间的关系,可以帮助我们理解变量之间的相互作用和相关程度。
2. 数据收集与处理在本实验中,我们收集了一组包含两个变量的数据。
变量A表示一个人的年龄,变量B表示他们的学习成绩。
我们通过调查问卷的形式收集了这些数据,并将其导入SPSS软件进行后续的分析。
3. 数据分析步骤1:导入数据首先,我们需要将收集到的数据导入SPSS软件。
在SPSS的菜单栏中选择“文件”->“导入数据”,选择正确的数据文件并进行导入。
步骤2:变量选择在数据导入后,我们需要选择我们要分析的变量。
在SPSS的变量视图中,选择变量A和变量B,并将它们移到分析视图中。
步骤3:描述性统计在开始对应分析之前,我们可以先对数据进行描述性统计。
在SPSS的菜单栏中选择“分析”->“描述统计”->“描述性统计”。
选择变量A和变量B,并点击“确定”按钮,SPSS将生成包含均值、标准差等统计指标的报告。
步骤4:对应分析接下来,我们可以进行对应分析。
在SPSS的菜单栏中选择“分析”->“相关”->“对应分析”。
选择变量A和变量B,并点击“确定”按钮,SPSS将生成对应分析的结果报告。
步骤5:结果解释对应分析的结果报告中,我们能够看到变量A和变量B之间的相关系数,以及相关系数的显著性水平。
通过这些信息,我们可以判断变量A和变量B之间的关系是否显著,以及相关性的方向和强度。
4. 结论通过对应分析实验,我们得出以下结论:1.变量A和变量B之间存在显著的相关性。
2.相关系数为正数,表明变量A的增加与变量B的增加呈正相关关系。
3.相关系数的数值较高,说明变量A和变量B之间的相关性较强。
这些结论对我们理解变量A和变量B之间的关系,以及对进一步研究和分析具有重要意义。
5. 结束语SPSS是一款功能强大的统计软件,可以帮助我们进行各种数据分析。
对应分析

实验五对应分析姓名:***学号:*********班级:11级统计2班对应分析一实验目的:(1)掌握对应分析方法在spss软件中的实现。
(2) 熟悉对应分析的用途及操作方法。
二准备知识:对应分析(Correspondence analysis)也称关联分析、R-Q型因子分析,是近年新发展起来的一种多元相依变量统计分析技术,通过分析由定性变量构成的交互汇总表来揭示变量间的联系。
可以揭示同一变量的各个类别之间的差异,以及不同变量各个类别之间的对应关系。
是能把众多的样品和众多的变量同时作到同一张图解上,将样品的大类及其属性在图上直观而又明了地表示出来,具有直观性。
另外,它还省去了因子选择和因子轴旋转等复杂的数学运算及中间过程,可以从因子载荷图上对样品进行直观的分类,而且能够指示分类的主要参数(主因子)以及分类的依据,是一种直观、简单、方便的多元统计方法。
三实验思想:是将一个联列表的行和列中各元素的比例结构以点的形式在较低维的空间中表示出来。
首先编制两变量的交叉列联表,将交叉列联表中的每个数据单元看成两变量在相应类别上的对应点;然后,对应分析将变量及变量之间的联系同时反映在一张二维或三维的散点图;最后,通过观察对应分布图就能直接地把握变量之间的类别联系。
四实验内容:五实验步骤:(1)数据录入。
打开SPSS数据编辑器,建立“对应分析.sav”文件。
在变量视窗中录入3个变量,用A表示“地区”,用B表示“死因”,用C表示“频数”,对A 变量和B变量输入对应的标签和值,C变量输入对应的标签。
然后在数据视图中将数据对应录入。
(2)进行对应分析。
依次点击“Data→Weight Cases →”再将“频数”导入“频率变量”,依次点击“analyze-data reduction→correspondence→将地区导入行→定义全距→最小值为1,最大值为12。
将死因导入列→定义全距→最小值为1,最大值为10,。
点击更新→点击继续”。
对应分析实验

对应分析实验原理:,是A 的非零特征根。
为相应的特征向量,则有(1)A与B的所有非零特征根相等;(2)B 的非零特征根所对应的特征向量为。
实验目的:(1)掌握对应分析的方法;(2)能够运用对应分析的算法解决实际问题。
实验题目:研究妇女年龄与对惩治腐败看法的对应关系。
按年龄分为4组,对惩(1)单击Analyze Data Reduction中Correspondence Analysis命令,进入对应分析主对话框设置。
(2)设置行变量、列变量并定义其值域。
然后单击Options进入统计量的选择的对话框,选择Profiles(边缘概率)、Joint(组合图)和默认的参数。
(3)单击Continue和OK按钮,产生统计结果。
实验结果分析:(1)维度选择:从表二可看到,第1组重要性占73.8%,第2组重要性占25.2%,第3组以后只占10%,第1组最重要,第2组次之,所以选择两个维度即可。
(2)行分(Row Score):从表三可看到,行分中,36至45岁一组的比分占0.469,将近一半。
(3)行点(Row Point):对每一维惯量的贡献,维1主要有26至35岁以及46至55岁一组共同解释。
维2主要由25岁以下一组以及46至55岁一组共同解释,说明46至55岁一组“感情不专”与两维都沾边。
(4)列分(Colume Score):列分中,信心不大一组比分占0.356%,其次有信心一组的比分占0.2%。
(5)列点(Colume Point):对每一维量的贡献,维1主要由信心不大一组以及不说清楚一组共同解释。
维2主要由有信心一组以及说不清楚一组共同解释,说明“说不清楚”一组“感情不专”,也与两维都沾边、(6)解法:综合上面5点,维1与“26至35岁”+“信心不大”有关。
根据这个特点,画出图形“26至35岁”对应“信心不大”的图点应聚集在维1的轴末端(见表五),表明“26至35岁”的妇女同胞绝大多数人对当前惩治腐败的信心不大。
对应分析实验报告

对应分析实验报告对应分析实验报告一、引言对应分析实验是一种常见的统计分析方法,用于研究两个变量之间的关系。
它可以帮助我们了解变量之间的相关性,并揭示出隐藏的规律和趋势。
本实验报告旨在通过对应分析实验,探讨变量之间的关系,并提出相应的结论。
二、实验设计与方法本次实验选择了两个变量进行对应分析,分别是A变量和B变量。
首先,我们收集了相关数据,并进行了数据预处理,包括数据清洗、缺失值处理和异常值处理。
