数据库格式及说明
db撰写格式

数据库(Database)的撰写格式通常包括以下几个部分:1.数据库名:这是数据库的唯一标识符,用于区分不同的数据库。
2.表名:这是数据库中表的唯一标识符,用于区分不同的表。
3.列名:这是表中的列的唯一标识符,用于区分不同的列。
4.数据类型:这指定了列中可以存储的数据的类型。
例如,INT、VARCHAR、DATE等。
5.约束:这包括主键约束、外键约束、唯一约束、非空约束等,用于限制表中数据的值和格式。
6.索引:这可以提高查询性能,通过创建索引来加快对表中数据的访问速度。
7.触发器、存储过程和函数:这些是数据库中的可执行代码,用于执行特定的操作或处理数据。
以下是一个简单的数据库表的示例:sql复制代码CREATE DATABASE MyDatabase;USE MyDatabase;CREATE TABLE Employees (EmployeeID INT PRIMARY KEY,FirstName VARCHAR(50),LastName VARCHAR(50),DateOfBirth DATE,Gender CHAR(1),CONSTRAINT CHK_Gender CHECK (Gender IN ('M', 'F')));在这个示例中,我们创建了一个名为“MyDatabase”的数据库,并在其中创建了一个名为“Employees”的表。
这个表有五个列:EmployeeID、FirstName、LastName、DateOfBirth 和Gender。
EmployeeID列被指定为主键,Gender列有一个检查约束,确保其值只能是'M'或'F'。
(完整word版)数据库设计说明书-国家标准格式

数据库设计文档规范一、引言1.1 编写目的说明:编写这份数据库设计说明书的目的,指出预期的读者范围.1.2 背景说明:a.待开发的数据库的名称和使用此数据库的软件系统的名称;b.列出本项目的任务提出者、开发者、用户以及将安装该软件和这个数据库的单位。
1.3 定义列出本文件中用到的专门术语的定义和缩写词的原词组。
1。
4 参考资料列出要用到的参考资料,如:a.本项目的经核准的计划任务书或合同、上级机关的批文;b.属于本项目的其他已发表的文件;c.本文件中各处引用的文件、资料,包括所要用到的软件开发标准。
列出这些文件的标题、文件编号、发表日期和出版单位,说明能够得到这些文件资料的来源二、外部设计2.1 标识符和状态联系用途,详细说明用于唯一地标识该数据库的代码、名称或标识符,附加的描述性信息亦要给出。
如果该数据库属于尚在实验中、尚大测试中或是暂时使用的,则要说明这一特点及其有效时间范围。
2.2 使用它的程序列出将要使用或访问此数据库的所有应用程序,对于这些应用程序的每一个,给出它的名称和版本号。
2.3 约定陈述一个程序员或一个系统分析员为了能使用此数据库而需要了解的建立标号、标识的约定,例如用于标识数据库的不同版本的约定和用于标识库内各个文卷、记录、数据项的命名约定等。
三、结构设计3.1 概念结构设计说明本数据库将反映的现实世界中的实体、属性和它们之间的关系等的原始数据形式,包括各数据项、记录、系、文卷的标识符、定义、类型、度量单位和值域,建立本数据库的每一幅用户视图。
3.2 逻辑结构设计说明把上述原始数据进行分解、合并后重新组织起来的数据库全局逻辑结构,包括所确定的关键字和属性、重新确定的记录结构和文卷结构、所建立的各个文卷之间的相互关系,形成本数据库的数据库管理员视图。
3。
2。
1 数据表3.2。
2存储过程3。
2。
3 触发器……四、运用设计4。
1 数据字典设计对数据库设计中涉及到的各种项目,如数据项、记录、系、文卷、模式、子模式等一般要建立起数据字典,以说明它们的标识符、同义名及有关信息。
数据库表描述-概述说明以及解释

数据库表描述-概述说明以及解释1.引言1.1 概述在数据库管理系统中,表是一种结构化的数据存储单元,它由行和列组成,用于存储具有相似特性的数据。
数据库表描述着整个数据库的结构和关系,是数据存储和管理的基本单位之一。
通过对数据库表的描述,我们可以清晰地了解数据的组织结构,实现数据的高效存储和管理。
在本文中,我们将介绍数据库表的定义、作用以及相关的设计原则,以帮助读者深入了解数据库表的重要性和设计要点。
通过本文的学习,读者将能够更好地理解和应用数据库表,提高数据库系统的性能和可维护性。
1.2文章结构文章结构部分主要包括本文的组织结构和内容安排。
在本文中,我们将分为引言、正文和结论三个部分来介绍数据库表的描述。
在引言部分,我们会概述本文的主题,介绍数据库表描述的重要性和背景,以及本文的目的和结构。
在正文部分,我们将详细讨论数据库表的定义、作用、组成要素和设计原则,从而帮助读者深入了解数据库表的概念和特点。
在结论部分,我们会总结数据库表描述的重要性,强调数据库表设计的关键因素,并对数据库表描述的未来发展进行展望。
通过全面地介绍数据库表的描述和设计原则,我们希望读者可以更好地理解和应用数据库表,提高数据管理和存储的效率和质量。
1.3 目的在数据库系统中,数据库表描述是非常重要的。
它可以帮助开发人员更好地了解数据库表的结构和功能,帮助维护人员更好地管理和维护数据库表,帮助用户更好地理解数据库表中存储的数据。
因此,本文的目的是通过对数据库表描述的介绍,帮助读者了解数据库表的重要性和作用,掌握数据库表的基本概念和设计原则,以提高数据库表设计的质量和效率。
同时,希望通过本文的讨论,引发对数据库表描述的思考和讨论,推动数据库表描述在未来的进一步发展和应用。
2.正文2.1 数据库表的定义和作用数据库表是数据库中的一个重要组成部分,它是用来存储数据的结构化方式。
每个数据库表都包含了一定数量的行和列,行代表记录,列代表属性。
用友GRPr9、u8数据库表结构-范本模板

