2013数学建模会议分组问题
2013年参加数学建模竞赛集训面试名单及分组

2013年参加数学建模竞赛集训面试名单及分组序号姓名笔试成绩校赛成绩面试地点备注1刘栋B一等C1072邵明杰B一等C1103周晋海B一等C1154程红伟B二等C1165宋雪岩B二等C117东6许天骄B二等C117西7刘文康A特等C1078张杨杨A二等C1109张金剑A特等C11510王凯鹏A一等C11611孙浩B一等C117东12王宇轩B二等C117西13王朝蕊B一等C10714马诗洋B一等C11015潘杰B一等C11516张宇涵A一等C11617郭展扩B一等C117东18李婷B二等C117西19李璞B一等C10720童康宁B二等C11021周刘拉B一等C11522李华清B一等C11623陈人冰B一等C117东24范浩祥B二等C117西25吴玉奇B二等C10726张俊B二等C11027沈晨阳B一等C11528张聪B二等C11629赵海峰B二等C117东30王茹B二等C117西31薛沨B一等C10732汤培梁B一等C11033张容肇B二等C11534王攀B一等C11635孟昱B二等C117东36郭知君B一等C117西37王锦锦A一等C10738师恺琪B二等C11039于文辉B一等C11540程海B一等C116 41李凯鑫B一等C117东42苏春晨B一等C117西43魏国建B特等C107 44吴奇B二等C110 45王睿A二等C115 46付惠泉B一等C116 47沈唱黎B二等C117东48李雁翎B二等C117西49鱼婷A一等C107 50蒋进军B二等C110 51刘振宇B二等C115 52张盛强B二等C116 53谢仁盛B一等C117东54于泉涌B一等C117西55张美A一等C107 56秦越B二等C110 57刘保君A一等C115 58赵子越A一等C116 59赵鹏宇B二等C117东60闫佳男A二等C117西61张诗杰B一等C107 62汪建明A一等C110 63陈彬彬B一等C115 64孙浩B二等C116 65林昱溪B二等C117东66李璐A C117西67张瑞B一等C107 68黄志新B一等C110 69王孝宇B二等C115 70杨亚明A C116 71刘文东A一等C117东72刘啸泽B C117西73陈柯宇B一等C107 74张珊A特等C110 75孙召昌B二等C115 76李媛媛B二等C116 77王凯月A C117东78刘宇航A二等C117西79杨帅涛A C107 80徐炜斌B一等C110 81张婧昕A一等C115 82张忠博A一等C11683郑洋德B一等C117东84施剑华B二等C117西85吴爱萍B二等C107 86李建苗B二等C110 87刘明珠A一等C115 88宋海杰B二等C116 89伍祈应A二等C117东90辛杰B二等C117西91吴科永B二等C107 92何睿杰A一等C110 93于伟A C115 94张余 A 一等C116 95程明畅B一等C117东96刘俊伟A C117西97聂迎A一等C107 98李豪B一等C110 99蒋祥明A C115 100谢维A二等C116 101黄智宇A二等C117东102杜景南A一等C117西103司萌萌B一等C107 104宋郝开B二等C110 105史思雨A一等C115 106宋嵩焘A一等C116 107韩宇欢A二等C117东108刘晓楠A二等C117西109于莹莹B C107 110林伟宏A一等C110 111王强B二等C115 112王文胜A C116 113王薇薇A一等C117东114陈香A二等C117西115张剑如A二等C107 116汪波A一等C110 117韩子轩A二等C115 118黎南烽B二等C116 119刘鹏辉B二等C117东120王亚宁A一等C117西121王亚利A二等C107 122杜永志A二等C110 123黄代炜A二等C115 124姚威B二等C116 125邓成河B一等C117东126崔元顺B二等C117西127胡璇B C107 128刘传兴A C110 129郭庆B一等C115 130黄华建A一等C116 131李津B一等C117东132李恂B一等C117西133文雪B一等C107 134刘瑞童B一等C110 135王远远B一等C115 136周柏宇B二等C116 137张鹤A二等C117东138王晓东A二等C117西139张淑娥B二等C107 140李信信A C110 141周培坤A C115 142岳明煜B一等C116 143徐猛B二等C117东144衡通A二等C117西145李佳伟B二等C107 146陈文康A一等C110 147马丁B一等C115 148吕鑫B一等C116 149王雅馨B一等C117东150翟娜B二等C117西151王腾A C107 152张彦芳A一等C110 153王英艺B一等C115 154王兴文A二等C116 155卫晓倩B二等C117东156姜思佳B一等C117西157王耀晖B二等C107 158夏宇哲B二等C110 159苏伟鑫B二等C115 160白忠明B二等C116 161李云A二等C117东162何方A C117西163蔡宇杰B二等C107 164陈霏B一等C110 165冯志燕A一等C115 166南智文A二等C116 167 黄玉辉 B 二等C117东。
2013年全国研究生数学建模竞赛E题

2013年全国研究生数学建模竞赛E题中等收入定位与人口度量模型研究居民收入分配关系到广大民众的生活水平,分配公平程度是广泛关注的话题。
其中中等收入人口比重是反映收入分配格局的重要指标,这一人口比重越大,意味着收入分配结构越合理,称之为“橄榄型”收入分配格局。
在这种收入分配格局下,收入差距不大,社会消费旺盛,人民生活水平高,社会稳定。
一般经济发达国家都具有这种分配格局。
我国处于经济转型期,收入分配格局处于重要的调整期,“橄榄型”收入分配格局正处于形成阶段。
因此,监控收入分配格局的变化是经济社会发展的重要课题,例如需要回答,与前年比较,去年的收入分配格局改善了吗?改善了多少?可见实际上需要回答三个问题:什么是“橄榄型”收入分配格局?收入分配格局怎样的变化可以称之为改善?改善了多少?直观上,中间部分人口增加,则收入分配格局向好的方向转化。
于是基本问题回答什么是中间部分。
一个国家的收入分配可以用统计分布表示,图1是某收入分配的密度函数x是众数点,m是中位数点,μf,其中0(x)x表示收入(仅考虑正的收入),≥是平均收入。
收入分配经验分析说明,收入分配曲线一般是所谓正偏的,即峰值点向左偏,右端拖一个长尾巴,且通常有μx<<m(1)记对应的分布函数为)Fp=表示收入低于或等于x的人口比例。
由于F,则)(x(xmF,(1)式意味着收入大于或等于平均收入的人口一定不到半数,因此(=)12是少数。
记收入低于或等于x 的人口群体拥有收入占总收入的比例为)(p L ,则应有⎰=x t t tf p L 0d )(1)(μ,)(x F p = (2))(p L 称之为收入分配的洛伦兹曲线。
显然,如果)(1p L 与)(2p L 是两个不同收入分配的洛伦兹曲线,若对任何)1,0(∈p 都有)()(21p L p L ≥,则)(1p L 对应的收入分配显然更优,因为在)(1p L 中,任何低收入端人口拥有的总收入比例更大。
数学建模会议分组问题

会议分组问题摘要本文解决会议分组问题,即在会议次数以及参会人数确定的情况下求取不同地区之间最大的见面概率的会议安排方式,通过设置相应参数,逐步建立数学模型,并采用Lingo编程进行计算,并最终确定会议人员参加会议的分组方案。
下面将分别对三个问题进行阐述:问题1是已知有名代表参加会议,要分个场次,每场会议中有个小组,先对数据进行了矩阵化处理,其中引入常值元素来区分不同地区的代表,以L×N的矩阵表示每个人在某一场的出席情况,以此建立非线性整数变量规划模型。
为了达到尽可能使来自不同地区的代表能有见面交流机会的目的,本文以每组代表人数基本均衡、每个会议每个代表有且只能在一个小组内为约束条件,根据M个矩阵的加和等一系列运算的结果,得到M场会议之后与会人员的见面情况,从而进行优化,最终确立出最优的分组方案。
针对问题2,本文通过建立分组矩阵、开会矩阵,制定约束条件,构造相遇矩阵以及构造异地代表是否见面函数,逐步建立最终的数学模型。
但是用lingo 计算大量数据的非线性模型运行时间太长,无法获得运算结果(超过5个小时),因此采用分部计算的形式来求解此模型,也就是一共有次会议,须经过多次迭代,每次迭代只计算一次会议的会面情况,每次迭代时更新目标函数的系数,上一次已经会面的代表假设为同一地区,则这次计算常值系数,只计算未见面的代表会见面次数的最大值,迭代完毕之后将次结果综合考虑,并最后得到模型的最优方案。
针对问题3,将问题1中的N、M、L分别取做8、5、5,采用问题(1)所建立的模型以及问题2设计的算法,运行程序,得到的分配结果如下:表2 会议的分组方案第一组第二组第三组第四组第五组第一次2、874、513、6第二次514、63、82、7第三次3、741、82、65第四次74、82、631、5第五次41、673、82关键词:会议分组;矩阵分析;迭代运算;整数规划;约束条件一、问题的重述会议分组是一个很实际的问题,目前国内外许多重要会议都是以分组形式进行研讨,以便充分交流、沟通。
数学建模会议分组问题