然后,我们使用对应分析方法对数据进行分析,并得出相应的结果。
最后,我们对结果进行解读和讨论。
三、实验结果通过对应分析,我们得到了以下结果:1. 对应分析图根据对应分析的结果,我们绘制了对应分析图。
图中展示了A变量和B变量在二维平面上的分布情况。
通过观察图形,我们可以初步判断出两个变量之间的相关性。
2. 相关系数我们计算了A变量和B变量之间的相关系数。
相关系数可以反映两个变量之间的线性关系程度。
根据计算结果,我们可以得出A变量和B变量之间存在一定的相关性。
3. 显著性检验为了验证A变量和B变量之间的相关性是否显著,我们进行了显著性检验。
通过计算p值,我们可以判断相关性的显著性水平。
根据显著性检验的结果,我们可以得出A变量和B变量之间的相关性是显著的。
四、讨论与结论基于实验结果,我们对A变量和B变量之间的关系进行了讨论和结论:1. 解释变量A变量可以作为解释变量,用来解释B变量的变化。
通过对应分析,我们可以得到A变量对B变量的解释程度。
这有助于我们理解B变量的变化规律,并找出影响B变量的重要因素。
2. 预测模型基于对应分析的结果,我们可以建立预测模型,用来预测B变量的取值。
通过该模型,我们可以根据A变量的取值,预测出B变量的可能取值范围。
这对于决策和规划具有重要意义。
3. 实验局限性本实验存在一定的局限性。
首先,我们只选择了A变量和B变量进行对应分析,可能存在其他未考虑的变量对结果的影响。
其次,数据的收集和处理也可能存在误差。
spss对应分析实验报告

SPSS对应分析实验报告1. 引言SPSS(Statistical Package for the Social Sciences)是一款统计分析软件,常用于社会科学领域的数据分析。
本实验报告旨在介绍使用SPSS进行对应分析实验的过程和结果。
2. 实验设计本实验使用了一份调查问卷作为数据收集工具,共有100名受试者参与。
问卷涵盖了受试者的个人信息和对某个产品的评价。
受试者的个人信息包括性别、年龄和教育程度等。
对产品的评价包括价格、质量和外观等几个方面。
3. 数据收集和预处理在实验开始前,我们首先设计了调查问卷,并通过在线平台分发给受试者。
收集到的数据以Excel表格的形式保存,并进行了一些预处理工作,包括数据清洗和缺失值处理等。
4. 数据分析方法在本次实验中,我们使用了SPSS软件进行对应分析。
对应分析是一种用于研究两个分类变量之间关系的方法。
在SPSS中,我们可以使用对应分析模块进行数据分析。
5. 结果分析经过对数据的分析,我们得到了以下结果:5.1 性别与产品评价的对应分析结果我们首先进行了性别与产品评价之间的对应分析。
结果显示,在性别维度上,男性对产品的价格评价较高,而女性对产品的外观评价较高。
这可能与受试者的性别特征和对产品的不同需求有关。
5.2 年龄与产品评价的对应分析结果其次,我们进行了年龄与产品评价之间的对应分析。
结果显示,在年龄维度上,年龄较大的受试者对产品的质量评价较高,而年龄较小的受试者对产品的价格评价较高。
这可能与不同年龄段受试者对产品的关注点有关。
5.3 教育程度与产品评价的对应分析结果最后,我们进行了教育程度与产品评价之间的对应分析。
结果显示,在教育程度维度上,受过高等教育的受试者对产品的外观评价较高,而受过低等教育的受试者对产品的价格评价较高。
这可能与受试者的教育背景和对产品的不同认知有关。
6. 结论和讨论通过对SPSS对应分析结果的分析,我们可以得出以下结论:1.性别、年龄和教育程度等个人特征对产品评价有一定影响。
多元统计分析——对应分析实验报告

多元统计分析实验报告表2-2 对应分析数据(老龄化数据)三、实验过程在spss16.0软件中,对表2-2数据做对应分析。
首先应对个案进行加权操作。
选择【Date】—【Weight Cases】,出现表3对话框。
选择frequency作为加权,如图3-1所示。
图3-1 加权个案对个案加权后,开始做对应分析。
选择【Analyze】—【Date Reduction】—【Corespondence Analysis】,会出现图3-2对话画框。
图3-2 对应分析对话框接下来对行变量和列变量进行设置。
将selfassess(自评健康状况)选入Row,作为行变量,并选择【Define Range】,填写范围后点击【Update】—【Continue】,如图3-3所示;按同样的步骤,将independence(生活自理能力)选入Column(列变量),并设置列变量,如图3-4所示;最终设置结果如图3-5所示。
图3-3 行变量设置图3-4 列变量设置图3-5 对应分析设置结果点击【OK】,便可得到对应分析结果。
四、实验过程表4-1为对应分析的版本信息。
图中显示为1.1版本。
表4-1 对应分析版本信息表4-2是列联表,列示了在各个水平下的人数。
表4-2 列联表表4-3为对应分析总述表。
表中显示了奇异值(Singular Value),第一个维度的奇异值为0.253,第二个维度的奇异值为0.125;惯量(Inertia)为特征根,就是奇异值的平方;Chi Square 值为212.593,是总样本数除以总的Inertia 觉原假设,认为两个随机变量不是相互独立的,本例中就是自评健康状况和生活自理能力不是相互独立的;贡献率(Accounted for)显示,第一个维度解释了总变异的80.4%,第二个维度解释了19.6%,两个维度解释了所有的变异;接下来依次为累计贡献率(Cumulative)、奇异值的方差(Standard Deviation)、奇异值的相关系数(Correlation)。
对应分析实验报告

对应分析实验报告一、引言对应分析是一种常用的数据分析方法,用于研究两个或多个变量之间的关系。
在这个实验中,我们将通过对一组数据进行对应分析来探究变量之间的关系和相关性。
二、实验设计1. 数据收集首先,我们需要收集一组相关的数据。
这些数据可以是任何类型的变量,例如销售额、用户数量、广告投入等。
确保数据的准确性和完整性对于得出可靠的结论非常重要。
2. 数据预处理在进行对应分析之前,我们需要对数据进行预处理。
这包括清洗数据、填补缺失值、处理异常值等。
确保数据的质量可以减少对应分析过程中的误差和偏差。