R9、u8帐务处理系统
主要数据结构
一、数据表基本信息:
附录:
1、Anyi2000账务系统自定义数据类型。
二、数据表结构说明:
1、表
注:当KzQx值为
‘R’=人员控制;‘K'=科目控制; ‘0’=部门控制;‘1’=项目控制;‘2’=个人往来控制;‘3’=单位往来控制;‘4’—‘9'=自定义辅助项控制;
另外:
在上述代码后跟小写字母‘a'表示允许,否则为禁止;
允许或禁止的具体内容见GL_Kzqx表。
注:当type值为
‘PL’=凭证类型代码;‘DQ’=地区代码;‘FS’=辅助说明项代码;‘FL’=辅助核算项类别代码‘G’=外币代码;‘W’=外币代码; ‘K'=科目代码; ‘X’=现金代码; ‘0'=部门代码
‘1’=项目代码;‘2’=职员代码;‘3'=往来单位代码; ‘4’—‘9'=辅助核算项代码
说明:kjqj,pzly,qzh仅在非汇总帐套中使用。
理正标准数据接口说明及格式

理正标准数据接口说明及格式标准数据接口是一种规范化的方法,用于在不同系统之间传输和交换数据。
它定义了数据的结构、格式、协议和操作规范,以确保数据的一致性和可靠性。
下面我将从多个角度全面介绍标准数据接口的说明和格式。
1. 数据接口的目的和重要性:标准数据接口的目的是实现系统之间的数据交互和集成,使得不同系统能够有效地共享和利用数据。
它可以提高数据的准确性、一致性和可靠性,减少数据传输错误和冗余,提高数据处理效率和系统的整体性能。
2. 数据接口的类型和常见格式:数据接口可以分为多种类型,常见的包括文件接口、API接口、数据库接口等。
不同类型的接口通常使用不同的数据格式来表示和传输数据。
文件接口,常见的文件格式包括CSV(逗号分隔值)、XML(可扩展标记语言)、JSON(JavaScript对象表示法)等。
这些格式具有简单易懂、跨平台兼容性好的特点,适用于批量数据传输和导入导出操作。
API接口,API(应用程序接口)是一种通过编程方式进行数据交互的接口。
常见的API格式包括RESTful API、SOAP(简单对象访问协议)等。
这些格式通常基于HTTP协议,支持实时数据传输和交互,适用于实时数据查询和更新操作。
数据库接口,数据库接口用于在不同数据库之间进行数据交互和同步。
常见的数据库接口格式包括ODBC(开放数据库连接)、JDBC(Java数据库连接)等。
这些格式提供了标准的数据库操作方法和语法,支持数据的读取、写入和更新。
3. 数据接口的说明和规范:为了确保数据接口的一致性和可靠性,通常需要提供详细的接口说明和规范。
这些说明和规范包括以下内容:接口协议和版本,明确接口使用的协议和版本号,例如HTTP、HTTPS、RESTful API v1.0等。
数据结构和字段定义,定义数据的结构和字段,包括字段名称、数据类型、长度、约束条件等。
这有助于确保数据的一致性和完整性。
接口操作和方法,定义接口支持的操作和方法,例如数据查询、数据写入、数据更新等。
常用生物数据库及数据格式