会议分组问题摘要本文解决会议分组问题,即在会议次数以及参会人数确定的情况下求取不同地区之间最大的见面概率的会议安排方式,通过设置相应参数,逐步建立数学模型,并采用Lingo编程进行计算,并最终确定会议人员参加会议的分组方案。
下面将分别对三个问题进行阐述:问题1是已知有名代表参加会议,要分个场次,每场会议中有个小组,先对数据进行了矩阵化处理,其中引入常值元素来区分不同地区的代表,以L×N的矩阵表示每个人在某一场的出席情况,以此建立非线性整数变量规划模型。
为了达到尽可能使来自不同地区的代表能有见面交流机会的目的,本文以每组代表人数基本均衡、每个会议每个代表有且只能在一个小组内为约束条件,根据M个矩阵的加和等一系列运算的结果,得到M场会议之后与会人员的见面情况,从而进行优化,最终确立出最优的分组方案。
针对问题2,本文通过建立分组矩阵、开会矩阵,制定约束条件,构造相遇矩阵以及构造异地代表是否见面函数,逐步建立最终的数学模型。
但是用lingo 计算大量数据的非线性模型运行时间太长,无法获得运算结果(超过5个小时),因此采用分部计算的形式来求解此模型,也就是一共有次会议,须经过多次迭代,每次迭代只计算一次会议的会面情况,每次迭代时更新目标函数的系数,上一次已经会面的代表假设为同一地区,则这次计算常值系数,只计算未见面的代表会见面次数的最大值,迭代完毕之后将次结果综合考虑,并最后得到模型的最优方案。
针对问题3,将问题1中的N、M、L分别取做8、5、5,采用问题(1)所建立的模型以及问题2设计的算法,运行程序,得到的分配结果如下:表2 会议的分组方案关键词:会议分组;矩阵分析;迭代运算;整数规划;约束条件一、问题的重述会议分组是一个很实际的问题,目前国内外许多重要会议都是以分组形式进行研讨,以便充分交流、沟通。
本文是将相应的参数进行了设置,参会代表N 名,M个场次,每场会议L个小组,并且要求每个小组的人数基本均衡。
数学建模会议分组问题

会议分组问题摘要本文解决会议分组问题,即在会议次数以及参会人数确定的情况下求取不同地区之间最大的见面概率的会议安排方式,通过设置相应参数,逐步建立数学模型,并采用Lingo编程进行计算,并最终确定会议人员参加会议的分组方案。
下面将分别对三个问题进行阐述:问题1是已知有名代表参加会议,要分个场次,每场会议中有个小组,先对数据进行了矩阵化处理,其中引入常值元素来区分不同地区的代表,以L×N的矩阵表示每个人在某一场的出席情况,以此建立非线性整数变量规划模型。
为了达到尽可能使来自不同地区的代表能有见面交流机会的目的,本文以每组代表人数基本均衡、每个会议每个代表有且只能在一个小组内为约束条件,根据M个矩阵的加和等一系列运算的结果,得到M场会议之后与会人员的见面情况,从而进行优化,最终确立出最优的分组方案。
针对问题2,本文通过建立分组矩阵、开会矩阵,制定约束条件,构造相遇矩阵以及构造异地代表是否见面函数,逐步建立最终的数学模型。
但是用lingo 计算大量数据的非线性模型运行时间太长,无法获得运算结果(超过5个小时),因此采用分部计算的形式来求解此模型,也就是一共有次会议,须经过多次迭代,每次迭代只计算一次会议的会面情况,每次迭代时更新目标函数的系数,上一次已经会面的代表假设为同一地区,则这次计算常值系数,只计算未见面的代表会见面次数的最大值,迭代完毕之后将次结果综合考虑,并最后得到模型的最优方案。
针对问题3,将问题1中的N、M、L分别取做8、5、5,采用问题(1)所建立的模型以及问题2设计的算法,运行程序,得到的分配结果如下:表2 会议的分组方案关键词:会议分组;矩阵分析;迭代运算;整数规划;约束条件一、问题的重述会议分组是一个很实际的问题,目前国内外许多重要会议都是以分组形式进行研讨,以便充分交流、沟通。
本文是将相应的参数进行了设置,参会代表N 名,M个场次,每场会议L个小组,并且要求每个小组的人数基本均衡。
2013全国大学生数学建模竞赛B题
将008代表的矩阵C8的第二列元素与其它矩 阵的第一列元素进行两两匹配。记录元素相 同的个数,个数除以1980为C8矩阵第二列对 其它矩阵第一列的边缘匹配度,记为:
比较这18个数据,最大的即为与008匹配的 碎纸片。然后以所找到的碎纸片的第二列开 始,求出它与其它矩阵第一列的边缘匹配度, 找出最大的,以此类推把19张碎纸片拼接完 成。
三.问题2的分析
英文碎纸片的分析 通过观察可以发现英文字母的主要的 部分拥有同一上界和同一下界,例如:
将图片中每一行中黑色像素数少于13的及 字母的次要部分转变为二值化矩阵中的0, 将每一行中黑色像素大于等于13的及字母 的主要部分转化为二值化矩阵中的1,这样 得到的新的二值化矩阵 。例如图像转变为 如下图的方式:
二.问题1的分析
步骤一:使用matlab中的imread函数 可以做出图片的灰度矩阵 ,读取每 张图片文件的数据,其目的是将附件 中给的 bmp 格式的碎纸片图以灰度 值矩阵的形式存储。再将灰度值矩阵 转化为 0-1 矩阵,来得到模型的数 据基础;
由于该像素图片转换后为
的矩阵,ቤተ መጻሕፍቲ ባይዱ
论文中无法放置,所以仅简单举例说明:
以纸片000与001为例,匹配方式可能为:
将①②的边缘匹配度相加得到边缘匹配度 之和,将③④的边缘匹配度相加得边缘匹 配度之和,两者的和做出比较。若仅有一 个大于等于1.9,则计算机输出该匹配度, 人工判断是否碎纸片是否匹配;若两者均 大于等于1.9,计算机把两个匹配度之和输 出,人工选择判断碎纸片应是否匹配与如 何匹配;若两者均小于1.9,则计算输出最 大者,人工判断碎纸片是否匹配。这样可 以得到一些在同一横行的碎纸片的拼接。
总体思路
三步走:分行,行内排序,行间排序
数学建模实践-评委分组问题
68 75 82 75 66 65 68 71 81 67 64 67 779 66 68 68 71
80 76 80 73 77 75 68 78 85 82 67 75 68 78 73 78 75 80 82 80 75 75 80 72 84 83 72
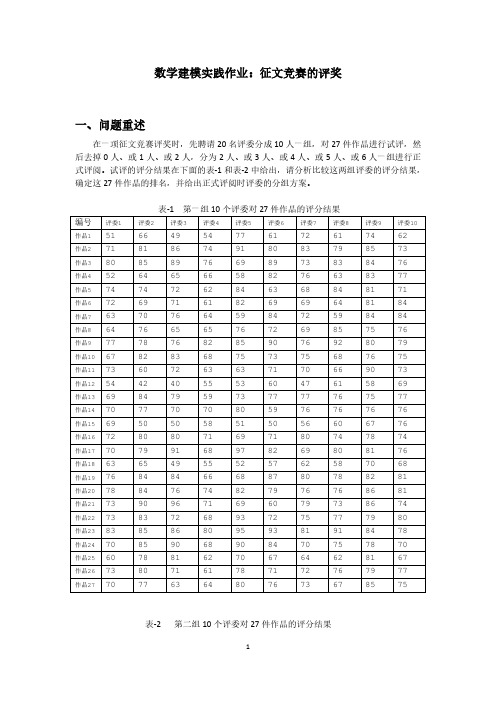
作品编号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
得分均值 65.4 77.15 77.5 69.9 72.7 69.25 68.4 69.15 79.85 71.5 65.85 61.1 71.7 72.8 62.2 72.4 76.9 62.65 75.6 77.5 74.65 74.4 81.35 74.75 68.7 72.9 72.25
方差 90.46316 36.97632 45.10526 72.51579 36.22105 47.46053 88.88421 62.13421 30.66053 39.21053 70.55526 104.2 37.37895 28.06316 73.01053 24.67368 52.09474 54.13421 58.04211 28.89474 78.13421 43.72632 46.13421 51.67105 51.58947 35.35789 33.88158
53 68 63 60 76 58 47 62 69 63 50 63 70 67 59 64 75 62 64 70 62 68 67 73 60 73 69
76 74 75 77 73 66 70 69 80 66 66 73 67 76 71 73 77 64 81 84 77 69 79 68 66 74 71
数学建模综合题目参考答案