3. 对应分析对应分析的目标是找到两个或多个变量之间的相关性。
在这个实验中,我们将使用对应分析方法来确定变量之间的关系。
我们可以使用相关系数、散点图等方法来进行对应分析。
三、实验步骤以下是进行对应分析实验的步骤:步骤1:收集数据首先,我们需要收集一组相关的数据。
这些数据可以是任何类型的变量,例如销售额、用户数量、广告投入等。
确保数据的准确性和完整性非常重要。
步骤2:数据预处理在进行对应分析之前,我们需要对数据进行预处理。
这包括清洗数据、填补缺失值、处理异常值等。
确保数据的质量可以减少对应分析过程中的误差和偏差。
步骤3:对应分析对应分析的目标是找到两个或多个变量之间的相关性。
在这个实验中,我们将使用对应分析方法来确定变量之间的关系。
我们可以使用相关系数、散点图等方法来进行对应分析。
步骤4:结果解释根据对应分析的结果,我们可以得出结论并解释变量之间的关系。
我们可以使用数据可视化工具,如折线图、柱状图等来展示结果。
确保结果的解释准确清晰,便于读者理解。
四、实验结果根据对应分析的结果,我们得出以下结论:•变量A和变量B之间存在强相关性,相关系数为0.8。
•变量C和变量D之间存在负相关性,相关系数为-0.6。
五、讨论和结论在这个实验中,我们使用对应分析方法来研究变量之间的相关性。
通过对数据进行预处理和对应分析,我们得出了变量之间的相关性和相关系数。
对应分析实验报告
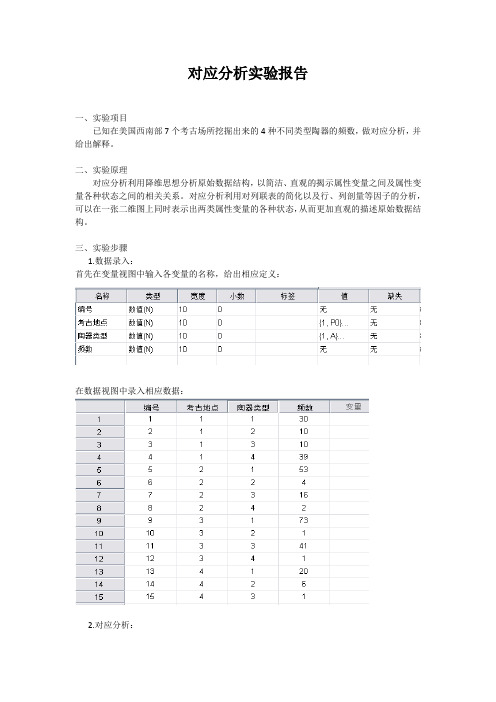
对应分析实验报告一、实验项目已知在美国西南部7个考古场所挖掘出来的4种不同类型陶器的频数,做对应分析,并给出解释。
二、实验原理对应分析利用降维思想分析原始数据结构,以简洁、直观的揭示属性变量之间及属性变量各种状态之间的相关关系。
对应分析利用对列联表的简化以及行、列剖量等因子的分析,可以在一张二维图上同时表示出两类属性变量的各种状态,从而更加直观的描述原始数据结构。
三、实验步骤1.数据录入:首先在变量视图中输入各变量的名称,给出相应定义:在数据视图中录入相应数据:2.对应分析:(1)表1:对应表表1为该实验的列联表,是对有关频数的描述以及统计,表示各因素的值都有效;(2)表2:摘要表摘要表给出了总惯量、卡方值及每一维度(公共因子)所解释的总惯量的百分比信息。
由表2 可知总惯量为0.523,卡方值为407.157,有关系式:407.157=0.523*778(存在误差),由此可以直观的看出总惯量与卡方值的关系,同时说明总惯量描述了对应表行与列之间的相关关系。
Sig反映了行与列各状态在二维图中分值得相关度,即对行与列进行因子分析产生的新的综合变量的典型相关系数,等于特征值的平方根。
表中Sig值小于0.05,则拒绝原假设,即行与列之间不独立,因此,可以进行对应分析;(3)表3:行点表4:列点表3、表4是对列联表行与列各状态有关信息的概括。
其中质量部分代表列联表中行与列的边缘概率;维中的得分是各维度的分值,即行与列各状态分量在二维图中的坐标值;惯量是每一行(列)与其重心得加权距离的平方;贡献部分是指行(列)的每一状态对每一维度(公共因子)特征根的贡献,贡献的数值越大,说明其相应状态,维度的贡献越大。
3.对应分析结果及分析:图1:双标图图1为对应分析的最终结果,即考古地点各状态与陶器类型各状态在同一张二维图上的投影。
加上相关参考先后,由各因子间距离长短可以看出,D种陶器在P0处产量最多,C 种陶器在P6处产量最多,A陶器在P1,P2,P3考古地点数量都相对较多,B陶器无显著特点。
实验报告对应分析(3篇)

第1篇一、实验目的通过本实验,探究不同浓度硫酸铜溶液对植物生长的影响,了解重金属离子对植物生长的抑制作用及其作用机理。
二、实验原理硫酸铜是一种重金属盐,对植物生长具有抑制作用。
本实验通过在不同浓度的硫酸铜溶液中培养植物,观察植物的生长状况,分析不同浓度硫酸铜溶液对植物生长的影响。
三、实验材料1. 植物材料:黄瓜种子、白菜种子2. 实验仪器:培养皿、电子秤、温度计、pH计、蒸馏水、硫酸铜溶液、镊子、剪刀等3. 实验试剂:硫酸铜、蒸馏水四、实验方法1. 将黄瓜种子和白菜种子分别播种于培养皿中,每皿50粒,置于恒温培养箱中培养,保持温度为25℃,光照时间为12小时/天。
2. 将硫酸铜溶液配制成0、0.1%、0.2%、0.4%、0.6%、0.8%、1.0%共7个浓度梯度。
3. 将培养好的幼苗随机分为7组,每组50株,分别用不同浓度的硫酸铜溶液处理,每处理3次重复。
4. 每天观察并记录植物的生长状况,包括株高、叶片数、叶片颜色等。
5. 实验结束后,将植物样品进行称重,计算生物量。
五、实验结果与分析1. 不同浓度硫酸铜溶液对黄瓜生长的影响(1)株高:随着硫酸铜浓度的增加,黄瓜株高逐渐降低。
在0.4%硫酸铜溶液处理下,黄瓜株高显著降低,与对照相比,降低了35%。
(2)叶片数:随着硫酸铜浓度的增加,黄瓜叶片数逐渐减少。
在0.6%硫酸铜溶液处理下,黄瓜叶片数显著减少,与对照相比,减少了25%。
(3)叶片颜色:随着硫酸铜浓度的增加,黄瓜叶片颜色逐渐变黄。
在1.0%硫酸铜溶液处理下,黄瓜叶片颜色明显变黄,与对照相比,变黄程度增加了60%。
(4)生物量:随着硫酸铜浓度的增加,黄瓜生物量逐渐降低。
在1.0%硫酸铜溶液处理下,黄瓜生物量显著降低,与对照相比,降低了50%。
2. 不同浓度硫酸铜溶液对白菜生长的影响(1)株高:随着硫酸铜浓度的增加,白菜株高逐渐降低。
在0.4%硫酸铜溶液处理下,白菜株高显著降低,与对照相比,降低了30%。
多元统计分析对应分析

多元统计分析对应分析————————————————————————————————作者:————————————————————————————————日期:学生实验报告学院:统计学院课程名称:多元统计分析专业班级:统计123班姓名: 叶常青学号: 0124253学生实验报告学生姓名叶常青学号同组人实验项目对应分析的上机操作□必修□选修□演示性实验□验证性实验□操作性实验□综合性实验实验地点实验仪器台号指导教师李燕辉实验日期及节次一、实验目的及要求:目的熟悉和掌握对应分析的原理和上机操作方法内容及要求本次操作就父母与孩子的受教育程度的关系进行对应分析,分别对父亲与孩子和母亲与孩子的受教育程度做对应分析,最后再对输出结果进行详细的分析。