10
FASTQ sequence format
与fasta格式类似 一条序列一般占用四行 序列和质量值各占一行
11
GenBank028 bp DNA linear PLN 21-JUN-1999 DEFINITION Saccharomyces cerevisiae TCP1-beta gene, partial cds; and Axl2p (AXL2) and Rev7p (REV7) genes, complete cds. ACCESSION U49845 VERSION U49845.1 GI:1293613 KEYWORDS . SOURCE Saccharomyces cerevisiae (baker's yeast) ORGANISM Saccharomyces cerevisiae Eukaryota; Fungi; Ascomycota; Saccharomycotina; Saccharomycetes; Saccharomycetales; Saccharomycetaceae; Saccharomyces. REFERENCE 1 (bases 1 to 5028) AUTHORS Torpey,L.E., Gibbs,P.E., Nelson,J. and Lawrence,C.W. TITLE Cloning and sequence of REV7, a gene whose function is required for DNA damage-induced mutagenesis in Saccharomyces cerevisiae JOURNAL Yeast 10 (11), 1503-1509 (1994) PUBMED 7871890 ...... FEATURES Location/Qualifiers CDS <1..206 /codon_start=3 /product="TCP1-beta" /protein_id="AAA98665.1" /db_xref="GI:1293614" /translation="SSIYNGISTSGLDLNNGTIADMRQLGIVESYKLKRAVVSSASEA AEVLLRVDNIIRARPRTANRQHM" gene 687..3158 /gene="AXL2" ...... ORIGIN 1 gatcctccat atacaacggt atctccacct caggtttaga tctcaacaac ggaaccattg 61 ccgacatgag acagttaggt atcgtcgaga gttacaagct aaaacgagca gtagtcagct ...... 4981 tgccatgact cagattctaa ttttaagcta ttcaatttct ctttgatc //
数据库物理存储格式-概述说明以及解释

数据库物理存储格式-概述说明以及解释1.引言1.1 概述数据库物理存储格式是指数据库在磁盘上的实际存储方式和结构。
在数据库管理系统中,物理存储格式是为了有效地组织和管理数据而设计的。
它直接影响着数据库的性能、可扩展性和数据的访问速度。
数据库物理存储格式一般包括以下几个方面:1. 存储结构:数据库物理存储格式使用一种特定的数据结构来组织和存储数据。
常见的存储结构包括表空间、页、块等,它们按照一定规则组织数据,以提高数据的访问效率和存储空间的利用率。
2. 存储方式:数据库物理存储格式可以采用不同的存储方式来存储数据。
常见的存储方式有堆文件、索引文件、分区存储等。
不同的存储方式适用于不同的数据操作场景,可以提高查询效率、降低存储成本等。
3. 数据布局:数据库物理存储格式还涉及到数据在磁盘上的分布方式。
合理的数据布局可以减少数据的碎片化,提高数据的访问效率。
常见的数据布局包括顺序存储、散列存储、索引存储等。
4. 存储策略:数据库物理存储格式也包括一些存储策略的选择。
比如,可以选择不同的压缩算法来减少数据占用的存储空间;可以选择不同的缓存机制来提高数据的访问速度等。
总而言之,数据库物理存储格式是数据库管理系统在磁盘上实际存储数据的一种组织方式,它直接关系到数据库的性能和可用性。
在设计和选择数据库物理存储格式时,需要综合考虑数据访问模式、硬件环境、查询性能等多个因素,以便为用户提供高效、可靠的数据服务。
文章结构部分主要描述了整篇文章的组织结构和各个部分的内容概述。
本文的结构如下:1. 引言1.1 概述引导读者了解数据库物理存储格式的重要性及其在数据库系统中的作用。
介绍了物理存储格式对于数据的组织和存储效率的影响。
1.2 文章结构本部分将详细阐述本篇长文的组织结构,帮助读者理解全文的脉络和各个章节的内容。
1.3 目的阐明本文旨在提供关于数据库物理存储格式的全面介绍,为读者提供基本概念和知识,帮助读者理解数据库的底层存储结构和优化技术。
数据库设计说明书【范本模板】

数据库设计说明书1. 引言在使用任何数据库之前,都必须设计好数据库,包括将要存储的数据的类型,数据之间的相互关系以及数据的组织形式。
数据库设计是指对于一个给定的应用环境,构造最优的数据库模式,建立数据库及其应用系统,使之能够有效地存储数据.为了合理地组织和高效率地存取数据,目前最好的方式,就是建立数据库系统,因此在系统的总体设计阶段,数据库的建立与设计是一项十分重要的内容。
由于数据库应用系统的复杂性,为了支持相关程序运行,数据库设计就变得异常复杂,因此最佳设计不可能一蹴而就,而只能是一种“反复探寻,逐步求精”的过程,也就是规划和结构化数据库中的数据对象以及这些数据对象之间关系的过程.1。
1 编写目的数据库设计的好坏是一个关键。
如果把企业的数据比做生命所必需的血液,那么数据库的设计就是应用中最重要的一部分,是一个系统的根基。
用于开发人员进行项目设计,以此作为编码的依据,同时也为后续的数据库维护工作提供了良好的使用说明,也可以作为未来版本升级时的重要参考资料。
数据库设计的目标是建立一个合适的数据模型。
这个数据模型应当是满足用户要求,既能合理地组织用户需要的所有数据,又能支持用户对数据的的所有处理功能。
并且要具有较高的范式,数据完整性好,效益高,便于理解和维护,没有数据冲突.2。
外部设计外部设计是研究和考虑所要建立的数据库的信息环境,对数据库应用领域中各种信息要求和操作要求进行详细地分析,了解应用领域中数据项、数据项之间的关系和所有的数据操作的详细要求,了解哪些因素对响应时间、可用性和可靠性有较大的影响等各方面的因素.2。
1 标识符和状态数据库表前缀: afunms用户名:root密码:root权限:全部有效时间:开发阶段说明:系统正式发布后,可能更改数据库用户/密码,请在统一位置编写数据库连接字符串,在发行前请予以改正。
2.2 使用它的程序本系统主要利用jsp作为前端的应用开发工具,使用MySQL作为后台的数据库,Linux或Windows均可作为系统平台。
MIT心律失常数据库数据格式解析