综合题目参考答案1. 赛程安排(2002年全国大学生数学建模竞赛D 题)(1)用多种方法都能给出一个达到要求的赛程。
(2)用多种方法可以证明支球队“各队每两场比赛最小相隔场次的上界”n r (如=5时上界为1)是,如:n ⎦⎤⎢⎣⎡-23n 设赛程中某场比赛是,两队, 队参加的下一场比赛是,两队(≠i j i i k k ),要使各队每两场比赛最小相隔场次为,则上述两场比赛之间必须有除,j r i ,以外的2支球队参赛,于是,注意到为整数即得。
j k r 32+≥r n r ⎥⎦⎤⎢⎣⎡-≤23n r (3)用构造性的办法可以证明这个上界是可以达到的,即对任意的编排出n 达到该上界的赛程。
如对于=8, =9可以得到:n n 1A 2A 3A 4A 5A 6A 7A 8A 每两场比赛相隔场次数相隔场次总数1A ×159131721253,3,3,3,3,3182A 1×206231126164,4,4,3,2,2193A 520×2410271522,4,4,4,3,2194A 9624×28243192,2,4,4,4,3195A 13231028×41872,2,2,4,4,4186A 171127144×8223,2,2,2,4,4177A 2126153188×124,3,2,2,2,4178A 251621972212×4,4,3,2,2,2171A 2A 3A 4A 5A 6A 7A 8A 9A 每两场比赛相隔场次数相隔场次总数1A ×366311126162114,4,4,4,4,4,4,282A 36×2277221217324,4,4,4,4,4,3273A 62×3515302025103,3,4,4,4,4,4264A 312735×318813234,4,4,4,3,3,3255A 117153×342429193,3,3,3,4,4,4246A 2622301834×49144,4,3,3,3,3237A 1612208244×33283,3,3,3,3,3,4228A 2117251329933×53,3,3,3,3,3,3,219A 13210231914285×3,4,3,4,3,4,324可以看到,=8时每两场比赛相隔场次数只有2,3,4,=9时每两场比n n 赛相隔场次数只有3,4,以上结果可以推广,即为偶数时每两场比赛相隔场n 次数只有,,,为奇数时只有,。
最new数学建模队员选拔组队问题PPT

问题二
队员编号
5 11 13 6 21 25 16 8 14 4
建模水平
0.032219 0.029622 0.027367 0.024771 0.024771 0.013769 0.030921 0.026069 0.023472 Max 0.0033517
编程水平
Max 0.009821 0.009821 0.009821 0.009821 0.009821 0.009821 0.005456 0.007639 0.005456 0.007639
⑶ 得特征向量并一致性检验
特征向量 0 [0.1095,0.3090,0.5815] 3.0037 最大特征值 一致性检验 CR CI 0.00185 0.0032 0.1
RI 0.58
通过一致性检
问题一
⑷ 对各项指标进行量化
① 将校赛名次一等奖,二等奖,三等奖,参赛 奖用7,5,3,1来代替 ②等级评分A,B,C,D用4.5,3.5,2.5,1.5来代替
第一组 第二组 第三组 第四组 第五组 最优 4 5 16 1 11 7 25 3 21 6 13 18 14 8 12 13 9 2 0.08856 0.08856 0.08856 0.080274 0.078721 0.076102 AAAA AAAA AAAA AAAB AABB ABBB
谢谢大家!
11
0.011786
12
0.006987
9
0.029002
1
0.032499
21
0.011786
13
0.006987
13
0.029002
16
0.032499
6
0.011786
数学建模最佳组队方案

数学建模论文加权向量组合安排最佳组队方案摘要:在一年一度的数学建模竞赛活动中,都会有很多院校组织学生参加数学建模竞赛,比赛规则就是3个人组成一个队,但是每个学校都会有同样的问题,那就是在挑选出来的参赛团队中如何安排组队才能使队伍实力最强,以及整个团队实力最强,即追求一种整体实力最大化,这是参赛之前每个院校必须做好的工作,组队原则是队员各方面能力能互补.根据某院校20名参赛预选队员,学校决定从20名队员中选出18名队员参加数学建模竞赛。
根据对20名队员各项(7项)衡量指标判定学生的综合素质,我们通过定义7项指标的权重得到一个正互反阵,采用层次分析法,进行分析,并且检验是否通过一致性检验,即则通过一致性检验,那么就可以知道每一个学生的综合成绩,通过筛选把最差的两个学生排除,就得到安排人数及名单,经检验在问题一中各项指标分层分析都通过一致性检验,运用MATLAB进行计算输出结果.在问题二中采用一随机三个人进行组合,进行随机组队,然后采用对每一个队组成的的一个矩阵这样的矩阵通过MATLAB计算有816个,那么就有816种组合方式,在矩阵中每一行表示学生的姓名,列表示学生的各项指标,为了让三个对员能够形成互补,我们采用调用函数方法进行搜索每一列最大值,构成一个新的数组,代表该队的各项能力水平,这样依次取出就得到816个队的各项指标的成绩,再与问题一里面的权重向量相乘,就得到一个的一个总体综合实力的矩阵,再通过排序筛选出最大的一个值,找到与之对应的组合队员,那么就可以确定该队实力最强。
问题三采用随机排序然后每隔3个数归为一个整体代表每一个,一共有六个,通过增加其随机次数来确定它的稳定值。
关键词:层次分析,随机数循环,加权向量,MATLAB,一致性检验一.问题重述:问题一:对于问题一的得要求要在20个队员中选出最好的18个人参加比赛,通过筛选把最后的两个同学进行排就可以确定参赛队员名单.问题二:对于问题二,根据题目要求通过对全局组合进行筛选,这里运用问题一里面的数据,通过层次分析出来的权向量,以及筛选出来的18个队员名单进行排列组合的所有可能性做一个全局计算,得到每种可能组队的一个总体评价分数指标,然后筛选出最大的一个分数,就可以知道该队的人员组合安排.问题三:对于问题三,根据题目要求筛选出来的18名队员组成的六个队需要进行一个科学合理的搭配使得总体水平效果最好,要解决的问题是具体安排每一个队由哪些人员组成,需要解决的是队员组成的队伍里面队员能够进行相互各方面的缺陷,这样才能使总体效果最好.二.模型假设:1. 假设竞赛水平的发挥只取决于表中所给的各项条件;2。
2013高教社杯全国大学生数学建模真题

问题2. 根据酿酒葡萄的理化指标和葡萄酒的质量对这些酿酒 葡萄进行分级。
从附件2可以得知影响酿酒葡萄的因素比较多,分析起来数据比较繁琐,为了结果 的准确性,抓住最主要的因素,之后进行分析,得到简化,从而可以更有力的说明 问题,故我们采用了主成分分析法.得到了主要因子,简化了过程,然后利用各个 所占的比例进行评分。一般情况下,我们可以采用5分制评分标准(见表1)进行 赋值,其中等级程度是相对而言的,最后得到每一个样品的分数。
1 3 5 7 9 11 13 15 17 19 21 23 25 27 样品
红葡萄酒1 红葡萄酒2
通过比较两种葡萄酒的方差,发现红葡萄酒2比较稳定
图2
标准差
红葡萄酒标准差比较
12 10 8 6 4 2 0
1 3 5 7 9 11 13 15 17 19 21 23 25 27 样品
红葡萄酒1 红葡萄酒2
表2 主要因子
5分 5 4 3 2 1 制
因子 氨 蛋 还 PH 黄
基白原
酮
酸质糖
醇
5分制54321因子氨基酸蛋白质还原糖PH黄酮醇利用 Excel计算,画图分析可以得出:
分数 分数
红葡萄酒评分
4.9 4.8 4.7 4.6 4.5 4.4 4.3 4.2 4.1
4 3.9
1 3 5 7 9 11 13 15 17 19 21 23 25 27 样品
利用附件2、3,在每一种理化指标的数据中,有多组数据 的时候,要采用平均值,然后根据对应的含量值建立模型, 就红葡萄酒中的“单宁”为例,令葡萄酒中的含量为,酿 酒葡萄中的含量为,和取表中的平均值,建立模型,其中 是与单位、溶解度、挥发性、沸点等物理化学性质相关的 系数。利用spss软件曲线拟合得出、的值,其他物质含量 可以与此同样的方法得出关系。最后再根据酿酒葡萄与葡 萄酒各个理化指标平均值,求出其线性关系。
2013全国大学生数学建模竞赛C题参考答案

