模式识别习题答案
模式识别试卷及答案

模式识别试卷及答案一、选择题(每题5分,共30分)1. 以下哪一项不是模式识别的主要任务?A. 分类B. 回归C. 聚类D. 预测答案:B2. 以下哪种算法不属于监督学习?A. 支持向量机(SVM)B. 决策树C. K最近邻(K-NN)D. K均值聚类答案:D3. 在模式识别中,以下哪一项是特征选择的目的是?A. 减少特征维度B. 增强模型泛化能力C. 提高模型计算效率D. 所有上述选项答案:D4. 以下哪种模式识别方法适用于非线性问题?A. 线性判别分析(LDA)B. 主成分分析(PCA)C. 支持向量机(SVM)D. 线性回归答案:C5. 在神经网络中,以下哪种激活函数常用于输出层?A. SigmoidB. TanhC. ReLUD. Softmax答案:D6. 以下哪种聚类算法是基于密度的?A. K均值聚类B. 层次聚类C. DBSCAND. 高斯混合模型答案:C二、填空题(每题5分,共30分)1. 模式识别的主要任务包括______、______、______。
答案:分类、回归、聚类2. 在监督学习中,训练集通常分为______和______两部分。
答案:训练集、测试集3. 支持向量机(SVM)的基本思想是找到一个______,使得不同类别的数据点被最大化地______。
答案:最优分割超平面、间隔4. 主成分分析(PCA)是一种______方法,用于降维和特征提取。
答案:线性变换5. 神经网络的反向传播算法用于______。
答案:梯度下降6. 在聚类算法中,DBSCAN算法的核心思想是找到______。
答案:密度相连的点三、简答题(每题10分,共30分)1. 简述模式识别的基本流程。
答案:模式识别的基本流程包括以下几个步骤:(1)数据预处理:对原始数据进行清洗、标准化和特征提取。
(2)模型选择:根据问题类型选择合适的模式识别算法。
(3)模型训练:使用训练集对模型进行训练,学习数据特征和规律。
模式识别考试题答案

模式识别考试题答案题1:设有如下三类模式样本集ω1,ω2和ω3,其先验概率相等,求Sw 和Sb ω1:{(1 0)T, (2 0) T, (1 1) T} ω2:{(-1 0)T, (0 1) T, (-1 1) T}ω3:{(-1 -1)T, (0 -1) T, (0 -2) T}解:由于本题中有三类模式,因此我们利用下面的公式:b S =向量类模式分布总体的均值为C ,))()((00031m m m m m P t i i i i --∑=ω,即:i31i i0m )p(E{x }m ∑===ωi m 为第i 类样本样本均值⎪⎪⎪⎪⎭⎫⎝⎛=⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡⎪⎪⎪⎪⎭⎫ ⎝⎛+⎪⎪⎪⎪⎭⎫ ⎝⎛--+⎪⎪⎪⎪⎭⎫⎝⎛=⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎣⎡⎪⎭⎫ ⎝⎛--⎪⎪⎪⎪⎭⎫⎝⎛--+⎪⎭⎫ ⎝⎛-⎪⎪⎪⎪⎭⎫ ⎝⎛-+⎪⎭⎫ ⎝⎛⎪⎪⎪⎪⎭⎫ ⎝⎛=--=⎪⎪⎪⎪⎭⎫ ⎝⎛-=⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡-+--=⎪⎪⎪⎪⎭⎫⎝⎛--=⎥⎦⎤⎢⎣⎡---++-=⎪⎪⎪⎪⎭⎫ ⎝⎛-=⎥⎦⎤⎢⎣⎡++-+-=⎪⎪⎪⎪⎭⎫ ⎝⎛=⎥⎦⎤⎢⎣⎡++++=∑=81628113811381628112181448144811681498149814981498116814481448112131911949119497979797949119491131)m m )(m m ()(P S 919134323131323431m 343121100131m 323211010131m ;313410012131m t0i 0i 31i i b10321ω;333t(i)(i)k k w i i i i i i i i 1i 11111S P()E{(x-m )(x-m )/}C [(x m )(x m )33361211999271612399279Tk ωω====•==--⎡⎤⎡⎤--⎢⎥⎢⎥==⎢⎥⎢⎥⎢⎥⎢⎥--⎢⎥⎢⎥⎣⎦⎣⎦∑∑∑题2:设有如下两类样本集,其出现的概率相等: ω1:{(0 0 0)T , (1 0 0) T , (1 0 1) T , (1 1 0) T}ω2:{(0 0 1)T , (0 1 0) T , (0 1 1) T , (1 1 1) T}用K-L 变换,分别把特征空间维数降到二维和一维,并画出样本在该空间中的位置。
模式识别作业题(1)

m 2 mn ] 是奇异的。 mn n 2
1
2、参考参考书 P314“模式识别的概要表示”画出第二章的知识结构图。 答:略。 3、现有两类分类问题。如下图所示, (1,