MIT心律失常数据库数据格式解析MIT心律失常数据库包含两个系列的心电数据,第一系列即“100”系列,是在4000个24小时的Holter记录中随机挑选的,包含23个数据(100~109,111~119,121~124);第二系列即“200”系列,是挑选的不太常见但临床上十分重要的心律失常数据,包含25个数据(200~203,205,207~210,212~215,217,219~223,228,230~234)。
其中102,104,107,217为Paced beats,207含有部分VF信号,201~203,210,217,219,221~222含有AF信号。
每个数据持续30分钟,并都有详细的注释。
MIT心律失常数据库每一个数据记录包括三个文件,“.hea”、“.dat”和“.atr”。
“.hea”为头文件,其由一行或多行ASCII码字符组成。
以100.hea为例第一行从左到右分别代表文件名,导联数,采样率,数据点数;第二行从左到右分别代表文件名,存储格式,增益,AD分辨率,ADC零值,导联1第一个值,校验数,数据块大小(0=可以从任意数据块输出,即可以从中间读取任意一段),导联号第三行代表导联2的信息,同第二行以#开始的为注释行,一般说明患者的情况以及用药情况等。
“.dat”为数据文件,MIT-BIH数据库中的数据存储格式有Format8、Format16、Format80、Format212、Format310等8种,心律失常数据库统一采用212格式进行存储。
“212”格式是针对两个信号的数据库记录,这两个信号的数据交替存储,每三个字节存储两个数据。
这两个数据分别采样自信号0和信号1,信号0的采样数据取自第一字节对(16位)的最低12位,信号1的采样数据由第一字节对的剩余4位(作为组成信号1采样数据的12位的高4位)和下一字节的8位(作为组成信号1采样数据的12位的低8位)共同组成。
以100.dat为例。
数据库格式及说明数据库格式

数据库格式及说明
一、数据库格式
2003年全国房地产经纪人执业资格考试报名库采用Dbase或Excel数据库。
数据库包含:姓名、身份证件名称、身份证件号码、档案号、第1科准考证号、第2科准考证号、第3科准考证号、第4科准考证号、级别、免试人员房地产估价师注册号(或非注册人员的资格证书编号)、性别、出生日期、专业技术职务、学历、工作单位等15个数据项。
其中级别有两种表示方式,一种用“3”表示,代表第一门免试,不参加成绩滚动;另一种用“4”表示,代表成绩参加滚动。
档案号为字符型,字节数为9位,具体规定为:第一、二位采用行政区代码中代表各省、自治区、直辖市的行政代码(见下表),第三、四位为年份代码(2003年代码为“03”),后五位各地自定。
准考证号为字符型,字节数为11位,具体规定如下:
第一位为科目号,四个科目代码分别为:
房地产基本制度与政策:1
房地产经纪概论:2
房地产经纪实务:3
房地产经纪相关知识:4
第二、三位采用省、自治区、直辖市的行政区代码(见下表);
第四、五位考区号;
第六、七位为考点号;
第八、九位为考场号;
第十、十一位为序号(不应超过30)。
各省、自治区、直辖市行政区代码表
二、填写说明
报名数据库中各字数均不能为空。
“(身份证/军官证/护照号)号码”一栏,军人填写军人证件号码,港澳台地区人员及外籍人员填写护照号码。
学历、专业技术职务等内容要填写中文全名,不得填写代码。
报名库中考生的姓名如出现异体字,需用*号代替,并附书面说明,加盖公章,连同身份证件复印件与报名库一起上报。
数据库的字符集格式