2013全国大学生数学建模竞赛C题参考答案第一篇:2013全国大学生数学建模竞赛C题参考答案2013高教社杯全国大学生数学建模竞赛C题评阅要点[说明]本要点仅供参考,各赛区评阅组应根据对题目的理解及学生的解答,自主地进行评阅。
问题1(1)补充1986年和1996年缺失的数据(第13层第5点),可用外推法或几何方法补充数据。
(2)因各层基本处于同一平面内,可先拟合出各层所在平面,将各测量点投影到拟合平面内,然后再用均匀物体的重心公式计算中心坐标。
注:(1)对1986年和1996年第13层,不补充数据,直接用7个点的数据计算中心坐标是错误的。
(2)用各层测量点坐标的平均值作为中心点坐标,不是一种好方法。
问题2(1)倾斜程度:对中心点作线性拟合,中轴线与水平面法向的夹角可作为倾斜程度的度量。
(2)弯曲程度:对中心点作三次样条拟合,三次样条曲线各点曲率的平均值可作为弯曲程度的度量。
也可用离散方法:连接各层的对应点,折线各顶点角度的平均值可作为弯曲程度的度量。
(3)扭曲程度:相邻两个平面的旋转角度可作为扭曲程度的度量。
问题3变形趋势:对问题2中的各种变形,关于时间作拟合,推测出未来几年的变化情况。
第二篇:2006全国大学生数学建模竞赛题目(A题)2006全国大学生数学建模竞赛题目-------A题:出版社的资源配置出版社的资源主要包括人力资源、生产资源、资金和管理资源等,它们都捆绑在书号上,经过各个部门的运作,形成成本(策划成本、编辑成本、生产成本、库存成本、销售成本、财务与管理成本等)和利润。
某个以教材类出版物为主的出版社,总社领导每年需要针对分社提交的生产计划申请书、人力资源情况以及市场信息分析,将总量一定的书号数合理地分配给各个分社,使出版的教材产生最好的经济效益。
事实上,由于各个分社提交的需求书号总量远大于总社的书号总量,因此总社一般以增加强势产品支持力度的原则优化资源配置。
资源配置完成后,各个分社(分社以学科划分)根据分配到的书号数量,再重新对学科所属每个课程作出出版计划,付诸实施。
数学建模学生面试问题(强烈推荐)

学生面试问题摘要本文研究的学生面试问题,是在给定学生数量的前提下,按照每名学生的面试组由四名老师组成,且各个学生的面试组两两不完全相同的要求,研究需要的老师数量,并求出面试分组方案。
为了保证面试的公平性,组织者还提出了四条要求,需要考虑除Y2外使其它三条要求尽量满足的分配方案。
第一问是已知学生数量为N,求任意两个面试组最多只有一名老师相同的最小老师数量,我们将此问题转化成一个0-1规划模型,并设计了优化搜索方法,通过MATLAB编程实现了最少M的近似解。
在第二问的解决中,首先对Y1-Y4四个要求进行了分析,并分别建立了相应的量化指标,在此基础上,建立了一个多目标规划模型。
针对学生数较多,模型求解运算量大的问题,特别设计了优化算法,减少了搜索中的运算量。
同时,通过讨论均衡与公平性的含义,以分目标为基础,建立了综合评价目标,以此为指引,使搜索算法更具有针对性。
计算结果表明,分配方案满足Y1-Y4的情况是非常好的。
第二问中还运用组合数学中区组设计的理论,论证了N=379、M=24时不存在完全满足均衡和公平要求的理想分配方案。
第三问中,将老师组分成文、理两类,首先修改了问题一中的相应模型和算法,给出了求解结果。
在第二问中提出了启发式-混合交叉算法,从模拟结果看,分配方案比原第二问中的方案要差些,但总体上在各个指标上满足的情况也是较好的。
第四问首先分析了均匀性与面试公平性的关系,并提出了公平率的评价指标。
为了解决学生与面试老师有特殊关系,及个别老师打分过于苛刻或宽松的问题,本文提出了规避的解决方法。
关键词:多目标规划算法评价指标1.问题重述某高校采用专家面试的方式进行自主招生录取工作。
经过初选合格进入面试的考生有N人,拟聘请老师M人进行面试。
每位学生要分别接受“面试组”的每一位老师的单独面试。
每个面试组由4名老师组成。
各位老师独立地对考生提问并根据其回答问题的情况给出评分。
为了保证面试工作的公平性,组织者提出如下要求:Y1:每位老师面试的学生数量应尽量均衡;Y2:面试不同考生的“面试组”成员不能完全相同;Y3:两个考生的“面试组”中有两位或三位老师相同的情形尽量的少;Y4:任意两位老师面试的两个学生集合中出现相同学生的人数尽量少。
2013高教社杯全国大学生数学建模竞赛