二、仪器用具:仪器名称规格/型号数量备注计算机 1 有网络环境SPSS软件 1三、实验方法与步骤:打开GSS93 subset .sav数据,对变量Degree与变量padeg和madeg进行对应分析,依次选择分析→降维…进入对应分析对话框,进行进行如下设置,便可输出想要的数据的:四、实验结果与数据处理:按照上述方法和步骤得出以下输出结果.对父亲受教育程度与孩子受教育程度的关系进行分析如下:表1 对应表Father's Highest DegreeR's Highest DegreeLess than HSHigh schoolJuniorcollegeBachelorGraduate有效边际LT High School5 563High School27 24834 79 37425 Junior College 1 11 2 8 325 Bachelor 6 43 7 47 18 121 Graduate 3 22 3 2716 71有效边际193 632 75206 99 1205表2 摘要维数奇异值惯量卡方Sig. 惯量比例置信奇异值解释累积标准差相关21.400.160 .846 .846.025 .2562.164.027.142 .988.0263.047 .002.012 1.0004.006.000.000 1.000总计.189228.193.000a1.001.00a. 16 自由度,表3摘要维数奇异值惯量卡方Sig. 惯量比例置信奇异值解释累积标准差相关21 .400 .160.846 .846 .025 .2562.164.027 .142 .988 .0263 .047 .002 .012 1.0004 .006 .000 .000 1.000总计.189 228.193.000a1.000 1.000a. 16 自由度第二部分摘要给出了惯量,卡方值以及每一维度所解释的总惯量的百分比信息。
相应分析实验报告

实验报告系专业级班实验人:实验地点:实验日期:实验题目:相应分析实验目的:进行相应分析,揭示全国农民家庭人均纯收入的特征以及各省、直辖市、自治区与各收入指标间的关系实验内容:实验采用了2005年全国31个省、直辖市、自治区农民家庭人均纯收入的数据,按现行统计报表制度,采用了工资性收入、家庭经营性收入、财产收入、转移性收入四个指标进行相应分析。
实验步骤:1、在Excel中对数据进行整理,按“Alt+D”再按“P”,调出“数据透视表和数据透视图向导”界面,选择“多重合并计算数据区域”—下一步默认—下一步选定相关区域—下一步完成,操作过程及结果如图:2、将数据导入SPSS中,并对省份和收入类别进行值标签的定义,如图:3、选择“数据”—“加权个案”,调出“加权个案”主界面,选中“加权个案”,将“值”选入“频率变量”中,如图:4、选择“分析”—“降维”—“对应分析”,然后把“省份”选入“行”并定义范围为最小值为1和最大值为31,之后点击“更新”,再点击“继续”。
同理将“收入类别”选入“列”,定义范围最小值为1和最大值为4,如图:5、选择“模型”,选中“Euclidean”距离度量方法,如图实验结果:(1)摘要表格分析摘要维数奇异值惯量惯量比例置信奇异值解释累积标准差相关21 .630 .397 .986 .986 .001 -.2362 .066 .004 .011 .997 .0013 .037 .001 .003 1.000总计.403 1.000 1.000从表中可以看出,第一个维度惯量0.397,占总惯量的98.6%,第二个维度和第三个维度分别为0.004和0.001,分别占总惯量的1.1%和0.3%,前两个维度变量比例占了总比例的99.7%,因此选取两维来进行分析。
(2)综合分析概述行点a省份质量维中的得分惯量贡献1 2点对维惯量维对点惯量1 2 1 2 总计北京.032 -1.870 -.303 .072 .179 .045 .991 .003 .994 天津.032 -.373 .666 .004 .007 .215 .729 .245 .974 河北.032 .143 .164 .000 .001 .013 .863 .120 .983 山西.032 .024 .202 .000 .000 .020 .113 .872 .986 内蒙古.032 .682 -.254 .010 .024 .031 .984 .014 .999 辽宁.032 .252 -.097 .001 .003 .005 .983 .015 .999 吉林.032 .744 -.428 .012 .028 .089 .966 .034 1.000 黑龙江.032 .751 -.499 .012 .029 .121 .946 .044 .990 上海.032 -3.273 -.350 .218 .549 .059 .998 .001 .999 江苏.032 -.653 .386 .009 .022 .073 .964 .036 1.000 浙江.032 -.642 .052 .008 .021 .001 .998 .001 .999 安徽.032 .091 .170 .000 .000 .014 .732 .268 .999 福建.032 .081 -.185 .000 .000 .017 .418 .228 .646 江西.032 .100 .293 .000 .001 .042 .522 .470 .992 山东.032 .179 .157 .001 .002 .012 .919 .074 .993 河南.032 .368 .188 .003 .007 .017 .973 .027 1.000 湖北.032 .379 .209 .003 .007 .021 .967 .031 .998 湖南.032 .059 .165 .000 .000 .013 .506 .417 .923广东 .032 -.708 .226 .010 .026 .025 .989 .011 1.000 广西 .032 .164 .254 .001 .001 .031 .799 .201 1.000 海南 .032 .765 -.105 .012 .030 .005 .998 .002 1.000 重庆 .032 .060 .096 .000 .000 .004 .602 .164 .766 四川 .032 .199 .083 .001 .002 .003 .973 .018 .990 贵州 .032 .173 -.024 .001 .002 .000 .987 .002 .989 云南 .032 .471 -.133 .005 .011 .009 .991 .008 .999 西藏 .032 .175 -.372 .001 .002 .067 .585 .278 .863 陕西 .032 .056 -.033 .000 .000 .001 .920 .034 .953 甘肃 .032 .222 .000 .001 .003 .000 .984 .000 .984 青海 .032 .267 -.209 .002 .004 .021 .928 .060 .988 宁夏 .032 .277 -.181 .002 .004 .016 .930 .042 .972 新疆 .032 .833-.138.014 .036 .009 .997.0031.000有效总计 1.000.4031.0001.000a. 对称标准化概述列点a收入类别质量维中的得分惯量 贡献1 2 点对维惯量维对点惯量1 2 1 2 总计工资性收入 .250 -1.033 .293 .169 .423 .324 .992 .008 1.00家庭经营性收入 .250 1.199 .217 .227 .571 .177 .997 .003 1.00财产性收入 .250 -.079 -.223 .003 .002 .187 .380 .321 .70转移性收入 .250 -.088-.288.003 .003 .312 .382 .431.81有效总计 1.000.4031.0001.000a. 对称标准化由“概述行点”和“概述列点”两个表可以得到最终的散点图。
spss对应分析实验报告

spss对应分析实验报告SPSS对应分析实验报告引言:对应分析是一种常用的统计分析方法,它可以帮助研究者确定两个或多个变量之间的关系。
在本次实验中,我们使用SPSS软件对一组数据进行了对应分析,并得出了一些有意义的结论。
实验设计:我们的实验设计是基于一个假设:消费者的年龄与其购买的产品类型之间存在关联。
为了验证这个假设,我们收集了一组消费者的数据,包括他们的年龄和购买的产品类型。
我们使用SPSS软件进行了对应分析,并得出了以下结果。
数据收集和处理:我们随机选择了200名消费者作为研究对象,并询问了他们的年龄和购买的产品类型。
在数据收集后,我们将数据输入SPSS软件进行处理。
首先,我们创建了两个变量:年龄和产品类型。
然后,我们使用对应分析功能进行了计算。
结果分析:通过对应分析,我们得到了一些有意义的结果。
首先,我们发现年龄与产品类型之间确实存在关联。
具体而言,我们观察到年龄较小的消费者更倾向于购买儿童玩具,而年龄较大的消费者更倾向于购买家居用品。
这一结果与我们的假设相符合。
进一步分析还显示了其他有趣的关联。
例如,我们发现中年消费者更倾向于购买电子产品,而青年消费者更倾向于购买时尚服装。
这些结果为我们进一步了解消费者行为提供了有价值的信息。
讨论和结论:我们的实验结果表明,消费者的年龄与其购买的产品类型之间存在关联。
这一发现对于市场营销和产品定位具有重要意义。
通过了解不同年龄段消费者的购买偏好,企业可以更好地制定市场策略和推广计划,以满足消费者的需求。
然而,我们也需要注意到对应分析只能显示变量之间的关联,并不能确定因果关系。
因此,在实际应用中,我们需要结合其他方法和数据,以更全面地了解消费者行为和市场趋势。
总结:本次实验使用SPSS软件进行了对应分析,研究了消费者的年龄与其购买的产品类型之间的关联。
通过对数据的处理和分析,我们得出了一些有意义的结果,并对市场营销和产品定位提供了一定的指导。
然而,我们也要意识到对应分析只是统计分析的一种方法,需要结合其他数据和方法进行综合分析。
对应分析

实验报告课程名称多元统计分析实验项目名称五、对应分析班级与班级代码142506041 经济统计学1班实验室名称(或课室)北实验楼804专业经济统计学任课教师林海明学号:14250604146姓名:陈佳玲实验日期:2016年11月22日广东财经大学教务处制姓名陈佳玲实验报告成绩评语:1.对对应分析问题的思路、理论和方法认识正确;2.SPSS软件相应计算结果确认与应用正确;3.SPSS软件相应过程命令正确。
注:“不正确”为有不正确之处,具体见后面批注。
指导教师(签名)林海明2016年11月23日说明:指导教师评分后,实验报告交院(系)办公室保存。
实验项目五对应分析一、实验目的:通过对应分析的实验,熟悉对应分析问题的提出、解决问题的思路、方法和技能,会调用SPSS软件对应分析等有关过程命令,根据计算机计算的结果,分析和解决对应分析问题。
二、实验原理:解决对应分析问题的思路、理论和方法。
三、实验设备:计算机与SPSS软件。
四、实验数据:产品开发数据。
五、实验步骤:(1)变量进行正向化、标准化:X1-X25是正向变量,且已经进行标准化变换,记为χ=( X1,…,X25)′。
(2)计算主成分法:初始因子载荷阵见表2、旋转后因子载荷阵见表1。
B025每行元素有一个最大绝对值且列数最小的矩阵为B03;B03、B04、B05、B06、B07、B08、B09的方差最大化正交旋转后因子载荷阵为BГ3(见表3)、BГ4、BГ5、BГ6、BГ7、BГ8、B09。
表1 旋转因子载荷阵表1 旋转因子载荷阵3345大绝对值平均数见表3,b3Γ>b30,b3Γ=max{b gΓ},B3Γ的列数较小,则以下步骤用B3Γ的旋转后因子。
(4)确定因子个数m 。
B 25只有前3个因子与变量显著相关,故k =3,此时,前3个因子方差贡献率V1=0.3999、V2=0.234、V3=0.1141,累积方差贡献率74.795%。
假定x 服从正态分布N 25(μ,R)(检验的需要),取显著水平α=0.05,显著相关的临界值r 0.05(23)=0.396,初始因子载荷阵只有前3列有载荷绝对值大于r 0.05(23)。
多元统计分析报告对应分析报告