字符集字符集定义了数据库中可以存储的字符范围和编码方式。
它指定了每个字符由多少位表示以及如何将这些位解释为字符。
常见的字符集•UTF-8:一种可变长度的编码,广泛用于 Web 和移动应用程序。
•UTF-16:一种固定长度的编码,通常用于 Windows 系统。
•UTF-32:一种固定长度的编码,用于存储大量字符。
•GBK:一种双字节字符集,用于简体中文。
•BIG5:一种双字节字符集,用于繁体中文。
格式格式描述了如何将字符存储在数据库中。
它指定了字符的排序顺序、字符大小写以及如何处理特殊字符。
常见的格式•Unicode:一种国际标准,定义了所有语言和脚本的字符。
•ASCII:一种 7 位编码,用于英语字母、数字和一些符号。
•EBCDIC:一种 8 位编码,主要用于 IBM 系统。
选择字符集和格式选择字符集和格式时需要考虑以下因素:•存储的数据类型:需要存储哪些语言和字符。
•应用程序兼容性:应用程序是否需要特定的字符集或格式。
•性能:不同的字符集和格式对查询和更新操作的性能影响。
•数据完整性:确保字符集和格式与预期的数据相匹配以避免数据损坏。
示例以下示例创建了一个名为users的表格,使用 UTF-8 字符集和 Unicode 格式:CREATE TABLE users (id INT NOT NULL AUTO_INCREMENT,name VARCHAR(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci,email VARCHAR(255) CHARACTER SET utf8 COLLATE utf8_unicode_ci);在该示例中,name和email字段使用 UTF-8 字符集和 Unicode 格式,允许存储各种语言和字符。
电子文档命名规则及数据库文件格式说明
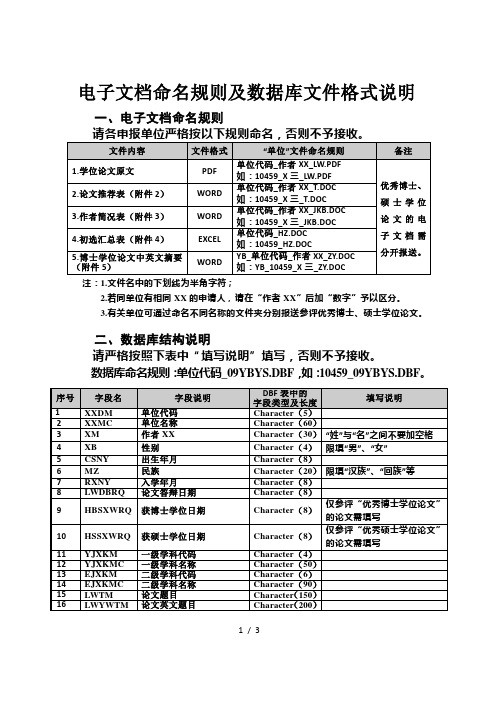
电子文档命名规则及数据库文件格式说明
一、电子文档命名规则
注:1.文件名中的下划线为半角字符;
2.若同单位有相同XX的申请人,请在“作者XX”后加“数字”予以区分。
3.有关单位可通过命名不同名称的文件夹分别报送参评优秀博士、硕士学位论文。
二、数据库结构说明
请严格按照下表中“填写说明”填写,否则不予接收。
数据库命名规则:单位代码_09YBYS.DBF,如:10459_09YBYS.DBF。
1 / 3
注:1.除在“填写说明”中有特殊说明的外,所以字段均为必填字段;
2.表中所有“年月”请用6位数字表示,如“1982年4月”请用“198204”表示;所有“日期”请用8位数字表示,如“2008年8月8日”请用“20080808”表示;
3.固定填写格式为“区号-”(连字符为半角),如“08”,手机前不要加“0”;
2 / 3
4.电子信箱中的“”符号请使用“半角”方式填写;
5.填写时请注意字段长度,若有超出,请使用简写,不得自行修改数据表结构。
3 / 3。
电子文档命名规则及数据库文件格式说明

电子文档命名规则及数据库文件格式说明电子文档命名规则及数据库文件格式说明对于任何一位从事文档或数据库管理的人员而言,命名规则及文件格式必定是一件非常重要的事情。
命名规则不仅能够方便管理者快速找到需要的文件,也可以方便其他人员进行查找和使用;而文件格式则关系到文件的保存、传输和共享方式,对于数据的准确性、安全性以及可用性都有着极为重要的影响。
因此,建立科学的文档命名规则和统一的文件格式标准,是信息化建设中不可或缺的一部分。
一、电子文档命名规则1. 命名规范电子文档命名规范不同于传统纸质文档,需要更加简洁明了。
为了方便管理与使用,一份电子文档应当有清晰的命名规范,命名需简洁明了,通常包括以下几个方面:(1)命名应当具有代表性。
命名应该包含有关文档的信息,包括其类型、内容、作者、日期等等。
(2)文件名应该具有可读性。
文件名应该用易于读懂的、易于理解的语言,这样可以方便管理者和使用者快速找到所需文档。
(3)避免使用特殊字符。
文件名中应该避免出现特殊字符,如/ \ : * ? " < > | 等等,因为这些字符在文件名中可能会引起一些不必要的问题和错误。
(4)命名原则应当遵循统一标准。
在一个组织内,应该建立一个统一的命名规范标准,所有文档的命名都应当按照这个标准进行规范。
2. 命名原则为了建立一个规范的文档命名标准,在制定命名规则时,我们可以考虑以下原则:(1)文件名包含关键信息。
文件名应该包含文档的内容、创建者、所属项目、创建日期等关键信息。
例如:“财务报表-张三-2020年3月.xlsx”。
(2)使用缩写。
在文件名过长或者文档内容和种类较多时,可以使用缩写减少文字量,同时需要保证缩写的明确和可理解性。
(3)避免重名。
如果文档命名不规范,就会出现重名的情况,因此在制定文件命名规则的时候,应该避免重名的情况。
(4)避免拼音重复。
在使用拼音命名时,一定要注意避免重复,因为拼音有很多单音词,而且拼音不够直观,易引起混淆。
SQLite数据库文件格式全面分析