承诺书我们仔细阅读了中国大学生数学建模竞赛的竞赛规则.我们完全明白,在竞赛开始后参赛队员不能以任何方式(包括电话、电子邮件、网上咨询等)与队外的任何人(包括指导教师)研究、讨论与赛题有关的问题.我们知道,抄袭别人的成果是违反竞赛规则的, 如果引用别人的成果或其他公开的资料(包括网上查到的资料),必须按照规定的参考文献的表述方式在正文引用处和参考文献中明确列出.我们郑重承诺,严格遵守竞赛规则,以保证竞赛的公正、公平性.如有违反竞赛规则的行为,将受到严肃处理.我们参赛选择的题号是(从A/B/C/D中选择一项填写): A我们的参赛报名号为(如果赛区设置报名号的话):我们所属学校(请填写完整的全名):重庆三峡学院参赛队员(打印并签名) :1.桂宇星2.李绍红3.张京花指导教师或指导教师组负责人(打印并签名):王良伟日期: 2013 年 9 月 16日赛区评阅编号(由赛区组委会评阅前进行编号):编号专用页赛区评阅编号(由赛区组委会评阅前进行编号):赛区评阅记录(可供赛区评阅时使用):评阅人评分备注全国统一编号(由赛区组委会送交全国前编号):全国评阅编号(由全国组委会评阅前进行编号):车道被占用对城市道路通行能力的影响摘要随着经济的发展,城市化进程加快,城市机动化越来越明显,家用轿车大幅度增加,交通问题已成为全球的一大主要难题.特别是大城市,发生车辆碰撞的可能性非常大,进而影响到道路的畅通性. 由于城市道路具有交通流密度大、连续性强等特点,车道一旦被占用,就会降低路段所有车道的通行能力,即使时间短,也可能引起车辆排队,出现交通阻塞,如果处理不当,甚至出现区域性拥堵,给城市交通造成很大压力. 本文以交通事故这种异常事件为例,通过观察视频, 对同一交通横断面不同车道的两个交通事故进行数据统计和分析,研究城市道路基本路段内交通事故影响时间、车辆排队长度、事故影响下不同时间段内断面流量变化之间的关系,得到在某种原因堵塞时,能够对车流排队的时间和长度进行客观的估计,为交通管制与控制部门采取交通管制提供了理论依据.针对问题一及视频1,我们将交通事故发生至撤离期间分成19个时间段,分别统计这19个阶段中经过事故横断面的车辆数,并参照城市道路工程设计规范,计算出19个时间段内实际道路交通量与畅通系数,结合Excel 软件绘图,从而获得了直观的反映出道路通行能力变化过程的结果:A 级稳定流(稍有阻滞):18、19组;B 级稳定流(有阻滞、可接受):1、2、7、8、9、10、16、17组;C 级接近非稳定流(阻滞):5、6、12、13、14、15组;D 级非稳定流(阻塞、严重阻滞):3、4组.针对问题二及视频2,类似于问题一所得出的结论,获得视频2中道路通行能力变化过程的结果. 关于视频1和视频2的道路流通量差异方面, 首先通过对不同目标设置权重,建立基于层次分析法的模糊评判关系,从定性上得出了视频1中的堵塞情况严重于视频1;另外,我们选取了事故事件中的部分时间点,结合聚类分析,从定量上也得出了视频1中的堵塞情况严重于视频2.针对问题三, 结合车流波动理论建立了交通事故下车辆排队长度(x )与横断面实际通行能力(2S )、拥堵持续时间(消散时间T )、路段上游车流量(Q )的模型如下1122f 0()S V (1)(T T )S S f K K x Q K QT +=-⨯-,其中f 12V ,,,,T S S f K K K 为参数.针对问题四, 我们将问题三所得出了模型进行非线性回归分析,确定各个参数的值,得出如下数值表达式:123(0.0001 1.0243)/.)(0.3253+).x x x ±⨯⨯y= (-00001其中123y,x ,,x x 分别为排队长度、上游车流量、道路实际通行能力系数、事故持续时间. 给定1x =1500,2x =0.5, y =140, 从而得出事故持续时间3x 的取值为8分钟左右.关键词:模糊评判,聚类分析,流体交通量,排队论,多元非线性回归一、问题重述1.1 问题背景车道被占用是指因交通事故、路边停车、占道施工等因素,导致车道或道路横断面通行能力在单位时间内降低的现象. 由于城市道路具有交通流密度大、连续性强等特点,一条车道被占用,也可能降低路段所有车道的通行能力,即使时间短,也可能引起车辆排队,出现交通阻塞.如处理不当,甚至出现区域性拥堵.车道被占用的情况种类繁多、复杂,正确估算车道被占用对城市道路通行能力的影响程度,将为交通管理部门正确引导车辆行驶、审批占道施工、设计道路渠化方案、设置路边停车位和设置非港湾式公交车站等提供理论依据.1.2 需要解决的问题(1).根据视频1,描述视频中交通事故发生至撤离期间,事故所处横断面实际通行能力的变化过程.(2). 根据问题1所得结论,结合视频2,分析说明同一横断面交通事故所占车道不同对该横断面实际通行能力影响的差异.(3). 构建数学模型,分析视频1(附件1)中交通事故所影响的路段车辆排队长度与事故横断面实际通行能力、事故持续时间、路段上游车流量间的关系.(4). 假如视频1(附件1)中的交通事故所处横断面距离上游路口变为140米,路段下游方向需求不变,路段上游车流量为1500pcu/h,事故发生时车辆初始排队长度为零,且事故持续不撤离.请估算,从事故发生开始,经过多长时间,车辆排队长度将到达上游路口.二、问题分析对于问题(1),先数出事故C处未发生的时候,单位时间内通过的车辆,求出正常情况下C处的实际通行能力,并以此为基准,然后,再数出发生事故之后单位时间内通过的车辆,并计算出他们的通行量,从而求出其通行率即为畅通系数.从而直观的反映出道路通行能力的变化过程.对于问题(2),题目要求结合问题一所得结论,对视频一条件下车道占用与视频二进行对比,从而说明同一横断面交通事故所占车道不同对该横断面实际通行能力影响的差异.考虑到道路交通是一个复杂的问题,可以通过基于层次分析法的模糊评判定性上进行讨论.又可以抽取事故期间的不同时间点,通过聚类分析,从定量上对两种情况进行讨论.对于问题(3),要求建议一种数学模型分析视频1(附件1)中交通事故所影响的路段车辆排队长度与事故横断面实际通行能力、事故持续时间、路段上游车流量间的关系,可以考虑构造交通流模型,结合车流波动理论进行讨论.对于问题(4),可以考虑对问题三所得出的函数关系式进行参数设定,可以考虑用非线性回归分析法,从而根据所得关系式解出时间.三、模型假设1、假设将所有车辆分为大型车和标准车两大类,大型车的折算系数取1.5,小型车的换算系数取1.0.2、假设在计算车流量时,所依据的道路横截面为一条直线.3、假设在计算车流量时,换算为车流量的标准单位时,可以用单位时间(1秒)的通行量乘以一年中的单位时间数得到.4、不考虑观测误差、随机误差和其他外在因素所产生的误差.5、假设车辆流在短时间内为连续流.四、变量与符号说明C一条车道的基本通行能力L连续车流的车头间距C n 条车道的基本通行能力y排队长度1x车流量2x横断面通行能力系数车流量3x持续时间五、模型建立与求解5.1 问题(1)的分析、模型建立与求解5.1.1建模准备5.1.1.1.一条车道的基本通行能力首先假设道路和交通状况都处于理想条件下,用技术性能相同的一种标避车,以最小的车头间距连续行驶的理想交通流,在单位时间内通过道路断面的最大车辆数,即基本通行能力,也称为理论通行能力,因为它是假定理想条件下的通行能力,实际上不可能达到.在一条车道连续行驶的车流中,跟随运行的前后相邻两车的间隔距离,即从前车的前端到后车的前端的间隔距离,叫车头间隔.车头间隔可用距离或行车时间来表示,用距离来表示车头间距的称为车头间距(m);用行车时间来表示车头间隔的称为车头时距(s). 路段上一条车道的通行能力,可按车头间距和车头时距两种方法来计算.其计算公式为0100040.3656+L+L.CL L ⨯==反车安,式中:C——一条车道的基本通行能力(pcu/h); v——行驶速度(km/h);L——连续车流的车头间距(m);L安——车辆安全车间距(m);L车——车辆的本身长度(m);L反——驾驶员在反应时间内车辆行驶的距离(m),=vL T反,T=1.2s 左右.由于基本通行能力计算时不考虑道路和交通条件的影响,因此多车道的基本通行能力可按下式计算:0C NC =,式中: N ——车道数;C ——n 条车道的基本通行能力; 0C —一条车道的基本通行能力.为了简化模型,由视频一的数据,我们观察了不同的10辆车在畅通条件下,我们把这10辆车通过通过折算率转换成标准车,如下表所示:. 车型 中 中 小 大 大 小 大 中 小 中 距离 240 240 240 240 240 240 240 240 240 240 时间 17 15 27 25 30 26 25 17 26 18 速度 50.82 57.6 32 34.56 28.8 33.23 34.56 50.82 33.23 48 算出平均值为:40.36标准车的长度为5.3m ,人的反应时间为1.2s ,反应距离为48.432 ,车辆安全车间距2m ,所以L= 56 m.其中 01000V C L==100040.3656⨯=720 .5.1.1.2多车道对路段通行能力的影响自路中心线起第一条车道的折减系数a 条为1.00,第二条车道为0.80~0.89, 第三条为0.65~0.78.其第二车道和第三车道可取中间值分别为0.85,0.72. 车道宽度3.25m ,通行能力折减系数0.94 按《道路通行能力分析》a 交=0.81)·(·C C a a a =理论交折道; 因此,1C =9460.810.94⨯⨯=720 ;2C =9460.850.810.94⨯⨯⨯=612 ; 3C =9460.720.810.94⨯⨯x=518 .故C 路段=1840pcu/h. 5.1.2数据的统计预处理观察视频一,我们将车辆发生碰撞到交通通畅的这一段时间分为24段,通过统计通过事故横断面的车辆,并转化为标准车辆数可得以下表格:车辆统计表1时间点 通过大车量 通过小车量当量车 堵车前1 1 1314.52 1 19 20.53 3 1822.5 4 4 14 20 5 1 14 15.5 6 0 13 13 7 1 1314.5堵 车 中8 0 14 14 9 1 18 19.5 10 0 13 13 11 1 8 9.5 12 0 14 14 13 1 14 15.5 14 1 15 16.5 15 1 14 15.5 16 1 14 15.5 17 0 14 14 18 1 11 12.5 19 2 9 12 20 1 10 11.5 21 2 11 14堵车后22 2 22 2523 0 20 20 24 1 23 24.55.1.3新物理量的创立与指标的分级仿照交通最大服务量pcu/(km*ln)我们创建新的物理量车道交通量pcu/(h*ln),通过对附件3道路实际路宽及车道数的了解, 参照PHF 即高峰小时的计算式:PHF=小时交通量/交通流率(该小时).对于1min 区间来说,1.60VPHF V =⨯式中: V ——小时交通量;1V ——高峰小时内最大的60min 交通量.我们定义新的物理量:通畅系数=实际车道交通量/标准车道交通量 化为当量车的表格如下:时间点 当量车 车道交通量 通畅系数 堵车前 70 377 堵 车中1 20 1191.6 0.79442 15.5 1143.45 0.7623 3 13 875.1 0.5834 4 14.5 871.8 0.5812 5 14 1045.65 0.69716 19.5 1024.65 0.68317 13 1135.95 0.75738 9.5 1113.9 0.7426 9 14 1197.45 0.7983 10 15.5 1164.3 0.7762 12 16.5 1017 0.6780 13 15.5 969.3 0.6462 14 15.5 1015.5 0.677015 14 981.45 0.654316 12.5 1136.850.7579 17 12 1122.3 0.7482 18 11.5 1368.6 0.9124 19 14 1494 0.9960 堵车后60 588通畅系数波动图由车道交通量分析同一时间通过同一车道的车辆越多则车道越通畅,因而通畅系数越大则表明道路通行能力越高,我们对通畅系数进行分级从而更加直观看出道路通行状况如下表所示: A 级稳定流(稍有阻滞) B 级稳定流 (有阻滞、可接受) C 级接近非稳定流 (阻滞) D 级非稳定流 (阻塞、严重阻滞)0.9—1.0 0.7—0.9 0.6—0.7 0.6及以下 第18,19组第1、2、7、8、9、10、16、17组 第5、6、12、13、14、15组第3、4组5.2 问题(2)的求解 5.2.1 问题(2)的分析根据问题1所得结论,结合视频2,我们采用了模糊评判模型和聚类分析模型分析说明同一横断面交通事故所占车道不同对该横断面实际通行能力影响的差异. 5.2.2模糊评判模型的建立与求解}{12u u ,...,u s n U =第一步,将因数集,将某种属性分为个子因素集12,,s U U U ⋯,其中i U = {i2ini i1u u ,...,u },, i=1,2s ,...,,且满足○1 12s n +n +...n =n; ○2 12...;S U U U ⋃⋃⋃= ○3 i j i j =φ≠⋂对任意的,U U . 第二步,对每一个因素集U i ,分别做出综合评判.设12{}m V v v v =⋯,,,为评语集,i U 中各因素相当于V 的权重分配是[]12,,.i i i ini A a a a =⋯若i R 为单因素评判矩阵,则得到一级评判向量i i i i1i2im ==[b ,b ,...n ],i=1,2,...,s.B A R第三步,将每个i U 看作一个因素,记为 12{,,...,}.s k u u u =这样,K 又是一个因素集,K 的单因素评判矩阵为11112122122212.m m S s s sm B b b b B b b b R B b b b ⎡⎤⎡⎤⎢⎥⎢⎥⎢⎥⎢⎥==⎢⎥⎢⎥⎢⎥⎢⎥⎣⎦⎣⎦将每个单因素看作一个矩阵,,按其重要性分配权重1[,...,]s A a a =,于是得到二级评判向量,1[...].m B A R b b =∙=在本问题中,一级指标对目标值对应的权重0.4,0.6.,在视频一的条件下,车道一、车道二,车道三对应的权重为0.5,0.25,0.25.在视频二对应的条件下,车道一、车道二,车道三对应的权重为0.25,0.5,0.5. 视频1表格如下: 视频1情况下的模糊评判指标一级指标 二级指标 优 良 中 合格 差拥堵截断面的大型车辆 车道一 0.1 0.3 0.4 0.1 0.1车道二 0.2 0.4 0.4 0 0车道三 0.1 0.3 0.5 0.1 0 拥堵截断面中的小型车辆 车道一 0 0.1 0.1 0.4 0.4车道二 0 0 0.1 0.4 0.5车道三 0.2 0.4 0.3 0.1 0结果:B A R =∙=[0.0950 0.2550 0.3150 0.1750 0.1600] 根据最大隶属度原则,评判结果为中. 视频2表格如下:视频2情况下的模糊评判指标一级指标 二级指标 优 良 中 合格 差拥堵截断面的大型车辆 车道一 0.1 0.3 0.4 0.2 0车道二 0 0.4 0.2 0.2 0.2车道三 0.2 0.3 0.4 0.1 0 拥堵截断面中的小型车辆车道一 0.1 0.1 0.1 0.4 0.3车道二 0.1 0.1 0.1 0.4 0.3车道三 0.2 0.4 0.2 0.1 0.1结果:B A R =∙==[0.1350 0.2950 0.2700 0.1900 0.1100] 根据最大隶属度原则,评判结果为良好. 结论分析:由模糊评判从定量上可以得出,视频一条件下道路情况要比视频二糟糕. 5.2.3聚类分析模型的建立与求解聚类分析主要包括样本相似性度量,类与类间相似性度量两个步骤. (1)样本的相似性度量在对样本进行聚类分析时,首先要确定样本的相似性度量,常用的样本相似性度量有马氏距离、车比雪夫距离、欧式距离等,下面介绍最常用的欧式距离法.记Ω是样本点集,距离),(y x d 是+→×R ΩΩ的一个函数,满足条件: ①;∈,,0≥),(Ωy x y x d②;=0=),(y x y x d 当且仅当 ③;∈,),,(=),(Ωy x x y d y x d ④.∈,,),,(+),(≤),(Ωz y x y z d z x d y x d这一距离的定义满足正定性、对称性和三角不等式.在聚类分析中,对于定量变量,最常用的是闵氏距离,即,0,]||[),(11>==q y x y x d qpk q k k q ∑-当2=q 时则得到欧式距离. (2)类与类间的相似性度量如果有两个样本类1G 和2G ,则可以用最短距离法、最长距离法、重心法、类平均法等方法度量它们之间的距离.下面介绍本文应用的类平均法.,),(*1),(122121∑∑∈∈G x G x j i i j x x d n n G G D = 它等于21,G G 中两样本点距离的平均,21,n n 分别为21,G G 中的样本点个数.下面选出的指标对酿酒葡萄样品进行聚类分析.首先对每个指标的数据ij p 进行标准化处理得到ijp ~,,,2,1,,,2,1,~n j m i s μp p jjij ij ===-其中,∑mi ij j p m μ11==,∑--m i j ij j μp m s 12)(11==,n j ,,2,1= ,n m ,分别表示选取的样点的数量和指标的数量.求解结果:样本间相似性采用欧式距离度量,类间距离的计算选用类平均法.视频1中我们收集的数据如下表所示:时间点 通过大车量 通过小车量 1/(该时刻区域内小车数目) 1/(该时刻区域内大车数目) 一车道车的数量/总车数1 1 13 0.07142857 1 0.33333333321 19 0.0555555561 0.43 3 18 0.071428571 0.33333333 0.6666666674 4 14 0.045454545 0.5 0.2857142865 1 14 0.05 1 0.256 0 13 0.055555556 0 0.27 1 13 0.066666667 1 0.31258 0 14 0.052631579 0 0.3030303039 1 18 0.071428571 1 0.2510 0 13 0.055555556 0 0.22222222211 1 8 0.071428571 1 0.2702702712 0 14 0.052631579 0 0.27777777813 1 14 0.043478261 1 0.32258064514 1 15 0.043478261 0.5 0.32258064515 1 14 0.037037037 0.5 0.27777777816 1 14 0.038461538 0.5 0.2702702717 0 14 0.035714286 1 0.29411764718 1 11 0.041666667 1 0.24390243919 2 9 0.05 1 0.29411764720 1 10 0.055555556 0 0.2702702721 2 11 0.0625 0 0.42 22 0.0625 0.5 0.41666666723 0 20 0.076923077 1 0.45454545524 1 23 0.083333333 1 0.666666667划分成3类的结果如下:第1类的有11 18 19 20 21第2类的有1 4 5 6 7 8 10 12 13 14 15 16 17第3类的有2 3 9 22 23 24**********************************划分成4类的结果如下:第1类的有22 24第2类的有2 3 9 23第3类的有11 18 19 20 21第4类的有1 4 5 6 7 8 10 12 13 14 15 16 17**********************************划分成5类的结果如下:第1类的有4第2类的有1 5 6 7 8 10 12 13 14 15 16 17第3类的有22 24第4类的有2 3 9 23第5类的有11 18 19 20 21聚类分析结果运行图视频2中我们收集数据如下所示:时间序号通过大车量通过小车量1/(该时刻区域内小车数目)1/(该时刻区域内大车数目)一车道车的数量/总车数1 2 19 0.1 0.5 0.3333332 1 18 0.05 1 0.3333333 0 20 0.1 0 0.6666674 3 13 0.046666667 0.333333 0.2857145 1 12 0.066666667 1 0.256 0 13 0.046666667 0 0.37 1 15 0.043478261 1 0.328 0 15 0.033333333 0 0.219 1 12 0.043478261 1 0.2510 0 13 0.056923077 0 0.22222211 1 14 0.041428571 1 0.2702712 0 15 0.047619048 0 0.27777813 1 15 0.043478261 1 0.32258114 1 14 0.043478261 1 0.32258115 0 13 0.037037037 0 0.27777816 1 10 0.038461538 1 0.2702717 0 12 0.035714286 0 0.29411818 2 13 0.041666667 0.5 0.24390219 1 17 0.05 1 0.29411820 0 17 0.055555556 0 0.2702721 1 18 0.0625 1 0.422 2 20 0.083333333 0.5 0.45454523 0 20 0.1 0 0.66666724 1 19 0.083333333 1 0.625划分成3类的结果如下:第1类的有16第2类的有4 5 6 7 8 9 10 11 12 13 14 15 17 18第3类的有1 2 3 19 20 21 22 23 24**********************************划分成4类的结果如下:第1类的有7 8 11 12 13 14第2类的有4 5 6 9 10 15 17 18第3类的有16第4类的有1 2 3 19 20 21 22 23 24**********************************划分成5类的结果如下:第1类的有2 19 20 21第2类的有1 3 22 23 24第3类的有7 8 11 12 13 14第4类的有4 5 6 9 10 15 17 18第5类的有16聚类分析结果运行图5.2.4模型评判由以上计算可知,多车道道路通行能力从中心至边缘车道依次递减.视频一中撞车位置在距道路中心一、二条车道上,因而可行车道为第三条车道;视频二中撞车位置在距道路中心二、三条车道上,因而可行车道为第一条车道.而从计算中可得,可上述结论,即视频二的事故所处断面实际通行能力要比视频一要强.这与实际情况比较吻合。
西安交大2013年数学建模校内赛赛题