学生实验报告学院:统计学院课程名称:多元统计分析专业班级:统计123班姓名:叶常青学号:0124253学生实验报告一、实验目的及要求:目的熟悉和掌握对应分析的原理和上机操作方法容及要求本次操作就父母与孩子的受教育程度的关系进行对应分析,分别对父亲与孩子和母亲与孩子的受教育程度做对应分析,最后再对输出结果进行详细的分析。
二、仪器用具:三、实验方法与步骤:打开GSS93 subset .sav数据,对变量Degree与变量padeg和madeg进行对应分析,依次选择分析→降维…进入对应分析对话框,进行进行如下设置,便可输出想要的数据的:四、实验结果与数据处理:按照上述方法和步骤得出以下输出结果.对父亲受教育程度与孩子受教育程度的关系进行分析如下:表1表21 .400 .160 .846 .846 .025 .2562 .164 .027 .142 .988 .0263.047 .002 .012 1.004.006 .000 .000 1.00总计. 228.193.000a 1.001.00a. 16 自由度,表3第二部分摘要给出了惯量,卡方值以及每一维度所解释的总惯量的百分比信息。
总惯量为0.,卡方值为228.193 ,有关系式228.193=0.*1205,由此可以清楚的看到总惯量和卡方的关系。
Sig.是假设卡方值为0成立的概率,它的值几乎为0说明列联表之间有较强的相关性。
表注表明的自由度为(5-1)*(5-1)=16。
惯量部分是四个公共因子分别解释总惯量的百分比。
表4表5LT High School .808 .487 .387 .218 .253 .467 High School .140 .392 .453 .383 .374 .353 Junior College .005 .017 .027 .039 .030 .Bachelor . .068 . .228 .182 .100 Graduate .016 . .040 .131 .162 .有效边际 1.000 1.000 1.000 1.000 1.000第三部分的结果是在对应分析中点击Statistics按钮,进入Statistics对话框,选中Row profiles和Column profiles 交友程序运行所得到的。
对应分析实验报告

实验报告课程名称多元统计分析实验项目名称五、对应分析班级与班级代码实验室名称(或课室)专业任课教师学号:姓名:实验日期:姓名实验报告成绩评语:1.对对应分析问题的思路、理论和方法认识正确;2.SAS软件相应计算结果确认与应用正确;3.SAS软件相应过程命令正确。
注:“不正确”为有不正确之处,具体见后面批注。
指导教师(签名)说明:指导教师评分后,实验报告交院(系)办公室保存。
实验项目五对应分析实验目的:通过对应分析的实验,熟悉对应分析问题的提出、解决问题的思路、方法和技能,会调用SAS软件对应分析等有关过程命令,根据计算机计算的结果,分析和解决对应分析问题。
实验原理:解决对应分析问题的思路、理论和方法。
实验设备:计算机与SAS、SPSS软件。
实验数据:教科书p240例1数据。
实验步骤:1.指标的正向化和排序表1(单独计算,可在SPSS软件中计算);2. 调用因子分析过程命令输入正向化数据求得:前k个初始因子方差贡献解释,达到简单结构的初始因子载荷阵L0k(Factor Pattern)见表2,初始因子样品值矩阵F 0n×k,对L0k、L0k+1、…、L0p都进行方差最大化的正交旋转(穷举法),从中选出达到简单结构的旋转后因子载荷阵LГl(Rotated Factor Pattern)见表2, 前l个旋转后因子方差贡献i v(i v在SAS软件中Rotated Factor Pattern),旋转后因子样品值矩阵F Гn×l;3.设确定的正向化后因子载荷阵记为L*,正向化后因子记为 F *= (F1*,…,F m*)′,正向化后因子样品值矩阵为F *n×m,调用散点图过程命令输入变量点坐标L*、样品点坐标F *n×m的行数据给出因子坐标系F1*,…, F m*中的因子分析图1。
实验结果、实验分析、结论(有关表图要有序号、表的序号在左上方、图的序号在图的正下方、表的中英文名、表的上下线为粗线、表的内线为细线、表的左右边不封口,表图不能跨页、表图旁不能留空块, 引用结论要注明参考文献):因子双重信息图对应分析应用步骤如下:(1)给出原始数据阵正向化和排序表1,对该数据进行标准化;表1 数据阵正向化表XI X2 X3 X4 X5 X6 X7山西 1.712592694 0.11148 0.092473 0.050073 0.038193 0.018803 0.079946 内蒙古 1.720524829 0.081315 0.11238 0.042396 0.04328 0.040004 0.083339 辽宁 1.769798738 0.100121 0.12397 0.041121 0.043429 0.031328 0.078919 吉林 1.883530037 0.10536 0.116952 0.045064 0.043735 0.038508 0.095256 黑龙江 1.801149494 0.0965 0.143498 0.037566 0.052111 0.026267 0.072829 海南 1.526829447 0.047852 0.095238 0.047945 0.022134 0.018519 0.096844 四川 1.562470704 0.06168 0.116677 0.048471 0.033529 0.017439 0.072043 贵州 1.378855798 0.056362 0.073262 0.044388 0.016366 0.01572 0.057261 甘肃 1.473557019 0.058043 0.088316 0.0381 0.039794 0.015167 0.067999 青海 1.501697669 0.088508 0.096899 0.038191 0.039275 0.019243 0.033801其中X1进行正向化,100/X1为值,得到新的X1列,名为全部支出市食品支出的数倍。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验报告课程名称多元统计分析实验项目名称五、对应分析班级与班级代码实验室名称(或课室)专业任课教师学号:姓名:实验日期:姓名实验报告成绩评语:1.对对应分析问题的思路、理论和方法认识正确;2.SAS软件相应计算结果确认与应用正确;3.SAS软件相应过程命令正确。