1 1 3 ) 、 ( , ) 、 (1, 3 ) 、 (1,-tan10°)为 3 2 2 3 3 ,- * tan 10° ) 、 (2,0)为 W2 类。 5 5
W1 类,其中(1,-tan10°)已知为噪声点; (1,0) 、 ( 自选距离度量方法和分类器算法,判别(
6 ,0)属于哪一类? 5
答:度量方法:根据题意假设各模式是以原点为圆心的扇状分布,以两个向量之间夹角(都 是以原点为起点)的余弦作为其相似性测度,P22。 然后使用 K 近邻法,K 取 3,求已知 7 个点与(
2
答: (1)×,不一定,因为仅仅是对于训练样本分得好而已。 (2)×,平均样本法不需要。 (3)√,参考书 P30,将 r 的值代入式(2.26)即得。 (4)√,参考书 P34,三条线线性相关。 ( 5 ) √ ,就是说解区是 “ 凸 ” 的,参考书 P37 ,也可以证明,设 W1T X’=a, W2T X’=b, 则 a≤λW1+(1-λ)W2≤b(设 a≤b) 。 (6)√,参考书 P38。 (7)×,前一句是错的,参考书 P46。 (8)×,是在训练过程中发现的,参考书 P51。 (9)×,最简单的情况,两个点(0,0)∈w1,(2,0)∈w2,用势函数法求出来的判决界面是 x1=1。 (10)√,一个很简单的小证明, 设 X1=a+K1*e,X2= a-K1*e,X3=b+K2*e,X4= b-K2*e, Sw=某系数*e*e’,设 e=[m n],则 e *e’= [
方法三:参照“两维三类问题的线性分类器的第二种情况(有不确定区域) ”的算法,求 G12,G23,G13。 G12*x1>0, G12*x2<0, G12=(-1,-1,-1)’ G23*x2>0, G23*x3<0, G23=(-1,-1,1)’ G13*x1>0, G13*x3<0, G12=(-1,-1,1)’ 有两条线重合了。
模式识别习题答案

将 w0 代入由 (∗∗) 得到的第二个等式得到:
1 [ N
Sw
+
N1N2 N2
(m1
−
m2)(m1
−
m2)T ]w
=
m1
−
m2
显然,
N1 N2 N2
(m1
−
m2
)(m1
−
m2
)T
w
在
m1 − m2
方向上,不妨令
N1 N2 N2
(m1
−
m2)(m1 − m2)T w = (1 − λ)(m1 − m2) 代入上式可得
g(x) = aT y, a = (1, 2, −2)T , y = (x1, x2, 1)T
(3)事实上, X 是 Y 中的一个 y3 = 1 超平面,两者有相同的表达式,因此对 原空间的划分相同。 4.8 证明在正态等协方差条件下,Fisher线性判别准则等价于贝叶斯判别。 证明: 在正态等协方差条件( Σ1 = Σ2 = Σ )下,贝叶斯判别的决策面方程为:
w xp = x ∓ r ∥w∥
根据超平面的定向,将 r 代入可得,
g(x) xp = x − ∥w∥2 w
4.4 对于二维线性判别函数
g(x) = x1 + 2x2 − 2
(1)将判别函数写成 g(x) = wT x + w0 的形式,并画出 g(x) = 0 的几何图形; (2)映射成广义齐次线性判别函数
∥∇J (a)∥2 ρk = ∇JT (a)D∇J(a)
时,梯度下降算法的迭代公式为
证明:
ak+1
=
ak
+
b
− aTk y1 ∥y1∥2
y1
大学模式识别考试题及答案详解

一、填空与选择填空(本题答案写在此试卷上,30分)1、模式识别系统的基本构成单元包括:模式采集、特征提取与选择和模式分类。
2、统计模式识别中描述模式的方法一般使用特真矢量;句法模式识别中模式描述方法一般有串、树、网。
3、聚类分析算法属于(1);判别域代数界面方程法属于(3)。
(1)无监督分类 (2)有监督分类(3)统计模式识别方法(4)句法模式识别方法4、若描述模式的特征量为0-1二值特征量,则一般采用(4)进行相似性度量。
(1)距离测度(2)模糊测度(3)相似测度(4)匹配测度5、下列函数可以作为聚类分析中的准则函数的有(1)(3)(4)。
(1)(2) (3)(4)6、Fisher线性判别函数的求解过程是将N维特征矢量投影在(2)中进行。
(1)二维空间(2)一维空间(3)N-1维空间7、下列判别域界面方程法中只适用于线性可分情况的算法有(1);线性可分、不可分都适用的有(3)。
(1)感知器算法(2)H-K算法(3)积累位势函数法8、下列四元组中满足文法定义的有(1)(2)(4)。
(1)({A, B}, {0, 1}, {A?01, A? 0A1 , A? 1A0 , B?BA , B? 0}, A)(2)({A}, {0, 1}, {A?0, A? 0A}, A)(3)({S}, {a, b}, {S ? 00S, S ? 11S, S ? 00, S ? 11}, S)(4)({A}, {0, 1}, {A?01, A? 0A1, A? 1A0}, A)二、(15分)简答及证明题(1)影响聚类结果的主要因素有那些?(2)证明马氏距离是平移不变的、非奇异线性变换不变的。