A题我国中长期人口结构与经济发展研究2013年两会期间传来消息,人口和计划生育委员会将被撤销,其计划生育管理和服务职责将与卫生部合并,组建国家卫生和计划生育委员会。
这被外界认为是中国未来将调整人口政策的信号。
目前,中国的生育率已经远远低于更替水平,未来人口结构极度老化和急剧萎缩不可避免。
如何适度调整人口政策,增加我国的经济活力,使经济能持续发展,是我国当前宏观人口政策研究的一个重要课题。
问题1:请查找相关数据,建立数学模型研究是否应该逐步放宽二胎政策?抑或直接取消计划性政策?问题2:请利用互联网数据,任选一个角度(比如老龄化,延迟退休年龄等),建立数学模型研究人口结构与经济发展的关系。
问题3:基于你的数学模型,说明如何制定有利于经济中长期发展的人口政策,给出你的理由与合理建议,并写封信给国家卫生和计划生育委员会阐述你的观点。
B题深圳关内外交通拥堵探究与治理(选自2013年“深圳杯”数学建模夏令营题目)交通拥堵是目前中国各大城市面临的共同难题,但拥堵的成因各不相同,因而需要在摸清规律的基础上有针对性地提出解决方案。
由于历史的原因,深圳由关内关外两个区域组成。
关外由宝安、龙岗两个行政区和光明新区、龙华新区、坪山新区、大鹏新区四个功能区组成;关内含罗湖、福田、南山、盐田四个行政区。
关外与关内由自然山丘隔开,沟通关内外的主要通道有宝安大道/新安(22.548005,113.902194)、107国道南头(22.552058,113.910531)、同安路荔山(22.558983,113.916094)、广深高速同乐(22.569654,113.923931)、南光高速(22.599412,113.932321)、沙河西路白芒(22.625915,113.938683)、福龙路(22.595767,114.016038)、梅观路(22.595717,114.050027)、清水河(22.618864,114.094852)、布吉关(22.585331,114.115838)、沙湾(22.605763,114.163884)、北山道盐田坳(22.604894,114.218802)、盐坝高速背仔角(22.601422,114.344448)等检查站,括号内为Google地图经纬度坐标。
数学建模学生面试问题(强烈推荐)