注:“不正确”为有不正确之处,具体见后面批注。
指导教师(签名)说明:指导教师评分后,实验报告交院(系)办公室保存。
实验项目五对应分析实验目的:通过对应分析的实验,熟悉对应分析问题的提出、解决问题的思路、方法和技能,会调用SAS软件对应分析等有关过程命令,根据计算机计算的结果,分析和解决对应分析问题。
实验原理:解决对应分析问题的思路、理论和方法。
实验设备:计算机与SAS、SPSS软件。
实验数据:教科书p240例1数据。
实验步骤:1.指标的正向化和排序表1(单独计算,可在SPSS软件中计算);2. 调用因子分析过程命令输入正向化数据求得:前k个初始因子方差贡献解释,达到简单结构的初始因子载荷阵L0k(Factor Pattern)见表2,初始因子样品值矩阵F 0n×k,对L0k、L0k+1、…、L0p都进行方差最大化的正交旋转(穷举法),从中选出达到简单结构的旋转后因子载荷阵LГl(Rotated Factor Pattern)见表2, 前l个旋转后因子方差贡献i v(i v在SAS软件中Rotated Factor Pattern),旋转后因子样品值矩阵F Гn×l;3.设确定的正向化后因子载荷阵记为L*,正向化后因子记为 F *= (F1*,…,F m*)′,正向化后因子样品值矩阵为F *n×m,调用散点图过程命令输入变量点坐标L*、样品点坐标F *n×m的行数据给出因子坐标系F1*,…, F m*中的因子分析图1。
实验结果、实验分析、结论(有关表图要有序号、表的序号在左上方、图的序号在图的正下方、表的中英文名、表的上下线为粗线、表的内线为细线、表的左右边不封口,表图不能跨页、表图旁不能留空块, 引用结论要注明参考文献):因子双重信息图对应分析应用步骤如下:(1)给出原始数据阵正向化和排序表1,对该数据进行标准化;表1 数据阵正向化表XI X2 X3 X4 X5 X6 X7山西 1.712592694 0.11148 0.092473 0.050073 0.038193 0.018803 0.079946 内蒙古 1.720524829 0.081315 0.11238 0.042396 0.04328 0.040004 0.083339 辽宁 1.769798738 0.100121 0.12397 0.041121 0.043429 0.031328 0.078919 吉林 1.883530037 0.10536 0.116952 0.045064 0.043735 0.038508 0.095256 黑龙江 1.801149494 0.0965 0.143498 0.037566 0.052111 0.026267 0.072829 海南 1.526829447 0.047852 0.095238 0.047945 0.022134 0.018519 0.096844 四川 1.562470704 0.06168 0.116677 0.048471 0.033529 0.017439 0.072043 贵州 1.378855798 0.056362 0.073262 0.044388 0.016366 0.01572 0.057261 甘肃 1.473557019 0.058043 0.088316 0.0381 0.039794 0.015167 0.067999 青海 1.501697669 0.088508 0.096899 0.038191 0.039275 0.019243 0.033801其中X1进行正向化,100/X1为值,得到新的X1列,名为全部支出市食品支出的数倍。
其余变量不变。
输入进sas系统,并进行标准化。
(1)选取简单结构的初始、旋转后因子载荷阵:主成分法下,设L0k(k列)是达到简单结构的初始因子载荷阵见表2,对L0k、L0k+1、…、L0p都进行方差最大化的正交旋转(穷举法),从中选出达到简单结构的旋转后因子载荷阵(用后面的因子载荷阵每行元素最大绝对值靠近1频数表3确定),记为LГl(l列)见表2;在L02、的时候初始因子载荷阵达到简单结构(3)确定因子是否旋转:L 0k 、L 0l Г比较,若L 0l Г达到更好的简单结构,则用旋转后因子;若L 0k 达到更好的简单结构或L 0l Г、L 0k 都是差异不大的简单结构,则用初始因子;根据表3的情况分析,选择初始因子。
(4)记达到更好简单结构的s 列因子载荷阵是L s ,相应的因子方差贡献率表4;根据临界值表中r (8)=0.631,在(L 02Г2,2/13λu 3,…,2/16λu 6)前2列有载荷绝对值大于显著相关的临界值,2列后没有载荷绝对值大于显著相关的临界值,故因子个数m = 2。
方差贡献率为 0.8028。
(4)确定因子轴F 1*,F 2*(因子个数2):若(L s ,2/11+s λe s +1,…,2/1p λe p ) [(2/11+s λe s +1,…,2/1p λe p )是p 列初始因子载荷阵后面的p -s 列]前2列有元素绝对值大于显著相关的临界值,2列后没有元素绝对值大于显著相关的临界值,则因子个数为2,相应的因子载荷阵记为L *见表2,L *回归的因子记为F 2*=( F 1*,F 2*)′,因子F 2*的样品值矩阵记为F *10×2见表5,F j *为F *n ×m 的第j 行;(5)因子载荷阵、因子及其样品值的正向化和因子命名:在L *的第j 列l j *的元素中,选出绝对值大于显著相关临界值的对应变量,归为因子F j *一组,正向化是:如果归为因子f j 一组变量及其l j *中的对应的相关系数符号的综合影响是越大越好,l j *、F j *取正号,否则,取负号成为-l j *、-F j *。