答:(1)分类准则,模式相似性测度,特征量的选择,量纲。
(2)证明:(2分)(2分)(1分)设,有非奇异线性变换:(1分)(4分)三、(8分)说明线性判别函数的正负和数值大小在分类中的意义并证明之。
答:(1)(4分)的绝对值正比于到超平面的距离平面的方程可以写成式中。
模式识别答案

模式识别答案模式识别试题⼆答案问答第1题答:在模式识别学科中,就“模式”与“模式类”⽽⾔,模式类是⼀类事物的代表,概念或典型,⽽“模式”则是某⼀事物的具体体现,如“⽼头”是模式类,⽽王先⽣则是“模式”,是“⽼头”的具体化。
问答第2题答:Mahalanobis距离的平⽅定义为:其中x,u为两个数据,是⼀个正定对称矩阵(⼀般为协⽅差矩阵)。
根据定义,距某⼀点的Mahalanobis距离相等点的轨迹是超椭球,如果是单位矩阵Σ,则Mahalanobis距离就是通常的欧⽒距离。
问答第3题答:监督学习⽅法⽤来对数据实现分类,分类规则通过训练获得。
该训练集由带分类号的数据集组成,因此监督学习⽅法的训练过程是离线的。
⾮监督学习⽅法不需要单独的离线训练过程,也没有带分类号(标号)的训练数据集,⼀般⽤来对数据集进⾏分析,如聚类,确定其分布的主分量等。
就道路图像的分割⽽⾔,监督学习⽅法则先在训练⽤图像中获取道路象素与⾮道路象素集,进⾏分类器设计,然后⽤所设计的分类器对道路图像进⾏分割。
使⽤⾮监督学习⽅法,则依据道路路⾯象素与⾮道路象素之间的聚类分析进⾏聚类运算,以实现道路图像的分割。
问答第4题答:动态聚类是指对当前聚类通过迭代运算改善聚类;分级聚类则是将样本个体,按相似度标准合并,随着相似度要求的降低实现合并。
问答第5题答:在给定观察序列条件下分析它由某个状态序列S产⽣的概率似后验概率,写成P(S|O),⽽通过O求对状态序列的最⼤似然估计,与贝叶斯决策的最⼩错误率决策相当。
问答第6题答:协⽅差矩阵为,则1)对⾓元素是各分量的⽅差,⾮对⾓元素是各分量之间的协⽅差。
2)主分量,通过求协⽅差矩阵的特征值,⽤得,则,相应的特征向量为:,对应特征向量为,对应。
这两个特征向量即为主分量。
3) K-L变换的最佳准则为:对⼀组数据进⾏按⼀组正交基分解,在只取相同数量分量的条件下,以均⽅误差计算截尾误差最⼩。
4)在经主分量分解后,协⽅差矩阵成为对⾓矩阵,因⽽各主分量间相关消除。
模式识别习题答案(第一次)

−1 2 1
1
3
n ∑ t2 i =C λ i=1 i
显然,此为一超椭球面的方程,主轴长度由{λi , i = 1, · · · , n}决定,方向由变 换矩阵A,也就是Σ的特征向量决定。 2.19 假定x和m是两个随机变量,并在给定m时,x的条件密度为
1 1 p(x|m) = (2π )− 2 σ −1 exp{− (x − m)2 /σ 2 } 2
c ∑ j =1 c ∫ ∑ j =1 Rj
P (x ∈ Rj |ωj )p(ωj ) =
p(x|ωj )p(ωj )dx
又因为p(e) = 1 − p(c),所以 min p(e) ⇒ max p(c) ⇒ max
c ∫ ∑ j =1 Rj
p(x|ωj )p(ωj )dx
由上式可得到判决准则:若p(x|ωi )p(ωi ) > p(x|ωj )p(ωj ), ∀j ̸= i,则x ∈ ωi 等价于若p(ωi |x) > p(ωj |x), ∀j ̸= i,则x ∈ ωi 。 2.6 对两类问题,证明最小风险贝叶斯决策规则可表示为 ω1 p(x|ω1 ) (λ12 − λ22 )P (ω2 ) 若 ≷ 则x ∈ p(x|ω2 ) (λ21 − λ11 )P (ω1 ) ω2 证明: R(α1 |x) = λ11 p(ω1 |x) + λ12 p(ω2 |x)R(α2 |x) = λ21 p(ω1 |x) + λ22 p(ω2 |x) 若R(α1 |x) < R(α2 |x),则x ∈ ω1 , 代入即得所求结果。 2.9 写出两类和多类情况下最小风险贝叶斯决策判别函数和决策面方程。 解:两类情况下判别函数为:g (x) = R(α1 |x)−R(α2 |x),决策面方程为:g (x) = 0; 多 类 情 况 下 定 义 一 组 判 别 函 数gi (x) = R(αi |x), i = 1, · · · , c, 如 果 对 所 有 的j ̸= i, 有 :gi (x) < gj (x), 则x ∈ ωi , 其 中 第i类 和 第j 类 之 间 的 决 策 面 为:gi (x) − gj (x) = 0。 ∑c 当然,将R(αi |x) = j =1 λ(αi , ωj )P (ωj |x), i = 1, · · · , a代入亦可。 2.15 证明多元正态分布的等密度点轨迹是一个超椭球面,且其主轴方向由Σ的特征 向量决定,轴长度由Σ的特征值决定。