SQLite数据库文件格式全面分析作者:空转0前言性急的兄弟可以跳过前言直接看第1章,特别性急的兄弟可以跳过前面各章,直接看鸣谢。
最近对SQLite数据库很感兴趣,认真地学了有半个多月了,越学越觉着好玩。
好玩归好玩,只是目前没什么实际用途,那就写点儿东西吧,否则半个月不是白学了嘛!SQLite数据库包括多方面的知识,比如VDBE什么的。
据说那些东西会经常变。
确实,我用的是3.6.18版,我看跟其它文档中描述的3.3.6的VDBE已经很不一样了。
所以决定先写文件格式,只要是3.?.?的版本,文件格式应该不会有太大变化吧。
网上介绍SQLite文件格式的文章并不少,但一般都是针对小文件:一个表,几条记录,两个页。
本文准备一直分析到比较大的文件,至少B-tree和B+tree中得有内结点(就是说不能只有一个既是根又是叶的结点,就是说表中得多点记录,得建索引),还要争取对SQLite的各类页都做出分析。
在分析的过程中,争取把SQLite数据库关于文件格式的基本规定也都介绍一下。
这样,本文既是一个综合性的技术文档,又带有实例说明,兄弟们参考时岂不是就很方便了吗?既然是技术文档,要想读懂总得先掌握点SQLite数据库的基本知识吧。
所以,先介绍参考文献。
0.1 参考文献1-The Definitive Guide to SQLite . Michael Owens:据说是比较经典的SQLite著作,我看写得是挺好的。
边看边翻译了其中的主要部分,但不敢拿出来,大家还是看原文吧。
2-SQLite源代码:其实有关SQLite的最原始说明可能都在源代码中了。
把此项列在第2,只是因为我是先看的书再看的代码,估计大家也会是这个顺序吧。
先浏览一下代码还是很有收获的,特别是几个主要的.h文件,对本文的写作很有帮助。
有关文件格式的说明主要在btreeInt.h中。
3-SQLite入门与分析:网上Arrowcat的系列文章。
Arrowcat应该是一个很博学的人,看他的文章收获很大,在此也算是鸣谢吧。
flexray 数据库arxml 的格式说明

flexray 数据库arxml 的格式说明FlexRay是一种用于车辆网络通信的通信协议,它提供了高可靠性和实时性能。
在FlexRay网络中,数据库ARXML扮演着关键的角色,它定义了网络中所有节点和信号的数据格式和属性。
本文将详细介绍FlexRay数据库ARXML的格式说明。
ARXML(AUTOSAR XML)是AUTOSAR(Automotive Open System Architecture)的一部分,它是一种基于XML的文件格式,用于描述车辆网络中的应用程序、ECU等的配置和通信信息。
ARXML格式在FlexRay网络中被广泛使用,以确保节点之间的正确通信和数据交换。
FlexRay数据库ARXML格式遵循AUTOSAR的数据模型,它由一系列XML元素组成。
其中,最重要的元素包括节点、信号、帧、簇等。
节点元素定义了FlexRay网络中的不同节点(如ECU或传感器)及其属性。
每个节点都有一个唯一的名称和标识符,以便识别和定位。
节点元素可以定义节点的物理连接、通信属性和参数等信息。
信号元素定义了网络中传输的数据。
每个信号都有一个名称和标识符,并指定了其所属的帧。
信号元素描述了信号的数据类型、长度、大小端格式等信息,以确保数据在不同节点之间的正确性。
帧元素定义了FlexRay网络中数据的传输单位。
每个帧都有一个唯一的名称、标识符和发送周期。
帧元素包含了多个信号元素,描述了帧中各个信号的传输类型、位位置、周期性和触发条件等属性。
簇元素将多个节点组合在一起,形成一个簇。
簇元素定义了簇内所有节点的关系和通信规则。
它指定了簇中节点之间的协作方式、时隙分配和通信规范等。
FlexRay数据库ARXML的格式说明可以通过使用AUTOSAR工具链中的编辑器或解析器进行创建、修改和解析。
这些工具提供了友好的界面和功能,以方便开发人员对ARXML文件的操作和管理。
总结而言,FlexRay数据库ARXML的格式说明是一种基于XML的文件格式,用于描述FlexRay网络中的节点、信号、帧和簇等元素。
sql 的编码格式-概述说明以及解释