学生面试问题摘要本文研究的学生面试问题,是在给定学生数量的前提下,按照每名学生的面试组由四名老师组成,且各个学生的面试组两两不完全相同的要求,研究需要的老师数量,并求出面试分组方案。
为了保证面试的公平性,组织者还提出了四条要求,需要考虑除Y2外使其它三条要求尽量满足的分配方案。
第一问是已知学生数量为N,求任意两个面试组最多只有一名老师相同的最小老师数量,我们将此问题转化成一个0-1规划模型,并设计了优化搜索方法,通过MATLAB编程实现了最少M的近似解。
在第二问的解决中,首先对Y1-Y4四个要求进行了分析,并分别建立了相应的量化指标,在此基础上,建立了一个多目标规划模型。
针对学生数较多,模型求解运算量大的问题,特别设计了优化算法,减少了搜索中的运算量。
同时,通过讨论均衡与公平性的含义,以分目标为基础,建立了综合评价目标,以此为指引,使搜索算法更具有针对性。
计算结果表明,分配方案满足Y1-Y4的情况是非常好的。
第二问中还运用组合数学中区组设计的理论,论证了N=379、M=24时不存在完全满足均衡和公平要求的理想分配方案。
第三问中,将老师组分成文、理两类,首先修改了问题一中的相应模型和算法,给出了求解结果。
在第二问中提出了启发式-混合交叉算法,从模拟结果看,分配方案比原第二问中的方案要差些,但总体上在各个指标上满足的情况也是较好的。
第四问首先分析了均匀性与面试公平性的关系,并提出了公平率的评价指标。
为了解决学生与面试老师有特殊关系,及个别老师打分过于苛刻或宽松的问题,本文提出了规避的解决方法。
关键词:多目标规划算法评价指标1.问题重述某高校采用专家面试的方式进行自主招生录取工作。
经过初选合格进入面试的考生有N人,拟聘请老师M人进行面试。
每位学生要分别接受“面试组”的每一位老师的单独面试。
每个面试组由4名老师组成。
各位老师独立地对考生提问并根据其回答问题的情况给出评分。
为了保证面试工作的公平性,组织者提出如下要求:Y1:每位老师面试的学生数量应尽量均衡;Y2:面试不同考生的“面试组”成员不能完全相同;Y3:两个考生的“面试组”中有两位或三位老师相同的情形尽量的少;Y4:任意两位老师面试的两个学生集合中出现相同学生的人数尽量少。
2013数学建模会议分组问题

会议分组问题摘要通过对问题的分析,我们确定运用优化的整数规划模型、矩阵理论和置换等方面的知识和技巧。
通过矩阵将决策变量和所要求解的目标函数建立联系。
在提出模型目标函数的过程中,首先我们提出了代表相遇次数的概念,用矩阵Q 表示其任意两个代表的相遇次数,并利用矩阵的Frobenius范数控制了Q中元素的大小及其均匀程度,得到目标函数f(x),从而求解代表的相遇次数。
第一个目标函数设定后,基于f(x)在群体整体换组时不能起到控制作用的问题,决定使用共同成员概念:即任意两组(可以属于不同场次)整个会议中的交集。
利用矩阵A,对矩阵的Frobenius范数的运用使群体整体换组现象得到了有效的遏制,对与会者混合程度进行了控制。
求解模型时,使用迭代算法,利用线性规划,在目标函数可行域范围内查找最优解可以利用MATLAB软件设计出计算可行初始解->随机产生一个可行解->局部优化->全局优化从而达到全局最优解的三步求解的方法,局部->全局的步骤解出了全局最优解,简化运算步骤的同时提高了结果优化程度,降低对初值的依赖程度,很好的达到了与会者需要充分混合的目的。
基于算法的目标函数,因为在建立时具有一般性,若需建立起优化全局的目标函数,只需对参数进行改变。
这样一来模型的推广得到了算法上的支持,带来了极大的便利。
我们此次建模得到了合适的人员分配结果,达到了建模的目的。
关键词:抽屉原理相遇矩阵共同成员 Frobenius范数一、问题重述目前,国内外许多重要会议都是以分组形式进行研讨,以便充分交流、沟通。
一般地,一个由N名代表参加的会议,要分为M个场次,每场会议分为L个小组,并且要求每个小组的人数基本均衡。
问题1:请建立分组方案的数学模型,使得尽可能让任意两个来自不同地区的委员之间都有见面交流的机会。
问题2:设计求解上述分组模型的有效算法。
问题3:现有一个学术团体要举行由37位专家参加的学术研讨会,每个专家所在地区的信息见表1。
数学建模会议分组问题