模式识别习题参考1_齐敏教材第6章
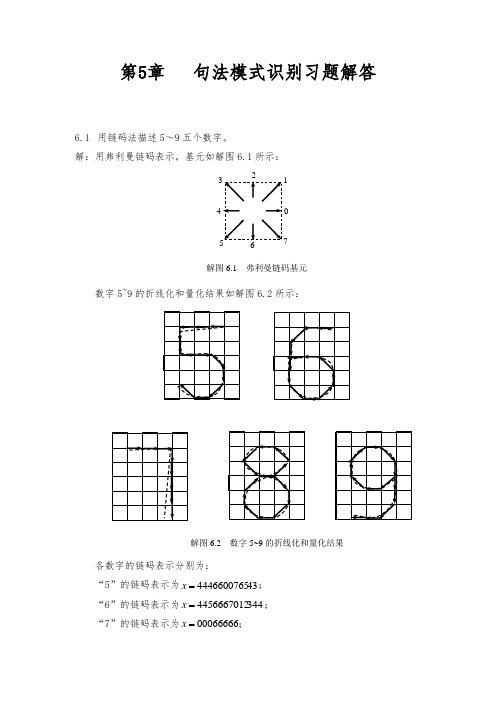
第5章 句法模式识别习题解答6.1 用链码法描述5~9五个数字。
解:用弗利曼链码表示,基元如解图6.1所示:数字5~9的折线化和量化结果如解图6.2所示:各数字的链码表示分别为:“5”的链码表示为434446600765=x ; “6”的链码表示为3444456667012=x ; “7”的链码表示为00066666=x ;0 17解图6.1 弗利曼链码基元解图6.2 数字5~9的折线化和量化结果“8”的链码表示为21013457076543=x ; “9”的链码表示为5445432107666=x 。
6.2 定义所需基本基元,用PDL 法描述印刷体英文大写斜体字母“H ”、“K ”和“Z ”。
解:设基元为:用PDL 法得到“H ”的链描述为)))))(~((((d d c d d x H ⨯+⨯+=;“K ”的链描述为))((b a d d x K ⨯⨯+=; “Z ”的链描述为))((c c g x Z ⨯-=。
6.3 设有文法),,,(S P V V G T N =,N V ,T V 和P 分别为},,{B A S V N =,},{b a V T =:P ①aB S →,②bA S →,③a A →,④aS A →⑤bAA A →,⑥b B →,⑦bS B →,⑧aBB B → 写出三个属于)(G L 的句子。
解:以上句子ab ,abba ,abab ,ba ,baab ,baba 均属于)(G L 。
bcadeabba abbA abS aB S ⇒⇒⇒⇒ ① ⑦ ② ③ab aB S ⇒⇒ ① ⑥ba bA S ⇒⇒② ③ abab abaB abS aB S ⇒⇒⇒⇒ ① ⑦ ① ⑥baab baaB baS bA S ⇒⇒⇒⇒ ② ④ ① ⑥baba babA baS bA S ⇒⇒⇒⇒② ④ ② ③6.4 设有文法),,,(S P V V G T N =,其中},,,{C B A S V N =,}1,0{=T V ,P 的各生成式为①A S 0→,②B S 1→,③C S 1→ ④A A 0→,⑤B A 1→,⑥1→A ⑦0→B ,⑧B B 0→,⑨C C 0→,⑩1→C问00100=x 是否属于语言)(G L ? 解:由可知00100=x 属于语言)(G L 。
模式识别习题及答案

模式识别习题及答案模式识别习题及答案模式识别是人类智能的重要组成部分,也是机器学习和人工智能领域的核心内容。
通过模式识别,我们可以从大量的数据中发现规律和趋势,进而做出预测和判断。
本文将介绍一些模式识别的习题,并给出相应的答案,帮助读者更好地理解和应用模式识别。
习题一:给定一组数字序列,如何判断其中的模式?答案:判断数字序列中的模式可以通过观察数字之间的关系和规律来实现。
首先,我们可以计算相邻数字之间的差值或比值,看是否存在一定的规律。
其次,我们可以将数字序列进行分组,观察每组数字之间的关系,看是否存在某种模式。
最后,我们还可以利用统计学方法,如频率分析、自相关分析等,来发现数字序列中的模式。
习题二:如何利用模式识别进行图像分类?答案:图像分类是模式识别的一个重要应用领域。
在图像分类中,我们需要将输入的图像分为不同的类别。
为了实现图像分类,我们可以采用以下步骤:首先,将图像转换为数字表示,如灰度图像或彩色图像的像素矩阵。
然后,利用特征提取算法,提取图像中的关键特征。
接下来,选择合适的分类算法,如支持向量机、神经网络等,训练模型并进行分类。
最后,评估分类结果的准确性和性能。
习题三:如何利用模式识别进行语音识别?答案:语音识别是模式识别在语音信号处理中的应用。
为了实现语音识别,我们可以采用以下步骤:首先,将语音信号进行预处理,包括去除噪声、降低维度等。
然后,利用特征提取算法,提取语音信号中的关键特征,如梅尔频率倒谱系数(MFCC)。
接下来,选择合适的分类算法,如隐马尔可夫模型(HMM)、深度神经网络(DNN)等,训练模型并进行语音识别。
最后,评估识别结果的准确性和性能。
习题四:如何利用模式识别进行时间序列预测?答案:时间序列预测是模式识别在时间序列分析中的应用。
为了实现时间序列预测,我们可以采用以下步骤:首先,对时间序列进行平稳性检验,确保序列的均值和方差不随时间变化。
然后,利用滑动窗口或滚动平均等方法,将时间序列划分为训练集和测试集。
模式识别课后习题答案