sql 的编码格式-概述说明以及解释1.引言1.1 概述SQL(结构化查询语言)是用于管理和操作关系型数据库的编程语言。
在进行SQL编码时,正确的编码格式对于保证数据的完整性、准确性和安全性至关重要。
本文将详细介绍SQL编码格式的定义、常见的SQL编码格式以及SQL编码格式的重要性。
在编写SQL语句时,需要按照一定的格式和规范来编码,以保证语句的可读性和易维护性。
SQL编码格式主要包括缩进、换行、大小写、注释等方面的规范。
首先,缩进在SQL编码中起到了对语句进行层级划分的作用,使得代码结构清晰可见。
通过缩进,可以清晰地区分出SELECT语句、FROM子句、WHERE子句等不同的部分。
其次,换行在SQL编码中能够使得复杂的SQL语句更易理解。
将不同的子句和关键字放在不同的行上,可以使得语句的层次更加明确,也便于注释和修改。
同时,对于SQL关键字和标识符的大小写,也需要遵循一定的编码规范。
一般来说,SQL关键字建议使用大写,而表名、列名等标识符则建议使用小写。
这样可以增加代码的可读性,并且能够避免与关键字冲突的问题。
此外,在SQL编码时添加注释是十分重要的。
注释能够增加代码的可维护性和可读性,帮助其他人更好地理解意图和功能。
注释可以在语句的前面或是行内进行添加,以帮助开发人员更好地理解该段代码的作用和目的。
综上所述,SQL编码格式在数据库开发中起到了至关重要的作用。
通过正确的缩进、换行、大小写和注释等编码格式,可以使得SQL语句更加易读、易懂,提高代码的可维护性和可读性。
在后续的章节中,本文将进一步讨论常见的SQL编码格式以及SQL编码格式的重要性。
1.2 文章结构本文主要以SQL 的编码格式为主题进行探讨和研究。
为了更好地阐述SQL 编码格式的定义、常见的格式以及其重要性,本文将从以下几个方面进行分析。
首先,将介绍SQL 编码格式的定义。
我们将解释什么是SQL 编码格式,它是一种用于编写SQL 语句的规范和约定。
GenBank数据库格式的详细说明

GenBank数据库格式的详细说明Posted on 19 四月 2009 by 柳城,阅读 609 简洁版GenBank是美国国立卫生研究院维护的基因序列数据库,汇集并注释了所有公开的核酸以及蛋白质序列。
每个记录代表了一个单独的、连续的、带有注释的DNA或RNA片段。
这些文件按类别分为几组:有些按照系统发生学划分,另外一些则按照生成这些序列数据的技术方法划分。
目前GenBank中所有的记录均来自于最初作者向DNA序列数据库的直接提交。
这些作者将序列数据作为论文的一部分来发表,或将数据直接公开。
GenBank由位于马里兰州Bethesda的美国国立卫生研究院下属国立生物技术信息中心建立,与日本DNA数据库(DDBJ)以及欧洲生物信息研究院的欧洲分子生物学实验室核苷酸数据库(EMBL)一起,都是国际核苷酸序列数据库合作的成员。
所有这三个中心都可以独立地接受数据提交,而三个中心之间则逐日交换信息,并制作相同的充分详细的数据库向公众开放(虽然格式上有细微的差别,并且所使用的信息系统也略有不同)。
GenBank数据库格式的详细说明/Sitemap/samplerecord.htmlEMBL和GenBank数据库格式的对比EMBL GenBank含义ID LOCUS 序列名称DE DEFINITION 序列简单说明AC ACCESSION 序列编号SV VERSION 序列版本号KW KEYWORDS 与序列相关的关键词OS SOURCE 序列来源的物种名OC ORGANISM 序列来源的物种学名和分类学位置RN REFERENCE 相关文献编号,或递交序列的注册信息RA AUTHORS 相关文献作者,或递交序列的作者RT TITLE 相关文献题目RL JOURNAL 相关文献刊物杂志名,或递交序列的作者单位RX MEDLINE 相关文献 Medline引文代码RC REMARK 相关文献注释RP 相关文献其它注释CC COMMENT 关于序列的注释信息DR 相关数据库交叉引用号FH FEATURES 序列特征表起始FT 序列特征表子项SQ BASE COUNT 碱基种类统计数空格ORIGIN 序列。
数据库 时间存储格式-定义说明解析

数据库时间存储格式-概述说明以及解释1.引言1.1 概述概述随着信息技术的不断发展,数据库在我们的生活中扮演着越来越重要的角色。
数据库是一个用于存储、管理和检索数据的工具,它可以帮助我们有效地组织和使用各种类型的数据。
时间作为一种重要的数据类型,在数据库中也有着广泛的应用。
数据库中的时间数据用于记录事件的发生时间、操作的时间戳等,因此时间的准确性和有效性对我们的数据管理和分析至关重要。
在选择和使用合适的时间存储格式时,我们需要考虑数据的存储空间、查询效率以及与外部系统的兼容性等因素。
本文将深入探讨数据库中时间的存储格式,包括常见的时间存储格式和它们的优缺点。
同时,我们还将对时间存储格式的选择与应用进行分析,以便读者在实际的数据库设计和使用过程中做出明智的决策。
通过对时间存储格式的研究与应用,我们可以更好地理解时间数据在数据库中的存储和处理方式,并提高数据库的效率和性能。
同时,我们也可以为今后的时间存储格式研究提供一些建议和展望,以期在数据库领域取得更大的进展。
在接下来的内容中,我们将首先介绍数据库的时间存储需求,包括存储时间的不同用途和需求。
然后,我们将详细介绍一些常见的时间存储格式,包括日期时间、时间戳和时间间隔等。
最后,我们将分析时间存储格式的选择与应用,并总结时间存储格式的重要性以及对其未来发展的建议和展望。
通过本文的阅读,读者将能够更好地理解数据库中时间的存储格式,并能够在实际应用中选择和使用合适的时间存储格式,从而提高数据库的效率和性能。
让我们一起深入探索数据库中时间存储格式的奥秘吧!1.2 文章结构文章结构是指文章的整体组织方式,包括各个部分的顺序、关联和层次结构。
一个清晰明确的文章结构能够使读者更容易理解文章内容,并能够有系统地阐述观点和思路。
本文的结构主要包括引言、正文和结论三个主要部分。
引言部分主要包括概述、文章结构和目的三个方面。
在概述中,我们将简要介绍数据库时间存储格式的背景和重要性,引起读者对这个问题的兴趣。
数据库设计说明书-国家标准格式