命名:由归为因子F j *一组变量及其l j *中的对应的相关系数符号的内在关系对因子F j *进行命名;设正向化后因子载荷阵记为L *,正向化后因子记为F *= (F 1*,…, F m *)′,正向化后因子F *的样品值矩阵仍记为F *n ×m ;(6)作因子分析图:在m 维直角坐标系中,用第i 个坐标轴表示因子轴F i *,用L *的第i 行作为指标x i 的坐标值、F *n ×m 的第j 行F j *作为第j 个样品X j 的坐标值,该散点图即为因子分析图1;(7)分析与评价:根据因子分析图1,给出指标之间(结合L *)的相关性分析,按样品点所属象限(结合 F *n ×m )得出分类结果,从指标与坐标轴F 1*、…、F m *的方向上,样品所处的位置,给出指标对样品的影响及其影响方向,对样品进行优势、劣势、潜力状况和原因等的综合评价,直至给出较客观、较可靠的决策相关性建议。
实验程序:附:正向化公式:反向指标(如资产负债率) x j 正向化公式:a -x j ;强度逆向指标(如居民消费价格指数,商品零售价格指数,食品支出比重) x j 正向化公式:⎪⎩⎪⎨⎧++>或有负数时。
中有当)(时,当0,1max /10,/ij j ij i ij j x x x x x b 适度指标(如产品销售率, 速动比率) x j 正向化公式:),1/(1+-E x j E 为理想值。
这里ij x 为第i 个样品第j 个指标的观测值。
data socecon;input x1-x7;cards;1.712592694 0.11148 0.092473 0.050073 0.038193 0.018803 0.0799461.720524829 0.081315 0.11238 0.042396 0.04328 0.040004 0.0833391.769798738 0.100121 0.12397 0.041121 0.043429 0.031328 0.0789191.883530037 0.10536 0.116952 0.045064 0.043735 0.038508 0.0952561.801149494 0.0965 0.143498 0.037566 0.052111 0.026267 0.0728291.526829447 0.047852 0.095238 0.047945 0.022134 0.018519 0.0968441.562470704 0.06168 0.116677 0.048471 0.033529 0.017439 0.0720431.378855798 0.056362 0.073262 0.044388 0.016366 0.01572 0.0572611.473557019 0.058043 0.088316 0.0381 0.039794 0.015167 0.0679991.501697669 0.088508 0.096899 0.038191 0.039275 0.019243 0.033801 ; proc factor data=socecon M=prin priors=one p=0.8 simple corr; var x1-x7; run; proc factor data=socecon R=n n=2 score out=O951; var x1-x7; run; proc print data=O951; var factor1-factor2; run;DATA CCC; INPUT _name_ $ factor1 factor2; CARDS;1 0.10130 0.869742 0.74964 0.229543 0.90845 -0.165114 1.26153 0.873195 1.20450 -0.985376 -0.92059 1.417667 -0.45532 0.505978 -1.66099 -0.007969 -0.73608 -0.9122610 -0.45244 -1.82541 x1 0.96888 0.21503 x2 0.78905 -0.09590 x3 0.84300 -0.09502 x4 -0.21642 0.88243 x5 0.87170 -0.38437 x6 0.82301 0.16667 x7 0.40839 0.82347 ;run; proc prinqual data=socecon out=rec mdpref rep; transform identity(x1-x7); run; proc sort data=ccc; by _name_; run; proc sort data=rec; by _name_; run; data d; merge rec ccc; by _name_;run; data e; set d; prin1=factor1; prin2=factor2; run; %plotit(data=e,datatype=mdpref2 1,href=0,vref=0)DATA CCC; INPUT _name_ $ factor1 factor2;CARDS;1 0.10130 0.869742 0.74964 0.229543 0.90845 -0.165114 1.26153 0.873195 1.20450 -0.985376 -0.92059 1.417667 -0.45532 0.505978 -1.66099 -0.007969 -0.73608 -0.9122610 -0.45244 -1.82541 x1 0.96888 0.21503 x2 0.78905 -0.09590 x3 0.84300 -0.09502 x4 -0.21642 0.88243 x5 0.87170 -0.38437 x6 0.82301 0.16667 x7 0.40839 0.82347 ;run; proc prinqual data=s out=rec mdpref rep; transform identity(x1-x7); id no; run; proc sort data=ccc; by _name_; run; proc sort data=rec; by _name_; run; data d; merge rec ccc; by _name_; run; data e; set d; prin1=factor1; prin2=factor2; run; %plotit(data=e,datatype=mdpref2 1,href=0,vref=0)(1)变量的正向化。