– (1) E{ln(x)|w1} = E{ln+1(x)|w2} – (2) E{l(x)|w2} = 1 – (3) E{l(x)|w1} − E2{l(x)|w2} = var{l(x)|w2}(教材中题目有问题) 证∫ 明ln+:1p对(x于|w(12)),dxE={ln∫(x()∫p(|wp(x(1x|}w|w=1)2))∫n)+nl1nd(xx)所p(x以|w∫,1)Ed{xln=(x∫)|w(1p(}p(x(=x|w|Ew1)2{))ln)n+n+11d(xx)又|wE2}{ln+1(x)|w2} = 对于(2),E{l(x)|w2} = l(x)p(x|w2)dx = p(x|w1)dx = 1
对于(3),E{l(x)|w1} − E2{l(x)|w2} = E{l2(x)|w2} − E2{l(x)|w2} = var{l(x)|w2}
• 2.11 xj(j = 1, 2, ..., n)为n个独立随机变量,有E[xj|wi] = ijη,var[xj|wi] = i2j2σ2,计 算在λ11 = λ22 = 0 及λ12 = λ21 = 1的情况下,由贝叶斯决策引起的错误率。(中心极限 定理)
R2
R1
容易得到
∫
∫
p(x|w2)dx = p(x|w1)dx
R1
R2
所以此时最小最大决策面使得P1(e) = P2(e)
• 2.8 对于同一个决策规则判别函数可定义成不同形式,从而有不同的决策面方程,指出 决策区域是不变的。
3
模式识别(第二版)习题解答
模式识别练习题及答案.docx

1=填空题1、模式识别系统的基本构成单元包括:模式采集、特征选择与提取和模式分类。
2、统计模式识别中描述模式的方法一般使用特征矢量;句法模式识别中模式描述方法一般有串、树、网。
3、影响层次聚类算法结果的主要因素有计算模式距离的测度、聚类准则、类间距离门限、预定的类别数目。
4、线性判别函数的正负和数值大小的几何意义是正(负)表示样本点位于判别界面法向量指向的正(负)半空间中;绝对值正比于样本点到判别界面的距离。
5、感知器算法丄。
(1 )只适用于线性可分的情况;(2)线性可分、不可分都适用。
6、在统计模式分类问题中,聂曼-皮尔逊判决准则主要用于某一种判决错误较另一种判决错误更为重愛情况;最小最大判别准则主要用于先验概率未知的情况。
7、“特征个数越多越有利于分类”这种说法正确吗?错误。
特征选择的主要目的是从n个特征中选出最有利于分类的的m个特征(m<n),以降低特征维数。
一般在可分性判据对特征个数具有单调性和(C n m»n )的条件下,可以使用分支定界法以减少计算量。
& 散度Jij越大,说明。
类模式与3j类模式的分布差别越大;当3类模式与(Oj类模式的分布相同时,Jij=_O_.选择题1、影响聚类算法结果的主要因素有(BCD ).A.已知类别的样本质量B.分类准则C.特征选取D.模式相似性测度2、模式识别中,马式距离较之于欧式距离的优点是(CD )。
A.平移不变性B.旋转不变性C.尺度不变性D.考虑了模式的分布3、影响基本K-均值算法的主要因素有(DAB )。
A.样本输入顺序B.模式相似性测度C.聚类准则D.初始类中心的选取4、在统计模式分类问题中,当先验概率未知时,可以使用(BD )。
A.最小损失准则B.最小最大损失准则C.最小误判概率准则D.N-P判决5、散度环是根据(C )构造的可分性判据。
A.先验概率B.后验概率C.类概率密度D.信息燔E.几何距离6、如果以特征向量的相关系数作为模式相似性测度,则影响聚类算法结果的主要因素有(B C )。
《模式识别》(边肇祺)习题答案

– (1) E {ln (x)|w1 } = E {ln+1 (x)|w2 } – (2) E {l(x)|w2 } = 1 – (3) E {l(x)|w1 } − E 2 {l(x)|w2 } = var{l(x)|w2 }(教材中题目有问题) ∫ ∫ (p(x|w1 ))n+1 n n 证明: 对于(1),E {l (x)|w1 } = l (x)p(x|w1 )dx = dx 又E {ln+1 (x)|w2 } = (p(x|w2 ))n ∫ ∫ (p(x|w1 ))n+1 n+1 l p(x|w2 )dx = dx 所以,E {ln (x)|w1 } = E {ln+1 (x)|w2 } (p(x|w2 ))n ∫ ∫ 对于(2),E {l(x)|w2 } = l(x)p(x|w2 )dx = p(x|w1 )dx = 1 对于(3),E {l(x)|w1 } − E 2 {l(x)|w2 } = E {l2 (x)|w2 } − E 2 {l(x)|w2 } = var{l(x)|w2 } • 2.11 xj (j = 1, 2, ..., n)为n个独立随机变量,有E [xj |wi ] = ijη ,var[xj |wi ] = i2 j 2 σ 2 ,计 算在λ11 = λ22 = 0 及λ12 = λ21 = 1的情况下,由贝叶斯决策引起的错误率。 (中心极限 定理) 解: 在0 − 1损失下,最小风险贝叶斯决策与最小错误率贝叶斯决策等价。 • 2.12 写出离散形式的贝叶斯公式。 解: P (wi |x) = ∑c P (x|wi )P (x) j =1 P (x|wi )P (wi )