数据库设计说明书-国家标准格式数据库设计说明书-国家标准格式1、引言1.1 文档目的1.2 文档范围1.3 读者对象1.4 参考资料2、数据库设计总览2.1 数据库系统概述2.2 数据库架构2.3 数据库结构图2.4 数据库功能需求2.5 数据库性能需求2.6 数据库安全需求3、数据库逻辑设计3.1 概念模型设计3.1.1 实体关系图3.1.2 属性定义3.1.3 实体关系模型3.2 数据字典3.3 数据约束3.3.1 实体完整性约束3.3.2 参照完整性约束3.3.3 域完整性约束3.3.4 用户定义完整性约束 3.4 数据库操作规范3.5 数据库视图设计4、数据库物理设计4.1 存储结构设计4.2 索引设计4.3 数据分区设计4.4 安全性设计4.5 性能优化设计4.6 备份与恢复设计5、数据库实施计划5.1 数据库安装与配置5.2 数据迁移计划5.3 数据库测试与验证5.4 数据库启动与运行监控6、数据库维护与管理说明6.1 数据库监控与性能调优 6.2 数据库安全管理6.3 数据库备份与恢复6.4 数据库升级与迁移6.5 数据库故障处理与恢复7、附录7.2 数据库系统配置信息 7.3 数据库表结构详细信息 7.4 数据库脚本本文档涉及附件:附件1:数据库结构图附件2:实体关系图附件3:数据字典附件4:数据库操作规范附件5:数据库视图设计法律名词及注释:- 数据库:根据国家《信息安全法》,数据库是指存储、加工、管理和使用的大量数据集合。
- 实体关系模型:实体关系模型是一种描述数据库中数据结构的概念模型,例如,实体(Entity)、属性(Attribute)和关系(Relationship)。
- 数据约束:数据约束是限制数据库中数据的一组规则,例如,实体完整性约束、参照完整性约束、域完整性约束和用户定义完整性约束。
数据库格式

- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据库格式及说明
2020年房地产估价师考试报送数据采用DBASE数据库格式。
各地要准确填写证件类别和证件号码。
身份证号码18位,必须与证件上的号码保持一致,不得做任何修改或添加任何标识。
国籍(地区)分6种情况填写:内地、香港、澳门、台湾、
外籍和其他。
档案号为字符型,字节数为9位,具体规定为:第一位为考试类别代码(房地产估价师考试代码为“9”),第二、三位为年份代码(2020年代码为“20”),第四、五位采用行政区代码中代表各省、自治区、直辖市的行政代码(见“各省、自治区、直辖市行政区代码表”,以下简称“代码表”),后四位各地自定。
准考证号为字符型,字节数为11位,具体规定如下:
第一位为科目号,四个科目代码分别为:
房地产基本制度与政策:1
房地产开发经营与管理:2
房地产估价理论与方法:3
房地产估价案例与分析:4
第二、三位采用省、自治区、直辖市的行政区代码(见“代码表”);
第四、五位为考区号;
第六、七位为考点号;
第八、九位为考场号;
第十、十一位为序号(不应超过30)。
35 福建36 江西37 山东
41 河南42 湖北43 湖南
44 广东45 广西46 海南
50 重庆51 四川52 贵州
53 云南54 西藏61 陕西
62 甘肃63 青海64 宁夏
65 新疆66 兵团
注:军队代码99
(三)要求
报名数据库中各字段均不能为空。
学历、专业技术职务等内容要填写中文全名,不得填写代码。
报名数据库中考生的姓名如果出现异体字,需用同音字加中括号代替,例如姓名为“王”,如果“”字无法录入,则录入“王[炎]”,并附书面说明,加盖公章,连同身份证件复印件与报名数据库一起上报。
为保证评卷、合分工作的顺利进行,各地要准确填写档案号。
对去年有保留成绩的考生,必须使用去年的档案号,对今年的新考生,在生成档案号时,必须按照上述规定进行。