资料范本本资料为word版本,可以直接编辑和打印,感谢您的下载数学建模会议分组问题地点:__________________时间:__________________说明:本资料适用于约定双方经过谈判,协商而共同承认,共同遵守的责任与义务,仅供参考,文档可直接下载或修改,不需要的部分可直接删除,使用时请详细阅读内容会议分组问题摘要本文解决会议分组问题,即在会议次数以及参会人数确定的情况下求取不同地区之间最大的见面概率的会议安排方式,通过设置相应参数,逐步建立数学模型,并采用编程进行计算,并最终确定会议人员参加会议的分组方案。
下面将分别对三个问题进行阐述:问题1是已知有名代表参加会议,要分个场次,每场会议中有个小组,先对数据进行了矩阵化处理,其中引入常值元素来区分不同地区的代表,以L×N 的矩阵表示每个人在某一场的出席情况,以此建立非线性整数变量规划模型。
为了达到尽可能使来自不同地区的代表能有见面交流机会的目的,本文以每组代表人数基本均衡、每个会议每个代表有且只能在一个小组内为约束条件,根据M个矩阵的加和等一系列运算的结果,得到M场会议之后与会人员的见面情况,从而进行优化,最终确立出最优的分组方案。
针对问题2,本文通过建立分组矩阵、开会矩阵,制定约束条件,构造相遇矩阵以及构造异地代表是否见面函数,逐步建立最终的数学模型。
但是用lingo计算大量数据的非线性模型运行时间太长,无法获得运算结果(超过5个小时),因此采用分部计算的形式来求解此模型,也就是一共有次会议,须经过多次迭代,每次迭代只计算一次会议的会面情况,每次迭代时更新目标函数的系数,上一次已经会面的代表假设为同一地区,则这次计算常值系数,只计算未见面的代表会见面次数的最大值,迭代完毕之后将次结果综合考虑,并最后得到模型的最优方案。
针对问题3,将问题1中的、、分别取做8、5、5,采用问题(1)所建立的模型以及问题2设计的算法,运行程序,得到的分配结果如下:表2 会议的分组方案关键词:会议分组;矩阵分析;迭代运算;整数规划;约束条件问题的重述会议分组是一个很实际的问题,目前国内外许多重要会议都是以分组形式进行研讨,以便充分交流、沟通。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
会议分组问题摘要通过对问题的分析,我们确定运用优化的整数规划模型、矩阵理论和置换等方面的知识和技巧。
通过矩阵将决策变量和所要求解的目标函数建立联系。
在提出模型目标函数的过程中,首先我们提出了代表相遇次数的概念,用矩阵Q 表示其任意两个代表的相遇次数,并利用矩阵的Frobenius范数控制了Q中元素的大小及其均匀程度,得到目标函数f(x),从而求解代表的相遇次数。
第一个目标函数设定后,基于f(x)在群体整体换组时不能起到控制作用的问题,决定使用共同成员概念:即任意两组(可以属于不同场次)整个会议中的交集。
利用矩阵A,对矩阵的Frobenius范数的运用使群体整体换组现象得到了有效的遏制,对与会者混合程度进行了控制。
求解模型时,使用迭代算法,利用线性规划,在目标函数可行域范围内查找最优解可以利用MATLAB软件设计出计算可行初始解->随机产生一个可行解->局部优化->全局优化从而达到全局最优解的三步求解的方法,局部->全局的步骤解出了全局最优解,简化运算步骤的同时提高了结果优化程度,降低对初值的依赖程度,很好的达到了与会者需要充分混合的目的。
基于算法的目标函数,因为在建立时具有一般性,若需建立起优化全局的目标函数,只需对参数进行改变。
这样一来模型的推广得到了算法上的支持,带来了极大的便利。
我们此次建模得到了合适的人员分配结果,达到了建模的目的。
关键词:抽屉原理相遇矩阵共同成员 Frobenius范数一、问题重述目前,国内外许多重要会议都是以分组形式进行研讨,以便充分交流、沟通。
一般地,一个由N名代表参加的会议,要分为M个场次,每场会议分为L个小组,并且要求每个小组的人数基本均衡。
问题1:请建立分组方案的数学模型,使得尽可能让任意两个来自不同地区的委员之间都有见面交流的机会。
问题2:设计求解上述分组模型的有效算法。
问题3:现有一个学术团体要举行由37位专家参加的学术研讨会,每个专家所在地区的信息见表1。
会议分5场进行,每场会议又分5个小组,每个小组人数要基本均衡。
请根据问题1所建立的模型以及问题2设计的算法,给出5场会议的每一场各个组中有哪些委员参加的安排方案。
说明:论文要附有求解问题3源程序的全部代码,并确保能够直接运行以检验结果的正确性。
二、模型假设(1)假设各场会议及各小组间是相互独立的;(2)假设所有代表严格遵守派遣方案,不会改变制定的分配方案; (3)假设来自不同地区的代表之间无其他差异; (4)假设每场会议各组人数分配为7,7,7,9,9。
注:对于假设(4),我们可以运用初等模型中的公平分配得到,具体过程如下:三、变量及符号说明和数学描述1、变量符号说明(1) ijk x :0-1决策变量,表示第i 位代表有否参加第k 场第j 组会议; (2) P :开会分组矩阵,表示整次会议每场代表的分组安排,其中k P 表示第k 场会议的分组矩阵,其行向量jk P 表示第k 场会议第j 组的分组矩阵;(3) Q :相遇矩阵; (4)()f x :目标函数一,用来控制代表相遇次数;(5) ()g x :目标函数二,用于控制不同场间组间共同成员个数; (6) ()F x :总的目标函数,综合考虑()f x 和()g x 的目标函数.2、变量符号数学描述(1)ijk 1,j 0,.x ⎧⎪=⎨⎪⎩表示第i 位代表参加第k 场第组的会议否则(2)()12=jk jkjkNjk P xx x ,k 表示第k 段会议,j 表示第j 组,k=1,2,…,M ,j=1,2,…,L,i=1,2,…,N .(3)1k 11k 21k 1k 212k 22k 2k 1k2kk x x x x x x =x x x N k N k M M NM Mk P P P P ⎛⎫⎛⎫⎪ ⎪ ⎪ ⎪= ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭(4)111121ML L LM P P P P P P P P ⎛⎫⎪ ⎪ ⎪⎛⎫⎪ ⎪⎪ ⎪== ⎪ ⎪⎪⎪⎪⎝⎭⎪ ⎪ ⎪⎝⎭(5)()1212TT TT L L P P Q P P P PP P ⎛⎫ ⎪ ⎪== ⎪ ⎪⎝⎭四、模型建立通过使用(0-1)整数规划来建立该问题的模型。
题目要求每个小组的人数基本均衡,使得尽可能让任意两个来自不同地区的委员之间都有见面交流的机会。
从这两个要求出发,分别从相遇代表次数和共同成员数目两个角度建立了两个目标函数。
再加上题设要求以及模型假设得到的约束条件,完成本模型的建立。
具体过程以及模型如下所示。
题目要求分组名单安排计划属于分派问题,常用0-1变量表示分派的决策变量,根据本题的特点现在把分派问题视为抽屉问题。
每场会议配给L 个抽屉,每组分一个,每个抽屉分为N 个空格(第1至第N 号),每位代表的编号放入空格。
如果空格处有对应的编号则ijk x 就是1,如果没有就是0.即ijk 1,k j i ,1,2,...,,1,2,...,,1,2,...,0,x i N j L k M====⎧⎨⎩第场第组第个空格有编号否则 根据以上的分法我们可以用由ijk x 组成的矩阵来表示开会时代表分布的具体情况。
令()12=jk jkjkNjk P xx x ,这表示第k 场第j 组的与会代表的分布情况。
每场会的具体安排由矩阵排列如下:1k 11k 21k 1k 212k 22k 2k 1k2kk x x x x x x =x x x N k N k M M NM Mk P P P P ⎛⎫⎛⎫⎪ ⎪ ⎪ ⎪= ⎪ ⎪ ⎪ ⎪⎝⎭⎝⎭1、建立目标函数基于计算过程中会遇到一个行向量与自己的转置相乘情况,运算的结果不仅对于我们的模型中无效,还会对计算情况有着较大的影响,我们先规定在计算中0,0,1,2,...,,1,2,...,.T T jk jk jk jk P P P P j L k M ====根据要求每个小组的人数基本均衡,使得尽可能让任意两个来自不同地区的委员之间都有见面交流的机会,分两部分来描述:1、会议安排应使任意两个代表在整个会议中见面的次数平均2、不同场会议在同一小组中一起开会的代表最少,最好代表之间都可以见面。
1、为了控制在不同场会议在同一小组中一起开会的代表数目并控制任意两个代表在整个会议中见面的次数,随机抽取两位代表,解出彼此在同组同时开会见面的次数见面次数采用0-1决策变量ijkx 来表示:11L Msjktjkj k xx ==∑∑表示第s 号代表与第t 号代表在M 场会议中相遇的总次数.基于运算方便的目的,列出两个代表相遇的矩阵Q 如下:()()12121122=++T TTT T TT L L L st N NL P P Q P P P P P P P P P P P q P ⨯⎛⎫⎪ ⎪==+= ⎪⎪⎝⎭其中11.L Mstsjk tjk j k q x x ===∑∑计算出全部st q 的和,求解得所有代表的相遇次数,考虑到代表彼此相遇的单个差异的不明显性,我们把()lst q 放大,再对()lst q 进行求和,设l 值等于2,使用矩阵Q 的Frobenius 范数达到放大st q 之间的差异的目的,既考虑到了全局相遇次数的同时也考虑到了单个相遇次数的差异,第一个目标函数建立如下:()()11lLLst s t f x q ===∑∑2、对于()f x ,其弱点有:当同一批人分别处于两场会议的某两组时,且在接下来的会议中会完全打乱分配,并尽可能弥补开始相遇次数增大的缺陷,保持成员见面的次数个别差异很小时,使用()f x 不能充分控制住。
因此这就需要我们再建立了一个目标函数来克服此弱点。
对于整个会议中任意抽取出的两个讨论组,称在这两个讨论组中都出现的代表称为这两个组的共同成员。
第k场第i 组与第t 场第j 组的共同成员个数为T ik jt P P . 我们用矩阵来排列这些数:()111111*********11111111111111111111121312TT TTL MLM T T T T L L L L ML MTTTTM LM M MM LM T T TT LM LM L LM MLM LM TT TT ML M P P P P P P P P P P P P P P P P A P P P P P P P P P P P P P P P P PP PP PP PP ⨯⎛⎫ ⎪⎪ ⎪ ⎪ ⎪=⎪⎪ ⎪ ⎪⎪ ⎪⎝⎭=21222323132333123TT T T MTTTT MT T TT L L L L M P P P P P P P P P P P P P P P P P P P P P P P P ⎛⎫⎪ ⎪ ⎪ ⎪ ⎪ ⎪⎝⎭A 是一个()2L M ⨯的矩阵,其中A 的对角线上的方块T k k P P 是第k 段会议段内各组的共同成员,其非对角线上的元素一定为0,而其对角线上的元素在上文中已经提到为无效量,故不计算A 对角线方块Tk k P P 中的元素,k=1,2,…,M.A 中每个元素为整个会议中任意两组(可以分别属于不同段)的共同成员个数。
如果出现上一段提出的问题,那么A 中元素的大小(除去对角线方块,1,2,...,T k k P P k M =中的元素)将会出现明显的不平均。
如果让A 中对角线方块,1,2,...,T k k P P k M =以外所有元素的尽可能平均的话,那么会议中任一组与任何该组所属的段以外的组的共同成员数量将会均匀分布。
于是,成员间自发组成的小组总在同一个讨论组中出现的现象将会得到遏制,与会成员将会尽可能平均分配。
类似上一个目标函数,为了达到描述A 中元素的平均程度的目的,可以使用矩阵A 的Frobenius 范数。
在此情况下,可以再次建立一个目标函数:()()2=T ik jt k tg x P P ≠∑)()()(21x g x f x F λλ+=其中2121,,1λλλλ=+为权系数),为总的目标函数。
2、约束条件利用已知题目条件设出相应的模型约束条件:(1) 在每一场会议中每个代表只能分入一个组里()11=111,1,2,...,.Ljk N j P k M ⨯==∑(2) 易知不同组间开会代表应该尽量相等,才可以使得相见的次数尽可能少,所以1,2,...,,1,2,,.T jk jk N p p j L k M L ⎡⎤===⎣⎦(3) 在具体计算时()f x ,相遇代表次数须在一个范围,即<M m q .(4) 类似地我们对()g x 考虑,共同成员个数也要在一个有意义的范围内,即T ik jt P P .<M-1.五、模型的求解1、详细求解方案使用MATLAB 对该模型求解。
模型变量总数为N ,对于每个变量来说,取值范围为0-1,如果N 取值较大时,求解大规模的数据时若使用穷举法,会使总的计算步骤较复杂。