证明: p(m|x) = p(x|m)p(m) p(x) p(x|m)p(m) =∫ p(x|m)p(m)dm { { } } 1 1 2 2 (2π ) 2 −1 exp − 1 (m − m )2 /σ 2 (2π ) 2 σ −1 exp − 1 σm 0 m 2 (x − m) /σ 2 =∫ } } { 1 { 1 1 −1 2 2 (2π ) 2 σ −1 exp − 2 (x − m)2 /σ 2 (2π ) 2 σm exp − 1 2 ( m − m 0 ) / σm d m [ ( ) ] 1 2 2 x + m σ2 2 (σ 3 + σm ) 2 σm 1 σ 2 + σm 0 = m− exp − 1 2 2 2 σ 2 σm σ 2 + σm (2π ) 2 σσm
《模式识别》(边肇祺)习题答案

• 2.13 把连续情况的最小错误率贝叶斯决策推广到离散情况,并写出其判别函数。 • 2.14 写出离散情况条件风险R(ai |x)的定义,并指出其决策规则。 解: R(ai |x) = = R(ak |x) = min
c ∑ j =1 c ∑ j =1
λij P (wj |x) λij p(x|wj )P (wj )////omit the same part p(x)
1
模式识别(第二版)习题解答
§1
绪论
略
§2
贝叶斯决策理论
• 2.1 如果只知道各类的先验概率,最小错误率贝叶斯决策规则应如何表示? 解:设一个有C 类,每一类的先验概率为P (wi ),i = 1, ..., C 。此时最小错误率贝叶斯 决策规则为:如果i∗ = max P (wi ),则x ∈ wi 。
• 2.4 分别写出在以下两种情况 1. P (x|w1 ) = P (x|w2 ) 2. P (w1 ) = P (w2 ) 下的最小错误率贝叶斯决策规则。 解: 当P (x|w1 ) = P (x|w2 )时,如果P (w1 ) > P (w2 ),则x ∈ w1 ,否则x ∈ w2 。 当P (w1 ) = P (w2 )时,如果P (x|w1 ) > P (x|w2 ),则x ∈ w1 ,否则x ∈ w2 。 • 2.5 1. 对c类情况推广最小错误率率贝叶斯决策规则; 2. 指出此时使错误率最小等价于后验概率最大,即P (wi |x) > P (wj |x) 对一切j ̸= i 成立时,x ∈ wi 。 2
p(x|w2 )dx =
R2
p(x|w1 )dx
所以此时最小最大决策面使得P1 (e) = P2 (e) • 2.8 对于同一个决策规则判别函数可定义成不同形式,从而有不同的决策面方程,指出 决策区域是不变的。
模式识别习题及答案

模式识别习题及答案案场各岗位服务流程销售大厅服务岗:1、销售大厅服务岗岗位职责:1)为来访客户提供全程的休息区域及饮品;2)保持销售区域台面整洁;3)及时补足销售大厅物资,如糖果或杂志等;4)收集客户意见、建议及现场问题点;2、销售大厅服务岗工作及服务流程阶段工作及服务流程班前阶段1)自检仪容仪表以饱满的精神面貌进入工作区域2)检查使用工具及销售大厅物资情况,异常情况及时登记并报告上级。
班中工作程序服务流程行为规范迎接指引递阅资料上饮品(糕点)添加茶水工作要求1)眼神关注客人,当客人距3米距离时,应主动跨出自己的位置迎宾,然后侯客迎询问客户送客户注意事项15度鞠躬微笑问候:“您好!欢迎光临!”2)在客人前方1-2米距离领位,指引请客人向休息区,在客人入座后问客人对座位是否满意:“您好!请问坐这儿可以吗?”得到同意后为客人拉椅入座“好的,请入座!”3)若客人无置业顾问陪同,可询问:请问您有专属的置业顾问吗?,为客人取阅项目资料,并礼貌的告知请客人稍等,置业顾问会很快过来介绍,同时请置业顾问关注该客人;4)问候的起始语应为“先生-小姐-女士早上好,这里是XX销售中心,这边请”5)问候时间段为8:30-11:30 早上好11:30-14:30 中午好 14:30-18:00下午好6)关注客人物品,如物品较多,则主动询问是否需要帮助(如拾到物品须两名人员在场方能打开,提示客人注意贵重物品);7)在满座位的情况下,须先向客人致歉,在请其到沙盘区进行观摩稍作等待;阶段工作及服务流程班中工作程序工作要求注意事项饮料(糕点服务)1)在所有饮料(糕点)服务中必须使用托盘;2)所有饮料服务均已“对不起,打扰一下,请问您需要什么饮品”为起始;3)服务方向:从客人的右面服务;4)当客人的饮料杯中只剩三分之一时,必须询问客人是否需要再添一杯,在二次服务中特别注意瓶口绝对不可以与客人使用的杯子接触;5)在客人再次需要饮料时必须更换杯子;下班程序1)检查使用的工具及销售案场物资情况,异常情况及时记录并报告上级领导;2)填写物资领用申请表并整理客户意见;3)参加班后总结会;4)积极配合销售人员的接待工作,如果下班时间已经到,必须待客人离开后下班;1.3.3.3吧台服务岗1.3.3.3.1吧台服务岗岗位职责1)为来访的客人提供全程的休息及饮品服务;2)保持吧台区域的整洁;3)饮品使用的器皿必须消毒;4)及时补充吧台物资;5)收集客户意见、建议及问题点;1.3.3.3.2吧台服务岗工作及流程阶段工作及服务流程班前阶段1)自检仪容仪表以饱满的精神面貌进入工作区域2)检查使用工具及销售大厅物资情况,异常情况及时登记并报告上级。
(完整word版)模式识别试题答案

(完整word版)模式识别试题答案模式识别非学位课考试试题考试科目:模式识别考试时间考生姓名:考生学号任课教师考试成绩一、简答题(每题6分,12题共72分):1、监督学习和非监督学习有什么区别?参考答案:当训练样本的类别信息已知时进行的分类器训练称为监督学习,或者由教师示范的学习;否则称为非监督学习或者无教师监督的学习。
2、你如何理解特征空间?表示样本有哪些常见方法?参考答案:由利用某些特征描述的所有样本组成的集合称为特征空间或者样本空间,特征空间的维数是描述样本的特征数量。
描述样本的常见方法:矢量、矩阵、列表等。
3、什么是分类器?有哪些常见的分类器?参考答案:将特征空中的样本以某种方式区分开来的算法、结构等。
例如:贝叶斯分类器、神经网络等。
4、进行模式识别在选择特征时应该注意哪些问题?参考答案:特征要能反映样本的本质;特征不能太少,也不能太多;要注意量纲。
5、聚类分析中,有哪些常见的表示样本相似性的方法?参考答案:距离测度、相似测度和匹配测度。
距离测度例如欧氏距离、绝对值距离、明氏距离、马氏距离等。
相似测度有角度相似系数、相关系数、指数相似系数等。
6、你怎么理解聚类准则?参考答案:包括类内聚类准则、类间距离准则、类内类间距离准则、模式与类核的距离的准则函数等。
准则函数就是衡量聚类效果的一种准则,当这种准则满足一定要求时,就可以说聚类达到了预期目的。
不同的准则函数会有不同的聚类结果。
7、一种类的定义是:集合S 中的元素x i 和x j 间的距离d ij 满足下面公式:∑∑∈∈≤-S x S x ij i jh d k k )1(1,d ij ≤ r ,其中k 是S 中元素的个数,称S 对于阈值h ,r 组成一类。
请说明,该定义适合于解决哪一种样本分布的聚类?参考答案:即类内所有个体之间的平均距离小于h ,单个距离最大不超过r ,显然该定义适合团簇集中分布的样本类别。
8、贝叶斯决策理论中,参数估计和非参数估计有什么区别?参考答案:参数估计就是已知样本分布的概型,通过训练样本确定概型中的一些参数;非参数估计就是未知样本分布概型,利用Parzen 窗等方法确定样本的概率密度分布规律。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
− b)y1
=
1 2∥y1∥2
代入即得。
4.15 证明:当取
[ N
NN
N ]T
b = ,··· , , ,··· ,
N1
N1 N2
N2
时,MSE解等价于Fisher解。证明:
记
b = [b1, b2]T
其中,
bi
=
[
N Ni
,
·
·
·
,
N Ni
]T,i源自=1,2,MSE解为:
a∗ = Y +b = (Y T Y )−1Y T b
4.10
证明在几何上,感知准则函数正比于被错分样本到决策面的距离之和。
证明:
感知器准则函数为
J (a)
=
∑
y∈Y
k
(−aT
y)
,其中
Yk
为错分样本的集合。被错
分样本(yi)到决策面(
aT y
=0
)的距离为
|aT yi| ∥a∥
,被错分样本到决策面的距
离之和为
F (a) = ∑ − aT yi ∥a∥
将 w0 代入由 (∗∗) 得到的第二个等式得到:
1 [ N
Sw
+
N1N2 N2
(m1
−
m2)(m1
−
m2)T ]w
=
m1
−
m2
显然,
N1 N2 N2
(m1
−
m2
)(m1
−
m2
)T
w
在
m1 − m2
方向上,不妨令
N1 N2 N2
(m1
−
m2)(m1 − m2)T w = (1 − λ)(m1 − m2) 代入上式可得
wT x + w0 = 0
其中
w = Σ−1(µ1 − µ2)
w0
=
−(µ1
−
µ2)T Σ−1 µ1
+ 2
µ2
+
ln
P (w1) w2
在Fisher线 性 判 别 中 , 如 果 用 样 本 均 值 和 协 方 差 来 估 计 µi 和 Σ , 那 么 使Fisher准则函数取极大值的最优投影方向与 Σ−1(µ1 − µ2) 相同,忽略常 数因子取 w∗ = Σ−1(µ1 − µ2) ,显然两种方法等价。
w xp = x ∓ r ∥w∥
根据超平面的定向,将 r 代入可得,
g(x) xp = x − ∥w∥2 w
4.4 对于二维线性判别函数
g(x) = x1 + 2x2 − 2
(1)将判别函数写成 g(x) = wT x + w0 的形式,并画出 g(x) = 0 的几何图形; (2)映射成广义齐次线性判别函数
1 N Sww = λ(m1 − m2) ⇒ w = λN Sw−1(m1 − m2)
忽略比例因子,它和Fisher判别函数是一致的。
2 第五章课后习题
5.2 已知两类问题如图(见 P.134 图 5.14 )所示,其中“ × ”表示 ω1 类训练集 的一个原型,“ ⃝ ”表示 ω2 类训练集的一个原型。 (1)找出紧互对原型对集合 P ; (2)找出与紧互对原型对集合相联系的超平面集 H ; (3)假设训练集样本与原型完全相同,找出由超平面集 H 产生的 z(x) 。 解: (1) P = {[(2, 5), (1, 3)][(3, 4), (3, 2)][(4, 6), (5, 5)]} (2)相应的超平面集为
y∈Y k
也即
J(a) = ∥a∥F (a)
则感知准则函数与被错分样本到超平面的距离之和成正比。
4.14 考虑准则函数
∑
J(a) =
(aT y − b)2
y∈Y (a)
2
其 中 , Y(⊣) 是 使aT y ≤ b的 样 本 集 合 。 设 y1 是 Y(ak) 中 的 唯 一 样 本 , 则 J (a) 的梯度为 ∇J (ak) = 2(aTk y1 − b)y1 ,二阶偏导数矩阵为 D = 2y1y1T 。 据此证明,若最优步长选择为
∥∇J (a)∥2 ρk = ∇JT (a)D∇J(a)
时,梯度下降算法的迭代公式为
证明:
ak+1
=
ak
+
b
− aTk y1 ∥y1∥2
y1
∇J (ak) = 2(aTk y1 − b)y1, D = 2y1y1T
进而可得
ρk
=
2(aTk y1
4(aTk y1 − b)2∥y1∥2 − b)y1T · 2y1y1T · 2(aTk y1
(∗)
对 Y 的所有行进行排序,使前 N1 个样本对应 ωi 类,剩下的 N2 个样本对
应 ω2 类,记
Y = I1 x1 −I2 −x2
其中 Ii 是全为 1 的 Ni 维向量, xi 有 Ni 行。代入MSE解的表达式即可得
N
(N1m1 + N2m2)T
w0 =
0
(N1m1 + N2m2) Sw + N1m1mT1 + N2m2mT2
解: (1)设 x 在超平面上的投影是 xp ,则显然:
wT xp + w0 = 0
w
x
−
xp
=
±r ∥w∥
将第二式代入第一式得到:
r = ± wT x + w0 = |g(x)|
∥w∥
∥w∥
显然,根据正交投影的性质,点 xp 满足 g(xp) = 0 ,且使得 ∥x − xp∥ 取得极 小值。
(2)由(1)可得,
g(x) = aT y, a = (1, 2, −2)T , y = (x1, x2, 1)T
(3)事实上, X 是 Y 中的一个 y3 = 1 超平面,两者有相同的表达式,因此对 原空间的划分相同。 4.8 证明在正态等协方差条件下,Fisher线性判别准则等价于贝叶斯判别。 证明: 在正态等协方差条件( Σ1 = Σ2 = Σ )下,贝叶斯判别的决策面方程为:
g(x) = aT y
(3)指出上述 X 空间实际上是 Y 空间的一个子空间,且 aT y = 0 对 X 子空间 的划分与原空间中 wT x + w0 = 0 对原 X 空间的划分相同,并在图上标示出 来。
1
解: (1)取 w = (1, 2)T , x = (x1, x2), w0 = −2即可,图形略。 (2)映射成广义齐次线性判别函数
w
N (m1 − m2)
(∗∗)
3
其中
1∑
mi
=
Ni
xi, i
xi ∈Ci
=
1, 2
∑2 ∑
Sw =
(xj − mi)(xj − mi)T
i=1 xj ∈Ci
记
m
为所有样本的均值,则
N1m1 + N2m2
=
N m, m
=
1 N
∑N
i=1
xi
,
由 (∗∗) 式得到的第一个等式可以得到:
N w0 + (N1m1 + N2m2)T w = 0 ⇒ w0 = −mT w
模式识别习题答案 (第 3 − 4 次)
金文马 北京大学数学科学学院
2010.12.08
1 第四章课后习题
4.1
(1)指出从
x
到超平面
g(x)
=
wT x+w0
=
0
的距离
r
=
|g(x)| ∥w∥
是在
g(xq )
=
0
的
约束条件下,使 ∥x − xq∥2 达到极小的解;
(2)指出在超平面上的投影是
g(x) xq = x − ∥w∥2 w